The premise: each time a certain API method is called within a Flask / SQLAlchemy app (a method that primarily involves saving something to the database), send various notifications, e.g. log to the standard logger, and send an email to site admins. However, the way the API works, is that several different methods can be forced to run in a single DB transaction, by specifying that SQLAlchemy only perform a commit when the last method is called. Ideally, no notifications should actually get triggered until the DB transaction has been successfully committed; and when the commit has finished, the notifications should trigger in the order that the API methods were called.
There are various possible solutions that can accomplish this, for example: a celery task queue, an event scheduler, and a synchronised / threaded queue. However, those are all fairly heavy solutions to this problem, because we only need a queue that runs inside one thread, and that lives for the duration of a single DB transaction (and therefore also only for a single request).
To solve this problem, I implemented a very lightweight function queue, where each queue is a deque instance, that lives inside flask.g, and that is therefore available for the duration of a given request context (or app context).
Communism – or, to be more precise, Marxism – made sweeping promises of a rosy utopian world society: all people are equal; from each according to his ability, to each according to his need; the end of the bourgeoisie, the rise of the proletariat; and the end of poverty. In reality, the nature of the communist societies that emerged during the 20th century was far from this grandiose vision.
Communism obviously was not successful in terms of the most obvious measure: namely, its own longevity. The world's first and its longest-lived communist regime, the Soviet Union, well and truly collapsed. The world's most populous country, the People's Republic of China, is stronger than ever, but effectively remains communist in name only (as does its southern neighbour, Vietnam).
However, this article does not seek to measure communism's success based on the survival rate of particular governments; nor does it seek to analyse (in any great detail) why particular regimes failed (and there's no shortage of other articles that do analyse just that). More important than whether the regimes themselves prospered or met their demise, is their legacy and their long-term impact on the societies that they presided over. So, how successful was the communism experiment, in actually improving the economic, political, and cultural conditions of the populations that experienced it?
I have become quite a fan of Python's built-in namedtuple collection lately. As others have already written, despite having been available in Python 2.x and 3.x for a long time now, namedtuple continues to be under-appreciated and under-utilised by many programmers.
# The ol'fashioned tuple way
fruits = [
('banana', 'medium', 'yellow'),
('watermelon', 'large', 'pink')]
for fruit in fruits:
print('A {0} is coloured {1} and is {2} sized'.format(
fruit[0], fruit[2], fruit[1]))
# The nicer namedtuple way
from collections import namedtuple
Fruit = namedtuple('Fruit', 'name size colour')
fruits = [
Fruit(name='banana', size='medium', colour='yellow'),
Fruit(name='watermelon', size='large', colour='pink')]
for fruit in fruits:
print('A {0} is coloured {1} and is {2} sized'.format(
fruit.name, fruit.colour, fruit.size))
namedtuples can be used in a few obvious situations in Python. I'd like to present a new and less obvious situation, that I haven't seen any examples of elsewhere: using a namedtuple instead of MagicMock or flexmock, for mocking objects in unit tests.
Them robots are gonna take our jobs! Image source:Day of the Robot.
Most discussion of late seems to treat this encroaching joblessness entirely as an economic issue. Families without incomes, spiralling wealth inequality, broken taxation mechanisms. And, consequently, the solutions being proposed are mainly economic ones. For example, a Universal Basic Income to help everyone make ends meet. However, in my opinion, those economic issues are actually relatively easy to address, and as a matter of sheer necessity we will sort them out sooner or later, via a UBI or via whatever else fits the bill.
The more pertinent issue is actually a social and a psychological one. Namely: how will people keep themselves occupied in such a world? How will people nourish their ambitions, feel that they have a purpose in life, and feel that they make a valuable contribution to society? How will we prevent the malaise of despair, depression, and crime from engulfing those who lack gainful enterprise? To borrow the colourful analogy that others have penned: assuming that there's food on the table either way, how do we head towards a Star Trek rather than a Mad Max future?
Most countries have one city which is clearly top of the pops. In particular, one city (which may not necessarily be the national capital) is usually the largest population centre and the main economic powerhouse of a given country. Humbly presented here is a quick and not-overly-scientific list of ten countries that are an exception to this rule. That is, countries where two cities (or more!) vie neck-and-neck for the coveted top spot.
Note: all population statistics are the latest numbers on relevant country- or city-level Wikipedia pages, as of writing, and all are for the cities' metropolitan area or closest available equivalent.
The infamous East India Company, "the Company that Owned a Nation", is remembered harshly by history. And rightly so. On the whole, it was an exploitative venture, and the British individuals involved with it were ruthless opportunists. The Company's actions directly resulted in the impoverishment, the subjugation, and in several instances the death of countless citizens of the Indian Subcontinent.
Company rule, and the subsequent rule of the British Raj, are also acknowledged as contributing positively to the shaping of Modern India, having introduced the English language, built the railways, and established political and military unity. But these are overshadowed by its legacy of corporate greed and wholesale plunder, which continues to haunt the region to this day.
I recently read Four Heroes of India (1898), by F.M. Holmes, an antique book that paints a rose-coloured picture of Company (and later British Government) rule on the Subcontinent. To the modern reader, the book is so incredibly biased in favour of British colonialism that it would be hilarious, were it not so alarming. Holmes's four heroes were notable military and government figures of 18th and 19th century British India.
Clive, Hastings, Havelock, Lawrence; with a Concluding Note on the Rule of Lord Mayo. Image source:eBay.
I'd like to present here four alternative heroes: men (yes, sorry, still all men!) who in my opinion represented the British far more nobly, and who left a far more worthwhile legacy in India. All four of these figures were founders or early members of The Asiatic Society (of Bengal), and all were pioneering academics who contributed to linguistics, science, and literature in the context of South Asian studies.
There are several different ways of commonly identifying the "official centre point" of a city. However, there's little international consensus as to the definition of such a point, and in many countries and cities the definition is quite vague.
Most reliable and most common, is to declare a Kilometre Zero marker as a city's (and often a region's or even a country's) official centre. Also popular is the use of a central post office for this purpose. Other traditional centre points include a city's cathedral, its main railway station, its main clock tower (which may be atop the post office / cathedral / railway station), its tallest building, its central square, its seat of government, its main park, its most famous tourist landmark, or the historical spot at which the city was founded.
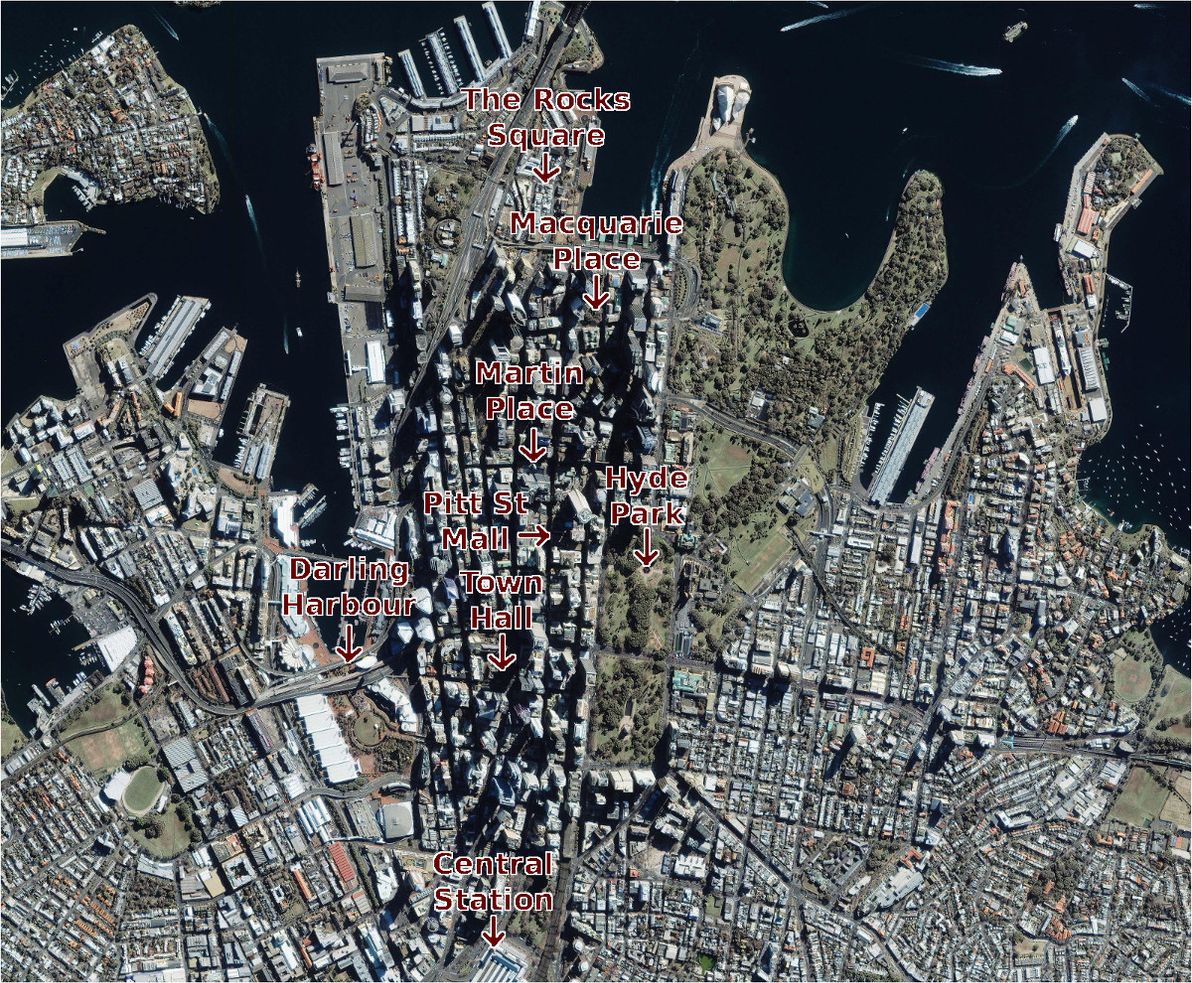
Satellite photo of Sydney CBD, annotated with locations of "official centre" candidates. Image source:Satellite Imaging Corp.
My home town of Sydney, Australia, is one of a number of cities worldwide that boasts most of the above landmarks, but all in different locations, and without any mandated rule as to which of them constitutes the official city centre. So, where exactly in Sydney does X mark the spot?
And now for something completely different, here's an interesting question. What terra firma places in the world are completely without roads? Where in the world will you find large areas, in which there are absolutely no official vehicle routes?
Naturally, such places also happen to be largely bereft of any other human infrastructure, such as buildings; and to be largely bereft of any human population. These are places where, in general, nothing at all is to be encountered save for sand, ice, and rock. However, that's just coincidental. My only criteria, for the purpose of this article, is a lack of roads.
Having a complete Windows (or Mac) desktop running within Linux has been possible for some time now, thanks to the wonders of Virtual Machine (VM) technology. However, the typical approach is to mount and boot a VM image, where the guest OS and hard disk are just files on the host filesystem. In this case, the guest OS can't be natively booted and run, because it doesn't occupy its own disk or partition on the physical hardware, and therefore it can't be picked up by the BIOS / boot manager.
I've been installing Windows and Linux on the same machine, in a dual-boot setup, for many years now. In this case, I boot natively into either one or the other of the installed OSes. However, I haven't run one "real" OS (i.e. an OS that's installed on a physical disk or partition) inside the other via a VM. At least, not until now.
At my new job this year, I discovered that it's possible to do such a thing, using a feature of VirtualBox called "Raw Disk Access". With surprisingly few hiccups, I got this running with Linux Mint 17.3 as the host, and with Windows 8.1 as the guest. Each OS is installed on a separate physical hard disk. I run Windows inside the VM most of the time, but I can still boot natively into the very same install of Windows at any time, if necessary.
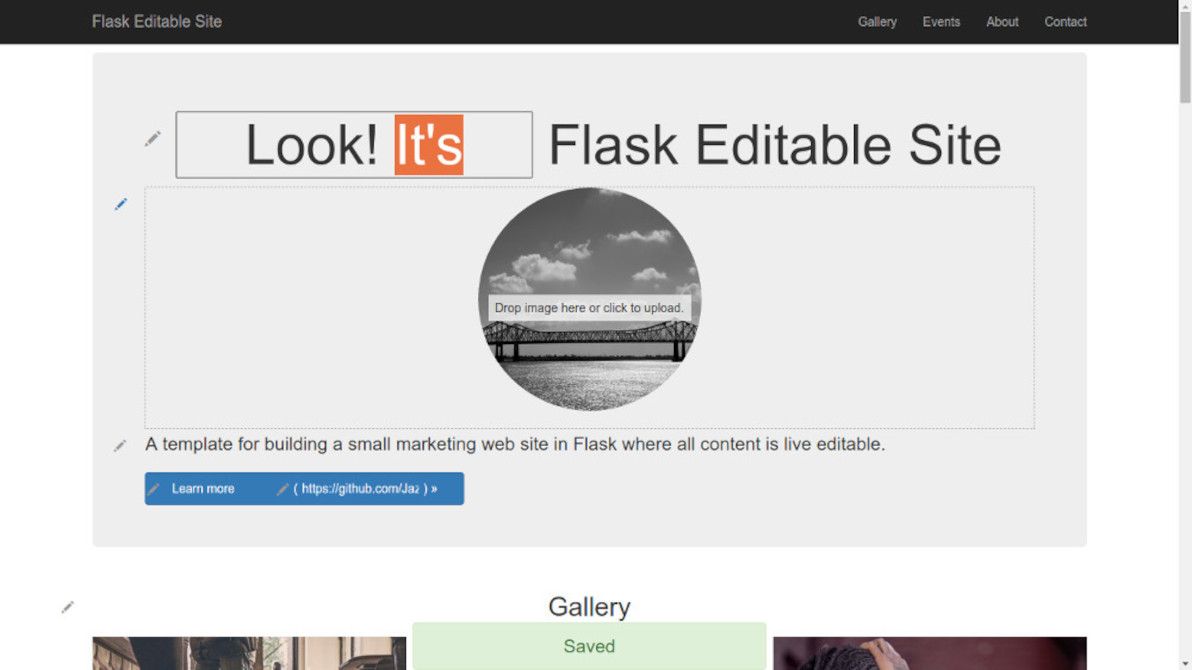
Text and image block editing with Flask Editable Site.
The aim of this app is to demonstrate that, with the help of modern JS libraries, and with some well-thought-out server-side snippets, it's now perfectly possible to "bake in" live in-place editing for virtually every content element in a typical brochureware site.
This app is not a CMS. On the contrary, think of it as a proof-of-concept alternative to a CMS. An alternative where there's no "admin area", there's no "editing mode", and there's no "preview button". There's only direct manipulation.
"Template" means that this is a sample app. It comes with a bunch of models that work out-of-the-box (e.g. text content block, image content block, gallery item, event). However, these are just a starting point: you can and should define your own models when building a real site. Same with the front-end templates: the home page layout and the CSS styles are just examples.