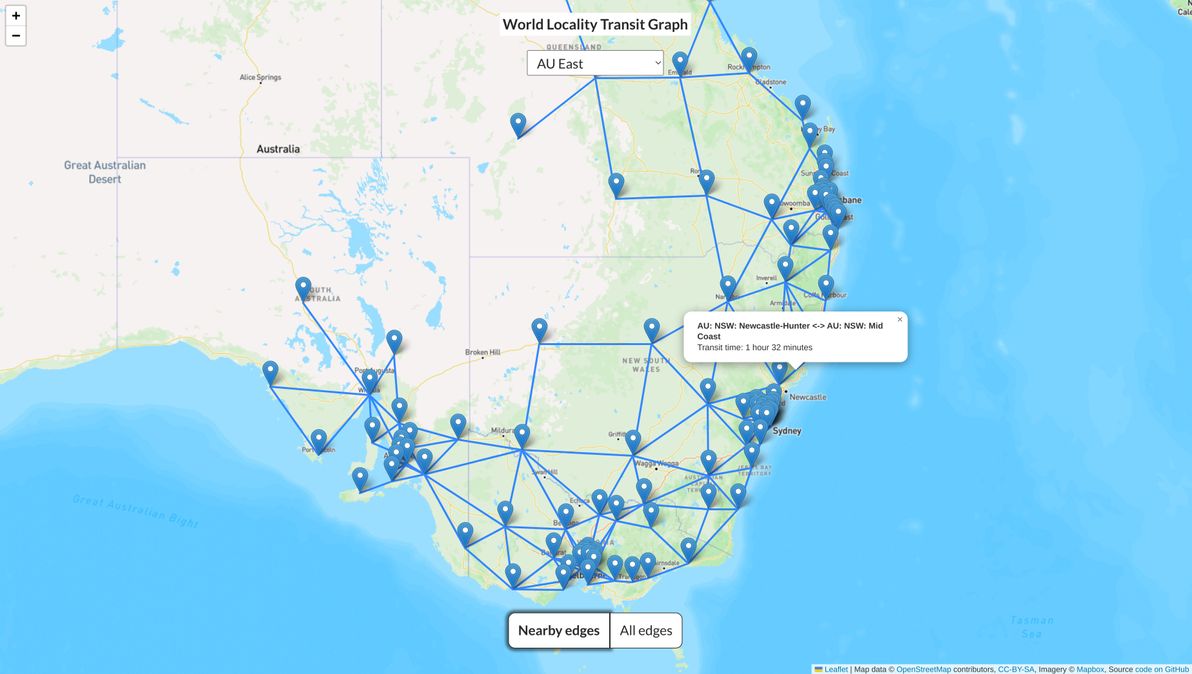
I built a dataset and map visualisation called the World Locality Transit Graph. Source code is on GitHub. It's a map of approximate transit times between any two given localities in various parts of the world.
World Locality Transit Graph showing the dataset for Eastern Australia
I built a little Python script called the Floyd-Warshall CSV Generator. It takes a CSV of graph edges as input, and generates a CSV of the edges that are the shortest paths between all pairs of vertices.
Over the past year or two, I've been heavily using FastAPI in my day job. I've been around the Python web framework block, and I gotta say, FastAPI really succeeds in its mission of building on the strengths of its predecessors (particularly Django and Flask), while feeling more modern and adhering to certain opinionated principles. In my opinion, it's pretty much exactly what the best-in-breed of the next logical generation of web frameworks should look like.
¡Ándale, ándale, arriba! Image source: The Guardian
Per the EU's GDPR and ePrivacy Directive, you must ask visitors to a website for their consent before setting any cookies, and/or before collecting any user tracking data. And because the GDPR applies to all EU citizens (who are residing within the EU), regardless of where in the world a website or its owner is based, in order to fully comply, in practice you should seek consent for all visitors to all websites globally.
In order to be GDPR-compliant, and in order to just be a good netizen, I made sure, when building GreenAsh v5 earlier this year, to not use services that set cookies at all, wherever possible. In previous iterations of GreenAsh, I used Google Analytics, which (like basically all Google services) is a notorious GDPR offender; this time around, I instead used Cloudflare Web Analytics, which is a good enough replacement for my modest needs, and which ticks all the privacy boxes.
However, on pages with forms at least, I still need Google reCAPTCHA. I'd like to instead use the privacy-conscious hCaptcha, but Netlify Forms only supports reCAPTCHA, so I'm stuck with it for now. Here's how I seek the user's consent before loading reCAPTCHA.
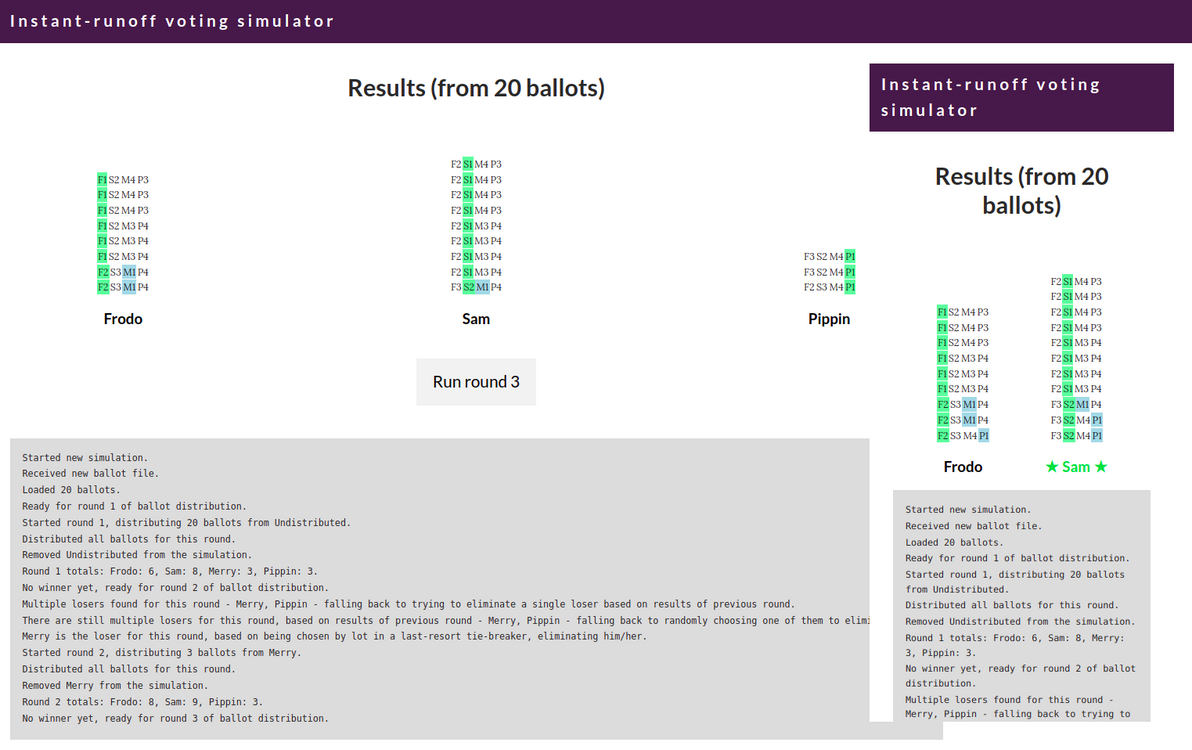
I built a simulator showing how instant-runoff voting (called preferential voting in Australia) works step-by-step. Try it now.
The simulator in action
I hope that, by being an interactive, animated, round-by-round visualisation of the ballot distribution process, this simulation gives you a deeper understanding of how instant-runoff voting works.
Continuing my foray into the world of Static Site Generators (SSGs), this time I decided to try out one that's quite different: TinaCMS (although Tina itself isn't actually an SSG, it's just an editing toolkit; so, strictly speaking, the SSG that I took for a spin is Next.js). Shiny new toys. The latest and greatest that the JAMstack has to offer. Very much all alpha (I encountered quite a few bugs, and there are still some important features missing entirely). But wow, it really does let you have your cake and eat it too: a fast, dumb, static site when logged out, that transforms into a rich, Git-backed, inline CMS when logged in!
Following on from my last experiment with Hugo, I decided to dabble in a different static site generator (SSG). This time, Eleventy. I've rebuilt another one of my golden oldies, Jaza's World, using it. And, similarly, source code is up on GitHub, and the site is hosted on Netlify. I'm pleased to say that Eleventy delivered in the areas where Hugo disappointed me most, although there were things about Hugo that I missed.
After having it on my to-do list for several years, I finally got around to trying out a static site generator (SSG). In particular, Hugo. I decided to take Hugo for a spin, by rebuilding one of my golden oldies, Jaza's World Trip, with it. And, for bonus points, I published the source code on GitHub, and I deployed the site on Netlify. Hugo is great software with a great community, however it didn't quite live up to my expectations.
I've created a new online home for my formidable collection of 25,000 personal photos. They now all live in an S3 bucket, and are viewable in a private gallery powered by the open-source AWSPics. In general, I'm happy with the new setup.
Theories abound regarding what makes a good dev. These theories generally revolve around one or more particular skills (both "hard" and "soft"), and levels of proficiency in said skills, that are "must-have" in order for a person to be a good dev. I disagree with said theories. I think that there's only one thing that makes a good dev, and it's not a skill at all. It's an attitude. A good dev cares about code.
There are many aspects of code that you can care about. Formatting. Modularity. Meaningful naming. Performance. Security. Test coverage. And many more. Even if you care about just one of these, then: (a) I salute you, for you are a good dev; and (b) that means that you're passionate about code, which in turn means that you'll care about more aspects of code as you grow and mature, which in turn means that you'll develop more of them there skills, as a natural side effect. The fact that you care, however, is the foundation of it all.