According to most linguistic / historical sources, the English language as we know it today is a West Germanic language (the other two languages in this family being German and Dutch). Modern English is the descendant of Old English, and Old English was essentially born when the Anglo-Saxons migrated to the isle of Great Britain in the 5th c. C.E., from their traditional homeland in the north-west of modern Germany. Prior to this time, it's believed that the inhabitants of all parts of the British Isles were predominantly Celtic speakers, with a small Latin influence resulting from the Roman occupation of Britain.
Of the languages that have influenced the development of English over the years, there are three whose effect can be overwhelmingly observed in modern English: French ("Old Norman"), Latin, and Germanic (i.e. "Old English"). But what about Celtic? It's believed that the majority of England's pre-Anglo-Saxon population spoke Brythonic (i.e. British Celtic). It's also been recently asserted that the majority of England's population today is genetically pre-Anglo-Saxon Briton stock. How, then — if those statements are both true — how can it be that the Celtic languages have left next to no legacy on modern English?
In the developed world, with its developed mapping providers and its developed satellite coverage, GPS is becoming ever more popular amongst automobile drivers. This is happening to the extent that I often wonder if the whole world is now running on autopilot. "In two hundred metres, take the second exit at the roundabout, then take the third left." Call me a luddite and a dinosaur if you must, all ye GPS faithful… but I refuse to use a GPS. I really can't stand the things. They're annoying to listen to. I can usually find a route just fine without them. And using them makes you navigationally illiterate. Join me in boycotting GPS!
Adding image fields to a Django model is easy, thanks to the built-in ImageField class. Auto-resizing uploaded images is also a breeze, courtesy of sorl-thumbnail and its forks/variants. But what about embedding resized images inline within text content? This is a very common use case for bloggers, and it's a final step that seems to be missing in Django at the moment.
Having recently migrated this site over from Drupal, my old blog posts had inline images embedded using image assist. Images could be inserted into an arbitrary spot within a text field by entering a token, with a syntax of [img_assist nid=123 ... ]. I wanted to be able to continue embedding images in roughly the same fashion, using a syntax as closely matching the old one as possible.
So, I've written a simple template filter that parses a text block for tokens with a syntax of [thumbnail image-identifier], and that replaces every such token with the image matching the given identifier, resized according to a pre-determined width and height (by sorl-thumbnail), and formatted as an image tag with a caption underneath. The code for the filter is below.
autop is a script that was first written for WordPress by Matt Mullenweg (the WordPress founder). All WordPress blog posts are filtered using wpautop() (unless you install an additional plug-in to disable the filter). The function was also ported to Drupal, and it's enabled by default when entering body text into Drupal nodes. As far as I'm aware, autop has never been ported to a language other than PHP. Until now.
In the process of migrating this site from Drupal to Django, I was surprised to discover that not only Django, but also Python in general, lacks any linebreak filtering function (official or otherwise) that's anywhere near as intelligent as autop. The built-in Django linebreaks filter converts all single newlines to <br /> tags, and all double newlines to <p> tags, completely irrespective of HTML block elements such as <code> and <script>. This was a fairly major problem for me, as I was migrating a lot of old content over from Drupal, and that content was all formatted in autop style. Plus, I'm used to writing content in that way, and I'd like to continue writing content in that way, whether I'm in a PHP environment or not.
Therefore, I've ported Drupal's _filter_autop() function to Python, and implemented it as a Django template filter. From the limited testing I've done, the function appears to be working just as well in Django as it does in Drupal. You can find the function below.
What can I say? It's been a while. I was bored. The old site and the old server were getting crusty. And my technology preferences have shifted rather dramatically of late. Hence, it is with great pride that I present to you the splendiferously jaw-dropping 4th edition of GreenAsh, my personal and professional web site all rolled into one (oh yes, I love to mix business and pleasure).
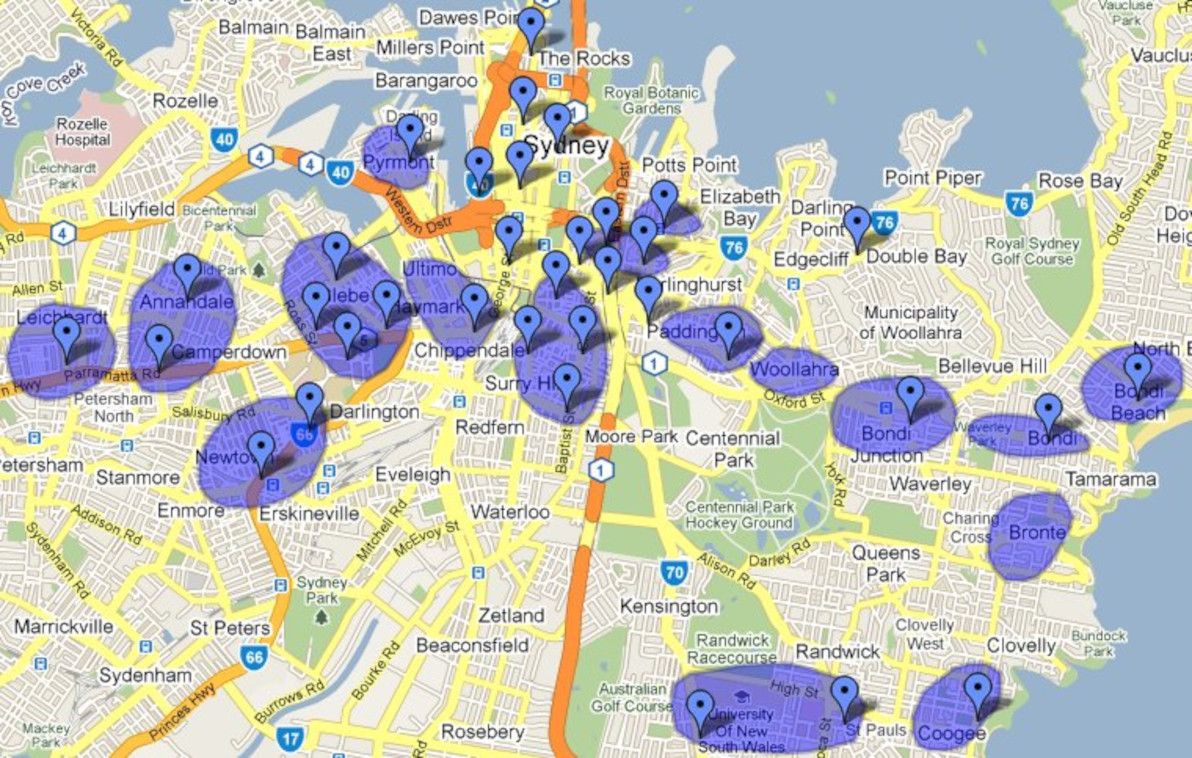
A work colleague of mine recently made a colourful remark to someone. "You live in [boring outer suburb]?", she gasped. "That's so Shelbyville!" Interesting term, "Shelbyville". Otherwise known as "the 'burbs", or "not where the hip-hop folks live". Got me thinking. Where in Sydney is a trendy place for young 20-somethings to live, and where is Shelbyville?
I've lived in Sydney all my life. I've almost always lived quite squarely in Shelbyville myself. However, since the age of 18, I've gotten to know most of the popular nightlife haunts pretty well. And since entering the world of student share-houses, I've also become pretty familiar with the city's accommodation hotspots. So, having this background, and being a fan of online mapping funkiness, I decided to sit down and make a map of the trendiest spots in Sydney to live and play.
Fat-Free is a brand-new PHP framework, and it's one of the coolest PHP projects I've seen in quite a long time. In stark contrast to the PHP tool that I use most often (Drupal), Fat-Free is truly miniscule, and it has no plans to get bigger. It also requires PHP 5.3, which is one version ahead of what most folks are currently running (PHP 5.3 is also required by FLOW3, another framework on my test-drive to-do list). A couple of weeks back, I decided to take Fat-Free for a quick spin and to have a look under its hood. I wanted to see how good its architecture is, how well it performs, and (most of all) whether it offers enough to actually be of use to a developer in getting a real-life project out the door.
I'm going to be comparing Fat-Free mainly with Django and Drupal, because they're the two frameworks / CMSes that I use the most these days. The comparison may at many times feel like comparing a cockroach to an elephant. But like Django and Drupal, Fat-Free claims to be a complete foundation for building a dynamic web site. It wants to compete with the big boys. So, I say, let's bring it on.
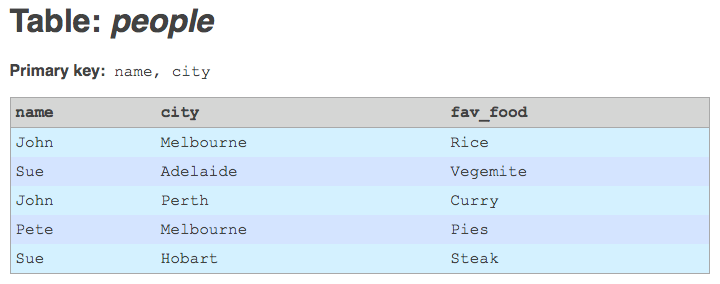
I have an interesting problem, on a data migration project I'm currently working on. I'm importing a large amount of legacy data into Drupal, using the awesome Migrate module (and friends). Migrate is a great tool for the job, but one of its limitations is that it requires the legacy database tables to have non-composite integer primary keys. Unfortunately, most of the tables I'm working with have primary keys that are either composite (i.e. the key is a combination of two or more columns), or non-integer (i.e. strings), or both.
Table with composite primary key.
The simplest solution to this problem would be to add an auto-incrementing integer primary key column to the legacy tables. This would provide the primary key information that Migrate needs in order to do its mapping of legacy IDs to Drupal IDs. But this solution has a serious drawback. In my project, I'm going to have to re-import the legacy data at regular intervals, by deleting and re-creating all the legacy tables. And every time I do this, the auto-incrementing primary keys that get generated could be different. Records may have been deleted upstream, or new records may have been added in between other old records. Auto-increment IDs would, therefore, correspond to different composite legacy primary keys each time I re-imported the data. This would effectively make Migrate's ID mapping tables corrupt.
A better solution is needed. A solution called hashing! Here's what I've come up with:
Remove the legacy primary key index from the table.
Create a new column on the table, of type BIGINT. A MySQL BIGINT field allocates 64 bits (8 bytes) of space for each value.
If the primary key is composite, concatenate the columns of the primary key together (optionally separated by a delimiter).
Calculate the SHA1 hash of the concatenated primary key string. An SHA1 hash consists of 40 hexadecimal digits. Since each hex digit stores 24 different values, each hex digit requires 4 bits of storage; therefore 40 hex digits require 160 bits of storage, which is 20 bytes.
Convert the numeric hash to a string.
Truncate the hash string down to the first 16 hex digits.
Convert the hash string back into a number. Each hex digit requires 4 bits of storage; therefore 16 hex digits require 64 bits of storage, which is 8 bytes.
Convert the number from hex (base 16) to decimal (base 10).
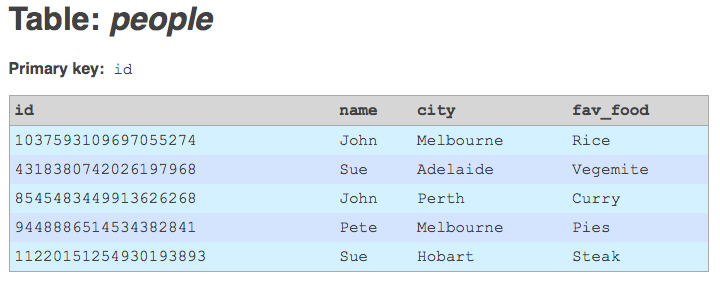
Store the decimal number in your new BIGINT field. You'll find that the number is conveniently just small enough to fit into this 64-bit field.
Now that the new BIGINT field is populated with unique values, upgrade it to a primary key field.
Add an index that corresponds to the legacy primary key, just to maintain lookup performance (you could make it a unique key, but that's not really necessary).
Table with integer primary key.
The SQL statement that lets you achieve this in MySQL looks like this:
ALTER TABLE people DROP PRIMARY KEY;
ALTER TABLE people ADD id BIGINT UNSIGNED NOT NULL FIRST;
UPDATE people SET id = CONV(SUBSTRING(CAST(SHA(CONCAT(name, ',', city)) AS CHAR), 1, 16), 16, 10);
ALTER TABLE people ADD PRIMARY KEY(id);
ALTER TABLE people ADD INDEX (name, city);
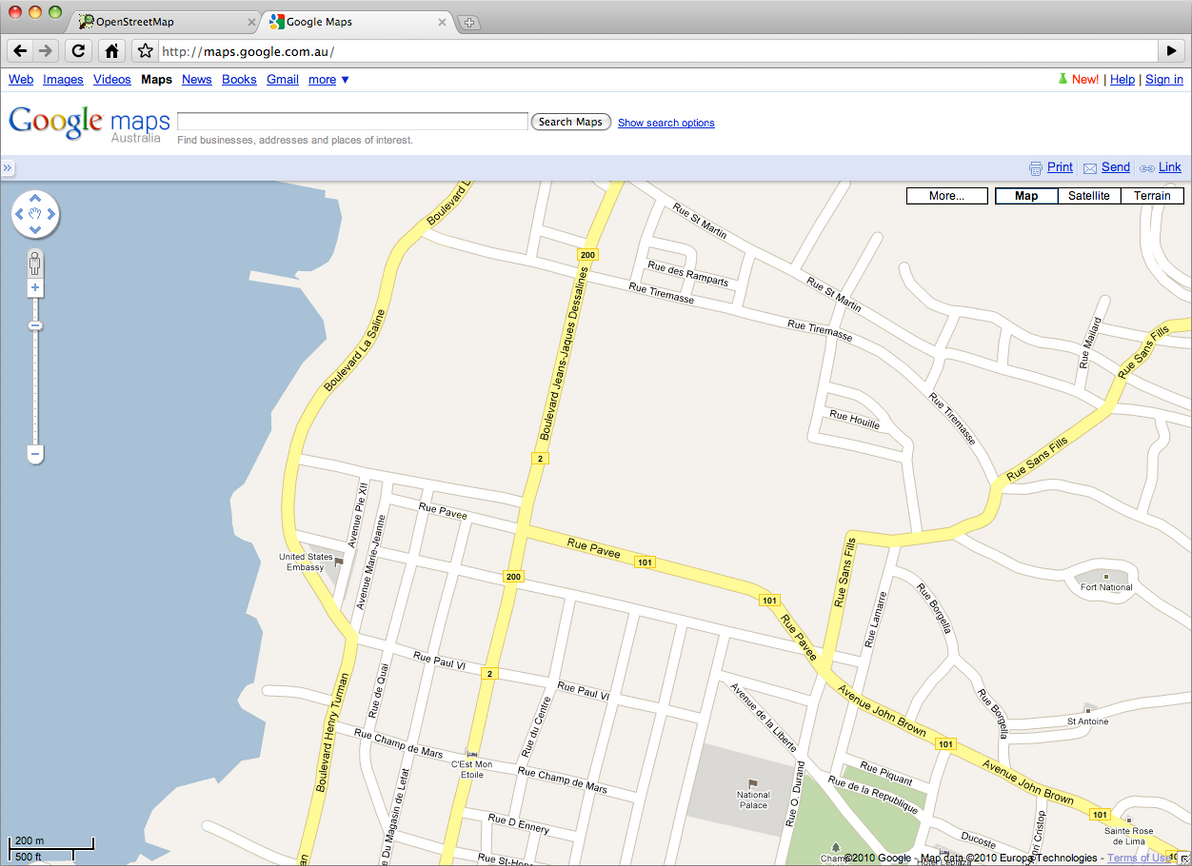
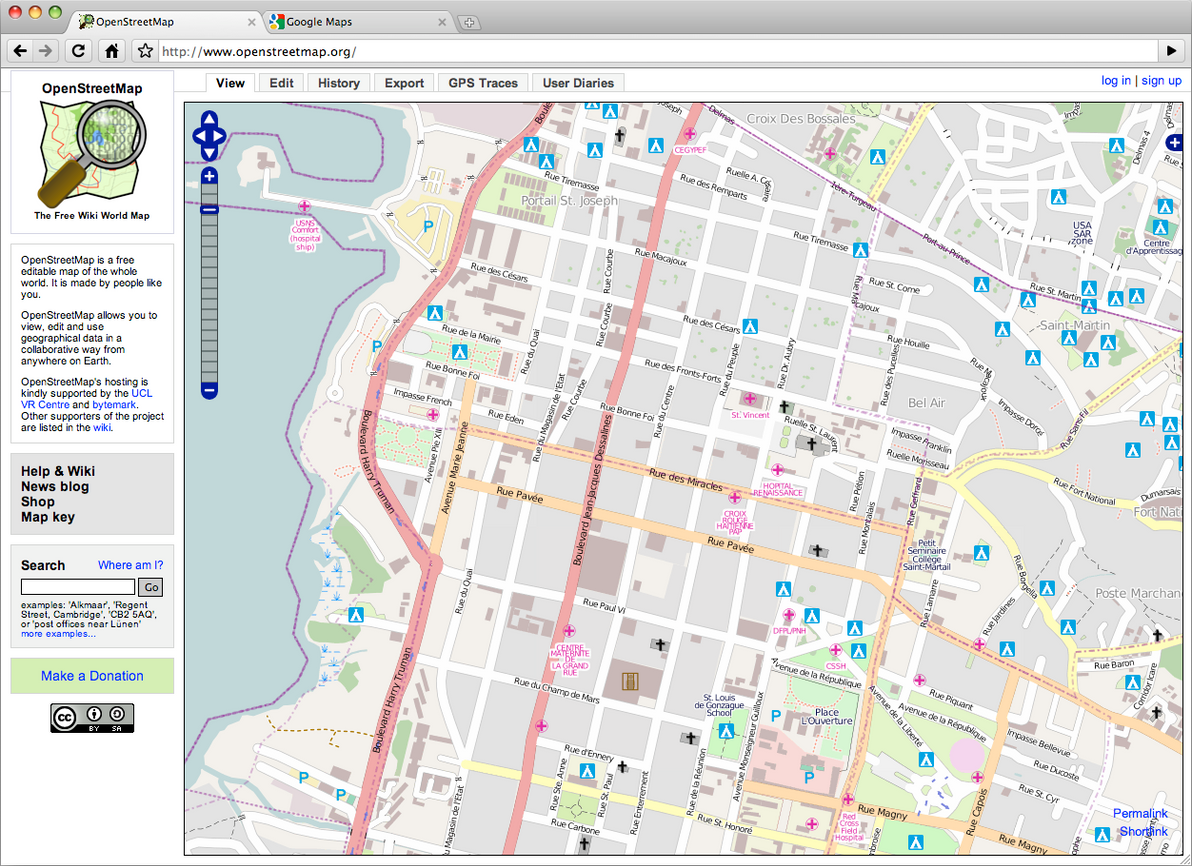
To see just how effective this volunteer mapping effort has been, I decided to do a quick visual comparison experiment. As of today, here's what downtown Port-au-Prince looks like in Google Maps:
Last weekend, I attended Social Innovation Camp Sydney 2010. SiCamp is an event where several teams have one weekend in which to take an idea for an online social innovation technology, and to make something of it. Ideally, the technology gets built and deployed by the end of the camp, but if a team doesn't reach that stage, simply developing the concept is an acceptable outcome as well.
I was part of a team of seven (including our team leader), and we were the team that built Refugee Buddy. As the site's slogan says: "Refugee Buddy is a way for you to welcome people to your community from other cultures and countries." It allows regular Australians to sign up and become volunteers to help out people in our community who are refugees from overseas. It then allows refugee welfare organisations (both governmnent and independent) to search the database of volunteers, and to match "buddies" with people in need.
Of the eight teams present at this OzSiCamp, we won! Big congratulations to everyone on the team: Oz, Alex, James, Daniela, Tom, (and Jeremy — that's me!) and most of all Joy, who came to the camp with a great concept, and who provided sound leadership to the rest of us. Personally, I really enjoyed working on Refugee Buddy, and I felt that the team had a great vibe and the perfect mix of skills.