Relational databases are able to store, with minimal fuss, pretty much any data entities you throw at them. For the more complex cases – particularly cases involving hierarchical data – they offer many-to-many relationships. Querying many-to-many relationships is usually quite easy: you perform a series of SQL joins in your query; and you retrieve a result set containing the combination of your joined tables, in denormalised form (i.e. with the data from some of your tables being duplicated in the result set).
A denormalised query result is quite adequate, if you plan to process the result set further – as is very often the case, e.g. when the result set is subsequently prepared for output to HTML / XML, or when the result set is used to populate data structures (objects / arrays / dictionaries / etc) in programming memory. But what if you want to export the result set directly to a flat format, such as a single CSV file? In this case, denormalised form is not ideal. It would be much better, if we could aggregate all that many-to-many data into a single result set containing no duplicate data, and if we could do that within a single SQL query.
This article presents an example of how to write such a query in MySQL – that is, a query that's able to aggregate complex many-to-many relationships, into a result set that can be exported directly to a single CSV file, with no additional processing necessary.
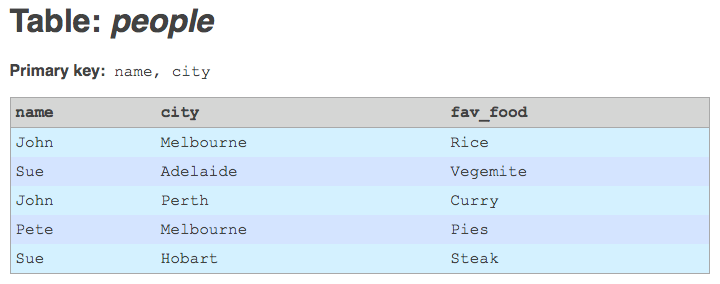
I have an interesting problem, on a data migration project I'm currently working on. I'm importing a large amount of legacy data into Drupal, using the awesome Migrate module (and friends). Migrate is a great tool for the job, but one of its limitations is that it requires the legacy database tables to have non-composite integer primary keys. Unfortunately, most of the tables I'm working with have primary keys that are either composite (i.e. the key is a combination of two or more columns), or non-integer (i.e. strings), or both.
Table with composite primary key.
The simplest solution to this problem would be to add an auto-incrementing integer primary key column to the legacy tables. This would provide the primary key information that Migrate needs in order to do its mapping of legacy IDs to Drupal IDs. But this solution has a serious drawback. In my project, I'm going to have to re-import the legacy data at regular intervals, by deleting and re-creating all the legacy tables. And every time I do this, the auto-incrementing primary keys that get generated could be different. Records may have been deleted upstream, or new records may have been added in between other old records. Auto-increment IDs would, therefore, correspond to different composite legacy primary keys each time I re-imported the data. This would effectively make Migrate's ID mapping tables corrupt.
A better solution is needed. A solution called hashing! Here's what I've come up with:
Remove the legacy primary key index from the table.
Create a new column on the table, of type BIGINT. A MySQL BIGINT field allocates 64 bits (8 bytes) of space for each value.
If the primary key is composite, concatenate the columns of the primary key together (optionally separated by a delimiter).
Calculate the SHA1 hash of the concatenated primary key string. An SHA1 hash consists of 40 hexadecimal digits. Since each hex digit stores 24 different values, each hex digit requires 4 bits of storage; therefore 40 hex digits require 160 bits of storage, which is 20 bytes.
Convert the numeric hash to a string.
Truncate the hash string down to the first 16 hex digits.
Convert the hash string back into a number. Each hex digit requires 4 bits of storage; therefore 16 hex digits require 64 bits of storage, which is 8 bytes.
Convert the number from hex (base 16) to decimal (base 10).
Store the decimal number in your new BIGINT field. You'll find that the number is conveniently just small enough to fit into this 64-bit field.
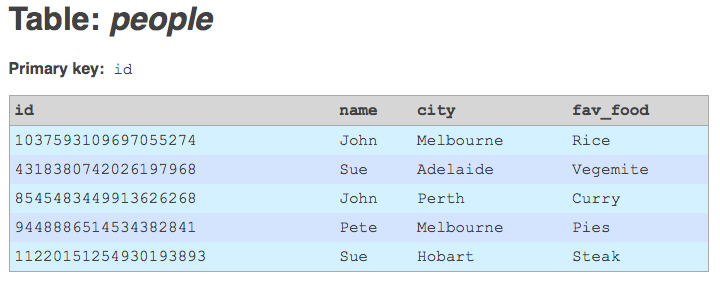
Now that the new BIGINT field is populated with unique values, upgrade it to a primary key field.
Add an index that corresponds to the legacy primary key, just to maintain lookup performance (you could make it a unique key, but that's not really necessary).
Table with integer primary key.
The SQL statement that lets you achieve this in MySQL looks like this:
ALTER TABLE people DROP PRIMARY KEY;
ALTER TABLE people ADD id BIGINT UNSIGNED NOT NULL FIRST;
UPDATE people SET id = CONV(SUBSTRING(CAST(SHA(CONCAT(name, ',', city)) AS CHAR), 1, 16), 16, 10);
ALTER TABLE people ADD PRIMARY KEY(id);
ALTER TABLE people ADD INDEX (name, city);