It's recently become quite popular for web sites to abandon the tasks of user authentication and account management, and to instead shoulder off this burden to a third-party service. One of the big services available for this purpose is Facebook. You may have noticed "Sign in with Facebook" buttons appearing ever more frequently around the 'Web.
The common workflow for Facebook user integration is: user is redirected to the Facebook login page (or is shown this page in a popup); user enters credentials; user is asked to authorise the sharing of Facebook account data with the non-Facebook source; a local account is automatically created for the user on the non-Facebook site; user is redirected to, and is automatically logged in to, the non-Facebook site. Also quite common is for the user's Facebook profile picture to be queried, and to be shown as the user's avatar on the non-Facebook site.
This article demonstrates how to achieve this common workflow in Django, with some added sugary sweetness: maintaning a whitelist of Facebook user IDs in your local database, and only authenticating and auto-registering users who exist on this whitelist.
It's been five years since it opened its doors to the general public; and, despite my avid hopes that it DIAF, the fact is that Facebook is not dead yet. Far from it. The phenomenon continues to take the world by storm, now ranking as the 2nd most visited web site in the world (after Google), and augmenting its loyal ranks with every passing day.
I've always hated Facebook. I originally joined not out of choice, but out of necessity, there being no other way to contact numerous friends of mine who had decided to boycott all alternative methods of online communication. Every day since joining, I've remained a reluctant member at best, and an open FB hater to say the least. The recent decisions of several friends of mine to delete their FB account outright, brings a warm fuzzy smile to my face. I haven't deleted my own FB account — I wish I could; but unfortunately, doing so would make numerous friends of mine uncontactable to me, and numerous social goings-on unknowable to me, today as much as ever.
There are, however, numerous features of FB that I have refused to utilise from day one, and that I highly recommend that all the world boycott. In a nutshell: any feature that involves FB being the primary store of your important personal data, is a feature that you should reject outright. Facebook is an evil company, and don't you forget it. They are not to be trusted with the sensitive and valuable data that — in this digital age of ours — all but defines who you are.
I recently added a Solr-powered search feature to this site (using django-haystack). Rather than go to the trouble (and server resources drain) of deploying Solr via Tomcat, I decided instead to deploy it via Jetty. There's a wiki page with detailed instructions for deploying Solr with Jetty, and the wiki page also includes a link to the jetty.sh startup script.
The instructions seem simple enough. However, I ran into some serious problems when trying to get the startup script to work. The standard java -jar start.jar was working fine for me. But after following the instructions to the letter, and after double-checking everything, a call to:
sudo /etc/init.d/jetty start
still resulted in my getting the (incredibly unhelpful) error message:
Starting Jetty: FAILED
My server is running Ubuntu Jaunty (9.04), and from my experience, the start-stop-daemon command in jetty.sh doesn't work on that platform. Let me know if you've experienced the same or similar issues on other *nix flavours or on other Ubuntu versions. Your mileage may vary.
For some time, I've been using the per-site cache feature that comes included with Django. This site's caching needs are very modest: small personal site, updated infrequently, with two simple blog-like sections and a handful of static pages. Plus, it runs fast enough even without any caching. A simple "brute force" solution like Django's per-site cache is more than adequate.
However, I grew tired of the fact that whenever I published new content, nothing was invalidated in the cache. I began to develop a routine of first writing and publishing the content in the Django admin, and then SSHing in to my box and restarting memcached. Not a good regime! But then again, I also couldn't bring myself to make the effort of writing custom invalidation routines for my cached pages. Considering my modest needs, it just wasn't worth it. What I needed was a solution that takes the same "brute force" page caching approach that Django's per-site cache already provided for me, but that also includes a similarly "brute force" approach to invalidation. Enter Jimmy Page.
Adding image fields to a Django model is easy, thanks to the built-in ImageField class. Auto-resizing uploaded images is also a breeze, courtesy of sorl-thumbnail and its forks/variants. But what about embedding resized images inline within text content? This is a very common use case for bloggers, and it's a final step that seems to be missing in Django at the moment.
Having recently migrated this site over from Drupal, my old blog posts had inline images embedded using image assist. Images could be inserted into an arbitrary spot within a text field by entering a token, with a syntax of [img_assist nid=123 ... ]. I wanted to be able to continue embedding images in roughly the same fashion, using a syntax as closely matching the old one as possible.
So, I've written a simple template filter that parses a text block for tokens with a syntax of [thumbnail image-identifier], and that replaces every such token with the image matching the given identifier, resized according to a pre-determined width and height (by sorl-thumbnail), and formatted as an image tag with a caption underneath. The code for the filter is below.
autop is a script that was first written for WordPress by Matt Mullenweg (the WordPress founder). All WordPress blog posts are filtered using wpautop() (unless you install an additional plug-in to disable the filter). The function was also ported to Drupal, and it's enabled by default when entering body text into Drupal nodes. As far as I'm aware, autop has never been ported to a language other than PHP. Until now.
In the process of migrating this site from Drupal to Django, I was surprised to discover that not only Django, but also Python in general, lacks any linebreak filtering function (official or otherwise) that's anywhere near as intelligent as autop. The built-in Django linebreaks filter converts all single newlines to <br /> tags, and all double newlines to <p> tags, completely irrespective of HTML block elements such as <code> and <script>. This was a fairly major problem for me, as I was migrating a lot of old content over from Drupal, and that content was all formatted in autop style. Plus, I'm used to writing content in that way, and I'd like to continue writing content in that way, whether I'm in a PHP environment or not.
Therefore, I've ported Drupal's _filter_autop() function to Python, and implemented it as a Django template filter. From the limited testing I've done, the function appears to be working just as well in Django as it does in Drupal. You can find the function below.
Fat-Free is a brand-new PHP framework, and it's one of the coolest PHP projects I've seen in quite a long time. In stark contrast to the PHP tool that I use most often (Drupal), Fat-Free is truly miniscule, and it has no plans to get bigger. It also requires PHP 5.3, which is one version ahead of what most folks are currently running (PHP 5.3 is also required by FLOW3, another framework on my test-drive to-do list). A couple of weeks back, I decided to take Fat-Free for a quick spin and to have a look under its hood. I wanted to see how good its architecture is, how well it performs, and (most of all) whether it offers enough to actually be of use to a developer in getting a real-life project out the door.
I'm going to be comparing Fat-Free mainly with Django and Drupal, because they're the two frameworks / CMSes that I use the most these days. The comparison may at many times feel like comparing a cockroach to an elephant. But like Django and Drupal, Fat-Free claims to be a complete foundation for building a dynamic web site. It wants to compete with the big boys. So, I say, let's bring it on.
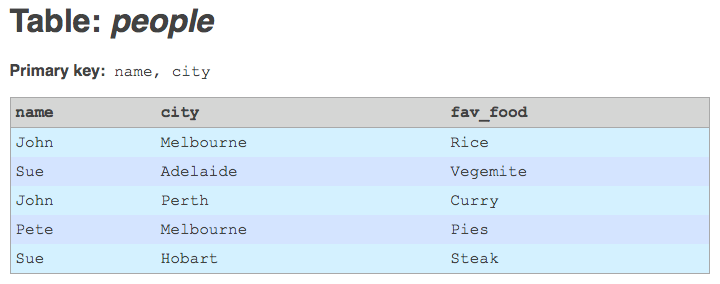
I have an interesting problem, on a data migration project I'm currently working on. I'm importing a large amount of legacy data into Drupal, using the awesome Migrate module (and friends). Migrate is a great tool for the job, but one of its limitations is that it requires the legacy database tables to have non-composite integer primary keys. Unfortunately, most of the tables I'm working with have primary keys that are either composite (i.e. the key is a combination of two or more columns), or non-integer (i.e. strings), or both.
Table with composite primary key.
The simplest solution to this problem would be to add an auto-incrementing integer primary key column to the legacy tables. This would provide the primary key information that Migrate needs in order to do its mapping of legacy IDs to Drupal IDs. But this solution has a serious drawback. In my project, I'm going to have to re-import the legacy data at regular intervals, by deleting and re-creating all the legacy tables. And every time I do this, the auto-incrementing primary keys that get generated could be different. Records may have been deleted upstream, or new records may have been added in between other old records. Auto-increment IDs would, therefore, correspond to different composite legacy primary keys each time I re-imported the data. This would effectively make Migrate's ID mapping tables corrupt.
A better solution is needed. A solution called hashing! Here's what I've come up with:
Remove the legacy primary key index from the table.
Create a new column on the table, of type BIGINT. A MySQL BIGINT field allocates 64 bits (8 bytes) of space for each value.
If the primary key is composite, concatenate the columns of the primary key together (optionally separated by a delimiter).
Calculate the SHA1 hash of the concatenated primary key string. An SHA1 hash consists of 40 hexadecimal digits. Since each hex digit stores 24 different values, each hex digit requires 4 bits of storage; therefore 40 hex digits require 160 bits of storage, which is 20 bytes.
Convert the numeric hash to a string.
Truncate the hash string down to the first 16 hex digits.
Convert the hash string back into a number. Each hex digit requires 4 bits of storage; therefore 16 hex digits require 64 bits of storage, which is 8 bytes.
Convert the number from hex (base 16) to decimal (base 10).
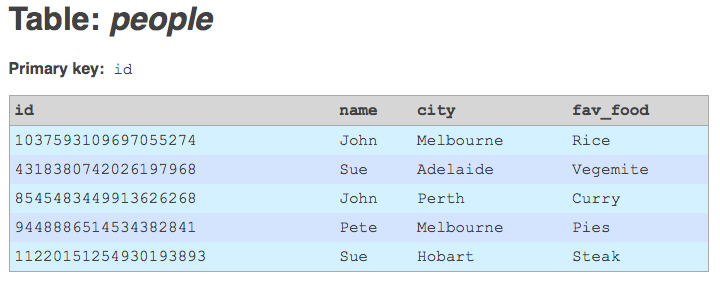
Store the decimal number in your new BIGINT field. You'll find that the number is conveniently just small enough to fit into this 64-bit field.
Now that the new BIGINT field is populated with unique values, upgrade it to a primary key field.
Add an index that corresponds to the legacy primary key, just to maintain lookup performance (you could make it a unique key, but that's not really necessary).
Table with integer primary key.
The SQL statement that lets you achieve this in MySQL looks like this:
ALTER TABLE people DROP PRIMARY KEY;
ALTER TABLE people ADD id BIGINT UNSIGNED NOT NULL FIRST;
UPDATE people SET id = CONV(SUBSTRING(CAST(SHA(CONCAT(name, ',', city)) AS CHAR), 1, 16), 16, 10);
ALTER TABLE people ADD PRIMARY KEY(id);
ALTER TABLE people ADD INDEX (name, city);
For my premiere debút into the world of jQuery plugin development, I've written a little plugin called text separator. As I wrote on its jQuery project page, this plugin:
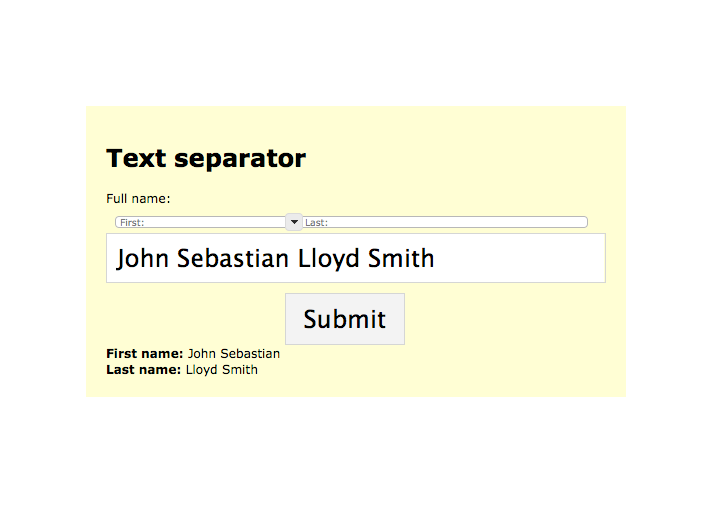
Lets you separate a text field into two parts, by dragging a slider to the spot at which you want to split the text. This plugin creates a horizontal slider above a text field. The handle on that slider is as long as its corresponding text field, and its handle 'snaps' to the delimiters in that text field (which are spaces, by default). With JS disabled, your markup should degrade gracefully to two separate text fields.
This was designed for allowing users to enter their 'full name' in one input box. The user enters their full name, and then simply drags the slider in order to mark the split betwen their first and last names. While typing, the slider automatically drags itself to the first delimiter in the input box.
Want to take it for a spin? Try a demo. You'll see something like this:
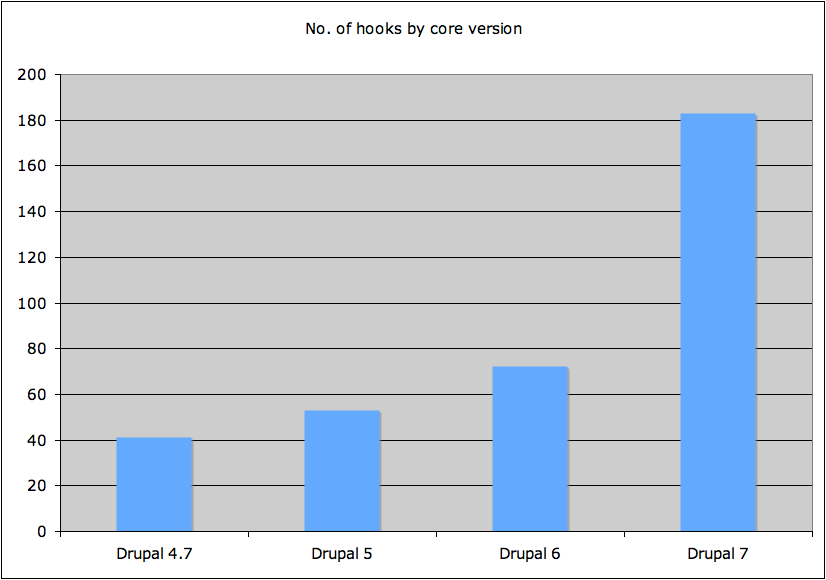
Of late, I seem to keep stumbling upon Drupal hooks that I've never heard of before. For example, I was just reading a blog post about what you can't modify in a _preprocess() function, when I saw mention of hook_theme_registry_alter(). What a mouthful. I ain't seen that one 'til now. Is it just me, or are new hooks popping up every second day in Drupal land? This got me wondering: exactly how many hooks are there in Drupal core right now? And by how much has this number changed over the past few Drupal versions? Since this information is conveniently available in the function lists on api.drupal.org, I decided to find out for myself. I counted the number of documented hook_foo() functions for Drupal core versions 4.7, 5, 6 and 7 (HEAD), and this is what I came up with (in pretty graph form):
Drupal hooks by core version
And those numbers again (in plain text form):
Drupal 4.7: 41
Drupal 5: 53
Drupal 6: 72
Drupal 7: 183
Aaaagggghhhh!!! Talk about an explosion — what we've got on our hands is nothing less than hook soup. The rate of growth of Drupal hooks is out of control. And that's not counting themable functions (and templates) and template preprocessor functions, which are the other "magically called" functions whose mechanics developers need to understand. And as for hooks defined by contrib modules — even were we only counting the "big players", such as Views — well, let's not even go there; it's really too massive to contemplate.