For a Flask-based project that I'm currently working on, I just added some front-end functionality that depends on Font Awesome. Getting Font Awesome to load properly (in well-behaved modern browsers) shouldn't be much of a chore. However, my app spans multiple subdomains (achieved with the help of Flask's Blueprints per-subdomain feature), and my static assets (CSS, JS, etc) are only served from one of those subdomains. And as it turns out (and unlike cross-domain CSS / JS / image requests), cross-domain font requests are forbidden unless the font files are served with an appropriate Access-Control-Allow-Origin HTTP response header. For example, this is the error message that's shown in Google Chrome for such a request:
Font from origin 'http://foo.local' has been blocked from loading by Cross-Origin Resource Sharing policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://bar.foo.local' is therefore not allowed access.
As a result of this, I had to quickly learn how to conditionally add custom HTTP response headers based on the URL being requested, both for Flask (when running locally with Flask's built-in development server), and for Apache (when running in staging and production). In a typical production Flask setup, it's impossible to do anything at the Python level when serving static files, because these are served directly by the web server (e.g. Apache, Nginx), without ever hitting WSGI. Conversely, in a typical development setup, there is no web server running separately to the WSGI app, and so playing around with static files must be done at the Python level.
In classical antiquity, a number of advanced civilisations flourished in the area that today comprises parts of Turkmenistan, Uzbekistan, Tajikistan, and Afghanistan. Through this area runs a river most commonly known by its Persian name, as the Amu Darya. However, in antiquity it was known by its Greek name, as the Oxus (and in the interests of avoiding anachronism, I will be referring to it as the Oxus in this article).
The Oxus region is home to archaeological relics of grand civilisations, most notably of ancient Bactria, but also of Chorasmia, Sogdiana, Margiana, and Hyrcania. However, most of these ruined sites enjoy far less fame, and are far less well-studied, than comparable relics in other parts of the world.
I recently watched an excellent documentary series called Alexander's Lost World, which investigates the history of the Oxus region in-depth, focusing particularly on the areas that Alexander the Great conquered as part of his legendary military campaign. I was blown away by the gorgeous scenery, the vibrant cultural legacy, and the once-majestic ruins that the series featured. But, more than anything, I was surprised and dismayed at the extent to which most of the ruins have been neglected by the modern world – largely due to the region's turbulent history of late.
This article has essentially the same aim as that of the documentary: to shed more light on the ancient cities and fortresses along the Oxus and nearby rivers; to get an impression of the cultures that thrived there in a bygone era; and to explore the climate change and the other forces that have dramatically affected the region between then and now.
For the past few months, my main dev project has been a custom tool that imports metric data from a variety of sources (via APIs), and that generates reports showing that data in numerous graphical and tabular formats. The app is private (and is still in alpha), so I'm afraid I can't go into more detail than that at this time.
I decided (and I was encouraged by stakeholders) to build the tool as a single-page application, i.e. as a web app where almost all of the front-end is powered by JavaScript, and where the page is redrawn via AJAX calls and client-side templates. This was my first experience developing such an app; as such, I'd like to reflect on the choices I made, and on my understanding of the technology as it stands now.
For those of you who have some experience working with Google's APIs, you may be aware of the fact that they fall into two categories: the Google Data APIs, which is mainly for older services; and the discovery-based APIs, which is mainly for newer services.
There has been considerable confusion regarding the difference between the two APIs. I'm no expert, and I admit that I too have fallen victim to the confusion at times. Both systems now require the use of OAuth2 for authentication (it's no longer possible to access any Google APIs without Oauth2). However, each of Google's APIs only falls into one of the two camps; and once authentication is complete, you must use the correct library (either GData or Discovery, for your chosen programming language) in order to actually perform API requests. So, all that really matters, is that for each API that you plan to use, you're crystal clear on which type of API it is, and you use the correct corresponding library.
The GData Python library has a very handy mechanism for exporting an authorised access token as a blob (i.e. a serialised string), and for later re-importing the blob back as a programmatic access token. I made extensive use of this when I recently worked with the Google Analytics API, which is GData-based. I couldn't find any similar functionality in the Discovery API Python library; and I wanted to interact similarly with the YouTube Data API, which is discovery-based. What to do?
For a recent project, I needed to know the LGAs (Local Government Areas) of all postcodes in Australia, and vice versa. As it turns out, there is no definitive Australia-wide list containing this data anywhere. People have been discussing the issue for some time, with no clear outcome. So, I decided to get creative.
If you want the full story: I imported both the LGA boundaries data and the Postal Area boundaries data from the ABS, into PostGIS, and I did an "Intersects" query on the two datasets. I exported the results of this query to CSV. Done! And all perfectly reproducible, using freely available public data sets, and using free and open-source software tools.
Tagging data (e.g. in a blog) is many-to-many data. Each content item can have multiple tags. And each tag can be assigned to multiple content items. Many-to-many data needs to be stored in a database. Preferably a relational database (e.g. MySQL, PostgreSQL), otherwise an alternative data store (e.g. something document-oriented like MongoDB / CouchDB). Right?
If you're not insane, then yes, that's right! However, for a recent little personal project of mine, I decided to go nuts and experiment. Check it out, this is my "mapping data" store:
Just a list of files in a directory.
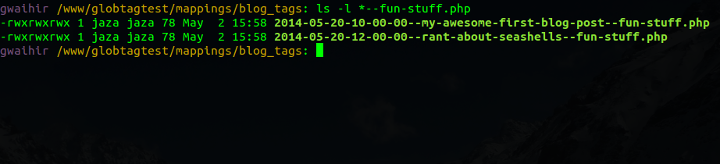
And check it out, this is me querying the data store:
Show me all posts with the tag 'fun-stuff'.
And again:
Show me all tags for the post 'rant-about-seashells'.
And that's all there is to it. Many-to-many tagging data stored in a list of files, with content item identifiers and tag identifiers embedded in each filename. Querying is by simple directory listing shell commands with wildcards (also known as "globbing").
Is it user-friendly to add new content? No! Does it allow the rich querying of SQL and friends? No! Is it scalable? No!
But… Is the basic querying it allows enough for my needs? Yes! Is it fast (for a store of up to several thousand records)? Yes! And do I have the luxury of not caring about user-friendliness or scalability in this instance? Yes!
Do you have multiple views on your Drupal site, where the content listing is themed to look exactly the same? For example, say you have a custom "search this site" view, a "featured articles" view, and an "articles archive" view. They all show the same fields — for example, "title", "image", and "summary". They all show the same content types – except that the first one shows "news" or "page" content, whereas the others only show "news".
If your design is sufficiently custom that you're writing theme-level Views template files, then chances are that you'll be in danger of creating duplicate templates. I've committed this sin on numerous sites over the past few years. On many occasions, my Views templates were 100% identical, and after making a change in one template, I literally copy-pasted and renamed the file, to update the other templates.
Until, finally, I decided that enough is enough – time to get DRY!
Being less repetitive with your Views templates is actually dead simple. Let's say you have three identical files – views-view-fields--search_this_site.tpl.php, views-view-fields--featured_articles.tpl.php, and views-view-fields--articles_archive.tpl.php. Here's how you clean up your act:
Delete the latter two files.
Add this to your theme's template.php file:
<?php
function mytheme_preprocess_views_view_fields(&$vars) {
if (in_array(
$vars['view']->name, array(
'search_this_site',
'featured_articles',
'articles_archive'))) {
$vars['theme_hook_suggestions'][] =
'views_view_fields__search_this_site';
}
}
Clear your cache (that being the customary final step when doing anything in Drupal, of course).
With virtually everything in Drupal, there are two ways to accomplish a task: The Easy Way, or The Right™ Way.
Deploying a new Drupal site for the first time is no exception. The Easy Way – and almost certainly the most common way – is to simply copy your local version of the database to production (or staging), along with user-uploaded files. (Your code needs to be deployed too, and The Right™ Way to deploy it is with version-control, which you're hopefully using… but that's another story.)
The Right™ Way to deploy a Drupal site for the first time (at least since Drupal 7, and "with hurdles" since Drupal 6), is to only deploy your code, and to reproduce your database (and ideally also user-uploaded files) with a custom installation profile, and also with significant help from the Features module.
The Right Way can be a deep rabbit hole, though. Image source:SIX Nutrition.
I've been churning out quite a lot of Drupal sites over the past few years, and I must admit, the vast majority of them were deployed The Easy Way. Small sites, single developer, quick turn-around. That's usually the way it rolls. However, I've done some work that's required custom installation profiles, and I've also been trying to embrace Features more; and so, for my most recent project – despite it being "yet another small-scale, one-dev site" – I decided to go the full hog, and to build it 100% The Right™ Way, just for kicks.
Does it give me a warm fuzzy feeling, as a dev, to be able to install a perfect copy of a new site from scratch? Hell yeah. But does that warm fuzzy feeling come at a cost? Hell yeah.
I recently built a web site using Mezzanine, a CMS built on top of Django. I decided to go with Mezzanine (which I've never used before) for two reasons: it nicely enhances Django's admin experience (plus it enhances, but doesn't get in the way of, the Django developer experience); and there's a shopping cart app called Cartridge that's built on top of Mezzanine, and for this particular site (a children's art class business in Sydney) I needed shopping cart / e-commerce functionality.
This suite turned out to deliver virtually everything I needed out-of-the-box, with one exception: Cartridge currently lacks support for payment methods that require redirecting to the payment gateway and then returning after payment completion (such as PayPal Website Payments Standard, or WPS). It only supports payment methods where payment is completed on-site (such as PayPal Website Payments Pro, or WPP). In this case, with the project being small and low-budget, I wanted to avoid the overhead of dealing with SSL and on-site payment, so PayPal WPS was the obvious candidate.
Turns out that, with a bit of hackery, making Cartridge play nice with WPS isn't too hard to achieve. Here's how you go about it.
Being a member of mainstream society isn't for everyone. Some want out.
Societal vices have always been bountiful. Back in the ol' days, it was just the usual suspects. War. Violence. Greed. Corruption. Injustice. Propaganda. Lewdness. Alcoholism. To name a few. In today's world, still more scourges have joined in the mix. Consumerism. Drug abuse. Environmental damage. Monolithic bureaucracy. And plenty more.
There always have been some folks who elect to isolate themselves from the masses, to renounce their mainstream-ness, to protect themselves from all that nastiness. And there always will be. Nothing wrong with doing so.
However, there's a difference between protecting oneself from "the evils of society", and blinding oneself to their very existence. Sometimes this difference is a fine line. Particularly in the case of families, where parents choose to shield from the Big Bad World not only themselves, but also their children. Protection is noble and commendable. Blindfolding, in my opinion, is cowardly and futile.