Per the EU's GDPR and ePrivacy Directive, you must ask visitors to a website for their consent before setting any cookies, and/or before collecting any user tracking data. And because the GDPR applies to all EU citizens (who are residing within the EU), regardless of where in the world a website or its owner is based, in order to fully comply, in practice you should seek consent for all visitors to all websites globally.
In order to be GDPR-compliant, and in order to just be a good netizen, I made sure, when building GreenAsh v5 earlier this year, to not use services that set cookies at all, wherever possible. In previous iterations of GreenAsh, I used Google Analytics, which (like basically all Google services) is a notorious GDPR offender; this time around, I instead used Cloudflare Web Analytics, which is a good enough replacement for my modest needs, and which ticks all the privacy boxes.
However, on pages with forms at least, I still need Google reCAPTCHA. I'd like to instead use the privacy-conscious hCaptcha, but Netlify Forms only supports reCAPTCHA, so I'm stuck with it for now. Here's how I seek the user's consent before loading reCAPTCHA.
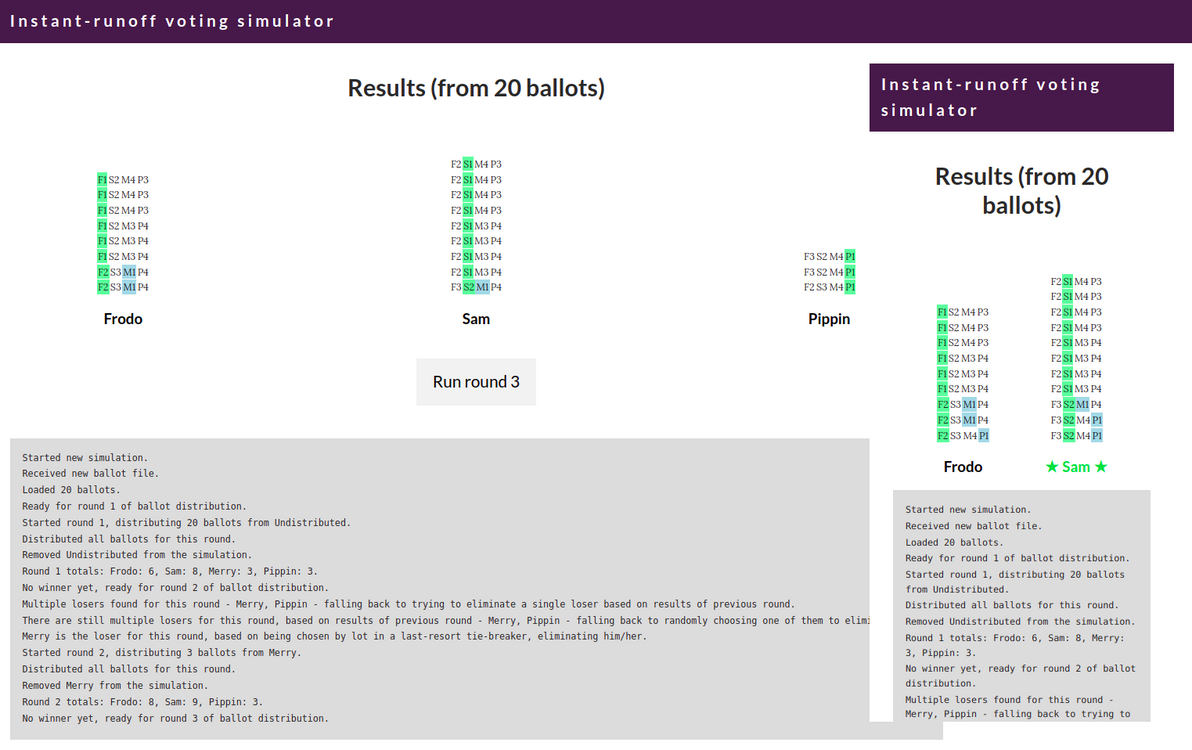
I built a simulator showing how instant-runoff voting (called preferential voting in Australia) works step-by-step. Try it now.
The simulator in action
I hope that, by being an interactive, animated, round-by-round visualisation of the ballot distribution process, this simulation gives you a deeper understanding of how instant-runoff voting works.
The Eiffel Tower, as it turns out, is far more than just the most iconic tourist attraction in the world. As the tallest structure ever built by man at the time – and holder of the record "tallest man-made structure in the world" for 41 years, following its completion in 1889 – it was a revolutionary feat of structural engineering. It was also highly controversial – deeply unpopular, one might even say – with some of the most prominent Parisians of the day fiercely protesting against its "monstruous" form. And Gustave Eiffel, its creator, was brilliant, ambitious, eccentric, and thick-skinned.
From reading the wonderful epic novel Paris, by Edward Rutherford, I learned some facts about Gustave Eiffel's life, and about the Eiffel Tower's original conception, its construction, and its first few decades as the exclamation mark of the Paris skyline, that both surprised and intrigued me. Allow me to share these tidbits of history in this here humble article.
When the Python codebase for a project (let's call the project LasagnaFest) starts getting big, and when you feel the urge to re-use a chunk of code (let's call that chunk foodutils) in multiple places, there are a variety of steps at your disposal. The most obvious step is to move that foodutils code into its own file (thus making it a Python module), and to then import that module wherever else you want in the codebase.
Most of the time, doing that is enough. The Python module importing system is powerful, yet simple and elegant.
But… what happens a few months down the track, when you're working on two new codebases (let's call them TortelliniFest and GnocchiFest – perhaps they're for new clients too), that could also benefit from re-using foodutils from your old project? What happens when you make some changes to foodutils, for the new projects, but those changes would break compatibility with the old LasagnaFest codebase?
What happens when you want to give a super-charged boost to your open source karma, by contributing foodutils to the public domain, but separated from the cruft that ties it to LasagnaFest and Co? And what do you do with secretfoodutils, which for licensing reasons (it contains super-yummy but super-secret sauce) can't be made public, but which should ideally also be separated from the LasagnaFest codebase for easier re-use?
Or – not to be forgotten – what happens when, on one abysmally rainy day, you take a step back and audit the LasagnaFest codebase, and realise that it's got no less than 38 different *utils chunks of code strewn around the place, and you ponder whether surely keeping all those utils within the LasagnaFest codebase is really the best way forward?
Moving foodutils to its own module file was a great first step; but it's clear that in this case, a more drastic measure is needed. In this case, it's time to split off foodutils into a separate, independent codebase, and to make it an external dependency of the LasagnaFest project, rather than an internal component of it.
This article is an introduction to the how and the why of cutting up parts of a Python codebase into dependencies. I've just explained a fair bit of the why. As for the how: in a nutshell, pip (for installing dependencies), the public PyPI repo (for hosting open-sourced dependencies), and a private PyPI repo (for hosting proprietary dependencies). Read on for more details.
Over the past century or so, much has been achieved in combating the famous Tyranny of Distance that naturally afflicts this land. High-quality road, rail, and air links now traverse the length and breadth of Oz, making journeys between most of her far-flung corners relatively easy.
Nevertheless, there remain a few key missing pieces, in the grand puzzle of a modern, well-connected Australian infrastructure system. This article presents five such missing pieces, that I personally would like to see built in my lifetime. Some of these are already in their early stages of development, while others are pure fantasies that may not even be possible with today's technology and engineering. All of them, however, would provide a new long-distance connection between regions of Australia, where there is presently only an inferior connection in place, or none at all.
Tagging data (e.g. in a blog) is many-to-many data. Each content item can have multiple tags. And each tag can be assigned to multiple content items. Many-to-many data needs to be stored in a database. Preferably a relational database (e.g. MySQL, PostgreSQL), otherwise an alternative data store (e.g. something document-oriented like MongoDB / CouchDB). Right?
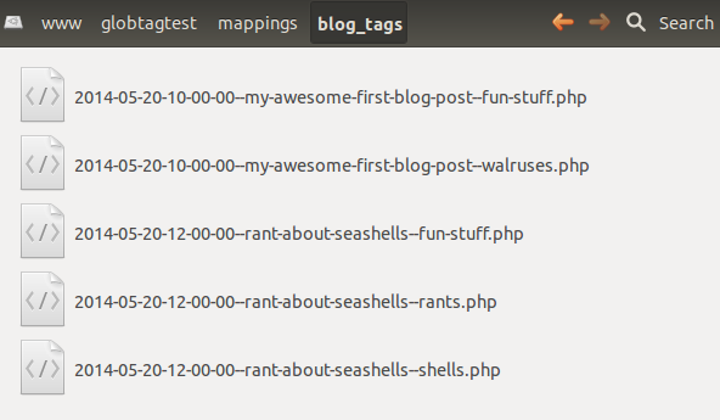
If you're not insane, then yes, that's right! However, for a recent little personal project of mine, I decided to go nuts and experiment. Check it out, this is my "mapping data" store:
Just a list of files in a directory.
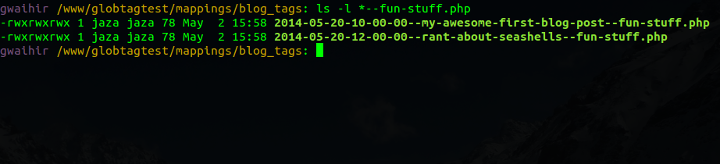
And check it out, this is me querying the data store:
Show me all posts with the tag 'fun-stuff'.
And again:
Show me all tags for the post 'rant-about-seashells'.
And that's all there is to it. Many-to-many tagging data stored in a list of files, with content item identifiers and tag identifiers embedded in each filename. Querying is by simple directory listing shell commands with wildcards (also known as "globbing").
Is it user-friendly to add new content? No! Does it allow the rich querying of SQL and friends? No! Is it scalable? No!
But… Is the basic querying it allows enough for my needs? Yes! Is it fast (for a store of up to several thousand records)? Yes! And do I have the luxury of not caring about user-friendliness or scalability in this instance? Yes!
As of about two months ago, I am a very late and reluctant entrant into the world of smartphones. All that my friends and family could say to me, was: "What took you so long?!" Being a web developer, everyone expected that I'd already long since jumped on the bandwagon. However, I was actually in no hurry to make the switch.
Techomeanies: sad dinosaur. Image source:Sticky Comics.
Being now acquainted with my new toy, I believe I can safely say that my reluctance was not (entirely) based on my being a "phone dinosaur", an accusation that some have levelled at me. Apart from the fact that they offer "a tonne of features that I don't need", I'd assert that the current state-of-the-art in smartphones suffers some serious usability, accessibility, and convenience issues. In short: these babies ain't so smart as their purty name suggests. These babies still have a lotta growin' up to do.
Relational databases are able to store, with minimal fuss, pretty much any data entities you throw at them. For the more complex cases – particularly cases involving hierarchical data – they offer many-to-many relationships. Querying many-to-many relationships is usually quite easy: you perform a series of SQL joins in your query; and you retrieve a result set containing the combination of your joined tables, in denormalised form (i.e. with the data from some of your tables being duplicated in the result set).
A denormalised query result is quite adequate, if you plan to process the result set further – as is very often the case, e.g. when the result set is subsequently prepared for output to HTML / XML, or when the result set is used to populate data structures (objects / arrays / dictionaries / etc) in programming memory. But what if you want to export the result set directly to a flat format, such as a single CSV file? In this case, denormalised form is not ideal. It would be much better, if we could aggregate all that many-to-many data into a single result set containing no duplicate data, and if we could do that within a single SQL query.
This article presents an example of how to write such a query in MySQL – that is, a query that's able to aggregate complex many-to-many relationships, into a result set that can be exported directly to a single CSV file, with no additional processing necessary.
It's recently become quite popular for web sites to abandon the tasks of user authentication and account management, and to instead shoulder off this burden to a third-party service. One of the big services available for this purpose is Facebook. You may have noticed "Sign in with Facebook" buttons appearing ever more frequently around the 'Web.
The common workflow for Facebook user integration is: user is redirected to the Facebook login page (or is shown this page in a popup); user enters credentials; user is asked to authorise the sharing of Facebook account data with the non-Facebook source; a local account is automatically created for the user on the non-Facebook site; user is redirected to, and is automatically logged in to, the non-Facebook site. Also quite common is for the user's Facebook profile picture to be queried, and to be shown as the user's avatar on the non-Facebook site.
This article demonstrates how to achieve this common workflow in Django, with some added sugary sweetness: maintaning a whitelist of Facebook user IDs in your local database, and only authenticating and auto-registering users who exist on this whitelist.
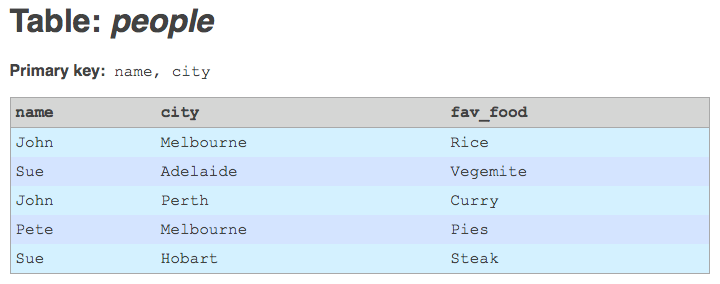
I have an interesting problem, on a data migration project I'm currently working on. I'm importing a large amount of legacy data into Drupal, using the awesome Migrate module (and friends). Migrate is a great tool for the job, but one of its limitations is that it requires the legacy database tables to have non-composite integer primary keys. Unfortunately, most of the tables I'm working with have primary keys that are either composite (i.e. the key is a combination of two or more columns), or non-integer (i.e. strings), or both.
Table with composite primary key.
The simplest solution to this problem would be to add an auto-incrementing integer primary key column to the legacy tables. This would provide the primary key information that Migrate needs in order to do its mapping of legacy IDs to Drupal IDs. But this solution has a serious drawback. In my project, I'm going to have to re-import the legacy data at regular intervals, by deleting and re-creating all the legacy tables. And every time I do this, the auto-incrementing primary keys that get generated could be different. Records may have been deleted upstream, or new records may have been added in between other old records. Auto-increment IDs would, therefore, correspond to different composite legacy primary keys each time I re-imported the data. This would effectively make Migrate's ID mapping tables corrupt.
A better solution is needed. A solution called hashing! Here's what I've come up with:
Remove the legacy primary key index from the table.
Create a new column on the table, of type BIGINT. A MySQL BIGINT field allocates 64 bits (8 bytes) of space for each value.
If the primary key is composite, concatenate the columns of the primary key together (optionally separated by a delimiter).
Calculate the SHA1 hash of the concatenated primary key string. An SHA1 hash consists of 40 hexadecimal digits. Since each hex digit stores 24 different values, each hex digit requires 4 bits of storage; therefore 40 hex digits require 160 bits of storage, which is 20 bytes.
Convert the numeric hash to a string.
Truncate the hash string down to the first 16 hex digits.
Convert the hash string back into a number. Each hex digit requires 4 bits of storage; therefore 16 hex digits require 64 bits of storage, which is 8 bytes.
Convert the number from hex (base 16) to decimal (base 10).
Store the decimal number in your new BIGINT field. You'll find that the number is conveniently just small enough to fit into this 64-bit field.
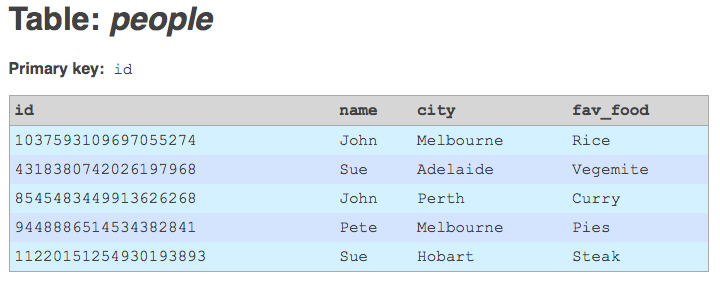
Now that the new BIGINT field is populated with unique values, upgrade it to a primary key field.
Add an index that corresponds to the legacy primary key, just to maintain lookup performance (you could make it a unique key, but that's not really necessary).
Table with integer primary key.
The SQL statement that lets you achieve this in MySQL looks like this:
ALTERTABLE people DROPPRIMARYKEY;
ALTERTABLE people ADD id BIGINT UNSIGNED NOTNULLFIRST;
UPDATE people SET id = CONV(SUBSTRING(CAST(SHA(CONCAT(name, ',', city)) ASCHAR), 1, 16), 16, 10);
ALTERTABLE people ADDPRIMARYKEY(id);
ALTERTABLE people ADD INDEX (name, city);