The Eiffel Tower, as it turns out, is far more than just the most iconic tourist attraction in the world. As the tallest structure ever built by man at the time – and holder of the record "tallest man-made structure in the world" for 41 years, following its completion in 1889 – it was a revolutionary feat of structural engineering. It was also highly controversial – deeply unpopular, one might even say – with some of the most prominent Parisians of the day fiercely protesting against its "monstruous" form. And Gustave Eiffel, its creator, was brilliant, ambitious, eccentric, and thick-skinned.
From reading the wonderful epic novel Paris, by Edward Rutherford, I learned some facts about Gustave Eiffel's life, and about the Eiffel Tower's original conception, its construction, and its first few decades as the exclamation mark of the Paris skyline, that both surprised and intrigued me. Allow me to share these tidbits of history in this here humble article.
I recently built a little web app called What If Stocks, to answer the question: based on a start and end date, and a pool of stocks and historical prices, what would have been the best stocks to invest in? This app isn't rocket science, it just ranks the stocks based on one simple metric: change in price during the selected period.
I imported into this app, price data from 2000 to 2018, for all ASX (Australian Securities Exchange) stocks that have existed for roughly the whole of that period. I then examined the results, for all possible 5-year and 10-year periods within that date range. I'd therefore like to share with you, what this app calculated to be the 12 Aussie stocks that have ranked No. 1, in terms of market price increase, for one or more of those periods.
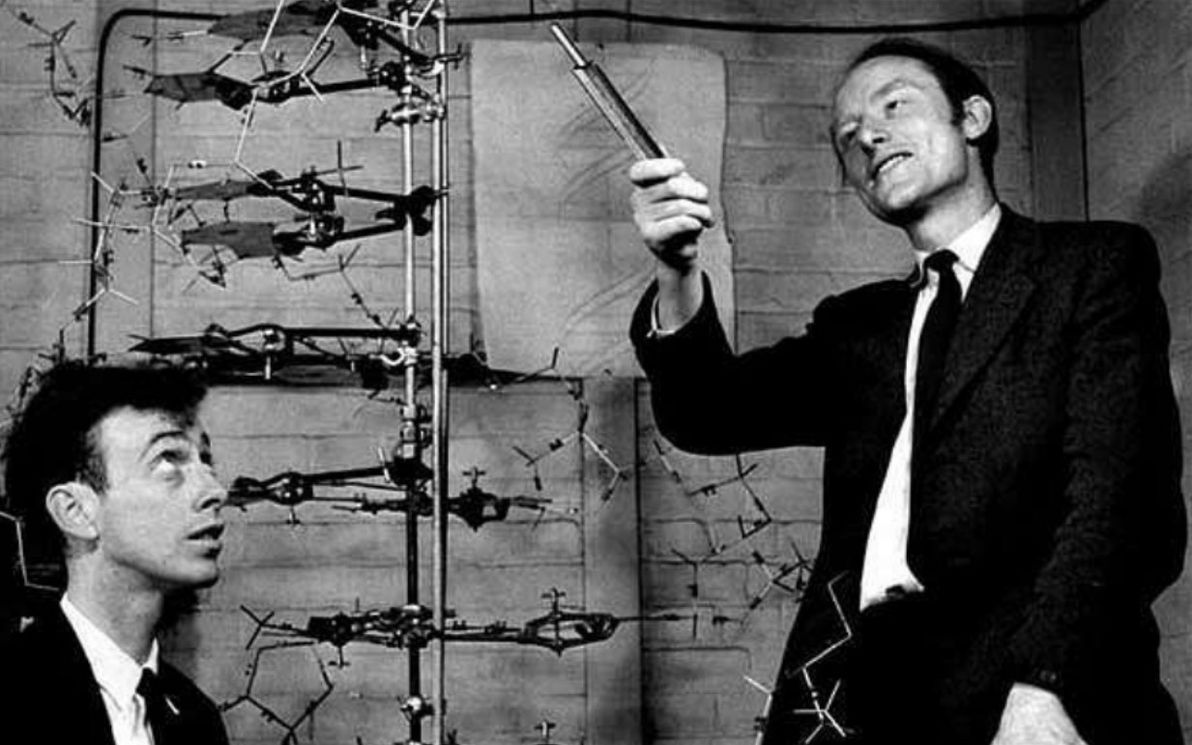
As a computer programmer – i.e. as someone whose day job is to write relatively dumb, straight-forward code, that controls relatively dumb, straight-forward machines – DNA is a fascinating thing. Other coders agree. It has been called the code of life, and rightly so: the DNA that makes up a given organism's genome, is the set of instructions responsible for virtually everything about how that organism grows, survives, behaves, reproduces, and ultimately dies in this universe.
Most intriguing and most tantalising of all, is the fact that we humans still have virtually no idea how to interpret DNA in any meaningful way. It's only since 1953 that we've understood what DNA even is; and it's only since 2001 that we've been able to extract and to gaze upon instances of the complete human genome.
As others have pointed out, the reason why we haven't had much luck in reading DNA, is because (in computer science parlance) it's not high-level source code, it's machine code (or, to be more precise, it's bytecode). So, DNA, which is sequences of base-4 digits, grouped into (most commonly) 3-digit "words" (known as "codons"), is no more easily decipherable than binary, which is sequences of base-2 digits, grouped into (for example) 8-digit "words" (known as "bytes"). And as anyone who has ever read or written binary (in binary, octal, or hex form, however you want to skin that cat) can attest, it's hard!
In this musing, I'm going to compare genetic code and computer code. I am in no way qualified to write about this topic (particularly about the biology side), but it's fun, and I'm reckless, and this is my blog so for better or for worse nobody can stop me.