A few weeks ago, I had my first and only conversation with an ardent "No" campaigner for the upcoming Australian referendum on the Voice to Parliament. (I guess we really do all live in our own little echo chambers, because all my close friends and family are in the "Yes" camp just like me, and I was genuinely surprised and caught off guard to have bumped into a No guy, especially smack-bang in my home territory of affluent upper-middle-class North Shore Sydney.) When I asked why he'll be voting No, he replied: "Because I'm not racist". Which struck me, ironically, as one of the more racist remarks I've heard in my entire life.
Now that's what I call getting your voice heard. Image source: Fandom
I seldom write purely political pieces. I'm averse to walking into the ring and picking a fight with anyone. And honestly I find not-particularly-political writing on other topics (such as history and tech) to be more fun. Nor do I consider myself to be all that passionate about indigenous affairs – at least, not compared with other progressive causes such as the environment or refugees (maybe because I'm a racist privileged white guy myself!). However, with only five days to go until Australia votes (and with the forecast for said vote looking quite dismal), I thought I'd share my two cents on what, in my humble opinion, the Voice is all about.
Ozersk (also spelled Ozyorsk) – originally known only by the codename Chelyabinsk-40 – is the site of the third-worst nuclear disaster in world history, as well as the birthplace of the Soviet Union's nuclear weapons arsenal. But I'll forgive you if you've never heard of it (I hadn't, until now). Unlike numbers one (Chernobyl) and two (Fukushima), the USSR managed to keep both the 1957 incident, and the place's very existence, secret for over 30 years.
Ozersk being so secret that few photos of it are available, is a good enough excuse, in my opinion, for illustrating this article with mildly amusing memes instead. Image source: Legends Revealed
Amazingly, to this day – more than three decades after the fall of communism – this city of about 100,000 residents (and its surrounds, including the Mayak nuclear facility, which is ground zero) remains a "closed city", with entry forbidden to all non-authorised personnel.
And, apart from being enclosed by barbed wire, it appears to also be enclosed in a time bubble, with the locals still routinely parroting the Soviet propaganda that labelled them "the nuclear shield and saviours of the world"; and with the Soviet-era pact still effectively in place that, in exchange for their loyalty, their silence, and a not-un-unhealthy dose of radiation, their basic needs (and some relative luxuries to boot) are taken care of for life.
Per the EU's GDPR and ePrivacy Directive, you must ask visitors to a website for their consent before setting any cookies, and/or before collecting any user tracking data. And because the GDPR applies to all EU citizens (who are residing within the EU), regardless of where in the world a website or its owner is based, in order to fully comply, in practice you should seek consent for all visitors to all websites globally.
In order to be GDPR-compliant, and in order to just be a good netizen, I made sure, when building GreenAsh v5 earlier this year, to not use services that set cookies at all, wherever possible. In previous iterations of GreenAsh, I used Google Analytics, which (like basically all Google services) is a notorious GDPR offender; this time around, I instead used Cloudflare Web Analytics, which is a good enough replacement for my modest needs, and which ticks all the privacy boxes.
However, on pages with forms at least, I still need Google reCAPTCHA. I'd like to instead use the privacy-conscious hCaptcha, but Netlify Forms only supports reCAPTCHA, so I'm stuck with it for now. Here's how I seek the user's consent before loading reCAPTCHA.
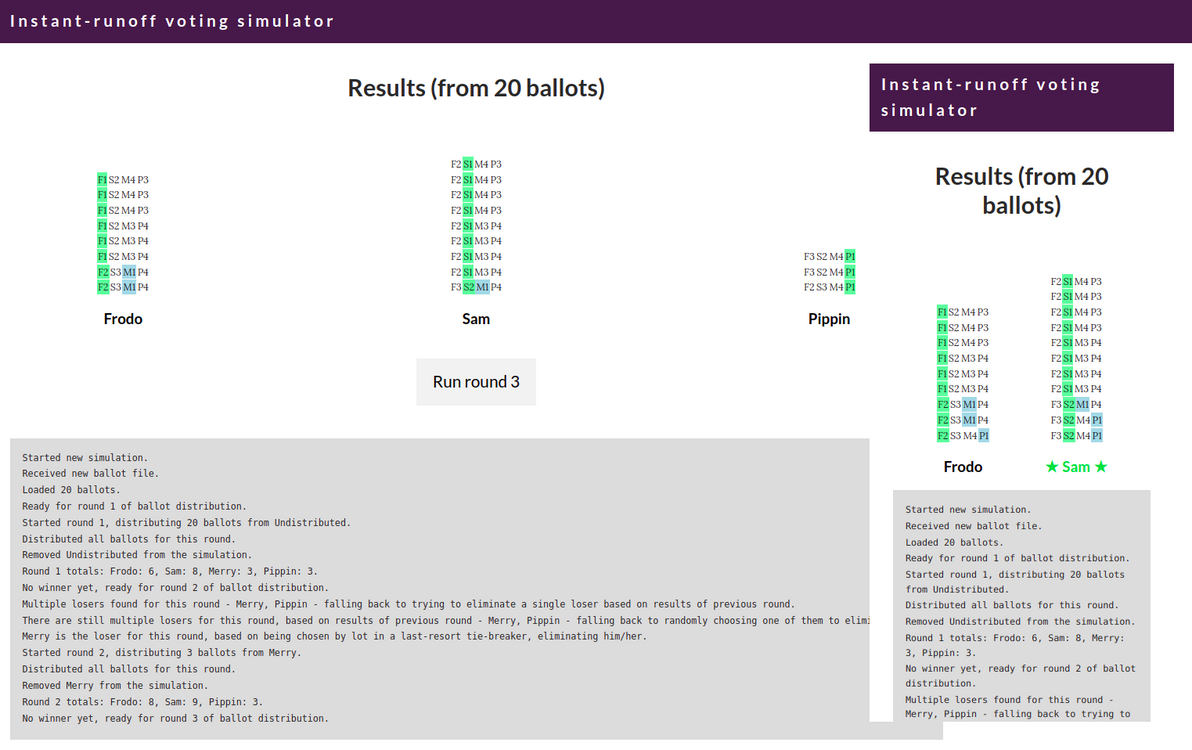
I built a simulator showing how instant-runoff voting (called preferential voting in Australia) works step-by-step. Try it now.
The simulator in action
I hope that, by being an interactive, animated, round-by-round visualisation of the ballot distribution process, this simulation gives you a deeper understanding of how instant-runoff voting works.
I have also made the casual observation, over the last three years, that Morrison makes few appearances on Aunty in general, compared with the commercial alternatives, particularly Sky News (which I personally have never watched directly, and have no plans to, but I've seen plenty of clips of Morrison on Sky repeated on the ABC and elsewhere).
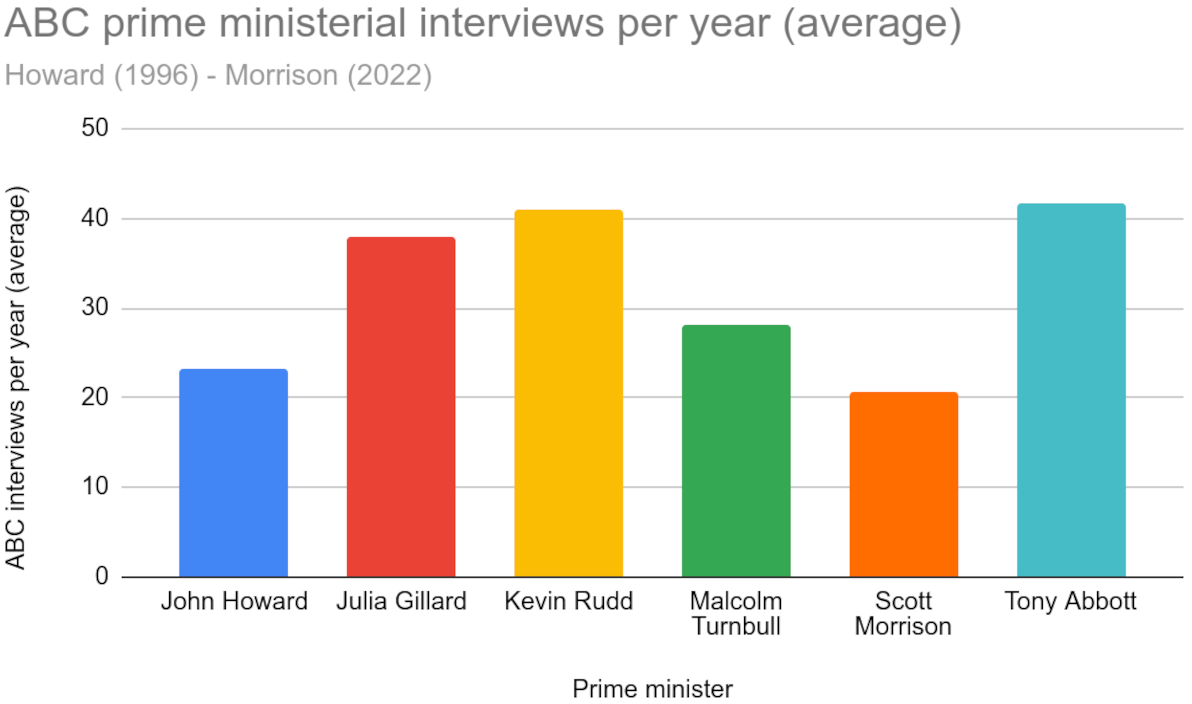
This led me to do some research, to find out: how often has Morrison taken part in ABC interviews, during his tenure so far as Prime Minister, compared with his predecessors? I compiled my findings, and this is what they show:
Morrison's ABC interview frequency compared to his forebears
It's official: Morrison has, on average, taken part in fewer ABC TV and Radio interviews, than any other Prime Minister in recent Australian history.
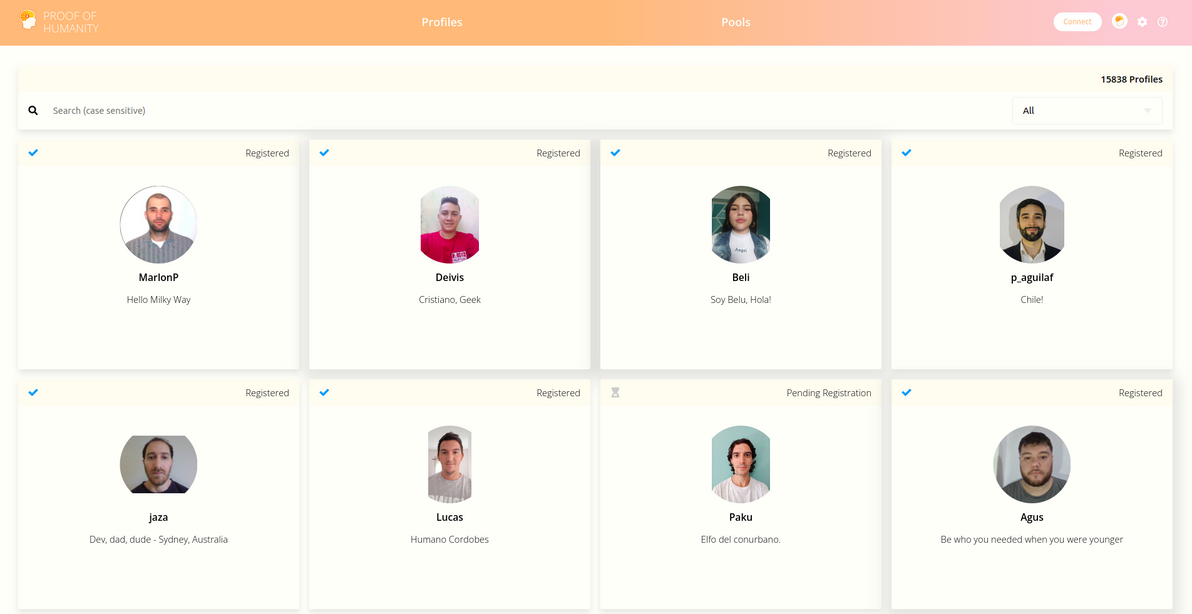
Proof of Humanity (PoH) is a project that I stumbled upon a few weeks ago. Its aim is to create a registry of every living human on the planet. So far, it's up to about 15,000 out of 7 billion.
Just for fun, I registered myself, so I'm now part of that tiny minority who, according to PoH, are verified humans! (Sorry, I guess the rest of you are just an illusion).
Actual bona fide humans
This is a brief musing on the PoH project: its background story, the people behind it, the technology powering it, the socio-economic philosophy behind it, the challenges it's facing, whether it stacks up, and what I think lies ahead.
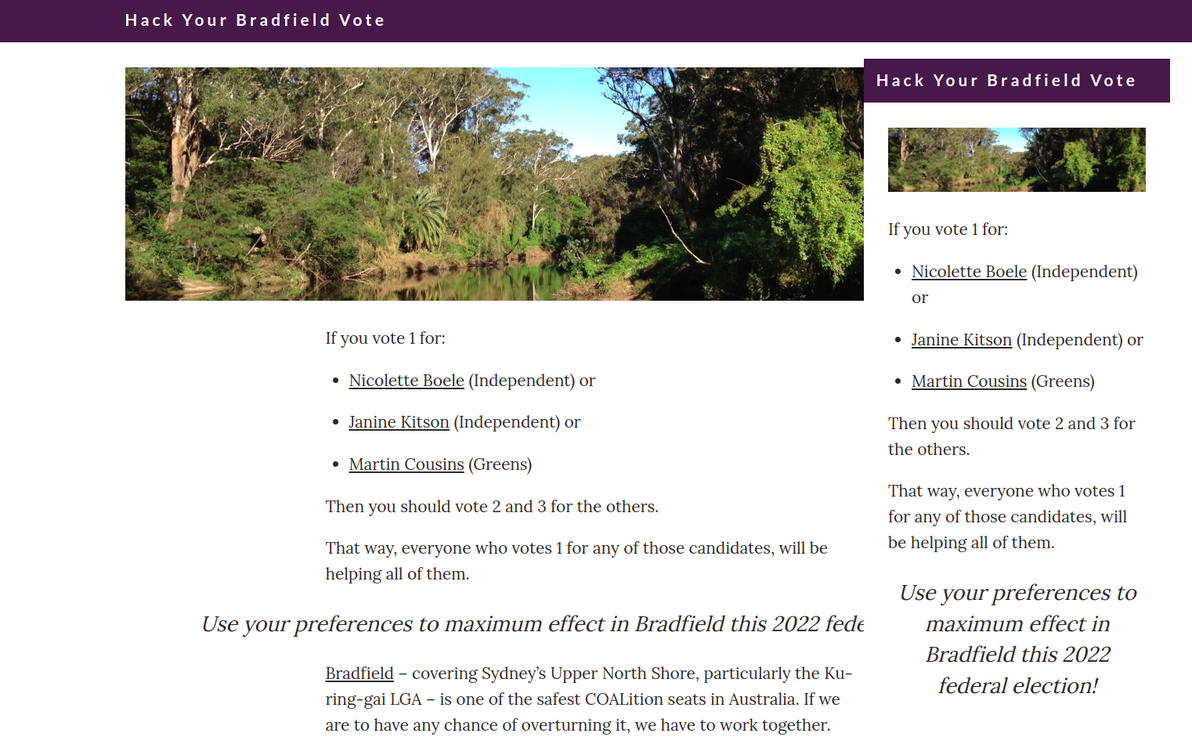
I built a tiny site, that I humbly hope makes a tiny difference in my home electorate of Bradfield, this 2022 federal election. Check out Hack Your Bradfield Vote.
How "Hack Your Bradfield Vote" looks on desktop and mobile
I'm not overly optimistic, here in what is one of the safest Liberal seats in Australia. But you never know, this may finally be the year when the winds of change rustle the verdant treescape of Sydney's leafy North Shore.
I've paid for either a "shared hosting" subscription, or a VPS subscription, for my own use, for the last two decades. Mainly for serving web traffic, but also for backups, for Git repos, and for other bits and pieces.
No more defending against evil villains! Image source: Meme Generator
In its place, I've taken the plunge and fully embraced SaaS. In particular, I've converted most of my personal web sites, and most of the other web sites under my purview, to be statically generated, and to be hosted on Netlify. I've also moved various backups to S3 buckets, and I've moved various Git repos to GitHub.
And so, you may lament that I'm yet one more netizen who has Less Power™ and less control. Yet another lost soul, entrusting these important things to the corporate overlords. And you have a point. But the case against SaaS is one that's getting harder to justify with each passing year. My new setup is (almost entirely) free (as in beer). And it's highly available, and lightning-fast, and secure out-of-the-box. And sysadmin is now Somebody Else's Problem. And the amount of ownership and control that I retain, is good enough for me.
The most noteworthy feature of the recently-launched GreenAsh v5, programming-wise, is its comment submission system. I enjoyed the luxury of the robust batteries-included comment engines of Drupal and Django, back in the day; but dynamic functionality like that isn't as straight-forward in the brave new world of SSG's. I promised that I'd provide a detailed run-down of what I built, so here goes.
Some of GreenAsh's oldest published comments, looking mighty fine in v5.




{kind=link}