Do you have multiple views on your Drupal site, where the content listing is themed to look exactly the same? For example, say you have a custom "search this site" view, a "featured articles" view, and an "articles archive" view. They all show the same fields — for example, "title", "image", and "summary". They all show the same content types – except that the first one shows "news" or "page" content, whereas the others only show "news".
If your design is sufficiently custom that you're writing theme-level Views template files, then chances are that you'll be in danger of creating duplicate templates. I've committed this sin on numerous sites over the past few years. On many occasions, my Views templates were 100% identical, and after making a change in one template, I literally copy-pasted and renamed the file, to update the other templates.
Until, finally, I decided that enough is enough – time to get DRY!
Being less repetitive with your Views templates is actually dead simple. Let's say you have three identical files – views-view-fields--search_this_site.tpl.php, views-view-fields--featured_articles.tpl.php, and views-view-fields--articles_archive.tpl.php. Here's how you clean up your act:
Delete the latter two files.
Add this to your theme's template.php file:
<?php
function mytheme_preprocess_views_view_fields(&$vars) {
if (in_array(
$vars['view']->name, array(
'search_this_site',
'featured_articles',
'articles_archive'))) {
$vars['theme_hook_suggestions'][] =
'views_view_fields__search_this_site';
}
}
Clear your cache (that being the customary final step when doing anything in Drupal, of course).
With virtually everything in Drupal, there are two ways to accomplish a task: The Easy Way, or The Right™ Way.
Deploying a new Drupal site for the first time is no exception. The Easy Way – and almost certainly the most common way – is to simply copy your local version of the database to production (or staging), along with user-uploaded files. (Your code needs to be deployed too, and The Right™ Way to deploy it is with version-control, which you're hopefully using… but that's another story.)
The Right™ Way to deploy a Drupal site for the first time (at least since Drupal 7, and "with hurdles" since Drupal 6), is to only deploy your code, and to reproduce your database (and ideally also user-uploaded files) with a custom installation profile, and also with significant help from the Features module.
The Right Way can be a deep rabbit hole, though. Image source:SIX Nutrition.
I've been churning out quite a lot of Drupal sites over the past few years, and I must admit, the vast majority of them were deployed The Easy Way. Small sites, single developer, quick turn-around. That's usually the way it rolls. However, I've done some work that's required custom installation profiles, and I've also been trying to embrace Features more; and so, for my most recent project – despite it being "yet another small-scale, one-dev site" – I decided to go the full hog, and to build it 100% The Right™ Way, just for kicks.
Does it give me a warm fuzzy feeling, as a dev, to be able to install a perfect copy of a new site from scratch? Hell yeah. But does that warm fuzzy feeling come at a cost? Hell yeah.
I build quite a few Drupal sites that use embedded YouTube videos, and my module of choice for handling this is Media: YouTube, which is built upon the popular Media module. The Media: YouTube module generally works great; but on one site that I recently built, I discovered one of its shortcomings. It doesn't let you display a YouTube video's duration.
I thought up a quick, performant and relatively easy way to solve this. With just a few snippets of custom code, and the help of the Computed Field module, showing video duration (in hours / minutes / seconds) for a Media: YouTube managed asset, is a walk in the park.
On a project I'm currently working on, I decided to try out something of a related flavour. I built a stand-alone app in Silex (a sort of Symfony2 distribution); but, per the project's requirements, I also managed to heavily integrate the app with an existing Drupal 7 site. The app does almost everything on its own, except that: it passes its output to drupal_render_page() before returning the request; and it checks that a Drupal user is currently logged-in and has a certain Drupal user role, for pages where authorisation is required.
The result is: an app that has its own custom database, its own routes, its own forms, its own business logic, and its own templates; but that gets rendered via the Drupal theming system, and that relies on Drupal data for authentication and authorisation. What's more, the implementation is quite clean (minimal hackery involved) – only a small amount of code is needed for the integration, and then (for the most part) Drupal and Silex leave each other alone to get on with their respective jobs. Now, let me show you how it's done.
On a number of my recently-built Drupal sites, I've become a fan of using the Computed Field module to provide a "search data" field, as a Views exposed filter. This technique has been documented by other folks here and there (I didn't invent it), so I won't cover its details here. Basically, it's a handy way to create a search form that searches exactly the fields you're interested in, thus providing you with more fine-grained control than the core Drupal search module, and with much less installation / configuration overhead than Apache Solr.
On one such site, which has about 4,000+ nodes that are searchable via this technique, I needed to add another field to the index, and re-generate the Computed Field data for every node. This data normally only gets re-generated when each individual node is saved. In my case, that would not be sufficient - I needed the entire search index refreshed immediately.
The obvious solution, would be to whip up a quick script that loops through all the nodes in question, and that calls node_save() on each pass through the loop. However, this solution has two problems. Firstly, node_save() is really slow (particularly when the node has a lot of other fields, such as was my case). So slow, in fact, that in my case I was fighting a losing battle against PHP "maximum execution time exceeded" errors. Secondly, node_save() is slow unnecessarily, as it re-saves all the data for all a node's fields (plus it invokes a bazingaful of hooks), whereas we only actually need to re-save the data for one field (and we don't need any hooks invoked, thanks).
In the interests of both speed and cutting-out-the-cruft, therefore, I present here an alternative solution: getting rid of the middle man (node_save()), and instead invoking the field_storage_write callback directly. Added bonus: I've implemented it using the Batch API functionality available via Drupal 7's hook_update_N().
I've been noticing more and more lately, that for every new Drupal site I build, I define a lot of custom blocks. I put the code for these blocks in one or more custom modules, and most of them are really simple. For me, at least, the most common task that these blocks perform, is to display one or more fields of the node (or other entity) page currently being viewed; and in second place, is the task of displaying a list of nodes from a nodequeue (as I'm rather a Nodequeue module addict, I tend to have nodequeues strewn all over my sites).
In short, I've gotten quite bored of copy-pasting the same block definition code over and over, usually with minimal changes. I also feel that such simple block definitions don't warrant defining a new custom module – as they have zero interesting logic / functionality, and as their purpose is purely presentational, I'd prefer to define them at the theme level. Additionally, every Drupal module has both administrative overhead (need to install / enable it on different environments, need to manage its deployment, etc), and performance overhead (every extra PHP include() call involves opening and reading a new file from disk, and every enabled Drupal module is a minimum of one extra PHP file to be included); so, less enabled modules means a faster site.
To make my life easier – and the life of anyone else in the same boat – I've written the Handy Block module. (As the project description says,) if you often have a bunch of custom modules on your site, that do nothing except implement block hooks (along with block callback functions), for blocks that do little more than display some fields for the entity currently being viewed, then Handy Block should… well, it should come in handy! You'll be able to do the same thing in just a few lines of your template.php file; and then, you can delete those custom modules of yours altogether.
Drupal 7's new Field API is a great feature. Unfortunately, theming an entity and its fields can be quite a daunting task. The main reason for this, is that the field variables that get passed to template files are not particularly themer-friendly. Themers are HTML markup and CSS coders; they're not PHP or Drupal coders. When themers start writing their node--page.tpl.php file, all they really want to know is: How do I output each field of this page [node type], exactly where I want, and with minimal fuss?
It is in the interests of improving the Drupal Themer Experience, therefore, that I present the Template Field Variables module. (As the project description says,) this module takes the mystery out of theming fieldable entities. For each field in an entity, it extracts the values that you actually want to output (from the infamous "massive nested arrays" that Drupal provides), and it puts those values in dead-simple variables.
Relational databases are able to store, with minimal fuss, pretty much any data entities you throw at them. For the more complex cases – particularly cases involving hierarchical data – they offer many-to-many relationships. Querying many-to-many relationships is usually quite easy: you perform a series of SQL joins in your query; and you retrieve a result set containing the combination of your joined tables, in denormalised form (i.e. with the data from some of your tables being duplicated in the result set).
A denormalised query result is quite adequate, if you plan to process the result set further – as is very often the case, e.g. when the result set is subsequently prepared for output to HTML / XML, or when the result set is used to populate data structures (objects / arrays / dictionaries / etc) in programming memory. But what if you want to export the result set directly to a flat format, such as a single CSV file? In this case, denormalised form is not ideal. It would be much better, if we could aggregate all that many-to-many data into a single result set containing no duplicate data, and if we could do that within a single SQL query.
This article presents an example of how to write such a query in MySQL – that is, a query that's able to aggregate complex many-to-many relationships, into a result set that can be exported directly to a single CSV file, with no additional processing necessary.
I recently found myself faced with an interesting little web dev challenge. Here's the scenario. You've got a site that's powered by a PHP CMS (in this case, Drupal). One of the pages on this site contains a number of HTML text blocks, each of which must be user-editable with a rich-text editor (in this case, TinyMCE). However, some of the HTML within these text blocks (in this case, the unordered lists) needs some fairly advanced styling – the kind that's only possible either with CSS3 (using, for example, nth-child pseudo-selectors), with JS / jQuery manipulation, or with the addition of some extra markup (for example, some first, last, and first-in-row classes on the list item elements).
Naturally, IE7+ compatibility is required – so, CSS3 selectors are out. Injecting element attributes via jQuery is a viable option, but it's an ugly approach, and it may not kick in immediately on page load. Since the users will be editing this content via WYSIWYG, we can't expect them to manually add CSS classes to the markup, or to maintain any markup that the developer provides in such a form. That leaves only one option: injecting extra attributes on the server-side.
When it comes to HTML manipulation, there are two general approaches. The first is Parsing HTML The Cthulhu Way (i.e. using Regular Expressions). However, you already have one problem to solve – do you really want two? The second is to use an HTML parser. Sadly, this problem must be solved in PHP – which, unlike some otherlanguages, lacks an obvioustool of choice in the realm of parsers. I chose to use PHP5's built-in DOMDocument library, which (from what I can tell) is one of the most mature and widely-used PHP HTML parsers available today. Here's my code snippet.
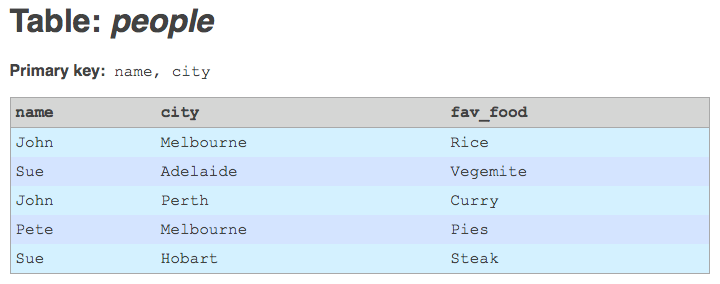
I have an interesting problem, on a data migration project I'm currently working on. I'm importing a large amount of legacy data into Drupal, using the awesome Migrate module (and friends). Migrate is a great tool for the job, but one of its limitations is that it requires the legacy database tables to have non-composite integer primary keys. Unfortunately, most of the tables I'm working with have primary keys that are either composite (i.e. the key is a combination of two or more columns), or non-integer (i.e. strings), or both.
Table with composite primary key.
The simplest solution to this problem would be to add an auto-incrementing integer primary key column to the legacy tables. This would provide the primary key information that Migrate needs in order to do its mapping of legacy IDs to Drupal IDs. But this solution has a serious drawback. In my project, I'm going to have to re-import the legacy data at regular intervals, by deleting and re-creating all the legacy tables. And every time I do this, the auto-incrementing primary keys that get generated could be different. Records may have been deleted upstream, or new records may have been added in between other old records. Auto-increment IDs would, therefore, correspond to different composite legacy primary keys each time I re-imported the data. This would effectively make Migrate's ID mapping tables corrupt.
A better solution is needed. A solution called hashing! Here's what I've come up with:
Remove the legacy primary key index from the table.
Create a new column on the table, of type BIGINT. A MySQL BIGINT field allocates 64 bits (8 bytes) of space for each value.
If the primary key is composite, concatenate the columns of the primary key together (optionally separated by a delimiter).
Calculate the SHA1 hash of the concatenated primary key string. An SHA1 hash consists of 40 hexadecimal digits. Since each hex digit stores 24 different values, each hex digit requires 4 bits of storage; therefore 40 hex digits require 160 bits of storage, which is 20 bytes.
Convert the numeric hash to a string.
Truncate the hash string down to the first 16 hex digits.
Convert the hash string back into a number. Each hex digit requires 4 bits of storage; therefore 16 hex digits require 64 bits of storage, which is 8 bytes.
Convert the number from hex (base 16) to decimal (base 10).
Store the decimal number in your new BIGINT field. You'll find that the number is conveniently just small enough to fit into this 64-bit field.
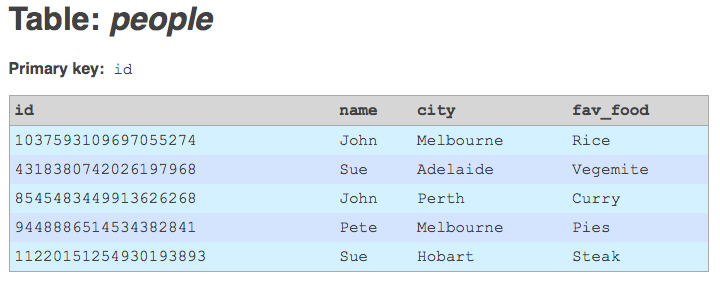
Now that the new BIGINT field is populated with unique values, upgrade it to a primary key field.
Add an index that corresponds to the legacy primary key, just to maintain lookup performance (you could make it a unique key, but that's not really necessary).
Table with integer primary key.
The SQL statement that lets you achieve this in MySQL looks like this:
ALTER TABLE people DROP PRIMARY KEY;
ALTER TABLE people ADD id BIGINT UNSIGNED NOT NULL FIRST;
UPDATE people SET id = CONV(SUBSTRING(CAST(SHA(CONCAT(name, ',', city)) AS CHAR), 1, 16), 16, 10);
ALTER TABLE people ADD PRIMARY KEY(id);
ALTER TABLE people ADD INDEX (name, city);