Database-free content tagging with files and glob
Tagging data (e.g. in a blog) is many-to-many data. Each content item can have multiple tags. And each tag can be assigned to multiple content items. Many-to-many data needs to be stored in a database. Preferably a relational database (e.g. MySQL, PostgreSQL), otherwise an alternative data store (e.g. something document-oriented like MongoDB / CouchDB). Right?
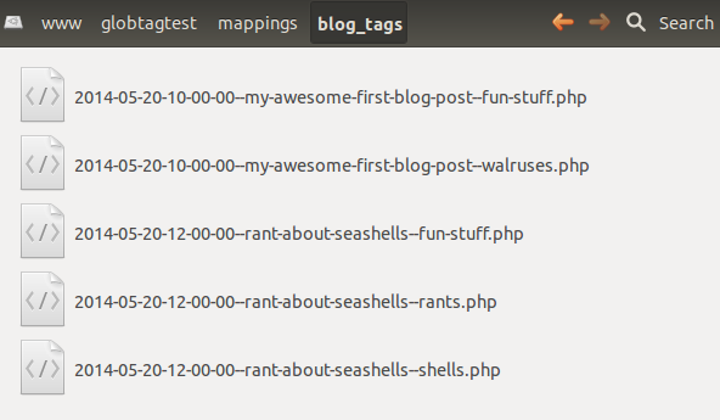
If you're not insane, then yes, that's right! However, for a recent little personal project of mine, I decided to go nuts and experiment. Check it out, this is my "mapping data" store:
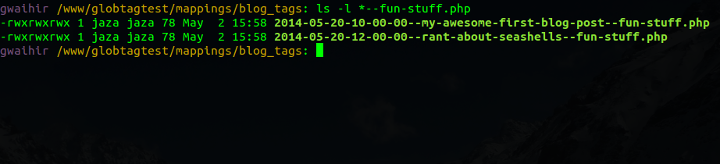
And check it out, this is me querying the data store:
And again:

And that's all there is to it. Many-to-many tagging data stored in a list of files, with content item identifiers and tag identifiers embedded in each filename. Querying is by simple directory listing shell commands with wildcards (also known as "globbing").
Is it user-friendly to add new content? No! Does it allow the rich querying of SQL and friends? No! Is it scalable? No!
But… Is the basic querying it allows enough for my needs? Yes! Is it fast (for a store of up to several thousand records)? Yes! And do I have the luxury of not caring about user-friendliness or scalability in this instance? Yes!
Implementation
For the project in which I developed this system, I implemented the querying with some simple PHP code. For example, this is my "content item" store:
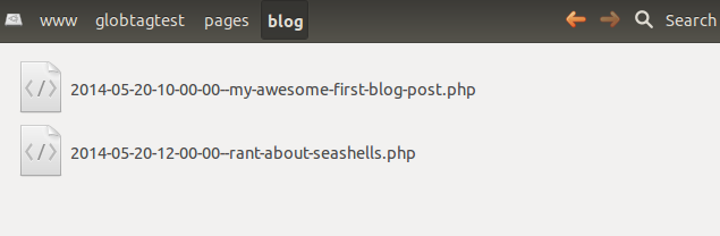
These are the functions to do some basic querying on all content:
<?php
/**
* Queries for all blog pages.
*
* @return
* List of all blog pages.
*/
function blog_query_all() {
$files = glob(BASE_FILE_PATH . 'pages/blog/*.php');
if (!empty($files)) {
foreach (array_keys($files) as $k) {
$files[$k] = str_replace(BASE_FILE_PATH . 'pages/blog/',
'',
$files[$k]);
}
rsort($files);
}
return $files;
}
/**
* Queries for blog pages with the specified year / month.
*
* @param $year
* Year.
* @param $month
* Month
*
* @return
* List of blog pages with the specified year / month.
*/
function blog_query_byyearmonth($year, $month) {
$files = glob(BASE_FILE_PATH . 'pages/blog/' .
$year . '-' . $month . '-*.php');
if (!empty($files)) {
foreach (array_keys($files) as $k) {
$files[$k] = str_replace(BASE_FILE_PATH . 'pages/blog/',
'',
$files[$k]);
}
}
return $files;
}
/**
* Gets the previous blog page (by date).
*
* @param $full_identifier
* Full identifier of current blog page.
*
* @return
* Full identifier of previous blog page.
*/
function blog_get_prev($full_identifier) {
$files = blog_query_all();
$curr_index = array_search($full_identifier . '.php', $files);
if ($curr_index !== FALSE && $curr_index < count($files)-1) {
return str_replace('.php', '', $files[$curr_index+1]);
}
return NULL;
}
/**
* Gets the next blog page (by date).
*
* @param $full_identifier
* Full identifier of current blog page.
*
* @return
* Full identifier of next blog page.
*/
function blog_get_next($full_identifier) {
$files = blog_query_all();
$curr_index = array_search($full_identifier . '.php', $files);
if ($curr_index !== FALSE && $curr_index !== 0) {
return str_replace('.php', '', $files[$curr_index-1]);
}
return NULL;
}
And these are the functions to query content by tag:
<?php
/**
* Queries for blog pages with the specified tag.
*
* @param $slug
* Tag slug.
*
* @return
* List of blog pages with the specified tag.
*/
function blog_query_bytag($slug) {
$files = glob(BASE_FILE_PATH .
'mappings/blog_tags/*--' . $slug . '.php');
if (!empty($files)) {
foreach (array_keys($files) as $k) {
$files[$k] = str_replace(BASE_FILE_PATH . 'mappings/blog_tags/',
'',
$files[$k]);
}
rsort($files);
}
return $files;
}
/**
* Gets a blog page's tags based on its full identifier.
*
* @param $full_identifier
* Blog page's full identifier.
*
* @return
* Tags.
*/
function blog_get_tags($full_identifier) {
$files = glob(BASE_FILE_PATH .
'mappings/blog_tags/' . $full_identifier . '*.php');
$ret = array();
if (!empty($files)) {
foreach ($files as $f) {
$ret[] = str_replace(BASE_FILE_PATH . 'mappings/blog_tags/' .
$full_identifier . '--',
'',
str_replace('.php', '', $f));
}
}
return $ret;
}
That's basically all the "querying" that this blog app needs.
In summary
What I've shared here, is part of the solution that I recently built when I migrated Jaza's World Trip (my travel blog from 2007-2008) away from (an out-dated version of) Drupal, and into a new database-free custom PHP thingamajig. (I'm considering writing a separate article about what else I developed, and I'm also considering cleaning it up and releasing it as a biolerplate PHP project template on GitHub… although not sure if it's worth the effort, we shall see).
This is an old blog site that I wanted to "retire", i.e. to migrate off a CMS platform, and into more-or-less static files. So, the filesystem-based data store that I developed in this case was a good match, because:
- No new content will be added to the site in the future
- Migrating the site to a different server (in the hypothetical future) would consist of simply copying all the files, and the new server would only need to support PHP (and PHP is the most commonly-supported web server technology in the world)
- If the data store performs well with the current volume of content, that's great; I don't care if it doesn't scale to millions of records (due to e.g. files-per-directory OS limits being reached, glob performance worsening), because it will never have that many
Most sites that I develop are new, and they don't fit this use case at all. They need a content management admin interface. They need to scale. And they usually need various other features (e.g. user login) that also commonly rely on a traditional database backend. However, for this somewhat unique use-case, building a database-free tagging data store was a fun experiment!