I built a little Python script called the Floyd-Warshall CSV Generator. It takes a CSV of graph edges as input, and generates a CSV of the edges that are the shortest paths between all pairs of vertices.
Over the past year or two, I've been heavily using FastAPI in my day job. I've been around the Python web framework block, and I gotta say, FastAPI really succeeds in its mission of building on the strengths of its predecessors (particularly Django and Flask), while feeling more modern and adhering to certain opinionated principles. In my opinion, it's pretty much exactly what the best-in-breed of the next logical generation of web frameworks should look like.
¡Ándale, ándale, arriba! Image source: The Guardian
The premise: each time a certain API method is called within a Flask / SQLAlchemy app (a method that primarily involves saving something to the database), send various notifications, e.g. log to the standard logger, and send an email to site admins. However, the way the API works, is that several different methods can be forced to run in a single DB transaction, by specifying that SQLAlchemy only perform a commit when the last method is called. Ideally, no notifications should actually get triggered until the DB transaction has been successfully committed; and when the commit has finished, the notifications should trigger in the order that the API methods were called.
There are various possible solutions that can accomplish this, for example: a celery task queue, an event scheduler, and a synchronised / threaded queue. However, those are all fairly heavy solutions to this problem, because we only need a queue that runs inside one thread, and that lives for the duration of a single DB transaction (and therefore also only for a single request).
To solve this problem, I implemented a very lightweight function queue, where each queue is a deque instance, that lives inside flask.g, and that is therefore available for the duration of a given request context (or app context).
I have become quite a fan of Python's built-in namedtuple collection lately. As others have already written, despite having been available in Python 2.x and 3.x for a long time now, namedtuple continues to be under-appreciated and under-utilised by many programmers.
# The ol'fashioned tuple way
fruits = [
('banana', 'medium', 'yellow'),
('watermelon', 'large', 'pink')]
for fruit in fruits:
print('A {0} is coloured {1} and is {2} sized'.format(
fruit[0], fruit[2], fruit[1]))
# The nicer namedtuple way
from collections import namedtuple
Fruit = namedtuple('Fruit', 'name size colour')
fruits = [
Fruit(name='banana', size='medium', colour='yellow'),
Fruit(name='watermelon', size='large', colour='pink')]
for fruit in fruits:
print('A {0} is coloured {1} and is {2} sized'.format(
fruit.name, fruit.colour, fruit.size))
namedtuples can be used in a few obvious situations in Python. I'd like to present a new and less obvious situation, that I haven't seen any examples of elsewhere: using a namedtuple instead of MagicMock or flexmock, for mocking objects in unit tests.
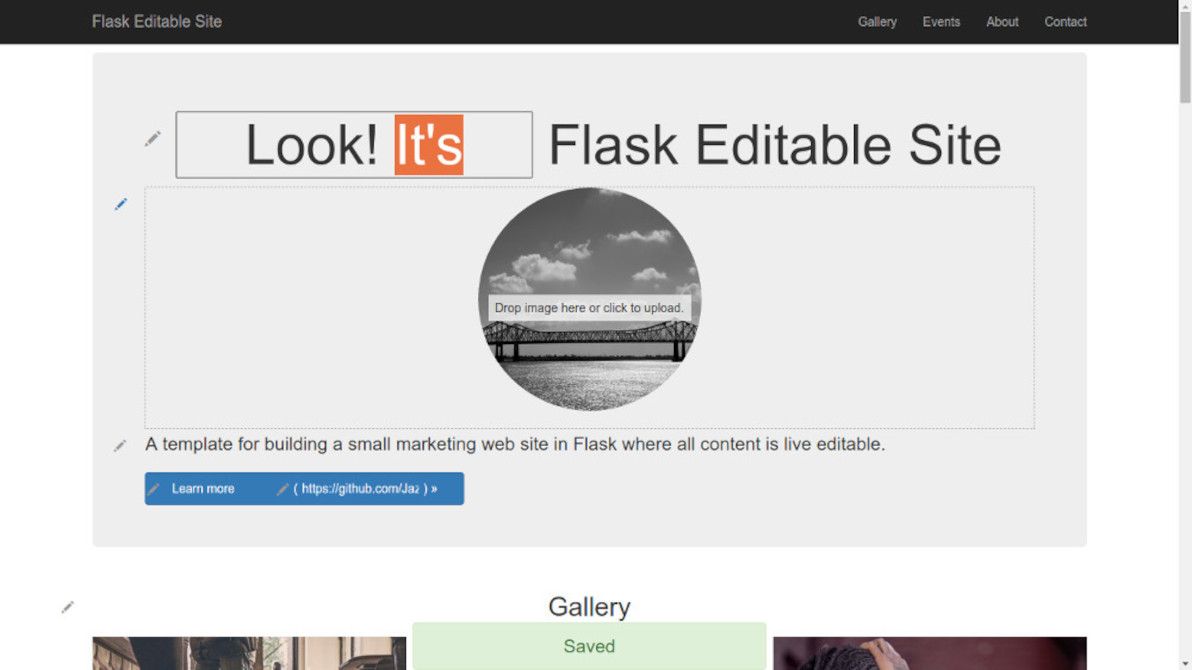
Text and image block editing with Flask Editable Site.
The aim of this app is to demonstrate that, with the help of modern JS libraries, and with some well-thought-out server-side snippets, it's now perfectly possible to "bake in" live in-place editing for virtually every content element in a typical brochureware site.
This app is not a CMS. On the contrary, think of it as a proof-of-concept alternative to a CMS. An alternative where there's no "admin area", there's no "editing mode", and there's no "preview button". There's only direct manipulation.
"Template" means that this is a sample app. It comes with a bunch of models that work out-of-the-box (e.g. text content block, image content block, gallery item, event). However, these are just a starting point: you can and should define your own models when building a real site. Same with the front-end templates: the home page layout and the CSS styles are just examples.
I'd never before stopped to think about whether or not there was a limit to how much you can put in a cookie. Usually, cookies only store very small string values, such as a session ID, a tracking code, or a browsing preference (e.g. "tile" or "list" for search results). So, usually, there's no need to consider its size limits.
However, while working on a new side project of mine that heavily uses session storage, I discovered this limit the hard (to debug) way. Anyway, now I've got one more adage to add to my developer's phrasebook: if you're trying to store more than 4KiB in a cookie, you're doing it wrong.
When the Python codebase for a project (let's call the project LasagnaFest) starts getting big, and when you feel the urge to re-use a chunk of code (let's call that chunk foodutils) in multiple places, there are a variety of steps at your disposal. The most obvious step is to move that foodutils code into its own file (thus making it a Python module), and to then import that module wherever else you want in the codebase.
Most of the time, doing that is enough. The Python module importing system is powerful, yet simple and elegant.
But… what happens a few months down the track, when you're working on two new codebases (let's call them TortelliniFest and GnocchiFest – perhaps they're for new clients too), that could also benefit from re-using foodutils from your old project? What happens when you make some changes to foodutils, for the new projects, but those changes would break compatibility with the old LasagnaFest codebase?
What happens when you want to give a super-charged boost to your open source karma, by contributing foodutils to the public domain, but separated from the cruft that ties it to LasagnaFest and Co? And what do you do with secretfoodutils, which for licensing reasons (it contains super-yummy but super-secret sauce) can't be made public, but which should ideally also be separated from the LasagnaFest codebase for easier re-use?
Or – not to be forgotten – what happens when, on one abysmally rainy day, you take a step back and audit the LasagnaFest codebase, and realise that it's got no less than 38 different *utils chunks of code strewn around the place, and you ponder whether surely keeping all those utils within the LasagnaFest codebase is really the best way forward?
Moving foodutils to its own module file was a great first step; but it's clear that in this case, a more drastic measure is needed. In this case, it's time to split off foodutils into a separate, independent codebase, and to make it an external dependency of the LasagnaFest project, rather than an internal component of it.
This article is an introduction to the how and the why of cutting up parts of a Python codebase into dependencies. I've just explained a fair bit of the why. As for the how: in a nutshell, pip (for installing dependencies), the public PyPI repo (for hosting open-sourced dependencies), and a private PyPI repo (for hosting proprietary dependencies). Read on for more details.
PostgreSQL is my favourite RDBMS, and it's the fave of many others too. And rightly so: it's a good database! Nevertheless, nobody's perfect.
When it comes to exporting Postgres data (as SQL INSERT statements, at least), the tool of choice is the standard pg_dump utility. Good ol' pg_dump is rock solid but, unfortunately, it doesn't allow for any row-level filtering. Turns out that, for a recent project of mine, a filtered SQL dump is exactly what the client ordered.
On account of this shortcoming, I spent some time whipping up a lil' Python script to take care of this functionality. I've converted the original code (written for a client-specific data set) to a more generic example script, which I've put up on GitHub under the name "PG Dump Filtered". If you're just after the code, then feel free to head over to the repo without further ado. If you'd like to stick around for the tour, then read on.
Flask is still a relative newcomer in the world of Python frameworks (it recently celebrated its fifth birthday); and because of this, it's still sometimes trailing behind its rivals in terms of plugins to scratch a given itch. I recently discovered that this was the case, with storing and retrieving user-uploaded files on Amazon S3.
For static files (i.e. an app's seldom-changing CSS, JS, and images), Flask-Assets and Flask-S3 work together like a charm. For more dynamic files, there exist numerous snippets of solutions, but I couldn't find anything to fill in all the gaps and tie it together nicely.
Due to a pressing itch in one of my projects, I decided to rectify this situation somewhat. Over the past few weeks, I've whipped up a bunch of Python / Flask tidbits, to handle the features that I needed:
I've also published an example app, that demonstrates how all these tools can be used together. Feel free to dive straight into the example code on GitHub; or read on for a step-by-step guide of how this Flask S3 tool suite works.
For a Flask-based project that I'm currently working on, I just added some front-end functionality that depends on Font Awesome. Getting Font Awesome to load properly (in well-behaved modern browsers) shouldn't be much of a chore. However, my app spans multiple subdomains (achieved with the help of Flask's Blueprints per-subdomain feature), and my static assets (CSS, JS, etc) are only served from one of those subdomains. And as it turns out (and unlike cross-domain CSS / JS / image requests), cross-domain font requests are forbidden unless the font files are served with an appropriate Access-Control-Allow-Origin HTTP response header. For example, this is the error message that's shown in Google Chrome for such a request:
Font from origin 'http://foo.local' has been blocked from loading by Cross-Origin Resource Sharing policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://bar.foo.local' is therefore not allowed access.
As a result of this, I had to quickly learn how to conditionally add custom HTTP response headers based on the URL being requested, both for Flask (when running locally with Flask's built-in development server), and for Apache (when running in staging and production). In a typical production Flask setup, it's impossible to do anything at the Python level when serving static files, because these are served directly by the web server (e.g. Apache, Nginx), without ever hitting WSGI. Conversely, in a typical development setup, there is no web server running separately to the WSGI app, and so playing around with static files must be done at the Python level.