GreenAshAll-natural web development, poignant wit, and hippie ramblings since 2004https://greenash.net.au/2025-01-07T00:00:00ZGetting MapLibre working for both native and web in Expo2025-01-07T00:00:00Z2025-01-07T00:00:00ZJazahttps://greenash.net.au/thoughts/2025/01/getting-maplibre-working-for-both-native-and-web-in-expo/
I've been dabbling of late in building a mobile app with React Native + Expo. One of the things that attracted me most to Expo, is that – on top of the "write once, run on iOS and Android" claim of React Native – Expo claims to also let an app run seamlessly on the web. Anyway, as it turns out (surprise surprise – not!), neither of those claims are particularly aligned with reality. I found this out – with the claim of "run on native and web" – as soon as I wanted to add a simple map to my app.
Behold, a MapLibre map, working both for native and for web, in Expo.
Below is my humble lil' guide to getting MapLibre working for both native and web in Expo. Note: if you want to skip the step-by-step shpiel, and you just want a working example with all the code, feel free to head straight to the Expo MapLibre native + web demo on GitHub.
Map library options
First of all, a quick rundown of the options that one has at one's disposal, when wanting to add a map to an Expo app.
The simplest and the most recommended option is to use react-native-maps. This is the only solution that works with Expo Go, and it's the only one that's documented in the official Expo docs.
However, it's explicitly stated that react-native-maps isn't web-compatible, so if you used it and you also wanted maps on web, your only choice would be to fall back to something like react-google-maps for web. Also, you'd (potentially) have to deal with Apple Maps on iOS vs Google Maps on Android. And – my main reason for steering clear of this option – you'd have to live with the these-days-horrific pricing and draconian ToS of the Google Maps API.
The next option is to use rnmapbox. This is the solution that I instinctively chose first up, and that I stuck with for quite a while, mainly because (for the past several years) I've become accustomed to using Mapbox instead of Google Maps anyway, for maps on old-skool web sites. Plus, rnmapbox claims to (somewhat) support Expo Web.
Unfortunately, "somewhat" is in my opinion an overly optimistic assessment of rnmapbox's web support – basically, instead of trying to go down that route, you should instead fall back to react-map-gl with mapbox-gl-js for web. Plus, I was surprised to learn that Mapbox is no longer the mapping provider of choice for hobbyists, since it decided to stop open-sourcing its mapping library.
Which led me to MapLibre, which is a fork of Mapbox (v1) before the folks at Mapbox decided to release v2 with a non-open-source license. So, with MapLibre (plus MapTiler), I don't have to worry about disagreeable pricing / ToS. And I get basically the same map library on native and web. Although not exactly the same library – it inherits the limitations of the Mapbox libraries, so you need to use maplibre-react-native for native, and fall back to react-map-gl with maplibre-gl-js for web.
Map features
What I needed, and what I'm demo'ing here, is a pretty simple map. It shows the user's location on load (if the user grants location permissions, otherwise it falls back to showing latitude / longitude 0,0 on load). And when the user presses the "Go" button, it grabs the current centre position of the map, and shows the latitude / longitude coordinates of that centre position. That's it!
You're likely to need more functionality than that for a map in your own app. Hopefully this provides you with a humble base to start off from. Good luck getting other bells and whistles working (for native and web)!
Walkthrough
To start off, you'll need an Expo project. If you don't already have one, you can create one with:
npx create-expo-app@latest MyApp
Then, you'll need to add both the native and the web mapping libraries as dependencies:
I like to put everything inside a src/ directory, which is supported but which is not the default for Expo. And I like a structure with various other directories under src/ (see link). My example code from here on assumes that structure. Feel free to suit to your tastes.
You'll need to sign up to MapTiler for an API key. Edit your .env.local file to include this:
The code from here on depends on various utility components, for styling of text and for positioning of elements. I won't go through all those components in this article, I leave it to you to refer to the src/components/ directory.
Before we get into the map code, we need to request location permission, and to get the user's current location (if the user grants permission). I originally had all of this inside the map components, but I then refactored the meat of it out into a utility function, which is very similar to the code in the expo-location docs, and which you can put at e.g. src/core/locationUtils.ts:
import * as Location from "expo-location";
import { Dispatch, SetStateAction } from "react";
export const setCurrentLocationIfAvailable = async (
setLocation: Dispatch<SetStateAction<Location.LocationObjectCoords>>,
setIsLocationUnavailable: Dispatch<SetStateAction<boolean>>,
) => {
let { status } = await Location.requestForegroundPermissionsAsync();
if (status !== "granted") {
setIsLocationUnavailable(true);
return;
}
try {
const currentLocation = await Location.getCurrentPositionAsync({});
setLocation(currentLocation.coords);
} catch (_e) {
setIsLocationUnavailable(true);
}
};
Now for the map itself. Let's start by putting the code to render the map for native into a component. This code goes at e.g. src/components/NativeMapView.tsx:
This just renders the map, centred and zoomed at the user's current location, without any additional behaviour defined. It's important that we only import from @maplibre/maplibre-react-native in this file, and not in any other files that get loaded for both native and web, because web will freak out if it sees that import.
Next comes the code to render the map for web into a component. This code goes at e.g. src/components/WebMapView.tsx:
Once again, this just renders the map, no additional behaviour. And it's important that we only import from react-map-gl/maplibre in this file, because native will freak out if it sees that import.
Now we're going to render the map together with a "Go" button, and we're going to add some additional behaviour, such that when the button is pressed, we grab the current centre coordinates of the map, and then trigger an event using those coordinates. First, the native code for all that, at e.g. src/components/LatLonMap.tsx:
import { useRef } from "react";
import { Button } from "react-native";
import { CenteredContainer } from "./CenteredContainer";
import { FloatingContainer } from "./FloatingContainer";
import { FullWidthContainer } from "./FullWidthContainer";
import { FullWidthAndHeightContainer } from "./FullWidthAndHeightContainer";
import { NativeMapView } from "./NativeMapView";
import { MapViewRef } from "@maplibre/maplibre-react-native";
interface LatLonMapProps {
onPress?: (latitude: number, longitude: number) => Promise<void>;
}
export const LatLonMap = (props: LatLonMapProps) => {
const mapRef = useRef<MapViewRef>(null);
return (
<FullWidthAndHeightContainer>
<NativeMapView mapRef={mapRef} />
<FloatingContainer>
<CenteredContainer>
<FullWidthContainer>
<Button
onPress={async () => {
if (!mapRef.current) {
throw new Error("Missing mapRef");
}
const center = await mapRef.current.getCenter();
if (props.onPress) {
await props.onPress(center[1], center[0]);
}
}}
title="Go"
/>
</FullWidthContainer>
</CenteredContainer>
</FloatingContainer>
</FullWidthAndHeightContainer>
);
};
And the web code for all that, at e.g. src/components/LatLonMap.web.tsx:
import { useRef } from "react";
import { Button } from "react-native";
import { CenteredContainer } from "./CenteredContainer";
import { FloatingContainer } from "./FloatingContainer";
import { FullWidthContainer } from "./FullWidthContainer";
import { FullWidthAndHeightContainer } from "./FullWidthAndHeightContainer";
import { WebMapView } from "./WebMapView";
import { MapRef } from "react-map-gl/maplibre";
interface LatLonMapProps {
onPress?: (latitude: number, longitude: number) => Promise<void>;
}
export const LatLonMap = (props: LatLonMapProps) => {
const mapRef = useRef<MapRef>(null);
return (
<FullWidthAndHeightContainer>
<WebMapView mapRef={mapRef} />
<FloatingContainer>
<CenteredContainer>
<FullWidthContainer>
<Button
onPress={async () => {
if (!mapRef.current) {
throw new Error("Missing mapRef");
}
const center = mapRef.current.getCenter();
if (props.onPress) {
await props.onPress(center.lat, center.lng);
}
}}
title="Go"
/>
</FullWidthContainer>
</CenteredContainer>
</FloatingContainer>
</FullWidthAndHeightContainer>
);
};
A few key things to note with the above code samples. First of all, we're using Expo's built-in system of platform-specific filename prefixes, to write both a native version (the "default" version ending in .tsx) and a web version (ending in .web.tsx) of the same component. We're importing our NativeMapView component in one version, and our WebMapView component in the other version. The mapRef variable is of a different type, and has a slightly different interface, in each version.
And, finally, we're defining onPress as a prop that gets passed in (and that gets given the coordinates as simple integer parameters when it's called), rather than defining what happens on button press directly in this component, so that we can implement the "on button press" behaviour just once in the calling code (and so that the calling code, rather than this component, gets to decide what happens on button press, thus making this component more reusable).
We're now done writing components. Let's use our new native- and web-compatible map component on our home screen – code goes at e.g. src/app/index.tsx:
The above code is where we implement the "on button press" behaviour. In this case, the behaviour is to redirect to the /lat-lon screen, and to pass the latitude and longitude values as URL parameters.
Lucky last step is to then display the latitude and longitude to the user – code goes at e.g. src/app/(app)/lat-lon.tsx:
import { Button, StyleSheet } from "react-native";
import { useLocalSearchParams } from "expo-router";
import { Link } from "expo-router";
import { ThemedText } from "../../components/ThemedText";
import { ThemedView } from "../../components/ThemedView";
export default function LatLonScreen() {
const { lat, lon } = useLocalSearchParams();
if (typeof lat !== "string") {
throw new Error("lat is not a string");
}
if (typeof lon !== "string") {
throw new Error("lon is not a string");
}
const latVal = parseFloat(lat);
const lonVal = parseFloat(lon);
return (
<ThemedView style={styles.container}>
<ThemedText>Latitude: {latVal}</ThemedText>
<ThemedText>Longitude: {lonVal}</ThemedText>
<Link href="/" asChild>
<Button onPress={() => {}} title="Back" />
</Link>
</ThemedView>
);
}
const styles = StyleSheet.create({
container: {
flex: 1,
alignItems: "center",
justifyContent: "center",
padding: 20,
},
});
Map done
There you have it: a map that looks and behaves virtually the same, on both native and web, implemented in a single codebase, with minimal platform-specific code required. I haven't thoroughly looked into how performant, how buggy, or overall how effective this solution is on all platforms, but hey, it's a start. Hope this helps you in your own Expo mapping endeavours.
]]>
Sea level rise is gonna get a whole lot realer2025-01-01T00:00:00Z2025-01-01T00:00:00ZJazahttps://greenash.net.au/thoughts/2025/01/sea-level-rise-is-gonna-get-a-whole-lot-realer/
I was alarmed to recently learn that plenty of folks out there on the interwebz don't believe that the seas have risen, at all, for several centuries. Although, in hindsight, I shouldn't be surprised: after all, there's no shortage of climate change deniers out there, and sea level rise is very (although not completely) interconnected with climate change.
To be fair to those folks, it's true that – as they claim – the water level of various landmarks around the world, such as the Statue of Liberty, Plymouth Rock, and (in my own stomping ground of Sydney Harbour) Fort Denison, has not "visibly" risen since they were erected.
The fact, per the consensus of reputable scientists, is that the global average sea level has risen by 15-25cm (6-10") since 1900. Now, I'm willing to entertain the notion that, alright, for all practical purposes, that's not much. And that's just the average. So I consider it not unreasonable to concede that there are numerous places in the world today, where the sea level has barely, if at all, risen.
The thing is, sea level rise lags behind global warming by several decades. So (if you'll excuse my hitting-rather-close-to-home choice of pun), what we've seen so far is just the tip of the iceberg. We've already locked in another 10-25cm (4-10") of sea level rise between now and 2050. And we're currently looking at a minimum 28-61cm (11-24") of sea level rise between now and 2100, and a minimum 40-95cm (16-38") of sea level rise between now and 2200. And those are the best-case scenarios, based: on the most conservative of scientists' conclusions; and on the world taking drastic action to reduce greenhouse gas emissions starting right now (a depressingly unlikely occurrence).
So, ok, perhaps sea level rise ain't gotten real yet for most people (although it sure has for some people). But I got news for y'all: it's gonna get a whole lot realer.
It's complicated
Sea level rise is, admittedly, one of the tricker symptoms of climate change to get your head around.
Firstly, it hasn't occurred – at least, not in most of the world – in as dramatic or as visible a manner as various other phenomena have. Glacial melting is clear as day, to anyone who is a local resident of, or a long-time vacationer to, one of the hotspots. Droughts, heatwaves and bushfires / wildfires have been noticeably increasing in both frequency and intensity, in North America, in Europe, and here in Australia (to name but a few places). Glaciers don't un-retreat, and charred countryside doesn't un-burn, when the tide goes out.
The only places in the world where the sea level rise merde (if you'll excuse my French) has already visibly hit the fan, are remote, impoverished, sparsely-populated, seldom-visited islands, particularly in the Pacific. So it's relatively easy, right now, for much of the world to feign blissful ignorance, if everything appears to still be cool and normal on the coastline down the road from your house.
The Maldives: not as idyllic as it looks. Image source:PxHere.
Also, the amount of sea level rise that has occurred over the past century-and-a-bit is, historically speaking, quite modest. Sure, it's the most significant rise in the past 3,000 years. However, from around 20,000 years ago (at the end of the last ice age), until around the start of Classical Antiquity, the sea level rose by about 125m (400'). That's great ammunition for deniers to go around claiming: "sea levels have always risen and fallen naturally, whatever is happening now has nothing to do with human activity".
Secondly, although scientists unanimously agree that sea level rise is accelerating and that it will get pretty bad pretty soon, there is massive uncertainty as to exactly how much and when. As I said, a 28-61cm (11-24") sea level rise between now and 2100 is the best-case forecast. The current worst-case forecast is a 1.3-1.6m (4-5') sea level rise between now and 2100. There are numerous forecasts in between.
Apart from not realising that it's already happening, and not realising that it lags behind air temperature changes by several decades, most people also don't realise for just how insanely long the sea level is going to keep on rising, as a result of industrialised humanity's love affair with carbon. In this arena too, estimates vary quite widely. But we're looking at a best-case forecast of a 2-3m (6-10') sea level rise over the next 2,000 years, and a current worse-case forecast of a 19-22m (62-72') sea level rise over the next 2,000 years.
But that's not all. The thing is, all that carbon we've emitted lately, it just ain't going anywhere in a hurry, it's going to keep hanging around like a bad smell. As such, we're looking a a best-case forecast of a 6-7m (19-23') sea level rise over the next 10,000 years, and a current worst-case forecast of a 52m (170') sea level rise over the next 10,000 years.
More of the world may well be going the way of Atlantis soon. Image source:Wallpaper Delight.
Get ready
The sea may have only barely perceptibly risen so far, but it's about to rise a whole lot more. It's going to happen soon enough, that it will have a real and devastating effect, not on your great-grandchildren, not on your grandchildren, but on your children (and mine) who have already been born. Even considering the best-case forecasts, the map of the world's coastlines will already be different by the end of this century; and it will be unrecognisable in millennia to come.
]]>
Introducing: World Locality Transit Graph2024-06-23T00:00:00Z2024-06-23T00:00:00ZJazahttps://greenash.net.au/thoughts/2024/06/introducing-world-locality-transit-graph/
I built a dataset and map visualisation called the World Locality Transit Graph. Source code is on GitHub. It's a map of approximate transit times between any two given localities in various parts of the world.
World Locality Transit Graph showing the dataset for Eastern Australia
About the graph
(Note: this section is copied from the README that can be seen on GitHub.)
A "locality", for the purposes of the graph, is:
In a large metropolitan area: a group of neighbourhoods / suburbs, e.g. "inner city", "southern suburbs"; such a locality should (as a rough guide) be 15-30 minutes transit time from its adjacent metropolitan localities
In a (small urban area or) semi-rural area: the whole main town / city, and usually also neighbouring towns / countryside, e.g. "foobar valley", "fizzbuzz peninsula"; such a locality should (as a rough guide) be 1-2 hours transit time from its adjacent semi-rural localities
In a remote rural area: all of the towns / countryside within a large area, e.g. "far north", "highlands"; such a locality should (as a rough guide) be 3-5 hours transit time from all adjacent localities
Additionally, regardless of whether it's big-city or middle-of-nowhere:
Someone who lives in one locality, should consider anyone living in the same locality as being "in my area" (folks in a city of several million people have quite a different definition of "in my area", compared to folks whose next-door neighbour is over the horizon!)
Each locality should have its own identity, both geographical and cultural; a person who lives in a locality should feel some connection (could be positive or negative!) to their locality's identity
Each locality is represented as a node in the graph. Two localities should be connected as "nearby edges" (i.e. there should be an edge connecting their nodes in the graph) if and only if:
They are geographically adjacent
It's possible to travel between them using one or more spontaneous transport modes, e.g. private car, some trains / buses / ferries, walking, bicycle, taxi (not non-spontaneous transport, i.e. not transport that has to be booked in advance, that may have infrequent service, and that may not be available 24/7, e.g. flights, some trains / buses / ferries)
Travel between them using the fastest available spontaneous transport mode is no more than approximately 5 hours (under ideal conditions, i.e. very low traffic, no adverse weather, no roadwork / trackwork)
There is also an edge for every single possible pair of localities (in each connected graph), with a transit time of up to 5.5 hours, which can be seen in the "all edges" map view. These edges are calculated and generated in advance, using the Floyd-Warshall CSV Generator.
Due to the "5-hour max transit time" rule, and due to the "only spontaneous transport modes" rule, it's actually multiple graphs, not just one graph. This is because there is often no way to travel between two localities while adhering to those rules, usually due to a body of water being in the way, but sometimes due to a land route being extremely long and desolate (e.g. crossing the Nullarbor Plain between South Australia and Western Australia takes at least 12 hours of non-stop driving).
Why these rules? Because, being a "transit graph", the idea is that it only models "local" travel, i.e. travel that someone would undertake with little or no notice, at little or no financial cost, ideally (for metropolitan localities) local enough that one could still make it back home for the night, or (for rural and semi-rural localities) at least local enough that one could easily complete the journey one-way in a single day.
So, the aim of this graph is to model, for each locality, all of the other nearby localities that are "close enough", in terms of transit time, for casual travel - perhaps to catch up with friends / family, perhaps for local tourism, perhaps for shopping - to be feasible on a regular basis.
Built as a static site, using Leaflet as the map engine, OpenStreetMap for map data, and Mapbox for map tiles. Graph nodes and edges are stored in CSV files in the csv/ directory of the repo.
So far, there is only data for Australia and New Zealand. More world regions coming soon. If you're keen to help out with expanding the dataset, contributions are welcome! Ideally in the form of GitHub pull requests, but otherwise, just get in touch and send me data.
Cool, but why?
I built it primarily because I have another project in mind, that I may or may not build to completion, and which I may or may not be blogging about in future, for which the dataset in this graph would be really useful.
Also: fun!
Also: as far as I'm aware, nothing like this currently exists.
Also: I'd say it's a good thing to have a free, open, and dead-simple dataset like this, that provides a good alternative / good fallback to, for example, Google Maps's route travel time estimates.
Hope you like the World Locality Transit Graph. Feedback welcome.
]]>
Introducing: Floyd-Warshall CSV Generator2024-06-09T00:00:00Z2024-06-09T00:00:00ZJazahttps://greenash.net.au/thoughts/2024/06/introducing-floyd-warshall-csv-generator/
I built a little Python script called the Floyd-Warshall CSV Generator. It takes a CSV of graph edges as input, and generates a CSV of the edges that are the shortest paths between all pairs of vertices.
That is, it generates all the possible (indirect) paths from one point to all other points, based on the (direct) paths that are already known, with duplicate (undirected) paths filtered out, and with paths whose cost is more than max-weight filtered out.
I wrote this script in order to generate the "all edges" data that's shown in the World Locality Transit Graph, which I'll also be blogging about real soon. Let me know if you put this script to any other interesting uses!
]]>
On FastAPI2024-04-28T00:00:00Z2024-04-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2024/04/on-fastapi/
Over the past year or two, I've been heavily using FastAPI in my day job. I've been around the Python web framework block, and I gotta say, FastAPI really succeeds in its mission of building on the strengths of its predecessors (particularly Django and Flask), while feeling more modern and adhering to certain opinionated principles. In my opinion, it's pretty much exactly what the best-in-breed of the next logical generation of web frameworks should look like.
¡Ándale, ándale, arriba! Image source: The Guardian
Let me start by lauding FastAPI's excellent documentation. Having a track record of rock-solid documentation, was (and still is!) – in my opinion – Django's most impressive achievement, and I'm pleased to see that it's also becoming Django's most enduring legacy. FastAPI, like Django, includes docs changes together with code changes in a single (these days called) pull request; it clearly documents that certain features are deprecated; and its docs often go beyond what is strictly required, by including end-to-end instructions for integrating with various third-party tools and services.
FastAPI's docs raise the bar further still, with more than a dash of humour in many sections, and with a frequent sprinkling of emojis as standard fare. That latter convention I have some reservations about – call me old-fashioned, but you could say that emoji-filled docs is unprofessional and is a distraction. However, they seem to enhance rather than detract from overall quality; and, you know what, they put a non-emoji real-life smile on my face. So, they get my tick of approval.
FastAPI more-or-less sits in the Flask camp of being a "microframework", in that it doesn't include an ORM, a template engine, or various other things that Django has always advertised as being part of its "batteries included" philosophy. But, on the other hand, it's more in the Django camp of being highly opinionated, and of consciously including things with which it wants a hassle-free experience. Most notably, it includes Swagger UI and Redoc out-of-the-box. I personally had quite a painful experience generating Swagger docs in Flask, back in the day; and I've been tremendously pleased with how API doc generation Just Works™ in FastAPI.
Much like with Flask, being a microframework means that FastAPI very much stands on the shoulders of giants. Just as Flask is a thin wrapper on top of Werkzeug, with the latter providing all things WSGI; so too is FastAPI a thin wrapper on top of Starlette, with the latter providing all things ASGI. FastAPI also heavily depends on Pydantic for data schemas / validation, for strongly-typed superpowers, for settings handling, and for all things JSON. I think it's fair to say that Pydantic is FastAPI's secret sauce.
My use of FastAPI so far has been rather unusual, in that I've been building apps that primarily talk to an Oracle database (and, indeed, this is unusual for Python dev more generally). I started out by depending on the (now-deprecated) cx_Oracle library, and I've recently switched to its successor python-oracledb. I was pleased to see that the finefolks at Oracle recently released full async support for python-oracledb, which I'm now taking full advantage of in the context of FastAPI. I wrote a little library called fastapi-oracle which I'm using as a bit of glue code, and I hope it's of use to anyone else out there who needs to marry those two particular bits of tech together.
There has been a not-insignificant amount of chit-chat on the interwebz lately, voicing concern that FastAPI is a one-man show (with its BDFL@tiangolo showing no intention of that changing anytime soon), and that the FastAPI issue and pull request queues receive insufficient TLC. Based on my experience so far, I'm not too concerned about this. It is, generally speaking, not ideal if a project has a bus factor of 1, and if support requests and bug fixes are left to rot.
However, in my opinion, the code and the documentation of FastAPI are both high-quality and highly-consistent, and I appreciate that this is largely thanks to @tiangolo continuing to personally oversee every small change, and that loosening the reins would mean a high risk of that deteriorating. And, speaking of quality, I personally have yet to uncover any bugs either in FastAPI or its core dependencies (which I'm pleasantly surprised by, considering how heavily I've been using it) – it would appear that the items languishing in the queue are lower priority, and it would appear that @tiangolo is on top of critical bugs as they arise.
In summary, I'm enjoying coding with FastAPI, I feel like it's a great fit for building Python web apps in 2024, and it will continue to be my Python framework of choice for the foreseeable future.
]]>
What (I think) the Voice is all about2023-10-09T00:00:00Z2023-10-09T00:00:00ZJazahttps://greenash.net.au/thoughts/2023/10/what-(i-think)-the-voice-is-all-about/
A few weeks ago, I had my first and only conversation with an ardent "No" campaigner for the upcoming Australian referendum on the Voice to Parliament. (I guess we really do all live in our own little echo chambers, because all my close friends and family are in the "Yes" camp just like me, and I was genuinely surprised and caught off guard to have bumped into a No guy, especially smack-bang in my home territory of affluent upper-middle-class North Shore Sydney.) When I asked why he'll be voting No, he replied: "Because I'm not racist". Which struck me, ironically, as one of the more racist remarks I've heard in my entire life.
Now that's what I call getting your voice heard. Image source: Fandom
I seldom write purely political pieces. I'm averse to walking into the ring and picking a fight with anyone. And honestly I find not-particularly-political writing on other topics (such as history and tech) to be more fun. Nor do I consider myself to be all that passionate about indigenous affairs – at least, not compared with other progressive causes such as the environment or refugees (maybe because I'm a racist privileged white guy myself!). However, with only five days to go until Australia votes (and with the forecast for said vote looking quite dismal), I thought I'd share my two cents on what, in my humble opinion, the Voice is all about.
I don't know about my fellow Yes advocates, but – call me cynical if you will – personally I have zero expectations of the plight of indigenous Australians actually improving, should the Voice be established. This is not about closing the gap. There are massive issues affecting Aborigines and Torres Strait Islanders, those issues have festered for a long time, and there's no silver bullet – no establishing of yet another advisory body, no throwing around of yet more money – that will magically or instantly change that. I hope that the Voice does make an inkling of a difference on the ground, but I'd say it'll be an inkling at best.
So then, what is this referendum about? It's about recognising indigenous Australians in the Constitution for the first time ever! (First-ever not racist mention, at least.) It's about adding something to the Constitution that's more than a purely symbolic gesture. It's about doing what indigenous Australians have asked for (yes, read the facts, they have asked for it!). It's about not having yet another decade or three of absolutely no progress being made towards reconciliation. And it's about Australia not being an embarassment to the world (in yet another way).
I'm not going to bother to regurgitate all the assertions of the Yes campaign, nor to try to refute all the vitriol of the No campaign, in this here humble piece (including, among the countless other bits of misinformation, the ridiculous claim that "the Voice is racist"). I just have this simple argument to put to y'all.
A vote for No is a vote for nothing. The Voice is something. It's not something perfect, but it's something, and it's an appropriate something for Australia in 2023, and it's better than nothing. And rather than being afraid of that modest little something (and expressing your fear by way of hostility), the only thing you should actually be afraid of – sure as hell the only thing I'm afraid of – is the shame and disgrace of doing more nothing.
]]>
Ozersk: the city on the edge of plutonium2022-08-29T00:00:00Z2022-08-29T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/08/ozersk-the-city-on-the-edge-of-plutonium/Ozersk (also spelled Ozyorsk) – originally known only by the codename Chelyabinsk-40 – is the site of the third-worst nuclear disaster in world history, as well as the birthplace of the Soviet Union's nuclear weapons arsenal. But I'll forgive you if you've never heard of it (I hadn't, until now). Unlike numbers one (Chernobyl) and two (Fukushima), the USSR managed to keep both the 1957 incident, and the place's very existence, secret for over 30 years.
Ozersk being so secret that few photos of it are available, is a good enough excuse, in my opinion, for illustrating this article with mildly amusing memes instead. Image source: Legends Revealed
Amazingly, to this day – more than three decades after the fall of communism – this city of about 100,000 residents (and its surrounds, including the Mayak nuclear facility, which is ground zero) remains a "closed city", with entry forbidden to all non-authorised personnel.
And, apart from being enclosed by barbed wire, it appears to also be enclosed in a time bubble, with the locals still routinely parroting the Soviet propaganda that labelled them "the nuclear shield and saviours of the world"; and with the Soviet-era pact still effectively in place that, in exchange for their loyalty, their silence, and a not-un-unhealthy dose of radiation, their basic needs (and some relative luxuries to boot) are taken care of for life.
Map of Ozersk and surrounds. Bonus: the most secret places and the most radioactive places are marked! Image source: Google Maps
So, as I said, there's very little information available on Ozersk, because to this day: it remains forbidden for virtually anyone to enter the area; it remains forbidden for anyone involved to divulge any information; and it remains forbidden to take photos / videos of it, or to access any documents relating to it. For over three decades, it had no name and was marked on no maps; and honestly, it seems like that might as well still be the case.
Frankly, even had the 1957 explosion not occurred, the area would still be horrendously contaminated. Both before and after that incident, they were dumping enormous quantities of unadulterated radioactive waste directly into the water bodies in the vicinity, and indeed, they continue to do so, to this day. It's astounding that anyone still lives there – especially since, ostensibly, you know, Russians are able to live where they choose these days.
I love the smell of strontium-90 in the morning. Image source: imgflip
As far as I can gather, from the available sources, most of the present-day residents of Ozersk are the descendants of those who were originally forced to go and live there in Stalin's time. And, apparently, most people who have been born and raised there since the fall of the USSR, choose to stay, due to: family ties; the government continuing to provide for their wellbeing; ongoing patriotic pride in fulfilling their duty; fear of the big bad world outside; and a belief (foolhardy or not) that the health risks are manageable. It's certainly possible that there are more sinister reasons why most people stay; but then again, in my opinion, it's not implausible that no outright threats or prohibitions are needed, in order to maintain the status quo.
Except Boris, every second Tuesday, when he does his vodka run. Image source: Wonkapedia
Only one insider appears to have denounced the whole spectacle in recent history: lifelong resident Nadezhda Kutepova, who gave an in-depth interview with Western media several years ago. Kutepova fled Ozersk, and Russia, after threats were made against her, due to her campaigning to expose the truth about the prevalence of radiation sickness in her home town.
And only one outsider appears to have ever gotten in covertly, lived, and told the tale: Samira Goetschel, who produced City 40, the world's only documentary about life in Ozersk (the film features interview footage with Kutepova, along with several other Ozersk locals). Honestly, life inside North Korea has been covered more comprehensively than this.
Surely you didn't think I'd get through a whole meme-replete article on nuclear disaster without a Simpsons reference?! Image source: imgflip
Considering how things are going in Putin's Russia, I don't imagine anything will be changing in Ozersk for a long time yet. Looks like business as usual – utterly trash the environment, manufacture dodgy nuclear stuff, maintain total secrecy, brainwash the locals, cause sickness and death – is set to continue indefinitely.
You can find much more in-depth information, in many of the articles and videos that I've linked to. Anyway, in a nutshell, Ozersk: you've never been there, and you'll never be able to go there, even if you wanted to. Which you don't. Now, please forget everything you've just read. This article will self-destruct in five seconds.
]]>
GDPR-compliant Google reCAPTCHA2022-08-28T00:00:00Z2022-08-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/08/gdpr-compliant-google-recaptcha/
Per the EU's GDPR and ePrivacy Directive, you must ask visitors to a website for their consent before setting any cookies, and/or before collecting any user tracking data. And because the GDPR applies to all EU citizens (who are residing within the EU), regardless of where in the world a website or its owner is based, in order to fully comply, in practice you should seek consent for all visitors to all websites globally.
In order to be GDPR-compliant, and in order to just be a good netizen, I made sure, when building GreenAsh v5 earlier this year, to not use services that set cookies at all, wherever possible. In previous iterations of GreenAsh, I used Google Analytics, which (like basically all Google services) is a notorious GDPR offender; this time around, I instead used Cloudflare Web Analytics, which is a good enough replacement for my modest needs, and which ticks all the privacy boxes.
However, on pages with forms at least, I still need Google reCAPTCHA. I'd like to instead use the privacy-conscious hCaptcha, but Netlify Forms only supports reCAPTCHA, so I'm stuck with it for now. Here's how I seek the user's consent before loading reCAPTCHA.
ready(() => {
const submitButton = document.getElementById('submit-after-recaptcha');
if (submitButton == null) {
return;
}
window.originalSubmitFormButtonText = submitButton.textContent;
submitButton.textContent = 'Prepare to ' + window.originalSubmitFormButtonText;
submitButton.addEventListener("click", e => {
if (submitButton.textContent === window.originalSubmitFormButtonText) {
return;
}
const agreeToCookiesMessage =
'This will load Google reCAPTCHA, which will set cookies. Sadly, you will ' +
'not be able to submit this form unless you agree. GDPR, not to mention ' +
'basic human decency, dictates that you have a choice and a right to protect ' +
'your privacy from the corporate overlords. Do you agree?';
if (window.confirm(agreeToCookiesMessage)) {
const recaptchaScript = document.createElement('script');
recaptchaScript.setAttribute(
'src',
'https://www.google.com/recaptcha/api.js?onload=recaptchaOnloadCallback' +
'&render=explicit');
recaptchaScript.setAttribute('async', '');
recaptchaScript.setAttribute('defer', '');
document.head.appendChild(recaptchaScript);
}
e.preventDefault();
});
});
I load this JS on every page, thus putting it on the lookout for forms that require reCAPTCHA (in my case, that's comment forms and the contact form). It changes the form's submit button text from, for example, "Send", to instead be "Prepare to Send" (as a hint to the user that clicking the button won't actually submit the form, there will be further action required before that happens).
It hijacks the button's click event, such that if the user hasn't yet provided consent, it shows a prompt. When consent is given, the Google reCAPTCHA JS is added to the DOM, and reCAPTCHA is told to call recaptchaOnloadCallback when it's done loading. If the user has already provided consent, then the button's default click behaviour of triggering form submission is allowed.
I embed this HTML inside every form that requires reCAPTCHA. It defines the wrapper element into which the reCAPTCHA is injected. And it defines recaptchaOnloadCallback, which changes the submit button text back to what it originally was (e.g. changes it from "Prepare to Send" back to "Send"), and which actually renders the reCAPTCHA widget.
This is what my GDPR-compliant, reCAPTCHA-enabled, Netlify-powered contact form looks like. The data-netlify-recaptcha attribute tells Netlify to require a successful reCAPTCHA challenge in order to accept a submission from this form.
The prompt before the reCAPTCHA in action
That's all there is to it! Not rocket science, but I just thought I'd share this with the world, because despite there being a gazillion posts on the interwebz advising that you "ask for consent before setting cookies", there seem to be surprisingly few step-by-step instructions explaining how to actually do that. And the standard advice appears to be to use a third-party script / plugin that implements an "accept cookies" popup for you, even though it's really easy to implement it yourself.
]]>
Introducing: Instant-runoff voting simulator2022-05-17T00:00:00Z2022-05-17T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/05/introducing-instant-runoff-voting-simulator/
I built a simulator showing how instant-runoff voting (called preferential voting in Australia) works step-by-step. Try it now.
The simulator in action
I hope that, by being an interactive, animated, round-by-round visualisation of the ballot distribution process, this simulation gives you a deeper understanding of how instant-runoff voting works.
There are other tools around that do basically the same thing as this simulator. Kudos to the authors of those tools. However, they only output a text log or a text-based table, they don't provide any visualisation or animation of the vote-counting process. And they spit out the results for all rounds all at once, they don't show (quite as clearly) how the results evolve from one round to the next.
Source code is all up on GitHub. It's coded in vanilla JS, with the help of the lovely Papa Parse library for CSV handling. I made a nice flowchart version of the code too.
With a federal election coming up, here in Australia, in just a few days' time, this simulator means there's now one less excuse for any of my fellow citizens to not know how the voting system works. And, in this election more than ever, it's vital that you properly understand why every preference matters, and how you can make every preference count.
I have also made the casual observation, over the last three years, that Morrison makes few appearances on Aunty in general, compared with the commercial alternatives, particularly Sky News (which I personally have never watched directly, and have no plans to, but I've seen plenty of clips of Morrison on Sky repeated on the ABC and elsewhere).
This led me to do some research, to find out: how often has Morrison taken part in ABC interviews, during his tenure so far as Prime Minister, compared with his predecessors? I compiled my findings, and this is what they show:
Morrison's ABC interview frequency compared to his forebears
It's official: Morrison has, on average, taken part in fewer ABC TV and Radio interviews, than any other Prime Minister in recent Australian history.
I hope you find my humble dataset useful. Apart from illustrating Morrison's disdain for the ABC, there are also tonnes of other interesting analyses that could be performed on the data, and tonnes of other conclusions that could be drawn from it.
My findings are hardly surprising, considering Morrison's flagrant preference for sensationalism, spin, and the far-right fringe. I leave it as an exercise to the reader, to draw from my dataset what conclusions you will, regarding the fate of the already Coalition-scarred ABC, should Morrison win a second term.
]]>
Is Australia supporting atrocities in West Papua?2022-04-30T00:00:00Z2022-04-30T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/04/is-australia-supporting-atrocities-in-west-papua/
A wee lil' fact check style analysis of The Juice Media's 2018 video Honest Government Ad: Visit West Papua. Not that I don't love TJM's videos (that would be un-Australien!). Just that a number of the claims in that particular piece took me by surprise.
Note: in keeping with what appears to be the standard in English-language media, for the rest of this article I'll be referring to the whole western half of the island of New Guinea – that is, to both of the present-day Indonesian provinces of Papua and West Papua – collectively as "West Papua".
Grasberg mine
Let's start with one of the video's least controversial claims – one that's about a simple objective fact, and one that has nothing to do with Australia:
[Grasberg mine] … the biggest copper and gold mine in the world
Close enough
I had never heard of the Grasberg mine before. Just like I had never heard much in general about West Papua before – even though it's only about 200km from (the near-uninhabited northern tip of) Australia. Which I guess is due to the scant media coverage afforded to what has become a forgotten region.
But. Are a significant number of Australian-trained Indonesian government personnel deployed in West Papua, compared with elsewhere in the vastness of Indonesia? We don't know (although it seems unlikely). Does Australia train Indonesian personnel in a manner that encourages violence towards civilians? No idea (but I should hope not). And does Australia have any control over what the Indonesian government does with the resources provided to it? Not really.
I agree that, considering the Indonesian military's track record of human rights abuses, it would probably be a good idea for Australia to stop resourcing it. The risk of Australia indirectly facilitating human rights abuses, in my opinion, outweighs the diplomatic and geopolitical benefits of neighbourly cooperation.
Nevertheless: Australia (as far as we know) has no boots on the ground in West Papua; (I have to reluctantly say that) Australia is not responsible for how the Indonesian military utilises the training and equipment that it has received; and there's insufficient evidence to link Australia's support of the Indonesian military to date, with goings-on in West Papua.
I declare this claim to be exaggerated.
Corporate plunder
so that our other mates [Rio Tinto, LG, BP, Freeport-McMoRan] can come in and start makin' the ching ching
Freeport-McMoRan has, of course, been Grasberg's principal owner and operator for most of the mine's history, as well as the principal entity that has been raking in on the mine's insane profits. The company has some business ventures in Australia, although its ties with the Australian economy, and therefore with the Australian government, appear to be quite modest.
BP is the main owner of the Tangguh gas field, which is probably the second-largest and second-most-lucrative (and second-most-polluting!) industrial enterprise in West Papua. BP is of course a British company, but it has a significant presence in Australia. LG appears to also be involved in Tangguh. LG is a Korean company, and it has modest ties to the Australian economy.
The Tangguh LNG site in West Papua Image source: KBR
So, all of these companies could be considered "mates" of the Australian government (some more so than others). And all of them are, or until recently were, "makin' the ching ching" in West Papua.
I declare this claim to be very close to the truth.
Stopping independence
Remember when two Papuans [Clemens Runaweri and Willem Zonggonau] tried to flee to the UN to expose this bulls***? We [Australia] prevented them from ever getting there, by detaining them on Manus Island
Checks out
Well, no, I don't remember it, because – apart from the fact that it happened long before I was born – it's an incident that has scarcely ever been covered by the media (much like the lack of media coverage of West Papua in general). Nevertheless, it did happen, and it is documented:
In May 1969, two young West Papuan leaders named Clemens Runaweri and Willem Zonggonau attempted to board a plane in Port Moresby for New York so that they could sound the alarm at UN headquarters. At the request of the Indonesian government, Australian authorities detained them on Manus Island when their plane stopped to refuel, ensuring that West Papuan voices were silenced.
After being briefly detained, the two men lived the rest of their lives in exile in Papua New Guinea. Zonggonau died in Sydney in 2006, where he and Runaweri were visiting, still campaigning to free their homeland until the end. Runaweri died in Port Moresby in 2011.
Celebrating half a century of locking up innocent people on remote Pacific islands Image source: The New York Times
I declare this claim to be 100% correct.
Training hitmen
We [Australia] helped train [at the Indonesia-Australia Defence Alumni Association (IKAHAN)] and arm those heroes [the hitmen who assassinated the Papuans' leader Theys Eluay in 2001]
I don't know why IKAHAN was mentioned together with the 2001 murder of Eluay, because it wasn't founded until 2011, so one couldn't possibly have anything to do with the other. It's possible that Eluay's killers received Australian-backed training elsewhere, but not there. Similarly, it's possible that training undertaken at IKAHAN has contributed to other shameful incidents in West Papua, but not that one. Mentioning IKAHAN does nothing except conflate the facts.
In any case, I repeat, (I have to reluctantly say that) Australia is not responsible for how the Indonesian military utilises the training and equipment that it has received; and there's insufficient evidence to link Australia's support of the Indonesian military to date, with goings-on in West Papua.
I declare this claim to be exaggerated.
Shipments from Cairns
which [Grasberg mine] is serviced by massive shipments from Cairns. Cairns! The Aussie town supplying West Papua's Death Star with all its operational needs
"Citations needed"
This claim really came at me out of left field. So much so, that it was the main impetus for me penning this article as a fact check. Can it be true? Is the laid-back tourist town of Cairns really the source of regular shipments of supplies, to the industrial hellhole that is Grasberg?
I honestly don't know how TJM got their hands on this bit of intel, because there's barely any mention of it in any media, mainstream or otherwise. Clearly, this was an arrangement that all involved parties made a concerted effort to keep under the radar for many years.
In any case, yes, it appears to be true. Or, at least, it was true at the time that the video was published, and it had been true for about 45 years, up until that time. Then, in 2019, the shipping, and Freeport-McMoRan's presence in town, apparently disappeared from Cairns, presumably replaced by alternative logistics based in Indonesia (and presumably due to the Indonesian government having negotiated to make itself the majority owner of Grasberg shortly before that).
It makes sense logistically. Cairns is one of the closest fully-equipped ports to Grasberg, only slightly further away than Darwin. Much closer than Jakarta or any of the other big ports in the Indonesian heartland. And I can imagine that, for various economic and political reasons, it may well have been easier to supply Grasberg primarily from Australia rather than from elsewhere within Indonesia.
I would consider that this claim fully checks out, if I could find more sources to corroborate it. However, there's virtually no word of it in any mainstream media; and the sources that do mention it are old and of uncertain reliability.
I declare this claim to be "citations needed".
Verdict
Australia is proud to continue its fine tradition of complicity in West Papua
Exaggerated
In conclusion, I declare that the video "Honest Government Ad: Visit West Papua", on the whole, checks out. In particular, its allegation of the Australian government being economically complicit in the large-scale corporate plunder and environmental devastation of West Papua – by way of it having significant ties with many of the multinational companies operating there – is spot-on.
But. Regarding the Australian government being militarily complicit in human rights abuses in West Papua, I consider that to be a stronger allegation than is warranted. Providing training and equipment to the Indonesian military, and then turning a blind eye to the Indonesian military's actions, is deplorable, to be sure. Australia being apathetic towards human rights abuses, would be a valid allegation.
To be "complicit", in my opinion, there would have to be Australian personnel on the ground, actively committing abuses alongside Indonesian personnel, or actively aiding and abetting such abuses.
Don't get me wrong, I most certainly am not defending Australia as the patron saint of West Papua, and I'm not absolving Australia of any and all responsibility towards human rights abuses in West Papua. I'm just saying that TJM got a bit carried away with the level of blame they apportioned to Australia on that front.
Protesting for West Papuan independence Image source: new mandala
Also, bear in mind that the only reason I'm "going soft" on Australia here, is due to a lack of evidence of Australia's direct involvement militarily in West Papua. It's quite possible that there is indeed a more direct involvement, but that all evidence of it has been suppressed, both by Indonesia and by Australia.
And hey, I'm trying to play devil's advocate in this here article, which means that I'm giving TJM more of a grilling than I otherwise would, were I to simply preach my unadulterated opinion.
I'd like to wholeheartedly thank TJM for producing this video (along with all their other videos). Despite me giving them a hard time here, the video is – as TJM themselves tongue-in-cheek say – "surprisingly honest!". It educated me immensely, and I hope it educates many more folks just as immensely, as to the lamentable goings-on, right on Australia's doorstep, about which we Aussies (not to mention the rest of the world) hear unacceptably little.
The Australian government is, at the very least, one of those responsible for maintaining the status quo in West Papua. And "business as usual" over there clearly includes a generous dollop of atrocities.
]]>
On the Proof of Humanity project2022-04-19T00:00:00Z2022-04-19T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/04/on-the-proof-of-humanity-project/Proof of Humanity (PoH) is a project that I stumbled upon a few weeks ago. Its aim is to create a registry of every living human on the planet. So far, it's up to about 15,000 out of 7 billion.
Just for fun, I registered myself, so I'm now part of that tiny minority who, according to PoH, are verified humans! (Sorry, I guess the rest of you are just an illusion).
Actual bona fide humans
This is a brief musing on the PoH project: its background story, the people behind it, the technology powering it, the socio-economic philosophy behind it, the challenges it's facing, whether it stacks up, and what I think lies ahead.
The story
Most people think of Proof of Humanity in terms of its technology. That is, as a cryptocurrency thing, because it's all built on the Ethereum blockchain. So, yes, it's a crypto project. But, unlike almost every other crypto project, it has little to do with money (although some critics disagree), and everything to do with democracy.
The story begins in 2012, in Buenos Aires, Argentina (a part of the world that I know well and that's close to my heart), when an online voting platform called DemocracyOS was built, and when Pia Mancini founded a new political party called Partido de la Red, which promised it would vote in congress the way constituents told it to vote, law by law (similar to many pirate parties around the world). In 2014, Pia presented all this in a TED talk.
How to upgrade democracy for the Internet era Image source: TED
DemocracyOS – which, by the way, is still alive and kicking – has nothing to do with crypto. It's just a simple voting app. Nor does it handle identity in any innovative way. The pilot in Argentina just relied on voters providing their official government-issued ID documents in order to vote. DemocracyOS is about enabling direct democracy, giving more people a voice, and fighting corruption.
In 2015, Pia Mancini and her partner Santiago Siri – along with Herb Stephens – founded Democracy Earth, which is when crypto entered the mix. The foundation's seminal paper "The Social Smart Contract" laid down (in exhaustive detail) the technical design for a new voting platform based on blockchain. The original plan was for the whole thing to be built on Bitcoin (Ethereum was brand-new at the time).
(Side note: the Democracy Earth paper was actually the thing that I stumbled across, while googling stuff related to direct democracy and liquid democracy. It was only that paper, that then led me to discover Proof of Humanity.)
To make the voting platform feasible, the paper argued, a decentralised "Proof of Identity" solution was needed – the design that the paper spells out for such a system, is clearly the "first draft" of what would later become Proof of Humanity. The paper also presents the spec for a universal basic income being paid to everyone on the platform, which is one of the key features of PoH today.
When Pia and Santiago welcomed their daughter Roma Siri into the world in 2015, they gave her the world's first ever "blockchain valid birth certificate" (using the Bitcoin blockchain). The declaration stated verbally in the video, and the display of the blockchain address in the visual recording, are almost exactly the same as the declaration and the public key that are present in the thousands of PoH registration videos to date.
Roma Siri: the world's first blockchain verified human
The original plan was for Democracy Earth itself to build a blockchain-based voting platform. Which they did: it was called Sovereign, and it launched in 2016. Whereas DemocracyOS enables direct democracy, Sovereign takes things a step further, and enables liquid democracy.
From right: Santiago Siri, Federico Ast, Paula Berman, and Juan Llanos, at the "first Proof of Humanity meetup" in Osaka, Japan, Oct 2019 Image source: Twitter
And fast-forward again to 2021. Proof of Humanity is launched, as an Ethereum Dapp ("decentralised app"). Officially, PoH is independent of any "real-life" people or organisations, and is purely governed by a DAO ("decentralised autonomous organisation").
The main selling point that PoH has pitched so far, is that everyone who successfully registers receives a stream of UBI tokens, which will (apparently!) reduce world poverty and global inequality.
PoH participants are also able to vote on "HIPs" (Humanity Improvement Proposals) – i.e. proposed changes to the PoH smart contract, so basically, equivalent to voting on pull requests for the project's main codebase – I've already cast my first vote. Voting is powered by Snapshot, which appears to be the successor platform to Sovereign – but I'm waiting for someone to reply to my question about that.
PoH is still in its infancy. It doesn't even have a Wikipedia page yet. I wrote a draft Proof of Humanity Wikipedia page, but, despite a lengthy argument with the moderators, I wasn't able to get it published, because apparently there's still insufficient reliable independent coverage of the project. You're welcome to add more sources, to try and satisfy the pedantic gatekeepers over there.
Challenges
By far the biggest challenge to the growth and the success of Proof of Humanity right now, is the exorbitant transaction fees (known as "gas fees") charged by the Ethereum network. Considering that its audience is (ostensibly) every human on the planet, you'd think that registering with PoH would be free, or at least very cheap. Think again!
You have to pay a deposit, which is currently 0.125 ETH (approximately $400 USD), and which is refunded once your profile is successfully verified (and believe me or not, but I'm telling you from personal experience, they do refund it). That amount isn't trivial, even for a privileged first-worlder like myself.
But you also, in my personal experience, have to pay at least another 10% on top of that (i.e. 0.012 ETH, or $40 USD), in non-refundable gas fees, to cover the estimated processing power required to execute the PoH smart contract for your profile. Plus another 10% or so (could well be more, depending on your circumstances) if you need to exchange fiat money for Ethereum, and back again, in order to pay the deposit and to recover it later.
So, a $400 USD deposit, which you lose if your profile is challenged (and your appeal fails), and which takes at least a week to get refunded to you. Plus $80 USD in fees. Plus it's all denominated in a highly volatile cryptocurrency, whose value could plummet at any time. That's a pretty steep price tag, for participation in "a cool experiment" that has no real-world utility right now. Would I spend that money and effort again, to renew my PoH profile when it expires in two years' time? Unless it gains some real-world utility, probably not.
Also a major challenge, is the question of how to give the UBI tokens any real value. UBI can be traded on the open market (although the only exchange that actually allows it to be bought and sold right now is the Argentinian Ripio). When Proof of Humanity launched in early 2021, 1 UBI was valued at approximately $1 USD. Since then, its value has consistently declined, and 1 UBI is now valued at approximately $0.04 USD.
UBI is highly inflationary by design. Every verified PoH profile results in 1 UBI being minted per hour. So every time the number of verified PoH profiles doubles, the rate of UBI minting doubles. And currently there's zero demand for UBI, because there's nothing useful that you can do with it (including investing or speculating in it!). The PoH community is actively discussing possible solutions, but there's no silver bullet.
To top it all off, it's still not clear whether or not PoH will live up to its purported aim, which is to create a Sybil-proof list of humans. The hypothesis underpinning it all, is that a video submission – featuring visual facial movement, and verbal narration – is too high a bar for AI to pass. Deepfake technology, while still in its infancy, is improving rapidly. PoH is betting on Deepfake's capability plateauing below that bar. Time will tell how that gamble unfolds.
PoH is also placing enormous trust in each member of the community of already-verified humans, to vet new profile submissions as representing real, unique humans. It's a radical and unproven experiment. That level of trust has traditionally been reserved for nation-states and their bureaucracies. There are defences built-in to PoH, but time will tell how resilient they are.
Musings
I'm not a crypto guy. The ETH that I bought in order to pay the PoH deposit, is my first ever cryptocurrency holding (and, in keeping with conservative mainstream advice, it's a modest amount, not more than I can afford to lose).
My interest in PoH is from a democratic empowerment point of view, not from a crypto nor a financial point of view. The founders of PoH claim to have the same underlying interest at heart. If that's so, then I'm afraid I don't really understand why they built it all on top of Ethereum, which is, at the end of the day, a financial instrument.
Sure, the PoH design relies on hash proofs, and it requires some kind of blockchain. But they could have built a new blockchain specifically for PoH, one that's not a financial instrument, and one that's completely free as in beer. Instead, they've built a system that's coupled to the monetary value of, at the mercy of the monetary fees of, and vulnerable to the monetary fraud / scams of, the underlying financial network.
Regarding UBI: I think I'm a fan of it – I more-or-less wrote a universal basic income proposal myself, nine years ago. Not unlike what PoH has done, I too proposed that a UBI should be issued in a new currency that's not controlled by any sovereign nation-state (although what I had in mind was that it be governed by some UN-like body, not by something as radical as a DAO).
However, I can't say I particularly like the way that "self-sovereignty" and UBI have been conflated in PoH. I would have thought that the most important use case for PoH would be democratic voting, and I feel that the whole UBI thing is a massive distraction from that. What's more, many of the people who have registered with PoH to date, have done so hoping to make a quick buck with UBI, and is that really the group of people we want, as the pioneers of PoH? (Plus, I hate to break it to you, all you folks banking on UBI, but you're going to be disappointed.)
So, do I think PoH "stacks up"? Well, it's not a scam, although clearly all the project's founders are heavily invested in crypto, and do stand to gain from the success of anything crypto-related. Call me naïve, but I think the people behind PoH are pure of heart, and are genuinely trying to make the world a better place. I can't say I agree with all their theories, but I applaud their efforts.
Just needed to add broccoli Image source: Meme Creator
And do I think PoH will succeed? If it can overcome the critical challenges that it's currently facing, then it stands some chance of one day reaching a critical mass, and of proving itself at scale. Although I think it's much more likely that it will remain a niche enclave. I'd be pleasantly surprised if PoH reaches 5 million users, which would be about 0.1% of internet-connected humanity, still a far cry from World Domination™.
Say what you will about it, Proof of Humanity is a novel, fascinating idea. Regardless of whether it ultimately succeeds in its aims, and regardless of whether it even can or should do so, I think it's an experiment worth conducting.
]]>
Introducing: Hack Your Bradfield Vote2022-04-10T00:00:00Z2022-04-10T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/04/introducing-hack-your-bradfield-vote/
I built a tiny site, that I humbly hope makes a tiny difference in my home electorate of Bradfield, this 2022 federal election. Check out Hack Your Bradfield Vote.
How "Hack Your Bradfield Vote" looks on desktop and mobile
I'm not overly optimistic, here in what is one of the safest Liberal seats in Australia. But you never know, this may finally be the year when the winds of change rustle the verdant treescape of Sydney's leafy North Shore.
]]>
I don't need a VPS anymore2022-03-22T00:00:00Z2022-03-22T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/03/i-dont-need-a-vps-anymore/
I've paid for either a "shared hosting" subscription, or a VPS subscription, for my own use, for the last two decades. Mainly for serving web traffic, but also for backups, for Git repos, and for other bits and pieces.
No more defending against evil villains! Image source: Meme Generator
In its place, I've taken the plunge and fully embraced SaaS. In particular, I've converted most of my personal web sites, and most of the other web sites under my purview, to be statically generated, and to be hosted on Netlify. I've also moved various backups to S3 buckets, and I've moved various Git repos to GitHub.
And so, you may lament that I'm yet one more netizen who has Less Power™ and less control. Yet another lost soul, entrusting these important things to the corporate overlords. And you have a point. But the case against SaaS is one that's getting harder to justify with each passing year. My new setup is (almost entirely) free (as in beer). And it's highly available, and lightning-fast, and secure out-of-the-box. And sysadmin is now Somebody Else's Problem. And the amount of ownership and control that I retain, is good enough for me.
The number one thing that I loathed about managing my own VPS, was security. A fully-fledged Linux instance, exposed to the public Internet 24/7, is a big responsibility. There are plenty of attack vectors: SSH credentials compromise; inadequate firewall setup; HTTP or other DDoS'ing; web application-level vulnerabilities (SQL injection, XSS, CSRF, etc); and un-patched system-level vulnerabilities (Log4j, Heartbleed, Shellshock, etc). Unless you're an experienced full-time security specialist, and you're someone with time to spare (and I'm neither of those things), there's no way you'll ever be on top of all that.
With the new setup, I still have some responsibility for security, but only the level of responsibility that any layman has for any managed online service. That is, responsibility for my own credentials, by way of a secure password, which is (wherever possible) complimented with robust 2FA. And, for GitHub, keeping my private SSH key safe (same goes for AWS secret tokens for API access). That's it!
I was also never happy with the level of uptime guarantee or load handling offered by a VPS. If there was a physical hardware fault, or a data centre networking fault, my server and everything hosted on it could easily become unreachable (fortunately this seldom happened to me, thanks to the fine folks at BuyVM). Or if there was a sudden spike in traffic (malicious or not), my server's CPU / RAM could easily get maxxed out and become unresponsive. Even if all my sites had been static when they were VPS-hosted, these would still have been constant risks.
Don't worry. I've sent an email. Image source: YouTube
With the new setup, both uptime and load have a much higher guarantee level, as my sites are now all being served by a CDN, either CloudFront or Netlify's CDN (which is similar enough to CloudFront). Pretty much the most highly available, highly resilient services on the planet. (I could have hooked up CloudFront, or another CDN, to my old VPS, but there would have been non-trivial work involved, particularly for dynamic content; whereas, for S3 / CloudFront, or for Netlify, the CDN Just Works™).
And then there's cost. I had quite a chunky 4GB RAM VPS for the last few years, which was costing me USD$15 / month. Admittedly, that was a beefier box than I really needed, although I had more intensive apps running on it, several years ago, than I've had running over the past year or two. And I felt that it was worth paying a bit extra, if it meant a generous buffer against sudden traffic spikes that might gobble up resources.
Ain't nothin' like a beefy server setup. Image source: The Register
Whereas now, my main web site hosting service, Netlify, is 100% free! (There are numerous premium bells and whistles that Netlify offers, but I don't need them). And my main code hosting service, GitHub, is 100% free too. And AWS is currently costing me less than USD$1 / month (with most of that being S3 storage fees for my private photo collection, which I never stored on my old VPS, and for which I used to pay Flickr quite a bit more money than that anyway). So I consider the whole new setup to be virtually free.
Apart from the security burden, sysadmin is simply never something that I've enjoyed. I use Ubuntu exclusively as my desktop OS these days, and I've managed a number of different Linux server environments (of various flavours, most commonly Ubuntu) over the years, so I've picked up more than a thing or two when it comes to Linux sysadmin. However, I've learnt what I have, out of necessity, and purely as a means to an end. I'm a dev, and what I actually enjoy doing, and what I try to spend most of my time doing, is dev work. Hosting everything in SaaS land, rather than on a VPS, lets me focus on just that.
In terms of ownership, like I said, I feel that my new setup is good enough. In particular, even though the code and the content for my sites now has its source of truth in GitHub, it's Git, it's completely exportable and sync-able, I can pull those repos to my local machine and to at-home backups as often as I want. Same for my files for which the source of truth is now S3, also completely exportable and sync-able. And in terms of control, obviously Netlify / S3 / CloudFront don't give me as many knobs and levers as things like Nginx or gunicorn, but they give me everything that I actually need.
I think I own my new setup well enough. Image source: Wikimedia Commons
Purists would argue that I've never even done real self-hosting, that if you're serious about ownership and control, then you host on bare metal that's physically located in your home, and that there isn't much difference between VPS- and SaaS-based hosting anyway. And that's true: a VPS is running on hardware that belongs to some company, in a data centre that belongs to some company, only accessible to you via network infrastructure that belongs to many companies. So I was already a heretic, now I've slipped even deeper into the inferno. So shoot me.
20-30 years ago, deploying stuff online required your own physical servers. 10-20 years ago, deploying stuff online required at least your own virtual servers. It's 2022, and I'm here to tell you, that deploying stuff online purely using SaaS / IaaS offerings is an option, and it's often the quickest, the cheapest, and the best-quality option (although can't you only ever pick two of those? hahaha), and it quite possibly should be your go-to option.
]]>
Email-based comment moderation with Netlify Functions2022-03-17T00:00:00Z2022-03-17T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/03/email-based-comment-moderation-with-netlify-functions/
The most noteworthy feature of the recently-launched GreenAsh v5, programming-wise, is its comment submission system. I enjoyed the luxury of the robust batteries-included comment engines of Drupal and Django, back in the day; but dynamic functionality like that isn't as straight-forward in the brave new world of SSG's. I promised that I'd provide a detailed run-down of what I built, so here goes.
Some of GreenAsh's oldest published comments, looking mighty fine in v5.
In a nutshell, the way it works is as follows:
The user submits their comment via a simple HTML form powered by Netlify Forms
The submission gets saved to the Netlify Forms data store
The submission-created event handler sends the site admin (me!) an email containing the submission data and a URL
The site admin opens the URL, which displays an HTML form populated with the submission data
After eyeballing the submission data, the site admin enters a secret token to authenticate
The site admin clicks "Approve", which writes the new comment to a JSON file, pushes the code change to the site's repo via the GitHub Contents API, and deletes the submission from the data store via the Netlify Forms API (or the site admin clicks "Delete", in which case it just deletes the submission from the data store)
Netlify rebuilds the site in response to a GitHub code change as usual, thus publishing the comment
The initial form submission is basically handled for me, by Netlify Forms. The bit where I had to write code only begins at the submission-created event handler. I could have POSTed form submissions directly to a serverless function, and that would have allowed me a lot more usage for free. Netlify Forms is a premium product, with a not-particularly-generous free tier of only 100 (non-spam) submissions per site per month. However, I'd rather use it, and live with its limits, because:
It has solid built-in spam protection, and defence against spam is something that was my problem for nearly the past 20 years, and I'd really really like for it to be Somebody Else's Problem from now on
It has its own data store of submissions, which I don't strictly need (because I'm emailing myself each submission), but which I consider really nice to have, if for any reason the email notifications don't reach me (and I also have many years of experience with unreliable email delivery), and which would be a pain (and totally not worth it) to build myself in a serverless way (would need something like DynamoDB, API Gateway, various lambda's, it would be a whole project in itself)
I can interact with that data store via a nice API
I can review spam submissions in the Netlify Forms UI (which is good, because I don't get notified of them, so otherwise I'd have no visibility over them)
Even if I bypassed Netlify Forms, I'd still have to send myself a customised email notification, which I do, using the SparkPost Transmissions API, which has a free tier limit of 500 emails per month anyway
So, the way the event handler works, is that all you have to do, in order to hook up a function, is to create a file in your repo with the correct magic name netlify/functions/submission-created.js (that's magic that isn't as well-documented as it could be, if you ask me, which is why I'm pointing it out here as explicitly as possible). You can see my full event handler code on GitHub. Here's the meat of it:
The way I'm crafting the notification email, is pretty similar to the way my comment notification emails worked before in Django. That is, the email includes the commenter's name and email, and the comment body, in readable plain text. And it includes a URL that you can follow, to go and moderate the comment. In Django, that was simply a URL to the relevant page in the admin. But this is a static site, it has no admin. So it's a URL to a form, and the URL includes all of the submission data, encoded into it as GET parameters.
How the comment notification email looks in GMail
Clicking the URL then displays an HTML form, which is generated by another serverless function, the code for which you can find here. That HTML form doesn't actually need to be generated by a function, it could itself be a static page (containing some client-side JS to populate the form fields from GET parameters), but it was just as easy to make it a function, and it effectively costs me no money either way, and I thought, meh, I'm in functions land anyway.
All the data in that form gets populated from what's encoded in the clicked-on URL, except for token, which I have to enter in manually. But, because it's a standard HTML password field, I can tell my browser to "remember password for this site", so it gets populated for me most of the time. And it's dead-simple HTML, so I was able to make it responsive with minimal effort, which is good, because it means I can moderate comments on my phone if I'm out and about.
The comment moderation form
Having this intermediary HTML form is necessary, because a clickable URL in an email can't POST directly (and I certainly don't want to actually write comments to the repo in a GET request). It's also good, because it means that the secret token has to be entered manually in the browser, which is more secure, and less mistake-prone, than the alternative, which would be sending the secret token in the notification email, and including it in the URL. And it gives me a slightly nicer UI (slightly nicer than email, that is) in which to eyeball the comment, and it gives me the opportunity to edit the comment before publishing it (which I sometimes do, usually just to fix formatting, not to censor or distort what people have to say!).
Next, we get to the business of actually approving or rejecting the comment. You can see my full comment action code on GitHub. Here's where the approval happens:
I'm using Eleventy's template data files (i.e. posts/subdir/my-first-blog-post.11tydata.json style files) to store the comments, in simple JSON files alongside the thought content files themselves, in the repo. So the comment approval function has to append to the relevant JSON file if it already exists, otherwise it has to create the relevant JSON file from scratch. That's why the first thing the function does, is try to get the existing JSON file and its comments, and if none exists, then it sets the list of existing comments to an empty array.
The function appends the new comment to the existing comments array, it serializes the new array to JSON, and it writes the new JSON file to the repo. Both interactions with the repo – reading the existing comments file, and writing the new file – are done using the GitHub Contents API, as simple HTTP calls (the PUT call results in a new commit on the repo's default branch). This way, the function doesn't have to actually interact with Git, i.e. it doesn't have to clone the repo, read from the filesystem, perform a commit, or push the change (and, therefore, nor does it need an SSH key, it just needs a GitHub API key).
The newly-approved comment in the GitHub UI's commit details screen
From that point on, just like for any other commit pushed to the repo's default branch, Netlify receives a webhook notification from GitHub, and that triggers a standard Netlify deploy, which builds the latest version of the site using Eleventy.
Netlify re-deploying the site with the new comment
The only other thing that the comment approval function does, is the same thing (and the only thing) that the comment rejection function does, which is to delete the submission via the Netlify Forms API. This isn't strictly necessary: I could just let the comments sit in the Netlify Forms data store forever (and as far as I know, Netlify has no limit on how many submissions it will store indefinitely for free, only on how many submissions it will process per month for free).
But by deleting each comment from there after I've moderated it, the Netlify Forms data store becomes a nice "todo queue", should I ever need one to refer to (i.e. should my inbox not be a good enough such queue). And I figure that a comment really doesn't need to be stored anywhere else, once it's approved and committed in Git (and, conversely, it really doesn't need to be stored anywhere at all, once it's rejected).
The new comment can be seen in the Netlify UI before it gets approved or rejected
The old Django-powered site was set up to immediately publish comments (i.e. no moderation) on thoughts that were less than one month old; and to publish comments after they'd been moderated, for thoughts that were up to one year old; and to close comment submission, for thoughts that were more than one year old.
Publishing comments immediately upon submission (or, at least, within a minute or two of submission, allowing for Eleventy build time / Netlify deploy time) would be possible in the new site, but personally I'm not comfortable with letting actual Git commits (as opposed to just database inserts) get triggered directly like that. So all comments will now be moderated. And, for now, I'm keeping comment submission open for all thoughts, old or new, and hopefully Netlify's spam protection will prove tougher than my old defences (the only reason why I'd closed comments for older thoughts, in the past, was due to a deluge of spam).
I should also note that the comment form on the new site has a (mandatory) "email" field, same as on the old site. However, on the old site, I was able to store the emails of commenters in the Django database indefinitely, but to not render them in the front-end, thus keeping them confidential. In the new site, I don't have that luxury, because if the emails are in Git, then (even if they're not rendered in the front-end) they're publicly visible on GitHub (unless I were to make the whole repo private, which I specifically don't want to do, I want the site itself to be open source!).
So, in the new site, emails of commenters are included in the notification email that gets sent to me (so that I can contact the commenter should I want to or need to), and they're stored (usually only temporarily) in the Netlify Forms data store, but they don't make it anywhere else. Rest assured, commenters, I respect your privacy, I will never publish your email address.
Commenting: because everyone's voice deserves to be heard! Image source:Illawarra Mercury
Well, there you have it, my answer to "what about comments" in the static serverless SaaS web of 2022. For your information, there's another, more official solution for powering comments with Netlify and Eleventy, with a great accompanying article.. And, full disclosure, I copied quite a few bits and pieces from that project. My main gripe with the approach taken there, is that it uses Slack, instead of email, for the notifications. It's not that I don't like Slack – I've been using it every day for work, across several jobs, for many years now (albeit not by choice) – but, call me old-fashioned if you will, I prefer good ol' email.
You've read this far, all about my whiz bang new comments system. Now, the least you can do is try it out, the form's directly below. :D
]]>
Introducing GreenAsh 52022-03-14T00:00:00Z2022-03-14T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/03/introducing-greenash-5/
After a solid run of twelve years, I've put GreenAsh v4 out to pasture, and I've launched v5 to fill its plush shoes.
Sporting a simple, readable, mobile-friendly design.
As was the case with v4, this new version isn't a complete redesign, it's a realign. First and foremost, the new design's aim is for the thought-reading experience to be a delightful one, with improved text legibility and better formatting of in-article elements. The new design is also (long overdue for GreenAsh!) fully responsive from the ground up, catering for mobile display just as much as desktop.
After nearly 18 years, this is the first ever version of GreenAsh to lack a database-powered back-end. 'Tis a bittersweet parting for me. The initial years of GreenAsh, powered by the One True™ LAMP Stack – originally, albeit briefly, using a home-grown PHP app, and then, for much longer, using Drupal – were (for me) exciting times that I will always remember fondly.
The past decade (and a bit) of the GreenAsh chronicles, powered by Django, has seen the site mature, both technology-wise and content-wise. In this, the latest chapter of The Life of GreenAsh, I hope not just to find some juniper bushes, but also to continue nurturing the site, particularly by penning thoughts of an ever higher calibre.
The most noteworthy feature that I've built in this new version, is a comment moderation and publishing system powered mainly by Netlify Functions. I'm quite proud of what I've cobbled together, and I'll be expounding upon it, in prose coming soon to a thought near you. Watch this space!
Some of the things that I had previously whinged about as being a real pain in Hugo, such as a tag cloud and a monthly / yearly archive, I've gotten built quite nicely here, using Eleventy, just as I had hoped I would. Some of the functionality that I had manually ported from Drupal to Django (i.e. from PHP to Python), back in the day, such as the autop filter, and the inline image filter, I have now ported from Django to Eleventy (i.e. from Python to Node.js).
As a side effect of the site now being hosted on Netlify, the site's source code is (for the first time) publicly available on GitHub, and even has an open-source license. So feel free to use it as you will.
All of the SSG-powered sites that I've built over the past year, have their media assets (mainly consisting of images) stored in S3 and served by CloudFront (and, in some cases, the site itself is also stored in S3 and is served by CloudFront, rather than being hosted on Netlify). GreenAsh v5 is no exception.
On account of the source code now being public, and of there no longer being any traditional back-end server, I've had to move some functionality out of GreenAsh, that I previously had bundled in to Django. In particular, I migrated my invoice data for freelance work – which had been defined as Django models, and stored in the sites's database, and exposed in the Django admin – to a simple Google Sheet, which, honestly (considering how little work I do on the side these days), will do, for the foreseeable future. And I migrated my résumé – which had been a password-protected Django view – to its own little password-protected S3 / CloudFront site.
The only big feature of v4 that's currently missing in v5, is site search. This is, of course, much easier to implement for a traditional back-end-powered site, than it is for an SSG-powered site. I previously used Whoosh with Django. Anyway, site search is only a nice-to-have feature, and this is only a small site that's easily browsable, and (in the meantime) folks can just use Google with the site: operator instead. And I hear it's not that hard to implement search for Eleventy these days, so maybe I'll whack that on to GreenAsh v5 sometime soon too.
I've been busy, SSG-ifying all my old sites, and GreenAsh is the lucky last. Now that GreenAsh v5 is live (and now that I've migrated various other non-web-facing things – mainly migrating backups of things to S3 buckets), that means I don't need a VPS anymore! I'll be writing a separate thought, sometime soon, about the pros and cons of still having a VPS in this day and age.
Hope y'all like the new décor.
]]>
The lost Armidale to Wallangarra railway2021-11-15T00:00:00Z2021-11-15T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/11/the-lost-armidale-to-wallangarra-railway/
Running more-or-less alongside the most remote section of the New England Highway, through the Northern Tablelands region of NSW, can be found the remnants of a once-proud train line. The Great Northern Railway, as it was known in its heyday, provided the only railway service linking Sydney and Brisbane, between 1889 and 1930. Regular passenger services continued until 1972, and the line has been completely closed since 1988.
Metro map style illustration of the old Armidale to Wallangarra passenger service Thanks to:Metro Map Maker
Although I once drove through most of the Northern Tablelands, I wasn't aware of this railway, nor of its sad recent history, at the time. I just stumbled across it a few days ago, browsing maps online. I decided to pen this here wee thought, mainly because I was surprised at how scant information there is about the old line and its stations.
Great Northern Railway as shown in the 1933 official NSW government map Image source:NSWrail.net
You may notice that some of the stops shown in the 1933 map, are missing from my metro map style illustration. I have omitted all of the stops that are listed as something other than "station" in this long list of facilities on the Main North Line. As far as I can tell, all of the stops listed as "unknown" or "loop", were at best very frugal platform sidings that barely qualified as stations, and their locations were never really populated towns (even going by the generous Aussie bush definition of "populated town", that is, "two people, three pubs").
All that remains of Bungulla, just south of Tenterfield Image source:NSWrail.net
Although some people haven't forgotten about it – particularly many of the locals – the railway is clearly disappearing from the collective consciousness, just as it's slowly but surely eroding and rotting away out there in the New England countryside.
Stonehenge station, just south of Glen Innes, has seen better days Image source:NSWrail.net
Some of the stations along the old line were (apparently) once decent-sized towns, but it's not just the railway that's now long gone, it's the towns too! For example, Bolivia (the place that first caught my eye on the map, and that got me started researching all this – who would have imagined that there's a Bolivia in NSW?!), which legend has it was a bustling place at the turn of the 20th century, is nothing but a handful of derelict buildings now.
Bolivia ain't even a one-horse town no more Image source:NSWrail.net
Other stations – and other towns, for that matter – along the old railway, appear to be faring better. In particular, Black Mountain station is being most admirably maintained by a local group, and Black Mountain village is also alive and well.
The main platform at Black Mountain station Image source:NSWrail.net
These days, on the NSW side, the Main North Line remains open up to Armidale, and a passenger train service continues to operate daily between Sydney and Armidale. On the Queensland side, the Southern line between Toowoomba and Wallangarra is officially still open to this day, and is maintained by Queensland Rail, however my understanding is that there's only a train actually on the tracks, all the way down to Wallangarra, once in a blue moon. On the Main line, a passenger service currently operates twice a week between Brisbane and Toowoomba (it's the Westlander service, which continues from Toowoomba all the way to Charleville).
The unique Wallangarra station, with its standard-guage NSW side, and its narrow-guage Qld side Image source:Wikimedia Commons
The chances of the Armidale to Wallangarra railway ever re-opening are – to use the historically appropriate Aussie vernacular – Buckley's and none. The main idea that the local councils have been bandying about for the past few years, has been to convert the abandoned line into a rail trail for cycling. It looks like that plan is on the verge of going ahead, even though a number of local citizens are vehemently opposed to it. Personally, I don't think a rail trail is such a bad idea: the route will at least get more use, and will receive more maintenance, than it has for the past several decades; and it would bring a welcome trickle of tourists and adventurers to the region.
The Armidale to Wallangarra railway isn't completely lost nor forgotten. But it's a woeful echo of its long-gone glory days (it isn't even properly marked on Google Maps – although it's pretty well-marked on OpenStreetMap, and it's still quite visible on Google Maps satellite imagery). And, regretfully, it's one of countless many derelict train lines scattered across NSW: others include the Bombala line (which I've seen numerous times, running adjacent to the Monaro Highway, while driving down to Cooma from Sydney), the Nyngan to Bourke line, and the Murwillumbah line.
May this article, if nothing else, at least help to document what exactly the stations were on the old line, and how they're looking in this day and age. And, whether it's a rail trail or just an old relic by the time I get around to it, I'll have to head up there and see the old line for myself. I don't know exactly what future lies ahead for the Armidale to Wallangarra railway, but I sincerely hope that, both literally and figuratively, it doesn't simply fade into oblivion.
]]>
Japan's cherry blossom: as indisputable as climate change evidence gets2021-07-25T00:00:00Z2021-07-25T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/07/japans-cherry-blossom-as-indisputable-as-climate-change-evidence-gets/
This year, Japan's earliest cherry blossom in 1,200 years made headlines around the world. And rightly so. Apart from being (as far as I can tell) a truly unparalleled feat of long-term record-keeping, it's also a uniquely strong piece of evidence in the case for man-made climate change.
I think this graph speaks for itself. Image source:BBC News
Green-minded lefties (of whom I count myself one) would tend to trust this data, without feeling the need to dig any deeper into where it came from, nor into how it got collated. However, putting myself in the shoes of a climate change sceptic, I can imagine that there are plenty of people out there who'd demand the full story, before being willing to digest the data, let alone to accept any conclusions arising from it. And hey, regardless of your political or other leanings, it's a good idea for everyone to conduct some due diligence background research, and to not blindly be believin' (especially not anything that you read online, because I hate to break it to you, but not everything on the internet is true!).
When I first saw the above graph – of the cherry blossom dates over 1,200 years – in the mainstream media, I assumed that the data points all came from a nice, single, clean, consistent source. Like, you know, a single giant tome, a "cherry blossom codex", that one wizened dude in each generation has been adding a line to, once a year, every year since 812 CE, noting down the date. But even the Japanese aren't quite that meticulous. The real world is messy!
According to the introductory text on the page from Osaka Prefecture University, the pre-modern data points – defined as being from 812 CE to 1880 – were collected:
… from many diaries and chronicles written by Emperors, aristocrats, goveners and monks at Kyoto …
For every data point, the source is listed. Many of the sources yield little or no results in a Google search. For example, try searching (including quotes) for "Yoshidake Hinamiki" (the source for the data points from 1402 and 1403), for which the only results are a handful of academic papers and books in which it's cited, and nothing actually explaining what it is, nor showing more than a few lines of the original text.
Or try searching for "Inryogen Nichiroku" (the source for various data points between 1438 and 1490), which has even fewer results: just the cherry blossom data in question, nothing else! I'm assuming that information about these sources is so limited, mainly due to there being virtually no English-language resources about them, and/or due to the actual titles of the sources having no standard for correct English transliteration. I'm afraid that, since my knowledge of Japanese is close to zilch, I'm unable to search for anything much online in Japanese, let alone for information about esoteric centuries-old texts.
The listed source for the very first data point of 812 CE is the Nihon Kōki. That book, along with the other five books that comprise the Rikkokushi – and all of which are compiled in the Ruijū Kokushi – appears to be one of the more famous sources. It was officially commissioned by the Emperor, and was authored by several statesmen of the imperial court. It appears to be generally considered as a reliable source of information about life in 8th and 9th century Japan.
Japanese literary works go back over a thousand years. Image source:Wikimedia Commons
The data points from 812 CE to 1400 are somewhat sporadic. There are numerous gaps, sometimes of as much as 20 years. Nevertheless, considering the large time scale under study, the data for that period is (in my unqualified layman's opinion) of high enough frequency for it to be statistically useful. The data points from 1400 onwards are more contiguous (i.e. there are far fewer gaps), so there appears to have been a fairly consistent and systematic record-keeping regime in place since then.
How much you want to trust the pre-modern data really depends, I guess, on what your opinion of Japanese civilisation is. When considering that matter, bear in mind that the Imperial House of Japan is believed to be the oldest continuous monarchy in the world, and that going back as far as the 8th century, Japan was already notable for its written works. Personally, I'd be willing to give millenium-old Japanese texts the benefit of the doubt in terms of their accuracy, more than I'd be willing to do so for texts from most other parts of the world from that era.
The man behind this data set, Yasuyuki Aono, is an Associate Professor in Environmental Sciences and Technology at Osaka Prefecture University (not a world-class university, but apparently it's roughly one of the top 20 universities in Japan). He has published numerous articles over his 30+ year career. His 2008 paper: Phenological data series of cherry tree flowering in Kyoto, Japan, and its application to reconstruction of springtime temperatures since the 9th century – the paper which is the primary source of much of the data set – is his seminal work, having been cited over 250 times to date.
So, the data set, the historical sources, and the academic credentials, all have some warts. But, in my opinion, those warts really are on the small side. It seems to me like pretty solid research. And it appears to have all been quite thoroughly peer reviewed, over numerous publications, in numerous different journals, by numerous authors, over many years. You can and should draw your own conclusions, but personally, I declare this data to be trustworthy, and I assert that anyone who doubts its trustworthiness (after conducting an equivalent level of background research to mine) is splitting hairs.
It don't get much simpler
Having got that due diligence out of the way, I hope that even any climate change sceptics out there who happen to have read this far (assuming that any such folk should ever care to read an article like this on a web site like mine) are willing to admit: this cherry blossom data is telling us something!
I was originally hoping to give this article a title that went something like: "Five indisputable bits of climate change evidence". That is, I was hoping to find four or so other bits of evidence as good as this one. But I couldn't! As far as I can tell, there's no other record of any other natural phenomenon on this Earth (climate change related or otherwise), that has been consistently recorded, in writing, more-or-less annually, for the past 1,000+ years. So I had to scrap that title, and just focus on the cherry blossoms.
The annual cherry blossom in Japan is a spectacle of great beauty. Image source:Wikimedia Commons
Apart from the sheer length of the time span, the other thing that makes this such a gem, is the fact that the data in question is so simple. It's just the date of when people saw their favourite flower bloom each year! It's pretty hard to record it wrongly – even a thousand years ago, I think people knew what day of the year it was. It's not like temperature, or any other non-discrete value, that has to be carefully measured, by trained experts, using sensitive calibrated instruments. Any old doofus can write today's date, and get it right. It's not rocket science!
That's why I really am excited about this cherry blossom data being the most indisputable evidence of climate change ever. It's not going back 200 years, it's going back 1,200 years. It's not projected data, it's actual data. It's not measured, it's observed. And it was pretty steady for a whole millenium, before taking a noticeable nosedive in the 20th century. If this doesn't convince you that man-made climate change is real, then you, my friend, have well and truly buried your head in the sand.
]]>
On Tina2021-06-25T00:00:00Z2021-06-25T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/06/on-tina/
Continuing my foray into the world of Static Site Generators (SSGs), this time I decided to try out one that's quite different: TinaCMS (although Tina itself isn't actually an SSG, it's just an editing toolkit; so, strictly speaking, the SSG that I took for a spin is Next.js). Shiny new toys. The latest and greatest that the JAMstack has to offer. Very much all alpha (I encountered quite a few bugs, and there are still some important features missing entirely). But wow, it really does let you have your cake and eat it too: a fast, dumb, static site when logged out, that transforms into a rich, Git-backed, inline CMS when logged in!
Yes, it's named after that Tina, from Napoleon Dynamite. Image source:Pinterest
Pressing on with my recent tradition of converting old sites of mine from dynamic to static, this time I converted Daydream Believers. I deliberately chose that site, because its original construction with Flask Editable Site had been an experiment, trying to achieve much the same dynamic inline editing experience as that provided by Tina. Plus, the site has been pretty much abandoned by its owners for quite a long time, so (much like my personal sites) there was basically no risk involved in touching it.
To give you a quick run-down of the history, Flask Editable Site was a noble endeavour of mine, about six years ago – the blurb from the demo sums it up quite well:
The aim of this app is to demonstrate that, with the help of modern JS libraries, and with some well-thought-out server-side snippets, it's now perfectly possible to "bake in" live in-place editing for virtually every content element in a typical brochureware site.
This app is not a CMS. On the contrary, think of it as a proof-of-concept alternative to a CMS. An alternative where there's no "admin area", there's no "editing mode", and there's no "preview button".
There's only direct manipulation.
That sounds eerily similar to "the acronym TinaCMS standing for Tina Is Not A CMS" (yes, yet another recursive acronym in the IT world, in the grand tradition of GNU), as explained in the Tina FAQ:
Tina introduces an entirely new paradigm to the content management space, which can make it difficult to grasp. In short, Tina is a toolkit for making your website its own CMS. It's a suite of packages that enables developers to build a customized content management system into the website itself.
(Who knows, maybe Flask Editable Site was one of the things that inspired the guys behind Tina – if so, I'd be flattered – although I don't believe they've heard of it).
Flask Editable Site boasted essentially the same user experience – i.e. that as soon as you log in, everything is editable inline. But the content got saved the old-skool CMS way, in a relational database. And the page(s) got rendered the old-skool CMS way, dynamically at run-time. And all of that required an old-skool deployment, on an actual server running Nginx / PostgreSQL / gunicorn (or equivalents). Plus, the Flask Editable Site inline components didn't look as good as Tina's do out-of-the-box (although I tried my best, I thought they looked half-decent).
So, I rebuilt Daydream Believers in what is currently the recommended Tina way (it's the way the tinacms.org website itself is currently built): TinaCMS running on top of Next.js, and saving content directly to GitHub via its API. Although I didn't use Tina's GitHub media store (which is currently the easiest way to manage images and other media with Tina), I instead wrote an S3 media store for Tina – something that Tina is sorely lacking, and that many other SSGs / headless CMSes already have. I hope to keep working on that draft PR and to get it merged sometime soon. The current draft works, I'm running it in production, but it has some rough edges.
Daydream Believers with TinaCMS editing mode enabled.
The biggest hurdle for me, in building my first Tina site, was the fact that a Tina website must be built in React. I've dabbled in React over the past few years, mainly in my full-time job, not particularly by choice. It's rather ironic that this is my first full project built in React, and it's a static website! It's not that I don't like the philosophy or the syntax of React, I'm actually pretty on board with all that (and although I loathe Facebook, I've never held that against React).
It's just that: React is quite a big learning curve; it bloats a web front-end with its gazillion dependencies; and every little thing in the front-end has to be built (or rebuilt) in React, because it doesn't play nicely with any non-React code (e.g. old-skool jQuery) that touches the DOM directly. Anyway, I've now learnt a fair bit of React (still plenty more learning to go); and the finished site seems to load reasonably fast; and I managed to get the JS from the old site playing reasonably nicely with the new site (some via a hacky plonking of old jQuery-based code inside the main React "app" component, and some via rewriting it as actual React code).
Nevertheless, I'm super impressed with it. This is the kind of delightful user experience that I and many others were trying to build 15+ years ago in Drupal. I've cared about making awesome editable websites for an awfully long time now, and I really am overjoyed to see that awesomeness evolving to a whole new level with Tina.
Compared to the other SSGs that I've used lately – Hugo and Eleventy – Tina (slash Next.js) does have some drawbacks. It's far less mature. It has a slower build time. It doesn't scale as well. The built front-end is fatter. You can't just copy-paste legacy JS into it. You have to accept the complexity cost of React (just to build a static site!). You have to concern yourself with how everything looks in edit mode. Quite a lot of boilerplate code is required for even the simplest site.
You can also accompany traditional SSGs, such as Hugo and Eleventy, with a pretty user-friendly (and free, and SaaS) git-based CMS, such as Forestry (PS: the Forestry guys created Tina) or Netlify CMS. They don't provide any inline editing UI, they just give you a more traditional "admin site". However, they do have pretty good "live preview" functionality. Think of them as a middle ground between a traditional SSG with no editing UI, and Tina with its rich inline editing.
So, would I use Tina again? For a smaller brochureware site, where editing by non-devs needs to be as user-friendly as possible, and where I have the time / money / passion (pick approximately two!) to craft a great experience, sure, I'd love to (once it's matured a bit more). For larger sites (100+ pages), and/or for sites where user-friendly editing isn't that important, I'd probably look elsewhere. Regardless, I'm happy to be on board for the Tina journey ahead.
]]>
Introducing: Is Pacific Highway Upgraded Yet?2021-06-08T00:00:00Z2021-06-08T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/06/introducing-is-pacific-highway-upgraded-yet/
Check out this fun little site that I just built: Is Pacific Highway Upgraded Yet?Spoiler alert: no it's not!
I got thinking about this, in light of the government's announcement at the end of 2020 that the Pacific Highway upgrade is finished. I was like, hang on, no it's not! How about a web site to tell people how long we've already been waiting for this (spoiler alert: ages!), and how much longer we'll probably be waiting?
Complete with a countdown timer, which is currently set to 1 Jan 2030, a date that I arbitrarily and fairly optimistically picked as the target completion date of the Hexham bypass (but that project is still in the planning stage, no construction dates have currently been announced).
Fellow Australians, enjoy!
]]>
On Eleventy2021-04-14T00:00:00Z2021-04-14T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/04/on-eleventy/
Following on from my last experiment with Hugo, I decided to dabble in a different static site generator (SSG). This time, Eleventy. I've rebuilt another one of my golden oldies, Jaza's World, using it. And, similarly, source code is up on GitHub, and the site is hosted on Netlify. I'm pleased to say that Eleventy delivered in the areas where Hugo disappointed me most, although there were things about Hugo that I missed.
11ty!
First and foremost, Eleventy allows virtually all the custom code you might need. This is in stark contrast to Hugo, with which my biggest gripe was its lack of support for any custom code whatsoever, except for template code. The most basic code hook that Eleventy supports – filters – will get you pretty far: I whipped up some filters for date formatting, for array slicing, for getting parent pages, and for getting subsets of tags. Eleventy's custom collections are also handy: for example, I defined a collection for my nav menu items. I didn't find myself needing to write any Eleventy plugins of my own, but my understanding is that you have access to the same Eleventy API methods in a plugin, as you do in a regular site-level .eleventy.js file.
One of Eleventy's most powerful features is its pagination. It's implemented as a "core plugin" (Pagination.js is the only file in Eleventy core's Plugins directory), but it probably makes sense to just think of it as a core feature, period. Its main use case is, unsurprisingly, for paging a list of content. That is, for generating /articles/, /articles/page/2/, /articles/page/99/, and so on. But it can handle any arbitrary list of data, it doesn't have to be "page content". And it can generate pages based on any permalink pattern, which you can set to not even include a "page number" at all. In this way, Eleventy can generate pages "dynamically" from data! Jaza's World doesn't have a monthly archive, but I could have created one using Eleventy pagination in this way (whereas a dynamically-generated monthly archive is currently impossible in Hugo, so I resorted to just manually defining a page for each month).
Jaza's World migrated to 11ty
Eleventy's pagination still has a few rough edges. In particular, it doesn't (really) currently support "double pagination". That is, /section-foo/parent-bar-generated-by-pagination/child-baz-also-generated-by-pagination/ (although it's the same issue even if parent-bar is generated just by a permalink pattern, without using pagination at that parent level). And I kind of needed that feature, like, badly, for the Gallery section of Jaza's World. So I added support for this to Eleventy myself, by way of letting the pagination key be determined dynamically based on a callback function. As of the time of writing, that PR is still pending review (and so for now, on Jaza's World, I'm running a branch build of Eleventy that contains my change). Hopefully it will get in soon, in which case the enhancement request for double pagination (which is currently one of three "pinned" issues in the Eleventy issue tracker) should be able to be considered fulfilled.
JavaScript isn't my favourite language. I've been avoiding heavy front-end JS coding (with moderate success) for some time, and I've been trying to distance myself from back-end Node.js coding too (with less success). Python has been my language of choice for yonks now. So I'm giving Eleventy a good rap despite it being all JS, not because of it. I like that it's a minimalist JS tool, that it's not tied to any massive framework (such as React), and that it appears to be quite performant (I haven't formally benchmarked it against Hugo, but for my modest needs so far, Eleventy has been on par, it generates Jaza's World with its 500-odd pages in about 2 seconds). And hey, JS is as good a language as any these days, for the kind of script snippets you need when using a static site generator.
Eleventy has come a long way in a short time, but nevertheless, I don't feel that it's worthy yet of being called a really solid tool. Hugo is certainly a more mature piece of software, and a more mature community. In particular, Eleventy feels like a one-man show (Hugo suffers from this too, but it seems to have developed a slightly better contributor base). Kudos to zachleat for all the amazing work he has done and continues to do, but for Eleventy to be sustainable long-term, it needs more of a team.
With Jaza's World, I played around with Eleventy a fair bit, and got a real site built and deployed. But there's more I could do. I didn't bother moving any of my custom code into their own files, nor into separate plugins, I just left them in .eleventy.js. I also didn't bother writing JS unit tests – for a more serious project, what I'd really like to do, is to have tests that run in a CI pipeline (ideally in GitHub Actions), and to only kick off a Netlify deployment once there's a green build (rather than the usual setup of Netlify deploying as soon as the master branch in GitHub is updated).
Site building in Eleventy has been fun, I reckon I'll be doing more of it!
]]>
On Hugo2021-02-11T00:00:00Z2021-02-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/02/on-hugo/
After having it on my to-do list for several years, I finally got around to trying out a static site generator (SSG). In particular, Hugo. I decided to take Hugo for a spin, by rebuilding one of my golden oldies, Jaza's World Trip, with it. And, for bonus points, I published the source code on GitHub, and I deployed the site on Netlify. Hugo is great software with a great community, however it didn't quite live up to my expectations.
Hugo: fast like a... gopher? Image source:Hugo
Memory lane
To give you a bit of history: worldtrip was originally built in Drupal (version 4.7), back in 2007. So it started its life as a real, old-school, PHP CMS driven blog. I actually wrote most of the blog entries from internet cafés around the world, by logging in and typing away – often while struggling with a non-English keyboard, a bad internet connection, a sluggish machine, and a malware-infested old Windows. Ah, the memories! And people posted comments too.
Then, in 2014, I converted it to a "static PHP site", which I custom-built. It was static as in "no database" – all the content was in flat files, virtually identical to the "content files" of Hugo and other SSGs – but not quite static as in "plain HTML files". It was still PHP, and so it still needed to be served by a PHP-capable web server (like Apache or Nginx with their various modules).
In retrospect, maybe I should have SSG-ified worldtrip in 2014. But SSGs still weren't much of a thing back then: Hugo was in its infancy; Netlify didn't exist yet; nor did any of the JS-based cool new kids. The original SSG, Jekyll, was around, but it wasn't really on my radar (I didn't try out Jekyll until around 2016, and I never ended up building or deploying a finished site with it). Plus I still wasn't quite ready to end my decade-long love affair with PHP (I finally got out of that toxic relationship for good, a few years later). Nor was I able to yet embrace the idea of hosting a whole web site on anything other than an old-school box: for a decade or so, all I had known was "shared hosting" and VPSes.
Hugo time
So, it's 2021, and I've converted worldtrip yet again, this time to Hugo. It's pretty much unchanged on the surface. The main difference is that the trip photos (both in the "gallery" section, and embedded in blog posts) are now sourced from an S3 bucket instead of from Flickr (I needed to make this change in order to retire my Flickr account). I also converted the location map from a Google map to a Leaflet / Mapbox map (this was also needed, as Google now charges for even the simplest Maps API usage). I could have made those changes without re-building the whole site, but they were a good excuse to do just that.
The Leaflet and Mapbox powered location map.
True to its word, I can attest that Hugo is indeed fast. On my local machine, Hugo generates all of the 2,000+ pages of worldtrip in a little over 2 seconds. And deploying it on Netlify is indeed easy-peasy. And free – including with a custom domain, with SSL, with quite generous bandwidth, with plenty of build minutes – so kudos to Netlify (and I hope they keep on being so generous!).
Hugo had pretty much everything I needed, to make re-building worldtrip a breeze: content types, front matter, taxonomies, menus, customisable URLs, templating (including partials and shortcodes), pagination, and previous / next links. It didn't support absolutely all of worldtrip's features out-of-the-box – but then again, nothing ever does, right? And filling in those remaining gaps was going to be easy, right?
As it turns out, building custom functionality in Hugo is quite hard.
The first pain point that I hit, was worldtrip's multi-level (country / city) taxonomy hierarchy. Others have shared their grief with this, and I shared mine there too. I got it working, but only by coding way more logic into a template than should have been necessary, and by abusing the s%#$ out of Hugo templating's scratch feature. The resulting partial template is an unreadable abomination. It could have been a nice, clean, testable function (and it previously was one, in PHP), were I able to write any actual code in a Hugo site (in Go or in any other language). But no, you can't write actual code in a Hugo site, you can only write template logic.
Update: I just discovered that support for return'ing a value of any type (rather than just rendering a string) was added to Hugo a few years back (and is documented, albeit rather tersely). So I could rely on Hugo's scratch a bit less, if I were to instead return the countries / cities array. But the logic still has to live in a template!
Same with the tag cloud. It's not such a big deal, it's a problem that various people have solved at the template level, and I did so too. What I did for weighted tags isn't totally illegible. But again, it was previously (pre-Hugo) implemented as a nice actual function in code, and now it's shoved into template logic.
The weighted tag cloud.
The photo gallery was cause for considerable grief too. Because I didn't want an individual page to be rendered for each photo, my first approach was to define the gallery items in data files. But I needed the listing to be paginated, and I soon discovered that Hugo's pagination only supports page collections, not arbitrary lists of data (why?!). So, take two, I defined them as headless bundles. But it just so happens that listing headless bundles (as opposed to just retrieving a single one) is a right pain, and if you're building up a list of them and then paginating that list, it's also hacky and very inefficient (when I tried it, my site took 4x longer to build, because it was calling readDir on the whole photo directory, for each paginated chunk).
Finally, I stumbled across Hugo's (quite new) "no render" feature, and I was able to define and paginate my gallery items (without having a stand-alone page for each photo) in an efficient and non-hacky way, by specifying the build options render = "never" and list = "local". I also fixed a bug in Hugo itself (my first tiny bit of code written in golang!), to exclude "no render" pages from the sitemap (as of writing, the fix has been merged but not included in a stable Hugo release), thus making it safe(r) to specify list = "always" (which you might need, instead of list = "local", if you want to list your items anywhere else on the site, other than on their parent page). So, at least with the photo gallery – in contrast to my other above-mentioned Hugo pain points – I'm satisfied with the end result. Nevertheless, a more-than-warranted amount of hair tearing-out did occur.
The worldtrip monthly archive wasn't particularly hard to implement, thanks to this guide that I followed quite closely. But I was disappointed that I had to create a physical "page" content file for each month, in order for Hugo to render it. Because guess what, Hugo doesn't have built-in support for chronological archive pages! And because, since Hugo offers no real mechanism for you to write code anywhere to (programmatically) render such pages, you just have to hack around that limitation. I didn't do what the author of that guide did (he added a stand-alone Node.js script to generate more archive "page" content files when needed), because worldtrip is a retired site that will never need more such pages generated, and because I'd rather avoid having totally-separate-to-Hugo build scripts like that. The monthly archive templates also contain more logic than they ideally should.
The monthly archive index page.
Mixed feelings
So, I succeeded in migrating worldtrip to Hugo. I can pat myself on the back, job well done, jolly good old chap. I don't regret having chosen Hugo: it really is fast; it's a well-written (to my novice golang eyes) and well-maintained open-source codebase; it boasts an active dev and support community; its documentation is of a high standard; and it comes built-in with 95% of the functionality that any static site could possibly need.
I wanted, and I still want, to love Hugo, for those reasons. And just because it's golang (which I have vaguely been wanting to learn lately … although I have invested time in learning the basics of other languages over the past several years, namely Erlang and Rust). And because it really seems like the best-in-breed among SSGs: it's focused on the basics of HTML page generation (not trying to "solve React for static sites", or other such nonsense, at the same time); it takes performance and scalability seriously; and it fosters a good dev, design, and content authoring experience.
However, it seems that, by design, it's completely impossible to write custom code in an actual programming language (not in a presentation-layer template), that's hooked in to Hugo in any way (apart from by hacking Hugo core). I don't mind that Hugo is opinionated. Many great pieces of software are opinionated – Django, for example.
But Django is far more flexible: you can programmatically render any page, with any URL, that takes your fancy; you can move any presentational logic you want into procedural code (usually either in the view layer, to populate template variables, or in custom template tags), to keep your templates simple; and you can model your data however you want (so you're free to implement something like a multi-level taxonomy yourself – although I admit that this isn't a fair apples vs apples comparison, as Django data is stored in a database). I realise that Django – and Rails, and Drupal, and WordPress – all generate dynamic sites; but that's no excuse, an SSG can and should allow the same level of flexibility via custom code.
Hugo is somewhat lacking in flexibility. Image source:pixabay
There has been some (but not that much) discussion about supporting custom code in Hugo (mainly for the purpose of fetching and parsing custom data, but potentially for more things). There are technical challenges (mainly related to Go being a compiled language), but it would be possible (not necessarily in Go, various other real programming languages have been suggested). Also some mention of custom template functions (that thread is already quite old though). Nothing has been agreed upon or built to date. I for one will certainly watch this space.
For my next static site endeavour, at least, I think I'll take a different SSG for a spin. I'm thinking Eleventy, which appears to allow a lot of custom code, albeit all JS. (And my next project will be a migration of another of my golden oldies, most likely Jaza's World, which has a similar tech history to worldtrip).
Will I use Hugo again? Probably. Will I contribute to Hugo more? If I have time, and if I have itches to scratch, then sure. However, I'm a dev, and I like to code. And Hugo, despite having so much going for it, seems to be completely geared towards people who aren't devs, and who just want to publish content. So I don't see myself ever feeling "right at home" with Hugo.
]]>
Private photo collections with AWSPics2021-02-02T00:00:00Z2021-02-02T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/02/private-photo-collections-with-awspics/
I've created a new online home for my formidable collection of 25,000 personal photos. They now all live in an S3 bucket, and are viewable in a private gallery powered by the open-source AWSPics. In general, I'm happy with the new setup.
For the past 15 years, I have painstakingly curated and organised my photos on Flickr. I have no complaints or regrets: Flickr was and still is a fantastic service, and in its heyday it was ahead of its time. However, after 15 years as a loyal Pro member, it's with bittersweet reluctance that I've decided to cancel my Flickr account. The main reason for my parting ways with Flickr, is that its price has increased (and is continuing to increase), quite significantly of late, after being set in stone for many years.
I also just wanted to build (and felt that I was quite overdue in building) a photo solution crafted (at least partially) with my own hands, and that I fully control, rather than just letting SaaS do all the work for me. Similarly, even though I've always trusted and I still trust Flickr with my data, I wanted to migrate my photos to a storage back-end that I own and manage myself, and an S3 bucket is just that (at the least, IaaS is closer to that ideal than SaaS is).
I had never made any of my personal photos private, although I always could have, back in the Flickr days. I never felt that it was necessary. I was young and free, and the photos were all of me hanging out with my friends, and/or gallivanting around the world with other carefree backpackers. But I'm at a different stage of my life now. These days, the photos are all of my kids, and so publishing them for the whole world to see is somewhat less appropriate. And AWSPics makes them all private by default. So, private it is.
Many thanks to jpsim for building AWSPics, it's a great little stack. AWSPics had nearly everything I needed, when I stumbled across it about 3 months ago, and I certainly could have used it as-is, no yours-truly dev required. But, me being a fastidious ol' dev, and it being open-source, naturally I couldn't help but add a few bells and whistles to it. In particular, I scratched my own itch by building support for collections of albums, so that I could preserve the three-level hierarchy of Collections -> Albums -> Pictures that I used religiously on Flickr. I also wrote a whole lot of unit tests for the AWSPics site builder (which is a Node.js Lambda function), before making any changes, to ensure that I didn't break existing functionality. Other than that, I just submitted a few minor bug fixes.
I'm not planning on enhancing AWSPics a whole lot more. It works for my humble needs. I'm a dev, not a designer, nor a photographer. Although 25,000 photos is a lot (and growing), and I feel like I'm pushing the site builder Lambda a bit close to its limits at the moment (it takes over a minute to run, and ideally a Lambda function completes within a few seconds). Adding support for partial site rebuilds (i.e. only rebuild specific albums or collections) would resolve that. Plus I'm sure there are a few more minor bits and pieces I could work on, should I have the time and the inclination.
Well, that's all I have to say about that. Just wanted to formally announce that shift that my photo collection has made, and to give kudos where it's deserved.
]]>
Good devs care about code2021-01-28T00:00:00Z2021-01-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/01/good-devs-care-about-code/
Theories abound regarding what makes a good dev. These theories generally revolve around one or more particular skills (both "hard" and "soft"), and levels of proficiency in said skills, that are "must-have" in order for a person to be a good dev. I disagree with said theories. I think that there's only one thing that makes a good dev, and it's not a skill at all. It's an attitude. A good dev cares about code.
There are many aspects of code that you can care about. Formatting. Modularity. Meaningful naming. Performance. Security. Test coverage. And many more. Even if you care about just one of these, then: (a) I salute you, for you are a good dev; and (b) that means that you're passionate about code, which in turn means that you'll care about more aspects of code as you grow and mature, which in turn means that you'll develop more of them there skills, as a natural side effect. The fact that you care, however, is the foundation of it all.
Put your hands in the air like you just don't care. Image source:TripAdvisor
If you care about code, then code isn't just a means to an end: it's an end unto itself. If you truly don't care about code at all, but only what it accomplishes, then not only are you not a good dev, you're not really a dev at all. Which is OK, not everyone has to be a dev. If what you actually care about is that the "Unfranked Income YTD" value is accurate, then you're probably a (good) accountant. If it's that the sidebar is teal, then you're probably a (good) graphic designer. If it's that national parks are distinguishable from state forests at most zoom levels, then you're probably a (good) cartographer. However, if you copy-pasted and cobbled together snippets of code to reach your goal, without properly reading or understanding or caring about the content, then I'm sorry, but you're not a (good) dev.
Of course, a good dev needs at least some "hard" skills too. But, as anyone who has ever interviewed or worked with a dev knows, those skills – listed so prominently on CVs and in JDs – are pretty worthless if there's no quality included. Great, 10 years of C++ experience! And you've always given all variables one-character names? Great, you know Postgres! But you never add an index until lots of users complain that a page is slow? Great, a Python ninja! What's that, you just write one test per piece of functionality, and it's a Selenium test? Call me harsh, but those sound to me like devs who just don't care.
"Soft" skills are even easier to rattle off on CVs and in JDs, and are worth even less if accompanied by the wrong attitude. Conversely, if a dev has the right attitude, then these skills flourish pretty much automatically. If you care about the code you write, then you'll care about documentation in wiki pages, blog posts, and elsewhere. You'll care about taking the initiative in efforts such as refactoring. You'll care about collaborating with your teammates more. You'll care enough to communicate with your teammates more. "Caring" is the biggest and the most important soft skill of them all!
Plus Jamiroquai dancing skills. Image source:Rick Kuwahara
Formal education in programming (from a university or elsewhere) certainly helps with developing your skills, and it can also start you on your journey of caring about code. But you can find it in yourself to care, and you can learn all the tools of the trade, without any formal education. Many successful and famous programmers are proof of that. Conversely, it's possible to have a top-notch formal education up your sleeve, and to still not actually care about code.
It's frustrating when I encounter code that the author clearly didn't care about, at least not in the same ways that I care. For example, say I run into a thousand-line function. Argh, why didn't they break it up?! It might bother me first and foremost because I'm the poor sod who has to modify that code, 5 years later; that is, now it's my problem. But it would also sadden me, because I (2021 me, at least!) would have cared enough to break it up (or at least I'd like to think so), whereas that dev at that point in time didn't care enough to make the effort. (Maybe that dev was me 5 years ago, in which case I'd be doubly disappointed, although wryly happy that present-day me has a higher care factor).
Some aspects of code are easy to start caring about. For example, meaningful naming. You can start doing it right now, no skills required, except common sense. You can, and should, make this New Year's resolution: "I will not name any variable, function, class, file, or anything else x, I will instead name it num_bananas_in_tummy"! Then follow through on that, and the world will be a better place. Amen.
Others are more challenging. For example, test coverage. You need to first learn how to write and run tests in one or more programming languages. That has gotten much easier over the past few decades, depending on the language, but it's still a learning curve. You also need to learn the patterns of writing good tests (which can be a whole specialised career in itself). Plus, you need to understand why tests (particularly unit tests), and test coverage, are important at all. Only then can you start caring. I personally didn't start writing or caring about tests until relatively recently, so I empathise with those of you who haven't yet got there. I hope to see you soon on the other side.
I suspect that this theory of mine applies in much the same way, to virtually all other professions in the world. Particularly professions that involve craftsmanship, but other professions too. Good pharmacists actually care about chemical compounds. Good chefs actually care about fresh produce. Good tailors actually care about fabrics. Good builders actually care about bricks. It's not enough to just care about the customers. It's not enough to just care about the end product. And it's certainly not enough to just care about the money. In order to truly excel at your craft, you've got to actually care about the raw material.
I'm not writing this as an attack on anyone that I know, or that I've worked with, or whose code I've seen. In fact, I've been fortunate in that almost all fellow devs with whom I have crossed paths, are folks who have demonstrated that they care, and who are therefore, in my humble opinion, good devs. And I'm not trying to make myself out to be the patron saint of caring about code, either. Sorry if I sound patronising in this article. I'm not perfect any more than anyone else is. Plenty of people care more than I do. And different people care about different things. And we're all on a journey: I cared about less aspects of code 10 years ago, than I do now; and I hope to care about more aspects of code than I do today, 10 years in the future.
]]>
Tolstoy: the forgotten philosopher2020-10-11T00:00:00Z2020-10-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2020/10/tolstoy-the-forgotten-philosopher/
I recently finished reading the classic novel War and Peace. The 19th-century epic is considered the masterpiece of Leo Tolstoy, and I must say it took me by surprise. In particular, I wasn't expecting its second epilogue, which is a distinct work of its own (and one that arguably doesn't belong in a novel): a philosophical essay discussing the question of "free will vs necessity". I know that the second epilogue isn't to everyone's taste, but personally I feel that it's a real gem.
So, while history has been just and generous in venerating Tolstoy as a novelist, I feel that his contribution to the field of philosophy has gone unacknowledged. This is no doubt in part because Tolstoy didn't consider himself a philosopher, and because he didn't pen any purely philosophical works (published separately from novels and other works), and because he himself criticised the value of such works. Nevertheless, I feel warranted in asking: is Tolstoy a forgotten philosopher?
Tolstoy statue in British Columbia Image source:Waymarking
Free will in War and Peace
The concept of free will that Tolstoy articulates in War and Peace (particularly in the second epilogue), in a nutshell, is that there are two forces that influence every decision at every moment of a person's life. The first, free will, is what resides within a person's mind (and/or soul), and is what drives him/her to act per his/her wishes. The second, necessity, is everything that resides external to a person's mind / soul (that is, a person's body is also for the most part considered external), and is what strips him/her of choices, and compels him/her to act in conformance with the surrounding environment.
Whatever presentation of the activity of many men or of an individual we may consider, we always regard it as the result partly of man's free will and partly of the law of inevitability.
War and Peace, second epilogue, chapter IX
A simple example that would appear to demonstrate acting completely according to free will: say you're in an ice cream parlour (with some friends), and you're tossing up between getting chocolate or hazelnut. There's no obvious reason why you would need to eat one flavour vs another. You're partial to both. They're both equally filling, equally refreshing, and equally (un)healthy. You'll be able to enjoy an ice cream with your friends regardless. You're free to choose!
You say: I am not and am not free. But I have lifted my hand and let it fall. Everyone understands that this illogical reply is an irrefutable demonstration of freedom.
War and Peace, second epilogue, chapter VIII
And another simple example that would appear to demonstrate being completely overwhelmed by necessity: say there's a gigantic asteroid on a collision course for Earth. It's already entered the atmosphere. You're looking out your window and can see it approaching. It's only seconds until it hits. There's no obvious choice you can make. You and all of humanity are going to die very soon. There's nothing you can do!
A sinking man who clutches at another and drowns him; or a hungry mother exhausted by feeding her baby, who steals some food; or a man trained to discipline who on duty at the word of command kills a defenseless man – seem less guilty, that is, less free and more subject to the law of necessity, to one who knows the circumstances in which these people were placed …
However, the main point that Tolstoy makes regarding these two forces, is that neither of them does – and indeed, neither of them can – ever exist in absolute form, in the universe as we know it. That is to say, a person is never (and can never be) free to decide anything 100% per his/her wishes; and likewise, a person is never (and can never be) shackled such that he/she is 100% compelled to act under the coercion of external agents. It's a spectrum! And every decision, at every moment of a person's life (and yes, every moment of a person's life involves a decision), lies somewhere on that spectrum. Some decisions are made more freely, others are more constrained. But all decisions result from a mix of the two forces.
In neither case – however we may change our point of view, however plain we may make to ourselves the connection between the man and the external world, however inaccessible it may be to us, however long or short the period of time, however intelligible or incomprehensible the causes of the action may be – can we ever conceive either complete freedom or complete necessity.
War and Peace, second epilogue, chapter X
So, going back to the first example: there are always some external considerations. Perhaps there's a little bit more chocolate than hazelnut in the tubs, so you'll feel just that little bit guilty if you choose the hazelnut, that you'll be responsible for the parlour running out of it, and for somebody else missing out later. Perhaps there's a deal that if you get exactly the same ice cream five times, you get a sixth one free, and you've already ordered chocolate four times before, so you feel compelled to order it again this time. Or perhaps you don't really want an ice cream at all today, but you feel that peer pressure compels you to get one. You're not completely free after all!
If we consider a man alone, apart from his relation to everything around him, each action of his seems to us free. But if we see his relation to anything around him, if we see his connection with anything whatever – with a man who speaks to him, a book he reads, the work on which he is engaged, even with the air he breathes or the light that falls on the things about him – we see that each of these circumstances has an influence on him and controls at least some side of his activity. And the more we perceive of these influences the more our conception of his freedom diminishes and the more our conception of the necessity that weighs on him increases.
War and Peace, second epilogue, chapter IX
And, going back to the second example: you always have some control over your own destiny. You have but a few seconds to live. Do you cower in fear, flat on the floor? Do you cling to your loved one at your side? Do you grab a steak knife and hurl it defiantly out the window at the approaching asteroid? Or do you stand there, frozen to the spot, staring awestruck at the vehicle of your impending doom? It may seem pointless, weighing up these alternatives, when you and your whole world are about to be pulverised; but aren't your last moments in life, especially if they're desperate last moments, the ones by which you'll be remembered? And how do you know for certain that there will be nobody left to remember you (and does that matter anyway)? You're not completely bereft of choices after all!
… even if, admitting the remaining minimum of freedom to equal zero, we assumed in some given case – as for instance in that of a dying man, an unborn babe, or an idiot – complete absence of freedom, by so doing we should destroy the very conception of man in the case we are examining, for as soon as there is no freedom there is also no man. And so the conception of the action of a man subject solely to the law of inevitability without any element of freedom is just as impossible as the conception of a man's completely free action.
War and Peace, second epilogue, chapter X
Background story
Tolstoy's philosophical propositions in War and Peace were heavily influenced by the ideas of one of his contemporaries, the German philosopher Arthur Schopenhauer. In later years, Tolstoy candidly expressed his admiration for Schopenhauer, and he even went so far as to assert that, philosophically speaking, War and Peace was a repetition of Schopenhauer's seminal work The World as Will and Representation.
Schopenhauer's key idea, was that the whole universe (at least, as far as any one person is concerned) consists of two things: the will, which doesn't exist in physical form, but which is the essence of a person, and which contains all of one's drives and desires; and the representation, which is a person's mental model of all that he/she has sensed and interacted with in the physical realm. However, rather than describing the will as the engine of one's freedom, Schopenhauer argues that one is enslaved by the desires imbued in his/her will, and that one is liberated from the will (albeit only temporarily) by aesthetic experience.
Schopenhauer: big on grey tufts, small on optimism Image source:9gag
Schopenhauer's theories were, in turn, directly influenced by those of Immanuel Kant, who came a generation before him, and who is generally considered the greatest philosopher of the modern era. Kant's ideas (and his works) were many (and I have already written about Kant's ideas recently), but the one of chief concern here – as expounded primarily in his Critique of Pure Reason – was that there are two realms in the universe: the phenomenal, that is, the physical, the universe as we experience and understand it; and the noumenal, that is, a theoretical non-material realm where everything exists as a "thing-in-itself", and about which we know nothing, except for what we are able to deduce via practical reason. Kant argued that the phenomenal realm is governed by absolute causality (that is, by necessity), but that in the noumenal realm there exists absolute free will; and that the fact that a person exists in both realms simultaneously, is what gives meaning to one's decisions, and what makes them able to be measured and judged in terms of ethics.
We can trace the study of free will further through history, from Kant, back to Hume, to Locke, to Descartes, to Augustine, and ultimately back to Plato. In the writings of all these fine folks, over the millennia, there can be found common concepts such as a material vs an ideal realm, a chain of causation, and a free inner essence. The analysis has become ever more refined with each passing generation of metaphysics scholars, but ultimately, it has deviated very little from its roots in ancient times.
It's unique
There are certainly parallels between Tolstoy's War and Peace, and Schopenhauer's The World as Will and Representation (and, in turn, with other preceding works), but I for one disagree that the former is a mere regurgitation of the latter. Tolstoy is selling himself short. His theory of free will vs necessity is distinct from that of Schopenhauer (and from that of Kant, for that matter). And the way he explains his theory – in terms of a "spectrum of free-ness" – is original as far as I'm aware, and is laudable, if for no other reason, simply because of how clear and easy-to-grok it is.
It should be noted, too, that Tolstoy's philosophical views continued to evolve significantly, later in his life, years after writing War and Peace. At the dawn of the 1900s (by which time he was an old man), Tolstoy was best known for having established his own "rational" version of Christianity, which rejected all the rituals and sacraments of the Orthodox Church, and which gained a cult-like following. He also adopted the lifestyle choices – extremely radical at the time – of becoming vegetarian, of renouncing violence, and of living and dressing like a peasant.
War and Peace is many things. It's an account of the Napoleonic Wars, its bloody battles, its geopolitik, and its tremendous human cost. It's a nostalgic illustration of the old Russian aristocracy – a world long gone – replete with lavish soirees, mountains of servants, and family alliances forged by marriage. And it's a tenderly woven tapestry of the lives of the main protagonists – their yearnings, their liveliest joys, and their deepest sorrows – over the course of two decades. It rightly deserves the praise that it routinely receives, for all those elements that make it a classic novel. But it also deserves recognition for the philosophical argument that Tolstoy peppers throughout the text, and which he dedicates the final pages of the book to making more fully fledged.
]]>
How can we make AI that reasons?2019-03-23T00:00:00Z2019-03-23T00:00:00ZJazahttps://greenash.net.au/thoughts/2019/03/how-can-we-make-ai-that-reasons/
The past decade or so has been touted as a high point for achievements in Artificial Intelligence (AI). For the first time, computers have demonstrated formidable ability in such areas as image recognition, speech recognition, gaming, and (most recently) autonomous driving / piloting. Researchers and companies that are heavily invested in these technologies, at least, are in no small way lauding these successes, and are giving us the pitch that the current state-of-the-art is nothing less than groundbreaking.
However, as anyone exposed to the industry knows, the current state-of-the-art is still plagued by fundamental shortcomings. In a nutshell, the current generation of AI is characterised by big data (i.e. a huge amount of sample data is needed in order to yield only moderately useful results), big hardware (i.e. a giant amount of clustered compute resources is needed, again in order to yield only moderately useful results), and flawed algorithms (i.e. algorithms that, at the end of the day, are based on statistical analysis and not much else – this includes the latest Convolutional Neural Networks). As such, the areas of success (impressive though they may be) are still dwarfed by the relative failures, in areas such as natural language conversation, criminal justice assessment, and art analysis / art production.
In my opinion, if we are to have any chance of reaching a higher plane of AI – one that demonstrates more human-like intelligence – then we must lessen our focus on statistics, mathematics, and neurobiology. Instead, we must turn our attention to philosophy, an area that has traditionally been neglected by AI research. Only philosophy (specifically, metaphysics and epistemology) contains the teachings that we so desperately need, regarding what "reasoning" means, what is the abstract machinery that makes reasoning possible, and what are the absolute limits of reasoning and knowledge.
What is reason?
There are many competing theories of reason, but the one that I will be primarily relying on, for the rest of this article, is that which was expounded by 18th century philosopher Immanuel Kant, in his Critique of Pure Reason and other texts. Not everyone agrees with Kant, however his is generally considered the go-to doctrine, if for no other reason (no pun intended), simply because nobody else's theories even come close to exploring the matter in such depth and with such thoroughness.
Immanuel Kant's head (lots of philosophy inside) Image source:Wikimedia Commons
One of the key tenets of Kant's work, is that there are two distinct types of propositions: an analytic proposition, which can be universally evaluated purely by considering the meaning of the words in the statement; and a synthetic proposition, which cannot be universally evaluated, because its truth-value depends on the state of the domain in question. Further, Kant distinguishes between an a priori proposition, which can be evaluated without any sensory experience; and an a posteriori proposition, which requires sensory experience in order to be evaluated.
So, analytic a priori statements are basically tautologies: e.g. "All triangles have three sides" – assuming the definition of a triangle (a 2D shape with three sides), and assuming the definition of a three-sided 2D shape (a triangle), this must always be true, and no knowledge of anything in the universe (except for those exact rote definitions) is required.
Conversely, synthetic a posteriori statements are basically unprovable real-world observations: e.g. "Neil Armstrong landed on the Moon in 1969" – maybe that "small step for man" TV footage is real, or maybe the conspiracy theorists are right and it was all a hoax; and anyway, even if your name was Buzz Aldrin, and you had seen Neil standing there right next to you on the Moon, how could you ever fully trust your own fallible eyes and your own fallible memory? It's impossible for there to be any logical proof for such a statement, it's only possible to evaluate it based on sensory experience.
Analytic a posteriori statements, according to Kant, are impossible to form.
Which leaves what Kant is most famous for, his discussion of synthetic a priori statements. An example of such a statement is: "A straight line between two points is the shortest". This is not a tautology – the terms "straight line between two points" and "shortest" do not define each other. Yet the statement can be universally evaluated as true, purely by logical consideration, and without any sensory experience. How is this so?
Kant asserts that there are certain concepts that are "hard-wired" into the human mind. In particular, the concepts of space, time, and causality. These concepts (or "forms of sensibility", to use Kant's terminology) form our "lens" of the universe. Hence, we are able to evaluate statements that have a universal truth, i.e. statements that don't depend on any sensory input, but that do nevertheless depend on these "intrinsic" concepts. In the case of the above example, it depends on the concept of space (two distinct points can exist in a three-dimensional space, and the shortest distance between them must be a straight line).
Another example is: "Every event has a cause". This is also universally true; at least, it is according to the intrinsic concepts of time (one event happens earlier in time, and another event happens later in time), and causality (events at one point in space and time, affect events at a different point in space and time). Maybe it would be possible for other reasoning entities (i.e. not humans) to evaluate these statements differently, assuming that such entities were imbued with different "intrinsic" concepts. But it is impossible for a reasoning human to evaluate those statements any other way.
The actual machinery of reasoning, as Kant explains, consists of twelve "categories" of understanding, each of which has a corresponding "judgement". These categories / judgements are essentially logic operations (although, strictly speaking, they predate the invention of modern predicate logic, and are based on Aristotle's syllogism), and they are as follows:
Group
Categories / Judgements
Quantity
Unity
Universal All trees have leaves
Plurality
Particular Some dogs are shaggy
Totality
Singular This ball is bouncy
Quality
Reality
Affirmative Chairs are comfy
Negation
Negative No spoons are shiny
Limitation
Infinite Oranges are not blue
Relation
Inherence / Subsistence
Categorical Happy people smile
Causality / Dependence
Hypothetical If it's February, then it's hot
Community
Disjunctive Potatoes are baked or fried
Modality
Existence
Assertoric Sharks enjoy eating humans
Possibility
Problematic Beer might be frothy
Necessity
Apodictic 6 times 7 equals 42
The cognitive mind is able to evaluate all of the above possible propositions, according to Kant, with the help of the intrinsic concepts (note that these intrinsic concepts are not considered to be "innate knowledge", as defined by the rationalist movement), and also with the help of the twelve categories of understanding.
Reason, therefore, is the ability to evaluate arbitrary propositions, using such cognitive faculties as logic and intuition, and based on understanding and sensibility, which are bridged by way of "forms of sensibility".
AI with intrinsic knowledge
If we consider existing AI with respect to the above definition of reason, it's clear that the capability is already developed maturely in some areas. In particular, existing AI – especially Knowledge Representation (KR) systems – has no problem whatsoever with formally evaluating predicate logic propositions. Existing AI – especially AI based on supervised learning methods – also excels at receiving and (crudely) processing large amounts of sensory input.
So, at one extreme end of the spectrum, there are pure ontological knowledge-base systems such as Cyc, where virtually all of the input into the system consists of hand-crafted factual propositions, and where almost none of the input is noisy real-world raw data. Such systems currently require a massive quantity of carefully curated facts to be on hand, in order to make inferences of fairly modest real-world usefulness.
Then, at the other extreme, there are pure supervised learning systems such as Google's NASNet, where virtually all of the input into the system consists of noisy real-world raw data, and where almost none of the input is human-formulated factual propositions. Such systems currently require a massive quantity of raw data to be on hand, in order to perform classification and regression tasks whose accuracy varies wildly depending on the target data set.
What's clearly missing, is something to bridge these two extremes. And, if transcendental idealism is to be our guide, then that something is "forms of sensibility". The key element of reason that humans have, and that machines currently lack, is a "lens" of the universe, with fundamental concepts of the nature of the universe – particularly of space, time, and causality – embodied in that lens.
What fundamental facts about the universe would a machine require, then, in order to have "forms of sensibility" comparable to that of a human? Well, if we were to take this to the extreme, then a machine would need to be imbued with all the laws of mathematics and physics that exist in our universe. However, let's assume that going to this extreme is neither necessary nor possible, for various reasons, including: we humans are probably only imbued with a subset of those laws (the ones that apply most directly to our everyday existence); it's probably impossible to discover the full set of those laws; and, we will assume that, if a reasoning entity is imbued only with an appropriate subset of those laws, then it's possible to deduce the remainder of the laws (and it's therefore also possible to deduce all other facts relating to observable phenomena in the universe).
I would, therefore, like to humbly suggest, in plain English, what some of these fundamental facts, suitable for comprising the "forms of sensibility" of a reasoning machine, might be:
There are four dimensions: three space dimensions, and one time dimension
An object exists if it occupies one or more points in space and time
An object exists at zero or one points in space, given a particular point in time
An object exists at zero or more points in time, given a particular point in space
An event occurs at one point in space and time
An event is caused by one or more different events at a previous point in time
Movement is an event that involves an object changing its position in space and time
An object can observe its relative position in, and its movement through, space and time, using the space concepts of left, right, ahead, behind, up, and down, and using the time concepts of forward and backward
An object can move in any direction in space, but can only move forward in time
I'm not suggesting that the above list is really a sufficient number of intrinsic concepts for a reasoning machine, nor that all of the above facts are the correct choice nor correctly worded for such a list. But this list is a good start, in my opinion. If an "intelligent" machine were to be appropriately imbued with those facts, then that should be a sufficient foundation for it to evaluate matters of space, time, and causality.
There are numerous other intrinsic aspects of human understanding that it would also, arguably, be essential for a reasoning machine to possess. Foremost of these is the concept of self: does AI need a hard-wired idea of "I"? Other such concepts include matter / substance, inertia, life / death, will, freedom, purpose, and desire. However, it's a matter of debate, rather than a given, whether each of these concepts is fundamental to the foundation of human-like reasoning, or whether each of them is learned and acquired as part of intellectual experience.
Reasoning AI
A machine as discussed so far is a good start, but it's still not enough to actually yield what would be considered human-like intelligence. Cyc, for example, is an existing real-world system that basically already has all these characteristics – it can evaluate logical propositions of arbitrary complexity, based on a corpus (a much larger one than my humble list above) of intrinsic facts, and based on some sensory input – yet no real intelligence has emerged from it.
One of the most important missing ingredients, is the ability to hypothesise. That is, based on the raw sensory input of real-world phenomena, the ability to observe a pattern, and to formulate a completely new, original proposition expressing that pattern as a rule. On top of that, it includes the ability to test such a proposition against new data, and, when the rule breaks, to modify the proposition such that the rule can accommodate that new data. That, in short, is what is known as deductive reasoning.
A child formulates rules in this way. For example, a child observes that when she drops a drinking glass, the glass shatters the moment that it hits the floor. She drops a glass in this way several times, just for fun (plenty of fun for the parents too, naturally), and observes the same result each time. At some point, she formulates a hypothesis along the lines of "drinking glasses break when dropped on the floor". She wasn't born knowing this, nor did anyone teach it to her; she simply "worked it out" based on sensory experience.
Some time later, she drops a glass onto the floor in a different room of the house, still from shoulder-height, but it does not break. So she modifies the hypothesis to be "drinking glasses break when dropped on the kitchen floor" (but not the living room floor). But then she drops a glass in the bathroom, and in that case it does break. So she modifies the hypothesis again to be "drinking glasses break when dropped on the kitchen or the bathroom floor".
But she's not happy with this latest hypothesis, because it's starting to get complex, and the human mind strives for simple rules. So she stops to think about what makes the kitchen and bathroom floors different from the living room floor, and realises that the former are hard (tiled), whereas the latter is soft (carpet). So she refines the hypothesis to be "drinking glasses break when dropped on a hard floor". And thus, based on trial-and-error, and based on additional sensory experience, the facts that comprise her understanding of the world have evolved.
Some would argue that current state-of-the-art AI is already able to formulate rules, by way of feature learning (e.g. in image recognition). However, a "feature" in a neural network is just a number, either one directly taken from the raw data, or one derived based on some sort of graph function. So when a neural network determines the "features" that correspond to a duck, those features are just numbers that represent the average outline of a duck, the average colour of a duck, and so on. A neural network doesn't formulate any actual facts about a duck (e.g. "ducks are yellow"), which can subsequently be tested and refined (e.g. "bath toy ducks are yellow"). It just knows that if the image it's processing has a yellowish oval object occupying the main area, there's a 63% probability that it's a duck.
Another faculty that the human mind possesses, and that AI currently lacks, is intuition. That is, the ability to reach a conclusion based directly on sensory input, without resorting to logic as such. The exact definition of intuition, and how it differs from instinct, is not clear (in particular, both are sometimes defined as a "gut feeling"). It's also unclear whether or not some form of intuition is an essential ingredient of human-like intelligence.
It's possible that intuition is nothing more than a set of rules, that get applied either before proper logical reasoning has a chance to kick in (i.e. "first resort"), or after proper logical reasoning has been exhausted (i.e. "last resort"). For example, perhaps after a long yet inconclusive analysis of competing facts, regarding whether your Uncle Jim is telling the truth or not when he claims to have been to Mars (e.g. "Nobody has ever been to Mars", "Uncle Jim showed me his medal from NASA", "Mum says Uncle Jim is a flaming crackpot", "Uncle Jim showed me a really red rock"), your intuition settles the matter with the rule: "You should trust your own family". But, on the other hand, it's also possible that intuition is a more elementary mechanism, and that it can't be expressed in the form of logical rules at all: instead, it could simply be a direct mapping of "situations" to responses.
Is reason enough?
In order to test whether a hypothetical machine, as discussed so far, is "good enough" to be considered intelligent, I'd like to turn to one of the domains that current-generation AI is already pursuing: criminal justice assessment. One particular area of this domain, in which the use of AI has grown significantly, is determining whether an incarcerated person should be approved for parole or not. Unsurprisingly, AI's having input into such a decision has so far, in real life, not been considered altogether successful.
The current AI process for this is based almost entirely on statistical analysis. That is, the main input consists of simple numeric parameters, such as: number of incidents reported during imprisonment; level of severity of the crime originally committed; and level of recurrence of criminal activity. The input also includes numerous profiling parameters regarding the inmate, such as: racial / ethnic group; gender; and age. The algorithm, regardless of any bells and whistles it may claim, is invariably simply answering the question: for other cases with similar input parameters, were they deemed eligible for parole? And if so, did their conduct after release demonstrate that they were "reformed"? And based on that, is this person eligible for parole?
Current-generation AI, in other words, is incapable of considering a single such case based on its own merits, nor of making any meaningful decision regarding that case. All it can do, is compare the current case to its training data set of other cases, and determine how similar the current case is to those others.
A human deciding parole eligibility, on the other hand, does consider the case in question based on its own merits. Sure, a human also considers the numeric parameters and the profiling parameters that a machine can so easily evaluate. But a human also considers each individual event in the inmate's history as a stand-alone fact, and each such fact can affect the final decision differently. For example, perhaps the inmate seriously assaulted other inmates twice while imprisoned. But perhaps he also read 150 novels, and finished a university degree by correspondence. These are not just statistics, they're facts that must be considered, and each fact must refine the hypothesis whose final form is either "this person is eligible for parole", or "this person is not eligible for parole".
A human is also influenced by morals and ethics, when considering the character of another human being. So, although the question being asked is officially: "is this person eligible for parole?", the question being considered in the judge's head may very well actually be: "is this person good or bad?". Should a machine have a concept of ethics, and/or of good vs bad, and should it apply such ethics when considering the character of an individual human? Most academics seem to think so.
According to Kant, ethics is based on a foundation of reason. But that doesn't mean that a reasoning machine is automatically an ethical machine, either. Does AI need to understand ethics, in order to possess what we would consider human-like intelligence?
Although decisions such as parole eligibility are supposed to be objective and rational, a human is also influenced by emotions, when considering the character of another human being. Maybe, despite the evidence suggesting that the inmate is not reformed, the judge is stirred by a feeling of compassion and pity, and this feeling results in parole being granted. Or maybe, despite the evidence being overwhelmingly positive, the judge feels fear and loathing towards the inmate, mainly because of his tough physical appearance, and this feeling results in parole being denied.
Should human-like AI possess the ability to be "stirred" by such emotions? And would it actually be desirable for AI to be affected by such emotions, when evaluating the character of an individual human? Some such emotions might be considered positive, while others might be considered negative (particularly from an ethical point of view).
I think the ultimate test in this domain – perhaps the "Turing test for criminal justice assessment" – would be if AI were able to understand, and to properly evaluate, this great parole speech, which is one of my personal favourite movie quotes:
There's not a day goes by I don't feel regret. Not because I'm in here, or because you think I should. I look back on the way I was then: a young, stupid kid who committed that terrible crime. I want to talk to him. I want to try and talk some sense to him, tell him the way things are. But I can't. That kid's long gone and this old man is all that's left. I got to live with that. Rehabilitated? It's just a bulls**t word. So you can go and stamp your form, Sonny, and stop wasting my time. Because to tell you the truth, I don't give a s**t.
In the movie, Red's parole was granted. Could we ever build an AI that could also grant parole in that case, and for the same reasons? On top of needing the ability to reason with real facts, and to be affected by ethics and by emotion, properly evaluating such a speech requires the ability to understand humour – black humour, no less – along with apathy and cynicism. No small task.
Conclusion
Sorry if you were expecting me to work wonders in this article, and to actually teach the world how to build artificial intelligence that reasons. I don't have the magic answer to that million dollar question. However, I hope I have achieved my aim here, which was to describe what's needed in order for it to even be possible for such AI to come to fruition.
It should be clear, based on what I've discussed here, that most current-generation AI is based on a completely inadequate foundation for even remotely human-like intelligence. Chucking big data at a statistic-crunching algorithm on a fat cluster might be yielding cool and even useful results, but it will never yield intelligent results. As centuries of philosophical debate can teach us – if only we'd stop and listen – human intelligence rests on specific building blocks. These include, at the very least, an intrinsic understanding of time, space, and causality; and the ability to hypothesise based on experience. If we are to ever build a truly intelligent artificial agent, then we're going to have to figure out how to imbue it with these things.
]]>
The eccentric tale of Gustave Eiffel and his Tower2018-10-16T00:00:00Z2018-10-16T00:00:00ZJazahttps://greenash.net.au/thoughts/2018/10/the-eccentric-tale-of-gustave-eiffel-and-his-tower/
The Eiffel Tower, as it turns out, is far more than just the most iconic tourist attraction in the world. As the tallest structure ever built by man at the time – and holder of the record "tallest man-made structure in the world" for 41 years, following its completion in 1889 – it was a revolutionary feat of structural engineering. It was also highly controversial – deeply unpopular, one might even say – with some of the most prominent Parisians of the day fiercely protesting against its "monstruous" form. And Gustave Eiffel, its creator, was brilliant, ambitious, eccentric, and thick-skinned.
From reading the wonderful epic novel Paris, by Edward Rutherford, I learned some facts about Gustave Eiffel's life, and about the Eiffel Tower's original conception, its construction, and its first few decades as the exclamation mark of the Paris skyline, that both surprised and intrigued me. Allow me to share these tidbits of history in this here humble article.
Gustave Eiffel hanging out with a model of his Tower. Image source:domain.com.au.
To begin with, the Eiffel Tower was not designed by Gustave Eiffel. The original idea and the first drafts of the design were produced by one Maurice Koechlin, who worked at Eiffel's firm. The same is true of Eiffel's other great claim to fame, the Statue of Liberty (which he built just before the Tower): after Eiffel's firm took over the project of building the statue, it was Koechlin who came up with Liberty's ingenious inner iron truss skeleton, and outer copper "skin", that makes her highly wind-resistant in the midst of blustery New York Harbour. It was a similar story for the Garabit Viaduct, and various other projects: although Eiffel himself was a highly capable engineer, it was Koechlin who was the mastermind, while Eiffel was the salesman and the celebrity.
Eiffel, and his colleagues Maurice Koechlin and Émile Nouguier, were engineers, not designers. In particular, they were renowned bridge-builders of their time. As such, their tower design was all about the practicalities of wind resistance, thermal expansion, and material strength; the Tower's aesthetic qualities were secondary considerations, with architect Stephen Sauvestre only being invited to contribute an artistic touch (such as the arches on the Tower's base), after the initial drafts were completed.
Koechlin's first draft of the Eiffel Tower. Image source:Wikimedia Commons.
The Eiffel Tower was built as the centrepiece of the 1889 Exposition Universelle in Paris, after winning the 1886 competition that was held to find a suitable design. However, after choosing it, the City of Paris then put forward only a small modicum of the estimated money needed to build it, rather than the Tower's full estimated budget. As such, Eiffel agreed to cover the remainder of the construction costs out of his own pocket, but only on the condition that he receive all commercial income from the Tower, for 20 years from the date of its inauguration. This proved to be much to Eiffel's advantage in the long-term, as the Tower's income just during the Exposition Universelle itself – i.e. just during the first six months of its operating life – more than covered Eiffel's out-of-pocket costs; and the Tower has consistently operated at a profit ever since.
Illustration of the Eiffel Tower during the 1889 World's Fair. Image source:toureiffel.paris.
Pioneering construction projects of the 19th century (and, indeed, of all human history before then too) were, in general, hardly renowned for their occupational safety standards. I had always assumed that the building of the Eiffel Tower, which saw workmen reach more dizzying heights than ever before, had taken no small toll of lives. However, it just so happens that Gustave Eiffel was more than a mere engineer and a bourgeois, he was also a pioneer of safety: thanks to his insistence on the use of devices such as guard rails and movable stagings, the Eiffel Tower project amazingly saw only one fatality; and it wasn't even really a workplace accident, as the deceased, a workman named Angelo Scagliotti, climbed the tower while off duty, to impress his girlfriend, and sadly lost his footing.
The Tower's three levels, and its lifts and staircases, have always been accessible to the general public. However, something that not all visitors to the Tower may be aware of, is that near the summit of the Tower, just above the third level's viewing platform, sits what was originally Gustave Eiffel's private apartment. For the 20 years that he owned the rights to the Tower, Eiffel also enjoyed his own bachelor pad at the top! Eiffel reportedly received numerous requests to rent out the pad for a night, but he never did so, instead only inviting distinguished guests of his choosing, such as (no less than) Thomas Edison. The apartment is now open to the public as a museum. Still no word regarding when it will be listed on Airbnb; although another private apartment was more recently added lower down in the Tower and was rented out.
Eiffel's modest abode atop the world, as it looks today. Image source:The Independent.
So why did Eiffel's contract for the rights to the Tower stipulate 20 years? Because the plan was, that after gracing the Paris cityscape for that many years, it was to be torn down! That's right, the Eiffel Tower – which today seems like such an invincible monument – was only ever meant to be a temporary structure. And what saved it? Was it that the City Government came to realise what a tremendous cash cow it could inherit? Was it that Parisians came to love and to admire what they had considered to be a detestable blight upon their elegant city? Not at all! The only thing that saved the Eiffel Tower was that, a few years prior to its scheduled doomsday, a little thing known as radio had been invented. The French military, who had started using the Tower as a radio antenna – realising that it was the best antenna in all of Paris, if not the world at that time – promptly declared the Tower vital to the defence of Paris, thus staving off the wrecking ball.
The big crew gathered at the base of the Tower, Jul 1888. Image source:busy.org.
And the rest, as they say, is history. There are plenty more intriguing anecdotes about the Eiffel Tower, if you're interested in delving further. The Tower continued to have a colourful life, after the City of Paris relieved Eiffel of his rights to it in 1909, and after his death in 1923; and the story continues to this day. So, next time you have the good fortune of visiting La belle Paris, remember that there's much more to her tallest monument than just a fine view from the top.
]]>
Twelve ASX stocks with record growth since 20002018-05-29T00:00:00Z2018-05-29T00:00:00ZJazahttps://greenash.net.au/thoughts/2018/05/twelve-asx-stocks-with-record-growth-since-2000/
I recently built a little web app called What If Stocks, to answer the question: based on a start and end date, and a pool of stocks and historical prices, what would have been the best stocks to invest in? This app isn't rocket science, it just ranks the stocks based on one simple metric: change in price during the selected period.
I imported into this app, price data from 2000 to 2018, for all ASX (Australian Securities Exchange) stocks that have existed for roughly the whole of that period. I then examined the results, for all possible 5-year and 10-year periods within that date range. I'd therefore like to share with you, what this app calculated to be the 12 Aussie stocks that have ranked No. 1, in terms of market price increase, for one or more of those periods.
If you've never heard of this company before, don't worry, neither had I. Incitec Pivot is a fertiliser and explosives chemicals production company. It's the largest fertiliser manufacturer in Australia, and the second-largest explosives chemicals manufacturer in the world. It began in the early 2000s as the merger of former companies Incitec Fertilizers and the Pivot Group.
Incitec Pivot was a very cheaply priced stock for its first few years on the ASX, 2003-2005. Then, between 2005 and 2008, its value rocketed up as it acquired numerous other companies, and significantly expanded its manufacturing operations. So, in terms of a 5-year or 10-year return, it was a fabulous stock to invest in throughout the 2003-2007 period. However, its growth has been mediocre or poor since 2008.
Monadelphous is a mining infrastructure (and other industrial infrastructure) construction company based in Perth. They build, expand, and manage big installations such as LNG plants, iron ore ports, oil pipelines, and water treatment plants, in Northern Australia and elsewhere.
By the volatile standards of the mining industry (which it's basically a part of), Monadelphous has experienced remarkably consistent growth. In particular, it enjoyed almost constant growth from 2000 to 2013, which means that, in terms of a 5-year or 10-year return, it was an excellent stock to invest in throughout the 2000-2007 period. Monadelphous is somewhat vulnerable to mining crashes, although it recovered well after the 2008 GFC. However, its growth has been mediocre or poor for much of the time since 2013.
No. 1 growth stock 2001-2011 ($0.0074 - $4.05, +55,000%), and 2002-2012, and 2003-2013
Fortescue is one of the world's largest iron ore producers. Started in the early 2000s as a tiny company, in the hands of Andrew Forrest (now one of Australia's richest people) it has grown to rival the long-time iron ore giants BHP and Rio Tinto. Fortescue owns and operates some of the world's largest iron ore mines, in the Pilbara region of Western Australia.
Fortescue was a small company and a low-value stock until 2006, when its share price shot up. Apart from a massive spike in 2008 (before the GFC), and various other high times since then, its price has remained relatively flat since then. So, in terms of a 5-year or 10-year return, it was an excellent investment throughout the 2000-2007 period. However, its growth has been mediocre or poor since 2008.
CTI is a freight and heavy hauling company based in Perth. It does a fair chunk of its business hauling and storing materials for the mining industry. However, it also operates a strong consumer parcel delivery service.
CTI experienced its price surge almost entirely during 2005 and 2006. Since then, its price has been fairly stable, except that it rose somewhat during the 2010-2013 mining boom, and then fell back to its old levels during the 2014-2017 mining crash. In terms of a 5-year or 10-year return, it was a good investment throughout the 2000-2011 period.
Credit Corp Group is a debt collection company. As that description suggests, and as some quick googling confirms, they're the kind of company you do not want to have dealings with. They are apparently one of those companies that hounds people who have unpaid phone bills, credit card bills, and the like.
Anyway, getting indebted persons to pay up (with interest, of course) is apparently a business that pays off, because Credit Corp has shown consistent growth for the entire period being analysed here. In terms of a 5-year or 10-year return, it was a solid investment for most of 2000-2018 (and it appears to still be on a growth trajectory), although it yielded not so great returns for those buying in 2003-2007. All up, one of the strongest growth stocks in this list.
Ainsworth Game Technology is a poker machine (aka slot machine) manufacturing company. It's based in Sydney, where it no doubt enjoys plenty of business, NSW being home to half of all pokies in Australia, and to the second-largest number of pokies in the world, beaten only by Las Vegas.
Ainsworth stocks experienced fairly flat long-term growth during 2000-2011, but then in 2012 and 2013 the price rose significantly. They have been back on a downhill slide since then, but remain strong by historical standards. In terms of a 5-year or 10-year return, it was a good investment throughout 2003-2011, a good chunk of the period being analysed.
Copper Strike is a mining company. It appears that in the past, it operated mines of its own (copper mines, as its name suggests). However, the only significant thing that it currently does, is make money as a large shareholder of another ASX-listed mining company, Syrah Resources (ASX:SYR), which Copper Strike spun off from itself in 2007, and whose principal activity is a graphite mine in Mozambique.
Copper Strike has experienced quite consistent strong growth since 2010. In terms of a 5-year or 10-year return, it has been a quality investment since 2004 (which is when it was founded and first listed). However, its relatively tiny market cap, plus the fact that it seems to lack any core business activity of its own, makes it a particularly risky investment for the future.
The only company on this list that absolutely everybody should have heard of, Domino's is Australia's largest pizza chain, and Australia is also home to the biggest market for Domino's in the world. Founded in Australia in 1983, Domino's has been a listed ASX company since 2005.
Domino's has been on a non-stop roller-coaster ride of growth and profit, ever since it first listed in 2005. In terms of a 5-year or 10-year return, it has been a fabulous investment since then, more-or-less up to the present day. However, the stock price of Domino's has been dealt a blow for the past two years or so, in the face of reported weak profits, and claims of widespread underpayment of its employees.
Vita Group is the not-so-well-known name of a well-known Aussie brand, the mobile phone retail chain Fone Zone. Although these days, there are only a few Fone Zone branded stores left, and Vita's main business consists of the 100 or so Telstra retail outlets that it owns and manages across the country.
Vita's share price rose to a great peak in 2016, and then fell. In terms of overall performance since it was listed in 2005, Vita's growth has been fairly flat. In terms of a 5-year or 10-year return, it has been a decent investment throughout 2005-2013. Vita may experience strong growth again in future, but it appears more likely to be a low-growth stable investment (at best) from here on.
Red River is a zinc mining company. Its main operation is the Thalanga mine in northern Queensland.
Red River is one of the most volatile stocks in this list. Its price has gone up and down on many occasions. In terms of a 5-year or 10-year return, it was a good investment for 2011-2013, but it was a dud for investment for 2005-2010.
Pro Medicus is a medical imaging software development company. Its flagship product, called Visage, provides a full suite of desktop and server software for use in radiology. Pro Medicus software is used by a number of health care providers in Australia, the US, and elsewhere.
Pro Medicus has been quite a modest stock for most of its history, reporting virtually flat price growth for a long time. However, since 2015 its price has rocketed up, and it's currently riding a big high. This has apparently been due to the company winning several big contracts, particularly with clinics in the US. It looks on track to continue delivering solid growth.
Macquarie Telecom Group is an enterprise telecommunications and data hosting services company. It provides connectivity services and data centres for various Australian government departments, educational institutions, and medium-to-large businesses.
Macquarie Telecom's share price crashed quite dramatically after the dot-com boom around 2000, and didn't really recover again until after the GFC in 2009. It has been riding the cloud boom for some time now, and it appears to be stable in the long-term. In terms of a 5-year or 10-year return, its viability as a good investment has been patchy throughout the past two decades, with some years faring better than others.
Winners or duds?
How good an investment each of these stocks actually was or is, is a far more complex question than what I'm presenting here. But, for what it's worth, what you have here are 12 stocks which, if you happened to buy and sell any of them at exactly the right time in recent history, would have yielded more bang for your buck than any other stocks over the same period. Given the benefit of hindsight (which is always such a wonderful thing, isn't it?), I thought it would be a fun little exercise to identify the stocks that were winners, based on this most dead-simple of all measures.
The most interesting conclusion that I'd like to draw from this list, is what a surprisingly diverse range of industries it encompasses. There is, of course, an over-representation from mining and commodities (the "wild west" of boom-and-bust companies), with six of the stocks (half of the list) more-or-less being from that sector (although only three are actual mining companies – the others are in: chemical processing; mining infrastructure; and mining transport). However, the other six stocks are quite a mixed bag: finance; gambling; fast food; tech retail; health tech; and telco.
What can we learn from this list, about the types of companies that experience massive stock price growth? Well, to rule out one factor: they can be in any industry. Price surges can be attributed to a range of factors, but I'd say that, for the companies in this list, the most common factor has been the securing of new contracts and of new sales pipelines. For some, it has been all about the value of a particular item of goods or services soaring on the global market at a fortuitous moment. And for others, it has simply been a matter of solid management and consistently good service driving the value of the company up and up over a sustained period.
Some of these companies are considered to be actual winners, i.e. they're companies that the experts have identified, on various occasions, as good investments, for more reasons than just the market price growth that I've pointed out here. Other companies in this list are effectively duds, i.e. experts have generally cast doom and gloom upon them, or have barely bothered to analyse them at all.
I hope you enjoyed this run-down of Aussie stocks that, according to my number-crunching, could have been your cash cows, if only you had been armed with this crystal ball back in the day. In future, I'm hoping to improve What If Stocks to provide more insights, and I'm also hoping to analyse stocks in various other markets other than on the ASX.
Acknowledgement: all price data used in this analysis has been sourced from the Alpha Vantage API. All analysis is based on adjusted close prices, i.e. historical prices adjusted to reflect all corporate actions (stock splits, mergers, and so forth) that have occurred between the historical date and the current date.
Disclaimer: this article does not contain or constitute investment advice in any way. The author of this article has neither any qualifications nor any experience in finance or investment. The author has no position in any of the stocks mentioned, nor does the author endorse any of the stocks mentioned.
]]>
DNA: the most chaotic, most illegible, most mature, most brilliant codebase ever2018-04-21T00:00:00Z2018-04-21T00:00:00ZJazahttps://greenash.net.au/thoughts/2018/04/dna-the-most-chaotic-most-illegible-most-mature-most-brilliant-codebase-ever/
As a computer programmer – i.e. as someone whose day job is to write relatively dumb, straight-forward code, that controls relatively dumb, straight-forward machines – DNA is a fascinating thing. Other coders agree. It has been called the code of life, and rightly so: the DNA that makes up a given organism's genome, is the set of instructions responsible for virtually everything about how that organism grows, survives, behaves, reproduces, and ultimately dies in this universe.
Most intriguing and most tantalising of all, is the fact that we humans still have virtually no idea how to interpret DNA in any meaningful way. It's only since 1953 that we've understood what DNA even is; and it's only since 2001 that we've been able to extract and to gaze upon instances of the complete human genome.
As others have pointed out, the reason why we haven't had much luck in reading DNA, is because (in computer science parlance) it's not high-level source code, it's machine code (or, to be more precise, it's bytecode). So, DNA, which is sequences of base-4 digits, grouped into (most commonly) 3-digit "words" (known as "codons"), is no more easily decipherable than binary, which is sequences of base-2 digits, grouped into (for example) 8-digit "words" (known as "bytes"). And as anyone who has ever read or written binary (in binary, octal, or hex form, however you want to skin that cat) can attest, it's hard!
In this musing, I'm going to compare genetic code and computer code. I am in no way qualified to write about this topic (particularly about the biology side), but it's fun, and I'm reckless, and this is my blog so for better or for worse nobody can stop me.
Authorship and motive
The first key difference that I'd like to point out between the two, is regarding who wrote each one, and why. For computer code, this is quite straightforward: a given computer program was written by one of your contemporary human peers (hopefully one who is still alive, as you can then ask him or her about anything that's hard to grok in the code), for some specific and obvious purpose – for example, to add two numbers together, or to move a chomping yellow pac-man around inside a maze, or to add somersaulting cats to an image.
For DNA, we don't know who, if anyone, wrote the first ever snippet of code – maybe it was G-d, maybe it was aliens from the Delta Quadrant, or maybe it was the random result of various chemicals bashing into each other within the primordial soup. And as for who wrote (and who continues to this day to write) all DNA after that, that too may well be The Almighty or The Borg, but the current theory of choice is that a given snippet of DNA basically keeps on re-writing itself, and that this auto-re-writing happens (as far as we can tell) in a pseudo-random fashion.
This guy didn't write binary or DNA, I'm pretty sure. Image source:Art UK.
Nor do we know why DNA came about in the first place. From a philosophical / logical point of view, not having an answer to the "who" question, kind of makes it impossible to address the "why", by defintion. If it came into existence randomly, then it would logically follow that it wasn't created for any specific purpose, either. And as for why DNA re-writes itself in the way that it does: it would seem that DNA's, and therefore life's, main purpose, as far as the DNA itself is concerned, is simply to continue existing / surviving, as evidenced by the fact that DNA's self-modification results, on average, over the long-term, in it becoming ever more optimally adapted to its surrounding environment.
Management processes
For building and maintaining computer software, regardless of "methodology" (e.g. waterfall, scrum, extreme programming), the vast majority of the time there are a number of common non-dev processes in place. Apart from every geek's favourite bit, a.k.a. "coding", there is (to name a few): requirements gathering; spec writing; code review; testing / QA; version control; release management; staged deployment; and documentation. The whole point of these processes, is to ensure: that a given snippet of code achieves a clear business or technical outcome; that it works as intended (both in isolation, and when integrated into the larger system); that the change it introduces is clearly tracked and is well-communicated; and that the codebase stays maintainable.
For DNA, there is little or no parallel to most of the above processes. As far as we know, when DNA code is modified, there are no requirements defined, there is no spec, there is no review of the change, there is no staging environment, and there is no documentation. DNA seems to follow my former boss's preferred methodology: JFDI. New code is written, nobody knows what it's for, nobody knows how to use it. Oh well. Straight into production it goes.
However, there is one process that DNA demonstrates in abundance: QA. Through a variety of mechanisms, the most important of which is repair enzymes, a given piece of DNA code is constantly checked for integrity errors, and these errors are generally repaired. Mutations (i.e. code changes) can occur during replication due to imperfect copying, or at any other time due to environmental factors. Depending on the genome (i.e. the species) in question, and depending on the gene in question, the level of enforcement of DNA integrity can vary, from "very relaxed" to "very strict". For example, bacteria experience far more mutation between generations than humans do. This is because some genomes consider themselves to still be in "beta", and are quite open to potentially dangerous experimentation, while other genomes consider themselves "mature", and so prefer less change and greater stability. Thus a balance is achieved between preservation of genes, and evolution.
The coding process
For computer software, the actual process of coding is relatively structured and rational. The programmer refers to the spec – which could be anything from a one-sentence verbal instruction bandied over the water-cooler, to a 50-page PDF (preferably it's something in between those two extremes) – before putting hands to keyboard, and also regularly while coding.
The programmer visualises the rough overall code change involved (or the rough overall components of a new codebase), and starts writing. He or she will generally switch between top-down (focusing on the framework and on "glue code") and bottom-up (focusing on individual functions) several times. The code will generally be refined, in response to feedback during code review, to fixing defects in the change, and to the programmer's constant critiquing of his or her own work. Finally, the code will be "done" – although inevitably it will need to be modified in future, in response to new requirements, at which point it's time to rinse and repeat all of the above.
For DNA, on the other hand, the process of coding appears (unless we're missing something?) to be akin to letting a dog randomly roll around on the keyboard while the editor window is open, then cleaning up the worst of the damage, then seeing if anything interesting was produced. Not the most scientific of methods, you might say? But hey, that's science! And it would seem that, amazingly, if you do that on a massively distributed enough scale, over a long enough period of time, you get intelligent life.
DNA modification in progress. Image source:DogsToday.
When you think about it, that approach isn't really dissimilar to the current state-of-the-art in machine learning. Getting anything approaching significant or accurate results with machine learning models, has only been possible quite recently, thanks to the availability of massive data sets, and of massive hardware platforms – and even when you let a ML algorithm loose in that environment for a decent period of time, it produces results that contain a lot of noise. So maybe we are indeed onto something with our current approach to ML, although I don't think we're quite onto the generation of truly intelligent software just yet.
Grokking it
Most computer code that has been written by humans for the past 40 years or so, has been high-level source code (i.e. "C and up"). It's written primarily to express business logic, rather than to tell the Von Neumann machine (a.k.a. the computer hardware) exactly what to do. It's up to the compiler / interpreter, to translate that "call function abc" / "divide variable pqr by 50" / "write the string I feel like a Tooheys to file xyz" code, into "load value of register 123" / "put that value in register 456" / "send value to bus 789" code, which in turn actually gets represented in memory as 0s and 1s.
This is great for us humans, because – assuming we can get our hands on the high-level source code – we can quite easily grok the purpose of a given piece of code, without having to examine the gory details of what the computer physically does, step-by-tiny-tedious-step, in order to achieve that noble purpose.
DNA, as I said earlier, is not high-level source code, it's machine code / bytecode (more likely the latter, in which case the actual machine code of living organisms is the proteins, and other things, that DNA / RNA gets "compiled" to). And it now seems pretty clear that there is no higher source code – DNA, which consists of long sequences of Gs, As, Cs, and Ts, is the actual source. The code did not start in a form where a given gene is expressed logically / procedurally – a form from which it could be translated down to base pairs. The start and the end state of the code is as base pairs.
A code that was cracked - can the same be done for DNA? Image source:The University Network.
It also seems that DNA is harder to understand than machine / assembly code for a computer, because an organic cell is a much more complex piece of hardware than a Von Neumann-based computer (which itself is a specific type of Turing machine). That's why humans were perfectly capable of programming computers using only machine / assembly code to begin with, and why some specialised programmers continue primarily coding at that level to this day. For a computer, the machine itself only consists of a few simple components, and the instruction set is relatively small and unambiguous. For an organic cell, the physical machinery is far more complex (and whether a DNA-containing cell is a Turing machine is itself currently an open research question), and the instruction set is riddled with ambiguous, context-specific meanings.
Since all we have is the DNA bytecode, all current efforts to "decode DNA" focus on comparing long strings of raw base pairs with each other, across different genes / chromosomes / genomes. This is akin to trying to understand what software does by lining up long strings of compiled hex digits for different binaries side-by-side, and spotting sequences that are kind-of similar. So, no offense intended, but the current state-of-the-art in "DNA decoding" strikes me as incredibly primitive, cumbersome, and futile. It's a miracle that we've made any progress at all with this approach, and it's only thanks to some highly intelligent people employing their best mathematical pattern analysis techniques, that we have indeed gotten anywhere.
Where to from here?
Personally, I feel that we're only really going to "crack" the DNA puzzle, if we're able to reverse-engineer raw DNA sequences into some sort of higher-level code. And, considering that reverse-engineering raw binary into a higher-level programming language (such as C) is a very difficult endeavour, and that doing the same for DNA is bound to be even harder, I think we have our work cut out for us.
My interest in the DNA puzzle was first piqued, when I heard a talk at PyCon AU 2016: Big data biology for pythonistas: getting in on the genomics revolution, presented by Darya Vanichkina. In this presentation, DNA was presented as a riddle that more programmers can and should try to help solve. Since then, I've thought about the riddle now and then, and I have occasionally read some of the plethora of available online material about DNA and genome sequencing.
DNA is an amazing thing: for approximately 4 billion years, it has been spreading itself across our planet, modifying itself in bizarre and colourful ways, and ultimately evolving (according to the laws of natural selection) to become the codebase that defines the behaviour of primitive lifeforms such as humans (and even intelligent lifeforms such as dolphins!).
Dolphins! (Brainier than you are). Image source:Days of the Year.
So, let's be realistic here: it took DNA that long to reach its current form; we'll be doing well if we can start to understand it properly within the next 1,000 years, if we can manage it at all before the humble blip on Earth's timeline that is human civilisation fades altogether.
]]>
Mobile phone IMEI whitelisting in Chile and elsewhere2017-12-11T00:00:00Z2017-12-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2017/12/mobile-phone-imei-whitelisting-in-chile-and-elsewhere/
Shortly after arriving in Chile recently, I was dismayed to discover that – due to a new law – my Aussie mobile phone would not work with a local prepaid Chilean SIM card, without me first completing a tedious bureaucratic exercise. So, whereas getting connected with a local mobile number was previously something that took about 10 minutes to achieve in Chile, it's now an endeavour that took me about 2 weeks to achieve.
It turns out that Chile has joined a small group of countries around the world, that have decided to implement a national IMEI (International Mobile Equipment Identity) whitelist. From some quick investigation, as far as I can tell, the only other countries that boast such a system are Turkey, Azerbaijan, Colombia, and Nepal. Hardly the most venerable group of nations to be joining, in my opinion.
As someone who has been to Chile many times, all I can say is: not happy! Bringing your own mobile device, and purchasing a local SIM card, is the cheapest and the most convenient way to stay connected while travelling, and it's the go-to method for a great many tourists travelling all around the world. It beats international roaming hands-down, and it eliminates the unnecessary cost of purchasing a new local phone all the time. I really hope that the Chilean government reconsiders the need for this law, and I really hope that no more countries join this misguided bandwagon.
Getting your IMEI whitelisted in Chile can be a painful process. Image source:imgflip.
IMEI what?
In case you've never heard of an IMEI, and have no idea what it is, basically it's a unique identification code for all mobile phones worldwide. Historically, there have been no restrictions on the use of mobile handsets, in particular countries or worldwide, according to the device's IMEI code. On the contrary, what's much more common than the network blocking a device, is for the device itself to block access to all networks except one, due to it needing to be unlocked.
A number of countries have implemented IMEI blacklists, mainly in order to render stolen mobile devices useless – these countries include Australia, New Zealand, the UK, and numerous others. In my opinion, a blacklist is a much better solution than a whitelist in this domain, because it only places an administrative burden on problem devices, while all other devices on the network are presumed to be valid and authorised to connect.
Ostensibly, Chile has passed this law primarily to ensure that all mobiles imported and sold locally by retailers are capable of receiving emergency alerts (i.e. for natural disasters, particularly earthquakes and tsunamis), using a special system called SAE (Sistema de Alerta de Emergencias). In actual fact, the system isn't all that special – it's standard Cell Broadcast (CB) messaging, the vast majority of smartphones worldwide already support it, and registering IMEIs is not in any way required for it to function.
For example, the same technology is used for the Wireless Emergency Alerts (WEA) system in the USA, and for the Earthquake Early Warning (EEW) system in Japan, and neither of those countries have an IMEI whitelist in place. Chile uses channel 919 for its SAE broadcasts, which appears to be a standard emergency channel that's already used by The Netherlands and Israel (again, countries without an IMEI whitelist), and possibly also by other countries.
…que todos los equipos comercializados en el país informen con certeza al usuario si funcionarán o no en las diferentes localidades a lo largo de Chile, según las tecnologías que se comercialicen en cada zona geográfica.
Which translates to English as:
…that all commercially available devices in the country provide a guarantee to the user of whether they will function or not in all of the various regions throughout Chile, according to the technologies that are deployed within each geographical area.
However, that same article suggests that this is a solution to a problem that doesn't currently exist – i.e. that the vast majority of devices already work nationwide, and that Chile's mobile network technology is already sufficiently standardised nationwide. It also suggests that the real reason why this law was introduced, was simply in order to stifle the smaller, independent mobile retailers and service providers with a costly administrative burden, and thus to entrench the monopoly of Chile's big mobile companies (and there are approximately three big players on the scene).
So, it seems that the Chilean government created this law thinking purely of its domestic implications – and even those reasons are unsound, and appear to be mired in vested interests. And, as far as I can see, no thought at all was given to the gross inconvenience that this law was bound to cause, and that it is currently causing, to tourists. The fact that the Movistar Chile IMEI registration online form (which I used) requires that you enter a RUT (a Chilean national ID number, which most tourists including myself lack), exemplifies this utter obliviousness of the authorities and of the big telco companies, regarding visitors to Chile perhaps wanting to use their mobile devices as they see fit.
In summary
Chile is now one of a handful of countries where, as a tourist, despite bringing from home a perfectly good cellular device (i.e. one that's unlocked and that functions with all the relevant protocols and frequencies), the pig-headed bureaucracy of an IMEI whitelist makes the device unusable. So, my advice to anyone who plans to visit Chile and to purchase a local SIM card for your non-Chilean mobile phone: register your phone's IMEI well in advance of your trip, with one of the Chilean companies licensed to "certify" it (the procedure is at least free, for one device per person per year, and can be done online), and thus avoid the inconvenience of your device not working upon arrival in the country.
]]>
A lightweight per-transaction Python function queue for Flask2017-12-04T00:00:00Z2017-12-04T00:00:00ZJazahttps://greenash.net.au/thoughts/2017/12/a-lightweight-per-transaction-python-function-queue-for-flask/
The premise: each time a certain API method is called within a Flask / SQLAlchemy app (a method that primarily involves saving something to the database), send various notifications, e.g. log to the standard logger, and send an email to site admins. However, the way the API works, is that several different methods can be forced to run in a single DB transaction, by specifying that SQLAlchemy only perform a commit when the last method is called. Ideally, no notifications should actually get triggered until the DB transaction has been successfully committed; and when the commit has finished, the notifications should trigger in the order that the API methods were called.
There are various possible solutions that can accomplish this, for example: a celery task queue, an event scheduler, and a synchronised / threaded queue. However, those are all fairly heavy solutions to this problem, because we only need a queue that runs inside one thread, and that lives for the duration of a single DB transaction (and therefore also only for a single request).
To solve this problem, I implemented a very lightweight function queue, where each queue is a deque instance, that lives inside flask.g, and that is therefore available for the duration of a given request context (or app context).
The code
The whole implementation really just consists of this one function:
from collections import deque
from flask import g
def queue_and_delayed_execute(
queue_key, session_hash, func_to_enqueue,
func_to_enqueue_ctx=None, is_time_to_execute_funcs=False):
"""Add a function to a queue, then execute the funcs now or later.
Creates a unique deque() queue for each queue_key / session_hash
combination, and stores the queue in flask.g. The idea is that
queue_key is some meaningful identifier for the functions in the
queue (e.g. 'banana_masher_queue'), and that session_hash is some
identifier that's guaranteed to be unique, in the case of there
being multiple queues for the same queue_key at the same time (e.g.
if there's a one-to-one mapping between a queue and a SQLAlchemy
transaction, then hash(db.session) is a suitable value to pass in
for session_hash).
Since flask.g only stores data for the lifetime of the current
request (or for the lifetime of the current app context, if not
running in a request context), this function should only be used for
a queue of functions that's guaranteed to only be built up and
executed within a single request (e.g. within a single DB
transaction).
Adds func_to_enqueue to the queue (and passes func_to_enqueue_ctx as
kwargs if it has been provided). If is_time_to_execute_funcs is
True (e.g. if a DB transaction has just been committed), then takes
each function out of the queue in FIFO order, and executes the
function.
"""
# Initialise the set of queues for queue_key
if queue_key not in g:
setattr(g, queue_key, {})
# Initialise the unique queue for the specified session_hash
func_queues = getattr(g, queue_key)
if session_hash not in func_queues:
func_queues[session_hash] = deque()
func_queue = func_queues[session_hash]
# Add the passed-in function and its context values to the queue
func_queue.append((func_to_enqueue, func_to_enqueue_ctx))
if is_time_to_execute_funcs:
# Take each function out of the queue and execute it
while func_queue:
func_to_execute, func_to_execute_ctx = (
func_queue.popleft())
func_ctx = (
func_to_execute_ctx
if func_to_execute_ctx is not None
else {})
func_to_execute(**func_ctx)
# The queue is now empty, so clean up by deleting the queue
# object from flask.g
del func_queues[session_hash]
To use the function queue, calling code should look something like this:
from flask import current_app as app
from flask_mail import Message
from sqlalchemy.exc import SQLAlchemyError
from myapp.extensions import db, mail
def do_api_log_msg(log_msg):
"""Log the specified message to the app logger."""
app.logger.info(log_msg)
def do_api_notify_email(mail_subject, mail_body):
"""Send the specified notification email to site admins."""
msg = Message(
mail_subject,
sender=app.config['MAIL_DEFAULT_SENDER'],
recipients=app.config['CONTACT_EMAIL_RECIPIENTS'])
msg.body = mail_body
mail.send(msg)
# Added for demonstration purposes, not really needed in production
app.logger.info('Sent email: {0}'.format(mail_subject))
def finalise_api_op(
log_msg=None, mail_subject=None, mail_body=None,
is_db_session_commit=False, is_app_logger=False,
is_send_notify_email=False):
"""Finalise an API operation by committing and logging."""
# Get a unique identifier for this DB transaction
session_hash = hash(db.session)
if is_db_session_commit:
try:
db.session.commit()
# Added for demonstration purposes, not really needed in
# production
app.logger.info('Committed DB transaction')
except SQLAlchemyError as exc:
db.session.rollback()
return {'error': 'error finalising api op'}
if is_app_logger:
queue_key = 'api_log_msg_queue'
func_to_enqueue_ctx = dict(log_msg=log_msg)
queue_and_delayed_execute(
queue_key=queue_key, session_hash=session_hash,
func_to_enqueue=do_api_log_msg,
func_to_enqueue_ctx=func_to_enqueue_ctx,
is_time_to_execute_funcs=is_db_session_commit)
if is_send_notify_email:
queue_key = 'api_notify_email_queue'
func_to_enqueue_ctx = dict(
mail_subject=mail_subject, mail_body=mail_body)
queue_and_delayed_execute(
queue_key=queue_key, session_hash=session_hash,
func_to_enqueue=do_api_notify_email,
func_to_enqueue_ctx=func_to_enqueue_ctx,
is_time_to_execute_funcs=is_db_session_commit)
return {'message': 'api op finalised ok'}
And that code can be called from a bunch of API methods like so:
If make_froggy_brightpink_and_highjump() is called from within a Flask app context, the app's log should include output that looks something like this:
INFO [2017-12-01 09:00:00] Committed DB transaction
INFO [2017-12-01 09:00:00] Froggy colour updated: 123; new value: bright_pink
INFO [2017-12-01 09:00:00] Made froggy jump: 123; jump height: 50 metres
INFO [2017-12-01 09:00:00] Sent email: Made froggy jump
The log output demonstrates that the desired behaviour has been achieved: first, the DB transaction finishes (i.e. the froggy actually gets set to bright pink, and made to jump high, in one atomic write operation); then, the API actions are logged in the order that they were called (first the colour was updated, then the froggy was made to jump); then, email notifications are sent in order (in this case, we only want an email notification sent for when the froggy jumps high – but if we had also asked for an email notification for when the froggy's colour was changed, that would have been the first email sent).
In summary
That's about all there is to this "task queue" implementation – as I said, it's very lightweight, because it only needs to be simple and short-lived. I'm sharing this solution, mainly to serve as a reminder that you shouldn't just use your standard hammer, because sometimes the hammer is disproportionately big compared to the nail. In this case, the solution doesn't need an asynchronous queue, it doesn't need a scheduled queue, and it doesn't need a threaded queue. (Although moving the email sending off to a celery task is a good idea in production; and moving the logging to celery would be warranted too, if it was logging to a third-party service rather than just to a local file.) It just needs a queue that builds up and that then gets processed, for a single DB transaction.
]]>
How successful was the 20th century communism experiment?2017-11-28T00:00:00Z2017-11-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2017/11/how-successful-was-the-20th-century-communism-experiment/
During the course of the 20th century, virtually every nation in the world was affected, either directly or indirectly, by the "red tide" of communism. Beginning with the Russian revolution in 1917, and ostensibly ending with the close of the Cold War in 1991 (but actually not having any clear end, because several communist regimes remain on the scene to this day), communism was and is the single biggest political and economic phenomenon of modern times.
Communism – or, to be more precise, Marxism – made sweeping promises of a rosy utopian world society: all people are equal; from each according to his ability, to each according to his need; the end of the bourgeoisie, the rise of the proletariat; and the end of poverty. In reality, the nature of the communist societies that emerged during the 20th century was far from this grandiose vision.
Communism obviously was not successful in terms of the most obvious measure: namely, its own longevity. The world's first and its longest-lived communist regime, the Soviet Union, well and truly collapsed. The world's most populous country, the People's Republic of China, is stronger than ever, but effectively remains communist in name only (as does its southern neighbour, Vietnam).
However, this article does not seek to measure communism's success based on the survival rate of particular governments; nor does it seek to analyse (in any great detail) why particular regimes failed (and there's no shortage of other articles that do analyse just that). More important than whether the regimes themselves prospered or met their demise, is their legacy and their long-term impact on the societies that they presided over. So, how successful was the communism experiment, in actually improving the economic, political, and cultural conditions of the populations that experienced it?
Communism: at least the party leaders had fun! Image source:FunnyJunk.
Success:
Health care in Cuba (internationally recognised as being one of the world's best and most accessible public health care systems)
The arts (Soviet theatre and Soviet ballet received funding and support for many years, as Cuban theatre still does; despite severely limiting artistic freedom, most communist regimes did actually make the arts thrive with subsidies)
Education (despite the heavy dose of propaganda in schools, almost all communist regimes have massively improved their populations' literacy rates, and have invested heavily in more schools and universities, and in universal access to them)
Industrialisation (putting aside for a moment the enormous sacrifices made to achieve it, the fact is that the USSR, China, and Vietnam transformed rapidly from agrarian economies into industrial powerhouses under communism, and they remain world industrial heavyweights today)
Freedom (all communist states so far in history have been totalitarian regimes, and have severely curtailed all freedoms – of speech, of movement, of artistic expression, of religion – and that oppressive legacy lives on to this day)
Corruption (far from the Marxist ideal of universal equality, it has most definitely been a case of some are more equal than others in communist states – communism has engendered endemic bribery and nepotism every time)
Human damage (rather than making everyone a winner, communism has generally made almost everyone a victim – as well as the huge number of people murdered, imprisoned, and tortured as enemies of a communist state, almost all citizens other than Party elites have endured prolonged suffering due to the states' constant intrusion into their lives)
Dudes, don't leave a comrade hanging. Image source:FunnyJunk.
Closing remarks
Personally, I have always considered myself quite a "leftie": I'm a supporter of socially progressive causes, and in particular, I've always been involved with environmental movements. However, I've never considered myself a socialist or a communist, and I hope that this brief article on communism reflects what I believe are my fairly balanced and objective views on the topic.
Based on my list of pros and cons above, I would quite strongly tend to conclude that, overall, the communism experiment of the 20th century was not successful at improving the economic, political, and cultural conditions of the populations that experienced it.
I'm reluctant to draw comparisons, because I feel that it's a case of apples and oranges, and also because I feel that a pure analysis should judge communist regimes on their merits and faults, and on theirs alone. However, the fact is that, based on the items in my lists above, much more success has been achieved, and much less failure has occurred, in capitalist democracies, than has been the case in communist states (and the pinnacle has really been achieved in the world's socialist democracies). The Nordic Model – and indeed the model of my own home country, Australia – demonstrates that a high quality of life and a high level of equality are attainable without going down the path of Marxist Communism; indeed, arguably those things are attainable only if Marxist Communism is avoided.
I hope you appreciate what I have endeavoured to do in this article: that is, to avoid the question of whether or not communist theory is fundamentally flawed; to avoid a religious rant about the "evils" of communism or of capitalism; and to avoid judging communism based on its means, and to instead concentrate on what ends it achieved. And I humbly hope that I have stuck to that plan laudably. Because if one thing is needed more than anything else in the arena of analyses of communism, it's clear-sightedness, and a focus on the hard facts, rather than religious zeal and ideological ranting.
]]>
Using Python's namedtuple for mock objects in tests2017-08-13T00:00:00Z2017-08-13T00:00:00ZJazahttps://greenash.net.au/thoughts/2017/08/using-pythons-namedtuple-for-mock-objects-in-tests/
I have become quite a fan of Python's built-in namedtuple collection lately. As others have already written, despite having been available in Python 2.x and 3.x for a long time now, namedtuple continues to be under-appreciated and under-utilised by many programmers.
# The ol'fashioned tuple way
fruits = [
('banana', 'medium', 'yellow'),
('watermelon', 'large', 'pink')]
for fruit in fruits:
print('A {0} is coloured {1} and is {2} sized'.format(
fruit[0], fruit[2], fruit[1]))
# The nicer namedtuple way
from collections import namedtuple
Fruit = namedtuple('Fruit', 'name size colour')
fruits = [
Fruit(name='banana', size='medium', colour='yellow'),
Fruit(name='watermelon', size='large', colour='pink')]
for fruit in fruits:
print('A {0} is coloured {1} and is {2} sized'.format(
fruit.name, fruit.colour, fruit.size))
namedtuples can be used in a few obvious situations in Python. I'd like to present a new and less obvious situation, that I haven't seen any examples of elsewhere: using a namedtuple instead of MagicMock or flexmock, for creating fake objects in unit tests.
namedtuple vs the competition
namedtuples have a number of advantages over regular tuples and dicts in Python. First and foremost, a namedtuple is (by defintion) more semantic than a tuple, because you can define and access elements by name rather than by index. A namedtuple is also more semantic than a dict, because its structure is strictly defined, so you can be guaranteed of exactly which elements are to be found in a given namedtuple instance. And, similarly, a namedtuple is often more useful than a custom class, because it gives more of a guarantee about its structure than a regular Python class does.
A namedtuple can craft an object similarly to the way that MagicMock or flexmock can. The namedtuple object is more limited, in terms of what attributes it can represent, and in terms of how it can be swapped in to work in a test environment. But it's also simpler, and that makes it easier to define and easier to debug.
Compared with all the alternatives listed here (dict, a custom class, MagicMock, and flexmock – all except tuple), namedtuple has the advantage of being immutable. This is generally not such an important feature, for the purposes of mocking and running tests, but nevertheless, immutability always provides advantages – such as elimination of side-effects via parameters, and more thread-safe code.
Really, for me, the biggest "quick win" that you get from using namedtuple over any of its alternatives, is the lovely built-in string representation that the former provides. Chuck any namedtuple in a debug statement or a logging call, and you'll see everything you need (all the fields and their values) and nothing you don't (other internal attributes), right there on the screen.
# Printing a tuple
f1 = ('banana', 'medium', 'yellow')
# Shows all attributes ordered nicely, but no field names
print(f1)
# ('banana', 'medium', 'yellow')
# Printing a dict
f1 = {'name': 'banana', 'size': 'medium', 'colour': 'yellow'}
# Shows all attributes with field names, but ordering is wrong
print(f1)
# {'colour': 'yellow', 'size': 'medium', 'name': 'banana'}
# Printing a custom class instance
class Fruit(object):
"""It's a fruit, yo"""
f1 = Fruit()
f1.name = 'banana'
f1.size = 'medium'
f1.colour = 'yellow'
# Shows nothing useful by default! (Needs a __repr__() method for that)
print(f1)
# <__main__.Fruit object at 0x7f1d55400e48>
# But, to be fair, can print its attributes as a dict quite easily
print(f1.__dict__)
# {'size': 'medium', 'name': 'banana', 'colour': 'yellow'}
# Printing a MagicMock
from mock import MagicMock
class Fruit(object):
name = None
size = None
colour = None
f1 = MagicMock(spec=Fruit)
f1.name = 'banana'
f1.size = 'medium'
f1.colour = 'yellow'
# Shows nothing useful by default! (and f1.__dict__ is full of a tonne
# of internal cruft, with the fields we care about buried somewhere
# amongst it all)
print(f1)
# <MagicMock spec='Fruit' id='140682346494552'>
# Printing a flexmock
from flexmock import flexmock
f1 = flexmock(name='banana', size='medium', colour='yellow')
# Shows nothing useful by default!
print(f1)
# <flexmock.MockClass object at 0x7f691ecefda0>
# But, to be fair, printing f1.__dict__ shows minimal cruft
print(f1.__dict__)
# {
# 'name': 'banana',
# '_object': <flexmock.MockClass object at 0x7f691ecefda0>,
# 'colour': 'yellow', 'size': 'medium'}
# Printing a namedtuple
from collections import namedtuple
Fruit = namedtuple('Fruit', 'name size colour')
f1 = Fruit(name='banana', size='medium', colour='yellow')
# Shows exactly what we need: what it is, and what all of its
# attributes' values are. Sweeeet.
print(f1)
# Fruit(name='banana', size='medium', colour='yellow')
As the above examples show, without any special configuration, namedtuple's string configuration Just Works™.
namedtuple and fake objects
Let's say you have a simple function that you need to test. The function gets passed in a superhero, which it expects is a SQLAlchemy model instance. It queries all the items of clothing that the superhero uses, and it returns a list of clothing names. The function might look something like this:
# myproject/superhero.py
def get_clothing_names_for_superhero(superhero):
"""List the clothing for the specified superhero"""
clothing_names = []
clothing_list = superhero.clothing_items.all()
for clothing_item in clothing_list:
clothing_names.append(clothing_item.name)
return clothing_names
Since this function does all its database querying via the superhero object that's passed in as a parameter, there's no need to mock anything via funky mock.patch magic or similar. You can simply follow Python's preferred pattern of duck typing, and pass in something – anything – that looks like a superhero (and, unless he takes his cape off, nobody need be any the wiser).
You could write a test for that function, using namedtuple-based fake objects, like so:
# myproject/superhero_test.py
from collections import namedtuple
from myproject.superhero import get_clothing_names_for_superhero
FakeSuperhero = namedtuple('FakeSuperhero', 'clothing_items name')
FakeClothingItem = namedtuple('FakeClothingItem', 'name')
FakeModelQuery = namedtuple('FakeModelQuery', 'all first')
def get_fake_superhero_and_clothing():
"""Get a fake superhero and clothing for test purposes"""
superhero = FakeSuperhero(
name='Batman',
clothing_items=FakeModelQuery(
first=lambda: None,
all=lambda: [
FakeClothingItem(name='cape'),
FakeClothingItem(name='mask'),
FakeClothingItem(name='boots')]))
return superhero
def test_get_clothing_for_superhero():
"""Test listing the clothing for a superhero"""
superhero = get_fake_superhero_and_clothing()
clothing_names = set(get_clothing_names_for_superhero(superhero))
# Verify that list of clothing names is as expected
assert clothing_names == {'cape', 'mask', 'boots'}
The same setup could be achieved using one of the alternatives to namedtuple. In particular, a FakeSuperhero custom class would have done the trick. Using MagicMock or flexmock would have been fine too, although they're really overkill in this situation. In my opinion, for a case like this, using namedtuple is really the simplest and the most painless way to test the logic of the code in question.
In summary
I believe that namedtuple is a great choice for fake test objects, when it fits the bill, and I don't know why it isn't used or recommended for this in general. It's a choice that has some limitations: most notably, you can't have any attribute that starts with an underscore (the "_" character) in a namedtuple. It's also not particularly nice (although it's perfectly valid) to chuck functions into namedtuple fields, especially lambda functions.
Personally, I have used namedtuples in this way quite a bit recently, however I'm still ambivalent about it being the best approach. If you find yourself starting to craft very complicated FakeFoonamedtuples, then perhaps that's a sign that you're doing it wrong. As with everything, I think that this is an approach that can really be of value, if it's used with a degree of moderation. At the least, I hope you consider adding it to your tool belt.
]]>
The Jobless Games2017-03-19T00:00:00Z2017-03-19T00:00:00ZJazahttps://greenash.net.au/thoughts/2017/03/the-jobless-games/
There is growing concern worldwide about the rise of automation, and about the looming mass unemployment that will logically result from it. In particular, the phenomenon of driverless cars – which will otherwise be one of the coolest and the most beneficial technologies of our time – is virtually guaranteed to relegate to the dustbin of history the "paid human driver", a vocation currently pursued by over 10 million people in the US alone.
Them robots are gonna take our jobs! Image source:Day of the Robot.
Most discussion of late seems to treat this encroaching joblessness entirely as an economic issue. Families without incomes, spiralling wealth inequality, broken taxation mechanisms. And, consequently, the solutions being proposed are mainly economic ones. For example, a Universal Basic Income to help everyone make ends meet. However, in my opinion, those economic issues are actually relatively easy to address, and as a matter of sheer necessity we will sort them out sooner or later, via a UBI or via whatever else fits the bill.
The more pertinent issue is actually a social and a psychological one. Namely: how will people keep themselves occupied in such a world? How will people nourish their ambitions, feel that they have a purpose in life, and feel that they make a valuable contribution to society? How will we prevent the malaise of despair, depression, and crime from engulfing those who lack gainful enterprise? To borrow the colourful analogy that others have penned: assuming that there's food on the table either way, how do we head towards a Star Trek rather than a Mad Max future?
Keep busy
The truth is, since the Industrial Revolution, an ever-expanding number of people haven't really needed to work anyway. What I mean by that is: if you think about what jobs are actually about providing society with the essentials such as food, water, shelter, and clothing, you'll quickly realise that fewer people than ever are employed in such jobs. My own occupation, web developer, is certainly not essential to the ongoing survival of society as a whole. Plenty of other occupations, particularly in the services industry, are similarly remote from humanity's basic needs.
So why do these jobs exist? First and foremost, demand. We live in a world of free markets and capitalism. So, if enough people decide that they want web apps, and those people have the money to make it happen, then that's all that's required for "web developer" to become and to remain a viable occupation. Second, opportunity. It needs to be possible to do that thing known as "developing web apps" in the first place. In many cases, the opportunity exists because of new technology; in my case, the Internet. And third, ambition. People need to have a passion for what they do. This means that, ideally, people get to choose an occupation of their own free will, rather than being forced into a certain occupation by their family or by the government. If a person has a natural talent for his or her job, and if a person has a desire to do the job well, then that benefits the profession as a whole, and, in turn, all of society.
Those are the practical mechanisms through which people end up spending much of their waking life at work. However, there's another dimension to all this, too. It is very much in the interest of everyone that makes up "the status quo" – i.e. politicians, the police, the military, heads of big business, and to some extent all other "well to-do citizens" – that most of society is caught up in the cycle of work. That's because keeping people busy at work is the most effective way of maintaining basic law and order, and of enforcing control over the masses. We have seen throughout history that large-scale unemployment leads to crime, to delinquency and, ultimately, to anarchy. Traditionally, unemployment directly results in poverty, which in turn directly results in hunger. But even if the unemployed get their daily bread – even if the crisis doesn't reach let them eat cake proportions – they are still at risk of falling to the underbelly of society, if for no other reason, simply due to boredom.
So, assuming that a significantly higher number of working-age men and women will have significantly fewer job prospects in the immediate future, what are we to do with them? How will they keep themselves occupied?
The Games
I propose that, as an alternative to traditional employment, these people engage in large-scale, long-term, government-sponsored, semi-recreational activities. These must be activities that: (a) provide some financial reward to participants; (b) promote physical health and social well-being; and (c) make a tangible positive contribution to society. As a massive tongue-in-cheek, I call this proposal "The Jobless Games".
My prime candidate for such an activity would be a long-distance walk. The journey could take weeks, months, even years. Participants could number in the hundreds, in the thousands, even in the millions. As part of the walk, participants could do something useful, too; for example, transport non-urgent goods or mail, thus delivering things that are actually needed by others, and thus competing with traditional freight services. Walking has obvious physical benefits, and it's one of the most social things you can do while moving and being active. Such a journey could also be done by bicycle, on horseback, or in a variety of other modes.
How about we all just go for a stroll? Image source:The New Paper.
Other recreational programs could cover the more adventurous activities, such as climbing, rafting, and sailing. However, these would be less suitable, because: they're far less inclusive of people of all ages and abilities; they require a specific climate and geography; they're expensive in terms of equipment and expertise; they're harder to tie in with some tangible positive end result; they're impractical in very large groups; and they damage the environment if conducted on too large a scale.
What I'm proposing is not competitive sport. These would not be races. I don't see what having winners and losers in such events would achieve. What I am proposing is that people be paid to participate in these events, out of the pocket of whoever has the money, i.e. governments and big business. The conditions would be simple: keep up with the group, and behave yourself, and you keep getting paid.
I see such activities co-existing alongside whatever traditional employment is still available in future; and despite all the doom and gloom predictions, the truth is that there always has been real work out there, and there always will be. My proposal is that, same as always, traditional employment pays best, and thus traditional employment will continue to be the most attractive option for how to spend one's days. Following that, "The Games" pay enough to get by on, but probably not enough to enjoy all life's luxuries. And, lastly, as is already the case in most first-world countries today, for the unemployed there should exist a social security payment, and it should pay enough to cover life's essentials, but no more than that. We already pay people sit down money; how about a somewhat more generous payment of stand up money?
Along with these recreational activities that I've described, I think it would also be a good idea to pay people for a lot of the work that is currently done by volunteers without financial reward. In a future with less jobs, anyone who decides to peel potatoes in a soup kitchen, or to host bingo games in a nursing home, or to take disabled people out for a picnic, should be able to support him- or herself and to live in a dignified manner. However, as with traditional employment, there are also only so many "volunteer" positions that need filling, and even with that sector significantly expanded, there would still be many people left twiddling their thumbs. Which is why I think we need some other solution, that will easily and effectively get large numbers of people on their feet. And what better way to get them on their feet, than to say: take a walk!
Large-scale, long-distance walks could also solve some other problems that we face at present. For example, getting a whole lot of people out of our biggest and most crowded cities, and "going on tour" to some of our smallest and most neglected towns, would provide a welcome economic boost to rural areas, considering all the support services that such activities would require; while at the same time, it would ease the crowding in the cities, and it might even alleviate the problem of housing affordability, which is acute in Australia and elsewhere. Long-distance walks in many parts of the world – particularly in Europe – could also provide great opportunities for an interchange of language and culture.
In summary
There you have it, my humble suggestion to help fill the void in peoples' lives in the future. There are plenty of other things that we could start paying people to do, that are more intellectual and that make a more tangible contribution to society: e.g. create art, be spiritual, and perform in music and drama shows. However, these things are too controversial for the government to support on such a large scale, and their benefit is a matter of opinion. I really think that, if something like this is to have a chance of succeeding, it needs to be dead simple and completely uncontroversial. And what could be simpler than walking?
Whatever solutions we come up with, I really think that we need to start examining the issue of 21st-century job redundancy from this social angle. The economic angle is a valid one too, but it has already been analysed quite thoroughly, and it will sort itself out with a bit of ingenuity. What we need to start asking now is: for those young, fit, ambitious people of the future that lack job prospects, what activity can they do that is simple, social, healthy, inclusive, low-impact, low-cost, and universal? I'd love to hear any further suggestions you may have.
]]>
Ten rival national top cities of the world2016-12-09T00:00:00Z2016-12-09T00:00:00ZJazahttps://greenash.net.au/thoughts/2016/12/ten-rival-national-top-cities-of-the-world/
Most countries have one city which is clearly top of the pops. In particular, one city (which may not necessarily be the national capital) is usually the largest population centre and the main economic powerhouse of a given country. Humbly presented here is a quick and not-overly-scientific list of ten countries that are an exception to this rule. That is, countries where two cities (or more!) vie neck-and-neck for the coveted top spot.
Note: all population statistics are the latest numbers on relevant country- or city-level Wikipedia pages, as of writing, and all are for the cities' metropolitan area or closest available equivalent. The list is presented in alphabetical order by country.
As all my fellow Aussies can attest, Sydney (pop: 4.9m) and Melbourne (pop: 4.5m) well and truly deserve to be at the top of this list. Arguably, no other two cities in the world are such closely-matched rivals. As well as their similarity in population size and economic prowess, Sydney and Melbourne have also been ruthlessly competing for cultural, political and touristic dominance, for most of Australia's (admittedly short) history.
Both cities have hosted the Summer Olympics (Melbourne in 1956, Sydney in 2000). Sydney narrowly leads in population and economic terms, but Melbourne proudly boasts being "the cultural capital of Australia". The national capital, Canberra, was built roughly halfway between Sydney and Melbourne, precisely because the two cities couldn't agree on which one should be the capital.
In the world's most populous country, the port city Shanghai (pop: 24.5m) and the capital Beijing (pop: 21.1m) compete to be Number One. These days, Shanghai is marginally winning on the population and economic fronts, but Beijing undoubtedly takes the lead in the political, cultural and historic spheres.
It should also be noted that China's third-most populous city, Guangzhou (pop: 20.8m), and its (arguably) fourth-most populous city, Shenzhen (pop: 18m), are close runners-up to Shanghai and Beijing in population and economic terms. The neighbouring cities of Guangzhou and Shenzhen, together with other adjacent towns and cities, make up what is now the world's most populous urban area, the Pearl River Delta Megacity. This area has a population of 44m, which can even jump to 54m if the nearby islands of Hong Kong are included.
Ecuador's port city Guayaquil (pop: 5.0m) and its capital Quito (pop: 4.2m) are the only pair of cities from Latin America to feature on the list. Most Latin American countries are well and truly dominated by one big urban area. In Ecuador, Guayaquil is the economic powerhouse, while Quito is the nation's political and cultural heart.
The urban areas of the capital Berlin (pop: 6.0m) and the port city Hamburg (pop: 5.1m) are (arguably) the two largest in the Bundesrepublik Deutschland. These cities vie closely for economic muscle, and both are also rich historic and cultural centres of Germany.
However, Germany is truly one of the most balanced countries in the world, in terms of having numerous cities that contend for being the top population and economic centre of the land. There are also Munich (pop: 4.5m) and Stuttgart (pop: 4.0m), the southernmost of the nation's big cities. Plus there are the "urban mega-regions" of the Ruhr (pop: 8.5m), and Frankfurt Rhine-Main (pop: 5.8m), which are too spread-out to be considered single metropolitan areas (and which lack a single metro area with the large population of the big cities), but which are key centres nonetheless. Unsurprisingly, the very geographical layout of the nation's cities are yet another testament to German planning and efficiency.
In La Bella Italia, Rome (pop: 4.3m) and Milan (pop: 4.2m) are the two most populous cities by a fair stretch. With its formidable fashion and finance industries (among many others), Milan is quite clearly the top economic centre of Italy.
In terms of culture, few other pairs of cities can boast such a grand and glorious rivalry as that of Rome and Milan. Naturally, with its Roman Empire legacy, and as the home of the Vatican (making Rome virtually unique globally in being a city with another country inside it!), Rome wins hands-down on the historical, political and touristic fronts. But in terms of art, cuisine, and media (to name a few), Milan packs a good punch. However, most everywhere in Italy pulls ahead of its weight in those areas, including the next-largest urban areas of Naples, Turin, Venice and Florence.
In the world's second-most-populous country, the mega-cities of Delhi (pop: 21.8m) and Mumbai (pop: 20.8m) compete for people, business, and chaos. Delhi takes the cake politically, culturally, historically, and (as I can attest from personal experience) chaotically. Mumbai, a much newer city – only really having come into existence since the days of the British Raj – is the winner economically.
The next most populous cities of India – Kolkata, Bangalore, and Chennai – are also massive population centres in their own right, and they're not far behind Delhi and Mumbai in terms of national importance.
South Africa is the only African nation to make this list. Its two chief cities are the sprawling metropolis of Johannesburg (pop: 4.4m), and the picturesque port city of Cape Town (pop: 3.7m). Johannesburg is not only the economic powerhouse of South Africa, but indeed of all Africa. Cape Town, on the other hand, is the historic centre of the land, and with the sea hugging its shores and the distinctive Table Mountain looming big behind, it's also a place of great natural beauty.
El Reino de España is dominated by the two big cities of Madrid (pop: 6.3m) and Barcelona (pop: 5.4m). Few other pairs of cities in the world fight so bitterly for economic and cultural superiority, and on those fronts, in Spain there is no clear winner. Having spent much of its history as the head of its own independent kingdom of Catalonia, Barcelona has a rich culture of its own. And while Madrid is the political capital of modern Spain, Barcelona is considered the more modern metropolis, and has established itself as the "cosmopolitan capital" of the land.
Madrid and Barcelona are not the only twin cities in this list where different languages are spoken, and where historically the cities were part of different nations or kingdoms. However, they are the only ones where open hostility exists and is a major issue to this day: a large faction within Catalonia (including within Barcelona) is engaged in an ongoing struggle to secede from Spain, and the animosity resulting from this struggle is both real and unfortunate.
The two biggest urban areas in Uncle Sam, New York (pop: 23.7m) and Los Angeles (pop: 18.7m), differ in many ways apart from just being on opposite coasts. Both are economic and cultural powerhouses: NYC with its high finance and its music / theatre prowess; LA with Hollywood and show biz. The City That Never Sleeps likes to think of itself as the beating heart of the USA (and indeed the world!), while the City of Angels doesn't take itself too seriously, in true California style.
These are the two biggest, but they are by no means the only big boys in town. The nation's next-biggest urban areas – Chicago, Washington-Baltimore, San Francisco Bay Area, Boston, Dallas, Philadelphia, Houston, Miami, and Atlanta (all with populations between 6m and 10m) – are spread out all across the continental United States, and they're all vibrant cities and key economic hubs.
Finally, in the long and thin nation of Vietnam, the two river delta cities of Ho Chi Minh (pop: 8.2m) in the south, and Hanoi (pop: 7.6m) in the north, have for a long time been the country's key twin hubs. During the Vietnam War, these cities became the respective national capitals of the independent Democratic South and Communist North Vietnam; but these days, Vietnam is well and truly unified, and north and south fly under the same flag.
Conclusion
That's it, my non-authoritative list of rival top cities in various countries around the world. I originally included more pairs of cities in the list, but I culled it down to only include cities that were very closely matched in population size. Numerous other contenders for this list consist of a City A that's bigger, and a City B that's smaller but is more famous or more historic than its twin. Anyway, hope you like my selection, feedback welcome.
]]>
Orientalists of the East India Company2016-10-18T00:00:00Z2016-10-18T00:00:00ZJazahttps://greenash.net.au/thoughts/2016/10/orientalists-of-the-east-india-company/
The infamous East India Company, "the Company that Owned a Nation", is remembered harshly by history. And rightly so. On the whole, it was an exploitative venture, and the British individuals involved with it were ruthless opportunists. The Company's actions directly resulted in the impoverishment, the subjugation, and in several instances the death of countless citizens of the Indian Subcontinent.
Company rule, and the subsequent rule of the British Raj, are also acknowledged as contributing positively to the shaping of Modern India, having introduced the English language, built the railways, and established political and military unity. But these are overshadowed by its legacy of corporate greed and wholesale plunder, which continues to haunt the region to this day.
I recently read Four Heroes of India (1898), by F.M. Holmes, an antique book that paints a rose-coloured picture of Company (and later British Government) rule on the Subcontinent. To the modern reader, the book is so incredibly biased in favour of British colonialism that it would be hilarious, were it not so alarming. Holmes's four heroes were notable military and government figures of 18th and 19th century British India.
Clive, Hastings, Havelock, Lawrence; with a Concluding Note on the Rule of Lord Mayo. Image source:eBay.
I'd like to present here four alternative heroes: men (yes, sorry, still all men!) who in my opinion represented the British far more nobly, and who left a far more worthwhile legacy in India. All four of these figures were founders or early members of The Asiatic Society (of Bengal), and all were pioneering academics who contributed to linguistics, science, and literature in the context of South Asian studies.
William Jones
The first of these four personalities was by far the most famous and influential. Sir William Jones was truly a giant of his era. The man was nothing short of a prodigy in the field of philology (which is arguably the pre-modern equivalent of linguistics). During his productive life, Jones is believed to have become proficient in no less than 28 languages, making him quite the polyglot:
Eight languages studied critically: English, Latin, French, Italian, Greek, Arabic, Persian, Sanscrit [sic]. Eight studied less perfectly, but all intelligible with a dictionary: Spanish, Portuguese, German, Runick [sic], Hebrew, Bengali, Hindi, Turkish. Twelve studied least perfectly, but all attainable: Tibetian [sic], Pâli [sic], Pahlavi, Deri …, Russian, Syriac, Ethiopic, Coptic, Welsh, Swedish, Dutch, Chinese. Twenty-eight languages.
Jones is most famous in scholarly history for being the person who first proposed the linguistic family of Indo-European languages, and thus for being one of the fathers of comparative linguistics. His work laid the foundations for the theory of a Proto-Indo-European mother tongue, which was researched in-depth by later linguists, and which is widely accepted to this day as being a language that existed and that had a sizeable native speaker population (despite there being no concrete evidence for it).
Jones spent 10 years in India, working in Calcutta as a judge. During this time, he founded The Asiatic Society of Bengal. Jones was the foremost of a loosely-connected group of British gentlemen who called themselves orientalists. (At that time, "oriental studies" referred primarily to India and Persia, rather than to China and her neighbours as it does today.)
Like his peers in the Society, Jones was a prolific translator. He produced the authoritative English translation of numerous important Sanskrit documents, including Manu Smriti (Laws of Manu), and Abhiknana Shakuntala. In the field of his "day job" (law), he established the right of Indian citizens to trial by jury under Indian jurisprudence. Plus, in his spare time, he studied Hindu astronomy, botany, and literature.
James Prinsep
The numismatist James Prinsep, who worked at the Benares (Varanasi) and Calcutta mints in India for nearly 20 years, was another of the notable British orientalists of the Company era. Although not quite in Jones's league, he was nevertheless an intelligent man who made valuable contributions to academia. His life was also unfortunately short: he died at the age of 40, after falling sick of an unknown illness and failing to recover.
Prinsep was the founding editor of the Journal of the Asiatic Society of Bengal. He is best remembered as the pioneer of numismatics (the study of coins) on the Indian Subcontinent: in particular, he studied numerous coins of ancient Bactrian and Kushan origin. Prinsep also worked on deciphering the Kharosthi and Brahmi scripts; and he contributed to the science of meteorology.
Charles Wilkins
The typographer Sir Charles Wilkins arrived in India in 1770, several years before Jones and most of the other orientalists. He is considered the first British person in Company India to have mastered the Sanskrit language. Wilkins is best remembered as having created the world's first Bengali typeface, which became a necessity when he was charged with printing the important text A Grammar of the Bengal Language (the first book written in Bengali to ever be printed), written by fellow orientalist Nathaniel Brassey Halhed, and more-or-less commissioned by Governor Warren Hastings.
It should come as no surprise that this pioneering man was one of the founders of The Asiatic Society of Bengal. Like many of his colleagues, Wilkins left a proud legacy as a translator: he was the first person to translate into English the Bhagavad Gita, the most revered holy text in all of Hindu lore. He was also the first director of the "India Office Library".
H. H. Wilson
The doctor Horace Hayman Wilson was in India slightly later than the other gentlemen listed here, not having arrived in India (as a surgeon) until 1808. Wilson was, for a part of his time in Company India, honoured with the role of Secretary of the Asiatic Society of Bengal.
Wilson was one of the key people to continue Jones's great endeavour of bridging the gap between English and Sanskrit. His key contribution was writing the world's first comprehensive Sanskrit-English dictionary. He also translated the Meghaduuta into English. In his capacity as a doctor, he researched and published on the matter of traditional Indian medical practices. He also advocated for the continued use of local languages (rather than of English) for instruction in Indian native schools.
The legacy
There you have it: my humble short-list of four men who represent the better side of the British presence in Company India. These men, and other orientalists like them, are by no means perfect, either. They too participated in the Company's exploitative regime. They too were part of the ruling elite. They were no Mother Teresa (the main thing they shared in common with her was geographical location). They did little to help the day-to-day lives of ordinary Indians living in poverty.
Nevertheless, they spent their time in India focused on what I believe were noble endeavours; at least, far nobler than the purely military and economic pursuits of many of their peers. Their official vocations were in administration and business enterprise, but they chose to devote themselves as much as possible to academia. Their contributions to the field of language, in particular – under that title I include philology, literature, and translation – were of long-lasting value not just to European gentlemen, but also to the educational foundations of modern India.
In recent times, the term orientalism has come to be synonymous with imperialism and racism (particularly in the context of the Middle East, not so much for South Asia). And it is argued that the orientalists of British India were primarily concerned with strengthening Company rule by extracting knowledge, rather than with truly embracing or respecting India's cultural richness. I would argue that, for the orientalists presented here at least, this was not the case: of course they were agents of British interests, but they also genuinely came to respect and admire what they studied in India, rather than being contemptuous of it.
The legacy of British orientalism in India was, in my opinion, one of the better legacies of British India in general. It's widely acknowledged that it had a positive long-term educational and intellectual effect on the Subcontinent. It's also a topic about which there seems to be insufficient material available – particularly regarding the biographical details of individual orientalists, apart from Jones – so I hope this article is useful to anyone seeking further sources.
]]>
Where is the official centre of Sydney?2016-03-28T00:00:00Z2016-03-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2016/03/where-is-the-official-centre-of-sydney/
There are several different ways of commonly identifying the "official centre point" of a city. However, there's little international consensus as to the definition of such a point, and in many countries and cities the definition is quite vague.
Most reliable and most common, is to declare a Kilometre Zero marker as a city's (and often a region's or even a country's) official centre. Also popular is the use of a central post office for this purpose. Other traditional centre points include a city's cathedral, its main railway station, its main clock tower (which may be atop the post office / cathedral / railway station), its tallest building, its central square, its seat of government, its main park, its most famous tourist landmark, or the historical spot at which the city was founded.
Satellite photo of Sydney CBD, annotated with locations of "official centre" candidates. Image source:Satellite Imaging Corp.
My home town of Sydney, Australia, is one of a number of cities worldwide that boasts most of the above landmarks, but all in different locations, and without any mandated rule as to which of them constitutes the official city centre. So, where exactly in Sydney does X mark the spot?
Martin Place
I'll start with the spot that most people – Sydneysiders and visitors alike – commonly consider to be Sydney's central plaza these days: Martin Place. Despite this high esteem that it enjoys, in typical unplanned Sydney fashion, Martin Place was actually never intended to even be a large plaza, let alone the city's focal point.
Martin Place from the western end, as it looks today. Image source:Wikimedia Commons.
The original "Martin Place" (for much of the 1800s) was a small laneway called Moore St between George and Pitt streets, similar to nearby Angel Place (which remains a laneway to this day). In 1892, just after the completion of the grandiose GPO Building at its doorstep, Martin Place was widened and was given its present name. It wasn't extended to Macquarie St, nor made pedestrian-only, until 1980 (just after the completion of the underground Martin Place Station).
The chief justification for Martin Place being a candidate on this list, is that it's the home of Sydney's central post office. The GPO building also has an impressive clock tower sitting atop it. In addition, Martin Place is home to the Reserve Bank of Australia, and the NSW Parliament and the State Library of NSW are very close to its eastern end. It's also geographically smack-bang in the centre of the "business end" of Sydney's modern CBD, and it's culturally and socially acknowledged as the city's centre.
Town Hall
If you ask someone on the street in Sydney where the city's "central spot" is, and if he/she hesitates for a moment, chances are that said person is tossing up between Martin Place and Town Hall. When saying the name "Town Hall", you could be referring to the underground train station (one of Sydney's busiest), to the Town Hall building itself, to Town Hall Square, or (most likely) to all of the above. Scope aside, Town Hall is one of the top candidates for being called the centre of Sydney.
View of the Town Hall building, busy George and Druitt Streets, and St Andrews Cathedral. Image source:FM Magazine.
As with Martin Place, Town Hall was never planned to either resemble its current form, nor to be a centric location. Indeed, during the early colonial days, the site in question was on the outskirts of Sydney Town, and was originally a cemetery. The Town Hall building was opened in the 1890s.
In terms of qualifying as the potential centre of Sydney, Town Hall has a lot going for it. As its name suggests, it's home to the building which is the seat of local government for the City of Sydney (the building also has a clock tower). With its sprawling underground train station, with numerous bus stops in and adjacent to it, and with its location at the intersection of major thoroughfares George St and Park / Druitt St, Town Hall is – in practice – Sydney's most important transport hub. It's home to St Andrew's Cathedral, the head of the Anglican church in Sydney. And it's adjacent to the Queen Victoria Building, which – although it has no official role – is considered one of Sydney's most beautiful buildings.
Town Hall is also in an interesting position in terms of urban geography. It's one of the more southerly candidates for "official centre". To its north, where the historic heart of Sydney lies, big businesses and workers in suits dominate. While to its south lies the "other half" of Sydney's CBD: some white-collar business, but more entertainment, restaurants, sleaze, and shopping. It could be said that Town Hall is where these two halves of the city centre meet and mingle.
Macquarie Place
I've now covered the two spots that most people would likely think of as being the centre of Sydney, but which were never historically planned as such, and which "the powers that be" have never clearly proclaimed as such. The next candidate is a spot which was actually planned to be the official city centre (at least, as much as anything has ever been "planned" in Sydney), but which today finds itself at the edge of the CBD, and which few people have even heard of.
The New South Wales "Kilometre Zero" obelisk in Macquarie Place. Image source:City Art Sydney.
At the time, the area of Macquarie Place was the geographic centre of Sydney Town. The original colonial settlement clung to what is today Circular Quay, as all trade and transport with the rest of the world was via the shipping in Sydney Cove. The early town also remained huddled close to the Tank Stream, which ran between Pitt and George streets before discharging into the harbour (today the Tank Stream has been entirely relegated to a stormwater drain), and which was Sydney's sole fresh water supply for many years. The "hypotenuse" edge of Macquarie Place originally ran alongside the Tank Stream; indeed, the plaza's triangular shape was due to the Tank Stream fanning out into a muddy delta (all long gone and below the ground today) as it approached the harbour.
James Meehan's 1803 map of Sydney, with the original Tank Stream marked. Image source:National Library of Australia.
The most striking and significant feature of Macquarie Place is its large stone obelisk, which was erected in 1818, and which remains the official Kilometre Zero marker of Sydney and of NSW to this day. The obelisk lists the distances, in miles, to various towns in the greater Sydney region. As is inscribed in the stonework, its purpose is:
To record that all the Public Roads Leading to the Interior of the Colony are Measured from it.
So, if it's of such historical importance, why is Macquarie Place almost unheard-of by Sydney locals and visitors alike? Well, first and foremost, the fact is that it's no longer the geographical, cultural, or commercial heart of the city. That ship sailed south some time ago. Also, apart from its decline in fame, Macquarie Place has also suffered from being literally, physically eroded over the years. The size of the plaza was drastically reduced in the 1840s, when Loftus St was built to link Bridge St to Circular Quay, and the entire eastern half of Macquarie Place was lost. The relatively small space is now also dwarfed by the skyscrapers that loom over it on all sides.
Macquarie Place is today a humble, shady, tranquil park in the CBD's north, frequented by tour groups and by a few nearby office workers. It certainly doesn't feel like the centre of a city of over 4 million people. However, it was declared Sydney's "town square" when it was inaugurated, and no other spot has been declared its successor ever since. So, I'd say that if you ask a Sydney history buff, then he/she would surely have to concede that Macquarie Place remains the official city centre.
Pitt St Mall
With the top three candidates done, I'll now cover the other punters that might contend for centre stage in Sydney. However, I doubt that anyone would seriously considers these other spots to be in the running. I'm just listing them for completeness. First off is Pitt St Mall.
Sydney's central shopping precinct of Pitt St Mall, with Sydney Tower visibly adjacent to it. Image source:Structural & Civil Engineers.
Pitt St is one of the oldest streets in Sydney. However, there was never any plan for it to house a plaza. For much of its history (for almost 100 years), one of Sydney's busiest and longest-serving tram lines ran up its entire length. Since at least the late 1800s, the middle section of Pitt St – particularly the now pedestrian-only area between King and Market streets – has been Sydney's prime retail and fashion precinct. Some time in the late 1980s, this area was closed to traffic, and it's been known as Pitt St Mall ever since.
Pitt St Mall does actually tick several boxes as a contender for "official city centre". First and foremost, it is geographically the centre of Sydney's modern CBD, lying exactly in the middle between Martin Place and Town Hall. It's also home to Sydney Tower, the city's tallest structure. Plus, it's where the city's heaviest concentration of shops and of shopping centres can be found. However, the Mall has no real historical, cultural, or social significance. It exists purely to enhance the retail experience of the area.
Central Station
Despite its name, Sydney's Central Railway Station is not in the middle of the city, but rather on the southern fringe of the CBD. Like its more centric cousin Town Hall, the site of Central Station was originally a cemetery (and the station itself was originally just south of its present location). Today, Central is Sydney's busiest passenger station. We Sydneysiders aren't taught in school that it's All Stations To Central for nothing.
Central Station as seen from adjacent Eddy Ave. Image source:Weekend Notes.
Central Station is the most geographically far-flung of the candidates listed in this article, and due to this, few people (if any) would seriously vote for it as Sydney's official centre. However, it does have some points in its favour. It is the city's main train station. Its Platform 1 is the official Kilometre Zero point of the NSW train network. And its clock tower dictates the official time of NSW trains (and, by extension, the official civil time in NSW).
Hyde Park
Although it's quite close to Town Hall and Pitt St Mall distance-wise, Hyde Park hugs the eastern edge of the Sydney CBD, rather than commanding centre stage. Inaugurated by Big Mac in 1810, together with Macquarie Place, Hyde Park is Sydney's oldest park, as well as its official main park.
Expansive view looking south-west upon Hyde Park. Image source:Floodslicer.
Macquarie's architect, Francis Greenway, envisaged Hyde Park eventually becoming Sydney's town square, however this never eventuated. Despite being Sydney's oldest park, present-day Hyde Park is also quite unrecognisable from its original form, having been completely re-designed and rebuilt several times. The obelisk at the head of Bathurst St, erected in 1857 (it's actually a sewer vent!), is probably the oldest artifact of the park that remains unchanged.
As well as being central Sydney's main green space, Hyde Park is also home to numerous important adjacent buildings, including St Mary's Cathedral (head of the Sydney Catholic Archdiocese), St James Church (the oldest church building in Sydney), the Supreme Court of NSW, and Hyde Park Barracks. Plus, Hyde Park boasts a colourful history, whose many anecdotes comprise an important part of the story of Sydney.
The Rocks Square
The place I'm referring to here doesn't even have a clearly-defined name. As far as I can tell, it's most commonly known as (The) Rocks Square, but it could also be called Clocktower Square (for the tower and shopping arcade adjacent to it), Argyle St Mall, Argyle St Market, or just "in front of The Argyle" (for the adjacent historic building and present-day nightclub). At any rate, I'm talking about the small, pedestrian-only area at the eastern end of Argyle St, in Sydney's oldest precinct, The Rocks.
Weekend markets at the eastern end of Argyle St, in The Rocks. Image source:David Ing.
This spot doesn't have a whole lot going for it. As I said, it's not even named properly, and it's not an official square or park of any sort. However, it's generally considered to be the heart of The Rocks, and in Sydney's earliest days it was the rough location of the city's social and economic centre. Immediately to the west of The Rocks Square, you can walk or drive through the Argyle Cut, which was the first major earth-moving project in Sydney's history. Today, The Rocks Square is a busy pedestrian thoroughfare, especially on weekends when the popular Rocks Markets are in full swing. And one thing that hasn't changed a bit since day one: there's no shortage of pubs, and other watering-holes, in and around this spot.
Darling Harbour
I'm only reluctantly including Darling Harbour on this list (albeit lucky last): clearly off to the west of the CBD proper, it's never been considered the "official centre" of Sydney by anyone. For much of its history, Darling Harbour was home to a collection of dirty, seedy dockyards that comprised the city's busiest port. The area was completely overhauled as the showpiece of Sydney's celebrations for the 1988 Australian Bicentennary celebrations. Since then, it's been one of Sydney's most popular tourist spots.
The centre of Darling Harbour, close the the IMAX Theatre. Image source:Wikimedia Commons.
Other than being a tourist trap, Darling Harbour's main claim to entitlement on this list is that it hosts the Sydney Convention Centre (the original centre was recently demolished, and is currently being rebuilt on a massive scale). The key pedestrian thoroughfare of Darling Harbour, just next to the IMAX Theatre (i.e. the spot in question for this list), is unfortunately situated directly below the Western Distributor, a large freeway that forms a roof of imposing concrete.
Final thoughts
Hope you enjoyed this little tour of the contenders for "official centre" of Sydney. Let me know if you feel that any other spots are worthy of being in the race. As for the winner: I selected what I believe are the three finalists, but I'm afraid I can't declare a clear-cut winner from among them. Purists would no doubt pick Macquarie Place, but in my opinion Martin Place and Town Hall present competition that can't be ignored.
Sydney at sunset, with the city centre marked in dark red. Image source:SkyscraperCity.
Who knows? Perhaps the illustrious Powers That Be – in this case, the NSW Government and/or the Sydney City Council – will, in the near future, clarify the case once and for all. Then again, considering the difficulty of choice (as demonstrated in this article), and considering the modus operandi of the guv'ment around here, it will probably remain in the "too hard" basket for many years to come.
]]>
Where there be no roads2016-03-09T00:00:00Z2016-03-09T00:00:00ZJazahttps://greenash.net.au/thoughts/2016/03/where-there-be-no-roads/
And now for something completely different, here's an interesting question. What terra firma places in the world are completely without roads? Where in the world will you find large areas, in which there are absolutely no official vehicle routes?
A road (of sorts) slowly being extended into the vast nothingness of Siberia. Image source:Favourite picture: Road construction in Siberia – RoadStars.
Naturally, such places also happen to be largely bereft of any other human infrastructure, such as buildings; and to be largely bereft of any human population. These are places where, in general, nothing at all is to be encountered save for sand, ice, and rock. However, that's just coincidental. My only criteria, for the purpose of this article, is a lack of roads.
Alaska
I was inspired to write this article after reading James Michener's epic novel Alaska. Before reading that book, I had only a vague knowledge of most things about Alaska, including just how big, how empty, and how inaccessible it is.
Map of Alaska: areas without roads (approximate) are highlighted in red. Image source: Google Earth (red highlighting by yours truly).
One might think that, on account of it being part of the United States, Alaska boasts a reasonably comprehensive road network. Think again. Unlike the "Lower 48" (as the contiguous USA is referred to up there), only a small part of Alaska has roads of any sort at all, and that's the south-east corner around Anchorage and Fairbanks. And even there, the main routes are really part of the American Interstate network only on paper.
As you can see from the map, the entire western part of the state, and most of the north of the state, lack any road routes whatsoever. The north-east is also almost without roads, except for the Dalton Highway – better known locally as "The Haul Road" – which is a crude and uninhabited route for most of its length.
There has been discussion for decades about the possibility of building a road to Nome, which is the biggest settlement in western Alaska. However, such a road remains a pipe dream. It's also impossible to drive to Barrow, which is the biggest place in northern Alaska, and also the northernmost city in North America. This is despite Barrow being only about 300km west of the Dalton Highway's terminus at the Prudhoe Bay oilfields.
Road building is a trouble-fraught enterprise in Alaska, where distances are vast, population centres are few (or none), and geography / climate is harsh. In particular, building roads on permafrost (of which much of Alaska's terrain is) can be challenging, because the frozen soil expands in summer, and violently cracks whatever is on top of it. Also, while solid in winter, permafrost turns to muddy swamps in summer.
Alaska's Yukon River frozen solid in winter. Image source:Yukon Animator.
It's no wonder, then, that for most of the far-flung outposts in northern and western Alaska, the main forms of transport are by sea or air. Where terrestrial transport is taken, it's most commonly in the form of a dog sled, and remains so to this day. In winter, Alaska's true main highways are its frozen rivers – particularly the mighty Yukon – which have been traversed by sled dogs, on foot (often with fatal results), and even by bicycle.
Canada
Much like its neighbour Alaska, northern Canada is also a vast expanse of frozen tundra that remains largely uninhabited. Considering the enormity of the area in question, Canada has actually made quite impressive progress in the building of roads further north. However, as the map illustrates, much of the north remains pristine and unblemished.
Map of Canada: areas without roads (approximate) are highlighted in red. Image source: Google Earth (red highlighting by yours truly).
Fun in the sun in Iqaluit, Nunavut. Image source:Huffington Post.
The Northwest Territories is barren in many places, too. The entire eastern pocket of the Territories, bordering Nunavut and Saskatchewan (i.e. everything east of Tibbitt Lake, where the Ingraham Trail ends), has not a single road. And there are no roads north of Wrigley (where the Mackenzie Highway ends), except for the northernmost section of the Dempster Highway up to Inuvik. There are also no roads north of the Dempster Highway in Yukon Territory. And, on the other side of Canada, there are no roads in Quebec or Labrador north of Caniapiscau and the Trans-Taiga Road.
Greenland
Continuing east around the Arctic Circle, we come to Greenland, which is the largest contiguous and permanently-inhabited land mass in the world to have no roads at all between its settlements. Greenland is also the world's largest island.
Map of Greenland: areas without roads (approximate) are highlighted in red. Image source: Google Earth (red highlighting by yours truly).
The reason for the lack of road connections is the Greenland ice sheet, the second-largest body of ice in the world (after the Antarctic ice sheet), which covers 81% of the territory's surface. (And, as such, the answer to the age-old question "Is Greenland really green?", is overall "No!"). The only way to travel between Greenland's towns year-round is by air, with sea travel being possible only in summer, and dog sledding only in winter.
Svalbard
I'm generally avoiding covering small islands in this article, and am instead focusing on large continental areas. However, Svalbard (with Spitsbergen actually being the main island) is the largest island in the world – apart from islands that fall within other areas covered in this article – that has no roads between any of its settlements.
Map of Svalbard: areas without roads (approximate) are highlighted in red. Image source: Google Earth (red highlighting by yours truly).
Svalbard is a Norwegian territory situated well north of the Arctic Circle. Its capital, Longyearbyen, is the northernmost city in the world. There are no roads linking Svalbard's handful of towns. Travel options involve air, sea, or snow.
Siberia
The largest geographical region of the world's largest country (Russia), and well known as a vast "frozen wasteland", it should come as no surprise that Siberia features in this article. Siberia is the last of the arctic areas that I'll be covering here (indeed, if you continue east, you'll get back to Alaska, where I started). Consisting primarily of vast tracts of taiga and tundra, Siberia – particularly further north and further east – is a sparsely inhabited land of extreme cold and remoteness.
Map of Siberia: areas without roads (approximate) are highlighted in red. Image source: Google Earth (red highlighting by yours truly).
Considering the size, the emptiness, and the often challenging terrain, Russia has actually made quite impressive achievements in building transport routes through Siberia. Starting with the late days of the Russian Empire, going strong throughout much of the Soviet Era, and continuing with the present-day Russian Federation, civilisation has slowly but surely made inroads (no pun intended) into the region.
North-west Russia – which actually isn't part of Siberia, being west of the Ural Mountains – is quite well-serviced by roads these days. There are two modern roads going north all the way to the Barents Sea: the R21 Highway to Murmansk, and the M8 route to Arkhangelsk. Further east, closer to the start of Siberia proper, there's a road up to Vorkuta, but it's apparently quite crude.
Crossing the Urals east into Siberia proper, Yamalo-Nenets has until fairly recently been quite lacking in land routes, particularly north of the capital Salekhard. However, that has changed dramatically of late in the remote (and sparsely inhabited) Yamal Peninsula, where there is still no proper road, but where the brand-new Obskaya-Bovanenkovo Railroad is operating. Purpose-built for the exploitation of what is believed to be the world's largest natural gas field, this is now the northernmost railway line in the world (and it's due to be extended even further north). Further up from Yamalo-Nenets, the islands of Novaya Zemlya are without land routes.
How do you get around Siberia if there are no roads? Try a reindeer sled! Image source:The Washington Post.
East of the Yamal Peninsula, the great roadless expanse of northern Siberia begins. In Krasnoyarsk Krai, the second-biggest geographical division in Russia, there are no real roads past the area more than a few hundred km's north of the city of Krasnoyarsk. Nothing, that is, except for the road and railway (until recently the world's northernmost) that reach the northern outpost of Norilsk; although neither road nor rail are properly connected to the rest of Russia.
The Sakha Republic, Russia's biggest geographical division, is completely roadless save for the main highway passing through its south-east corner, and its capital, Yakutsk. In the far north of Sakha, on the shores of the Arctic Ocean, the town of Tiksi is reckoned to be the most remote settlement in all of Russia. Here in the depths of Siberia, the main transport is via the region's mighty rivers, of which the Lena forms the backbone of Sakha. In winter, dog sleds and ice vehicles are the norm.
In the extreme north-east of Siberia, where Chukotka and the Kamchatka Peninsula can be found, there are no road routes whatsoever. Transport in these areas is solely by sea, air, or ice. The only road that comes close to these areas is the Kolyma Highway, also infamously known as the Road of Bones; this route has been improved in recent years, although it's still hair-raising for much of its length, and it's still one of the most remote highways in the world. There are also no roads to Okhotsk (which was the first and the only Russian settlement on the Pacific coast for many centuries), nor to anywhere else in northern Khabarovsk Krai.
Tibet
A part of the People's Republic of China (whether they like it or not) since 1951, Tibet has come a long way since the old days, when the entire kingdom did not have a single road. Today, China claims that 70% of all villages in Tibet are connected by road. And things have also stepped up quite a big notch, since the 2006 opening of the Trans-Tibetan Railway, which is a marvel of modern engineering, and is (at over 5,000m in one section) the new highest-altitude railway in the world.
Map of Tibet: areas without roads (approximate) are highlighted in red. Image source: Google Earth (red highlighting by yours truly).
Virtually the entire southern half of Tibet boasts a road network today. However, the central north area of the region – as well as a fair bit of adjacent terrain in neighbouring Xinjiang and Qinghai provinces – still appears to be without roads. This area also looks like it's devoid of any significant settlements, with nothing much around except high-altitude tundra.
Sahara
Leaving the (mostly icy) roadless realms of North America and Eurasia behind us, it's time to turn our attention southward, where the regions in question are more of a mixed bag. First up: the Sahara, the world's largest desert, which covers almost all of northern Africa, and which is virtually uninhabited save for its semi-arid fringes.
Map of the Sahara: areas without roads (approximate) are highlighted in red. Image source: Google Earth (red highlighting by yours truly).
As the map shows, most of the parched interior of the Sahara is without roads. This includes: north-eastern Mauritania, northern Mali, south-eastern and south-western Algeria, northern Niger, southern Libya, northern Chad, north-west Sudan, and south-west Egypt. For all of the above, the only access is by air, by well-equipped 4WD convoy, or by camel caravan.
The only proper road cutting through this whole area, is the optimistically named Trans-Sahara Highway, the key part of which is the crossing from Agadez, Niger, north to Tamanrasset, Algeria. However, although most of the overall route (going all the way from Nigeria to Algeria) is paved, the section north of Agadez is still largely just a rough track through the sand, with occasional signposts indicating the way. There is also a rough track from Mali to Algeria (heading north from Kidal), but it appears to not be a proper road, even by Saharan standards.
The classic way to cross the Sahara: with the help of the planet's best desert survivors. Image source:Found the World.
I should also state (the obvious) here, namely that Saharan and Sub-Saharan Africa is not only one of the most arid and sparsely populated places on Earth, but that it's also one of the poorest, least developed, and most politically unstable places on Earth. As such, it should come as no surprise that overland travel through most of the roadless area is currently strongly discouraged, due to the security situation in many of the listed countries.
Australia
No run-down of the world's great roadless areas would be complete without including my sunburnt homeland, Australia. As I've blogged about before, there's a whole lot of nothing in the middle of this joint.
Map of Australia: areas without roads (approximate) are highlighted in red. Image source: Google Earth (red highlighting by yours truly).
The biggest area of Australia to still lack road routes, is the heart of the Outback, in particular most of the east of Western Australia, and neighbouring land in the Northern Territory and South Australia. This area is bisected by only a single half-decent route (running east-west), the Outback Way – a route that is almost entirely unsealed – resulting in a north and a south chunk of roadless expanse.
The north chunk is centred on the Gibson Desert, and also includes large parts of the Great Sandy Desert and the Tanami Desert. The Gibson Desert, in particular, is considered to be the most remote place in Australia, and this is evidenced by its being where the last uncontacted Aboriginal tribe was discovered – those fellas didn't come outta the bush there 'til 1984. The south chunk consists of the Great Victoria Desert, which is the largest single desert in Australia, and which is similarly remote.
After that comes the area of Lake Eyre – Australia's biggest lake and, in typical Aussie style, one that seldom has any water in it – and the Simpson Desert to its north. The closest road to Lake Eyre itself is the Oodnadatta Track, and the only road that skirts the edge of the Simpson Desert is the Plenty Highway (which is actually part of the Outback Way mentioned above).
Close to Lake Eyre: not much around for miles. Image source:Avalook.
On the Apple Isle of Tasmania, the entire south-west region is an uninhabited, pristine, climatically extreme wilderness, and it's devoid of any roads at all. The only access is by sea or air: even 4WD is not an option in this hilly and forested area. Tasmania's famous South Coast Track bushwalk begins at the outpost of Melaleuca, where there is nothing except a small airstrip, and which can effectively only be reached by light aircraft. Not a trip for the faint-hearted.
Finally, in the extreme north-east of Australia, Cape York Peninsula remains one of the least accessible places on the continent, and has almost no roads (particularly the closer you get to the tip). The Peninsula Development Road, going as far north as Weipa, is the only proper road in the area: it's still largely unsealed, and like all other roads in the area, is closed and/or impassable for much of the year due to flooding. Up from there, Bamaga Road and the road to the tip are little more than rough tracks, and are only navigable by experienced 4WD'ers for a few months of the year. In this neck of the woods, you'll find that crocodiles, mosquitoes, jellyfish, and mud are much more common than roads.
New Zealand
Heading east across the ditch, we come to the Land of the Long White Cloud. The South Island of New Zealand is well-known for its dazzling natural scenery: crystal-clear rivers, snow-capped mountains, jutting fjords, mammoth glaciers, and rolling hills. However, all that doesn't make for areas that are particularly easy to live in, or to construct roads through.
Map of New Zealand (South Island): areas without roads (approximate) are highlighted in red. Image source: Google Earth (red highlighting by yours truly).
Essentially, the entire south-west edge of NZ's South Island is without road access. In particular, all of Fiordland National Park: the whole area south of Milford Sound, and east of Te Anau. Same deal for Mount Aspiring National Park, between Milford Sound and Jackson Bay. The only exception is Milford Sound itself, which can be accessed via the famous Homer Tunnel, an engineering feat that pierces the walls of Fiordland against all odds.
Chile
You'd think that, being such a long and thin country, getting at least one road to traverse the entire length of Chile wouldn't be so hard. Think again. Chile is the world's longest north-south country, and spans a wide range of climatic zones, from hot dry desert in the north, to glacial fjord-land in the extreme south. If you've seen Chile desde Arica hasta Punta Arenas (as I have!), then you've witnessed first-hand the geographical variety that it has to offer.
Map of Chile (far south): areas without roads (approximate) are highlighted in red. Image source: Google Earth (red highlighting by yours truly).
Roads can be found in all of Chile, except for one area: in the far south, between Villa O'Higgins and Torres del Paine. That is, the southern-most portion of Región de Aysén, and the northern half of Región de Magallanes, are entirely devoid of roads. This is mainly on account of the Southern Patagonian Ice Field, one of the world's largest chunks of ice outside of the polar regions. This ice field was only traversed on foot, for the first time in history, as recently as 1998; it truly is one of our planet's final unconquered frontiers. No road will be crossing it anytime soon.
Majestic Glaciar O'Higgins, at the northern end of the Southern Patagonian Ice Field. Image source:Mallin Colorado.
The Chilean government has for many decades maintained the monumental effort of extending the Carretera Austral ever further south. The route reached its current terminus at Villa O'Higgins in 2000. The ultimate aim, of course, is to connect isolated Magallanes (which to this day can only be reached by road via Argentina) with the rest of the country. But considering all the ice, fjords, and extreme conditions in the way, it might be some time off yet.
Amazon
We now come to what is by far the most lush and life-filled place in this article: the Amazon Basin. Spanning several South American countries, the Amazon is home to the world's largest river (by water volume) and river system. Although there are some big settlements in the area (including Iquitos, the world's biggest city that's not accessible by road), in general there are more piranhas and anacondas than there are people in this jungle (the piranhas help to keep it that way!).
Map of the Amazon Basin: areas without roads (approximate) are highlighted in red. Image source: Google Earth (red highlighting by yours truly).
Considering the challenges, quite a number of roads have actually been built in the Amazon in recent decades, particularly in the Brazilian part. The best-known of these is the Transamazônica, which – although rough and muddy as can be – has connected vast swaths of the jungle to civilisation. It should also be noted, that extensive road-building in this area is not necessarily a good thing: publicly-available satellite imagery clearly illustrates that, of the 20% of the Amazon that has been deforested to date, much of it has happened alongside roads.
The main parts of the Amazon that remain completely without roads are: western Estado do Amazonas and northern Estado do Pará in Brazil; most of north-eastern Peru (Departamento de Loreto); most of eastern Ecuador (the provinces in the Región amazónica del Ecuador); most of south-eastern Colombia (Amazonas, Vaupés, Guainía, Caquetá, and Guaviare departamentos); southern Venezuela (Estado de Amazonas); and the southern part of all the Guyanas (British Guyana, Suriname, and French Guiana).
Iquitos, Peru: a river city like no other. Image source:Getty Images.
The Amazon Basin probably already has more roads than it needs (or wants). In this part of the world, the rivers are the real highways – especially the Amazon itself, which has heavy marine traffic, despite being more than 5km wide in many parts (and that's in the dry season!). In fact, it's hard for terrestrial roads to compete with the rivers: for example, the BR-319 to Manaus has been virtually washed away by the jungle, and the main access to the Amazon's biggest city remains by boat.
Antarctica
It's the world's fifth-largest continent. It's completely covered in ice. It has no permanent human population. It has no countries or (proper) territories. And it has no roads. And none of this should be a surprise to anyone!
Map of Antarctica: areas without roads (approximate) are highlighted in red. Image source:Wikimedia Commons (red highlighting by yours truly).
As you might have guessed, not only are there no roads linking anywhere to anywhere else within Antarctica (except for ice trails), but (unlike every other area covered in this article) there aren't even any local roads within Antarctic settlements. The only regular access to Antarctica, and around Antarctica, is by air; even access by ship is difficult without helicopter support.
Where to?
There you have it: an overview of some of the most forlorn, desolate, but also beautiful places in the world, where the wonders of roads have never in all of human history been built. I've tried to cover as many relevant places as I can (and I've certainly covered more than I originally intended to), but of course I couldn't ever cover all of them. As I said, I've avoided discussion of islands, as a general rule, mainly because there is a colossal number of roadless islands around, and the list could go on forever.
I hope you've found this spin around the globe informative. And don't let such a minor inconvenience as a lack of roads stop you from visiting as many of these places as you can! Comments and feedback welcome.
]]>
Running a real Windows install in VirtualBox on Linux2016-02-01T00:00:00Z2016-02-01T00:00:00ZJazahttps://greenash.net.au/thoughts/2016/02/running-a-real-windows-install-in-virtualbox-on-linux/
Having a complete Windows (or Mac) desktop running within Linux has been possible for some time now, thanks to the wonders of Virtual Machine (VM) technology. However, the typical approach is to mount and boot a VM image, where the guest OS and hard disk are just files on the host filesystem. In this case, the guest OS can't be natively booted and run, because it doesn't occupy its own disk or partition on the physical hardware, and therefore it can't be picked up by the BIOS / boot manager.
I've been installing Windows and Linux on the same machine, in a dual-boot setup, for many years now. In this case, I boot natively into either one or the other of the installed OSes. However, I haven't run one "real" OS (i.e. an OS that's installed on a physical disk or partition) inside the other via a VM. At least, not until now.
At my new job this year, I discovered that it's possible to do such a thing, using a feature of VirtualBox called "Raw Disk Access". With surprisingly few hiccups, I got this running with Linux Mint 17.3 as the host, and with Windows 8.1 as the guest. Each OS is installed on a separate physical hard disk. I run Windows inside the VM most of the time, but I can still boot natively into the very same install of Windows at any time, if necessary.
Instructions
This should go without saying, but please back up all your data before proceeding. What I'm explaining here is dangerous, and if anything goes wrong, you are likely to lose data on your PC.
If installing the two OSes on the same physical disk, then wipe the disk and create partitions for each OS as necessary (as is standard for dual-boot installs). (You can also shrink an existing Windows partition and then create the Linux partitions with the resulting free space, but this is more dangerous). If installing on different physical disks, then just keep reading.
Install Windows on its respective disk or partition (if it's not installed already, e.g. included with a home PC, SOE configured copy on a corporate PC). Windows should boot by default.
Go into your PC's BIOS setup (e.g. by pressing F12 when booting up), and ensure that "Secure Boot" and "Fast Boot" are disabled (if present), and ensure that "Launch CSM" / "Launch PXE OpROM" (or similar) are enabled (if present).
Install your preferred flavour of Linux on the other disk or partition. After doing this, GRUB should boot on startup, and it should let you choose to load Windows or Linux.
Install VirtualBox on Debian-based systems (e.g. Mint, Ubuntu) with:
Use a tool such as fdisk or parted to determine the partitions that the VM will need to access. In my case, for my Windows disk, it was partitions 1 (boot / EFI), 4 (recovery), and 5 (OS / "C drive").
Partition table of my Windows disk as shown in GParted.
Use this command (with your own filename / disk / partitions specified) to create the "raw disk", which is effectively a file that acts as a pointer to a disk / partition on which an OS is installed:
Create a new VM in the VirtualBox GUI, with the OS and version that correspond to your install of Windows. In the "Storage" settings for the VM, add a hard disk (when prompted, click "Choose existing disk"), and point it to the .vmdk file that you created.
VirtualBox treats the "raw" .vmdk file as if it were a virtual disk contained in a file.
Start up your VM. You should see the same desktop that you have when you boot Windows natively!
Install VirtualBox Guest Additions as you would for a normal Windows VM, in order to get the usual VM bells and whistles (i.e. resizable window, mouse / clipboard integration, etc).
After you've been running your "real" Windows in the VM for a while, it will ask you to "Activate Windows". It will do this even if your Windows install is already activated when running natively. This is because Windows sees itself running within the VM, and sees "different hardware" (i.e. it thinks it's been installed on a second physical machine). You will have to activate Windows a second time within the VM (e.g. using a corporate bulk license key, by calling Microsoft, etc).
Done
That's all there is to it. I should acknowledge that this guide is based on various other guides with similar instructions. Most online sources seem to very strongly warn that running Windows in this way is dangerous and can corrupt your system. Personally, I've now been running "raw" Windows in a VM like this every day for several weeks, with no major issues. The VM does crash sometimes (once every few days for me), as VMs do, and as Windows does. But nothing more serious than that.
I guess I should also warn readers of the potential dangers of this setup. It worked for me, but YMMV. I've also heard rumour that on Windows 8 and higher, the problems of Windows not being able to adapt itself to boot on "different hardware" each startup (the real physical hardware, vs the hardware presented by VirtualBox) are much less than they used to be. Certainly doesn't seem to be an issue for me.
At any rate, I'm now happy; at least, as happy as someone who runs Windows in a VM all day can physically be. Hey, at least it's Linux outside that box on my screen. Good luck in having your cake and eating it, too.
]]>
Introducing Flask Editable Site2015-10-27T00:00:00Z2015-10-27T00:00:00ZJazahttps://greenash.net.au/thoughts/2015/10/introducing-flask-editable-site/
I'd like to humbly present Flask Editable Site, a template for building a small marketing web site in Flask where all content is live editable. Here's a demo of the app in action.
Text and image block editing with Flask Editable Site.
The aim of this app is to demonstrate that, with the help of modern JS libraries, and with some well-thought-out server-side snippets, it's now perfectly possible to "bake in" live in-place editing for virtually every content element in a typical brochureware site.
This app is not a CMS. On the contrary, think of it as a proof-of-concept alternative to a CMS. An alternative where there's no "admin area", there's no "editing mode", and there's no "preview button". There's only direct manipulation.
"Template" means that this is a sample app. It comes with a bunch of models that work out-of-the-box (e.g. text content block, image content block, gallery item, event). However, these are just a starting point: you can and should define your own models when building a real site. Same with the front-end templates: the home page layout and the CSS styles are just examples.
About that "template" idea
I can't stress enough that this is not a CMS. There are of course plenty of CMSes out there already, in Python and in every other language under the sun. Several of those CMSes I have used extensively. I've even been paid to build web sites with them, for most of my professional life so far. I desire neither to add to that list, nor to take on the heavy maintenance burden that doing so would entail.
What I have discovered as a web developer, and what I'm sure that all web developers discover sooner or later, is that there's no such thing as the perfect CMS. Possibly, there isn't even such thing as a good CMS! If you want to build a web site with a content management experience that's highly tailored to the project in question, then really, you have to build a unique custom CMS just for that site. Deride me as a perfectionist if you want, but that's my opinion.
There is such a thing as a good framework. Flask Editable Site, as its name suggests, uses the Flask framework, which has the glorious honour of being my favourite framework these days. And there is definitely such a thing as a good library. Flask Editable Site uses a number of both front-end and back-end libraries. The best libraries can be easily mashed up together in different configurations, on top of different frameworks, to help power a variety of different apps.
Flask Editable Site is not a CMS. It's a sample app, which is a template for building a unique CMS-like app tailor-made for a given project. If you're doing it right, then no two projects based on Flask Editable Site will be the same app. Every project has at least slightly different data models, users / permissions, custom forms, front-end widgets, and so on.
So, there's the practical aim of demonstrating direct manipulation / live editing. However, Flask Editable Site has a philosophical aim, too. The traditional "building a super one-size-fits-all app to power 90% of sites" approach isn't necessarily a good one. You inevitably end up fighting the super-app, and hacking around things to make it work for you. Instead, how about "building and sharing a template for making each site its own tailored app"? How about accepting that "every site is a hack", and embracing that instead of fighting it?
Thanks and acknowledgements
Thanks to all the libraries that Flask Editable Site uses; in each case, I tried to choose the best library available at the present time, for achieving a given purpose:
Dantecontenteditable WYSIWYG editor, a Medium editor clone. I had previously used MediumEditor, and I recommend it too, but I feel that Dante gives a more polished out-of-the-box experience for now. I think the folks at Medium have done a great job in setting the bar high for beautiful rich-text editing, which is an important part of the admin experience for many web sites / apps.
Dropzone.js image upload widget. C'mon, people, it's 2015. Death to HTML file fields for uploads. Drag and drop with image preview, bring it on. From my limited research, Dropzone.js seems to be the clear leader of this pack at the moment.
Bootstrap 3 for pretty CSS styles and grid layouts. I admit I've become a bit of a Bootstrap addict lately. For developers with non-existent artistic ability, like myself, it's impossible to resist. Font Awesome is rather nice, too.
Markovify for random text generation. I discovered this one (and several alternative implementations of it) while building Flask Editable Site, and I'm hooked. Adios, Lorem Ipsum, and don't hit the door on your way out.
Bootstrap Freelancer theme by Start Bootstrap. Although Flask Editable Site uses vanilla Bootstrap, I borrowed various snippets of CSS / JS from this theme, as well as the overall layout.
cookiecutter-flask, a Flask app template. I highly recommend this as a guide to best-practice directory layout, configuration management, and use of patterns in a Flask app. Thanks to these best practices, Flask Editable Site is also reasonably Twelve-Factor compliant, especially in terms of config and backing services.
Flask Editable Site began as the codebase for The Daydream Believers Performers web site, which I built pro-bono as a side project recently. So, acknowledgements to that group for helping to make Flask Editable Site happen.
For the live editing UX, I acknowledge that I drew inspiration from several examples. First and foremost, from Mezzanine, a CMS (based on Django) which I've used on occasion. Mezzanine puts "edit" buttons in-place next to most text fields on a site, and pops up a traditional (i.e. non contenteditable) WYSIWYG editor when these are clicked.
I also had a peek at Create.js, which takes care of the front-end side of live content editing quite similarly to the way I've cobbled it together. In Flask Editable Site, the combo of Dante editor and my custom "autosave" JS could easily be replaced with Create.js (particularly when using Hallo editor, which is quite minimalist like Dante); I guess it's just a question of personal taste.
Sir Trevor JS is an interesting new kid on the block. I'm quite impressed with Sir Trevor, but its philosophy of "adding blocks of anything down the page" isn't such a great fit for Flask Editable Site, where the idea is that site admins can only add / edit content within specific constraints for each block on the page. However, for sites with no structured content models, where it's OK for each page to be a free canvas (or for a "free canvas" within, say, each blog post on a site), I can see Sir Trevor being a real game-changer.
There's also X-editable, which is the only JS solution that I've come across for nice live editing of list-type content (i.e. checkoxes, radio buttons, tag fields, autocomplete boxes, etc). I haven't used X-editable in Flask Editable Site, because I'm mainly dealing with text and image fields (and for date / time fields, I prefer a proper calendar widget). But if I needed live editing of list fields, X-editable would be my first choice.
Final thoughts
I must stress that, as I said above, Flask Editable site is a proof-of-concept. It doesn't have all the features you're going to need for your project foo. In particular, it doesn't support very many field types: only text ("short text" and "rich text"), date, time, and image. It should also support inline images and (YouTube / Vimeo) videos out-of-the-box, as this is included with Dante, but I haven't tested it. For other field types, forks / pull requests / sister projects are welcome.
If you look at the code (particularly the settings.py file and the home view), you should be able to add live editing of new content models quite easily, with just a bit of copy-pasting and tweaking. The idea is that the editable.views code is generic enough, that you won't need to change it at all when adding new models / fields in your back-end. At least, that's the idea.
Quite a lot of the code in Flask Editable Site is more complex than it strictly needs to be, in order to support "session store mode", where all content is saved to the current user's session instead of to the database (preferably using something like Memcached or temp files, rather than cookies, although that depends on what settings you use). I developed "session store mode" in order to make the demo site work without requiring any hackery such as a scheduled DB refresh (which is the usual solution in such cases). However, I can see it also being useful for sandbox environments, for UAT, and for reviewing design / functionality changes without "real" content getting in the way.
The app also includes a fair bit of code for random generation and selection of sample text and image content. This was also done primarily for the purposes of the demo site. But, upon reflection, I think that a robust solution for randomly populating a site's content is really something that all CMS-like apps should consider more seriously. The exact algorithms and sample content pools for this, of course, are a matter of taste. But the point is that it's not just about pretty pictures and amusing Dickensian text. It's about the mindset of treating content dynamically, and of recognising the bounds and the parameters of each placeholder area on the page. And what better way to enforce that mindset, than by seeing a different random set of content every time you restart the app?
I decided to make this project a good opportunity for getting my hands dirty with thorough unit / functional testing. As such, Flask Editable Site is my first open-source effort that features automated testing via Travis CI, as well as test coverage reporting via Coveralls. As you can see on the GitHub page, tests are passing and coverage is pretty good. The tests are written in pytest, with significant help from webtest, too. I hope that the tests also serve as a template for other projects; all too often, with small brochureware sites, formal testing is done sparingly if at all.
Regarding the "no admin area" principle, Flask Editable Site has taken quite a purist approach to this. Personally, I think that radically reducing the role of "admin areas" in web site administration will lead to better UX. Anything that's publicly visible on the site, should be editable first and foremost via direct manipulation. However, in reality there will always be things that aren't publicly visible, and that admins still need to edit. For example, sites will always need user / role CRUD pages (unless you're happy to only manage users via shell commands). So, if you do add admin pages to a project based on Flask Editable Site, please don't feel as though you're breaking some golden rule.
Hope you enjoy playing around with the app. Who knows, maybe you'll even build something useful based on it. Feedback, bug reports, pull requests, all welcome.
]]>
Cookies can't be more than 4KiB in size2015-10-15T00:00:00Z2015-10-15T00:00:00ZJazahttps://greenash.net.au/thoughts/2015/10/cookies-cant-be-more-than-4kib-in-size/
Did you know: you can't reliably store more than 4KiB (4096 bytes) of data in a single browser cookie? I didn't until this week.
What, I can't have my giant cookie and eat it too? Outrageous! Image source:Giant Chocolate chip cookie recipe.
I'd never before stopped to think about whether or not there was a limit to how much you can put in a cookie. Usually, cookies only store very small string values, such as a session ID, a tracking code, or a browsing preference (e.g. "tile" or "list" for search results). So, usually, there's no need to consider its size limits.
However, while working on a new side project of mine that heavily uses session storage, I discovered this limit the hard (to debug) way. Anyway, now I've got one more adage to add to my developer's phrasebook: if you're trying to store more than 4KiB in a cookie, you're doing it wrong.
In my case – working with Flask, which depends on Werkzeug – trying to store an oversized cookie doesn't throw any errors, it simply fails silently. I've submitted a patch to Werkzeug, to make oversized cookies raise an exception, so hopefully it will be more obvious in future when this problem occurs.
Also, as several others have pointed out, trying to store too much data in cookies is a bad idea anyway, because that data travels with every HTTP request and response, so it should be as small as possible. As I learned, if you find that you're dealing with non-trivial amounts of session data, then ditch client-side storage for the app in question, and switch to server-side session data storage (preferably using something like Memcached or Redis).
]]>
Robert Dawson: the first anthropologist of Aborigines?2015-09-26T00:00:00Z2015-09-26T00:00:00ZJazahttps://greenash.net.au/thoughts/2015/09/robert-dawson-the-first-anthropologist-of-aborigines/
The treatment of Aboriginal Australians in colonial times was generally atrocious. This is now well known and accepted by most. Until well into the 20th century, Aborigines were subjected to exploitation, abuse, and cold-blooded murder. They were regarded as sub-human, and they were not recognised at all as the traditional owners of their lands. For a long time, virtually no serious attempts were made to study or to understand their customs, their beliefs, and their languages. On the contrary, the focus was on "civilising" them by imposing upon them a European way of life, while their own lifestyle was held in contempt as "savage".
I recently came across a gem of literary work, from the early days of New South Wales: The Present State of Australia, by Robert Dawson. The author spent several years (1826-1828) living in the Port Stephens area (about 200km north of Sydney), as chief agent of the Australian Agricultural Company, where he was tasked with establishing a grazing property. During his time there, Dawson lived side-by-side with the Worimi indigenous peoples, and Worimi anecdotes form a significant part of his book (which, officially, is focused on practical advice for British people considering migration to the Australian frontier).
Robert Dawson of the Australian Agricultural Company. Image source:Wikimedia Commons.
In this article, I'd like to share quite a number of quotes from Dawson's book, which in my opinion may well constitute the oldest known (albeit informal) anthropological study of Indigenous Australians. Considering his rich account of Aboriginal tribal life, I find it surprising that Dawson seems to have been largely forgotten by the history books, and that The Present State of Australia has never been re-published since its first edition in 1830 (the copies produced in 1987 are just fascimiles of the original). I hope that this article serves as a tribute to someone who was an exemplary exception to what was then the norm.
Language
The book includes many passages containing Aboriginal words interspersed with English, as well as English words spelt phonetically (and amusingly) as the tribespeople pronounced them; contemporary Australians should find many of these examples familiar, from the modern-day Aboriginal accents:
Before I left Port Stephens, I intimated to them that I should soon return in a "corbon" (large) ship, with a "murry" (great) plenty of white people, and murry tousand things for them to eat … They promised to get me "murry tousand bark." "Oh! plenty bark, massa." "Plenty black pellow, massa: get plenty bark." "Tree, pour, pive nangry" (three, four, five days) make plenty bark for white pellow, massa." "You come back toon?" "We look out for corbon ship on corbon water," (the sea.) "We tee, (see,) massa." … they sent to inform me that they wished to have a corrobery (dance) if I would allow it.
(page 60)
On occasion, Dawson even goes into grammatical details of the indigenous languages:
"Bael me (I don't) care." The word bael means no, not, or any negative: they frequently say, "Bael we like it;" "Bael dat good;" "Bael me go dere."
(page 65)
It's clear that Dawson himself became quite prolific in the Worimi language, and that – at least for a while – an English-Worimi "creole" emerged as part of white-black dialogue in the Port Stephens area.
Food and water
Although this is probably one of the better-documented Aboriginal traits from the period, I'd also like to note Dawson's accounts of the tribespeoples' fondness for European food, especially for sugar:
They are exceedingly fond of biscuit, bread, or flour, which they knead and bake in the ashes … but the article of food which appears most delicious to them, is the boiled meal of Indian corn; and next to it the corn roasted in the ashes, like chestnuts: of sugar too they are inordinately fond, as well as of everything sweet. One of their greatest treats is to get an Indian bag that has had sugar in it: this they cut into pieces and boil in water. They drink this liquor till they sometimes become intoxicated, and till they are fairly blown out, like an ox in clover, and can take no more.
(page 59)
Dawson also described their manner of eating; his account is not exactly flattering, and he clearly considers this behaviour to be "savage":
The natives always eat (when allowed to do so) till they can go on no longer: they then usually fall asleep on the spot, leaving the remainder of the kangaroo before the fire, to keep it warm. Whenever they awake, which is generally three or four times during the night, they begin eating again; and as long as any food remains they will never stir from the place, unless forced to do so. I was obliged at last to put a stop, when I could, to this sort of gluttony, finding that it incapacitated them from exerting themselves as they were required to do the following day.
(page 123)
Regarding water, Dawson gave a practical description of the Worimi technique for getting a drink in the bush in dry times (and admits that said technique saved him from being up the creek a few times); now, of course, we know that similar techniques were common for virtually all Aboriginal peoples across Australia:
It sometimes happens, in dry seasons, that water is very scarce, particularly near the shores. In such cases, whenever they find a spring, they scratch a hole with their fingers, (the ground being always sandy near the sea,) and suck the water out of the pool through tufts or whisps of grass, in order to avoid dirt or insects. Often have I witnessed and joined in this, and as often felt indebted to them for their example.
They would walk miles rather than drink bad water. Indeed, they were such excellent judges of water, that I always depended upon their selection when we encamped at a distance from a river, and was never disappointed.
(page 150)
Tools and weapons
In numerous sections, Dawson described various tools that the Aborigines used, and their skill and dexterity in fashioning and maintaining them:
[The old man] scraped the point of his spear, which was at least about eight feet long, with a broken shell, and put it in the fire to harden. Having done this, he drew the spear over the blaze of the fire repeatedly, and then placed it between his teeth, in which position he applied both his hands to straighten it, examining it afterwards with one eye closed, as a carpenter would do his planed work. The dexterous and workmanlike manner in which he performed his task, interested me exceedingly; while the savage appearance and attitude of his body, as he sat on the ground before a blazing fire in the forest, with a black youth seated on either side of him, watching attentively his proceedings, formed as fine a picture of savage life as can be conceived.
(page 16)
To the modern reader such as myself, Dawson's use of language (e.g. "a picture of savage life") invariably gives off a whiff of contempt and "European superiority". Personally, I try to give him the benefit of the doubt, and to brush this off as simply "using the vernacular of the time". In my opinion, this is fair justification for Dawson's manner of writing to some extent; but it also shows that he wasn't completely innocent, either: he too held some of the very views which he criticised in his contemporaries.
The tribespeople also exercised great agility in gathering the raw materials for their tools and shelters:
Before a white man can strip the bark beyond his own height, he is obliged to cut down the tree; but a native can go up the smooth branchless stems of the tallest trees, to any height, by cutting notches in the surface large enough only to place the great toe in, upon which he supports himself, while he strips the bark quite round the tree, in lengths from three to six feet. These form temporary sides and coverings for huts of the best description.
(page 19)
And they were quite dexterous in their crafting of nets and other items:
They [the women] make string out of bark with astonishing facility, and as good as you can get in England, by twisting and rolling it in a curious manner with the palm of the hand on the thigh. With this they make nets … These nets are slung by a string round their forehead, and hang down their backs, and are used like a work-bag or reticule. They contain all the articles they carry about with them, such as fishing hooks made from oyster or pearl shells, broken shells, or pieces of glass, when they can get them, to scrape the spears to a thin and sharp point, with prepared bark for string, gum for gluing different parts of their war and fishing spears, and sometime oysters and fish when they move from the shore to the interior.
(page 67)
Music and dance
Dawson wrote fondly of his being witness to corroborees on several occasions, and he recorded valuable details of the song and dance involved:
A man with a woman or two act as musicians, by striking two sticks together, and singing or bawling a song, which I cannot well describe to you; it is chiefly in half tones, extending sometimes very high and loud, and then descending so low as almost to sink to nothing. The dance is exceedingly amusing, but the movement of the limbs is such as no European could perform: it is more like the limbs of a pasteboard harlequin, when set in motion by a string, than any thing else I can think of. They sometimes changes places from apparently indiscriminate positions, and then fall off in pairs; and after this return, with increasing ardour, in a phalanx of four and five deep, keeping up the harlequin-like motion altogether in the best time possible, and making a noise with their lips like "proo, proo, proo;" which changes successively to grunting, like the kangaroo, of which it is an imitation, and not much unlike that of a pig.
(page 61)
Note Dawson's poetic efforts to bring to life the corroboree in words, with "bawling" sounds, "phalanx" movements, and "harlequin-like motion". Modern-day writers probably wouldn't bother to go to such lengths, instead assuming that their audience is familiar with the sights and sounds in question (at the very least, from TV shows). Dawson, who was writing for a Victorian English audience, didn't enjoy this luxury.
Families
In an era when most "white fellas" in the Colony were irrevocably destroying traditional Aboriginal family ties (a practice that was to continue well into the 20th century), Dawson was appreciating and making note of the finer details that he witnessed:
They are remarkably fond of their children, and when the parents die, the children are adopted by the unmarried men and women, and taken the greatest care of.
(page 68)
He also observed the prevalence of monogamy amongst the tribes he encountered:
The husband and wife are in general remarkably constant to each other, and it rarely happens that they separate after having considered themselves as man and wife; and when an elopement or the stealing of another man's gin [wife] takes place, it creates great, and apparently lasting uneasiness in the husband.
(page 154)
As well as the enduring bonds between parents and children:
The parents retain, as long as they live, an influence over their children, whether married or not – I then asked him the reason of this [separating from his partner], and he informed me his mother did not like her, and that she wanted him to choose a better.
(page 315)
Dawson made note of the good and the bad; in the case of families, he condoned the prevalence of domestic violence towards women in the Aboriginal tribes:
On our first coming here, several instances occurred in our sight of the use of this waddy [club] upon their wives … When the woman sees the blow coming, she sometimes holds her head quietly to receive it, much like Punch and his wife in the puppet-shows; but she screams violently, and cries much, after it has been inflicted. I have seen but few gins [wives] here whose heads do not bear the marks of the most dreadful violence of this kind.
(page 66)
Clothing
Some comical accounts of how the Aborigines took to the idea of clothing in the early days:
They are excessively fond of any part of the dress of white people. Sometimes I see them with an old hat on: sometimes with a pair of old shoes, or only one: frequently with an old jacket and hat, without trowsers: or, in short, with any garment, or piece of a garment, that they can get.
(page 75)
They usually reacted well to gifts of garments:
On the following morning I went on board the schooner, and ordered on shore a tomahawk and a suit of slop clothes, which I had promised to my friend Ben, and in which he was immediately dressed. They consisted of a short blue jacket, a checked shirt, and a pair of dark trowsers. He strutted about in them with an air of good-natured importance, declaring that all the harbour and country adjoining belonged to him. "I tumble down [born] pickaninny [child] here," he said, meaning that he was born there. "Belonging to me all about, massa; pose you tit down here, I gib it to you." "Very well," I said: "I shall sit down here." "Budgeree," (very good,) he replied, "I gib it to you;" and we shook hands in ratification of the friendly treaty.
(page 12)
Death and religion
Yet another topic which was scarcely investigated by Dawson's colonial peers – and which we now know to have been of paramount importance in all Aborigines' belief systems — rituals regarding death and mourning:
… when any of their relations die, they show respect for their memories by plastering their heads and faces all over with pipe-clay, which remains till it falls off of itself. The gins [wives] also burn the front of the thigh severely, and bind the wound up with thin strips of bark. This is putting themselves in mourning. We put on black; they put on white: so that it is black and white in both cases.
(page 74)
The Aborigines that Dawson became acquainted with, were convinced that the European settlers were re-incarnations of their ancestors; this belief was later found to be fairly widespread amongst Australia's indigenous peoples:
I cannot learn, precisely, whether they worship any God or not; but they are firm in their belief that their dead friends go to another country; and that they are turned into white men, and return here again.
(page 74)
Dawson appears to have debated this topic at length with the tribespeople:
"When he [the devil] makes black fellow die," I said, "what becomes of him afterwards?" "Go away Englat," (England,) he answered, "den come back white pellow." This idea is so strongly impressed upon their minds, that when they discover any likeness between a white man and any one of their deceased friends, they exclaim immediately, "Dat black pellow good while ago jump up white pellow, den come back again."
(page 158)
Inter-tribe relations
During his time with the Worimi and other tribes, Dawson observed many of the details of how neighbouring tribes interacted, for example, in the case of inter-tribal marriage:
The blacks generally take their wives from other tribes, and if they can find opportunities they steal them, the consent of the female never being made a question in the business. When the neighbouring tribes happen to be in a state of peace with each other, friendly visits are exchanged, at which times the unmarried females are carried off by either party.
(page 153)
In one chapter, Dawson gives an amusing account of how the Worimi slandered and villainised another tribe (the Myall people), with whom they were on unfriendly terms:
The natives who domesticate themselves amongst the white inhabitants, are aware that we hold cannibalism in abhorrence; and in speaking of their enemies, therefore, to us, they always accuse them of this revolting practice, in order, no doubt, to degrade them as much as possible in our eyes; while the other side, in return, throw back the accusation upon them. I have questioned the natives who were so much with me, in the closest manner upon this subject, and although they persist in its being the practice of their enemies, still they never could name any particular instances within their own knowledge, but always ended by saying: "All black pellow been say so, massa." When I have replied, that Myall black fellows accuse them of it also, the answer has been, "Nebber! nebber black pellow belonging to Port Tebens, (Stephens;) murry [very] corbon [big] lie, massa! Myall black pellows patter (eat) always."
(page 125)
The book also explains that the members of a given tribe generally kept within their own ancestral lands, and that they were reluctant and fearful of too-often making contact with neighbouring tribes:
… the two natives who had accompanied them had become frightened at the idea of meeting strange natives, and had run away from them about the middle of their journey …
(page 24)
Relations with colonists
Throughout the book, general comments are made that insinuate the fault and the aggression in general of "white fella" in the Colony:
The natives are a mild and harmless race of savages; and where any mischief has been done by them, the cause has generally arisen, I believe, in bad treatment by their white neighbours. Short as my residence has been here, I have, perhaps, had more intercourse with these people, and more favourable opportunities of seeing what they really are, than any other person in the colony.
(page 57)
Dawson provides a number of specific examples of white aggression towards the Aborigines:
The natives complained to me frequently, that "white pellow" (white fellows) shot their relations and friends; and showed me many orphans, whose parents had fallen by the hands of white men, near this spot. They pointed out one white man, on his coming to beg some provisions for his party up the river Karuah, who, they said, had killed ten; and the wretch did not deny it, but said he would kill them whenever he could.
(page 58)
Sydney
As a modern-day Sydneysider myself, I had a good chuckle reading Dawson's account of his arrival for the first time in Sydney, in 1826:
There had been no arrival at Sydney before us for three or four months. The inhabitants were, therefore, anxious for news. Parties of ladies and gentlemen were parading on the sides of the hills above us, greeting us every now and then, as we floated on; and as soon as we anchored, (which was on a Sunday,) we were boarded by numbers of apparently respectable people, asking for letters and news, as if we had contained the budget of the whole world.
(page 46)
View of Sydney Cove from Dawes Point by Joseph Lycett, ca 1817-1818. Image source:Wikipedia.
No arrival in Sydney, from the outside world, for "three or four months"?! Who would have thought that a backwater penal town such as this, would one day become a cosmopolitan world city, that sees a jumbo jet land and take off every 5 minutes, every day of the week? Although, it seems that even back then, Dawson foresaw something of Sydney's future:
On every side of the town [Sydney] houses are being erected on new ground; steam engines and distilleries are at work; so that in a short time a city will rise up in this new world equal to any thing out of Europe, and probably superior to any other which was ever created in the same space of time.
(page 47)
And, even back then, there were some (like Dawson) who preferred to get out of the "rat race" of Sydney town:
Since my arrival I have spent a good deal of time in the woods, or bush, as it is called here. For the last five months I have not entered or even seen a house of any kind. My habitation, when at home, has been a tent; and of course it is no better when in the bush.
(page 48)
Stockton Beach, just below Port Stephens, was several years ago declared Worimi land. Image source:NSW National Parks.
There's still a fair bit of bush all around Sydney; although, sadly, not as much as there was in Dawson's day.
General remarks
Dawson's impression of the Aborigines:
I was much amused at this meeting, and above all delighted at the prompt and generous manner in which this wild and untutored man conducted himself towards his wandering brother. If they be savages, thought I, they are very civil ones; and with kind treatment we have not only nothing to fear, but a good deal to gain from them. I felt an ardent desire to cultivate their acquaintance, and also much satisfaction from the idea that my situation would afford me ample opportunities and means for doing so.
(page 11)
Nomadic nature of the tribes:
When away from this settlement, they appear to have no fixed place of residence, although they have a district of country which they call theirs, and in some part of which they are always to be found. They have not, as far as I can learn, any king or chief.
(page 63)
Tribal punishment:
I have never heard but of one punishment, which is, I believe, inflicted for all offences. It consists in the culprit standing, for a certain time, to defend himself against the spears which any of the assembled multitude think proper to hurl at him. He has a small target [shield] … and the offender protects himself so dexterously by it, as seldom to receive any injury, although instances have occurred of persons being killed.
(page 64)
Generosity of Aborigines (also illustrating their lack of a concept of ownership / personal property):
They are exceedingly kind and generous towards each other: if I give tobacco or any thing else to any man, it is divided with the first he meets without being asked for it.
(page 68)
Ability to count / reckon:
They have no idea of numbers beyond five, which are reckoned by the fingers. When they wish to express a number, they hold up so many fingers: beyond five they say, "murry tousand," (many thousands.)
(page 75)
Protocol for returning travellers in a tribe:
It is not customary with the natives of Australia to shake hands, or to greet each other in any way when they meet. The person who has been absent and returns to his friends, approaches them with a serious countenance. The party who receives him is the first to speak, and the first questions generally are, where have you been? Where did you sleep last night? How many days have you been travelling? What news have you brought? If a member of the tribe has been very long absent, and returns to his family, he stops when he comes within about ten yards of the fire, and then sits down. A present of food, or a pipe of tobacco is sent to him from the nearest relation. This is given and received without any words passing between them, whilst silence prevails amongst the whole family, who appear to receive the returned relative with as much awe as if he had been dead, and it was his spirit which had returned to them. He remains in this position perhaps for half an hour, till he receives a summons to join his family at the fire, and then the above questions are put to him.
(page 132)
Final thoughts
The following pages are not put forth to gratify the vanity of authorship, but with the view of communicating facts where much misrepresentation has existed, and to rescue, as far as I am able, the character of a race of beings (of whom I believe I have seen more than any other European has done) from the gross misrepresentations and unmerited obloquy that has been cast upon them.
(page xiii)
Dawson wasn't exactly modest, in his assertion of being the foremost person in the Colony to make a fair representation of the Aborigines; however, I'd say his assertion is quite accurate. As far as I know, he does stand out as quite a solitary figure for his time, in his efforts to meaningfully engage with the tribes of the greater Sydney region, and to document them in a thorough and (relatively) unprejudiced work of prose.
I would therefore recommend those who would place the Australian natives on the level of brutes, to reflect well on the nature of man in his untutored state in comparison with his more civilized brother, indulging in endless whims and inconsistencies, before they venture to pass a sentence which a little calm consideration may convince them to be unjust.
(page 152)
Dawson's criticism of the prevailing attitudes was scathing, although it was clearly criticism that was ignored and unheeded by his contemporaries.
It is not sufficient merely as a passing traveller to see an aboriginal people in their woods and forests, to form a just estimate of their real character and capabilities … To know them well it is necessary to see much more of them in their native wilds … In this position I believe no man has ever yet been placed, although that in which I stood approached more nearly to it than any other known in that country.
(page 329)
With statements like this, Dawson is inviting his fellow colonists to "go bush" and to become acquainted with an Aboriginal tribe, as he did. From others' accounts of the era, those who followed in his footsteps were few and far between.
I have seen the natives from the coast far south of Sydney, and thence to Morton Bay (sic), comprising a line of coast six or seven hundred miles; and I have also seen them in the interior of Argyleshire and Bathurst, as well as in the districts of the Hawkesbury, Hunter's River, and Port Stephens, and have no reason whatever to doubt that they are all the same people.
(page 336)
So, why has a man and a book with so much to say about early contact with the Aborigines, lain largely forgotten and abandoned by the fickle sands of history? Probably the biggest reason, is that Dawson was just a common man. Sure, he was the first agent of AACo: but he was no intrepid explorer, like Burke and Wills; nor an important governor, like Arthur Phillip or Lachlan Macquarie. While the diaries and letters of bigwigs like these have been studied and re-published constantly, not everyone can enjoy the historical limelight.
No doubt also a key factor, was that Dawson ultimately fell out badly with the powerful Macarthur family, who were effectively his employers during his time in Port Stephens. The Present State of Australia is riddled with thinly veiled slurs at the Macarthurs, and it's quite likely that this guaranteed the book's not being taken seriously by anyone, in the Colony or elsewhere, for a long time.
Dawson's work is, in my opinion, an outstanding record of indigenous life in Australia, at a time when the ancient customs and beliefs were still alive and visible throughout most of present-day NSW. It also illustrates the human history of a geographically beautiful region that's quite close to my heart. Like many Sydneysiders, I've spent several summer holidays at Port Stephens during my life. I've also been camping countless times at nearby Myall Lakes; and I have some very dear family friends in Booral, a small town which sits alongside the Karuah River just upstream from Port Stephens (and which also falls within Worimi country).
In leaving as a legacy his narrative of the Worimi people and their neighbours (which is, as far as I know, the only surviving first-hand account of these people from the coloial era of any significance), I believe that Dawson's work should be lauded and celebrated. At a time when the norm for bush settlers was to massacre and to wreak havoc upon indigenous peoples, Dawson instead chose to respect and to make friends with those that he encountered.
Personally, I think the honour of "first anthropologist of the Aborigines" is one that Dawson can rightly claim (although others may feel free to dispute this). Descendants of the Worimi live in the Port Stephens area to this day; and I hope that they appreciate Dawson's tribute, as no doubt the spirits of their ancestors do.
]]>
Splitting a Python codebase into dependencies for fun and profit2015-06-30T00:00:00Z2015-06-30T00:00:00ZJazahttps://greenash.net.au/thoughts/2015/06/splitting-a-python-codebase-into-dependencies-for-fun-and-profit/
When the Python codebase for a project (let's call the project LasagnaFest) starts getting big, and when you feel the urge to re-use a chunk of code (let's call that chunk foodutils) in multiple places, there are a variety of steps at your disposal. The most obvious step is to move that foodutils code into its own file (thus making it a Python module), and to then import that module wherever else you want in the codebase.
Most of the time, doing that is enough. The Python module importing system is powerful, yet simple and elegant.
But… what happens a few months down the track, when you're working on two new codebases (let's call them TortelliniFest and GnocchiFest – perhaps they're for new clients too), that could also benefit from re-using foodutils from your old project? What happens when you make some changes to foodutils, for the new projects, but those changes would break compatibility with the old LasagnaFest codebase?
What happens when you want to give a super-charged boost to your open source karma, by contributing foodutils to the public domain, but separated from the cruft that ties it to LasagnaFest and Co? And what do you do with secretfoodutils, which for licensing reasons (it contains super-yummy but super-secret sauce) can't be made public, but which should ideally also be separated from the LasagnaFest codebase for easier re-use?
Or – not to be forgotten – what happens when, on one abysmally rainy day, you take a step back and audit the LasagnaFest codebase, and realise that it's got no less than 38 different *utils chunks of code strewn around the place, and you ponder whether surely keeping all those utils within the LasagnaFest codebase is really the best way forward?
Moving foodutils to its own module file was a great first step; but it's clear that in this case, a more drastic measure is needed. In this case, it's time to split off foodutils into a separate, independent codebase, and to make it an external dependency of the LasagnaFest project, rather than an internal component of it.
This article is an introduction to the how and the why of cutting up parts of a Python codebase into dependencies. I've just explained a fair bit of the why. As for the how: in a nutshell, pip (for installing dependencies), the public PyPI repo (for hosting open-sourced dependencies), and a private PyPI repo (for hosting proprietary dependencies). Read on for more details.
Levels of modularity
One of the (many) joys of coding in Python is the way that it encourages modularity. For example, let's start with this snippet of completely non-modular code:
There are, in my opinion, three different levels of re-factoring that you can apply, in order to make it more modular. You can think of these levels like the layers of a lasagna, if you want. Or not.
Each successive level of re-factoring involves a bit more work in the short-term, but results in more convenient re-use in the long-term. So, which level is appropriate, depends on the likelihood that you (or others) will want to re-use a given chunk of code in the future.
First, you can split the logic out of the procedural blurg, and into a function in the same file:
And, finally, you can move that file out of your codebase, upload it to a Python package repository (the most common such repository being PyPI), and then declare it as a dependency of your codebase using pip:
As I said, achieving this last level of modularity isn't always necessary or appropriate, due to the overhead involved. For a given chunk of code, there are always going to be trade-offs to consider, and as a developer it's always going to be your judgement call.
Splitting out code
For the times when it is appropriate to go that "last mile" and split code out as an external dependency, there are (in my opinion) insufficient resources regarding how to go about it. I hope, therefore, that this section serves as a decent guide on the matter.
Factor out coupling
The first step in making until-now "project code" an external dependency, is removing any coupling that the chunk of code may have to the rest of the codebase. For example, the foodutils code shown above is nice and de-coupled; but what if it instead looked like so:
foodutils.py:
from mysettings import NUM_QUESTION_MARKS
def greet_dude_with_food(dude_name, food_today):
return "Hey {dude_name}! Want a {food_today} today{q_marks}".format(
dude_name=dude_name,
food_today=food_today,
q_marks='?'*NUM_QUESTION_MARKS)
This would be problematic, because this code relies on the assumption that it lives in a codebase containing a mysettings module, and that the configuration value NUM_QUESTION_MARKS is defined within that module.
We can remove this coupling by changing NUM_QUESTION_MARKS to be a parameter passed to greet_dude_with_food, like so:
The dependent code in this project could then pass in the required config value when it calls greet_dude_with_food, like so:
foodgreeter.py:
from foodutils import greet_dude_with_food
from mysettings import NUM_QUESTION_MARKS
dude_name = 'Johnny'
food_today = 'lasagna'
print(greet_dude_with_food(
dude_name=dude_name,
food_today=food_today,
num_question_marks=NUM_QUESTION_MARKS))
Once the code we're re-factoring no longer depends on anything elsewhere in the codebase, it's ready to be made an external dependency.
New repo for dependency
Next comes the step of physically moving the given chunk of code out of the project's codebase. In most cases, this means deleting the given file(s) from the project's version control repository (you are using version control, right?), and creating a new repo for those file(s) to live in.
For example, if you're using Git, the steps would be something like this:
The given chunk of code now has its own dedicated repo. But it's not yet a project, in its own right, and it can't yet be referenced as a dependency. To do that, we'll need to add some more files to the new repo, mainly consisting of metadata describing "who" this project is, and what it does.
Next, add a version number to the code. The best way to do this, is to add it at the top of the main Python file, e.g. by adding this to the top of foodutils.py:
__version__ = '0.1.0'
After that, we're going to add the standard metadata files that almost all open-source Python projects have. Most importantly, a setup.py file that looks something like this:
import os
import setuptools
module_path = os.path.join(os.path.dirname(__file__), 'foodutils.py')
version_line = [line for line in open(module_path)
if line.startswith('__version__')][0]
__version__ = version_line.split('__version__ = ')[-1][1:][:-2]
setuptools.setup(
name="foodutils",
version=__version__,
url="https://github.com/misterfoo/foodutils",
author="Mister foo",
author_email="mister@foo.com",
description="Utils for handling food.",
long_description=open('README.rst').read(),
py_modules=['foodutils'],
zip_safe=False,
platforms='any',
install_requires=[],
classifiers=[
'Development Status :: 2 - Pre-Alpha',
'Environment :: Web Environment',
'Intended Audience :: Developers',
'Operating System :: OS Independent',
'Programming Language :: Python',
'Programming Language :: Python :: 2',
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.3',
],
)
And also, a README.rst file:
foodutils
=========
Utils for handling food.
Once you've created those files, commit them to the new repo.
Push the repo
Great – the chunk of code now lives in its own repo, and it contains enough metadata for other projects to see what its name is, what version(s) of it there are, and what function(s) it performs. All that needs to be done now, is to decide where this repo will be hosted. But to do this, you first need to answer an important non-technical question: to open-source the code, or to keep it proprietary?
In general, you should open-source your dependencies whenever possible. You get more eyeballs (for free). Famous hairy people like Richard Stallman will send you flowers. If nothing else, you'll at least be able to always easily find your code, guaranteed (if you can't remember where it is, just Google it!). You get the drift. If open-sourcing the code, then the most obvious choice for where to host the repo is GitHub. (However, I'm not evangelising GitHub here, remember there are other options, kids).
Open source is kool, but sometimes you can't or you don't want to go down that route. That's fine, too – I'm not here to judge anyone, and I can't possibly be aware of anyone else's business / ownership / philosophical situation. So, if you want to keep the code all to your little self (or all to your little / big company's self), you're still going to have to host it somewhere. And no, "on my laptop" does not count as your code being hosted somewhere (well, technically you could just keep the repo on your own PC, and still reference it as a dependency, but that's a Bad Idea™). There are a number of hosting options: for example, on a VPS that you control; or using a managed service such as GitHub private, Bitbucket, or Assembla (note: once again, not promoting any specific service provider, just listing the main players as options).
So, once you've decided whether or not to open-source the code, and once you've settled on a hosting option, push the new repo to its hosted location.
Upload to PyPI
Nearly there now. The chunk of code has been de-coupled from its dependent project; it's been put in a new repo with the necessary metadata; and that repo is now hosted at a permanent location somewhere online. All that's left, is to make it known to the universe of Python projects, so that it can be easily listed as a dependency of other Python projects.
If you've developed with Python before (and if you've read this far, then I assume you have), then no doubt you've heard of pip. Being the Python package manager of choice these days, pip is the tool used to manage Python dependencies. pip can find dependencies from a variety of locations, but the place it looks first and foremost (by default) is on the Python Package Index (PyPI).
If your dependency is public and open-source, then you should add it to PyPI. Each time you release a new version, then (along with committing and tagging that new version in the repo) you should also upload it to PyPI. I won't go into the details in this article; please refer to the official docs for registering and uploading packages on PyPI. When following the instructions there, you'll generally want to package your code as a "universal wheel", you'll generally use the PyPI website form to register a new package, and you'll generally use twine to upload the package.
If your dependency is private and proprietary, then PyPI is not an option. The easiest way to deal with private dependencies (also the easiest way to deal with public dependencies, for that matter), is to not worry about proper Python packaging at all, and simply to use pip's ability to directly reference a source repo (including a specific commit / tag), e.g:
However, that has a number of disadvantages, the most visible disadvantage being that pip install will run much slower, because it has to do a git pull every time you ask it to check that foodutils is installed (even if you specify the same commit / tag each time).
A better way to deal with private dependencies, is to create your own "private PyPI". Same as with public packages: each time you release a new version, then (along with committing and tagging that new version in the repo) you should also upload it to your private PyPI. For instructions regarding this, please refer to my guide for how to set up and use a private PyPI repo. Also, note that my guide is for quite a minimal setup, although it contains links to some alternative setup options, including more advanced and full-featured options. (And if using a private PyPI, then take note of my guide's instructions for what to put in your local ~/.pip/pip.conf file).
Reference the dependency
The chunk of code is now ready to be used as an external dependency, by any project. To do this, you simply list the package in your project's requirements.txt file; whether the package is on the public PyPI, or on a private PyPI of your own, the syntax is the same:
foodutils==0.1.0 # From pypi.myserver.com
Then, just run your dependencies through pip as usual:
pip install -r requirements.txt
And there you have it: foodutils is now an external dependency. You can list it as a requirement for LasagnaFest, TortelliniFest, GnocchiFest, and as many other projects as you need.
Final thoughts
This article was born out of a series of projects that I've been working on over the past few months (and that I'm still working on), written mainly in Flask (these apps are still in alpha; ergo, sorry, can't talk about their details yet). The size of the projects' codebases grew to be rather unwieldy, and the projects have quite a lot of shared functionality.
I started out by re-using chunks of code between the different projects, with the hacky solution of sym-linking from one codebase to another. This quickly became unmanageable. Once I could stand the symlinks no longer (and once I had some time for clean-up), I moved these shared chunks of code into separate repos, and referenced them as dependencies (with some being open-sourced and put on the public PyPI). Only in the last week or so, after losing patience with slow pip installs, and after getting sick of seeing far too many -e git+http://git… strings in my requirements.txt files, did I finally get around to setting up a private PyPI, for better dealing with the proprietary dependencies of these codebases.
I hope that this article provides some clear guidance regarding what can be quite a confusing task, i.e. that of creating and maintaining a private Python package index. Aside from being a technical guide, though, my aim in penning this piece is to explain how you can split off component parts of a monolithic codebase into re-usable, independent separate codebases; and to convey the advantages of doing so, in terms of code quality and maintainability.
Flask, my framework of choice these days, strives to consist of a series of independent projects (Flask, Werkzeug, Jinja, WTForms, and the myriad Flask-* add-ons), which are compatible with each other, but which are also useful stand-alone or with other systems. I think that this is a great example for everyone to follow, even humble "custom web-app" developers like myself. Bearing that in mind, devoting some time to splitting code out of a big bad client-project codebase, and creating more atomic packages (even if not open-source) upon whose shoulders a client-project can stand, is a worthwhile endeavour.
]]>
Generating a Postgres DB dump of a filtered relational set2015-06-22T00:00:00Z2015-06-22T00:00:00ZJazahttps://greenash.net.au/thoughts/2015/06/generating-a-postgres-db-dump-of-a-filtered-relational-set/PostgreSQL is my favourite RDBMS, and it's the fave of many others too. And rightly so: it's a good database! Nevertheless, nobody's perfect.
When it comes to exporting Postgres data (as SQL INSERT statements, at least), the tool of choice is the standard pg_dump utility. Good ol' pg_dump is rock solid but, unfortunately, it doesn't allow for any row-level filtering. Turns out that, for a recent project of mine, a filtered SQL dump is exactly what the client ordered.
On account of this shortcoming, I spent some time whipping up a lil' Python script to take care of this functionality. I've converted the original code (written for a client-specific data set) to a more generic example script, which I've put up on GitHub under the name "PG Dump Filtered". If you're just after the code, then feel free to head over to the repo without further ado. If you'd like to stick around for the tour, then read on.
Worlds apart
For the example script, I've set up a simple schema of four entities: worlds, countries, cities, and people. This schema happens to be purely hierarchical (i.e. each world has zero or more countries, each country has zero or more cities, and each city has zero or more people), for the sake of simplicity; but the script could be adapted to any valid set of foreign-key based relationships.
CREATE TABLE world (
name character varying(255) NOT NULL,
created_at timestamp without time zone,
updated_at timestamp without time zone,
active boolean NOT NULL,
uuid bytea,
id integer NOT NULL
);
ALTER TABLE ONLY world
ADD CONSTRAINT world_pkey PRIMARY KEY (id);
CREATE TABLE country (
name character varying(255) NOT NULL,
created_at timestamp without time zone,
updated_at timestamp without time zone,
active boolean NOT NULL,
uuid bytea,
id integer NOT NULL,
world_id integer,
bigness numeric(10,2)
);
ALTER TABLE ONLY country
ADD CONSTRAINT country_pkey PRIMARY KEY (id);
ALTER TABLE ONLY country
ADD CONSTRAINT country_world_id_fkey FOREIGN KEY (world_id)
REFERENCES world(id);
CREATE TABLE city (
name character varying(255) NOT NULL,
created_at timestamp without time zone,
updated_at timestamp without time zone,
active boolean NOT NULL,
uuid bytea,
id integer NOT NULL,
country_id integer,
weight integer,
is_big boolean DEFAULT false NOT NULL,
pseudonym character varying(255) DEFAULT ''::character varying
NOT NULL,
description text DEFAULT ''::text NOT NULL
);
ALTER TABLE ONLY city
ADD CONSTRAINT city_pkey PRIMARY KEY (id);
ALTER TABLE ONLY city
ADD CONSTRAINT city_country_id_fkey FOREIGN KEY (country_id)
REFERENCES country(id);
CREATE TABLE person (
name character varying(255) NOT NULL,
created_at timestamp without time zone,
updated_at timestamp without time zone,
active boolean NOT NULL,
uuid bytea,
id integer NOT NULL,
city_id integer,
person_type character varying(255) NOT NULL
);
ALTER TABLE ONLY person
ADD CONSTRAINT person_pkey PRIMARY KEY (id);
ALTER TABLE ONLY person
ADD CONSTRAINT person_city_id_fkey FOREIGN KEY (city_id)
REFERENCES city(id);
Using this schema, data belonging to two different worlds can co-exist in the same database. For example, we can have data for the world "Krypton" co-exist with data for the world "Romulus":
INSERT INTO world (name, created_at, updated_at, active, uuid, id)
VALUES ('Krypton', '2015-06-01 09:00:00.000000',
'2015-06-06 09:00:00.000000', true,
'\x478a43577ebe4b07ba8631ca228ee42a', 1);
INSERT INTO world (name, created_at, updated_at, active, uuid, id)
VALUES ('Romulus', '2015-06-01 10:00:00.000000',
'2015-06-05 13:00:00.000000', true,
'\x82e2c0ac3ba84a34a1ad3bbbb2063547', 2);
INSERT INTO country (name, created_at, updated_at, active, uuid, id,
world_id, bigness)
VALUES ('Crystalland', '2015-06-02 09:00:00.000000',
'2015-06-08 09:00:00.000000', true,
'\xcd0338cf2e3b40c3a3751b556a237152', 1, 1, 3.86);
INSERT INTO country (name, created_at, updated_at, active, uuid, id,
world_id, bigness)
VALUES ('Greenbloodland', '2015-06-03 11:00:00.000000',
'2015-06-07 13:00:00.000000', true,
'\x17591321d1634bcf986d0966a539c970', 2, 2, NULL);
INSERT INTO city (name, created_at, updated_at, active, uuid, id,
country_id, weight, is_big, pseudonym, description)
VALUES ('Kryptonopolis', '2015-06-05 09:00:00.000000',
'2015-06-11 09:00:00.000000', true,
'\x13659f9301d24ea4ae9c534d70285edc', 1, 1, 100, true,
'Pointyville',
'Nice place, once you get used to the pointiness.');
INSERT INTO city (name, created_at, updated_at, active, uuid, id,
country_id, weight, is_big, pseudonym, description)
VALUES ('Rom City', '2015-06-04 09:00:00.000000',
'2015-06-13 09:00:00.000000', true,
'\xc45a9fb0a92a43df91791b11d65f5096', 2, 2, 200, false,
'',
'Gakkkhhhh!');
INSERT INTO person (name, created_at, updated_at, active, uuid,
city_id, person_type)
VALUES ('Superman', '2015-06-14 09:00:00.000000',
'2015-06-15 22:00:00.000000', true,
'\xbadd1ca153994deca0f78a5158215cf6', 1,
'Awesome Heroic Champ');
INSERT INTO person (name, created_at, updated_at, active, uuid,
city_id, person_type)
VALUES ('General Zod', '2015-06-14 10:00:00.000000',
'2015-06-15 23:00:00.000000', true,
'\x796031428b0a46c2a9391eb5dc45008a', 1,
'Bad Bloke');
INSERT INTO person (name, created_at, updated_at, active, uuid,
city_id, person_type)
VALUES ('Mister Funnyears', '2015-06-14 11:00:00.000000',
'2015-06-15 22:30:00.000000', false,
'\x22380f6dc82d47f488a58153215864cb', 2,
'Mediocre Dude');
INSERT INTO person (name, created_at, updated_at, active, uuid,
city_id, person_type)
VALUES ('Captain Greeny', '2015-06-15 05:00:00.000000',
'2015-06-16 08:30:00.000000', true,
'\x485e31758528425dbabc598caaf86fa4', 2,
'Weirdo');
In this case, our two key stakeholders – the Kryptonians and the Romulans – have been good enough to agree to their respective data records being stored in the same physical database. After all, they're both storing the same type of data, and they accept the benefits of a shared schema in terms of cost-effectiveness, maintainability, and scalability.
However, these two stakeholders aren't exactly the best of friends. In fact, they're not even on speaking terms (have you even seen them both feature in the same franchise, let alone the same movie?). Plus, for legal reasons (and in the interests of intergalactic peace), there can be no possibility of Kryptonian records falling into Romulan hands, or vice versa. So, it really is critical that, as far as these two groups are concerned, the data appears to be completely partitioned.
(It's also lucky that we're using Postgres and Python, which all parties appear to be cool with – the Klingons are mad about Node.js and MongoDB these days, so the Romulans would never have come on board if we'd gone down that path…).
Fortunately, thanks to the wondrous script that's now been written, these unlikely DB room-mates can have their dilithium and eat it, too. The Romulans, for example, can simply specify their World ID of 2:
And they'll get a DB dump of what is (as far as they're concerned) … well, the whole world! (Note: please do not change your dietary habits per above innuendo, dilithium can harm your unborn baby).
And all thanks to a lil' bit of Python / SQL trickery, to filter things according to their world:
# ...
# Thanks to:
# http://bytes.com/topic/python/answers/438133-find-out-schema-psycopg
t_cur.execute((
"SELECT column_name "
"FROM information_schema.columns "
"WHERE table_name = '%s' "
"ORDER BY ordinal_position") % table)
t_fields_str = ', '.join([x[0] for x in t_cur])
d_cur = conn.cursor()
# Start constructing the query to grab the data for dumping.
query = (
"SELECT x.* "
"FROM %s x ") % table
# The rest of the query depends on which table we're at.
if table == 'world':
query += "WHERE x.id = %(world_id)s "
elif table == 'country':
query += "WHERE x.world_id = %(world_id)s "
elif table == 'city':
query += (
"INNER JOIN country c "
"ON x.country_id = c.id ")
query += "WHERE c.world_id = %(world_id)s "
elif table == 'person':
query += (
"INNER JOIN city ci "
"ON x.city_id = ci.id "
"INNER JOIN country c "
"ON ci.country_id = c.id ")
query += "WHERE c.world_id = %(world_id)s "
# For all tables, filter by the top-level ID.
d_cur.execute(query, {'world_id': world_id})
With a bit more trickery thrown in for good measure, to more-or-less emulate pg_dump's export of values for different data types:
# ...
# Start constructing the INSERT statement to dump.
d_str = "INSERT INTO %s (%s) VALUES (" % (table, t_fields_str)
d_vals = []
for i, d_field in enumerate(d_row):
d_type = type(d_field).__name__
# Rest of the INSERT statement depends on the type of
# each field.
if d_type == 'datetime':
d_vals.append("'%s'" % d_field.isoformat().replace('T', ' '))
elif d_type == 'bool':
d_vals.append('%s' % (d_field and 'true' or 'false'))
elif d_type == 'buffer':
d_vals.append(r"'\x" + ("%s'" % hexlify(d_field)))
elif d_type == 'int':
d_vals.append('%d' % d_field)
elif d_type == 'Decimal':
d_vals.append('%f' % d_field)
elif d_type in ('str', 'unicode'):
d_vals.append("'%s'" % d_field.replace("'", "''"))
elif d_type == 'NoneType':
d_vals.append('NULL')
d_str += ', '.join(d_vals)
d_str += ');'
And that's the easy part done! Now, on to working out how to efficiently do Postgres master-slave replication over a distance of several thousand light years, without disrupting the space-time continuum.
(livelong AND prosper);
Hope my little example script comes in handy, for anyone else needing a version of pg_dump that can do arbitrary filtering on inter-related tables. As I said in the README, with only a small amount of tweaking, this script should be able to produce a dump of virtually any relational data set, filtered by virtually any criteria that you might fancy.
Also, this script is for Postgres: the pg_dump utility lacks any query-level filtering functionality, so using it in this way is simply not an option. The script could also be quite easily adapted to other DBMSes (e.g. MySQL, SQL Server, Oracle), although most of Postgres' competitors have a dump utility with at least some filtering capability.
]]>
Storing Flask uploaded images and files on Amazon S32015-04-20T00:00:00Z2015-04-20T00:00:00ZJazahttps://greenash.net.au/thoughts/2015/04/storing-flask-uploaded-images-and-files-on-amazon-s3/Flask is still a relative newcomer in the world of Python frameworks (it recently celebrated its fifth birthday); and because of this, it's still sometimes trailing behind its rivals in terms of plugins to scratch a given itch. I recently discovered that this was the case, with storing and retrieving user-uploaded files on Amazon S3.
For static files (i.e. an app's seldom-changing CSS, JS, and images), Flask-Assets and Flask-S3 work together like a charm. For more dynamic files, there exist numerous snippets of solutions, but I couldn't find anything to fill in all the gaps and tie it together nicely.
Due to a pressing itch in one of my projects, I decided to rectify this situation somewhat. Over the past few weeks, I've whipped up a bunch of Python / Flask tidbits, to handle the features that I needed:
I've also published an example app, that demonstrates how all these tools can be used together. Feel free to dive straight into the example code on GitHub; or read on for a step-by-step guide of how this Flask S3 tool suite works.
Using s3-saver
The key feature across most of this tool suite, is being able to use the same code for working with local and with S3-based files. Just change a single config option, or a single function argument, to switch from one to the other. This is critical to the way I need to work with files in my Flask projects: on my development environment, everything should be on the local filesystem; but on other environments (especially production), everything should be on S3. Others may have the same business requirements (in which case you're in luck). This is most evident with s3-saver.
Here's a sample of the typical code you might use, when working with s3-saver:
from io import BytesIO
from os import path
from flask import current_app as app
from flask import Blueprint
from flask import flash
from flask import redirect
from flask import render_template
from flask import url_for
from s3_saver import S3Saver
from project import db
from library.prefix_file_utcnow import prefix_file_utcnow
from foo.forms import ThingySaveForm
from foo.models import Thingy
mod = Blueprint('foo', __name__)
@mod.route('/', methods=['GET', 'POST'])
def home():
"""Displays the Flask S3 Save Example home page."""
model = Thingy.query.first() or Thingy()
form = ThingySaveForm(obj=model)
if form.validate_on_submit():
image_orig = model.image
image_storage_type_orig = model.image_storage_type
image_bucket_name_orig = model.image_storage_bucket_name
# Initialise s3-saver.
image_saver = S3Saver(
storage_type=app.config['USE_S3'] and 's3' or None,
bucket_name=app.config['S3_BUCKET_NAME'],
access_key_id=app.config['AWS_ACCESS_KEY_ID'],
access_key_secret=app.config['AWS_SECRET_ACCESS_KEY'],
field_name='image',
storage_type_field='image_storage_type',
bucket_name_field='image_storage_bucket_name',
base_path=app.config['UPLOADS_FOLDER'],
static_root_parent=path.abspath(
path.join(app.config['PROJECT_ROOT'], '..')))
form.populate_obj(model)
if form.image.data:
filename = prefix_file_utcnow(model, form.image.data)
filepath = path.abspath(
path.join(
path.join(
app.config['UPLOADS_FOLDER'],
app.config['THINGY_IMAGE_RELATIVE_PATH']),
filename))
# Best to pass in a BytesIO to S3Saver, containing the
# contents of the file to save. A file from any source
# (e.g. in a Flask form submission, a
# werkzeug.datastructures.FileStorage object; or if
# reading in a local file in a shell script, perhaps a
# Python file object) can be easily converted to BytesIO.
# This way, S3Saver isn't coupled to a Werkzeug POST
# request or to anything else. It just wants the file.
temp_file = BytesIO()
form.image.data.save(temp_file)
# Save the file. Depending on how S3Saver was initialised,
# could get saved to local filesystem or to S3.
image_saver.save(
temp_file,
app.config['THINGY_IMAGE_RELATIVE_PATH'] + filename,
model)
# If updating an existing image,
# delete old original and thumbnails.
if image_orig:
if image_orig != model.image:
filepath = path.join(
app.config['UPLOADS_FOLDER'],
image_orig)
image_saver.delete(filepath,
storage_type=image_storage_type_orig,
bucket_name=image_bucket_name_orig)
glob_filepath_split = path.splitext(path.join(
app.config['MEDIA_THUMBNAIL_FOLDER'],
image_orig))
glob_filepath = glob_filepath_split[0]
glob_matches = image_saver.find_by_path(
glob_filepath,
storage_type=image_storage_type_orig,
bucket_name=image_bucket_name_orig)
for filepath in glob_matches:
image_saver.delete(
filepath,
storage_type=image_storage_type_orig,
bucket_name=image_bucket_name_orig)
else:
model.image = image_orig
# Handle image deletion
if form.image_delete.data and image_orig:
filepath = path.join(
app.config['UPLOADS_FOLDER'], image_orig)
# Delete the file. In this case, we have to pass in
# arguments specifying whether to delete locally or on
# S3, as this should depend on where the file was
# originally saved, rather than on how S3Saver was
# initialised.
image_saver.delete(filepath,
storage_type=image_storage_type_orig,
bucket_name=image_bucket_name_orig)
# Also delete thumbnails
glob_filepath_split = path.splitext(path.join(
app.config['MEDIA_THUMBNAIL_FOLDER'],
image_orig))
glob_filepath = glob_filepath_split[0]
# S3Saver can search for files too. When searching locally,
# it uses glob(); when searching on S3, it uses key
# prefixes.
glob_matches = image_saver.find_by_path(
glob_filepath,
storage_type=image_storage_type_orig,
bucket_name=image_bucket_name_orig)
for filepath in glob_matches:
image_saver.delete(filepath,
storage_type=image_storage_type_orig,
bucket_name=image_bucket_name_orig)
model.image = ''
model.image_storage_type = ''
model.image_storage_bucket_name = ''
if form.image.data or form.image_delete.data:
db.session.add(model)
db.session.commit()
flash('Thingy %s' % (
form.image_delete.data and 'deleted' or 'saved'),
'success')
else:
flash(
'Please upload a new thingy or delete the ' +
'existing thingy',
'warning')
return redirect(url_for('foo.home'))
return render_template('home.html',
form=form,
model=model)
As is hopefully evident in the sample code above, the idea with s3-saver is that as little S3-specific code as possible is needed, when performing operations on a file. Just find, save, and delete files as usual, per the user's input, without worrying about the details of that file's storage back-end.
s3-saver uses the excellent Python boto library, as well as Python's built-in file handling functions, so that you don't have to. As you can see in the sample code, you don't need to directly import either boto, or the file-handling functions such as glob or os.remove. All you need to import is io.BytesIO, and os.path, in order to be able to pass s3-saver the parameters that it needs.
Using url-for-s3
This is a simple utility function, that generates a URL to a given S3-based file. It's designed to match flask.url_for as closely as possible, so that one can be swapped out for the other with minimal fuss.
from __future__ import print_function
from flask import url_for
from url_for_s3 import url_for_s3
from project import db
class Thingy(db.Model):
"""Sample model for flask-s3-save-example."""
id = db.Column(db.Integer(), primary_key=True)
image = db.Column(db.String(255), default='')
image_storage_type = db.Column(db.String(255), default='')
image_storage_bucket_name = db.Column(db.String(255), default='')
def __repr__(self):
return 'A thingy'
@property
def image_url(self):
from flask import current_app as app
return (self.image
and '%s%s' % (
app.config['UPLOADS_RELATIVE_PATH'],
self.image)
or None)
@property
def image_url_storageaware(self):
if not self.image:
return None
if not (
self.image_storage_type
and self.image_storage_bucket_name):
return url_for(
'static',
filename=self.image_url,
_external=True)
if self.image_storage_type != 's3':
raise ValueError((
'Storage type "%s" is invalid, the only supported ' +
'storage type (apart from default local storage) ' +
'is s3.') % self.image_storage_type)
return url_for_s3(
'static',
bucket_name=self.image_storage_bucket_name,
filename=self.image_url)
The above sample code illustrates how I typically use url_for_s3. For a given instance of a model, if that model's file is stored locally, then generate its URL using flask.url_for; otherwise, switch to url_for_s3. Only one extra parameter is needed: the S3 bucket name.
I can then easily show the "storage-aware URL" for this model in my front-end templates.
Using flask-thumbnails-s3
In my use case, the majority of the files being uploaded are images, and most of those images need to be resized when displayed in the front-end. Also, ideally, the dimensions for resizing shouldn't have to be pre-specified (i.e. thumbnails shouldn't only be able to get generated when the original image is first uploaded); new thumbnails of any size should get generated on-demand per the templates' needs. The front-end may change according to the design / branding whims of clients and other stakeholders, further on down the road.
flask-thumbnails handles just this workflow for local files; so, I decided to fork it and to create flask-thumbnails-s3, which works the same as flask-thumbnails when set to use local files, but which can also store and retrieve thumbnails on a S3 bucket.
{% if image %}
<div>
<img src="{{ image|thumbnail(size,
crop=crop,
quality=quality,
storage_type=storage_type,
bucket_name=bucket_name) }}"
alt="{{ alt }}" title="{{ title }}" />
</div>
{% endif %}
Like its parent project, flask-thumbnails-s3 is most commonly invoked by way of a template filter. If a thumbnail of the given original file exists, with the specified size and attributes, then it's returned straightaway; if not, then the original file is retrieved, a thumbnail is generated, and the thumbnail is saved to the specified storage back-end.
At the moment, flask-thumbnails-s3 blocks the running thread while it generates a thumbnail and saves it to S3. Ideally, this task would get sent to a queue, and a "dummy" thumbnail would be returned in the immediate request, until the "real" thumbnail is ready in a later request. The Sorlery plugin for Django uses the queued approach. It would be cool if flask-thumbnails-s3 (optionally) did the same. Anyway, it works without this fanciness for now; extra contributions welcome!
(By the way, in my testing, this is much less of a problem if your Flask app is deployed on an Amazon EC2 box, particularly if it's in the same region as your S3 bucket; unsurprisingly, there appears to be much less latency between an EC2 server and S3, than there is between a non-Amazon server and S3).
Using flask-admin-s3-upload
The purpose of flask-admin-s3-upload is basically to provide the same 'save' functionality as s3-saver, but automatically within Flask-Admin. It does this by providing alternatives to the flask_admin.form.upload.FileUploadField and flask_admin.form.upload.ImageUploadField classes, namely flask_admin_s3_upload.S3FileUploadField and flask_admin_s3_upload.S3ImageUploadField.
(Anecdote: I actually wrote flask-admin-s3-upload before any of the other tools in this suite, because I began by working with a part of my project that has no custom front-end, only a Flask-Admin based management console).
Using the utilities provided by flask-admin-s3-upload is fairly simple:
from os import path
from flask_admin_s3_upload import S3ImageUploadField
from project import admin, app, db
from foo.models import Thingy
from library.admin_utils import ProtectedModelView
from library.prefix_file_utcnow import prefix_file_utcnow
class ThingyView(ProtectedModelView):
column_list = ('image',)
form_excluded_columns = ('image_storage_type',
'image_storage_bucket_name')
form_overrides = dict(
image=S3ImageUploadField)
form_args = dict(
image=dict(
base_path=app.config['UPLOADS_FOLDER'],
relative_path=app.config['THINGY_IMAGE_RELATIVE_PATH'],
url_relative_path=app.config['UPLOADS_RELATIVE_PATH'],
namegen=prefix_file_utcnow,
storage_type_field='image_storage_type',
bucket_name_field='image_storage_bucket_name',
))
def scaffold_form(self):
form_class = super(ThingyView, self).scaffold_form()
static_root_parent = path.abspath(
path.join(app.config['PROJECT_ROOT'], '..'))
if app.config['USE_S3']:
form_class.image.kwargs['storage_type'] = 's3'
form_class.image.kwargs['bucket_name'] = \
app.config['S3_BUCKET_NAME']
form_class.image.kwargs['access_key_id'] = \
app.config['AWS_ACCESS_KEY_ID']
form_class.image.kwargs['access_key_secret'] = \
app.config['AWS_SECRET_ACCESS_KEY']
form_class.image.kwargs['static_root_parent'] = \
static_root_parent
return form_class
admin.add_view(ThingyView(Thingy, db.session, name='Thingies'))
Note that flask-admin-s3-upload only handles saving, not deleting (the same as the regular Flask-Admin file / image upload fields only handle saving). If you wanted to handle deleting files in the admin as well, you could (for example) use s3-saver, and hook it in to one of the Flask-Admin event callbacks.
In summary
I'd also like to mention: one thing that others have implemented in Flask, is direct JavaScript-based upload to S3. Implementing this sort of functionality in my tool suite would be a great next step; however, it would have to play nice with everything else I've built (particularly with flask-thumbnails-s3), and it would have to work for local- and for S3-based files, the same as all the other tools do. I don't have time to address those hurdles right now – another area where contributions are welcome.
I hope that this article serves as a comprehensive guide, of how to use the Flask S3 tools that I've recently built and contributed to the community. Any questions or concerns, please drop me a line.
]]>
Five long-distance and long-way-off Australian infrastructure links2015-01-03T00:00:00Z2015-01-03T00:00:00ZJazahttps://greenash.net.au/thoughts/2015/01/five-long-distance-and-long-way-off-australian-infrastructure-links/
Australia. It's a big place. With only a handful of heavily populated areas. And a whole lot of nothing in between.
No, really. Nothing. Image source:Australian Outback Buffalo Safaris.
Over the past century or so, much has been achieved in combating the famous Tyranny of Distance that naturally afflicts this land. High-quality road, rail, and air links now traverse the length and breadth of Oz, making journeys between most of her far-flung corners relatively easy.
Nevertheless, there remain a few key missing pieces, in the grand puzzle of a modern, well-connected Australian infrastructure system. This article presents five such missing pieces, that I personally would like to see built in my lifetime. Some of these are already in their early stages of development, while others are pure fantasies that may not even be possible with today's technology and engineering. All of them, however, would provide a new long-distance connection between regions of Australia, where there is presently only an inferior connection in place, or none at all.
Tunnel to Tasmania
Let me begin with the most nut-brained idea of all: a tunnel from Victoria to Tasmania!
As the sole major region of Australia that's not on the continental landmass, currently the only options for reaching Tasmania are by sea or by air. The idea of a tunnel (or bridge) to Tasmania is not new, it has been sporadically postulated for over a century (although never all that seriously). There's a long and colourful discussion of routes, cost estimates, and geographical hurdles at the Bass Strait Tunnel thread on Railpage. There's even a Facebook page promoting a Tassie Tunnel.
Although it would be a highly beneficial piece of infrastructure, that would in the long-term (among other things) provide a welcome boost to Tasmania's (and Australia's) economy, sadly the Tassie Tunnel is probably never going to happen. The world's longest undersea tunnel to date (under the Tsugaru Strait in Japan) spans only 54km. A tunnel under the Bass Strait, directly from Victoria to Tasmania, would be at least 200km long; although if it went via King Island (to the northwest of Tas), it could be done as two tunnels, each one just under 100km. Both the length and the depth of such a tunnel make it beyond the limits of contemporary engineering.
Aside from the engineering hurdle – and of course the monumental cost – it also turns out that the Bass Strait is Australia's main seismic hotspot (just our luck, what with the rest of Australia being seismically dead as a doornail). The area hasn't seen any significant undersea volcanic activity in the past few centuries, but experts warn that it could start letting off steam in the near future. This makes it hardly an ideal area for building a colossal tunnel.
Railway from Mt Isa to Tennant Creek
Great strides have been made in connecting almost all the major population centres of Australia by rail. The first significant long-distance rail link in Oz was the line from Sydney to Melbourne, which was completed in 1883 (although a change-of-gauge was required until 1962). The Indian Pacific (Sydney to Perth), a spectacular trans-continental achievement and the nation's longest train line – not to mention one of the great railways of the world – is the real backbone on the map, and has been operational since 1970. The newest and most long-awaited addition, The Ghan (Adelaide to Darwin), opened for business in 2004.
The Ghan roaring through the outback. Image source:Fly With Me.
Today's nation-wide rail network (with regular passenger service) is, therefore, at an impressive all-time high. Every state and territory capital is connected (except for Hobart – a Tassie Tunnel would fix that!), and numerous regional centres are in the mix too. Despite the fact that many of the lines / trains are old and clunky, they continue (often stubbornly) to plod along.
If you look at the map, however, you might notice one particularly glaring gap in the network, particularly now that The Ghan has been established. And that is between Mt Isa in Queensland (the terminus of The Inlander service from Townsville), and Tennant Creek in the Northern Territory (which The Ghan passes through). At the moment, travelling continuously by rail from Townsville to Darwin would involve a colossal horse-shoe journey via Sydney and Adelaide, which only an utter nutter would consider embarking upon. Whereas with the addition of this relatively small (1,000km or so) extra line, the journey would be much shorter, and perfectly feasible. Although still long; there's no silver bullet through the outback.
A railway from Mt Isa to Tennant Creek – even though it would traverse some of the most remote and desolate land in Australia – is not a pipe dream. It's been suggested several times over the past few years. As with the development of the Townsville to Mt Isa railway a century ago, it will need the investment of the mining industry in order to actually happen. Unfortunately, the current economic situation means that mining companies are unlikely to invest in such a project at this time; what's more, The Inlander is a seriously decrepit service (at risk of being decommissioned) on an ageing line, making it somewhat unsuitable for joining up with a more modern line to the west.
Nonetheless, I have high hopes that we will see this railway connection built in the not-too-distant future, when the stars are next aligned.
Highway to Cape York
Australia's northernmost region, the Cape York Peninsula, is also one of the country's last truly wild frontiers. There is now a sealed all-weather highway all the way around the Australian mainland, and there's good or average road access to the key towns in almost all regional areas. Cape York is the only place left in Oz that lacks such roads, and that's also home to a non-trivial population (albeit a small 20,000-ish people, the majority Aborigines, in an area half the size of Victoria). Other areas in Oz with no road access whatsoever, such as south-west Tasmania, and most of the east of Western Australia, are lacking even a trivial population.
The biggest challenge to reliable transport in the Cape is the wet season: between December and April, there's so much rainfall that all the rivers become flooded, making roads everywhere impassable. Aside from that, the Cape also presents other obstacles, such as being seriously infested with crocodiles.
There are two main roads that provide access to the Cape: the Peninsula Developmental Road (PDR) from Lakeland to Weipa, and the Northern Peninsula Road (NPR), from the junction north of Coen on to Bamaga. The PDR is slowly improving, but the majority of it is still unsealed and is closed for much of the wet season. The NPR is worse: little (if any) of the route is sealed, and a ferry is required to cross the Jardine River (approaching the road's northern terminus), even at the height of the dry season.
A proper Cape York Highway, all the way from Lakeland to The Tip, is in my opinion bound to get built eventually. I've seen mention of a prediction that we should expect it done by 2050; if that estimate can be met, I'd call it a great achievement. To bring the Cape's main roads up to highway standard, they'd need to be sealed all the way, and there would need to be reasonably high bridges over all the rivers. Considering the very extreme weather patterns up that way, the route will never be completely flood-proof (much as the fully-sealed Barkly Highway through the Gulf of Carpentaria, south of the Cape, isn't flood-proof either); but if a journey all the way to The Tip were possible in a 2WD vehicle for most of the year, that would be a grand accomplishment.
High-speed rail on the Eastern seaboard
Of all the proposals being put forward here, this is by far the most well-known and the most oft talked about. Many Australians are in agreement with me, on the fact that a high-speed rail link along the east coast is sorely needed. Sydney to Canberra is generally touted as an appropriate first step, Sydney to Melbourne is acknowledged as the key component, and Sydney to Brisbane is seen as a very important extension.
Sadly, despite all the good news – the glowing recommendations of the government study; the enthusiasm of countless Australians; and some valiant attempts to stave off inertia – Australia has been waiting for high-speed rail an awfully long time, and it's probably going to have to keep on waiting. Because, with the cost of a complete Brisbane-Sydney-Canberra-Melbourne network estimated at around AUD$100 billion, neither the government nor anyone else is in a hurry to cough up the requisite cash.
This is the only proposal in this article, about an infrastructure link to complement another one (of the same mode) that already exists. I've tried to focus on links that are needed where currently there is nothing at all. However, I feel that this propoal belongs here, because despite its proud and important history, the ageing eastern seaboard rail network is rapidly becoming an embarrassment to the nation.
This Greens flyer says it better than I can. Image source:Adam Bandt MP.
The corner of Australia where 90% of the population live, deserves (and needs) a train service for the future, not one that belongs in a museum. The east coast interstate trains still run on diesel, as the lines aren't even electrified outside of the greater metropolitan areas. The network's few (remaining) passenger services share the line with numerous freight trains. There are still a plethora of old-fashioned level crossings. And the majority of the route is still single-track, causing regular delays and seriously limiting the line's capacity. And all this on two of the world's busiest air routes, with the road routes also struggling under the load.
Come on, Aussie – let's join the 21st century!
Self-sustaining desert towns
My final idea, some may consider a little kookoo, but I truly believe that it would be of benefit to our great sunburnt country. As should be clear by now, immense swathes of Australia are empty desert. There are many dusty roads and 4WD tracks traversing the country's arid centre, and it's not uncommon for some of the towns along these routes to be 1,000km's or more distant from their nearest neighbour. This results in communities (many of them indigenous) that are dangerously isolated from each other and from critical services; it makes for treacherous vehicle journeys, where travellers must bring extra necessities such as petrol and water, just to last the distance; and it means that Australia as a whole suffers from more physical disconnects, robbing contiguity from our otherwise unified land.
Many outback communities and stations are a long way from their nearest neighbours. Image source:news.com.au.
Good transport networks (road and rail) across the country are one thing, but they're not enough. In my opinion, what we need to do is to string out more desert towns along our outback routes, in order to reduce the distances of no human contact, and of no basic services.
But how to support such towns, when most outback communities are struggling to survive as it is? And how to attract more people to these towns, when nobody wants to live out in the bush? In my opinion, with the help of modern technology and of alternative agricultural methods, it could be made to work.
Towns need a number of resources in order to thrive. First and foremost, they need water. Securing sufficient water in the outback is a challenge, but with comprehensive conservation rules, and modern water reuse systems, having at least enough water for a small population's residential use becomes feasible, even in the driest areas of Australia. They also need electricity, in order to use modern tools and appliances. Fortunately, making outback towns energy self-sufficient is easier than it's ever been before, thanks to recent breakthroughs in solar technology. A number of these new technologies have even been pilot-tested in the outback.
In order to be self-sustaining, towns also need to be able to cultivate their own food in the surrounding area. This is a challenge in most outback areas, where water is scarce and soil conditions are poor. Many remote communities rely on food and other basic necessities being trucked in. However, a number of recent initiatives related to desert greening may help to solve this thorny (as an outback spinifex) problem.
Most promising is the global movement (largely founded and based in Australia) known as permaculture. A permaculture-based approach to desert greening has enjoyed a vivid and well-publicised success on several occasions; most notably, Geoff Lawton's project in the Dead Sea Valley of Jordan about ten years ago. There has been some debate regarding the potential ability of permaculture projects to green the desert in Australia. Personally, I think that the pilot projects to date have been very promising, and that similar projects in Australia would be, at the least, a most worthwhile endeavour. There are also various other projects in Australia that aim to create or nurture green corridors in arid areas.
As for where to build a new corridor of desert towns, my preference would be to target an area as remote and as spread-out as possible. For example, along the Great Central Road (which is part of the "Outback Highway"). This might be an overly-ambitious route, but it would certainly be one of the most suitable.
And regarding the "tough nut" of how to attract people to come and live in new outback towns – when it's hard enough already just to maintain the precarious existing population levels – I have no easy answer. It has been suggested that, with the growing number of telecommuters in modern industries (such as IT), and with other factors such as the high real estate prices in major cities, people will become increasingly likely to move to the bush, assuming there's adequately good-quality internet access in the respective towns. Personally, as an IT professional who has worked remotely on many occasions, I don't find this to be a convincing enough argument.
I don't think that there's any silver bullet to incentivising a move to new desert towns. "Candy dangling" approaches such as giving away free houses in the towns, equipping buildings with modern sustainable technologies, or even giving cash gifts to early pioneers – these may be effective in getting a critical mass of people out there, but it's unlikely to be sufficient to keep them there in the long-term. Really, such towns would have to develop a local economy and a healthy local business ecosystem in order to maintain their residents; and that would be a struggle for newly-built towns, the same as it's been a struggle for existing outback towns since day one.
In summary
Love 'em or hate 'em, admire 'em or attack 'em, there's my list of five infrastructure projects that I think would be of benefit to Australia. Some are more likely to happen than others; unfortunately, it appears that none of them is going to be fully realised any time soon. Feedback welcome!
]]>
Conditionally adding HTTP response headers in Flask and Apache2014-12-29T00:00:00Z2014-12-29T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/12/conditionally-adding-http-response-headers-in-flask-and-apache/
For a Flask-based project that I'm currently working on, I just added some front-end functionality that depends on Font Awesome. Getting Font Awesome to load properly (in well-behaved modern browsers) shouldn't be much of a chore. However, my app spans multiple subdomains (achieved with the help of Flask's Blueprints per-subdomain feature), and my static assets (CSS, JS, etc) are only served from one of those subdomains. And as it turns out (and unlike cross-domain CSS / JS / image requests), cross-domain font requests are forbidden unless the font files are served with an appropriate Access-Control-Allow-Origin HTTP response header. For example, this is the error message that's shown in Google Chrome for such a request:
Font from origin 'http://foo.local' has been blocked from loading by Cross-Origin Resource Sharing policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://bar.foo.local' is therefore not allowed access.
As a result of this, I had to quickly learn how to conditionally add custom HTTP response headers based on the URL being requested, both for Flask (when running locally with Flask's built-in development server), and for Apache (when running in staging and production). In a typical production Flask setup, it's impossible to do anything at the Python level when serving static files, because these are served directly by the web server (e.g. Apache, Nginx), without ever hitting WSGI. Conversely, in a typical development setup, there is no web server running separately to the WSGI app, and so playing around with static files must be done at the Python level.
The code
For a regular Flask request that's handled by one of the app's custom routes, adding another header to the HTTP response would be a simple matter of modifying the flask.Response object before returning it. However, static files (in a development setup) are served by Flask's built-in app.send_static_file() function, not by any route that you have control over. So, instead, it's necessary to intercept the response object via Flask's API.
Fortunately, this interception is easily accomplished, courtesy of Flask's app.after_request() function, which can either be passed a callback function, or used as a decorator. Here's what did the trick for me:
import re
from flask import Flask
from flask import request
app = Flask(__name__)
def add_headers_to_fontawesome_static_files(response):
"""
Fix for font-awesome files: after Flask static send_file() does its
thing, but before the response is sent, add an
Access-Control-Allow-Origin: *
HTTP header to the response (otherwise browsers complain).
"""
if (request.path and
re.search(r'\.(ttf|woff|svg|eot)$', request.path)):
response.headers.add('Access-Control-Allow-Origin', '*')
return response
if app.debug:
app.after_request(add_headers_to_fontawesome_static_files)
For a production setup, the above Python code achieves nothing, and it's therefore necessary to add something like this to the config file for the app's VirtualHost:
<VirtualHost *:80>
# ...
Alias /static /path/to/myapp/static
<Location /static>
Order deny,allow
Allow from all
Satisfy Any
SetEnvIf Request_URI "\.(ttf|woff|svg|eot)$" is_font_file
Header set Access-Control-Allow-Origin "*" env=is_font_file
</Location>
</VirtualHost>
Done
And there you go: an easy way to add custom HTTP headers to any response, in two different web server environments, based on a conditional request path. So far, cleanly serving cross-domain font files is all that I've neede this for. But it's a very handy little snippet, and no doubt there are plenty of other scenarios in which it could save the day.
]]>
Forgotten realms of the Oxus region2014-10-11T00:00:00Z2014-10-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/10/forgotten-realms-of-the-oxus-region/
In classical antiquity, a number of advanced civilisations flourished in the area that today comprises parts of Turkmenistan, Uzbekistan, Tajikistan, and Afghanistan. Through this area runs a river most commonly known by its Persian name, as the Amu Darya. However, in antiquity it was known by its Greek name, as the Oxus (and in the interests of avoiding anachronism, I will be referring to it as the Oxus in this article).
The Oxus region is home to archaeological relics of grand civilisations, most notably of ancient Bactria, but also of Chorasmia, Sogdiana, Margiana, and Hyrcania. However, most of these ruined sites enjoy far less fame, and are far less well-studied, than comparable relics in other parts of the world.
I recently watched an excellent documentary series called Alexander's Lost World, which investigates the history of the Oxus region in-depth, focusing particularly on the areas that Alexander the Great conquered as part of his legendary military campaign. I was blown away by the gorgeous scenery, the vibrant cultural legacy, and the once-majestic ruins that the series featured. But, more than anything, I was surprised and dismayed at the extent to which most of the ruins have been neglected by the modern world – largely due to the region's turbulent history of late.
This article has essentially the same aim as that of the documentary: to shed more light on the ancient cities and fortresses along the Oxus and nearby rivers; to get an impression of the cultures that thrived there in a bygone era; and to explore the climate change and the other forces that have dramatically affected the region between then and now.
Getting to know the rivers
First and foremost, an overview of the major rivers in question. Understanding the ebbs and flows of these arteries is critical, as they are the lifeblood of a mostly arid and unforgiving region.
The Oxus is the largest river (by water volume) in Central Asia. Due to various geographical factors, it's also changed its course more times (and more dramatically) than any other river in the region, and perhaps in the world.
The source of the Oxus is the Wakhan river, which begins at Baza'i Gonbad at the eastern end of Afghanistan's remote Wakhan Corridor, often nicknamed "The Roof of the World". This location is only 40km from the tiny and seldom-crossed Sino-Afghan border. Although the Wakhan river valley has never been properly "civilised" – neither by ancient empires nor by modern states (its population is as rugged and nomadic today as it was millenia ago) – it has been populated continuously since ancient times.
Next in line downstream is the Panj river, which begins where the Wakhan and Pamir rivers meet. For virtually its entire length, the Panj follows the Afghanistan-Tajikistan border; and it winds a zig-zag course through rugged terrain for much of its course, until it leaves behind the modern-day Badakhstan province towards its end. Like the Wakhan, the mountainous upstream part of the Panj was never truly conquered; however, the more accessible downstream part was the eastern frontier of ancient Bactria.
The Oxus proper begins where the Panj and Vakhsh rivers meet, on the Afghanistan-Tajikistan border. It continues along the Afghanistan-Uzbekistan border, and then along the Afghanistan-Turkmenistan border, until it enters Turkmenistan where the modern-day Karakum Canal begins. The river's course has been fairly stable along this part of the route throughout recorded history, although it has made many minor deviations, especially further downstream where the land becomes flatter. This part of the river was the Bactrian heartland in antiquity.
The rest of the river's route – mainly through Turkmenistan, but also hugging the Uzbek border in sections, and finally petering out in Uzbekistan – traverses the flat, arid Karakum Desert. The course and strength of the river down here has changed constantly over the centuries; for this reason, the Oxus has earned the nickname "the mad river". In ancient times, the Uzboy river branched off from the Oxus in northern Turkmenistan, and ran west across the desert until (arguably) emptying into the Caspian Sea. However, the strength of the Uzboy gradually lessened, until the river completely perished approximately 400 years ago. It appears that the Uzboy was considered part of the Oxus (and was given no name of its own) by many ancient geographers.
The Oxus proper breaks up into an extensive delta once in Uzbekistan; and for most of recorded history, it emptied into the Aral Sea. However, due to an aggressive Soviet-initiated irrigation campaign since the 1950s (the culmination of centuries of Russian planning and dreaming), the Oxus delta has rescinded significantly, and the river's waters fizzle out in the desert before reaching the sea. This is one of the major causes of the death of the Aral Sea, one of the worst environmental disasters on the planet.
Although geographically separate, the nearby Murghab river is also an important part of the cultural and archaeological story of the Oxus region (its lower reaches in modern-day Turkmenistan, at least). From its confluence with the Kushk river, the Murghab meanders gently down through semi-arid lands, before opening into a large delta that fans out optimistically into the unforgiving Karakum desert. The Murghab delta was in ancient times the heartland of Margiana, an advanced civilisation whose heyday largely predates that of Bactria, and which is home to some of the most impressive (and under-appreciated) archaeological sites in the region.
I won't be covering it in this article, as it's a whole other landscape and a whole lot more history; nevertheless, I would be remiss if I failed to mention the "sister" of the Oxus, the Syr Darya river, which was in antiquity known by its Greek name as the Jaxartes, and which is the other major artery of Central Asia. The source of the Jaxartes is (according to some) not far from that of the Oxus, high up in the Pamir mountains; from there, it runs mainly north-west through Kyrgyzstan, Uzbekistan, and then (for more than half its length) Kazakhstan, before approaching the Aral Sea from the east. Like the Oxus, the present-day Jaxartes also peters out before reaching the Aral; and since these two rivers were formerly the principal water sources of the Aral, that sea is now virtually extinct.
Hyrcania
Having finished tracing the rivers' paths from the mountains to the desert, I will now – Much like the documentary – explore the region's ancient realms the other way round, beginning in the desert lowlands.
The heartland of Hyrcania (more often absorbed into a map of ancient Parthia, than given its own separate mention) – in ancient times just as in the present-day – is Golestan province, Iran, which is a fertile and productive area on the south-west shores of the Caspian. This part of Hyrcania is actually outside of the Oxus region, and so falls off this article's radar. However, Hyrcania extended north into modern-day Turkmenistan, reaching the banks of the then-flowing Uzboy river (which was ambiguously referred to by Greek historians as the "Ochos" river).
Settlements along the lower Uzboy part of Hyrcania (which was on occasion given a name of its own, Nesaia) were few. The most notable surviving ruin there is the Igdy Kala fortress, which dates to approximately the 4th century BCE, and which (arguably) exhibits both Parthian and Chorasmian influence. Very little is known about Igdy Kala, as the site has seldom been formally studied. The question of whether the full length of the Uzboy ever existed remains unresolved, particularly regarding the section from Sarykamysh Lake to Igdy Kala.
By including Hyrcania in the Oxus region, I'm tentatively siding with those that assert that the "greater Uzboy" did exist; if it didn't (i.e. if the Uzboy finished in Sarykamysh Lake, and if the "lower Uzboy" was just a small inlet of the Caspian Sea), then the extent of cultural interchange between Hyrcania and the actual Oxus realms would have been minimal. In the documentary, narrator David Adams is quite insistent that the Oxus was connected to the Caspian in antiquity, making frequent reference to the works of Patrocles; while this was quite convenient for the documentary's hypothesis that the Oxo-Caspian was a major trade route, the truth is somewhat less black-and-white.
Chorasmia
North-east of Hyrcania, crossing the lifeless Karakum desert, lies Chorasmia, better known for most of its history as Khwarezm. Chorasmia lies squarely within the Oxus delta; although the exact location of its capitals and strongholds has shifted considerably over the centuries, due to political upheavals and due to changes in the delta's course. In antiquity (particularly in the 4th and 3rd centuries BCE), Chorasmia was a vassal state of the Achaemenid Persian empire, much like the rest of the Oxus region; the heavily Persian-influenced language and culture of Chorasmia, which can still be faintly observed in modern times, harks back to this era.
This region was strongest in medieval times, and its medieval capital at the present-day ghost city of Konye-Urgench – known in its heyday as Gurganj – was Chorasmia's most significant seat of power. Gurganj was abandoned in the 16th century CE, when the Oxus changed course and left the once-fertile city and surrounds without water.
It's unknown exactly where antiquity-era Chorsamia was centred, although part of the ruins of Kyrk Molla at Gurganj date back to this period, as do part of the ruins of Itchan Kala in present-day Khiva (which was Khwarezm's capital from the 17th to the 20th centuries CE). Probably the most impressive and best-preserved ancient ruins in the region, are those of the Ayaz Kala fortress complex, parts of which date back to the 4th century BCE. There are numerous other "Kala" (the Chorasmian word for "fortress") nearby, including Toprak Kala and Kz'il Kala.
One of the less-studied sites – but by no means a less significant site – is Dev-kesken Kala, a fortress lying due west of Konye-Urgench, on the edge of the Ustyurt Plateau, overlooking the dry channel of the former upper Uzboy river. Much like Konye-Urgench (and various other sites in the lower Oxus delta), Dev-kesken Kala was abandoned when the water stopped flowing, in around the 16th century CE. The city was formerly known as Vazir, and it was a thriving hub of medieval Khwarezm. Also like other sites, parts of the fortress date back to the 4th century BCE.
I should also note that Dev-kesken Kala was one of the most difficult archaeological sites (of all the sites I'm describing in this article) to find information online for. I even had to create the Dev-Kesken Wikipedia article, which previously didn't exist (my first time creating a brand-new page there). The site was also difficult to locate on Google Earth (should now be easier, the co-ordinates are saved on the Wikipedia page). The site is certainly under-studied and under-visited, considering its distinctive landscape and its once-proud history; however, it is remote and difficult to access, and I understand that this Uzbek-Turkmen frontier area is also rather unsafe, due to an ongoing border dispute.
Margiana
South of Chorasmia – crossing the Karakum desert once again – one will find the realm that in antiquity was known as Margiana (although that name is simply the hellenised version of the original Persian name Margu). Much like Chorasmia, Margiana is centred on a river delta in an otherwise arid zone; in this case, the Murghab delta. And like the Oxus delta, the Murghab delta has also dried up and rescinded significantly over the centuries, due to both natural and human causes. Margiana lies within what is present-day southern Turkmenistan.
Although the Oxus doesn't run through Margiana, the realm is nevertheless part of the Oxus region (more surely so than Hyrcania, through which a former branch of the Oxus arguably runs), for a number of reasons. Firstly, it's geographically quite close to the Oxus, with only about 200km of flat desert separating the two. Secondly, the Murghab and the Oxus share many geographical traits, such as their arid deltas (as mentioned above), and also their habit of frequently and erratically changing course. Lastly, and most importantly, there is evidence of significant cultural interchange between Margiana and the other Oxus realms throughout civilised history.
The political centre of Margiana – in the antiquity period and for most of the medieval period, too – was the city of Merv, which was known then as Gyaur Kala (and also briefly by its hellenised name, Antiochia Margiana). Today, Merv is one of the largest and best-preserved archaeological sites in all the Oxus region, although most of the visible ruins are medieval, and the older ruins still lie largely buried underneath. The site has been populated since at least the 5th century BCE.
Although Merv was Margiana's capital during the Persian and Greek periods, the site of most significance around here is the far older Gonur Tepe. The site of Gonur was completely unknown to modern academics until the 1970s, when the legendary Soviet archaeologist Viktor Sarianidi discovered it (Sarianidi sadly passed away less than a year ago, aged 84). Gonur lies in what is today the parched desert, but what was – in Gonur's heyday, in approximately 2,000 BCE – well within the fertile expanse of the then-greater Murghab delta.
The vast bronze age complex of Gonur Tepe. Image source:Boskawola.
Gonur was one of the featured sites in the documentary series – and justly so, because it's the key site of the so-called Bactria-Margiana Archaeological Complex. It's also a prime example of a "forgotten realm" in the region: to this day, few tourists and journalists have ever visited it (David Adams and his crew were among those that have made the arduous journey); and, apart from Sarianidi (who dedicated most of his life to studying Gonur and nearby ruins), few archaeologists have explored the site, and insufficient effort is being made by authorities and by academics to preserve the crumbling ruins. All this is a tragedy, considering that some have called for bronze-age Margiana to be added to the list of the classic "cradles of civilisation", which includes Egypt, Babylon, India, and China.
There are many other ruins in Margiana that were part of the bronze-age culture centred in Gonur. One of the other more promiment sites is Altyn Tepe, which lies about 200km south-west of Gonur, still within Turkmenistan but close to the Iranian border. Altyn Tepe, like Gonur, reached its zenith around 2,000 BCE; the site is characterised by a large Babylon-esque ziggurat. Altyn Tepe was also studied extensively by Sarianidi; and it too has been otherwise largely overlooked during modern times.
Sogdiana
Crossing the Karakum desert again (for the last time in this article) – heading north-east from Margiana – and crossing over to the northern side of the Oxus river, one may find the realm that in antiquity was known as Sogdiana (or Sogdia). Sogdiana principally occupies the area that is modern-day southern Uzbekistan and western Tajikistan.
The Sogdian heartland is the fertile valley of the Zeravshan river (old Persian name), which was once known by its Greek name, as the Polytimetus, and which has also been called the Sughd, in honour of its principal inhabitants (modern-day Tajikistan's Sughd province, through which the river runs, likewise honours them).
The Zeravshan's source is high in the mountains near the Tajik-Kyrgyz border, and for its entire length it runs west, passing through the key ancient Sogdian cities of Panjakent, Samarkand (once known as Maracanda), and Bukhara (which all remain vibrant cities to this day), before disappearing in the desert sands approaching the Uzbek-Turkmen border. The Zeravshan probably reached the Oxus and emptied into it – once upon a time – near modern-day Türkmenabat, which in antiquity was known as Amul, and in medieval times as Charjou. For most of its history, Amul lay just beyond the frontiers of Sogdiana, and it was the crossroads of all the principal realms of the Oxus region mentioned in this article.
Although Sogdiana is an integral part of the Oxus region, and although it was a dazzling civilisation in antiquity (indeed, it was arguably the most splendid of all the Oxus realms), I'm only mentioning it in this article for completeness, and I will refrain from exploring its archaeology in detail. (You may also have noted that the Zeravshan river and the Sogdian cities are missing from my custom map of the region). This is because I don't consider Sogdiana to be "forgotten", in anywhere near the sense that the other realms are "forgotten".
The key Sogdian sites – particularly Samarkand and Bukhara, which are both today UNESCO-listed – enjoy international fame; they have been studied intensively by modern academics; and they are the biggest tourist attractions in all of Central Asia. Apart from Sogdiana's prominence in Silk Road history, and its impressive and well-preserved architecture, the relative safety and stability of Uzbekistan – compared with its fellow Oxus-region neighbours Turkmenistan, Tajikistan, and Afghanistan – has resulted in the Sogdian heartland receiving the attention it deserves from the curious modern world.
Also – putting aside its "not forgotten" status – the partial exclusion (or, perhaps more accurately, the ambivalent inclusion) of Sogdiana from the Oxus region has deep historical roots. Going back to Achaemenid Persian times, Sogdiana was the extreme northern frontier of Darius's empire. And when the Greeks arrived and began to exert their influence, Sogdiana was known as Transoxiana, literally meaning "the land across the Oxus". Thus, from the point of view of the two great powers that dominated the region in antiquity – the Persians and the Greeks – Sogdiana was considered as the final outpost: a buffer between their known, civilised sphere of control; and the barbarous nomads who dwelt on the steppes beyond.
Bactria
Finally, after examining the other realms of the Oxus region, we come to the land that was the region's showpiece in the antiquity period: Bactria. The Bactrian heartland can be found south of Sogdiana, separated from it by the (relatively speaking) humble Chul'bair mountain range. Bactria occupies a prime position along the Oxus river: that is, it's the first section lying downstream of overly-rugged terrain; and it's upstream enough that it remains quite fertile to this day, although it's significantly less fertile than it was millennia ago. Bactria falls principally within modern-day northern Afghanistan; but it also encroaches into southern Uzbekistan and Tajikistan.
Historians know more about antiquity-era Bactria than they do about the rest of the Oxus region, primarily because Bactria was better incorporated into the great empires of that age than were its neighbours, and therefore far more written records of Bactria have survived. Bactria was a semi-autonomous satrapy (province) of the Persian empire since at least the 6th century BCE, although it was probably already under Persian influence well before then. It was conquered by Alexander the Great in 328 BCE (after he had already marched through Sogdiana the year before), thus marking the start of Greco-Bactrian rule, making Bactria the easternmost hellenistic outpost of the ancient world.
However, considering its place in the narrative of these empires, and considering its being recorded by both Persian and Greek historians, surprisingly little is known about the details of ancient Bactria today. This is why the documentary was called "Alexander's Lost World". Much like its neighbours, the area comprising modern-day Bactria is relatively seldom visited and seldom studied, due to its turbulent recent history.
The first archaeological site that I'd like to discuss in this section is that of Kampyr Tepe, which lies on the northern bank of the Oxus (putting it within Uzbek territory), just downstream from modern-day Termez. Kampyr Tepe was constructed around the 4th century BCE, possibly initially as a garrison by Alexander's forces. It was a thriving city for several centuries after that. It would have been an important defensive stronghold in antiquity, lying as it does near the western frontier of Bactria proper, not far from the capital, and affording excellent views of the surrounding territory.
There is evidence that a number of different religious groups co-existed peacefully in Kampyr Tepe: relics of Hellenism, Zoroastrianism, and Buddhism from similar time periods have been discovered here. The ruins themselves are in good condition, especially considering the violence and instability that has affected the site's immediate surroundings in recent history. However, the reason for the site's admirable state of preservation is also the reason for its inaccessibility: due to its border location, Kampyr Tepe is part of a sensitive Uzbek military-controlled zone, and access is highly restricted.
The capital of Bactria was the grand city of Bactra, the location of which is generally accepted to be a circular plateau of ruins touching the northern edge of the modern-day city of Balkh. These lie within the delta of the modern-day Balkh river (once known as the Bactrus river), about 70km south of where the Oxus presently flows. In antiquity, the Bactrus delta reached the Oxus and fed into it; but the modern-day Balkh delta (like so many other deltas mentioned in this article) fizzles out in the sand.
Today, the most striking feature of the ruins is the 10km-long ring of thick, high walls enclosing the ancient city. Balkh is believed to have been inhabited since at least the 27th century BCE, although most of the archaeological remains only date back to about the 4th century BCE. The ruins at Balkh are currently on UNESCO's tentative World Heritage list. It's likely that the plateau at Balkh was indeed ancient Bactra; however, this has never been conclusively proven. Modern archaeologists barely had any access to the site until 2003, due to decades of military conflict in the area. To this day, access continues to be highly restricted, for security reasons.
The formidable walls surrounding the ruins of Bactra, adjacent to modern-day Balkh. Image source:Hazara Association of UK.
Bactria was an important centre of Zoroastianism, and Bactra is one of (and is the most likely of) several contenders claiming to be the home of the mythical prophet Zoroaster. Tentatively related to this, is the fact that Bactra was also (possibly) once known as Zariaspa. A few historians have gone further, and have suggested that Bactra and Zariaspa were two different cities; if this is the case, then a whole new can of worms is opened, because it begs a multitude of further questions. Where was Zariaspa? Was Bactra at Balkh, and Zariaspa elsewhere? Or were Bactra and Zariaspa actually the same city… but located elsewhere?
Based on the theory of Ptolemy (and perhaps others), in the documentary David Adams strongly hypothesises that: (a) Bactra and Zariaspa were twin cities, next to each other; (b) the twin-city of Bactra-Zariaspa was located somewhere on the Oxus north of Balkh (he visits and proposes such a site, which I believe was somewhere between modern-day Termez and Aiwanj); and (c) this site, rather than Balkh, was the capital of the Greco-Bactrian kingdom that followed Alexander's conquest. While this is certainly an interesting hypothesis – and while it's true that there hasn't been nearly enough excavation or analysis done in modern times to rule it out – the evidence and the expert opinion, as it stands today, would suggest that Adams's hypothesis is wrong. As such, I think that his assertion of "the lost city of Bactra-Zariaspa" lying on the Oxus, rather than in the Bactrus delta, was stated rather over-confidently and with insufficient disclaimers in the documentary.
Upper Bactria
Although not historically or culturally distinct from the Bactrian heartland, I'm analysing "Upper Bactria" (i.e. the part of Bactria upstream of modern-day Balkh province) separately here, primarily to maintain structure in this article, but also because this farther-flung part of the realm is geographically quite rugged, in contrast to the heartland's sweeping plains.
First stop in Upper Bactria is the archaeological site of Takhti Sangin. This ancient ruin can be found on the Tajik side of the border; and since it's located at almost the exact spot where the Panj and Vakhsh rivers meet to become the Oxus, it could also be said that Takhti Sangin is the last site along the Oxus proper that I'm examining. However, much like the documentary, I'll be continuing the journey further upstream to the (contested) "source of the Oxus".
The principal structure at Takhti Sangin was a large Zoroastrian fire temple, which in its heyday boasted a pair of constantly-burning torches at its main entrance. Most of the remains at the site date back to the 3rd century BCE, when it became an important centre in the Greco-Bactrian kingdom (and when it was partially converted into a centre of Hellenistic worship); but the original temple is at least several centuries older than this, as attested to by various Achaemenid Persian-era relics.
Takhti Sangin is also the place where the famous "Oxus treasure" was discovered in the British colonial era (most of the treasure can be found on display at the British Museum to this day). In the current era, visitor access to Takhti Sangin is somewhat more relaxed than is access to the Bactrian sites further downstream (mentioned above) – there appear to be tour operators in Tajikistan running regularly-scheduled trips there – but this is also a sensitive border area, and as such, access is controlled by the Tajik military (who maintain a constant presence). Much like the sites of the Bactrian heartland, Takhti Sangin has been studied only sporadically by modern archaeologists, and much remains yet to be clarified regarding its history.
Moving further upstream, to the confluence of the Panj and Kokcha rivers, one reaches the site of Ai-Khanoum (meaning "Lady Moon" in modern Uzbek), which is believed (although not by all) to be the legendary city that was known in antiquity as Alexandria Oxiana. This was the most important Greco-Bactrian centre in Upper Bactria: it was built in the 3rd century BCE, and appears to have remained relatively vibrant for several centuries thereafter. It's also the site furthest upstream on the Oxus, for which there is significant evidence to indicate a Greco-Bactrian presence. It's a unique site within the Oxus region, in that it boasts the typical urban design of a classical Greek city; it's virtually "a little piece of Greece" in Central Asia. It even housed an amphitheatre and a gymnasium.
Ai-Khanoum certainly qualifies as a "lost" city: it was unknown to all save some local tribespeople, until the King of Afghanistan chanced upon it during a hunting trip in 1961. Due primarily to the subsequent Afghan-Soviet war, the site has been poorly studied (and also badly damaged) since then. In the documentary, it's explained how (and illustrated with some impressive 3D animation) – according to some – the Greco-Bactrian city was built atop the ruins of an older city, probably of Persian origin, which was itself once a dazzling metropolis. The documentary also indicates that access to Ai-Khanoum is currently tricky, and must be coordinated with the Afghan military; the site itself is also difficult to physically reach, as it's basically an island amongst the rivers that converge around it, depending on seasonal fluctuations.
The final site that I'd like to discuss regarding the realm of Bactria, is that of Sar-i Sang (a name meaning "place of stone"). At this particularly remote spot in the mountains of Badakhstan, there barely exists a town, neither today nor in ancient times. The nearest settlement of any size is modern-day Fayzabad, the provincial capital. From Ai-Khanoum, the Kokcha river winds upstream and passes through Fayzabad; and from there, the Kokcha valley continues its treacherous path up into the mountains, with Sar-i Sang located about 100km's south of Fayzabad.
Sar-i Sang is not a town, it's a mine: at an estimated 7,000 years of age, it's believed to be the oldest continuously-operating mine in the world. Throughout recorded history, people have come here seeking the beautiful precious stone known as lapis lazuli, which exists in veins of the hillsides here in the purest form and in the greatest quantity known on Earth.
Although Sar-i Sang (also known as Darreh-Zu) is quite distant from all the settlements of ancient Bactria (and quite distant from the Oxus), the evidence suggests that throughout antiquity the Bactrians worked the mines here, and that lapis lazuli played a significant role in Bactria's international trade. Sar-i Sang lapis lazuli can be found in numerous famous artifacts of other ancient empires, including the tomb of Tutankhamun in Egypt. Sources also suggest that this distinctive stone was Bactria's most famous export, and that it was universally associated with Bactria, much like silk was associated with China.
The Wakhan
Having now discussed the ancient realms of the Oxus from all the way downstream in the hot desert plains, there remains only one segment of this epic river left to explore: its source far upstream. East of Bactria lies one of the most inaccessible, solitary, and unspoiled places in the world: the Wakhan Corridor. Being the place where a number of very tall mountain ranges meet – among them the Pamirs, the Hindu Kush, and the Karakoram – the Wakhan has often been known as "The Roof of the World".
The Wakhan today is a long, slim "panhandle" of territory within Afghanistan, bordered to the north by Tajikistan, to the south by Pakistan, and to the east by China. This distinctive borderline was a colonial-era invention, a product of "The Great Game" played out between Imperial Russia and Britain, designed to create a buffer zone between these powers. Historically, however, the Wakhan has been nomadic territory, belonging to no state or empire, and with nothing but the immensity of the surrounding geography serving as its borders (as it continues to be on the ground to this day). The area is also miraculously bereft of the scourges of war and terrorism that have plagued the rest of Afghanistan in recent years.
Much like the documentary, my reasons for discussing the Wakhan are primarily geographic ones. The Wakhan is centred around a single long valley, whose river – today known as the Panj, and then higher up as the Wakhan river – is generally recognised as the source of the Oxus. It's important to acknowledge this high-altitude area, which plays such an integral role in feeding the river that diverse cultures further downstream depend upon, and which has fuelled the Oxus's long and colourful history.
There are few significant archaeological sites within the Wakhan. The ancient Kaakha fortress falls just outside the Wakhan proper, at the extreme eastern-most extent of the influence of antiquity-era kingdoms in the Oxus region. The only sizeable settlement in the Wakhan itself is the village of Sarhad, which has been continuously inhabited for millennia, and which is the base of the unique Wakhi people, who are the Wakhan's main tribe (Sarhad is also where the single rough road along the Wakhan valley ends). Just next to Sarhad lies the Kansir fort, built by the Tibetan empire in the 8th century CE, a relic of the battle that the Chinese and Tibetan armies fought in the Wakhan in the year 747 CE (this was probably the most action that the Wakhan has ever seen in its history).
Close to the very spot where the Wakhan river begins is Baza'i Gonbad (or Bozai Gumbaz, in Persian "domes of the elders"), a collection of small, ancient mud-brick domes about which little is known. As there's nothing else around for miles, they are occasionally used to this day as travellers' shelters. They are believed to be the oldest structures in the Wakhan, but it's unclear who built them (it was probably one of the nomadic Kyrgyz tribes that roam the area), or when.
Regarding which famous people have visited the Wakhan throughout history: it appears almost certain that Marco Polo passed through the Wakhan in the 13th century CE, in order to reach China; and a handful of other Europeans visited the Wakhan in the subsequent centuries (and it's almost certain that the only "tourists" to ever visit the Wakhan are those of the past century or so). In the documentary, David Adams suggests repeatedly in the final episode (that in which he journeys to the Wakhan) that Alexander – either the man himself, or his legions – not only entered the Wakhan Corridor, but even crossed one of its high passes over to Pakistan. I've found no source to clearly corroborate this claim; and after posing the question to a forum of Alexander-philes, it appears quite certain that neither Alexander nor his legions ever set foot in the Wakhan.
Conclusion
So, there you have it: my humble overview of the history of a region ruled by rivers, empires, and treasures. As I've emphasied throughout this article, the Oxus region is most lamentably a neglected and under-investigated place, considering its colourful history and its rich tapestry of cultures and landscapes. My aim in writing this piece is simply to inform anyone else who may be interested, and to better preserve the region's proud legacy.
I must acknowledge and wholeheartedly thank David Adams and his team for producing the documentary Alexander's Lost World, which I have referred to throughout this article, and whose material I have re-analysed as the basis of my writings here. The series has been criticised by history buffs for its various inaccuracies and unfounded claims; and I admit that I too, in this article, have criticised it several times. However, despite this, I laud the series' team for producing a documentary that I enjoyed immensely, and that educated me and inspired me to research the Oxus region in-depth. Like the documentary, this article is about rivers and climate change as the primary forces of the region, and Alexander the Great (along with other famous historical figures) is little more than a sidenote to this theme.
I am by no means an expert on the region, nor have I ever travelled to it (I have only "vicariously" travelled there, by watching the documentary and by writing this article!). I would love to someday set my own two feet upon the well-trodden paths of the Oxus realms, and to see these crumbling testaments to long-lost g-ds and kings for myself. For now, however, armchair history blogging will have to suffice.
]]>
First experiences developing a single-page JS-driven web app2014-08-26T00:00:00Z2014-08-26T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/08/first-experiences-developing-a-single-page-js-driven-web-app/
For the past few months, my main dev project has been a custom tool that imports metric data from a variety of sources (via APIs), and that generates reports showing that data in numerous graphical and tabular formats. The app is private (and is still in alpha), so I'm afraid I can't go into more detail than that at this time.
I decided (and I was encouraged by stakeholders) to build the tool as a single-page application, i.e. as a web app where almost all of the front-end is powered by JavaScript, and where the page is redrawn via AJAX calls and client-side templates. This was my first experience developing such an app; as such, I'd like to reflect on the choices I made, and on my understanding of the technology as it stands now.
Drowning in frameworks
I never saw one before in my life, and I hope I never see one of those fuzzy miserable things again. Image source:Memory Alpha (originally from Star Trek TOS Season 2 Ep 13).
Building single-page applications is all the rage these days; as such, a gazillion frameworks have popped up, all promising to take the pain out of the dev work for you. In reality, when your problem is that you need to create an app, and you think: "I know, I'll go and choose a JS framework", now you have two problems.
Actually, that's not the full story either. When you choose the wrong JS* framework – due to it being unsuitable for your project, and/or due to your failing to grok it – and you have to look for a framework a second time, and port the code you've already started writing… now you've got three problems!
(* I'd prefer to just refer to these frameworks as "JS", rather than use the much-bandied-about term "MVC", because not all such frameworks are MVC, and because one's project may be unsuitable for client-side MVC anyway).
Ah, the joy of first-time blunders.
I started by choosing Ember.js. It's one of the most popular frameworks at the moment. It does everything you could possibly need for your funky new JS app. Turns out that: (a) Ember was complete overkill for my relatively simple app; and (b) despite my best efforts, I failed to grok Ember, and I felt that my time would be better spent switching to something else and thereafter working more efficiently, than continuing to grapple with Ember's philosophy and complexity.
In the end, I settled on Sammy.js. This is one of the lesser-known frameworks out there. It boasts far less features than Ember.js (and even so, I haven't used all that Sammy.js offers either). It doesn't get in the way of my app's functionality. Many of its features are just a thin wrapper on top of jQuery, which I already know intimately. It adds a few bits 'n' pieces into my existing JS ecosystem, to give my app more structure and more interactivity; rather than nuking my existing ecosystem, and making me feel like single-page JS is a whole new language.
My advice to others who are choosing a whiz-bang JS framework for the first time: don't necessarily go with the most popular or the most full-featured framework you find (although don't discard such options either); think long and hard about what your app will actually do (more on that below), and choose an appropriate framework for your use-case; and make liberal use of online resources such as reviews (I also found TodoMVC extremely useful, plus I used its well-written code samples as the foundation for my own code).
What seems to be the problem?
Nothing to see here, people. Image source:Funny Junk (originally from South Park).
Ok, so you're going to write a single-page JS app. What will your app actually do? "Single-page JS app" can mean anything; and if we're trying to find the appropriate tool for the job, then the job itself needs to be clearly defined. So, let's break it down a bit.
Is the app (mainly) read-write, or is it read-only? This is a critical question, possibly more so than anything else. One of the biggest challenges with rich JS apps, is synchronising data between client and server. If data is only flowing one day (downstream), that's a whole lot less complexity than if data is flowing upstream as well.
Turns out that JS frameworks, in general, have dedicated a lot of their feature set to supporting read-write apps. They usually do this by having "models" (the "M" in "MVC"), which are the "source of truth" on the client-side; and by "binding" these models to elements in the DOM. When the value of a DOM element changes, that triggers a model data change, which in turn (often) triggers a server-side data update. Conversely, when new data arrives from the server, the model data is updated accordingly, and that update then propagates automatically to a value in the DOM.
Even the quintessential "Todo app" example has two-way data. Turns out, however, that my app only has one-way data. My app is all about sending queries to the server (with some simple filters), and receiving metric data in response. What's more, the received data is aggregate data (ready to be rendered as charts and tables), not individual entities that can easily be stored in a model. So, turns out that my life is easier without worrying about models or event bindings at all. Receive JSON, pipe it to the chart renderer (NVD3 for most charts), end of story.
Can displayed data change dynamically within a single JS route, or can it only change when the route changes? Once again, the former entails a lot more complexity than the latter. In my app's case, each JS route (handled by Sammy.js, same as with other frameworks, as "the part of the URL after the hash character") is a single report (containing one or more graphs and tables). The report elements themselves aren't dynamic (except that hovering over various graph elements shows more info). Changing the filters of the current report, or going to a different report, involves executing a new JS route.
So, if data isn't changing dynamically within a single JS route, why bother with complex event bindings? Some simple "old-skool" jQuery event handlers may be all that's necessary.
In summary, in the case of my app, all that it really needed in a JS framework was: client-side routing (which Sammy.js provides using nice, simple callbacks); local storage (Sammy.js has a thin wrapper on top of the HTML5 local storage API); AJAX communication (Sammy.js has a thin wrapper on top of jQuery for this); and templating (out-of-the-box Sammy.js supports John Resig's JS micro-templating system). And that's already a whole lot of funky new client-side components to learn and use. Why complicate things further?
All in all, I enjoyed building my first single-page JS app, and I'm reasonably happy with how it turned out to be architected. The front-end uses Sammy.js, D3.js/NVD3, and Bootstrap. The back-end uses Flask (Python) and MongoDB. Other than the login page and the admin pages, the app only has one non-JSON server-side route (the home page), and the rest is handled with client-side routes. The client-side is fairly simple, compared to many rich JS apps being built today; but then again, every app is unique.
I think that right now, we're still in Wild West times as far as building single-page apps goes. In particular, there are way too many frameworks in abundance; as the space matures, no doubt most of these frameworks will die off, and only a handful will thrive in the long-term. There's also a shortage of good advice about design patterns for single-page apps so far, although Mixu's book is a great foundation resource.
Single-page JS technology has plenty of advantages: it can lead to a more responsive, more beautiful app; and, when done right, its JS component can be architected just as cleanly and correctly as everything would be (traditionally) architected on the server-side. Remember, though, that it's just one piece in the puzzle, and that it only needs to be as complex as the app you're building.
]]>
Mixing GData auth with Google Discovery API queries2014-08-11T00:00:00Z2014-08-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/08/mixing-gdata-auth-with-google-discovery-api-queries/
For those of you who have some experience working with Google's APIs, you may be aware of the fact that they fall into two categories: the Google Data APIs, which is mainly for older services; and the discovery-based APIs, which is mainly for newer services.
There has been considerable confusion regarding the difference between the two APIs. I'm no expert, and I admit that I too have fallen victim to the confusion at times. Both systems now require the use of OAuth2 for authentication (it's no longer possible to access any Google APIs without Oauth2). However, each of Google's APIs only falls into one of the two camps; and once authentication is complete, you must use the correct library (either GData or Discovery, for your chosen programming language) in order to actually perform API requests. So, all that really matters, is that for each API that you plan to use, you're crystal clear on which type of API it is, and you use the correct corresponding library.
The GData Python library has a very handy mechanism for exporting an authorised access token as a blob (i.e. a serialised string), and for later re-importing the blob back as a programmatic access token. I made extensive use of this when I recently worked with the Google Analytics API, which is GData-based. I couldn't find any similar functionality in the Discovery API Python library; and I wanted to interact similarly with the YouTube Data API, which is discovery-based. What to do?
Mix 'n' match
The GData API already supports converting a Credentials object to an OAuth2 token object. This is great for an app that has user-facing OAuth2, where a Credentials object is available at the time of making API requests. However, in my situation – making API requests in a server-side script, that runs via cron with no user-facing OAuth2 – that's not much use. I have the opposite problem: I can easily get the token object, but I don't have any Credentials object already instantiated.
Well, it turns out that manually instantiating your own Credentials object isn't that hard. So, this is how I go about querying the YouTube Data API:
import httplib2
import gdata.gauth
from apiclient.discovery import build
from oauth2client.client import OAuth2Credentials
from mysettings import token_blob_string, \
youtube_playlist_id, \
page_size, \
next_page_token
# De-serialise the access token that can be conveniently stored in a
# Python settings file elsewhere, as a blob (string).
# GData provides the blob functionality, but the Discovery API library
# doesn't.
token = gdata.gauth.token_from_blob(token_blob_string)
# Manually instantiate an OAuth2Credentials object from the
# de-serialised access token.
credentials = OAuth2Credentials(
access_token=token.access_token,
client_id=token.client_id,
client_secret=token.client_secret,
refresh_token=token.refresh_token,
token_expiry=None,
token_uri=token.token_uri,
user_agent=None)
http = credentials.authorize(httplib2.Http())
youtube = build('youtube', 'v3', http=http)
# Profit!
response = youtube.playlistItems().list(
playlistId=youtube_playlist_id,
part="snippet",
maxResults=page_size,
pageToken=next_page_token
).execute()
Easy win
And there you go: you can have your cake and eat it, too! All you need is an OAuth2 access token that you've already saved elsewhere as a blob string; and with that, you can query discovery-based Google APIs from anywhere you want, at any time, with no additional OAuth2 hoops to jump through.
If you want more details on how to serialise and de-serialise access token blobs using the GData Python library, others have explained it step-by-step, I'm not going to repeat all of that here. I hope this makes life a bit easier, for anyone else who's trying to deal with "offline" long-lived access tokens and the discovery-based Google APIs.
]]>
Australian LGA to postcode mappings with PostGIS and Intersects2014-07-12T00:00:00Z2014-07-12T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/07/australian-lga-to-postcode-mappings-with-postgis-and-intersects/
For a recent project, I needed to know the LGAs (Local Government Areas) of all postcodes in Australia, and vice versa. As it turns out, there is no definitive Australia-wide list containing this data anywhere. People have been discussing the issue for some time, with no clear outcome. So, I decided to get creative.
If you want the full story: I imported both the LGA boundaries data and the Postal Area boundaries data from the ABS, into PostGIS, and I did an "Intersects" query on the two datasets. I exported the results of this query to CSV. Done! And all perfectly reproducible, using freely available public data sets, and using free and open-source software tools.
The process
I started by downloading the Geo data that I needed, from the ABS. My source was the page Australian Statistical Geography Standard (ASGS): Volume 3 - Non ABS Structures, July 2011. This was the most recent page that I could find on the ABS, containing all the data that I needed. I downloaded the files "Local Government Areas ASGS Non ABS Structures Ed 2011 Digital Boundaries in MapInfo Interchange Format", and "Postal Areas ASGS Non ABS Structures Ed 2011 Digital Boundaries in MapInfo Interchange Format".
Big disclaimer: I'm not an expert at anything GIS- or spatial-related, I'm a complete n00b at this. I decided to download the data I needed in MapInfo format. It's also available on the ABS web site in ArcGIS Shapefile format. I could have downloaded the Shapefiles instead – they can also be imported into PostGIS, using the same tools that I used. I chose the MapInfo files because I did some quick Googling around, and I got the impression that MapInfo files are less complex and are somewhat more portable. I may have made the wrong choice. Feel free to debate the merits of MapInfo vs ArcGIS files for this task, and to try this out yourself using ArcGIS instead of MapInfo. I'd be interested to see the difference in results (theoretically there should be no difference… in practice, who wants to bet there is?).
I then had to install PostGIS (I already had Postgres installed) and related tools on my local machine (running Ubuntu 12.04). I'm not providing PostGIS installation instructions here, there's plenty of information available elsewhere to help you get set up with all the tools you need, for your specific OS / requirements. Installing PostGIS and related tools can get complicated, so if you do decide to try all this yourself, don't say I didn't warn you. Ubuntu is probably one of the easier platforms on which to install it, but there are plenty of guides out there for Windows and Mac too.
Once I was all set up, I imported the data files into a PostGIS-enabled Postgres database with these commands:
If you're interested in the OGR Toolkit (ogr2ogr and friends), there are plenty of resources available; in particular, this OGR Toolkit guide was very useful for me.
After playing around with a few different map projections, I decided that EPSG:4283 was probably the correct one to use as an argument to ogr2ogr. I based my decision on seeing the MapInfo projection string "CoordSys Earth Projection 1, 116" in the header of the ABS data files, and then finding this list of common Australian-used map projections. Once again: I am a total n00b at this. I know very little about map projections (except that it's a big and complex topic). Feel free to let me know if I've used completely the wrong projection for this task.
I renamed the imported tables to 'lga' and 'postcodes' respectively, and I then ran this from the psql shell, to find all LGAs that intersect with all postal areas, and to export the result to a CSV:
\copy (SELECT l.state_name_2011,
l.lga_name_2011,
p.poa_code_2011
FROM lga l
INNER JOIN postcodes p
ON ST_Intersects(
l.wkb_geometry,
p.wkb_geometry)
ORDER BY l.state_name_2011,
l.lga_name_2011,
p.poa_code_2011)
TO '/path/to/lga_postcodes.csv' WITH CSV HEADER;
Final remarks
That's about it! Also, some notes of mine (mainly based on the trusty Wikipedia page Local Government in Australia):
There's no data for the ACT, since the ACT has no LGAs
Almost the entire Brisbane and Gold Coast metro areas, respectively, are one LGA
Some areas of Australia aren't part of any LGA (although they're all remote areas with very small populations)
Quite a large number of valid Australian postcodes are not part of any LGA (because they're for PO boxes, for bulk mail handlers, etc, and they don't cover a geographical area as such, in the way that "normal" postcodes do)
I hope that this information is of use, to anyone else who needs to link up LGAs and postcodes in a database or in a GIS project.
]]>
Database-free content tagging with files and glob2014-05-20T00:00:00Z2014-05-20T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/05/database-free-content-tagging-with-files-and-glob/
Tagging data (e.g. in a blog) is many-to-many data. Each content item can have multiple tags. And each tag can be assigned to multiple content items. Many-to-many data needs to be stored in a database. Preferably a relational database (e.g. MySQL, PostgreSQL), otherwise an alternative data store (e.g. something document-oriented like MongoDB / CouchDB). Right?
If you're not insane, then yes, that's right! However, for a recent little personal project of mine, I decided to go nuts and experiment. Check it out, this is my "mapping data" store:
Just a list of files in a directory.
And check it out, this is me querying the data store:
Show me all posts with the tag 'fun-stuff'.
And again:
Show me all tags for the post 'rant-about-seashells'.
And that's all there is to it. Many-to-many tagging data stored in a list of files, with content item identifiers and tag identifiers embedded in each filename. Querying is by simple directory listing shell commands with wildcards (also known as "globbing").
Is it user-friendly to add new content? No! Does it allow the rich querying of SQL and friends? No! Is it scalable? No!
But… Is the basic querying it allows enough for my needs? Yes! Is it fast (for a store of up to several thousand records)? Yes! And do I have the luxury of not caring about user-friendliness or scalability in this instance? Yes!
Implementation
For the project in which I developed this system, I implemented the querying with some simple PHP code. For example, this is my "content item" store:
Another list of files in a directory.
These are the functions to do some basic querying on all content:
<?php
/**
* Queries for all blog pages.
*
* @return
* List of all blog pages.
*/
function blog_query_all() {
$files = glob(BASE_FILE_PATH . 'pages/blog/*.php');
if (!empty($files)) {
foreach (array_keys($files) as $k) {
$files[$k] = str_replace(BASE_FILE_PATH . 'pages/blog/',
'',
$files[$k]);
}
rsort($files);
}
return $files;
}
/**
* Queries for blog pages with the specified year / month.
*
* @param $year
* Year.
* @param $month
* Month
*
* @return
* List of blog pages with the specified year / month.
*/
function blog_query_byyearmonth($year, $month) {
$files = glob(BASE_FILE_PATH . 'pages/blog/' .
$year . '-' . $month . '-*.php');
if (!empty($files)) {
foreach (array_keys($files) as $k) {
$files[$k] = str_replace(BASE_FILE_PATH . 'pages/blog/',
'',
$files[$k]);
}
}
return $files;
}
/**
* Gets the previous blog page (by date).
*
* @param $full_identifier
* Full identifier of current blog page.
*
* @return
* Full identifier of previous blog page.
*/
function blog_get_prev($full_identifier) {
$files = blog_query_all();
$curr_index = array_search($full_identifier . '.php', $files);
if ($curr_index !== FALSE && $curr_index < count($files)-1) {
return str_replace('.php', '', $files[$curr_index+1]);
}
return NULL;
}
/**
* Gets the next blog page (by date).
*
* @param $full_identifier
* Full identifier of current blog page.
*
* @return
* Full identifier of next blog page.
*/
function blog_get_next($full_identifier) {
$files = blog_query_all();
$curr_index = array_search($full_identifier . '.php', $files);
if ($curr_index !== FALSE && $curr_index !== 0) {
return str_replace('.php', '', $files[$curr_index-1]);
}
return NULL;
}
And these are the functions to query content by tag:
<?php
/**
* Queries for blog pages with the specified tag.
*
* @param $slug
* Tag slug.
*
* @return
* List of blog pages with the specified tag.
*/
function blog_query_bytag($slug) {
$files = glob(BASE_FILE_PATH .
'mappings/blog_tags/*--' . $slug . '.php');
if (!empty($files)) {
foreach (array_keys($files) as $k) {
$files[$k] = str_replace(BASE_FILE_PATH . 'mappings/blog_tags/',
'',
$files[$k]);
}
rsort($files);
}
return $files;
}
/**
* Gets a blog page's tags based on its full identifier.
*
* @param $full_identifier
* Blog page's full identifier.
*
* @return
* Tags.
*/
function blog_get_tags($full_identifier) {
$files = glob(BASE_FILE_PATH .
'mappings/blog_tags/' . $full_identifier . '*.php');
$ret = array();
if (!empty($files)) {
foreach ($files as $f) {
$ret[] = str_replace(BASE_FILE_PATH . 'mappings/blog_tags/' .
$full_identifier . '--',
'',
str_replace('.php', '', $f));
}
}
return $ret;
}
That's basically all the "querying" that this blog app needs.
In summary
What I've shared here, is part of the solution that I recently built when I migrated Jaza's World Trip (my travel blog from 2007-2008) away from (an out-dated version of) Drupal, and into a new database-free custom PHP thingamajig. (I'm considering writing a separate article about what else I developed, and I'm also considering cleaning it up and releasing it as a biolerplate PHP project template on GitHub… although not sure if it's worth the effort, we shall see).
This is an old blog site that I wanted to "retire", i.e. to migrate off a CMS platform, and into more-or-less static files. So, the filesystem-based data store that I developed in this case was a good match, because:
No new content will be added to the site in the future
Migrating the site to a different server (in the hypothetical future) would consist of simply copying all the files, and the new server would only need to support PHP (and PHP is the most commonly-supported web server technology in the world)
If the data store performs well with the current volume of content, that's great; I don't care if it doesn't scale to millions of records (due to e.g. files-per-directory OS limits being reached, glob performance worsening), because it will never have that many
Most sites that I develop are new, and they don't fit this use case at all. They need a content management admin interface. They need to scale. And they usually need various other features (e.g. user login) that also commonly rely on a traditional database backend. However, for this somewhat unique use-case, building a database-free tagging data store was a fun experiment!
]]>
Sharing templates between multiple Drupal views2014-04-24T00:00:00Z2014-04-24T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/04/sharing-templates-between-multiple-drupal-views/
Do you have multiple views on your Drupal site, where the content listing is themed to look exactly the same? For example, say you have a custom "search this site" view, a "featured articles" view, and an "articles archive" view. They all show the same fields — for example, "title", "image", and "summary". They all show the same content types – except that the first one shows "news" or "page" content, whereas the others only show "news".
If your design is sufficiently custom that you're writing theme-level Views template files, then chances are that you'll be in danger of creating duplicate templates. I've committed this sin on numerous sites over the past few years. On many occasions, my Views templates were 100% identical, and after making a change in one template, I literally copy-pasted and renamed the file, to update the other templates.
Until, finally, I decided that enough is enough – time to get DRY!
Being less repetitive with your Views templates is actually dead simple. Let's say you have three identical files – views-view-fields--search_this_site.tpl.php, views-view-fields--featured_articles.tpl.php, and views-view-fields--articles_archive.tpl.php. Here's how you clean up your act:
Delete the latter two files.
Add this to your theme's template.php file:
<?php
function mytheme_preprocess_views_view_fields(&$vars) {
if (in_array(
$vars['view']->name, array(
'search_this_site',
'featured_articles',
'articles_archive'))) {
$vars['theme_hook_suggestions'][] =
'views_view_fields__search_this_site';
}
}
Clear your cache (that being the customary final step when doing anything in Drupal, of course).
I've found that views-view-fields.tpl.php-based files are the biggest culprits for duplication; but you might have some other Views templates in need of cleaning up, too, such as:
<?php
function mytheme_preprocess_views_view(&$vars) {
if (in_array(
$vars['view']->name, array(
'search_this_site',
'featured_articles',
'articles_archive'))) {
$vars['theme_hook_suggestions'][] =
'views_view__search_this_site';
}
}
And, if your views include a search / filtering form, perhaps also:
<?php
function mytheme_preprocess_views_exposed_form(&$vars) {
if (in_array(
$vars['view']->name, array(
'search_this_site',
'featured_articles',
'articles_archive'))) {
$vars['theme_hook_suggestions'][] =
'views_exposed_form__search_this_site';
}
}
That's it – just a quick tip from me for today. You can find out more about this technique on the Custom Theme Hook Suggestions documentation page, although I couldn't find an example for Views there, nor anywhere else online for that matter; hence this article. Hopefully this results in a few kilobytes saved, and (more importantly) a lot of unnecessary copy-pasting of template files saved, for fellow Drupal devs and themers.
]]>
The cost of building a "perfect" custom Drupal installation profile2014-04-16T00:00:00Z2014-04-16T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/04/the-cost-of-building-a-perfect-custom-drupal-installation-profile/
With virtually everything in Drupal, there are two ways to accomplish a task: The Easy Way, or The Right™ Way.
Deploying a new Drupal site for the first time is no exception. The Easy Way – and almost certainly the most common way – is to simply copy your local version of the database to production (or staging), along with user-uploaded files. (Your code needs to be deployed too, and The Right™ Way to deploy it is with version-control, which you're hopefully using… but that's another story.)
The Right™ Way to deploy a Drupal site for the first time (at least since Drupal 7, and "with hurdles" since Drupal 6), is to only deploy your code, and to reproduce your database (and ideally also user-uploaded files) with a custom installation profile, and also with significant help from the Features module.
The Right Way can be a deep rabbit hole, though. Image source:SIX Nutrition.
I've been churning out quite a lot of Drupal sites over the past few years, and I must admit, the vast majority of them were deployed The Easy Way. Small sites, single developer, quick turn-around. That's usually the way it rolls. However, I've done some work that's required custom installation profiles, and I've also been trying to embrace Features more; and so, for my most recent project – despite it being "yet another small-scale, one-dev site" – I decided to go the full hog, and to build it 100% The Right™ Way, just for kicks. In order to force myself to do things properly, I re-installed my dev site from scratch (and thus deleted my dev database) several times a day; i.e. I continuously tested my custom installation profile during dev.
Does it give me a warm fuzzy feeling, as a dev, to be able to install a perfect copy of a new site from scratch? Hell yeah. But does that warm fuzzy feeling come at a cost? Hell yeah.
What's involved
For our purposes, the contents of a typical Drupal database can be broken down into three components:
Critical configuration
Secondary configuration
Content
Critical configuration is: (a) stuff that should be set immediately upon site install, because important aspects of the site depend on it; and (b) stuff that cannot or should not be managed by Features. When building a custom installation profile, all critical configuration should be set with custom code that lives inside the profile itself, either in its hook_install() implementation, or in one of its hook_install_tasks() callbacks. The config in this category generally includes: the default theme and its config; the region/theme for key blocks; user roles, basic user permissions, and user variables; date formats; and text formats. This config isn't all that hard to write (see Drupal core's built-in installation profiles for good example code), and it shouldn't need much updating during dev.
Secondary configuration is: (a) stuff that can be set after the main install process has finished; and (b) stuff that's managed by Features. These days, thanks to various helpers such as Strongarm and Features Extra, there isn't much that can't be exported and managed in this way. All secondary configuration should be set in exportable definitions in Features-generated modules, which need to be added as dependencies in the installation profile's .info file. On my recent project, this included: many variables; content types; fields; blocks (including Block Class classes and block content); views; vocabularies; image styles; nodequeues; WYSIWYG profiles; and CER presets.
Secondary config isn't hard to write – in fact, it writes itself! However, it is a serious pain to maintain. Every time that you add or modify any piece of secondary content on your dev site, you need to perform the following workflow:
Does an appropriate feature module already exist for this config? If not, create a new feature module, export it to your site's codebase, and add the module as a dependency to the installation profile's .info file.
Is this config new? If so, manually add it to the relevant feature.
For all new or updated config: re-create the relevant feature module, thus re-exporting the config.
I found that I got in the habit of checking my site's Features admin page, before committing whatever code I was about to commit. I re-exported all features that were flagged with changes, and I tried to remember if there was any new config that needed to be added to a feature, before going ahead and making the commit. Because I decided to re-install my dev site from scratch regularly, and to scrap my local database, I had no choice but to take this seriously: if there was any config that I forgot to export, it simply got lost in the next re-install.
Content is stuff that is not config. Content depends on all critical and secondary config being set. And content is not managed by Features: it's managed by users, once the site is deployed. (Content can now be managed by Features, using the UUID module – but I haven't tried that approach, and I'm not particularly convinced that it's The Right™ Way.) On my recent project, content included: nodes (of course); taxonomy terms; menu items; and nodequeue mappings.
An important part of handing over a presentable site to the client, in my experience, is that there's at least some demo / structural content in place. So, in order to handle content in my "continuously installable" setup, I wrote a bunch of custom Drush commands, which defined all the content in raw PHP using arrays / objects, and which imported all the content using Drupal's standard API functions (i.e. node_save() and friends). This also included user-uploaded files (i.e. images and documents): I dumped all these into a directory outside of my Drupal root, and imported them using the Field API and some raw file-copying snippets.
All rosy?
The upside of it all: I lived the dream on this project. I freed myself from database state. Everything I'd built was safe and secure within the code repo, and the only thing that needed to be deployed to staging / production was the code itself.
Join me, comrades! Join me and all Drupal sites will be equal! (But some more equal than others).
(Re-)installing the site consisted of little more than running (something similar to) these Drush commands:
drush cc all
drush site-install --yes mycustomprofile --account-mail=info@blaaaaaaaa.com --account-name=admin --account-pass=blaaaaaaa
drush features-revert-all --yes
drush mymodule-install-content
The downside of it: constantly maintaining exported features and content-in-code eats up a lot of time. As a rough estimate, I'd say that it resulted in me spending about 30% more time on the project than I would have otherwise. Fortunately, the project was still delivered ahead of schedule and under budget; had constraints been tighter, I probably couldn't have afforded the luxury of this experiment.
Unfortunately, Drupal just isn't designed to store either configuration or content in code. Doing either is an uphill battle. Maintaining all config and content in code was virtually impossible in Drupal 5 and earlier; it had numerous hurdles in Drupal 6; and it's possible (and recommended) but tedious in Drupal 7. Drupal 8 – despite the enormous strides forward that it's making with the Configuration Management Initiative (CMI) – will still, at the end of the day, treat the database rather than code as the "source of truth" for config. Therefore, I assert that, although it will be easier than ever to manage all config in code, the "configuration management" and "continuous deployment" problems still won't be completely solved in Drupal 8.
I've been working increasingly with Django over the past few years, where configuration only exists in code (in Python settings, in model classes, in view callables, etc), and where only content exists in the database (and where content has also been easily exportable / deployable using fixtures, since before Drupal "exportables" were invented); and in that world, these are problems that simply don't exist. There's no need to ever synchronise between the "database version" of config and the "code version" of config. Unfortunately, Drupal will probably never reach this Zen-like ideal, because it seems unlikely that Drupal will ever let go of the database as a config store altogether.
Anyway, despite the fact that a "perfect" installation profile probably isn't justifiable for most smaller Drupal projects, I think that it's still worthwhile, in the same way that writing proper update scripts is still worthwhile: i.e. because it significantly improves quality; and because it's an excellent learning tool for you as a developer.
]]>
Using PayPal WPS with Cartridge (Mezzanine / Django)2014-03-31T00:00:00Z2014-03-31T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/03/using-paypal-wps-with-cartridge-mezzanine-django/
I recently built a web site using Mezzanine, a CMS built on top of Django. I decided to go with Mezzanine (which I've never used before) for two reasons: it nicely enhances Django's admin experience (plus it enhances, but doesn't get in the way of, the Django developer experience); and there's a shopping cart app called Cartridge that's built on top of Mezzanine, and for this particular site (a children's art class business in Sydney) I needed shopping cart / e-commerce functionality.
This suite turned out to deliver virtually everything I needed out-of-the-box, with one exception: Cartridge currently lacks support for payment methods that require redirecting to the payment gateway and then returning after payment completion (such as PayPal Website Payments Standard, or WPS). It only supports payment methods where payment is completed on-site (such as PayPal Website Payments Pro, or WPP). In this case, with the project being small and low-budget, I wanted to avoid the overhead of dealing with SSL and on-site payment, so PayPal WPS was the obvious candidate.
Turns out that, with a bit of hackery, making Cartridge play nice with WPS isn't too hard to achieve. Here's how you go about it.
I'm assuming that you've already got an environment set up, that's equipped for Django development. I.e. you've already installed Python (my examples here are tested on Python 2.7), a database engine (preferably SQLite on your local environment), pip (recommended), and virtualenv (recommended). If you want to implement these examples fully, then as well as a dev environment with these basics set up, you'll also need a server to which you can deploy a Django site, and on which you can set up a proper public domain or subdomain DNS (because the PayPal API won't actually talk to your localhost, it refuses to do that).
You'll also need a PayPal (regular and "sandbox") account, which you will use for authenticating with the PayPal API.
Here are the basic dependencies for the project. I've copy-pasted this straight out of my requirements.txt file, which I install on a virtualenv using pip install -E . -r requirements.txt (I recommend you do the same):
Note:for dcramer/django-paypal, which has no versioned releases, I'm using the latest git commit as of writing this. I recommend that you check for a newer commit and update your requirements accordingly. For the other dependencies, you should also be able to update version numbers to latest stable releases without issues (although Mezzanine 3.0.x / Cartridge 0.9.x is only compatible with Django 1.6.x, not Django 1.7.x which is still in beta as of writing this).
Once you've got those dependencies installed, make sure this Mezzanine-specific setting is in your settings.py file:
# If True, the south application will be automatically added to the
# INSTALLED_APPS setting.
USE_SOUTH = True
Then, let's get a new project set up per Mezzanine's standard install:
(When it asks "Would you like to install an initial demo product and sale?", I've gone with "yes" for my test / demo project; feel free to do the same, if you'd like some products available out-of-the-box with which to test checkout / payment).
This will get the Mezzanine foundations installed for you. The basic configuration of the Django / Mezzanine settings file, I leave up to you. If you have some experience already with Django (and if you've got this far, then I assume that you do), you no doubt have a standard settings template already in your toolkit (or at least a standard set of settings tweaks), so feel free to use it. I'll be going over the settings you'll need specifically for this app, in just a moment.
Fire up ye 'ol runserver, open your browser at http://localhost:8000/, and confirm that the "Congratulations!" default Mezzanine home page appears for you. Also confirm that you can access the admin. And that's the basics set up!
At this point, you should also be able to test out adding an item to your cart and going to checkout. After entering some billing / delivery details, on the 'payment details' screen it should ask for credit card details. This is the default Cartridge payment setup: we'll be switching this over to PayPal shortly.
Configure Django settings
I'm not too fussed about what else you have in your Django settings file (or in how your Django settings are structured or loaded, for that matter); but if you want to follow along, then you should have certain settings configured per the following guidelines (note: much of these instructions are virtually the same as the cartridge-payments install instructions):
Your TEMPLATE_CONTEXT_PROCESSORS is to include (as well as 'mezzanine.conf.context_processors.settings'):
Set a value for the PAYPAL_CURRENCY setting, for example:
# Currency type.
PAYPAL_CURRENCY = "AUD"
Set a value for the PAYPAL_BUSINESS setting, for example:
# Business account email. Sandbox emails look like this.
PAYPAL_BUSINESS = 'cartwpstest@blablablaaaaaaa.com'
Set a value for the PAYPAL_RECEIVER_EMAIL setting, for example:
PAYPAL_RECEIVER_EMAIL = PAYPAL_BUSINESS
Set a value for the PAYPAL_RETURN_WITH_HTTPS setting, for example:
# Use this to enable https on return URLs. This is strongly recommended! (Except for sandbox)
PAYPAL_RETURN_WITH_HTTPS = False
Configure the PAYPAL_RETURN_URL setting to this:
# Function that returns args for `reverse`.
# URL is sent to PayPal as the for returning to a 'complete' landing page.
PAYPAL_RETURN_URL = lambda cart, uuid, order_form: ('shop_complete', None, None)
Configure the PAYPAL_IPN_URL setting to this:
# Function that returns args for `reverse`.
# URL is sent to PayPal as the URL to callback to for PayPal IPN.
# Set to None if you do not wish to use IPN.
PAYPAL_IPN_URL = lambda cart, uuid, order_form: ('paypal.standard.ipn.views.ipn', None, {})
Configure the PAYPAL_SUBMIT_URL setting to this:
# URL the secondary-payment-form is submitted to
# For real use set to 'https://www.paypal.com/cgi-bin/webscr'
PAYPAL_SUBMIT_URL = 'https://www.sandbox.paypal.com/cgi-bin/webscr'
After doing this, you'll probably need to manually create a migration in order to get this field added to your database (per Mezzanine's field injection caveat docs), and you'll then need to apply that migration (in this example, I'm adding the migration to an app called 'content' in my project):
Although it shouldn't be necessary, I've found that I need to copy the templates provided by explodes/cartridge-payments into my project's templates directory, otherwise they're ignored and Cartridge's default payment template still gets used:
Place the following code somewhere in your codebase (per the django-paypal docs, I placed it in the models.py file for one of my apps):
# ...
from importlib import import_module
from mezzanine.conf import settings
from cartridge.shop.models import Cart, Order, ProductVariation, \
DiscountCode
from paypal.standard.ipn.signals import payment_was_successful
# ...
def payment_complete(sender, **kwargs):
"""Performs the same logic as the code in
cartridge.shop.models.Order.complete(), but fetches the session,
order, and cart objects from storage, rather than relying on the
request object being passed in (which it isn't, since this is
triggered on PayPal IPN callback)."""
ipn_obj = sender
if ipn_obj.custom and ipn_obj.invoice:
s_key, cart_pk = ipn_obj.custom.split(',')
SessionStore = import_module(settings.SESSION_ENGINE) \
.SessionStore
session = SessionStore(s_key)
try:
cart = Cart.objects.get(id=cart_pk)
try:
order = Order.objects.get(
transaction_id=ipn_obj.invoice)
for field in order.session_fields:
if field in session:
del session[field]
try:
del session["order"]
except KeyError:
pass
# Since we're manually changing session data outside of
# a normal request, need to force the session object to
# save after modifying its data.
session.save()
for item in cart:
try:
variation = ProductVariation.objects.get(
sku=item.sku)
except ProductVariation.DoesNotExist:
pass
else:
variation.update_stock(item.quantity * -1)
variation.product.actions.purchased()
code = session.get('discount_code')
if code:
DiscountCode.objects.active().filter(code=code) \
.update(uses_remaining=F('uses_remaining') - 1)
cart.delete()
except Order.DoesNotExist:
pass
except Cart.DoesNotExist:
pass
payment_was_successful.connect(payment_complete)
This little snippet that I whipped up, is the critical spoonful of glue that gets PayPal WPS playing nice with Cartridge. Basically, when a successful payment is realised, PayPal WPS doesn't force the user to redirect back to the original web site, and therefore it doesn't rely on any redirection in order to notify the site of success. Instead, it uses PayPal's IPN (Instant Payment Notification) system to make a separate, asynchronous request to the original web site – and it's up to the site to receive this request and to process it as it sees fit.
This code uses the payment_was_successful signal that django-paypal provides (and that it triggers on IPN request), to do what Cartridge usually takes care of (for other payment methods), on success: i.e. it clears the user's shopping cart; it updates remaining quantities of products in stock (if applicable); it triggers Cartridge's "product purchased" actions (e.g. email an invoice / receipt); and it updates a discount code (if applicable).
Apply a hack to cartridge-payments (file lib/python2.7/site-packages/payments/multipayments/forms/paypal.py) per this diff:
After line 25 (charset = forms.CharField(widget=forms.HiddenInput(), initial='utf-8')), add this:
Apply a hack to django-paypal (file src/django-paypal/paypal/standard/forms.py) per these instructions:
After line 15 ("%H:%M:%S %b. %d, %Y PDT",), add this:
"%H:%M:%S %d %b %Y PST", # note this
"%H:%M:%S %d %b %Y PDT", # and that
That should be all you need, in order to get checkout with PayPal WPS working on your site. So, deploy everything that's been done so far to your online server, log in to the Django admin, and for some of the variations for the sample product in the database, add values for "number in stock".
Then, log out of the admin, and navigate to the "shop" section of the site. Try out adding an item to your cart.
Basic Django / Mezzanine / Cartridge site: adding an item to shopping cart.
Once on the "your cart" page, continue by clicking "go to checkout". On the "billing details" page, enter sample billing information as necessary, then click "next". On the "payment" page, you should see a single button labelled "pay with pay-pal".
Click the button, and you should be taken to the PayPal (sandbox, unless configured otherwise) payment landing page. For test cases, log in with a PayPal test account, and click 'Pay Now' to try out the process.
If payment is successful, you should see the PayPal confirmation page, saying "thanks for your order". Click the link labelled "return to email@here.com" to return to the Django site. You should see Cartridge's "order complete" page.
Basic Django / Mezzanine / Cartridge site: order complete screen.
And that's it, you're done! You should be able to verify that the IPN callback was triggered, by checking that the "number in stock" has decreased to reflect the item that was just purchased, and by confirming that an order email / confirmation email was received.
Finished process
I hope that this guide is of assistance, to anyone else who's looking to integrate PayPal WPS with Cartridge. The difficulties associated with it are also documented in this mailing list thread (to which I posted a rough version of what I've illustrated in this article). Feel free to leave comments here, and/or in that thread.
Hopefully the hacks necessary to get this working at the moment, will no longer be necessary in the future; it's up to the maintainers of the various projects to get the fixes for these committed. Ideally, the custom signal implementation won't be necessary either in the future: it would be great if Cartridge could work out-of-the-box with PayPal WPS. Unfortunately, the current architecture of Cartridge's payment system simply isn't designed for something like IPN, it only plays nicely with payment methods that keep the user on the Django site the entire time. In the meantime, with the help of this article, you should at least be able to get it working, even if more custom code is needed than what would be ideal.
]]>
Protect the children, but don't blindfold them2014-03-18T00:00:00Z2014-03-18T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/03/protect-the-children-but-dont-blindfold-them/
Being a member of mainstream society isn't for everyone. Some want out.
Societal vices have always been bountiful. Back in the ol' days, it was just the usual suspects. War. Violence. Greed. Corruption. Injustice. Propaganda. Lewdness. Alcoholism. To name a few. In today's world, still more scourges have joined in the mix. Consumerism. Drug abuse. Environmental damage. Monolithic bureaucracy. And plenty more.
There always have been some folks who elect to isolate themselves from the masses, to renounce their mainstream-ness, to protect themselves from all that nastiness. And there always will be. Nothing wrong with doing so.
However, there's a difference between protecting oneself from "the evils of society", and blinding oneself to their very existence. Sometimes this difference is a fine line. Particularly in the case of families, where parents choose to shield from the Big Bad World not only themselves, but also their children. Protection is noble and commendable. Blindfolding, in my opinion, is cowardly and futile.
There are plenty of examples from bygone times, of historical abstainers from mainstream society. Monks and nuns, who have for millenia sought serenity, spirituality, abstinence, and isolation from the material. Hermits of many varieties: witches, grumpy old men / women, and solitary island-dwellers.
Religion has long been an important motive for seclusion. Many have settled on a reclusive existence as their solution to avoiding widespread evils and being closer to G-d. Other than adult individuals who choose a monastic life, there are also whole communities, composed of families with children, who live in seclusion from the wider world. The Amish in rural USA are probably the most famous example, and also one of the longest-running such communities. Many ultra-orthodox Jewish communities, particularly within present-day Israel, could also be considered as secluded.
More recently, the "commune living" hippie phenomenon has seen tremendous growth worldwide. The hippie ideology is, of course, generally an anti-religious one, with its acceptance of open relationships, drug use, lack of hierarchy, and often a lack of any formal G-d. However, the secluded lifestyle of hippie communes is actually quite similar to that of secluded religious groups. It's usually characterised by living amidst, and in tune with, nature; rejecting modern technology; and maintaining a physical distance from regular urban areas. The left-leaning members of these communities tend to strongly shun consumerism, and to promote serenity and spirituality, much like their G-d fearing comrades.
In a bubble
Like the members of these communities, I too am repulsed by many of the "evils" within the society in which we live. Indeed, the idea of joining such a community is attractive to me. It would be a pleasure and a relief to shut myself out from the blight that threatens me, and from everyone that's "infected" by it. Life would be simpler, more peaceful, more wholesome.
I empathise with those who have chosen this path in life. Just as it's tempting to succumb to all the world's vices, so too is it tempting to flee from them. However, such people are also living in a bubble. An artificial world, from which the real world has been banished.
What bothers me is not so much the independent adult people who have elected for such an existence. Despite all the faults of the modern world, most of us do at least enjoy far-reaching liberty. So, it's a free land, and adults are free to live as they will, and to blind themselves to what they will.
What does bother me, is that children are born and raised in such an existence. The adult knows what it is that he or she is shut off from, and has experienced it before, and has decided to discontinue experiencing it. The child, on the other hand, has never been exposed to reality, he or she knows only the confines of the bubble. The child is blind, but to what, it knows not.
This is a cowardly act on the part of the parents. It's cowardly because a child only develops the ability to combat and to reject the world's vices, such as consumerism or substance abuse, by being exposed to them, by possibly experimenting with them, and by making his or her own decisions. Parents that are serious about protecting their children do expose them to the Big Bad World, they do take risks; but they also do the hard yards in preparing their children for it: they ensure that their children are raised with education, discipline, and love.
Blindfolding children to the reality of wider society is also futile — because, sooner or later, whether still as children or later as adults, the Big Bad World exposes itself to all, whether you like it or not. No Amish countryside, no hippie commune, no far-flung island, is so far or so disconnected from civilisation that its inhabitants can be prevented from ever having contact with it. And when the day of exposure comes, those that have lived in their little bubble find themselves totally unprepared for the very "evils" that they've supposedly been protected from for all their lives.
Keep it balanced
In my opinion, the best way to protect children from the world's vices, is to expose them in moderation to the world's nasty underbelly, while maintaining a stable family unit, setting a strong example of rejecting the bad, and ensuring a solid education. That is, to do what the majority of the world's parents do. That's right: it's a formula that works reasonably well for billions of people, and that has been developed over thousands of years, so there must be some wisdom to it.
Obviously, children need to be protected from dangers that could completely overwhelm them. Bringing up a child in a favela environment is not ideal, and sometimes has horrific consequences, just watch City of G-d if you don't believe me. But then again, blindfolding is the opposite extreme; and one extreme can be as bad as the other. Getting the balance somewhere in between is the key.
]]>
Some observations on living in Chile2013-11-19T00:00:00Z2013-11-19T00:00:00ZJazahttps://greenash.net.au/thoughts/2013/11/some-observations-on-living-in-chile/
For almost two years now, I've been living in the grand metropolis of Santiago de Chile. My time here will soon be coming to an end, and before I depart, I'd like to share some of my observations regarding the particularities of life in this city and in this country – principally, as compared with life in my home town, Sydney Australia.
There are plenty of articles round and about the interwebz, aimed more at the practical side of coming to Chile: i.e. tips regarding how to get around; lists of rough prices of goods / services; and crash courses in Chilean Spanish. There are also a number of commentaries on the cultural / social differences between Chile and elsewhere – on the national psyche, and on the political / economic situation.
My endeavour is to avoid this article from falling neatly into either of those categories. That is, I'll be covering some eccentricities of Chile that aren't practical tips as such, although knowing about them may come in handy some day; and I'll be covering some anecdotes that certainly reflect on cultural themes, but that don't pretend to paint the Chilean landscape inside-out, either.
Here in Chile, all that is money-related is monthly. You pay everything monthly (your rent, all your bills, all membership fees e.g. gym, school / university fees, health / home / car insurance, etc); and you get paid monthly (if you work here, which I don't). I know that Chile isn't the only country with this modus operandi: I believe it's the European system; and as far as I know, it's the system in various other Latin American countries too.
In Australia – and as far as I know, in most English-speaking countries – there are no set-in-stone rules about the frequency with which you pay things, or with which you get paid. Bills / fees can be weekly, monthly, quarterly, annual… whatever (although rent is generally charged and is talked about as a weekly cost). Your pay cheque can be weekly, fortnightly, monthly, quarterly… equally whatever (although we talk about "how much you earn" annually, even though hardly anyone is paid annually). I guess the "all monthly" system is more consistent, and I guess it makes it easier to calculate and compare costs. However, having grown up with the "whatever" system, "all monthly" seems strange and somewhat amusing to me.
In Chile, although payment due dates can be anytime throughout the month, almost everyone receives their salary at fin de mes (the end of the month). I believe the (rough) rule is: the dosh arrives on the actual last day of the month if it's a regular weekday; or the last regular weekday of the month, if the actual last day is a weekend or public holiday (which is quite often, since Chile has a lot of public holidays – twice as many as Australia!).
This system, combined with the last-minute / impulsive form of living here, has an effect that's amusing, frustrating, and (when you think about it) depressingly predictable. As I like to say (in jest, to the locals): in Chile, it's Christmas time every end-of-month! The shops are packed, the restaurants are overflowing, and the traffic is insane, on the last day and the subsequent few days of each month. For the rest of the month, all is quiet. Especially the week before fin de mes, which is really Struggle Street for Chileans. So extreme is this fin de mes culture, that it's even busy at the petrol stations at this time, because many wait for their pay cheque before going to fill up the tank.
This really surprised me during my first few months in Chile. I used to ask: ¿Qué pasa? ¿Hay algo important hoy? ("What's going on? Is something important happening today?"). To which locals would respond: Es fin de mes! Hoy te pagan! ("It's end-of-month! You get paid today!"). These days, I'm more-or-less getting the hang of the cycle; although I don't think I'll ever really get my head around it. I'm pretty sure that, even if we did all get paid on the same day in Australia (which we don't), we wouldn't all rush straight to the shops in a mad stampede, desperate to spend the lot. But hey, that's how life is around here.
Cuotas
Continuing with the socio-economic theme, and also continuing with the "all-monthly" theme: another Chile-ism that will never cease to amuse and amaze me, is the omnipresent cuotas ("monthly instalments"). Chile has seen a spectacular rise in the use of credit cards, over the last few decades. However, the way these credit cards work is somewhat unique, compared with the usual credit system in Australia and elsewhere.
Any time you make a credit card purchase in Chile, the cashier / shop assistant will, without fail, ask you: ¿cuántas cuotas? ("how many instalments?"). If you're using a foreign credit card, like myself, then you must always answer: sin cuotas ("no instalments"). This is because, even if you wanted to pay for your purchase in chunks over the next 3-24 months (and trust me, you don't), you can't, because this system of "choosing at point of purchase to pay in instalments" only works with local Chilean cards.
Chile's current president, the multi-millionaire Sebastian Piñera, played an important part in bringing the credit card to Chile, during his involvement with the banking industry before entering politics. He's also generally regarded as the inventor of the cuotas system. The ability to choose your monthly instalments at point of sale is now supported by all credit cards, all payment machines, all banks, and all credit-accepting retailers nationwide. The system has even spread to some of Chile's neighbours, including Argentina.
Unfortunately, although it seems like something useful for the consumer, the truth is exactly the opposite: the cuotas system and its offspring, the cuotas national psyche, has resulted in the vast majority of Chileans (particularly the less wealthy among them) being permanently and inescapably mired in debt. What's more, although some of the cuotas offered are interest-free (with the most typical being a no-interest 3-instalment plan), some plans and some cards (most notoriously the "department store bank" cards) charge exhorbitantly high interest, and are riddled with unfair and arcane terms and conditions.
Última hora
Chile's a funny place, because it's so "not Latin America" in certain aspects (e.g. much better infrastructure than most of its neighbours), and yet it's so "spot-on Latin America" in other aspects. The última hora ("last-minute") way of living definitely falls within the latter category.
In Chile, people do not make plans in advance. At least, not for anything social- or family-related. Ask someone in Chile: "what are you doing next weekend?" And their answer will probably be: "I don't know, the weekend hasn't arrived yet… we'll see!" If your friends or family want to get together with you in Chile, don't expect a phone call the week before. Expect a phone call about an hour before.
I'm not just talking about casual meet-ups, either. In Chile, expect to be invited to large birthday parties a few hours before. Expect to know what you're doing for Christmas / New Year a few hours before. And even expect to know if you're going on a trip or not, a few hours before (and if it's a multi-day trip, expect to find a place to stay when you arrive, because Chileans aren't big on making reservations).
This is in stark contrast to Australia, where most people have a calendar to organise their personal life (something extremely uncommon in Chile), and where most peoples' evenings and weekends are booked out at least a week or two in advance. Ask someone in Sydney what their schedule is for the next week. The answer will probably be: "well, I've got yoga tomorrow evening, I'm catching up with Steve for lunch on Wednesday, big party with some old friends on Friday night, beach picnic on Saturday afternoon, and a fancy dress party in the city on Saturday night." Plus, ask them what they're doing in two months' time, and they'll probably already have booked: "6 nights staying in a bungalow near Batemans Bay".
The última hora system is both refreshing and frustrating, for a planned-ahead foreigner like myself. It makes you realise just how regimented, inflexible, and lacking in spontenaeity life can be in your home country. But, then again, it also makes you tear your hair out, when people make zero effort to co-ordinate different events and to avoid clashes. Plus, it makes for many an awkward silence when the folks back home ask the question that everybody asks back home, but that nobody asks around here: "so, what are you doing next weekend?" Depends which way the wind blows.
Sit down
In Chile (and elsewhere nearby, e.g. Argentina), you do not eat or drink while standing. In most bars in Chile, everyone is sitting down. In fact, in general there is little or no "bar" area, in bars around here; it's all tables and chairs. If there are no tables or chairs left, people will go to a different bar, or wait for seats to become vacant before eating / drinking. Same applies in the home, in the park, in the garden, or elsewhere: nobody eats or drinks standing up. Not even beer. Not even nuts. Not even potato chips.
In Australia (and in most other English-speaking countries, as far as I know), most people eat and drink while standing, in a range of different contexts. If you're in a crowded bar or pub, eating / drinking / talking while standing is considered normal. Likewise for a big house party. Same deal if you're in the park and you don't want to sit on the grass. I know it's only a little thing; but it's one of those little things that you only realise is different in other cultures, after you've lived somewhere else.
It's also fairly common to see someone eating their take-away or other food while walking, in Australia. Perhaps some hot chips while ambling along the beach. Perhaps a sandwich for lunch while running (late) to a meeting. Or perhaps some lollies on the way to the bus stop. All stuff you wouldn't blink twice at back in Oz. In Chile, that is simply not done. Doesn't matter if you're in a hurry. It couldn't possibly be such a hurry, that you can't sit down to eat in a civilised fashion. The Chilean system is probably better for your digestion! And they have a point: perhaps the solution isn't to save time by eating and walking, but simply to be in less of a hurry?
Do you see anyone eating / drinking and standing up? I don't. Image source:Dondequieroir.
Walled and shuttered
One of the most striking visual differences between the Santiago and Sydney streetscapes, in my opinion, is that walled-up and shuttered-up buildings are far more prevalent in the former than in the latter. Santiago is not a dangerous city, by Latin-American or even by most Western standards; however, it often feels much less secure than it should, particularly at night, because often all you can see around you is chains, padlocks, and sturdy grilles. Chileans tend to shut up shop Fort Knox-style.
Walk down Santiago's Ahumada shopping strip in the evening, and none of the shopfronts can be seen. No glass, no lit-up signs, no posters. Just grey steel shutters. Walk down Sydney's Pitt St in the evening, and – even though all the shops close earlier than in Santiago – it doesn't feel like a prison, it just feels like a shopping area after-hours.
In Chile, virtually all houses and apartment buildings are walled and gated. Also, particularly ugly in my opinion, schools in Chile are surrounded by high thick walls. For both houses and schools, it doesn't matter if they're upper- or lower-class, nor what part of town they're in: that's just the way they build them around here. In Australia, on the other hand, you can see most houses and gardens from the street as you go past (and walled-in houses are criticised as being owned by "paranoid people"); same with schools, which tend to be open and abundant spaces, seldom delimiting their boundary with anything more than a low mesh fence.
As I said, Santiago isn't a particularly dangerous city, although it's true that robbery is far more common here than in Sydney. The real difference, in my opinion, is that Chileans simply don't feel safe unless they're walled in and shuttered up. Plus, it's something of a vicious cycle: if everyone else in the city has a wall around their house, and you don't, then chances are that your house will be targeted, not because it's actually easier to break into than the house next door (which has a wall that can be easily jumped over anyway), but simply because it looks more exposed. Anyway, I will continue to argue to Chileans that their country (and the world in general) would be better with less walls and less barriers; and, no doubt, they will continue to stare back at me in bewilderment.
Santiago's central shopping strip on Sunday: grey on grey. Image source:eszsara (Flickriver).
In summary
So, there you have it: a few of my random observations about life in Santiago, Chile. I hope you've found them educational and entertaining. Overall, I've enjoyed my time in this city; and while I'm sometimes critical of and poke fun at Santiago's (and Chile's) peculiarities, I'm also pretty sure I'll miss then when I'm gone. If you have any conclusions of your own regarding life in this big city, feel free to share them below.
]]>
How smart are smartphones?2013-11-02T00:00:00Z2013-11-02T00:00:00ZJazahttps://greenash.net.au/thoughts/2013/11/how-smart-are-smartphones/
As of about two months ago, I am a very late and reluctant entrant into the world of smartphones. All that my friends and family could say to me, was: "What took you so long?!" Being a web developer, everyone expected that I'd already long since jumped on the bandwagon. However, I was actually in no hurry to make the switch.
Techomeanies: sad dinosaur. Image source:Sticky Comics.
Being now acquainted with my new toy, I believe I can safely say that my reluctance was not (entirely) based on my being a "phone dinosaur", an accusation that some have levelled at me. Apart from the fact that they offer "a tonne of features that I don't need", I'd assert that the current state-of-the-art in smartphones suffers some serious usability, accessibility, and convenience issues. In short: these babies ain't so smart as their purty name suggests. These babies still have a lotta growin' up to do.
Hello Operator, how do I send a telegram to Aunt Gertie in Cheshire using Android 4.1.2? Image source:sondasmcschatter.
Touchy
Mobile phones with few buttons are all the rage these days. This is principally thanks to the demi-g-ds at Apple, who deign that we mere mortals should embrace all that is white with chrome bezel.
Apple has been waging war on the button for some time. For decades, the Mac mouse has been a single-button affair, in contrast to the two- or three-button standard PC rodent. Since the dawn of the iEra, a single (wheel-like) button has predominated all iShtuff. (For a bit of fun, watch how this single-button phenomenon reached its unholy zenith with the unveiling of the MacBook Wheel). And, most recently, since Apple's invention of the i(AmTheOneTrue)Phone (of which all other smartphones are but a paltry and pathetic imitation attempted by mere mortals), smartphones have been almost by definition "big on touch-screen, low on touch-button".
Oh sorry, did I forget to mention that I can't resist bashing the Cult of Mac at every opportunity? Image source:Crazy Art Ideas.
I'm not happy about this. I like buttons. You can feel buttons. There is physical space between each button. Buttons physically move when you press them.
You can't feel the icons on a touch screen. A touch screen is one uninterrupted physical surface. And a touch screen doesn't provide any tactile response when pressed.
There is active ongoing research in this field. Just this year, the world's first fully-functional bumpy touchscreen prototype was showcased, by California-based Tactus. However, so far no commercial smartphones have been developed using this technology. Hopefully, in another few years' time, the situation will be different; but for the current state-of-the-art smartphones, the lack of tactile feedback in the touch screens is a serious usability issue.
Related to this, is the touch-screen keyboard that current-generation smartphones provide. Seriously, it's a shocker. I wouldn't say I have particularly fat fingers, nor would I call myself a luddite (am I not a web developer?). Nevertheless, touch-screen keyboards frustrate the hell out of me. And, as I understand it, I'm not alone in my anguish. I'm far too often hitting a letter adjacent to the one I poked. Apart from the lack of extruding keys / tactile feedback, each letter is also unmanageably small. It takes me 20 minutes to write an e-mail on my smartphone, that I can write in about 4 minutes on my laptop.
Touch screens have other issues, too. Manufacturers are struggling to get touch sensitivity level spot-on: from my personal experience, my Galaxy S3 is far too hyper-sensitive, even the lightest brush of a finger sets it off; whereas my fiancée's iPhone 4 is somewhat under-sensitive, it almost never responds to my touch until I start poking it hard (although maybe it just senses my anti-Apple vibes and says STFU). The fragility of touch screens is also of serious concern – as a friend of mine recently joked: "these new phones are delicate little princesses". Fortunately, I haven't had any shattered or broken touch-screen incidents as yet (only a small superficial scratch so far); but I've heard plenty of stories.
Before my recent switch to Samsung, I was a Nokia boy for almost 10 years – about half that time (the recent half) with a 6300; and the other half (the really good ol' days) with a 3100. Both of those phones were "bricks", as flip-phones never attracted me. Both of them were treated like cr@p and endured everything (especially the ol' 3100, which was a wonderfully tough little bugger). Both had a regular keypad (the 3100's keypad boasted particularly rubbery, well-spaced buttons), with which I could write text messages quickly and proficiently. And both sported more button real-estate than screen real-estate. All good qualities that are naught to be found in the current crop of touch-monsters.
Great, but can you make calls with it?
After the general touch-screen issues, this would have to be my next biggest criticism of smartphones. Big on smart, low on phone.
But hey, I guess it's better than "big on shoe, low on phone". Image source:Ars Technica.
Smartphones let you check your email, update your Facebook status, post your phone-camera-taken photos on Instagram, listen to music, watch movies, read books, find your nearest wood-fired pizza joint that's open on Mondays, and much more. They also, apparently, let you make and receive phone calls.
It's not particularly hard to make calls with a smartphone. But, then again, it's not as easy as it was with "dumb phones", nor is it as easy as it should be. On both of the smartphones that I'm now most familiar with (Galaxy S3 and iPhone 4), calling a contact requires more than the minimum two clicks ("open contacts", and "press call"). On the S3, this can be done with a click and a "swipe right", which (although I've now gotten used to it) felt really unintuitive to begin with. Plus, there's no physical "call" button, only a touch-screen "call" icon (making it too easy to accidentally message / email / Facebook someone when you meant to call them, and vice-versa).
Receiving calls is more problematic, and caused me significant frustration to begin with. Numerous times, I've rejected a call when I meant to answer it (by either touching the wrong icon, or by the screen getting brushed as I extract the phone from my pocket). And really, Samsung, what crazy-a$$ Gangman-style substances were you guys high on, when you decided that "hold and swipe in one direction to answer, hold and swipe in the other direction to reject" was somehow a good idea? The phone is ringing, I have about five seconds, so please don't make me think!
In my opinion, there REALLY should be a physical "answer / call" button on all phones, period. And, on a related note, rejecting calls and hanging up (which are tasks just as critical as are calling / answering) are difficulty-fraught too; and there also REALLY should be a physical "hang up" button on all phones, period. I know that various smartphones have had, and continue to have, these two physical buttons; however, bafflingly, neither the iPhone nor the Galaxy include them. And once again, Samsung, one must wonder how many purple unicorns were galloping over the cubicles, when you decided that "let's turn off the screen when you want to hang up, and oh, if by sheer providence the screen is on when you want to hang up, the hang-up button could be hidden in the slid-up notification bar" was what actual carbon-based human lifeforms wanted in a phone?
Hot and shagged out
Two other critical problems that I've noticed with both the Galaxy and the iPhone (the two smartphones that are currently considered the crème de la crème of the market, I should emphasise).
Firstly, they both start getting quite hot, after just a few minutes of any intense activity (making a call, going online, playing games, etc). Now, I understand that smartphones are full-fledged albeit pocked-sized computers (for example, the Galaxy S3 has a quad-core processor and 1-2GB of RAM). However, regular computers tend to sit on tables or floors. Holding a hot device in your hands, or keeping one in your pocket, is actually very uncomfortable. Not to mention a safety hazard.
Secondly, there's the battery-life problem. Smartphones may let you do everything under the sun, but they don't let you do it all day without a recharge. It seems pretty clear to me that while smartphones are a massive advancement compared to traditional mobiles, the battery technology hasn't advanced anywhere near on par. As many others have reported, even with relatively light use, you're lucky to last a full day without needing to plug your baby in for some intravenous AC TLC.
In summary
I've had a good ol' rant, about the main annoyances I've encountered during my recent initiation into the world of smartphones. I've focused mainly on the technical issues that have been bugging me. Various online commentaries have discussed other aspects of smartphones: for example, the oft-unreasonable costs of owning one; and the social and psychological concerns, such as aggression / meanness, impatience / chronic boredom, and endemic antisocial behaviour (that last article also mentions another concern that I've written about before, how GPS is eroding navigational ability). While in general I agree with these commentaries, personally I don't feel they're such critical issues – or, to be more specific, I guess I feel that these issues already existed and already did their damage in the "traditional mobile phone" era, and that smartphones haven't worsened things noticeably. So, I won't be discussing those themes in this article.
Anyway, despite my scathing criticism, the fact is that I'm actually very impressed with all the cool things that smartphones can do; and yes, although I was dragged kicking and screaming, I have also succumbed and joined the "dark side" myself, and I must admit that I've already made quite thorough use of many of my smartphone's features. Also, it must be remembered that – although many people already claim that they "can hardly remember what life was like before smartphones" – this is a technology that's still in its infancy, and it's only fair and reasonable that there are still numerous (technical and other) kinks yet to be ironed out.
]]>
Symfony2: as good as PHP gets?2013-10-16T00:00:00Z2013-10-16T00:00:00ZJazahttps://greenash.net.au/thoughts/2013/10/symfony2-as-good-as-php-gets/
I've been getting my hands dirty with Symfony2 of late. At the start of the year, I was introduced to it when I built an app using Silex (a Symfony2 distribution). The special feature of my app was that it allows integration between Silex and Drupal 7.
More recently, I finished another project, which I decided to implement using Symfony2 Standard Edition. Similar to my earlier project, it had the business requirement that it needed tight integration with a Drupal site; so, for this new project, I decided to write a Symfony2 Drupal integration bundle.
Overall, I'm quite impressed with Symfony2 (in its various flavours), and I enjoy coding in it. I've been struggling to enjoy coding in Drupal (and PHP in general) – the environment that I know best – for quite some time. That's why I've been increasingly turning to Django (and other Python frameworks, e.g. Flask), for my dev projects. Symfony2 is a very welcome breath of fresh air in the PHP world.
However, I can't help but think: is Symfony2 "as good as PHP gets"? By that, I mean: Symfony2 appears to have borrowed many of the best practices that have evolved in the non-PHP world, and to have implemented them about as well as they physically can be implemented in PHP (indeed, the same could be said of PHP itself of late). But, PHP being so inferior to most of its competitors in so many ways, PHP implementations are also doomed to being inferior to their alternatives.
Pragmatism
I try to be a pragmatic programmer – I believe that I'm getting more pragmatic, and less sentimental, as I continue to mature as a programmer. That means that my top concerns when choosing a framework / environment are:
Which one helps me get the job done in the most efficient manner possible? (i.e. which one costs my client the least money right now)
Which one best supports me in building a maintainable, well-documented, re-usable solution? (i.e. which one will cost my client the least money in the long-term)
Which one helps me avoid frustrations such as repetitive coding, reverse-engineering, and manual deployment steps? (i.e. which one costs me the least headaches and knuckle-crackings)
Symfony2 definitely gets more brownie points from me than Drupal does, on the pragmatic front. For projects whose data model falls outside the standard CMS data model (i.e. pages, tags, assets, links, etc), I need an ORM (which Drupal's field API is not). For projects whose business logic falls outside the standard CMS business logic model (i.e. view / edit pages, submit simple web forms, search pages by keyword / tag / date, etc), I need a request router (which Drupal's menu API is not). It's also a nice added bonus to have a view / template system that gives me full control over the output without kicking and screaming (as is customary for Drupal's theme system).
However, Symfony2 Standard Edition is a framework, and Drupal is a CMS. Apples and oranges.
Django is a framework. It's also been noted already, by various other people, that many aspects of Symfony2 were inspired by their counterparts in Django (among other frameworks, e.g. Ruby on Rails). So, how about comparing Symfony2 with Django?
Although they're written in different languages, Symfony2 and Django actually have quite a lot in common. In particular, Symfony2's Twig template engine is syntactically very similar to the Django template language; in fact, it's fairly obvious that Twig's syntax was ripped off from inspired by that of Django templates (Twig isn't the first Django-esque template engine, either, so I guess that if imitation is the highest form of flattery, then the Django template language should be feeling thoroughly flattered by now).
The request routing / handling systems of Symfony2 and Django are also fairly similar. However, there are significant differences in their implementation styles; and in my personal opinion, the Symfony2 style feels more cumbersome and less elegant than the Django style.
For example, here's the code you'd need to implement a basic 'Hello World' callback:
In Symfony2
app/AppKernel.php (in AppKernel->registerBundles()):
<?php
$bundles = array(
// ...
new Hello\Bundle\HelloBundle(),
);
<?php
namespace Hello\Bundle\Controller;
use Symfony\Component\HttpFoundation\Response;
class DefaultController extends Controller
{
/**
* @Route("/")
*/
public function indexAction()
{
return new Response('Hello World');
}
}
In Django
project/settings.py:
INSTALLED_APPS = [
# ...
'hello',
]
project/urls.py:
from django.conf.urls import *
from hello.views import index
urlpatterns = patterns('',
# ...
url(r'^$', index, name='hello'),
)
project/hello/views.py:
from django.http import HttpResponse
def index(request):
return HttpResponse("Hello World")
As you can see above, the steps involved are basically the same for each system. First, we have to register with the framework the "thing" that our Hello World callback lives in: in Symfony2, the "thing" is called a bundle; and in Django, it's called an app. In both systems, we simply add it to the list of installed / registered "things". However, in Symfony2, we have to instantiate a new object, and we have to specify the namespace path to the class; whereas in Django, we simply add the (path-free) name of the "thing" to a list, as a string.
Next, we have to set up routing to our request callback. In Symfony2, this involves using a configuration language (YAML), rather than the framework's programming language (PHP); and it involves specifying the "path" to the callback, as well as the format in which the callback is defined ("annotation" in this case). In Django, it involves importing the callback "callable" as an object, and adding it to the "urlpatterns" list, along with a regular expression defining its URL path.
Finally, there's the callback itself. In Symfony2, the callback lives in a FooController.php file within a bundle's Controller directory. The callback itself is an "action" method that lives within a "controller" class (you can have multiple "actions", in this example there's just one). In Django, the callback doesn't have to be a method within a class: it can be any Python "callable", such as a "class object"; or, as is the case here, a simple function.
I could go on here, and continue with more code comparisons (e.g. database querying / ORM system, form system, logging); but I think what I've shown is sufficient for drawing some basic observations. Feel free to explore Symfony2 / Django code samples in more depth if you're still curious.
Funny language
Basically, my criticism is not of Symfony2, as such. My criticism is more of PHP. In particular, I dislike both the syntax and the practical limitations of the namespace system that was introduced in PHP 5.3. I've blogged before about what bugs me in a PHP 5.3-based framework, and after writing that article I was accused that my PHP 5.3 rants were clouding my judgement of the framework. So, in this article I'd like to more clearly separate language ranting from framework ranting.
Language rant
In the PHP 5.3+ namespace system:
The namespace delimiter is the backslash character; whereas in other (saner) languages it's the dot character
You have to specify the "namespace path" using the "namespace" declaration at the top of every single file in your project that contains namespaced classes; whereas in other (saner) languages the "namespace path" is determined automatically based on directory structure
You can only import namespaces using their absolute path, resulting in overly verbose "use" declarations all over the place; wheras in other (saner) languages relative (and wildcard) namespace imports are possible
Framework rant
In Symfony2:
You're able to define configuration (e.g. routing callbacks) in multiple formats, with the preferred format being YAML (although raw PHP configuration is also possible), resulting in an over-engineered config system, and unnecessary extra learning for an invented format in order to perform configuration in the default way
Only a class method can be a routing callback, a class itself or a stand-alone function cannot be a callback, as the routing system is too tightly coupled with PHP's class- and method-based namespace system
An overly complex and multi-levelled directory structure is needed for even the simplest projects, and what's more, overly verbose namespace declarations and import statements are found in almost every file; this is all a reflection of Symfony2's dependence on the PHP 5.3+ namespace system
In summary
Let me repeat: I really do think that Symfony2 is a great framework. I've done professional work with it recently. I intend to continue doing professional work with it in the future. It ticks my pragmatic box of supporting me in building a maintainable, well-documented, re-usable solution. It also ticks my box of avoiding reverse-engineering and manual deployment steps.
However, does it help me get the job done in the most efficient manner possible? If I have to work in PHP, then yes. If I have the choice of working in Python instead, then no. And does it help me avoid frustrations such as repetitive coding? More-or-less: Symfony2 project code isn't too repetitive, but it certainly isn't as compact as I'd like my code to be.
Symfony2 is brimming with the very best of what cutting-edge PHP has to offer. But, at the same time, it's hindered by its "PHP-ness". I look forward to seeing the framework continue to mature and to evolve. And I hope that Symfony2 serves as an example to all programmers, working in all languages, of how to build the most robust product possible, within the limits of that product's foundations and dependencies.
]]>
Current state of the Cape to Cairo Railway2013-08-01T00:00:00Z2013-08-01T00:00:00ZJazahttps://greenash.net.au/thoughts/2013/08/current-state-of-the-cape-to-cairo-railway/
In the late 19th century, the British-South-African personality Cecil Rhodes dreamed of a complete, uninterrupted railway stretching from Cape Town, South Africa, all the way to Cairo, Egypt. During Rhodes's lifetime, the railway extended as far north as modern-day Zimbabwe – which was in that era known by its colonial name Rhodesia (in honour of Rhodes, whose statesmanship and entrepreneurism made its founding possible). A railway traversing the entire north-south length of Africa was an ambitious dream, for an ambitious man.
Rhodes's dream remains unfulfilled to this day.
The famous "Rhodes Colossus", superimposed upon the present-day route of the Cape to Cairo Railway. "The Rhodes Colossus" illustration originally from Punch magazine, Vol. 103, 10 Dec 1892; image courtesy of Wikimedia Commons. Africa satellite image courtesy of Google Earth.
Nevertheless, significant additions have been made to Africa's rail network during the interluding century; and, in fact, only a surprisingly small section of the Cape to Cairo route remains bereft of the Iron Horse's footprint.
Although both information about – (a) the historical Cape to Cairo dream; and (b) the history / current state of the route's various railway segments – abound, I was unable to find any comprehensive study of the current state of the railway in its entirety.
This article, therefore, is an endeavour to examine the current state of the full Cape to Cairo Railway. As part of this study, I've prepared a detailed map of the route, which marks in-service sections, abandoned sections, and missing sections. The map has been generated from a series of KML files, which I've made publicly available on GitHub, and for which I welcome contributions in the form of corrections / tweaks to the route.
Southern section
As its name suggests, the line begins in Cape Town, South Africa. The southern section of the railway encompasses South Africa itself, along with the nearby countries that have historically been part of the South African sphere of influence: that is, Botswana, Zimbabwe, and Zambia.
Southern section of the Cape to Cairo Railway: Cape Town to Kapiri Mposhi.
The first segment – Cape Town to Johannesburg – is also the oldest, the best-maintained, and the best-serviced part of the entire route. The first train travelled this segment in 1892. There has been continuous service ever since. It's the only train route in all of Africa that can honestly claim to provide a "European standard" of passenger service, between the two major cities that it links. That is, there are numerous classes of service operating on the line – ranging from basic inter-city commuter trains, to business-style fast trains, to luxury sleeper trains – running several times a day.
So, the first leg of the railway is the one that we should be least worried about. Hence, it's marked in green on the map. This should come as no surprise, considering that South Africa has the best-developed infrastructure in all of Africa (by a long shot), as well as Africa's largest economy.
After Johannesburg, we continue along the railway that was already fulfilling Cecil Rhodes's dream before his death. This segment runs through modern-day Botswana, which was previously known as Bechuanaland Protectorate. From Johannesburg, it connects to the city of Mafeking, which was the capital of the former Bechuanaland Protectorate, but which today is within South Africa (where it is a regional capital). The line then crosses the border into Botswana, passes through the capital Gaborone, and continues to the city of Francistown in Botswana's north-east.
Unfortunately, since the opening of the Beitbridge Bulawayo Railway in Zimbabwe in 1999 (providing a direct train route between Zimbabwe and South Africa for the first time), virtually all regular passenger service on this segment (and hence, virtually all regular passenger service on Botswana's train network) has been cancelled. The track is still being maintained, and (apart from some freight trains) there are still occasional luxury tourist trains using the route. However, it's unclear if there are still any regular passenger services between Johannesburg and Mafeking (if there are, they're very few); and sources indicate that there are no regular passenger services at all between Mafeking and Francistown. Hence, the segment is marked in yellow on the map.
(I should also note that the new direct train route from South Africa to Zimbabwe, does actually provide regular passenger service, from Johannesburg to Messina, and then from Beitbridge to Bulawayo, with service missing only in the short border crossing between Messina and Beitbridge. However, I still consider the segment via Botswana to be part of the definitive "Cape to Cairo" route: because of its historical importance; and because only quite recently has service ceased on this segment and has an alternative segment been open.)
From Francistown onwards, the situation is back in the green. There is a passenger train from Francistown to Bulawayo, that runs three times a week. I should also mention here, that Bulawayo is quite a significant spot on the Cape to Cairo Railway, as (a) the grave of Cecil Rhodes can be found atop "World's View", a panoramic hilltop in nearby Matobo National Park; and (b) Bulawayo was the first city that the railway reached in (former) Rhodesia, and to this day it remains Zimbabwe's rail hub. Bulawayo is also home to a railway museum.
For the remainder of the route through Zimbabwe, the line remains in the green. There's a daily passenger service from Bulawayo to Victoria Falls. Sadly, this spectacular leg of the route has lost much of its former glory: due to Zimbabwe's recent economic and political woes, the trains are apparently looking somewhat the worse for wear. Nevertheless, the service continues to be popular and reasonably reliable.
The green is briefly interrupted by a patch of yellow, at the border crossing between Zimbabwe and Zambia. This is because there has been no passenger service over the famous Victoria Falls Bridge – which crosses the Zambezi River at spraying distance from the colossal waterfall, connecting the towns of Victoria Falls and Livingstone – more-or-less since the 1970s. Unless you're on board one of the infrequent luxury tourist trains that still traverse the bridge, it must be crossed on foot (or using local transport). It should also be noted that although the bridge is still most definitely intact and looking solid, it's more than 100 years old, and experts have questioned whether it's receiving adequate care and maintenance.
Victoria Falls Bridge: a marvel of modern engineering, straddles one of the world's natural wonders. Image sourced from: Car Hire Victoria Falls.
Once in Zambia – formerly known as Northern Rhodesia – regular passenger services continue north to the capital, Lusaka; and from there, onward to the crossroads town of Kapiri Mposhi. It's here that the southern portion of the modern-day Cape to Cairo railway ends, since Kapiri Mposhi is the meeting-point of the colonial-era, British-built, South-African / Rhodesian railway network, and a modern-era East-African rail link that was unanticipated in Rhodes's plan.
I should also mention here that the colonial-era network continues north from Kapiri Mposhi, crossing the border with modern-day DR Congo (formerly known as the Belgian Congo), and continuing up to the shores of Lake Tanganyika, where it terminates at the town of Kalemie. The plan in the colonial era was that the Cape to Cairo passenger link would continue north via the Great Lakes in this region of Africa – in the form of lake / river ferries, up to Lake Albert, on the present-day DR Congo / Ugandan border – after which the rail link would resume, up to Egypt via Sudan.
However, I don't consider this segment to be part of the definitive "Cape to Cairo" route, because: (a) further rail links between the Great Lakes, up to Lake Albert, were never built; (b) the line running through eastern DR Congo, from the Zambian border to Kalemie on Lake Tanganyika, is apparently in serious disrepair; and (c) an alternative continuous rail link has existed, since the 1970s, via East Africa, and the point where this link terminates in modern-day Uganda is north of Lake Albert anyway. Therefore, the DR Congo – Great Lakes segment is only being mentioned here as an anecdote of history; and we now turn our attention to the East African network.
Eastern section
The Eastern section of the railway is centred in modern-day Tanzania and Kenya, although it begins and ends within the inland neighbours of these two coastal nations – Zambia and Uganda, respectively. This region, much like Southern Africa, was predominantly ruled under British colonialism in the 19th century (which is why Kenya, the region's hub, was formerly known as British East Africa). However, modern-day Tanzania (formerly called Tanganyika, before the union of Tanganyika with Zanzibar) was originally German East Africa, before becoming a British protectorate in the 20th century.
Eastern section of the Cape to Cairo Railway: Kapiri Mposhi to Gulu.
Kapiri Mposhi, in Zambia, is the start of the TAZARA Railway; this railway runs through the north-east of Zambia, crosses the border to Tanzania near Mbeya, and finishes on the Indian Ocean coast at Dar es Salaam, Tanzania's largest city.
The TAZARA is the newest link in the Cape to Cairo railway network: it was built and financed by the Chinese, and was opened in 1976. It's the only line in the network – and one of the only railway lines in all of Africa – that was built (a) by non-Europeans; and (b) in the post-colonial era. It was not envisioned by Rhodes (nor by his contemporaries), who wanted the line to pass through wholly British-controlled territory (Tanzania was still German East Africa in Rhodes's era). The Zambians wanted it, in order to alleviate their dependence (for international transport) on their southern neighbours Rhodesia and South Africa, with whom tensions were high in the 1970s, due to those nations' Apartheid governments. The line has been in regular operation since opening; hence, it's marked in green on the map.
The TAZARA: a "modern" rail link... African style. Image source: Mzuzu Transit.
Although the TAZARA line doesn't quite touch the other Tanzanian railway lines that meet in Dar es Salaam, I haven't marked any gap in the route at Dar es Salaam. This is for two reasons. Firstly, from what I can tell (by looking at maps and satellite imagery), the terminus of the TAZARA in Dar es Salaam is physically separated from the other lines, by a distance of less than two blocks, i.e. a negligible amount. Secondly, the TAZARA is (as of 1998) physically connected to the other Tanzanian railway lines, at a junction near the town of Kidatu, and there is a cargo transshipment facility at this location. However, I don't believe there's any passenger service from Kidatu to the rest of the Tanzanian network (only cargo trains). So, the Kidatu connection is being mentioned here only as an anecdote; in my opinion, the definitive "Cape to Cairo" route passes through, and connects at, Dar es Salaam.
From Dar es Salaam, the line north is part of the decaying colonial-era Tanzanian rail network. This line extends up to the city of Arusha; the part that we're interested in ends at Moshi (east of Arusha), from where another line branches off, crossing the border into Kenya. Sadly, there has been no regular passenger service on the Arusha line for many years; therefore, nor is there any service to Moshi.
After crossing the Kenyan border, the route passes through the town of Taveta, before continuing on to Voi; here, there is a junction with the most important train line in Kenya: that which connects Mombasa and Nairobi. As with the Arusha line, the Moshi – Voi line has also been bereft of regular passenger service for many years. This entire portion of the rail network appears to be in a serious state of neglect. If there are any trains running in this area, they would be occasional freight trains; and if any track maintenance is being performed on these lines, it would be the bare minimum. Therefore, the full segment from Dar es Salaam to Voi is marked in yellow on the map.
From Voi, there are regular passenger services on the main Kenyan rail line to Nairobi; and onward from Nairobi, there are further passenger services (which appear to be less reliable, but regular nonetheless) to the city of Kisumu, which borders Lake Victoria. The part of this route that we're interested in ends at Nakuru (about halfway between Nairobi and Kisumu), from where another line branches off towards Uganda. The route through Kenya, from Voi to Nakuru, is therefore in the green.
After Nakuru, the line meanders its way towards the Ugandan border; and at Tororo (a city on the Ugandan side), it connects with the Ugandan network. There is apparently no longer any passenger service available from Nakuru to Tororo – i.e. there is no service between Kenya and Uganda. As such, this segment is marked in yellow.
The once-proud Ugandan railway network today lies largely abandoned, a victim of Uganda's tragic history of dictatorship, bloodshed and economic disaster since the 1970s. The only inter-city line that maintains regular passenger service, is the main line from the capital, Kampala, to Tororo. As this line terminates at Kampala, on the shores of Lake Victoria (like the Kenyan line to Kisumu), it is of little interest to us.
From Tororo, Uganda's northern railway line stretches north and then west across the country in a grand arc, before terminating at Pakwach, the point where the Albert Nile river begins, adjacent to Lake Albert. (This line supposedly once continued from Pakwach to Arua; however, I haven't been able to find this extension marked on any maps, nor visible in any satellite imagery). The northernmost point of this railway line is at Gulu; and so, it is the segment of the line up to Gulu that interests us.
Sadly, the entire segment from Tororo to Gulu appears to be abandoned; whether there is even freight service today seems doubtful; thus, this segment is marked in yellow. And, doubly sad, Gulu is also the point at which a continuous, uninterrupted rail network all the way from Cape Town, comes to its present-day end. No rail line was ever constructed north of Gulu in Uganda. Therefore, it is at Gulu that the East African portion of the Cape to Cairo Railway bids us farewell.
Northern section
The northern section of the railway is mainly within Sudan and Egypt – although we'll be tracking (the missing section of) the route from northern Uganda; and, since 2011, the route also passes through the newly-independent South Sudan. As with its southern and eastern African counterparts, the northern part of the railway was primarily built by the British, during their former colonial rule in the region.
Northern section of the Cape to Cairo Railway: Gulu to Cairo.
We pick up from where we finished in the previous section: Gulu in northern Uganda. As has already been mentioned: from Gulu, we hit the first (of only two) – and the most significant – of the missing links in the Cape to Cairo Railway. The next point where the railway begins again, is the city of Wau, located in north-western South Sudan. Therefore, this segment of the route is marked in red on the map. In the interests of at least marking some form of transport along the missing link, the red line follows the main highway route through the region: the Ugandan A104 highway from Gulu north to the border; and from there, at the city of Nimule (just over the border in South Sudan), the South Sudanese A43 highway to Juba (the capital), and then on to Wau (this highway route is about 1,000km in total).
There has been no shortage of discussion, both past and present, regarding plans to bridge this important gap in the rail network. There have even been recent official announcements by the governments of Uganda and of South Sudan, declaring their intention to build a new rail segment from Gulu to Wau. However, there hasn't been any concrete action since the present-day railheads were established about 50 years ago; and, considering that northern Uganda / South Sudan is one of the most troubled regions in the world today, I wouldn't hold my breath waiting for any fresh steel to appear on the ground (not to mention waiting for repairs of the existing neglected / war-damaged train lines). The folks over there have plenty of other, more urgent matters to attend to.
Wau is the southern terminus of the Sudanese rail network. From Wau, the line heads more-or-less straight up, crossing the border from South Sudan into Sudan, and joining the Khartoum – Darfur line at Babanusa. The Babanusa – Wau line was one of the last train lines to be completed in Sudan, opening in 1962 (around the same time as the Tororo – Gulu – Pakwach line opened in neighbouring Uganda). I found a colourful account of a passenger journey along this line, from around 2000. As I understand it, shortly after this time, the line was damaged by mines and explosives, a victim of the civil war. The line is supposedly rehabilitated, and passenger service has ostensibly resumed – however, personally I'm not convinced that this is the case. Therefore, this segment is marked in yellow on the map.
Similarly, the remaining segment of rail onwards to the capital – Babanusa to Khartoum – was apparently damaged during the civil war (that's on top of the line's ageing and dismally-maintained state). There are supposedly efforts underway to rehabilitate this line (along with the rest of the Sudanese rail network in general), and to restore regular services along it. I haven't been able to confirm whether passenger services have yet been restored; therefore, this segment is also marked in yellow on the map.
From the Sudanese capital Khartoum, the country's principal train line traverses the rest of the route north, running along the banks of the Upper Nile for about half the route, before making a beeline across the harsh expanse of the Nubian Desert, and terminating just before the Egyptian border at the town of Wadi Halfa, on the shores of Lake Nasser (the Sudanese side of which is called Lake Nubia). Although trains do appear to get suspended for long-ish intervals, this is the best-maintained route in war-ravaged Sudan, and it appears that regular passenger services are operating from Khartoum to Wadi Halfa. Therefore, this segment is marked in green on the map.
The border crossing from Sudan into Egypt is the second of the two missing links in the Cape to Cairo Railway. In fact, there isn't even a road connecting the two nations, at least not anywhere near the Nile / Lake Nasser. However, this missing link is of less concern, because: (a) the distance is much less (approximately 350km); and (b) Lake Nasser is a large and easily navigable body of water, with regular ferry services connecting Wadi Halfa in Sudan with Aswan in Egypt. Indeed, the convenience and the efficiency of the ferry service (along with the cargo services operating on the lake) is the very reason why nobody's ever bothered to build a rail link through this segment. So, this segment is marked in red on the map: the red line more-or-less follows the ferry route over the lake.
Aswan is Egypt's southernmost city; this has been the case for millenia, since it was the southern frontier of the realm of the Pharoahs, stretching back to ancient times. Aswan is also the southern terminus of the Egyptian rail network's main line; from here, the line snakes its way north, tracing the curves of the heavily-populated Nile River valley, all the way to Cairo, after which the vast Nile Delta begins.
Train service running alongside the famous Nile River. Image source: About.com: Cruises.
The Aswan – Cairo line – the very last segment of Rhodes's grand envisioned network – is second only to the network's very first segment (Cape Town – Johannesburg) in terms of service offerings. There are a range of passenger services available, ranging from basic economy trains, to luxury tourist-oriented sleeper coaches, traversing the route daily. Although Egypt is currently in the midst of quite dramatic political turmoil (indeed, Egypt's recent military coup and ongoing protests are front-page news as I write this), as far as I know these issues haven't seriously disrupted the nation's train services. Therefore, this segment is marked in green on the map.
I should also note that after Cairo, Egypt's main rail line continues on to Alexandria on the Mediterranean coast. However, of course, the Cairo – Alexandria segment is not marked on the map, because it's a map of the Cape to Cairo railway, not the Cape to Alexandria railway! Also, Cairo could be considered to be "virtually" on the Mediterranean coast anyway, as it's connected by various offshoots of the Nile (in the Nile Delta) to the Mediterranean, with regular maritime traffic along these waterways.
End of the line
Well, there you have it: a thorough exercise in mapping and in narrating the present-day path of the Cape to Cairo Railway.
Personally, I've never been to Africa, let alone travelled any part of this long and diverse route. I'd love to do so, one day: although as I've described above, many parts of the route are currently quite a challenge to travel through, and will probably remain so for the foreseeable future. Naturally, I'd be delighted if anyone who has travelled any part of the route could share their "war stories" as comments here.
One question that I've asked myself many times, while researching and writing this article, is: in what year was the Cape to Cairo Railway at its best? (I.e. in what year was more of the line "green" than in any other year?). It would seem that the answer is probably 1976. This year was certainly not without its problems; but, at least as far as the Cape to Cairo endeavour goes, I believe that it was "as good as it's ever been".
This was the year that the TAZARA opened (which is to this day the "latest piece in the puzzle"), providing its inaugural Zambia – Tanzania service. It was one year before the 1977 dissolution of the East African Railways and Harbours Corporation, which jointly developed and managed the railways of Kenya, Uganda, and Tanzania (EAR&H's peak was probably in 1962, it was already in serious decline by 1976, but nevertheless it continued to provide comprehensive services until its end). And it was a year when Sudan's railways were in better operating condition, that nation being significantly less war-damaged than it is today (although Sudan had already suffered several years of civil war by then).
Unfortunately, it was also a year in which the Rhodesian Bush War was raging intensely – as such, on account of the hostilities between then-Rhodesia and Zambia, the Victoria Falls Bridge was largely closed to all traffic at that time (and, indeed, all travel within then-Rhodesia was probably quite difficult at that time). Then again, this hostility was also the main impetus for the construction of the TAZARA link; so, in the long-term, the tensions in then-Rhodesia actually improved the rail network more than they hampered it.
Additionally, it was a year in which Idi Amin's brutal reign of terror in Uganda was at its height. At that time, travel within Uganda was extremely dangerous, and infrastructure was being destroyed more commonly than it was being maintained.
I'm not the first person to make the observation – a fairly obvious one, after studying the route and its history – that travelling from Cape Town to Cairo overland (by train and/or by other transportation) never has been, and to this day is not, an easy expedition! There are numerous change-overs required, including change of railway guage, change to land vehicle, change to maritime vehicle, and more. The majority of the rail (and other) services along the route are poorly-maintained, prone to breakdowns, almost guaranteed to suffer extensive delays / cancellations, and vulnerable to seasonal weather fluctuations. And – as if all those "regular" hurdles weren't enough – many (perhaps the majority) of the regions through which the route passes are currently, or have in recent history been, unstable and dangerous trouble zones.
Hope you enjoyed my run-down (or should I say run-up?) of the Cape to Cairo Railway. Note that – as well as the KML files, which can be opened in Google Earth for best viewing of the route – the route is available here as a Google map.
Your contribution to the information presented here would be most welcome. If you have experience with path editing / Google Earth / KML (added bonus if you're Git / GitHub savvy, and know how to send pull requests), check out the route KML on GitHub, and feel free to refine it. Otherwise, feel free to post your route corrections, your African railway anecdotes, and all your most scathing criticism, using the comment form below (or contact me directly).
]]>
Money: the ongoing evolution2013-04-10T00:00:00Z2013-04-10T00:00:00ZJazahttps://greenash.net.au/thoughts/2013/04/money-the-ongoing-evolution/
In this article, I'm going to solve all the monetary problems of the modern world.
Oh, you think that's funny? I'm being serious.
Alright, then. I'm going to try and solve them. Money is a concept, a product and a system that's been undergoing constant refinement since the dawn of civilisation; and, as the world's current financial woes are testament to, it's clear that we still haven't gotten it quite right. That's because getting financial systems right is hard. If it were easy, we'd have done it already.
I'm going to start with some background, discussing the basics such as: what is money, and where does it come from? What is credit? What's the history of money, and of credit? How do central banks operate? How do modern currencies attain value? And then I'm going to move on to the fun stuff: what can we do to improve the system? What's the next step in the ongoing evolution of money and finance?
Disclaimer: I am not an economist or a banker; I have no formal education in economics or finance; and I have no work experience in these fields. I'm just a regular bloke, who's been thinking about these big issues, and reading up on a lot of material, and who would like to share his understandings and his conclusions with the world.
Ancient history
Money has been around for a while. When I talk about money, I'm talking cash. The stuff that leaves a smell on your fingers. The stuff that jingles in your pockets. Cold hard cash.
The earliest known example of money dates back to the 7th century BC, when the Lydians minted coins using a natural gold-based alloy called electrum. They were a crude affair – with each coin being of a slightly different shape – but they evolved to become reasonably consistent in their weight in precious metal; and many of them also bore official seals or insignias.
From Lydia, the phenomenom of minted precious-metal coinage spread: first to her immediate neighbours – the Greek and Persian empires – and then to the rest of the civilised world. By the time the Romans rose to significance, around the 3rd century BC, coinage had become the norm as a medium of exchange; and the Romans established this further with their standard-issue coins, most notably the Denarius, which were easily verifiable and reliable in their precious metal content.
Money, therefore, is nothing new. This should come as no surprise to you.
What may surprise you, however, is that credit existed before the arrival of money. How can that be? I hear you say. Isn't credit – the business of lending, and of recording and repaying a debt – a newer and more advanced concept than money? No! Quite the reverse. In fact, credit is the most fundamental concept of all in the realm of commerce; and historical evidence shows that it was actually established and refined, well before cold hard cash hit the scene. I'll elaborate further when I get on to definitions (next section). For now, just bear with me.
One of the earliest known historical examples of credit – in the form of what essentially amount to "IOU" documents – is from Ancient Babylonia:
… in ancient Babylonia … common commercial documents … are what are called "contract tablets" or "shuhati tablets" … These tablets, the oldest of which were in use from 2000 to 3000 years B. C. are of baked or sun-dried clay … The greater number are simple records of transactions in terms of "she," which is understood by archaeologists to be grain of some sort.
…
From the frequency with which these tablets have been met with, from the durability of the material of which they are made, from the care with which they were preserved in temples which are known to have served as banks, and more especially from the nature of the inscriptions, it may be judged that they correspond to the medieval tally and to the modern bill of exchange; that is to say, that they are simple acknowledgments of indebtedness given to the seller by the buyer in payment of a purchase, and that they were the common instrument of commerce.
But perhaps a still more convincing proof of their nature is to be found in the fact that some of the tablets are entirely enclosed in tight-fitting clay envelopes or "cases," as they are called, which have to be broken off before the tablet itself can be inspected … The particular significance of these "case tablets" lies in the fact that they were obviously not intended as mere records to remain in the possession of the debtor, but that they were signed and sealed documents, and were issued to the creditor, and no doubt passed from hand to hand like tallies and bills of exchange. When the debt was paid, we are told that it was customary to break the tablet.
We know, of course, hardly anything about the commerce of those far-off days, but what we do know is, that great commerce was carried on and that the transfer of credit from hand to hand and from place to place was as well known to the Babylonians as it is to us. We have the accounts of great merchant or banking firms taking part in state finance and state tax collection, just as the great Genoese and Florentine bankers did in the middle ages, and as our banks do to-day.
Source:What is Money? Original source: The Banking Law Journal, May 1913, By A. Mitchell Innes.
As the source above mentions (and as it describes in further detail elsewhere), another historical example of credit – as opposed to money – is from medieval Europe, where the split tally stick was commonplace. In particular, in medieval England, the tally stick became a key financial instrument used for taxation and for managing the Crown accounts:
A tally stick is "a long wooden stick used as a receipt." When money was paid in, a stick was inscribed and marked with combinations of notches representing the sum of money paid, the size of the cut corresponding to the size of the sum. The stick was then split in two, the larger piece (the stock) going to the payer, and the smaller piece being kept by the payee. When the books were audited the official would have been able to produce the stick with exactly matched the tip, and the stick was then surrendered to the Exchequer.
Tallies provide the earliest form of bookkeeping. They were used in England by the Royal Exchequer from about the twelfth century onward. Since the notches for the sums were cut right through both pieces and since no stick splits in an even manner, the method was virtually foolproof against forgery. They were used by the sheriff to collect taxes and to remit them to the king. They were also used by private individuals and institutions, to register debts, record fines, collect rents, enter payments for services rendered, and so forth. By the thirteenth century, the financial market for tallies was sufficiently sophisticated that they could be bought, sold, or discounted.
It should be noted that unlike the contract tablets of Babylonia (and the similar relics of other civilisations of that era), the medieval tally stick existed alongside an established metal-coin-based money system. The ancient tablets recorded payments made, or debts owed, in raw goods (e.g. "on this Tuesday, Bishbosh the Great received eight goats from Hammalduck", or "as of this Thursday, Kimtar owes five kwetzelgrams of silver and nine bushels of wheat to Washtawoo"). These societies may have, in reality, recorded most transactions in terms of precious metals (indeed, it's believed that the silver shekel emerged as the standard unit in ancient Mesopotamia); but these units had non-standard shapes and were unsigned, whereas classical coinage was uniform in shape, and possessed insignias.
In medieval England, the common currency was sterling silver, which consisted primarily of silver penny coins (but there were also silver shilling coins, and gold pound coins). The medieval tally sticks recorded payments made, or debts owed, in monetary value (e.g. "on this Monday, Lord Snottyham received one shilling and eight pence from James Yoohooson", or "as of this Wednesday, Lance Alot owes sixpence to Sir Robin").
Definitions
Enough history for now. Let's stop for a minute, and get some basic definitions clear.
First and foremost, the most basic question of all, but one that surprisingly few people have ever actually stopped to think about: what is money?
Money itself … is useless until the moment we use it to purchase or invest in something. Although money feels as if it has an objective value, its worth is almost completely subjective.
The seller and the depositor alike receive a credit, the one on the official bank and the other direct on the government treasury, The effect is precisely the same in both cases. The coin, the paper certificates, the bank-notes and the credit on the books of the bank, are all indentical in their nature, whatever the difference of form or of intrinsic value. A priceless gem or a worthless bit of paper may equally be a token of debt, so long as the receiver knows what it stands for and the giver acknowledges his obligation to take it back in payment of a debt due.
Money, then, is credit and nothing but credit. A's money is B's debt to him, and when B pays his debt, A's money disappears. This is the whole theory of money.
Source:What is Money? Original source: The Banking Law Journal, May 1913, By A. Mitchell Innes.
For some, money is a substance in which one may bathe. Image source:DuckTales…Woo-ooo!
I think the first definition is the easiest to understand. Money is a medium of exchange: it has no value in and of itself; but it allows us to more easily exchange between ourselves, things that do have value.
I think the last definition, however, is the most honest. Money is credit: or, to be more correct, money is a type of credit; a credit that is expressed in a uniform, easily quantifiable / divisible / exchangeable unit of measure (as opposed to a credit that's expressed in goats, or in bushels of wheat).
(Note: the idea of money as credit, and of credit as debt, comes from the credit theory of money, which was primarily formulated by Innes (quoted above). This is just one theory of money. It's not the definitive theory of money. However, I tend to agree with the theory's tenets, and various parts of the rest of this article are founded on the theory. Also, it should not be confused with The Theory of Money and Credit, a book from the Austrian School of economics, which asserts that the only true money is commodity money, and which is thus pretty well the opposite extreme from the credit theory of money.)
Which brings us to the next defintion: what is credit?
In the article giving the definition of "money as credit", it's also mentioned that "credit" and "debt" are effectively the same thing; just that the two words represent the two sides of a single relationship / transaction. So, then, perhaps it would make more sense to define what is debt:
Middle English dette: from Old French, based on Latin debitum 'something owed', past participle of debere 'owe'.
A debt is something that one owes; it is one's obligation to give something of value, in return for something that one received.
Conversely, a credit is the fact of one being owed something; it is a promise that one has from another person / entity, that one will be given something of value in the future.
So, then, if we put the two definitions together, we can conclude that: money is nothing more than a promise, from the person / entity who issued the money, that they will give something of value in the future, to the current holder of the money.
Perhaps the simplest to understand example of this, in the modern world, is the gift card typically offered by retailers. A gift card has no value itself: it's nothing more than a promise by the retailer, that they will give the holder of the card a shirt, or a DVD, or a kettle. When the card holder comes into the shop six months later, and says: "I'd like to buy that shirt with this gift card", what he/she really means is: "I have here a written promise from you folks, that you will give me a shirt; I am now collecting what was promised". Once the shirt has been received, the gift card is suddenly worthless, as the documented promise has been fulfilled; this is why, when the retailer reclaims the gift card, they usually just dispose of it.
However, there is one important thing to note: the only value of the gift card, is that it's a promise of being exchangeable for something else; and as long as that promise remains true, the gift card has value. In the case of a gift card, the promise ceases to be true the moment that you receive the shirt; the card itself returns to its original issuer (the retailer), and the story ends there.
Money works the same way, only with one important difference: it's a promise from the government, of being exchangeable for something else; and when you exchange that money with a retailer, in return for a shirt, the promise remains true; so the money still has value. As long as the money continues to be exchanged between regular citizens, the money is not returned to its original issuer, and so the story continues.
So, as with a gift card: the moment that money is returned to its original issuer (the government), that money is suddenly worthless, as the documented promise has been fulfilled. What do we usually return money to the government for? Taxes. What did the government originally promise us, by issuing money to us? That it would take care of us (it doesn't buy us flowers or send us Christmas cards very often; it demonstrates its caring for us mainly with other things, such as education and healthcare). What happens when we pay taxes? The government takes care of us for another year (it's supposed to, anyway). Therefore, the promise ceases to be true; and, believe it or not, the moment that the government reclaims the money in taxes, that money ceases to exist.
The main thing that a government promises, when it issues money, is that it will take care of its citizens; but that's not the only promise of money. Prior to quite recent times, money was based on gold: people used to give their gold to the government, and in return they received money; so, money was a promise that the government would give you back your gold, if you ever wanted to swap again.
In the modern economic system, the governments of the world no longer promise to give you gold (although most governments still have quite a lot of gold, in secret buildings with a lot of fancy locks and many armed guards). Instead, by issuing money these days, a government just promises that its money is worth as much as its economy is worth; this is why governments and citizens the world over are awfully concerned about having a "strong economy". However, what exactly defines "the economy" is rather complicated, and it only gets trickier with every passing year.
So, a very useful side effect of money – as opposed to gift cards – is that as long as the promise of money remains true (i.e. as long as the government keeps taking care of its people, and as long as the economy remains strong), regular people can use whatever money they have left-over (i.e. whatever money doesn't return to the government, at which point it ceases to exist), as a useful medium of exchange in regular day-to-day commerce. But remember: when you exchange your money for a kettle at the shop, this is what happens: at the end of the day, you have a kettle (something of value); and the shop has a promise from the government that it is entitled to something (presumably, something of value).
Recent history
Back to our history class. This time, more recent history. The modern monetary system could be said to have begun in 1694, when the Bank of England was founded. The impetus for establishing it should be familiar to all 21st-century readers: the government of England was deeply in debt; and the Bank was founded in order to acquire a loan of £1.2 million for the Crown. Over the subsequent centuries, it evolved to become the world's first central bank. Also, of great note, this marked the first time in history that a bank (rather than the king) was given the authority to mint new money.
The grand tradition of English banking: The Dawes, Tomes, Mousely, Grubbs, Fidelity Fiduciary Bank. Image source:Scene by scene Mary Poppins.
During the 18th and 19th centuries, and also well into the 20th century, the modern monetary system was based on the gold standard. Under this system, countries tied the value of their currency to gold, by guaranteeing to buy and sell gold at a fixed price. As a consequence, the value of a country's currency depended directly on the amount of gold reserves in its possession. Also, consequently, money at that time represented a promise, by the money's issuer, to give an exact quantity of gold to its current holder. This could be seen as a hangover from ancient and medieval times, when money was literally worth the weight of gold (or, more commonly, silver) of which the coins were composed (as discussed above).
During that same time period, the foundation currency – and by far the dominant currency – of the world monetary system was the British Pound. As the world's strongest economy, the world's largest empire (and hence the world's largest trading bloc), and the world's most industrialised nation, all other currencies were valued relative to the Pound. The Pound became the reserve currency of choice for nations worldwide, and most international transactions were denominated with it.
In the aftermath of World War II, the Allies emerged victorious; but the Pound Sterling met its defeat at long last, at the hands of a new world currency: the US Dollar. Because the War had taken place in Europe (and Asia), the financial cost to the European Allied powers was crippling; North America, on the other hand, hadn't witnessed a single enemy soldier set foot on its soil, and so it was that, with the introduction of the Bretton Woods system in 1944, the Greenback rapidly and ruthlessly conquered the world.
The Dollars are Coming! Image source: The Guardian: Reel history.
Under the Bretton Woods system, the gold standard remained in place: the only real difference, was that gold was now spelled with a capital S with a line through it ($), instead of being spelled with a capital L with a line through it (£). The US Dollar replaced the Pound as the dominant world reserve currency and international transaction currency.
The gold standard finally came to an end when, in 1971, President Nixon ended the direct convertibility of US Dollars to gold. Since then, the USD has continued to reign supreme over all other currencies (although it's been increasingly facing competition). However, under the current system, there is no longer a "other currencies -> USD -> gold" pecking order. Theoretically, all currencies are now created equal; and gold is now just one more commodity on the world market, rather than "the shiny stuff that gives money value".
Since the end of Bretton Woods, the world's major currencies exist in a floating exchange rate regime. This means that the only way to measure a given currency's value, is by determining what quantity of another given currency it's worth. Instead of being tied to the value of a real-life object (such as gold), the value of a currency just "floats" up and down, depending on the fluctuations in that country's economy, and depending on the fluctuations in peoples' relative perceptions of its value.
What we have now
The modern monetary system is a complex beast, but at its heart it consists of three players.
The mythical Hydra, a multi-headed monster. Grandaddy of the modern monetary system, perhaps? Image source:HydraVM.
First, there are the governments of the world. In most countries, there's a department that "represents" the government as a whole, within the monetary system: this is usually called the "Treasury"; it may also be called the Ministry of Finance, among other names. Contrary to what you might think, Treasury does not bring new money into existence (even though Treasury usually governs a country's mint, and thus Treasury is the manufacturer of new physical money).
As discussed in definitions (above), in a "pure" system, money comes into existence when the government issues it (as a promise), and money ceases to exist when the government takes it back (in return for fulfilling a promise). However, in the modern system, the job of bringing new money into existence has been delegated; therefore, money does not cease to exist, the moment that it returns to the government (i.e. the "un-creation" of money has also been delegated).
This delegation allows the government itself to function like any other individual or entity within the system. That is, the government has an "account balance", it receives monetary income (via taxation), it spends money (via its budget program), and it can either be "in the green" or "in the red" (with a strong tendency towards the latter). Thus, the government itself doesn't have to worry too much about the really complicated parts of the modern monetary system; and instead, it can just get on with the job of running the country. The government can also borrow money, to supplement what it receives from taxation; and it can lend money, in addition to its regular spending.
Second, there are these things called "central banks" (also known as "reserve banks", among other names). In a nutshell: the central bank is the entity to which all that stuff I just mentioned gets delegated. The central bank brings new money into existence – officially on behalf of the government; but since the government is usually highly restricted from interfering with the central bank's operation, this is a half-truth at best. It creates new money in a variety of ways. One way – which in practice is usually responsible for only a small fraction of overall money creation, but which I believe is worth focusing on nonetheless – is by buying government (i.e. Treasury) bonds.
Just what is a bond? (Seems we're not yet done with definitions, after all.) A bond is a type of debt (or a type of credit, depending on your perspective). A lends money to B, and in return, B gives A bonds. The bonds are a promise that the debt will be repaid, according to various terms (time period, interest payable, etc). So, bonds themselves have no value: they're just a promise that the holder of the bonds will receive something of value, at some point in the future. In the case of government bonds, the bonds are a promise that the government will provide something of value to their current holder.
But, hang on… isn't that also what money is? A promise that the government will provide something of value to the current holder of the money? So, let me get this straight: the Treasury writes a document (bonds) saying "The government (on behalf of the Treasury) promises to give the holder of this document something of value", and gives it to the central bank; and in return, the central bank writes a document (money) also saying "The government (on behalf of the central bank) promises to give the holder of this document something of value", and gives it to the Treasury; and at the end of the day, the government has more money? Or, in other words (no less tangled): the government lends itself money, and money is also itself a government loan? Ummm… WTF?!
Glad I'm not the only one that sees a slight problem here. Image source:Lol Zone.
Third, there are the commercial banks. The main role of these (private) companies is to safeguard the deposits of, and provide loans to, the general public. The main (original) source of commercial banks' money, is from the deposits of their customers. However, thanks to the practice of fractional reserve banking that's prevalent in the modern monetary system, commercial banks are also responsible for about 95% of the money creation that occurs today; almost all of this private-bank-created money is interest (and principal) from loans. So, yes: money is created out of thin air; and, yes, the majority of money is not created by the government (either on behalf of Treasury or the central bank), but by commercial banks. No surprise, then, that about 97% of the world's money exists only electronically in commercial bank accounts (with physical cash making up the other 3%).
This presents another interesting conundrum: all money supposedly comes from the government, and is supposedly a promise from the government that they will provide something of value; but in today's reality, most of our money wasn't created by the government, it was created by commercial banks! So, then: if I have $100 in my bank account, does that money represent a promise from the government, or a promise from the commercial banks? And if it's a promise from the commercial banks… what are they promising? Beats me. As far as I know, commercial banks don't promise to take care of society; they don't promise to exchange money for gold; I suppose the only possibility is that, much as the government promises that money is worth as much as the nation's economy is worth, commercial banks promise that money is worth as much as they are worth.
And what are commercial banks worth? A lot of money (and not much else), I suppose… which starts taking us round in circles.
I should also mention here, that the central banks' favourite and most oft-used tool in controlling the creation of money, is not the buying or selling of bonds; it's something else that we hear about all the time in the news: the raising or lowering of official interest rates. Now that I've discussed how 95% of money creation occurs via the creation of loans and interest within commercial banks, it should be clear why interest rates are given such importance by government and by the media. The central bank only sets the "official" interest rate, which is merely a guide for commercial banks to follow; but in practice, commercial banks adjust their actual interest rates to closely match the official one. So, in case you had any lingering doubts: the central banks and the commercial banks are, of course, all "in on it" together.
Oh yeah, I almost forgot… and then there are regular people. Just trying to eke out a living, doing whatever's necessary to bring home the dough, and in general trying to enjoy life, despite the best efforts of the multi-headed beast mentioned above. But they're not so important; in fact, they hardly count at all.
In summary: today's system is very big and complex, but for the most part it works. Somehow. Sort of.
Broken promises
In case you haven't worked it out yet: money is debt; debt is credit; and credit is promises.
Bankers, like politicians, are big on promises. In fact, bankers are full of promises (by definition, since they're full of money). And, also like politicians, bankers are good at breaking promises.
Or, to phrase it more accurately: bankers are good at convincing you to make promises (i.e. to take out a loan); and they're good at promising you that you'll have no problem in not breaking your promises (i.e. in paying back the loan); and they're good at promising you that making and not breaking your promises will be really worthwhile for you (i.e. you'll get a return on your loan); and (their favourite part) they're exceedingly good at holding you to your promises, and at taking you to the dry cleaners in the event that you are truly unable to fulfil your promises.
Since money is debt, and since money makes the world go round, the fact that the world is full of debt really shouldn't make anyone raise an eyebrow. What this really means, is that the world is full of promises. This isn't necessarily a bad thing, assuming that the promises being made are fair. In general, however, they are grossly unfair.
Let's take a typical business loan as an example. Let's say that Norbert wants to open a biscuit shop. He doesn't have enough money to get started, so he asks the bank for a loan. The bank lends Norbert a sum of money, with a total repayment over 10 years of double the value of the sum being lent (as is the norm). Norbert uses the money to buy a cash register, biscuit tins, and biscuits, and to rent a suitable shop venue.
There are two possibilities for Norbert. First, he generates sufficient business selling biscuits to pay off the loan (which includes rewarding the bank with interest payments that are worth as much as it cost him to start the business), and he goes on selling biscuits happily ever after. Second, he fails to bring in enough revenue from the biscuit enterprise to pay off the loan, in which case the bank seizes all of his business-related assets, and he's left with nothing. If he's lucky, Norbert can go back to his old job as a biscuit-shop sales assistant.
What did Norbert input, in order to get the business started? All his time and energy, for a sustained period. What was the real cost of this input? Very high: Norbert's time and energy is a tangible asset, which he could have invested elsewhere had he chosen (e.g. in building a giant Lego elephant). And what is the risk to Norbert? Very high: if business goes bad (and the biscuit market can get volatile at times), he loses everything.
What did the bank input, in order to get the business started? Money. What was the real cost of this input? Nothing: the bank pulled the money out of thin air in order to lend it to Norbert; apart from some administrative procedures, the bank effectively spent nothing. And what is the risk to the bank? None: if business goes well, they get back double the money that they lent Norbert (which was fabricated the moment that the loan was approved anyway); if business goes bad, they seize all Norbert's business-related assets (biscuit tins and biscuits are tangible assets), and as for the money… well, they just fabricated it in the first place anyway, didn't they?
Broke(n) nations
One theme that I haven't touched on specifically so far, is the foreign currency exchange system. However, I've already explained that money is worth as much as a nation's economy is worth; so, logically, the stronger a nation's economy is, the more that nation's money is worth. This is the essence of foreign currency exchange mechanics. Here's a formula that I just invented, but that I believe is reasonably accurate, for determining the exchange rate r between two given currencies a and b:
Where sx is the strength of the given economy, and qx is the quantity of the given currency in existence.
So, for example, say we want to determine the exchange rate of US Dollars to Molvanîan Strubls. Let's assume that the US economy is worth "1,000,000" (which is good), and that there are 1,000,000 US Dollars (a) in existence; and let's assume that the Molvanîan economy is worth "100" (which is not so good), and that there are 1,000,000,000 Molvanîan Strubls (b) in existence. Substituting values into the formula, we get:
This, in my opinion, should be sufficient demonstration of why the currencies of strong economies have value, and why people the world over like getting their hands dirty with them; and why the currencies of weak economies lack value, and why their only practical use is for cleaning certain dirty orifices of one's body.
Or, for a real-world example of a currency worth less than its weight in toilet paper, see Zimbabwe. Image source:praag.org.
Now, getting back to the topic of lending money. Above, I discussed how banks lend money to individuals. As it turns out, banks also lend money to foreign countries. Either commercial banks, central banks, or an international bank (such as the IMF), doesn't matter in this context. And, either foreign individuals, foreign companies, or foreign governments, doesn't matter either in this context. The point is: there are folks whose local currency isn't accepted worldwide (if it's even accepted locally), and who need to purchase goods and services from the world market; and so, these folks ask for a loan from banks elsewhere, who are able to lend them money in a strong currency.
The example scenario that I described above (Norbert), applies equally here. Only this time, Norbert is a group of people from a developing country (let's call them The Morbert Group), and the bank is a corporation from a developed country. As in Norbert's case, The Morbert Group input a lot of time and effort to start a new business; and the bank input money that it pulled out of thin air. And, as in Norbert's case, The Morbert Group has a high risk of losing everything, and at the very least is required to pay an exorbitant amount of interest on its loan; whereas the bank has virtually no risk of losing anything, as it's a case of "the house always wins".
So, the injustice of grossly unfair and oft-broken promises between banks and society doesn't just occur within a single national economy, it occurs on a worldwide scale within today's globalised economy. Yes, the bank is the house; and yes (aside from a few hiccups), the house just keeps winning and winning. This is how, in the modern monetary system, a nation's rich people keep getting richer while its poor people keep getting poorer; and it's how the world's rich countries keep getting richer, while the poor countries keep getting poorer.
Serious problems
Don't ask "how did it come to this?" I've just spent a large number of words explaining how it's come to this (see everything above). Face the facts: it has come to this. The modern monetary system has some very serious problems. Here's my summary of what I think those problems are:
Currency inequality promotes poverty. In my opinion, this is the worst and the most disgraceful of all our problems. A currency is only worth as much as its nation's economy is worth. This is wrong. It means that the people who are issued that currency, participate in the global economy with a giant handicap. It's not their fault that they were born in a country with a weaker economy. Instead, a currency should be worth as much as its nation's people are worth. And all people in all countries are "worth" the same amount (or, at least, they should be).
Governments manipulate currency for their own purposes. All (widely-accepted) currency in the world today is issued by governments, and is controlled by the world's central banks. While many argue that the tools used to manipulate the value of currency – such as adjusting interest rates, and trading in bonds – are "essential" for "stabilising" the economy, it's clear that very often, governments and/or banks abuse these tools in the pursuit of more questionable goals. Governments and central banks (particularly those in "strong" countries, such as the US) shouldn't have the level of control that they do over the global financial system.
Almost all new money is created by commercial banks. The creation of new money should not be entrusted to a handful of privileged companies around the world. These companies continue to simply amass ever-greater quantities of money, further promoting poverty and injustice. Money creation should be more fairly distributed between all individuals and between all nations.
It's no longer clear what gives money its value. In the olden days, money was "backed" by gold. Under the current system, money is supposedly backed by the value of the issuing country's economy. However, the majority of new money today is created by commercial banks, so it's unclear if that's really true or not. Perhaps a new way definition of what "backs" money is needed?
Now, at long last – after much discussion of promises made and promises broken – it's time to fulfil the promise that I made at the start of this article. Time to solve all the monetary problems of the modern world!
Possible solutions
One alternative to the modern monetary system, and its fiat money roots (i.e. money "backed by nothing"), is a return to the gold standard. This is actually one of the more popular alternatives, with many arguing that it worked for thousands of years, and that it's only for the past 40-odd years (i.e. since the Nixon Shock in 1971) that we've been experimenting with the current (broken) system.
This is a very conservative argument. The advocates of "bringing back the gold standard" are heavily criticised by the wider community of economists, for failing to address the issues that caused the gold standard to be dropped in the first place. In particular, the critics point out that the modern world economy has been growing much faster than the world's supply of gold has been growing, and that there literally isn't enough physical gold available, for it to serve as the foundation of the modern monetary system.
Personally, I take the critics' side: the gold standard worked up until modern times; but gold is a finite resource, and it has certain physical characteristics that limit its practical use (e.g. it's quite heavy, it's not easily divisible into sufficiently small parts, etc). Gold will always be a valuable commodity – and, as the current economic crisis shows, people will always turn to gold when they lose confidence in even the most stable of regular currencies – but its days as the foundation of currency were terminated for a reason, and so I don't think it's altogether bad that we relegate the gold standard to the annals of history.
How about getting rid of money altogether? For virtually as long as money has existed, it's been often labelled "the root of all evil". The most obvious solution to the world's money problems, therefore, is one that's commonly proposed: "let's just eliminate money." This has been the cry of hippies, of communists, of utopianists, of futurists, and of many others.
Imagine no possessions... I wonder if you can. Image source:Etsy.
Unfortunately, the most prominent example so far in world history of (effectively) eliminating money – 20th century communism – was also an economic disaster. In the Soviet Union, although there was money, the price of all basic goods and services was fixed, and everything was centrally distributed; so money was, in effect, little more than a rationing token. Hence the famous Russian joke: "We pretend to work, They pretend to pay us".
Utopian science fiction is also rife with examples of a future without money. The best-known and best-developed example is Star Trek (an example with which I'm also personally well-acquainted). In the Star Trek universe, where virtually all of humanity's basic needs (i.e. food, clothing, shelter, education, medicine) are provided for in limitless supply by modern technology, "the economics of the future are somewhat different". As Captain Picard says in First Contact: "The acquisition of wealth is no longer the driving force in our lives. We work to better ourselves and the rest of humanity." This is a great idea in principle; but Star Trek also fails to address the practical issues of such a system, any better than contemporary communist theory does.
Star Trek IV: "They're still using money. We need to get some." Image source:Moar Powah.
While I'm strongly of the opinion that our current monetary system needs reform, I don't think that abolishing the use of money is: (a) practical (assuming that we want trade and market systems to continue existing in some form); or (b) going to actually address the issues of inequality, corruption, and systemic instability that we'd all like to see improved. Abolishing money altogether is not practical, because we do require some medium of exchange in order for the civilised world (which has always been built on trade) to function; and it's not going to address the core issues, because money is not the root of all evil, money is just a tool which can be used for either good or bad purposes (the same as a hammer can be used to build a house or to knock someone on the head – the hammer itself is "neutral"). The problem is not money; the problem is greed.
For a very different sci-fi take on the future of money, check out the movie In Time (2011). In this dystopian work, there is a new worldwide currency: time. Every human being is born with a "biological watch", that shows on his/her forearm how much time he/she has left to live. People can earn time, trade with time, steal time, donate time, and store time (in time banks). If you "time out" (i.e. run out of time), you die instantly.
In Time: you're only worth as many seconds as you have left to live. Image source:MyMovie Critic.
The monetary system presented by In Time is interesting, because it's actually very stable (i.e. the value of "time" is very clear, and time as a currency is quite resilient to inflation / deflation, speculation, etc), and it's a currency that's "backed" by a real commodity (i.e. time left alive; commodities don't get much more vital). However, the system also has gross potential for inequality and corruption – and indeed, in the movie, it's clearly demonstrated that everyone could live indefinitely if the banks just kept rewarding infinte quantities of time; but instead. time is meagerly rationed out by the rich and powerful elite (who can create more time out of thin air whenever they want, much as today's elite do with money), in order to enforce a status quo upon the impoverished masses.
One of the most concerted efforts that has been made in recent times, to disrupt (and potentially revolutionise) the contemporary monetary system, is the much-publicised Bitcoin project. Bitcoin is a virtual currency, which isn't issued or backed by any national government (or by any official organisation at all, for that matter), but which is engineered to mimic many of the key characteristics of gold. In particular, there's a finite supply of Bitcoins; and new Bitcoins can only be created by "mining" them.
Bitcoin makes no secret of the fact that it aims to become a new global world currency, and to bring about the demise of traditional government-issued currency. As I've already stated here, I'm in favour of replacing the current world currencies; and I applaud Bitcoin's pioneering endeavours to do this. Bitcoin sports the key property that I think any contender to the "brave new world of money" would need: it's not generated by central banks, nor by any other traditional contemporary authority. However, there are a number of serious flaws in the Bitcoin model, which (in my opinion) mean that Bitcoin cannot and (more importantly) should not ever achieve this.
Most importantly, Bitcoin fails to adequately address the issue of "money creation should be fairly distributed between all". In the Bitcoin model, money creation is in the hands of those who succeed in "mining" new Bitcoins; and "mining" Bitcoins consists of solving computationally expensive cryptographic calculations, using the most powerful computer hardware possible. So, much as Bitcoin shares many of gold's advantages, it also shares many of its flaws. Much as gold mining unfairly favours those who discover the gold-hills first, and thereafter favours those with the biggest drills and the most grunt; so too does Bitcoin unfairly favour those who knew about Bitcoin from the start, and thereafter favour those with the beefiest and best-engineered hardware.
Mining: a dirty business that rewards the boys with the biggest toys. Image source:adelaidenow.
Bitcoin also fails to address the issue of "what gives money its value". In fact, "what gives Bitcoin its value" is even less clear than "what gives contemporary fiat money its value". What "backs" Bitcoin? Not gold. Not any banks. Not any governments or economies. Supposedly, Bitcoin "is" the virtual equivalent of gold; but then again (as others have stated), I'll believe that the day I'm shown how to convert digital Bitcoins into physical metal chunks that are measured in Troy ounces. It's also not clear if Bitcoin is a commodity or a currency (or both, or neither); and if it's a commodity, it's not completely clear how it would succeed as the foundation of the world monetary system, where gold failed.
Plus, assuming that Bitcoin is the virtual equivalent of gold, the fact that it's virtual (i.e. technology-dependent for its very existence) is itself a massive disadvantage, compared to a physical commodity. What happens if the Internet goes down? What happens if there's a power failure? What happens if the world runs out of computer hardware? Bye-bye Bitcoin. What happens to gold (or physical fiat money) in any of these cases? Nothing.
Additionally, there's also significant doubt and uncertainty over the credibility of Bitcoin, meaning that it fails to address the issue of "manipulation of currency [by its issuers] for their own purposes". In particular, many have accused Bitcoin of being a giant scam in the form of a Ponzi scheme, which will ultimately crash and burn, but not before the system's founders and earliest adopters "jump ship" and take a fortune with them. The fact that Bitcoin's inventor goes by the fake name "Satoshi Nakamoto", and has disappeared from the Bitcoin community (and kept his true identity a complete mystery) ever since, hardly enhances Bitcoin's reputation.
This article is not about Bitcoin; I'm just presenting Bitcoin here, as one of the recently-proposed solutions to the problems of the world monetary system. I've heavily criticised Bitcoin here, to the point that I've claimed it's not suitable as the foundation of a new world monetary system. However, let me emphasise that I also really admire the positive characteristics of Bitcoin, which are numerous; and I hope that one day, a newer incarnation is born that borrows these positive characteristics of Bitcoin, while also addressing Bitcoin's flaws (and we owe our thanks to Bitcoin's creator(s), for leaving us an open-source system that's unencumbered by copyright, patents, etc). Indeed, I'd say that just as non-virtual money has undergone numerous evolutions throughout history (not necessarily with each new evolution being "better" than its predecessors); so too will virtual currency undergo numerous evolutions (hopefully with each new evolution being "better"). Bitcoin is only the beginning.
My humble proposal
The solution that I'd like to propose, is a hybrid of various properties of what's been explored already. However, the fundamental tenet of my solution, is something that I haven't discussed at all so far, and it is as follows:
Every human being in the world automatically receives an "allowance", all the time, all their life. This "allowance" could be thought of as a "global minimum wage"; although everyone receives it regardless of, and separate to, their income from work and investments. The allowance could be received once a second, or once a day, or once a month – doesn't really matter; I guess that's more a practical question of the trade-off in: "the more frequent the allowance, the more overhead involved; the less frequent the allowance, the less accurate the system is."
Ideally, the introduction of this allowance would be accompanied by the introduction of a new currency; and this allowance would be the only permitted manner in which new units of the currency are brought into existence. That is, new units of the currency cannot be generated ad lib by central banks or by any other organisation (and it would be literally impossible to circumvent this, a la Bitcoin, thus making the currency a commodity rather than a fiat entity). However, a new currency is not the essential idea – the global allowance per person is the core – and it could be done with one or more existing currencies, although this would obviously have disadvantages.
The new currency for distributing the allowance would also ideally exist primarily in digital form. It would be great if, unlike Bitcoin and its contemporaries, the currency could also exist in a physical commodity form, with an easy way of transforming the currency between digital and physical form, and vice versa. This would require technology that doesn't currently exist – or, at the least, some very clever engineering with the use of current technology – and is more "wishful thinking" at this stage. Additionally, the currency could also exist as an "account balance" genetically / biologically stored within each person, much like in the movie In Time; except that you don't die if you run out of money (you just ain't got no money). However, all of this is non-essential bells and whistles, supplementing my core proposal.
There are a number of other implementation details, that I don't think particularly need to all be addressed at the conceptual level, but that would be significant at the practical level. For example: should the currency be completely "tamper-proof", or should there be some new international body that could modify various parameters (e.g. change the amount of the allowance)? And should the allowance be exactly the same for everyone, or should it vary according to age, physical location, etc? Personally, I'd opt for a completely "tamper-proof" currency, and for a completely standard allowance; but other opinions may differ.
Taxation would operate in much the same way as it does now (i.e. a government's primary source of revenue, would be taxing the income of its citizens); however, the wealth difference between countries would reduce significantly, because at a minimum, every country would receive revenue purely based on its population.
A global allowance (issued in the form of a global currency), doesn't necessarily mean a global government (although the two would certainly function much better together). It also doesn't necessarily mean the end of national currencies; although national currencies would probably, in the long run, struggle to compete for value / relevance with a successful global currency, and would die out.
If there's a global currency, and a global allowance for everyone on the planet, but still individual national governments (some of which would be much poorer and less developed than others), then taxation would still be at the discretion of each nation. Quite possibly, all nations would end up taxing 100% of the allowance that their citizens receive (and corrupt third-world nations would definitely do this); in which case it would not actually be an allowance for individuals, but just a way of enforcing more economic equality between countries based on population.
However, this doesn't necessarily make the whole scheme pointless. If a developing country receives the same revenue from its population's global allowance, as a developed country does (due to similar population sizes), then: the developing country would be able to compete more fairly in world trade; it would be able to attract more investment; and it wouldn't have to ask for loans and to be indebted to wealthier countries.
So, with such a system, the generated currency wouldn't be backed by anything (no more than Bitcoin is backed by anything) – but it wouldn't be fiat, either; it would be a commodity. In effect, people would be the underlying commodity. This is a radical new approach to money. It would also have potential for corruption (e.g. it could lead to countries kidnapping / enslaving each others' populations, in order to steal the commodity value of another country). However, appropriate practical safeguards in the measuring of a country's population, and in the actual distribution of new units of the currency, should be able to prevent this.
It's not absolutely necessary that a new global currency is created, in order to implement the "money for all countries based on population" idea: all countries could just be authorised to mint / receive a quantity of an existing major currency (e.g. USD or EUR) proportional to its population. However, this would be more prone to corruption, and would lack the other advantages of a new global currency (i.e. not backed by any one country, not produced by any central bank).
It has been suggested that a population-based currency is doomed to failure:
So here is were [sic] you need to specify. What happens at round two?
If you do nothing things would go back to how they are now. The rich countries would have the biggest supply of this universal currency (and the most buying power) and the poor countries would loose [sic] their buying power after this one explosive buying spree.
And things would go back to exactly as they are now- no disaster-but no improvemen [sic] to anything.
But if youre [sic] proposing to maintain this condition of equal per capita money supply for every nation then you have to rectify the tendency of the universal currency to flow back to the high productivity countries. Buck the trend of the market somehow.
Dont [sic] know how you would do it. And if you were able to do it I would think that it would cause severe havoc to the world economy.It would amount to very severe global income redistribution.
The poor countries could use this lopsided monetary system to their long term advantage by abstaining from buying consumer goods and going full throttle into buying capital goods from industrialized world to industrialize their own countries. In the long term that would be good for them and for the rich countries as well.
So it could be viewed as a radical form of foreign aid. But its [sic] a little too radical.
Alright: so once you get to "round two" in this system, the developed countries once again have more money than the developing countries. However, that isn't any worse than what we've got at the moment.
And, alright: so this system would effectively amount to little more than a radical form of foreign aid. But why "too radical"? In my opinion, the way the world currently manages foreign aid is not working (as evidenced by the fact that the gap between the world's richest and poorest nations is increasing, not decreasing). The world needs a radical form of foreign aid. So, in my opinion: if the net result of a global currency whose creation and distribution is tied to national populations, is a radical form of foreign aid; then, surely what would be a good system!
Conclusion
So, there you have it. A monster of an article examining the entire history of money, exploring the many problems with the current world monetary system, and proposing a humble solution, which isn't necessarily a good solution (in fact, it isn't even necessarily better than, or as good as, the other possible solutions that are presented here), but which at least takes a shot at tackling this age-old dilemna. Money: can't live with it; can't live without it.
Money has already been a work-in-progress for about 5,000 years; and I'm glad to see that at this very moment, efforts are being actively made to continue refining that work-in-progress. I think that, regardless of what theory of money one subscribes to (e.g. money as credit, money as a commodity, etc), one could describe money as being the "grease" in the global trade machine, and actual goods and services as being the "cogs and gears" in the machine. That is: money isn't the machine itself, and the machine itself is more important than money; but then again, the machine doesn't function without money; and the better the money works, the better the machine works.
So, considering that trade is the foundation of our civilised existence… let's keep refining money. There's still plenty of room for improvement.
]]>
Configuring Silex (Symfony2) and Monolog to email errors2013-03-30T00:00:00Z2013-03-30T00:00:00ZJazahttps://greenash.net.au/thoughts/2013/03/configuring-silex-symfony2-and-monolog-to-email-errors/
There's a pretty good documentation page on how to configure Monolog to email errors in Symfony2. This, and all other documentation that I could find on the subject, works great if: (a) you're using the Symfony2 Standard Edition; and (b) you want to send emails with Swift Mailer. However, I couldn't find anything for my use case, in which: (a) I'm using Silex; and (b) I want to send mail with PHP's native mail handler (Swift Mailer is overkill for me).
Turns out that, after a bit of digging and poking around, it's not so hard to cobble together a solution that meets this use case. I'm sharing it here, in case anyone else finds themselves with similar needs in the future.
The code
Assuming that you've installed both Silex and Monolog (by adding silex/silex and monolog/monolog to the require section of your composer.json file, or by some alternate install method), you'll need something like this for your app's bootstrap code (in my case, it's in my project/app.php file):
I've got some code here for determining the current environment (which can be prod, staging or dev), and for only enabling the error emailing functionality for environments other than dev. Up to you whether you want / need that functionality; plus, this example is just one of many possible ways to implement it.
That's about it, really. Using this code, you can have a Silex app which logs errors to a file (the usual) when running in your dev environment, but that also sends an error email to one or more addresses, when running in your other environments. Not rocket science – but, in my opinion, it's an important setup to be able to achieve in pretty much any web framework (i.e. regardless of your technology stack, receiving email notification of critical errors is a recommended best practice); and it doesn't seem to be documented anywhere so far for Silex.
]]>
Show a video's duration with Media: YouTube and Computed Field2013-03-28T00:00:00Z2013-03-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2013/03/show-a-videos-duration-with-media-youtube-and-computed-field/
I build quite a few Drupal sites that use embedded YouTube videos, and my module of choice for handling this is Media: YouTube, which is built upon the popular Media module. The Media: YouTube module generally works great; but on one site that I recently built, I discovered one of its shortcomings. It doesn't let you display a YouTube video's duration.
I thought up a quick, performant and relatively easy way to solve this. With just a few snippets of custom code, and the help of the Computed Field module, showing video duration (in hours / minutes / seconds) for a Media: YouTube managed asset, is a walk in the park.
Getting set up
First up, install the Media: YouTube module (and its dependent modules) on a Drupal 7 site of your choice. Then, add a YouTube video field to one of the site's content types. For this example, I added a field called 'Video' (field_video) to my content type 'Page' (page). Be sure to select a 'field type' of 'File', and a 'widget' of type 'Media file selector'. In the field settings, set 'Allowed remote media types' to just 'Video', and set 'Allowed URI schemes' to just 'youtube://'.
To configure video display, go to 'Administration > Configuration > Media > File types' in your site admin, and for 'Video', click on 'manage file display'. You should be on the 'default' tab. For 'Enabled displays', enable just 'YouTube Video'. Customise the other display settings to your tastes.
Add a YouTube video to one of your site's pages. For this example, I've chosen one of the many clips highlighting YouTube's role as the zenith of modern society's intellectual capacity: a dancing duck.
To show the video within your site's theme, open up your theme's template.php file, and add the following preprocess function (in this example, my theme is called foobar):
And add the following snippet to your node.tpl.php file or equivalent (in my case, I added it to my node--page.tpl.php file):
<!-- template stuff bla bla bla -->
<?php if (!empty($video)): ?>
<?php print $video; ?>
<?php endif; ?>
<!-- more template stuff bla bla bla -->
The duck should now be dancing for you:
Embrace The Duck.
Getting the duration
On most sites, you won't have any need to retrieve and display the video's duration by itself. As you can see, the embedded YouTube element shows the duration pretty clearly, and that's adequate for most use cases. However, if your client wants the duration shown elsewhere (other than within the embedded video area), or if you're just in the mood for putting the duration between a spantabulously vomitive pair of <font color="pink"><blink>2:48</blink></font> tags, then keep reading.
Unfortunately, the Media: YouTube module doesn't provide any functionality whatsoever for getting a video's duration (or much other video metadata, for that matter). But, have no fear, it turns out that a quick code snippet for querying a YouTube video's duration, based on video ID, is pretty quick and painless in bare-bones PHP. Add this to a custom module on your site (in my case, I added it to my foobar_page.module):
<?php
/**
* Gets a YouTube video's duration, based on video ID.
*
* Copied (almost exactly) from:
* http://stackoverflow.com/questions/9167442/
* get-duration-from-a-youtube-url/9167754#9167754
*
* @param $video_id
* YouTube video ID.
*
* @return
* Video duration (or FALSE on failure).
*/
function foobar_page_get_youtube_video_duration($video_id) {
$data = @file_get_contents('http://gdata.youtube.com/feeds/api/videos/'
. $video_id . '?v=2&alt=jsonc');
if ($data === FALSE) {
return FALSE;
}
$obj = json_decode($data);
return $obj->data->duration;
}
Great – turns out that querying the YouTube API for the duration is very easy. But we don't want to perform an external HTTP request, every time we want to display a video's duration: that would be a potential performance issue (and, in the event that YouTube is slow or unavailable, it would completely hang the page loading process). What we should do instead, is only query the duration from YouTube when we save a node (or other entity), and then store the duration locally for easy retrieval later.
Storing the duration
There are a number of possibilities, for how to store this data. Using Drupal's variable_get() and variable_set() functionality is one option (with either one variable per duration value, or with all duration values stored in a single serialized variable). However, that has numerous disadvantages: it would negatively affect performance (both for retrieving duration values, and for the whole Drupal site); and, at the end of the day, it's an abuse of the Drupal variable system, which is only meant to be used for one-off values, not for values that are potentially set for every node on your site (sadly, it would be far from the first such case of abuse of the Drupal variable system – but the fact that other people / other modules do it, doesn't make it any less dodgy).
Patching the Media: YouTube module to have an extra database field for video duration, and making the module retrieve and store this value, would be another option. However, that would be a lot more work and a lot more code; it would also mean having a hacked version of the module, until (if and when) a patch for the module (that we'd have to submit and refine) gets committed on drupal.org. Plus, it would mean learning a whole lot more about the Field API, the Media module, and the File API than any sane person would care to subject his/her self to.
Enter the Computed Field module. With the help of this handy module, we have the possibility of implementing a better, faster, nicer solution.
Add this to a custom module on your site (in my case, I added it to my foobar_page.module):
Next, install the Computed Field module on your Drupal site. Add a new field to your content type, called 'Video duration' (field_video_duration), with 'field type' and 'widget' of type 'Computed'. On the settings page for this field, you should see the message: "This field is COMPUTED using computed_field_field_video_duration_compute()". In the 'database storage settings', ensure that 'Data type' is 'text', and that 'Data length' is '255'. You can leave all other settings for this field at their defaults.
Re-save the node that has YouTube video content, in order to retrieve and save the new computed field value for the duration.
Displaying the duration
For the formatting of the duration (the raw value of which is stored in seconds), in hours:minutes:seconds format, here's a dodgy custom function that I whipped up. Use it, or don't – totally your choice. If you choose to use, then add this to a custom module on your site:
<?php
/**
* Formats the given time value in h:mm:ss format (if it's >= 1 hour),
* or in mm:ss format (if it's < 1 hour).
*
* Based on Drupal's format_interval() function.
*
* @param $interval
* Time interval (in seconds).
*
* @return
* Formatted time value.
*/
function foobar_page_format_time_interval($interval) {
$units = array(
array('format' => '%d', 'value' => 3600),
array('format' => '%d', 'value' => 60),
array('format' => '%02d', 'value' => 1),
);
$granularity = count($units);
$output = '';
$has_value = FALSE;
$i = 0;
foreach ($units as $unit) {
$format = $unit['format'];
$value = $unit['value'];
$new_val = floor($interval / $value);
$new_val_formatted = ($output !== '' ? ':' : '') .
sprintf($format, $new_val);
if ((!$new_val && $i) || $new_val) {
$output .= $new_val_formatted;
if ($new_val) {
$has_value = TRUE;
}
}
if ($interval >= $value && $has_value) {
$interval %= $value;
}
$granularity--;
$i++;
if ($granularity == 0) {
break;
}
}
return $output ? $output : '0:00';
}
Update your mytheme_preprocess_node() function, with some extra code for making the formatted video duration available in your node template:
<?php
/**
* Preprocessor for node.tpl.php template file.
*/
function foobar_preprocess_node(&$vars) {
if ($vars['node']->type == 'page' &&
!empty($vars['node']->field_video['und'][0]['fid'])) {
$video_file = file_load($vars['node']->field_video['und'][0]['fid']);
$vf = file_view_file($video_file, 'default', '');
$vars['video'] = drupal_render($vf);
if (!empty($vars['node']->field_video_duration['und'][0]['value'])) {
$vars['video_duration'] = foobar_page_format_time_interval(
$vars['node']->field_video_duration['und'][0]['value']);
}
}
}
Finally, update your node.tpl.php file or equivalent:
<!-- template stuff bla bla bla -->
<?php if (!empty($video)): ?>
<?php print $video; ?>
<?php endif; ?>
<?php if (!empty($video_duration)): ?>
<p><strong>Duration:</strong> <?php print $video_duration; ?></p>
<?php endif; ?>
<!-- more template stuff bla bla bla -->
Reload the page on your site, and lo and behold:
We have duration!
Final remarks
I hope this example comes in handy, for anyone else who needs to display YouTube video duration metadata in this way.
I'd also like to strongly note, that what I've demonstrated here isn't solely applicable to this specific use case. With some modification, it could easily be applied to various different related use cases. Other than duration, you could retrieve / store / display any of the other metadata fields available via the YouTube API (e.g. date video uploaded, video category, number of comments). Or, you could work with media from another source, using another Drupal media-enabled module (e.g. Media: Vimeo). Or, you could store externally-queried data for some completely different field. I encourage you to experiment and to use your imagination, when it comes to the Computed Field module. The possibilities are endless.
]]>
Natural disaster risk levels of the world's largest cities2013-03-14T00:00:00Z2013-03-14T00:00:00ZJazahttps://greenash.net.au/thoughts/2013/03/natural-disaster-risk-levels-of-the-worlds-largest-cities/
Every now and again, Mother Nature reminds us that despite all of our modern technological and cultural progress, we remain mere mortals, vulnerable as always to her wrath. Human lives and human infrastructure continue to regularly fall victim to natural disasters such as floods, storms, fires, earthquakes, tsunamis, and droughts. At times, these catastrophes can even strike indiscriminately at our largest and most heavily-populated cities, including where we least expect them.
This article is a listing and an analysis of the world's largest cities (those with a population exceeding 10 million), and of their natural disaster risk level in a variety of categories. My list includes 23 cities, which represent a combined population of approximately 380 million people. That's roughly 5% of the world's population. Listing and population figures based on Wikipedia's list of metropolitan areas by population.
The world's largest cities. Satellite image courtesy of Google Maps.
The list
City
Country
Population (millions)
Natural disaster risks
Tokyo
Japan
32.45
Summary: very well-prepared for high risk of flooding, storms, and earthquakes.
Flood risk: high Flood preparedness: high
Storm risk: high Storm preparedness: high
Fire risk: low Fire preparedness: medium
Earthquake risk: high Earthquake preparedness: high
Flood refers to risk of the metropolitan area itself becoming inundated with water.
Storm refers to risk of disaster storms (as opposed to regular storms), which are variously called "hurricanes", "cyclones", "monsoons", "typhoons", and other names (depending on region / climate).
Fire refers to risk of wildfire / bushfire (as opposed to urban fire) from forest or wilderness areas surrounding or within the metropolitan area.
Earthquake refers to risk of the metropolitan area itself being shaken by seismic activity.
Tsunami refers to risk of a seismically-trigged ocean wave hitting the metropolitan area itself.
Drought refers to risk of drought affecting the agricultural region in which the metropolitan area lies.
Analysis
The list above presents quite the sobering picture: of the 23 cities analysed, 9 are critically unprepared for one or more high risks; 10 could be better prepared for one or more high risks; and only 4 are well-prepared for high risks (of which there's one that has no high risks). All in all, the majority of the inhabitants of the world's largest cities live with a signficant risk of natural disaster, for which the city is not sufficiently well-prepared.
By far the most common natural disaster plaguing the list is flooding: it affects 19 of the 23 cities (with many of these cities also at risk from storms). This is understandable, since the majority of the world's large cities are situated on the coast. 15 of the 23 cities in the list are on or very near to the seashore. What's more, about half of the 23 cities are also on or very near to a river delta, with several of them being considered "mega-delta cities" – that is, cities whose metropolitan area lies within a flood-plain.
With the methodology I've used in this analysis, it doesn't really matter what the risk of a given natural disaster striking a city is; what's significant, is how prepared a given city is to handle its most high-risk disasters. After all, if a city is very well-prepared for a high risk, then a large part of the risk effectively cancels itself out (although the risk that remains is still significant, as some cities are at risk of truly monumental disasters for which one can never fully prepare). On the other hand, if a city is critically unprepared for a high risk, this means that really there are no mitigating factors – that city will suffer tremendously when disaster hits.
It should come as no surprise, therefore, that the summary / risk level for each city depends heavily on that country's level of development. For example, the Japanese cities are some of the most disaster-prone cities in the world; but they're also safer than numerous other, less disaster-prone cities, because of Japan's incredibly high level of preparedness for natural disasters (in particular, its world-class earthquake-proof building standards, and its formidable flood-control infrastructure). At the other extreme, the Indian cities are significantly less disaster-prone than many others (in particular, India has a low earthquake risk); but they're more dangerous, due to India's poor overall urban infrastructure, and its poor or non-existent flood-control infrastructure.
Conclusion
So: if you're picking one of the world's largest cities to live in, which would be a good choice? From the list above, the clear winner is Moscow, which is the only city with no high risk of any of the world's more common natural disasters. However, it does get pretty chilly there (Moscow has the highest latitude of all the cities in the list), and Russia has plenty of other issues aside from natural disasters.
The other cities in my list with a tick of approval are the Japanese mega-cities, Tokyo and Osaka. Although Japan is one of the most earthquake-prone places on Earth, you can count on the Japanese for being about 500 years ahead of the rest of the world earthquake-proof-wise, as they are about 500 years ahead of the rest of the world technology-wise in general. Hong Kong would also be a good choice, in picking a city very well-prepared for the natural disasters that it most commonly faces.
For all of you that are living in the other mega-cities of the developed world: watch out, because you're all living in cities that could be better prepared for natural disasters. I'm looking at you Seoul, New York, Los Angeles, London, and Paris. Likewise to the cities on the list in somewhat less-developed countries: i.e. Mexico City, São Paulo, Cairo, Buenos Aires, and Rio de Janeiro. You're all lagging behind in natural disaster risk management.
As for the cities on my list that are "in the red": you should seriously consider other alternatives, before choosing to live in any of these places. The developing nations of Indonesia, India, China, The Philippines, Bangladesh, and Pakistan are home to world mega-cities; however, their population bears (and, in many cases, regularly suffers) a critical level of exposure to natural disaster risk. Jakarta, Delhi, Mumbai, Shanghai, Manila, Kolkata, Dhaka, Beijing, and Karachi: thinking of living in any of these? Think again.
]]>
Rendering a Silex (Symfony2) app via Drupal 72013-01-25T00:00:00Z2013-01-25T00:00:00ZJazahttps://greenash.net.au/thoughts/2013/01/rendering-a-silex-symfony2-app-via-drupal-7/
There's been a lot of talk recently regarding the integration of the Symfony2 components, as a fundamental part of Drupal 8's core system. I won't rabble on repeating the many things that have already been said elsewhere; however, to quote the great Bogeyman himself, let me just say that "I think this is the beginning of a beautiful friendship".
On a project I'm currently working on, I decided to try out something of a related flavour. I built a stand-alone app in Silex (a sort of Symfony2 distribution); but, per the project's requirements, I also managed to heavily integrate the app with an existing Drupal 7 site. The app does almost everything on its own, except that: it passes its output to drupal_render_page() before returning the request; and it checks that a Drupal user is currently logged-in and has a certain Drupal user role, for pages where authorisation is required.
The result is: an app that has its own custom database, its own routes, its own forms, its own business logic, and its own templates; but that gets rendered via the Drupal theming system, and that relies on Drupal data for authentication and authorisation. What's more, the implementation is quite clean (minimal hackery involved) – only a small amount of code is needed for the integration, and then (for the most part) Drupal and Silex leave each other alone to get on with their respective jobs. Now, let me show you how it's done.
Drupal setup
To start with, set up a new bare-bones Drupal 7 site. I won't go into the details of Drupal installation here. If you need help with setting up a local Apache VirtualHost, editing your /etc/hosts file, setting up a MySQL database / user, launching the Drupal installer, etc, please refer to the Drupal installation guide. For this guide, I'll be using a Drupal 7 instance that's been installed to the /www/d7silextest directory on my local machine, and that can be accessed via http://d7silextest.local.
D7 Silex test site after initial setup.
Once you've got that (or something similar) up and running, and if you're keen to follow along, then keep up with me as I outline further Drupal config steps. Firstly, go to administration > people > permissions > roles, create a new role called 'administrator' (if it doesn't exist already). Then, assign the role to user 1.
Next, download the patches from Need DRUPAL_ROOT in include of template.php and Need DRUPAL_ROOT when rendering CSS include links, and apply them to your Drupal codebase. Note: these are some bugs in core, where certain PHP files are being included without properly appending the DRUPAL_ROOT prefix. As of writing, I've submitted these patches to drupal.org, but they haven't yet been committed. Please check the status of these issue threads – if they're now resolved, then you may not need to apply the patches (check exactly which version of Drupal you're using, as of Drupal 7.19 the patches are still needed).
If you're using additional Drupal contrib or custom modules, they may also have similar bugs. For example, I've also submitted Need DRUPAL_ROOT in require of include files for the Revisioning module (not yet committed as of writing), and Need DRUPAL_ROOT in require of og.field.inc for the Organic Groups module (now committed and applied in latest stable release of OG). If you find any more DRUPAL_ROOT bugs, that prevent an external script such as Symfony2 from utilising Drupal from within a subdirectory, then please patch these bugs yourself, and submit patches to drupal.org as I've done.
Enable the menu module (if it's not already enabled), and define a 'Page' content type (if not already defined). Create a new 'Page' node (in my config below, I assume that it's node 1), with a menu item (e.g. in 'main menu'). Your new test page should look something like this:
D7 Silex test site with test page.
That's sufficient Drupal configuration for the purposes of our example. Now, let's move on to Silex.
Silex setup
To start setting up your example Silex site, create a new directory, which is outside of your Drupal site's directory tree. In this article, I'm assuming that the Silex directory is at /www/silexd7test. Within this directory, create a composer.json file with the following:
Get Composer (if you don't have it), by executing this command:
curl -s http://getcomposer.org/installer | php
Once you've got Composer, installing Silex is very easy, just execute this command from your Silex directory:
php composer.phar install
Next, create a new directory called web in your silex root directory; and create a file called web/index.php, that looks like this:
<?php
/**
* @file
* The PHP page that serves all page requests on a Silex installation.
*/
require_once __DIR__ . '/../vendor/autoload.php';
$app = new Silex\Application();
$app['debug'] = TRUE;
$app->get('/', function() use($app) {
return '<p>You should see this outputting ' .
'within your Drupal site!</p>';
});
$app->run();
That's a very basic Silex app ready to go. The app just defines one route (the 'home page' route), which outputs the text You should see this outputting within your Drupal site! on request. The Silex app that I actually built and integrated with Drupal did a whole more of this – but for the purposes of this article, a "Hello World" example is all we need.
To see this app in action, in your Drupal root directory create a symlink to the Silex web folder:
ln -s /www/silexd7test/web/ silexd7test
Now you can go to http://d7silextest.local/silexd7test/, and you should see something like this:
Silex serving requests stand-alone, under Drupal web path.
So far, the app is running under the Drupal web path, but it isn't integrated with the Drupal site at all. It's just running its own bootstrap code, and outputting the response for the requested route without any outside help. We'll be changing that shortly.
Integration
Open up the web/index.php file again, and change it to look like this:
<?php
/**
* @file
* The PHP page that serves all page requests on a Silex installation.
*/
require_once __DIR__ . '/../vendor/autoload.php';
$app = new Silex\Application();
$app['debug'] = TRUE;
$app['drupal_root'] = '/www/d7silextest';
$app['drupal_base_url'] = 'http://d7silextest.local';
$app['is_embedded_in_drupal'] = TRUE;
$app['drupal_menu_active_item'] = 'node/1';
/**
* Bootstraps Drupal using DRUPAL_ROOT and $base_url values from
* this app's config. Bootstraps to a sufficient level to allow
* session / user data to be accessed, and for theme rendering to
* be invoked..
*
* @param $app
* Silex application object.
* @param $level
* Level to bootstrap Drupal to. If not provided, defaults to
* DRUPAL_BOOTSTRAP_FULL.
*/
function silex_bootstrap_drupal($app, $level = NULL) {
global $base_url;
// Check that Drupal bootstrap config settings can be found.
// If not, throw an exception.
if (empty($app['drupal_root'])) {
throw new \Exception("Missing setting 'drupal_root' in config");
}
elseif (empty($app['drupal_base_url'])) {
throw new \Exception("Missing setting 'drupal_base_url' in config");
}
// Set values necessary for Drupal bootstrap from external script.
// See:
// http://www.csdesignco.com/content/using-drupal-data-functions-
// and-session-variables-external-php-script
define('DRUPAL_ROOT', $app['drupal_root']);
$base_url = $app['drupal_base_url'];
// Bootstrap Drupal.
require_once DRUPAL_ROOT . '/includes/bootstrap.inc';
if (is_null($level)) {
$level = DRUPAL_BOOTSTRAP_FULL;
}
drupal_bootstrap($level);
if ($level == DRUPAL_BOOTSTRAP_FULL &&
!empty($app['drupal_menu_active_item'])) {
menu_set_active_item($app['drupal_menu_active_item']);
}
}
/**
* Checks that an authenticated and non-blocked Drupal user is tied to
* the current session. If not, deny access for this request.
*
* @param $app
* Silex application object.
*/
function silex_limit_access_to_authenticated_users($app) {
global $user;
if (empty($user->uid)) {
$app->abort(403, 'You must be logged in to access this page.');
}
if (empty($user->status)) {
$app->abort(403, 'You must have an active account in order to ' .
'access this page.');
}
if (empty($user->name)) {
$app->abort(403, 'Your session must be tied to a username to ' .
'access this page.');
}
}
/**
* Checks that the current user is a Drupal admin (with 'administrator'
* role). If not, deny access for this request.
*
* @param $app
* Silex application object.
*/
function silex_limit_access_to_admin($app) {
global $user;
if (!in_array('administrator', $user->roles)) {
$app->abort(403,
'You must be an administrator to access this page.');
}
}
$app->get('/', function() use($app) {
silex_bootstrap_drupal($app);
silex_limit_access_to_authenticated_users($app);
silex_limit_access_to_admin($app);
$ret = '<p>You should see this outputting within your ' .
'Drupal site!</p>';
return !empty($app['is_embedded_in_drupal']) ?
drupal_render_page($ret) :
$ret;
});
$app->run();
A number of things have been added to the code in this file, so let's examine them one-by-one. First of all, some Drupal-related settings have been added to the Silex $app object. The drupal_root and drupal_base_url settings, are the critical ones that are needed in order to bootstrap Drupal from within Silex. Because the Silex script is in a different filesystem path from the Drupal site, and because it's also being served from a different URL path, these need to be manually set and passed on to Drupal.
The is_embedded_in_drupal setting allows the rendering of the page via drupal_render_page() to be toggled on or off. The script could work fine without this, and with rendering via drupal_render_page() hard-coded to always occur; allowing it to be toggled is just a bit more elegant. The drupal_menu_active_item setting, when set, triggers the Drupal menu path to be set to the path specified (via menu_set_active_item()).
The route handler for our 'home page' path now calls three functions, before going on to render the page. The first one, silex_bootstrap_drupal(), is pretty self-explanatory. The second one, silex_limit_access_to_authenticated_users(), checks the Drupal global $user object to ensure that the current user is logged-in, and if not, it throws an exception. Similarly, silex_limit_access_to_admin() checks that the current user has the 'administrator' role (with failure resulting in an exception).
To test the authorisation checks that are now in place, log out of the Drupal site, and visit the Silex 'front page' at http://d7silextest.local/silexd7test/. You should see something like this:
Silex denying access to a page because Drupal user is logged out
The drupal_render_page() function is usually – in the case of a Drupal menu callback – passed a callback (a function name as a string), and rendering is then delegated to that callback. However, it also accepts an output string as its first argument; in this case, the passed-in string is outputted directly as the content of the 'main page content' Drupal block. Following that, all other block regions are assembled, and the full Drupal page is themed for output, business as usual.
To see the Silex 'front page' fully rendered, and without any 'access denied' message, log in to the Drupal site, and visit http://d7silextest.local/silexd7test/ again. You should now see something like this:
Silex serving output that's been passed through drupal_render_page().
And that's it – a Silex callback, with Drupal theming and Drupal access control!
Final remarks
The example I've walked through in this article, is a simplified version of what I implemented for my recent real-life project. Some important things that I modified, for the purposes of keeping this article quick 'n' dirty:
Changed the route handler and Drupal bootstrap / access-control functions, from being methods in a Silex Controller class (implementing Silex\ControllerProviderInterface) in a separate file, to being functions in the main index.php file
Changed the config values, from being stored in a JSON file and loaded via Igorw\Silex\ConfigServiceProvider, to being hard-coded into the $app object in raw PHP
Took out logging for the app via Silex\Provider\MonologServiceProvider
My real-life project is also significantly more than just a single "Hello World" route handler. It defines its own custom database, which it accesses via Doctrine's DBAL and ORM components. It uses Twig templates for all output. It makes heavy use of Symfony2's Form component. And it includes a number of custom command-line scripts, which are implemented using Symfony2's Console component. However, most of that is standard Silex / Symfony2 stuff which is not so noteworthy; and it's also not necessary for the purposes of this article.
I should also note that although this article is focused on Symfony2 / Silex, the example I've walked through here could be applied to any other PHP script that you might want to integrate with Drupal 7 in a similar way (as long as the PHP framework / script in question doesn't conflict with Drupal's function or variable names). However, it does make particularly good sense to integrate Symfony2 / Silex with Drupal 7 in this way, because: (a) Symfony2 components are going to be the foundation of Drupal 8 anyway; and (b) Symfony2 components are the latest and greatest components available for PHP right now, so the more projects you're able to use them in, the better.
]]>
Node.js itself is blocking, only its I/O is non-blocking2012-11-15T00:00:00Z2012-11-15T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/11/nodejs-itself-is-blocking-only-its-io-is-non-blocking/
I've recently been getting my feet wet, playing around with Node.js (yes, I know – what took me so long?). I'm having a lot of fun, learning new technologies by the handful. It's all very exciting.
I just thought I'd stop for a minute, however, to point out one important detail of Node.js that had me confused for a while, and that seems to have confused others, too. More likely than not, the first feature of Node.js that you heard about, was its non-blocking I/O model.
Now, please re-read that last phrase, and re-read it carefully. Non. Blocking. I/O. You will never hear anywhere, from anyone, that Node.js is non-blocking. You will only hear that it has non-blocking I/O. If, like me, you're new to Node.js, and you didn't stop to think about what exactly "I/O" means (in the context of Node.js) before diving in (and perhaps you weren't too clear on "non-blocking", either), then fear not.
What exactly – with reference to Node.js – is blocking, and what is non-blocking? And what exactly – also with reference to Node.js – is I/O, and what is not I/O? Let me clarify, for me as much as for you.
Blocking vs non-blocking
Let's start by defining blocking. A line of code is blocking, if all functionality invoked by that line of code must terminate before the next line of code executes.
This is the way that all traditional procedural code works. Here's a super-basic example of some blocking code in JavaScript:
In this example, the first line of code is blocking. Therefore, the first line must finish doing everything we told it to do, before our CPU gives the second line of code the time of day. Therefore, we are guaranteed to get this output:
Peking duck
Coconut lychee
Now, let me introduce you to Kev the Kook. Rather than just outputting the above lines to console, Kev wants to thoroughly cook his Peking duck, and exquisitely prepare his coconut lychee, before going ahead and brashly telling the guests that the various courses of their dinner are ready. Here's what we're talking about:
function prepare_peking_duck() {
var duck = slaughter_duck();
duck = remove_feathers(duck);
var oven = preheat_oven(180, 'Celsius');
duck = marinate_duck(duck, "Mr Wu's secret Peking herbs and spices");
duck = bake_duck(duck, oven);
serve_duck_with(duck, 'Spring rolls');
}
function prepare_coconut_lychee() {
bowl = get_bowl_from_cupboard();
bowl = put_lychees_in_bowl(bowl);
bowl = put_coconut_milk_in_bowl(bowl);
garnish_bowl_with(bowl, 'Peanut butter');
}
prepare_peking_duck();
console.log('Peking duck is ready');
prepare_coconut_lychee();
console.log('Coconut lychee is ready');
In this example, we're doing quite a bit of grunt work. Also, it's quite likely that the first task we call will take considerably longer to execute than the second task (mainly because we have to remove the feathers, that can be quite a tedious process). However, all that grunt work is still guaranteed to be performed in the order that we specified. So, the Peking duck will always be ready before the coconut lychee. This is excellent news, because eating the coconut lychee first would simply be revolting, everyone knows that it's a dessert dish.
Now, let's suppose that Kev previously had this code implemented in server-side JavaScript, but in a regular library that provided only blocking functions. He's just decided to port the code to Node.js, and to re-implement it using non-blocking functions.
Up until now, everything was working perfectly: the Peking duck was always ready before the coconut lychee, and nobody ever went home with a sour stomach (well, alright, maybe the peanut butter garnish didn't go down so well with everyone… but hey, just no pleasing some folks). Life was good for Kev. But now, things are more complicated.
In contrast to blocking, a line of code is non-blocking, if the next line of code may execute before the line of functionality invoked by that line of code has terminated.
Back to Kev's Chinese dinner. It turns out that in order to port the duck and lychee code to Node.js, pretty much all of his high-level functions will have to call some non-blocking Node.js library functions. And the way that non-blocking code essentially works is: if a function calls any other function that is non-blocking, then the calling function itself is also non-blocking. Sort of a viral, from-the-inside-out effect.
Kev hasn't really got his head around this whole non-blocking business. He decides, what the hell, let's just implement the code exactly as it was before, and see how it works. To his great dismay, though, the results of executing the original code with Node.js non-blocking functions is not great:
Peking duck is ready
Coconut lychee is ready
/path/to/prepare_peking_duck.js:9
duck.toString();
^
TypeError: Cannot call method 'toString' of undefined
at remove_feathers (/path/to/prepare_peking_duck.js:9:8)
This output worries Kev for two reasons. Firstly, and less importantly, it worries him because there's an error being thrown, and Kev doesn't like errors. Secondly, and much more importantly, it worries him because the error is being thrown after the program successfully outputs both "Peking duck is ready" and "Coconut lychee is ready". If the program isn't able to get past the end of remove_feathers() without throwing a fatal error, then how could it possibly have finished the rest of the duck and lychee preparation?
The answer, of course, is that all of Kev's dinner preparation functions are now effectively non-blocking. This means that the following happened when Kev ran his script:
Called prepare_peking_duck()
Called slaughter_duck()
Non-blocking code in slaughter_duck() doesn't execute until
after current blocking code is done. Is supposed to return an int,
but actually returns nothing
Called remove_feathers() with return value of slaughter_duck()
as parameter
Non-blocking code in remove_feathers() doesn't execute until
after current blocking code is done. Is supposed to return an int,
but actually returns nothing
Called other duck-preparation functions
They all also contain non-blocking code, which doesn't execute
until after current blocking code is done
Printed 'Peking duck is ready'
Called prepare_coconut_lychee()
Called lychee-preparation functions
They all also contain non-blocking code, which doesn't execute
until after current blocking code is done
Printed 'Coconut lychee is ready'
Returned to prepare_peking_duck() context
Returned to slaughter_duck() context
Executed non-blocking code in slaughter_duck()
Returned to remove_feathers() context
Error executing non-blocking code in remove_feathers()
Before too long, Kev works out – by way of logical reasoning – that the execution flow described above is indeed what is happening. So, he comes to the realisation that he needs to re-structure his code to work the Node.js way: that is, using a whole lotta callbacks.
After spending a while fiddling with the code, this is what Kev ends up with:
This runs without errors. However, it produces its output in the wrong order – this is what it spits onto the console:
Coconut lychee is ready
Peking duck is ready
This output is possible because, with the code in its current state, the execution of both of Kev's preparation routines – the Peking duck preparation, and the coconut lychee preparation – are sent off to run as non-blocking routines; and whichever one finishes executing first gets its callback fired before the other. And, as mentioned, the Peking duck can take a while to prepare (although utilising a cloud-based grid service for the feather plucking can boost performance).
Now, as we already know, eating the coconut lychee before the Peking duck causes you to fart a Szechuan Stinker, which is classified under international law as a chemical weapon. And Kev would rather not be guilty of war crimes, simply on account of a small culinary technical hiccup.
This final execution-ordering issue can be fixed easily enough, by converting one remaining spot to use a nested callback pattern:
prepare_peking_duck(function(err) {
console.log('Peking duck is ready');
prepare_coconut_lychee(function(err) {
console.log('Coconut lychee is ready');
});
});
Finally, Kev can have his lychee and eat it, too.
I/O vs non-I/O
I/O stands for Input/Output. I know this because I spent four years studying Computer Science at university.
Actually, that's a lie. I already knew what I/O stood for when I was about ten years old.
But you know what I did learn at university? I learnt more about I/O than what the letters stood for. I learnt that the technical definition of a computer program, is: an executable that accepts some discrete input, that performs some processing, and that finishes off with some discrete output.
Actually, that's a lie too. I already knew that from high school computer classes.
You know what else is a lie? (OK, not exactly a lie, but at the very least it's confusing and incomplete). The description that Node.js folks give you for "what I/O means". Have a look at any old source (yes, pretty much anywhere will do). Wherever you look, the answer will roughly be: I/O is working with files, doing database queries, and making web requests from your app.
As I said, that's not exactly a lie. However, that's not what I/O is. That's a set of examples of what I/O is. If you want to know what the definition of I/O actually is, let me tell you: it's any interaction that your program makes with anything external to itself. That's it.
I/O usually involves your program reading a piece of data from an external source, and making it available as a variable within your code; or conversely, taking a piece of data that's stored as a variable within your code, and writing it to an external source. However, it doesn't always involve reading or writing data; and (as I'm trying to emphasise), it doesn't need to involve that, in order to fall within the definition of I/O for your program.
At a basic technical level, I/O is nothing more than any instance of your program invoking another program on the same machine. The simplest example of this, is executing another program via a command-line statement from your program. Node.js provides the non-blocking I/O function child_process.exec() for this purpose; running shell commands with it is pretty easy.
The most common and the most obvious example of I/O, reading and writing files, involves (under the hood) your program invoking the various utility programs provided by all OSes for interacting with files. open is another program somewhere on your system. read, write, close, stat, rename, unlink – all individual utility programs living on your box.
From this perspective, a DBMS is just one more utility program living on your system. (At least, the client utility lives on your system – where the server lives, and how to access it, is the client utility's problem, not yours). When you open a connection to a DB, perform some queries (regardless of them being read or write queries), and then close the connection, the only really significant point (for our purposes) is that you're making various invocations to a program that's external to your program.
Similarly, all network communication performed by your program is nothing more than a bunch of invocations to external utility programs. Although these utility programs provide the illusion (both to the programmer and to the end-user) that your program is interacting directly with remote sources, in reality the direct interaction is only with the utilities on your machine for opening a socket, port mapping, TCP / UDP packet management, IP addressing, DNS lookup, and all the other gory details.
And, of course, working with HTTP is simply dealing with one extra layer of utility programs, on top of all the general networking utility programs. So, when you consider it from this point of view, making a JSON API request to an online payment broker over SSL, is really no different to executing the pwd shell command. It's all I/O!
I hope I've made it crystal-clear by now, what constitutes I/O. So, conversely, you should also now have a clearer idea of exactly what constitutes non-I/O. In a nutshell: any code that does not invoke any external programs, any code that is completely insular and that performs all processing internally, is non-I/O code.
The philosophy behind Node.js, is that most database-driven web apps – what with their being database-driven, and web-based, and all – don't actually have a whole lot of non-I/O code. In most such apps, the non-I/O code consists of little more than bits 'n' pieces that happen in between the I/O bits: some calculations after retrieving data from the database; some rendering work after performing the business logic; some parsing and validation upon receiving incoming API calls or form submissions. It's rare for web apps to perform any particularly intensive tasks, without the help of other external utilities.
Some programs do contain a lot of non-I/O code. Typically, these are programs that perform more heavy processing based on the direct input that they receive. For example, a program that performs an expensive mathematical computation, such as finding all Fibonacci numbers up to a given value, may take a long time to execute, even though it only contains non-I/O code (by the way, please don't write a Fibonacci number app in Node.js). Similarly, image processing utility programs are generally non-I/O, as they perform a specialised task using exactly the image data provided, without outside help.
Putting it all together
We should now all be on the same page, regarding blocking vs non-blocking code, and regarding I/O vs non-I/O code. Now, back to the point of this article, which is to better explain the key feature of Node.js: its non-blocking I/O model.
As others have explained, in Node.js everything runs in parallel, except your code. What this means is that all I/O code that you write in Node.js is non-blocking, while (conversely) all non-I/O code that you write in Node.js is blocking.
So, as Node.js experts are quick to point out: if you write a Node.js web app with non-I/O code that blocks execution for a long time, your app will be completely unresponsive until that code finishes running. As I said: please, no Fibonacci in Node.js.
When I started writing in Node.js, I was under the impression that the V8 engine it uses automagically makes your code non-blocking, each time you make a function call. So I thought that, for example, changing a long-running while loop to a recursive loop would make my (completely non-I/O) code non-blocking. Wrong! (As it turns out, if you'd like a language that automagically makes your code non-blocking, apparently Erlang can do it for you – however, I've never used Erlang, so can't comment on this).
In fact, the secret to non-blocking code in Node.js is not magic. It's a bag of rather dirty tricks, the most prominent (and the dirtiest) of which is the process.nextTick() function.
As others have explained, if you need to write truly non-blocking processor-intensive code, then the correct way to do it is to implement it as a separate program, and to then invoke that external program from your Node.js code. Remember:
Not in your Node.js code == I/O == non-blocking
I hope this article has cleared up more confusion than it's created. I don't think I've explained anything totally new here, but I believe I've explained a number of concepts from a perspective that others haven't considered very thoroughly, and with some new and refreshing examples. As I said, I'm still brand new to Node.js myself. Anyway, happy coding, and feel free to add your two cents below.
]]>
Batch updating Drupal 7 field data2012-11-08T00:00:00Z2012-11-08T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/11/batch-updating-drupal-7-field-data/
On a number of my recently-built Drupal sites, I've become a fan of using the Computed Field module to provide a "search data" field, as a Views exposed filter. This technique has been documented by other folks here and there (I didn't invent it), so I won't cover its details here. Basically, it's a handy way to create a search form that searches exactly the fields you're interested in, thus providing you with more fine-grained control than the core Drupal search module, and with much less installation / configuration overhead than Apache Solr.
On one such site, which has about 4,000+ nodes that are searchable via this technique, I needed to add another field to the index, and re-generate the Computed Field data for every node. This data normally only gets re-generated when each individual node is saved. In my case, that would not be sufficient - I needed the entire search index refreshed immediately.
The obvious solution, would be to whip up a quick script that loops through all the nodes in question, and that calls node_save() on each pass through the loop. However, this solution has two problems. Firstly, node_save() is really slow (particularly when the node has a lot of other fields, such as was my case). So slow, in fact, that in my case I was fighting a losing battle against PHP "maximum execution time exceeded" errors. Secondly, node_save() is slow unnecessarily, as it re-saves all the data for all a node's fields (plus it invokes a bazingaful of hooks), whereas we only actually need to re-save the data for one field (and we don't need any hooks invoked, thanks).
In the interests of both speed and cutting-out-the-cruft, therefore, I present here an alternative solution: getting rid of the middle man (node_save()), and instead invoking the field_storage_write callback directly. Added bonus: I've implemented it using the Batch API functionality available via Drupal 7's hook_update_N().
Show me the code
The below code uses a (pre-defined) Computed field called field_search_data, and processes nodes of type event, news or page. It also sets the limit per batch run to 50 nodes. Naturally, all of this should be modified per your site's setup, when borrowing the code.
<?php
/**
* Batch update computed field values for 'field_search_data'.
*/
function mymodule_update_7000(&$sandbox) {
$entity_type = 'node';
$field_name = 'field_search_data';
$langcode = 'und';
$storage_module = 'field_sql_storage';
$field_id = db_query('SELECT id FROM {field_config} WHERE ' .
'field_name = :field_name', array(
':field_name' => $field_name
))->fetchField();
$field = field_info_field($field_name);
$types = array(
'event',
'news',
'page',
);
// Go through all published nodes in all of the above node types,
// and generate a new 'search_data' computed value.
$instance = field_info_instance($entity_type,
$field_name,
$bundle_name);
if (!isset($sandbox['progress'])) {
$sandbox['progress'] = 0;
$sandbox['last_nid_processed'] = -1;
$sandbox['max'] = db_query('SELECT COUNT(*) FROM {node} WHERE ' .
'type IN (:types) AND status = 1 ORDER BY nid', array(
':types' => $types
))->fetchField();
// I chose to delete existing data for this field, so I can
// clearly monitor in phpMyAdmin the field data being re-generated.
// Not necessary to do this.
// NOTE: do not do this if you have actual important data in
// this field! In my case it's just a search index, so it's OK.
// May not be so cool in your case.
db_query('TRUNCATE TABLE {field_data_' . $field_name . '}');
db_query('TRUNCATE TABLE {field_revision_' . $field_name . '}');
}
$limit = 50;
$result = db_query_range('SELECT nid FROM {node} WHERE ' .
'type IN (:types) AND status = 1 AND nid > :lastnid ORDER BY nid',
0, $limit, array(
':types' => $types,
':lastnid' => $sandbox['last_nid_processed']
));
while ($nid = $result->fetchField()) {
$entity = node_load($nid);
if (!empty($entity->nid)) {
$items = isset($entity->{$field_name}[$langcode]) ?
$entity->{$field_name}[$langcode] :
array();
_computed_field_compute_value($entity_type, $entity, $field,
$instance, $langcode, $items);
if ($items !== array() ||
isset($entity->{$field_name}[$langcode])) {
$entity->{$field_name}[$langcode] = $items;
// This only writes the data for the single field we're
// interested in to the database. Much less expensive than
// the easier alternative, which would be to node_save()
// every node.
module_invoke($storage_module, 'field_storage_write',
$entity_type, $entity, FIELD_STORAGE_UPDATE,
array($field_id));
}
}
$sandbox['progress']++;
$sandbox['last_nid_processed'] = $nid;
}
if (empty($sandbox['max'])) {
$sandbox['#finished'] = 1.0;
}
else {
$sandbox['#finished'] = $sandbox['progress'] / $sandbox['max'];
}
if ($sandbox['#finished'] == 1.0) {
return t('Updated \'search data\' computed field values.');
}
}
The feature of note in this code, is that we're updating Field API data without calling node_save(). We're doing this by manually generating the new Computed Field data, via _computed_field_compute_value(); and by then invoking the field_storage_write callback with the help of module_invoke().
Unfortunately, doing it this way is a bit complicated - these functions expect a whole lot of Field API and Entity API parameters to be passed to them, and preparing all these parameters is no walk in the park. Calling node_save() takes care of all this legwork behind the scenes.
This approach still isn't lightning-fast, but it performs significantly better than its alternative. Plus, by avoiding the usual node hook invocations, we also avoid any unwanted side-effects of simulating a node save operation (e.g. creating a new revision, affecting workflow state).
To execute the procedure as it's implemented here, all you need to do is visit update.php in your browser (or run drush updb from your terminal), and it will run as a standard Drupal database update. In my case, I chose to implement it in hook_update_N(), because: it gives me access to the Batch API for free; it's guaranteed to run only once; and it's protected by superuser-only access control. But, for example, you could also implement it as a custom admin page, calling the Batch API from a menu callback within your module.
Just one example
The use case presented here – a Computed Field used as a search index for Views exposed filters – is really just one example of how this technique could come in handy. What I'm trying to provide in this article, is a code template that can be applied to any scenario in which a single field (or a small number of fields) needs to be modified across a large volume of existing nodes (or other entities).
I can think of quite a few other potential scenarios. A custom "phone" field, where a region code needs to be appended to all existing data. A "link" field, where any existing data missing a "www" prefix needs to have it added. A node reference field, where certain saved Node IDs need to be re-mapped to new values, because the old pages have been archived. Whatever your specific requirement, I hope this code snippet makes your life a bit easier, and your server load a bit lighter.
]]>
How compatible are the world's major religions?2012-10-17T00:00:00Z2012-10-17T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/10/how-compatible-are-the-worlds-major-religions/
There are a tonne of resources around that compare the world's major religions, highlighting the differences between each. There are some good comparisons of Eastern vs Western religions, and also numerous comparisons of Christianity vs non-Christianity.
However, I wasn't able to find any articles that specifically investigate the compatibility between the world's major religions. The areas where different religions are "on the same page", and are able to understand each other and (in the better cases) to respect each other; vs the areas where they're on a different wavelength, and where a poor capacity for dialogue is a potential cause for conflict.
I have, therefore, taken the liberty of penning such an analysis myself. What follows is a very humble list of aspects in which the world's major religions are compatible, vs aspects in which they are incompatible.
Compatible:
Divinity (usually although not universally manifested by the concept of a G-d or G-ds; this is generally a religion's core belief)
Sanctity (various events, objects, places, and people are considered sacred by the religion)
Community (the religion is practiced by more than one person; the religion's members assemble in order to perform significant tasks together; the religion has the fundamental properties of a community – i.e. a start date, a founder or founders, a name / label, a size as measured by membership, etc)
Personal communication with the divine and/or personal expression of spirituality (almost universally manifested in the acts of prayer and/or meditation)
Stories (mythology, stories of the religion's origins / founding, parables, etc)
Membership and initiation (i.e. a definition of "who is a member" of the religion, and defined methods of obtaining membership – e.g. by birth, by initiation ritual, by force)
Material expression, often (although not always) involving symbolism (e.g. characteristic clothing, music, architecture, and artwork)
Ethical guidance (in the form of books, oral wisdom, fundamental precepts, laws, codes of conduct, etc – although it should also be noted that religion and ethics are two different concepts)
Social guidance (marriage and family; celebration of festivities and special occasions; political views; behaviour towards various societal groups e.g. children, elders, community leaders, disadvantaged persons, members of other religions)
Right and wrong, in terms of actions and/or thoughts (i.e. definition of "good deeds", and of "sins"; although the many connotations of sin – e.g. punishment, divine judgment, consequences in the afterlife – are not universal)
Common purpose (although it's impossible to definitively state what religion's purpose is – e.g. religion provides hope; "religion's purpose is to provide a sense of purpose"; religion provides access to the spiritual and the divine; religion exists to facilitate love and compassion – also plenty of sceptical opinions, e.g. religion is the "opium of the masses"; religion is superstition and dogma for fools)
Explanation of the unknown (religion provides answers where reason and science cannot – e.g. creation, afterlife)
Incompatible:
The nature of divinity (one G-d vs many G-ds; G-d-like personification of divinity vs more abstract concept of a divine force / divine plane of existence; infinite vs constrained extent of divine power)
Acknowledgement of other religions (not all religions even acknowledge the existence of others; of those that do, many refuse to acknowledge their validity; and of those that acknowledge validity, most consider other religions as "inferior")
Tolerance of other religions (while some religions encourage harmony with the rest of the world, other religions promote various degrees of intolerance – e.g. holy war, forced conversion, socio-economic discrimination)
Community structure (religious communities range from strict bureaucratic hierarchies, to unstructured liberal movements, with every possible shade of grey in between)
What has a "soul" (all objects in the universe, from rocks upward, have a soul; vs only living organisms have a soul; vs only humans have a soul; vs there is no such thing as a soul)
Afterlife (re-incarnation vs eternal afterlife vs soul dies with body; consequences, if any, of behaviour in life on what happens after death)
Acceptable social norms (monogamous vs polygamous marriage; fidelity vs open relationships; punishment vs leniency towards children; types of prohibited relationships)
Form of rules (strict laws with strict punishments; vs only general guidelines / principles)
Ethical stances (on a broad range of issues, e.g. abortion, drug use, homosexuality, tattoos / piercings, blood transfusions, organ donation)
Leader figure(s) (Christ vs Moses vs Mohammed vs Buddha vs saints vs pagan deities vs Confucius)
Holy texts (Qu'ran vs Bible vs Torah vs Bhagavad Gita vs Tripitaka)
Ritual manifestations (differences in festivals; feasting vs fasting vs dietary laws; song, dance, clothing, architecture)
Why can't we be friends?
This quick article is my take on the age-old question: if all religions are supposedly based on universal peace and love, then why have they caused more war and bloodshed than any other force in history?
My logic behind comparing religions specifically in terms of "compatibility", rather than simply in terms of "similarities and differences", is that a compatibility analysis should yield conclusions that are directly relevant to the question that we're all asking (i.e. Why can't we be friends?). Logically, if religions were all 100% compatible with each other, then they'd never have caused any conflict in all of human history. So where, then, are all those pesky incompatibilities, that have caused peace-avowing religions to time and again be at each others' throats?
The answer, I believe, is the same one that explains why Java and FORTRAN don't get along well (excuse the geek reference). They both let you write computer programs – but on very different hardware, and in very different coding styles. Or why Chopin fans and Rage Against the Machine fans aren't best friends. They both like to listen to music, but at very different decibels, and with very different amounts of tattoos and piercings applied. Or why a Gemini and a Cancer weren't meant for each other (if you happen to believe in astrology, which I don't). They're both looking for companionship in this big and lonely world, but they laugh and cry in different ways, and the fact is they'll just never agree on whether sushi should be eaten with a fork or with chopsticks.
Religions are just one more parallel. They all aim to bring purpose and hope to one's life; but they don't always quite get there, because along the way they somehow manage to get bogged down discussing on which day of the week only raspberry yoghurt should be eaten, or whether the gates of heaven are opened by a lifetime of charitable deeds or by just ringing the buzzer.
Religion is just one more example of a field where the various competing groups all essentially agree on, and work towards, the same basic purpose; but where numerous incompatibilities arise due to differences in their implementation details.
Perhaps religions could do with a few IEEE standards? Although, then again, perhaps if the world can't even agree on a globally compatible standard for something as simple as what type of electrical plug to use, I doubt there's any hope for religion.
]]>
How close is the European Union to being a federation?2012-08-28T00:00:00Z2012-08-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/08/how-close-is-the-european-union-to-being-a-federation/
There has been considerable debate over the past decade or so, regarding the EU and federalism. Whether the EU is already a federation. Whether the EU is getting closer to being a federation. Whether the EU has the intention of becoming a federation. Just what the heck it means, anyway, to be a federation.
This article is my quick take, regarding the current status of the federal-ness of the EU. Just a simple layman's opinion, on what is of course quite a complex question. Perhaps not an expert analysis; but, hopefully, a simpler and more concise run-down than experts elsewhere have provided.
Central bank (the ECB only applies to the Eurozone, not the whole EU; the ECB is less powerful than other central banks around the world, as member states still maintain their own individual central banks)
Integrated legislative system (European Union law still based largely on treaties rather than statutes / precedents; most EU law applies only indirectly on member states; almost no European Union criminal law)
Federal constitution (came close, but was ultimately rejected; current closest entity is the Treaty of Lisbon)
Federal law enforcement (Europol has no executive powers, and is not a federal police force; the police forces and other law-enforcement bodies of each member state still maintain full responsibility and full jurisdiction)
Integrated judicial system (European Court of Justice only has jurisdiction over EU law, has neither direct nor appellate jurisdiction over the laws of member states; as such, the ECJ is not a federal supreme / high court)
Single nationality (each member state still issues its own passports, albeit with "EU branding"; member state citizenships / nationalities haven't been replaced with single "European" citizenship / nationality)
Unified immigration law (each member state still has jurisdiction over most forms of immigration, including the various permanent residency categories and also citizenship; EU has only unified immigration in specific cases, such as visa-free periods for eligible tourists, and the Blue Card for skilled work visas)
Military (each member state maintains its own military, although the EU does co-ordinate defence policy between members; EU itself only has a peacekeeping force)
Taxation (EU does not tax citizens directly, only charges a levy on the government of each member state)
Unified health care system (still entirely separate systems for each member state)
Unified education system (still entirely separate systems for each member state)
Unified foreign relations (member state embassies worldwide haven't been replaced with "European" embassies; still numerous treaties and bilateral relations exist directly between member states and other nations worldwide)
Unified representation in the UN (each member-state still has its own UN seat)
Unified national symbols (the EU has a flag, an anthem, various headquarter buildings, a president, a capital city, official languages, and other symbols; but member states retain their own symbols in all of the above; and the symbols of individual member states are generally still of greater importance than the EU symbols)
Sovereignty under international law (each member-state is still a sovereign power)
Verdict
The EU is still far from being a federated entity, in its present incarnation. It's also highly uncertain whether the EU will become more federated in the future; and it's generally accepted that at the moment, many Europeans have no desire for the EU to federate further.
Europe has achieved a great deal in its efforts towards political and economic unity. Unfortunately, however, a number of the European nations have been dragged kicking and screaming every step of the way. On account of this, there have been far too many compromises made, mainly in the form of agreeing to exceptions and exclusions. There are numerous binding treaties, but there is no constitution. There is a quasi-supreme court, but it has no supreme jurisdiction. There is a single currency and a border-free zone, apart from where there isn't. In fact, there is even a European Union, apart from where there isn't (with Switzerland and Norway being the most conspicuously absent parties).
Federalism just doesn't work like that. In all the truly federated unions in the world, all of the above issues have been resolved unequivocally – no exceptions, no special agreements. Whichever way you look at it – by comparison with international standards; by reference to formal definitions; or simply by logical reasoning and with a bit of common sense – the European Union is an oxymoron at best, and the United States of Europe remains an improbable dream.
]]>
Syria, past and present: mover and shaken2012-08-19T00:00:00Z2012-08-19T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/08/syria-past-and-present-mover-and-shaken/
For the past few weeks, the world's gaze has focused on Syria, a nation currently in the grip of civil war. There has been much talk about the heavy foreign involvement in the conflict — both of who's been fuelling the fire of rebel aggression, and of who's been defending the regime against global sanctions and condemnation. While it has genuine grassroots origins – and while giving any one label to it (i.e. to an extremely complex situation) would be a gross over-simplification — many have described the conflict as a proxy war involving numerous external powers.
Foreign intervention is nothing new in Syria, which is the heart of one of the most ancient civilised regions in the world. Whether it be Syria's intervention in the affairs of others, or the intervention of others in the affairs of Syria – both of the above have been going on unabated for thousands of years. With an alternating role throughout history as either a World Power in its own right, or as a point of significance to other World Powers (with the latter being more often the case), Syria could be described as a serious "mover and shaken" kind of place.
This article examines, over the ages, the role of the land that is modern-day Syria (which, for convenience's sake and at the expense of anachronism, I will continue to refer to as "Syria"), in light of this theme. It is my endeavour that by exploring the history of Syria in this way, I am able to highlight the deep roots of "being influential" versus "being influenced by" – a game that Syria has been playing expertly for millennia – and that ultimately, I manage to inform readers from a new angle, regarding the current tragic events that are occurring there.
Ancient times
The borders of Syria in the ancient world were not clearly defined; however, for as far back as its recorded history extends, the region has been centred upon the cities of Damascus and Aleppo. These remain the two largest and most important cities in Syria to this day. They are also both contenders for the claim of oldest continuously-inhabited city in the world.
One or the other of these two cities has almost always been the seat of power; and on various occasions, Syria has been reduced (by the encroachment of surrounding kingdoms / empires) to little more than the area immediately surrounding one or both of these cities. From the capital, the dominion of Syria has generally extended west to the coastal plains region (centred on the port of Latakia), east to the Euphrates river and beyond (the "Al-Jazira" region), and south to the Hawran Plateau.
Syria's recorded history begins in the Late Bronze Age / Early Iron Age, c. 1200 BC. In this era, the region was populated and ruled by various ancient kingdoms, including the Phoenicians (based in modern-day Lebanon, to the west of Syria), the Hittites (based in modern-day Turkey, to the north of Syria), the Assyrians (based in modern-day Northern Iraq, to the east of Syria), and the ancient Egyptians. Additionally, Syria was often in contact (both friendly and hostile) with the ancient kingdom of Israel, and with the other Biblical realms — including Ammon, Moab, Edom (all in modern-day Jordan), and Philistia (in modern day Israel and Gaza) — which all lay to the south. Most importantly, however, it was around this time that the Arameans emerged.
The Arameans can be thought of as the original, defining native tribe of Syria. The Arameans began as a small kingdom in southern Syria, where they captured Damascus and made it their capital; this also marked the birth of Damascus as a city of significance. The Arameans' early conquests included areas in southern modern-day Lebanon (such as the Bekaa Valley), and in northern modern-day Israel (such as Rehov). Between 1100 BC and 900 BC, the Aramean kingdoms expanded northward to the Aleppo area, and eastward to the Euphrates area. All of this area (i.e. basically all of modern-day Syria) was in ancient times known as Aram, i.e. land of the Arameans.
Aram in the ancient Levant (c. 1000 BC*). Satellite image courtesy of Google Earth.
*Note:Antioch was not founded until c. 320 BC; it is included on this map as a point of reference, due to its significance in later ancient Syrian history.
The story of Aramaic
It is with the Arameans that we can observe the first significant example, in Syria's long history, of a land that has its own distinct style of "influencing" and of "being influenced by". The Arameans are generally regarded by historians as a weak civilisation, that was repeatedly conquered and dominated by neighbouring empires. They never united into a single kingdom; rather, they were a loose confederation of city-states and tribes. The Aramean civilisation in its original form – i.e. as independent states, able to assert their self-determination – came to an end c. 900 BC, when the entire region was subjugted by the Neo Assyrian Empire. Fairly clear example of "being influenced by".
Ironically, however, this subjugation was precisely the event that led to the Arameans subsequently leaving a profound and long-lasting legacy upon the entire region. During the rule of the Neo Assyrians in Syria, a significant portion of the Aramean population migrated – both voluntarily and under duress – to the Assyrian heartland and to Babylonia. Once there, the Aramaic language began to spread: first within the Empire's heartland; and ultimately throughout the greater Empire, which at its height included most of the Fertile Crescent of the ancient Middle East.
The Aramaic language was the lingua franca of the Middle East between approximately 700 BC and 700 AD. Aramaic came to displace its "cousin" languages, Hebrew and Phoenician, in the areas of modern-day Israel and Lebanon. Hebrew is considered the "language of the Jews" and the "language of the Bible"; however, for the entire latter half or so of Bibical Israel's history, the language of conversation was Aramaic, with Hebrew relegated to little more than ritual and scriptural use. It is for this reason that Jesus spoke Aramaic; and it is also for this reason that most of the later Jewish scriptural texts (including several books of the Tanakh, and almost the entire Talmud) were written in Aramaic.
Aramaic included various dialects: of these, the most influential was Syriac, which itself evolved into various regional sub-dialects. Syriac was originally the dialect used by the Imperial Assyrians in their homeland – but in later years, it spread west to northern Syria and to Turkey; and east to Persia, and even as far as India. Syriac played a significant role in the early history of Christianity, and a small number of Christian groups continue to read Syriac Christian texts to this day. Another important dialect of ancient Aramaic was Mandaic, which was the dominant dialect spoken by those Aramaic speakers who settled in ancient Persia.
Although not a direct descendant of Aramaic, Arabic is another member of the Semitic language family; and spoken Arabic was heavily influenced by Aramaic, in the centuries preceding the birth of Islam. The Arabic writing system is a direct descendant of the Nabatean (ancient Jordanian) Aramaic writing system. With the rise of Islam, from c. 630 AD onwards, Arabic began to spread throughout the Middle East, first as the language of religion, then later as the language of bureaucracy, and ultimately as the new lingua franca. As such, it was Arabic that finally ended the long and influential dominance of Aramaic in the region. To this day, the majority of the formerly Aramaic-speaking world – including Syria itself – now uses Arabic almost universally.
Aramaic remains a living language in the modern world, although it is highly endangered. To this day, Aramaic's roots in ancient Aram are attested to, by the fact that the only remaining native speakers of (non-Syriac / non-Mandaic) Aramaic, are the residents of a handful of remote villages, in the mountains of Syria near Damascus. It seems that Aramaic's heyday, as the de facto language of much of the civilised world, has long passed. Linguistically speaking, Syria has long since been "under the influence"; nevertheless, Syria's linguistic heyday still lives on in an isolated corner of the nation's patchwork.
Syria and the Empires
After the conquest of Syria by the Assyrians in c. 900 BC, Syria continued to be ruled by neighbouring or distant empires for the next 1,500 years. Towards the end of the 7th century BC, the Assyrians were overshadowed by the Babylonians, and by c. 600 BC the Babylonians had conquered Syria. Shortly after, the Babylonians were overwhelmed by the growing might of the Persian Empire, and by c. 500 BC Syria was under Persian dominion. Little is known about Syria during these years, apart from accounts of numerous rebellions (particularly under Assyrian rule). However, it seems unlikely that the changes of governance in this era had any noticeable cultural or political effect on Syria.
All that changed c. 330 BC, when Alexander the Great conquered Syria – along with conquering virtually the entire Persian Empire in all its vastness – and Syria, for the first time, fell under the influence of an Empire to its west, rather than to its east (it also came to be known as "Syria" only from this time onward, as the name is of Greek origin). The Greeks built a new capital, Antioch, which dealt a severe blow to Damascus, and which shifted Syria's seat of power to the north for the first time (the Greeks also established Aleppo, which they called Beroea; from its onset, the city was of some importance). The Greeks also imposed their language and religion upon Syria, as they did upon all their Empire; however, these failed to completely replace the Aramaic language and the old religious worship, which continued to flourish outside of the Greek centres.
Syria remained firmly under occidental dominion for quite some time thereafter. The Armenian kingdom conquered Greek Syria in 83 BC, although the Armenians held on to it for only a brief period. Syria was conquered by the Romans, and was made a Roman province in 64 BC; this marked the start of more than 300 years of Syrian administration directly by Imperial Rome.
Syria remained subordinate during this time; however, Antioch was one of the largest and most powerful cities of the Empire (surpassed only by Rome and Byzantium), and as such, it enjoyed a certain level of autonomy. As in the Greek era, Syria continued to be influenced by both the Imperial language (now Latin – although Greek remained more widely-used than Latin in Syria and its neighbours), and by the Imperial religion ("Greco-Roman"); and as in Greek times, this influence continued to grow, but it never completely engulfed Syria.
Syria was also heavily influenced by, and heavily influential in, the birth and early growth of Christianity. From c. 252 AD, Antioch became the home of the world's first organised Christian Church, which later became the Antiochian Orthodox Church (this Church has since moved its headquarters to Damascus). It is said that Paul the Apostle was converted while travelling on the Road to Damascus – thus giving Damascus, too, a significant role in the stories of the New Testament.
From 260 to 273 AD, Syria was controlled by the rebel group of the Roman Empire that governed from Palmyra, a city in central Syria. This rebel government was crushed by the Romans, and Syria and its neighbouring provinces subsequently returned to Roman rule. For the next hundred or so years, the split of the Roman Empire into Western and Eastern halves developed in various stages; until c. 395 AD, when Constantinople (formerly known as Byzantium) officially became the capital of the new Eastern Roman Empire (or "Byzantine Empire"), and Syria (along with its neighbours) became a Byzantine province.
Both the capital (Antioch), and the province of Syria in general, continued to flourish for the next several hundred years of Byzantine rule (including Aleppo, which was second only to Antioch in this era) – until the Muslim conquest of Syria in c. 635 AD, when Antioch fell into a steep decline from which it never recovered. Antioch was finally destroyed c. 1260 AD, thus terminating the final stronghold of Byzantine influence in Syria.
The Muslim conquest of Syria
In 636 AD, the Muslims of Arabia conquered Syria; and Caliph Muawiya I declared Damascus his new home, as well as the capital of the new Islamic world. This marked a dramatic and sudden change for Syria: for the first time in almost 1,000 years, Damascus was re-instated as the seat of power; and, more importantly, Syria was to return to Semitic rule after centuries of Occidental rule.
This also marked the start of Syria's Golden Age: for the first and only time in its history, Syria was to be the capital of a world empire, a serious "mover" and an influencer. Under the Ummayad dynasty, Syria commanded an empire of considerable proportions, stretching all the way from Spain to India. Much of the wealth, knowledge, and strength of this empire flowed directly to the rulers in Damascus.
During the Ummayad Caliphate, Syria was home to an Arab Muslim presence for the first time. The Empire's ruling elite were leading families from Mecca, who moved permanently to Damascus. The conquerors were ultimately the first and the only rulers, in Syria's history, to successfully impose a new language and a new religion on almost the entire populace. However, the conversion of Syria was not an overnight success story: in the early years of the Caliphate, the population of Syria remained predominantly Aramaic- and Greek-speaking, as well as adherents to the old "pagan" religions. It wasn't until many centuries later, that Syria became the majority Arab-speaking, Islam-adherent place that it is today. The fact that Syria being anything other than an "Arab Muslim country" seems far-fetched to a modern reader, is testament to the thoroughness with which the Ummayads and their successors undertook their transformation campaign.
Syria's Golden Age ended in 750 AD, with the Abbasid Dynasty replacing the Ummayads as rulers of the Islamic world, and with the Empire's capital shifting from Damascus to Baghdad. The rest of Syria's history through Medieval times was far from Golden – the formerly prosperous and unified region was divided up and conquered many times over.
A variety of invaders left their mark on Syria in these centuries: Byzantines successfully re-captured much of the north, and even briefly conquered Damascus in 975 AD; the Seljuk Turks controlled much of Syria from Damascus (and Aleppo) c. 1079-1104 AD; Crusaders invaded Syria (along with its neighbours), and caused rampant damage and bloodshed, during the various Crusades that took place throughout the 1100's AD; the Ayyubid Dynasty of Egypt (under Saladin and his successors) intermittently ruled Syria throughout the first half of the 1200's AD; the Mongols attacked Syria numerous times between 1260 and 1300 AD (but failed to conquer Syria or the Holy Land); the Mamluks ruled Syria (from Egypt) for most of the period 1260-1516 AD; and Tamerlane of Samarkand attacked Syria in 1400 AD, sacking both Aleppo and Damascus, and massacring thousands of the inhabitants (before being driven out again by the Mamluks).
It should also be noted that at some point during these turbulent centuries, the Alawite ethnic group and religious sect was born in the north-west of Syria, and quietly grew to dominate the villages of the mountains and the coastal plains near Latakia. The Alawites remained an isolated and secluded rural group until modern times.
These tumultuous and often bloody centuries of Syrian history came to an end in the 1500s, when the Ottoman Turks defeated the Mamluks, and wrested control of Syria and neighbouring territories from them. The subsequent four centuries, under the rule of the Ottoman Empire, marked a welcome period of peace and stability for Syria (in contrast to the devasation of the Crusader and Mongol invasion waves in prior centuries). However, the Ottomans also severely neglected Syria, along with the rest of the Levant, treating the region ever-increasingly as a provincial backwater.
The Ottomans made Aleppo the Syrian capital, thus shifting Syria's power base back to the north after almost nine centuries of Damascus rule (although by this time, Antioch had long been lying in ruins). In the Ottoman period, Aleppo grew to become Syria's largest city (and one of the more important cities of the Empire), far outstripping Damascus in terms of fame and fortune. However, Syria under the Ottomans was an impoverished province of an increasingly ageing empire.
Modern times
The modern world galloped abruptly into Syria on 1 Oct 1918, when the 10th Australian Light Horse Brigade formally accepted the surrender of Damascus by the Ottoman Empire, on behalf of the WWI Allied Forces. The cavalry were shortly followed by the arrival of Lawrence of Arabia, who helped to establish Emir Faisal as the interim leader of a British-backed Syrian government. Officially, from 1918-1920, Syria fell under the British- and French-headed Occupied Enemy Territory Administration.
For the first time since the end of the Ummayad Caliphate, almost 12 centuries prior, Syria became a unified sovereign power again on 7 Mar 1920, when Faisal became king of a newly-declared independent Greater Syria (and as with Caliph Muawiya 12 centuries earlier, King Faisal was also from Mecca). Faisal had been promised Arab independence and governorship by the Allies during WWI, in return for the significant assistance that he and his Arabian brethren provided in the defeat of the Ottomans. However, the Allies failed to live up to their promise: the French successfully attacked the fledgling kingdom; and on 14 Jul 1920, Syria's brief independence ended, and the French Mandate of Syria began its governance. King Faisal was shortly thereafter sent into exile.
Syria had enjoyed a short yet all-too-sweet taste of independence in 1920, for the first time in centuries; and under the French Mandate, the people of Syria demonstrated on numerous occasions that the tasting had left them hungry for permanent self-determination. France, however – which was supposedly filling no more than a "caretaker" role of the region, and which was supposedly no longer a colonial power – consistently crushed Syrian protests and revolts in the Mandate period with violence and mercilessness, particularly in the revolt of 1925.
During the French Mandate, the Alawites emerged as a significant force in Syria for the first time. Embittered by centuries of discrimination and repression under Ottoman rule, this non-Sunni muslim group – along with other minority groups, such as the Druze – were keen to take advantage of the ending of the old status quo in Syria.
Under their governance, the French allowed the north-west corner of Syria – which was at the time known by its Ottoman name, the Sanjuk of Alexandretta – to fall into Turkish hands. This was a major blow to the future Syrian state – although the French hardly cared about Syria's future; they considered the giving-away of the region as a good political move with Turkey. The region was declared the independent Republic of Hatay in 1938; and in 1939, the new state voted to join Turkey as Hatay Province. This region is home to the ruins of Antioch, which was (as discussed earlier) the Syrian capital for almost 1,000 years. It is therefore understandable that Hatay continues to be a thorn in Syrian-Turkish relations to this day.
Syria adopted various names under French rule. From 1922, it was called the "Syrian Federation" for several years; and from 1930, it was called the Syrian Republic. Also, in 1936, Syria signed a treaty of independence from France. However, despite the treaties and the name changes, in reality Syria remained under French Mandate control (including during WWII, first under Vichy French rule and then under Free French rule) until 1946, when the last French troops finally left for good.
Syria has been a sovereign nation (almost) continuously since 17 Apr 1946. However, the first few decades of modern independent Syria were turbulent. Syria experiened numerous changes of government during the 1950s, several of which were considered coups. From 1958-1961, Syria ceded its independence and formed the United Arab Republic with Eygpt; however, this union proved short-lived, and Syria regained its previous sovereignty after the UAR's collapse. Syria has officially been known as the Syrian Arab Republic since re-declaring its independence on 28 Sep 1961.
Syria's government remained unstable for the following decade: however, in 1963, the Ba'ath party took over the nation's rule; and since then, the Ba'ath remain the ruling force in Syria to this day. The Ba'ath themselves experienced several internal coups for the remainder of the decade. Finally, in Nov 1970, then Defence Minister Hafez al-Assad orchestrated a coup; and Syria's government has effectively remained unchanged from that time to the present day. Hafez al-Assad was President until his death in 2000; at which point he was succeeded by his son Bashar al-Assad, who remains President so far amidst Syria's recent return to tumult.
The Assad family is part of Syria's Alawite minority; and for the entire 42-year reign of the Assads, the Alawites have come to dominate virtually the entire top tier of Syria's government, bureaucracy, military, and police force. Assad-ruled Syria has consistently demonstrated favouritism towards the Alawites, and towards various other minority groups (such as the Druze); while flagrantly discriminating against Syria's Sunni Muslim majority, and against larger minority groups (such as the Kurds). Syria's current civil war is, therefore, rooted in centuries-old sectarian bitterness as a highly significant factor.
Modern independent Syria continues its age-old tradition of both being significantly influenced by other world powers, and of exerting an influence of its own (particularly upon its neighbours), in a rather tangled web. Syria has been a strong ally of Russia for the majority of its independent history, in particular during the Soviet years, when Syria was considered to be on the USSR's side of the global Cold War. Russia has provided arms to Syria for many years, and to this day the majority of the Syrian military's weapons arsenal is of Soviet origin. Russia demonstrated its commitment to its longstanding Syrian alliance as recently as last month, when it and China (who acted in support of Russia) vetoed a UN resolution that aimed to impose international sanctions on the Syrian regime.
Syria has also been a friend of Iran for some time, and is considered Iran's closest ally. The friendship between these two nations began in the 1980s, following Iran's Islamic revolution, when Syria supported Iran in the Iran-Iraq War. In the recent crisis, Iran has been the most vocal supporter of the Assad regime, repeatedly asserting that the current conflict in Syria is being artificially exacerbated by US intervention. Some have commented that Iran and Syria are effectively isolated together – that is, neither has any other good friends that it can rely on (even a number of other Arab states, most notably Saudi Arabia, have vocally shunned the regime) – and that as such, the respective Ayatollah- and Alawite-ruled regimes will be allies to the bitter end.
In terms of exerting an influence of its own, the principal example of this in modern Syria is the state's heavy sponsorship of Hezbollah, and its ongoing intervention in Lebanon, on account of Hezbollah among other things. Syria supports Hezbollah for two reasons: firstly, in order to maintain a strong influence within Lebanese domestic politics and power-plays; and secondly, as part of its ongoing conflict with Israel.
Of the five Arab states that attacked Israel in 1948 (and several times again thereafter), Syria is the only one that still has yet to establish a peace treaty with the State of Israel. As such – despite the fact that not a single bullet has been fired between Israeli and Syrian forces since 1973 – the two states are still officially at war. Israel occupied the Golan Heights in the 1967 Six-Day War, and remains in control of the highly disputed territory to this day. The Golan Heights has alternated between Israeli and Syrian rule for thousands of years – evidence suggests that the conflict stretches back as far as Israelite-Aramean disputes three millenia ago – however, the area is recognised as sovereign Syrian territory by the international community today.
The story continues
As I hope my extensive account of the land's narrative demonstrates, Syria is a land that has seen many rulers and many influences come and go, for thousands of years. Neither conflict, nor revolution, nor foreign intervention, are anything new for Syria.
The uprising against Syria's ruling Ba'ath government began almost 18 months ago, and it has become a particularly brutal and destructive conflict in recent months. It seems unlikely that Syria's current civil war will end quickly – on the contrary, it appears to be growing ever-increasingly drawn-out, at this stage. Various international commentators have stated that it's "almost certain" that the Assad regime will ultimately fall, and that it's now only a matter of time. Personally, I wouldn't be too quick to draw such conclusions – as my historical investigations have revealed, Syria is a land of surprises, as well as a land where webs of interrelations stretch back to ancient times.
The Assad regime was merely the latest chapter in Syria's long history; and whatever comes next, will merely be the land's following chapter. For a land that has witnessed the rise and fall of almost every major empire in civilised history; that has seen languages, religions, and ethnic groups make their distinctive mark and leave their legacy; for such a land as this, the current events – dramatic, tragic, and pivotal though they may be – are but a drop in the ocean.
]]>
Israel's new Law of Return2012-06-18T00:00:00Z2012-06-18T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/06/israels-new-law-of-return/
Until a few days ago, I had no idea that Israel is home to an estimated 60,000 African refugees, the vast majority of whom come from South Sudan or from Eritrea, and almost all of whom have arrived within the past five years or so. I was startled as it was, to hear that so many refugees have arrived in Israel in such a short period; but I was positively shocked, when I then discovered that Israel plans to deport them, commencing immediately. The first plane to Juba, the capital of South Sudan, left last night.
South Sudan is the world's newest nation – it declared its independence on 9 Jul 2011. Israel was one of the first foreign nations to establish formal diplomatic ties with the fledgling Republic. Subsequently, Israel wasted no time in announcing publicly that all South Sudanese refugees would soon be required to leave; they were given a deadline of 31 Mar 2012, and were informed that they would be forcibly deported if still in Israel after that date.
Israel claims that, since having gained independence, it is now safe for South Sudanese nationals to return home. However, independent critics rebuke this, saying that there is still significant armed conflict between Sudan, South Sudan, and numerous rebel groups in the region. Aside from the ongoing security concerns, South Sudan is also one of the world's poorest and least-developed countries; claiming that South Sudan is ready to repatriate its people, is a ridiculous notion at best.
Israel helped formulate the UN Refugee Convention of 1951. This was in the aftermath of the Holocaust, an event in which millions of Jewish lives could have been saved, had the rest of the world accepted more European Jews as refugees. Israel, of course, is itself one of the world's most famous "refugee nations", as the majority of the nation's founders were survivors of Nazi persecution in Europe, seeking to establish a permanent homeland where Jews could forevermore seek shelter from oppression elsewhere.
It's ironic, therefore, that Israel – of all nations – until recently had no formal policy regarding asylum seekers, nor any formal system for managing an influx of asylum seekers. (And I thought Australia's handling of asylum seekers was bad!) To this day, Israel's immigration policy consists almost entirely of the Law of Return, which allows any Jew to immigrate to the country hassle-free.
Well, it seems to me that this law has recently been amended. For Jewish refugees, the Law is that you can Return to Israel (no matter what). For non-Jews, the Law is that you're forced to Return from Israel, back to wherever you fled from. Couldn't get much more double standards than that!
Irony and hypocrisy
Many Israelis are currently up in arms over the African migrants that have "infiltrated" the country. Those Israelis obviously have very short memories (and a very poor grasp of irony). After all, it was only 21 years ago, in 1991, when Operation Solomon resulted in the airlifting of almost 15,000 black Africans from Ethiopia to Israel, as a result of heightened security risks for those people in Ethiopia. Today, over 120,000 Ethiopian Jews (African-born and Israeli-born) live in Israel.
Apparently, that's quite acceptable – after all, they were Jewish black Africans. As such, they were flown from Africa to Israel, courtesy of the State, and were subsequently welcomed with open arms. It seems that for non-Jewish black Africans (in this case, almost all of them are Christians), the tables get turned – they get flown from Israel back to Africa; and they're even given a gift of €1,000 per person, in the hope that they go away and stay away.
Oh, and in case the historical parallels aren't striking enough: the home countries of these refugees – South Sudan and Eritrea – happen to both be neighbouring Ethiopia (in fact, Operations Moses and Joshua, the precursors to Operation Solomon, involved airlifting Ethiopian Jewish refugees from airstrips within Sudan – whether modern-day South Sudan or not, is uncertain).
It's also a historical irony, that these African refugees are arriving in Israel on foot, after crossing the Sinai desert and entering via Egypt. You'd think that we Jews would have more compassion for those making an "exodus" from Egypt. However, if Israel does feel any compassion towards these people, it certainly has a strange way of demonstrating it: Israel is currently in the process of rapidly constructing a new fence along the entire length of its desert border with Egypt, the primary purpose of which is to stop the flow of illegal immigrants that cross over each year.
It's quite ironic, too, that many of the African refugees who arrive in Israel are fleeing religious persecution. After all, was the modern State of Israel not founded for exactly this purpose – to provide safe haven to those fleeing discrimination elsewhere in the world, based on their religious observance? And, after all, is it not logical that those fleeing such discrimination should choose to seek asylum in the Holy Land? Apart from South Sudan, a large number of the recent migrants are from Eritrea, a country that has banned all religious freedom, and that has the world's lowest Press Freedom Index rating in the world (179th, lower even than North Korea).
Much ado about nothing
Israel is a nation that lives in fear of many threats. The recent arrival of African refugees has been identified by many Israelis (and by the government) as yet another threat, and as such, the response has been one of fear. Israel fears that these "infiltrators" will increase crime on the nation's streets. It fears that they will prove an economic burden. And it fears that they will erode the Jewish character of the State.
These fears, in my opinion, are actually completely unfounded. On the contrary, Israel's fear of the new arrivals is nothing short of ridiculous. The refugees will not increase crime in Israel; they will not prove an economic burden; and (the issue that worries Israel most of all) they will not erode the Jewish character of the state.
As recent research has shown, humanitarian immigrants in general make a significant positive contribution to their new home country; this is a contribution that is traditionally under-estimated, or even refuted altogether. Refugees, if welcomed and provided with adequate initial support, are people who desire to, and who in most cases do, contribute back to their new host country. They're desperately trying to escape a life of violence and poverty, in order to start anew; if given the opportunity to fulfil their dream, they generally respond gratefully.
Israel is a new player in the field of humanitarian immigration (new to ethnically-agnostic humanitarian immigration, at least). I can only assume that it's on account of this lack of experience, that Israel is failing to realise just how much it has to gain, should it welcome these refugees. If welcomed warmly and given citizenship, the majority of these Africans will support Israel in whatever way Israel asks them to. Almost all of them will learn Hebrew. A great number will join the IDF. And quite a few will even convert to Judaism. In short, these immigrants could prove to be just the additional supporters of the Jewish status quo that Israel needs.
What is Israel's biggest fear in this day and age? That the nation's Arab / Palestinian population is growing faster than its Jewish population; and that in 20 years' time, the Jews will be voted out of their own State by an Arab majority. As such, what should Israel be actively trying to do? It's in Israel's interests to actively encourage any immigration that contributes people / votes to the Jewish side of the equation. And, in my opinion, if Israel were to accept these African refugees with open arms today, then in 20 years' time they would be exactly the additional people / votes that the status quo requires.
Finally, as many others have already stated: apart from being ironic, hypocritical, impractical, and (most likely) illegal, Israel's current policy towards its African refugees is inhumane. As a Jew myself, I feel ashamed and incredulous that Israel should behave in this manner, when a group of desperate and abandoned people comes knocking at its doorstep. It is an embarrassment to Jews worldwide. We of all people should know better and act better.
]]>
Introducing the Drupal Handy Block module2012-06-08T00:00:00Z2012-06-08T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/06/introducing-the-drupal-handy-block-module/
I've been noticing more and more lately, that for every new Drupal site I build, I define a lot of custom blocks. I put the code for these blocks in one or more custom modules, and most of them are really simple. For me, at least, the most common task that these blocks perform, is to display one or more fields of the node (or other entity) page currently being viewed; and in second place, is the task of displaying a list of nodes from a nodequeue (as I'm rather a Nodequeue module addict, I tend to have nodequeues strewn all over my sites).
In short, I've gotten quite bored of copy-pasting the same block definition code over and over, usually with minimal changes. I also feel that such simple block definitions don't warrant defining a new custom module – as they have zero interesting logic / functionality, and as their purpose is purely presentational, I'd prefer to define them at the theme level. Additionally, every Drupal module has both administrative overhead (need to install / enable it on different environments, need to manage its deployment, etc), and performance overhead (every extra PHP include() call involves opening and reading a new file from disk, and every enabled Drupal module is a minimum of one extra PHP file to be included); so, less enabled modules means a faster site.
To make my life easier – and the life of anyone else in the same boat – I've written the Handy Block module. (As the project description says,) if you often have a bunch of custom modules on your site, that do nothing except implement block hooks (along with block callback functions), for blocks that do little more than display some fields for the entity currently being viewed, then Handy Block should… well, it should come in handy! You'll be able to do the same thing in just a few lines of your template.php file; and then, you can delete those custom modules of yours altogether.
The custom module way
Let me give you a quick example. Your page node type has two fields, called sidebar_image and sidebar_text. You'd like these two fields to display in a sidebar block, whenever they're available for the page node currently being viewed.
Using a custom module, how would you achieve this?
First of all, you have to build the basics for your new custom module. In this case, let's say you want to call your module pagemod – you'll need to start off by creating a pagemod directory (in, for example, sites/all/modules/custom), and writing a pagemod.info file that looks like this:
name = Page Mod
description = Custom module that does bits and pieces for page nodes.
core = 7.x
files[] = pagemod.module
You'll also need an almost-empty pagemod.module file:
<?php
/**
* @file
* Custom module that does bits and pieces for page nodes.
*/
Your module now exists – you can enable it if you want. Now, you can start building your sidebar block – let's say that you want to call it sidebar_snippet. First off, you need to tell Drupal that the block exists, by implementing hook_block_info() (note: this and all following code goes in pagemod.module, unless otherwise indicated):
Next, you need to define what gets shown in your new block. You do this by implementing hook_block_view():
<?php
/**
* Implements hook_block_view().
*/
function pagemod_block_view($delta = '') {
switch ($delta) {
case 'sidebar_snippet':
return pagemod_sidebar_snippet_block();
}
}
To keep things clean, it's a good idea to call a function for each defined block in hook_block_view(), rather than putting all your code directly in the hook function. Right now, you only have one block to render; but before you know it, you may have fifteen. So, let your block do its stuff here:
<?php
/**
* Displays the sidebar snippet on page nodes.
*/
function pagemod_sidebar_snippet_block() {
// Pretend that your module also contains this function - for code
// example, see handyblock_get_curr_page_node() in handyblock.module.
$node = pagemod_get_curr_page_node();
if (empty($node->nid) || !($node->type == 'page')) {
return;
}
if (!empty($node->field_sidebar_image['und'][0]['uri'])) {
// Pretend that your module also contains this function - for code
// example, see tpl_field_vars_styled_image_url() in
// tpl_field_vars.module
$image_url = pagemod_styled_image_url($node->field_sidebar_image
['und'][0]['uri'],
'sidebar_image');
$body = '';
if (!empty($node->field_sidebar_text['und'][0]['safe_value'])) {
$body = $node->field_sidebar_text['und'][0]['safe_value'];
}
$block['content'] = array(
'#theme' => 'pagemod_sidebar_snippet',
'#image_url' => $image_url,
'#body' => $body,
);
return $block;
}
}
Almost done. Drupal now recognises that your block exists, which means that you can enable your block and assign it to a region on the administer -> structure -> blocks page. Drupal will execute the code you've written above, when it tries to display your block. However, it won't yet display anything much, because you've defined your block as having a custom theme function, and that theme function hasn't been written yet.
Because you're an adherent of theming best practices, and you like to output all parts of your page using theme templates rather than theme functions, let's register this themable item, and let's define it as having a template:
And, as the final step, you'll need to create a pagemod-sidebar-snippet.tpl.php file (also in your pagemod module directory), to actually output your block:
Give your Drupal cache a good ol' clear, and voila – it sure took a while, but you've finally got your sidebar block built and displaying.
The Handy Block way
Now, to contrast, let's see how you'd achieve the same result, using the Handy Block module. No need for any of the custom pagemod module stuff above. Just enable Handy Block, and then place this code in your active theme's template.php file:
The MYTHEME_handyblock() callback automatically takes care of all three of the Drupal hook implementations that you previously had to write manually: hook_block_info(), hook_block_view(), and hook_theme(). The MYTHEME_handyblock_BLOCKNAME_alter() callback lets you do whatever you want to your block, after automatically providing the current page node as context, and setting the block's theme callback (in this case, the callback is controlling the block's visibility based on whether an image is available or not; and it's populating the block with the image and text fields).
Handy Block has done the "paperwork" (i.e. the hook implementations), such that Drupal expects a handyblock-sidebar-snippet.tpl.php file for this block (in your active theme's directory). So, let's create one (looks the same as the old pagemod-sidebar-snippet.tpl.php template):
After completing these steps, clear your Drupal cache, and assign your block to a region – and hey presto, you've got your custom block showing. Only this time, no custom module was needed, and significantly fewer lines of code were written.
In summary
Handy Block is not rocket science. (As the project description says,) this is a convenience module, for module developers and for themers. All it really does, is automate a few hook implementations for you. By implementing the Handy Block theme callback function, Handy Block implements hook_theme(), hook_block_info(), and hook_block_view() for you.
Handy Block is for Drupal site builders, who find themselves building a lot of blocks that:
Display more than just static text (if that's all you need, just use the 'add block' feature in the Drupal core block module)
Display something which is pretty basic (e.g. fields of the node currently being viewed), but which does require some custom code (albeit code that doesn't warrant a whole new custom module on your site)
Require a custom theme template
I should also mention that, before starting work on Handy Block, I had a look around for similar existing Drupal modules, and I found two interesting candidates. Both can be used to do the same thing that I've demonstrated in this article; however, I decided to go ahead and write Handy Block anyway, and I did so because I believe Handy Block is a better tool for the job (for the target audience that I have in mind, at least). Nevertheless, I encourage you to have a look at the competition as well.
The first alternative is CCK Blocks. This module lets you achieve similar results to Handy Block – however, I'm not so keen on it for several reasons: all its config is through the Admin UI (and I want my custom block config in code); it doesn't let you do anything more than output fields of the entity currently being viewed (and I want other options too, e.g. output a nodequeue); and it doesn't allow for completely custom templates for each block (although overriding its templates would probably be adequate in many cases).
The second alternative is Bean. I'm actually very impressed with what this module has to offer, and I'm hoping to take it for a spin sometime soon. However, for me, it seems that the Bean module is too far in the opposite extreme (compared to CCK Blocks) – whereas CCK blocks is too "light" and only has an admin UI for configuration, the Bean module is too complicated for simple use cases, as it requires implementing no small amount of code, within some pretty complex custom hooks. I decided against using Bean, because: it requires writing code within custom modules (not just at the theme layer); it's designed for things more complicated than just outputting fields of the entity currently being viewed (e.g. for performing custom Entity queries in a block, but without the help of Views); and it's above the learning curve of someone who primarily wears a Drupal themer hat.
Apart from the administrative and performance benefits of defining custom blocks in your theme's template.php file (rather than in a custom module), doing all the coding at the theme level also has another advantage. It makes custom block creation more accessible to people who are primarily themers, and who are reluctant (at best) module developers. This is important, because those big-themer-hat, small-developer-hat people are the primary target audience of this module (with the reverse – i.e. big-developer-hat, small-themer-hat people – being the secondary target audience).
Such people are scared and reluctant to write modules; they're more comfortable sticking to just the theme layer. Hopefully, this module will make custom block creation more accessible, and less daunting, for such people (and, in many cases, custom block creation is a task that these people need to perform quite often). I also hope that the architecture of this module – i.e. a callback function that must be implemented in the active theme's template.php file, not in a module – isn't seen as a hack or as un-Drupal-like. I believe I've justified fairly thoroughly, why I made this architecture decision.
I also recommend that you use Template Field Variables in conjunction with Handy Block (see my previous article about Template Field Variables). Both of them are utility modules for themers. The idea is that, used stand-alone or used together, these modules make a Drupal themer's life easier. Happy theming, and please let me know your feedback about the module.
]]>
Introducing the Drupal Template Field Variables module2012-05-29T00:00:00Z2012-05-29T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/05/introducing-the-drupal-template-field-variables-module/
Drupal 7's new Field API is a great feature. Unfortunately, theming an entity and its fields can be quite a daunting task. The main reason for this, is that the field variables that get passed to template files are not particularly themer-friendly. Themers are HTML markup and CSS coders; they're not PHP or Drupal coders. When themers start writing their node--page.tpl.php file, all they really want to know is: How do I output each field of this page [node type], exactly where I want, and with minimal fuss?
It is in the interests of improving the Drupal Themer Experience, therefore, that I present the Template Field Variables module. (As the project description says,) this module takes the mystery out of theming fieldable entities. For each field in an entity, it extracts the values that you actually want to output (from the infamous "massive nested arrays" that Drupal provides), and it puts those values in dead-simple variables.
What we've got
Let me tell you a story, about an enthusiastic fledgling Drupal themer. The sprightly lad has just added a new text field, called byline, to his page node type in Drupal 7. He wants to output this field at the bottom of his node--page.tpl.php file, in a blockquote tag.
Using nothing but Drupal 7 core, how does he do it?
He's got two options. His first option — the "Drupal 7 recommended" option — is to use the Render API, to hide the byline from the spot where all the node's fields get outputted by default; and to then render() it further down the page.
Well, says the budding young themer, that sure sounds easy enough. So, the themer goes and reads up on how to use the Render API, finds the example snippets of hide($content['bla']); and print render($content['bla']);, and whips up a template file:
<?php
/* My node--page.tpl.php file. It rocks. */
?>
<?php // La la la, do some funky template stuff. ?>
<?php // Don't wanna show this in the spot where Drupal vomits
// out content by default, let's call hide(). ?>
<?php hide($content['field_byline']); ?>
<?php // Now Drupal can have a jolly good ol' spew. ?>
<?php print render($content); ?>
<?php // La la la, more funky template stuff. ?>
<?php // This is all I need in order to output the byline at the
// bottom of the page in a blockquote, right? ?>
<blockquote><?php print render($content['field_byline']); ?></blockquote>
Now, let's see what page output that gives him:
<!-- La la la, this is my page output. -->
<!-- La la la, Drupal spewed out all my fields here. -->
<!-- La la... hey!! What the..?! Why has Drupal spewed out a -->
<!-- truckload of divs, and a label, that I didn't order? -->
<!-- I just want the byline, $#&%ers!! -->
<blockquote><div class="field field-name-field-byline field-type-text field-label-above"><div class="field-label">Byline: </div><div class="field-items"><div class="field-item even">It's hip to be about something</div></div></div></blockquote>
Our bright-eyed Drupal theming novice was feeling pretty happy with his handiwork so far. But now, disappointment lands. All he wants is the actual value of the byline. No div soup. No random label. He created a byline field. He saved a byline value to a node. Now he wants to output the byline, and only the byline. What more could possibly be involved, in such a simple task?
He racks his brains, searching for a solution. He's not a coder, but he's tinkered with PHP before, and he's pretty sure it's got some thingamybob that lets you cut stuff out of a string that you don't want. After a bit of googling, he finds the code snippets he needs. Ah! He exclaims. This should do the trick:
<?php // I knew I was born to be a Drupal ninja. Behold my
// marvellous creation! ?>
<blockquote><?php print str_replace('<div class="field field-name-field-byline field-type-text field-label-above"><div class="field-label">Byline: </div><div class="field-items"><div class="field-item even">', '', str_replace('</div></div></div>', '', render($content['field_byline']))); ?></blockquote>
Now, now, Drupal veterans – don't cringe. I know you've all seen it in a real-life project. Perhaps you even wrote it yourself, once upon a time. So, don't be too quick to judge the young grasshopper harshly.
However, although the str_replace() snippet does indeed do the trick, even our newbie grasshopper recognises it for the abomination and the kitten-killer that it is, and he cannot live knowing that a git blame on line 47 of node--page.tpl.php will forever reveal the awful truth. So, he decides to read up a bit more, and he finally discovers that the recommended solution is to create your own field.tpl.php override file. So, he whips up a one-line field--field-byline.tpl.php file:
<?php print render($item); ?>
And, at long last, he's got the byline and just the byline outputting… and he's done it The Drupal Way!
The newbie themer begins to feel more at ease. He's happy that he's learnt how to build template files in a Drupal 7 theme, without resorting to hackery. To celebrate, he snacks on juicy cherries dipped in chocolate-flavoured custard.
But a niggling concern remains at the back of his mind. Perhaps what he's done is The Drupal Way, but he's still not convinced that it's The Right Way. It seems like a lot of work — calling hide(); in one spot, having to call print render(); (not just print) further down, having to override field.tpl.php — and all just to output a simple little byline. Is there really no one-line alternative?
Ever optimistic, the aspiring Drupal themer continues searching, until at last he discovers that it is possible to access the raw field values from a node template. And so, finally, he settles for a solution that he's more comfortable with:
<?php
/* My node--page.tpl.php file. It rocks. */
?>
<?php // La la la, do some funky template stuff. ?>
<?php // Still need hide(), unless I manually output all my node fields,
// and don't call print render($content);
// grumble grumble... ?>
<?php hide($content['field_byline']); ?>
<?php // Now Drupal can have a jolly good ol' spew. ?>
<?php print render($content); ?>
<?php // La la la, more funky template stuff. ?>
<?php // Yay - I actually got the raw byline value to output here! ?>
<blockquote><?php print check_plain($node->field_byline[$node->language][0]['value']); ?></blockquote>
And so the sprightly young themer goes on his merry way, and hacks up .tpl.php files happily ever after.
Why all that sucks
That's the typical journey of someone new to Drupal theming, and/or new to the Field API, who wants to customise the output of fields for an entity. It's flawed for a number of reasons:
We're making themers learn how to make function calls unnecessarily. It's OK to make them learn function calls if they need to do something fancy. But in the case of the Render API, they need to learn two – hide() and render() – just to output something. All they should need to know is print.
We're making themers understand a complex, unnecessary, and artificially constructed concept: the Render API. Themers don't care how Drupal constructs the page content, they don't care what render arrays are (or if they exist); and they shouldn't have to care.
We're making it unnecessarily difficult to output raw values, using the recommended theming method (i.e. using the Render API). In order to output raw values using the render API, you basically have to override field.tpl.php in the manner illustrated above. This will prove to be too advanced (or simply too much effort) for many themers, who may resort to the type of string-replacement hackery described above.
The only actual method of outputting the raw value directly is fraught with problems:
It requires a long line of code, that drills deep into nested arrays / objects before it can print the value
Those nested arrays / objects are hard even for experienced developers to navigate / debug, let alone newbie themers
It requires themers to concern themselves with field translation and with the i18n API
Guesswork is needed for determining the exact key that will yield the outputtable value, at the end of the nested array (usually 'value', but sometimes not, e.g. 'url' for link fields)
It's highly prone to security issues, as there's no way that novice themers can be expected to understand when to use 'value' vs 'safe_value', when check_plain() / filter_xss_admin() should be called, etc. (even experienced developers often misuse or omit Drupal's string output security, as anyone who's familiar with the Drupal security advisories would know)
In a nutshell: the current system has too high a learning curve, it's unnecessarily complex, and it unnecessarily exposes themers to security risks.
A better way
Now let me tell you another story, about that same enthusiastic fledgling Drupal themer, who wanted to show his byline in a blockquote tag. This time, he's using Drupal 7 core, plus the Template Field Variables module.
First, he opens up his template.php file, and adds the following:
After doing this (and after clearing his cache), he opens up his node (of type 'page') in a browser; and because he's set 'debug' => TRUE (above), he sees this output on page load:
$body =
<p>There was a king who had twelve beautiful daughters. They slept in
twelve beds all in one room; and when they went to bed, the doors were
shut and locked up; but every morning their shoes were found to be
quite worn through as if they had been danced in all night; and yet
nobody could find out how it happened, or where they had been.</p>
<p>Then the king made it known to all the land, that if any person
could discover the secret, and find out where it was that the
princesses danced in the night, he should have the one he liked best
for his wife, and should be king after his ...
$byline =
It's hip to be about something
And now, he has all the info he needs in order to write his new node--page.tpl.php file, which looks like this:
<?php
/* My node--page.tpl.php file. It rocks. */
?>
<?php // La la la, do some funky template stuff. ?>
<?php // No spewing, please, Drupal - just the body field. ?>
<?php print $body; ?>
<?php // La la la, more funky template stuff. ?>
<?php // Output the byline here, pure and simple. ?>
<blockquote><?php print $byline; ?></blockquote>
He sets 'debug' => FALSE in his template.php file, he reloads the page in his browser, and… voila! He's done theming for the day.
About the module
The story that I've told above, describes the purpose and function of the Template Field Variables module better than a plain description can. (As the project description says,) it's a utility module for themers. Its only purpose is to make Drupal template development less painful. It has no front-end. It stores no data. It implements no hooks. In order for it to do anything, some coding is required, but only coding in your theme files.
I've illustrated here the most basic use case of Template Field Variables, i.e. outputting simple text fields. However, the module's real power lies in its ability to let you print out the values of more complex field types, just as easily. Got an image field? Want to print out the URL of the original-size image, plus the URLs of any/all of the resized derivatives of that image… and all in one print statement? Got a date field, and want to output the 'start date' and 'end date' values with minimal fuss? Got a nodereference field, and want to output the referenced node's title within an h3 tag? Got a field with multiple values, and want to loop over those values in your template, just as easily as you output a single value? For all these use cases, Template Field Variables is your friend.
If you never want to again see a template containing:
And if, from this day forward, you only ever want to see a template containing:
<?php print $foo; ?>
Then I really think you should take Template Field Variables for a spin. You may discover, for the first time in your life, that Drupal theming can actually be fun. And sane.
]]>
Flattening many-to-many fields for MySQL to CSV export2012-05-23T00:00:00Z2012-05-23T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/05/flattening-many-to-many-fields-for-mysql-to-csv-export/
Relational databases are able to store, with minimal fuss, pretty much any data entities you throw at them. For the more complex cases – particularly cases involving hierarchical data – they offer many-to-many relationships. Querying many-to-many relationships is usually quite easy: you perform a series of SQL joins in your query; and you retrieve a result set containing the combination of your joined tables, in denormalised form (i.e. with the data from some of your tables being duplicated in the result set).
A denormalised query result is quite adequate, if you plan to process the result set further – as is very often the case, e.g. when the result set is subsequently prepared for output to HTML / XML, or when the result set is used to populate data structures (objects / arrays / dictionaries / etc) in programming memory. But what if you want to export the result set directly to a flat format, such as a single CSV file? In this case, denormalised form is not ideal. It would be much better, if we could aggregate all that many-to-many data into a single result set containing no duplicate data, and if we could do that within a single SQL query.
This article presents an example of how to write such a query in MySQL – that is, a query that's able to aggregate complex many-to-many relationships, into a result set that can be exported directly to a single CSV file, with no additional processing necessary.
Example: a lil' Bio database
For this article, I've whipped up a simple little schema for a biographical database. The database contains, first and foremost, people. Each person has, as his/her core data: a person ID; a first name; a last name; and an e-mail address. Each person also optionally has some additional bio data, including: bio text; date of birth; and gender. Additionally, each person may have zero or more: profile pictures (with each picture consisting of a filepath, nothing else); web links (with each link consisting of a title and a URL); and tags (with each tag having a name, existing in a separate tags table, and being linked to people via a joining table). For the purposes of the example, we don't need anything more complex than that.
Here's the SQL to create the example schema:
CREATE TABLE person (
pid int(10) unsigned NOT NULL AUTO_INCREMENT,
firstname varchar(255) NOT NULL,
lastname varchar(255) NOT NULL,
email varchar(255) NOT NULL,
PRIMARY KEY (pid),
UNIQUE KEY email (email),
UNIQUE KEY firstname_lastname (firstname(100), lastname(100))
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;
CREATE TABLE tag (
tid int(10) unsigned NOT NULL AUTO_INCREMENT,
tagname varchar(255) NOT NULL,
PRIMARY KEY (tid),
UNIQUE KEY tagname (tagname)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;
CREATE TABLE person_bio (
pid int(10) unsigned NOT NULL,
bio text NOT NULL,
birthdate varchar(255) NOT NULL DEFAULT '',
gender varchar(255) NOT NULL DEFAULT '',
PRIMARY KEY (pid),
FULLTEXT KEY bio (bio)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE person_pic (
pid int(10) unsigned NOT NULL,
pic_filepath varchar(255) NOT NULL,
PRIMARY KEY (pid, pic_filepath)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE person_link (
pid int(10) unsigned NOT NULL,
link_title varchar(255) NOT NULL DEFAULT '',
link_url varchar(255) NOT NULL DEFAULT '',
PRIMARY KEY (pid, link_url),
KEY link_title (link_title)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE person_tag (
pid int(10) unsigned NOT NULL,
tid int(10) unsigned NOT NULL,
PRIMARY KEY (pid, tid)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
And here's the SQL to insert some sample data into the schema:
INSERT INTO person (firstname, lastname, email) VALUES ('Pete', 'Wilson', 'pete@wilson.com');
INSERT INTO person (firstname, lastname, email) VALUES ('Sarah', 'Smith', 'sarah@smith.com');
INSERT INTO person (firstname, lastname, email) VALUES ('Jane', 'Burke', 'jane@burke.com');
INSERT INTO tag (tagname) VALUES ('awesome');
INSERT INTO tag (tagname) VALUES ('fantabulous');
INSERT INTO tag (tagname) VALUES ('sensational');
INSERT INTO tag (tagname) VALUES ('mind-boggling');
INSERT INTO tag (tagname) VALUES ('dazzling');
INSERT INTO tag (tagname) VALUES ('terrific');
INSERT INTO person_bio (pid, bio, birthdate, gender) VALUES (1, 'Great dude, loves elephants and tricycles, is really into coriander.', '1965-04-24', 'male');
INSERT INTO person_bio (pid, bio, birthdate, gender) VALUES (2, 'Eccentric and eclectic collector of phoenix wings. Winner of the 2003 International Small Elbows Award.', '1982-07-20', 'female');
INSERT INTO person_bio (pid, bio, birthdate, gender) VALUES (3, 'Has purply-grey eyes. Prefers to only go out on Wednesdays.', '1990-11-06', 'female');
INSERT INTO person_pic (pid, pic_filepath) VALUES (1, 'files/person_pic/pete1.jpg');
INSERT INTO person_pic (pid, pic_filepath) VALUES (1, 'files/person_pic/pete2.jpg');
INSERT INTO person_pic (pid, pic_filepath) VALUES (1, 'files/person_pic/pete3.jpg');
INSERT INTO person_pic (pid, pic_filepath) VALUES (3, 'files/person_pic/jane_on_wednesday.jpg');
INSERT INTO person_link (pid, link_title, link_url) VALUES (2, 'The Great Blog of Sarah', 'http://www.omgphoenixwingsaresocool.com/');
INSERT INTO person_link (pid, link_title, link_url) VALUES (3, 'Catch Jane on Blablablabook', 'http://www.blablablabook.com/janepurplygrey');
INSERT INTO person_link (pid, link_title, link_url) VALUES (3, 'Jane ranting about Thursdays', 'http://www.janepurplygrey.com/thursdaysarelame/');
INSERT INTO person_tag (pid, tid) VALUES (1, 3);
INSERT INTO person_tag (pid, tid) VALUES (1, 4);
INSERT INTO person_tag (pid, tid) VALUES (1, 5);
INSERT INTO person_tag (pid, tid) VALUES (1, 6);
INSERT INTO person_tag (pid, tid) VALUES (2, 2);
Querying for direct CSV export
If we were building, for example, a simple web app to output a list of all the people in this database (along with all their biographical data), querying this database would be quite straightforward. Most likely, our first step would be to query the one-to-one data: i.e. query the main 'person' table, join on the 'bio' table, and loop through the results (in a server-side language, such as PHP). The easiest way to get at the rest of the data, in such a case, would be to then query each of the many-to-many relationships (i.e. user's pictures; user's links; user's tags) in separate SQL statements, and to execute each of those queries once for each user being processed.
In that scenario, we'd be writing four different SQL queries, and we'd be executing SQL numerous times: we'd execute the main query once, and we'd execute each of the three secondary queries, once for each user in the database. So, with the sample data provided here, we'd be executing SQL 1 + (3 x 3) = 10 times.
Alternatively, we could write a single query which joins together all of the three many-to-many relationships in one go, and our web app could then just loop through a single result set. However, this result set would potentially contain a lot of duplicate data, as well as a lot of NULL data. So, the web app's server-side code would require extra logic, in order to deal with this messy result set effectively.
In our case, neither of the above solutions is adequate. We can't afford to write four separate queries, and to perform 10 query executions. We don't want a single result set that contains duplicate data and/or excessive NULL data. We want a single query, that produces a single result set, containing one person per row, and with all the many-to-many data for each person aggregated into that person's single row.
Here's the magic SQL that can make our miracle happen:
SELECT person_base.pid,
person_base.firstname,
person_base.lastname,
person_base.email,
IFNULL(person_base.bio, '') AS bio,
IFNULL(person_base.birthdate, '') AS birthdate,
IFNULL(person_base.gender, '') AS gender,
IFNULL(pic_join.val, '') AS pics,
IFNULL(link_join.val, '') AS links,
IFNULL(tag_join.val, '') AS tags
FROM (
SELECT p.pid,
p.firstname,
p.lastname,
p.email,
IFNULL(pb.bio, '') AS bio,
IFNULL(pb.birthdate, '') AS birthdate,
IFNULL(pb.gender, '') AS gender
FROM person p
LEFT JOIN person_bio pb
ON p.pid = pb.pid
) AS person_base
LEFT JOIN (
SELECT join_tbl.pid,
IFNULL(
GROUP_CONCAT(
DISTINCT CAST(join_tbl.pic_filepath AS CHAR)
SEPARATOR ';;'
),
''
) AS val
FROM person_pic join_tbl
GROUP BY join_tbl.pid
) AS pic_join
ON person_base.pid = pic_join.pid
LEFT JOIN (
SELECT join_tbl.pid,
IFNULL(
GROUP_CONCAT(
DISTINCT CONCAT(
CAST(join_tbl.link_title AS CHAR),
'::',
CAST(join_tbl.link_url AS CHAR)
)
SEPARATOR ';;'
),
''
) AS val
FROM person_link join_tbl
GROUP BY join_tbl.pid
) AS link_join
ON person_base.pid = link_join.pid
LEFT JOIN (
SELECT join_tbl.pid,
IFNULL(
GROUP_CONCAT(
DISTINCT CAST(t.tagname AS CHAR)
SEPARATOR ';;'
),
''
) AS val
FROM person_tag join_tbl
LEFT JOIN tag t
ON join_tbl.tid = t.tid
GROUP BY join_tbl.pid
) AS tag_join
ON person_base.pid = tag_join.pid
ORDER BY lastname ASC,
firstname ASC;
If you run this in a MySQL admin tool that supports exporting query results directly to CSV (such as phpMyAdmin), then there's no more fancy work needed on your part. Just click 'Export -> CSV', and you'll have your results looking like this:
pid,firstname,lastname,email,bio,birthdate,gender,pics,links,tags
3,Jane,Burke,jane@burke.com,Has purply-grey eyes. Prefers to only go out on Wednesdays.,1990-11-06,female,files/person_pic/jane_on_wednesday.jpg,Catch Jane on Blablablabook::http://www.blablablabook.com/janepurplygrey;;Jane ranting about Thursdays::http://www.janepurplygrey.com/thursdaysarelame/,
2,Sarah,Smith,sarah@smith.com,Eccentric and eclectic collector of phoenix wings. Winner of the 2003 International Small Elbows Award.,1982-07-20,female,,The Great Blog of Sarah::http://www.omgphoenixwingsaresocool.com/,fantabulous
1,Pete,Wilson,pete@wilson.com,Great dude, loves elephants and tricycles, is really into coriander.,1965-04-24,male,files/person_pic/pete1.jpg;;files/person_pic/pete2.jpg;;files/person_pic/pete3.jpg,,sensational;;mind-boggling;;dazzling;;terrific
The query explained
The most important feature of this query, is that it takes advantage of MySQL's ability to perform subqueries. What we're actually doing, is we're performing four separate queries: one query on the main person table (which joins to the person_bio table); and one on each of the three many-to-many elements of a person's bio. We're then joining these four queries, and selecting data from all of their result sets, in the parent query.
The magic function in this query, is the MySQL GROUP_CONCAT() function. This basically allows us to join together the results of a particular field, using a delimiter string, much like the join() array-to-string function in many programming languages (i.e. like PHP's implode() function). In this example, I've used two semicolons (;;) as the delimiter string.
In the case of person_link in this example, each row of this data has two fields ('link title' and 'link URL'); so, I've concatenated the two fields together (separated by a double-colon (::) string), before letting GROUP_CONCAT() work its wonders.
The case of person_tags is also interesting, as it demonstrates performing an additional join within the many-to-many subquery, and returning data from that joined table (i.e. the tag name) as the result value. So, all up, each of the many-to-many relationships in this example is a slightly different scenario: person_pic is the basic case of a single field within the many-to-many data; person_link is the case of more than one field within the many-to-many data; and person_tags is the case of an additional one-to-many join, on top of the many-to-many join.
Final remarks
Note that although this query depends on several MySQL-specific features, most of those features are available in a fairly equivalent form, in most other major database systems. Subqueries vary quite little between the DBMSes that support them. And it's possible to achieve GROUP_CONCAT() functionality in PostgreSQL, in Oracle, and even in SQLite.
It should also be noted that it would be possible to achieve the same result (i.e. the same end CSV output), using 10 SQL query executions and a whole lot of PHP (or other) glue code. However, taking that route would involve more code (spread over four queries and numerous lines of procedural glue code), and it would invariably suffer worse performance (although I make no guarantees as to the performance of my example query, I haven't benchmarked it with particularly large data sets).
This querying trick was originally written in order to export data from a Drupal MySQL database, to a flat CSV file. The many-to-many relationships were referring to field tables, as defined by Drupal's Field API. I made the variable names within the subqueries as generic as possible (e.g. join_tbl, val), because I needed to copy the subqueries numerous times (for each of the numerous field data tables I was dealing with), and I wanted to make as few changes as possible on each copy.
The trick is particularly well-suited to Drupal Field API data (known in Drupal 6 and earlier as 'CCK data'). However, I realised that it could come in useful with any database schema where a "flattening" of many-to-many fields is needed, in order to perform a CSV export with a single query. Let me know if you end up adopting this trick for schemas of your own.
]]>
Enriching user-entered HTML markup with PHP parsing2012-05-10T00:00:00Z2012-05-10T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/05/enriching-user-entered-html-markup-with-php-parsing/
I recently found myself faced with an interesting little web dev challenge. Here's the scenario. You've got a site that's powered by a PHP CMS (in this case, Drupal). One of the pages on this site contains a number of HTML text blocks, each of which must be user-editable with a rich-text editor (in this case, TinyMCE). However, some of the HTML within these text blocks (in this case, the unordered lists) needs some fairly advanced styling – the kind that's only possible either with CSS3 (using, for example, nth-child pseudo-selectors), with JS / jQuery manipulation, or with the addition of some extra markup (for example, some first, last, and first-in-row classes on the list item elements).
Naturally, IE7+ compatibility is required – so, CSS3 selectors are out. Injecting element attributes via jQuery is a viable option, but it's an ugly approach, and it may not kick in immediately on page load. Since the users will be editing this content via WYSIWYG, we can't expect them to manually add CSS classes to the markup, or to maintain any markup that the developer provides in such a form. That leaves only one option: injecting extra attributes on the server-side.
When it comes to HTML manipulation, there are two general approaches. The first is Parsing HTML The Cthulhu Way (i.e. using Regular Expressions). However, you already have one problem to solve – do you really want two? The second is to use an HTML parser. Sadly, this problem must be solved in PHP – which, unlike some otherlanguages, lacks an obvioustool of choice in the realm of parsers. I chose to use PHP5's built-in DOMDocument library, which (from what I can tell) is one of the most mature and widely-used PHP HTML parsers available today. Here's my code snippet.
Markup parsing function
<?php
/**
* Parses the specified markup content for unordered lists, and enriches
* the list markup with unique identifier classes, 'first' and 'last'
* classes, 'first-in-row' classes, and a prepended inside element for
* each list item.
*
* @param $content
* The markup content to enrich.
* @param $id_prefix
* Each list item is given a class with name 'PREFIX-item-XX'.
* Optional.
* @param $items_per_row
* For each Nth element, add a 'first-in-row' class. Optional.
* If not set, no 'first-in-row' classes are added.
* @param $prepend_to_li
* The name of an HTML element (e.g. 'span') to prepend inside
* each liist item. Optional.
*
* @return
* Enriched markup content.
*/
function enrich_list_markup($content, $id_prefix = NULL,
$items_per_row = NULL, $prepend_to_li = NULL) {
// Trim leading and trailing whitespace, DOMDocument doesn't like it.
$content = preg_replace('/^ */', '', $content);
$content = preg_replace('/ *$/', '', $content);
$content = preg_replace('/ *\n */', "\n", $content);
// Remove newlines from the content, DOMDocument doesn't like them.
$content = preg_replace('/[\r\n]/', '', $content);
$doc = new DOMDocument();
$doc->loadHTML($content);
foreach ($doc->getElementsByTagName('ul') as $ul_node) {
$i = 0;
foreach ($ul_node->childNodes as $li_node) {
$li_class_list = array();
if ($id_prefix) {
$li_class_list[] = $id_prefix . '-item-' . sprintf('%02d', $i+1);
}
if (!$i) {
$li_class_list[] = 'first';
}
if ($i == $ul_node->childNodes->length-1) {
$li_class_list[] = 'last';
}
if (!empty($items_per_row) && !($i % $items_per_row)) {
$li_class_list[] = 'first-in-row';
}
$li_node->setAttribute('class', implode(' ', $li_class_list));
if (!empty($prepend_to_li)) {
$prepend_el = $doc->createElement($prepend_to_li);
$li_node->insertBefore($prepend_el, $li_node->firstChild);
}
$i++;
}
}
$content = $doc->saveHTML();
// Manually fix up HTML entity encoding - if there's a better
// solution for this, let me know.
$content = str_replace('–', '–', $content);
// Manually remove the doctype, html, and body tags that DOMDocument
// wraps around the text. Apparently, this is the only easy way
// to fix the problem:
// http://stackoverflow.com/a/794548
$content = mb_substr($content, 119, -15);
return $content;
}
?>
This is a fairly simple parsing routine, that loops through the li elements of the unordered lists in the text, and that adds some CSS classes, and also prepends a child node. There's some manual cleanup needed after the parsing is done, due to some quirks associated with DOMDocument.
Markup parsing example
For example, say your users have entered the following markup:
You can then whip up some CSS to make your designer happy:
#fruit ul {
list-style-type: none;
}
#fruit ul li {
display: block;
width: 150px;
padding: 20px 20px 20px 45px;
float: left;
margin: 0 0 20px 20px;
background-color: #bbddfb;
position: relative;
}
#fruit ul li.first-in-row {
clear: both;
margin-left: 0;
}
#fruit ul li span {
display: block;
position: absolute;
left: 20px;
top: 23px;
width: 15px;
height: 15px;
background-color: #191970;
}
#fruit ul li.first, #fruit ul li.last {
background-color: #968adc;
}
#fruit ul li.fruit-item-03, #fruit ul li.fruit-item-05 {
background-color: #7bdca6;
}
#fruit ul li.first span, #fruit ul li.last span {
background-color: #4b0082;
}
#fruit ul li.fruit-item-03 span, #fruit ul li.fruit-item-05 span {
background-color: #00611c;
}
Your finished product is bound to win you smiles on every front:
How the parsed markup looks when rendered
Obviously, this is just one example of how a markup parsing function might look, and of the exact end result that you might want to achieve with such parsing. Take everything presented here, and fiddle liberally to suit your needs.
In the approach I've presented here, I believe I've managed to achieve a reasonable balance between stakeholder needs (i.e. easily editable content, good implementation of visual design), hackery, and technical elegance. Also note that this article is not at all CMS-specific (the code snippets work stand-alone), nor is it particularly parser-specific, or even language-specific (although code snippets are in PHP). Feedback welcome.
]]>
Argentina: ¿que onda?2012-04-21T00:00:00Z2012-04-21T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/04/argentina-que-onda/
A few days ago, Argentina decided to nationalise YPF, which is the largest oil company operating in the country. It's doing this by expropriating almost all of the YPF shares currently owned by Spanish firm Repsol. The move has resulted in Spain — and with it, the entire European Union — condemning Argentina, and threatening to relatiate with trade sanctions.
This is the latest in a long series of decisions that Argentina has made throughout its modern history, all of which have displayed: hot-headed nationalist sentiment; an arrogant and apathetic attitude towards other nations; and utter disregard for diplomatic and economic consequences. As with previous decisions, it's also likely that this one will ultimately cause Argentina more harm than good.
I think it's time to ask: Argentina, why do you keep shooting yourself in the foot? Argentina, are you too stubborn, are you too proud, or are you just plain stupid? Argentina, ¿que onda?
I've spent quite a lot of time in Argentina. My first visit was five years ago, as a backpacker. Last year I returned, and I decided to stay for almost six months, volunteering in a soup kitchen and studying Spanish (in Mendoza). So, I believe I've come to know the country and its people reasonably well — about as well as a foreigner can hope to know it, in a relatively short time.
I also really like Argentina. I wouldn't have chosen to spend so much time there, if I disliked the place. Argentines have generally been very warm and welcoming towards me. Argentines love to enjoy life, as is evident in their love of good food, fine beverages, and amazing (and late) nightlife. They are a relaxed people, who value their leisure time, never work too hard, and always have one minute more for a casual chat.
During my first visit to Argentina, this was essentially my complete view of the nation. However, having now spent significantly more time in the country, I realise that this was a rather rose-coloured view, and that it far from makes up the full story. Argentina is also a country facing many, many problems.
Questionable choices
What pains me most about Argentina, is that it seems to have everything going for it, and yet it's so much less than it could be. Argentina is a land of enormous potential, most of it squandered. A land of opportunities that are time and time again passed up. It's a nation that seems to be addicted to making choices that are "questionable", to put it nicely.
The most famous of these voluntary decisions in Argentina's history was when, in 1982, the nation decided to declare war on Great Britain over the Falkland Islands (Islas Malvinas). By most logical counts, this was a bad decision for a number of reasons.
Diplomatically, the Falklands war was bad: most of the world condemned Argentina for attacking the sovereign territory of another nation pre-emptively — few countries were sympathetic to Argentina's cause. Economically it was bad: it took a heavy toll on Argentina's national budget, and it also resulted in the UK (and the wider European community) imposing various trade sanctions on Argentina. And militarily it was bad: by all accounts, it should have been clear to the Argentine generals that the British military was far superior to their own, and that a war for Argentina was almost completely unwinnable.
Argentina shocked the world again when, in late 2001, it decided to default on its enormous debt to the IMF. Around the same time, the government also froze all bank accounts in the country, and severely limited the bank withdrawals that private citizens could make. Shortly thereafter, Argentina also abandoned its 10-year-long policy of pegging its currency to the US Dollar, as a result of the economic crisis that this policy had ended in.
While this decision was one of the more understandable in Argentina's history — the country's economy was in a desperate state, and few other options were available — it was still highly questionable. Defaulting on virtually the entire national debt had disastrous consequences for Argentina's international economic relations. In the short-term, foreign investment vanished from Argentina, a blow that took many years thereafter to recover (and one that continues a struggled recovery, to this day). Of all the choices open to it, Argentina elected the one that would shatter the rest of the world's confidence in its economic stability, more than any other.
And now we see history repeating itself, with Argentina once again damaging its own economic credibility, by effectively stealing a company worth billions of dollars from Spain (which, to make matters even worse, is one of Argentina's larger trading partners). We should hardly be surprised.
Culture, not just politics
It would be a bit less irrational, if we could at least confine these choices to having been "imposed" on the nation by its politicians. However, this would be far from accurate. On the contrary, all of these choices (with the possible exception of the loan defaulting) were overwhelmingly supported by the general public of Argentina. To this day, you don't have to travel far in Argentina, before you see a poster or a graffitied wall proclaiming: "Las Malvinas son Argentinas" ("The Falklands are Argentine"). And, similarly, this week's announcement to nationalise YPF was accompanied by patriotic protestors displaying banners of: "YPF de los Argentinos".
So, how can this be explained culturally? How can a nation that on the surface appears to be peaceful, fun-loving, and Western in attitude, also consistently support decisions of an aggressive character that isolate the country on the international stage?
As I said, I've spent some time in Argentina. And, as I've learned, the cultural values of Argentina appear at first to be almost identical to those of Western Europe, and of other Western nations such as Canada, Australia, and New Zealand. Indeed, most foreigners comment, when first visiting, that Argentina is by far the most European place in Latin America. However, after getting to know Argentines better, one comes to realise that there are actually some significant differences in cultural values, lying just under the surface.
Firstly, Argentina has a superiority complex. Many Argentines honestly believe that their country is one of the mightiest, the smartest, and the richest in the world. Obviously, both the nation's history, and independent statistics (by bodies such as the UN), make it clear that Argentina is none of these things. That, however, seems to be of little significance to the average Argentine. Indeed, a common joke among Argentines is that: "Argentina should be attached to Europe, but by some mistake it floated over and joined South America". Also particularly baffling, is that many Argentines seem to be capable of maintaining their superiority, while at the same time serving up a refreshingly honest criticism of their nation's many problems. This superiority complex can be explained in large part by my second point.
Secondly, Argentina has a (disturbingly high) penchant for producing and for swallowing its own propaganda. For a country that supposedly aspires to be a liberal Western democracy, Argentina is rife with misinformation about its own history, about its own geography, and about the rest of the world. In my opinion, the proliferation of exaggerated or outright false teachings in Argentina borders on a Soviet-Russian level of propaganda. Some studies indicate that a prolonged and systematic agenda of propaganda in education is to blame for Argentina's current misinformed state. I'm no expert on Argentina's educational system, and anyway I'd prefer not to pin the blame on any one factor, such as schooling. But for me, there can be no doubt: Argentines are more accustomed to digesting their own version of the truth, than they are to listening to any facts from the outside.
Finally, Argentina has an incredibly strong level of patriotism in its national psyche. Patriotism may not at first seem any different in Argentina, to patriotism in other countries. It's strong in much of the world, and particularly in much of the rest of Latin America. But there's something about the way Argentines identify with their nation — I can't pinpoint it exactly, but perhaps the way they cling to national icons such as football and mate, or the level of support they give to their leaders — there's something that's different about Argentine patriotism. In my opinion, it's this sentiment that fuels irrational thinking and irrational decisions in Argentina more than anything else. It's this patriotism that somehow disfigures the logic of Argentines into thinking: "whatever we decide as a nation is right, and the rest of the world can get stuffed".
Final thoughts
It really does pain me to say negative things about Argentina, because it's a country that I've come to know and to love dearly, and I have almost nothing but happy memories from all my time spent there. This is also the first time I've written an article critical of Argentina; and perhaps I've become a little bit Argentine myself, because I feel just a tad bit "unpatriotic" in publishing what I've written.
However, I felt that I needed to explore why this country, that I feel such affection for, continually chooses to isolate itself, to damage itself, and to stigmatise itself. I'm living in Chile this year, just next door; and I must admit, I feel melancholy at being away from the buena onda, but also relief at keeping some distance from the enormous instability that is Argentina.
]]>
Django Facebook user integration with whitelisting2011-11-02T00:00:00Z2011-11-02T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/11/django-facebook-user-integration-with-whitelisting/
It's recently become quite popular for web sites to abandon the tasks of user authentication and account management, and to instead shoulder off this burden to a third-party service. One of the big services available for this purpose is Facebook. You may have noticed "Sign in with Facebook" buttons appearing ever more frequently around the 'Web.
The common workflow for Facebook user integration is: user is redirected to the Facebook login page (or is shown this page in a popup); user enters credentials; user is asked to authorise the sharing of Facebook account data with the non-Facebook source; a local account is automatically created for the user on the non-Facebook site; user is redirected to, and is automatically logged in to, the non-Facebook site. Also quite common is for the user's Facebook profile picture to be queried, and to be shown as the user's avatar on the non-Facebook site.
This article demonstrates how to achieve this common workflow in Django, with some added sugary sweetness: maintaning a whitelist of Facebook user IDs in your local database, and only authenticating and auto-registering users who exist on this whitelist.
Install dependencies
I'm assuming that you've already got an environment set up, that's equipped for Django development. I.e. you've already installed Python (my examples here are tested on Python 2.6 and 2.7), a database engine (preferably SQLite on your local environment), pip (recommended), and virtualenv (recommended). If you want to implement these examples fully, then as well as a dev environment with these basics set up, you'll also need a server to which you can deploy a Django site, and on which you can set up a proper public domain or subdomain DNS (because the Facebook API won't actually talk to or redirect back to your localhost, it refuses to do that).
You'll also need a Facebook account, with which you will be registering a new "Facebook app". We won't actually be developing a Facebook app in this article (at least, not in the usual sense, i.e. we won't be deploying anything to facebook.com), we just need an app key in order to talk to the Facebook API.
Here are the Python dependencies for our Django project. I've copy-pasted this straight out of my requirements.txt file, which I install on a virtualenv using pip install -E . -r requirements.txt (I recommend you do the same):
The first requirement, Django itself, is pretty self-explanatory. The next one, django-allauth, is the foundation upon which this demonstration is built. This app provides authentication and account management services for Facebook (plus Twitter and OAuth currently supported), as well as auto-registration, and profile pic to avatar auto-copying. The version we're using here, is my GitHub fork of the main project, which I've hacked a little bit in order to integrate with our whitelisting functionality.
The Facebook Python SDK is the base integration library provided by the Facebook team, and allauth depends on it for certain bits of functionality. Plus, we've installed django-avatar so that we get local user profile images.
Once you've got those dependencies installed, let's get a new Django project set up with the standard command:
django-admin.py startproject myproject
This will get the Django foundations installed for you. The basic configuration of the Django settings file, I leave up to you. If you have some experience already with Django (and if you've got this far, then I assume that you do), you no doubt have a standard settings template already in your toolkit (or at least a standard set of settings tweaks), so feel free to use it. I'll be going over the settings you'll need specifically for this app, in just a moment.
Fire up ye 'ol runserver, open your browser at http://localhost:8000/, and confirm that the "It worked!" page appears for you. At this point, you might also like to enable the Django admin (add 'admin' to INSTALLED_APPS, un-comment the admin callback in urls.py, and run syncdb; then confirm that you can access the admin). And that's the basics set up!
Register the Facebook app
Now, we're going to jump over to the Facebook side of the setup, in order to register our site as a Facebook app, and to then receive our Facebook app credentials. To get started, go to the Apps section of the Facebook Developers site. You'll probably be prompted to log in with your Facebook account, so go ahead and do that (if asked).
On this page, click the button labelled "Create New App". In the form that pops up, in the "App Display Name" field, enter a unique name for your app (e.g. the name of the site you're using this on — for the example app that I registered, I used the name "FB Whitelist"). Then, tick "I Agree" and click "Continue".
Once this is done, your Facebook app is registered, and you'll be taken to a form that lets you edit the basic settings of the app. The first setting that you'll want to configure is "App Domain": set this to the domain or subdomain URL of your site (without an http:// prefix or a trailing slash). A bit further down, in "Website — Site URL", enter this URL again (this time, with the http:// prefix and a trailing slash). Be sure to save your configuration changes on this page.
Next is a little annoying setting that must be configured. In the "Auth Dialog" section, for "Privacy Policy URL", once again enter the domain or subdomain URL of your site. Enter your actual privacy policy URL if you have one; if not, don't worry — Facebook's authentication API refuses to function if you don't enter something for this, so the URL of your site's front page is better than nothing.
Note: at some point, you'll also need to go to the "Advanced" section, and set "Sandbox Mode" to "Disabled". This is very important! If your app is set to Sandbox mode, then nobody will be able to log in to your Django site via Facebook auth, apart from those listed in the Facebook app config as "developers". It's up to you when you want to disable Sandbox mode, but make sure you do it before non-dev users start trying to log in to your site.
On the main "Settings — Basic" page for your newly-registered Facebook app, take note of the "App ID" and "App Secret" values. We'll be needing these shortly.
Configure Django settings
I'm not too fussed about what else you have in your Django settings file (or in how your Django settings are structured or loaded, for that matter); but if you want to follow along, then you should have certain settings configured per the following guidelines:
(You'll need to re-run syncdb after enabling these apps).
(Note: django-allauth also expects the database schema for the email confirmation app to exist; however, you don't actually need this app enabled. So, what you can do, is add 'emailconfirmation' to your INSTALLED_APPS, then syncdb, then immediately remove it).
Set a value for the AVATAR_STORAGE_DIR setting, for example:
AVATAR_STORAGE_DIR = 'uploads/avatars'
Set a value for the LOGIN_REDIRECT_URL setting, for example:
LOGIN_REDIRECT_URL = '/'
Set this:
ACCOUNT_EMAIL_REQUIRED = True
Additionally, you'll need to create a new Facebook App record in your Django database. To do this, log in to your shiny new Django admin, and under "Facebook — Facebook apps", add a new record:
For "Name", copy the "App Display Name" from the Facebook page.
For both "Application id" and "Api key", copy the "App ID" from the Facebook page.
For "Application secret", copy the "App Secret" from the Facebook page.
Once you've entered everything on this form (set "Site" as well), save the record.
Implement standard Facebook authentication
By "standard", I mean "without whitelisting". Here's how you do it:
Add these imports to your urls.py:
from allauth.account.views import logout
from allauth.socialaccount.views import login_cancelled, login_error
from allauth.facebook.views import login as facebook_login
And (in the same file), add these to your urlpatterns variable:
<div class="socialaccount_ballot">
<ul class="socialaccount_providers">
{% if not user.is_authenticated %}
{% if allauth.socialaccount_enabled %}
{% include "socialaccount/snippets/provider_list.html" %}
{% include "socialaccount/snippets/login_extra.html" %}
{% endif %}
{% else %}
<li><a href="{% url account_logout %}?next=/">Logout</a></li>
{% endif %}
</ul>
</div>
(Note: I'm assuming that by this point, you've set up the necessary URL callbacks, views, templates, etc. to get a working front page on your site; I'm not going to hold your hand and go through all that).
If you'd like, you can customise the default authentication templates provided by django-allauth. For example, I overrode the socialaccount/snippets/provider_list.html and socialaccount/authentication_error.html templates in my test implementation.
That should be all you need, in order to get a working "Login with Facebook" link on your site. So, deploy everything that's been done so far to your online server, navigate to your front page, and click the "Login" link. If all goes well, then a popup will appear prompting you to log in to Facebook (unless you already have an active Facebook session in your browser), followed by a prompt to authorise your Django site to access your Facebook account credentials (to which you and your users will have to agree), and finishing with you being successfully authenticated.
The authorisation prompt during the initial login procedure.
You should be able to confirm authentication success, by noting that the link on your front page has changed to "Logout".
Additionally, if you go into the Django admin (you may first need to log out of your Facebook user's Django session, and then log in to the admin using your superuser credentials), you should be able to confirm that a new Django user was automatically created in response to the Facebook auth procedure. Additionally, you should find that an avatar record has been created, containing a copy of your Facebook profile picture; and, if you look in the "Facebook accounts" section, you should find that a record has been created here, complete with your Facebook user ID and profile page URL.
Facebook account record in the Django admin.
Great! Now, on to the really fun stuff.
Build a whitelisting app
So far, we've got a Django site that anyone can log into, using their Facebook credentials. That works fine for many sites, where registration is open to anyone in the general public, and where the idea is that the more user accounts get registered, the better. But what about a site where the general public cannot register, and where authentication should be restricted to only a select few individuals who have been pre-registered by site admins? For that, we need to go beyond the base capabilities of django-allauth.
Create a new app in your Django project, called fbwhitelist. The app should have the following files (file contents provided below):
models.py :
from django.contrib.auth.models import User
from django.db import models
class FBWhiteListUser(models.Model):
name = models.CharField(max_length=100)
email = models.EmailField(unique=True)
social_id = models.CharField(verbose_name='Facebook user ID',
blank=True, max_length=100)
active = models.BooleanField(default=False)
def __unicode__(self):
return self.name
class Meta:
verbose_name = 'facebook whitelist user'
verbose_name_plural = 'facebook whitelist users'
ordering = ('name', 'email')
def save(self, *args, **kwargs):
try:
old_instance = FBWhiteListUser.objects.get(pk=self.pk)
if not self.active:
if old_instance.active:
self.deactivate_user()
else:
if not old_instance.active:
self.activate_user()
except FBWhiteListUser.DoesNotExist:
pass
super(FBWhiteListUser, self).save(*args, **kwargs)
def delete(self):
self.deactivate_user()
super(FBWhiteListUser, self).delete()
def deactivate_user(self):
try:
u = User.objects.get(email=self.email)
if u.is_active and not u.is_superuser and not u.is_staff:
u.is_active = False
u.save()
except User.DoesNotExist:
pass
def activate_user(self):
try:
u = User.objects.get(email=self.email)
if not u.is_active:
u.is_active = True
u.save()
except User.DoesNotExist:
pass
import re
import urllib2
from django import forms
from django.contrib import admin
from django.contrib.auth.models import User
from allauth.facebook.models import FacebookAccount
from allauth.socialaccount import app_settings
from allauth.socialaccount.helpers import _copy_avatar
from utils import slugify
from models import FBWhiteListUser
class FBWhiteListUserAdminForm(forms.ModelForm):
class Meta:
model = FBWhiteListUser
def __init__(self, *args, **kwargs):
super(FBWhiteListUserAdminForm, self).__init__(*args, **kwargs)
def save(self, *args, **kwargs):
m = super(FBWhiteListUserAdminForm, self).save(*args, **kwargs)
try:
u = User.objects.get(email=self.cleaned_data['email'])
except User.DoesNotExist:
u = self.create_django_user()
if self.cleaned_data['social_id']:
self.create_facebook_account(u)
return m
def create_django_user(self):
name = self.cleaned_data['name']
email = self.cleaned_data['email']
active = self.cleaned_data['active']
m = re.search(r'^(?P<first_name>[^ ]+) (?P<last_name>.+)$', name)
name_slugified = slugify(name)
first_name = ''
last_name = ''
if m:
d = m.groupdict()
first_name = d['first_name']
last_name = d['last_name']
u = User(username=name_slugified,
email=email,
last_name=last_name,
first_name=first_name)
u.set_unusable_password()
u.is_active = active
u.save()
return u
def create_facebook_account(self, u):
social_id = self.cleaned_data['social_id']
name = self.cleaned_data['name']
try:
account = FacebookAccount.objects.get(social_id=social_id)
except FacebookAccount.DoesNotExist:
account = FacebookAccount(social_id=social_id)
account.link = 'http://www.facebook.com/profile.php?id=%s' % social_id
req = urllib2.Request(account.link)
res = urllib2.urlopen(req)
new_link = res.geturl()
if not '/people/' in new_link and not 'profile.php' in new_link:
account.link = new_link
account.name = name
request = None
if app_settings.AVATAR_SUPPORT:
_copy_avatar(request, u, account)
account.user = u
account.save()
class FBWhiteListUserAdmin(admin.ModelAdmin):
list_display = ('name', 'email', 'active')
list_filter = ('active',)
search_fields = ('name', 'email')
fields = ('name', 'email', 'social_id', 'active')
def __init__(self, *args, **kwargs):
super(FBWhiteListUserAdmin, self).__init__(*args, **kwargs)
form = FBWhiteListUserAdminForm
admin.site.register(FBWhiteListUser, FBWhiteListUserAdmin)
(Note: also ensure that you have an empty __init__.py file in your app's directory, as you do with most all Django apps).
Also, of course, you'll need to add 'fbwhitelist' to your INSTALLED_APPS setting (and after doing that, a syncdb will be necessary).
Most of the code above is pretty basic, it just defines a Django model for the whitelist, and provides a basic admin view for that model. In implementing this code, feel free to modify the model and the admin definitions liberally — in particular, you may want to add additional fields to the model, per your own custom project needs. What this code also does, is automatically create both a corresponding Django user, and a corresponding socialaccount Facebook account record (including Facebook profile picture to django-avatar handling), whenever a new Facebook whitelist user instance is created.
Integrate it with django-allauth
In order to let django-allauth know about the new fbwhitelist app and its FBWhiteListUser model, all you need to do, is to add this to your Django settings file:
If you're interested in the dodgy little hacks I made to django-allauth, in order to make it magically integrate with a specified whitelist app, here's the main code snippet responsible, just for your viewing pleasure (from _process_signup in socialaccount/helpers.py):
# Extra stuff hacked in here to integrate with
# the account whitelist app.
# Will be ignored if the whitelist app can't be
# imported, thus making this slightly less hacky.
whitelist_model_setting = getattr(
settings,
'SOCIALACCOUNT_WHITELIST_MODEL',
None
)
if whitelist_model_setting:
whitelist_model_path = whitelist_model_setting.split(r'.')
whitelist_model_str = whitelist_model_path[-1]
whitelist_path_str = r'.'.join(whitelist_model_path[:-1])
try:
whitelist_app = __import__(whitelist_path_str, fromlist=[whitelist_path_str])
whitelist_model = getattr(whitelist_app, whitelist_model_str, None)
if whitelist_model:
try:
guest = whitelist_model.objects.get(email=email)
if not guest.active:
auto_signup = False
except whitelist_model.DoesNotExist:
auto_signup = False
except ImportError:
pass
Basically, the hack attempts to find and to query our whitelist model; and if it doesn't find a whitelist instance whose email matches that provided by the Facebook auth API, or if the found whitelist instance is not set to 'active', then it halts auto-creation and auto-login of the user into the Django site. What can I say… it does the trick!
Build a Facebook ID lookup utility
The Django admin interface so far for managing the whitelist is good, but it does have one glaring problem: it requires administrators to know the Facebook account ID of the person they're whitelisting. And, as it turns out, Facebook doesn't make it that easy for regular non-techies to find account IDs these days. It used to be straightforward enough, as profile page URLs all had the account ID in them; but now, most profile page URLs on Facebook are aliased, and the account ID is pretty well obliterated from the Facebook front-end.
So, let's build a quick little utility that looks up Facebook account IDs, based on a specified email. Add these files to your 'fbwhitelist' app to implement it:
facebook.py :
import urllib
class FacebookSearchUser(object):
@staticmethod
def get_query_email_request_url(email, access_token):
"""Queries a Facebook user based on a given email address. A valid Facebook Graph API access token must also be provided."""
args = {
'q': email,
'type': 'user',
'access_token': access_token,
}
return 'https://graph.facebook.com/search?' + \
urllib.urlencode(args)
views.py :
from django.utils.simplejson import loads
import urllib2
from django.conf import settings
from django.contrib.admin.views.decorators import staff_member_required
from django.http import HttpResponse, HttpResponseBadRequest
from fbwhitelist.facebook import FacebookSearchUser
class FacebookSearchUserView(object):
@staticmethod
@staff_member_required
def query_email(request, email):
"""Queries a Facebook user based on the given email address. This view cannot be accessed directly."""
access_token = getattr(settings, 'FBWHITELIST_FACEBOOK_ACCESS_TOKEN', None)
if access_token:
url = FacebookSearchUser.get_query_email_request_url(email, access_token)
response = urllib2.urlopen(url)
fb_data = loads(response.read())
if fb_data['data'] and fb_data['data'][0] and fb_data['data'][0]['id']:
return HttpResponse('Facebook ID: %s' % fb_data['data'][0]['id'])
else:
return HttpResponse('No Facebook credentials found for the specified email.')
return HttpResponseBadRequest('Error: no access token specified in Django settings.')
urls.py :
from django.conf.urls.defaults import *
from views import FacebookSearchUserView
urlpatterns = patterns('',
url(r'^facebook_search_user/query_email/(?P<email>[^\/]+)/$',
FacebookSearchUserView.query_email,
name='fbwhitelist_search_user_query_email'),
)
Plus, add this to the urlpatterns variable in your project's main urls.py file:
In your MEDIA_ROOT directory, create a file js/fbwhitelistadmin.js, with this content:
(function($) {
var fbwhitelistadmin = function() {
function init_social_id_from_email() {
$('.social_id').append('<input type="submit" value="Find Facebook ID" id="social_id_get_from_email" /><p>After entering an email, click "Find Facebook ID" to bring up a new window, where you can see the Facebook ID of the Facebook user with this email. Copy the Facebook user ID number into the text field "Facebook user ID", and save. If it is a valid Facebook ID, it will automatically create a new user on this site, that corresponds to the specified Facebook user.</p>');
$('#social_id_get_from_email').live('click', function() {
var email_val = $('#id_email').val();
if (email_val) {
var url = 'http://fbwhitelist.greenash.net.au/fbwhitelist/facebook_search_user/query_email/' + email_val + '/';
window.open(url);
}
return false;
});
}
return {
init: function() {
if ($('#content h1').text() == 'Change facebook whitelist user') {
$('#id_name, #id_email, #id_social_id').attr('disabled', 'disabled');
}
else {
init_social_id_from_email();
}
}
}
}();
$(document).ready(function() {
fbwhitelistadmin.init();
});
})(django.jQuery);
And to load this file on the correct Django admin page, add this code to the FBWhiteListUserAdmin class in the fbwhitelist/admin.py file:
class Media:
js = ("js/fbwhitelistadmin.js",)
Additionally, you're going to need a Facebook Graph API access token. To obtain one, go to a URL like this:
Replacing the APP_ID, SITE_URL, and APP_SECRET bits with your relevant Facebook credentials, and replacing TEMP_CODE with the code from the URL above. You should then see a plain-text page response in this form:
access_token=ACCESS_TOKEN
And the ACCESS_TOKEN bit is what you need to take note of. Add this value to your settings file:
Of very important note, is the fact that what you've just saved in your settings is a long-life offline access Facebook access token. We requested that the access token be long-life, with the scope=offline_access parameter in the first URL request that we made to Facebook (above). This means that the access token won't expire for a very long time, so you can safely keep it in your settings file without having to worry about constantly needing to change it.
Exactly how long these tokens last, I'm not sure — so far, I've been using mine for about six weeks with no problems. You should be notified if and when your access token expires, because if you provide an invalid access token to the Graph API call, then Facebook will return an HTTP 400 response (bad request), and this will trigger urllib2.urlopen to raise an HTTPError exception. How you get notified, will depend on how you've configured Django to respond to uncaught exceptions; in my case, Django emails me an error report, which is sufficient notification for me.
Your Django admin should now have a nice enough little addition for Facebook account ID lookup:
Facebook account ID lookup integrated into the whitelist admin.
I say "nice enough", because it would also be great to change this from showing the ID in a popup, to actually populating the form field with the ID value via JavaScript (and showing an error, on fail, also via JavaScript). But honestly, I just haven't got around to doing this. Anyway, the basic popup display works as is — only drawback is that it requires copy-pasting the ID into the form field.
Finished product
And that's everything — your Django-Facebook auth integration with whitelisting should now be fully functional! Give it a try: attempt to log in to your Django site via Facebook, and it should fail; then add your Facebook account to the whitelist, attempt to log in again, and there should be no errors in sight. It's a fair bit of work, but this setup is possible once all the pieces are in place.
I should also mention that it's quite ironic, my publishing this long and detailed article about developing with the Facebook API, when barely a month ago I wrote a scathing article on the evils of Facebook. So, just to clarify: yes, I do still loathe Facebook, my opinion has not taken a somersault since publishing that rant.
However— what can I say, sometimes you get clients that want Facebook integration. And hey, them clients do pay the bills. Also, even I cannot deny that Facebook's enormous user base makes it an extremely attractive authentication source. And I must also concede that since the introduction of the Graph API, Facebook has become a much friendlier and a much more stable platform for developers to work with.
]]>
A blood pledge to never vote for Tony Abbott2011-10-27T00:00:00Z2011-10-27T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/10/a-blood-pledge-to-never-vote-for-tony-abbott/This is a pledge in blood this man will go.
Two weeks ago, the Gillard government succeeded in passing legislation for a new carbon tax through the lower house of the Australian federal parliament. Shortly after, opposition leader Tony Abbott made a "pledge in blood", promising that: "We will repeal the tax, we can repeal the tax, we must repeal the tax".
The passing of the carbon tax bill represents a concerted effort spanning at least ten years, made possible by the hard work and the sacrifice of numerous Australians (at all levels, including at the very top). Australia is the highest per-capita greenhouse gas emitter in the developed world. We need climate change legislation enactment urgently, and this bill represents a huge step towards that endeavour.
I don't usually publish direct political commentary here. Nor do I usually name and shame. But I feel compelled to make an exception in this case. For me, Tony Abbott's response to the carbon tax can only possibly be addressed in one way. He leaves us with no option. If this man has sworn to repeal the good work that has flourished of late, then the solution is simple. Tony Abbott must never lead this country. The consequences of his ascension to power would be, in a nutshell, diabolical.
Of course, there are also a plethora of other reasons to not vote for tony. His hard-line Christian stance on issues such as abortion, gay marriage, and euthanasia. His xenophobia towards what he perceives as "the enemies of our Christian democratic society", i.e. Muslims and other minority groups. His policies regarding Aboriginal rights. His pathetic opportunism of the scare-campaign bandwagon to "stop the boats". His unashamed labelling of himself as "Howard 2.0". His budgie smugglers (if somehow — perhaps due to a mental disability — nothing else about the possibility of Abbott being PM scares the crap out of you, at least consider this!).
In last year's Federal election, I was truly terrified at the real and imminent possibility that Abbott could actually win (and I wasn't alone). I was aghast at how incredibly close he came to claiming the top job, although ultimately very relieved in seeing him fail (a very Bush-esque affair, in my opinion, was Australia's post-election kerfuffle of 2010 — which I find fitting, since I find Abbott almost as nauseating as the legendarily dimwitted G-W himself).
I remain in a state of trepidation, as long as Abbott continues to have a chance of leading this country. Because, laugh as we may at Gillard's 2010 election slogan of "Moving Forward Together", I can assure you that Abbott's policy goes more along the line of "Moving Backward Stagnantly".
]]>
Geeks vs hippies2011-10-11T00:00:00Z2011-10-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/10/geeks-vs-hippies/The duel to end them all. Who shall prevail?
Geeks. The socially awkward, oft-misunderstood tech wizzes that are taking over the world. And hippies. The tree-huggin', peace-n-lovin' ragtags that are trying to save the world, one spliff at a time.
I've long considered myself to be a member of both these particular minority groups, to some extent. I'm undoubtedly quite a serious case of geek; and I also possess strong hippie leanings, at the least. And I don't believe I'm alone, either. Nay — the Geekius Hippius is, in fact, a more common species than you might at first think.
I present here a light-hearted comparison of these two breeds. Needless to say, readers be warned: this article contains high level stereotyping.
Demographics
Gender balance. Geeks have long been smitten with the curse of the sausage-fest. In my undergrad IT program, there were two girls and 23 guys; this is pretty well on par, in my experience. I estimate that 90-95% male, 5-10% female, is a not uncommon gender ratio in geek circles. With hippies, on the other hand, it's all much more balanced, with my estimate being 40-50% male, 50-60% female, being a common gender ratio amongst a given group of hippies. So, yes, male geeks should consider hanging out with hippies more, as there are opportunities to meet actual real-life females.
Occupation / wealth. Geeks are typically engaged in professional full-time work; and while they're not always paid as much as they deserve (being oft exploited by less tech-savvy but more ruthless business types), they're generally comfortable, and can even expect to acquire some financial investments in life. Hippies are frequently unemployed and penniless, with many engaged in work for NGOs and other struggling outfits that can barely afford to remunerate them. Many hippies truly do possess almost no financial wealth, although there are plenty of exceptions.
Socio-economic background. A large number of geeks hail from white, middle-class homes. Asian geeks also make up a sizable contingent (with Korean StarCraft fanatics alone enjoying a massive representation); and the infamous "Russian hackers" are more than just a myth. Hippies are perhaps even more predominantly white and middle-class, despite their typical rejection of said heritage. Some upper-class folk enjoy going undercover and slumming it as hippies. Migrant groups are less likely to identify as hippies, although they have a presence in the movement too.
Habits
Fashion. The geek is easily identifiable by his/her conference t-shirt or geek humour t-shirt (or possibly a faeces-coloured formal shirt), accompanied with nondescript jeans, and a practical pair of runners. A rather oversized pair of glasses is a geek hallmark, and a tad bit of facial hair doesn't go astray either. The hippie can be spotted in his/her head-to-toe outfit of thoroughly worn-out and faded vestments, including: a festival t-shirt, stripey pants, and thongs (or he/she may simply go barefoot). On the hair and accessories front, the hippie is typically equipped with: dreads, tats, bandanas, artesanal jewellery, and hair in all parts (ladies not excluded).
Preferred hangouts. The native habitat of the geek is an air-conditioned environment, equipped with fast, reliable Internet. Common hibernation spots include libraries, office spaces, and Internet cafes. Geeks are averse to lingering in public spaces for extended periods, on account of the overwhelming presence of normal people engaged in healthy socialising. The hippie's preferred urban hangout is a dilapidated run-down venue, sporting some blaring alternate music, Che Guevara posters, and coffee tables constructed from used nappies. Hippies are also accustomed to central public spaces, on account of the demonstrations that they stage in them. Additionally, they enjoy hanging out in the bush, naked near a river, with a pleasant campfire crackling nearby.
Diet. The geek subsists on a staple diet of pizza, coke, and cheap beer. Other fast food such as Asian, Mexican, and Italian take-away is also a source of nourishment. Nevertheless, more health- or consumer-conscious geek diets do exist. The hippie diet is significantly different, in that it's… well, far more hippie. A vegetarian or even vegan regime is standard fare. The hippie is quite likely to cook most of his/her own cuisine, and will often religiously enforce a devotion to organic ingredients.
Drug use. Geeks are typically averse to most drugs, although there are exceptions. Hippies, on the other hand, are massive consumers of a plethora of drugs across the board. In particular, the concept of a non-weed-smoking hippie is virtually an oxymoron.
Interests
Musical abilities. Both geeks and hippies are often musical types. Geeks are more likely to wield an old-school instrument (e.g. piano, trumpet, violin), to possess a formal musical education, and to sport experience in choirs or ensembles. Jazz is a preferred geek genre; and synth music composition, along with DJ'ing, are all the geek rage. Hippies are more likely proponents of a percussion or woodwind instrument (e.g. bongos, didgeridoo). Possession and strumming of a guitar is considered valid ID in most hippie circles. Hippies are commonly self-taught musicians, and are very likely to participate in a small band or a musical clan.
Sport. Not the strong point of the geek, who will generally struggle to name the most popular sport of his/her country, without the aid of Wikipedia. However, geeks are often fans of recreational or adventure sport. Similarly, hippies seldom concern themselves with the sports of the Bourgeoisie "masses" (although many are at least somewhat skilled in playing them). They too enjoy recreational sport, all the more if practised in a pristine wilderness environment. Many hippies are also skilled in performance or "circus" sports, such as tightrope and juggling.
Preferred books and movies. The geek species enjoys an intimate relationship with the science fiction and fantasy genres. A geek lacking at least a rudimentary mastery of Jedi mind control, Sindarin Elvish, or Klingon, is at risk of banishment from geekdom. The hippie is fond of such revered authors as Karl Marx and Mahatma Gandhi, and enjoys the (free) screening of documentaries (preferably leftist opinionated ones). The hippie also commonly nurtures an affection for the science fiction and fantasy genres.
World views
Political views. The geek is a left-leaning creature, but is also sceptical of the extreme left (as he/she is of most anything). The geek is an environmentally conscious being, but is generally reluctant to support socialist and other movements. To call the hippie a left-leaning creature is an understatement at best. The hippie is a creature of causes, diving head-first into socialism, along with feminist / gay / indigenous / migrant advocacy groups. The hippie can be relied on to provide a highly opinionated, and reasonably well-educated, opinion on most any sphere of world affairs.
Religious views. Most geeks are quite conservative on this front, sticking to old-school religions such as Christianity, Judaism, and Islam; although few geeks are strongly religious. Atheist geeks are not uncommon either. Hippies almost unanimously share a vehement rejection of traditional religion. Many alternatives appeal to them, including Eastern religion, Paganism, mysticism, meditation and Yoga. Many hippies are also vocal atheists or nihilists.
]]>
Don't trust Facebook with your data2011-10-04T00:00:00Z2011-10-04T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/10/dont-trust-facebook-with-your-data/
It's been five years since it opened its doors to the general public; and, despite my avid hopes that it DIAF, the fact is that Facebook is not dead yet. Far from it. The phenomenon continues to take the world by storm, now ranking as the 2nd most visited web site in the world (after Google), and augmenting its loyal ranks with every passing day.
I've always hated Facebook. I originally joined not out of choice, but out of necessity, there being no other way to contact numerous friends of mine who had decided to boycott all alternative methods of online communication. Every day since joining, I've remained a reluctant member at best, and an open FB hater to say the least. The recent decisions of several friends of mine to delete their FB account outright, brings a warm fuzzy smile to my face. I haven't deleted my own FB account — I wish I could; but unfortunately, doing so would make numerous friends of mine uncontactable to me, and numerous social goings-on unknowable to me, today as much as ever.
There are, however, numerous features of FB that I have refused to utilise from day one, and that I highly recommend that all the world boycott. In a nutshell: any feature that involves FB being the primary store of your important personal data, is a feature that you should reject outright. Facebook is an evil company, and don't you forget it. They are not to be trusted with the sensitive and valuable data that — in this digital age of ours — all but defines who you are.
Don't upload photos
I do not upload any photos to FB. No exceptions. End of story. I uploaded a handful of profile pictures back in the early days, but it's been many years since I did even that.
People who don't know me so well, will routinely ask me, in a perplexed voice: "where are all your Facebook photos?" As if not putting photos on Facebook is akin to not diving onto the road to save an old lady from getting hit by a five-car road train.
My dear friends, there are alternatives! My photos all live on Flickr. My Flickr account has an annual fee, but there are a gazillion advantages to Flickr over FB. It looks better. It doesn't notify all my friends every time I upload a photo. For a geek like me, it has a nice API (FB's API being anything but nice).
But most importantly, I can trust Flickr with my photos. For many of us, our photos are the most valuable digital assets we possess, both sentimentally, and in information identity monetary terms. If you choose to upload your photos to FB, you are choosing to trust FB with those photos, and you are relinquishing control of them over to FB. I know people who have the only copy of many of their prized personal photos on FB. This is an incredibly bad idea!
FB's Terms of Service are, to say the least, horrendous. They reserve the right to sell, to publish, to data mine, to delete, and to prevent deletion of, anything that you post on FB. Flickr, on the other hand, guarantees in its Terms of Service that it will do none of these things; on the contrary, it even goes so far as to allow you to clearly choose the license of every photo you upload to the site (e.g. Creative Commons). Is FB really a company that you're prepared to trust with such vital data?
Don't tag photos
If you're following my rule above, of not uploading photos to FB, then not tagging your own photos should be unavoidable. Don't tag your friends' photos either!
FB sports the extremely popular feature of allowing users to draw a box around their friends' faces in a photo, and to tag those boxes as corresponding to their friends' FB accounts. For a geek like myself, it's been obvious since the moment I first encountered this feature, that it is Pure Evil™. I have never tagged a single face in a FB photo (although unfortunately I've been tagged in many photos by other people). Boycott this tool!
Why is FB photo tagging Pure Evil™, you ask? Isn't it just a cool idea, that means that when you hover over peoples' faces in a photo, you are conveniently shown their names? No — it has other conveniences, not for you but for the FB corporation, for other businesses, and for governments; and those conveniences are rather more sinister.
Facial recognition software technology has been advancing at a frighteningly rapid pace, over the past several years. Up until now, the accuracy of such technology has been insufficient for commercial or government use; but we're starting to see that change. We're seeing the emergence of tools that are combining the latest algorithms with information on the Web. And, as far as face-to-name information online goes, FB — thanks to the photo-tagging efforts of its users — can already serve as the world's largest facial recognition database.
This technology, combined with other data mining tools and applications, make tagged FB photos one of the biggest potential enemies of privacy and anti- Big Brother in the world today. FB's tagged photo database is a wet dream for the NSA and cohort. Do you want to voluntarily contribute to the wealth of everything they know about everyone? Personally, I think they know more than enough about us already.
Don't send FB messages when you could send an e-mail
This is a simple question of where your online correspondence is archived, and of how much you care about that. Your personal messages are an important digital asset of yours. Are they easily searchable? Are you able to export them and back them up? Do you maintain effective ownership of them? Do you have any guarantee that you'll be able to access them in ten years' time?
If a significant amount of your correspondence is in FB messages, then then the answer to all the above questions is "no". If, on the other hand, you still use old-fashioned e-mail to send privates messages whenever possible, then you're in a much better situation. Even if you use web-based e-mail such as Gmail (which I use), you're still far more in control of your mailbox content than you are with FB.
For me, this is also just a question of keeping all my personal messages in one place, and that place is my e-mail archives. Obviously, I will never have everything sent to my FB message inbox. So, it's better that I keep it all centralised where it's always been — in my good "ol' fashioned" e-mail client.
Other boycotts
Don't use FB Pages as your web site. Apart from being unprofessional, and barely a step above (*shudder*) MySpace (which is pushing up the daisies, thank G-d), this is once again a question of trust and of content ownership. If you care about the content on your web site, you should care about who's caring for your web site, too. Ideally, you're caring for it yourself, or you're paying someone reliable to do so for you. At least go one step up, and use Google Sites — because Google isn't as evil as FB.
Don't use FB Notes as your blog. Same deal, really. If you were writing an old-fashioned paper diary, would you keep it on top of your highest bookshelf at home, or would you chain it to your third cousin's dog's poo-covered a$$? Well, guess what — FB is dirtier and dodgier than a dog's poo-covered a$$. So, build your own blog! Or at least use Blogger or Wordpress.com, or something. But not FB!
Don't put too many details in your FB profile fields. This is more the usual stuff that a million other bloggers have already discussed, about maintaining your FB privacy. So I'll just be quick. Anything that you're not comfortable with FB knowing about, doesn't belong in your FB profile. Where you live, where you work, where you studied. Totally optional information. Relationship status — I recommend never setting it. Apart from the giant annoyance of 10 gazillion people being notified of when you get together or break up with your partner, does a giant evil corporation really need to know your relationship / marital status, either?
Don't friend anyone you don't know in real life. Again, many others have discussed this already. You need to understand the consequences of accepting someone as your friend on FB. It means that they have access to a lot of sensitive and private information about you (although hopefully, if you follow all my advice, not all that much private information). It's also a pretty lame ego boost to add friends whom you don't know in real life.
Don't use any FB apps. I don't care what they do, I don't care how cool they are. I don't want them, I don't need them. No marketplace, thanks! No stupid quizzes, thanks! And please, for the love of G-d, I swear I will donate my left testicle to feed starving pandas in Tibet before I ever play Farmville. No thankyou sir.
Don't like things on FB. I hate the "Like" button. It's a useless waste-of-time gimmick. It also has some (small) potential to provide useful data mining opportunities to the giant evil FB corporation. I admit, I have on occasion liked things. But that goes against my general rule of hating FB and everything on it.
What's left?
So, if you boycott all these things, what's left on FB, you ask? Actually, in my opinion, with all these things removed, what you're left with is the pure essentials of FB, and when viewed by themselves they're really not too bad.
The core of FB is, of course: having a list of friends; sharing messages and external content with groups of your friends (on each others' walls); and being notified of all your friends' activity through your stream. There is also events, which is in my opinion the single most useful feature of FB — they really have done a good job at creating and refining an app for organising events and tracking invite RSVPs; and for informal social functions (at least), there actually isn't any decent competition to FB's events engine available at present. Plus, the integration of the friends list and the event invite system does work very nicely.
What's left, at the core of FB, doesn't involve trusting FB with data that may be valuable to you for the rest of your life. Links and YouTube videos that you share with your friends, have a useful lifetime of about a few days at best. Events, while potentially sensitive in that they reveal your social activity to Big Brother, do at least also have limited usefulness (as data assets) past the date of the event.
Everything else is valuable data, and it belongs either in your own tender loving hands, or in the hands of a provider signficantly more responsible and trustworthy than FB.
]]>
World domination by box office cinema admissions2011-07-18T00:00:00Z2011-07-18T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/07/world-domination-by-box-office-cinema-admissions/
It's no secret that Hollywood is the entertainment capital of the world. Hollywood blockbuster movies are among the most influential cultural works in the history of humanity. This got me thinking: exactly how many corners of the globe have American movies spread to; and to what extent have they come to dominate entertainment in all those places? Also, is Hollywood really as all-powerful a global cinema force as we believe; or does it have some bona fide competition these days?
I spent a bit of time recently, hunting for sets of data that could answer these questions in an expansive and meaningful way. And I'm optimistic that what I've come up with satisfies both of those things: in terms of expansive, I've got stats (admittedly of varying quality) for most of the film-watching world; and in terms of meaningful, I'm using box office admission numbers, which I believe are the most reliable international measure of film popularity.
So, without further ado, here are the stats that I've come up with:
Country
Admissions (millions)
US admissions (percent of total)
EU admissions (percent of total)
Local admissions (percent of total)
Other admissions (percent remainder)
India
2,900.0
Gross (millions): $1,860.0
Year: 2009
6.0%
US admissions (millions): 174.0
US admissions notes: based on 2007 figures.
0.8%
EU admissions (millions): 23.2
EU admissions notes: based on 2007 figures.
92.0%
Local admissions (millions): 2,668.0
Local admissions notes: 2009 figures.
1.2%
US
1,364.0
Gross (millions): $9,360.0
Year: 2009
91.5%
US admissions (millions): 1,248.1
US admissions notes: 2008 figures.
7.2%
EU admissions (millions): 98.2
EU admissions notes: 2008 figures.
n/a
1.3%
China
217.8
Gross (millions): $906.3
Year: 2009
38.0%
US admissions (millions): 82.8
US admissions notes: Based on total admissions for US movies in top 10 admissions in country.
4.0%
EU admissions (millions): 8.7
EU admissions notes: Based on total admissions for EU movies in top 10 admissions in country.
56.6%
Local admissions (millions): 123.3
Local admissions notes: 2009 figures.
1.4%
France
200.9
Gross (millions): $1,710.0
Year: 2009
49.8%
US admissions (millions): 100.0
US admissions notes: 2007 figures.
50.2%
EU admissions (millions): 100.9
EU admissions notes: 2007 figures.
n/a
0.0%
Mexico
178.0
Gross (millions): $562.5
Year: 2009
90.0%
US admissions (millions): 160.2
US admissions notes: Based on total admissions for US movies in top 10 admissions in country.
1.0%
EU admissions (millions): 1.8
EU admissions notes: Based on total admissions for EU movies in top 10 admissions in country.
7.5%
Local admissions (millions): 13.4
Local admissions notes: 2009 figures.
1.5%
UK
173.5
Gross (millions): $1,470.0
Year: 2009
77.0%
US admissions (millions): 133.6
US admissions notes: Based on 2008 figures.
21.5%
EU admissions (millions): 37.3
EU admissions notes: Based on 2008 figures.
n/a
1.5%
Japan
169.3
Gross (millions): $2,200.0
Year: 2009
38.0%
US admissions (millions): 64.3
US admissions notes: Based on total admissions for US movies in top 20 admissions in country.
2.0%
EU admissions (millions): 3.4
EU admissions notes: Based on total admissions for EU movies in top 20 admissions in country.
56.9%
Local admissions (millions): 96.3
Local admissions notes: 2009 figures.
1.5%
South Korea
156.8
Gross (millions): $854.4
Year: 2009
46.0%
US admissions (millions): 72.1
US admissions notes: Based 2008 figures.
2.5%
EU admissions (millions): 3.9
EU admissions notes: Based on 2008 figures.
48.8%
Local admissions (millions): 76.5
Local admissions notes: 2009 figures.
2.7%
Germany
146.3
Gross (millions): $1,360.0
Year: 2009
65.0%
US admissions (millions): 95.1
US admissions notes: Based on total admissions for US movies in top 20 admissions in country.
34.4%
EU admissions (millions): 50.3
EU admissions notes: Based on total admissions for EU movies in top 20 admissions in country.
n/a
0.6%
Russia & CIS
138.5
Gross (millions): $735.7
Year: 2009
60.0%
US admissions (millions): 83.1
US admissions notes: Based on total admissions for US movies in top 20 admissions in country.
12.0%
EU admissions (millions): 16.6
EU admissions notes: Based on total admissions for EU movies in top 20 admissions in country.
23.9%
Local admissions (millions): 33.1
Local admissions notes: 2009 figures.
4.1%
Brazil
112.7
Gross (millions): $482.9
Year: 2009
75.0%
US admissions (millions): 84.5
US admissions notes: Based on total admissions for US movies in top 10 admissions in country.
10.0%
EU admissions (millions): 11.3
EU admissions notes: Based on total admissions for EU movies in top 10 admissions in country.
14.3%
Local admissions (millions): 16.1
Local admissions notes: 2009 figures.
0.7%
Italy
111.2
Gross (millions): $940.0
Year: 2009
64.0%
US admissions (millions): 71.2
US admissions notes: Based on total admissions for US movies in top 20 admissions in country.
29.4%
EU admissions (millions): 32.7
EU admissions notes: Based on total admissions for EU movies in top 20 admissions in country.
n/a
6.6%
Spain
109.5
Gross (millions): $928.5
Year: 2009
65.0%
US admissions (millions): 71.2
US admissions notes: Based on total admissions for US movies in top 20 admissions in country.
32.0%
EU admissions (millions): 35.0
EU admissions notes: Based on total admissions for EU movies in top 20 admissions in country.
n/a
3.0%
Canada
108.0
Gross (millions): $863.0
Year: 2009
88.5%
US admissions (millions): 95.6
US admissions notes: 2008 figures.
8.0%
EU admissions (millions): 8.6
EU admissions notes: 2008 figures.
2.8%
Local admissions (millions): 3.0
Local admissions notes: 2009 figures.
0.7%
Australia
90.7
Gross (millions): $848.4
Year: 2009
84.2%
US admissions (millions): 76.4
US admissions notes: 2008 figures.
10.0%
EU admissions (millions): 9.1
EU admissions notes: 2008 figures.
5.0%
Local admissions (millions): 4.5
Local admissions notes: 2009 figures.
0.8%
Philippines
65.4
Gross (millions): $113.8
Year: 2008
80.0%
US admissions (millions): 52.3
US admissions notes: Based on total gross for US movies in top 100 movies in country.
4.0%
EU admissions (millions): 2.6
EU admissions notes: Based on total gross for EU movies in top 100 movies in country.
15.0%
Local admissions (millions): 9.8
Local admissions notes: General estimate based on number of local films made.
1.0%
Indonesia
50.1
Gross (millions): $102.2
Year: 2008
80.0%
US admissions (millions): 40.1
US admissions notes: Based on total gross for US movies in top 100 movies in country.
4.0%
EU admissions (millions): 2.0
EU admissions notes: Based on total gross for EU movies in top 100 movies in country.
15.0%
Local admissions (millions): 7.5
Local admissions notes: General estimate based on number of local films made.
1.0%
Malaysia
44.1
Gross (millions): $114.1
Year: 2009
82.0%
US admissions (millions): 36.2
US admissions notes: Based on total gross for US movies in top 100 movies in country.
4.0%
EU admissions (millions): 1.8
EU admissions notes: Based on total gross for EU movies in top 100 movies in country.
13.7%
Local admissions (millions): 6.0
Local admissions notes: 2009 figures.
0.3%
Poland
39.2
Gross (millions): $218.1
Year: 2009
70.0%
US admissions (millions): 27.4
US admissions notes: Based on total admissions for US movies in top 10 admissions in country.
29.5%
EU admissions (millions): 11.6
EU admissions notes: Based on total admissions for EU movies in top 10 admissions in country.
n/a
0.5%
Turkey
36.9
Gross (millions): $198.0
Year: 2009
42.0%
US admissions (millions): 15.5
US admissions notes: 2009 figures.
6.0%
EU admissions (millions): 2.2
EU admissions notes: Based on total admissions for EU movies in top 10 admissions in country.
50.9%
Local admissions (millions): 18.8
Local admissions notes: 2009 figures.
1.1%
Argentina
33.3
Gross (millions): $126.1
Year: 2009
76.0%
US admissions (millions): 25.3
US admissions notes: Based on total admissions for US movies in top 10 admissions in country.
7.0%
EU admissions (millions): 2.3
EU admissions notes: Based on total admissions for EU movies in top 10 admissions in country.
16.0%
Local admissions (millions): 5.3
Local admissions notes: 2009 figures.
1.0%
Netherlands
27.3
Gross (millions): $279.5
Year: 2009
65.0%
US admissions (millions): 17.7
US admissions notes: Based on total admissions for US movies in top 10 admissions in country.
33.4%
EU admissions (millions): 9.1
EU admissions notes: Based on total admissions for EU movies in top 10 admissions in country.
n/a
1.6%
Colombia
27.3
Gross (millions): $91.7
Year: 2009
82.0%
US admissions (millions): 22.4
US admissions notes: Based on total admissions for US movies in top 10 admissions in country.
10.0%
EU admissions (millions): 2.7
EU admissions notes: Based on total admissions for EU movies in top 10 admissions in country.
4.8%
Local admissions (millions): 1.3
Local admissions notes: 2009 figures.
3.2%
Thailand
27.1
Gross (millions): $101.3
Year: 2008
60.0%
US admissions (millions): 16.3
US admissions notes: Based on total gross for US movies in top 100 movies in country.
1.0%
EU admissions (millions): 0.3
EU admissions notes: Based on total gross for EU movies in top 100 movies in country.
37.5%
Local admissions (millions): 10.2
Local admissions notes: 2009 figures.
1.5%
South Africa
26.1
Gross (millions): $52.3
Year: 2008
72.0%
US admissions (millions): 18.8
US admissions notes: Based on total gross for US movies in top 100 movies in country.
10.0%
EU admissions (millions): 2.6
EU admissions notes: Based on total gross for EU movies in top 100 movies in country.
15.0%
Local admissions (millions): 3.9
Local admissions notes: General estimate based on number of local films made.
3.0%
Egypt
25.6
Gross (millions): $54.9
Year: 2009
16.0%
US admissions (millions): 4.1
US admissions notes: Based on total gross for US movies in top 100 movies in country.
2.0%
EU admissions (millions): 0.4
EU admissions notes: Based on total gross for EU movies in top 100 movies in country.
80.0%
Local admissions (millions): 20.5
Local admissions notes: 2009 figures.
2.0%
Taiwan
23.6
Gross (millions): $172.3
Year: 2009
75.0%
US admissions (millions): 17.7
US admissions notes: Based on total gross for US movies in top 100 movies in country.
2.0%
EU admissions (millions): 0.5
EU admissions notes: Based on total gross for EU movies in top 100 movies in country.
22.3%
Local admissions (millions): 5.3
Local admissions notes: 2009 figures (including Chinese films).
0.7%
Belgium
22.6
Gross (millions): $187.3
Year: 2009
60.0%
US admissions (millions): 13.6
US admissions notes: Based on total gross for US movies in top 100 movies in country.
37.9%
EU admissions (millions): 8.6
EU admissions notes: Based on total gross for EU movies in top 100 movies in country.
n/a
2.1%
Singapore
22.0
Gross (millions): $115.3
Year: 2009
90.0%
US admissions (millions): 19.8
US admissions notes: Based on total admissions for US movies in top 10 admissions in country.
3.0%
EU admissions (millions): 0.7
EU admissions notes: Based on total admissions for EU movies in top 10 admissions in country.
3.8%
Local admissions (millions): 0.9
Local admissions notes: 2009 figures.
3.2%
Venezuela
22.0
Gross (millions): $163.6
Year: 2008
90.0%
US admissions (millions): 19.8
US admissions notes: Based on total admissions for US movies in top 10 admissions in country.
6.0%
EU admissions (millions): 1.3
EU admissions notes: Based on total admissions for EU movies in top 10 admissions in country.
0.6%
Local admissions (millions): 0.1
Local admissions notes: 2009 figures.
3.4%
Hong Kong
20.1
Gross (millions): $152.2
Year: 2008
70.0%
US admissions (millions): 14.1
US admissions notes: Based on total admissions for US movies in top 10 admissions in country.
3.0%
EU admissions (millions): 0.6
EU admissions notes: Based on total admissions for EU movies in top 10 admissions in country.
21.0%
Local admissions (millions): 4.2
Local admissions notes: 2009 figures.
6.0%
Note:this table lists all countries with annual box office admissions of more than 20 million tickets sold. The countries are listed in descending order of number of box office admissions. The primary source for the data in this table (and for this article in general), is the 2010 edition of the FOCUS: World Film Market Trends report, published by the European Audiovisual Observatory.
The Mighty Hollywood
Before I comment on anything else, I must make the point loudly and clearly: Hollywood is still the most significant cinema force in the world, as it has consistently been since the dawn of movie-making over a century ago. There can be no denying that. By every worldwide cinema-going measure, movies from the United States are still No. 1: quantity of box office tickets sold; gross box office profit; and extent of geopolitical box office distribution.
The main purpose of this article, is to present the cinema movements around the world that are competing with Hollywood, and to demonstrate that some of those movements are significant potential competition for Hollywood. I may, at times in this article, tend to exaggerate the capacity of these regional players. If I do, then please forgive me, and please just remind yourself of the cold, harsh reality, that when Hollywood farts, the world takes more notice than when Hollywood's contenders discover life on Mars.
Seriously, Hollywood is mighty
Having made my above point, let's now move on, and have a look at the actual stats that show just how frikkin' invincible the USA's film industry is today:
The global distribution of US movies is massive: of the 31 countries listed in the table above, 24 see more than 50% of their box office admissions being for US movies.
The US domestic cinema industry is easily the most profitable in the world, raking in more than US$9 billion annually; and also the most extensive in the world, with almost 40,000 cinema screens across the country (2009 stats).
The US film industry is easily the most profitable in the world: of the 20 top films worldwide by gross box office, all of them are at least partly Hollywood-produced; and of those, 13 are 100% Hollywood-produced.
Cinéma Européen
In terms of global distribution, and hence also in terms of global social and cultural impact, European movies quite clearly take the lead, after Hollywood (of course). That's why, in the table above, the only two film industries whose per-country global box office admissions I've listed, are those of the United States and of the European Union. The global distribution power of all the other film industries is, compared to these two heavyweights, negligible.
Within the EU, by far the biggest film producer — and the most successful film distributor — is France. This is nothing new: indeed, the world's first commercial public film screening was held in Paris, in 1895, beating New York's début by a full year. Other big players are Germany, Spain, Italy, and the UK. While the majority of Joe Shmoe cinema-goers worldwide have always craved the sex, guns and rock 'n' roll of Hollywood blockbusters, there have also always been those who prefer a more cultured, refined and sophisticated cinema experience. Hence, European cinema is — while not the behemoth that is Hollywood — strong as ever.
France is the only country in Europe — or the world — where European films represent the majority of box office admissions; and even in France, they just scrape over the 50% mark, virtually tied with Hollywood admissions. In the other European countries listed in the table above (UK, Germany, Italy, Spain, Poland, Netherlands, and Belgium), EU admissions make up around 30-35% of the market, with American films taking 60-75% of the remaining share. In the rest of the world, EU admissions don't make it far over the 10% mark; although their share remains significant worldwide, with 24 of the 31 countries in the table above having 3% or more EU admissions.
Oh My Bollywood!
You may have noticed that in the table, the US is not first in the list. That's because the world's largest cinema-going market (in terms of ticket numbers, not gross profit) is not the US. It's India. Over the past several decades, Bollywood has risen substantially, to become the second-most important film industry in the world (i.e. it's arguably more important than the European industry).
India has over 1.2 billion people, giving it the second-largest population in the world (after China). However, Indians love cinema much more than the Chinese do. India has for quite some time been the world's No. 1 producer of feature films. And with 2.9 billion box office admissions annually, the raw cinema-going numbers for India are more than double those of the US, which follows second worldwide.
Apart from being No. 1 in domestic box office admissions, India also has the highest percentage of admissions for local films, and the lowest percentage of admissions for US films, in the world. That means that when Indians go to the cinema, they watch more local movies, and less American movies, than any other people in the world (exactly what the social and cultural implications of that are, I leave for another discussion — perhaps better analysed in a PhD thesis than in a blog post!). That also gives Bollywood the No. 2 spot for international box office admissions.
However, massive as Bollywood's presence and its influence is domestically within India (and in the rest of South Asia), its global reach is pretty slim. Bollywood's No. 2 spot for international box office admissions, stems 99% from its domestic admissions. The vast majority of Bollywood movies are never even shipped outside of the region, let alone screened in cinemas. A significant number are also filmed in the Hindi language, and are never dubbed or subtitled in English (or any other languages), due to lack of an international market.
There are some exceptions. For example, a number of Bollywood films are distributed and screened in cinemas in the UK, targeting the large Indian community there (the number of films is relatively small compared to the size of the Bollywood industry, but it's a significant number within the UK cinema market). However, despite its growing international fame, Bollywood remains essentially a domestic affair.
The rest of the world has yet to truly embrace the lavish psychedelic costumes; the maximum interval of six minutes between twenty-minute-long, spontaneous, hip-swinging, sari-swirling song-and-dance routines; or the idea that the plot of every movie should involve a poor guy falling in love with a rich girl whose parents refuse for them to marry (oh, and of course there must also be a wedding, and it must be the most important and extravagent scene of the movie). Bollywood — what's not to love?
Nollywood, anyone?
We're all familiar with Bollywood… but have you heard of Nollywood? It's the film industry of Nigeria. And, in case you didn't know, in the past decade or so Nollywood has exploded from quite humble beginnings, into a movement of epic proportions and of astounding success. In 2009, Nollywood rose up to become the No. 2 producer of feature films in the world (second only to the Indian industry, and pushing Hollywood down to third place).
However, you may have noticed that Nigeria isn't in the table above at all. That's because cinema screens in Nigeria are few and far between, and almost all Nollywood films are released straight to home media (formerly VHS, these days DVD). So, Nollywood is an exceptional case study here, because the focus of this article is to measure the success of film industries by box office admissions; and yet Nollywood, which has rapidly become one of the most successful film industries in the world, lacks almost any box office admissions whatsoever.
There are few hard statistics available for distribution of films within Nigeria (or in most of the rest of Africa), in terms of box office admissions, DVD sales (with almost all being sold in ramshackle markets, and with many being pirated copies), or anything else. However, the talk of the town is that the majority of movies watched in Nigeria, and in many other countries in Africa, are local Nollywood flicks. In Nigeria itself, the proportion of local-vs-Hollywood film-watching may even be reaching Indian levels, i.e. more than 90% of viewings being of local films — although it's impossible to give any exact figures.
Nollywood's distribution reach is pretty well limited to domestic Nigeria, and the surrounding African regions. Bollywood boasts a significantly greater international distribution… and Bollywood's reach ain't amazing, either. The low-budget production and straight-to-disc distribution strategies of Nollywood have proved incredibly successful locally. However, this means that most Nollywood movies aren't even suitable for cinema projection without serious editing (in terms of technology and cinematography), and this has probably been a factor in limiting Nollywood's growth in other markets, where traditional box office distribution is critical to success.
East Asian cinema
The film industries of the Orient have always been big. In particular, the industries of China and Japan, respectively, are each only slightly behind Hollywood in number of feature films produced annually (and Korea is about on par with Italy). Many East Asian film industries enjoy considerable local success, as evidenced in the table above, where several Asian countries are listed as having a significant percentage of local box office admissions (in China, Japan and Korea, local films sweep away 50% or more of the box office admissions).
Much like Bollywood, the film industries of many East Asian countries have often fallen victim to cliché and "genre overdose". In China and Hong Kong, the genre of choice has long been martial arts, with Kung Fu movies being particularly popular. In Japan and Korea, the most famous genre traditionally has been horror, and in more recent decades (particularly in Japan), the anime genre has enjoyed colossal success.
East Asian film is arguably the dominant cultural film force within the region (i.e. dominant over Hollywood). It's also had a considerable influence on the filmmaking tradition of Hollywood, with legends such as Japan's Akira Kurosawa being cited by numerous veteran Hollywood directors, such as Martin Scorsese.
However, well-established though it is, the international distribution of East Asian films has always been fairly limited. Some exceptional films have become international blockbusters, such as the (mainly) Chinese-made Crouching Tiger, Hidden Dragon (2000). Japanese horror and anime films are distributed worldwide, but they have a cult following rather than a mainstream appreciation in Western countries. When most Westerners think of "Asian" movies, they most likely think of Jackie Chan and Bruce Lee, the majority of whose films were Hollywood productions. Additionally, the international distribution of movies from other strong East Asian film industries, such as those of Thailand and Taiwan, is almost non-existent.
Middle Eastern cinema
The most significant player in Middle Eastern cinema is Egypt, which has a long and glorious film-making tradition. The Egyptian film industry accounts for a whopping 80% of Egypt's domestic box office admissions; and, even more importantly, Egyptian films are exported to the rest of the Arabic-speaking world (i.e. to much of the rest of the Middle East), and (to some extent) to the rest of the Muslim world.
Turkey is also a cinema powerhouse within the Middle East. Turkey's film industry boasts 51% of the local box office admissions, and Turkey as a whole is the largest cinema-going market in the region. The international distribution of Turkish films is, however, somewhat more limited, due to the limited appeal of Turkish-language cinema in other countries.
Although it's not in the table above, and although limited data is available for it, Iran is the other great cinema capital of the region. Iran boasted a particularly strong film industry many decades ago, before the Islamic Revolution of 1979; nevertheless, the industry is still believed to afford significant local market share today.
Also of note is Israel, which is the most profitable cinema-going market in the region after Turkey, and which supports a surprisingly productive and successful film industry (with limited but far-reaching international distribution), given the country's small population.
Other players worldwide
Russia & CIS. Although US box office admissions dominate these days, the Russian film industry wins almost 25% of admissions. This is very different to the Soviet days, when foreign films were banned, and only state-approved (and highly censored) films were screened in cinemas. Russian movies are mainly distributed within the former Soviet Union region, although a small number are exported to other markets.
Latin America. The largest markets for box office admissions in the region are Mexico, Brazil, and Argentina. Admissions in all of Latin America are majority Hollywood; however, in these "big three", local industries are also still quite strong (particularly in Brazil and Argentina, each with about 15% local admissions; about half that number in more US-dominated Mexico). Local industries aren't as strong as they used to be, but they're still most definitely alive. Latin American films are distributed and screened worldwide, although their reception is limited. There have been some big hits, though, in the past decade: Mexico's Amores Perros (2000); Argentina's Nueve Reinas (2000); and Brazil's Cidade de Deus (2002).
South Africa. Despite having a fairly large box office admission tally, there's not a whole lot of data available for local market share in the South African film industry. Nevertheless, it is a long-established film-making country, and it continues to produce a reasonable number of well-received local films every year. South Africa distributes films internationally, although generally not with blockbuster success — but there have been exceptions, e.g. Tsotsi (2005).
In summary
If you've made it this far, you must be keen! (And this article must be at least somewhat interesting). Sorry, this has turned out to be a bit longer than average for a thought article; but hey, turns out there are quite a lot of strong film industries around the world, and I didn't want to miss any important ones.
So, yes, Hollywood's reach is still universal, and its influence not in any way or in any place small. But no, Hollywood is not the only force in this world that is having a significant cultural effect, via the medium of the motion picture. There are numerous other film industries today, that are strong, and vibrant, and big. Some of them have been around for a long time, and perhaps they just never popped up on the ol' radar before (e.g. Egypt). Others are brand-new and are taking the world by storm (e.g. Nollywood).
Hollywood claims the majority of film viewings in many countries around the world, but not everywhere. Particularly, on the Indian Subcontinent (South Asia), in the Far East (China, Japan, Korea), and in much of the Middle East (Egypt, Turkey, Iran), the local film industries manage to dominate over Hollywood in this regard. Considering that those regions are some of the most populous in the world, Hollywood's influence may be significantly less than many people like to claim.
But, then again, remember what I said earlier: Hollywood farts, whole world takes notice; film-makers elsewhere discover life on Mars, doesn't even make the back page.
]]>
Kosher and the Land that G-d forgot2011-07-07T00:00:00Z2011-07-07T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/07/kosher-and-the-land-that-g-d-forgot/
Per the laws of kashrut, the Jewish religion prohibits the consumption of meat from many animals and birds. Islam's laws of halal enact very similar prohibitions.
Australia and New Zealand are two countries located very far from the Middle East, the home of Judaism and Islam. Their native wildlife is completely different to that found anywhere else in the world. Of course, since European settlement began, they've been thoroughly introduced to the fauna of the wider world. Indeed, these two countries are today famous for being home to some of the world's largest sheep and cattle populations.
However, let's put aside the present-day situation for now, and take ourselves back in time a thousand or so years. Artificial transcontinental animal transportation has not yet begun. The world's animals still live in the regions that G-d ordained for them to live in. G-d has peppered almost every corner of the globe with at least some variety of kosher birds and mammals. Every major world region, bar one.
My fellow Aussies and Kiwis, I'm afraid the verdict is clear: we are living in the Land that G-d forgot.
Legal recap
Can it really be true? is there not a single native Aussie or Kiwi bird or mammal, that's fit for a chassid's shabbos lunch? Is our Great Southern Land really the world's Traif Buffet Grande?
Before we jump to such shocking conclusions, let's review some basic definitions. According to Jewish law, a mammal is kosher if it has split hooves and chews its cud (plus, it should be herbivorous). For birds, there is no clear and simple rule in determining kosher status, and so the most important rule is that there is a lond-standing tradition (a mesorah) of its being kosher (although there are some guidelines for birds, e.g. only non-predatory birds, peelable gizzard / stomach lining).
The kosher map
After doing some pretty thorough research, I've discovered that there are only eight groups of fauna in the world whose meat is kosher. These groups, and their kosher species, are:
*For these South American deer species, I found no kosher list that could verify their kashrut status; however, many other sources explicitly state that all deer is kosher, and these species are definitely all deer.
All the species of cattle originate from Asia (particularly from the Indian Subcontinent), except for the Muskox which is from the Arctic regions of North America (and the inclusion of the Muskox is stretching the definition of cattle somewhat). Sheep and goats originate mainly from the Middle East and surrounds, except for the Bighorn and Dall sheep (which are North American). All three of cattle, sheep, and goats, are believed to trace their domesticated origins to the Fertile Crescent area of the Middle East.
Bison are closely related to cattle, but are ultimately a different group. Bison are one of the least clustered of the animal groups discussed here, being scattered all over the world: the American buffalo is North American; the Cape buffalo hails from South Africa; the Water buffalo is native to South-East Asia; and the Wisent is of Eastern European origin. The deer are also a widely dispersed group, being spread over all the Americas, Europe, and Asia.
The large number of antelope species are almost all from Eastern and Southern Africa. Exceptions include the Blackbuck, which is of Indian origin; and the Pronghorn, which is the North American antelope ambassador. The Giraffe and its only (surviving) close relative, the Okapi, both hail from Central Africa.
There are also the birds, most of which originate from an extensive number of regions and continents (including Europe, Asia, Africa, and the Americas), due to their being migratory. The Chicken is of Indian Subcontinent origin; the Muscovy duck hails from Central / South America; the Pheasant is of Eastern European origin; and the Turkey is North American.
And so, here we can see all of these animals, indicated quite roughly on a world map (image is of this kosher animals Google map):
Map showing the native locations of kosher animals around the world.
No kosher tucker
The map speaks for itself, really. For most of human history, Oz and NZ went unnoticed to the rest of the human-inhabited world. Clearly, the Man Up High also didn't notice those funny bits Down Under, when he was plonking kosher land animals down upon the rest of the Earth. Or maybe — Day 6 being a Friday and all — he knocked off early and went to the pub, and he just never got around to koshering Australasia.
No kosher marsupials — forget about Roo, Wallaby, Koala, and Wombat — they're all traif. Same deal for the monotremes: Platypus and Echidna are off the menu. Not to mention croccies… oy vey! Oh, and I know you were thinking about Emu — but you can stop thinking, I already checked. As for NZ, it hasn't even got a single native land-dwelling mammal, let alone a kosher one. I guess even the goyim have to make do around there — although at least they could roast up a Kea or a Kiwi if they started feeling peckish.
Seriously, it's pretty slack. I know that the Aborigines and the Maoris never even had the opportunity to hear about kosher (which is bad enough). But assuming they somehow had caught wind of it, and had decided to join the bandwagon; surely, they would have felt pretty jaded and ripped off, upon learning that the All-Merciful One had given them the cold shoulder in the meat department.
Possible explanations
We all know that Australia is the oldest continent on Earth. So, I can think of one explanation easily enough. G-d created the world 6,000 years ago. The whole world, that is, except Oz and NZ. He created those places 40,000 years ago; he plonked the Roos and the Aborigines down in Oz; and he just let 'em sit there for 34,000 years, and hang around idly until he popped back and finished off the rest of the world. If this theory is true, then I guess being left out to dry in the bush for that long would make the Aborigines feel pretty jaded anyway (apart from their already feeling jaded re: lack of kosher meat on their continent).
Another theory: maybe Oz and NZ were a bit of a hippie commune experiment, and G-d decided that if (by some bizarre turn of events) the Blackfellas did happen to hear about kashrut and (even more bizarrely) liked the sound of it, then they should stick to a veggie diet anyway. Or, if they got really desperate, there are — after all — native kosher fish on Oz and NZ's coasts; so they could grill up a salmon or two. But, as any carnivorous man knows, fish just ain't no substitute for a good chunk of medium-rare goodness (yes, I know, I'm a crap hippie).
We should also consider that, as everyone knows, Australasia was a bit of an experimental zone in general for the Man Up High. Some have even gone further, and argued that Australasia was His dumping ground for failed experiments. If this was the case, then it logically follows that He would never place any kosher animals — which we can only assume were what He considered his greatest success story — in that very same manure hole.
I believe I already mentioned the theory about knocking off early on Friday afternoon and going to the pub. (In fact, if that theory is true, it would seem that that act has been G-d's greatest legacy to Australasia.)
Forgotten Land
We already knew about quite a few fairly essential things that G-d forgot to put in Australia. For example, water. And rivers that have water. And mountains (real ones). Also non-poisonous snakes and spiders. And something (anything) in the middle (apart from a big rock).
This is just further proof that Australia really isn't the Chosen Land. No non-traif meat available. Anyway, at least you can thank Him for the next time you're stuck in the Outback, when a feast of witchety grubs could save you from starvation.
]]>
Thread progress monitoring in Python2011-06-30T00:00:00Z2011-06-30T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/06/thread-progress-monitoring-in-python/
My recent hobby hack-together, my photo cleanup tool FotoJazz, required me getting my hands dirty with threads for the first time (in Python or otherwise). Threads allow you to run a task in the background, and to continue doing whatever else you want your program to do, while you wait for the (usually long-running) task to finish (that's one definition / use of threads, anyway — a much less complex one than usual, I dare say).
However, if your program hasn't got much else to do in the meantime (as was the case for me), threads are still very useful, because they allow you to report on the progress of a long-running task at the UI level, which is better than your task simply blocking execution, leaving the UI hanging, and providing no feedback.
As part of coding up FotoJazz, I developed a re-usable architecture for running batch processing tasks in a thread, and for reporting on the thread's progress in both a web-based (AJAX-based) UI, and in a shell UI. This article is a tour of what I've developed, in the hope that it helps others with their thread progress monitoring needs in Python or in other languages.
The FotoJazzProcess base class
The foundation of the system is a Python class called FotoJazzProcess, which is in the project/fotojazz/fotojazzprocess.py file in the source code. This is a base class, designed to be sub-classed for actual implementations of batch tasks; although the base class itself also contains a "dummy" batch task, which can be run and monitored for testing / example purposes. All the dummy task does, is sleep for 100ms, for each file in the directory path provided:
#!/usr/bin/env python
# ...
from threading import Thread
from time import sleep
class FotoJazzProcess(Thread):
"""Parent / example class for running threaded FotoJazz processes.
You should use this as a base class if you want to process a
directory full of files, in batch, within a thread, and you want to
report on the progress of the thread."""
# ...
filenames = []
total_file_count = 0
# This number is updated continuously as the thread runs.
# Check the value of this number to determine the current progress
# of FotoJazzProcess (if it equals 0, progress is 0%; if it equals
# total_file_count, progress is 100%).
files_processed_count = 0
def __init__(self, *args, **kwargs):
"""When initialising this class, you can pass in either a list
of filenames (first param), or a string of space-delimited
filenames (second param). No need to pass in both."""
Thread.__init__(self)
# ...
def run(self):
"""Iterates through the files in the specified directory. This
example implementation just sleeps on each file - in subclass
implementations, you should do some real processing on each
file (e.g. re-orient the image, change date modified). You
should also generally call self.prepare_filenames() at the
start, and increment self.files_processed_count, in subclass
implementations."""
self.prepare_filenames()
for filename in self.filenames:
sleep(0.1)
self.files_processed_count += 1
You could monitor the thread's progress, simply by checking obj.files_processed_count from your calling code. However, the base class also provides some convenience methods, for getting the progress value in a more refined form — i.e. as a percentage value, or as a formatted string:
# ...
def percent_done(self):
"""Gets the current percent done for the thread."""
return float(self.files_processed_count) / \
float(self.total_file_count) \
* 100.0
def get_progress(self):
"""Can be called at any time before, during or after thread
execution, to get current progress."""
return '%d files (%.2f%%)' % (self.files_processed_count,
self.percent_done())
The FotoJazzProcessShellRun command-line progress class
FotoJazzProcessShellRun contains all the code needed to report on a thread's progress via the command-line. All you have to do is instantiate it, and pass it a class (as an object) that inherits from FotoJazzProcess (or, if no class is provided, it uses the FotoJazzProcess base class). Then, execute the instantiated object — it takes care of the rest for you:
class FotoJazzProcessShellRun(object):
"""Runs an instance of the thread with shell output / feedback."""
def __init__(self, init_class=FotoJazzProcess):
self.init_class = init_class
def __call__(self, *args, **kwargs):
# ...
fjp = self.init_class(*args, **kwargs)
print '%s threaded process beginning.' % fjp.__class__.__name__
print '%d files will be processed. ' % fjp.total_file_count + \
'Now beginning progress output.'
print fjp.get_progress()
fjp.start()
while fjp.is_alive() and \
fjp.files_processed_count < fjp.total_file_count:
sleep(1)
if fjp.files_processed_count < fjp.total_file_count:
print fjp.get_progress()
print fjp.get_progress()
print '%s threaded process complete. Now exiting.' \
% fjp.__class__.__name__
if __name__ == '__main__':
FotoJazzProcessShellRun()()
At this point, we're able to see the progress feedback in action already, through the command-line interface. This is just running the dummy batch task, but the feedback looks the same regardless of what process is running:
Thread progress output on the command-line.
The way this command-line progress system is implemented, it provides feedback once per second (timing handled with a simple sleep() call), and outputs feedback in terms of both number of files and percentage done. These details, of course, merely form an example for the purposes of this article — when implementing your own command-line progress feedback, you would change these details per your own tastes and needs.
The web front-end: HTML
Cool, we've now got a framework for running batch tasks within a thread, and for monitoring the progress of the thread; and we've built a simple interface for printing the thread's progress via command-line execution.
That was the easy part! Now, let's build an AJAX-powered web front-end on top of all that.
To start off, let's look at the basic HTML we'd need, for allowing the user to initiate a batch task (e.g. by pushing a submit button), and to see the latest progress of that task (e.g. with a JavaScript progress bar widget):
Close your eyes for a second, and pretend we've also just coded up some gorgeous, orgasmic CSS styling for this markup (and don't worry about the class / id names for now, either — they're needed for the JavaScript, which we'll get to shortly). Now, open your eyes, and behold! A glorious little web-based dialog for our dummy task:
Web-based dialog for initiating and monitoring our dummy task.
The web front-end: JavaScript
That's a lovely little interface we've just built. Now, let's begin to actually make it do something. Let's write some JavaScript that hooks into our new submit button and progress indicator (with the help of jQuery, and the jQuery UI progress bar — this code can be found in the static/js/fotojazz.js file in the source code):
This code is best read by starting at the bottom. First off, we call fotojazz.operations.init(). If you look up just a few lines, you'll see that function defined (it's the init: function() one). In the init() function, the first thing we do is initialise a (disabled) jQuery progress bar widget, on our div with class operation-progress. Then, we call process_start(), passing in a process_css_name of 'dummy', and a process_class_name of 'FotoJazzProcess'.
The process_start() function binds all of its code to the click() event of our submit button. So, when we click the button, an AJAX request is sent to the path /process/start/process_class_name/ on the server side. We haven't yet implemented this server-side callback, but for now let's assume that (as its pathname suggests), this callback starts a new process thread, and returns some info about the new thread (e.g. a reference ID, a progress indication, etc). The AJAX 'success' callback for this request then waits 100ms (with the help of setTimeout()), before calling process_progress(), passing it the CSS name and the class name that process_start() originally received, plus data.key, which is the unique ID of the new thread on the server.
The main job of process_progress(), is to make AJAX calls to the server that request the latest progress of the thread (again, let's imagine that the callback for this is done on the server side). When it receives the latest progress data, it then updates the jQuery progress bar widget's value, waits 100ms, and calls itself recursively. Via this recursion loop, it continues to update the progress bar widget, until the process is 100% complete, at which point the JavaScript terminates, and our job is done.
This code is extremely generic and re-usable. There's only one line in all the code, that's actually specific to the batch task that we're running: the process_start('dummy', 'FotoJazzProcess'); call. To implement another task on the front-end, all we'd have to do is copy and paste this one-line function call, changing the two parameter values that get passed to it (along with also copy-pasting the HTML markup to match). Or, if things started to get unwieldy, we could even put the function call inside a loop, and iterate through an array of parameter values.
The web front-end: Python
Now, let's take a look at the Python code to implement our server-side callback paths (which, in this case, are built as views in the Flask framework, and can be found in the project/fotojazz/views.py file in the source code):
from uuid import uuid4
from flask import jsonify
from flask import Module
from flask import request
from project import fotojazz_processes
# ...
mod = Module(__name__, 'fotojazz')
# ...
@mod.route('/process/start/<process_class_name>/')
def process_start(process_class_name):
"""Starts the specified threaded process. This is a sort-of
'generic' view, all the different FotoJazz tasks share it."""
# ...
process_module_name = process_class_name
if process_class_name != 'FotoJazzProcess':
process_module_name = process_module_name.replace('Process', '')
process_module_name = process_module_name.lower()
# Dynamically import the class / module for the particular process
# being started. This saves needing to import all possible
# modules / classes.
process_module_obj = __import__('%s.%s.%s' % ('project',
'fotojazz',
process_module_name),
fromlist=[process_class_name])
process_class_obj = getattr(process_module_obj, process_class_name)
# ...
# Initialise the process thread object.
fjp = process_class_obj(*args, **kwargs)
fjp.start()
if not process_class_name in fotojazz_processes:
fotojazz_processes[process_class_name] = {}
key = str(uuid4())
# Store the process thread object in a global dict variable, so it
# continues to run and can have its progress queried, independent
# of the current session or the current request.
fotojazz_processes[process_class_name][key] = fjp
percent_done = round(fjp.percent_done(), 1)
done=False
return jsonify(key=key, percent=percent_done, done=done)
@mod.route('/process/progress/<process_class_name>/')
def process_progress(process_class_name):
"""Reports on the progress of the specified threaded process.
This is a sort-of 'generic' view, all the different FotoJazz tasks
share it."""
key = request.args.get('key', '', type=str)
if not process_class_name in fotojazz_processes:
fotojazz_processes[process_class_name] = {}
if not key in fotojazz_processes[process_class_name]:
return jsonify(error='Invalid process key.')
# Retrieve progress of requested process thread, from global
# dict variable where the thread reference is stored.
percent_done = fotojazz_processes[process_class_name][key] \
.percent_done()
done = False
if not fotojazz_processes[process_class_name][key].is_alive() or \
percent_done == 100.0:
del fotojazz_processes[process_class_name][key]
done = True
percent_done = round(percent_done, 1)
return jsonify(key=key, percent=percent_done, done=done)
As with the JavaScript, these Python functions are completely generic and re-usable. The process_start() function dynamically imports and instantiates the process class object needed for this particular task, based on the parameter sent to it in the URL path. It then kicks off the thread, and stores the thread in fotojazz_processes, which is a global dictionary variable. A unique ID is generated as the key for this dictionary, and that ID is then sent back to the javascript, via the JSON response object.
The process_progress() function retrieves the running thread by its unique key, and finds the progress of the thread as a percentage value. It also checks if the thread is now finished, as this is valuable information back on the JavaScript end (we don't want that recursive AJAX polling to continue forever!). It also returns its data to the front-end, via a JSON response object.
With code now in place at all necessary levels, our AJAX interface to the dummy batch task should now be working smoothly:
The dummy task is off and running, and the progress bar is working.
Absolutely no extra Python view code is needed, in order to implement new batch tasks. As long as the correct new thread class (inheriting from FotoJazzProcess) exists and can be found, everything Just Works™. Not bad, eh?
Final thoughts
Progress feedback on threads is a fairly common development pattern in more traditional desktop GUI apps. There's a lot of info out there on threads and progress bars in Python's version of the Qt GUI library, for example. However, I had trouble finding much info about implementing threads and progress bars in a web-based app. Hopefully, this article will help those of you looking for info on the topic.
The example code I've used here is taken directly from my FotoJazz app, and is still loosely coupled to it. As such, it's example code, not a ready-to-go framework or library for Python threads with web-based progress indication. However, it wouldn't take that much more work to get the code to that level. Consider it your homework!
Also, an important note: the code demonstrated in this article — and the FotoJazz app in general — is not suitable for a real-life online web app (in its current state), as it has not been developed with security, performance, or scalability in mind at all. In particular, I'm pretty sure that the AJAX in its current state is vulnerable to all sorts of CSRF attacks; not to mention the fact that all sorts of errors and exceptions are liable to occur, most of them currently uncaught. I'm also a total newbie to threads, and I understand that threads in web apps are particularly prone to cause strange explosions. You must remember: FotoJazz is a web-based desktop app, not an actual web app; and web-based desktop app code is not necessarily web-app-ready code.
Finally, what I've demonstrated here is not particularly specific to the technologies I've chosen to use. Instead of jQuery, any number of other JavaScript libraries could be used (e.g. YUI, Prototype). And instead of Python, the whole back-end could be implemented in any other server-side language (e.g. PHP, Java), or in another Python framework (e.g. Django, web.py). I'd be interested to hear if anyone else has done (or plans to do) similar work, but with a different technology stack.
]]>
FotoJazz: A tool for cleaning up your photo collection2011-06-29T00:00:00Z2011-06-29T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/06/fotojazz-a-tool-for-cleaning-up-your-photo-collection/
I am at times quite a prolific photographer. Particularly when I'm travelling, I tend to accumulate quite a quantity of digital snaps (although am still working on the quality of said snaps). I'm also a reasonably organised and systematic person: as such, I've developed a workflow for fixing up, naming and archiving my soft-copy photos; and I've also come to depend on a variety of scripts and little apps, that perform various steps of the workflow for me.
Sadly, my system has had some disadvantages. Most importantly, there are too many separate scripts / apps involved, and with too many different interfaces (mix of manual point-and-click, drap-and-drop, and command-line). Ideally, I'd like all the functionality unified in one app, with one streamlined graphical interface (and also everything with equivalent shell access). Also, my various tools are platform-dependent, with most of them being Windows-based, and one being *nix-based. I'd like everything to be platform-independent, and in particular, I'd like everything to run best on Linux — as I'm trying to do as much as possible on Ubuntu these days.
Plus, I felt in the mood for getting my hands dirty coding up the photo-management app of my dreams. Hence, it is with pleasure that I present FotoJazz, a browser-based (plus shell-accessible) tool built with Python and Flask.
The FotoJazz web browser interface in action.
FotoJazz is a simple app, that performs a few common tasks involved in cleaning up photos copied off a digital camera. It does the following:
Orientation
FotoJazz rotates an image to its correct orientation, per its Exif metadata. This is done via the exiftran utility. Some people don't bother to rotate their photos, as many modern apps pay attention to the Exif orientation metadata anyway, when displaying a photo. However, not all apps do (in particular, the Windows XP / Vista / 7 default photo viewer does not). I like to be on the safe side, and to rotate the actual image myself.
I was previously doing this manually, using the 'rotate left / right' buttons in the Windows photo viewer. Hardly ideal. Discovering exiftran was a very pleasant surprise for me — I thought I'd at least have to code an auto-orientation script myself, but turns out all I had to do was build on the shoulders of giants. After doing this task manually for so long, I can't say I 100% trust the Exif orientation tags in my digital photos. But that's OK — while I wait for my trust to develop, FotoJazz lets me review Exiftran's handiwork as part of the process.
Date / time shifting
FotoJazz shifts the Exif 'date taken' value of an image backwards or forwards by a specified time interval. This is handy in two situations that I find myself facing quite often. First, the clock on my camera has been set wrongly, usually if I recently travelled to a new time zone and forgot to adjust it (or if daylight savings has recently begun or ended). And secondly, if I copy photos from a friend's camera (to add to my own photo collection), and the clock on my friend's camera has been set wrongly (this is particularly bad, because I'll usually then be wanting to merge my friend's photos with my own, and to sort the combined set of photos by date / time). In both cases, the result is a batch of photos whose 'date taken' values are off by a particular time interval.
FotoJazz lets you specify a time interval in the format:
[-][Xhr][Xm][Xs]
For example, to shift dates forward by 3 hours and 30 seconds, enter:
3hr30s
Or to shift dates back by 23 minutes, enter:
-23m
I was previously doing this using Exif Date Changer, a small freeware Windows app. Exif Date Changer works quite well, and it has a nice enough interface; but it is Windows-only. It also has a fairly robust batch rename feature, which unfortunately doesn't support my preferred renaming scheme (which I'll be discussing next).
Batch rename
FotoJazz renames a batch of images per a specified prefix, and with a unique integer ID. For example, say you specify this prefix:
new_york_trip_may2008
And say you have 11 photos in your set. The photos would then be renamed to:
As you can see, the unique ID added to the filenames is padded with leading zeros, as needed per the batch. This is important for sorting the photos by filename in most systems / apps.
I was previously using mvb for this. Mvb ("batch mv") is a bash script that renames files according to the same scheme — i.e. you specify a prefix, and it renames the files with the prefix, plus a unique incremented ID padded with zeros. Unfortunately, mvb always worked extremely slowly for me (probably because I ran it through cygwin, hardly ideal).
Date modified
FotoJazz updates the 'date modified' metadata of an image to match its 'take taken' value. It will also fix the date accessed, and the Exif 'PhotoDate' value (which might be different to the Exif 'PhotoDateOriginal' value, which is the authoritative 'date taken' field). This is very important for the many systems / apps that sort photos by their 'date modified' file metadata, rather than by their 'date taken' Exif metadata.
I was previously using JpgDateChanger for this task. I had no problems with JpgDateChanger — it has a great drag-n-drop interface, and it's very fast. However, it is Windows-based, and it is one more app that I have to open as part of my workflow.
Shell interface
The FotoJazz command-line interface.
All of the functionality of FotoJazz can also be accessed via the command-line. This is great if you want to use one or more FotoJazz features as part of another script, or if you just don't like using GUIs. For example, to do some date shifting on the command line, just enter a command like this:
More information on shell usage is available in the README file.
Technical side
I've been getting into Python a lot lately, and FotoJazz was a good excuse to do some solid Python hacking, I don't deny it. I've also been working with Django a lot, but I haven't before used a Python microframework. FotoJazz was a good excuse to dive into one for the first time, and the microframework that I chose was Flask (and Flask ships with the Jinja template engine, something I was also overdue on playing with).
From my point of view, FotoJazz's coolest code feature is its handling of the batch photo tasks as threads. This is mainly encapsulated in the FotoJazzProcess Python class in the code. The architecture allows the tasks to run asynchronously, and for either the command-line or the browser-based (slash AJAX-based) interface to easily provide feedback on the progress of the thread. I'll be discussing this in more detail, in a separate article — stay tuned.
FotoJazz makes heavy use of pyexiv2 for its reading / writing of Jpg Exif metadata within a Python environment. Also, as mentioned earlier, it uses exiftran for the photo auto-orientation task; exiftran is called directly on the command-line, and its stream output is captured, monitored, and transformed into progress feedback on the Python end.
Get the code
All the code is availble on GitHub. Use it as you will: hack, fork, play.
]]>
On the Torah and the Word of G-d2011-06-01T00:00:00Z2011-06-01T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/06/on-the-torah-and-the-word-of-g-d/
The Torah — also known as the Old Testament, the Pentateuch, or the Five Books of Moses — is the foundation document of the Jewish religion (among others), and it's regarded by Orthodox Jews (among others) as the infallible Word of G-d. It's generally believed that the Torah in its entirety was conveyed orally to Moses on Mount Sinai, approximately 3,300 years ago; and that Moses transcribed the Torah exactly as it was revealed to him.
Most of the Torah is rock solid: sensible laws; moralistic stories; clear presentation of history; and other important information, such as geneaologies, rituals, and territorial boundaries. However, sometimes them five books throw some serious curve balls. I've selected here a few sections from the wonderful O.T, that in my opinion are so outrageously messed up, that they cannot possibly be the Divine Word. I believe in G-d, one hundred percent. But I see no reason to believe that these particular passages have a Divine source.
Ball-grabbing
Here's the situation. You're a married woman, and you and your husband are out with mates for the evening. Your husband gets into a heated debate with one of his male friends. The heated debate quickly escalates into a fistfight. You decide to resolve the conflict, quickly and simply. You grab your man by the nuts, and pull him away.
According to the torah, in this extremely specific situation, that's a crime that will cost you a hand (presumably, the hand responsible for said ball-grabbing). For, as it is written:
[11] When men strive together one with another, and the wife of the one draweth near to deliver her husband out of the hand of him that smiteth him, and putteth forth her hand, and taketh him by the secrets; [12] then thou shalt cut off her hand, thine eye shall have no pity.
As a man, I think this is a great rule. I am all for explicitly prohibiting my future wife from resorting to sack-wrenching, as a means of intervening in my secret mens' business.
However, as a rational human being, I am forced to conclude, beyond any doubt, that this verse of the Torah simply cannot be the Word of G-d. I'm sorry, but it makes no sense that G-d didn't have time to mention anything about chemical warfare, or about protection of the endangered Yellow-browed Toucanet in Peru; yet he found the time to jot down: "By the way, ladies, don't end a brawl by yanking your man's nads."
Our Sages™ explain to us that this verse shouldn't be taken literally, and that what it's actually referring to is a more general prohibition on causing public shame and humiliation to others. They argue that, thanks to this verse, the Torah is actually ahead of most modern legal systems, in that it explicitly enshrines dignity as a legal concept, and that it provides measures for the legal protection of one's dignity.
Sorry, dear Sages, but I don't buy that. You can generalise and not take literally all you want. But for me, there's no shying away from the fact that the Torah calls for cutting off a woman's hand if she goes in for the nut-grabber. That's an extreme punishment, and honestly, the whole verse is just plain silly. This was clearly written not by G-d, but by a middle-aged priest who'd been putting up with his wife's nad-yanking for 30-odd years, and who'd just decided that enough was enough.
Parental discipline
You're a 16-year-old male. You live in a well-to-do middle-class neighbourhood, your parents are doctor and lawyer (respectively), and you go to a respectable private school. So, naturally, you've been binge drinking since the age of 12, you sell ecstasy and cocaine at the bus stop, you run a successful pimping business in the school toilets, you're an anaemic quasi-albino goth, and you're pretty handy with a flick-knife at 2am at the local train station. Your parents can't remember the last time you said anything to them, other than: "I f$@%ing hate you."
Your parents have pretty well given up on you. Fortunately, the Torah provides one final remedy that they haven't yet tried. For, as it is written:
[18] If a man have a stubborn and rebellious son, that will not hearken to the voice of his father, or the voice of his mother, and though they chasten him, will not hearken unto them; [19] then shall his father and his mother lay hold on him, and bring him out unto the elders of his city, and unto the gate of his place; [20] and they shall say unto the elders of his city: 'This our son is stubborn and rebellious, he doth not hearken to our voice; he is a glutton, and a drunkard.' [21] And all the men of his city shall stone him with stones, that he die; so shalt thou put away the evil from the midst of thee; and all Israel shall hear, and fear.
The Torah sanctions stoning to death as a form of parental discipline… w00t! Ummm… yeah, I'm sorry, guys; but once again, according to every fibre of my mind and soul, I conclude that this cannot be the Word of G-d. No G-d of mine would condone this crap.
Once again, at this point we should turn to Our Sages™, who explain that this law is designed purely to be a deterrent for rebellious children, and that the prescribed punishment could never actually be imposed. They note that this passage lists so many conditions, in order for a son to meet the definition of "rebellious", that it's virtually impossible for anyone to actually be eligible for this punishment. They conclude that the scenario described here is purely hypothetical, and that it's intended that no son ever actually be stoned to death per this law.
Again, dear Sages, I'm afraid that just doesn't cut it for me. First of all, the conditions laid out in this passage aren't impossible; in my opinion, it wouldn't be very hard at all for them to be met. And secondly, on account of its conditions being possible in a real situation, this passage constitutes an incredibly reckless and dangerous addition to the Torah. Never intended to be enforced? Bull $@%t. I'd bet my left testicle that this law — just like many other sanctioned-stoning-to-death laws, e.g. adultery, idolatry — was invoked and was enforced numerous times, back in the biblical era.
Stoning to death as a form of parental punishment. Not written by G-d. If you ask me, 'twas written by a priestly couple, back in the day, who were simply tearing their hair out trying to get their adolescent son to stop dealing frankincense and myhhr to Welsh tart junkies behind the juniper bush.
The anti-castrato anti-modern-family regime
The Torah generally follows the well-accepted universal rules of who you're allowed to discriminate against. Everyone knows that you're allowed to pick on women, slaves (i.e. black people), proselytes (biblical equivalent of illegal aliens, i.e. Mexicans), homosexuals, Amalek (biblical equivalent of rogue states, i.e. North Korea), and of course Jews (who, despite all that "chosen people" crap, did have a pretty rough time in the O.T — so if you're wondering who started that "pick on the Jews" trend, it was G-d).
But the Torah had to take it just one step further, and break the Golden Rule: don't pick on the handicapped! According to the Torah, those who are handicapped in the downstairs department (plus bastard children are thrown in for good measure), are to be rejected from all paintball games, Iron Maiden concerts, trips to Nimbin, and other cool events. For all eternity. For, as it is written:
[2] He that is crushed or maimed in his privy parts shall not enter into the assembly of the Lord. [3] A bastard shall not enter into the assembly of the Lord; even to the tenth generation shall none of his enter into the assembly of the Lord.
I guess the whole "even to the tenth generation" postscript was only added to the bastard law, and not to the crushed-nuts law, because adding it to the former would have been kinda superfluous. If you're chanting in the Pope's soprano choir, it's a pretty safe bet there won't be even one more generation in your grand lineage, let alone ten.
Turning once again to Our Sages™, it seems they don't see much problem with this law (a cause for concern in itself, if you ask me), because they don't particularly bother to justify it as a metaphor or a hypothetical. They merely clarify that this law applies to voluntary or accidental mutilation, and not to birth defects or diseases. Well, isn't that a relief! They also clarify that the punishment of not being able to "enter into the assembly of the Lord" refers to being prohibited from marrying a Jewish woman.
I'm sorry, but specific discrimination against victims of ball-crushing (possibly on account of women violating the ball-grabbing law, as discussed above) is, in my opinion, not the Word of G-d. This law was clearly an addition penned by a member of the Temple elite, who had already exhausted the approved list of groups suitable to pick on (see above), and who just couldn't resist breaking the universal rule and picking on the handicapped. The very same guy probably then interpreted his own law, to mean that he could park his donkey right outside the door of the blacksmith's, which was quite clearly marked as a disabled-only spot.
Slow poisoning of suspected adulteresses
Everyone knows that the Bible proscribes stoning to death for proven offenders of adultery. While we may not all agree with the severity of the punishment, I personally can sort-of accept it as the Word of G-d. However, the Torah also describes, in intricate detail, a bizarre and disturbing procedure for women who are suspected of being adulteresses, but against whom there is no damning evidence. For, as it is written:
[11] and the Lord spoke unto Moses, saying: [12] Speak unto the children of Israel, and say unto them: If any man's wife go aside, and act unfaithfully against him, [13] and a man lie with her carnally, and it be hid from the eyes of her husband, she being defiled secretly, and there be no witness against her, neither she be taken in the act; [14] and the spirit of jealousy come upon him, and he be jealous of his wife, and she be defiled; or if the spirit of jealousy come upon him, and he be jealous of his wife, and she be not defiled; [15] then shall the man bring his wife unto the priest, and shall bring her offering for her, the tenth part of an ephah of barley meal; he shall pour no oil upon it, nor put frankincense thereon; for it is a meal-offering of jealousy, a meal-offering of memorial, bringing iniquity to remembrance. [16] And the priest shall bring her near, and set her before the Lord. [17] And the priest shall take holy water in an earthen vessel; and of the dust that is on the floor of the tabernacle the priest shall take, and put it into the water. [18] And the priest shall set the woman before the Lord, and let the hair of the woman's head go loose, and put the meal-offering of memorial in her hands, which is the meal-offering of jealousy; and the priest shall have in his hand the water of bitterness that causeth the curse. [19] And the priest shall cause her to swear, and shall say unto the woman: 'If no man have lain with thee, and if thou hast not gone aside to uncleanness, being under thy husband, be thou free from this water of bitterness that causeth the curse; [20] but if thou hast gone aside, being under thy husband, and if thou be defiled, and some man have lain with thee besides thy husband-- [21] then the priest shall cause the woman to swear with the oath of cursing, and the priest shall say unto the woman--the Lord make thee a curse and an oath among thy people, when the Lord doth make thy thigh to fall away, and thy belly to swell; [22] and this water that causeth the curse shall go into thy bowels, and make thy belly to swell, and thy thigh to fall away'; and the woman shall say: 'Amen, Amen.' [23] And the priest shall write these curses in a scroll, and he shall blot them out into the water of bitterness. [24] And he shall make the woman drink the water of bitterness that causeth the curse; and the water that causeth the curse shall enter into her and become bitter. [25] And the priest shall take the meal-offering of jealousy out of the woman's hand, and shall wave the meal-offering before the Lord, and bring it unto the altar. [26] And the priest shall take a handful of the meal-offering, as the memorial-part thereof, and make it smoke upon the altar, and afterward shall make the woman drink the water. [27] And when he hath made her drink the water, then it shall come to pass, if she be defiled, and have acted unfaithfully against her husband, that the water that causeth the curse shall enter into her and become bitter, and her belly shall swell, and her thigh shall fall away; and the woman shall be a curse among her people. [28] And if the woman be not defiled, but be clean; then she shall be cleared, and shall conceive seed. [29] This is the law of jealousy, when a wife, being under her husband, goeth aside, and is defiled; [30] or when the spirit of jealousy cometh upon a man, and he be jealous over his wife; then shall he set the woman before the Lord, and the priest shall execute upon her all this law. [31] And the man shall be clear from iniquity, and that woman shall bear her iniquity.
In case the language above eludes and confounds you, let me recap. You're a married woman. Your husband suspects you've been engaged in wild orgies with the gardeners, every time he goes to London on a business trip (of course, he never gets up to any mischief on his trips either); but as nobody else is ever home during these trips, he has no proof of his suspicion. In order to alleviate his suspicions, he brings you before a Temple Priest, who forces you to drink something called the "water of bitterness" (generally understood to be more-or-less poison).
Apparently, if you're innocent, then the water of bitterness will have no effect, and the final proof of your acquittal will be your ability to fall pregnant in a few months' time; or, if you're guilty, then the water of bitterness will cause you severe internal damage, and it will possibly kill you — in particular, it will definitely f$@% up your reproductive organs. Amen.
Woaaaahhhhh! I'm sorry. That is NOT the Word of G-d. That is F$@%ED UP.
I don't know about you, but this reminds me of the good old-fashioned, tried-and-tested method of determining if a woman is a witch: if she floats, she's a witch; if not, she's innocent (too bad about her drowning, eh?). This ceremony — called the sotah — is a sort of perverse backwards version of a witch-trial: if she's been playing around, the poison f$@%s her up; if not, she will (theoretically) be well and healthy.
And now, a word from Our Sages™. Once again (as with the parental discipline law, see above), the Learned Ones brush this one off as being purely a deterrent law, never meant to be actually enforced. Once again, I say: bull$@%t. If this truly was the intention of this law, it was pretty damn recklessly implemented.
At least the "rebellious son" law has a reasonable set of conditions to be met before the prescribed punishment can be effected; for this law, the only relevant condition is that "the spirit of jealousy cometh upon a man". Jeez, a jealous and suspicious partner — that hardly ever happens.
I really, truly, shudder to think how many times this ritual was carried out in the biblical era. If this were a real, secular law in any country today, I can guarantee there'd be a queue of seeming husbands five miles long, at the door of every local court in the land.
Final thoughts
I'm proudly Jewish, always have been, always will be. I also firmly believe in G-d's existence. But that doesn't mean I have to accept every word of my religion's holy book as infallible. Call me a heretic if you will. But G-d gave us intellect, critical judgement and, above all, common sense. Failing to exercise it, on everything including G-d's Holy Scriptures — now, that would be a gross sacrilege and an act of heresy (and one of which billions of blind followers throughout history are, in my opinion, guilty).
If a law's literal interpretation seems absurd, then there's a problem with the law. If a law has to be justified as a metaphor, as a hypothetical, or as an allegory before it seems rational, then there's a problem with the law. We would never accept laws in our modern legal systems, if they required a metaphysical interpretation before they seemed reasonable. Why then do we accept such laws in religious canon? Baffles me.
One of my aims in this article, was to present some of the most repulsive literally-read verses in the Torah, and to also present the explanations that scholars have provided, over the ages, to justify them. Commentary on the Bible is all well and good: but commentary should be a more detailed discussion of canon text that already has a solid foundation; it should not be a futile defence of canon text whose foundation is rotten. The literal meaning of the Bible is its foundation; and if the foundation is warped, so too is everything built upon it.
* — references marked with an asterisk not actually used in this article, included in this list just for fun.
]]>
Five good reasons to not take drugs2011-05-24T00:00:00Z2011-05-24T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/05/five-good-reasons-to-not-take-drugs/
The use of narcotic substances isn't usually a topic about which I have strong feelings. I don't take drugs myself, and I tend not to associate myself with people who do; but then again, I see no reason to stop other members of society from exercising their liberties, in the form of recreational drug use. I've never before spoken much about this subject.
However, one of my best friends recently died from a drug overdose. On account of that, I feel compelled to pen a short article, describing what I believe are some good reasons to choose to not take drugs.
1. They harm you
It's no secret that narcotic substances cause physical and mental damage to those who use them. Recreational users are often quick to deny the risks, but ultimately there's no hiding from the truth.
The list of physical problems that can directly arise from drug use is colossal: heart attack; stroke; liver failure; diabetes; asthma; eye deterioration; and sexual impotence, to name a few common ones. In the case of injected drugs, the risk of HIV / AIDS from infected needles is, of course, also a major risk.
Physical damage is, however, generally nothing compared to the long-term mental damage caused by narcotics: anxiety; hallucination; schizophrenia; and profound depression, to name but a few. Perhaps the worst mental damage of all, though, is the chemical addiction that results from the use of most narcotics.
Narcotic substances can, and often do, radically change someone's personality. They result in the user transforming into a different person, and this seldom means transforming for the better. The worst harm they do, is that they rob you of who you once were, with little hope of return. Couple this with the problem of addiction, and the only way forward for many drug users is downhill.
2. They're expensive
This is in one respect the most trivial reason to not take drugs, and in another respect a very serious concern. Anyway, the fact is that at their Western "street prices", drugs are no cheap hobby. For some people (unfortunately not for everyone), the fact that drugs are clearly a ripoff and an utter waste of money, is enough to act as a deterrant.
At the trivial end of things, the fact that recreational drug use is expensive isn't by itself a concern. All hobbies cost something. You could easily pay more for a golf club membership, or for an upmarket retail therapy spree, or for a tropical paradise vacationing habit. If your income can support your leisure, then hey, you might as well enjoy life.
However, as mentioned above, drugs are addictive. As such, a mounting drug addiction inevitably leads to an exponential increase in the cost of maintaining the habit. No matter how much money you have, eventually a drug addiction will consume all of it, and it will leave you so desperate for more, that no avenue to cash will be below you.
Drug users that begin "recreationally", all too often end up stealing, cheating and lying, just to scrounge up enough cash for the next fix. As such, it's not the price itself of drugs, but rather the depths to which addicts are prepared to plunge in order to pay for them, that is the real problem.
3. They're illegal
Whether you have much respect for the law or not, the fact is that narcotics are illegal in every corner of the world, and by consuming them you are breaking the law. If you don't respect the law, you should at least bear in mind that possession of narcotics carries serious criminal penalties in most countries, ranging from a small monetary fine, to the extreme sentence of capital punishment.
There's also a lot more to the illegality of drugs than the final act of the consumer, in purchasing and using them. By consuming drugs, you are supporting and contributing to the largest form of organised crime in the world. Drug users are in effect giving their endorsement to the entire illegal chain that constitutes the global narcotic enterprise, from cultivation and processing, to trafficking, to dealing on the street.
The mafia groups responsible for the global drug business, also routinely commit other crimes, most notably homicide, kidnapping, torture, extortion, embezzlement, and bribery. These other crimes exist in synergy with the drug enterprise: one criminal activity supports the others, and vice versa. Whether or not you believe drug use should be a crime, the fact is that drug use indirectly results in many other activities, of whose criminal nature there can be no doubt.
4. They harm communities and environments
Related to (although separate from) the illegality issue above, there is also a bigger picture regarding the harm that's caused by drug use. Many hobbies have some negative impact on the wider world. Hunting whales endangers a species; buying Nike shoes promotes child labour; flying to Hawaii produces carbon emissions. However, the wider harm caused by drug use, compared to other more benign hobbies, is very great indeed.
Most narcotics are grown and produced in third world countries. The farmers and labourers who produce them, at the "bottom of the chain", do so often under threat of death, often for little monetary gain, and often at risk of pursuit by authorities. Meanwhile, the drug barons at the "top of the chain" routinely bribe authorities, extort those below them, and reap enormous profit from all involved.
In many drug-producing countries, wilderness areas such as rainforests are destroyed in order to cultivate more illegal crops. Thus, narcotics are responsible for environmental problems such as deforestation, and often with subsequent side-effects of deforestation such as soil erosion, salinity, and species extinction.
The drug industry routinely attracts poor and uneducated people who are desperate for work opportunities. However, it ultimately provides these people with little monetary gain and no economic security. Additionally, youths in impoverished areas are enticed to take up a criminal life as traffickers, dealers, and middlemen, leaving them and their families with a poor reputation and with many serious risks.
5. They harm friends and family
For anyone who cares about their friends and family — and everyone should, they're the most important thing in all our lives — the negative impact of drug use on loved ones, is possibly the worst of all the ways in which drugs cause harm.
Friends and family have to bear the pain of seeing a drug user suffer and degenerate from the effects of prolonged use. It is also they who end up caring for the drug user, which is a task possibly even more difficult than the care of a seriously ill friend or relative usually is.
Worst of all, drugs can lead people to steal from, lie to, verbally abuse, and even physically attack friends and family. Then there is the ultimate woe: the pain of drug abuse claiming the life of a close friend or relative. The harm to a drug user ends at the final hour; but for friends and family, the suffering and grief continue for many long years.
Final thoughts
As I said, I'm not a drug user myself. I've only taken illicit drugs once in my life (hallucinogens), several years ago. I admit, it was a very fun experience. However, in retrospect, taking the drugs was also clearly a stupid decision. At the time, I was not thinking about any of the things that I've discussed in this article.
I regret very few things in my life, but I regret the choice that I made that day. I feel fortunate that the drugs left me with no addiction and with no long-term harm, and I have no intention whatsoever of taking drugs again in my life.
Yes, drugs are fun. But the consequences of taking them are not. As discussed here, the consequences are dead serious and they are quite real. I remain a libertarian, as far as drugs go — if you want to consume them, I see no reason to stop you. But seriously, think twice before deciding to take that route.
This article is dedicated to the memory of Josh Gerber, one of my best friends for many years, and the tragic victim of a drug overdose in May 2011. Chef of the highest calibre, connoisseur of fine music, always able to make me laugh, a critical thinker and a person of refined wit. May he be remembered for how he lived, not for how he died.
]]>
Highway border crossings between Chile and Argentina2011-04-26T00:00:00Z2011-04-26T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/04/highway-border-crossings-between-chile-and-argentina/
I've spent a fair bit of time, on several occasions, travelling in South America, including in Chile and Argentina. I've crossed the land border between these two countries several times, in several different places. It's an extremely long border, measuring 5,308km in total.
Recently, I was looking for a list of all the official crossings between the two countries. Finding such a list, in clear and authoritative form, proved more difficult than I expected. Hence, one thing led to another; and before I knew it, I'd embarked upon a serious research mission to develop such a list myself. So, here it is — a list of all highway border crossings between Chile and Argentina, that are open to the general public.
The northern part of the Chile-Argentina frontier is generally hot, dry, and slightly flatter at the top. I found the frontier's northern crossings to be the best-documented, and hence the easiest to research. They're also generally the easiest crossings to make, as they pose the least risk of being impassable due to snowstorms.
Of the northern crossings, the only one I've travelled on is Paso Jama; although I didn't go through the pass itself, I crossed into Chile from Laguna Verde in Bolivia, and cut into the Chilean part of the highway from there (as part of a 4WD tour of the Salar de Uyuni).
Chilean regions: II (Antofagasta), III (Atacama).
Argentine provinces: Jujuy, Salta, Catamarca, La Rioja.
Although Pircas Negras is seldom used today, it was historically the main crossing in the Atacama area (rather than Paso San Francisco).
Central crossings
The Central part of the frontier is the most frequently crossed, as it's where you'll find the most direct route from Santiago to Buenos Aires. Unfortunately, Paso Los Libertadores is the only high-quality road in this entire section of the frontier — the mountains are particularly high, and construction of passes is particularly challenging, around here. After all, Aconcagua (the highest mountain in all the Americas) can be clearly seen right next to the main road.
As such, Los Libertadores is an extremely busy pass year-round; this is exacerbated by snowstorms forcing the pass to close during the height of winter, and also occasionally even in summer (despite there being a tunnel under the highest point of the route). I've travelled Los Libertadores twice (once in each direction), and it's a route with beautiful scenery; the zig-zags down the precipitous Chilean side of the pass are also quite hair-raising.
There has recently been talk of constructing a tunnel under the mountains in this area, thus rendering Paso Agua Negra a historical route. This would help alleviate the very high traffic at Paso Los Libertadores. No concrete plans as yet.
The Transandino railway can still be seen running generally adjecent to the highway from Santiago to Mendoza, but there have been no trains at all running since 1984.
Lake district crossings
The lake districts of both Chile and Argentina are famed for their "Swiss Alps of the South" picturesque beauty, and the border crossings in this area are among the most spectacular of all vistas that the region has to offer. There are numerous border crossings in this area, most of which are quite good roads, and two of which are highway-grade.
Paso Cardenal Antonio Samoré is the only one down here that I've crossed. The roads here are all liable to close due to snow conditions; although I was lucky enough to cross in September with no problems.
I should also note that I've explicitly excluded the famous and beautiful Paso Pérez Rosales (Puerto Montt - S.C. de Bariloche) from the list here: this is because, although it's a paved highway-grade road the whole way, the highway is interrupted by a (long) lake crossing. I'm only including on this list crossings that can be made in one complete, uninterrupted land vehicle journey.
Chilean regions: VIII (Biobío), IX (Araucanía), XIV (Los Ríos).
This pass is actually in Region X (Los Lagos), just over the border from Region XIV (Los Ríos).
Southern crossings
These are the passes of the barren, empty pampas of Southern Patagonia. There are no main roads around here, and in some cases there are barely any towns for the roads to connect to, either. I haven't personally travelled any of these crossings, nor have I visited this part of Chile or Argentina at all.
Some of these highways go through rivers, with satellite imagery showing no bridges connecting the two sides; I can only assume that the rivers are passable in 4WD, assuming the water levels are low, or assuming the rivers are partly frozen. This was also by far the most difficult region to research: information about these passes is scarce and undetailed.
Chilean regions: X (Los Lagos), XI (Aisén).
Argentine provinces: Chubut, Santa Cruz.
Chile-Argentina border crossings: southern.
Name
Route
Type
Paso Futaleufu
Futaleufu - Esquel
Secondary highway
Paso Río Encuentro
Palena - Esquel
Minor highway
Paso Las Pampas
Cisnes - Esquel
Minor highway
Paso Río Frias
Cisnes - Comodoro Rivadavia
Minor highway
Paso Pampa Alta
Coyhaique - Comodoro Rivadavia
Minor highway
Paso Coyhaique
Coyhaique - Comodoro Rivadavia
Minor highway
Paso Triana
Coyhaique - Comodoro Rivadavia
Minor highway
Paso Huemules
Coyhaique - Comodoro Rivadavia
Secondary highway
Paso Ingeniero Ibáñez-Pallavicini
Puerto Ibáñez - Perito Moreno
Minor highway
Paso Río Jeinemeni
Puerto Guadal - Perito Moreno
Minor highway
Paso Roballos
Cochrane - Bajo Caracoles
Minor highway
Paso Rio Mayer Ribera Norte
O'Higgins - Las Horquetas
Minor highway
Paso Rio Mosco
O'Higgins - Las Horquetas
Minor highway
Extreme south crossings
The passes of the extreme south are easily crossed when weather conditions are good, as the mountains are much lower down here (or are basically plateaus). In winter, however, land transport is seldom an option. There is one main road in the extreme south, connecting Punta Arenas and Rio Gallegos.
The only crossing I've made in the extreme south is through Paso Rio Don Guillermo, which is unsealed and is little more than a cattle track (although it's pretty straight and flat). The buses from Puerto Natales to El Calafate use this pass: the entrance to the road has a chain across it on both ends, which is unlocked by border police to let the buses through.
Chilean regions: XII (Magallanes).
Argentine provinces: Santa Cruz, Tierra del Fuego.
]]>
Travel is a luxury2011-03-25T00:00:00Z2011-03-25T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/03/travel-is-a-luxury/
International travel has become so commonplace nowadays, some people do it just for a long weekend. Others go for two-year backpacking marathons. And with good reason, too. Travelling has never been easier, it's never been cheaper, and it's never before been so accessible. I, for one, do not hesitate to take advantage of all this.
One other thing, though. It's also never been easier to inadvertently take it all for granted. To forget that just one generation ago, there were no budget intercontinental flights, no phrasebooks, no package tours, no visa-free agreements. And, of course, snail mail and telegrams were a far cry from our beloved modern Internet.
But that's not all. The global travel that many of us enjoy today, is only possible thanks to a dizzying combination of fortunate circumstances. And this tower (no less) of circumstances is far from stable. On the contrary: it's rocking to and fro like a pirate ship on crack. I know it's hard for us to comprehend, let alone be constantly aware of, but it wasn't like this all that long ago, and it simply cannot last like this much longer. We are currently living in a window of opportunity like none ever before. So, carpe diem — seize the day!
Have you ever before thought about all the things that make our modern globetrotting lives possible? (Of course, when I say "us", I'm actually referring to middle- or upper-class citizens of Western countries, a highly privileged minority of the world at large). And have you considered that if just one of these things were to swing suddenly in the wrong direction, our opportunities would be slashed overnight? Scary thought, but undeniably true. Let's examine things in more detail.
International relations
In general, these are at an all-time global high. Most countries in the world currently hold official diplomatic relations with each other. There are currently visa-free arrangements (or very accessible tourist visas) between most Western countries, and also between Western countries and many developing countries (although seldom vice versa, a glaring inequality). It's currently possible for a Western citizen to temporarily visit virtually every country in the world; although for various developing countries, some bureaucracy wading may be involved.
International relations is the easiest thing for us to take for granted, and it's also the thing that could most easily and most rapidly change. Let's assume that tomorrow, half of Asia and half of Africa decided to deny all entry to all Australians, Americans, and Europeans. It could happen! It's the sovereign right of any nation, to decide who may or may not enter their soil. And if half the governments of the world decide — on the spur of the moment — to bar entry to all foreigners, there's absolutely nothing that you or I can do about it.
Armed conflict
This is (of course) always a problem in various parts of the world. Parts of Africa, Asia, and Latin America are currently unsafe due to armed conflict, mainly from guerillas and paramilitary groups (although traditional war between nations still exists today as well). Armed conflict is relatively contained within pockets of the globe right now.
But that could very easily change. World War III could erupt tomorrow. Military activity could commence in parts of the world that have been boring and peaceful for decades, if not centuries. Also, in particular, most hostility in the world today is currently directed towards other local groups; that hostility could instead be directed at foreigners, including tourists.
War between nations is also the most likely cause for a breakdown in international relations worldwide (it's not actually very likely that they'd break down for no reason — although a global spout of insane dictators is not out of the question). This form of conflict is currently very confined. But if history is any guide, then that is an extremely uncommon situation that cannot and will not last.
Infectious diseases
This is also a problem that has never gone away. However, it's currently relatively safe for tourists to travel to almost everywhere in the world, assuming that proper precautions are taken. Most infectious diseases can be defended against with vaccines. AIDS and other STDs can be controlled with safe and hygienic sexual activity. Water-borne sicknesses such as giardia, and mosquito-borne sicknesses such as malaria, can be defended against with access to bottled water and repellents.
Things could get much worse. We've already seen, with recent scares such as Swine Flu, how easily large parts of the world can become off-limits due to air-borne diseases for which there is no effective defence. In the end, it turned out that Swine Flu was indeed little more than a scare (or an epidemic well-handled; perhaps more a matter of opinion than of fact). If an infectious disease were contagious enough and aggressive enough, we could see entire continents being indefinitely declared quarantine zones. That could put a dent in some people's travel plans!
Environmental contamination
There are already large areas of the world that are effectively best avoided, due to some form of serious environmental contamination. But today's picture is merely the tip of the iceberg. If none of the other factors get worse, then I guarantee that this is one factor that will. It's happening as we speak.
Air pollution is already extreme in many of the world's major cities and industrial areas, particularly in Asia. However, serious though it is, large populations are managing to survive in areas where it's very high. Water contamination is a different story. If an entire country, or even an entire region, has absolutely no potable water, then living and travelling in those areas becomes quite hard.
Of course, the most serious form of environmental contamination possible, is a nuclear disaster. Unfortanately, the potential for nuclear catastrophe is still positively massive. Nuclear disarmament has been a slow and limited process. And weapons aside, nuclear reactors are still abundant in much of the world. A Chernobyl-like event on a scale 100 times bigger — that could sure as hell put travel plans to entire continents on hold indefinitely.
Flights
The offering of long-distance international flights today is simply mind-boggling. The extensive number of routes / destinations, the frequency, and of course the prices; all are at an unprecedented level of awesomeness. It's something you barely think about: if you want to get from London to Singapore next week, just book a flight. You'll be there in 14 hours or so.
Sorry to burst the bubble, folks; but this is one more thing that simply cannot and will not last. We already saw, with last year's Iceland volcano eruption, just how easily the international aviation network can collapse, even if only temporarily. Sept 11 pretty well halted global flights as well. A more serious environmental or security problem could halt flights for much, much longer.
And if nothing else grounds the planes first, then sooner or later, we're going to run out of oil. In particular, jet fuel is the highest-quality, most refined of all petroleum, and it's likely to be the first that we deplete within the next century. At the moment, we have no real alternative fuel — hopefully, a renewable form of jet propulsion will find itself tested and on the market before we run out.
Money
Compared to all the hypothetical doomsday scenarios discussed above, this may seem like a trivial non-issue. But in fact, money is the most fundamental of all enablers of our modern globetrotting lifestyle, and it's the enabler that's most likely to disappear first. The fact is that many of us have an awful lot of disposable cash (especially compared with the majority of the world's population), and that cash goes an awfully long way in many parts of the world. This is not something we should be taking for granted.
The global financial crisis has already demonstrated the fragility of our seemingly secure wealth. However, despite the crisis, most Westerners still have enough cash for a fair bit of long-distance travel. Some are even travelling more than ever, because of the crisis — having lost their jobs, and having saved up cash over a long period of time, many have found it the perfect opportunity to head off on a walkabout.
Then there is the strange and mysterious matter of the international currency exchange system. I don't claim to be an expert on the topic, by any means. Like most simple plebs, I know that my modest earnings (by Western standards) tower above the earnings of those in developing countries; and I know that when I travel to developing countries, my Western cash converts into no less than a veritable treasure trove. And I realise that this is pretty cool. However, it's also a giant inequality and injustice. And like all glaring inequalities throughout history, it's one that will ultimately fall. The wealth gap between various parts of the world will inevitably change, and it will change drastically. This will of course be an overwhelmingly good thing; but it will also harm your travel budget.
Final words
Sorry that this has turned out to be something of a doomsday rant. I'm not trying to evoke the end of the world, with all these negative hypotheticals. I'm simply trying to point out that if any one of a number of currently positive factors in the world were to turn sour, then 21st century travel as we know it could end. And it's not all that likely that any one of these factors, by itself, will head downhill in the immediate future. But the combination of all those likelihoods does add up rather quickly.
I'd like to end this discussion on a 100% positive note. Right now, none of the doom-n-gloom scenarios I've mentioned has come to fruition. Right now, for many of us, la vita e bella! (Although for many many others, life is le shiiiite). Make the most of it. See the world in all its glory. Go nuts. Global travel has been one of the most difficult endeavours of all, for much of human history; today, it's at our fingertips. As Peter Pan says: "Second star to the right, and straight on 'till morning."
]]>
Solr, Jetty, and daemons: debugging jetty.sh2011-02-10T00:00:00Z2011-02-10T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/02/solr-jetty-and-daemons-debugging-jettysh/
I recently added a Solr-powered search feature to this site (using django-haystack). Rather than go to the trouble (and server resources drain) of deploying Solr via Tomcat, I decided instead to deploy it via Jetty. There's a wiki page with detailed instructions for deploying Solr with Jetty, and the wiki page also includes a link to the jetty.sh startup script.
The instructions seem simple enough. However, I ran into some serious problems when trying to get the startup script to work. The standard java -jar start.jar was working fine for me. But after following the instructions to the letter, and after double-checking everything, a call to:
sudo /etc/init.d/jetty start
still resulted in my getting the (incredibly unhelpful) error message:
Starting Jetty: FAILED
My server is running Ubuntu Jaunty (9.04), and from my experience, the start-stop-daemon command in jetty.sh doesn't work on that platform. Let me know if you've experienced the same or similar issues on other *nix flavours or on other Ubuntu versions. Your mileage may vary.
When Jetty fails to start, it doesn't log the details of the failure anywhere. So, in attempting to nail down the problem, I had no choice but to open up the jetty.sh script, and to get my hands dirty with some old-skool debugging. It didn't take me too long to figure out which part of the script I should be concentrating my efforts on, it's the lines of code from 397-425:
##################################################
# Do the action
##################################################
case "$ACTION" in
start)
echo -n "Starting Jetty: "
if (( NO_START )); then
echo "Not starting jetty - NO_START=1";
exit
fi
if type start-stop-daemon > /dev/null 2>&1
then
unset CH_USER
if [ -n "$JETTY_USER" ]
then
CH_USER="-c$JETTY_USER"
fi
if start-stop-daemon -S -p"$JETTY_PID" $CH_USER -d"$JETTY_HOME" -b -m -a "$JAVA" -- "${RUN_ARGS[@]}" --daemon
then
sleep 1
if running "$JETTY_PID"
then
echo "OK"
else
echo "FAILED"
fi
fi
To be specific, the line with if start-stop-daemon … (line 416) was clearly where the problem lay for me. So, I decided to see exactly what this command looks like (after all the variables have been substituted), by adding a line to the script that echo'es it:
That's a good start. Now, I have a command that I can try to run manually myself, as a debugging test. So, I took the above statement, pasted it into my terminal, and whacked a sudo in front of it:
Well, that didn't give me any error messages; but then again, no positive feedback, either. To see if this command was successful in launching the Jetty daemon, I tried:
Next, I decided to investigate the man page for the start-stop-daemon command. I'm no sysadmin or Unix guru — I've never dealt with this command before, and I have no idea what its options are.
When I have a Unix command that doesn't work, and that doesn't output or log any useful information about the failure, the first thing I look for is a "verbose" option. And it just so turns out that start-stop-daemon has a -v option. So, next step for me was to add that option and try again:
Unfortunately, no cigar; the result of running that was exactly the same. Still absolutely no output (so much for verbose mode!), and ps aux showed the daemon had not launched.
Next, I decided to read up (in the man page) on the various options that the script was using with the start-stop-daemon command. Turns out that the -b option is rather a problematic one — as the manual says:
Typically used with programs that don't detach on their own. This option will force start-stop-daemon to fork before starting the process, and force it into the background. WARNING: start-stop-daemon cannot check the exit status if the process fails to execute for any reason. This is a last resort, and is only meant for programs that either make no sense forking on their own, or where it's not feasible to add the code for them to do this themselves.
Ouch — that sounds suspicious. Ergo, next step: remove that option, and try again:
Running that command resulted in me seeing a fairly long Java exception report, the main line of which was:
java.io.FileNotFoundException: /path/to/solr/--daemon (No such file or directory)
Great — removing the -b option meant that I was finally able to see the error that was occurring. And… seems like the error is that it's trying to add the --daemon option to the solr filepath.
I decided that this might be a good time to read up on what exactly the --daemon option is. And as it turns out, the start-stop-daemon command has no such option. No wonder it wasn't working! (No such option in the java command-line app, either, or in any other standard *nix util that I was able to find).
I have no idea what this option is doing in the jetty.sh script. Perhaps it's available on some other *nix variants? Anyway, doesn't seem to be recognised at all on Ubuntu. Any info that may shed some light on this mystery would be greatly appreciated, if there are any start-stop-daemon experts out there.
Next step: remove the --daemon option, re-add the -b option, remove the -v option, and try again:
Now that I'd successfully managed to launch the daemon with a manual terminal command, all that remained was to modify the jetty.sh script, and to do some integration testing. So, I removed the --daemon option from the relevant line of the script (line 416), and I tried:
sudo /etc/init.d/jetty start
And it worked. That command gave me the output:
Starting Jetty: OK
And a call to ps aux | grep java was also able to verify that the daemon was running.
Just one final step left in testing: restart the server (assuming that the Jetty startup script was added to Ubuntu's startup list at some point, manually or using update-rc.d), and see if Jetty is running. So, I restarted (sudo reboot), and… bup-bummmmm. No good. A call to ps aux | grep java showed that Jetty had not launched automatically after restart.
I remembered the discovery I'd made earlier, that the -b option is "dangerous". So, I removed this option from the relevant line of the script (line 416), and restarted the server again.
And, at long last, it worked! After restarting, a call to ps aux | grep java verified that the daemon was running. Apparently, Ubuntu doesn't like its startup daemons forking as background processes, this seems to result in things not working.
However, there is one lingering caveat. With this final solution — i.e. both the --daemon and the -b options removed from the start-stop-daemon call in the script — the daemon launches just fine after restarting the server. However, with this solution, if the daemon stops for some reason, and you need to manually invoke:
sudo /etc/init.d/jetty start
Then the daemon will effectively be running as a terminal process, not as a daemon process. This means that if you close your terminal session, or if you push CTRL+C, the process will end. Not exactly what init.d scripts are designed for! So, if you do need to manually start Jetty for some reason, you'll have to use another version of the script that maintains the -b option (adding an ampersand — i.e. the & symbol — to the end of the command should also do the trick, although that's not 100% reliable).
So, that's the long and winding story of my recent trials and tribulations with Solr, Jetty, and start-stop-daemon. If you're experiencing similar problems, hope this explanation is of use to you.
]]>
Jimmy Page: site-wide Django page caching made simple2011-01-31T00:00:00Z2011-01-31T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/01/jimmy-page-site-wide-django-page-caching-made-simple/
For some time, I've been using the per-site cache feature that comes included with Django. This site's caching needs are very modest: small personal site, updated infrequently, with two simple blog-like sections and a handful of static pages. Plus, it runs fast enough even without any caching. A simple "brute force" solution like Django's per-site cache is more than adequate.
However, I grew tired of the fact that whenever I published new content, nothing was invalidated in the cache. I began to develop a routine of first writing and publishing the content in the Django admin, and then SSHing in to my box and restarting memcached. Not a good regime! But then again, I also couldn't bring myself to make the effort of writing custom invalidation routines for my cached pages. Considering my modest needs, it just wasn't worth it. What I needed was a solution that takes the same "brute force" page caching approach that Django's per-site cache already provided for me, but that also includes a similarly "brute force" approach to invalidation. Enter Jimmy Page.
Jimmy Page is the world's simplest generational page cache. It essentially functions on just two principles:
It caches the output of all pages on your site (for which you use its @cache_view decorator).
It invalidates* the cache for all pages, whenever any model instance is saved or deleted (apart from those models in the "whitelist", which is a configurable setting).
* Technically, generational caches never invalidate anything, they just increment the generation number of the cache key, and store a new version of the cached content. But if you ask me, it's easiest to think of this simply as "invalidation".
That's it. No custom invalidation routines needed. No stale cache content, ever. And no excuse for not applying caching to the majority of pages on your site.
If you ask me, the biggest advantage to using Jimmy Page, is that you simply don't have to worry about which model content you've got showing on which views. For example, it's perfectly possible to write routines for manually invalidating specific pages in your Django per-site cache. This is done using Django's low-level cache API. But if you do this, you're left with the constant headache of having to keep track of which views need invalidating when which model content changes.
With Jimmy Page, on the other hand, if your latest blog post shows on five different places on your site — on its own detail page, on the blog index page, in the monthly archive, in the tag listing, and on the front page — then don't worry! When you publish a new post, the cache for all those pages will be re-generated, without you having to configure anything. And when you decide, in six months' time, that you also want your latest blog post showing in a sixth place — e.g. on the "about" page — you have to do precisely diddly-squat, because the cache for the "about" page will already be getting re-generated too, sans config.
Of course, Jimmy Page is only going to help you if you're running a simple lil' site, with infrequently-updated content and precious few bells 'n' whistles. As the author states: "This technique is not likely to be effective in sites that have a high ratio of database writes to reads." That is, if you're running a Twitter clone in Django, then Jimmy Page probably ain't gonna help you (and it will very probably harm you). But if you ask me, Jimmy Page is the way to go for all your blog-slash-brochureware Django site caching needs.
]]>
On and off2011-01-23T00:00:00Z2011-01-23T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/01/on-and-off/
English is a language bursting with ambiguity and double meanings. But the words "on" and "off" would have to be two of the worst offenders. I was thinking about words that foreign-language speakers would surely find particularly hard to master, when learning to speak English. And I couldn't go past these two. From the most basic meaning of the words, which relates to position — e.g. "the book is on the table", and "the plane is off the ground" — "on" and "off" have been overloaded more thoroughly than an Indian freight train.
To start with, let's focus on the more common and important meanings of these words. The most fundamental meaning of "on" and "off", is to describe something as being situated (or not situated) atop something else. E.g: "the dog is on the mat", and "the box is off the carpet". "On" can also describe something as being stuck to or hanging from something else. E.g: "my tattoo is on my shoulder", "the painting is on the wall". (To describe the reverse of this, it's best to simply say "not on", as saying "off" would imply that the painting has fallen off — but let's not go there just yet!).
"On" and "off" also have the fundamental meaning of describing something as being activated (or de-activated). This can be in regard to electrical objects, e.g: "the light is on / off", or simply "it's on / off". It can also be in regard to events, e.g: "your favourite TV show is on now". For the verb form of activating / de-activating something, simply use the expressions: "turn it on / off".
But from these simple beginnings… my, oh my, how much more there is to learn! Let's dive into some expressions that make use of "on" and "off".
Bored this weekend? Maybe you should ask your mates: "what's on?" Maybe you're thinking about going to Fiji next summer — if so: "it's on the cards". And when you finally do get over there, let your folks know: "I'm off!". And make sure your boss has given you: "the week off". If you're interested in Nigerian folk music, you might be keeping it: "on your radar". After 10 years spreading the word about your taxidermy business, everyone finally knows about it: "you're on the map". And hey, your services are "on par" with any other stuffed animal enterprise around.
Or we could get a bit saucier with our expressions. Next time you chance to see a hottie at yer local, let her know: "you turn me on". Or if she just doesn't do it for you: "she turns me off" (don't say it to her face). Regarding those sky-blue eyes, or that unsightly zit, respectively: "what a turn-on / what a turn-off". After a few drinks, maybe you'll pluck up the courage to announce: "let's get it on". And later on, in the bedroom — who knows? You may even have occasion to comment: "that gets me off".
And the list "goes on". When you're about to face the music, you tell the crew: "we're on". When it's you're shout, tell your mates: "drinks are on me". When you've had a bad day at work, you might want to whinge to someone, and: "get it off your chest". When you call auntie Daisy for her birthday, she'll probably start: "crapping on and on". When you smell the milk in the fridge, you'll know whether or not it's: "gone off".
Don't believe the cops when they tell you that your information is strictly: "off the record". And don't let them know that you're "off your face" on illicit substances, either. They don't take kindly to folks who are: "high on crack". So try and keep the conversation: "off-topic". No need for everything in life to stay: "on track". In the old days, of course, if you got up to any naughty business like that, it was: "off with your head!".
If you're into soccer, you'll want to "kickoff" to get the game started. But be careful you don't stray: "offside". If you can't "get a handle on" those basics, you might be "better off" playing something else. Like croquet. Or joining a Bob Sinclair tribute band, and singing: "World, Hold On".
That's about all the examples I can think of for now. I'm sure there are more, though. Feel free to drop a comment with your additional uses of "on" and "off", exposed once and for all as two words in the English language that "get around" more than most.
]]>
The Art of Sport2011-01-09T00:00:00Z2011-01-09T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/01/the-art-of-sport/
Soccer (or football) is the most popular sport in the world today; likewise, with over 700 million viewers, the 4-yearly FIFA World Cup is the most watched event in human history. Why is this so? Is it mere chance — a matter of circumstance — that soccer has so clearly and definitively wooed more devotees than any other sport? I think not. Team sports are an approximation of military battle. All such sports endeavour to foster the same strategies that can be used effectively in traditional warfare. Soccer, in my opinion, fosters those strategies better than any other sport; this is because, in tactical terms, it is the most pure sport in the modern world.
Now, if what I said above went right over your head, then I won't be offended if you call me a crazy ranting nutter, and you stop reading right now. But I was thinking about this a fair bit lately, and I feel compelled to pen my thoughts here.
It's pretty much a universal rule that simpler is better. If something is fettered with bells and whistles that do little to enhance it, and that unnecessarily add to its complexity, then that something has a problem. If, on the other hand, something has all the features that it needs in order to function, and no more, then that something is going places. Does a tree need a satellite dish in order to absorb sunlight? No (although a tall tree can be an excellent place to put your home satellite dish for maximum effectiveness … but I digress). Does it need leaves? Yes. This is what we call good design.
What is the purpose of team sports? Well, there are a few possible answers to that question (depending on who you talk to); but, if you ask me, the fundamental purpose of all team sports is to allow for a tactical competition. In the case of most sports, that competition is expressed physically. But it's not the physical aspect of the sport that really determines who will win it; we all know that neither athletic superiority, nor equipment superiority, directly translates into a winning team. At the end of the day, it's tactical superiority that determines the winning team, more than anything else.
As in war.
I must admit, I suck at soccer. Always have. And I always wondered why I sucked at it. Was I such a slow runner? Such a poor tackler? Lousy foot-eye co-ordination? I always believed it was these things. But now, I see that I was wrong. I don't suck for any of those reasons. I suck because I have a poor instinct for tactics on the battlefield. If I were thrown into a bloodthirsty life-or-death war, I'm pretty sure I'd suck there too, for the same reason.
Because I suck, and because I know why, I therefore believe myself perfectly qualified to define the two skills that are fundamental to being a good soccer player:
Dexterity with one's feet
Instinct for playing-field tactics
Soccer is an incredibly well-designed game, because it's so simple. You only have to use your feet, not your hands, in order to further your objective; and your feet are also used in order to move yourself around the field. This means that one part of the body is able to perform two different functions, both of which are essential for play. It also has the side-effect of making a player's height much less relevant than it is in games that involve using one's hands. For example, basketball is probably the hand ball-based game most similar to soccer; and yet, look at the critical factor that a person's height plays there.
Soccer has a really simple objective. Get the ball in the goal. One goal is one point. Get more points than the other team. That's it. No situations in which more than one point can be scored at a time. No exceptions to the basic rule that a goal equals a point.
Similarly, soccer has really simple equipment. All you really need, is a ball. Preferably an inflatable plastic and leather ball, as today's hi-tech manufactured soccer balls contain; but a traditional rubber or animal-bladder ball will suffice, too. You need something to mark the goalposts: this is ideally a proper wooden frame for each goal; but hey, we've all played soccer games where two hats are used to mark the goals at each end. Other than that, you need … a flat grassy area?
The only thing about soccer that's actually complicated, is the strategy. And strategy isn't an essential part of the game.
Unless, of course, you want to win. Which an awful lot of sportspeople tend to want to do. And, in which case, strategy is most definitely not optional.
It's precisely because the rules and the playing field / equipment are so simple, that so much room is left for complex strategy. Apart from the bare basics, everything is left up to the players to decide. Stronger offence or stronger defence? Run down the wing or try and duck through the middle? Try and run through with small passes, or risk a big kick over the main defence line?
Apart from that bigger picture stuff, most of the strategy in soccer is actually very small picture. Which way is my marked player about to go, left or right? Try a real tackle now, or bluff a tackle and do the real one later? Mark a player in an obvious way, or try and be more subtle about it? Which teammate to pass to — which one looks more ready, and which is in a better position?
The most popular games in the world, are those in which you can learn the basic rules in about ten minutes, but in which you couldn't learn every intricacy of strategy in ten lifetimes. Chess is one such game. Soccer is another. These games are so popular, because they succeed (where other games fail) in stimulating our most primal instincts. The rules are important, but they're few. You can't win just by knowing the rules. If you want to win, then you must know your environment; you must know your ability; and above all, you must know your enemy.
It's a game called survival.
]]>
The English Language and The Celtic Question2010-08-30T00:00:00Z2010-08-30T00:00:00ZJazahttps://greenash.net.au/thoughts/2010/08/the-english-language-and-the-celtic-question/
According to most linguistic / historical sources, the English language as we know it today is a West Germanic language (the other two languages in this family being German and Dutch). Modern English is the descendant of Old English, and Old English was essentially born when the Anglo-Saxons migrated to the isle of Great Britain in the 5th c. C.E., from their traditional homeland in the north-west of modern Germany. Prior to this time, it's believed that the inhabitants of all parts of the British Isles were predominantly Celtic speakers, with a small Latin influence resulting from the Roman occupation of Britain.
Of the languages that have influenced the development of English over the years, there are three whose effect can be overwhelmingly observed in modern English: French ("Old Norman"), Latin, and Germanic (i.e. "Old English"). But what about Celtic? It's believed that the majority of England's pre-Anglo-Saxon population spoke Brythonic (i.e. British Celtic). It's also been recently asserted that the majority of England's population today is genetically pre-Anglo-Saxon Briton stock. How, then — if those statements are both true — how can it be that the Celtic languages have left next to no legacy on modern English?
The Celtic Question — or "Celtic Puzzle", as some have called it — is one that has spurred heated debate and controversy amongst historians for many years. The traditional explanation of the puzzle, is the account of the Germanic migration to Britain, as given in the Anglo-Saxon Chronicle. As legend has it, in the year 449 C.E., two Germanic brothers called Hengest and Horsa were invited to Britain by Vortigern (King of the Britons) as mercenaries. However, after helping the Britons in battle, the two brothers murdered Vortigern, betrayed the Britons, and paved the way for an invasion of the land by the Germanic tribes the Angles, the Saxons and the Jutes.
Over the subsequent centuries, the Britons were either massacred, driven into exile, or subdued / enslaved. Such was the totality of the invasion, that aside from geographical place-names, virtually no traces of the old Brythonic language survived. The invaded land came to be known as "England", deriving from "Angle-land", in honour of the Angles who were one of the chief tribes responsible for its inception.
Various historians over the years have suggested that the Anglo-Saxons committed genocide on the indigenous Britons that failed to flee England (those that did flee went to Wales, Cornwall, Cumbria and Brittany). This has always been a contentious theory, mainly because there is no historical evidence to support any killings on a scale necessary to constitute "genocide" in England at this time.
More recently, the geneticist Stephen Oppenheimer has claimed that the majority of English people today are the descendants of indigenous Britons. Oppenheimer's work, although being far from authoritative at this time (many have criticised its credibility), is nevertheless an important addition to the weight of the argument that a large-scale massacre of the Celtic British people did not occur.
(Unfortunately, Oppenheimer has gone beyond his field of expertise,which is genetics, and has drawn conclusions on the linguistic history of Britain — namely, he argues that the pre-Roman inhabitants of England were not Celtic speakers, but that they were instead Germanic speakers. This argument is completely flawed from an academic linguistic perspective; and sadly, as a consequence, Oppenheimer's credibility in general has come to be questioned.)
Explanations to the riddle
Although the Celtic Question may seem like a conundrum, various people have come up with logical, reasonable explanations for it. One such person is Geoffrey Sampson, who has written a thorough essay about the birth of the English language. Sampson gives several sound reasons why Celtic failed to significantly influence the Anglo-Saxon language at the time of the 5th century invasions. His first reason is that Celtic and Germanic are two such different language groups, that they were too incompatible to easily mix and merge:
The Celtic languages… are very different indeed from English. They are at least as "alien" as Russian, or Greek, say.
His second reason is that, while many Britons surely did remain in the conquered areas of England, a large number must have also "run to the hills":
But when we add the lack of Celtic influence on the language, perhaps the most plausible explanation is an orderly retreat by the ancient Britons, men women and children together, before invaders that they weren't able to resist. Possibly they hoped to regroup in the West and win back the lands they had left, but it just never happened.
I also feel compelled to note that while Sampson is a professor and his essay seems reasonably well-informed, I found a rather big blotch to his name. He was accused of expressing racism, after publishing another essay on his web site entitled "There's Nothing Wrong with Racism". This incident seems to have cut short the aspirations that he had of pursuing a career in politics. Also, even before doing the background research and unearthing that incident, I felt suspicion stirring within me when I read this line, further down in his essay on the English language, regarding the Battle of Hastings:
The battle today is against a newer brand of Continental domination.
That sounds to me like the remark of an unashamed typical old-skool English xenophobiac. Certainly, anyone who makes remarks like that, is someone I'd advise listening to with a liberal grain of salt.
Another voice on this topic is Claire Lovis, who has written a great balanced piece regarding the Celtic influence on the English language. Lovis makes an important point when she remarks on the stigmatisation of Celtic language and culture by the Anglo-Saxons:
The social stigma attached to the worth of Celtic languages in British society throughout the last thousand years seems responsible for the dearth of Celtic loan words in the English language… Celtic languages were viewed as inferior, and words that have survived are usually words with geographical significance, and place names.
Lovis re-iterates, at the end of her essay, the argument that the failure of the Celtic language to influence English was largely the result of its being looked down upon by the ruling invaders:
The lack of apparent word sharing is indicative of how effective a social and political tool language can be by creating a class system through language usage… the very social stigma that suppressed the use of Celtic language is the same stigma that prevents us learning the full extent of the influence those languages have had on English.
The perception of Celtic language and culture as "inferior" can, of course, be seen in the entire 1,000-year history of England's attitudes and treatment towards her Celtic neighbours, particularly in Scotland and Ireland. The Ango-Saxon medieval (and even modern) England consistently displayed contempt and intolerance towards those with a Celtic heritage, and this continues — at least to some extent — even to the present day.
My take on the question
I agree with the explanations given by Sampson and Lovis, namely that:
Celtic was "alien" to the Anglo-Saxon language, hence it was a question of one language dominating over the other, with a mixed language being an unlikely outcome
Many Celtic people fled England, and those that remained were in no position to preserve their language or culture
Celtic was stigmatised by the Anglo-Saxons over a prolonged period of time, thus strongly encouraging the Britons to abandon their old language and to wholly embrace the language of the invaders
The strongest parallel that I can think of for this "Celtic death" in England, is the Spanish conquest of the Americas. In my opinion, the imposition of Spanish language and culture upon the various indigenous peoples of the New World in the 16th century — in particular, upon the Aztecs and the Mayans in Mexico — seems very similar to the situation with the Germanics and the Celtics in the 5thcentury:
The Spanish language and the native American languages were completely "alien" to each other, leaving little practical possibility of the languages easily fusing (although I'd say that, in Mexico in particular, indigenous language actually managed to infiltrate Spanish much more effectively than Celtic ever managed to infiltrate English)
The natives of the New World either fled the conquistadores, or they were enslaved / subdued (or, of course, they died — mostly from disease)
The indigenous languages and cultures were heavily stigmatised and discouraged (in the case of the Spanish inquisition, on pain of death — probably more extreme than what happened at any time during the Anglo-Saxon invasion of Britain), thus strongly encouraging the acceptance of the Spanish language (and, of course, the Catholic Church)
In Mexico today, the overwhelming majority of the population is classified as being ethnically "mestizo" (meaning "mixture"), with the genetics of the mestizos tending generally towards the indigenous side. That is, the majority of Mexicans today are of indigenous stock. And yet, the language and culture of modern Mexico are almost entirely Spanish, with indigenous languages all but obliterated, and with indigenous cultural and religious rites severely eroded (in the colonial heartland, that is — in the jungle areas, in particular the Mayan heartland of the south-east, indigenous language and culture remains relatively strong to the present day).
Mexico is a comparatively modern and well-documented example of an invasion, where the aftermath is the continuation of an indigenous genetic majority, coupled with the near-total eradication of indigenous language. By looking at this example, it isn't hard to imagine how a comparable scenario could have unfolded (and most probably did unfold) 1,100 years earlier in Britain.
There doesn't appear to be any parallel in terms of religious stigmatisation — certainly nothing like the Spanish Inquisition occurred during the Anglo-Saxon invasion of Britain, and to suggest as much would be ludicrous — and all of Britain was swept by a wave of Christianity just a few centuries after, anyway (and no doubt the Anglo-Saxon migrations were still occurring while Britain was being converted en masse away from both Celtic and Germanic paganism). There's also no way to know whether the Britons were forcibly indoctrinated with the Anglo-Saxon language and culture — by way of breaking up families, stealing children, imposing changes on pain of death, and so on — or whether they embraced the Anglo-Saxon language and culture of their own volition, under the sheer pressure of stigmatisation and the removal of economic / social opportunity for those who resisted change. Most likely, it was a combination of both methods, varying between places and across time periods.
The Brythonic language is now long since extinct, and the fact is that we'll never really know how it was that English came to wholly displace it, without being influenced by it to any real extent other than the preservation of a few geographical place names (and without the British people themselves disappearing genetically). The Celtic question will likely remain unsolved, possibly forever. But considering that modern English is the world's first de facto global lingua franca (not to mention the native language of hundreds of millions of people, myself included), it seems only right that we should explore as much as we can into this particularly dark aspect of our language's origins.
]]>
Boycott GPS2010-08-25T00:00:00Z2010-08-25T00:00:00ZJazahttps://greenash.net.au/thoughts/2010/08/boycott-gps/
Last month, I went on a road trip with a group of friends, up the east coast of Queensland. We hired two campervans, and we spent just over a week cruising our way from Brisbane to Cairns. Two of my friends insisted on bringing their GPS devices with from home. Personally, I don't use a GPS; but these friends of mine use them all the time, and they assured me that having them on the trip would make our lives much easier, and hence that the trip would be much more enjoyable.
I had my doubts. Australia — for those of you that don't know — is a simple country with simple roads. The coast of Queensland is no exception. There's one highway, and it's called Route 1, and it goes up the coast in a straight line, from Brisbane to Cairns, for about 1,600 km's. If you see a pub, it means you've driven through a town. If you see two pubs, a petrol station, a real estate agent and a post office (not necessarily all in different buildings), that's a big town. If you see houses as well, you must be in a capital city. It's pretty hard to get lost. Why would we need a GPS?
To cut a long story short, the GPSes were a major annoyance throughout the trip, and they were of no real help for the vast majority our our travelling. Several times, they instructed us to take routes that were a blatant deviation from the main route that prominent road signs had marked, and that were clearly not the quickest route anyhow. They discouraged going off the beaten track and exploring local areas, because they have no "shut up I'm going walkabout now" mode. And, what got to me more than anything, my travel buddies were clearly unable to navigate along even the simplest stretch of road without them, and it made me sad to see my friends crippled by these devices that they've come to so depend upon.
In the developed world, with its developed mapping providers and its developed satellite coverage, GPS is becoming ever more popular amongst automobile drivers. This is happening to the extent that I often wonder if the whole world is now running on autopilot. "In two hundred metres, take the second exit at the roundabout, then take the third left."
Call me a luddite and a dinosaur if you must, all ye GPS faithful… but I refuse to use a GPS. I really can't stand the things. They're annoying to listen to. I can usually find a route just fine without them. And using them makes you navigationally illiterate. Join me in boycotting GPS!
GPS is eroding navigational skills
This is my main gripe with GPS devices. People who use them seem to become utterly dependent on them, sticking with them like crack junkies stick to the walls of talcum powder factories. If a GPS addict is at any time forced to drive without his/her beloved electronic companion, he/she is utterly lost. Using a GPS all the time makes you forget how to navigate. It means that you don't explore or immerse yourself in the landscape around you. It's like walking through a maze blindfolded.
I must point out, though, that GPS devices don't have to make us this stupid. However, this is the way the current generation of devices are designed. Current GPSes encourage stimulus-driven rather than spatially-driven navigation. Unless you spend quite a lot of time changing the default settings, 99% of consumer-car GPSes will only show you the immediate stretch of road in front of you in their map display, and the audio will only instruct you as to the next immediate action you are to take.
Worse still, the action-based instructions that GPSes currently provide are completely devoid of the contextual richness that we'd utilise, were we humans still giving verbal directions to each other. If you were driving to my house, I'd tell you: "turn right when you see the McDonald's, then turn left just before the church, at the bottom of the hill". The GPS, on the other hand, would only tell you: "in 300 metres, turn right, then take the second left". And, because you've completely tuned in to the hypnotic words of the GPS, and tuned out to the world around you, it's unlikely you'd even notice that there's a Maccas, or a church, or a hill, near my house.
Even the US military is having trouble with its troops suffering from reduced navigational ability, as a direct result of their dependence on field GPS devices. Similarly, far North American Inuits are rapidly losing the traditional arctic navigation skills that they've been passing down through the generations for centuries, due to the recent introduction of GPS aids amongst hunters and travellers in their tribes. So, if soldiers who are highly trained in pathfinding, and polar hunters who have pathfinding in their blood — if these people's sense of direction is eroding, what hope is there for us mere mortals?
I got started thinking about this, when I read an article about this possibility: Could GPS create a world without signs? I found this to be a chilling prediction to reflect upon, particularly for a GPS-phobe like myself. The eradication of traditional street signs would really be the last straw. It would mean that the GPS-averse minority would ultimately be forced to convert — presumably by law, since if we assume that governments allowed most street signs to discontinue, we can also assume that they'd make GPS devices compulsory for safety reasons (not to mention privacy concerns, anyone?).
Explorer at heart
I must admit, I'm a much more keen navigator and explorer than your average Joe. I've always adored maps — when I was a kid, I used to spend hours poring over the street directory, or engrossing myself in an atlas that was (at the time) taller than me. Nowadays, I can easily burn off an entire evening panning and zooming around Google Earth.
I love to work out routes myself. I also love to explore the way as I go. Being a keen urban cyclist, this is an essential skill — cycling is also one of the best methods for learning your way around any local area. It also helped me immensely in my world trip several years ago, particularly when hiking in remote mountain regions, but also in every new city I arrived at. I'm more comfortable if I know the compass bearings in any given place I find myself, and I attempt to derive compass bearings using the position of the sun whenever I can.
So, OK, I'm a bit weird, got a bit of a map and navigation fetish. I also admit, I took the Getting Lost orientation test, and scored perfectly in almost every area (except face recognition, which is not my strong point).
I'm one of those people who thinks it would be pretty cool to have lived hundreds of years ago, when intrepid sailors ventured (with only the crudest of navigational aids) to far-flung oceans, whose edges were marked on maps as being guarded by fierce dragons; and when fearless buccaneers ventured across uncharted continents, hoping that the natives would point them on to the next village, rather than skewer them alive and then char-grill their livers for afternoon tea. No wonder, then, that I find it fun being without GPS, whether I'm driving around suburban Sydney, or ascending a mountain in Bolivia.
Then again, I'm also one of those crazy luddites that think the world would be better without mobile phones. But that's a rant for another time.
]]>
An inline image Django template filter2010-06-06T00:00:00Z2010-06-06T00:00:00ZJazahttps://greenash.net.au/thoughts/2010/06/an-inline-image-django-template-filter/
Adding image fields to a Django model is easy, thanks to the built-in ImageField class. Auto-resizing uploaded images is also a breeze, courtesy of sorl-thumbnail and its forks/variants. But what about embedding resized images inline within text content? This is a very common use case for bloggers, and it's a final step that seems to be missing in Django at the moment.
Having recently migrated this site over from Drupal, my old blog posts had inline images embedded using image assist. Images could be inserted into an arbitrary spot within a text field by entering a token, with a syntax of [img_assist nid=123 ... ]. I wanted to be able to continue embedding images in roughly the same fashion, using a syntax as closely matching the old one as possible.
So, I've written a simple template filter that parses a text block for tokens with a syntax of [thumbnail image-identifier], and that replaces every such token with the image matching the given identifier, resized according to a pre-determined width and height (by sorl-thumbnail), and formatted as an image tag with a caption underneath. The code for the filter is below.
import re
from django import template
from django.template.defaultfilters import stringfilter
from sorl.thumbnail.main import DjangoThumbnail
from models import InlineImage
register = template.Library()
regex = re.compile(r'\[thumbnail (?P<identifier>[\-\w]+)\]')
@register.filter
@stringfilter
def inline_thumbnails(value):
new_value = value
it = regex.finditer(value)
for m in it:
try:
image = InlineImage.objects.get(identifier=identifier)
thumbnail = DjangoThumbnail(image.image, (500, 500))
new_value = new_value.replace(m.group(), '<img src="%s%s" width="%d" height="%d" alt="%s" /><p><em>%s</em></p>' % ('http://mysite.com', thumbnail.absolute_url, thumbnail.width(), thumbnail.height(), image.title, image.title))
except InlineImage.DoesNotExist:
pass
return new_value
This code belongs in a file such as appname/templatetags/inline_thumbnails.py within your Django project directory. It also assumes that you have an InlineImage model that looks something like this (in your app's models.py file):
from django.db import models
class InlineImage(models.Model):
created = models.DateTimeField(auto_now_add=True)
modified = models.DateTimeField(auto_now=True)
title = models.CharField(max_length=100)
image = models.ImageField(upload_to='uploads/images')
identifier = models.SlugField(unique=True)
def __unicode__(self):
return self.title
ordering = ('-created',)
Say you have a model for your site's blog posts, called Entry. The main body text field for this model is content. You could upload an InlineImage with identifier hokey-pokey. You'd then embed the image into the body text of a blog post like so:
<p>You put your left foot in,
You put your left foot out,
You put your left foot in,
And you shake it all about.</p>
[thumbnail hokey-pokey]
<p>You do the Hokey Pokey and you turn around,
That's what it's all about.</p>
To render the blog post content with the thumbnail tokens converted into actual images, simply filter the variable in your template, like so:
The code here is just a simple example — if you copy it and adapt it to your own needs, you'll probably want to add a bit more functionality to it. For example, the token could be extended to support specifying image alignment (left/right), width/height per image, caption override, etc. But I didn't particularly need any of these things, and I wanted to keep my code simple, so I've omitted those features from my filter.
]]>
An autop Django template filter2010-05-30T00:00:00Z2010-05-30T00:00:00ZJazahttps://greenash.net.au/thoughts/2010/05/an-autop-django-template-filter/autop is a script that was first written for WordPress by Matt Mullenweg (the WordPress founder). All WordPress blog posts are filtered using wpautop() (unless you install an additional plug-in to disable the filter). The function was also ported to Drupal, and it's enabled by default when entering body text into Drupal nodes. As far as I'm aware, autop has never been ported to a language other than PHP. Until now.
In the process of migrating this site from Drupal to Django, I was surprised to discover that not only Django, but also Python in general, lacks any linebreak filtering function (official or otherwise) that's anywhere near as intelligent as autop. The built-in Django linebreaks filter converts all single newlines to <br /> tags, and all double newlines to <p> tags, completely irrespective of HTML block elements such as <code> and <script>. This was a fairly major problem for me, as I was migrating a lot of old content over from Drupal, and that content was all formatted in autop style. Plus, I'm used to writing content in that way, and I'd like to continue writing content in that way, whether I'm in a PHP environment or not.
Therefore, I've ported Drupal's _filter_autop() function to Python, and implemented it as a Django template filter. From the limited testing I've done, the function appears to be working just as well in Django as it does in Drupal. You can find the function below.
import re
from django import template
from django.template.defaultfilters import force_escape, stringfilter
from django.utils.encoding import force_unicode
from django.utils.functional import allow_lazy
from django.utils.safestring import mark_safe
register = template.Library()
def autop_function(value):
"""
Convert line breaks into <p> and <br> in an intelligent fashion.
Originally based on: http://photomatt.net/scripts/autop
Ported directly from the Drupal _filter_autop() function:
http://api.drupal.org/api/function/_filter_autop
"""
# All block level tags
block = '(?:table|thead|tfoot|caption|colgroup|tbody|tr|td|th|div|dl|dd|dt|ul|ol|li|pre|select|form|blockquote|address|p|h[1-6]|hr)'
# Split at <pre>, <script>, <style> and </pre>, </script>, </style> tags.
# We don't apply any processing to the contents of these tags to avoid messing
# up code. We look for matched pairs and allow basic nesting. For example:
# "processed <pre> ignored <script> ignored </script> ignored </pre> processed"
chunks = re.split('(</?(?:pre|script|style|object)[^>]*>)', value)
ignore = False
ignoretag = ''
output = ''
for i, chunk in zip(range(len(chunks)), chunks):
prev_ignore = ignore
if i % 2:
# Opening or closing tag?
is_open = chunk[1] != '/'
tag = re.split('[ >]', chunk[2-is_open:], 2)[0]
if not ignore:
if is_open:
ignore = True
ignoretag = tag
# Only allow a matching tag to close it.
elif not is_open and ignoretag == tag:
ignore = False
ignoretag = ''
elif not ignore:
chunk = re.sub('\n*$', '', chunk) + "\n\n" # just to make things a little easier, pad the end
chunk = re.sub('<br />\s*<br />', "\n\n", chunk)
chunk = re.sub('(<'+ block +'[^>]*>)', r"\n\1", chunk) # Space things out a little
chunk = re.sub('(</'+ block +'>)', r"\1\n\n", chunk) # Space things out a little
chunk = re.sub("\n\n+", "\n\n", chunk) # take care of duplicates
chunk = re.sub('\n?(.+?)(?:\n\s*\n|$)', r"<p>\1</p>\n", chunk) # make paragraphs, including one at the end
chunk = re.sub("<p>(<li.+?)</p>", r"\1", chunk) # problem with nested lists
chunk = re.sub('<p><blockquote([^>]*)>', r"<blockquote\1><p>", chunk)
chunk = chunk.replace('</blockquote></p>', '</p></blockquote>')
chunk = re.sub('<p>\s*</p>\n?', '', chunk) # under certain strange conditions it could create a P of entirely whitespace
chunk = re.sub('<p>\s*(</?'+ block +'[^>]*>)', r"\1", chunk)
chunk = re.sub('(</?'+ block +'[^>]*>)\s*</p>', r"\1", chunk)
chunk = re.sub('(?<!<br />)\s*\n', "<br />\n", chunk) # make line breaks
chunk = re.sub('(</?'+ block +'[^>]*>)\s*<br />', r"\1", chunk)
chunk = re.sub('<br />(\s*</?(?:p|li|div|th|pre|td|ul|ol)>)', r'\1', chunk)
chunk = re.sub('&([^#])(?![A-Za-z0-9]{1,8};)', r'&\1', chunk)
# Extra (not ported from Drupal) to escape the contents of code blocks.
code_start = re.search('^<code>', chunk)
code_end = re.search(r'(.*?)<\/code>$', chunk)
if prev_ignore and ignore:
if code_start:
chunk = re.sub('^<code>(.+)', r'\1', chunk)
if code_end:
chunk = re.sub(r'(.*?)<\/code>$', r'\1', chunk)
chunk = chunk.replace('<\\/pre>', '</pre>')
chunk = force_escape(chunk)
if code_start:
chunk = '<code>' + chunk
if code_end:
chunk += '</code>'
output += chunk
return output
autop_function = allow_lazy(autop_function, unicode)
@register.filter
def autop(value, autoescape=None):
return mark_safe(autop_function(value))
autop.is_safe = True
autop.needs_autoescape = True
autop = stringfilter(autop)
Update (31 May 2010): added the "Extra (not ported from Drupal) to escape the contents of code blocks" part of the code.
To use this filter in your Django templates, simply save the code above in a file called autop.py (or anything else you want) in a templatetags directory within one of your installed apps. Then, just declare {% load autop %} at the top of your templates, and filter your markup variables with something like {{ object.content|autop }}.
Note that this is pretty much a direct port of the Drupal / PHP function into Django / Python. As such, it's probably not as efficient nor as Pythonic as it could be. However, it seems to work quite well. Feedback and comments are welcome.
]]>
Introducing GreenAsh 42010-05-25T00:00:00Z2010-05-25T00:00:00ZJazahttps://greenash.net.au/thoughts/2010/05/introducing-greenash-4/
It's that time again. GreenAsh makeover time!
What can I say? It's been a while. I was bored. The old site and the old server were getting crusty. And my technology preferences have shifted rather dramatically of late. Hence, it is with great pride that I present to you the splendiferously jaw-dropping 4th edition of GreenAsh, my personal and professional web site all rolled into one (oh yes, I love to mix business and pleasure).
New design
The latest incarnation of GreenAsh sports a design with plenty of fresh goodness. I've always gone for quite a minimalist look with GreenAsh (mainly because my design prowess is modest to say the least). The new design is, in my opinion, even more minimalist than its predecessors. For example, I've gotten rid of the CSS background images that previously sat on the home page, and the new background header image is a far smaller and less conspicuous alternative than the giant fluoro-green monstrosity before it.
Front page of the new GreenAsh 4
Elements such as dates submitted, tags, and authors are some of the finer details that have been tuned up visually for this edition. I've also added some very narrow sidebars, which are being used for these elements among other things. The thoughts index page now has a tag cloud.
I've tried to focus on the details rather than the devil. After all, that old devil likes to hang out in the details anyway. For example, the portfolio section has received a pretty extensive visual overhaul. Portfolio entries can now be browsed from a single page, using a funky jQuery-powered filtering interface. The experience degrades nicely without JavaScript, of course. The site's static informational pages — the services, about, and contact pages — have also had their details spruced up. These pages now have distinctively styled subtitles, stand-out text blocks, and call-to-action buttons.
I'd like to think of this edition as more of a realign than a redesign. I've maintained the main page area width of 740px, which existing content is already optimised for. However, the addition of the narrow sidebars has upped the overall width to 960px, and I'm now making use of the excellent 960 grid system for the overall layout. Thoughts are still fresh (on the front page). Colours haven't changed too radically. The new header is not all that dissimilar to the one before it. And so it goes on.
Crusty content purge
It's not just the design that's been cleaned up this time. I've also taken the liberty of getting rid of quite a lot of content (and functionality relating to that content), as part of this spring-clean.
In particular, the old GreenAsh resources library is no more. It was a key component of GreenAsh back in the day. Back in 2004, I'd just finished high school, I had a lot of fresh and useful study notes to share with the world, and I was working part-time as a tutor. But much has changed since then. I never ended up transferring all my notes into soft copy (although I did get through a surprising number of them). I've long retired from the tutoring business. My notes are out-of-date and of little use to anyone. Plus, I was sick of maintaining the convoluted registration and access-control system I'd set up for the resource library, and I was sick of whinging school-kids e-mailing me and complaining that they couldn't view the notes.
Speaking of registration, that's completely gone too. The only reason anyone registered was in order to access the resource library, so there's no point maintaining user accounts here anymore. All comments from registered users have been transformed into anonymous comments (with the author's name recorded in plain text).
The news archive is also history. I hardly ever posted news items. It was designed for announcing site news and such, but the truth is that most changes to the site aren't worth announcing, and/or aren't things that anyone besides myself would care about. Having scrapped the news section once and for all, I was also able to scrap the 'posts' section (which originally contained 'deals', 'thoughts', and 'news'), and to finally make thoughts a top-level section.
Some other crusty old bits of content, such as polls, image galleries, and a few random menu callbacks, are now also gone forever. I know the polls were kinda fun, but seriously — GreenAsh has grown up since its infancy, and pure gimmickry such as polls no longer has a place here.
The switch to Django
After being powered by Drupal for over 5 years, I made the big decision to re-develop GreenAsh in Django for this edition. The decision to switch was not an easy one, but it was one that I felt I had to make. Over the past year or so, I've been doing my professional coding work increasingly in Python/Django rather than in PHP/Drupal. On a personal level (related but separate), I've also been feeling increasingly disillusioned with PHP/Drupal; and increasingly excited by, and impressed with, Python/Django. In short, Drupal is no fun for me anymore, and Django feels like a breath of fresh air in a musty cellar.
This version of GreenAsh, therefore, is the first ever version that hasn't been built with PHP. GreenAsh is now powered by Django. The thoughts archive and the portfolio archive were migrated over from Drupal using a custom import script. Standard Django apps — e.g. comments, syndication, taggit, thumbnail — are being used behind the scenes (particularly to power the thoughts section). All is now being handled with Django models, views, and templates — not that much to talk about, really, as the back-end is by-and-large pretty simple for Django to handle. Although there are a few cool bits 'n' pieces at work, and I'll be blogging about them here as time permits.
The switch to Django also necessitated migrating GreenAsh to a new hosting solution. After 6 years on the same shared hosting account, GreenAsh has now (finally) moved to a VPS. All requests are now being served by Nginx as the first port of call, and most are then being proxied through to Apache. Having a VPS is pretty cool in general, because it means I have total control over the server, so I get to install whatever I want.
Loose ends
As always, this launch has seen the bulk of the changes on my to-do list done, but there are still plenty of loose ends to tie up. The thoughts index page needs a 'browse by year' block. Thought detail pages could use 'previous (newer) thought' and 'next (older) thought' links. The portfolio JavaScript browsing interface could use a few rough edges cleaned up, such as accordion opening-closing for each facet (year, type, paid), and fading instead of hiding/showing for transitions. The static informational pages should be editable as content blocks on the back-end (currently hard-coded in templates). The sitemap.xml and robots.txt files need to be restored. Some global redirection (e.g. from www to non-www) needs to take place. I need a smarter linebreak filter (one that's aware of big code blocks).
The new content could also still use work in some places. In particular, my portfolio is horrendously out-of-date, and I'll be updating it with my newer work as soon as I can. The 'about' page and the other static pages could still use a bit more work.
I hope you like the new GreenAsh. Relax, enjoy, and happy perusing.
]]>
Non-Shelbyville Sydney map2010-05-15T00:00:00Z2010-05-15T00:00:00ZJazahttps://greenash.net.au/thoughts/2010/05/non-shelbyville-sydney-map/
A work colleague of mine recently made a colourful remark to someone. "You live in [boring outer suburb]?", she gasped. "That's so Shelbyville!" Interesting term, "Shelbyville". Otherwise known as "the 'burbs", or "not where the hip-hop folks live". Got me thinking. Where in Sydney is a trendy place for young 20-somethings to live, and where is Shelbyville?
I've lived in Sydney all my life. I've almost always lived quite squarely in Shelbyville myself. However, since the age of 18, I've gotten to know most of the popular nightlife haunts pretty well. And since entering the world of student share-houses, I've also become pretty familiar with the city's accommodation hotspots. So, having this background, and being a fan of online mapping funkiness, I decided to sit down and make a map of the trendiest spots in Sydney to live and play.
Map of non-Shelbyville Sydney
This map represents my opinion, and my opinion only. It's based on where I most commonly go out at night with my friends and colleagues, and on where my friends and colleagues live or have lived. I make no pretense: this map is biased, and any fellow Sydney-sider will no doubt have numerous criticisms of its inclusions and its omissions. If you wish to voice your qualms, feel free to leave a comment. I'll do my best to go through and justify the most controversial details of the map. But, in general, my justification is simply that "this is a map of my Sydney, so of course it's not going to be exactly the same as a map of your Sydney".
In this map, the coloured dots represent nightlife hotspots. In general, they represent exact streets or clusters of streets that are home to a number of bars, although some dots are pinpointing individual bars. The coloured regions represent accommodation hotspots. These regions should be thought of as covering a general area — usually a suburb or a group of neighbouring suburbs — rather than covering exact streets.
The nightlife hotspots and the accommodation hotspots almost always overlap. You could say that one defines the other, and vice versa. The main exception to this rule is the Sydney CBD (i.e. George St, Martin Place, and Darling Harbour), which has the biggest nightlife concentration of anywhere, but which has almost no permanent accommodation, apart from a few recently-built towering monstrosities (and I wouldn't consider them trendy, as they're super-pricey and utterly soulless). There are a few other exceptions, which I'll get to shortly.
As you can see, the map is concentrated around the city centre, the Inner West, and the Eastern Suburbs. As a (recently-graduated) Uni student and a young professional, these are the areas that are almost exclusively on my radar these days.
The trendy areas
Inner West. Glebe, Newtown, Annandale and Leichhardt are the heart of where to stay and where to party in the Inner West. In particular, Newtown — the hippie student capital of Sydney — is one of my most frequent night hangouts. The suburbs surrounding Newtown (e.g. Erskineville, Stanmore) are also great places to live, although I can't say I party in those places myself.
Around City Centre. Surry Hills is on the CBD's doorstep, and it's a very trendy place both for living and for partying. Surry Hills is also where I work, so I've inevitably been frequenting many of its watering-holes of late. Ultimo and Chippendale are also close to my heart, as that's the neighbourhood of my old uni. At the last minute, I included Pyrmont, as it has nice accommodation these days; however, its only real night attraction is the casino, and casinos ain't particularly my thing. The Rocks is special, because it's a really good place to go out for drinks, but it's basically inside the CBD, and I don't know anyone who actually lives there. I reluctantly decided to include Darlinghurst and The Cross, as they're becoming increasingly hip places of abode — and they're also home to Sydney's most intense all-night party joints — but personally, I don't go out to that area at night, and I don't see the attraction of living next door to hookers and crack junkies.
Eastern Suburbs. Much of the East is overpriced beyond trendy standards, and/or is suburban Shelbyville. I've identified five main spots that go (more-or-less) in a line between City and Surf, and that aren't in this category: Paddington, Woollahra, Bondi Junction, Bondi, and Bondi Beach. Woollahra doesn't offer much nightlife itself, but its location between Paddington and The Jungo means that plenty of choice is nearby. Double Bay has some decent bars come evening-time, but considering that the only person I know who lives there is my Grandma, I can't really call it a trendy place to live. Bronte is a bit of a special case: I've never been out there at night, and I don't think it has much in the way of bars, but I know quite a few people that have lived there; plus, it really is a lovely beach. Coogee is actually the most remote place (from the city) that made it on the map, but there's no way I could have left it out. Also, the Randwick / UNSW area probably doesn't seriously qualify as a trendy spot; but because so many of my friends study at and/or live near UNSW, it qualifies for me.
Sorry, it's Shelbyville
Balmain. Also surrounding suburbs (i.e. Rozelle, Lilyfield, Drummoyne). I know that plenty of young and trendy people live and hang out in these places. But personally, I don't know anyone who lives in these areas, and I've never been out to them at night.
Harbour bays in the East. This mainly includes Elizabeth Bay, Rose Bay, and Watsons Bay. I know they all have some decent night hangouts. But all of them are also luxury suburbs, not for mere mortals; I for one don't have any friends living in those places.
Manly. I know that Manly people will never forgive me for this. I also know that Manly is a super-cool place both to live and to hang out. But I'm sorry — it's just too far from everywhere else! This is why people in non-Shelbyville Sydney, whether justified or not, call Manly Shelbyville.
Lower North Shore. North Sydney, Crows Nest, Neutral Bay, and Mosman. All Shelbyville. I'm a North Shore boy, so having lived there, and having now moved out into the real world, I should know. Yes, there are bars in all these suburbs. But does anyone from out of the area actually go to them? And would anyone actually move to these areas in order to be "where the action is"? No.
Everywhere else in Sydney is well and truly Shelbyville. My home through the teenage years — the mid North Shore around Chatswood and Gordon — is Shelbyville. No questions asked. My current abode — the Strathfield and Burwood area — is Shelbyville. No exception. The Shire is Shelbyville. Rockdale / Brighton is Shelbyville. Maroubra is Shelbyville. The Northern Beaches are Shelbyville. Parramatta is Shelbyville. And the Rest of the West is so daym Shelbyville it's not funny.
Further reading
Some sources that I used to get a feel for different opinions about Sydney's cool corners:
]]>
Taking PHP Fat-Free Framework for a test drive2010-05-06T00:00:00Z2010-05-06T00:00:00ZJazahttps://greenash.net.au/thoughts/2010/05/taking-php-fat-free-framework-for-a-test-drive/Fat-Free is a brand-new PHP framework, and it's one of the coolest PHP projects I've seen in quite a long time. In stark contrast to the PHP tool that I use most often (Drupal), Fat-Free is truly miniscule, and it has no plans to get bigger. It also requires PHP 5.3, which is one version ahead of what most folks are currently running (PHP 5.3 is also required by FLOW3, another framework on my test-drive to-do list). A couple of weeks back, I decided to take Fat-Free for a quick spin and to have a look under its hood. I wanted to see how good its architecture is, how well it performs, and (most of all) whether it offers enough to actually be of use to a developer in getting a real-life project out the door.
I'm going to be comparing Fat-Free mainly with Django and Drupal, because they're the two frameworks / CMSes that I use the most these days. The comparison may at many times feel like comparing a cockroach to an elephant. But like Django and Drupal, Fat-Free claims to be a complete foundation for building a dynamic web site. It wants to compete with the big boys. So, I say, let's bring it on.
Installation
Even if you're a full-time PHP developer, chances are that you don't have PHP 5.3 installed. On Windows, latest stable 5.3 is available to download as an auto-installer (just like latest stable 5.2, which is also still available). On Mac, 5.3 is bundled with Snow Leopard (OS 10.6), but only 5.2 is bundled with Leopard (10.5). As I've written about before, PHP on Mac has a lot of installation issues and annoyances in general. If possible, avoid anything remotely out-of-the-ordinary with PHP on Mac. On Ubuntu, PHP is not bundled, but can be installed with a one-line apt-get command. In Karmic (9.10) and earlier recent versions, the php5 apt package links to 5.2, and the php5-devel apt package links to 5.3 (either way, it's just a quick apt-get to install). In the brand-new Lucid (10.04), the php5 apt package now links to 5.3. Why do I know about installing PHP on all three of these different systems? Let's just say that if you previously used Windows for coding at home, but you've now switched to Ubuntu for coding at home, and you use Mac for coding at work, then you too would be a fruit-loop schizophrenic.
Upgrading from 5.2 to 5.3 shouldn't be a big hurdle for you. Unfortunately, I happened to be in pretty much the worst possible situation. I wanted to install 5.3 on Mac OS 10.5, and I wanted to keep 5.2 installed and running as my default version of PHP (because the bulk of my PHP work is in Drupal, and Drupal 6 isn't 100% compatible with PHP 5.3). This proved to be possible, but only just — it was a nightmare. Please, don't try and do what I did. Totally not worth it.
After I got PHP 5.3 up and running, installing Fat-Free itself proved to be pretty trivial. However, I encountered terrible performance when trying out a simple "Hello, World" demo, off the bat with Fat-Free (page loads of 10+ seconds). This was a disheartening start. Nevertheless, it didn't put me off — I tracked down the source of the crazy lag to a bug with Fat-Free's blacklist system, which I reported and submitted a patch for. A fix was committed the next day. How refreshing! Also felt pretty cool to be trying out a project where it's so new and experimental, you have to fix a bug before you can take it for a test drive.
Routing
As with every web framework, the page routing system is Fat-Free's absolute core functionality. Fat-Free makes excellent use of PHP 5.3's new JavaScript-like support for functions as first-class objects in its routing system (including anonymous functions). In a very Django-esque style, you can pass anonymous functions (along with regular functions and class methods) directly to Fat-Free's route() method (or you can specify callbacks with strings).
Wildcard and token support in routes is comparable to that of the Drupal 6 menu callback system, although routes in Fat-Free are not full-fledged regular expressions, and hence aren't quite as flexible as Django's URL routing system. There's also the ability to specify multiple callbacks/handlers for a single route. When you do this, all the handlers for that route get executed (in the order they're defined in the callback). This is an interesting feature, and it's actually one that I can think of several uses for in Django (in particular).
In the interests of RESTful-ness, Fat-Free has decided that HTTP request methods (GET, POST, etc) must be explicitly specified for every route definition. E.g. to define a simple GET route, you must write:
<?php
F3::route('GET /','home');
?>
I think that GET should be the default request method, and that you shouldn't have to explicitly specify it for every route in your site. Or (in following Django's "configuration over convention" rule, which Fat-Free also espouses), at least have a setting variable called DEFAULT_REQUEST_METHOD, which itself defaults to GET. There's also much more to RESTful-ness than just properly using HTTP request methods, including many aspects of the response — HTTP response codes, MIME types, and XML/JSON response formats spring to mind as the obvious ones. And Fat-Free offers no help for these aspects, per se (although PHP does, for all of them, so Fat-Free doesn't really need to).
Templates
Can't say that Fat-Free's template engine has me over the moon. Variable passing and outputting is simple enough, and the syntax (while a bit verbose) is passable. The other key elements (described below) would have to be one of Fat-Free's weaker points.
Much like Django (and in stark contrast to Drupal), Fat-Free has its own template parser built-in, and you cannot execute arbitrary PHP within a template. In my opinion, this is a good approach (and Drupal's approach is a mess). However, you can more-or-less directly execute a configurable subset of PHP core functions, with Fat-Free's allow() method. You can, for example, allow all date and pcre functions to be called within templates, but nothing else. This strikes me as an ugly compromise: a template engine should either allow direct code execution, or it shouldn't (and I'd say that it always shouldn't). Seems like a poor substitute for a proper, Django-style custom filter system (which Fat-Free is lacking). Of course, Django's template system isn't perfect, either.
Fat-Free's template "directives" (include, exclude, check, and repeat) have an ugly, XML-style syntax. Reminds me of the bad old XTemplate days in Drupal theming. This is more a matter of taste, but nevertheless, I feel that the reasoning behinnd XML-style template directives is flawed (allows template markup to be easily edited in tools like Dreamweaver … *shudder*), and that the reasoning behind custom-style template directives is valid (allows template directives to be clearly distinguished from markup in mostgoodtext editors). What's more, the four directives are hard-coded into Fat-Free's serve() function — no chance whatsoever of having custom directives. Much like the function-calling in templates, this seems like a poor substitue for a proper, Django-style custom tag system.
ORM
Straight off the bat, my biggest and most obvious criticism of Axon, the Fat-Free ORM, is that it has no model classes as such, and that it has no database table generation based on model classes. All that Axon does is generate a model class that corresponds to a simple database table (which it analyses on-the-fly). You can subclass Axon, and explicitly define model classes that way — although with no field types as such, there's little to be gained. This is very much Axon's greatest strength (so simple! no cruft attached!) and its greatest weakness (makes it so bare-bones, it only just meets the definition of an ORM). Axon also makes no attempt to support relationships, and the front-page docs justify this pretty clearly:
Axon is designed to be a record-centric ORM and does not pretend to be more than that … By design, the Axon ORM does not provide methods for directly connecting Axons to each other, i.e. SQL joins – because this opens up a can of worms.
Axon pretty much does nothing but let you CRUD a single table. It can be wrangled into doing some fancier things — e.g. the docs have an example of creating simple pagination using a few lines of Axon code — but not a great deal. If you need more than that, SQL is your friend. Personally, I agree with the justification, and I think it's a charming and well-designed micro-ORM.
Bells and whistles
Page cache: Good. Just specify a cache period, in seconds, as an argument to route(). Pages get cached to a file server-side (by default — using stream wrappers, you could specify pretty much any "file" as a cache source). Page expiry also gets set as an HTTP response header.
Query cache: Good. Just specify a cache period, in seconds, when calling sql(). Query only gets executed once in that time frame.
JS and CSS compressor: Good. Minifies all files you pass to it. Drupal-style.
GZip: all responses are GZipped using PHP's built-in capabilities, whenever possible. Also Drupal-style.
XML sitemap: Good. Super-light sitemap generator. Incredible that in such a lightweight framework, this comes bundled (not bundled with Drupal, although it is with Django). But, considering that every site should have one of these, this is very welcome indeed.
Image resizing: Good. Drupal 7 will finally bundle this (still an add-on in Django). This is one thing, more than perhaps anything else, that gets left out of web frameworks when it shouldn't be. In Fat-Free, thumb() is your friend.
HTTP request utility: Good. Analogous to drupal_http_request(), and similar stuff can be done in Django with Python's httplib/urllib. Server-side requests, remote service calls, here we come.
Static file handler: Good. Similar to Drupal's private file download mode, and (potentially) Django's static media serving. Not something you particularly want to worry about as a developer.
Benchmarking: Good. profile() is your friend. Hopefully, your Fat-Free apps will be so light, that all this will ever do is confirm that everything's lightning-fast.
Throttle: Good. This was removed from Drupal core, and it's absent entirely from Django. Another one of those things that you wouldn't be thinking about for every lil web project, but that could come in pretty handy for your next DDoS incident.
Unit testing: Good. This framework is tiny, but it still has pretty decent unit test support. In contrast to the Drupal 6 to 7 bloat, this just goes to show that unit testing support doesn't have to double your framework's codebase.
Debug / production modes: Good. For hiding those all-too-revealing error messages, mainly.
Error handling: Good. Default 404 / etc callback, can be customised.
Autoload: OK. Very thin wrapper around PHP 5.3's autoloading system. Not particularly needed, since autoload is so quick and easy anyway.
Form handler: OK. Basic validation system, value passing system, and sanitation / XSS protection system. Nice that it's light, but I can't help but yearn for a proper API, like what Drupal or Django has.
Captcha: OK. But considering that the usefulness and suitability of captchas is being increasingly questioned these days, seems a strange choice to include this in such a lightweight framework. Not bundled with Drupal or Django.
Spammer blacklisting: Seems a bit excessive, having it built-in to the core framework that all requests are by default checked against a third-party spam blacklist database. Plus, wasn't until my patch that the EXEMPT setting was added for 127.0.0.1. Nevertheless, this is probably more of a Good Idea™ than it is anything bad.
Fake images: Gimmick, in my opinion. Useful, sure. But really, creating a div with fixed dimensions, specifying fixed dimensions for an existing image, or even just creating real images manually — these are just some of your other layout testing options available. Also, you'll want to create your own custom 'no image specified' image for most sites anyway.
Identicons: Total gimmick. I've never built a site with these (actually, I've never even heard the word 'identicon' before). Total waste of 134 lines of code (but hey, at least it's only 134 — after all, this is Fat-Free).
What's missing?
Apart from the issues that I've already mentioned about various aspects of Fat-Free (e.g. with the template engine, with the form handler, with the ORM), the following things are completely absent from Fat-Free, and they're present in both Drupal and Django, and in my opinion they're sorely missed:
Authentication
Session management
E-mail sending utility
File upload / storage utility
Link / base URL / route reverse utility
CSRF protection
Locales / i18n
Admin interface
RSS / Atom
The verdict
Would I use it for a real project? Probably not.
I love that it's so small and simple. I love that it assists with so many useful tasks in such a straightforward way.
But.
It's missing too many things that I consider essential. Lack of authentication and session management is a showstopper for me. Sure, there are some projects where these things aren't needed at all. But if I do need them, there's no way I'm going to build them myself. Not when 10,000 other frameworks have already built them for me. Same with e-mail sending. No way that any web developer, in the year 2010, should be expected to concern his or her self with MIME header, line ending, or encoding issues.
It's not flexible or extensible enough. A template engine that supports 4 tags, and that has no way of supporting more, is really unacceptable. An ORM that guesses my table structure, and that has no way of being corrected if its guess is wrong, is unacceptable.
It includes some things that are just stupid. I'm sorry, but I'd find it very hard to use a framework that had built-in identicon generation, and to still walk out my front door every day and hold my head up proudly as a mature and responsible developer. OK, maybe I'm dramatising a bit there. But, seriously … do I not have a point?
Its coding style bothers me. In particular, I've already mentioned my qualms re: the XML-style templating. The general PHP 5.3 syntax doesn't particularly appeal to me, either. I've been uninspired for some time by the C++-style :: OO syntax that was introduced in PHP 5.0. Now, the use of the backslash character as a namespace delimiter is the icing on the cake. Yuck! Ever heard of the dot character, PHP? They're used for namespaces / packages in every other programming language in the 'hood. Oh, that's right, you can't use the dot, because it's your string concatenation operator (gee, wasn't that a smart move?). And failing the dot, why the backslash? Could you not have at least used the forward slash instead? Or do you prefer specifying your paths MS-DOS style? Plus the backslash is the universal escaping operator within string literals.
I'm a big fan of the new features in PHP 5.3. However, that doesn't change the fact that those features have already existed for years in other languages, and with much more elegant syntax. I've been getting much more into Python of late, and having become fairly accustomed by now with that elusive, almost metaphysical ideal of "Pythonic code", what I've observed with PHP 5.3 in Fat-Free is really not impressing me.
]]>
Generating unique integer IDs from strings in MySQL2010-03-19T00:00:00Z2010-03-19T00:00:00ZJazahttps://greenash.net.au/thoughts/2010/03/generating-unique-integer-ids-from-strings-in-mysql/
I have an interesting problem, on a data migration project I'm currently working on. I'm importing a large amount of legacy data into Drupal, using the awesome Migrate module (and friends). Migrate is a great tool for the job, but one of its limitations is that it requires the legacy database tables to have non-composite integer primary keys. Unfortunately, most of the tables I'm working with have primary keys that are either composite (i.e. the key is a combination of two or more columns), or non-integer (i.e. strings), or both.
Table with composite primary key.
The simplest solution to this problem would be to add an auto-incrementing integer primary key column to the legacy tables. This would provide the primary key information that Migrate needs in order to do its mapping of legacy IDs to Drupal IDs. But this solution has a serious drawback. In my project, I'm going to have to re-import the legacy data at regular intervals, by deleting and re-creating all the legacy tables. And every time I do this, the auto-incrementing primary keys that get generated could be different. Records may have been deleted upstream, or new records may have been added in between other old records. Auto-increment IDs would, therefore, correspond to different composite legacy primary keys each time I re-imported the data. This would effectively make Migrate's ID mapping tables corrupt.
A better solution is needed. A solution called hashing! Here's what I've come up with:
Remove the legacy primary key index from the table.
Create a new column on the table, of type BIGINT. A MySQL BIGINT field allocates 64 bits (8 bytes) of space for each value.
If the primary key is composite, concatenate the columns of the primary key together (optionally separated by a delimiter).
Calculate the SHA1 hash of the concatenated primary key string. An SHA1 hash consists of 40 hexadecimal digits. Since each hex digit stores 24 different values, each hex digit requires 4 bits of storage; therefore 40 hex digits require 160 bits of storage, which is 20 bytes.
Convert the numeric hash to a string.
Truncate the hash string down to the first 16 hex digits.
Convert the hash string back into a number. Each hex digit requires 4 bits of storage; therefore 16 hex digits require 64 bits of storage, which is 8 bytes.
Convert the number from hex (base 16) to decimal (base 10).
Store the decimal number in your new BIGINT field. You'll find that the number is conveniently just small enough to fit into this 64-bit field.
Now that the new BIGINT field is populated with unique values, upgrade it to a primary key field.
Add an index that corresponds to the legacy primary key, just to maintain lookup performance (you could make it a unique key, but that's not really necessary).
Table with integer primary key.
The SQL statement that lets you achieve this in MySQL looks like this:
ALTER TABLE people DROP PRIMARY KEY;
ALTER TABLE people ADD id BIGINT UNSIGNED NOT NULL FIRST;
UPDATE people SET id = CONV(SUBSTRING(CAST(SHA(CONCAT(name, ',', city)) AS CHAR), 1, 16), 16, 10);
ALTER TABLE people ADD PRIMARY KEY(id);
ALTER TABLE people ADD INDEX (name, city);
Note: you will also need to alter the relevant migrate_map_X tables in your database, and change the sourceid and destid fields in these tables to be of type BIGINT.
Hashing has a tremendous advantage over using auto-increment IDs. When you pass a given string to a hash function, it always yields the exact same hash value. Therefore, whenever you hash a given string-based primary key, it always yields the exact same integer value. And that's my problem solved: I get constant integer ID values each time I re-import my legacy data, so long as the legacy primary keys remain constant between imports.
Storing the 64-bit hash value in MySQL is straightforward enough. However, a word of caution once you continue on to the PHP level: PHP does not guarantee to have a 64-bit integer data type available. It should be present on all 64-bit machines running PHP. However, if you're still on a 32-bit processor, chances are that a 32-bit integer is the maximum integer size available to you in PHP. There's a trick where you can store an integer of up to 52 bits using PHP floats, but it's pretty dodgy, and having 64 bits guaranteed is far preferable. Thankfully, all my environments for my project (dev, staging, production) have 64-bit processors available, so I'm not too worried about this issue.
I also have yet to confirm 100% whether 16 out of 40 digits from an SHA1 hash is enough to guarantee unique IDs. In my current legacy data set, I've applied this technique to all my tables, and haven't encountered a single duplicate (I also experimented briefly with CRC32 checksums, and very quickly ran into duplicate ID issues). However, that doesn't prove anything — except that duplicate IDs are very unlikely. I'd love to hear from anyone who has hard probability figures about this: if I'm using 16 digits of a hash, what are the chances of a collision? I know that Git, for example, stores commit IDs as SHA1 hashes, and it lets you then specify commit IDs using only the first few digits of the hash (e.g. the first 7 digits is most common). However, Git makes no guarantee that a subset of the hash value is unique; and in the case of a collision, it will ask you to provide enough digits to yield a unique hash. But I've never had Git tell me that, as yet.
]]>
Haiti coverage in OpenStreetMap vs Google Maps2010-03-11T00:00:00Z2010-03-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2010/03/haiti-coverage-in-openstreetmap-vs-google-maps/
I was recently reading about how OpenStreetMap has been helping the Haiti relief effort, in the wake of the devastating earthquake that hit Haiti's capital back in January. Being one of the poorest and least developed countries in the world, Haiti's map coverage is very poor. However, a group of volunteers have radically changed that, and this has directly helped the aid effort on the ground in Haiti.
To see just how effective this volunteer mapping effort has been, I decided to do a quick visual comparison experiment. As of today, here's what downtown Port-au-Prince looks like in Google Maps:
Port-au-Prince in Google Maps
And here it is in OpenStreetMap:
Port-au-Prince in OpenStreetMap
Is that not utterly kick-a$$? Google may be a great company with wonderful ideas, but even the Internet's biggest player (and the current leader in online mapping) simply cannot compete with the speed and the effectiveness that the OSM Haiti crisis project has demonstrated.
For those of you that aren't aware, OpenStreetMap is a map of the world that anyone can contribute to — the Wikipedia of online maps. This Haiti mapping effort is of course a massive help to the aid workers who are picking up the broken pieces of that country. But it's also testament to the concept that free and open data — coupled with a willingness to contribute — is not only feasible, it's also superior to commercial efforts (when push comes to quake).
]]>
Refugee Buddy: a project of OzSiCamp Sydney 20102010-03-10T00:00:00Z2010-03-10T00:00:00ZJazahttps://greenash.net.au/thoughts/2010/03/refugee-buddy-a-project-of-ozsicamp-sydney-2010/
Last weekend, I attended Social Innovation Camp Sydney 2010. SiCamp is an event where several teams have one weekend in which to take an idea for an online social innovation technology, and to make something of it. Ideally, the technology gets built and deployed by the end of the camp, but if a team doesn't reach that stage, simply developing the concept is an acceptable outcome as well.
I was part of a team of seven (including our team leader), and we were the team that built Refugee Buddy. As the site's slogan says: "Refugee Buddy is a way for you to welcome people to your community from other cultures and countries." It allows regular Australians to sign up and become volunteers to help out people in our community who are refugees from overseas. It then allows refugee welfare organisations (both governmnent and independent) to search the database of volunteers, and to match "buddies" with people in need.
Of the eight teams present at this OzSiCamp, we won! Big congratulations to everyone on the team: Oz, Alex, James, Daniela, Tom, (and Jeremy — that's me!) and most of all Joy, who came to the camp with a great concept, and who provided sound leadership to the rest of us. Personally, I really enjoyed working on Refugee Buddy, and I felt that the team had a great vibe and the perfect mix of skills.
OzSiCamp Sydney 2010 was the first "build a site in one weekend" event in which I've participated. It was hectic, but fun. I may have overdosed on Mentos refreshments on the Saturday night (in fact, I never want to eat another Mentos again). All up, I think it was a great experience — and in our case, one with a demonstrable concrete result — and I hope to attend similar events in the future.
For building Refugee Buddy, our team decided to use Django, a Python web framework. This was basically the decision of Oz and myself: we were the two programmers on the team; and we both have solid experience with developing sites in Django, primarily from using it at Digital Eskimo (where we both work). Oz is a Django junkie; and I've been getting increasingly proficient in it. Other teams built their sites using Ruby on Rails, Drupal, MediaWiki, and various other platforms.
Going with a Django team rather than a Drupal team (and pushing for Django rather than Drupal) was a step in a new direction for me. It surprised my fellow members of the Sydney Drupal community who were also in attendance. And, to tell the truth, I also surprised myself. Anyway, I think Django was a superior match for the project compared to Drupal, and the fact that we were able to build the most fully-functioning end product out of all the teams, pretty much speaks for itself.
Refugee Buddy is an open source project, and the full code is available on GitHub. Feel free to get involved: we need design and dev help for the long-term maintenance and nurturing of the site. But most of all, I encourage you all to visit Refugee Buddy, and to sign up as a buddy.
]]>
Media through the ages2009-12-30T00:00:00Z2009-12-30T00:00:00ZJazahttps://greenash.net.au/thoughts/2009/12/media-through-the-ages/
The 20th century was witness to the birth of what is arguably the most popular device in the history of mankind: the television. TV is a communications technology that has revolutionised the delivery of information, entertainment and artistic expression to the masses. More recently, we have all witnessed (and participated in) the birth of the Internet, a technology whose potential makes TV pale into insignificance in comparison (although, it seems, TV isn't leaving us anytime soon). These are fast-paced and momentous times we live in. I thought now would be a good opportunity to take a journey back through the ages, and to explore the forms of (and devices for) media and communication throughout human history.
Our journey begins in prehistoric times, (arguably) before man even existed in the exact modern anatomical form that all humans exhibit today. It is believed that modern homo sapiens emerged as a distinct genetic species approximately 200,000 years ago, and it is therefore no coincidence that my search for the oldest known evidence of meaningful human communication also brought me to examine this time period. Evidence suggests that at around this time, humans began to transmit and record information in rock carvings. These are also considered the oldest form of human artistic expression on the planet.
From that time onwards, it's been an ever-accelerating roller-coaster ride of progress, from prehistoric forms of media such as cave painting and sculpture, through to key discoveries such as writing and paper in the ancient world, and reaching an explosion of information generation and distribution in the Renaissance, with the invention of the printing press in 1450AD. Finally, the modern era of the past two centuries has accelerated the pace to dizzying levels, beginning with the invention of the photograph and the invention of the telegraph in the early 19th century, and culminating (thus far) with mobile phones and the Internet at the end of the 20th century.
List of communication milestones
I've done some research in this area, and I've compiled a list of what I believe are the most significant forms of communication or devices for communication throughout human history. You can see my list in the table below. I've also applied some categorisation to each item in the list, and I'll discuss that categorisation shortly.
Note: pre-modern dates are approximations only, and are based on the approximations of authoritative sources. For modern dates, I have tried to give the date that the device first became available to (and first started to be used by) the general public, rather than the date the device was invented.
Directionality and preservation
My categorisation system in the list above is loosely based on coolscorpio's types of communication. However, I have used the word "directionality" to refer to his "downward, upward and lateral communication"; and I have used the word "preservation" and the terms "transient and permanent" to refer to his "oral and written communication", as I needed terms more generic than "oral and written" for my data set.
Preservation of information is something that we've been thinking about as a species for an awfully long time. We've been able to record information in a permanent, durable form, more-or-less for as long as the human race has existed. Indeed, if early humans hadn't found a way to permanently preserve information, then we'd have very little evidence of their being able to conduct advanced communication at all.
Since the invention of writing, permanent preservation of information has become increasingly widespread*. However, oral language has always been our richest and our most potent form of communication, and it hasn't been until modern times that we've finally discovered ways of capturing it; and even to this very day, our favourite modern oral communication technology — the telephone — remains essentially transient and preserves no record of what passes through it.
Directionality of communication has three forms: from a small group of people (often at the "top") down to a larger group (at the "bottom"); from a large group up to a small one; and between any small groups in society laterally. Human history has been an endless struggle between authority and the masses, and that struggle is reflected in the history of human communication: those at the top have always pushed for the dominance of "down" technologies, while those at the bottom have always resisted, and have instead advocated for more neutral technologies. From looking at the list above, we can see that the dominant communications technologies of the time have had no small effect on the strength of freedom vs authority of the time.
Prehistoric human society was quite balanced in this regard. There were a number of powerful forms of media that only those at the top (i.e. chiefs, warlords) had practical access to. These were typically the more permanent forms of media, such as the paintings on the cave walls. However, oral communication was really the most important media of the time, and it was equally accessible to all members of society. Additionally, societies were generally grouped into relatively small tribes and clans, leaving less room for layers of authority between the top and bottom ranks.
The ancient world — the dawn of human "civilisation" — changed all this. This era brought about three key communications media that were particularly well-suited to a "down" directionality, and hence to empowering authority above the common populace: megalithic architecture (technically pre-ancient, but only just); metallurgy; and writing. Megalithic architecture allowed kings and Pharoahs to send a message to the world, a message that would endure the sands of time; but it was hardly a media accessible to all, as it required armies of labourers, teams of designers and engineers, as well as hordes of natural and mineral resources. Similarly, metallurgy's barrier to access was the skilled labour and the mineral resources required to produce it. Writing, today considered the great enabler of access to information and of global equality, was in the ancient world anything but that, because all but the supreme elite were illiterate, and the governments of the day wanted nothing more but to maintain that status quo.
Gutenberg's invention of the printing press in 1450 AD is generally considered to be the most important milestone in the history of human communication. Most view it purely from a positive perspective: it helped spread literacy to the masses; and it allowed for the spread of knowledge as never before. However, the printing press was clearly a "down" technology in terms of directionality, and this should not be overlooked. To this very day, access to mass printing and distribution services is a privilege available only to those at the very top of society, and it is a privilege that has been consistently used as a means of population control and propaganda. Don't get me wrong, I agree with the general consensus that the positive effects of the printing press far outweigh its downside, and I must also stress that the printing press was an essential step in the right direction towards technologies with more neutral directionality. But essentially, the printing press — the key device that led to the dawn of the Renaissance — only served to further entrench the iron fist of authority that saw its birth in the ancient world.
Modern media technology has been very much a mixed bag. On the plus side, there have been some truly direction-neutral communication tools that are now accessible to all, with photography, video-recording, and sound-recording technologies being the most prominent examples. There is even one device that is possibly the only pure lateral-only communication tool in the history of the world, and it's also become one of the most successful and widespread tools in history: the telephone. On the flip side, however, the modern world's two most successful devices are also the most sinister, most potent "down" directionality devices that humanity has ever seen: TV and radio.
The television (along with film and the cinema, which is also a "down" form of media) is the defining symbol of the 20th century, and it's still going strong into the 21st. Unfortunately, the television is also the ultimate device allowing one-way communication from those at the top of society, to those at the bottom. By its very definition, television is "broadcast" from the networks to the masses; and it's quite literally impossible for it to allow those at the receiving end to have their voices heard. What the Pyramids set in stone before the ancient masses, and what the Gutenberg bibles stamped in ink before the medieval hordes, the television has now burned into the minds of at least three modern generations.
The Internet, as you should all know by now, is changing everything. However, the Internet is also still in its infancy, and the Internet's fate in determining the directionality of communication into the next century is still unclear. At the moment, things look very positive. The Internet is the most accessible and the most powerful direction-neutral technology the world has ever seen. Blogging (what I'm doing right now!) is perhaps the first pure "up" directionality technology in the history of mankind, and if so, then I feel privileged to be able to use it.
The Internet allows a random citizen to broadcast a message to the world, for all eternity, in about 0.001% of the time that it took a king of the ancient world to deliver a message to all the subjects of his kingdom. I think That's Cool™. But the question is: when every little person on the planet is broadcasting information to the whole world, who does everyone actually listen to? Sure, there are literally millions of personal blogs out there, much like this one; and anyone can look at any of them, with just the click of a button, now or 50 years from now (50 years… at least, that's the plan). But even in an information ecosystem such as this, it hasn't taken long for the vast majority of people to shut out all sources of information, save for a select few. And before we know it — and without even a drop of blood being shed in protest — we're back to 1450 AD all over again.
It's a big 'Net out there, people. Explore it.
* Note: I've listed television and radio as being "permanent" preservation technologies, because even though the act of broadcasting is transient, the vast majority of television and radio transmissions throughout modern times have been recorded and formally archived.
]]>
What are fossil fuels?2009-10-25T00:00:00Z2009-10-25T00:00:00ZJazahttps://greenash.net.au/thoughts/2009/10/what-are-fossil-fuels/
Let me begin with a little bit of high school revision. Fossil fuels are composed primarily of carbon and hydrogen. There are basically three types of fossil fuels on Earth: coal, oil, and natural gas. It's common knowledge that fossil fuels are the remains of prehistoric plants and animals. That's why they're called "fossil fuels" (although they're not literally made from prehistoric bones, or at least not in any significant amount). Over a period of millions of years, these organic remains decomposed, and they got buried deep beneath rock and sea beds. A combination of heat and pressure caused the organic material to chemically alter into the fuel resources that we're familiar with today. The fuels became trapped between layers of rock in the Earth's geological structure, thus preserving them and protecting them from the elements up to the present day.
Hang on. Let's stop right there. Fossil fuels are dead plants and animals. And we burn them in order to produce the energy that powers most of our modern world (86% of it, to be precise). In other words, modern human civilisation depends (almost exclusively) upon the incineration of the final remains of some of the earliest life on Earth. In case there weren't enough practical reasons for us to stop burning fossil fuels, surely that's one hell of a philosophical reason. Wouldn't you say so?
The term "fossil fuels" seems to be bandied about more and more casually all the time. World energy is built upon fossil fuels, and this is of course a massive problem for a number of practical reasons. We should all be familiar by now with these reasons: they're a non-renewable source of energy; they're a major source of greenhouse gas emissions (and hence a major contributor to global warming); and they generate toxic air and water pollution. However, we seldom seem to stop and simply think about the term "fossil fuels" itself, and what it means.
The various fossil fuels trace their origins back to anywhere between 60 million and 300 million years ago. Coal is generally considered to be the older of the fuels, with most of it having formed 300 to 350 million years ago during the Carboniferous period (the period itself is named after coal). 300 million years ago, life on Earth was very different to how it looks today. Most of the world was a giant swamp. Continents were still unstable and were entirely unrecognisable from their present shapes and positions. And life itself was much more primitive: the majority of lifeforms were simple microscopic organisms such as phytoplankton; plants were dominated by ferns and algae (flowers weren't yet invented); terrestrial animals were limited to small reptiles and amphibians (the long-lost ancestors of those we know today); and only fish had reached a relatively more advanced state of evolution. Birds and mammals wouldn't be invented for quite a few more million years.
Coal is believed to be composed of the remains of all of these lifeforms, to some extent. The largest component of most coal is either plant matter, or the remains of microscopic organisms; however, the primitive animals of the Carboniferous period are no doubt also present in smaller quantities.
Oil and natural gas — which are typically formed and are found together — are believed on the whole to have formed much later, generally around 60 million years ago. Like coal, oil and natural gas are composed primarily of plant matter and of microscopic organisms (with both being more of marine origin for oil and natural gas than for coal). It's a popular belief that oil contains the decomposed remains of the dinosaurs; and while this is probably true to some extent, the reality is that dinosaurs and other complex animals of the time are probably only present in very small quantities in oil.
So, all of the three fossil fuels contain the remains of dead plants and animals, but:
the remains contain far more plant (and microscopic organism) matter than they do animal matter;
the remains have been chemically altered, to the extent that cell structures and DNA structures are barely present in fossil fuels; and
most of the lifeforms are from a time so long ago that they'd be virtually unrecognisable to us today anyway.
And does that matter? Does that in any way justify the fact that we're incinerating the remains of ancient life on Earth? Does that change the fact that (according to the theory of evolution) we're incinerating our ancestors to produce electricity and to propel our cars?
I don't think so. Life is life. And primitive / chemically altered or not, fossil fuels were not only life, they were the precursor to our own life, and they were some of the first true lifeforms ever to dwell on this planet. I don't know about you, but I believe that the remains of such lifeforms deserve some respect. I don't think that a coal-fired power station is an appropriate final destination for such remains. Carboniferous life is more than simply historic, it is prehistoric. And prehistoric life is something that we should handle with dignity and care. It's not a resource. It's a sacred relic of a time older than we can fathom. Exploiting and recklessly destroying such a relic is surely a bad omen for our species.
]]>
jQuery text separator plugin2009-07-10T00:00:00Z2009-07-10T00:00:00ZJazahttps://greenash.net.au/thoughts/2009/07/jquery-text-separator-plugin/
For my premiere debút into the world of jQuery plugin development, I've written a little plugin called text separator. As I wrote on its jQuery project page, this plugin:
Lets you separate a text field into two parts, by dragging a slider to the spot at which you want to split the text. This plugin creates a horizontal slider above a text field. The handle on that slider is as long as its corresponding text field, and its handle 'snaps' to the delimiters in that text field (which are spaces, by default). With JS disabled, your markup should degrade gracefully to two separate text fields.
This was designed for allowing users to enter their 'full name' in one input box. The user enters their full name, and then simply drags the slider in order to mark the split betwen their first and last names. While typing, the slider automatically drags itself to the first delimiter in the input box.
Want to take it for a spin? Try a demo. You'll see something like this:
Text separator screenshot
This plugin isn't being used on any live site just yet, although I do have a project in the pipeline that I hope to use it with (more details on that at some unspecified future time). As far as I know, there's nothing else out there that does quite what this plugin lets you do. But please, don't hesitate to let me know if I'm mistaken in that regard.
The way it works is a little unusual, but simple enough once you get your head around it. The text that you type into the box is split (by delimiter) into "chunks". A hidden span is then created for each chunk, and also for each delimiter found. These hidden spans have all their font attributes set to match those of the input box, thus ensuring that each span is exactly the same size as its corresponding input box text. The spans are absolutely positioned beneath the input box. This is the only way (that I could find) of calculating the width in pixels of all or part of the text typed into an input box.
The max range value for the slider is set to the width of the input box (minus any padding it may have). Then, it's simply a matter of catching / triggering the slider handle's "change" event, and of working out the delimiter whose position is nearest to the position that the handle was moved to. Once that's done, the handle is "snapped" to that delimiter, and the index of the delimiter in question is recorded.
Text separator is designed to be applied to a div with two form <input type="text" /> elements inside it. It transforms these two elements into a single input box with a slider above it. It converts the original input boxes into hidden fields. It also copies the split values back into those hidden fields whenever you type into the box (or move the slider). This means that when you submit the form, you get the same two separate values that you'd expect were the plugin not present. Which reminds me that I should also say: without JS, the page degrades to the two separate input boxes that are coded into the HTML. Try it out for yourself on the demo page (e.g. using the "disable all JavaScript" feature of the Firefox Web Developer addon).
This first version of text separator still has a few rough edges. I really haven't tested how flexible it is just yet, in terms of either styling or behaviour — it probably needs more things pulled out of their hard-coded state, and moved into config options. It still isn't working perfectly on Internet Explorer (surprise!): the hidden spans don't seem to be getting the right font size, and so the position that the slider snaps to isn't actually corresponding to the position of the delimiters. Also a bit of an issue with the colour of the input box in Safari. Feedback and patches are welcome, preferably on the plugin's jQuery project page.
In terms of what text separator can do for the user experience and the usability of a web form, I'd also appreciate your feedback. Personally, I really find that it's a pain to have to enter your first and last names into separate text fields, on the registration forms of many sites. I know that personally, I would prefer to enter my full name into a text separator-enabled form. Am I on the right track? Will a widget like this enhance or worsen something like a registration form? Would you use it on such forms for your own sites? And I'd also love to hear your ideas about what other bits of data this plugin might be useful for, apart from separating first and last names.
I hope that you find this plugin useful. Play on.
]]>
Hook soup2009-06-17T00:00:00Z2009-06-17T00:00:00ZJazahttps://greenash.net.au/thoughts/2009/06/hook-soup/
Of late, I seem to keep stumbling upon Drupal hooks that I've never heard of before. For example, I was just reading a blog post about what you can't modify in a _preprocess() function, when I saw mention of hook_theme_registry_alter(). What a mouthful. I ain't seen that one 'til now. Is it just me, or are new hooks popping up every second day in Drupal land? This got me wondering: exactly how many hooks are there in Drupal core right now? And by how much has this number changed over the past few Drupal versions? Since this information is conveniently available in the function lists on api.drupal.org, I decided to find out for myself. I counted the number of documented hook_foo() functions for Drupal core versions 4.7, 5, 6 and 7 (HEAD), and this is what I came up with (in pretty graph form):
Drupal hooks by core version
And those numbers again (in plain text form):
Drupal 4.7: 41
Drupal 5: 53
Drupal 6: 72
Drupal 7: 183
Aaaagggghhhh!!! Talk about an explosion — what we've got on our hands is nothing less than hook soup. The rate of growth of Drupal hooks is out of control. And that's not counting themable functions (and templates) and template preprocessor functions, which are the other "magically called" functions whose mechanics developers need to understand. And as for hooks defined by contrib modules — even were we only counting the "big players", such as Views — well, let's not even go there; it's really too massive to contemplate.
In fairness, there are a number of good reasons why the amount of hooks has gone up so dramatically in Drupal 7:
Splitting various "combo" hooks into a separate hook for each old $op parameter, the biggest of these being the death of hook_nodeapi()
The rise and rise of the _alter() hooks
Birth of fields in core
Birth of file API in core
Nevertheless, despite all these good reasons, the number of core hooks in HEAD right now is surely cause for concern. More hooks means a higher learning curve for people new to Drupal, and a lot of time wasted in looking up API references even for experienced developers. More hooks also means a bigger core codebase, which goes against our philosophy of striving to keep core lean, mean and super-small.
In order to get a better understanding of why D7 core has so many hooks, I decided to do a breakdown of the hooks based on their type. I came up with the "types" more-or-less arbitrarily, based on the naming conventions of the hooks, and also based on the purpose and the input/output format of each hook. The full list of hooks and types can be found further down. Here's the summary (in pretty graph form):
Hook breakdown by type
And those numbers again (in plain text form):
Type
No. of hooks
misc action
44
info
30
alter
27
delete
20
insert
13
load
12
update
10
validate
6
form
4
misc combo
4
prepare
4
view
4
presave
3
check
2
As you can see, most of the hooks in core are "misc action" hooks, i.e. they allow modules to execute arbitrary (or not-so-arbitrary) code in response to some sort of action, and that action isn't covered by the other hook types that I used for classification. For the most part, the misc action hooks all serve an important purpose; however, we should be taking a good look at them, and seeing if we really need a hook for that many different events. DX is a balancing act between flexibility-slash-extensibility, and flexibility-slash-extensibility overload. Drupal has a tendency to lean towards the latter, if left unchecked. Also prominent in core are the "info" and "alter" hooks which, whether they end in the respective _info or _alter suffixes or not, return (for info) or modify (for alter) a more-or-less non-dynamic structured array of definitions. The DX balancing act applies to these hooks just as strongly: do we really need to allow developers to define and to change that many structured arrays, or are some of those hooks never likely to be implemented outside of core?
I leave further discussion on this topic to the rest of the community. This article is really just to present the numbers. If you haven't seen enough numbers or lists yet, you can find some more of them below. Otherwise, glad I could inform you.
(D7 list accurate as of 17 Jun 2009; type breakdown for D7 list added arbitrarily by yours truly)
]]>
Installing the uploadprogress PECL extension on Leopard2009-05-28T00:00:00Z2009-05-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2009/05/installing-the-uploadprogress-pecl-extension-on-leopard/
The uploadprogress PECL extension is a PHP add-on that allows cool AJAX uploading like never before. Version 3 of Drupal's FileField module is designed to work best with uploadprogress enabled. As such, I found myself installing a PECL extension for the first time. No doubt, many other Drupal developers will soon be finding themselves in the same boat.
Unfortunately, for those of us on Mac OS X 10.5 (Leopard), installing uploadprogress ain't all smooth sailing. The problem is that the extension must be compiled from source in order to be installed; and on Leopard machines, which all run on a 64-bit processor, it must be compiled as a 64-bit binary. However, the gods of Mac (in their infinite wisdom) decided to include with Leopard (after Xcode is installed) a C compiler that still behaves in the old-school way, and that by default does its compilation in 32-bit mode. This is a right pain in the a$$, and if you're unfamiliar with the consequences of it, you'll likely see a message like this coming up in your Apache error log when you try to install uploadprogress and restart your server:
PHP Warning: PHP Startup: Unable to load dynamic library '/usr/local/php5/lib/php/extensions/no-debug-non-zts-20060613/uploadprogress.so' - (null) in Unknown on line 0
Hmmm… (null) in Unknown on line 0. WTF is that supposed to mean? (You ask). Well, it means that the extension was compiled for the wrong environment; and when Leopard tries to execute it, a low-level error called a segmentation fault occurs. In short, it means that your binary is $#%&ed.
But fear not, Leopard PHP developers! Here are some instructions for how to install uploadprogress by compiling it as a 64-bit binary:
Download and extract the latest tarball of the source code for uploadprogress.
If using the Entropy PHP package (which I would highly recommend for all Leopard users), follow the advice from this forum thread (2nd comment, by Taracque), and change all your php binaries in /usr/bin to be symlinks to the proper versions in /usr/local/php5/bin.
cd to the directory containing the extracted tarball that you downloaded, e.g. cd /download/uploadprogress-1.0.0
Type: sudo phpize
Analogous to these instructions on SOAP, type: MACOSX_DEPLOYMENT_TARGET=10.5 CFLAGS="-arch x86_64 -g -Os -pipe -no-cpp-precomp" CCFLAGS="-arch x86_64 -g -Os -pipe" CXXFLAGS="-arch x86_64 -g -Os -pipe" LDFLAGS="-arch x86_64 -bind_at_load" ./configure This is the most important step, so make sure you type it in correctly! (If you get any sort of "permission denied" errors with this, then type sudo su before running it, and type exit after running it).
Type: sudo make
Type: sudo make install
Add the line extension=uploadprogress.so to your php.ini file (for Entropy users, this can be found at /usr/local/php5/lib/php.ini )
Restart apache by typing: sudo apachectl restart
If all is well, then a phpinfo() check should output an uploadprogress section, with a listing for the config variables uploadprogress.file.contents_template, uploadprogress.file.filename_template, and uploadprogress.get_contents. Your Drupal status report should be happy, too. And, of course, FileField will totally rock.
]]>
Self-referencing symlinks can hang your IDE2009-04-15T00:00:00Z2009-04-15T00:00:00ZJazahttps://greenash.net.au/thoughts/2009/04/self-referencing-symlinks-can-hang-your-ide/
One of my current Drupal projects (live local) has been giving me a headache lately, due to a small but very annoying problem. My PHP development tools of choice, at the moment, are Eclipse PDT and TextMate. Both of these generally work great for me. I prefer TextMate if I have the choice (better config options + much more usable), but I switch to Eclipse whenever I need a good debugger (or a bit of contextual help / autocomplete). However, they haven't been working well for me in this case. Every time I try to load in the source code for this one particular project, the IDE either hangs indefinitely (in Eclipse), or it slows down to a crawl (in TextMate). I've been tearing my hair out, trying to work out the cause of this problem, which has forced me to edit individual files for several weeks, and which has meant that I can't have a debugger or an IDE workspace for this project. Finally, I've nailed it: self-referencing symlinks are the culprit.
The project is a Drupal multisite setup, and like most multisite setups, it uses a bunch of symlinks in order for multiple subdomains to share a single codebase. For each subdomain, I create a symlink that points to the directory in which it resides; in effect, each symlink points to itself. When Apache comes along, it treats a symlink as the "directory" for a subdomain, and it follows it. By the time Drupal is invoked, we're in the root of the Drupal codebase shared by all the subdomains. Everything works great. All our favourite friends throw a party. Champagne bottles pop.
The bash command to create the symlinks is pretty simple — for each symlink, it looks something like this:
ln -s . subdomain
Unfortunately, a symlink like this does not play well with certain IDEs that try to walk your filesystem. When they hit such a symlink, they get stuck infinitely recursing (or at least, they keep recursing for a long time before they give up). The solution? Simple: delete such symlinks from your development environment. If this is what's been dragging your system down, then removing them will instantly cure all your woes. For each symlink, deleting it is as simple as:
rm subdomain
(Don't worry, deleting a symlink doesn't also delete the thing that it's pointing at).
It seems obvious, now that I've worked it out; but this annoying "slow-down" of Eclipse and TextMate had me stumped for quite a while until today. I've only recently switched to Mac, and I've only made the switch because I'm working at Digital Eskimo, which is an all-out Mac shop. I'm a Windows user most of the time (God help me), and Eclipse on Windows never gave me this problem. I use the new Vista symbolic links functionality, which actually works great for me (and which is possibly the only good reason to upgrade from XP to Vista). Eclipse on Windows apparently doesn't try to follow Vista symlinks. This is probably why it took me so long so figure it out (that, and Murphy's Law) — I already had the symlinks when I started the project on Windows, and Eclipse wasn't hanging on me then.
I originally thought that the cause of the problem was Git. Live local is the first project that I've managed with Git, and I know that Git has a lot of metadata, as well as compressed binary files for all the non-checked-out branches and tags of a repository. These seemed likely candidates for making Eclipse and TextMate crash, especially since neither of these tools have built-in support for Git. But I tried importing the project without any Git metadata, and it was still hanging forever. I also thought maybe it was some of the compressed JavaScript in the project that was to blame (e.g. jQuery, TinyMCE). Same story: removing the compressed JS files and importing the directory was still ridiculoualy slow.
IDEs should really be smart enough to detect self-referencing or cyclic symlinks, and to stop themselves from recursing infinitely over them. There is actually a bug filed for TextMate already, so maybe this will be fixed in future versions of TextMate. Couldn't find a similar bug report for Eclipse. Anyway, for now, you'll just have to be careful when using symlinks in your (Drupal or other) development environment. If you have symlinks, and if your IDE is crashing, then try taking out the symlinks, and see if all becomes merry again. Also, I'd love to hear if other IDEs handle this better (e.g. Komodo, PHPEdit), or if they crash just as dismally when faced with symlinks that point to themselves.
]]>
Deployment and migration: hot at DrupalCon DC2009-03-19T00:00:00Z2009-03-19T00:00:00ZJazahttps://greenash.net.au/thoughts/2009/03/deployment-and-migration-hot-at-drupalcon-dc/
There was no shortage of kick-a$$ sessions at the recent DrupalCon DC. The ones that really did it for me, however, were those that dealt with the thorny topic of deployment and migration. This is something that I've been thinking about for quite a long time, and it's great to see that a lot of other Drupal people have been doing likewise.
The thorniness of the topic is not unique to Drupal. It's a tough issue for any system that stores a lot of data in a relational database. Deploying files is easy: because files can be managed by anynumber of modern VCSes, it's a snap to version, to compare, to merge and to deploy them. But none of this is easily available when dealing with databases. The deployment problem is similar for all of the popular open source CMSes. There are also solutions available for many systems, but they tend to vary widely in their approach and in their effectiveness. In Drupal's case, the problem is exacerbated by the fact that a range of different types of data are stored together in the database (e.g. content, users, config settings, logs). What's more, different use cases call for different strategies regarding what to stage, and what to "edit live".
Context, Spaces and Exportables
The fine folks from Development Seed gave a talk entitled: "A Paradigm for Reusable Drupal Features". I understand that they first presented the Context and Spaces modules about six months ago, back in Szeged. At the time, these modules generated quite a buzz in the community. Sadly, I wasn't able to make it to Szeged; just as well, then, that I finally managed to hear about them in DC.
Context and Spaces alone don't strike me as particularly revolutionary tools. The functionality that they offer is certainly cool, and it will certainly change the way we make Drupal sites, but I heard several people at the conference describe them as "just an alternative to Panels", and I think that pretty well sums it up. These modules won't rock your world.
Exportables, however, will.
The concept of exportables is simply the idea that any piece of data that gets stored in a Drupal database, by any module, should be able to be exported as a chunk of executable PHP code. Just think of the built-in "export" feature in Views. Now think of export (and import) being as easy as that for any Drupal data — e.g. nodes, users, terms, even configuration variables. Exportables isn't an essential part of the Context and Spaces system, but it has been made an integral part of it, because Context and Spaces allows for most data entities in core to be exported (and imported) as exportables, and because Context and Spaces wants all other modules to similarly allow for their data entities to be handled as exportables.
The "exportables" approach to deployment has these features:
The export code can be parsed by PHP, and can then be passed directly to Drupal's standard foo_save() functions on import. This means minimal overhead in parsing or transforming the data, because the exported code is (literally) exactly what Drupal needs in order to programmatically restore the data to the database.
Raw PHP code is easier for Drupal developers to read and to play with than YetAnotherXMLFormat or MyStrangeCustomTextFormat.
Exportables aren't tied directly to Drupal's database structure — instead, they're tied to the accepted input of its standard API functions. This makes the exported data less fragile between Drupal versions and Drupal instances, especially compared to e.g. raw SQL export/import.
Exportables generally rely on data entities that have a unique string identifier. This makes them difficult to apply, because most entities in Drupal's database currently only have numeric IDs. Numeric, auto-incrementing IDs are hard for exportables to deal with, because they cause conflict when deploying data from one site to another (numeric IDs are not unique between Drupal instances). The solution to this is to encourage the wider use of string-based, globally unique IDs in Drupal.
Exportables can be exported to files, which can then be managed using a super-cool VCS, just like any other files.
Using exportables as a deployment and migration strategy for Drupal strikes me as ingenious in its simplicity. It's one of those solutions that it's easy to look at, and say: "naaaaahhhh… that's too simple, it's not powerful enough"; whereas we should instead be looking at it, and saying: "woooaaahhh… that's so simple, yet so powerful!" I have high hopes for Context + Spaces + Exportables becoming the tool of choice for moving database changes from one Drupal site to another.
Deploy module
Greg Dunlap was one of the people who hosted the DC/DC Staging and Deployment Panel Discussion. In this session, he presented the Deploy module. Deploy really blew me away. The funny thing was, I'd had an idea forming in my head for a few days prior to the conference, and it had gone something like this:
"Gee, wouldn't it be great if there was a module that just let you select a bunch of data items [on a staging Drupal site], through a nice easy UI, and that deployed those items to your live site, using web services or something?"
Well, that's exactly what Deploy does! It can handle most of the database-stored entities in Drupal core, and it can push your data from one Drupal instance to another, using nothing but a bit of XML-RPC magic, along with Drupal's (un)standard foo_get() and foo_save() functions. Greg (aka heyrocker) gave a live demo during the session, and it was basically a wet dream for anyone who's ever dealt with ongoing deployment and change management on a Drupal site.
Deploy is very cool, and it's very accessible. It makes database change deployment as easy as a point-and-click operation, which is great, because it means that anyone can now manage a complex Drupal environment that has more than just a single production instance. However, it lacks most of the advantages of exportables; particularly, it doesn't allow exporting to files, so you miss out on the opportunity to version and to compare the contents of your database. Perhaps the ultimate tool would be to have a Deploy-like front-end built on top of an Exportables framework? Anyway, Deploy is a great piece of work, and it's possible that it will become part of the standard toolbox for maintainers of small- and medium-sized Drupal sites.
Other solutions
The other solutions presented at the Staging and Deployment Panel Discussion were:
Sacha Chua from IBM gave an overview of her "approach" to deployment, which is basically a manual one. Sacha keeps careful track of all the database changes that she makes on a staging site, and she then writes a code version of all those changes in a .install file script. Her only rule is: "define everything in code, don't have anything solely in the database". This is a great rule in theory, but in practice it's currently a lot of manual work to rigorously implement. She exports whatever she can as raw PHP (e.g. views and CCK types are pretty easy), and she has a bunch of PHP helper scripts to automate exporting the rest (and she has promised to share these…), but basically this approach still needs a lot of work before it's efficient enough that we can expect most developers to adopt it.
Kathleen Murtagh presented the DBScripts module, which is her system of dealing with the deployment problem. The DBScripts approach is basically to deploy database changes by dumping, syncing and merging at the MySQL / filesystem level. This is hardly an ideal approach: dealing with raw SQL dumps can get messy at the best of times. However, DBScripts is apparently stable and can perform its job effectively, so I guess that Kathleen knows how to wade through that mess, and come out clean on the other side. DBScripts will probably be superseded by alternative solutions in the future; but for now, it's one of the better options out there that actually works.
Shaun Haber from Warner Bros Records talked about the scripts that he uses for deployment, which are (I think?) XML-based, and which attempt to manually merge data where there may potentially be conflicting numeric IDs between Drupal instances. These scripts were not demo'ed, and they sound kinda nasty — there was a lot of talk about "pushing up" IDs in one instance, in order to merge in data from another instance, and other similarly dangerous operations. The Warner Records solution is custom and hacky, but it does work, and it's a reflection of the measures that people are prepared to take in order to get a viable deployment solution, for lack of an accepted standard one as yet.
There were also other presentations given at DC/DC, that dealt with the deployment and migration topic:
Moshe Weitzman and Mike Ryan (from Cyrve) gave the talk "Migration: not just for the birds", where they demo'ed the cool new Table Wizard module, a generic tool that they developed to assist with large-scale data migration from any legacy CMS into Drupal. Once you've got the legacy data into MySQL, Table Wizard takes care of pretty much everything else for you: it analyses the legacy data and suggests migration paths; it lets you map legacy fields to Drupal fields through a UI; and it can test, perform, and re-perform the actual migration incrementally as a cron task. Very useful tool, especially for these guys, who are now specialising in data migration full-time.
I unfortunately missed this one, but Chris Bryant gave the talk "Drupal Patterns — Managing and Automating Site Configurations". Along with Context and Spaces, the Patterns module is getting a lot of buzz as one of the latest-and-greatest tools that's going to change the way we do Drupal. Sounds like Patterns is taking a similar approach to Context and Spaces, except that it's centred around configuration import / export rather than "feature" definitions, and that it uses YAML/XML rather than raw PHP Exportables. I'll have to keep my eye on this one as well.
Come a long way
I have quite a long history with the issue of deployment and migration in Drupal. Back in 2006, I wrote the Import / Export API module, whose purpose was primarily to help in tackling the problem once and for all. Naturally, it didn't tackle anything once and for all. The Import / Export API was an attempt to solve the issue in as general a way as possible. It tried to be a full-blown Data API for Drupal, long before Drupal even had a Data API (in fact, Drupal still doesn't have a proper Data API!). In the original version (for Drupal 4.7), the Schema API wasn't even available.
The Import / Export API works in XML by default (although the engine is pluggable, and CSV is also supported). It bypasses all of Drupal's standard foo_load() and foo_save() functions, and deals directly with the database — which, at the end of the day, has more disadvantages than advantages. It makes an ambitious attempt to deal with non-unique numeric IDs across multiple instances, allowing data items with conflicting IDs to be overwritten, modified, ignored, etc — inevitably, this is an overly complex and rather fragile part of the module. However, when it works, it does allow any data between any two Drupal sites to be merged in any shape or form you could imagine — quite cool, really. It was, at the end of the day, one hell of a learning experience. I'm confident that we've come forward since then, and that the new solutions being worked on are a step ahead of what I fleshed out in my work back in '06.
In my new role as a full-time developer at Digital Eskimo, and particularly in my work on live local, I've been exposed to the ongoing deployment challenge more than ever before. Sacha Chua said in DC that (paraphrased):
"Manually re-doing your database changes through the UI of the production site is currently the most common deployment strategy for Drupal site maintainers."
And, sad as that statement sounds, I can believe it. I feel the pain. We need to sort out this problem once and for all. We need a clearer separation between content and configuration in Drupal, and site developers need to be able to easily define where to draw that line on a per-site basis. We need a proper Data API so that we really can easily and consistently migrate any data, managed by any old module, between Drupal instances. And we need more globally unique IDs for Drupal data entities, to avoid the nightmare of merging data where non-unique numeric IDs are in conflict. When all of that happens, we can start to build some deployment tools for Drupal that seriously rock.
]]>
First DrupalCamp Australia was a success2008-11-13T00:00:00Z2008-11-13T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/11/first-drupalcamp-australia-was-a-success/
A few weeks ago (on Sat 18th Oct 2008), we (a.k.a. the Sydney Drupal Users' Group) held the first ever DrupalCamp Australia. Sorry for the late blog post — but hey, better late than never. This was Sydney's second full-day Drupal event, and as with the first one (back in May), it was held at the University of Sydney (many thanks to Jim Woulfe from the Faculty of Pharmacy, for providing the venue). This was Sydney's biggest Drupal event to date: we had an incredible turnout of 50 people (that's right — we were booked out), and for part of the day we had two presentation tracks running in adjacent rooms.
DrupalCamp Australia logoMorning welcome to DrupalCamp AustraliaGeeks in a room
Congratulations to everyone who presented: the overall quality of the presentations was excellent. I'm afraid I didn't see all of the talks, but I'd like to thank the people whose talks I can remember, including: Peter Moulding on the Domain Access module and on multi-site setups; Justin Freeman (from Agileware) on various modules, including Export to OpenOffice (not yet released); Jeff Hanbury (from Marmaladesoul) on Panels and theming; Justin Randell on what's new in Drupal 7; myself on "patch politics" and CVS; Gordon Heydon on Git and on E-Commerce; Erle Pereira on Drupal basics; and Simon Roberts on unit testing. Apologies for anyone I've missed (please buzz me and I'll add you).
Thanks to the organisations that sponsored this event (yes, we now have sponsors!) — they're listed on the event page. Mountains of thanks to Ryan Cross for organising the whole thing, and for being the rock of the group for the past year or so. Ryan also designed the funky logo for this event, which in my opinion is a very spiffy-looking logo indeed. And finally, thanks to everyone who attended (especially the usual suspects from Melbourne, Canberra, Brisbane, and even New Zealand): you made the day what it was. Viva Drupal Sydney!
]]>
Listing every possible combination of a set2008-10-17T00:00:00Z2008-10-17T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/10/listing-every-possible-combination-of-a-set/
The problem is simple. Say you have a set of 12 elements. You want to find and to list every possible unique combination of those elements, irrespective of the ordering within each combination. The number of elements making up each combination can range between 1 and 12. Thanks to the demands of some university work, I've written a script that does just this (written in PHP). Whack it on your web server (or command-line), give it a spin, hack away at it, and use it to your heart's content.
List of all possible combinations
The most important trick with this problem was to find only the possible combinations (i.e. unique sets irrespective of order), rather than all possible permutations (i.e. unique sets where ordering matters). With my first try, I made a script that first found all possible permutations, and that then culled the list down to only the unique combinations. Since the number of possible permutations is monumentally greater than the number of combinations for a given set, this quickly proved unwieldy: the script was running out of memory with a set size of merely 7 elements (and that was after I increased PHP's memory limit to 2GB!).
The current script uses a more intelligent approach in order to only target unique combinations, and (from my testing) it's able to handle a set size of up to ~15 elements. Still not particularly scalable, but it was good enough for my needs. Unfortunately, both permutations and combinations increase factorially in relation to the set size; and if you know anything about computational complexity, then you'll know that an algorithm which runs in factorial time is about the least scalable type of algorithm that you can write.
This script produces essentially equivalent output to this "All Combinations" applet, except that it's an open-source customisable script instead of a closed-source proprietary applet. I owe some inspiration to the applet, simply for reassuring me that it can be done. I also owe a big thankyou to Dr. Math's Permutations and Combinations, which is a great page explaining the difference between permutations and combinations, and providing the formulae used to calculate the totals for each of them.
]]>
A count of Unicode characters grouped by script2008-10-14T00:00:00Z2008-10-14T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/10/a-count-of-unicode-characters-grouped-by-script/
We all know what Unicode is (if you don't, then read all about it and come back later). We all know that it's big. Hey, of course it's big: its aim is to allow for the representation of characters from every major language script in the world. That's gotta be a lot of characters, right? It's reasonably easy to find out how many unicode characters there are in total: e.g. the Wikipedia page (linked above) states that: "As of Unicode 5.1 there are 100,507 graphic [assigned] characters." I got a bit curious today, and — to my disappointment — after some searching, I was unable to find a nice summary of how many characters there are in each script that Unicode supports. And thus it is that I present to you my count of all assigned Unicode characters (as of v5.1), grouped by script and by category.
The raw data
Fact: Unicode's "codespace" can represent up to 1,114,112 characters in total.
Fact: As of today, 100,540 of those spaces are in use by assigned characters (excluding private use characters).
The Unicode people provide a plain text listing of all supported Unicode scripts, and the number of assigned characters in each of them. I used this listing in order to compile a table of assigned character counts grouped by script. Most of the hard work was done for me. The table is almost identical to the one you can find on the Wikipedia Unicode scripts page, except that this one is slightly more updated (for now!).
Unicode script name
Category
ISO 15924 code
Number of characters
Common
Miscellaneous
Zyyy
5178
Inherited
Miscellaneous
Qaai
496
Arabic
Middle Eastern
Arab
999
Armenian
European
Armn
90
Balinese
South East Asian
Bali
121
Bengali
Indic
Beng
91
Bopomofo
East Asian
Bopo
65
Braille
Miscellaneous
Brai
256
Buginese
South East Asian
Bugi
30
Buhid
Philippine
Buhd
20
Canadian Aboriginal
American
Cans
630
Carian
Ancient
Cari
49
Cham
South East Asian
Cham
83
Cherokee
American
Cher
85
Coptic
European
Copt
128
Cuneiform
Ancient
Xsux
982
Cypriot
Ancient
Cprt
55
Cyrillic
European
Cyrl
404
Deseret
American
Dsrt
80
Devanagari
Indic
Deva
107
Ethiopic
African
Ethi
461
Georgian
European
Geor
120
Glagolitic
Ancient
Glag
94
Gothic
Ancient
Goth
27
Greek
European
Grek
511
Gujarati
Indic
Gujr
83
Gurmukhi
Indic
Guru
79
Han
East Asian
Hani
71578
Hangul
East Asian
Hang
11620
Hanunoo
Philippine
Hano
21
Hebrew
Middle Eastern
Hebr
133
Hiragana
East Asian
Hira
89
Kannada
Indic
Knda
84
Katakana
East Asian
Kana
299
Kayah Li
South East Asian
Kali
48
Kharoshthi
Central Asian
Khar
65
Khmer
South East Asian
Khmr
146
Lao
South East Asian
Laoo
65
Latin
European
Latn
1241
Lepcha
Indic
Lepc
74
Limbu
Indic
Limb
66
Linear B
Ancient
Linb
211
Lycian
Ancient
Lyci
29
Lydian
Ancient
Lydi
27
Malayalam
Indic
Mlym
95
Mongolian
Central Asian
Mong
153
Myanmar
South East Asian
Mymr
156
N'Ko
African
Nkoo
59
New Tai Lue
South East Asian
Talu
80
Ogham
Ancient
Ogam
29
Ol Chiki
Indic
Olck
48
Old Italic
Ancient
Ital
35
Old Persian
Ancient
Xpeo
50
Oriya
Indic
Orya
84
Osmanya
African
Osma
40
Phags-pa
Central Asian
Phag
56
Phoenician
Ancient
Phnx
27
Rejang
South East Asian
Rjng
37
Runic
Ancient
Runr
78
Saurashtra
Indic
Saur
81
Shavian
Miscellaneous
Shaw
48
Sinhala
Indic
Sinh
80
Sundanese
South East Asian
Sund
55
Syloti Nagri
Indic
Sylo
44
Syriac
Middle Eastern
Syrc
77
Tagalog
Philippine
Tglg
20
Tagbanwa
Philippine
Tagb
18
Tai Le
South East Asian
Tale
35
Tamil
Indic
Taml
72
Telugu
Indic
Telu
93
Thaana
Middle Eastern
Thaa
50
Thai
South East Asian
Thai
86
Tibetan
Central Asian
Tibt
201
Tifinagh
African
Tfng
55
Ugaritic
Ancient
Ugar
31
Vai
African
Vaii
300
Yi
East Asian
Yiii
1220
Regional and other groupings
The only thing that I added to the above table myself, was the data in the "Category" column. This data comes from the code charts page of the Unicode web site. This page lists all of the scripts in the current Unicode standard, and it groups them into a number of categories, most of which describe the script's regional origin. As far as I can tell, nobody's collated these categories with the character-count data before, so I had to do it manually.
Into the "Miscellaneous" category, I put the "Common" and the "Inherited" scripts, which contain numerous characters that are shared amongst multiple scripts (e.g. accents, diacritical marks), as well as a plethora of symbols from many domains (e.g. mathematics, music, mythology). "Common" also contains the characters used by the IPA. Additionally, I put Braille (the "alphabet of bumps" for blind people) and Shavian (invented phonetic script) into "Miscellaneous".
From the raw data, I then generated a summary table and a pie graph of the character counts for all the scripts, grouped by category:
Category
No of characters
% of total
African
915
0.91%
American
795
0.79%
Ancient
1724
1.71%
Central Asian
478
0.48%
East Asian
84735
84.28%
European
2455
2.44%
Indic
1185
1.18%
Middle Eastern
1254
1.25%
Miscellaneous
5978
5.95%
Philippine
79
0.08%
South East Asian
942
0.94%
Unicode character count by category
Attack of the Han
Looking at this data, I can't help but gape at the enormous size of the East Asian character grouping. 84.3% of the characters in Unicode are East Asian; and of those, the majority belong to the Han script. Over 70% of Unicode's assigned codespace is occupied by a single script — Han! I always knew that Chinese contained thousands upon thousands of symbols; but who would have guessed that their quantity is great enough to comprise 70% of all language symbols in known linguistic history? That's quite an achievement.
And what's more, this is a highly reduced subset of all possible Han symbols, due mainly to the Han unification effort that Unicode imposed on the script. Han unification has resulted in all the variants of Han — the notable ones being Chinese, Japanese, and Korean — getting represented in a single character set. Imagine the size of Han, were its Chinese / Japanese / Korean variants represented separately — no wonder (despite the controversy and the backlash) they went ahead with the unification!
Broader groupings
Due to its radically disproportionate size, the East Asian script category squashes away virtually all the other Unicode script categories into obscurity. The "Miscellaneous" category is also unusually large (although still nowhere near the size of East Asian). As such, I decided to make a new data table, but this time with these two extra-large categories excluded. This allows the size of the remaining categories to be studied a bit more meaningfully.
For the remaining categories, I also decided to do some additional grouping, to further reduce disproportionate sizes. These additional groupings are my own creation, and I acknowledge that some of them are likely to be inaccurate and not popular with everyone. Anyway, take 'em or leave 'em: there's nothing official about them, they're just my opinion:
I grouped the "African" and the "American" categories into a broader "Native" grouping: I know that this word reeks of arrogant European colonial connotations, but nevertheless, I feel that it's a reasonable name for the grouping. If you are an African or a Native American, then please treat the name academically, not personally.
I also brought the "Indic", "Central Asian", and "Philippine" categories together into an "Indic" grouping. I did this because, after doing some research, it seems that the key Central Asian scripts (e.g. Mongolian, Tibetan) and the pre-European Philippine scripts (e.g. Tagalog) both have clear Indic roots.
I left the "Ancient", "South-East Asian", "European" and "Middle Eastern" groupings un-merged, as they don't fit well with any other group, and as they're reasonably well-proportioned on their own.
Here's the data for the broader groupings:
Grouping
No of characters
% of total
Ancient
1724
17.54%
Indic
1742
17.73%
Native
1710
17.40%
European
2455
24.98%
Middle Eastern
1254
12.76%
South-Eastern
942
9.59%
Unicode character count by grouping
And there you have it: a breakdown of the number of characters in the main written scripts of the world, as they're represented in Unicode. European takes the lead here, with the Latin script being the largest in the European group by far (mainly due to the numerous variants of the Latin alphabet, with accents and other symbols used to denote regional languages). All up, a relatively even spread.
I hope you find this interesting — and perhaps even useful — as a visualisation of the number of characters that the world's main written scripts employ today (and throughout history). If you ever had any doubts about the sheer volume of symbols used in East Asian scripts (but remember that the vast majority of them are purely historic and are used only by academics), then those doubts should now be well and truly dispelled.
It will also be interesting to see how this data changes, over the next few versions of Unicode into the future. I imagine that only the more esoteric categories will grow: for example, ever more obscure scripts will no doubt be encoded and will join the "Ancient" category; and my guess is that ever more bizarre sets of symbols will join the "Miscellaneous" category. There may possibly be more additions to the "Native" category, although the discovery of indigenous writing systems is far less frequent than the discovery of indigenous oral languages. As for the known scripts of the modern world, I'd say they're well and truly covered already.
]]>
Randfixedsum ports in C# and PHP2008-09-24T00:00:00Z2008-09-24T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/09/randfixedsum-ports-in-cs-and-php/
For a recent programming assignment that I was given at university, I was required to do some random number generation. I decided to write my program in such a way that it needed a set of random numbers (with a fixed set size), each of which had to be within a fixed range, and all of which had to add up to a fixed total. In other words, what I needed was a function that let me say: "give me 50 random numbers, and make sure that each of those numbers is between 1 and 20, and also make sure that the total of all those numbers is 200... and remember, despite all that, they have to be random!" Only problem? Finding a function that returns such data is extremely difficult.
Fortunately, I stumbled across the ingenious randfixedsum, by Roger Stafford. Randfixedsum — as its name suggests — does exactly what I was looking for. The only thing that was stopping me from using it, is that it's written in Matlab. And I needed it in C# (per the requirements of my programming assignment). And that, my friends, is the story of why I decided to port it! This was the first time I've ever used Matlab (actually, I used Octave, a free alternative), and it's pretty different to anything else I've ever programmed with. So I hope I've done a decent job of porting it, but let me know if I've made any major mistakes. I also ported the function over to PHP, as that's my language of choice these days. Download, tinker, and enjoy.
My ported functions produce almost identical output to the Matlab original. The main difference is that my versions only return a 1-dimensional set of numbers, as opposed to an n-dimensional set. Consequently, they also neglect to return the volume of the set, since this is always equal to the length of the set when there's only one dimension. I didn't port the n-dimensions functionality, because in my case I didn't need it — if you happen to need it, then you're welcome to port it yourself. You're also welcome to "port my ports" to whatever other languages take your fancy. Porting them from vector-based Matlab to procedural-based C# and PHP was the hard part. Porting them to any other procedural or OO language from here is the easy part. Please let me know if you make any versions of your own — I'd love to take a look at them.
]]>
Legislation and programming: two peas in a pod2008-08-27T00:00:00Z2008-08-27T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/08/legislation-and-programming-two-peas-in-a-pod/
The language of law and the language of computers hardly seem like the most obvious of best buddies. Legislation endeavours to be unambiguous, and yet it's infamous for being plagued with ambiguity problems, largely because it's ultimately interpreted by subjective and unpredictable humang beings. Computer code doesn't try to be unambiguous, it simply is unambiguous — by its very definition. A piece of code, when supplied with any given input, is quite literally incapable of returning inconsistent output. A few weeks ago, I finished an elective subject that I studied at university, called Legal Method and Research. The main topic of the subject was statutory interpretation: that is, the process of interpreting the meaning of a single unit of law, and applying a given set of facts to it. After having completed this subject, one lesson that I couldn't help but take away (being a geek 'n' all) was how strikingly similar the structure of legislation is to the structure of modern programming code. This is because at the end of the day, legislation — just like code — needs to be applied to a real case, and it needs to yield a Boolean outcome.
I'm now going to dive straight into a comparison of statutory language and programming code, by picking out a few examples of concepts that exist in both domains with differing names and differing forms, but with equivalent underlying purposes. I'm primarily using concept names from the programming domain, because that's the domain that I'm more familiar with. Hopefully, if legal jargon is more your thing, you'll still be able to follow along reasonably well.
Boolean operators
In the world of programming, almost everything that computers can do is founded on three simple Boolean operations: AND, OR, and NOT. The main use of these operators is to create a compound condition — i.e. a condition that can only be satisfied by meeting a combination of criteria. In legislation, Boolean operators are used just as extensively as they are in programming, and they also form the foundation of pretty much any statement in a unit of law. They even use exactly the same three English words.
In law:
FREEDOM OF INFORMATION ACT 1989 (NSW)
Transfer of applications
Section 20: Transfer of applications
An agency to which an application has been made may transfer the application to another agency:
if the document to which it relates:
is not held by the firstmentioned agency but is, to the knowledge of the firstmentioned agency, held by the other agency, or
is held by the firstmentioned agency but is more closely related to the functions of the other agency, and
if consent to the application being transferred is given by or on behalf of the other agency.
Every unit of data (i.e. every variable, constant, etc) in a computer program has a type. The way in which a type is assigned to a variable varies between programming languages: sometimes it's done explicitly (e.g. in C), where the programmer declares each variable to be "of type x"; and sometimes it's done implicitly (e.g. in Python), where the computer decides at run-time (or at compile-time) what the type of each variable is, based on the data that it's given. Regardless of this issue, however, in all programming languages the types themselves are clearly and explicitly defined. Almost all languages also have primitive and structured data types. Primitive types usually include "integer", "float", "boolean" and "character" (and often "string" as well). Structured types consist of attributes, and each attribute is either of a primitive type, or of another structured type.
Legislation follows a similar pattern of clearly specifying the "data types" for its "variables", and of including definitions for each type. Variables can be of a number of different types in legislation, however "person" (and sub-types) is easily the most common. Most Acts contain a section entitled "definitions", and it's not called that for nothing.
In law:
SALES TAX ASSESSMENT ACT 1992 (Cth) No. 114
Section 5: General definitions
In this Act, unless the contrary intention appears:
...
"eligible Australian traveller" means a person defined to be an eligible Australian traveller by regulations made for the purposes of this definition;
<?php
class Person {
protected PersonType personType;
/* ... */
}
class EligibleAustralianTraveller extends Person {
private RegulationSet regulationSet;
/* ... */
}
?>
Also related to defined types is the concept of graphs. In programming, it's very common to think of a set of variables as nodes, which are connected to each other with lines (or "edges"). The connections between nodes often makes up a significant part of the definition of a structured data type. In legislation, the equivalent of nodes is people, and the equivalent of connecting lines is relationships. In accordance with the programming world, a significant part of most definitions in legislation are concerned with the relationship that one person has to another. For example, various government officers are defined as being "responsible for" those below them, and family members are defined as being "related to" each other by means such as marriage and blood.
Exception handling
Many modern programming languages support the concept of "exceptions". In order for a program to run correctly, various conditions need to be met; if one of those conditions should fail, then the program is unable to function as intended, and it needs to have instructions for how to deal with the situation. Legislation is structured in a similar way. In order for the law to be adhered to, various conditions need to be met; if one of those conditions should fail, then the law has been "broken", and consequences should follow.
Legislation is generally designed to "assume the worst". Law-makers assume that every requirement they dictate will fail to be met; that every prohibition they publish will be violated; and that every loophole they leave unfilled will be exploited. This is why, to many people, legislation seems to spend 90% of its time focused on "exception handling". Only a small part of the law is concerned with what you should do. The rest of it is concerned with what you should do when you don't do what you should do. Programming and legislation could certainly learn a lot from each other in this area — finding loopholes through legal grey areas is the equivalent of hackers finding backdoors into insecure systems, and legislation is as full of loopholes as programs are full of security vulnerabilities. Exception handling is also something that's not implemented particularly cleanly or maintainably in either domain.
In law:
HUMAN TISSUE ACT 1982 (Vic)
Section 24: Blood transfusions to children without consent
Where the consent of a parent of a child or of a person having authority to consent to the administration of a blood transfusion to a child is refused or not obtained and a blood transfusion is administered to the child by a registered medical practitioner, the registered medical practitioner, or any person acting in aid of the registered medical practitioner and under his supervision in administering the transfusion shall not incur any criminal liability by reason only that the consent of a parent of the child or a person having authority to consent to the administration of the transfusion was refused or not obtained if-
in the opinion of the registered medical practitioner a blood transfusion was-
a reasonable and proper treatment for the condition from which the child was suffering; and
<?php
class Transfusion {
public static void main() {
try {
this.giveBloodTransfusion();
}
catch (ConsentNotGivenException e) {
this.isDoctorLiable = e.isReasonableJustification;
}
}
private void giveBloodTransfusion() {
this.performTransfusion();
if (!this.consentGiven) {
throw new ConsentNotGivenException();
}
}
}
?>
Final thoughts
The only formal academic research that I've found in this area is the paper entitled "Legislation As Logic Programs", written in 1992 by the British computer scientist Robert Kowalski. This was a fascinating project: it seems that Kowalski and his colleages were actually sponsored, by the British government, to develop a prototype reasoning engine capable of assisting people such as judges with the task of legal reasoning. Kowalski has one conclusion that I can't help but agree with wholeheartedly:
The similarities between computing and law go beyond those of linguistic style. They extend also to the problems that the two fields share of developing, maintaining and reusing large and complex bodies of linguistic texts. Here too, it may be possible to transfer useful techniques between the two fields.
(Kowalski 1992, part 7)
Legislation and computer programs are two resources that are both founded on the same underlying structures of formal logic. They both attempt to represent real-life, complex human rules and problems, in a form that can be executed to yield a Boolean outcome. And they both suffer chronically with the issue of maintenance: how to avoid bloat; how to keep things neat and modular; how to re-use and share components wherever possible; how to maintain a stable and secure library; and how to keep the library completely up-to-date and on par with changes in the "real world" that it's trying to reflect. It makes sense, therefore, that law-makers and programmers (traditionally not the most chummy of friends) really should engage in collaborative efforts, and that doing so would benefit both groups tremendously.
There is, of course, one very important thing that almost every law contains, and that judges must evaluate almost every day. One thing that no computer program contains, and that no CPU in the world is capable of evaluating. That thing is a single word. A word called "reasonable". People's fate as murderers or as innocents hinges on whether or not there's "reasonable doubt" on the facts of the case. Police are required to maintain a "resonable level" of law and order. Doctors are required to exercise "reasonable care" in the treatment of their patients. The entire legal systems of all the civilised world depend on what is possibly the most ambiguous and ill-defined word in the entire English language: "reasonable". And to determine reasonableness requires reasoning — the outcome is Boolean, but the process itself (of "reasoning") is far from a simple yes or no affair. And that's why I don't expect to see a beige-coloured rectangular box sitting in the judge's chair of my local court any time soon.
]]>
On the causes of the First World War2008-06-24T00:00:00Z2008-06-24T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/06/on-the-causes-of-the-first-world-war/
WWI was one of the most costly and the most gruesome of wars that mankind has ever seen. It was also one of the most pointless. I've just finished reading The First Casualty, a ripper of a novel by author and playwright Ben Elton. The novel is set in 1917, and much of the story takes place at the infamous Battle of Passchendaele, which is considered to have been the worst of all the many hellish battles in the war. I would like to quote one particular passage from the book, which I believe is the best summary of the causes of WWI that I've ever read:
'The question I always asks is, why did anyone give a fuck about this bleeding Archduke Ferdinand what's-his-face in the first place?' one fellow said. 'I mean, come on, nobody had even heard of the cunt till he got popped off. Now the entire fucking world is fighting 'cos of it.'
'You dozy arse', another man admonished, 'that was just a bleeding spark, that was. It was a spark. Europe was a tinder box, wasn't it? Everyone knows that.'
'Well, I don't see as how he was even worth a spark, mate,' the first man replied. 'Like I say, who'd even heard of the cunt?'
A corporal weighed in to settle the matter.
'Listen, it's yer Balkans, innit? Always yer Balkans. Balkans, Balkans, Balkans. You see, yer Austro-Hungarians—'
'Who are another bunch we never gave a fuck about till all this kicked off,' the first man interjected.
'Shut up an' you might learn something,' the corporal insisted. 'You've got your Austro-Hungarians supposed to be in charge in Sarajevo but most of the Bosnians is Serbs, right, or at least enough of 'em is to cause a t'do.'
'What's Sarajevo got to do with Bosnia then?'
'Sarajevo's in Bosnia, you monkey! It's the capital.'
'Oh. So?'
'Well, your Austrians 'ave got Bosnia, right, but your Bosnians are backed by your Serbs, right? So when a Bosnian Serb shoots—'
'A Bosnian or a Serb?'
'A Bosnian and a bleeding Serb, you arse. When this Bosnian Serb loony shoots Ferdinand who's heir to the Austro-Hungarian throne, the Austrians think, right, here's a chance to put Serbia back in its bleeding box for good, so they give 'em an ultimatum. They says, "You topped our Archduke so from now on you can bleeding knuckle under or else you're for it." Which would have been fine except the Serbs were backed by the Russians, see, and the Russians says to the Austrians, you has a go at Serbia, you has a go at us, right? But the Austrians is backed by the Germans who says to the Russians, you has a go at Austria, you has a go at us, right? Except the Russians is backed by the French who says to the Germans, you has a go at Russia, you has a go at us, right? And altogether they says kick off! Let's be having you! And the ruck begins.'
'What about us then?' the first man enquired. The rest of the group seemed to feel that this was the crux of it.
'Entente bleeding cordiale, mate,', the corporal replied. 'We was backing the French except it wasn't like an alliance — it was just, well, it was a bleedin' entente, wasn't it.'
'An' what's an entente when it's at home?'
'It means we wasn't obliged to fight.'
'Never! You mean we didn't have to?'
'Nope.'
'Why the fuck did we then?'
'Fuckin' Belgium.'
'Belgium?'
'That's right, fuckin' Belgium.'
'Who gives a fuck about Belgium?'
'Well, you'd have thought no one, wouldn't you? But we did. 'Cos the German plan to get at the French was to go through Belgium, but we was guaranteeing 'em, see. So we says to the Germans, you has a go at Belgium, you has a go at us. We'd guaranteed her, see. It was a matter of honour. So in we came.'
Kingsley could not resist interjecting.
'Of course it wasn't really about honour,' he said.
'Do what?' queried the corporal.
'Well, we'd only guaranteed Belgium because we didn't want either Germany or France dominating the entire Channel coast. In the last century we thought that letting them both know that if they invaded Belgium they'd have us to deal with would deter them.'
'But it didn't.'
'Sadly not.'
'So what about the Italians, an' the Japs, an' the Turks, an' the Yanks, eh? How did they end up in it?' asked the original inquisitor.
'Fuck knows,' said the corporal. 'I lost track after the Belgians.'
Ben Elton (2005), 'The First Casualty', Ch. 36: 'A communal interlude', Bantam Press, pp. 206-208.
And if I'm not mistaken, that pretty well sums it up. I remember studying WWI, back in high school. Like so many other students of history, I couldn't help but notice the irony of it — the sheer and absurd stupidity of an entire continent (supposedly the most advanced in all the world, at the time), falling like a pack of dominoes and descending into an all-out bloodbath. It would have been funny, were it not for the fact that half the young men of early 20th-century Europe paid for it with their lives.
It would have been great if they'd simply told me to read this, instead of having me study and memorise the ridiculous chain of events that led up to the Great War. 'Russia declares war on Austria', 'Germany declares war on Russia', 'France declares war on Germany', etc. I've also finally unravelled the mystery of how the hell it was that us Aussies managed to get roped into the war, and of how the hell our most sacred event of national heritage involved several thousand of our Grandads getting mowed down by machine-guns on a beach in Turkey. I guess we fall into the category of: 'Fuck knows... I lost track after the Belgians.'
]]>
Drupal and Apache in Vista: some tips2008-06-05T00:00:00Z2008-06-05T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/06/drupal-and-apache-in-vista-some-tips/
I bought a new laptop at the start of this year, and since then I've experienced the "privilege"pile of festering camel dung that is being a user of Windows Vista. As with most things in Vista, installing Drupal and Apache is finickier than it used to be, back on XP. When I first went through the process, I encountered a few particularly weird little gotchas, and I scribbled them down for future reference. Here are some things to look out for, when the inevitable day comes in which you too will shine the light of Drupal upon the dark and smelly abyss of Vista:
Don't use the stop / start / restart Apache controls in the start menu (start > programs > Apache > control), as they are unreliable; use services.msc insetad (start > run > "services.msc").
Don't edit httpd.conf through the filesystem — use the 'edit httpd.conf' icon in the start menu instead (start > programs > Apache > configure), as otherwise your saved changes may not take effect.
If you're seeing the error message "http request status - fails" on Drupal admin pages, then try editing your 'c:\windows\system32\drivers\etc\hosts' file, and taking out the IPv6 mapping of localhost, as this can confuse the Windows mapping of 127.0.0.1 to localhost (restart for this to take effect).
Don't use Vista! If, however, you absolutely have no choice, then refer to steps 1-3.
]]>
Drupal at the 2008 Sydney CeBIT Expo2008-05-26T00:00:00Z2008-05-26T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/05/drupal-at-the-2008-sydney-cebit-expo/
The past week has been a big one, for the small but growing Sydney Drupal Users' Group. Last week, on Tuesday through Thursday (May 20-22), we manned the first-ever Drupal stall at the annual Sydney CeBIT Expo. CeBIT is one of the biggest technology shows in Australia — and the original CeBIT in Germany is the biggest exhibition in the world. For three days, we helped "spread the word" by handing out leaflets, running lives demos, and talking the talk to the Expo's many visitors.
Ryan and James at CeBIT 2008Drupal demo laptops at CeBIT 2008
The Sunday before (May 18), we also arranged a full-day get-together at the University of Sydney, as a warm-up for CeBIT: there were a few informal presentations, and we got some healthy geeked-up discussion happening.
Drupal May 2008 meetup at Sydney UniDinner and drinks after the May 2008 Drupal meetup
Thanks to everyone who travelled to Sydney for the meetup and Expo, from places far and wide. Kudos to Michael and Alan from CaignWebs in Brisbane; to Simon Roberts from Melbourne; and especially to the fine folks from Catalyst IT in New Zealand, who hopped over the ditch just to say hello. Many thanks also to everyone who helped with organising the past week's events. Along with everyone (mentioned above) who visited from other cities, the events wouldn't have happened without the help of Ashley, of Drew, and particularly of Ryan.
I gave a presentation at the Sunday meetup, entitled: "Drupal's System Requirements: Past, Present and Future". I talked about the minimum PHP5 and MySQL5 version requirements that will be introduced as of Drupal 7, and the implications of this for Drupal's future. The presentation sparked an interesting discussion on PDO and on Objest-Oriented-ness. You can find my slides below. Other presentations included: "Drupal's Boost module (by Simon); "The Drupy (Drupal in Python) project" (by the Catalyst guys); and "The Drupal Sydney Community" (by Ryan).
]]>
The Net, ten years ago2008-03-09T00:00:00Z2008-03-09T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/03/the-net-ten-years-ago/
Internet access is available anywhere these days — even on tropical islands in south-east Asia. Several weeks ago, I was on the island of Ko Tao in southern Thailand. Myself and several of my mates were discussing our views on the price of Internet usage. Most of us were in agreement that the standard Ko Tao rate of 2 baht per minute (about AUD$5 per hour) — which was standard across all of the island's many cafés — was exhorbitant, unacceptable and unjustifiable. One bloke, however, had visited the island ten years previously. He thought that the rate was completely fair — as he remembered that ten years earlier, the entire island had boasted only a single place offering access; and that back then, they were charging 60B/min! Nowadays, the standard rate in most parts of Thailand is about ½B/min, or even ¼B/min if you know where to look. This massive price difference got me thinking about what else regarding the 'Net has changed between 1998 and 2008. And the answer is: heck, what hasn't?
After my recent series of blog posts discussing serious environmental issues, I figured it's time to take a break, and to provide a light interlude that makes you laugh instead of furrow your eyebrows. So let me take you on a trip down memory lane, and pay a tribute to those golden days when text was ASCII, and download speeds were one digit.
What it was like...
IRC was all the rage. High-school teenie-boppers knew their /msg from their /part, and they roamed the public chat networks without fear of 80-year-old paedophiles going by the alias "SexySue_69". ICQ was a new and mysterious technology, and MSN had barely hit the block.
56kbps dial-up Internet was lightning fast, and was only for the rich and famous. All the plebs were still on regular old 14.4. Downloading a single MP3 meant that your entire afternoon was gone.
IE3 and Netscape 3 were the cutting-edge browsers of choice. Ordinary non-geeky netizens knew what Mosaic and Lynx were. "Firefox" was (probably) a Japanese Anime character from Final Fantasy VII.
Most of our computers were running the latest-and-greatest offering from Microsoft, remembered (with horror) for all eternity as "Windows 98". Fans of the Apple Macintosh (and yes, its full name was still used back then) were equally fortunate to be using Mac OS 9.
On the web design front, table-based layouts were the only-based layouts around.
If you wanted to show that you were really cool and that you could make your website stand out, you used the HTML<blink> tag.
Long before MySpace, personal home pages on Angelfire and GeoCities was what all your friends were making.
Life-changing interactive technologies such as ActiveX and RealPlayer were hitting the scene.
There was no Google! If you wanted to search the 'Net, then you had a choice of using such venerable engines as Lycos, Excite, or even HotBot.
AOL were still mailing out their "Get started with AOL" CDs all over the world for free. Bored young high-schoolers worldwide were using this as a gateway to discovering the excellent utility of CDs as damage-inflicting frisbees.
Forget BitTorrent: back then, unlimited quantities of pirated music were still available on Napster! Search, click, wait 2 hours, and then listen to your hearts' content.
There was no spam! Receiving an e-mail entitled "Make millions without working" or "Hot girls waiting to meet you" were still such a novelty, that it was worth printing them out and showing them to your mates, who would then debate whether or not the said "hot girls" were genuine and were worth responding to.
People (no — I mean real people) still used newsgroups. They were worth subscribing to, replying to, and keeping up with.
Blasphemies such as Word's "Save as HTML" feature, or Microsoft FrontPage 98, were still considered "professional web design tools".
The Internet was still called the "Information Superhighway".
What it's still like
There's still Porn™. And plenty of it.
The same people who still look at porn, are still reading Slashdot every day. And they're still running the same version of Slackware Linux, on a machine that they claim hasn't needed a reboot since 1993. And they're still spilling fat gobs of pizza sauce all over their DVORAK keyboards. Which they still believe will take off one day.
There are still n00bz. In fact, there are more now than there ever were before.
]]>
Step one: consume less2008-02-25T00:00:00Z2008-02-25T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/02/step-one-consume-less/
Consume less, and all else will follow. It's as simple as that. The citizens of the modern developed world are consuming far above their needs. The planet's resources are being gnawed away, and are diminishing at an alarming rate. The environmental side-effects are catastrophic. And the relentless organism that is our global 21st-century economy rolls ever on, growing fatter every year, leaving ever less pockets of the Earth unscathed, and seemingly unstoppable. But despite the apparent doom and gloom, the solution is ridiculously simple. It all begins with us. Or perhaps I have it all wrong: perhaps that's precisely why it's so complicated.
I recently finished reading an excellent book: Collapse, by Jared Diamond. Diamond explains in this book, through numerous examples, the ways in which we are consuming above our needs, and he points out the enormous gap in the average consumption of 1st- vs 3rd-world citizens. He also explains the myriad ways in which we can reduce our personal consumption, and yet still maintain a healthy modern existence. In the conclusion of this book, Diamond presents a powerful yet perfectly sensible suggestion to the problem of global over-consumption: it's we that do the consuming; and as such, the power to make a difference is in our hands.
Consumer boycott
It's a simple matter of chain reactions. First, we (local consumers) choose to purchase less products. Next, the retail and wholesale businesses in our area experience a drastic decrease in their sales — resulting in an (unfortunate but inevitable) loss of income for them — and as such, they radically downsize their offerings, and are forced to stock a smaller quantity of items. After that, manufacturers and packagers begin to receive smaller bulk orders from their wholesale customers, and they in turn slow down their production, and pump out a lower quantity of goods. Finally, the decreased demand hits the primary producers (e.g. miners, farmers, fishermen and loggers) at the bottom of the chain, and they consequently mine less metals, clear less grazing fields, catch less fish and chop down less trees.
A simple example of this would be if, for example, the entire population of a major metropolitan city decided to boycott all (new, not second-hand) furniture purchases, building and renovation efforts for an entire year. If this happened, then the first people to be affected would be furniture businesses, building companies and home improvement stores, who would quickly be forced to stock far less items (and to employ far less people in building far less houses). Next, timber wholesalers and distributors would follow suite by stocking less bulk-quantity timber. Finally, logging companies would inevitably be forced to simply chop down less trees, as they would simply have insufficient customers to buy all the resultant timber. And when you think about it, almost every major city in the world could do this, as most cities literally do have enough existing houses, commercial buildings and furnishings, that their entire population could choose not to buy or build anything new for an entire year, and yet everyone would still have ample supplies.
What so many people fail to realise is this: it's we that are the source of the problem; and as such, it's we that are also the only chance of there being a solution. There's only ever one way to tackle a big problem, and that's by digging down until you find the root cause, and attacking the problem directly at that root. We can launch protests and demonstrations against governments and big businesses — but they're not the root of the problem, they just represent us. We can write letters, draw cartoons, publish blog posts, and capture footage for the media — but they're not the root of the problem, they just inform us. And we can blame environmental stuff-ups such as oil spills, fossil fuel burning and toxic waste dumping — but they're not the problem either, they're the side-effects of the problem. The problem is our own greed: we lavish ourselves with goods, and the world suffers as a consequence.
Obstacles and solutions
One of the biggest obstacles with the principle of reducing consumption, is the automatic rhetoric that so many people — laymen and politicians alike — will blurt out at the mere suggestion of it: "the economy would collapse, and unemployment would go through the roof." While this is true to some extent, it is at the end of the day not correct. Yes, the economy would suffer in the short-term: but in the long-term, the prices of less-consumed goods would rise to reflect the new demand, and businesses would find a new level at which to competitively operate. Yes, unemployment would spike for a time: but before long, new jobs would open up, and the service economy would expand to accommodate a higher number of workers. Ultimately, our current inflated rate of consumption is unsustainable for the economy, as it's only a matter of time before various resources begin to run out. Reducing consumption before that happens is going to make the inevitable day a lot less unpleasant, and it will impact our lifestyle a lot less if we've already made an effort to adjust.
At the more personal level, the main obstacle is education: informing people of how much they're consuming unnecessarily; explaining the ways in which consumption can be reduced; and increasing awareness of the impacts of over-consumption, on the environment and on the rest of global society. Few developed-world people realise that they consume more than 10 times as much as their third-world neighbours, in almost every major area — from food, to clothing, to electronic, to stationery, to toys, to cigarettes. Less still are aware of exactly what kind of a difference they can make, by purchasing such things as new vs recycled paper, or old-growth vs plantation timber products. And what's more, few have a clear idea of what (small but important) steps they can take, in order to slowly but surely reduce their consumption: things such as hand-me-down clothing, home-grown vegetable gardening, and a paperless office being just a few. As I blogged about previously, new approaches to reuse can also play an integral part in the process.
Finally, we get to the most basic and yet the most tricky obstacle of them all. As I wrote at the start of this blog entry, consuming less is the simplest thing we can do to help this planet, and yet also the most complicated. And the reason for this can be summed up in one smelly, ugly little word: greed. The fact is, we humans are naturally greedy. And when we live in a world where supermarkets and mega-stores offer aisle after aisle of tantalising purchases, and where our wallets are able to cater to all but the dearest of them, the desire to buy and to consume can be nothing less than irresistible. And to solve this one, it's simply a matter of remembering that you need a better reason to buy something, than simply because "it's there" and "I can afford it". Hang on. Do you need it? What's wrong with what you've already got? And how long will the new purchase last? (Boycotting cheap consumer goods with a "4-year life span" is also a good idea — it's not just a longer-term investment, it's also a consumption cut.)
I don't have the answer to the problem of the greediness that's an inherent part of human nature in all of us. But I do believe that with a bit more education, and a bit more incentive, we'll all be able to exercise more self-discipline in our spending-driven lives. And if we can manage that, then we will be step one in a chain reaction that will radically reshape the global economy, and that will bring that previously-thought unstoppable beast to a grinding halt.
]]>
Robotic garbage sorting2008-01-12T00:00:00Z2008-01-12T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/01/robotic-garbage-sorting/
The modern world is producing, purchasing, and disposing of consumer products at an ever-increasing rate. This is hardly news to anyone. Two other facts are also well-known, to anyone who's stopped and thought about them for even five minutes of their life. First, that our planet Earth only has a finite reservoir of raw materials, which is constantly diminishing (thanks to us). And second, that we first-world consumers are throwing the vast majority of our used-up or unwanted products straight into the rubbish bin, with the result that as much as 90% of household waste ends up in landfill.
When you think about all that, it's no wonder they call it "waste" .There's really no other word to describe the process of taking billions of tonnes of manufactured goods — a significant portion of which could potentially be re-used — and tossing them into a giant hole in the ground (or into a giant patch in the ocean). I'm sorry, but it's sheer madness! And with each passing day, we are in ever more urgent need of a better solution than the current "global disposal régime".
Cleaner alternatives
There are a number of alternatives to disposing of our garbage by way of dumping (be it in landfill, in the ocean, underground, or anywhere else). Examples of these alternatives:
We can incinerate our garbage. This does nothing to pollute the surface of the Earth; however, it does pollute our air and our atmosphere (quite severely), and it also means that the materials we incinerate are essentially lost to us forever. They're still floating around within the planet's ecosystem somewhere, but they're not recoverable to us within the foreseeable future.
We can place our garbage in a compost. This is a great, non-polluting, sustainable alternative when it's available: but unfortunately, only organic garbage actually decomposes properly, whereas other garbage (particularly plastic) remains intact in the ground for potentially hundreds of years.
We can even send our garbage into space. To the naïve reader, this may seem like the perfect alternative: non-polluting, not taking up space anywhere, and not our planet's problem anymore. But sending garbage into space is actually none of these things. It does pollute: the conventional rocket technology required to launch it is intensely polluting, as it involves millions of tonnes of fuel. It does take up space: even though we're sending it into space, we're still dumping it — and as far as I'm concerned, dumping is dumping (regardless of location). And contrary to "not being our planet's problem" anymore, sending garbage into space ignores the fundamental fact that the Earth is a giant ecosystem, and that it has finite resources, and that those resources (whatever form they're in, "garbage" or otherwise) should stay within our ecosystem at all costs. Flinging them away outside the planet is equivalent to chopping off your own arm, and flinging it into a shark-infested river. It's gone, it's no longer a part of you.
At the end of the day, none of these fancy and complicated alternatives is all that attractive. There's only one truly sustainable alternative to dumping, and it's the simplest and most basic one of all: reusing and recycling. Reuse, in particular, is the ideal solution for dealing with garbage: it's a potentially 100% non-polluting process; it takes up no more space than it began with; and best of all, it's the ultimate form of waste recovery. It lets us take something that we thought was utterly worthless and ready to rot in a giant heap for 1,000 years, and puts it back into full service fulfilling its original intended purpose. Similarly, recycling is almost an ideal solution as well. Recycling always inevitably involves some pollution as a side-effect of the process: but for many materials, this pollution is quite minimal. And recycling doesn't automatically result in recovery of off-the-shelf consumer goods, as does actual re-use: but it does at least recover the raw materials from which we can re-manufacture those goods.
As far as cleaner alternatives to dealing with our garbage go, re-use and recycling (in that order) are the clear winners. The only remaining question is: if continued dumping is suicide, and if re-use and recycling are so much better, then why — after several decades of having the issue in our faces — have we still only implemented it for such a pathetically small percentage of our waste? And the answer is: re-use and recycling involve sorting through the giant mess that is the modern world's garbage heap; and at present, it's simply too hard (or arguably impossible) to wade through it all. We lack the pressure, the resources, but most of all the technology to effectively carry out the sorting necessary for 100% global garbage re-use and recycling to become a reality.
Human-powered sorting
The push for us humans to take upon ourselves the responsibility of sorting out our trash, for the purposes of re-use and recycling, is something that has been growing steadily over the past 30 years or so. Every first-world country in the world — and an increasing number of developing countries — has in place laws and initiatives, from the municipal to the national level, aimed at groups from households to big businesses, and executed through measures ranging from legislation to education. As such, both re-use and recycling are now a part of everyday life for virtually all of us. And yet — despite the paper bins and the bottle bins now being filled on every street corner — those plain old rubbish bins are still twice the size, and are just as full, and can also be found on every single street corner. The dream of "0% rubbish" is far from a reality, even as we've entered the 21st century.
And the reasons for this disheartening lack of progress? First, the need to initiate more aggressive recycling is not yet urgent enough: in most parts of the world, there's still ample space left for use as landfill, and hence the situation isn't yet dire enough that we feel the pressure to act. Second, reusing and recycling is still a costly and time-consuming process, and neither big groups (such as governments) nor little groups (such as families) are generally willing to make that investment — at the moment, they still perceive the costs as outweighing the benefits. Third and finally, the bottom line is that people are lazy: an enormous amount of items that could potentially be reused or recycled, are simply dumped in the rubbish bin due to carelessness; and no matter how much effort we put into legislation and education, that basic fact of human nature will always plague us.
I retract what I just said, for the case of two special and most impressive contemporary examples. First, there are several towns in Japan where aggressive recycling has actually been implemented successfully: in the town of Kamikatsu in particular, local residents are required to sort their garbage into 44 different recycling categories; and the town's goal of 0% trash by 2020 is looking to be completely realistic. Second, the city of Taipei — in Taiwan — is rolling out tough measures aimed to reduce the city's garbage output to ¼ its current size. However, these two cases concern two quite unique places. Japan and Taiwan are both critically short of land, and thus are under much more pressure than other countries to resolve their landfill and incinerator dependence urgently. Additionally, they're both countries where (traditionally) the government is headstrong, where the people are obedient, and (in my opinion) where the people also have much less of a "culture of laziness" than do other cultures in the world. As such, I maintain that these two examples — despite being inspiring — are exceptional; and that we can't count on human-powered sorting alone, as a solution to the need for more global reuse and recycling.
Robot-powered sorting
Could robots one day help us sort our way out of this mess? If we can't place hope in ourselves, then we should at least endeavour to place some hope in technology instead. Technology never has all the answers (on the contrary, it often presents more problems than it does solutions): but in this case, it looks like some emerging cutting-edge solutions do indeed hold a lot of promise for us.
On the recycling front, there is new technology being developed that allows for the robotic recognition of different types of material compositions, based purely on visual analysis. In particular, the people over at SINTEF (a Norwegian research company) have invented a device that can "see" different types of rubbish, by recognising the unique "fingerprint" that each material exhibits when light is reflected off it. The SINTEF folks have already been selling their technology on the public market for 2 years, in the form of a big box that can have rubbish fed into it, and that will spit the rubbish back out in several different bags — one bag for each type of material that it can distinguish. Well, that's the issue of human laziness overcome on the recycling front: we don't need to (and we can't) rely on millions of consumers to be responsible sorters and disposers; now we can just throw everything into one bin, and the bin itself will be smart enough to do the sorting for us!
On the reuse front, technology is still rather experimental and in its infancy; but even here, the latest research is covering tremendous ground. The most promising thing that I've heard about, is what took place back in 1995 at the University of Chicago's Animate Agent Laboratory: scientists there developed a robot that accepted visual input, and that could identify as garbage random objects on a regular household floor, and dispose of them accordingly. What I'm saying is: the robot could recognise a piece of paper, or an empty soft-drink can, or a towel, or whatever else you might occasionally find on the floor of a household room. Other people have also conducted academic studies into this area, with similarly pleasing results. Very cool stuff.
Technology for reuse is much more important than technology for recycling, because reuse (as I explained above) should always be the first recourse for dealing with rubbish (and with recycling coming second); and because the potential benefits of technology-assisted reuse are so vast. However, technology-assisted reuse is also inherently more difficult, as it involves the robotic recognition of actual, human-centric end-user objects and products; whereas technology-assisted recycling simply involves the recognition of chemical substances. But imagine the opportunities, if robots could actually recognise the nature and purpose of everything that can be found in a modern-day rubbish bin (or landfill heap). Literally billions of items around the world could be sorted, and separated from the useless heap that sits rotting in the ground. Manufactured goods could (when discovered) be automatically sent back to the manufacturer, for repair and re-sale. Goods in reasonable condition could simply be cleaned, and could then be sent directly back to a retailer for repeated sale; or perhaps could instead be sent to a charity organisation, to provide for those in need. Specific types of items could be recognised and given to specific institutions: stationary to schools, linen to hospitals, tools and machinery to construction workers, and so on.
In my opinion, robotic garbage sorting is (let us hope) closer than we think; and when it arrives en masse, it could prove to be the ultimate solution to the issue of global sustainability and waste management. In order for our current ways of mass production and mass consumption to continue — even on a much smaller scale than what we're at now — it's essential that we immediately stop "wasting waste". We need to start reusing everyting, and recycling everything else (in the cases where even robot-assisted reuse is impossible). We need to stop thinking of the world's enormous quantity of garbage as a pure liability, and to start thinking of it as one of our greatest untapped resource reservoirs. And with the help of a little junk-heap sorting — on a scale and at a health and safety risk too great for us to carry out personally, but quite feasible for robots — that reservoir will very soon be tapped.
]]>
The bicycle-powered home2007-12-20T00:00:00Z2007-12-20T00:00:00ZJazahttps://greenash.net.au/thoughts/2007/12/the-bicycle-powered-home/
The exercise bike has been around for decades now, and its popularity is testament to the great ideas that it embodies. Like the regular bicycle, it's a great way to keep yourself fit and healthy. Unlike the regular bicycle, however, it has the disadvantages of not being usable as a form of transport or (for most practical purposes) as a form of other sport, and of not letting you get out and enjoy the fresh air and the outdoor scenery. Fortunately, it's easy enough for a regular bike to double as an exercise bike, with the aid of a device called a trainer, which can hold a regular bike in place for use indoors. Thus, you really can use just one bicycle to live out every dream: it can transport you, it can keep you fit, and it can fill out a rainy day as well.
Want to watch TV in your living room, but feeling guilty about being inside and growing fat all day? Use an exercise bike, and you can burn up calories while enjoying your favourite on-screen entertainment. Feel like some exercise, but unable to step out your front door due to miserable weather, your sick grandma who needs taking care of, or the growing threat of fundamentalist terrorism in your neighbourhood streets? Use an exercise bike, and you can have the wind in your hair without facing the gale outside. These are just some of the big benefits that you get, either from using a purpose-built exercise bike, or from using a regular bike mounted on a trainer.
Now, how about adding one more great idea to this collection. Want to contribute to clean energy, but still enjoy all those watt-guzzling appliances in your home? Use an electricity-generating exercise bike, and you can become a part of saving the world, by bridging the gap between your quadriceps and the TV. It may seem like a crazy idea, only within the reach of long-haired pizza-eating DIY enthusiasts; but in fact, pedal power is a perfectly logical idea: one that's available commercially for home use by anyone, as well as one that's been adopted for large and well-publicised community events. I have to admit, I haven't made, bought or used such a bike myself (yet) — all I've done so far is think of the idea, find some other people (online) who have done more than just think, and then write this blog post — but I'd love to do so sometime in the near future.
I first thought of the idea of an energy-generating exercise bike several weeks ago: I'm not sure what prompted me to think of it; but since then, I've been happy to learn that I'm not the first to think of it, and indeed that many others have gone several steps further than me, and have put the idea into practice in various ways. Below, I've provided an overview of several groups and individuals who have made the pedal-power dream a reality — in one way or another — and who have made themselves known on the web. I hope (and I have little doubt) that this is but the tip of the iceberg, and that there are in fact countless others in this world who have also contributed their time and effort to the cause, but who I don't know about (either because they have no presence on the web, or because their web presence wasn't visible enough for me to pick it up). If you know of any others who deserve a mention — or if you yourself have done something worth mentioning — then mention away. G-d didn't give us the "add comment" button at the bottom of people's blogs for nothing, you know.
Pedal Power en masse
The Pedal Powered Innovations project is run by bicycle-freak Bart Orlando, with the help of volunteers at the Campus Center for Appropriate Technology (a group at Humboldt State University in northern California). Bart and the CCAT people have been working for over a decade now, and in that time they've built some amazing and (at times) impressively large-scale devices, all of which are very cool applications of the "bicycles as electrical generators" idea.
Human Energy Converter (photo)
You can see more photos and more detailed info on their website, but here's a list of just some of the wacky contraptions they've put together:
Human Energy Converter: multi-bike generator system (the original was comprised of 14 individual bikes), used to power microphones for public speeches, stereo systems for outdoor concerts, and sound-and-light for environmental protests.
Household appliance generator: various appliances that have been successfully used through being powered by a bicycle. Examples include a blender, a sewing machine, and a washing machine.
Entertainment device generator: yet more devices that can successfully be bicycle-powered. Examples include TVs, VCRs, and large batteries.
Great work, guys! More than anything, the CCAT project demonstrates just how many different things can potentially be "pedal powered", from the TV in your living room, to the washing machine out back in the laundry, to a large-scale community gathering. It's all just a question of taking all that kinetic energy that gets generated anyway from the act of cycling, and of feeding into a standard AC socket. I'll have to go visit this workshop one day — and to find out if there are any other workshops like this elsewhere in the world.
Pedal-A-Watt in the home
The folks over at Convergence Tech, Inc have developed a commercial product called The Pedal-A-Watt Stationary Bike Power Generator. The product is a trainer (i.e. a holder for a regular road or mountain bike) that collects the electricity produced while pedalling, and that is able to feed up to 200 watts of power into any home device — that's enough to power most smaller TVs, as well as most home PCs. It's been available for 8 years: and although it's quite expensive, it looks to be very high-quality and very cool, not to mention the fact that it will reduce your electricity bill in the long run. Plus, as far as I know, it's almost the only product of its type on the market.
Pedal-A-Watt (photo)
DIY projects
The most comprehensive DIY effort at "pedal power" that I found on the web, is the home-made bicycle powered television that the guys over at Scienceshareware.com have put together. This project is extremely well-documented: as well as a detailed set of instructions (broken down into 10 web pages) on how to achieve the set-up yourself (with numerous technical explanations and justifications accompanying each step), they've also got a YouTube video demonstrating the bike-powered TV. In the demonstration, they show that they were able to not only provide full power to a 50 watt colour TV using a single bicycle; there was also plenty of excess energy that they were able to collect and store inside a car battery. The instructions are very technical (so get ready to pull out those high-school physics and electronics textbooks, guys), but very informative; and they also have no shortage of safety warnings, and of advice on how to carry out the project in your own home reasonably safely.
Another excellent home-grown effort, built and documented last year by the people at the Campaign For Real Events, is their 12-volt exercise bike generator. This bike was originally built for a commercial TV project; but when that project got canned, the bike was still completed, and was instead donated to non-profit community use. The DIY instructions for this bike aren't quite as extensive as the Scienceshareware.com ones, but they're still quite technical (e.g. they include a circuit diagram); and it's still a great example of just what you can do, with an exercise bike and a few other cheaply- or freely-obtainable parts (if you know what you're doing). The Campaign For Real Events group has also, more recently, begun producing "pedal power" devices on a more large-scale basis — except that they're not making them for commercial use, just for various specific community and governmental uses.
Other ideas people
Like myself, plenty of other people have also posted their ideas about "how cool pedal power would be" onto the web. For example, just a few months ago, someone posted a thread on the Make Magazine forum, entitled: How do I build an exercise bike-powered TV? We're not all DIY experts — nor are we all electronics or hardware buffs — but even laymen like you and me can still realise the possibilities that "pedal power" offers, and contribute our thoughts and our opinions on it. And even that is a way of making a difference: by showing that we agree, and that we care, we're still helping to bring "pedal power" closer to being a reality. Not all of the online postings about bicycle-TV combinations are focused on "pedal power", though: many are confined to discussing the use of a bike as an infrared remote control replacement, e.g. triggering the TV getting turned on by starting to pedal on the bike. Also a good idea — although it doesn't involve any electricity savings.
In short, it's green
Yes: it's green. And that's the long and the short of why it's so good, and of why I'm so interested in it. Pedal power may not be the most productive form of clean energy that we have available today: but it's productive enough to power the average electronic devices that one person is likely to use in their home; and (as mentioned above) it has the added benefit of simultaneously offering all the other advantages that come with using an exercise bike. And that's why pedal power just might be the clean energy with less environmental impact, and more added value, than virtually any other form of clean energy on the planet. Plus, its low energy output could also be viewed as an advantage of sorts: if pedal power really did take off, then perhaps it would eventually encourage product manufacturers to produce lower energy-consumption devices; and, in turn, it would thus encourage consumers to "not use more devices than your own two feet can power". This philosophy has an inherent logic and self-sufficiency to it that I really appreciate.
I like cycling. I like this planet. I hope you do too. And I hope that if you do indeed value both of these things, as I do (or that if you at least value the latter), then you'll agree with me that in this time of grave environmental problems — and with dirty forms of electricity production (e.g. coal, oil) being a significant cause of many of these problems — we need all the clean energy solutions we can get our hands on. And I hope you'll agree that as clean energy solutions go, they don't get much sweeter than pedal power. Sure, we can rely on the sun and on photovoltaic collectors for our future energy needs. Sure, we can also rely on the strength of winds, or on the hydraulic force of rivers, or on the volcanic heat emitted from natural geothermal vents. But at the end of the day, everyone knows that if you want to get something done, then you shouldn't rely on anything or anyone except yourself: and with that in mind, what better to rely on for your energy needs, than your own legs and your ability to keep on movin' em?
]]>
Consciously directed healing2007-11-02T00:00:00Z2007-11-02T00:00:00ZJazahttps://greenash.net.au/thoughts/2007/11/consciously-directed-healing/
The human body is a self-sustaining and self-repairing entity. When you cut your hand, when you blister your foot, or when you burn your tongue, you know — and you take it for granted — that somehow, miraculously, your body will heal itself. All it needs is time.
This miracle is possible, because our bodies are equipped with resources more vast and more incredible than most people ever realise, let alone think about. Doctors know these resources inside-out — they're called cells. We have billions upon billions of cells, forming the building-blocks of ourselves: each of them is an independent living thing; and yet each is also purpose-built for serving the whole in a specific way, and is 100% at the disposal of the needs of the whole. We have cells that make us breathe. Cells that make us digest. Cells that make us grow. And, most important of all, cells that tell all the other cells what to do — those are known as brain cells.
In the case of common muscle injuries, it's the tissue cells (i.e. the growing cells — they make us grow by reproducing themselves) and the brain cells, among others, that are largely responsible for repairs. When an injury occurs, the brain cells receive reports of the location and the extent of the problem. They then direct the tissue cells around the affected area to grow — i.e. to reproduce themselves — into the injury, thus slowly bringing new and undamanged tissue to the trouble spot, and bit-by-bit restoring it to its original and intended state. Of course, it's a lot more complicated than that: I'm not a doctor, so I'm not going to pretend I understand it properly. But as far as I'm aware, that's the basics of it.
However, there are many injuries that are simply too severe for the body to repair by itself in this way. In these cases, help may be needed in the form of lotions, medicines, or even surgery. Now, what I want to know is: why is this so? With all its vast resources, what is it that the human body finds so difficult and so time-consuming in healing a few simple cuts and bruises? Surely — with a little bit of help, and a lot more conscious concentration — we should be capable of repairing so much more, all by ourselves.
More brain power
There is a widely-known theory that we humans only use 10% of our brains. Now, this theory has many skeptics: and those skeptics pose extremely valid arguments against the theory. For example, we may only use 10-20% of our brains at any one time, but we certainly use the majority of our brains at some point in our lives. Also, brain research is still (despite years of money and effort) an incredibly young field, and scientists really have no idea how much of our brains we use, at this point in time. However, it still seems fairly likely that we do indeed only use a fraction of our brain's capacity at any given time — even in times of great pain and injury — and that were we able to use more of that capacity, and to use it more effectively, that would benefit us in numerous manifold ways.
I personally am inclined to agree with the myth-toting whackos, at least to some extent: I too believe that the human brain is a massively under-utilised organ of the body; and that modern medicine has yet to uncover the secrets that will allow us to harness that extra brain power, in ways that we can barely imagine. I'm certainly not saying that I agree with the proponents of the Quantum-Touch theory, who claim to be able to "heal others by directing their brain's energy" — that's a bit far-fetched for my liking. Nor am I in any way agreeing with ideas such as psychokinesis, which claims that the mere power of the brain is capable of anything, from levitating distant objects to affecting the thoughts and senses of others. No: I'm not agreeing with anything that dodgy or supernatural-like.
I am, however, saying that the human brain is a very powerful organ, and that if we could utilise it more, then our body would be able to do a lot more things (including the self-healing that it's already been capable of since time immemorial) a lot more effectively.
More concentration
As well as utilising more of our brains, there is also (even more vexingly) the issue of directing all that extra capacity to a particular purpose. Now, in my opinion, this is logically bound to be the trickier bit, from a scientific standpoint. For all practical purposes, we're already able to put our brains into an "extreme mode", where we utilise a lot more capacity all at once. What do you think conventional steroids do? Or the myriad of narcotic "party drugs", such as Speed and Ecstasy, that are so widely sought-after worldwide? Upping the voltage isn't that hard: we've already figured it out. But where does it go? We have no idea how to direct all that extra capacity, except into such useless (albeit fun) pursuits as screaming, running, or dancing like crazy. What a waste.
I don't know what the answer to this one is: whether it be a matter of some future concentration-enhancing medicine; of simply having a super-disciplined mind; or of some combination of this and other solutions. Since nobody to date has conclusively proven and demonstrated that they can direct their brain's extra capacity to somewhere useful, without medical help, I doubt that anything truly amazing is physically possible, with concentration alone. But whatever the solution is, it's only a matter of time before it is discovered; and its discovery is bound to have groundbreaking implications for medicine and for numerous other fields.
Future glimpse
Basically, what I'm talking about in this article is a future wonder-invention, that will essentially allow us to utilise our brain's extra capacity, and to direct that extra capacity to somewhere useful, for the purpose of carrying out conventional self-healing in a much faster and more effective way than is currently possible. This is not about doing anything that's simply impossible, according to the laws of medicine or physics — such as curing yourself of cancer, or vaporising your enemies with a stare — it's about taking something that we do now, and enhancing it. I'm not a scientist or a doctor, I'm just someone who has too much time on his hands, and who occasionally thinks about how cool it would be for the world to have things like this. Nevertheless, I really do believe that consciously directed healing is possible, and that it's only a matter of time before we work out how to do it.
]]>
Developing home + developed income = paradise2007-10-13T00:00:00Z2007-10-13T00:00:00ZJazahttps://greenash.net.au/thoughts/2007/10/developing-home-developed-income-paradise/
Modern economics is infinitely bizarre. We all know it. I'm not here to prove it; I'm just here to provide one more example of it — and the example is as follows. You're an educated, middle-class professional: you've lived in a developed country your whole life; and now you've moved to a developing country. Your work is 99% carried out online, and your clients live all over the world. So you move to this less-affluent country, and you continue to work for your customers in the First World. Suddenly, your home is a dirt-cheap developing nation, and your income is in the way of formidable developed-nation currency.
I've just finished a six-month backpacking tour of South America, and one of my backpacking friends down there is doing just this. He's a web designer (similar to my own profession, that of web developer): essentially the ideal profession for working from anywhere in the world, and for having clients anywhere else in the world. He's just starting to settle down in Buenos Aires, Argentina: a place with a near-Western quality of infrastructure; but a country where the cost of living and the local currency value is significantly lower than that of Western nations. He's the perfect demonstration of this new global employment phenomenon in action. All he needs is a beefy laptop, and a reasonably phat Internet connection. Once he has that, he's set up to live where he will, and to have clients seek him out wherever he may be.
The result of this setup? Well, I'm no economist — so correct me if I'm wrong — but it would seem that the result must invariably be a paradise existence, where you can live like a king and still spend next to nothing!
To tell the truth, I'm really surprised that I haven't heard much about this idea in the media thus far. It seems perfectly logical to me, considering the increasingly globalised and online nature of life and work. If anyone has seen any articles or blog posts elsewhere that discuss this idea, feel free to point them out to me in the comments. I also can't really think of any caveats to this setup. As long as the nature of your work fits the bill, there should be nothing stopping you from "doing the paradise thing", right? As far as I know, it should be fine from a legal standpoint, for most cases. And assuming that your education, your experience, and your contacts are from the Western world, they should be happy to give you a Western standard of pay — it should make no difference to them where you're physically based. Maybe I'm wrong: maybe if too many people did this, such workers would simply end up getting exploited, the same as locals in developing countries get exploited by big Western companies.
But assuming that I'm not wrong, and that my idea can and does work in practice — could this be the next big thing in employment, that we should expect to see happening over the next few years? And if so, what are the implications for those of us that do work online, and that are candidates for this kind of life?
]]>
Useful SQL error reporting in Drupal 62007-10-13T00:00:00Z2007-10-13T00:00:00ZJazahttps://greenash.net.au/thoughts/2007/10/useful-sql-error-reporting-in-drupal-6/
The upcoming Drupal 6 has a very small but very useful new feature, which went into CVS quietly and with almost no fanfare about 6 weeks ago. The new feature is called "useful SQL error reporting". As any Drupal developer would know, whenever you're coding away at that whiz-bang new module, and you've made a mistake in one of your module's database queries, Drupal will glare at you with an error such as this:
SQL error reporting in Drupal 5
Text reads:
user warning: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'd5_node n INNER JOIN d5_users u ON u.uid = n.uid INNER JOIN d5_node_revisions r ' at line 1 query: SELECT n.nid, n.vid, n.type, n.status, n.created, n.changed, n.comment, n.promote, n.sticky, r.timestamp AS revision_timestamp, r.title, r.body, r.teaser, r.log, r.format, u.uid, u.name, u.picture, u.data FROMMM d5_node n INNER JOIN d5_users u ON u.uid = n.uid INNER JOIN d5_node_revisions r ON r.vid = n.vid WHERE n.nid = 1 <strong>in C:\www\drupal5\includes\database.mysql.inc on line 172.</strong>
That message is all well and good: it tells you that the problem is an SQL syntax error; it prints out the naughty query that's causing you the problem; and it tells you that Drupal's "includes/database.mysql.inc" file is where the responsible code lies. But that last bit — about the "database.mysql.inc" file — isn't quite true, is it? Because although that file does indeed contain the code that executed the naughty query (namely, the db_query() function in Drupal's database abstraction system), that isn't where the query actually is.
In Drupal 6, this same message becomes a lot more informative:
SQL error reporting in Drupal 6
Text reads:
user warning: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'd6_node n INNER JOIN d6_users u ON u.uid = n.uid INNER JOIN d6_node_revisions r ' at line 1 query: SELECT n.nid, n.vid, n.type, n.language, n.title, n.uid, n.status, n.created, n.changed, n.comment, n.promote, n.moderate, n.sticky, n.tnid, n.translate, r.nid, r.vid, r.uid, r.title, r.body, r.teaser, r.log, r.timestamp AS revision_timestamp, r.format, u.name, u.data FROMMM d6_node n INNER JOIN d6_users u ON u.uid = n.uid INNER JOIN d6_node_revisions r ON r.vid = n.vid WHERE n.nid = 2 <strong>in C:\www\drupal\modules\node\node.module on line 669.</strong>
This may seem like a small and insignificant new feature. But considering that a fair chunk of the average Drupal developer's debugging time is consumed by fixing SQL errors, it's going to be a godsend for many, many people. The value and the usefulness of this feature, for developers and for others, should not be underestimated.
]]>
Economics and doomed jobs2007-07-07T00:00:00Z2007-07-07T00:00:00ZJazahttps://greenash.net.au/thoughts/2007/07/economics-and-doomed-jobs/
There are a great many people in this world — particularly in third-world countries — that spend their entire lives performing jobs that are dangerous, labour-intensive, unhealthy, and altogether better-suited for machines. I've often heard the argument that "it's better that they do what they do, than that they have no job at all". Examples of such jobs include labouring in textile sweatshops, packaging raw meat in processing plants, taking care of dangerous and disease-prone animals, and working in mines with atrocious conditions and poisonous fumes.
After visiting the hellish mines of Potosí in Bolivia, I disagree with the "better than no job at all" argument more strongly than ever. I'm now 100% convinced that it's better for jobs as atrocious as this to disappear from the face of the Earth; and that it's better for those affected to become unemployed and to face economic hardship in the short-term, while eventually finding newer and better jobs; than to continue in their doomed and unpleasant occupations forever.
As far as I've been able to tell so far, most people in this world seem to believe that it's better for really unpleasant jobs to exist, than for all the people performing them to be unemployed. In fact, more than anyone else, the majority of people performing these jobs believe this (apparently) logical rhetoric. Most people believe it, because it is very simple, and on the surface it does make sense. Yes, a lot of people have jobs that are barely fit for humans to perform. Yes, it affects their health and the health of their children. Yes, they get paid peanuts for it, and they're being exploited. But then again, they have little or no education, and there are almost no other jobs available in their area. And it's all they know. Isn't it better that they're at least able to put food on the table, and to feed their family, than that they're able to do nothing at all?
But the thing is, if there's one thing that the past 200 years of industrial progress have shown us, it's that replacing manual-labour human-performed jobs with machines does not destroy employment opportunities. Quite the opposite, in fact. Sure, it makes a lot of people unemployed and angry in the short-term. But in the long-term, it creates a lot of newer and much better jobs. Jobs that foster education, good working conditions, and higher levels of skill and innovation. Jobs that are not ridiculously dangerous and unpleasant. Jobs that are fit for intelligent, capable 21st-century human beings to get involved in.
Take the textile industry, for example. Originally, all clothing was made by hand, by artisans such as weavers, sewing people, and knitters. These days, much of the time those jobs are performed by machines, and the human occupations that used to exist for them are largely obsolete. However, there are now new jobs. There are people who perform maintenance work on the weaving machines, and on the sewing machines. There are people who design new ways of making the weaving machines and the sewing machines work better. There are people who consult with the public, on what they'd like to see done better in the textile industry, and on what they'd be willing to pay more for if it was done to a higher calibre. There are an endless number of newer and better jobs, that have sprung up as a result of the lower jobs changing from human labour to automated mechanisation.
And the other economic issue that the Potosí experience has brought to my attention, is that of small ventures vs. big companies. Now, this is another one where a lot of people are not going to be on my side. The classic argument is that it's a real shame that the single-man or the family-run business is being swallowed up, by the beast that is the multi-national corporation. In the old days, people say, a man was able to earn an honest living; and he was able to really create an enterprise of his own, and to reap the rewards of working for himself. These days, everyone has sold their soul to big corporations; and the corporation owns everything, while exploiting the people at the bottom, and only giving each of them the measliest pittance of a salary that it can get away with.
For some industries, I agree that this really is a shame. For many of the industries that humans can, and have, performed better and more skilfully in small-group enterprises for thousands of years — such as medicine, sport, literature, and most especially music — the big corporation has definitely done more harm than good. But for the industries that are built on mechanisation, and that require large amounts of investment and organisation — such as transportation, modern agriculture, and mining — I've now seen it being done with the big corporation (in Western countries, such as Australia), and without the big corporation (in third-world countries, such as Bolivia). And it's clear that the big corporation is actually needed, if the operation is to be carried out with any degree of planning, safety, or efficiency.
The sad fact is that big ventures require big organisations behind them. Mining is a big venture: it involves huge amounts of raw material, machinery, personnel, transportation, land, and money. It is, by its very nature, an unsustainable and an environmentally destructive venture, and as such is is "bad": but it is also necessary, in order for the products and the goods of our modern world to be produced; and as such, I'm sorry to say that it's not going away any time soon. And so, bearing that in mind, I'd rather see mining done "right" — by big corporations, that know what they're doing — than done "wrong", by 400 co-operatives that squabble and compete, and that get very little done, while also doing nothing to improve the lives or the jobs of their people.
This is why I now look at "doomed jobs" and "doomed little-man ventures" in many industries, and instead of feeling sorry for their inevitable demise and hardship, I instead believe that their doom is ultimately for the best. In due course, all those unemployed labourers will, inevitably, move up in the world, and will be able to contribute to humanity in bigger and more meaningful ways, while having a more pleasant and a more fulfilling life. And, in due course, the corporate-run ventures will actually be more organised and more beneficial for everyone, than a gaggle of individually-run ventures could ever possibly be.
Of course, the forced change of occupation will be rejected by some; it will be unattainable for others; and it will come at a high cost for all. And naturally, the corporations will cut corners and will exploit the people at the bottom, unless (and, in many cases, even when) subject to the most rigorous of government regulations and union pressures. But ultimately, for modern and industrialised fields of work, it's the only way.
Because of all this, I look forward to the day when the mountain of Cerro Rico in Bolivia comes crashing down, and when the miners of Potosí (most of whom hopefully will not get killed by the mountain collapsing) are left wondering what the hell to do with their lives. The day that this happens, will be the day that those people stop spending their lives doing work that's barely fit for cattle, and start finding other jobs, that are more appropriate for adult human beings with a brain and a decent amount of common sense.
]]>
Let the cameras do the snapping2007-04-11T00:00:00Z2007-04-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2007/04/let-the-cameras-do-the-snapping/
For all of the most memorable moments in life — such as exotic vacations, milestone birthday parties, and brushes with fame — we like to have photographs. Videos are good too — sometimes it's even nice (although something of a luxury) to use more traditional methods, such as composing song, producing paintings, or interpreting the moment with dance — but really, still photographs are by far the most common and the most convenient way to preserve the best moments in life.
For some people, photography is an art and a life-long passion: there is great pride to be had in capturing significant occasions on film or in pixels. But for others (such as myself), taking photos can quickly become little more than a bothersome chore, and one that detracts from the very experiences that you're trying to savour and to have a memento of.
For those of us in the latter category, wouldn't it be great if our cameras just took all the pictures for us, leaving us free to do other things?
Smart cameras
I was thinking about this the other day, after a particularly intense day of photo-taking on my current world trip. I decided that it would be very cool, and that it probably wouldn't be that hard to do (what with the current state of intelligent visual computer systems), and that seriously, it should be realistic for us to expect this kind of technology to hit the shelves en masse within the next 30 years. Max.
Sunset over Lima
Think about it. Robotic cameras that follow you around — perhaps they sit on your shoulder, or perhaps they trail behind you on wheels (or legs!) — and that do all the snapping for you. No need for you to point and shoot. They'll be able to intelligently identify things of interest, such as groups of people, important landmarks, and key moments. They'll have better reflexes than you. They'll know more about lighting, saturation, aperture, shutter speed, and focus, than you could learn in a lifetime. They'll be able to learn as they go, to constantly improve their skills, and to contribute their learning back to a central repository, to be shared by millions of other robotic cameras around the world.
Meanwhile, you'll be able to actually do stuff, apart from worrying about whether or not this is a good time to take a picture.
Not science fiction
What's more, judging by recent developments, this may not be as far off as you think.
Already, numerous researchers and technologists around the world are developing machines and software routines that pave the way for exactly this vision. In particular, some Japanese groups are working on developing robotic cameras for use in broadcasting, to make the cameraman an obsolete occupation on the studio floor. They're calling this automatic program production for television networks, and they're being sponsored and supported by the Japan Broadcasting Corporation.
This is still only early stages. The cameras can be told to focus on particular objects (usually moving people), and they can work with each other to capture the best angles and such. But it's very promising, and it's certainly laying a firm foundation for the cameras of the future, where detecting what to focus on (based on movement, among other metrics) will be the key differentiator between intelligent and dumb photographic systems.
I know that many people will find this vision ludicrous, and that many more will find it to be a scary prediction of the end of photography as a skill and as an art. But really, there's no reason to be afraid. As with everything, robotic cameras will be little more than a tool; and despite being reasonably intelligent, I doubt that they'll ever completely replace the human occupation of photographer. What's more, they'll open up whole new occupations, such as programmers who can develop their own intelligent algorithms (or add-ons for bigger algorithms), which will be valuable and marketable as products.
I realise that not all of you will feel this way; but I for one am looking forward to a future where the cameras do the snapping for me.
I believe that someone was videoing my presentation, but I'm not sure if the video is online yet, or if it will be; and if it is online, I don't know where. I also don't know if I'm supposed to be posting my slides to some official spot, rather than just posting them here, where you can find them through Planet Drupal. So if anyone knows the answers to these things, please post your answers here as comments. Anyway, glad you found this, and enjoy the slides.
]]>
You're part of this world... aren't you?2007-02-09T00:00:00Z2007-02-09T00:00:00ZJazahttps://greenash.net.au/thoughts/2007/02/youre-part-of-this-world-arent-you/
For the past century, humanity has fallen into the habit of wreaking ever-more serious havoc upon the natural environment, and of conveniently choosing to ignore any and all side-effects that this behaviour may entail. This can easily be explained by the modern, middle-class habitats of the living room, the local supermarket, and the air-conditioned office: in these surroundings, we are able to damage and destroy without even realising it; and at the same time, we are completely shielded from, and oblivious to, the consequences of our actions.
The pitfalls are so many, that if we actually stopped to think about them, we'd all realise that we have no choice but to go and live in a cave for the rest of our lives. TV? Runs on power, comes from coal (in many places), contributes heat to the planet. Air-conditioning? Both of the above as well, multiplied by about a hundred. Car? Runs on petrol, comes from oilfields that were once natural habitats, combusts and produces CO2 that warms up the planet. Retail food? Comes from farms, contributing to deforestation and erosion, built on lands where native flora once grew and where native fauna once lived, carried on trucks and ships that burn fuel, packaged in plastic wrappers and tin cans that get thrown away and sent to landfill.
The act of writing this thought? Using electricity and an Internet connection, carried on power lines and data cables that run clean through forests, that squash creatures at the bottom of the ocean, powering a computer made of plastics and toxic heavy metals that will one day be thrown into a hole in the ground. I could go on all day.
Our daily lives are a crazy black comedy of blindness: each of us is like a blind butcher who carves up his customers, thinking that they're his animal meats; or like a blind man in his house, who thinks he's outside enjoying a breeze, when he's actually feeling the blizzard blowing in through his bedroom window. It would be funny, if it wasn't so pitifully tragic, and so deadly serious. We've forgotten who we are, and where we are, and what we're part of. We've become blind to the fact that we're living beings, and that we exist on a living planet, and that we're a part of the living system on this planet.
Hobbits ask ents if they're part of this world
Finally, however, more and more people are taking off the blindfold, and realising that they do actually exist in this world, and that closing the window isn't the answer to stopping that breeze from getting warmer.
When people take off the blindfold, they immediately see that every little thing that we do in this world has consequences. In this age of globalisation, these consequences can be much more far-reaching than we might imagine. And at a time when our natural environment is in greater peril than ever before, they can also be serious enough to affect the future of the world for generations to come.
In a recent address to the National Press Club of Australia, famed environmentalist Dr David Suzuki suggests that it's time we all started to "think big". The most effective way to start getting serious about sustainability, and to stop worldwide environmental catastrophe, is for all of us to understand that our actions can have an impact on environmental issues the world over, and that it is our responsibility to make a positive rather than a negative impact.
The world's leading scientists are taking a stronger stance than ever on the need for the general public to get serious about sustainability. Last week, the Intergovernmental Panel on Climate Change released a report on global warming, the most comprehensive and authoritative one written to date. The report has erased any doubts that people may have had about (a) the fact that global warming exists, and (b) the fact that humanity is to blame for it, saying that it is "very likely" — 90%+ probability — that human action has been the overwhelming cause of rising temperatures.
Governments of the world are finally starting to listen to the experts as well. The release of the IPCC report prompted the Bush Administration to officially accept that humanity is causing global warming for the first time ever. The Howard government, here in Australia, is making slightly more effort [than its usual nothing] to do something about climate change, by introducing new clean energy initiatives, such as solar power subsidies, "clean coal" development, and a (highly controversial) push for nuclear power — although all of that is probably due to the upcoming federal election. And the European Union is going to introduce stricter emission limits for all cars sold in Europe, known as the 'Euro 5 emissions standards'.
And, of course, the new documentary / movie by Al Gore, An Inconvenient Truth, has done wonders for taking the blindfold off of millions of Joe Citizens the world over, and for helping them to see just what's going on around them. After I saw this film, it made me shudder to think just what a different world we'd be living in today, if Al Gore had been elected instead of George Dubbya back in 2000. How many wars could have been prevented, how many thousands of people could have lived, how many billions of tonnes of fuel could have been spared, and how many degrees celsius could the world's average temperature have been reduced, if someone like Al Gore had been in charge for the past 7 years?
It's great to see the global environmental movement gaining a new level of respect that it's never before attained. And it's great so see that more people than ever are realising the truth about environmental activism: it's not about chaining yourself to trees, growing your hair down to your bum, and smoking weed all day (although there's nothing wrong with doing any of those things :P); it's about saving the planet. Let's hope we're not too late.
]]>
GreenAsh ground-up videocast: Part III: Custom theming with Drupal 4.72006-12-31T00:00:00Z2006-12-31T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/12/videocast-custom-theming-drupal-4-7/
This video screencast is part III of a series that documents the development of a new, real-life Drupal website from the ground up. It shows you how to create a custom theme that gives your site a unique look-and-feel, using Drupal's built-in PHPTemplate theme engine. Tasks that are covered include theming blocks, theming CCK node types, and theming views. Video produced by GreenAsh Services, and sponsored by Hambo Design. (21:58 min 24.1MB H.264)
I hope that all you fellow Drupalites have enjoyed this series, and I wish you a very happy new year!
This is the final episode in this series. If you haven't done so already, go and watch part I and part II.
Note: to save the video to your computer, right-click it and select 'Save Link As...' (or equivalent action). You will need QuickTime v7 or higher in order to watch the video.
]]>
GreenAsh ground-up videocast: Part II: Installing and using add-on modules with Drupal 4.72006-12-24T00:00:00Z2006-12-24T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/12/videocast-installing-addon-modules-drupal-4-7/
This video screencast is part II of a series that documents the development of a new, real-life Drupal website from the ground up. It shows you how to install a number of the more popular add-on modules from the contributions repository, and it steps through a detailed demonstration of how to configure these modules. The add-on modules that are covered include Views, CCK, Pathauto, and Category. Video produced by GreenAsh Services, and sponsored by Hambo Design. (28:44 min — 35.1MB H.264)
Stay tuned for part III, which will be the final episode in this series, and which will cover custom theming with PHPTemplate. If you haven't done so already, go and watch part I.
Note: to save the video to your computer, right-click it and select 'Save Link As...' (or equivalent action). You will need QuickTime v7 or higher in order to watch the video.
]]>
Freaky Teletubby hypnosis2006-12-23T00:00:00Z2006-12-23T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/12/freaky-teletubby-hypnosis/
I used to think that the Teletubbies were just cute, fat, bouncy, innocent little TV celebrities. But I've finally come to realise the truth that was so obvious all along: the Teletubbies are evil.
And very hypnotic
The evil, hypnotic Teletubbies
I've heard tales for many years that the Teletubbies have a hypnotic effect on little kids. More recently, I've witnessed this hypnosis first-hand, as it infected my little step-sister. Today, the final blow came. For a few terrifying minutes, I myself fell victim to the magnetism of the Teletubbies.
The thing that I found most compelling to watch was the landscape. It's so neat, so bright and green and pastel-coloured, so blatantly artificial (although I've heard, ironically, that the show is actually filmed on location at a real country farm in England, with a fair bit of special effects added in). It looks like something out of a computer game. Or like an alien planet (insert sinister laugh here).
I guess the British love the show so much because, unlike the real England, it never rains in Teletubbyland! There's (almost) always a clear blue sky, and a happy, smiling, laughing orange sun shining down from overhead.
The sun is always smiling... errr, I mean... shining
Speaking of which, what is the deal with that stupid baby-faced sun? Another strangely hypnotic feature of the show, the sun seems to randomly smile, laugh, and make weird baby noises. There are also numerous eerie moments in the show, where the sun and the teletubbies just stop whatever they're doing (which generally isn't much), and stare at each other for a while, apparently locked in a fervent lover's trance.
The narrator
This has to be one of the freakiest things about the Teletubbies. I don't know where they found this guy, but he's bad news. It's not just his incredibly insightful comments, such as "Teletubbies love each other very much" (said as Teletubbies embrace in a [literally] pear-shaped group orgy). It's the way he says them. He's completely unexcited, completely unenthusiastic. He could teach Bernie Fraser how to talk boring.
Not only is he utterly uninspiring with his droning monotone; he also repeats everything over and over again. For example:
Dipsy's hat Dipsy's hat Fancy that It's Dipsy's hat.
This most eloquent of poems must have been recited at least 5 times, in the space of just one episode. I'm not sure if the intent is to hypnotise or to tranquilise; the end result is a bit of both.
Flubs
Then there's all the other things: the visual appearance of the Teletubbies themselves; the baby-like chatter that they constantly engage in; the distinctive (no doubt alien) antennae that they all have implanted in their cotton wool skulls; the random rabbits; etc. All up, the Teletubbies makes for a most disturbing 30 minutes of entertainment.
Child psychologists are right to worry about their effect on the next generation. South Park and The Simpsons are right to... errr... critique them. In fact, white Western toddlers the [white Western] world over would be much better served, in my opinion, by learning about the good 'ol American values of animal cruelty, fast food addiction, death by mutilation, panoptic racism, and so on (all of which can be found in South Park and The Simpsons, amongst other quality TV shows); than they would be by obvserving the bouncing motions of a group of oversized talking beanbags.
Those flubby tubbies are starting to freak me out.
Shake what yo' Tubbie Momma gave you
Check out these videos — they're far less disturbing than the real Teletubbies TV episodes:
]]>
GreenAsh ground-up videocast: Part I: Installing and configuring Drupal 4.72006-12-17T00:00:00Z2006-12-17T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/12/videocast-installing-and-configuring-drupal-4-7/
This video screencast is part I of a series that documents the development of a new, real-life Drupal website from the ground up. It shows you how to download Drupal 4.7, install it, and perform some basic initial configuration tasks. Video produced by GreenAsh Services, and sponsored by Hambo Design. (11:35 min — 10.2MB H.264)
Stay tuned for part II, which will cover the installation and configuration of add-on modules, such as Views, CCK, Pathauto, and Category; and part III, which will cover custom theming with PHPTemplate.
Note: to save the video to your computer, right-click it and select 'Save Link As...' (or equivalent action). You will need QuickTime v7 or higher in order to watch the video.
]]>
Pleasure vs pro2006-11-15T00:00:00Z2006-11-15T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/11/pleasure-vs-pro/
It's become popular in recent times for people to quit their boring day jobs, and instead to work full-time on something that they really love doing. We've all heard people say: now I'm spending every day doing what I enjoy most, and I couldn't be happier.
This has been happening in my industry (the IT industry) perhaps more than in any other. Deflated workers have flocked away — fleeing such diverse occupations as database admin, systems admin, support programmer, and project manager — driven by the promise of freedom from corporate tyranny, and hoping to be unshackled from the manacles of boring and unchallenging work. The pattern can be seen manifesting itself in other industries, too, from education to music, and from finance to journalism. More than ever, people are getting sick of doing work that they hate, and of being employed by people who wouldn't shed a tear if their pet panda kicked the bucket and joined the bleedin' choir invisibile.
And why are people doing this? The biggest reason is simply because — now more than ever — they can. With IT in particular, it's never been easier to start your own business from scratch, to develop and market hip-hop new applications in very small teams (or even alone), and to expand your skill set far beyond its humble former self. On top of that, people are being told (via the mass media) not only that they can do it, but that they should. It's all the rage. Doing-what-thou-lovest is the new blue. Considering the way in which a career has been reduced to little more than yet another consumer product (in recent times), this attitude should come as no surprise. After all, a job where you do exactly what you want sounds much better than a job where you do exactly what you're told.
Call me a cynic, but I am very dubious of the truth of this approach. In my experience, as soon as you turn a pleasurable pastime into a profession, you've suddenly added a whole new bucket of not-so-enjoyable tasks and responsibilities into the mix; and in the process, you've sacrificed at least some of the pleasure. You've gone from the humble foothills to the pinnacle of the mountaintop — so to speak — in the hope of enjoying the superior view and the fresh air; only to discover that the mountain frequently spews ash and liquid hot magma from its zenith, thus rather spoiling the whole venture.
When I say that these things are in my experience, I am (of course) referring to my experience in the world of web design and development. I've been doing web design in one form or another for about 8 years now. That's almost as long as I've been online (which is for almost 9 years). I'm proud to say that ever since I first joined the web as one of its netizens (wherever did that term go, anyway? Or did it never really make it in the first place? *shrugs*), at age 12, I've wanted to make my own mark on it. Back then, in 1998, equipped with such formidable tools as Microsoft Word™ and its Save as HTML feature, and inhabiting a jungle where such tags as
<blink>
and
<marquee>
were considered "Web Standards", it was all fun and games. In retrospect, I guess I really was making my mark on the web, in the most crude sense of the term. But hey: who wasn't, back then?
From these humble beginnings, my quirky little hobby of producing web sites has grown into a full-fledged business. Well, OK: not exactly full-fledged (I still only do it on the side, in between study and other commitments); but it's certainly something that's profitable, at any rate. Web design (now known as web development, according to the marketing department of my [one-man] company) is no longer a hobby for me. It's a business. I have clients. And deadlines. And accounts. Oh, and a bit of web development in between all that, too. Just a bit.
Don't get me wrong. I'm not trying to complain about what I do. I chose to be a web developer, and I love being a web developer. I'm not saying that it's all a myth, and that you can't work full-time on something that you're passionate about, and retain your passion for it. But I am saying that it's a challenge. I am saying that doing an activity as a professional is very, very different from doing it as an amateur enthusiast. This may seem like an obvious statement, but in Wild Wild West industries such as web development, it's one that not everyone has put much thought into.
Going pro has many distinct advantages: you push yourself harder; you gain much more knowledge of (and experience in) your domain; you become a part of the wider professional community; and of course, you have some bread on the table at the end of the day. But it also has its drawbacks: you have to work all the time, not just when you're in the mood for it; you're not always doing exactly what you want to do, or not always doing things exactly the way you want them done; and worst of all, you have to take care of all the other "usual" things that come with running a small business of any kind. The trick is to make sure that the advantages always outweigh the drawbacks. That's all that any of us can hope for, because drawbacks are a reality in every sphere of life. They don't go away: they just get overshadowed by good things.
Looking back on my choice of career — in light of this whole pleasure-vs-pro argument — I'm more confident than ever that I've made the right move by going into the IT profession. Back when I was in my final year of high school, I was tossing up between a career in IT, and a career in Journalism (or in something else related to writing). Now that IT is my day job, my writing hobby is safe and sound as a pristine, undefiled little pastime. And in my opinion, IT (by its very nature) is much more suitable as a profession than as a pastime, and writing (similarly) is much more suitable as a pastime than as a profession. That's how I see it, anyway.
For all of you who are planning to (or who already have) quit your boring day jobs, in order to follow your dreams, I say: good luck to you, and may you find your dreams, rather than just finding another boring day job! If you're ever feeling down while following your dreams, just think about what you're doing, and you'll realise that you've actually got nothing to feel down about. Nothing at all.
]]>
GreenAsh 3.0: how did they do it?2006-10-04T00:00:00Z2006-10-04T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/10/greenash-3-0-how-did-they-do-it/
After much delay, the stylish new 3rd edition of GreenAsh has finally hit the web! This is the first major upgrade that GreenAsh has had in almost 2 years, since it was ported over from home-grown CMS (v1) to Drupal (v2). I am proud to say that I honestly believe this to be the cleanest (inside and out), the most mature, and the sexiest edition to date. And as you can see, it is also one of the biggest upgrades that the site has ever had, and possibly the last really big upgrade that it will have for quite some time.
The site has been upgraded from its decaying and zealously hacked Drupal 4.5 code base, to the latest stable (and much-less-hacked) 4.7 code base. This fixes a number of security vulnerabilities that previously existed, as well as bringing the site back into the cutting edge of the Drupal world, and making it compatible with all the latest goodies that Drupal has to offer.
New theme
GreenAsh 3.0 sports a snazzy new theme, complete with fresh branding, graphics, and content layout. The new theme is called Lorien, and as with previous site designs, it gives GreenAsh a public face using nothing but accessible, validated, and standards-compliant markup:
GreenAsh 3.0
GreenAsh 2.0 was styled with the Mithrandir theme:
GreenAsh 2.0
And GreenAsh 1.0, which was not Drupal-powered, did not technically have a 'theme' at all; but for historical purposes, let's call its design the GreenAsh theme:
GreenAsh 1.0
New modules
GreenAsh 3.0 is also using quite a few new modules that are only available in more recent versions of Drupal. The views module is being used to generate custom node listings in a number of places on the site, including for all of the various bits that make up the new front page, and also for the revamped recent posts page. The pathauto module is now generating human-readable URLs for all new pages of the site, in accordance with the site's navigation structure. Because the URL format of the site's pages has changed, a number of old URLs are now obselete, and these are being redirected to their new equivalents, with the help of the path redirect module.
The improved captcha module is providing some beginner-level maths questions to all aspiring new users, anonymous commenters, and anonymous contact form submitters, and is proving to be an effective combatant of spam. Also, the very nifty nice menus module is being used for administrator-only menus, to provide a simple and unobtrusive navigational addition to the site when needed.
Best of all, the site has finally been switched over to the category module, which was built and documented by myself, and which had the purpose from the very beginning of being installed right here, in order to meet the hefty navigational and user experience demands that I have placed upon this site. Switching to the category module was no small task: it required many hours of careful data migration, site re-structuring, and menu item mayhem. I certainly do not envy anyone who is making the switch from a taxonomy or book installation to a category module installation. But, despite the migration being not-for-the-faint-hearted, everything seems to be running smoothly now, and the new system is providing a vastly improved end-user and site administrator experience.
New user experience
I have implemented a number of important changes to the user experience of the site, which will hopefully make your visit to the site more enjoyable and useful:
Re-designed front page layout
Switch to a simple and uncluttered 1-column layout for all other pages
New category-module-powered navigation links and table-of-contents links
Automatic new user account approval after 72 hours
Removed a number of pages from the site's hierarchy, to reduce unnecessary information overload
Ongoing effort
Obviously, there are still a number of loose ends to tie up. For example, the content on some pages may still require updating. Additionally, some pages are still yet to be added (such as the listings in the sites folio). Further tweaks and adjustments will probably also be made to the look and feel of the site in the near future, to continue to improve it and to make it distinctly branded.
Feedback, comments, suggestions, criticisms, cookies, cakes, donations, and lingerie are all welcome to be thrown my way. Throwing apple cores is discouraged: if you think the new site stinks that badly, why not be constructive and throw a can of deodorant instead? Anyway, I really do hope you all like the site post-upgrade, and I wish you all the best in your exploration of the new and improved GreenAsh 3.0!
]]>
Must have, must do2006-09-16T00:00:00Z2006-09-16T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/09/must-have-must-do/
I have a beautiful little step-sister, who is almost three years old. She has the face of an angel, and she could charm a slab of granite if she had to; but boy, can she put up a storm when she doesn't get her way. Like all three-year-olds, she is very concerned with having things. There are a great many things that she wants to have. Sweets, videos, clothes, toys, rides on the swing, trips to the supermarket, and plastic dummies are some of the higher-priority of these things.
Lately, her choice of vernacular expression has taken an interesting route. And no, it's not the scenic route, either: it's the I-ain-stuffin-around freeway express route. She no longer wants things; she needs them. Mummy, I neeed some biscuits, and I neeed to go on the swing. I guess it's the logical choice of words to use, from her point of view: she's worked out that a need is stronger and more urgent than a want; so clearly, using the word 'need' is a more effective way of getting what you 'want'. Of course, she doesn't yet understand the concept of reserving the use of strong language for when it really is 'needed' (no pun intended). In fact, even some adults don't understand this concept.
We humans are naturally selfish creatures. This selfishness is most evident in children, who are completely uninhibited in expressing their every desire. But really, most adults retain this selfishness for their entire lives; the difference is only that they learn to conceal it, to mask it, and to express it more subtly. In many cases, the only things that really change are the desires themselves: the colourful, innocent little desires of childhood are replaced by bigger and less virtuous ones, such as ego, money, and sex.
But actually, there's more to it than this. Perhaps it's just me, but I think that the very nature of our desires changes over time. As children, we are obsessed with owning or possessing things: our entire lives revolve around having toys, having food, having entertainment. But as we get older, we seem to become less concerned with having things, and more concerned with doing things. We're still very much acting selfishly, but our goals and aspirations change dramatically. And in a way, that's what makes all the difference.
I've noticed this change in myself, and in many of the close friends that I've grown up with. When I was a wee lad, for example, I was extremely fond of Lego™. Barely a waking moment went by in which I wasn't salivating over the next Lego model on my wish-list, or plotting up cunning ways by which I could obtain more of the stuff. Many other toys and gizmos filled my heart with longing throughout my childhood: TV shows, magic cards, and console / computer games, to name a few. For many years, these were the things that made life worth living for. Without them, the world was an empty void.
But as I've grown older and hoarier (although not that hoary), these possessions have begun to seem much less important. Where has it gone, all that desire to accumulate things? It seems to have been extinguished. In its place is a new desire, far more potent than its predecessor ever was: a desire to do things. To see the world. To share my knowledge. To build useful tools. To help out.
I see the same changes in many of my peers. All of the things that they once considered to be of prime importance - the rock-star posters, the model aeroplane collections, the signed baseball caps - it seems that all of a sudden, nobody has time for them anymore. Everybody is too busy doing things: earning a university degree; gaining work experience; volunteering in their spare time. Even socialising seems to have subtly changed: from having friends, to being friends (a small but fundamental change in perception).
Now, while I am arguing that we humans have a greater desire to do positive acts as we enter adulthood, I am not arguing that this desire stems from any noble or benevolent motive. On the contrary, the motive generally remains the same as ever: self-benefit. There are many personal rewards to be found from doing things that make a difference: ego boost, political power, popularity, and money are some of the more common ones. Nevertheless, motives aside, the fact that we have this desire, and that we act on it, is surely a good thing, in and of itself.
This shift in our underlying desires strikes me as a fascinating change, and also as one of the key transitions between childhood and adulthood. Of course, I could be wrong, it could be just me - perhaps everyone else was born wanting to make a difference by doing, and it's just me that was the spoilt, selfish little kid who always wanted more toys to play with. If that's the case, then I can live with that. But until I'm proven wrong, I think I'll stick with my little theory.
]]>
Import / Export API: final thoughts2006-09-07T00:00:00Z2006-09-07T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/09/import-export-api-final-thoughts/
The Summer of Code has finally come to an end, and it's time for me to write up my final thoughts on my involvement in it. The Import / Export API module has been a long and challenging project, but it's also been great fun and has, in my opinion, been a worthwhile cause to devote my time to. My mentor has given my work the final tick of approval (which is great!), and I personally feel that the project has been an overwhelming success.
Filling out the final student evaluation for the SoC was an interesting experience, because it made me realise that as someone with significant prior experience in developing for my mentor organisation (i.e. Drupal), I was actually in the minority. Many of the questions didn't apply to me, or weren't entirely relevant, as they assumed that I was just starting out with my mentor organisation, and that the SoC was my 'gateway' to learning the ropes of that organisation. I, on the other hand, already had about 18 months of experience as a Drupal developer when the SoC began, and I always viewed SoC as an opportunity to work on developing an important large-scale module (that I wouldn't have had time to develop otherwise), rather than as a 'Drupal boot camp'.
The Import / Export API is also something of a unique project, in that it's actually quite loosely coupled to Drupal. I never envisaged that it would turn out like this, but the API is actually so loosely coupled, that it could very easily be used as an import / export tool for almost any other application. This makes me question whether it would have been better to develop the API as a completely stand-alone project, with zero dependency on Drupal, rather than as a Drupal module, with a few (albeit fairly superficial) dependencies. In this context, the API is a bit like CiviCRM, in that it is basically a fully-functional application (or library, in the API's case) all by itself, but in that it relies on Drupal for a few lil' things, such as providing a pretty face to the user, and integration as part of a content-managed web site.
The module today
For those of you that haven't tried it out yet, the API is an incredibly useful and flexible tool, when it comes to getting data in and out of your site. The module currently supports importing and exporting any entity in Drupal core, in either XML or in CSV format. Support for CCK nodes, node types, and fields is also currently included. All XML tags or CSV field names can have custom mappings defined during import or export. At the moment, the UI is very basic (the plan is to work on this some more in the future), but it exposes the essential functionality of the API well enough, and it's reasonably easy to use.
The module is superior to existing import modules, because it allows you to import a variety of different entities, but to maintain and to manage the relationships between those entities. For example: nodes, comments, and users are all different entities, but they are also all related to each other; nodes are written by users, and comments are written about particular nodes by users. You could import nodes and users using the node_import and user_import modules. But these two modules would not make any effort to link your nodes to your users, or to maintain any link that existed in your imported data. The Import / Export API recognises and maintains all such links.
As for stability, the API still has a few significant known bugs lurking around in it, but overall it's quite stable and reliable. The API is still officially in beta mode, and more beta testing is still very much welcome. Many thanks to the people who have dedicated their time to testing and bug fixing thus far (you know who you are!) - it wouldn't be the useful tool that it is without your help.
The module tomorrow
And now for the most important question of all: what is the future of the API? What additional features would I (and others) like to see implemented post-SoC? What applications are people likely to build on top of it? And will the module, in some shape or form, to a greater or lesser extent, ever become part of Drupal core?
First, the additional features. I was hoping to get some of these in as part of the SoC timeframe, but as it turned out, I barely had time to meet the base requirements that I originally set for myself. So here's my wish list for the API (and in my case, mere wishing ain't gonna make 'em happen - only coding will!):
File handling. The 'file' field type in the current API is nothing more than a stub - at present, it's almost exactly the same as the 'string' field type. I would like to actually implement file handling, so that files can be seamlessly imported and exported, along with the database-centric data in a Drupal site. Many would argue that this is critical functionality. I feel you, folks - that's why this is no. 1.
Filtering and sorting in queries. The 'db' engines of the API are cutting-edge in their support for references and relationships, but they currently lack all but the most basic support for filtering and sorting in database queries. Ideally, the API will have an extensible system for this, similar to what is currently offered for node queries by the views module. A matching UI of views' calibre would be awesome, too.
Good-looking and flexible UI. The current UI is about as basic as it gets. The long-term plan is to move the UI out into a separate project (it's already a separate module), and to expose much more of the API through the interface, e.g. disabling import / export of specified fields, forcing of ID key generation / key matching and updating, control over alternate key handling. There are also plenty of cosmetic improvements that could be made to the UI, e.g. more wizard-like form dialogs (I think I'll wait for Drupal 5.0 / FAPI 2.0 before doing this), flexible control of output format (choice between file download, save output on server, display raw output, etc).
Validate and submit (and more?) callbacks. This is really kind of dependent on the API's status in regards to going into Drupal core (see further down). But the general plan is to implement FAPI-like validate and submit callbacks within the API's data definition system.
Next, there are the possible applications of the API. The API is a great foundation for a plethora of possibilities. I have faith that, over the course of the near future, developers will start to have a look at the API, and that they will recognise its potential, and that they will start to develop really cool things on top of it. Of course, I may be wrong. It's possible that almost no developers will ever look at the API, and that the API will rot away in the dark corners of Drupal contrib, before sinking slowly into the depths of oblivion. But I hope that doesn't happen.
Some of the possible applications that have come to my mind, and that other people have mentioned to me:
Finally, there is the question of whether or not (and what parts of) the API will ever find itself in Drupal core. From the very beginning, my mentor Adrian has been letting me in on his secret super-evil plan for world domination (or, at the least, for Drupal domination). I can confide to all of you that getting parts of the API in core is part of this plan. In particular, the data definition system is a potential candidate for what will be the new 'data model / data layer / data API' foundation of FAPI 3.0 (i.e. Drupal post-upcoming-5.0-release).
However, I cannot guarantee that the data definition system of the API will ever make it into core, and I certainly cannot predict in what form it will be by the time that it gets in (if it gets in, that is). Adrian has let slip a few ideas of his own lately (in the form of PHP pseudo-code), and his ideas for a data definition system seem to be quite different from mine. No doubt every other Drupal developer will also have their own ideas on this - after all, it will be a momentous change for Drupal when it happens, and everyone has a right to be a part of that change. Anyway, Adrian has promised to reveal his grand plans for FAPI 3.0 during his presentation at the upcoming Brussels DrupalCon (which I unfortunately won't be able to attend), so I'm sure that after that has happened, we'll all be much more enlightened.
The API's current data definition system is not exactly perfectly suited for Drupal core. It was developed specifically to support a generic import / export system, and that fact shows itself in many ways. The system is based around directly reflecting the structure of the Drupal database, for the purposes of SQL query generation and plain text transformation. That will have to change if the system goes into Drupal core, because Drupal core has very different priorities. Drupal core is concerned more with a flexible callback system, with a robust integration into the form generation system, and with rock-solid performance all round. Whether the data definition system of the API is able to adapt to meet these demands, is something that remains to be seen.
Further resources
Well, that's about all that I have to say about the Import / Export API module, and about my involvement in the 2006 Google Summer of Code. But before you go away, here are some useful links to get you started on your forays into the world of importing and exporting in Drupal:
Many thanks to Angie Byron (a.k.a. webchick) for your great work last year on the Forms API QuickStart guide and reference guide documents, which proved to be an invaluable template for me to use in writing these documents for the Import / Export API. Thanks also, Angie, for your great work as part of the SoC organising team this year!
And, last but not least, a big thankyou to Adrian, Sami, Rob, Karoly, Moshe, Earl, Dan, and everyone else who has helped me to get through the project, and to learn heaps and to have plenty of fun along the way. I couldn't have done it without you - all of you!
SoC - it's been a blast. ;-)
]]>
Stop shining that light in my face2006-08-19T00:00:00Z2006-08-19T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/08/stop-shining-that-light-in-my-face/
Evangelism. For centuries, many of the world's largest and most influential religions have practiced it. The word itself is generally associated with Christianity, and rightly so. But a number of other religions, such as Islam, also actively encourage it.
The idea behind evangelism is that one particular religion is the one true way to find G-d and to live a good life. It is therefore a duty, and an act of kindness, for the followers of that religion to "spread the word", and to help all of humanity to "see the light".
The catalyst behind my writing this article was that I happened to run into a Christian evangelist today, whilst out walking on the streets. I've never actually stopped and talked to one of these people before: my standard procedure is to ignore them when out and about, and to slam the door in their faces when they come a-knocking. This, quite understandably, is also how most other people react. But today I stopped and talked.
To cut a long story short, I walked away from the conversation almost an hour later, more certain than ever that evangelism is a bad idea.
Now, don't get me wrong: I'm all for the spreading of knowledge, and I think that connecting with and learning about religions and cultures outside of your own is a very worthwhile endeavour. I have personally devoted a fair amount of effort into this form of learning, and I don't regret one minute of it.
But imposing your ideas onto others is a whole different ball game. Teaching is one thing, and dictating is quite another. Unfortunately, evangelism is not about the sharing of knowledge or opinions. Sharing would involve telling people: "these are my beliefs, what are yours?" Instead, evangelism involves telling people: "these are my beliefs, and if you know what's good for you, they'll be yours too".
I happen to be a member of the Jewish faith, although I ain't the most religious Jew on the block, and I don't agree with everything that my religion has to say. I believe that Jesus was a great bloke, who obviously performed a great many charitable deeds in his life, and who was revered and respected by many of his contemporaries. As far as I'm concerned, someone who blesses fishermen and promotes world peace is a nice guy.
Nice guy, sure; but not son of G-d. Nice guy, sure; but not responsible for atoning for the sins of every man, woman, and child, for all eternity, that believes in his divinity. Nice guy. Jewish too, by the way (not roman). But that's it.
Today, my over-zealous acquaintance in the shopping mall told me his beliefs, which happened to be slightly different to my own. I had no problem with listening to them. According to my acquaintance, Jesus is the son of G-d, he was resurrected from the dead, and he atoned for all the sins of his followers through his death. I am aware that this is the belief held by millions of Christians around the world, and I respect that belief, and I have no desire to impose any other conflicting belief upon any Christian person. I just happen to have a different belief, that's all.
However, after that, things started getting a bit ugly. Next, I was informed that I am in grave danger. It is imperative that I accept a belief in Jesus and in Christianity, because only then will I be forgiven for all of my sins. Should I fail to accept this belief, I am doomed to eternity in hell.
Thanks for the warning, buddy - I appreciate you looking out for me, and I'm grateful that you've been kind enough to help me avoid eternal damnation 'n' all. But actually, I happen to believe that everyone goes to heaven (with a sprinkling of hellish punishment on the way, of course, depending on how much you've sinned), and that I already have a means of getting the all-clear from the Big Man regarding forgiveness, through my own religion.
The response? I'm wrong. I'm doomed. I haven't seen the light. Such a pity - it seemed, at first, that there was hope for me. If only I wasn't so damn stubborn.
Actually, I did see the light. How could I miss it, when it was being shone right in my face? For the sake of everyone's retinas, I say to all evangelists: stop shining that accursed light in our faces! Instead, why don't you practice what you preach, and respect the rights of others to serve G-d and to be charitable in their own way?
I don't respond well to advertisements that proclaim too-good-to-be-true offers. Hence my reaction to the whole "believe-in-my-way-and-all-your-sins-are-forgiven" thing. I also don't respond well to threats. Hence my reaction to the whole "believe-in-my-way-or-spend-eternity-in-hell" thing. It amazes and deeply disturbs me that this crude and archaic form of coercion has been so successful throughout the history of organised religion. But then again, those "$0 mobile phone" deals have been quite successful as well. I guess some people really are a bit simple.
I applaud the millions of Christian people (some of whom are my personal friends or acquaintances) who openly criticise and shun the evangelism of their brethren. It's a relief to know that the majority of people agree with my opinion that evangelism is the wrong way to go.
What this world needs is a bit more respect for others. We need to respect the rights of other people to live out a good life, according to whatever religion or doctrine they choose. We need to accept that if people want to conform to our ways, then they'll come of their own volition, and not through coercion. And we need to accept that imposing one's beliefs upon others is an arrogant, disrespectful, and hostile act that is not appreciated. World peace is a long way off. The practice of evangelism is a sound way to keep it like that. A better alternative is to agree to disagree, and to get on with doing things that really do make the world a better place.
]]>
Import / Export API: progress report #42006-08-11T00:00:00Z2006-08-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/08/import-export-api-progress-report-4/
In a small, poorly ventilated room, somewhere in Australia, there are four geeky fingers and two geeky thumbs, and they are attached to two geeky hands. All of the fingers and all of the thumbs are racing haphazardly across a black keyboard, trying to churn out PHP; but mostly they're just tapping repeatedly, and angrily, on the 'backspace' key. A pair of eyes squint tiredly at the LCD monitor before them, trying to discern whether the miniscule black dot that they perceive is a speck of dirt, or yet another pixel that has gone to pixel heaven.
But the black dot is neither of these things. The black dot is but a figment of this young geek's delirious and overly-caffeinated imagination. Because, you see, on this upside-down side of the world, where the seasons are wrong and the toilets flush counter-clockwise, there is a Drupaller who has been working on the Summer of Code all winter long. And he has less than two weeks until the deadline!
That's right: in just 10 days, the Summer of Code will be over, and the Drupal Import / Export API will (hopefully) have met its outcomes, and will be ready for public use. That is the truth. Most of the other statements that I made above, however, are not the truth. In fact:
I still don't drink any coffee at all (and I call myself a geek?!);
as far as I can see (and I may be wrong, I admit), my monitor is still pixel-perfect.
Anyway, on to the real deal...
The current status of the Import / Export API is as follows. The DB, XML, and CSV engines are now all complete, and are (I hope) at beta-quality. However, they are still in need of a fair bit of testing and bug fixing. The same can be said for the alternate key and ID key handling systems. The data definitions for all Drupal 4.7 core entities (except for a few that weren't on the to-do list) are now complete.
There are two things that still need to be done urgently. The first of these is a system for passing custom mappings (and other attributes), for any field, into the importexportapi_get_data() function. The whole point of the mapping system is that field mappings are completely customisable, but this point cannot be realised until custom mappings can actually be provided to the API. The second of these is the data definitions for CCK fields and node types. Many people have been asking me about this, including my mentor Adrian, and it will certainly be very cool when it is ready and working.
One more thing that also needs to be done before the final deadline, is to write a very basic UI module, that allows people to actually demo the API. I won't be able to build my dream import / export whiz-bang get-and-put-anything-in-five-easy-steps UI in 10 days. But I should be able to build something functional enough, that it allows people (such as my reviewers) to test out and enjoy the key things that the API can do. Once this UI module is written, I will be removing all of the little bits of UI cruftiness that are currently in the main module.
Was there something I didn't mention? Ah, yes. Documentation, documentation, documentation - how could I forget thee? As constant as the northern star, and almost as hard to find, the task of documentation looms over us all. I will be endeavouring to produce a reference guide for the import / export API within the deadline, which will be as complete as possible. But no guarantees that it will be complete within that time. The reference guide will focus on documenting the field types and their possible attributes, much like the Drupal forms API reference does. Other docs - such as tutorials, explanations, and tips - will come later.
There are many things that the API is currently lacking, and that I would really like to see it ultimately have. Most of these things did not occur to me until I was well into coding the project, and none of them will actually be coded until after the project has finished. One of these things is an extensible query filtering and sorting system, much like the system that the amazing views module boasts. Another is a validation and fine-grained error-handling system (mainly for imports).
But more on these ideas another time. For now, I have a module to finish coding.
]]>
Import / Export API: progress report #32006-07-15T00:00:00Z2006-07-15T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/07/import-export-api-progress-report-3/
The Summer of Code is now past its half-way mark. For some reason, I passed the mid-term evaluation, and I'm still here. Blame my primary mentor, Adrian, who was responsible for passing me with flying colours. The API is getting ever closer to meeting its success criteria, although not as close as I'd hoped for it to be by this point.
My big excuse for being behind schedule is that I got extremely sidetracked, with my recent work on the Drupal core patch to get a subset of CCK into core (CCK is the Content Construction Kit module, the successor to Flexinode, a tool for allowing administrators to define new structured content types in Drupal). However, this patch is virtually complete now, so it shouldn't be sidetracking me any more.
A very crude XML import and export is now possible. This is a step up from my previous announcements, where I had continually given the bad news that importing was not yet ready at all. You can now import data from an XML file into the database, and stuff will actually happen! But just what you can import is very limited; and if you step outside of that limit, then you're stepping beyond the API's still-constricted boundaries.
The ID and reference handling system - which is set to be one of the API's killer features - is only half-complete at present. I've spent a lot of time today working on the ID generation system, which is an important part of the overall reference handling system, and which is now almost done. This component of the API required a lot of thinking and planning before it happened, as can be seen by the very complicated Boolean decision table that I've documented. This is for working out the various scenarios that need to be handled, and for planning the control logic that determines what actions take place for each scenario.
Unfortunately, as I said, the reference handling system is only half-done. And it's going to stay that way for a while, because I'm away on vacation for the next full week. I hate to just pack up and leave at this critical juncture of development, but hey: I code all year round, and I only get to ski for one week of the year! Anyway, despite being a bit behind schedule, I'm very happy with the quality and the cleanliness of the code thus far (same goes for the documentation, within and outside of the code). And in the Drupal world, the general attitude is that it's better to get something done a bit late, as long as it's done right. I hope that I'm living up to that attitude, and I wish that the rest of the world followed the same mantra.
]]>
Drupal lite: Drupal minus its parts2006-06-28T00:00:00Z2006-06-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/06/drupal-lite-drupal-minus-its-parts/
It is said that a house is the sum of its parts. If you take away all the things that make it a house, then it is no longer a house. But how much can you remove, before it can no longer be called a house? This is an age-old question in the school of philosophy, and it is one for which every person has a different answer. If you take away the doors, the windows, the roof, the floorboads, the inside walls, the power lines, and the water pipes, is it still a house? In developing Drupal Lite, I hope to have answered this question in relation to Drupal. What are the absolute essentials, without which Drupal simply cannot be called Drupal? If you remove nodes, users, and the entire database system from Drupal, is it still Drupal?
Drupal Lite is, as its name suggests, a very lightweight version of Drupal, that I whipped up in about two hours last night. I developed it because I've been asked to develop a new site, which will consist mainly of static brochureware pages, with a contact form or two, and perhaps a few other little bits of functionality; but which will have to run with no database. Of course, I could just do it the ol' fashioned way, with static HTML pages, and with a CGI script for the contacts forms. Or I could whip up some very basic PHP for template file inclusion.
But muuum, I wanna use Druuupal!
Too bad, right? No database, no Drupal - right? Wrong.
Drupal Lite would have to be the lightest version of Drupal known to man. It's even lighter than what I came up with the last time that I rewrote Drupal to be lighter. And unlike with my previous attempt, I didn't waste time doing anything stupid, like attempting to rewrite Drupal in an object-oriented fashion. In fact, I barely did any hacking at all. I just removed an enormous amount of code from Drupal core, and I made some small modifications to a few little bits (such as the module loader, and the static variable system), to make them database-unreliant.
This has all been done for a practical purpose. But it brings up the interesting question: just how much can you remove from Drupal, before what you've got left can no longer be called Drupal? The answer, in my opinion, is: lots. Everything that is database-reliant has been removed from Drupal Lite. This includes: nodes; users; blocks; filters; logs; access control (for all practical purposes); caching (at present - until file-based caching gets into core); file management; image handling; localization; search; URL aliasing (could have been rewritten to work with conf variables - but I didn't bother); and, of course, the DB abstraction system itself.
This proves, yet again, that Drupal is a hacker's paradise. It really is so solid - you can cut so much out of it, and if you (sort of) know what you're doing, it still works. There are just endless ways that you can play with Drupal, and endless needs that you can bend it to.
So what's left, you ask? What can Drupal still do, after it is so savagely crippled, and so unjustly robbed of many of its best-known features? Here's what Drupal Lite can offer you:
Persistent variables (by setting the $conf variable in your settings.php file)
Module loading
Hook system
Menu callback
Theming
Forms API (although there's not much you can do with submitted form data, except for emailing it, or saving it to a text file)
Clean URLs
Breadcrumbs
User messages
404 / 403 handling
Error handling
Page redirection
Site offline mode
Basic formatting, validation, filtering, and security handling
Link and base URL handling
Unicode handling
Multisite setup (in theory - not tested)
This is more than enough for most brochureware sites. I also wrote a simple little module called 'static', that lets you define menu callbacks for static pages, and to include the content of such pages automatically, from separate template-ish files. This isn't as good as pages that are editable by non-geeky site admins (for which you need the DB and the node system), but it still allows you to cleanly define/write the content for each page; and the content of the template file for each page is virtually identical to the content of a node's body, meaning that such pages could easily be imported into a real Drupal site in future.
Speaking of which, compatibility with the real Drupal is a big feature of Drupal Lite. Any modules that are developed for Drupal Lite should work with Drupal as well. PHPTemplate (or other) themes written for Drupal Lite should work with a real Drupal site, except that themes don't have any block or region handling in Drupal Lite. Overall, converting a Drupal Lite site to the Real Deal™ should be a very easy task; and this is important for me, since I'd probably do that conversion for the site I'll be working on, if more server resources ever become available.
Drupal Lite is not going to be maintained (much), and I most certainly didn't write it as a replacement for Drupal. I just developed it for a specific need that I have, and I'm making it publicly available for anyone else who has a similar need. Setting up Drupal Lite basically consists of setting a few $conf values in settings.php, and creating your static page template files.
If you're interested, download Drupal Lite and have a peek under the hood. The zipped file is a teeny 81k - so when you do look under the hood, don't be surprised at how little you'll find! Otherwise, I'd be interested to just hear your thoughts.
A note to my dear friend Googlebot: in your infinite wisdom, I hope that you'll understand the context in which I used the phrase "hacker's paradise" in the text above. Please forgive me for this small travesty, and try to avoid indexing this page under the keyword "Windows 98". ;-)
]]>
Import / Export API: progress report #22006-06-26T00:00:00Z2006-06-26T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/06/import-export-api-progress-report-2/
The mid-program mentor evaluation (a.k.a. crunch time) for the Summer of Code is almost here, and as such, I've been working round-the-clock to get my project looking as presentable as possible. The Import / Export API module has made significant progress since my last report, but there's still plenty of work left to be done.
It gives me great pride to assert that if you download the module right now, you'll find that it actually does something. :-) I know, I know - it doesn't do much (in fact, I may simply be going delusional and crazy from all the coding I've been doing, and it may actually do nothing) - but what it does do is pretty cool. The XML export engine is now functional, which means that you can already use the module to export any entities that currently have a definition available (which is only users and roles, at present), as plain-text XML:
XML export screenshot
The import system isn't quite ready to go as yet, but the XML-to-array engine is pretty much done, and with a little more work, the array-to-DB engine will be done as well.
The really exciting stuff, however, has been happening under the hood, in the dark and mysterious depths of the API's code. Alright, alright - exciting if you're the kind of twisted individual that believes recursive array building and refactored function abstraction are hotter than Angelina's Tomb Raiders™. But hey, who doesn't?
Some of the stuff that's been keeping me busy lately:
The new Get and Put API has been implemented. All engines now implement either a 'get' or a 'put' operation (e.g. get data from the database, put data into an XML string). All exports and imports are now distinctly broken up into a 'get' and a 'put' component, with the data always being in a standard structured form in-between.
Nested arrays are now fully supported, even though I couldn't find any structures in Drupal that require a nested array definition (I wrote a test module that uses nested arrays, just to see that it works).
The definition building system has been made more powerful. Fields can now be modified at any time after the definition 'library' is first built. Specific engines can take the original definitions, and build them using their own custom callbacks, for adding and modifying custom attributes.
Support for Alternate key fields has been added. This means that you can export unique identifiers that are more human-friendly than database IDs (e.g. user names instead of user IDs), and these fields will automatically get generated whenever their ID equivalents are found in a definition. This will get really cool when the import system is ready - you will be able to import data that only has alternate keys, and not ID keys - and the system will be able to translate them for you.
Also, for those of you that want to get involved in this project, and to offer your feedback and opinions, head on over to the Import / Export API group, which is part of the new groups.drupal.org community site, and which is open for anyone to join. I'd love to hear whatever you may have to say about the module - anything from questions about how it can help you in your quest for the holy grail (sorry, only African Swallows can be exported at this time, support for European Swallows is not yet ready), to complaints about it killing your parrot (be sure that it isn't just resting) - all this and more is welcome.
I hope to have more code, and another report, ready in the near future. Thanks for reading this far!
]]>
On death and free minds2006-06-12T00:00:00Z2006-06-12T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/06/on-death-and-free-minds/
For many years, a certain scene from a certain movie has troubled me deeply. In The Matrix (1999), there is a scene where the character 'Neo' is killed. Stone dead, no heartbeat for over thirty seconds, multiple bulletholes through chest. And then his girlfriend, 'Trinity', kisses him; and just like in the fairy tales, he magically comes back to life.
I have had far more than the recommended dosage of The Matrix in my time. In watching the film, my friends and I have developed a tradition of sorts, in that we have always derided this particular scene as being 'fake' and 'medically impossible'. We endlessly applaud the dazzling special effects, the oh-so-cool martial arts, the ultra-quotable screenplay, and the relishably noirish techniques, all of which the film overall is brimming with; nevertheless, we cannot help but feel disappointed by this one spot, where it seems that romantic melodrama has thwarted plausibility.
But like Neo, I believe that I may finally have the answer.
Ironically (and, since The Matrix itself has so much irony of a similar nature, doubly ironically), the answer has been staring me in the face all along. Indeed, like Morpheus, I too "came to realise the obviousness of the truth".
In almost any other movie, there can be no acceptable excuse for bringing someone back from the dead. It's a moviemaking sin. It's the lazy way to set the film's plot back on course, and the cheap way to engender drama and climax. This is because films are expected to follow the same rules that apply in the real world. When someone dies in real life, they stay dead. There is no way to reverse what is, by its very definition, fatal. Even in the realm of sci-fi, where technology is capable of anything, there is an unwritten rule that even the best gadgets cannot undo death - at least not without some serious scientific justification. Surely The Matrix is not exempt from this rule? Surely the film's producers cannot expect to conjure up the impossible on-screen, and expect something as unscientific as a kiss to qualify as "serious scientific justification"?
But what we can so easily forget, when making all these judgements, is the central theme and message of The Matrix. This message is constantly re-iterated throughout the film:
There Are No Rules
There is no spoon
Free your mind
What is real?
The mind makes it real
In a nutshell, this quote sums it up best:
What you must learn is that these rules are no different than the rules of a computer system. Some of them can be bent. Others can be broken.
By being 'The One', Neo's job is to understand and fully absorb the concept that everything in life is a rule, and that every rule can be broken. What is a rule? A rule is something that determines cause and effect. What happens if you are able to 'break' a rule? The cause occurs, but the effect does not. Simple as that. The only tricky bit is: how do you break a rule? You choose to deny that the rule applies to you, and therefore you are not governed by that rule. That last bit is the only bit that we haven't (yet?) proven in real life.
So, what are some basic rules that virtually all of the main characters in The Matrix learn to break, and that the audience is generally able to accept as being 'broken'? Gravity. Speed. Agility. Stamina. To name a few.
Matrix agents shooting
When you think about it like this, it becomes clear that death is just another one of these rules; and that if (according to 'Matrix logic') you are able to choose to deny death, then being killed (i.e. 'the cause') should not necessarily result in your dying (i.e. 'the effect'). In fact, when you follow this logic, then it could be argued that had Neo died permanently, he would have been permanently affected by the 'rule of death', and hence the movie would have been inconsistent. Instead, the movie portrays death as 'the ultimate rule to overcome'; and when Neo does succeed in thwarting it, he suddenly finds himself utterly unshackled from the confines that the Matrix attempts to place upon him.
The mind has an instinctive conviction that when the body is fatally injured, the whole bang shoot (i.e. mind / body / soul) ceases to function. By freeing your mind of this conviction, you are freeing yourself from the consequences that the conviction entails. That's the theory being touted, anyway. Personally, I find it to be a very self-centred and arrogant theory, but an enthralling one nonetheless.
This logic has helped me to 'accept' Neo's death and re-animation somewhat. But I still have a healthy level of cynicism, and I hope you do too. Despite all the work I've just done justifying it, the re-animation was a second-rate effort at tying up the story, and it was particularly poorly executed with the Hollywood kiss 'n' all. This sin is only barely explainable, and is certainly not admirable. But at least it is (in my eyes, at least) excusable, which is more than I can say for any other movies that do it.
]]>
Import / Export API: progress report #12006-06-06T00:00:00Z2006-06-06T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/06/import-export-api-progress-report-1/
It's been almost two weeks since the 2006 Summer of Code began, and with it, my work to develop an import / export API module for Drupal. In case you missed it, my work is being documented on this wiki. My latest code is now also available as a project on drupal.org. Since I've barely started, I think that this is a stupid time to sit back and reflect on what I've done so far. But I'm doing it anyway.
Let's start with some excuses. I'm working full-time at the moment, I've got classes on in between, and I just joined the cast of an amateur musical (seriously, what was I thinking?). So due to my current shortage of time, I've decided to focus on documentation for now, which - let's face it - should ideally be done in large quantities before any code is produced, anyway. So I've posted a fair bit of initial documentation on the wiki, including research on existing import / export solutions in Drupal, key features of the new API, and possible problems that will be encountered.
Last weekend, I decided that I was kind of sick of documentation, and that I could ignore the urge to code no longer. Hence, the beginnings of the API are now in place, and are up in Drupal CVS. I will no doubt be returning to documentation over the next few days, in the hope of fattening up my shiny new wiki, which is currently looking rather anorexic.
On a related note: anonymous commenting has been disabled on the wiki, as it was receiving unwelcome comment spam. If you want to post comments, you will HaveToLogin using your name InCamelCase (which is getting on my nerves a bit - but I have to admit that it does the job and does it well).
So far, I've coded the first draft of the data definition for the 'user' entity, and in the process, I've defined-through-experimentation what a data definition will look like in my module. The data definition attributes and structure are currently undocumented, and I see no reason to change that until it all matures a lot more. But ultimately, the plan is to have a reference for it, similar to the Drupal forms API reference.
There are six 'field types' in the current definition system: string (the default), int, float, file, array, and entity. An 'entity' is the top-level field, and is for all practical purposes not a field, but is rather the thing that fields go in. An array is for holding lists of values, and is what will be used for representing 1-M (and even N-M) data within the API. Note to self: support for nested arrays is currently lacking, and is desperately needed.
I have also coded the beginnings of the export engine. This engine is currently capable of taking a data definition, querying the database according to that definition, and providing an array of results, that are structured into the definition (as 'value' fields), and that can then be passed to the rendering part of the engine. The next step is to actually write the rendering part of the engine, and to plug an XML formatter into this engine to begin with. Once that's done, it will be possible to test the essentials of the export process (i.e. database -> array data -> text file data) from beginning to end. I think it's important to show this end-to-end functionality as early on as possible, to prove to myself that I'm on the right track, and to provide real feedback that the system is working. Once this is done, the complexities can be added (e.g. field mapping system, configurable field output).
Overall, what I've coded so far looks very much like a cross between the forms API (with _alter() hooks, recursive array building, and extensible definitions), and the views module (with a powerful definition system, that gets used to build queries). Thank you to the respective authors of both these systems: Adrian / Vertice (one of my mentors); and Earl / Merlinofchaos (who is not my mentor, but who is a mentor, as well as a cool cool coder). Your efforts have provided me with heaps of well-engineered code to copy - er, I mean, emulate! If my project is able to be anywhere near as flexible or as powerful as either of these two systems, I will be very happy.
Thanks also to Adrian and to Sami for the feedback that you've given me so far. I've been in contact with both of my mentors, and both of them have been great in terms of providing advice and guidance.
]]>
An undo button for Drupal2006-05-24T00:00:00Z2006-05-24T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/05/an-undo-button-for-drupal/
Every time that you perform any action in a desktop application, you can hit the trusty 'undo' button, to un-wreak any havoc that you may have just wreaked. Undo and redo functionality comes free with any text-based desktop application that you might develop, because it's a stock standard feature in virtually every standard GUI library on the planet. It can also be found in most other desktop applications, such as graphics editors, animation packages, and even some games. Programming this functionality into applications such as live client-side editors is extremely easy, because the data is all stored directly in temporary memory, and so keeping track of the last 'however many' changes is no big deal.
One of the biggest shortcomings of web applications in general, is that they lack this crucial usability (and arguably security) feature. This is because web applications generally work with databases (or with other permanent storage systems, such as text files) when handling data between multiple requests. They have no other choice, since all temporary memory is lost as soon as a single page request finishes executing. However, despite this, implementing an 'undo' (and 'redo') system in Drupal should be a relatively simple task - much simpler, in fact, than you might at first think.
Consider this: virtually all data in Drupal is stored in a database - generally, a single database; and all queries on that database are made through the db_query() function, which is the key interface in Drupal's database abstraction layer. Also, all INSERT, UPDATE, and DELETE queries in Drupal are (supposed to be) constructed with placeholders for actual values, and with variables passed in separately, to be checked before actually getting embedded into a query.
It would therefore be a simple task to change the db_query() function, so that it recorded all INSERT, UPDATE, and DELETE queries, and the values that they affect, somewhere in the database (obviously, the queries for keeping track of all other queries would have to be excluded from this, to prevent infinite loops from occurring). This could even be done with Drupal's existing watchdog system, but a separate system with its own properly-structured database table(s) would be preferable.
Once this base system is in place, an administrative front-end could be developed, to browse through the 'recently executed changes' list, to undo or redo the last 'however many' changes, and to set the amount of time for which changes should be stored (just as can be done for logs and statistics already in Drupal), among other things. Because it is possible to put this system in place for all database queries in Drupal, undo and redo functionality could apply not just to the obvious 'content data' (e.g. nodes, comments, users, terms / vocabularies, profiles), but also to things that are more 'system data' (e.g. variables, sequences, installed modules / themes).
An 'undo / redo' system would put Drupal at the bleeding edge of usability in the world of web applications. It would also act as a very powerful in-built data auditing and monitoring system, which is an essential feature for many of Drupal's enterprise-level clientele. And, of course, it would provide top-notch data security, as it would virtually guarantee that any administrative blunder, no matter how fatal, can always be reverted. Perhaps there could even be a special 'emergency undo' interface (e.g. an 'undo.php' page, similar to 'update.php'), for times when a change has rendered your site inaccessible. Think of it as Drupal's 'emergency boot disk'.
This is definitely something to add to my todo list, hopefully for getting done between now and the 4.8 code freeze. However, with my involvement in the Google Summer of Code seeming very likely, I may not have much time on my hands for it.
]]>
Australia's first Drupal meetup, and my weekend in Melbourne2006-04-23T00:00:00Z2006-04-23T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/04/australias-first-drupal-meetup-and-my-weekend-in-melbourne/
I've just gotten back from a weekend away in Melbourne (I live in Sydney), during which I attended Australia's first ever Drupal meetup! We managed a turnout of 7 people, which made for a very cosy table at the Joe's Garage cafe.
The people present were:
Gordon and John at the Melbourne meetupDavid and Simon at the Melbourne meetupMichael and Andrew at the Melbourne meetupAndrew and Jeremy at the Melbourne meetup
As you can see, Gordon impressed us all by getting a T-shirt custom-made with the Druplicon graphic on it:
Gordon with the Druplicon T-shirt
The meetup went on for about 2 hours, during which time we all introduced ourselves, asked a barrage of questions, told a small number of useful answers (and plenty of useless ones), drank a variety of hot beverages, and attempted to hear each other above the noisy (but very good) jazz music.
As the most experienced Drupalite in Australia, Gordon was the one that did the most answering of questions. Gordon was the person that arranged this meetup (thanks for organising it, mate!), as well as the only one among us who works full-time as a Drupal consultant (with John and myself working as consultants part-time). What's more, Gordon is now the maintainer of the E-Commerce module.
However, I still had time to do a bit of category module evangelism, which has become my number one hobby of late.
One of the hottest topics on everyone's mind was the need for training, in order to bring more Drupal contributors and consultants into the fold. This is an issue that has received a lot of attention recently in the Drupal community, and we felt that the need is just as great in Australia as it is elsewhere. Australia is no exception to the trend of there being more Drupal work than there is a supply of skilled Drupal developers.
While I was in Melbourne, I had a chance to catch up with some friends of mine, and also to do a bit of sightseeing. Here are some of the sights and sounds of Melbourne:
Melbourne's Yarra RiverTrams in MelbourneFlinders St StationFederation Square
I was also very pleased (and envious) to see that Melbourne is a much more bicycle-friendly city than Sydney:
Cyclists in MelbourneBike racks in Melbourne CBD
In summary, it was well worth going down to Melbourne for the weekend, and the highlight of the weekend was definitely the Drupal meetup! I am very proud to be one of the people that attended the historic first ever Aussie Drupal get-together, and I really hope that there will be many more.
So, why didn't I go to DrupalCon Vancouver? Well, Vancouver is just a little bit further away for me than Melbourne. That's why I think the next worldwide DrupalCon should be in Sydney. ;-)
]]>
An IE AJAX gotcha: page caching2006-03-13T00:00:00Z2006-03-13T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/03/an-ie-ajax-gotcha-page-caching/
While doing some AJAX programming, I discovered a serious and extremely frustrating bug when using XMLHTTP in Internet Explorer. It appears that IE is prone to malfunctioning, unless a document accessed through AJAX has its HTTP header set to disallow caching. Beware!
I was working on the Drupalactiveselect module, which allows one select box on a form to update the options in another form dynamically, through AJAX. I was having a very strange problem, where the AJAX worked fine when I first loaded the page in IE, but then refused to work properly whenever I refreshed or re-accessed the page. Only closing and re-opening the browser window would make it work again. Past the first time / first page load, everything went haywire.
Finally, I found a page suggesting that I set the HTTP response headers to disallow caching. It worked! My beautiful AJAX is now working in IE, just as well as it is working in decent browsers (i.e. Firefox et al). What I did was put the following response headers in the page (using the PHP header() function):
<?php header("Expires: Sun, 19 Nov 1978 05:00:00 GMT");
header("Last-Modified: " . gmdate("D, d M Y H:i:s") . " GMT");
header("Cache-Control: no-store, no-cache, must-revalidate");
header("Cache-Control: post-check=0, pre-check=0", false);
header("Pragma: no-cache");
?>
These are the same response headers that the Drupal core uses for cached pages (that's where I copied them from). Evidently, when IE is told to invoke an AJAX HTTP request on a page that it thinks it should 'cache', it simply can't handle it.
So, for anyone else that finds that their AJAX code is bizarrely not working in IE after the first page load, this may be the answer! May this post end your troubles sooner rather than later.
]]>
A patch of flowers, a patch of code2006-01-20T00:00:00Z2006-01-20T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/01/a-patch-of-flowers-a-patch-of-code/
The word patch has several different meanings. The first is that with which a gardener would be familiar. Every gardener has a little patch of this planet that he or she loves and tends to. In the gardening sense, a patch is a rectangular plot of land filled with dirt and flora; but, as gardeners know, it is also so much more than that. It is a living thing that needs care and attention; and in return, it brings great beauty and a feeling of fulfilment. A patch is also a permanent space on the land - a job that is never finished, some would say - and for as long as it is tended, it will flower and blossom.
Another meaning of patch is that usually applied to clothing and fabrics. To a tailor or a seamstress, a patch is a small piece of material, sewn over a hole or a rent in a garment. It is an imperfect and often temporary fix for a permanently damaged spot. A patch in this sense, therefore, connotes ugliness and scarring. A seamstress is hardly going to put as much time and attention into a patch as she would into a new garment: why bother, when it is only a 'quick fix', and will never look perfect anyway? There is no pride to be gained in making unseemly little patches. Designing and crafting something new, where all of the parts blend together into a beautiful whole, is considered a much more noble endeavour.
The latter and less glamorous meaning of this word seems to be the one that applies more widely. When a doctor tends your wounds, he or she may tell you that you're being patched up. Should you ever happen to meet a pirate, you may notice that he wears an eye patch (as well as saying "arrr, me hearties, where be ye wallets and mobile phones?"). And if you're a software programmer, and you find a bug in your program, then you'll know all about patching them pesky bugs, to try and make them go away.
But is it really necessary for software patches to live up to their unsightly reputation? Do patches always have to be quick 'n' dirty fixes, done in order to fix a problem that nobody believes will ever heal fully? Must they always be temporary fixes that will last only a few weeks, or perhaps a few months, before they have to be re-plastered?
As with most rhetorical questions that are asked by the narrator of a piece of writing, and that are constructed to be in a deliberately sarcastic tone, the answer to all of the above is, of course, 'no'. ;-)
I used to believe that software patches were inherently dirty things. This should come as no surprise, seeing that the only time I ever used to encounter patches, was when I needed to run Windows™ Update, which invariably involves downloading a swarm of unruly patches, 99% of which I am quite certain were quick and extremely dirty fixes. I'm sure that there are many others like me, who received their education on the nature of patches from Microsoft; but such people are misinformed, because this is analogous to being educated on the nature of equality by growing up in Soviet Russia.
Now, I'm involved in the Drupal project as a developer. Drupal is an open-source project - like many others - where changes are made by first being submitted to the community, in the form of a patch. I've seen a number of big patches go through the process of review and refinement, before finally being included in Drupal; and more recently, I've written some patches myself, and taken them through this process. Just yesterday, I got a fairly big patch of mine committed to Drupal, after spending many weeks getting feedback on it and improving it.
Developing with Drupal has taught me one very important thing about patches. When done right, they are neither quick nor dirty fixes. Patching the right way involves thinking about the bigger picture, and about making the patch fit in seamlessly with everything that already exists. It involves lengthy reviews and numerous modifications, often by a whole team of people, in order to make it as close to perfect as it can practically be.
But most of all, true patching involves dedication, perseverance, and love. A patch done right is a patch that you can be proud of. It doesn't give the garment an ugly square mark that people would wish to hide; it makes the garment look more beautiful than ever it was before. Patching is not only just as noble an endeavour as is designing and building software from scratch; it is even more so, because it involves building on the amazing and well-crafted work of others; and when done right, it allows the work of many people to amazingly (miraculously?) work together in harmony.
And as for patches being temporary and transient - that too is a myth. Any developer knows that once they make a contribution to a piece of software, they effectively own a little piece of its code. They become responsible for maintaining that piece, for improving it, and for giving it all the TLC that it needs. If they stick around and nurture their spot, then in time it will blossom, and its revitalising scent will spread and sweeten all the other spots around it.
Let's stop thinking about patches in their negative sense, and start thinking about them in their positive sense. That's the first step, and the hardest of all. After that, the next step - making and maintaining patches in the positive sense - will be child's play.
]]>
A novel style2006-01-03T00:00:00Z2006-01-03T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/01/a-novel-style/
The novel is considered the most ubiquitous of all forms of literature. You can find novels by the truckload in any old bookstore. Over the past 200 years, the novel has risen to become unsurpassed king of the written world, easily overtaking society's old favourite, the play. Whereas Shakespeare was once the most revered figure in all of literature, his name now contends with those of countless famous novelists, such as J.D. Salinger, Leo Tolstoy, George Orwell, and J.R.R. Tolkien (to name a few).
A few days ago, I finished reading Sir Arthur Conan Doyle's famous book, The Adventures of Sherlock Holmes (1892). This was the first time that the famous detective's adventures had been published in a permanent tome, rather than in a more transient volume, such as a journal or a magazine. It contains 12 short stories of intrigue, perplexity, and 'logical deduction', and it was a great read.
But as I neared the end of this book, something about it suddenly struck me. There was something about the way it was written, which was profoundly different to the way that more recent books are usually written. It was more profound than simply the old-fashioned vocabulary, or than the other little hallmarks of the time, such as fashion, technology, politics, and class division. It was the heavy use of dialogue. In particular, the dialogue of characters speaking to each other when recalling past events. Take, for example, this quote from the 11th story in the book, The Beryl Coronet:
[Alexander Holder speaks] "Yesterday morning I was seated in my office at the bank, when a card was brought in to me by one of the clerks. I started when I saw the name, for it was that of none other than - well, perhaps even to you I had better say no more than that it was a name which is a household word all over the earth - one of the highest, noblest, most exalted names in England. I was overwhelmed by the honour, and attempted, when he entered, to say so, but he plunged at once into business with the air of a man who wishes to hurry quickly through a disagreeable task.
"'Mr Holder', said he, 'I have been informed that you are in the habit of advancing money.' ...
In this example, not only is the character (Mr Holder) reciting a past event, but he is even reciting a past conversation that he had with another character! To the modern reader, this should universally scream out at you: old fashioned! Why does the character have to do all this recitation? Why can't the author simply take us back to the actual event, and narrate it himself? If the same thing were being written in a modern book, it would probably read something like this:
Alexander Holder was seated in his office at the bank. It had been a busy morning, riddled with pesky clients, outstanding loans, and pompous inspectors. Holder was just about to get up and locate a fresh supply of tea, when one of his clerks bustled in, brandishing a small card.
He read the name. Not just any name: a name that almost every household in the land surely knows. One of the highest, noblest, most exalted names in England.
"Thankyou", Holder said curtly.
Before he even had a chance to instruct his clerk that the guest was to be ushered in immediately, the man entered of his own accord. Holder was overwhelmed by the honour, and attempted to say so; but he barely had time to utter one syllable, for his guest plunged at once into business, with the air of a man who wishes to hurry quickly through a disagreeable task.
"Mr Holder", said he, with a wry smile, "I have been informed that you are in the habit of advancing money." ...
This new, 'modernified' version of Doyle's original text probably feels much more familiar to the modern reader.
It is my opinion that Sherlock Holmes is written very much like a play. The number of characters 'on stage' is kept to a minimum, and dialogues with other characters are recalled rather than narrated. Most of the important substance of the story is enclosed within speech marks, with as little as possible being expounded by the narrator. I have read other 19th century novels that exhibit this same tendency, and really it should come as no surprise to anyone. After all, in those days the play was still considered the dominant literary form, with the novel being a fledgling new contender. Novelists, therefore, were very much influenced by the style and language of plays - many of them were, indeed, playwrights as well as novelists. Readers, in turn, would have felt comforted by a story whose language leaned towards that of the plays that many of them often watched.
My 'new version' of the story, however - which is written in a style used by many contemporary novels - exhibits a different deviation from the novel style. It is written more like a movie. In this style, emphasis is given to providing information through visual objects, such as scenery, costumes, and props. Physical dynamics of the characters, such as hand gestures and facial expressions, are described in greater detail. Parts of the story are told through these elements wherever possible, instead of through dialogue, which is kept fairly spartan. Once again, this should be no groundbreaking surprise, since movies are the most popular form in which to tell a story in the modern world. Modern novelists, therefore, and modern readers, are influenced by the movie style, and inevitably imbue it within the classic novel style.
So, in summary: novels used to be written like plays; now they're written like movies.
This brings us to the question: what is the true 'novel style', and just how common (or uncommon) is it?
By looking at the Wikipedia entry on 'Novel', it is obvious that the novel itself is an unstable and, frankly, indefinable form that has evolved over many centuries, and that has been influenced by a great many other literary and artistic forms. However, although the search for an exact definition for a novel is not a task that I feel capable of undertaking, I would like to believe that a 'true novel' is one that is not written in the style of any other form (such as a play or a movie), but that exhibits its own unique and unadulterated form.
Just how many 'true novels' there are, I cannot say. As a generalisation, most of the 'pulp fiction' paperback type books, of the past several decades, are probably written more like movies than like true novels. The greatest number of true novels have definitely been written from the early 20th century onwards, although some older authors, such as Charles Dickens, certainly managed to craft true novels as well. As for the questions of whether the pursuit of finding or writing 'true novels' is a worthwhile enterprise, or of whether the 'true novel' has a future or not, or even of whether or not it matters how 'pure' novels are: I have no answer for them, and I suspect that there is none.
But considering that the novel is my favourite and most oft-read literary form, and that it's probably yours too, I believe that it couldn't hurt to invest a few minutes of your life in considering issues such as these.
]]>
One year of Drupal2005-12-26T00:00:00Z2005-12-26T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/12/one-year-of-drupal/
Last week marked my first Drupalversary: I have been a member of drupal.org for one year! Since starting out as yet another webmaster looking for a site management solution, I have since become an active member of the Drupal community, a professional Drupal consultant, a module developer, and a core system contributor. Now it's time to look back at the past year, to see where Drupal has come, to see what it's done for me (and vice versa), and to predict what I'll be up to Drupal-wise over the course of the next year.
In November last year, I was still desperately endeavouring to put together my own home-grown CMS, which I planned to use for managing the original GreenAsh website. I was learning first-hand what a mind-bogglingly massive task it is to write a CMS, whilst I was also still getting my fingers around the finer points of PHP. Despair was setting in, and I was beginning to look around for a panacea, in the form of an existing open source application.
But the open source CMS offerings that I found didn't give me much hope. PHP-Nuke didn't just make me sick - it gave me radiation poisoning. e107 promised amazing ease-of-use - and about as much flexibility as a 25-year home loan. Plone offered everything I could ever ask for - and way more than I ever would ask for, including its own specialised web server (yeah - just what I need for my shared hosting environment!). Typo3 is open source and mature - but it wants to be commercial, and its code architecture just doesn't cut it. Mambo (whose developers have now all run away and formed Joomla) came really close to being the one for me, but it just wasn't flexible, hackable, or lovable enough to woo me over. And besides, look what a mess its community is in now.
And then, one day, I stumbled upon SpreadFirefox, which at the time sported a little 'Powered by CivicSpace' notice at the bottom of its front page; and which in turn led me to CivicSpace Labs; which finally led me to Drupal, where I fell in love, and have stayed ever since. And that's how I came to meet Drupal, how I came to use it for this site and for many others, and how I came to be involved with it in ever more and more ways.
Over the past year, I've seen many things happen over in DrupalLand - to name a few: the 4.6.0 official release; threereal-worldconferences (all of which were far, far away from Sydney, and which I unhappily could not attend); an infrastructure collapse and a major hardware migration; involvement in the Google Summer of Code; major code overhauls (such as the Forms API); a massive increase in the user community; and most recently, the publishing of the first ever Drupal book. It's been an awesome experience, watching and being a part of the rapid and exciting evolution of this piece of software; and learning how it is that thousands of people dispersed all over the world are able to co-operate together, using online tools (many of which the community has itself developed), to build the software platform that is powering more and more of the next generation of web sites.
So what have I done for Drupal during my time with it so far? Well, my number one obsession from day one has been easy and powerful site structuring, and I have contributed to this worthwhile cause (and infamous Drupal weak spot) in many ways. I started out last January by hacking away at the taxonomy and taxonomy_context modules (my first foray into the Drupal code base), and working out how to get beautiful breadcrumbs, flexible taxonomy hierarchies, and meaningful URL aliasing working on this site. I published my adventures in a three-part tutorial, making taxonomy work my way. These tutorials are my biggest contribution to Drupal documentation to date, and have been read and praised by a great many Drupal users. The work that I did for these tutorials paved the way for the later release of the distant parent and taxonomy_assoc modules (taxonomy_assoc being my first Drupal module), which make site structuring just that little bit more powerful, for those wishing to get more out of the taxonomy system.
The category module has been my dream project for most of this year, and I've been trying to find time to work on it ever since I published my proposal about it back in May. It's now finally released - even if it's not quite finished and still has plenty of bugs - and I'm already blown away by how much easier it's made my life than the old ways of "taxonomy_hack". I plan to launch an official support and documentation site for the category module soon, and to make the module's documentation as good as can be. I've also been responding to taxonomy-related support requests in the drupal.org forums for a long time now, and I sincerely hope that the category module is able to help all the users that I've encountered (and many more yet to come) who find that the taxonomy system is unable to meet their needs.
For much of the past year, I've also been involved in professional work as a Drupal consultant. Most notable has been my extended work on the Mighty Me web site, which is still undergoing its final stage of development, and which will hopefully be launched soon. I also developed a Drupal pilot site for WWF-Australia (World Wide Fund for Nature), which unfortunately did not proceed past the pilot stage, but which I nevertheless continued to be involved in developing (as a non-Drupal site). As well as some smaller development jobs, I also provided professional Drupal teaching to fellow web designers on several occasions, thereby spreading the 'Drupal word', and hopefully bringing more people into the fold.
So what have I got planned in the Drupal pipeline for the next year? Drupal itself certainly has plenty of exciting developments lined up for the coming year, and I can hardly hope to rival those, although I will do my best to make my contributions shine. Getting the category module finished and stable for the Drupal 4.7 platform is obviously my primary goal. I'd also like to upgrade this site and some others to Drupal 4.7, and do some serious theme (re-)designing. I've only just started getting involved in contributing code to the Drupal core, in the form of patches, and I'd like to do more of this rather than less. Another idea that's been in my head for some time has been to sort out the hacks that I've got, for filtering out duplicate statistics and non-human site visitors from my access logs and hit counters, and turning them into a proper module called the 'botstopper' module. I don't know how much more than that I can do, as I will be having a lot of work and study commitments this year, and they will probably be eating into much of my time. But I'll always find time for posting messages in the Drupal forums, for adding my voice to the mailing lists, and even for hanging out on the Drupal IRC channels.
My first year of Drupal has been an experience that I am deeply grateful for. I have worked with an amazing piece of software, and I have been given incredibly worthwhile professional and personal opportunities; but above all, I have joined a vibrant and electric community, and have come to know some great people, and to learn a whole world of little gems from them. Drupal's second greatest strength is its power as a community-building platform. Its greatest strength is the power and the warmth of the Drupal community itself.
]]>
Draft dodging: the first and final version2005-11-12T00:00:00Z2005-11-12T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/11/draft-dodging-the-first-and-final-version/
The concept of a 'draft version' has always seemed rather alien to me. Many of you may think of this as odd. I'm aware that many people have no confidence in things that they have written - things such as essays, short stories, and reports - until they have reviewed and edited their work, and have produced a 'final version' in which spelling, grammar, and semantic mistakes are fixed up. I've always considered this practice of progressing from one distinct version of a document to another - that is, from draft to final - to be unnecessary and a waste of time.
Now, before you accuse me of boasting and of being arrogant, let me just make it clear that my writing does not magically materialise in my head in the sleek, refined form that is its finished state, as I will now explain. What happens is that without ever even realising it, I always correct and analyse my writing as I go, making sure that my first version is as near to final as can be. Essentially, as each word or sentence sprouts forth from my mind, it passes through a rigorous process of editing and correction, so that by the time it reaches the page, it has already evolved from raw idea, to crudely communicated language, to polished and sophisticated language.
The diagram below illustrates this process:
Flow of words diagram
The circular dots travelling through the body represent snippets of language. The grey-coloured barriers represent 'stations', at which all the snippets are reviewed and polished before being allowed to pass through. As the snippets pass through each barrier, their level of sheen improves (as indicated by the red, yellow, blue, and green colouring).
This is not something I ever chose to do. It wasn't through any ingenuity on my part, or on the part of anyone around me, that I wound up doing things like this. It's just the way my brain works. I'm a meticulous person: I can't cope with having words on the page that aren't presentable to their final audience. The mere prospect of it makes my hair turn grey and my ears droop (with only one of those two statements being true, at most ;-)). I'm also extremely impatient: I suspect that I learnt how to polish my words on-the-fly out of laziness; that is, I learnt because I dread ever having to actually read through my own crufty creation and undertake the rigour of improving it.
It recently occurred to me that I am incapable of writing in 'rough form'. I find it hard even to articulate 'rough words' within the privacy of my own head, let alone preserving that roughness through the entire journey from brain to fingertips. I am simply such a product of my own relentless régime, that I cannot break free from this self-imposed rigour.
Is this a blessing or a curse?
The advantages of this enforced rigour are fairly obvious. I never have to write drafts: as soon as I start putting pen to paper (or fingers to keyboard, as the case may be), I know that every word I write is final and is subject to only a cursory review later on. This is a tremendously useful skill to employ in exams, where editing time is a rare luxury, and where the game is best won by driving your nails home in one hit. In fact, I can't imagine how anyone could compose an extended answer under exam conditions, without adjusting their brain to work this way.
Dodging drafts is a joy even when time is not of the essence. For example, writing articles such as this one in my leisure time is a much less tedious and more efficient task, without the added hassle of extensive editing and fixing of mistakes.
However, although dodging drafts may appear to be a win-win strategy, I must assert from first-hand experience that it is not a strategy entirely without drawbacks. Not every single piece of writing that we compose in our daily lives is for public consumption. Many bits and pieces are composed purely for our own personal use: to-do lists, post-it notes, and mind maps are all examples of this.
Since these pieces of writing are not intended to be read by anyone other than the original author, there is no need to review them, or to produce a mistake-free final version thereof. But for me, there are no exceptions to the rigorous process of brain-to-fingertip on-the-fly reviewing. These writings are meant to be written in draft form; but I am compelled to write them in something much more closely resembling a presentable form! I am forced to expend more effort than is necessary on ensuring a certain level of quality in the language, and the result is a piece of writing that looks wrong and stupid.
For times like this, it would be great if I had a little switch inside my head, and if I could just turn my 'rigour filtering' on or off depending on my current needs. Sadly, no such switch is currently at my disposal, and despite all my years of shopping around, I have yet to find a manufacturer willing to produce one for me.
Making the first version the final version is an extremely useful skill, no doubt about it. I feel honoured and privileged to have been bestowed with this gift, and I don't wish for one second that I was without it. However, sometimes it would be nice if I was able to just 'let the words spew' from my fingers, without going to the trouble of improving their presentation whilst writing.
]]>
A plain-text program design standard2005-10-07T00:00:00Z2005-10-07T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/10/a-plain-text-program-design-standard/
I've been working on a project at University, in which my team had to produce a large number of software design documents, in order to fulfil the System Architecture objectives of the project. The documents included UML class diagrams, UML sequence diagrams, class-based system specifications, and more.
The design phase of our project is now finished, but all of these documents now have to be translated into working code. This basically involves taking the high-level design structure specified in the design documents, and converting it into skeleton code in the object-oriented programming language of our choice. Once that's done, this 'skeleton code' of stubs has to actually be implemented.
Of course, all of this is manual work. Even though the skeleton code is virtually the same as the system specifications, which in turn are just a text-based representation of the graphical class diagram, each of these artefacts are created using separate software tools, and each of them must be created independently. This is not the first Uni project in which I've had to do this sort of work; but due to the scale of the project I'm currently working on, it really hit me that what we have to do is crazy, and that surely there's a better, more efficient way of producing all these equivalent documents.
Wouldn't it be great if I could write just one design specification, and if from that, numerous diagrams and skeleton code could all be auto-generated? Wouldn't it make everyone's life easier if the classes and methods and operations of a system only needed to be specified in one document, and if that one document could be processed in order to produce all the other equivalent documents that describe this information? What the world needs is a plain-text program design standard.
I say plain-text, because this is essential if the standard is to be universally accessible, easy to parse and process, and open. And yes, by 'standard', I do mean 'open standard'. That is: firstly, a standard in which documents are text rather than binary, and can be easily opened by many existing text editors; and secondly (and more importantly), a standard whose specification is published on the public domain, and that can therefore be implemented and interfaced to by any number of third-party developers. Such a standard would ideally be administered and maintained by a recognised standards body, such as the ISO, ANSI, the OMG, or even the W3C.
I envision that this standard would be of primary use in object-oriented systems, but then again, it could also be used for more conventional procedural systems, and maybe even for other programming paradigms, such as functional programming (e.g. in Haskell). Perhaps it could even be extended to the database arena, to allow automation between database design tasks (e.g. ERD diagramming) and SQL CREATE TABLE statements.
This would be the 'dream standard' for programmers and application developers all over the world. It would cut out an enormous amount of time that is wasted on repetitive and redundant work that can potentially be automated. To make life simpler (and for consistency with all the other standards of recent times), the standard would be an XML-based markup language. At its core would simply be the ability to define the classes, attributes, and operations of a system, in both a diagram-independent and a language-independent manner.
Here's what I imagine a sample of a document written to such a standard might look like (for now, let's call it ODML, or Object Design Markup Language):
(Sorry about the underscores, guys - due to technical difficulties in getting indenting spaces to output properly, I decided to resort to using them instead.)
From this simple markup, programs could automatically generate design documents, such as class diagrams and system specifications. Using the same markup, skeleton code could also be generated for any OO language, such as Java, C#, C++, and PHP.
I would have thought that surely something this cool, and this important, already exists. But after doing some searching on the Web, I was unable to find anything that came even remotely near to what I've described here. However, I'd be most elated to learn that I simply hadn't searched hard enough!
When I explained this idea to a friend of mine, he cynically remarked that were such a standard written, and tools for it developed, it would make developers' workloads greater rather than smaller. He argued that this would be the logical expected result, based on past improvements in productivity. Take the adoption of the PC, for example: once people were able to get more work done in less time, managers the world over responded by simply giving people more work to do! The same applies to the industrial revolution of the 19th century (once workers had machines to help them, they could produce more goods); to the invention of the electric light bulb (if you have light to see at night, then you can work 24/7); and to almost every other technological advancement that you can think of. I don't deny that an effective program design standard would quite likely have the same effect. However, that's an unavoidable side effect of any advancement in productivity, and is no reason to shun the introduction of the advancement.
A plain-text program design standard would make the programmers and system designers of the world much happier people. No question about it. Does such a thing exist already? If so, where the hell do I get it? If not, I hope someone invents it real soon!
]]>
Web 2.0, and other nauseating buzzwords2005-10-01T00:00:00Z2005-10-01T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/10/web-2-0-and-other-nauseating-buzzwords/
Attending the Web Essentials 2005 conference (others' thoughts on WE05) was the best thing I've done this year. I'm not kidding. The Navy SEALs, the heart surgeons, and the rocket scientists (i.e. the best of the best) in web design all spoke there. Among my favourites were: Tantek Çelik, the creator of the famous Box Model hack (a.k.a. the Tan hack) and markup guru; Eric CSS Meyer (his middle initials speak for themselves); Jeffrey Veen, whose partner Jesse James Garrett coined the 2005 Acronym of the Year (AJAX), and who is one of the more enthusiastic speakers I've ever heard; and Doug Bowman, who is blessed with an artistic talent, that he couples with a devotion to web standards, and with a passionate sense of vision.
Since Jakob Nielsen was absent, one thing I didn't get out of the conference was a newfound ability to write short sentences (observe above paragraph). :-)
But guys, why did you have to overuse that confounded, annoying buzzword Web 2.0? Jeff in particular seemed to really shove this phrase in our faces, but I think many of the other speakers did also. Was it just me, or did this buzzword really buzz the hell out of some people? I know I'm more intolerant than your average geek when it comes to buzzwords, but I still feel that this particular one rates exceptionally poor on the too much marketing hype to handle scale. It's so corny! Not to mention inaccurate: "The Web™" isn't something that's "released" or packaged in nice, easy-to-manage versions, any more than it's a single technology, or even (arguably) a single set of technologies.
AJAX I can handle. It stands for something. It's real. It's cool. "Blog" I can handle (ostensibly this is a "blog entry" - although I always try to write these thoughts as formal articles of interest, rather than as mere "today I did this..." journal entries). It's short for "web log". That's even more real, and more cool. "Podcast" I can tolerate. It's a fancy hip-hop way of saying "downloadable audio", but I guess it is describing the emerging way in which this old technology is being used. But as for ye, "Web 2.0", I fart in your general direction. The term means nothing. It represents no specific technology, and no particular social phenomenon. It's trying to say "we've progressed, we're at the next step". But without knowing about the things it implies - the things that I can handle, like RSS, CSS, "The Semantic Web", and Accessibility - the phrase itself is void.
Most of all, I can't handle the undertone of "Web 2.0" - it implies that "we're there" - as if we've reached some tangible milestone, and from now on everything's going to be somehow different. The message of this mantra is that we've been climbing a steep mountain, and that right now we're standing on a flat ledge on the side of the mountain, looking down at what we've just conquered. This is worse than void, it is misleading. We're not on a ledge: there are no ledges! We're on the same steep mountainside we've been on for the past 10 years. We can look down at any old time, and see how far we've come. The point we're at now is the same gradient as the rest of the mountain.
And also (back to WE05), what's with the MacOcracy? In the whole two days of this conference, scarcely a PC was to be seen. Don't get me wrong, I'm not voicing any anxious concern as to why we web developers aren't doing things the beloved Microsoft way. I have as little respect for Windows, et al. as the next geek. But I still use it. Plenty of my friends (equally geeky) are also happy to use it.
I've always had some "issues" with using Mac, particularly since the arrival of OS X. Firstly, my opinion is that Mac is too user-friendly for people in the IT industry. Aren't we supposed to be the ones that know everything about computers? Shouldn't we be able to use any system, rather than just the easiest and most usable system available? But hey, I guess a lot of web designers really are just that - designers - rather than actual "IT people". And we all know how designers love their Macs.
Secondly, Macs have increasingly become something of a status symbol and a fashion icon. To be seen with a Mac is to be "hip". It's a way of life: having an iBook, an iPod, an iCal. Becoming an iPerson. Well, I get the same nauseous feeling - the same gut reaction that is a voice inside me screaming "Marketing Hype!" - whenever I hear about the latest blasted iWhatever. Mac has been called the "BMW" of Operating Systems. What kind of people drive BMWs? Yeah, that's right - do you want to be that kind of person? I care a lot about not caring about that. All that image stuff. Keeping away from Macs is a good way to do that.
Lastly (after this, I'm done paying out Macs, I promise!), there's the whole overdone graphical slickness thing in OS X. The first time I used the beloved "dock" in Mac OS X, I nearly choked on my disgust. Talk about overcapitalisation! Ever hear the joke about what happened when the zealot CEO, the boisterous marketing department, and the way-too-much-time-on-their-hands graphics programmers got together? What happened was the OS X dock! Coupled with the zip-away minimising, the turning-cube login-logout, and all the rest of it, the result is an OS that just presents one too many animations after another!
Maybe I just don't get it. Sorry, strike that. Definitely I don't get it. Buzzwords, shiny OSes, all that stuff - I thought web development was all about semantics, and usability, and usefulness - the stuff that makes sense to me. Why don't you just tell me to go back to my little corner, and to keep coding my PHP scripts, and to let the designers get on with their designing, and with collecting their well-designed hip-hop gadgets. Which I will do, gladly.
Anyway, back to the conference. I discovered by going to Web Essentials that I am in many ways different to a lot of web designers out there. In many other ways, I'm also quite similar. I share the uncomfortable and introverted character of many of my peers. We share a love of good, clean, plain text code - be it programming or markup - and the advantages of this over binary formats. We share a love of sometimes quirky humour. We share the struggle for simplicity in our designs. We share the desire to learn from each other, and consequentially we share each others' knowledge. We share, of course, a love of open standards, and of all the benefits that they entail. And we share a love of food, in high quality as well as high quantity. We share the odd drink or 12 occasionally, too.
]]>
The river without a river-bed2005-08-12T00:00:00Z2005-08-12T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/08/the-river-without-a-river-bed/
A few days ago, I was fortunate enough to be able to get away from my urban life for the weekend. I escaped the concrete and the cars, I abandoned my WiFi and my WorRies, and I dwelt for two days in a secluded retreat, far from civilisation, amidst a tranquil rainforest-like reserve.
I sat by a river one morning, and watched it for some time. It was a beautiful river: from where I sat, looking upstream, the water was perfectly still and tranquil. Almost like a frozen lake, like the ones you see on the backs of postcards that people send when vacationing in Canada. The tranquil waters were confined by a wide ledge, over which they cascaded in a sleek, thin waterfall. Past the waterfall, the river flowed messily and noisily through a maze of rocks and boulders - sometimes into little rock-pools, sometimes through crevasses and cracks - always onwards and downstream.
It was on one of these boulders, immediately downstream of the waterfall, that I sat and cogitated. I thought about how rivers usually flow from the mountains to the sea (as this one seemed to be doing); about how river valleys are usually V-shaped and steep-sided (as opposed to glacier-formed valleys, which are usually U-shaped and gentle-sided); about how the water flows down the river-bed, constantly, continuously, along the exact same path, for hundreds of millions of years.
How transient, then, is man, who cannot even maintain a constant course for a few thousand years. A man could sit by a river, and watch it for all the days of his life; and in dedicating his entire life (of 80 or so years) thusly, he would have shared in less than a second of the river's life. All the 10,000 or so years of civilised man's time upon this Earth, would equate to about 10 minutes in the passing of the river. Barely long enough to qualify a mention, in nature's reckoning. Blink and you've missed us.
A river is very much a metaphor for the cycle of all things in nature. A river flows from its source, down its long-established river-bed, until it reaches its destination; the water then journeys until it once again reaches its source, and so the cycle continues. The animal kingdom, like a river, is based upon cycles: animals are born, they live out their lives; and when they pass on, their offspring live on to continue the great cycle that is life.
As with a river, the animal kingdom flows steadily down a long-established course; the cycle is the same from one generation to the next. But, also like a river, the animal kingdom may alter its course slightly, from time to time, as external factors force it to adapt to new conditions. If a boulder lands in the middle of a river, the course will change so that the water flows around the boulder; similarly, if food diminishes in the middle of an animal group's grazing area, the group will migrate to a nearby area where food is still plentiful. But the river will never change its course radically, and never of its own accord. The same can be said of the animal kingdom.
But what of mankind?
Mankind was once a member of the animal kingdom. In those times, our lives changed only very gradually (if at all) from one generation to the next. We were but drops in the flow of the great river, endlessly coursing downstream, endlessly being reborn upstream, part of the symmetrical and seemingly perpetual cycle of nature. Like the rest of our animal brethren, we adapted to new conditions when necessary, but we took no steps to instigate change of our own accord. We were subject to the law of inertia: that is, the law that nothing changes unless forced to do so by an external force.
And so it was, that Australopithecus evolved into Homo Erectus, which in turn evolved into Homo Sapiens; that is, the species that is the mankind of today. But when we reached the end of that line of human evolution, something begun that had never happened before. The river, which had altered its course only according to the law of inertia thus far, reached a point where it began to diverge, but without the encouragement of any apparent external force. Mankind began to cascade off in a new direction, when it had no urgent need to do so. It was almost as if the river was flowing uphill.
We have followed this divergence from the natural cyclic flow, unto the present day, and seem if anything to be following it ever more vigorously as the years march on. From the invention of the wheel, to the age of farming and tilling the Earth, to the age of iron and steel, to the industrial revolution, to the space age, and now to the information age: with an ambition fuelled by naught but the sweetness of our own success, we are ploughing ever on, into the unknown.
Mankind is now a river that plots its own course, oblivious to the rocks and the dirt that try feebly to gird it. The river flows as erratically as it does fiercely: the only certainty, it seems, is that it will always flow somewhere new with its next turn. And so there is no cycle: for the waves upon which one generation ride, the next generation never sees; and the new waves are so different in composition from the old, that the two bear little or no resemblance to each other.
A river sans a river-bed, We craft our muddy track, Whither will the current lead? None know, except not back.
We dash the rocks with vigour, We drown the shrubs and trees, Destroying all that's in our way, Not least our memories.
The river-banks once led us, Along a certain way, Who leads us now in darkness? Whatever fool that may.
What is our destination? What beacon do we seek? A tower of enlightenment, Or a desert, dead and bleak.
Is it a good thing or a bad thing, this unstoppable torrent upon which for 10,000 years we have ridden, and which it seems is only just beginning? Is it progress? Is it natural? I would argue with (what I suspect is) the majority: I say that it is a good thing, even if it goes against the example set to us by every single other entity, living or non-living, that we see around us. I advocate progress. I advocate moving forward, and living in times of innovation - even if such times are also inevitably times of uncertainty.
The only thing I don't advocate, is the cost of our progress on the natural environment. If we're going to break free of the law of inertia, and move ever onwards, we have a responsibility to do so without damaging the other forms of life around us. As the threats of global warming and of rising pollution levels are telling us, we are still a part of the natural ecosystem, no matter how hard we try to diverge and isolate ourselves from it. We depend on our planet: we need it to be living, breathing, and healthy; we need to get serious about conservation, for our own sake, if not for nature's.
Nature is a beautiful thing; but it is also filled with a profound and subtle wisdom. I sat upon a rock and watched the river flow by, and thought about life for a while. Those that come after me should be able to do the same. We've laid waste to enough rivers, streams, and (even) seas in our time. Let's be neighbours with those that still remain.
]]>
What a mean word2005-08-12T00:00:00Z2005-08-12T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/08/what-a-mean-word/
Some words are perfectly suited to their alternative definitions. The word 'mean' is one of these. 'Mean' refers to the average of a set of numbers. For example, you can calculate the mean of your school marks, or the mean of your bank savings, or the mean of many other things. A mean is a cruel, unforgiving, and brutally honest number: in short, it really is a mean number.
What brought this to mind was my recent University results. My marks have been pretty good so far, during my time at uni: overall I've scored pretty highly. But there have been a few times, here and where, where I've slipped a bit below my standard. For those of you that don't know, the big thing that everyone's worried about at uni is their GPA (Grade Point Average), which is - as its name suggests - the mean of all your marks in all your subjects to date.
My GPA is pretty good (I ain't complaining), but it's a number that reflects my occasional slip-ups as clearly as it does my usual on-par performance. Basically, it's a mean number. It's a number that remembers every little bad thing you've done, so that no matter how hard you try to leave your mistakes behind you, they keep coming back to haunt you. It's a merciless number, based purely on facts and logic and cold, hard mathematics, with no room for leniency or compassion.
A mean makes me think of what (some people believe) happens when you die: your whole life is shown before you, the good and the bad; and all the little things are added up together, in order to calculate some final value. This value is the mean of your life's worth: all your deeds, good and bad, are aggregated together, for The Powers That Be to use in some almighty judgement. Of course, many people believe that this particular mean is subject to a scaling process, which generally turns out to be advantageous to the end number (i.e. the Lord is merciful, he forgives all sins, etc).
Mean is one of many words in the English language that are known as polysemes (polysemy is not to be confused with polygamy, which is an entirely different phenomenon!). A polyseme is a type of homonym (words that are spelt the same and/or sound the same, but have different meanings). But unlike other homonyms, a polyseme is one where the similarily in sound and/or spelling is not just co-incidental - it exists because the words have related meanings.
For example, the word 'import' is a homonym, because its two meanings ('import goods from abroad', and 'of great import') are unrelated. Although, for 'import', as for many other homonyms, it is possible to draw a loose connection between the meanings (e.g. perhaps 'of great import' came about because imported goods were historically usually more valuable / 'important' than local goods, or vice versa).
The word 'shot', on the other hand, is clearly a polyseme. As this amusing quote on the polyseme 'shot' demonstrates, 'a shot of whisky', 'a shot from a gun', 'a tennis shot', etc, are all related semantically. I couldn't find a list of polysemes on the web, but this list of heteronyms / homonyms (one of many) has many words that are potential candidates for being polysemes. For example, 'felt' (the fabric, and the past tense of 'feel') could easily be related: perhaps the first person who 'felt' that material decided that it had a nice feeling, and so decided to name the material after that first impression response.
I couldn't find 'mean' listed anywhere as a polyseme. In fact, for some strange reason, I didn't even see it under the various lists of homonyms on the net - and it clearly is a homonym. But personally, I think it's both. Very few homonyms are clearly polysemes - for most the issue is debatable, and is purely a matter of speculation, impossible to prove (without the aid of a time machine, as with so many other things!) - but that's my $0.02 on the issue, anyway.
The movie Robin Hood: Men in Tights gives an interesting hypothesis on how and why one particular word in the English language is a polyseme. At the end of the movie, the evil villain King John is cast down by his brother, King Richard. In order to make a mockery of the evil king, Richard proclaims: "henceforth all toilets in the land shall be known as Johns". Unfounded humour, or a plausible explanation? Who knows?
There are surely many more homonyms in the English language that, like 'mean' and 'felt' and 'shot', are also polysemes. If any of you have some words that you'd like to nominate as polysemes, feel free. The more bizarre the explanation, the better.
]]>
Room to swing a cat2005-07-28T00:00:00Z2005-07-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/07/room-to-swing-a-cat/
There's a proverb in the English language, commonly used to describe small rooms and small spaces: it's the "not enough room to swing a cat" proverb. Here's an example of it: when you show your friend the bedroom of your new apartment, they might tell you: "there isn't even enough room to swing a cat in here!" When you hear this, you'll probably look around, nod your head, and reply: "yeah, I know... but for fifty bucks a week, it'll do". The conversation will continue, and this odd little proverb will soon be forgotten.
But have you ever stopped to think about what this proverb means? I mean, seriously: who the hell swings cats? Why would someone tell you that there isn't enough room to swing a cat somewhere? How do they know? Have they tried? Is it vitally important that the room is big enough to swing a cat in? If so, then whoever resides in that room:
is somewhat disturbed; and
shouldn't own a cat.
Now, correct me if I'm wrong - I'm more a dog person myself, so my knowledge of cats is limited - but my understanding has always been that swinging cats around in a circular arc (possibly repeatedly) is generally not a good idea. Unless your cat gets a bizarre sense of pleasure from being swung around, or your cat has suddenly turned vicious and you're engaged in mortal combat with it, or you've just had a really bad day and need to take your anger out on something that's alive (and that can't report you to the police), or there's some other extraneous circumstance, I would imagine that as a cat owner you generally wouldn't display your love and affection for your feline friend in this manner.
Picture this: someone's looking at an open house. They go up to the real estate agent, and ask: "excuse me, but is there enough room to swing a cat in here? You see, I have a cat, and I like to swing it - preferably in my bedroom, but any room will do - so it's very important that the main bedroom's big enough." I'm sure real estate agents get asked that one every day!
What would the response be? Perhaps: "well, this room's 5.4m x 4.2m, and the average arm is 50cm long from finger to shoulder, and the average cat is roughly that much again. So if you're going to be doing full swings, that's at least a 2m diameter you'll be needing. So yeah, there should be plenty of space for it in here!"
I'm guessing that this proverb dates back to medieval times, when tape measures were a rare commodity, and cats were in abundance. For lack of a better measuring instrument, it's possible that cats became the preferred method of checking that a room had ample space. After all, a room that you can swing a cat around in is fairly roomy. But on the flip side, they must have gone through a lot of cats back then.
Also, if swinging animals around is your thing, then it's clear that cats are the obvious way to go. Dogs dribble too much (saliva would fly around the room); birds would just flap away; rabbits are too small to have much fun with; and most of the other animals (e.g. horses, cows, donkeys) are too big for someone to even grab hold of their legs, let alone to get them off the ground. If someone told you that a room was big enough to swing a cow around in, it just wouldn't sound right. You'd wonder about the person saying it. You'd wonder about the room. You'd wonder about the physics of the whole thing. Basically, you'd become very concerned about all of the above.
In case you know anyone who's in the habit of swinging cats, here's a little sign that you can stick on your bedroom door, just to let them know that funny business with cats is not tolerated in your corner of the world:
No cat swinging
I hope that gives you a bit more of an insight into the dark, insidious world of cat swinging. Any comments or suggestions, feel free to leave them below.
]]>
The glossy future2005-07-04T00:00:00Z2005-07-04T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/07/the-glossy-future/
According to science fiction, humanity should by now be exploring the depths of outer space in sleek, warp-powered vehicles. Instead of humble suburban houses, we should all be living in gargantuan towers, that soar up into the sky at impossible angles, and that burrow down deep into the Earth. Instead of growing old and sick, we should be staying young and healthy for an unnaturally long time, thanks to the wonders of modern medicine.
This fantastical Utopia of the 21st century, however, could hardly be further from our own reality. What's interesting to note, however, is that there are a whole bunch of amazing things in this world today, that would have been considered science fiction not that long ago; but that these things are quite different to what the prophecies of science and of popular fiction have foretold.
The general pattern, as far as I can tell, is that it's the fun, the colourful, and the sexy ideas that inevitably wind up being predicted; and that it's the useful, the mundane, and the boring ideas that actually come into existence, and that (to a greater or lesser extent) become part of the global furnishings in which we live.
Take the Internet, for example. As a basic idea, the Internet is not very sexy (how ironic!): it's just a whole bunch of computers, all around the world, that are able to communicate with each other. How about computers? Even less sexy: a pile of circuits and resistors, that can perform complex calculations real fast. The mobile phone (a.k.a. cell phone)? Big deal: a phone that you can carry in your pocket. These are all things that we take for granted every day. They're also all things that have radically changed the way we live. Only, not in the sexy way that we imagined.
Where are the laser guns? Where are the cool spaceships? Where are the zero-gravity shoes, the holographic worlds, and the robotic people? When can you beam me up? Where's the sexy stuff? Sure, my iPod™ looks cool, but chopping my foot off and swallowing a pill to make it grow back would be so much cooler.
Flavours of prediction
Futuristic predictions come in two main flavours: the sleek, awe-inspiringly glossy flavour; and the crude, depressingly 'realistic' flavour. The science fiction movie genre has gone through both these phases. In the earlier years (the 60s and 70s), the genre seemed to favour the former flavour (the futuristic Utopia); and in the latter years (the 80s and 90s), it seemed to favour the latter flavour (usually in the form of a post-disaster world).
Take, for example, this shot from the classic Stanley Kubrick film, 2001: A Space Odyssey:
Galactic waltz in 2001: A Space Odyssey
This is a beautiful machine, full of graceful curves and subtle gradients - very much compatible with the elegant classical music to which it 'waltzes'. This kind of spaceship is the perfect example of a 'glossy' future - that is, one that has been made to look perfect and insatiable. Here's another example of a future that's been glossed up:
Sunset on Coruscant in Star Wars
This shot is from Star Wars: Episode II - Attack of the Clones. I'm actually cheating a bit here, because Star Wars is technically set 'a long time ago, in a galaxy far away'; and also because Episode II was made recently, not in the 60s or 70s. Also, Star Wars has traditionally had less glossy-looking scenery than this. But nevertheless, this shot gets the point across pretty well: the future is a gleaming city of spires and curvaceous arches, with thousands of little shuttles zooming through the sky.
And now for something completely different, here's a shot from Ridley Scott's film Blade Runner:
Ziggurat in Blade Runner
This is a totally different prediction of the future: not attractive, but grotesque; not full of life, but devoid of it; not designed, but mass-manufactured. This is not just a different image, but a whole different philosophy on how to foretell the future. Similar things can be said about this shot from The Matrix Reloaded:
Zion dock in The Matrix Reloaded
While this one isn't quite so obviously blocky and noirish as the Blade Runner shot, it still looks more 'realistic' than 'futuristic', if you know what I mean. It's got that industrial, scrap-metal-dump-site kind of look about it.
Conclusions
So, which of these flavours of prediction is accurate? Will the future continue to disappoint, as it has up until now, or will it live up to its glossy predictions?
As I said earlier, it's the cool ideas that get predicted, and the practical ideas that actually happen. Bearing that in mind, I think that many of the cool ideas from science fiction will become a part of our real lives in the not-too-distant future (in fact, many of them are already), but not in the sexy way that they've been portrayed by the mass media.
Many of the ideas that futurists have come up with will never (foreseeably) actually happen, because they're simply too impractical to implement in the real world, or because implementing them is way beyond our current capacity in the realms of science. And, as we've seen in the past few decades, many useful but mundane innovations will continue to spring up, without ever having been predicted by even the most talented of modern prophets. Maybe such ideas are just too simple. Maybe they're too boring. Maybe they're just easier to sell in desktop form, or in pocket form, than in panoramic wide-screen digital surround-sound form.
I don't guarantee that the future will be any glossier than the present. The future might not be as jazzed up as Hollywood has made it.
But one thing's for sure: the future will be cool.
]]>
Movies for the masses2005-06-09T00:00:00Z2005-06-09T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/06/movies-for-the-masses/
2005 marks the 100th anniversary of the cinema industry. In 1905 (according to this film history timeline, and this article on film), the world's first movie theatre opened in Pittsburgh, Pennsylvania. The first ever motion picture, called "The Oberammergau Passion", was produced in 1898. What does all this mean? Movies have now been around for 108 years. They're older than almost anyone alive today. They're a part of the lives of all of us, and of everyone we know. The movie is one of the 20th century's greatest triumphs. Compared with other great inventions of the age - such as the atomic bomb - when it comes to sheer popularity, the movie wins hands down.
I've had an amazing vision of something that is bound to happen, very soon, in the world of movies. I will explain my vision at the end. If you're really impatient, then feel free to skip my ramblings, and cut to the chase. Otherwise, I invite you to read on.
Rambling review of American Epic
I just finished watching Part 1 of Cecil B. DeMille: American Epic (on ABC TV). DeMille was one of the greatest filmmakers of all time. I watched this documentary because DeMille produced The Ten Commandments, which is one of my favourite movies of all time. When I saw the ad for this show a few nights ago - complete with clips from the movie, and some of the most captivating music I've ever heard (the music from the movie, that is) - I knew I had to watch it.
This documentary revealed quite a few interesting things about Cecil B. DeMille. Here are the ones that stayed with me:
In his 50+ years of movie-making, he produced an astounding 70+ feature films!
He was actually a failed playwright and actor, who turned to film as an act of desperation. His failure in the world of theatre filled him with an incredible ambition and drive for the rest of his life.
He founded Hollywood. That's right: when he arrived in Los Angeles in 1913, Hollywood was a sleepy village with nothing but farmland around it. He set up the first movie studio ever in Hollywood. He chose to establish himself in the town, because the scenery of the area was just what he needed to film his first movie (The Squaw Man).
He first produced The Ten Commandments in 1923. All those countless times I've watched the 1956 version (I watch it at least once every year): and never once did I realise or suspect that it was actually the second version that he made. The documentary shows clips from the original film, and it's uncanny how striking the resemblances are. The 'day of exodus' scene, the 'chariot chase' scene, and the famous 'splitting of the sea' scene, all look pretty much the same as their later equivalents, just with way worse special effects and no sound.
When he produced The King of Kings in 1927, it originally portrayed the Children of Israel as being responsible for the death of dear old Brian (AKA Jesus). But the outcry from the American Jewish community at the time was so severe, the ending had to be changed before the film was released.
Although his mother was Jewish - and although his biggest film ever was the story of the birth of the Jewish people - he was apparently a tad bit anti-semitic. He considered himself to be a devout Christian, and somewhat resented his Jewish blood. He wouldn't let one of his relatives appear in any of his films, or in any photographs associated with them, because she had a 'Jewish nose' (hey, I know all about that, I know just how she feels!).
Anyway, most of the documentary was about DeMille's work producing silent films, during the 1913-1929 period. Watching these films always gives me a weird feeling, because I've always considered film to be a 'modern' medium, and yet to me, there's absolutely nothing modern about these films. They look ancient. They are ancient. They're archaeological relics. They may as well belong in the realms of Shakespeare, and Plato, and all the other great works of art that are now in the dim dark past. We give these old but great works a benevolent name (how generous of us): we call them classics.
But even at the very start of his producer / director career, the hallmarks of DeMille's work are clear; the same hallmarks that I know and love so well, from my many years of fondness for The Ten Commandments. Even in his original silent, black-and-white-not-even-grey, who-needs-thirty-frames-in-a-second-anyway films, you can see the grandeur, the lavish costumes, the colossal sets, the stunning cast, and the incontestible dignity that is a DeMille movie.
Cut to the chase
Watching all this stuff about the dawn of the film industry, and the man that made Hollywood's first feature films, got me thinking. I thought about how old all those movies are. Old, yet still preserved in the dusty archives of Paramount Pictures (I know because the credits of the documentary said so). Old, yet still funny, still inspiring, still able to be appreciated. Old, but not forgotten.
I wondered if I could get any of these old, silent films from the 1920s (and before) on video or DVD. Probably not, I thought. I wondered if I could get access to them at all. The 1923 original of The Ten Commandments, in particular, is a film that I'd very much like to see in full. But alas, no doubt the only way to access them is to go to the sites where they're archived, and pay a not-too-shabby fee, and have to use clunky old equipment to view them.
Have you ever heard of Project Gutenberg? They provide free, unlimited access to the full text of over 15,000 books online. Most of the books are quite old, and they are able to legally publish them online royalty-free, because the work's copyright has expired, due to lapse of time since the author's death. Project Gutenberg FAQ 11 says that as a general rule, works published in the USA pre-1923 no longer have copyright (this is a rough guideline - many complicated factors will affect this figure on a case-by-case basis).
Project Gutenberg's library consists almost entirely of literary text at the moment. But the time is now approaching (if it hasn't arrived already) when the world's oldest movies will lose their copyright, and will be able to be distributed royalty-free to the general public. Vintage films would make an excellent addition to online archives such as Project Gutenberg. These films are the pioneers of a century of some of the richest works of art and creativity that man has ever produced. They are the pioneers of the world's favourite medium of entertainment. They should be free, they should be online, and they should be available to everyone.
When this happens (and clearly it's a matter or when, not if), it's going to be a fantastic step indeed. The educational and cultural value of these early films is not to be underestimated. These films are part of the heritage of anyone who's spent their life watching movies - that would be most of the developed world.
These films belong to the masses.
]]>
Busker bigotry2005-05-14T00:00:00Z2005-05-14T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/05/busker-bigotry/
I have a confession to make. I am guilty of the crime of busker bigotry. I justify my sin by convincing myself that it's not my fault. It's one of life's greatest dilemnas: you can't drop a coin to every busker that you pass in the street. It's simply not feasible. You'd probably go broke; and even if you could afford to do it, there are a plethora of other reasons against doing it (e.g. constant weight of coins, stopping and getting wet if it's raining, risk of getting mugged, etc).
I was walking through the Devonshire St tunnel, in Sydney's Central Railway Station, about a week ago. 'The tunnel' is one of those places that seems to inexorably draw buskers to it, much like members of the female race are inexorably drawn towards shoe shops (whilst members of the male race are inexorably oblivious to the existence of shoe shops - I can honestly say that I can't remember ever walking past such a place, and consciously noticing or registering the fact that it's there).
Normally, as I walk through the tunnel - passing on average about five buskers - I don't stop to even consider dropping a coin for any of them. It doesn't really matter how desperate or how pitiful they look, nor how much effort they're putting in to their performance. I walk through there all the time. I'm in a hurry. I don't have time to stop and pull out my wallet, five times per traverse, several traverses per week. And anyway, I didn't ask to be entertained whilst commuting, so why should I have to pay?
But last week, I was walking through the tunnel as usual, when I saw some buskers that I just couldn't not stop and listen to. They were a string quartet. Four musicians, obviously talented and accomplished professionals, playing a striking piece of classical music. Their violin and cello cases were open on the ground, and they weren't exactly empty. Evidently, a lot of people had already felt compelled to stop and show their appreciation. I too felt this need. I pulled out my wallet and gave them a few coins.
This is a rare act for me to engage in. What was it that triggered me to support these particular buskers, when I had indifferently ignored so many before them, and would continue to ignore so many after them? What mode of measurement had I used to judge their worthiness, and why had I used this mode?
The answer is simple. I stopped because I thought: These guys are good. Really good. I like the music they're playing. I'm being entertained by them. The least I can do, in return for this, is to pay them. Basically, I felt that they were doing something for me - I was getting something out of their music - and so I felt obliged to pay them for their kind service.
And then it occurred to me what my mode of measurement is: my judgement of a busker is based solely on whether or not I notice and enjoy their music enough to warrant my stopping and giving them money. That is, if I consciously decide that I like what they're playing, then I give money; otherwise, I don't.
Nothing else enters into the equation. Fancy instruments, exotic melodies, and remarkable voices contribute to the decision. Pitiful appearance, desperate pleas, and laudable (if fruitless) effort do not. Talk about consumer culture. Talk about heartless. But hey, don't tell me you've never done the same thing. We all have. Like I said, you can't stop for every busker. You have to draw the line somewhere, and somehow.
]]>
In search of an all-weather bike2005-04-29T00:00:00Z2005-04-29T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/04/in-search-of-an-all-weather-bike/
I ride my bike whenever I can. For me, it's a means of transportation more than anything else. I ride it to get to university; I ride it to get to work; sometimes I even ride it to get to social events. Cycling is a great way to keep fit, to be environmentally friendly, and to enjoy the (reasonably) fresh air.
But quite often, due to adverse weather, cycling is simply not an option. Plenty of people may disagree with me, but I'm sure that plenty will also agree strongly when I say that riding in heavy rain is no fun at all.
There are all sorts of problems with riding in the rain, some being more serious than others. First, there's the problem of you and your cargo getting wet. This can be avoided easily enough, by putting a waterproof cover on your cargo (be it a backpack, saddle bags, or whatever), and by wearing waterproof gear on your person (or by wearing clothes that you don't mind getting wet). Then there's the problem of skidding and having to ride more carefully, which really you can't do much about (even the big pollution machines, i.e. cars, that we share the road with, are susceptible to this problem). And finally, there's the problem of the bike itself getting wet. In particular, problems arise when devices such as the brakes, the chain, and the derailleur are exposed to the rain. This can be averted somewhat by using fenders, or mudguards, to protect the vital mechanical parts of the bike.
But really, all of these are just little solutions to little problems. None of them comes close to solving the big problem of: how can you make your riding experience totally weatherproof? That's what I'm looking for: one solution that will take care of all my problems; a solution that will protect me, my bag, and almost all of my bike, in one fell swoop. What I need is...
A roof for my bike!
But does such a thing exist? Has anyone ever successfully modified their bike, so that it has a kind of roof and side bits that can protect you from the elements? Surely there's someone else in this world as chicken of the rain as me, but also a little more industrious and DIY-like than me?
The perfect solution, in my opinion, would be a kind of plastic cover, that you could attach to a regular diamond-frame bike, and that would allow you to ride your bike anywhere that you normally would, only with the added benefit of protection from the rain. It would be a big bubble, I guess, sort of like an umbrella for you and your bike. Ideally, it would be made of clear plastic, so that you could see out of it in all directions. And it would be good if the front and side sections (and maybe the back too - and the roof) were flaps that you could unzip or unbutton, to let in a breeze when the weather's bad but not torrential. The 'bubble cover' would have to be not much wider than the handlebars of your bike - otherwise the bike becomes too wide to ride down narrow paths, and the coverage of the bike (i.e. where you can take it) becomes restricted.
If it exists, I thought, then surely it'll be on Google. After all, as the ancient latin saying goes: "In Googlis non est, ergo non est" (translation:"If it's not in Google, it doesn't exist"). So I started to search for words and phrases, things that I hoped would bring me closer to my dream of an all-weather bike.
Playing hard to get
I searched for "all-weather bike". Almost nothing. "Weatherproof bike". Almost nothing. "Bike roof". A whole lot of links to bicycle roof racks for your car. "Bike roof -rack". Yielded a few useless links. "Bike with roof". Barely anything. "Waterproof cover +bicycle". Heaps of links to covers that you can put on your bike, to keep it dry when it's lying in the back yard. But no covers that you can use while you're riding the bike.
This was getting ridiculous. Surely if there was something out there, I would have found it by now? Could it be true that nobody in the whole world had made such a device, and published it on the web? No, it couldn't be! This is the information age! There are over 6 billion people in the world, and as many as 20% of them (that's over 1.2 billion people) have access to the Internet. What are the odds that not even 1 person in 1.2 billion has done this?
I must be searching for the wrong thing, I thought. I looked back to my last search: "bike canopy". What else has a canopy? I know! A golf buggy! So maybe, I thought, if I search for information about golf buggies / carts, I'll find out what the usual word is for describing roofs on small vehicles. So I searched for golf buggies. And I found one site that described a golf buggy with a roof as an 'enclosed vehicle'. Ooohhh... enclosed, that sounds like a good word!
So I searched for "enclosed bike". A whole lot of links about keeping your bike enclosed in lockers and storage facilities. Fine, then: "enclosed bike -lockers". Got me to an article about commuting to work by bike. Intersting article, but nothing in it about enclosing your bike.
Velomobiles
Also, further down in the list of results, was the amazing go-one. This is what a go-one looks like:
Go-one velomobile
Now, if that isn't the coolest bike you've ever seen, I don't know what is! As soon as I saw that picture, I thought: man, I want that bike.
The go-one is actually a tricycle, not a bicycle. Specifically, it's a special kind of trike called a recumbent trike. Recumbents have a big comfy seat that you can sit back and relax in, and you stick your feet out in front of you to pedal. Apparently, they're quite easy to ride once you get used to them, and they can even go faster than regular bikes; but I don't see myself getting used to them in a hurry.
The go-one is also a special kind of trike called a velomobile. Velomobiles are basically regular recumbents, with a solid outer shell whacked on the top of them. Almost all the velomobiles and velomobile makers in the world are in Europe - specifically, in the Netherlands and in Germany. But velomobiles are also beginning to infiltrate into the USA; and there's even a velomobile called the Tri-Sled Sorcerer that's made right here in Australia!
Here's a list of some velomobile sites that I found whilst surfing around:
Information about velomobiles from the International Human Powered Vehicles Association. This is the body that officially governs velomobile use worldwide. Has many useful links.
This site is dedicated to recumbents of all types. This article surveys pretty much every velomobile currently available on the commercial market - great if you're looking to get the low-down on all the models. Only bad thing is that half the images are broken.
Velomobiles are the closest thing (and the only thing that comes close at all) to my dream of an enclosed bike. There's no doubt that they shield you from the elements. In fact, most of them have been designed specifically as a replacement for travelling by car. However, there are a few disadvantages that would make them unsuitable for my needs:
Too heavy: can't just lift them up and carry them over railings, up steps, etc.
Too wide: only really suitable for roads, not for footpaths (sidewalks), narrow lanes, and even some bike tracks.
Too expensive: all the currently available velomobiles are really quite expensive. The go-one is one of the pricier ones, with a starting price of 9500 Euro (almost AUD$16,000!), but even the cheaper ones are at least AUD$5,000. Until velomobiles start to come down in price, there's no way that I could afford one.
Still hopeful
I've decided to stop searching for my dream enclosed bike - it looks like the velomobile is the closest I'm going to get to finding it. But who knows? Maybe I still haven't looked in the right places. I don't need something like a velomobile, which is pretty much a pedal-powered car. All I'm looking for is a simple waterproof bubble that can be fitted to a regular bike. I still believe that someone out there has made one. It's just a matter of finding him/her.
If any of you know of such a device, please, post a comment to this article letting me know about it. If I actually find one, I might even try it out!
]]>
Showing sneak previews in Drupal2005-04-05T00:00:00Z2005-04-05T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/04/showing-sneak-previews-in-drupal/
Drupal comes with a powerful permissions system that lets you control exactly who has access to what on your site. However, one thing that you can't do with Drupal is prohibit users from viewing certain content, but still let them see a preview of it. This quick-hack tutorial shows you how to do just that.
There are several modules (most of them non-core) available for Drupal, that let you restrict access to content through various different mechanisms. The module that I use is taxonomy access, and this hack is designed to work primarily with content that is protected using this module. However, the principle of the hack is so basic, you could apply it to any of the different node protection and node retrieval mechanisms that Drupal offers, with minimal difficulty (this is me guessing, by the way - maybe it's actually not easy - why don't you find out? :-)).
This hack is a patch for Drupal's core taxonomy module (4.5.x version). Basically, what it does is eliminate the mechanisms in the taxonomy system that check access permissions when a node is being previewed. The taxonomy system doesn't handle the full text viewing of a node - that's managed by the node system and by the many modules that extend it - so there is no way that this patch will allow unauthorised access to the full text of your nodes! Don't worry about that happening - you would have to start chopping code off the node system before that becomes even a possibility.
Important note: this patch only covers node previews in taxonomy terms, not node previews in other places on your site (e.g. on the front page - assuming that your front page is the default /q=node path). If you display protected content on the front page of your site, you'll need to patch the node system in order to get the previews showing up on that front page. Since GreenAsh only displays protected content in taxonomy listings, I've never needed (and hence never bothered) to hack anything else except the taxonomy system in this regard.
Protect your nodes
Showing you the patch isn't going to be very useful unless you've got some protected nodes in your system already. So if you haven't already gone and got taxonomy_access, and used it to restrict access to various categories of nodes, then please do so now!
The patch
As I said, it's extremely simple. All you have to to is open up your modules/taxonomy.module file, and find the following code:
<?php
/**
* Finds all nodes that match selected taxonomy conditions.
*
* @param $tids
* An array of term IDs to match.
* @param $operator
* How to interpret multiple IDs in the array. Can be "or" or "and".
* @param $depth
* How many levels deep to traverse the taxonomy tree. Can be a nonnegative
* integer or "all".
* @param $pager
* Whether the nodes are to be used with a pager (the case on most Drupal
* pages) or not (in an XML feed, for example).
* @return
* A resource identifier pointing to the query results.
*/
function taxonomy_select_nodes($tids = array(), $operator = 'or', $depth = 0, $pager = TRUE) {
if (count($tids) > 0) {
// For each term ID, generate an array of descendant term IDs to the right depth.
$descendant_tids = array();
if ($depth === 'all') {
$depth = NULL;
}
foreach ($tids as $index => $tid) {
$term = taxonomy_get_term($tid);
$tree = taxonomy_get_tree($term->vid, $tid, -1, $depth);
$descendant_tids[] = array_merge(array($tid), array_map('_taxonomy_get_tid_from_term', $tree));
}
if ($operator == 'or') {
$str_tids = implode(',', call_user_func_array('array_merge', $descendant_tids));
$sql = 'SELECT DISTINCT(n.nid), n.sticky, n.created FROM {node} n '. node_access_join_sql() .' INNER JOIN {term_node} tn ON n.nid = tn.nid WHERE tn.tid IN ('. $str_tids .') AND n.status = 1 AND '. node_access_where_sql() .' ORDER BY n.sticky DESC, n.created DESC';
$sql_count = 'SELECT COUNT(DISTINCT(n.nid)) FROM {node} n '. node_access_join_sql() .' INNER JOIN {term_node} tn ON n.nid = tn.nid WHERE tn.tid IN ('. $str_tids .') AND n.status = 1 AND '. node_access_where_sql();
}
else {
$joins = '';
$wheres = '';
foreach ($descendant_tids as $index => $tids) {
$joins .= ' INNER JOIN {term_node} tn'. $index .' ON n.nid = tn'. $index .'.nid';
$wheres .= ' AND tn'. $index .'.tid IN ('. implode(',', $tids) .')';
}
$sql = 'SELECT DISTINCT(n.nid), n.sticky, n.created FROM {node} n '. node_access_join_sql() . $joins .' WHERE n.status = 1 AND '. node_access_where_sql() . $wheres .' ORDER BY n.sticky DESC, n.created DESC';
$sql_count = 'SELECT COUNT(DISTINCT(n.nid)) FROM {node} n '. node_access_join_sql() . $joins .' WHERE n.status = 1 AND '. node_access_where_sql() . $wheres;
}
if ($pager) {
$result = pager_query($sql, variable_get('default_nodes_main', 10) , 0, $sql_count);
}
else {
$result = db_query_range($sql, 0, 15);
}
}
return $result;
}
?>
Now replace it with this code:
<?php
/**
* Finds all nodes that match selected taxonomy conditions.
* Hacked to ignore node access conditions, so that nodes are always listed in taxonomy listings,
* but cannot actually be opened without the proper permissions - by Jaza on 2005-01-16.
*
* @param $tids
* An array of term IDs to match.
* @param $operator
* How to interpret multiple IDs in the array. Can be "or" or "and".
* @param $depth
* How many levels deep to traverse the taxonomy tree. Can be a nonnegative
* integer or "all".
* @param $pager
* Whether the nodes are to be used with a pager (the case on most Drupal
* pages) or not (in an XML feed, for example).
* @return
* A resource identifier pointing to the query results.
*/
function taxonomy_select_nodes($tids = array(), $operator = 'or', $depth = 0, $pager = TRUE) {
if (count($tids) > 0) {
// For each term ID, generate an array of descendant term IDs to the right depth.
$descendant_tids = array();
if ($depth === 'all') {
$depth = NULL;
}
foreach ($tids as $index => $tid) {
$term = taxonomy_get_term($tid);
$tree = taxonomy_get_tree($term->vid, $tid, -1, $depth);
$descendant_tids[] = array_merge(array($tid), array_map('_taxonomy_get_tid_from_term', $tree));
}
if ($operator == 'or') {
$str_tids = implode(',', call_user_func_array('array_merge', $descendant_tids));
$sql = 'SELECT DISTINCT(n.nid), n.sticky, n.created FROM {node} n '. /* node_access_join_sql() .*/ ' INNER JOIN {term_node} tn ON n.nid = tn.nid WHERE tn.tid IN ('. $str_tids .') AND n.status = 1 '. /*AND '. node_access_where_sql() .*/ ' ORDER BY n.sticky DESC, n.created DESC';
$sql_count = 'SELECT COUNT(DISTINCT(n.nid)) FROM {node} n '. /*node_access_join_sql() .*/ ' INNER JOIN {term_node} tn ON n.nid = tn.nid WHERE tn.tid IN ('. $str_tids .') AND n.status = 1 '/*. AND '. node_access_where_sql()*/;
}
else {
$joins = '';
$wheres = '';
foreach ($descendant_tids as $index => $tids) {
$joins .= ' INNER JOIN {term_node} tn'. $index .' ON n.nid = tn'. $index .'.nid';
$wheres .= ' AND tn'. $index .'.tid IN ('. implode(',', $tids) .')';
}
$sql = 'SELECT DISTINCT(n.nid), n.sticky, n.created FROM {node} n './*'. node_access_join_sql() .*/ $joins .' WHERE n.status = 1 './*AND '. node_access_where_sql() .*/ $wheres .' ORDER BY n.sticky DESC, n.created DESC';
$sql_count = 'SELECT COUNT(DISTINCT(n.nid)) FROM {node} n './*'. node_access_join_sql() .*/ $joins .' WHERE n.status = 1 './*AND '. node_access_where_sql() .*/ $wheres;
}
if ($pager) {
$result = pager_query($sql, variable_get('default_nodes_main', 10) , 0, $sql_count);
}
else {
$result = db_query_range($sql, 0, 15);
}
}
return $result;
}
?>
As you can see, all the node_access functions, which are used to prevent the SQL queries from retrieving protected content, have been commented out. So when retrieving node previews, the taxonomy system now effectively ignores all access rights, and always displays a preview no matter who's viewing it. It's only when you try to actually go to the full-text version of the node that you'll get an 'access denied' error.
Drupal does not allow this behaviour at all (unless you hack it), and rightly so, because it is obviously bad design to show users a whole lot of links to pages that they can't actually access. But there are many situations where you want to give your visitors a 'sneak preview' of what a certain piece of content is, and the only way to do it is using something like this. It's a form of advertising: by displaying only a part of the node, you're enticing your visitors to do whatever it is that they have to do (e.g. register, pay money, poison your mother-in-law) in order to access it. So, because I think other Drupal admins would also find this functionality useful, I've published it here.
]]>
Aussie Daylight Savings PHP function2005-03-27T00:00:00Z2005-03-27T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/03/aussie-daylight-savings-php-function/
Want to know how the GreenAsh clock always tells you, with perfect accuracy, the time in Sydney Australia? Our secret is a little PHP function that modifies the clock according to the rules of NSW Daylight Savings Time. No, in case you were wondering, we don't stay up until 2am twice each year, ready to change the site's time zone configuration at exactly the right moment! A simple little bit of programming does that for us. And unlike a human, computer code doesn't fall asleep waiting for the clock to tick over.
The function that we use is based on the rules of NSW Daylight Savings Time, as explained at Lawlink's Time in NSW page (they also have another excellent page that explains the history of Daylight Saving in NSW, for those that are interested). The current set-up for Daylight Saving is as follows:
Starts: 2am, last Sunday in October.
Ends: 3am, last Sunday in March.
What happens during Daylight Saving: clocks go forward one hour.
And that's really all there is to it! So without further ado, I present to you the PHP function that GreenAsh uses in order to calculate whether or not it is currently DST.
<?php
/**
* Determine if a date is in Daylight Savings Time (AEST - NSW).
* By Jaza, 2005-01-03 (birthday function).
*
* @param $timestamp
* the exact date on which to make the calculation, as a UNIX timestamp (should already be set to GMT+10:00).
* @return
* boolean value of TRUE for DST dates, and FALSE for non-DST dates.
*/
function daylight_saving($timestamp) {
$daylight_saving = FALSE;
$current_month = gmdate('n', $timestamp);
$current_day = gmdate('d', $timestamp);
$current_weekday = gmdate('w', $timestamp);
// Daylight savings is between October and March
if($current_month >= 10 || $current_month <= 3) {
$daylight_saving = TRUE;
if($current_month == 10 || $current_month == 3) {
// It starts on the last Sunday of October, and ends on the last Sunday of March.
if($current_day >= 25) {
if($current_day - $current_weekday >= 25) {
if($current_weekday == 0) {
// Starts at 2am in the morning.
if(gmdate('G', $timestamp) >= 2) {
$daylight_saving = $current_month == 10 ? TRUE : FALSE;
} else {
$daylight_saving = $current_month == 10 ? FALSE : TRUE;
}
} else {
$daylight_saving = $current_month == 10 ? TRUE : FALSE;
}
} else {
$daylight_saving = $current_month == 10 ? FALSE : TRUE;
}
} else {
$daylight_saving = $current_month == 10 ? FALSE : TRUE;
}
}
}
return $daylight_saving;
}
?>
It's not the world's most easy-to-read or easy-to-maintain function, I know, but it does the job and it does it well. If you're worried about its reliablility, let me assure you that it's been in operation on our site for almost a full calendar year now, so it has been tested to have worked for both the start and the end of Daylight Savings.
So until they change the rules about Daylight Savings again (they're talking about doing this at the moment, I think), or until there's one year where they change the rules just for that year, because of some special circumstance (like in 2000, when they started Daylight Savings early so that it would be in effect for the Sydney Olympics), this function will accurately and reliably tell you whether or not a given date and time falls within the NSW Daylight Savings period.
I wrote this function myself, because I couldn't find any PHP on the net to do it for me. I'm posting the code here to avoid this hassle for other webmasters in the future. Feel free to use it on your own site, to modify it, or to put it to other uses. As long as you acknowledge me as the original author, and as long as you don't sell it or do any other un-GPL-like things with it, the code is yours to play with!
]]>
Desire and suffering2005-03-23T00:00:00Z2005-03-23T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/03/desire-and-suffering/
I remember learning once about the Eastern philosophy relating to the nature of suffering. It was during a religious studies course that I took during my senior years of high school. Part of the course involved a study of Buddhism, and the Buddhist / Hindu ideas about what causes suffering. Those of you that are somewhat familiar with this, you should already have an idea of what I'm talking about. Those of you that are very familiar with it, you probably know far more than I do (I'm no expert on the matter, I have only a very basic knowledge), so please forgive me for any errors or gross simplifications that I make.
In essence (as I was taught, anyway), Buddhists believe that all suffering is caused by desire. It's really quite a logical concept:
we desire what we do not have;
we suffer because we desire things and we do not have them;
therefore, if we free ourselves from desire (i.e. if we do not desire anything), then we become free of suffering (i.e. we achieve the ultimate level of happiness in life).
I haven't read the book The Art of Happiness, by His Holiness the Dalai Lama (I'm waiting for the movie to come out), but I'm guessing that this is the basic message that it gives. Although I could be wrong - if you really want to know, you really should just buy the book!
The concept is so simple, and when you think about it, it's kind of cool how it just makes sense™. Put it in the perspective of modern Western culture, which is (in stark contrast to this philosophy) totally centred around the consumer and the individual's wants. In Western society, our whole way of thinking is geared towards fulfilling our desires, so that we can then be happy (because we have what we want). But as everyone knows, the whole Western individual-consumer-selfish-driven philosophy is totally flawed in practice, because:
as soon as we fulfil one desire, it simply leads to more desires (the old OK, I've bought a Mercedes, now I want a Porsche example comes to mind here);
there are heaps of desires that everyone has, that will never be fulfilled (hence you will never truly be happy).
Then there is the great big fat lie of the consumer era: things that we desire aren't really desires, because most of them are actually things that we need, not things that we want. Justifying that we need something has become second nature. I need the new 40GB iPod, because otherwise I'll go crazy sitting on the train for 2 hours each way, each day, on the way to work. I need a top-of-the-range new computer, because my old one is too slow and is stopping me from getting my work done productively. I need a designer jacket, because it's nearly winter and my old ones are ready for the bin, and I'll be cold without it. I need the biggest thing on the menu at this restaurant, because I'm really hungry and I haven't eaten since lunch. We know, deep down, that we don't need any of these things, just as we know that having them won't make us "happy". But we kid ourselves anyway.
And this is where the whole Buddhism thing starts to make sense. Hang on, you think. If I just stop desiring that new iPod, and that fast PC, and that designer jacket, and that massive steak, then I won't have the problem of being unhappy that I haven't got them. I don't really need them anyway, and if I can just stop wanting them, I'll be better off anyway. I can spend my money on more important things. And so you see how, as I said, it really does just make sense™.
But all this got me thinking, what about other things? Sure, it's great to stop desiring material objects, but what of the more abstract desires? There are other things that we desire, and that we suffer from because of our desire, but that don't lead to simply more greed. Love is the obvious example. We all desire love, but once you've found one person that you love, then (assuming you've found someone you really love) you stop desiring more people to love (well... that's the theory, anyway - but let's not get into that :-)).
Another is knowledge. Now, this is a more complicated one. There are really no constants when it comes to knowledge. Sometimes you desire knowledge, and sometimes you don't. Sometimes fulfilling your desire (for knowledge) leads to more desire, but other times, it actually stops you desiring any more. Sometimes fulfilling a desire for knowledge makes you happy, and sometimes it makes you realise that it wasn't such a good idea to desire it in the first place.
Take for example history. You have a desire to learn more about World War II. You have a thirst for knowledge about this particular subject. But when you actually fulfil that desire, by acquiring a degree of knowledge, it leads to a desire not to know any more. Learning about the holocaust is horrible - you wish you'd never learnt it in the first place. You wish you could unlearn it.
Take another example, this time from the realm of science. In this example, assume that you have no desire whatsoever to learn about astronomy. You think it's the most boring topic on Earth (or beyond :-)). But then someone tells you about how they've just sent a space probe to Titan (one of Saturn's moons), and how it's uncovering new facts that could lead to the discovery of life beyond Earth. Suddenly, you want to learn more about this, and your initial lack of desire turns into an eventual desire for more knowledge.
Clearly, knowledge and the desire for it cannot be explained with the same logic that we were using earlier. It doesn't follow the rules. With knowldge, desire can lead to no desire, and vice versa. Fulfilment can lead to sadness, or to happiness. So the question that I'm pondering here is basically: is it bad to desire knowledge? Is this one type of desire that it's good to have? Is there any constant effect of attaining knowledge, or does it depend entirely on what the knowledge is and how you process it?
My answer would be that yes, it's always good to desire knowledge. Even if you cannot say with certainty whether the result of attaining knowledge is "good" or "bad" (if such things can even be measured), it's still good to always desire to know more, just for the sake of being a more informed and more knowledgeable human being. Of course, I can't even tell you what exactly knowledge is, and how you can tell knowledge apart from - well, from information that's total rubbish - that would be a whole new topic. But my assertion is that whatever the hell knowledge is, it's good to have, it's good to desire, and it's good to accumulate over the long years of your life.
Buddhist philosophy probably has its own answers to these questions. I don't know what they are, so because of my lack of knowledge (otherwise known as ignorance!), I'm trying to think of some answers of my own. And I guess that in itself is yet another topic: is it better to be told the answers to every big question about life and philosophy, or is it sometimes better to come up with your own? Anyway, this is one little complex question that I'm suggesting an answer to. But by no means is it the right answer. There is no right answer. There is just you and your opinion. Think about it, will you?
]]>
The fantasy genre: an attempt to explain its success2005-02-21T00:00:00Z2005-02-21T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/02/the-fantasy-genre-an-attempt-to-explain-its-success/
It has now been more than 50 years since J.R.R. Tolkien published the first volume of his epic trilogy - The Lord of the Rings - marking the birth of the modern fantasy genre. Tolkien's masterpiece was voted "best book of the 20th century" a few years ago, and it has been read and cherished by millions of devotees worldwide. Ever since then, fantasy books have been springing up left, right, and centre; and judging by the way they keep on selling (and selling), it seems that the fans just can't get enough of them. David Eddings' Belgariad (and others); Robert Jordan's Wheel of Time; Terry Goodkind's Sword of Truth; and Ursula LeGuin's Earthsea: these are but a handful of the vast treasure trove of fantasy works, to be found on the shelves of bookshops the world over.
But just what is it that makes these books so damn popular? As I lay awake last night, having just finished reading Harry Potter and the Goblet of Fire (I'll talk about J.K. Rowling's work in a minute), I pondered this question, and I would now like to share with you all the conclusions that I came up with.
We all know that fantasy books all have a lot in common. A lot. In fact, most of them are so similar, that once you've read a few, you could read the rest of them with your eyes shut, and still be able to take a pretty good guess at what the plot is. They all follow the classic formula, which goes something along these lines:
Young boy (or girl, or creature... or hobbit) grows up in rural setting, living peaceful childhood, knowing nothing about magic, dark lords, wizards, etc.
Hero is forced to leave beloved home (may or may not have found true love by now), because dark power is growing stronger, and hero must go on dangerous journey to escape.
Hero soon realises that his parents/ancestors (whom he never met - up until now he thought those nice country bumpkins who raised him were his closest family) were powerful wizards, or kings/queens, or something else really famous.
Hero discovers that he has amazing magical powers, and that he was born with a destiny to overthrow some terrifying evil power. He is taught how to use his cool abilities.
Hero overcomes all odds, battles huge monsters, forges empires, unites many nations, fulfils several gazillion prophecies, defeats dark lord (who always has some weird, hard-to-pronounce name - not that that matters, because everyone is scared to pronounce it anyway), marries beautiful princess/sorceress love of his life (who is also really brave, fulfilled many prophecies, and helped him do battle), and everyone lives happily ever after.
Fantasy books are also always set in a pre-industrial world, where by some amazing miracle, every nation on the planet has managed to stay in the middle ages for several thousand years, without a single person inventing things such as gunpowder, petrol engines, or electronics (although they have all the things that would naturally lead up to such inventions, such as steel, sulfur, etc). Instead of all these modern inventions, fantasy worlds are filled with magic. In most books, magic is a natural phenomenon that some people are born with, and that most are not. There are various magical creatures (e.g. elves, vampires, dragons), all sorts of magical artefacts, and usually various branches (or specialised areas) within the field of magic.
The common argument for why fantasy books are so popular, is because people say that they're "perfect worlds". Yet this is clearly not so: if they're perfect, then why do they all have dark lords that want to enslave the entire human race; terrifying and revolting evil creatures; warring nations that don't get on with each other; and hunger, disease, poverty, and all the other bad things that afflict us the same way in the real world? Fantasy worlds may have magic, but magic doesn't make the world perfect: as with anything, magic is just a tool, and it can be used (and is used) for good or for evil.
So fantasy worlds aren't perfect. If they were, then the whole good vs evil idea, which is central to every fantasy book, would be impossible to use as the basis for the book's plot.
Now, let's go back to that idea of a pre-industrial world. Every since the industrial revolution of the 1840s, many people upon this Earth have grown worried that we are destroying the planet, that we are making the world artificial, and that all the beautiful natural creations that make up the planet are wasting away. Fantasy worlds, which are all set before the growth of industry, are lacking this ugly taint. Fantasy worlds are always natural.
And that, in my opinion, is why people can't get enough of fantasy books. Everything about fantasy worlds is natural. The environment is natural: most of the world is untouched wilderness, and human settlements (e.g. farms and cities) do not have a noticeable impact upon that environment. It's a bit like those strategy-based computer games, where no matter what you do or build upon the terrain map, you have no effect upon the map itself: it remains the same. The people are natural: they show qualities like bravery, honour, dignity, and trust; qualities that many consider to be disappearing from the human race today. Even magic, which is not part of any natural world that we know, is a natural part of the fantasy landscape: people are born with it, people use it instinctively, and it can be used to accomplish things that are still not possible with modern technology, but in a natural and clean way.
Harry Potter is unique among fantasy books, because unlike most fantasy worlds, which are totally contrived and are alien to our own, the world of Harry Potter is part of our own modern world. This lets us contrast the fantasy environment with our own very clearly: and the result, almost invariably, is that we find the fantasy world much more attractive than our own. It may lack all the modern wonders that we have artificially created - and that we consider to be our greatest achievements - but it seems to easily outdo these things with its own, natural wonders: magic, raw human interaction, and of course, a pristine natural environment.
It's quite ironic, really, that we so often applaud ourselves on being at the height of our intellectual, social, and technological greatness (and we're getting higher every day, or so we're told), but that when it comes down to it, we consider a world without all these great things to be much more appealing. Traversing a continent on horseback seems far more... chivalric... than zooming over it in a 747. The clash of a thousand swords seems much more... glorious... than the bang of a million guns. And the simple act of lighting a candle, and reading great and spectacular works of literature in leather-bound volumes in the dark of night, seems much more... fulfilling... than turning on a light bulb, and booting up your computer, so that you can go online and read people's latest not-at-all-great-or-spectacular blog entries, in one of many sprawling big cities that never sleeps.
Thanks to the path module and its URL aliasing functionality, Drupal is one of the few CMSs that allows your site to have friendly and meaningful URLs for every page. So whereas in other systems, your average URL might look something like this:
In Drupal, your average URL (potentially - if you bother to alias everything) would look more like this:
www.mysite.com/my_favourite_model_aeroplanes
This was actually the pivotal feature that made me choose Drupal, as my favourite platform for web development. After I started using Drupal, I discovered that it hadn't always had such pretty URLs: and even now, the URLs are not so great when its URL rewriting facility is off (e.g. index.php?q=node/81); and still not perfect when URL rewriting is on, but aliases are not defined (e.g. node/81). But at its current stage of development, Drupal allows you to provide reasonably meaningful path aliases for every single page of your site.
In my opinion, the aliasing system is reasonable, but not good enough. In particular, a page's URL should reflect its position in the site's master hierarchy. Just as breadcrumbs tell you where you are, and what pages (or categories) are 'above' you, so too should URLs. In fact, I believe that a site's URLs should match its breadcrumbs exactly. This is actually how most of Drupal's administration pages work already: for example, if you go to the admin/user/configure/permission page of your Drupal site, you will see that the breadcrumbs (in combination with tabs and the page heading) mark your current location as:
home -> administer -> users -> configure -> permissions
Unfortunately, the hierarchies and the individual URLs for the administration pages are hard-coded, and there is currently no way to create similar structures (with matching URLs) for the public pages of your site.
Battle plan
Our aim, for this final part of the series, is to create a patch that allows Drupal to automatically generate hierarchical URL aliases, based (primarily) on our site's taxonomy structure. We should not have to modify the taxonomy system at all in order to do this: path aliases are handled only by path.module, and by a few mechanisms within the core code of Drupal. We can already assign simple aliases both to nodes, and to taxonomy terms, such as:
taxonomy/term/7 : research_papers
So what we want is a system that will find the alias of the current page, and the alises of all its parents, and join them together to form a hierarchical URL, such as:
(if an article with this name - or a similar name - actually exists on the Internet, then please let me know about it as a matter of the utmost urgency ;-))
As with part 2, in order to implement the patch that I cover in this article, it is essential that you've already read (and hopefully implemented) the patches from part 1 (basic breadcrumbs and taxonomy), and preferable (although not essential) that you've also gone through part 2 (cross-vocabulary taxonomy hierarchies). Once again, I am assuming that you've still got your Drupal test site that we set up in part 1, and that you're ready to keep going from where we finished last time.
The general rule, when writing patches for any piece of software, is to try and modify add-on modules instead of core components wherever possible, and to modify the code of the core system only when there is no other alternative. In the first two parts of the series, we were quite easily able to stay on the good side of this rule. The only places where we have modified code so far is in taxonomy.module and taxonomy_context.module. But aliasing, as I said, is handled both by path.module and by the core system; so this time, we may have no choice but to join the dark side, and modify some core code.
Ancient GreenAsh proverb: When advice on battling the dark side you need, then seek it you must, from Master Yoda.
Right now we do need some advice; but unfortunately, since I was unable to contact the great Jedi master himself (although I did find a web site where Yoda will tell you the time), we'll have to make do by consulting the next best thing, drupal.org.
Let's have a look at the handbook entry that explains Drupal's page serving mechanism (page accessed on 2005-02-14 - contents may have changed since then). The following quote from this page might be able to help us:
Drupal handbook: If the value of q [what Drupal calls the URL] is a path alias, Drupal replaces the value of q with the actual path that the value of q is aliased to. This sleight-of-hand happens before any modules see the value of q. Cool.
Module initialization now happens via the module_init() function.
(The part of the article that this quote comes from, is talking about code in the includes/common.inc file).
Oh-oh: that's bad news for us! According to this quote, when a page request is given to Drupal, the core system handles the conversion of aliases to system paths, before any modules are loaded. This means that not only are alias-to-path conversions (and vice versa) handled entirely by the Drupal core; but additionally, the architecture of Drupal makes it impossible for this functionality to be controlled from within a module! Upon inspecting path.module, I was able to verify that yes, indeed, this module only handles the administration of aliases, not the actual use of them. The code that's responsible for this lies within two files - bootstrap.inc and common.inc - that together contain a fair percentage of the fundamental code comprising the Drupal core. So roll your sleeves up, and prepare to get your hands really dirty: this time, we're going to be patching deep down at the core.
Step 1: give everything an alias
Implementing a hierarchical URL aliasing system isn't going to be of much use, unless everything in the hierarchy has an alias. So before we start coding, let's go the the administer -> url aliases page of the test site, and add the following aliases (you can change the actual alias names to suit your own tastes, if you want):
System path
Alias
taxonomy/term/1
posts
taxonomy/term/2
news
taxonomy/term/3
by_priority_news
taxonomy/term/4
important_news
You should already have an alias in place for node/1, but if you don't, add one now. After doing this, the admin page for your aliases should look like this:
List of URL aliases (screenshot)
Step 2: the alias output patch
Drupal's path aliasing system requires two distinct subsystems in order to work properly: the 'outgoing' system, which converts an internal system path into its corresponding alias (if any), before outputting it to the user; and the 'incoming' system, which converts an aliased user-supplied path back into its corresponding internal system path. We are going to begin by patching the 'outgoing' system.
Open up the file includes/bootstrap.inc, and find the following code in it:
<?php
/**
* Given an internal Drupal path, return the alias set by the administrator.
*/
function drupal_get_path_alias($path) {
if (($map = drupal_get_path_map()) && ($newpath = array_search($path, $map))) {
return $newpath;
}
elseif (function_exists('conf_url_rewrite')) {
return conf_url_rewrite($path, 'outgoing');
}
else {
// No alias found. Return the normal path.
return $path;
}
}
?>
Now replace it with this code:
<?php
/**
* Given an internal Drupal path, return the alias set by the administrator.
* Patched to return an extended alias, based on context.
* Patch done by x on xxxx-xx-xx.
*/
function drupal_get_path_alias($path) {
if (($map = drupal_get_path_map()) && ($newpath = array_search($path, $map))) {
return _drupal_get_path_alias_context($newpath, $path, $map);
}
elseif (function_exists('conf_url_rewrite')) {
return conf_url_rewrite($path, 'outgoing');
}
else {
// No alias found. Return the normal path.
return $path;
}
}
/**
* Given an internal Drupal path, and the alias of that path, return an extended alias based on context.
* Written by Jaza on 2004-12-26.
* Implemented by x on xxxx-xx-xx.
*/
function _drupal_get_path_alias_context($newpath, $path, $map) {
//If the alias already has a context defined, do nothing.
if (strstr($newpath, "/")) {
return $newpath;
}
// Break up the original path.
$path_split = explode("/", $path);
$anyslashes = FALSE;
$contextpath = $newpath;
// Work out the new path differently depending on the first part of the old path.
switch (strtolower($path_split[0])) {
case "node":
// We are only interested in pages of the form node/x (not node/add, node/x/edit, etc)
if (isset($path_split[1]) && is_numeric($path_split[1]) && $path_split[1] > 0) {
$nid = $path_split[1];
$result = db_query("SELECT * FROM {node} WHERE nid = %d", $nid);
if ($node = db_fetch_object($result)) {
//Find out what 'Sections' term (and 'Forums' term, for forum topics) this node is classified as.
$result = db_query("SELECT tn.* FROM {term_node} tn INNER JOIN {term_data} t ON tn.tid = t.tid WHERE tn.nid = %d AND t.vid IN (1,2)", $nid);
switch ($node->type) {
case "page":
case "story":
case "weblink":
case "webform":
case "poll":
while ($term = db_fetch_object($result)) {
// Grab the alias of the parent term, and add it to the front of the full alias.
$result = db_query("SELECT * FROM {url_alias} WHERE src = 'taxonomy/term/%d'", $term->tid);
if ($alias = db_fetch_object($result)) {
$contextpath = $alias->dst. "/". $contextpath;
if (strstr($alias->dst, "/"))
$anyslashes = TRUE;
}
// Keep grabbing more parent terms and their aliases, until we reach the top of the hierarchy.
$result = db_query("SELECT parent as 'tid' FROM {term_hierarchy} WHERE tid = %d", $term->tid);
}
break;
case "forum":
// Forum topics must be treated differently to other nodes, since:
// a) They only have one parent, so no loop needed to traverse the hierarchy;
// b) Their parent terms are part of the forum module, and so the path given must be relative to the forum module.
if ($term = db_fetch_object($result)) {
$result = db_query("SELECT * FROM {url_alias} WHERE src = 'forum/%d'", $term->tid);
if ($alias = db_fetch_object($result)) {
$contextpath = "contact/forums/". $alias->dst. "/". $contextpath;
if (strstr($alias->dst, "/"))
$anyslashes = TRUE;
}
}
break;
case "image":
// For image nodes, override the default path (image/) with this custom path.
$contextpath = "images/". $contextpath;
break;
}
}
// If the aliases of any parent terms contained slashes, then an absolute path has been defined, so scrap the whole
// context-sensitve path business.
if (!$anyslashes) {
return $contextpath;
}
else {
return $newpath;
}
}
else {
return $newpath;
}
break;
case "taxonomy":
// We are only interested in pages of the form taxonomy/term/x
if (isset($path_split[1]) && is_string($path_split[1]) && $path_split[1] == "term" && isset($path_split[2]) &&
is_numeric($path_split[2]) && $path_split[2] > 0) {
$tid = $path_split[2];
// Change the boolean variable below if you don't want the cross-vocabulary-aware query.
$distantparent = TRUE;
if ($distantparent) {
$sql_taxonomy = 'SELECT t.* FROM {term_data} t, {term_hierarchy} h LEFT JOIN {term_distantparent} d ON h.tid = d.tid '.
'WHERE h.tid = %d AND (d.parent = t.tid OR h.parent = t.tid)';
}
else {
$sql_taxonomy = 'SELECT t.* FROM {term_data} t, {term_hierarchy} h '.
'WHERE h.tid = %d AND h.parent = t.tid';
}
while (($result = db_query($sql_taxonomy, $tid)) && ($term = db_fetch_object($result))) {
// Grab the alias of the current term, and the aliases of all its parents, and put them all together.
$result = db_query("SELECT * FROM {url_alias} WHERE src = 'taxonomy/term/%d'", $term->tid);
if ($alias = db_fetch_object($result)) {
$contextpath = $alias->dst. "/". $contextpath;
if (strstr($alias->dst, "/")) {
$anyslashes = TRUE;
}
}
$tid = $term->tid;
}
// Don't use the hierarchical alias if any absolute-path aliases were found.
if (!$anyslashes) {
return $contextpath;
}
else {
return $newpath;
}
}
else {
return $newpath;
}
break;
case "forum":
// If the term is a forum topic, then display the path relative to the forum module.
return "contact/forums/". $contextpath;
break;
case "image":
// We only want image pages of the form image/tid/x
// (i.e. image gallery pages - not regular taxonomy term pages).
if (isset($path_split[1]) && is_string($path_split[1]) && $path_split[1] == "tid" && isset($path_split[2]) &&
is_numeric($path_split[2]) && $path_split[2] > 0) {
$tid = $path_split[2];
// Since taxonomy terms for images are not of the form image/tid/x, this query does not need to be cross-vocabulary aware.
$sql_taxonomy = 'SELECT t.* FROM {term_data} t, {term_hierarchy} h '.
'WHERE h.tid = %d AND h.parent = t.tid';
while (($result = db_query($sql_taxonomy, $tid)) && ($term = db_fetch_object($result))) {
// Grab the alias of this term, and the aliases of its parent terms.
$result = db_query("SELECT * FROM {url_alias} WHERE src = 'image/tid/%d'", $term->tid);
if ($alias = db_fetch_object($result)) {
$contextpath = $alias->dst. "/". $contextpath;
if (strstr($alias->dst, "/")) {
$anyslashes = TRUE;
}
}
$tid = $term->tid;
}
// The alias must be relative to the image galleries page.
$contextpath = "images/galleries/". $contextpath;
if (!$anyslashes) {
return $contextpath;
}
else {
return $newpath;
}
}
else {
return $newpath;
}
break;
default:
return $newpath;
}
}
?>
Phew! That sure was a long function. It would probably be better to break it up into smaller functions, but in order to keep all the code changes in one place (rather than messing up bootstrap.inc further), we'll leave it as it is for this tutorial.
As you can see, we've modified drupal_get_path_alias() so that it calls our new function, _drupal_get_path_alias_context(), and relies on that function's output to determine its return value (note the underscore at the start of the new function - this denotes that it is a 'helper' function that is not called externally). The function is too long and complex to analyse in great detail here: the numerous comments that pepper its code will help you to understand how it works.
Notice that the function as I use it is designed to produce hierarchical aliases for a whole lot of different node types (the regular method works for page, story, webform, weblink, and poll; and special methods are used for forum and image). You can add or remove node types from this list, depending on what modules you use on your specific site(s), and also depending on what node types you want this system to apply to. Please observe that book nodes are not covered by this function; this is because:
I don't use book.module - I find that a combination of several other modules (mainly taxonomy and taxonomy_context) achieve similar results to a book hierarchy, but in a better way;
Book hierarchies have nothing to do with taxonomy hierarchies - they are a special type of system where one node is actually the child of another node (rather than being the child of a term) - but my function is designed specifically to parse taxonomy hierarchies;
Books and taxonomy terms are incompatible - you cannot assign a book node under a taxonomy hierarchy - so making a node part of a book hierarchy means that you're sacrificing all the great things about Drupal's taxonomy system.
So if you've been reading this article because you're looking for a way to make your book hierarchies use matching hierarchical URLs, then I'm very sorry, but you've come to the wrong place. It probably wouldn't be that hard to extend this function so that it includes book hierarchies, but I'm not planning to make that extension any time in the near future. This series is about using taxonomy, not about using the book module. And I am trying to encourage you to use taxonomy, as an alternative (in some cases) to the book module, because I personally believe that taxonomy is a much better system.
After you've implemented this new function of mine, reload the front page of your test site. You'll see that hierarchical aliases are now being outputted for all your taxonomy terms, and for your node. Cool! That looks pretty awesome, don't you think? However (after you've calmed down, put away the champagne, and stopped celebrating), if you try following (i.e. clicking) any of these links, you'll see that they don't actually work yet; you just get a 'page not found' error, like this one:
Node page not found (screenshot)
This is because we've implemented the 'outgoing' system for our hierarchical aliases, but not the 'incoming' system. So Drupal now knows how to generate these aliases, but not how to turn them back into system paths when the user follows them.
Step 3: the alias input patch
While the patch for the 'outgoing' system was very long and intricate, in some ways, working out how to patch the 'incoming' system is even more complicated; because although we don't need to write nearly as much code for the 'incoming' system, we need to think very carefully about how we want it to work. Let's go through some thought processes before we actually get to the patch:
The module that handles the management of aliases is path.module. This module has a rule that every alias in the system must be unique. We haven't touched the path module, so this rule is still in place. We're also storing the aliases for each page just as we always did - as individual paths that correspond to their matching Drupal system paths - we're only joining the aliases together when they get outputted.
If we think about this carefully, it means that in our new hierarchical aliasing system, we can always evaluate the alias just by looking at the part of it that comes after the last slash. That is, our patch for the 'incoming' system will only need to look at the end of the alias: it can quite literally ignore the rest.
Keeping the system like this has one big advantage and one big disadvantage. The big advantage is that the alias will still resolve, whether the user types in only the last part of it, or the entire hierarchical alias, or even something in between - so there is a greater chance that the user will get to where they want to go. The big disadvantage is that because every alias must still be unique, we cannot have two context-sensitive paths that end in the same way. For example, we cannot have one path posts/news/computer_games, and another path hobbies/geeky/computer_games - as far as Drupal is concerned, they're the same path - and the path module simply will not allow two aliases called 'computer_games' to be added. This disadvantage can be overcome by using slightly more detailed aliases, such as computer_games_news and computer_games_hobbies (you might have noticed such aliases being used here on GreenAsh), so it's not a terribly big problem.
There is another potential problem with this system - it means that you don't have enough control over the URLs that will resolve within your own site. This is a security issue that could have serious and embarrassing side effects, if you don't do anything about it. For example, say you have a hierarchical URL products/toys/teddy_bear, and a visitor to your site liked this page so much, they wanted to put a link to it on their own web site. They could link to products/toys/teddy_bear, products/teddy_bear, teddy_bear, etc; or, they might link to this_site_stinks/teddy_bear, or elvis_is_still_alive_i_swear/ and_jfk_wasnt_shot_either/ and_man_never_landed_on_the_moon_too/ teddy_bear, or some other really inappropriate URL that shouldn't be resolving as a valid page on your web site. In order to prevent this from happening, we will need to check that every alias in the hierarchy is a valid alias on your site: it doesn't necessarily matter whether the combination of aliases forms a valid hierarchy, just that all of the aliases are real and are actually stored in your Drupal system.
OK, now that we've got all those design quandaries sorted out, let's do the patch. Open up the file includes/common.inc, and find the following code in it:
<?php
/**
* Given a path alias, return the internal path it represents.
*/
function drupal_get_normal_path($path) {
if (($map = drupal_get_path_map()) && isset($map[$path])) {
return $map[$path];
}
elseif (function_exists('conf_url_rewrite')) {
return conf_url_rewrite($path, 'incoming');
}
else {
return $path;
}
}
?>
Now replace it with this code:
<?php
/**
* Given a path alias, return the internal path it represents.
* Patched to search for the last part of the alias by itself, before searching for the whole alias.
* Patch done by x on xxxx-xx-xx.
*/
function drupal_get_normal_path($path) {
$path_split = explode("/", $path);
// $path_end holds ONLY the part of the URL after the last slash.
$path_end = end($path_split);
$path_valid = TRUE;
$map = drupal_get_path_map();
foreach ($path_split as $path_part) {
// If each part of the path is valid, then this is a valid hierarchical URL.
if (($map) && (!isset($map[$path_part]))) {
$path_valid = FALSE;
}
}
if (($map) && (isset($map[$path_end])) && ($path_valid)) {
// If $path_end is a proper alias, then resolve the path solely according to $path_end.
return $map[$path_end];
}
elseif (($map) && (isset($map[$path]))) {
return $map[$path];
}
elseif (function_exists('conf_url_rewrite')) {
return conf_url_rewrite($path, 'incoming');
}
else {
return $path;
}
}
?>
After you implement this part of the patch, all your hierarchical URLs should resolve, much like this:
Test node with working alias (screenshot)
That's all, folks
Congratulations! You have now finished my tutorial on creating automatically generated hierarchical URL aliases, which was the last of my 3-part series on getting the most out of Drupal's taxonomy system. I hope that you've gotten as much out of reading this series, as I got out of writing it. I also hope that I've fulfilled at least some of the aims that I set out to achieve at the beginning, such as lessening the frustration that many people have had with taxonomy, and bringing out some new ideas for the future direction of the taxonomy system.
I also should mention that as far as I'm concerned, the content of this final part of the series (hierarchical URL aliasing) is the best part of the series by far. I only really wrote parts 1 and 2 as a means to an end - the things that I've demonstrated in this final episode are the things that I'm really proud of. As you can see, everything that I've gone through in this series - hierarchical URL aliases in particular - has been successfully implemented on this very site, and is now a critical functional component of the code that powers GreenAsh. And by the way, hierarchical URL aliases work even better when used in conjunction with the new autopath module, which generates an alias for your nodes if you don't enter one manually.
As with part 2, the code in this part is not perfect, has not been executed all that gracefully, and is completely lacking a frontend administration interface. My reasons excuses for this are the same as those given in part 2; and as with cross-vocabulary hierarchies, I hope to improve the code for hierarchical URL aliases in the future, and hopefully to release it as a contributed Drupal module some day. But rather than keep you guys - the Drupal community - waiting what could be a long time, I figure that I've got working code right here and right now, so I might as well share it with you, because I know that plenty of you will find it useful.
The usual patches and replacement modules can be found at the bottom of the page. I hope that you've found this series to be beneficial to you: feel free to voice whatever opinions or criticisms you may have by posting a comment (link at the bottom of the page). And who knows... there may be more Drupal goodies available on GreenAsh sometime in the near future!
In part 1 of this series, we examined a few of the bugs in the breadcrumb generation mechanisms employed by Drual's taxonomy system. We didn't really implement anything new: we just patched up some of the existing functionality so that it worked better. Our 'test platform' for Drupal now boasts beautiful breadcrumbs - both for nodes and for terms - that reflect a master taxonomy hierarchy quite accurately (as they should).
Now, things are going to start getting more serious. We're going to be adding a new custom table to Drupal's database structure, putting some data in it, and changing code all over the place in order to use this new data. The result of this: a cross-vocabulary hierarchy structure, in which a term in one vocab may have a 'distant parent' in another one.
Before you read on, though, please be aware that I'm assuming you've already read and (possibly) implemented what was introduced in part 1, basic breadcrumbs and taxonomy. I will be jumping in right at the deep end in this article. There is no sprawling introduction, no guide to setting up your clean Drupal installation, and no instructions on adding categories and content. Basically, if you're planning on doing the stuff in this article, you should have already done all the stuff in the previous one: and that includes the patches to taxonomy and taxonomy_context, because the patches here are dependant on those I've already demonstrated.
Still here? Glad to have you, soldier hacker. OK, our goal in this tutorial is to allow a term in one vocabulary to have a 'distant parent' in another one. Our changes cannot break the existing system, which relies on the top-level term(s) in any vocabulary having a parent ID of 0 (i.e. having no parent): seeing that we will have to give some top-level terms an actual (i.e. non-zero) parent ID, in order to achieve our goal, things could get a bit tricky if we're not careful. Once we've implemented such a system, we want to see it being reflected in our breadcrumbs: that is, we want breadcrumbs that at times span more than one vocabulary.
But... why?
Why do we need to be able to link together terms in different vocabularies, you ask? We can see why by looking at what we've got now in our current Drupal test system. At the moment, there are two vocabularies: Sections (which has a top-level term posts, and news, which is a child of posts); and News by priority (which also has a top-level term - browse by priority - and a child term important). So this is our current taxonomy hierarchy:
(Sections) Posts -> News
(News by priority) Browse by priority -> Important
But the term browse by priority is really a particular method of browsing news items. It only applies to news items, not to nodes categorised in any of the other terms in Sections. So really, our hierarchy should be like this:
(Sections) Posts -> News -> (News by priority) Browse by priority -> Important
Once we've changed the hierarchy so that it makes more sense, the potential next step becomes obvious. We can make more vocabularies, and link them to the term news, and classify news items according to many different structures! For example:
Posts -> News -> Browse by priority -> Important
Posts -> News -> Browse by category -> Computer hardware
Posts -> News -> Browse by mood -> Angry
Posts -> News -> Browse by length -> Long and rambling
And so, by doing this, we really have achieved the best of both worlds: we can utilise the power of taxonomy exactly as it was designed to be utilised - for categorising nodes under many different vocabularies, according to many different criteria; plus, at the same time we can still maintain a single master hierarchy for the entire site! Cool, huh?
Now, while you may be nodding your head right now, and thinking: "yeah, that is pretty cool"; I know that you might also be shaking your head, and still wondering: "why?" And after explaining my motivations, I can understand why many of you would fail to see the relevance or the usefulness of such a system in any site of your own. This is something that not every site needs - it's only for sites where you have lots of nodes, and you need (or want) to classify them in many different ways - and it's also simply not for everyone: many of you, I'm sure, would prefer sticking to the current system, which is more flexible than mine, albeit with some sacrifice to your site's structure. So don't be alarmed if you really don't want to implement this, but you do want to implement the hierarchical URL system in part 3: it is quite possible to skip this, and go straight on to the final part of the series, and still have a fully functional code base.
Step 1: modify the database
OK, let's get started! In order to get through this first part of the tutorial, it is essential that you have a backend database tool at your disposal. If you don't have it already, I highly recommend that you grab a copy of phpMyAdmin, which uses a PHP-based web interface, and is the world's most popular MySQL administration tool (for a good reason, too). Some other alternatives include Drupal's dba.module (which I hear is alright); and for those of you that are feeling particularly geeky, there is always the MySQL command line tool itself (part of all MySQL installations). If you're using PostgreSQL, then I'm afraid my only experience with this environment is one where I used a command line tool, so I don't know what to recommend to you. Also, nothing in this tutorial has been tested in PostgreSQL: you have been warned.
Using your admin tool, open up the database for your Drupal test site, and have a look at the tables (there's quite a lot of them). For this tutorial, we're only interested in those beginning with term_, as they're the ones that store information about our taxonomy terms. The first table you should get to know is term_data, as this is where the actual terms are stored. If you browse the contents of this table, you should see something like this:
Contents of term_data table (screenshot)
The table that we're really interested in, however, is term_hierarchy: this is where Drupal stores the parent(s) of each taxonomy term for your site. If you browse the contents of term_hierarchy, what you see should look a fair bit like this:
Contents of term_hierarchy table (screenshot)
Looking at this can be a bit confusing, because all you can see are the term IDs, and no actual names. If you want to map the IDs to their corresponding terms, you might want to keep term_data open in another window as a reference.
As you can see, each term has another term as its parent, except the top-level terms, which have a tid of zero (0). Now, if you wanted to make some of those top-level terms the children of other terms (in different vocabs), the first solution you'd think of would undoubtedly be to simply change those tids from zero to something else. You can try this if you want; or you can save yourself the hassle, and trust me when I tell you: it doesn't work. If you do this, then when you go into the administer -> categories page on your site, the term whose parent ID you changed - and all its children - will have disappeared off the face of the output. And what's more, doing this won't make Drupal generate the cross-vocabulary breadcrumbs that we're aiming for. So we need to think of a plan B.
What we need is a way to let Drupal know about our cross-vocabulary hierarchies, without changing anything in the term_hierarchy table. And the way that we're going to do this is by having another table, with exactly the same structure as term_hierarchy, but with a record of all the terms on our site that have distant parents (instead of those that have local parents). We're going to create a new table in our database, called term_distantparent. To do this, open up the query interface in your admin tool, and enter the following SQL code:
CREATE TABLE term_distantparent (
tid int(10) unsigned NOT NULL default 0,
parent int(10) unsigned NOT NULL default 0,
PRIMARY KEY (tid),
KEY IdxDistantParent (parent)
) TYPE=MyISAM;
As the code tells us, this table is to have a tid column and a parent column (just like term_hierarchy); its primary key (value that must be unique for each row) is to be tid; and the parent column is to be indexed for fast access. The table is to be of type MyISAM, which is the default type for MySQL, and which is used by all tables in a standard Drupal database. The screenshot below shows how phpMyAdmin describes our new table, after it's been created:
Newly created term_distantparent table (screenshot)
The next step, now that we have this shiny new table, is to insert some data into it. In order to work out what values need to be inserted, you should refer to your term_data table. Find the tid of the term news (2 for me), and of the term browse by priority (3 for me). Then use this SQL script to insert a cross-vocabulary relationship into your new table (substituting the correct values for your database, if need be):
You will now be able to browse the contents of your term_distantparent table, and what you see should look like this:
Term_distantparent with data (screenshot)
Step 2: modify the SQL
Our Drupal database now has all the information it needs to map together a cross-vocabulary hierarchy. All we have to do now is tell Drupal where this data is, and what should be done with it. We will do this by modifying the SQL that the taxonomy module currently uses for determining the current term and its parents.
Open up taxonomy.module, and find the following piece of code:
<?php
/**
* Find all parents of a given term ID.
*/
function taxonomy_get_parents($tid, $key = 'tid') {
if ($tid) {
$result = db_query('SELECT t.* FROM {term_hierarchy} h, {term_data} t WHERE h.parent = t.tid AND h.tid = %d ORDER BY weight, name', $tid);
$parents = array();
while ($parent = db_fetch_object($result)) {
$parents[$parent->$key] = $parent;
}
return $parents;
}
else {
return array();
}
}
?>
Now replace it with this code:
<?php
/**
* Find all parents of a given term ID.
* Patched to allow cross-vocabulary relationships.
* Patch done by x on xxxx-xx-xx.
*/
function taxonomy_get_parents($tid, $key = 'tid', $distantparent = FALSE) {
if ($tid) {
if ($distantparent) {
// Cross-vocabulary-aware SQL query
$sql_distantparent = 'SELECT t.* FROM {term_data} t, {term_hierarchy} h LEFT JOIN {term_distantparent} d ON h.tid = d.tid '.
'WHERE h.tid = %d AND (d.parent = t.tid OR h.parent = t.tid)';
$result = db_query($sql_distantparent, $tid);
} else {
//Original drupal query
$result = db_query('SELECT t.* FROM {term_hierarchy} h, {term_data} t WHERE h.parent = t.tid AND h.tid = %d ORDER BY weight, name', $tid);
}
$parents = array();
while ($parent = db_fetch_object($result)) {
$parents[$parent->$key] = $parent;
}
return $parents;
}
else {
return array();
}
}
?>
The original SQL query was designed basically to look in term_hierarchy for the parents of a given term, and to return any results found. The new query, on the other hand, looks in both term_distantparent and in term_hierarchy for parents of a given term: if results are found in the former table, then they are returned; otherwise, results from the latter are returned. This means that distant parents are now looked for as a matter of priority over local parents (so for all those terms with a local parent ID of zero, the local parent is discarded); and it also means that the existing (local parent) functionality of the taxonomy system functions exactly as it did before, so nothing has been broken.
Notice that an optional boolean argument has been added to the function, with a default value of false ($distantparent = FALSE). When the function is called without this new argument, it uses the original SQL query; only when called with the new argument (and with it set to TRUE) will the distant parent query become activated. This is to prevent any problems for other bits of code (current or future) that might be calling the function, and expecting it to work in its originally intended way.
Step 3: modify the dependent functions
We've now implemented everything that logically needs to be implemented, in order for Drupal to function with cross-vocabulary hierarchies. All that must be done now is some slight modifications to the dependent functions: that is, the functions that make use of the code containing the SQL we've just modified. This should be easy for anyone who's familiar with ("Hi Everybody!" "Hi...") Dr. Nick from The Simpsons, as he gives us the following advice when trying to isolate a problem: "The knee bone's connected to the: something. The something's connected to the: red thing. The red thing's connected to my: wristwatch. Uh-oh." So let's see if we can apply Dr. Nick's method to the problem at hand - only let's hope we have more success with it than he did. And by the way, feel free to sing along as we go.
The taxonomy_get_parents() function is called by the: taxonomy_get_parents_all() function.
So find the following code in taxonomy.module:
<?php
/**
* Find all ancestors of a given term ID.
*/
function taxonomy_get_parents_all($tid) {
$parents = array();
if ($tid) {
$parents[] = taxonomy_get_term($tid);
$n = 0;
while ($parent = taxonomy_get_parents($parents[$n]->tid)) {
$parents = array_merge($parents, $parent);
$n++;
}
}
return $parents;
}
?>
And replace it with this code:
<?php
/**
* Find all ancestors of a given term ID.
* Patched to call helper functions using the optional "distantparent" argument, so that cross-vocabulary-aware queries are activated.
* Patch done by x on xxxx-xx-xx.
*/
function taxonomy_get_parents_all($tid, $distantparent = FALSE) {
$parents = array();
if ($tid) {
$parents[] = taxonomy_get_term($tid);
$n = 0;
while ($parent = taxonomy_get_parents($parents[$n]->tid, 'tid', $distantparent)) {
$parents = array_merge($parents, $parent);
$n++;
}
}
return $parents;
}
?>
What's next, Dr. Nick?
The taxonomy_get_parents_all() function is called by the: taxonomy_context_get_breadcrumb() function.
Ooh... hang on, Dr. Nick. Before we go off and replace the code in this function, we should be aware that we already modified its code in part 1, in order to implement our breadcrumb patch. So we have to make sure that when we add our new code, we also keep the existing changes. This is why both the original and the new code below still have the breadcrumb patch in them.
OK, now find the following code in taxonomy_context.module:
<?php
/**
* Return the breadcrumb of taxonomy terms ending with $tid
* Patched to display the current term only for nodes, not for terms
* Patch done by x on xxxx-xx-xx
*/
function taxonomy_context_get_breadcrumb($tid, $mode) {
$breadcrumb[] = l(t("Home"), "");
if (module_exist("vocabulary_list")) {
$vid = taxonomy_context_get_term_vocab($tid);
$vocab = taxonomy_get_vocabulary($vid);
$breadcrumb[] = l($vocab->name, "taxonomy/page/vocab/$vid");
}
if ($tid) {
$parents = taxonomy_get_parents_all($tid);
if ($parents) {
$parents = array_reverse($parents);
foreach ($parents as $p) {
// The line below implements the breadcrumb patch
if ($mode != "taxonomy" || $p->tid != $tid)
$breadcrumb[] = l($p->name, "taxonomy/term/$p->tid");
}
}
}
return $breadcrumb;
}
?>
And replace it with this code:
<?php
/**
* Return the breadcrumb of taxonomy terms ending with $tid
* Patched to display the current term only for nodes, not for terms
* Patch done by x on xxxx-xx-xx
* Patched to call taxonomy_get_parents_all() with the optional $distantparent argument set to TRUE, to implement cross-vocabulary hierarches.
* Patch done by x on xxxx-xx-xx
*/
function taxonomy_context_get_breadcrumb($tid, $mode) {
$breadcrumb[] = l(t("Home"), "");
if (module_exist("vocabulary_list")) {
$vid = taxonomy_context_get_term_vocab($tid);
$vocab = taxonomy_get_vocabulary($vid);
$breadcrumb[] = l($vocab->name, "taxonomy/page/vocab/$vid");
}
if ($tid) {
// New $distantparent argument added with value TRUE
$parents = taxonomy_get_parents_all($tid, TRUE);
if ($parents) {
$parents = array_reverse($parents);
foreach ($parents as $p) {
// The line below implements the breadcrumb patch
if ($mode != "taxonomy" || $p->tid != $tid)
$breadcrumb[] = l($p->name, "taxonomy/term/$p->tid");
}
}
}
return $breadcrumb;
}
?>
Any more, Dr. Nick?
The taxonomy_context_get_breadcrumb() function is called by the: taxonomy_context_init() function.
That's alright: we're not passing the $distantparent argument up the line any further, and we already fixed up the call from this function in part 1.
After that, Dr. Nick?
The taxonomy_context_init() function is called by the: Drupal _init hook.
Hooray! We've reached the end of our great long function-calling chain; Drupal handles the rest of the function calls from here on. Thanks for your help, Dr. Nick! We should now be able to test out our cross-vocabulary hierarchy, by loading a term that has a distant parent somewhere in its ancestry, and having a look at the breadcrumbs. Try opening the page for the term important (you can find a link to it from your node) - it should look something like this:
Term with cross-vocabulary breadcrumbs (screenshot)
And what a beautiful sight that is! Breadcrumbs that span more than one vocabulary: simply perfect.
Room for improvement
What I've presented in this tutorial is a series of code patches, and a database modification. I've used minimal tools and made minimal changes, and what I set out to achieve now works. However, I am more than happy to admit that the whole thing could have been executed much better, and that there is plenty of room for improvement, particularly in terms of usability (and reusability).
My main aim - by implementing a cross-vocabulary hierarchy - was to get the exact menu structure and breadcrumb navigation that I wanted. Because this was all I really cared about, I have left out plenty of things that other people might consider an essential (but missing) part of my patch. For example, I have not implemented distant children, only distant parents. This means that if you're planning to use taxonomy_context for automatically generating a list of subterms (which I don't do), then distant children won't be generated unless you add further functionality to my patch.
There is also the obvious lack of any frontend admin interface whatsoever for managing distant parents. Using my patch as it is, distant parents must be managed by manually adding rows to the database table, using a backend admin tool such as phpMyAdmin. It would be great if my patch had this functionality, but since I haven't needed it myself as yet, and I haven't had the time to develop it either, it's simply not there.
The $distantparent variable should ideally be able to be toggled through a frontend interface, so that the entire cross-vocabulary functionality could be turned on or off by the site's administrator, without changing the actual code. The reasons for this being absent are the same as the reasons (given above) for the lack of a distant parent editing interface. Really, in order for this system to be executed properly, either the taxonomy interface needs to be extended quite a bit, or an entire distantparent module needs to be written, to implement all the necessary frontend administration features.
At the moment, I'm still relatively new to Drupal, and have no experience in using Drupal's core APIs to write a proper frontend interface (let alone a proper Drupal module). Hopefully, I'll be able to get into this side of Drupal sometime in the near future, and learn how to actually develop proper stuff for Drupal, in which case I'll surely be putting the many and varied finishing touches on cross-vocabulary hierarchies - finishing touches that this tutorial is lacking.
As with part 1, patches and replacement code can be found at the bottom of the page (patches are to be run against a clean install, not against code from part 1). Stay tuned for part 3 - the grand finale to this series - in which we put together everything we've done so far, and much more, in order to produce an automatic hierarchical URL aliasing system, such that the URLs on every page of your site match your breadcrumbs and your taxonomy structure. Until then, happy coding!
]]>
Basic breadcrumbs and taxonomy2005-02-09T00:00:00Z2005-02-09T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/02/basic-breadcrumbs-and-taxonomy/
Part 1 of"making taxonomy work my way".
Update (6th Apr 2005):parts of this tutorial no longer need to be followed. Please see this comment before implementing anything shown here.
As any visitor to this site will soon realise, I love Drupal, the free and open source Content Management System (CMS) without which GreenAsh would be utterly defunct. However, even I must admit that Drupal is far from perfect. Many aspects of it - in particular, some of its modules - leave much to be desired. The taxonomy module is one such little culprit.
If you browse through someoftheforumtopics at drupal.org, you'll see that Drupal's taxonomy system is an extremely common cause of frustration and confusion, for beginners and veterans alike. Many people don't really know what the word 'taxonomy' means, or don't see why Drupal uses this word (instead of just calling it 'categories'). Some have difficulty grasping the concept of a many-to-many relationship, which taxonomy embraces with its open and flexible classification options. And quite a few people find it frustrating that taxonomy has so much potential, but that very little of it has actually been implemented. And then there are the bugs.
In this series, I show you how to patch up some of taxonomy's bugs; how to combine it with other Drupal modules to make it more effective; and also how to extend it (by writing custom code) so that it does things that it could never do before, but that it should have been able to do right from the start. In sharing all these new ideas and techniques, I hope to make life easier for those of you that use and depend on taxonomy; to give hope to those of you that have given up altogether on taxonomy; to open up new possibilities for the future of the official taxonomy module (and for the core Drupal platform); and to kindle discussion and criticism on the material that I present.
The primary audience of this series is fellow web developers that are a part of the Drupal community. In order to appreciate the ideas presented here, and to implement the examples given, it is recommended that you have at the very least used and administered a Drupal site before. Knowledge of PHP programming and of MySQL / PostgreSQL (or even other SQL) queries would be good. You do not need to be a hardcore Drupal developer to understand this series - I personally do not consider myself to be one (yet :-)) - but it would be good if you've tinkered with Drupal's code and have at least some familiarity with it, as I do. If you're not part of this audience, then by all means read on, but don't be surprised if very soon (if not already!) you have no idea what I'm talking about.
I thought part 1 was about breadcrumbs...??
And it is - you're quite right! So, now that I've got all that introductory stuff out of the way, let's get down to the guts of this post, which is - as the title suggests - basic breadcrumbs and taxonomy (for those of you that don't see any bread, be it white, multi-grain, or wholemeal, check out this definition of a breadcrumb).
Because let's face it, that's what breadcrumbs are: basic. It's one of those fundamental things that you'd expect would work 100% right out of the box: you make a new site, you post content to it, you assign the content a category, and you take it for granted that a breadcrumb will appear, showing you where that post belongs in your site's category tree. At least, I thought it was basic when I started out on this side of town. Jakob Nielson (the web's foremost expert on usability) thinks so too, as this article on deep linking shows. But apparently, Drupal thinks differently.
It's the whole many-to-many relationship business that makes things complicated in Drupal. With a CMS that supports only one-to-many relationships (that is, each piece of content has only one parent category - but the parent category can have many children), making breadcrumbs is simple: you just trace a line from a piece of content, to its parent, to it's parent's parent, and so on. But with Drupal's taxonomy, one piece of content might have 20 parents, and each of them might have another 10 each. Try tracing a line through that jungle! The fact that although you can use many-to-many relationships, you don't have to, doesn't make a difference: taxonomy was designed to support complex relationships, and if it is to do that properly, it has to sacrifice breadcrumbs. And that's the way it works in Drupal: the taxonomy system seldom displays breadcrumbs for terms, and never displays them for nodes.
Well, I have some slightly different ideas to Drupal's taxonomy developers, when it comes to breadcrumbs. Firstly, I believe that an entire site should fall under a single 'master' category hierarchy, and that breadcrumbs should be displayed on every single page of the site without fail, reflecting a page's position in this hierarchy. I also believe that this master hierarchy system can co-exist with the power and flexibility that is inherent to Drupal's taxonomy system, but that additional categories should be considered 'secondary' to the master one.
Look at the top of this page. Check out those neat breadcrumbs. That's what this entire site looks like (check for yourself if you don't believe me). By the end of this first part of the series, you will be able to make your site's breadcrumbs as good as that. You'll also have put in place the foundations for yet more cool stuff, that can be done by extending the power of taxonomy.
Get your environment ready
In order to develop and document the techniques shown here, I have used a test environment, i.e. a clean copy of Drupal, installed on my local machine (which is Apache / PHP / MySQL enabled). If you want to try this stuff out for yourself, then I suggest you do the same. Here's my advice for setting up an environment in which you can fiddle around:
Grab a clean copy of Drupal (i.e. one that you've just downloaded fresh from drupal.org, and that you haven't yet hacked to death). I'm not stopping you from using a hacked version, but don't look at me when none of my tricks work on your installation. I've used Drupal 4.5.2 to do everything that you'll see here (latest stable release as at time of writing), so although I encourage you to use the newest version - if a newer stable release is out as at the time of you reading this (it's always good to keep up with the official releases) - naturally I make no guarantee that these tricks will work on anything other than vanilla 4.5.2.
Install your copy of Drupal. I'm assuming that you know how to do this, so I'll be brief: unzip the files; set up your database (I use MySQL, and make no guarantee that my stuff will work with PostgreSQL); tinker with conf.php; and I think that's about it.
Configure your newly-installed Drupal site: create the initial account; configure the basic settings (e.g. site name, mission / footer, time zone, cache off, clean URLs on); and enable a few core modules (in particular path module, forum and menu would be good too, you can choose some others if you want). The taxonomy module should be enabled by default, but just check that it is.
Download and install taxonomy_context.module (24 Sep 2004 4.5.x version used in my environment). I consider this module to be essential for anyone who wants to do anything half-decent using taxonomy: most of its features - such as basic breadcrumbing capabilities and term descriptions - are things that really should be part of the core taxonomy module. You will need taxonomy_context for virtually everything that I will be showing you in this series. Note: make sure you move the file taxonomy_context.module from your /modules/taxonomy_context folder, to your /modules folder, otherwise certain things will not work.
Once you've done all that, you have set yourself up with a base system that you can use to implement all my tricks! Your Drupal site should now look something like this:
Very basic drupal site (screenshot)
Add some taxonomy terms and some content
I have written some simple instructions (below) for adding the dummy taxonomy that I used in my test environment. Your taxonomy does not have to be exactly the same as mine, although the structure that I use should be followed, as it is important in achieving the right breadcrumb effect:
In the navigation menu for your new site, go to administer -> categories, then click the add vocabulary tab.
Add a new vocabulary called 'Sections'. Make it required for all node types except forum topics, and give it a single or multiple hierarchy. Also give it a light weight (e.g. -8).
Add a term called 'posts' to your new 'Sections' vocab.
Add another term called 'news', as a child of 'posts'.
Add another vocab called 'News by priority'. Make it apply only to stories, give it a single or multiple hierarchy, don't make it required, and give it a heavier weight than the 'Sections' vocab. Note: it was a deliberate choice to give this vocab a name that suggests it is a child of the term 'news' in the 'Sections' vocab. This was done in preparation for part 2 of this series, setting up a cross-vocabulary hierarchy. If you have no interest in part 2, then you can call this vocab whatever you want (but you still need a second vocab).
Add a term 'browse by priority' to the 'news by priority' vocab. Note: the use of a name that is almost identical to the vocab's name is deliberate - the reason for this is explained in part 2 of the series.
Add another term 'important' as a child of 'browse by priority'.
Well done - you've just set up a reasonably complex taxonomy structure. Your 'categories' page should now look something like this:
Test site with categories (screenshot)
Now that you have some categories in place, it's time to create a node and assign it some terms. So in the navigation menu, go to create content -> story; enter a title and an alias for your node; make it part of the 'news' section, and the 'important' priority; enter some body text; and then submit it. Your node should look similar to this:
Node with categories assigned (screenshot)
First bug: nodes have no breadcrumbs
OK, so now that you've created a node, and you've assigned some categories to it, let's examine the state of those breadcrumbs. If you go to a taxonomy page, such as the page for the term 'news', you'll see that breadcrumbs are being displayed very nicely, and that they reflect our 'sections' hierarchy (e.g. home -> posts -> news). But if you go to a node page (of which there is only one, at the moment - unless you've created more), a huge problem is glaring (or failing to glare, in this case) right at you: there are no breadcrumbs!
But don't panic - the solution is right here. First, you must bring up the Drupal directory on your filesystem, and open the file /modules/taxonomy_context.module. Find the following code in taxonomy_context (Note: the taxonomy_context module is updated regularly, so this code and other code in the tutorials may not exactly match the code that you have):
<?php
/**
* Implementation of hook_init
* Set breadcrumb, and show some infos about terms, subterms
*/
function taxonomy_context_init() {
$mode = arg(0);
$paged = !empty($_GET["from"]);
if (variable_get("taxonomy_context_use_style", 1)) {
drupal_set_html_head('<style type="text/css" media="all">@import "modules/taxonomy_context/taxonomy_context.css";
</style>');
}
if (($mode == "node") && (arg(1)>0)) {
$node = node_load(array("nid" => arg(1)));
$node_type = $node->type;
}
// Commented out in response to issue http://drupal.org/node/11407
// if (($mode == "taxonomy") || ($node_type == "story") || ($node_type == "page")) {
// drupal_set_breadcrumb( taxonomy_context_get_breadcrumb($context->tid));
// }
}
?>
And replace it with this code:
<?php
/**
* Implementation of hook_init
* Set breadcrumb, and show some infos about terms, subterms
* Patched to make breadcrumbs on nodes work, by using taxonomy_context_get_context() call
* Patch done by x on xxxx-xx-xx
*/
function taxonomy_context_init() {
$mode = arg(0);
$paged = !empty($_GET["from"]);
// Another little patch to make the CSS link only get inserted once
static $taxonomy_context_css_inserted = FALSE;
if (variable_get("taxonomy_context_use_style", 1) && !$taxonomy_context_css_inserted) {
drupal_set_html_head('<style type="text/css" media="all">@import "modules/taxonomy_context/taxonomy_context.css";
</style>');
$taxonomy_context_css_inserted = TRUE;
}
if (($mode == "node") && (arg(1)>0)) {
$node = node_load(array("nid" => arg(1)));
$node_type = $node->type;
}
// Commented out in response to issue [http://]drupal.org/node/11407
// Un-commented for breadcrumb patch
// NOTE: you don't have to have all the node types below - only story and page are essential
$context = taxonomy_context_get_context();
$context_types = array(
"story",
"page",
"image",
"weblink",
"webform",
"poll"
);
if ( ($mode == "taxonomy") || (is_numeric(array_search($node_type, $context_types))) ) {
drupal_set_breadcrumb( taxonomy_context_get_breadcrumb($context->tid, $mode));
}
}
?>
Note: when copying any of the code examples here, you should replace the lines that say "Patch done by x on xxxx-xx-xx" with your name, and the date that you copied the code. This makes it easier to keep track of any deviations that you make from the official Drupal code base, and means that upgrading to a new version of Drupal is only 'very difficult', instead of 'impossible' ;-).
This patch makes breadcrumbs appear for any node type that is included in the $content_types array (which you should edit to suit your needs), based on the site's taxonomy hierarchy. After implementing this patch, you should see something like this when you view a node:
Basic node with breadcrumbs (screenshot)
Second bug: node breadcrumbs based on the wrong vocab
We've made a good start: previously, nodes had no breadcrumbs at all, and now they do have breadcrumbs (and they're based on taxonomy). But they don't reflect the right vocab! Remember what I said earlier about a single 'master' taxonomy hierarchy for your site, and about other taxonomies being 'secondary'? In our site, the master vocab is 'Sections'. However, the breadcrumbs for our node are reflecting 'News by priority', which is a secondary vocab. We need to find a way of telling Drupal on which vocab to base its breadcrumbs for nodes.
Once again, bring up the Drupal directory on your filesystem, and this time open the file /modules/taxonomy.module. Find the following code in taxonomy:
<?php
/**
* Find all terms associated to the given node.
*/
function taxonomy_node_get_terms($nid, $key = 'tid') {
static $terms;
if (!isset($terms[$nid])) {
$result = db_query('SELECT t.* FROM {term_data} t, {term_node} r WHERE r.tid = t.tid AND r.nid = %d ORDER BY weight, name', $nid);
$terms[$nid] = array();
while ($term = db_fetch_object($result)) {
$terms[$nid][$term->$key] = $term;
}
}
return $terms[$nid];
}
?>
And replace it with this code:
<?php
/**
* Find all terms associated to the given node.
* SQL patch made by x on xxxx-xx-xx, to sort taxonomies by vocab weight rather than by term weight
*/
function taxonomy_node_get_terms($nid, $key = 'tid') {
static $terms;
if (!isset($terms[$nid])) {
$result = db_query('SELECT t.* FROM {term_data} t, {term_node} r, {vocabulary} v '.
'WHERE r.tid = t.tid AND t.vid = v.vid AND r.nid = %d ORDER BY v.weight, v.name', $nid);
$terms[$nid] = array();
while ($term = db_fetch_object($result)) {
$terms[$nid][$term->$key] = $term;
}
}
return $terms[$nid];
}
?>
Drupal doesn't realise this, but it already knows which vocab is the master vocab. We specified it to be 'Sections' when we gave it a lighter weight than 'News by priority'. In my system, the rule is that the vocab with the lightest weight (or the lowest name alphabetically) becomes the master one. So all we had to do in this patch, was to tell Drupal how to find the master vocab, based on this rule.
This was done by changing the SQL, so that when Drupal looks for all terms associated to a particular node, it sorts those terms by putting the ones with a vocab of the lightest weight first. Previously, it sorted terms according to the weight of the actual term. The original version makes sense for nodes that have several terms in one vocabulary, and also for terms that have more than one parent; but it doesn't make sense for nodes that have terms in more than one vocabulary, and this is a key feature of Drupal that many sites utilise.
After you implement this patch (assuming that you followed the earlier instruction about making the 'sections' vocab of a lighter weight than the 'news by priority' vocab), you can rest assured that the breadcrumb trail will always be for the 'sections' vocab, with any node that is so classified. Your node should now look something like this:
Node with correct breadcrumbs (screenshot)
Note that this patch also changes the order in which a node's terms are printed out (sorted by vocab weight also).
Third bug: taxonomy breadcrumbs include the current term
While the previous bug only affected the breadcrumbs on node pages, this one only affects breadcrumbs on taxonomy term pages. Try viewing a node: you will see that the breadcrumb trail includes the parent terms of that page, but that the current page itself is not included. This is how it should be: you don't want the current page at the end of the breadcrumb, because you can determine the current page by looking at the title! And also, each part of the breadcrumb trail is a link, so if the current page is part of the trail, then every page on your site has a link to itself (very unprofessional).
If you view a taxonomy term, you will see that the term you are looking at is part of the breadcrumb trail for that page. To fix this final bug (for part 1 of this series), bring up your Drupal directory again, open /modules/taxonomy_context.module, and find the following code in taxonomy_context:
<?php
/**
* Return the breadcrumb of taxonomy terms ending with $tid
*/
function taxonomy_context_get_breadcrumb($tid) {
$breadcrumb[] = l(t("Home"), "");
if (module_exist("vocabulary_list")) {
$vid = taxonomy_context_get_term_vocab($tid);
$vocab = taxonomy_get_vocabulary($vid);
$breadcrumb[] = l($vocab->name, "taxonomy/page/vocab/$vid");
}
if ($tid) {
$parents = taxonomy_get_parents_all($tid);
if ($parents) {
$parents = array_reverse($parents);
foreach ($parents as $p) {
$breadcrumb[] = l($p->name, "taxonomy/term/$p->tid");
}
}
}
return $breadcrumb;
}
?>
Now replace it with this code:
<?php
/**
* Return the breadcrumb of taxonomy terms ending with $tid
* Patched to display the current term only for nodes, not for terms
* Patch done by x on xxxx-xx-xx
*/
function taxonomy_context_get_breadcrumb($tid, $mode) {
$breadcrumb[] = l(t("Home"), "");
if (module_exist("vocabulary_list")) {
$vid = taxonomy_context_get_term_vocab($tid);
$vocab = taxonomy_get_vocabulary($vid);
$breadcrumb[] = l($vocab->name, "taxonomy/page/vocab/$vid");
}
if ($tid) {
$parents = taxonomy_get_parents_all($tid);
if ($parents) {
$parents = array_reverse($parents);
foreach ($parents as $p) {
// The line below implements the breadcrumb patch
if ($mode != "taxonomy" || $p->tid != $tid)
$breadcrumb[] = l($p->name, "taxonomy/term/$p->tid");
}
}
}
return $breadcrumb;
}
?>
The logic in the if statement that we've added does two things to fix up this bug: if we're not looking at a taxonomy term (and are therefore looking at a node), then always display the current term in the breadcrumb (thus leaving the already perfect breadcrumb system for nodes untouched); and if we're looking at a taxonomy term, and the breadcrumb we're about to print is a link to the current term, then don't print it. Note that this patch will only work if you've moved your taxonomy_context.module file, as explained earlier (it's really weird, I know, but if you leave the file in its subfolder, then this patch has no effect whatsoever - and I have no idea why).
After implementing this last patch, your taxonomy pages should now look something like this:
Taxonomy page with correct breadcrumb (screenshot)
That's all (for now)
Congratulations! If you've implemented everything in this tutorial, then you've now created a Drupal-powered web site that produces super-cool breadcrumbs based on a taxonomy hierarchy. Next time you're at a party, and are making endeavours with someone of the opposite gender, try that line on them (and let me know just how badly it went down). If you haven't implemented anything, then I can't help but call you a tad bit lazy: but hey, at least you read it all!
If you've been wondering where you can get a proper patch file with which to try this stuff out, you'll find two of them at the bottom of the page. See the Drupal handbook entry on using patch files if you've never used Drupal patches before. The patch code is identical to the code cited in this text: as with the cited code, the diff was performed against a vanilla 4.5.2 source tree. Also at the bottom of the page, you can download the entire code for taxonomy.module and taxonomy_context.module: you can put these files straight in your Drupal /modules folder, and all you have to do then is rename them.
Armed with the knowledge that you now have, you can hopefully utilise the power of taxonomy quite a bit better than you could before. But this is only the beginning.
Continue on to part 2, where we get our hands (and our Drupal code base) really dirty by implementing a cross-vocabulary hierarchy system, allowing one taxonomy term to be a child of another term in a different vocabulary, and hence producing (among other things) even sweeter breadcrumbs!
]]>
Vive la HTML2005-01-30T00:00:00Z2005-01-30T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/01/vive-la-html/
HTML - otherwise known as HyperText Markup Language - is the simplest, the most powerful, the most accessible, and the most convertible electronic document format on the planet. Invented in 1991 by Tim Berners-Lee, who is considered to be the father of the World Wide Web, HTML is the language used to write virtually every web page in existence today.
HTML, however, is not what you see when you open a web page in your browser (and I hope that you're using one of the manygoodbrowsers out there, rather than the one bad browser). When you open a web page, the HTML is transformed into a (hopefully) beautiful layout of fonts, images, colours, and all the other elements that make up a visually pleasing document. However, try viewing the source code of a web page (this one, for example). You can usually do this by going to the 'view' pull-down menu in your browser, and selecting 'source' or 'page source'.
What you'll see is a not-so-beautiful plain text document. You may notice that many funny words in this document are enclosed in little things called chevrons (greater-than signs and less-than signs), like so:
<p><strong>Greetings</strong>, dear reader!</p>
The words in chevrons are called tags. In HTML, to make anything look remotely fancy, you need to use tags. In the example above, the word "greetings" is surrounded by a 'strong' tag, to make it appear bold. The whole sentence is enclosed in a 'p' tag, to indicate that those words form a single paragraph. The result of this HTML, when transformed using a web browser, is:
Greetings, dear reader!
So now you all know what HTML is (in a nutshell - a very small nutshell). It is a type of document that you create in plain text format. This is different to other formats, such as Microsoft Word (where you need a special program, i.e. Word, to produce a document, because the document is not stored as plain text). You can use any text editor - even one as simple as Windows Notepad - to write an HTML document. HTML uses special elements, called tags, to describe the structure and (in part) the styling of a document. When you open an HTML document using a web browser, the plain text is transformed into what is commonly known as a 'web page'.
Now, what would be your reaction if I said that everyone, from this point onwards, should write (almost) all of their documents in raw HTML? What would you say if I told you to ditch Word, where you can make text bold or italics or underlined by pushing a button, and instead to writedocumentslike this? Would you think I'm nuts? Probably. Obsessive plain-text geeky purist weirdo? I don't deny it. If you've lost hope already, feel free to leave. Or if you think perhaps - just perhaps - there could be a light at the end of this tunnel, then keep reading.
<matrixramble>
Morpheus: You take the blue pill, the story ends, you wake up in your bed and believe whatever you want to believe. [Or] you take the red pill, you stay in Wonderland, and I show you how deep the rabbit hole goes.
Remember, all I'm offering is the truth, nothing more.
The Matrix (1999)
You may also leave now if you've never heard that quote before, or if you've never quoted it yourself. Or if you don't believe that this world has, indeed, "been pulled over your eyes to blind you from the truth... ([and] that you are a slave)".
</matrixramble>
Just kidding. Please kindly ignore the Matrix ramble above.
Anyway, back to the topic. At the beginning of this article, I briefly mentioned a few of the key strengths of HTML. I will now go back to these in greater detail, as a means of convincing you that HTML is the most appropriate format in which to write (almost) all electronic documents.
It's simple
As far as text-based, no-nonsense computer languages go, HTML is really simple. If you want to write plain text, just write it. If you want to do something fancier (e.g. make the plain text look nice, embed an image, structure the text as a table), then you use tags. All tags have a start (e.g. ), and a finish (e.g. ) - although some tags have their start and their finish together (e.g. ). There are over 100 tags, but you don't need to memorise them - you can just look them up, or use special editors to insert them for you. Most tags are self-explanatory.
HTML is not only simple to write, it is also simple to read. You'd be surprised how easy it is to read and to edit an HTML document in its raw text form, if you just know the incredibly simple format of a tag (which I've already told you). And unlike with non-text-based formats, such as Word and PDF, anyone can edit the HTML that you write, and vice versa. Have you ever been unable to open a Word document, because you're running the wrong version of Microsoft Office? How about not being able to open a PDF document, because your copy of Adobe Acrobat is out of date? Problems such as these simply do not happen with HTML: it's plain text, you can open it with the oldest and most basic programs in existence!
As far as simplicity goes, there are no hidden catches. HTML is not a programming language (something that can only be used by short guys with big glasses in dark smelly rooms). It is a markup language. It requires no maths (luckily for me), no logic or problem-solving skills, and very little general technical knowledge. All you need to know is a few tags, and where to write them amidst the plain text of your document, and you're set to go!
It's powerful
The Golden Rule of Geekdom is to never, ever, underestimate the power of plain text. Anyone who considers themself to 'be in computers', or 'in IT', will tell you that:
Text-based things are almsot always more powerful than their graphical equivalents, in the world of computers (e.g. Unix vs Windows/Mac);
All graphical tools - whether they be for document writing, or for anything else - are generating code beneath their shiny exterior, and this code is usually stored as text (characters); and
Generated code is seldom to be trusted - (wholly or partly) hand-written code is (if the hand-writer knows what he/she is doing) cleaner, more efficient, and more reliable.
HTML is no exception to these rules. It is as powerful as other document formats in most ways (although not in all ways, even I admit). It is far cleaner and more efficient than most other formats with similar capabilities (e.g. Rich Text Format - try reading that in plain text!). And best of all, it leaves no room for fear or paranoia that the underlying code of your document is wretched, because you can read that code yourself!
If you're worried that HTML is not powerful enough to meet your needs, go visit a web page. Any web page will do: you're looking at one now, but as any astronomer can tell you, there are plenty of stars in the sky to choose from. Look at the text formatting, the page layout, the use of images, the input forms, and everything else that makes up a modern piece of the Internet. Not bad, huh?
Now look at the source code for that web page. That's right: the whole thing was written with HTML.
Note that many sites embed other technologies, such as Flash, JavaScript, and Java applets within their HTML - but the backbone of the page is almost always HTML. Also note that almost all modern web sites use HTML in conjunction with CSS - that's Cascading Style Sheets, a topic beyond the scope of this article - to produce meticulously crafted designs by controlling how each tag renders itself. When HTML, CSS, and JavaScript are combined together, they form a technology known as DHTML (Dynamic HTML), the power of which is far beyond anything possible in formats such as Word and PDF.
It's accessible
The transition from paper-based to online documents is one of the biggest, and potentially most beneficial changes, in what has been dubbed the 'information revolution'. Multiple copies of documents can now be made electronically, saving millions of sheets of paper every year. Backup is as easy as pushing a button, to copy a document from one electronic storage device to another. Information can now be put online, and read by millions of people around the world in literally a matter of seconds. But unless we make this transition the right way, we will reap only a fraction of the benefits that we could.
Electronic documents are potentially the most accessible pieces of information the world has ever seen. When designed and written properly, not only can they be distributed globally in a matter of seconds, they can also be viewed by anyone, using any device, in any form, and in any language. Unfortunately, just because a document is in electronic form, that alone does not guarantee this Utopian level of accessibility. In fact, as with anything, perfection can never be a given. But by providing a solid foundation with which to write accessible documents, this goal becomes much more plausible. And the best foundation for accessible electronic documents, is an accessible electronic document format. Enter HTML.
HTML was designed from the ground up as an accessible language. By its very definition - as the language used to construct the World Wide Web - it is essential that the exact same HTML document is able to be viewed easily by different people from all around the world, using different hardware and software, and sometimes with radically different presentation requirements.
The list below describes some of the key issues concerning accessibility, as well as how HTML caters for these issues, compared with its two main rivals, Word and PDF.
Screen size
Even amongst regular PC users - the group that forms the largest majority in the online world - everyone has a different screen size. An accessible document format needs to be able to display equally well on an 11" little squeak as on a 23" big boy. This issue has become even more crucial in recent years, with the advent of Internet-enabled pocket devices such as PDA's and mobile (cell) phones. HTML handles this fine, as it is able to display a document with variable margins, user-defined font sizes, and so on. Word handles this reasonably well, largely due to its different 'views' such as a 'layout view' and 'online view', many of which are suited to variable screen sizes. PDF fails miserably in this regard, because it is designed specifically to display a document as it appears in printed form, and is totally incapable of handling variable margins.
Cross-platform compatibility
Electronic documents should be usable on any operating system, as well as on any hardware. HTML can be viewed on absolutely any desktop system (e.g. Windows, Mac, Linux, Solaris, FreeBSD, OS/2), and also on PDAs, mobile phones, WebTVs, Internet fridges... you name it, HTML works on it. PDF - as it's name suggests, with the 'P' for 'Portable' - is also pretty good in this regard, since it's able to run on all major systems, although it isn't so easy to view on smaller devices, as is HTML. Word is compatible only with Windows and Mac PCs - which is so lame it's not even worth commenting on, really.
Language barriers
This is one of the more frustrating aspects of accessibility, as it is one where technology has not yet caught up to the demands of the globalised world. Automated translation is far from perfect at the moment, however it is there, and it does work (but could work better). HTML documents are translated on-the-fly every day, through services such as Altavista's BabelFish, and Google's Language tools. This is made easier through HTML's ability to store the language of a document in a special metadata format. PDF and Word documents are not as readily translatable, although plug-ins are available to give them translating capabilities.
Users with poor eyesight
Many computer users require all documents to be displayed to them with large font sizes, due to their poor vision. HTML achieves this through a mechanism known as relative font sizes. This means that instead of specifying the exact size of text, authors of HTML documents are instead able to use 'fuzzy' terms, such as 'medium' and 'large' (as well as other units of size, e.g. em's). Users can then set the base size themselves: if their vision is impaired, they can increase the base size, and all text on the page will be enlarged accordingly. Word and PDF do not offer this, although they make up for it somewhat with their zoom functionality. However, this can often be cumbersome to use, and often results in horizontal scrolling.
Blind users
This is where HTML really shines above all other document formats. HTML is the only format that, when used properly, can actually be narrated to blind users through a screen reader, with little or no loss in meaning compared with users that are absorbing the document visually. Because HTML has so much structure and semantic information, screen readers are able to determine what parts of the document to emphasise, they can process complex tabular information in auditory form, and they can interpret metadata such as page descriptions and keywords. And if the page uses proper navigation by way of hyperlinks, blind users can even skip straight to the content they want, by performing the equivalent of a regular user's 'click' action. Word and PDF lag far behind in this regard: screen readers can do little more than read out their text in a flat monotone.
It's convertible
Just like a Porsche Boxster... only not quite so sexy. This final advantage of HTML is one that I've found particularly useful, and is - in my opinion - the fundamental reason why all documents should be written in HTML first.
HTML documents can be converted to Word, PDF, RTF, and many other formats, really easily. You can open an HTML document directly in Word, and then just 'Save As...' it in whatever format takes your fancy. The reverse, however, is not nearly so simple. If you were to type up a document in Word, and then use Word's 'Save as HTML' function to convert it to a web page, you would be greeted with an ugly sight indeed. Well, perhaps not such an ugly sight if viewed in a modern web browser; but if you look at the source code that Word generates, you might want to have a brown paper bag (or a toilet) very close by. Word generates revolting HTML code. Remember what I said about never trusting generated code?
Have a look at the following example. The two sets of HTML code below will both display the text "Hello, world!" when viewed in a web browser. Here is the version generated by Word:
This is really important. The ability to convert a document from one format to another, cleanly and efficiently, is something that everyone needs to be able to do, in this modern day and age. This is relevant to everyone, not just to web designers and computer professionals. Sooner or later, your boss is going to ask you to put your research paper online, so he/she can tell his/her friends where to go if they want to read it. And chances are, that document won't have been written originally in HTML. So what are you going to do? Will you convert it using Word, and put up with the nauseating filth that it outputs? Will you just convert it to PDF, and whack that poorly accessible file on the net? Why not just save yourself the hassle, and write it in HTML first. That way, you can convert it to any other format at the click of a button (cleanly and efficiently), and when the time comes to put it online - and let me tell you, it will come - you'll be set to go.
A great (free) text editor for those using Micro$oft Windows. Fully supports HTML (as well as many other markup and programming languages), with highlighting of tags, automatic indenting, and expandable/collapsible hierarchies. Even if you never plan to write a line of HTML in your life, this is a great program to have lying around anyway.
Another great (and free) plain-text HTML editor for Windows, although this one is much more complex and powerful than Notepad++. HTML-kit aims to be more than just a text editor (although it does a great job of that too): it is a full-featured development environment for building a respectable web site. It has heaps of cool features, such as markup validation, automatic code tidying, and seamless file system navigation. Oh yeah, and speaking of validation...
The World Wide Web Consortium - or W3C - are the folks that actually define what HTML is, as in the official standard. Remember I mentioned Tim Berners-Lee, bloke that invented HTML? Yeah, well he's the head of the W3C. Anyway, they provide an invaluable tool here that checks your HTML code, and validates it to make sure that it's... well, valid! A must for web developers, and for anyone that's serious about learning and using HTML.
This site is devoted to teaching you HTML, and lots of it. The tutorials are pretty good, but I find the A-Z tag reference the most useful thing about this site. It's run by Richard Rutter, one of the world's top guns in web design and all that stuff.
]]>
Why junk collecting is good2005-01-21T00:00:00Z2005-01-21T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/01/why-junk-collecting-is-good/
Everyone collects something that's a little weird. Sport fanatics collect footy jerseys and signed cricket bats. Internet junkies collect MP3s and ripped DVDs. Nature lovers collect pets and plants. People with too much money collect Ferraris and yachts and tropical islands. People who can't think of anything else to collect go for stamps.
Personally, I collect tickets. I absolutely love collecting every ticket that I (or my friends or family or acquaintances) can get my hands on. It started off as just train tickets, but over the years my collection has grown to include movie tickets, bus tickets, plane tickets, ski tickets, theme park tickets, concert tickets, and many more.
When I see my friends after not having seen them for a while, I am greeted not with a handshake or a hug, but with a formidable pile of tickets that they've saved up for me. When my wallet gets too full with them, I empty them out and add them to the ever-burgeoning box in my room. I even received several thousand train tickets for my birthday last year. Basically, I am a ticket whore. No matter how many of the ruddy things I get, my thirst for more can never be quenched.
The obvious question that has confronted me many times: why? Why oh why, of all things, do I collect tickets? I mean, it's not like I do anything with them - they just sit in my room in a big box, and collect dust! What's the point? Do I plan to ever use these tickets to contribute to the global good of humanity? Am I hoping that in 5000 year's time, they'll be vintage collector's items, and my great-x104-grandchildren will be able to sell them and become millionaires? Am I waiting until I have enough that if I chucked them in a big bucket of water and swirled them around, I'd have enough recycled paper to last me for the rest of my life? WHY?
The answer to this is the same as the answer to why most people collect weird junk: why not? No, at the moment I don't have any momentous plans for my beloved tickets. I just continue to mindlessly collect them, as I have done for so long already. But does there have to be a reason, a point, a great guiding light for everything we do in life? If you ask me, it's enough to just say: "I've done it for this long, a bit more couldn't hurt". Of course, this philosophy applies strictly to innocent things such as ticket-collecting: please do not take this to imply in any way that I condone serial killing / acts of terrorism / etc etc, under the same umbrella. But for many other weird junk-collecting hobbies (e.g. sand grain collecting, rusty ex-electronic-component collecting, leaf collecting - and no, I don't collect any of these! ... yet :-)), the same why not principle can and should be applied.
So yes, ticket collecting is pointless, and despite that - no, because of that - I will continue to engage in it for as long as I so fancy. No need to spurt out any philosophical mumbo-jumbo about how I'm making a comment on nihilism or chaos theory or the senselessness of life or any of that, because I'm not. I just like collecting tickets! Plans for the future? I will definitely count them one day... should be a riveting project. I may take up the suggestion I was given once, about stapling them all together to make the world's longest continuous string of tickets. Yeah, Guinness Book of Records would be good. But then again, I might do nothing with them. After all, there's just so many of them!
]]>
Always read the book first2005-01-16T00:00:00Z2005-01-16T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/01/always-read-the-book-first/
I've been saying it for years now, but I'll say it again: seeing the movie before reading the book is always a bad idea. For one thing, nine times out of ten, the movie is nowhere near as good as the book. And in the rare cases where it is better, it still leaves out huge chunks of the book, while totally spoiling other parts! Also, the book is invariably always written (long) before the movie is made (at least, it is for every book-movie combo that I can think of - maybe there are some exceptions). So if the author wrote the book before the producer made the movie, it makes sense that you should read the book before seeing the movie (I know, feeble logic alert - but hey, who asked you anyway?).
The reason for my sudden urge to express this opinion, is a particular series of books that I'm reading now. I've (stupidly) been putting off reading Harry Potter for many years now, but have finally gotten round to reading it at the moment. Unfortunately, I saw two of the movies - 'Harry Potter and the Philosopher's Stone', and 'Harry Potter and the Prisoner of Azkaban' - before starting the books. Although I was reluctant to see them, I was able to put off reading the books by myself, but not able to get out of seeing the movies with my friends.
Luckily, when I started reading 'Harry Potter and the Philosopher's Stone' (that's 'sorcerer' for all you Americans out there), I couldn't remember much of the movie, so the book wasn't too spoiled. However, having a predefined visual image of the characters was a definite drawback (unable to let the imagination flow), as was knowledge of some of the Potter-lingo (e.g. 'muggles'), and of the nature of magic. 'Harry Potter and the Chamber of Secrets' (which I still haven't seen the movie for) was a much better read, as I knew nothing of the storyline, and had no predefined image of all the new characters.
I'm up to the third one now ('Prisoner of Azkaban'), and having seen the movie not that long ago, I can remember most of it pretty clearly. To be quite honest, having the movie in my head is ruining the book. I'm not digging any of the suspense, because I already know what's going to happen! There are no grand visual concoctions growing in my head, because I've already got some shoved in there! It's a downright pain, and I wish I'd never seen the movie. I'm definitely not seeing any more 'Harry Potter' movies until I've finished the books.
This is in contrast to my experience with 'Lord of the Rings'. I honestly believe this to be the best book of all time, but perhaps if I'd seen the movie(s) first, rather than reading all the books twice before seeing any of the movies, my opinion might differ. The movies of LOTR are absolute masterpieces, no doubt about that. But seeing them after having read the books makes them infinitely more worthwhile. When you see the landscapes on the big screen, you also see the kings and queens and battles and cities of long-gone history, that aren't part of the movie, and that non-readers have no idea about. When you hear the songs (usually only in part), you know the full verses, and you know the meaning behind them. And when things are done wrongly in the movie, they stick out to you like a sore thumb, while to the rest of the audience they are accepted as the original gospel truth. Tragic, nothing less.
So my advice, to myself and to all of you, is to always read the book first, because it's always better than the movie, and while watching the movie (first) spoils the book, doing the reverse has the opposite effect!
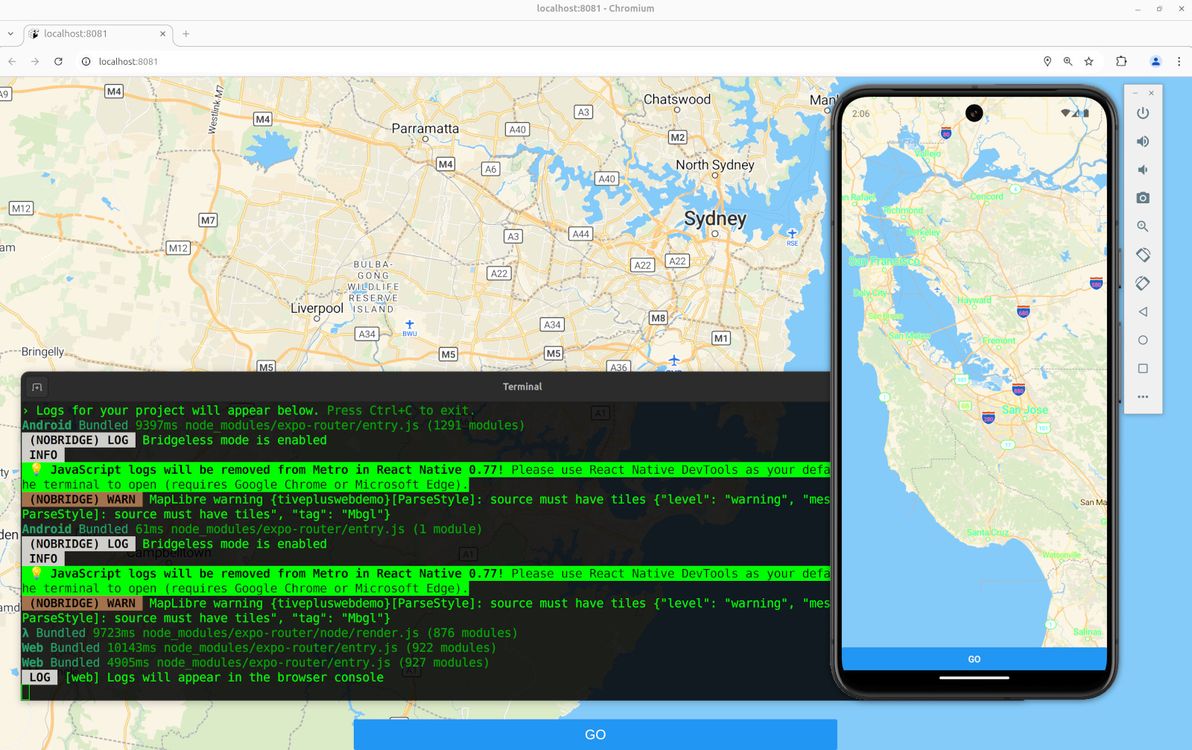



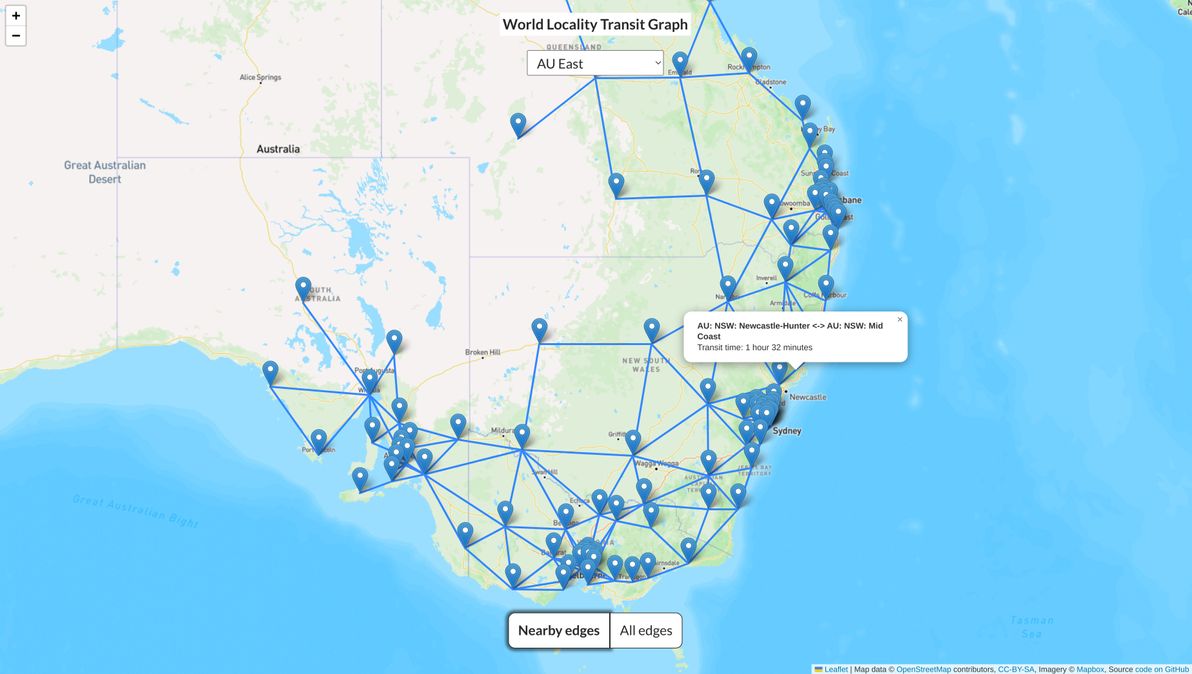



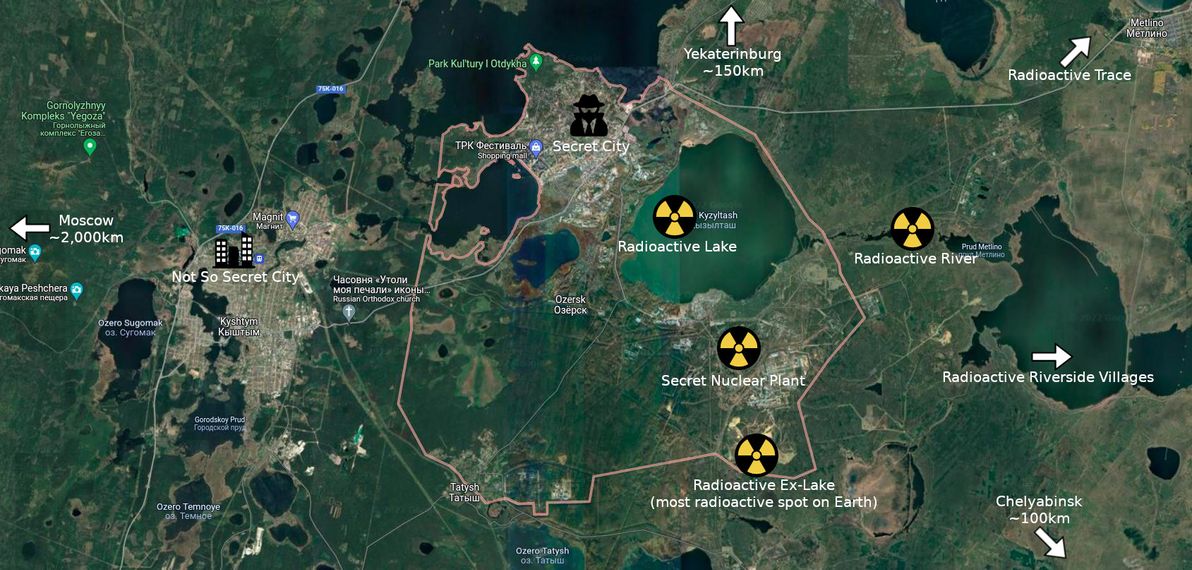




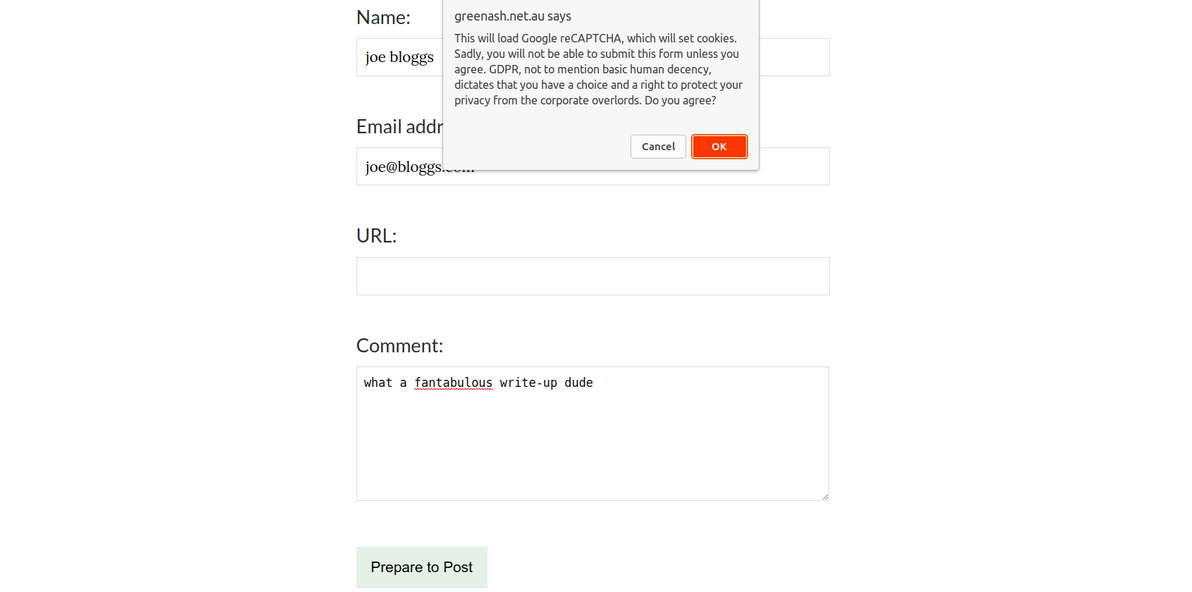
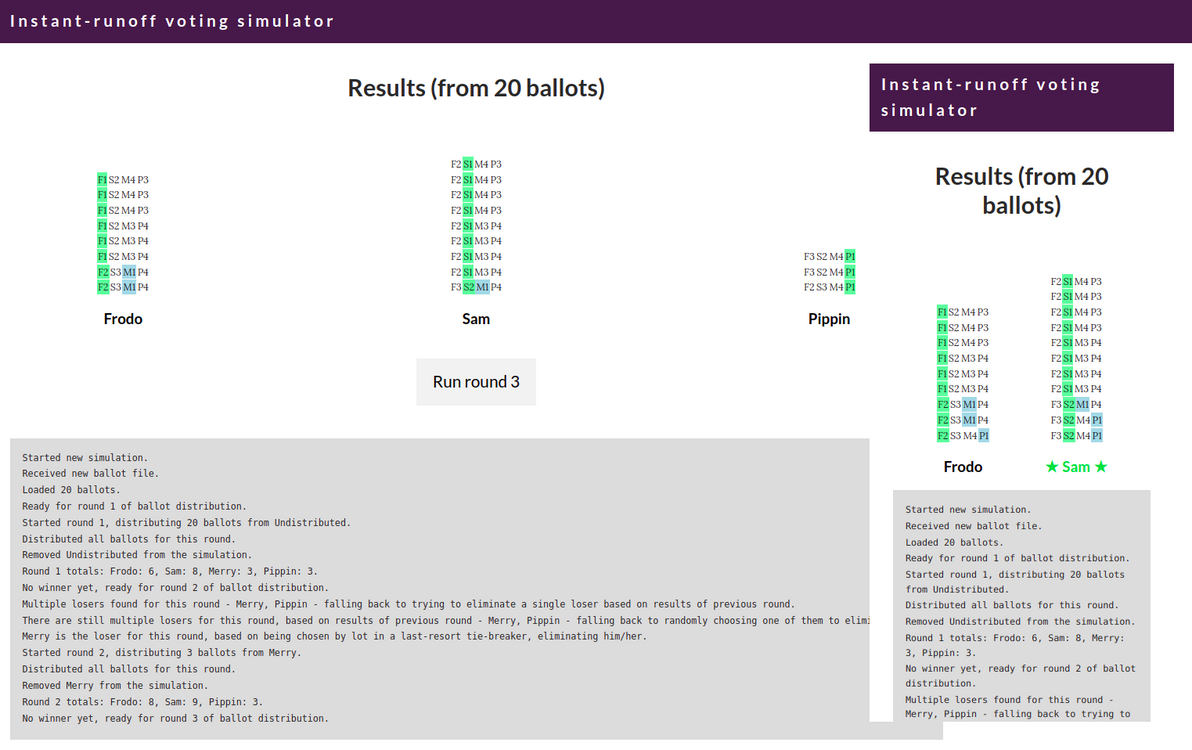
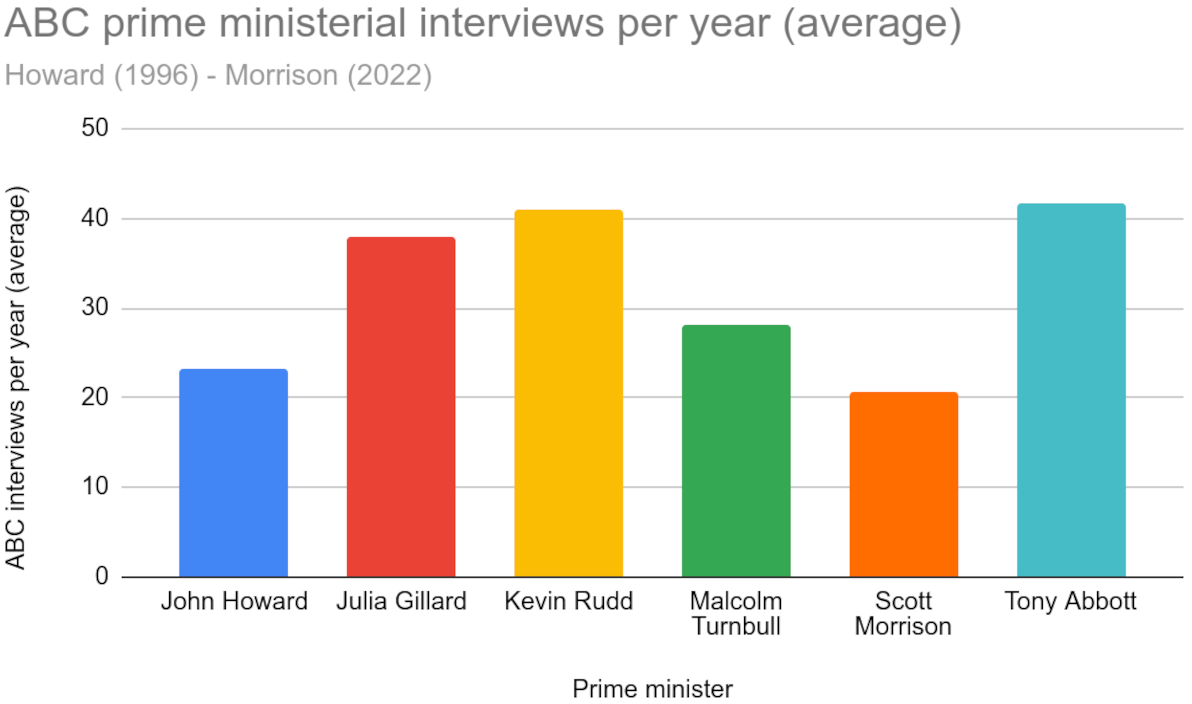















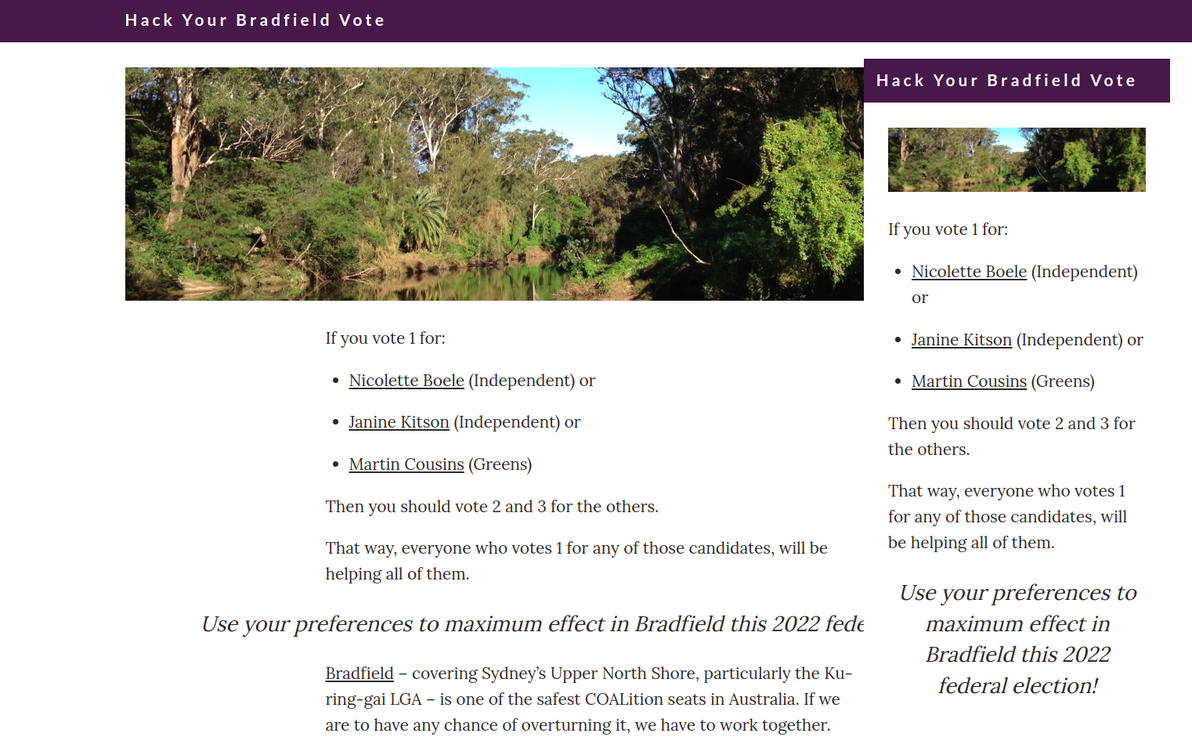






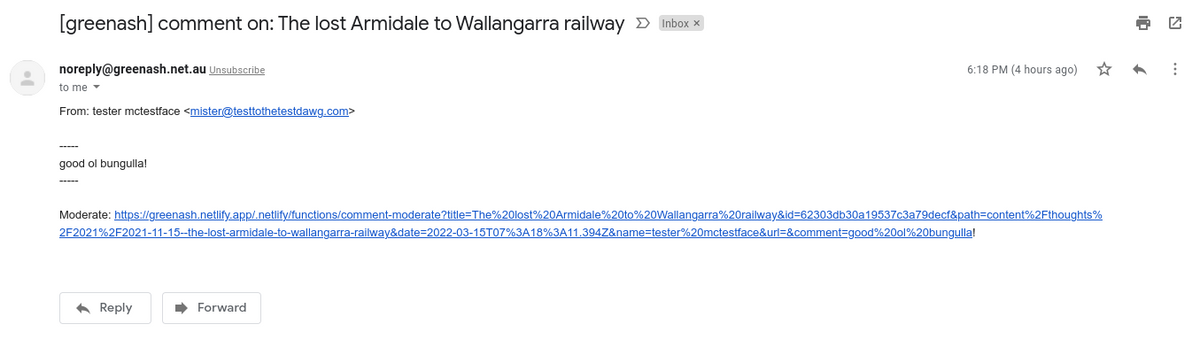

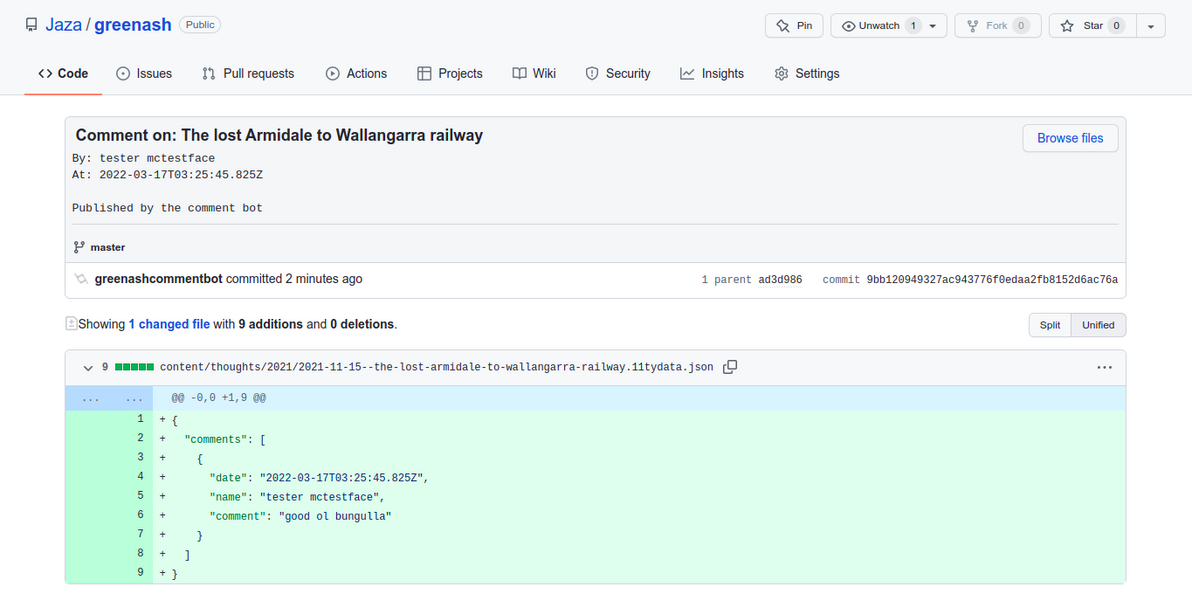
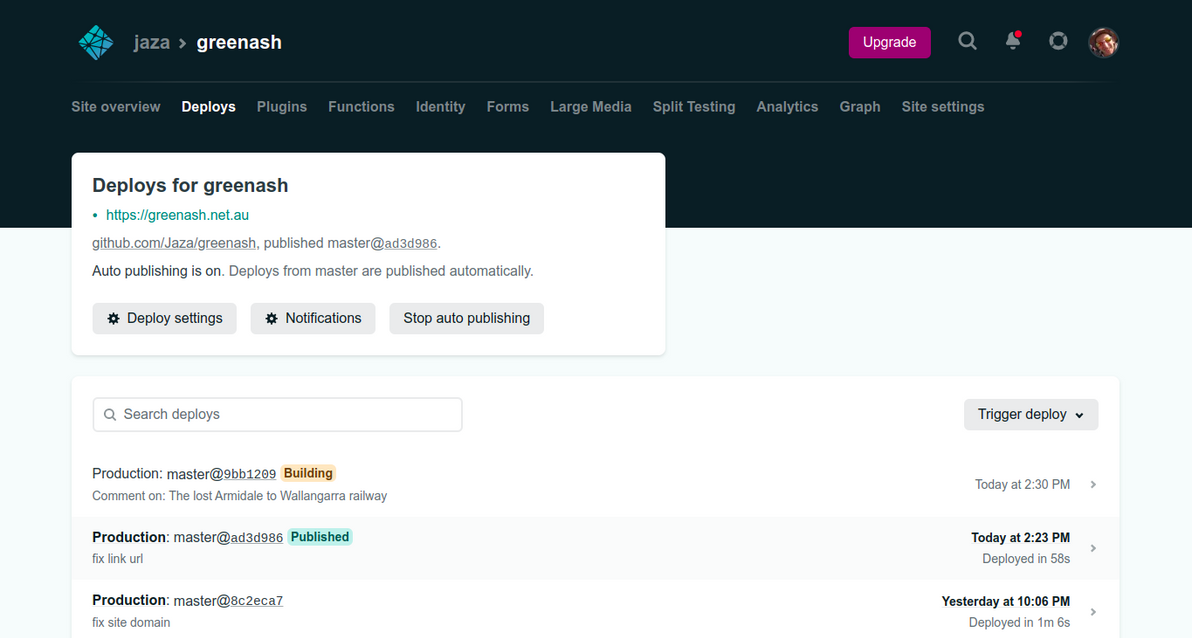


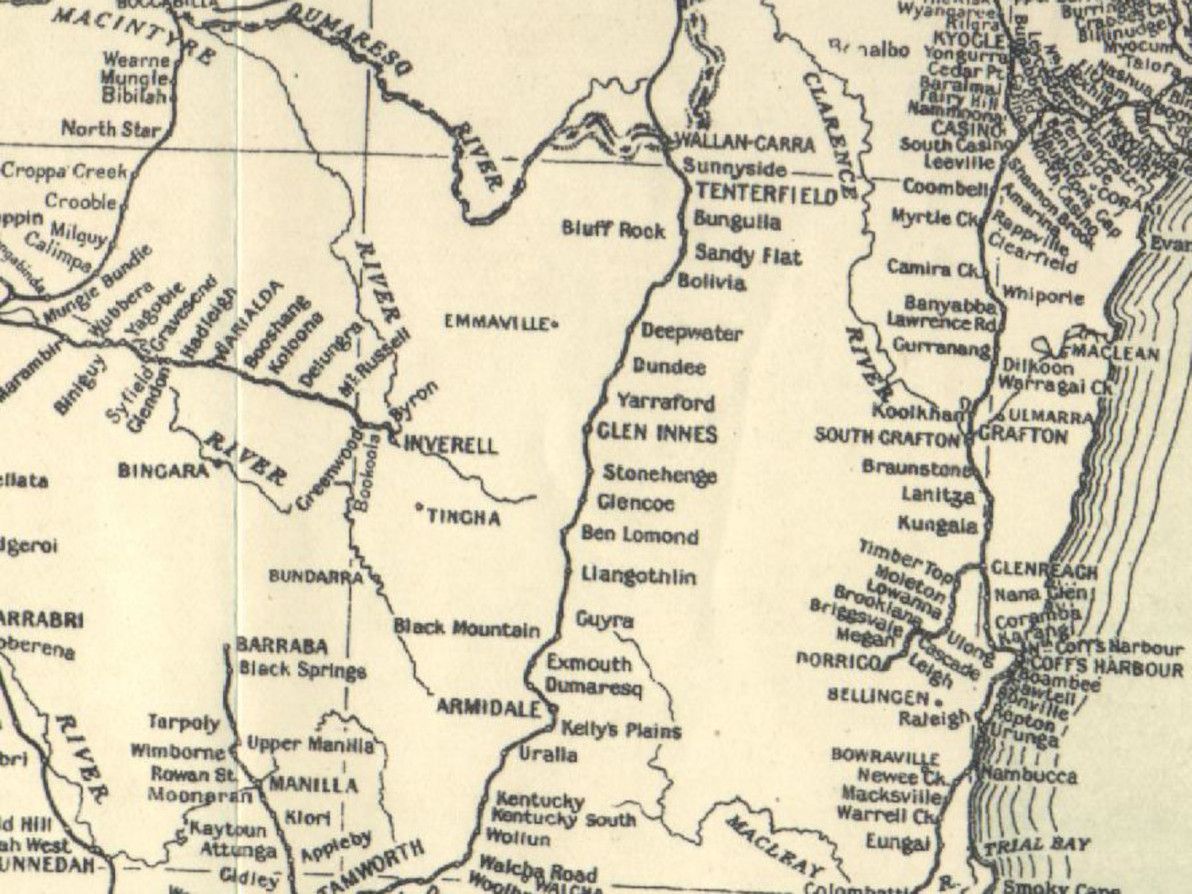













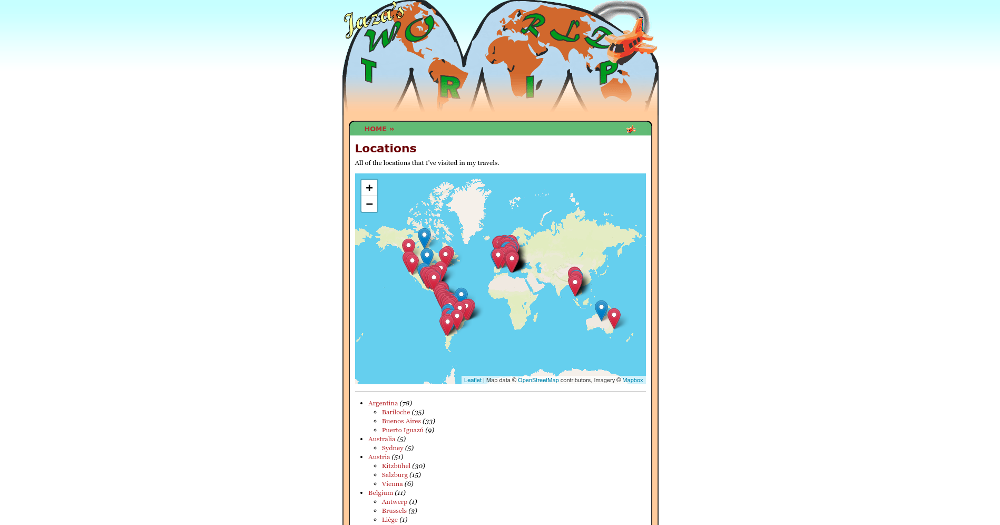







































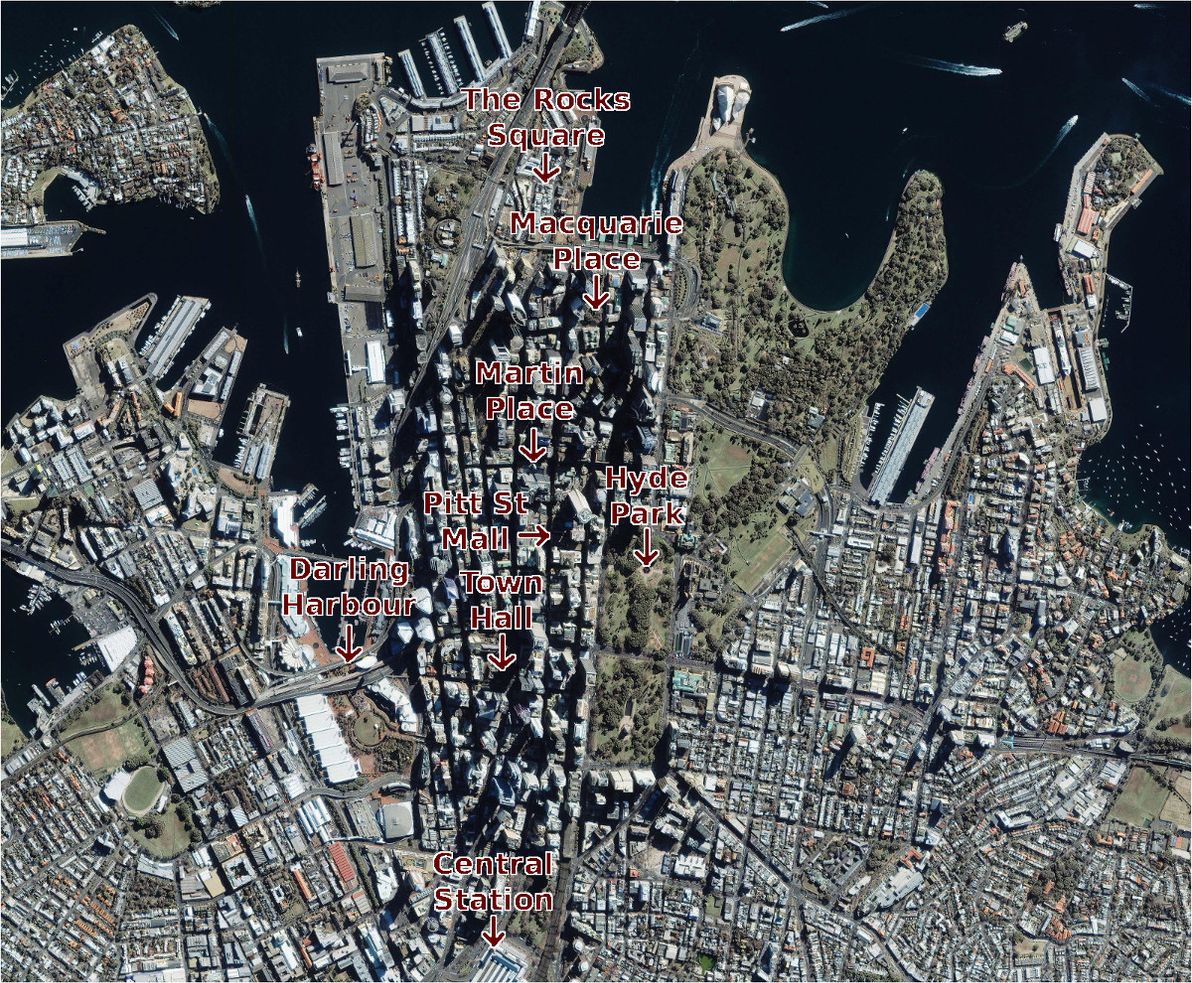


















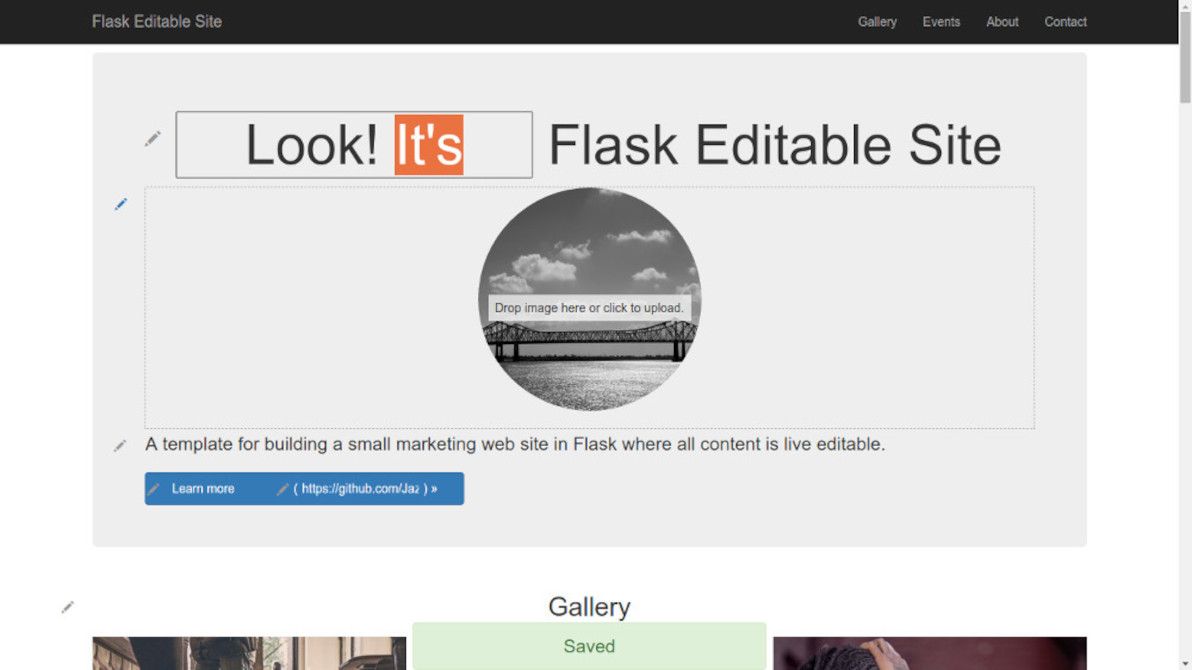




























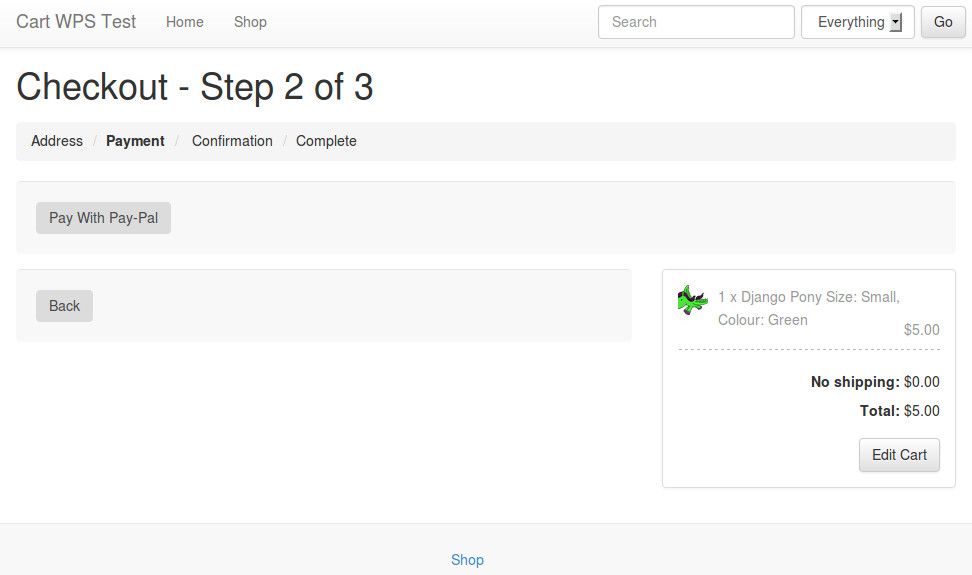
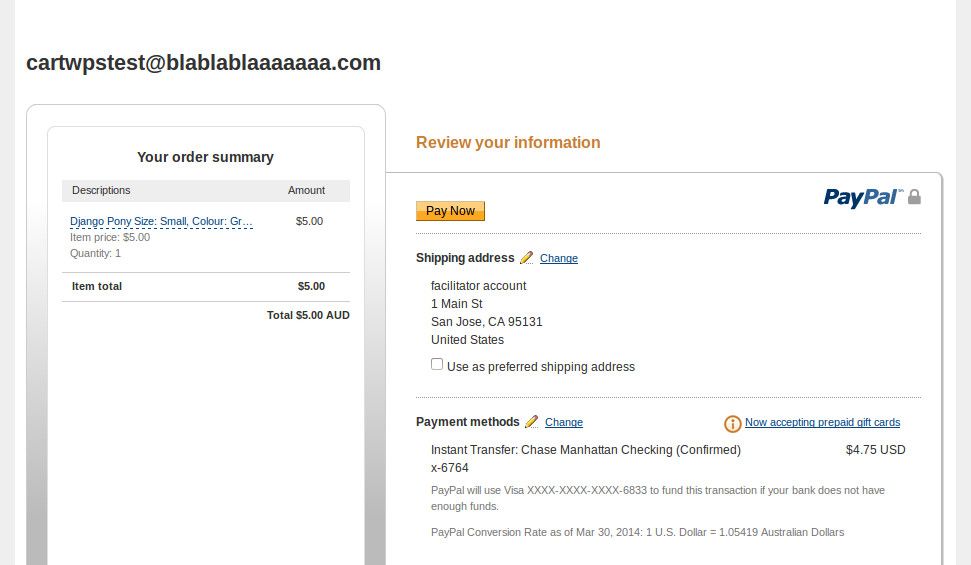




















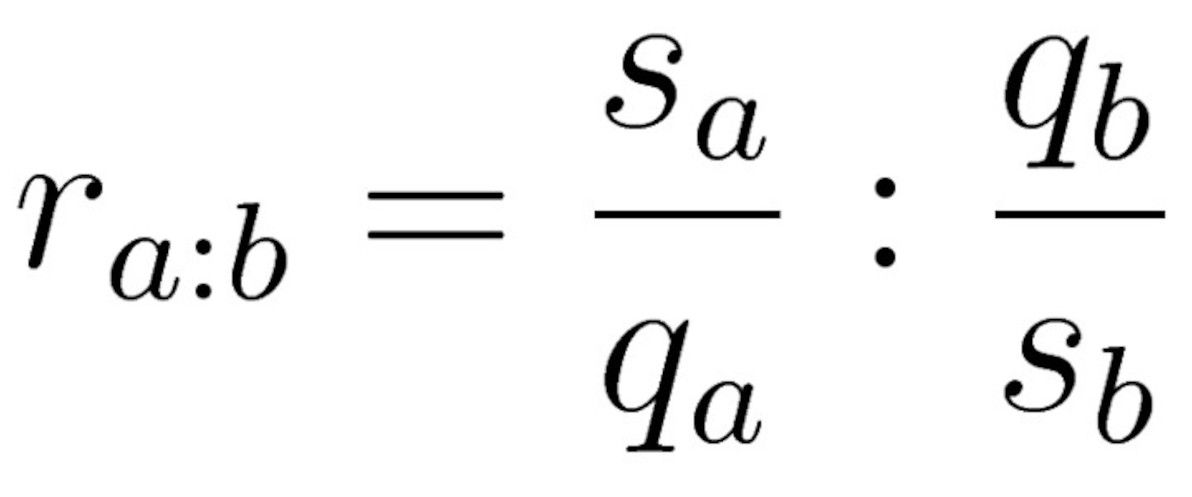




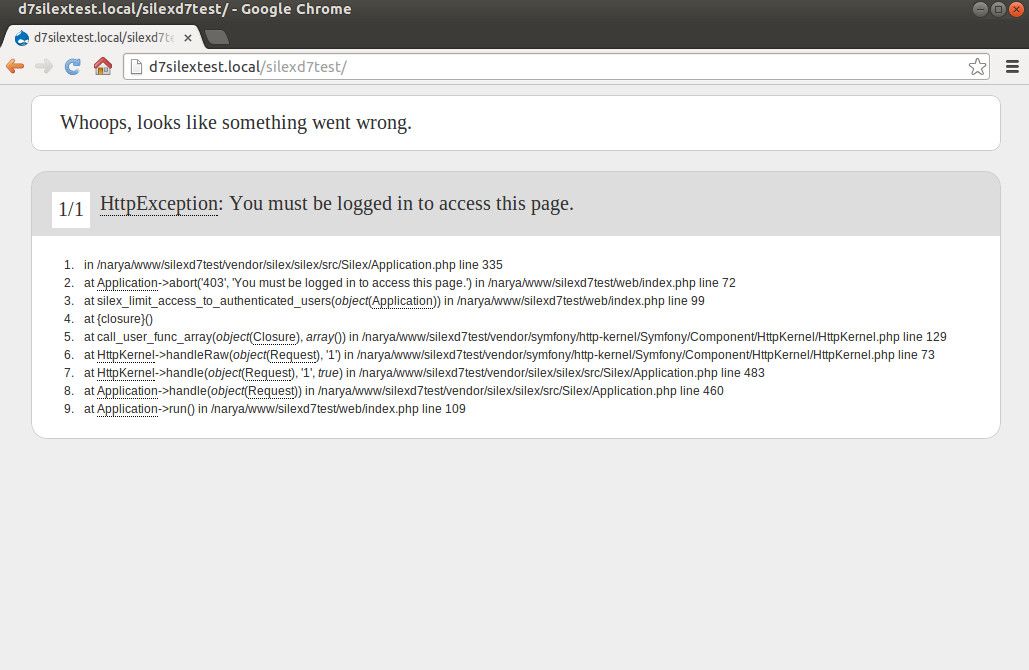

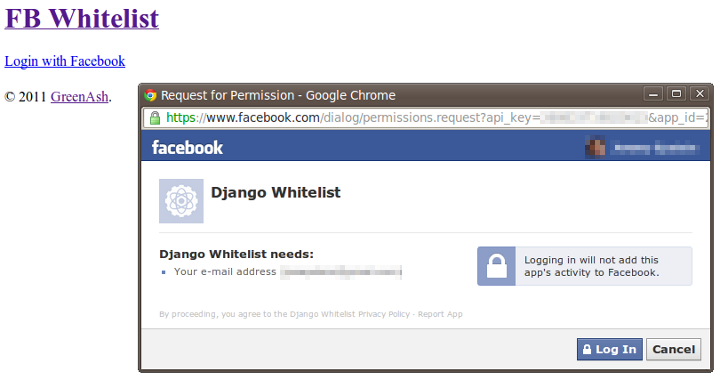


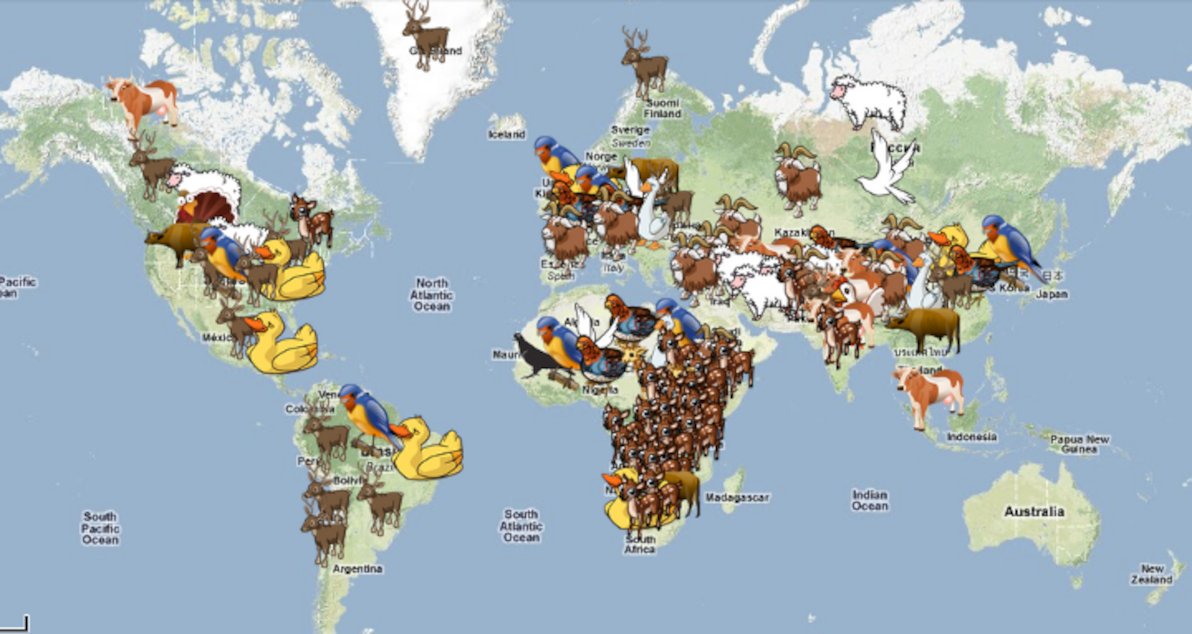
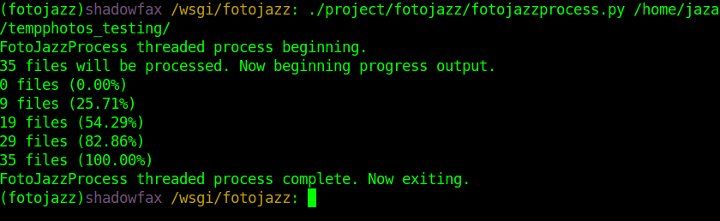
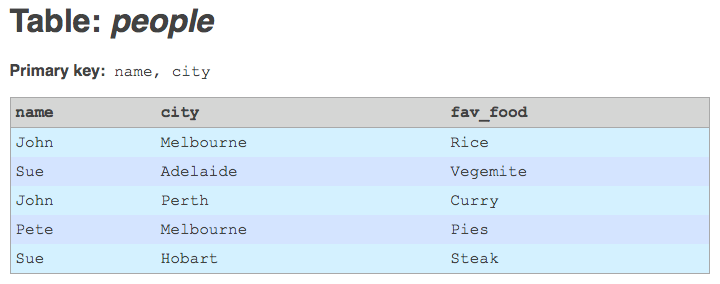
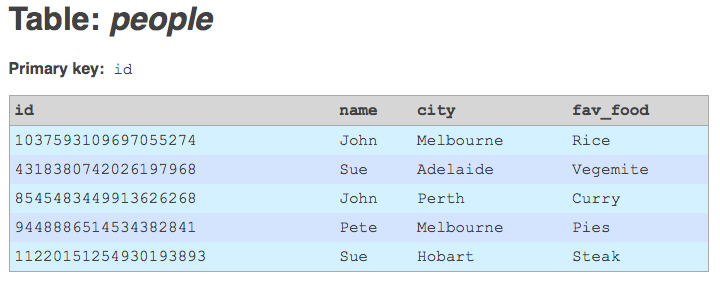
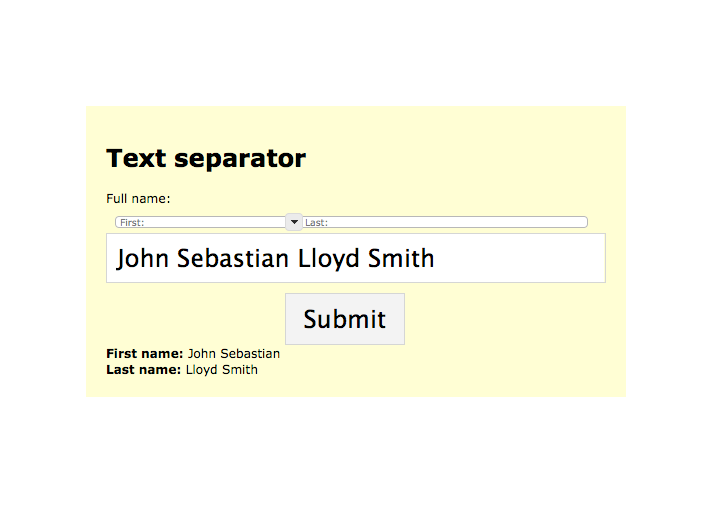
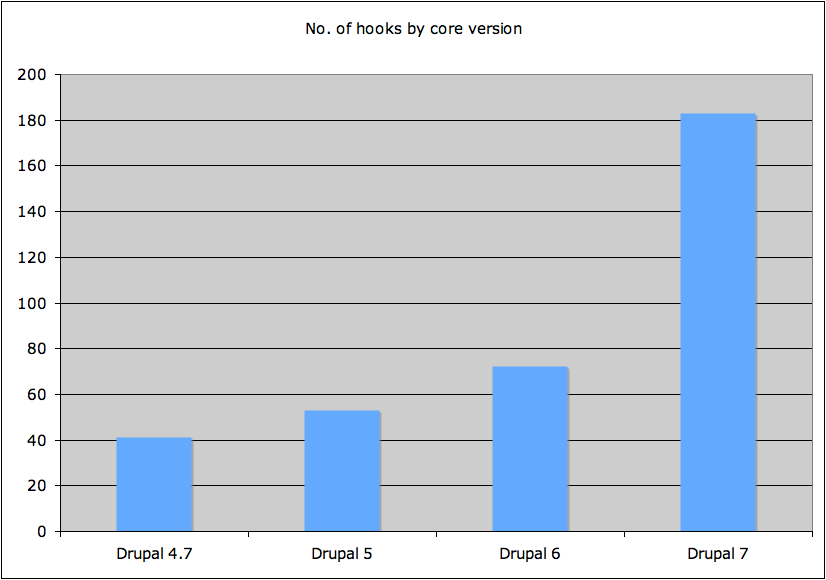




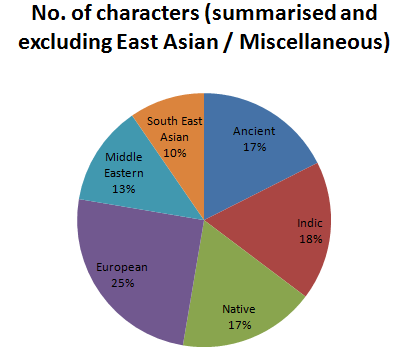









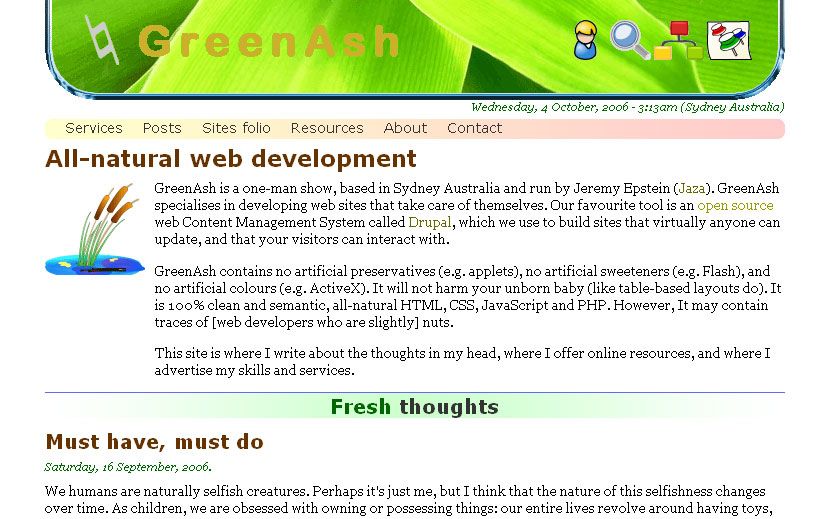
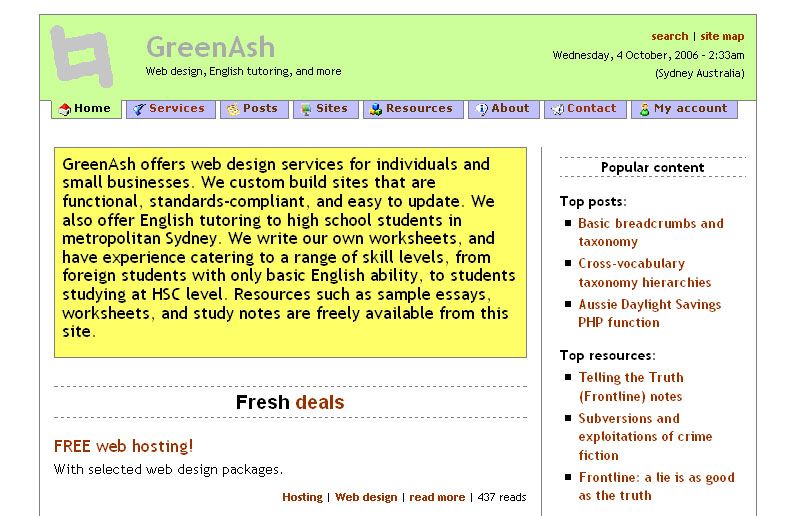
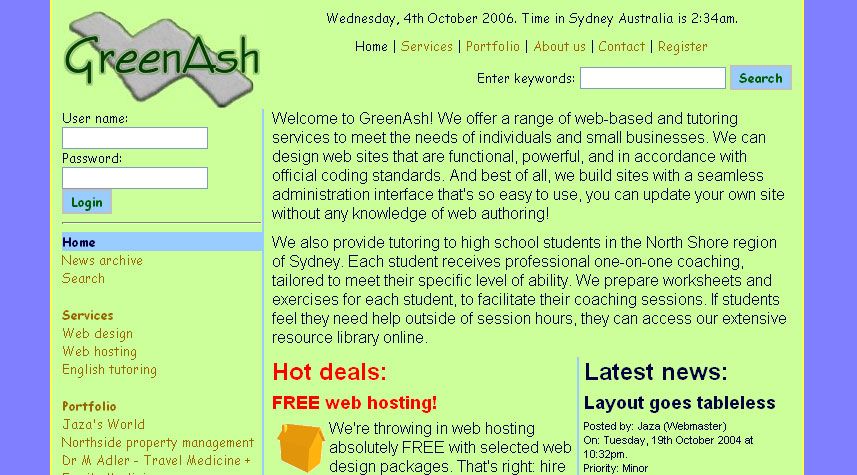


















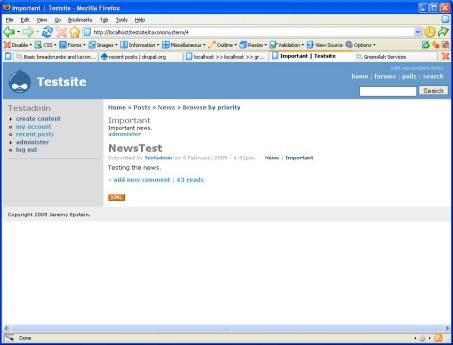
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}