A count of Unicode characters grouped by script
We all know what Unicode is (if you don't, then read all about it and come back later). We all know that it's big. Hey, of course it's big: its aim is to allow for the representation of characters from every major language script in the world. That's gotta be a lot of characters, right? It's reasonably easy to find out how many unicode characters there are in total: e.g. the Wikipedia page (linked above) states that: "As of Unicode 5.1 there are 100,507 graphic [assigned] characters." I got a bit curious today, and — to my disappointment — after some searching, I was unable to find a nice summary of how many characters there are in each script that Unicode supports. And thus it is that I present to you my count of all assigned Unicode characters (as of v5.1), grouped by script and by category.
The raw data
Fact: Unicode's "codespace" can represent up to 1,114,112 characters in total.
Fact: As of today, 100,540 of those spaces are in use by assigned characters (excluding private use characters).
The Unicode people provide a plain text listing of all supported Unicode scripts, and the number of assigned characters in each of them. I used this listing in order to compile a table of assigned character counts grouped by script. Most of the hard work was done for me. The table is almost identical to the one you can find on the Wikipedia Unicode scripts page, except that this one is slightly more updated (for now!).
| Unicode script name | Category | ISO 15924 code | Number of characters |
|---|---|---|---|
| Common | Miscellaneous | Zyyy | 5178 |
| Inherited | Miscellaneous | Qaai | 496 |
| Arabic | Middle Eastern | Arab | 999 |
| Armenian | European | Armn | 90 |
| Balinese | South East Asian | Bali | 121 |
| Bengali | Indic | Beng | 91 |
| Bopomofo | East Asian | Bopo | 65 |
| Braille | Miscellaneous | Brai | 256 |
| Buginese | South East Asian | Bugi | 30 |
| Buhid | Philippine | Buhd | 20 |
| Canadian Aboriginal | American | Cans | 630 |
| Carian | Ancient | Cari | 49 |
| Cham | South East Asian | Cham | 83 |
| Cherokee | American | Cher | 85 |
| Coptic | European | Copt | 128 |
| Cuneiform | Ancient | Xsux | 982 |
| Cypriot | Ancient | Cprt | 55 |
| Cyrillic | European | Cyrl | 404 |
| Deseret | American | Dsrt | 80 |
| Devanagari | Indic | Deva | 107 |
| Ethiopic | African | Ethi | 461 |
| Georgian | European | Geor | 120 |
| Glagolitic | Ancient | Glag | 94 |
| Gothic | Ancient | Goth | 27 |
| Greek | European | Grek | 511 |
| Gujarati | Indic | Gujr | 83 |
| Gurmukhi | Indic | Guru | 79 |
| Han | East Asian | Hani | 71578 |
| Hangul | East Asian | Hang | 11620 |
| Hanunoo | Philippine | Hano | 21 |
| Hebrew | Middle Eastern | Hebr | 133 |
| Hiragana | East Asian | Hira | 89 |
| Kannada | Indic | Knda | 84 |
| Katakana | East Asian | Kana | 299 |
| Kayah Li | South East Asian | Kali | 48 |
| Kharoshthi | Central Asian | Khar | 65 |
| Khmer | South East Asian | Khmr | 146 |
| Lao | South East Asian | Laoo | 65 |
| Latin | European | Latn | 1241 |
| Lepcha | Indic | Lepc | 74 |
| Limbu | Indic | Limb | 66 |
| Linear B | Ancient | Linb | 211 |
| Lycian | Ancient | Lyci | 29 |
| Lydian | Ancient | Lydi | 27 |
| Malayalam | Indic | Mlym | 95 |
| Mongolian | Central Asian | Mong | 153 |
| Myanmar | South East Asian | Mymr | 156 |
| N'Ko | African | Nkoo | 59 |
| New Tai Lue | South East Asian | Talu | 80 |
| Ogham | Ancient | Ogam | 29 |
| Ol Chiki | Indic | Olck | 48 |
| Old Italic | Ancient | Ital | 35 |
| Old Persian | Ancient | Xpeo | 50 |
| Oriya | Indic | Orya | 84 |
| Osmanya | African | Osma | 40 |
| Phags-pa | Central Asian | Phag | 56 |
| Phoenician | Ancient | Phnx | 27 |
| Rejang | South East Asian | Rjng | 37 |
| Runic | Ancient | Runr | 78 |
| Saurashtra | Indic | Saur | 81 |
| Shavian | Miscellaneous | Shaw | 48 |
| Sinhala | Indic | Sinh | 80 |
| Sundanese | South East Asian | Sund | 55 |
| Syloti Nagri | Indic | Sylo | 44 |
| Syriac | Middle Eastern | Syrc | 77 |
| Tagalog | Philippine | Tglg | 20 |
| Tagbanwa | Philippine | Tagb | 18 |
| Tai Le | South East Asian | Tale | 35 |
| Tamil | Indic | Taml | 72 |
| Telugu | Indic | Telu | 93 |
| Thaana | Middle Eastern | Thaa | 50 |
| Thai | South East Asian | Thai | 86 |
| Tibetan | Central Asian | Tibt | 201 |
| Tifinagh | African | Tfng | 55 |
| Ugaritic | Ancient | Ugar | 31 |
| Vai | African | Vaii | 300 |
| Yi | East Asian | Yiii | 1220 |
Regional and other groupings
The only thing that I added to the above table myself, was the data in the "Category" column. This data comes from the code charts page of the Unicode web site. This page lists all of the scripts in the current Unicode standard, and it groups them into a number of categories, most of which describe the script's regional origin. As far as I can tell, nobody's collated these categories with the character-count data before, so I had to do it manually.
Into the "Miscellaneous" category, I put the "Common" and the "Inherited" scripts, which contain numerous characters that are shared amongst multiple scripts (e.g. accents, diacritical marks), as well as a plethora of symbols from many domains (e.g. mathematics, music, mythology). "Common" also contains the characters used by the IPA. Additionally, I put Braille (the "alphabet of bumps" for blind people) and Shavian (invented phonetic script) into "Miscellaneous".
From the raw data, I then generated a summary table and a pie graph of the character counts for all the scripts, grouped by category:
| Category | No of characters | % of total |
|---|---|---|
| African | 915 | 0.91% |
| American | 795 | 0.79% |
| Ancient | 1724 | 1.71% |
| Central Asian | 478 | 0.48% |
| East Asian | 84735 | 84.28% |
| European | 2455 | 2.44% |
| Indic | 1185 | 1.18% |
| Middle Eastern | 1254 | 1.25% |
| Miscellaneous | 5978 | 5.95% |
| Philippine | 79 | 0.08% |
| South East Asian | 942 | 0.94% |
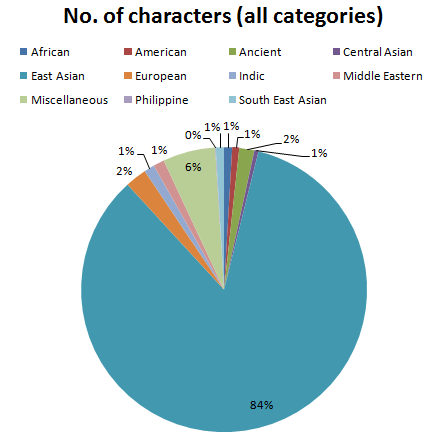
Attack of the Han
Looking at this data, I can't help but gape at the enormous size of the East Asian character grouping. 84.3% of the characters in Unicode are East Asian; and of those, the majority belong to the Han script. Over 70% of Unicode's assigned codespace is occupied by a single script — Han! I always knew that Chinese contained thousands upon thousands of symbols; but who would have guessed that their quantity is great enough to comprise 70% of all language symbols in known linguistic history? That's quite an achievement.
And what's more, this is a highly reduced subset of all possible Han symbols, due mainly to the Han unification effort that Unicode imposed on the script. Han unification has resulted in all the variants of Han — the notable ones being Chinese, Japanese, and Korean — getting represented in a single character set. Imagine the size of Han, were its Chinese / Japanese / Korean variants represented separately — no wonder (despite the controversy and the backlash) they went ahead with the unification!
Broader groupings
Due to its radically disproportionate size, the East Asian script category squashes away virtually all the other Unicode script categories into obscurity. The "Miscellaneous" category is also unusually large (although still nowhere near the size of East Asian). As such, I decided to make a new data table, but this time with these two extra-large categories excluded. This allows the size of the remaining categories to be studied a bit more meaningfully.
For the remaining categories, I also decided to do some additional grouping, to further reduce disproportionate sizes. These additional groupings are my own creation, and I acknowledge that some of them are likely to be inaccurate and not popular with everyone. Anyway, take 'em or leave 'em: there's nothing official about them, they're just my opinion:
- I grouped the "African" and the "American" categories into a broader "Native" grouping: I know that this word reeks of arrogant European colonial connotations, but nevertheless, I feel that it's a reasonable name for the grouping. If you are an African or a Native American, then please treat the name academically, not personally.
- I also brought the "Indic", "Central Asian", and "Philippine" categories together into an "Indic" grouping. I did this because, after doing some research, it seems that the key Central Asian scripts (e.g. Mongolian, Tibetan) and the pre-European Philippine scripts (e.g. Tagalog) both have clear Indic roots.
- I left the "Ancient", "South-East Asian", "European" and "Middle Eastern" groupings un-merged, as they don't fit well with any other group, and as they're reasonably well-proportioned on their own.
Here's the data for the broader groupings:
| Grouping | No of characters | % of total |
|---|---|---|
| Ancient | 1724 | 17.54% |
| Indic | 1742 | 17.73% |
| Native | 1710 | 17.40% |
| European | 2455 | 24.98% |
| Middle Eastern | 1254 | 12.76% |
| South-Eastern | 942 | 9.59% |
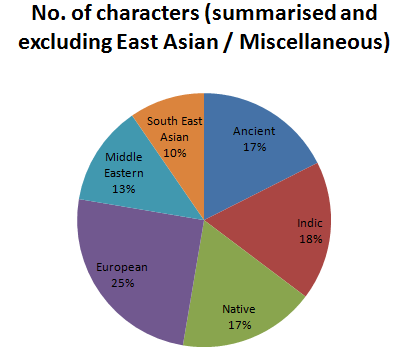
And there you have it: a breakdown of the number of characters in the main written scripts of the world, as they're represented in Unicode. European takes the lead here, with the Latin script being the largest in the European group by far (mainly due to the numerous variants of the Latin alphabet, with accents and other symbols used to denote regional languages). All up, a relatively even spread.
I hope you find this interesting — and perhaps even useful — as a visualisation of the number of characters that the world's main written scripts employ today (and throughout history). If you ever had any doubts about the sheer volume of symbols used in East Asian scripts (but remember that the vast majority of them are purely historic and are used only by academics), then those doubts should now be well and truly dispelled.
It will also be interesting to see how this data changes, over the next few versions of Unicode into the future. I imagine that only the more esoteric categories will grow: for example, ever more obscure scripts will no doubt be encoded and will join the "Ancient" category; and my guess is that ever more bizarre sets of symbols will join the "Miscellaneous" category. There may possibly be more additions to the "Native" category, although the discovery of indigenous writing systems is far less frequent than the discovery of indigenous oral languages. As for the known scripts of the modern world, I'd say they're well and truly covered already.