This suite turned out to deliver virtually everything I needed out-of-the-box, with one exception: Cartridge currently lacks support for payment methods that require redirecting to the payment gateway and then returning after payment completion (such as PayPal Website Payments Standard, or WPS). It only supports payment methods where payment is completed on-site (such as PayPal Website Payments Pro, or WPP). In this case, with the project being small and low-budget, I wanted to avoid the overhead of dealing with SSL and on-site payment, so PayPal WPS was the obvious candidate.
Turns out that, with a bit of hackery, making Cartridge play nice with WPS isn't too hard to achieve. Here's how you go about it.
Install dependencies
Note / disclaimer: this section is mostly copied from my Django Facebook user integration with whitelisting article from over two years ago, because the basic dependencies are quite similar.
I'm assuming that you've already got an environment set up, that's equipped for Django development. I.e. you've already installed Python (my examples here are tested on Python 2.7), a database engine (preferably SQLite on your local environment), pip (recommended), and virtualenv (recommended). If you want to implement these examples fully, then as well as a dev environment with these basics set up, you'll also need a server to which you can deploy a Django site, and on which you can set up a proper public domain or subdomain DNS (because the PayPal API won't actually talk to your localhost, it refuses to do that).
You'll also need a PayPal (regular and "sandbox") account, which you will use for authenticating with the PayPal API.
Here are the basic dependencies for the project. I've copy-pasted this straight out of my requirements.txt file, which I install on a virtualenv using pip install -E . -r requirements.txt (I recommend you do the same):
Django==1.6.2
Mezzanine==3.0.9
South==0.8.4
Cartridge==0.9.2
cartridge-payments==0.97.0
-e git+https://github.com/dcramer/django-paypal.git@4d582243#egg=django_paypal
django-uuidfield==0.5.0Note: for dcramer/django-paypal, which has no versioned releases, I'm using the latest git commit as of writing this. I recommend that you check for a newer commit and update your requirements accordingly. For the other dependencies, you should also be able to update version numbers to latest stable releases without issues (although Mezzanine 3.0.x / Cartridge 0.9.x is only compatible with Django 1.6.x, not Django 1.7.x which is still in beta as of writing this).
Once you've got those dependencies installed, make sure this Mezzanine-specific setting is in your settings.py file:
# If True, the south application will be automatically added to the
# INSTALLED_APPS setting.
USE_SOUTH = True
Then, let's get a new project set up per Mezzanine's standard install:
mezzanine-project myproject
cd myproject
python manage.py createdb
python manage.py migrate --all(When it asks "Would you like to install an initial demo product and sale?", I've gone with "yes" for my test / demo project; feel free to do the same, if you'd like some products available out-of-the-box with which to test checkout / payment).
This will get the Mezzanine foundations installed for you. The basic configuration of the Django / Mezzanine settings file, I leave up to you. If you have some experience already with Django (and if you've got this far, then I assume that you do), you no doubt have a standard settings template already in your toolkit (or at least a standard set of settings tweaks), so feel free to use it. I'll be going over the settings you'll need specifically for this app, in just a moment.
Fire up ye 'ol runserver, open your browser at http://localhost:8000/, and confirm that the "Congratulations!" default Mezzanine home page appears for you. Also confirm that you can access the admin. And that's the basics set up!
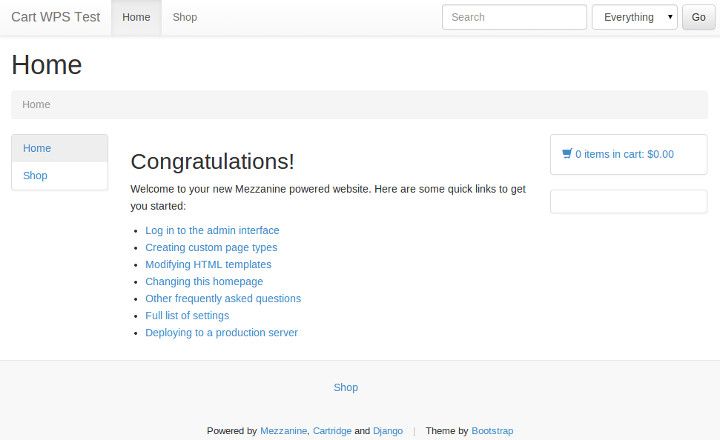
At this point, you should also be able to test out adding an item to your cart and going to checkout. After entering some billing / delivery details, on the 'payment details' screen it should ask for credit card details. This is the default Cartridge payment setup: we'll be switching this over to PayPal shortly.
Configure Django settings
I'm not too fussed about what else you have in your Django settings file (or in how your Django settings are structured or loaded, for that matter); but if you want to follow along, then you should have certain settings configured per the following guidelines (note: much of these instructions are virtually the same as the cartridge-payments install instructions):
- Your
TEMPLATE_CONTEXT_PROCESSORSis to include (as well as'mezzanine.conf.context_processors.settings'):
[ 'payments.multipayments.context_processors.settings', ](See the TEMPLATE_CONTEXT_PROCESSORS documentation for the default value of this setting, to paste into your settings file).
- Re-configure the
SHOP_CHECKOUT_FORM_CLASSsetting to this:
SHOP_CHECKOUT_FORM_CLASS = 'payments.multipayments.forms.base.CallbackUUIDOrderForm' - Disable the
PRIMARY_PAYMENT_PROCESSOR_IN_USEsetting:
PRIMARY_PAYMENT_PROCESSOR_IN_USE = False - Configure the
SECONDARY_PAYMENT_PROCESSORSsetting to this:
SECONDARY_PAYMENT_PROCESSORS = ( ('paypal', { 'name' : 'Pay With Pay-Pal', 'form' : 'payments.multipayments.forms.paypal.PaypalSubmissionForm' }), ) - Set a value for the
PAYPAL_CURRENCYsetting, for example:
# Currency type. PAYPAL_CURRENCY = "AUD" - Set a value for the
PAYPAL_BUSINESSsetting, for example:
# Business account email. Sandbox emails look like this. PAYPAL_BUSINESS = 'cartwpstest@blablablaaaaaaa.com' - Set a value for the
PAYPAL_RECEIVER_EMAILsetting, for example:
PAYPAL_RECEIVER_EMAIL = PAYPAL_BUSINESS - Set a value for the
PAYPAL_RETURN_WITH_HTTPSsetting, for example:
# Use this to enable https on return URLs. This is strongly recommended! (Except for sandbox) PAYPAL_RETURN_WITH_HTTPS = False - Configure the
PAYPAL_RETURN_URLsetting to this:
# Function that returns args for `reverse`. # URL is sent to PayPal as the for returning to a 'complete' landing page. PAYPAL_RETURN_URL = lambda cart, uuid, order_form: ('shop_complete', None, None) - Configure the
PAYPAL_IPN_URLsetting to this:
# Function that returns args for `reverse`. # URL is sent to PayPal as the URL to callback to for PayPal IPN. # Set to None if you do not wish to use IPN. PAYPAL_IPN_URL = lambda cart, uuid, order_form: ('paypal.standard.ipn.views.ipn', None, {}) - Configure the
PAYPAL_SUBMIT_URLsetting to this:
# URL the secondary-payment-form is submitted to # For real use set to 'https://www.paypal.com/cgi-bin/webscr' PAYPAL_SUBMIT_URL = 'https://www.sandbox.paypal.com/cgi-bin/webscr' - Configure the
PAYPAL_TESTsetting to this:
# For real use set to False PAYPAL_TEST = True - Configure the
EXTRA_MODEL_FIELDSsetting to this:
EXTRA_MODEL_FIELDS = ( ( "cartridge.shop.models.Order.callback_uuid", "django.db.models.CharField", (), {"blank" : False, "max_length" : 36, "default": ""}, ), )After doing this, you'll probably need to manually create a migration in order to get this field added to your database (per Mezzanine's field injection caveat docs), and you'll then need to apply that migration (in this example, I'm adding the migration to an app called 'content' in my project):
mkdir /projectpath/content/migrations
touch /projectpath/content/migrations/__init__.py
python manage.py schemamigration cartridge.shop --auto --stdout > /projectpath/content/migrations/0001_cartridge_shop_add_callback_uuid.pypython manage.py migrate --all
- Your
INSTALLED_APPSis to include (as well as the basic'mezzanine.*'apps, and'cartridge.shop'):
[ 'payments.multipayments', 'paypal.standard.ipn', ](You'll need to re-run
python manage.py migrate --allafter enabling these apps).
Implement PayPal payment
Here's how you do it:
- Add this to your
urlpatternsvariable in yoururls.pyfile (replace the part afterpaypal-ipn-with a random string of your choice):
[ (r'^paypal-ipn-8c5erc9ye49ia51rn655mi4xs7/', include('paypal.standard.ipn.urls')), ] - Although it shouldn't be necessary, I've found that I need to copy the templates provided by
explodes/cartridge-paymentsinto my project'stemplatesdirectory, otherwise they're ignored and Cartridge's default payment template still gets used:cp -R /projectpath/lib/python2.7/site-packages/payments/multipayments/templates/shop /projectpath/templates/ - Place the following code somewhere in your codebase (per the django-paypal docs, I placed it in the
models.pyfile for one of my apps):
# ... from importlib import import_module from mezzanine.conf import settings from cartridge.shop.models import Cart, Order, ProductVariation, \ DiscountCode from paypal.standard.ipn.signals import payment_was_successful # ... def payment_complete(sender, **kwargs): """Performs the same logic as the code in cartridge.shop.models.Order.complete(), but fetches the session, order, and cart objects from storage, rather than relying on the request object being passed in (which it isn't, since this is triggered on PayPal IPN callback).""" ipn_obj = sender if ipn_obj.custom and ipn_obj.invoice: s_key, cart_pk = ipn_obj.custom.split(',') SessionStore = import_module(settings.SESSION_ENGINE) \ .SessionStore session = SessionStore(s_key) try: cart = Cart.objects.get(id=cart_pk) try: order = Order.objects.get( transaction_id=ipn_obj.invoice) for field in order.session_fields: if field in session: del session[field] try: del session["order"] except KeyError: pass # Since we're manually changing session data outside of # a normal request, need to force the session object to # save after modifying its data. session.save() for item in cart: try: variation = ProductVariation.objects.get( sku=item.sku) except ProductVariation.DoesNotExist: pass else: variation.update_stock(item.quantity * -1) variation.product.actions.purchased() code = session.get('discount_code') if code: DiscountCode.objects.active().filter(code=code) \ .update(uses_remaining=F('uses_remaining') - 1) cart.delete() except Order.DoesNotExist: pass except Cart.DoesNotExist: pass payment_was_successful.connect(payment_complete)This little snippet that I whipped up, is the critical spoonful of glue that gets PayPal WPS playing nice with Cartridge. Basically, when a successful payment is realised, PayPal WPS doesn't force the user to redirect back to the original web site, and therefore it doesn't rely on any redirection in order to notify the site of success. Instead, it uses PayPal's IPN (Instant Payment Notification) system to make a separate, asynchronous request to the original web site – and it's up to the site to receive this request and to process it as it sees fit.
This code uses the
payment_was_successfulsignal thatdjango-paypalprovides (and that it triggers on IPN request), to do what Cartridge usually takes care of (for other payment methods), on success: i.e. it clears the user's shopping cart; it updates remaining quantities of products in stock (if applicable); it triggers Cartridge's "product purchased" actions (e.g. email an invoice / receipt); and it updates a discount code (if applicable). Apply a hack to
cartridge-payments(filelib/python2.7/site-packages/payments/multipayments/forms/paypal.py) per this diff:After line 25 (
charset = forms.CharField(widget=forms.HiddenInput(), initial='utf-8')), add this:custom = forms.CharField(required=False, widget=forms.HiddenInput())After line 49 (
(tax_price if tax_price else const.Decimal('0'))), add this:try: s_key = request.session.session_key except: # for Django 1.4 and above s_key = request.session._session_keyAfter line 70 (
self.fields['business'].initial = settings.PAYPAL_BUSINESS), add this:self.fields['custom'].initial = ','.join([s_key, str(request.cart.pk)])Apply a hack to
django-paypal(filesrc/django-paypal/paypal/standard/forms.py) per these instructions:After line 15 (
"%H:%M:%S %b. %d, %Y PDT",), add this:"%H:%M:%S %d %b %Y PST", # note this "%H:%M:%S %d %b %Y PDT", # and that
That should be all you need, in order to get checkout with PayPal WPS working on your site. So, deploy everything that's been done so far to your online server, log in to the Django admin, and for some of the variations for the sample product in the database, add values for "number in stock".
Then, log out of the admin, and navigate to the "shop" section of the site. Try out adding an item to your cart.
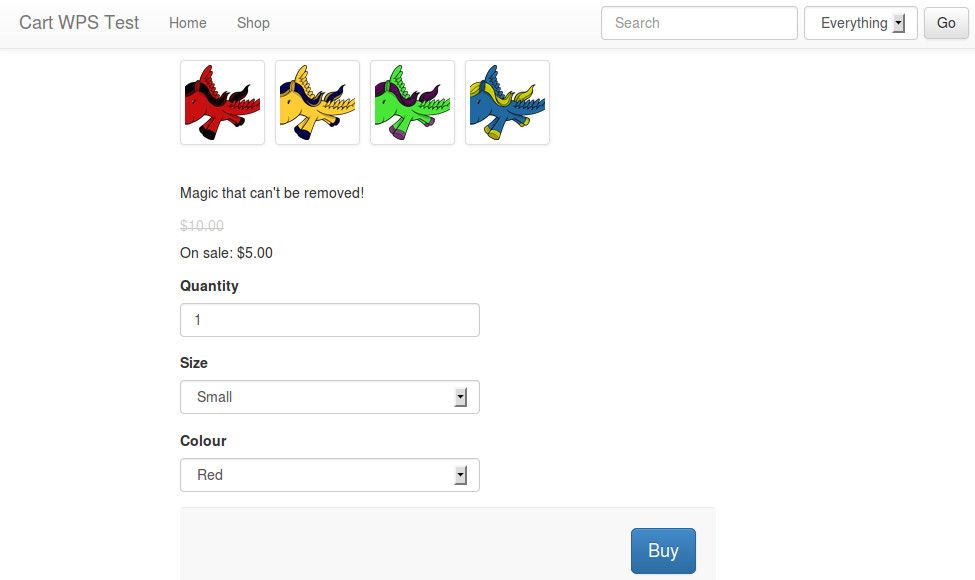
Once on the "your cart" page, continue by clicking "go to checkout". On the "billing details" page, enter sample billing information as necessary, then click "next". On the "payment" page, you should see a single button labelled "pay with pay-pal".
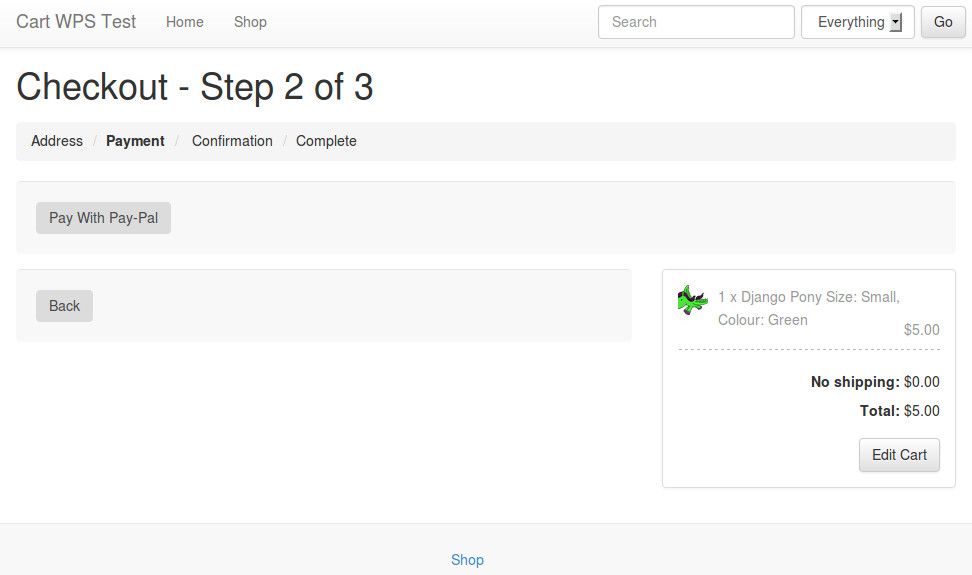
Click the button, and you should be taken to the PayPal (sandbox, unless configured otherwise) payment landing page. For test cases, log in with a PayPal test account, and click 'Pay Now' to try out the process.
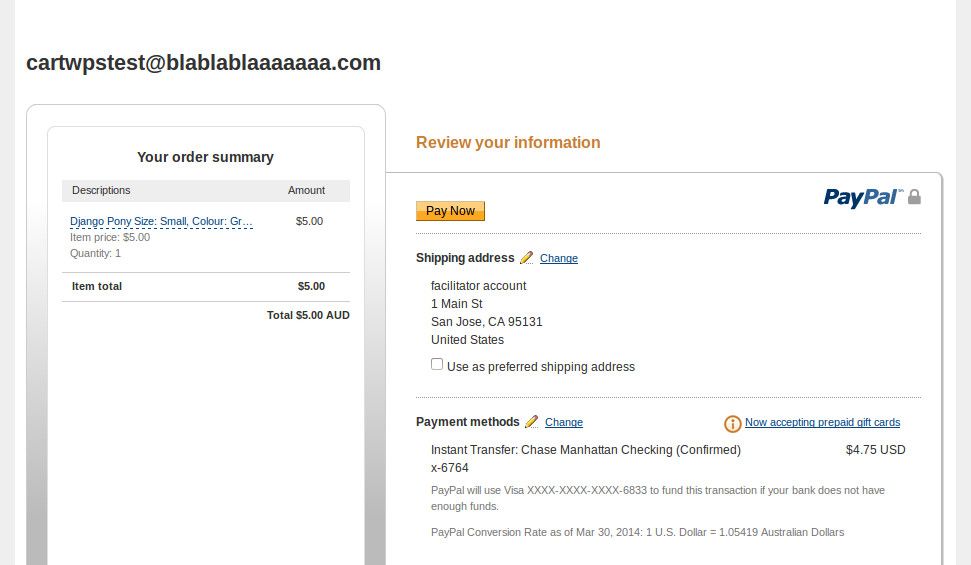
If payment is successful, you should see the PayPal confirmation page, saying "thanks for your order". Click the link labelled "return to email@here.com" to return to the Django site. You should see Cartridge's "order complete" page.
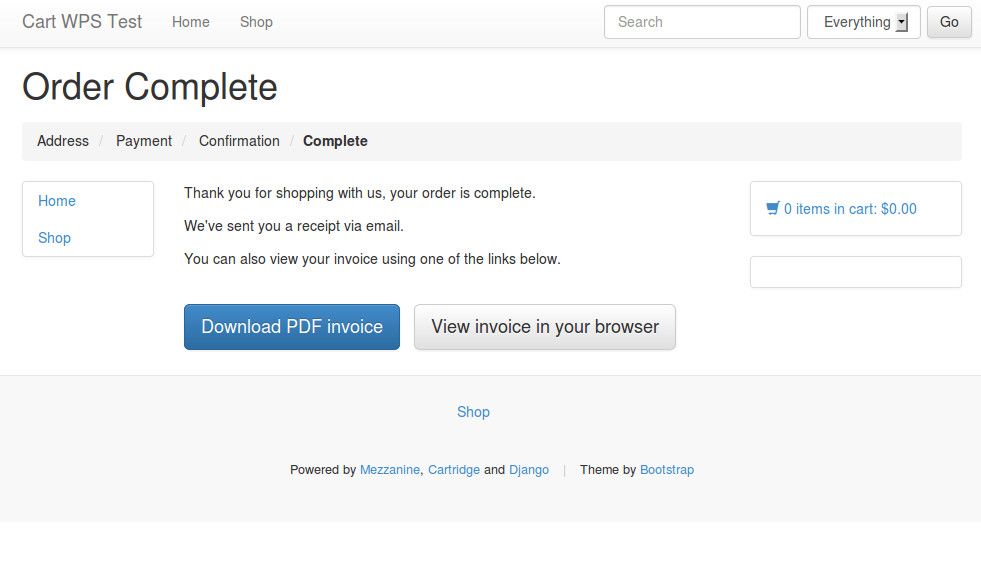
And that's it, you're done! You should be able to verify that the IPN callback was triggered, by checking that the "number in stock" has decreased to reflect the item that was just purchased, and by confirming that an order email / confirmation email was received.
Finished process
I hope that this guide is of assistance, to anyone else who's looking to integrate PayPal WPS with Cartridge. The difficulties associated with it are also documented in this mailing list thread (to which I posted a rough version of what I've illustrated in this article). Feel free to leave comments here, and/or in that thread.
Hopefully the hacks necessary to get this working at the moment, will no longer be necessary in the future; it's up to the maintainers of the various projects to get the fixes for these committed. Ideally, the custom signal implementation won't be necessary either in the future: it would be great if Cartridge could work out-of-the-box with PayPal WPS. Unfortunately, the current architecture of Cartridge's payment system simply isn't designed for something like IPN, it only plays nicely with payment methods that keep the user on the Django site the entire time. In the meantime, with the help of this article, you should at least be able to get it working, even if more custom code is needed than what would be ideal.
]]>