programming - GreenAshPoignant wit and hippie ramblings that are pertinent to programminghttps://greenash.net.au/thoughts/topics/programming/2024-06-23T00:00:00ZIntroducing: World Locality Transit Graph2024-06-23T00:00:00Z2024-06-23T00:00:00ZJazahttps://greenash.net.au/thoughts/2024/06/introducing-world-locality-transit-graph/
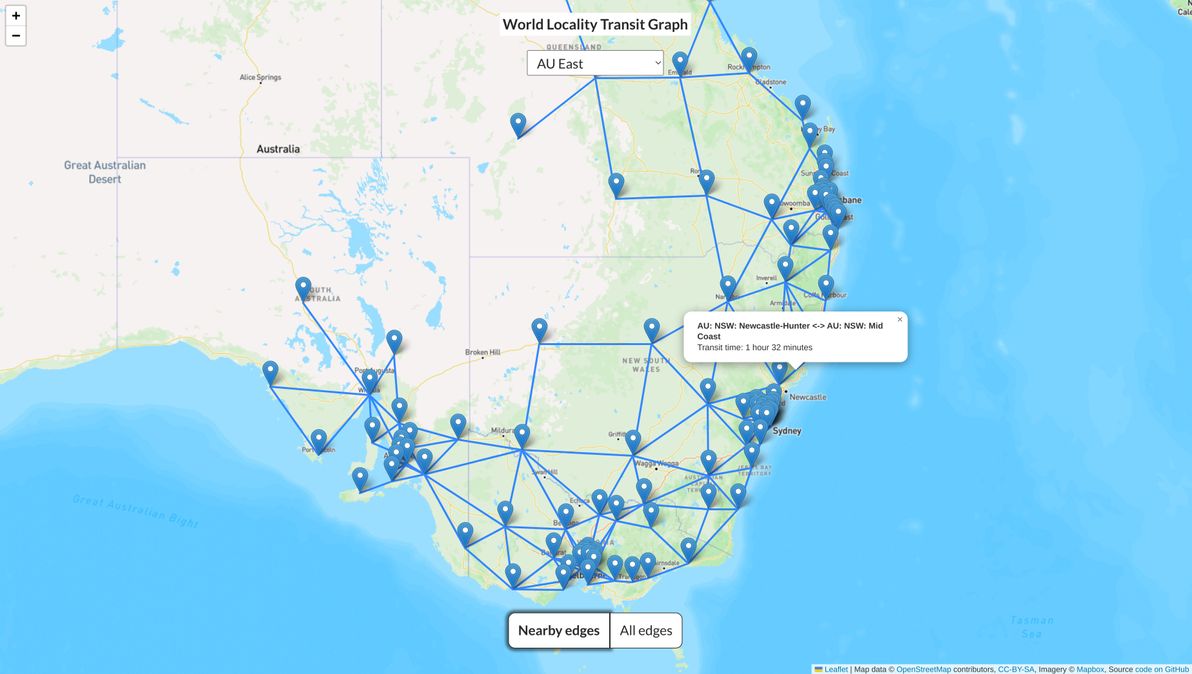
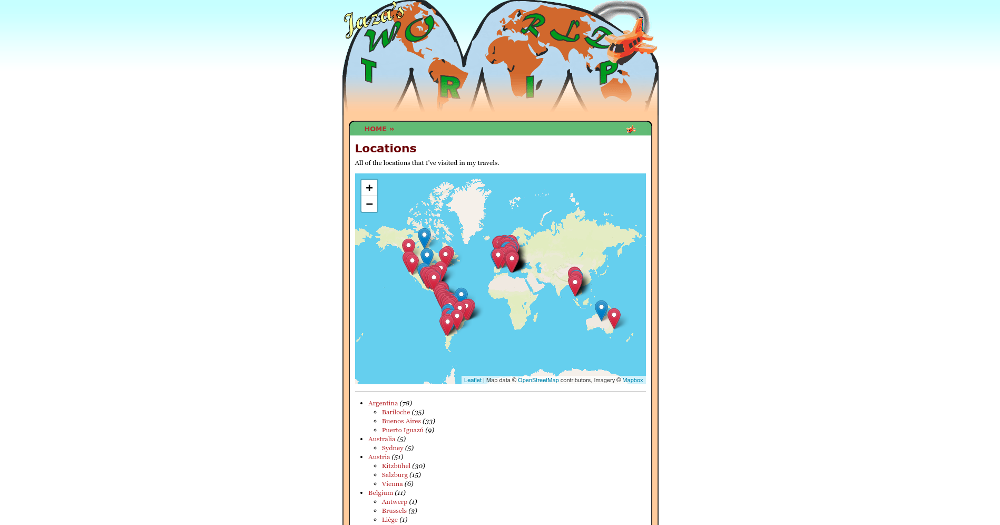
I built a dataset and map visualisation called the World Locality Transit Graph. Source code is on GitHub. It's a map of approximate transit times between any two given localities in various parts of the world.
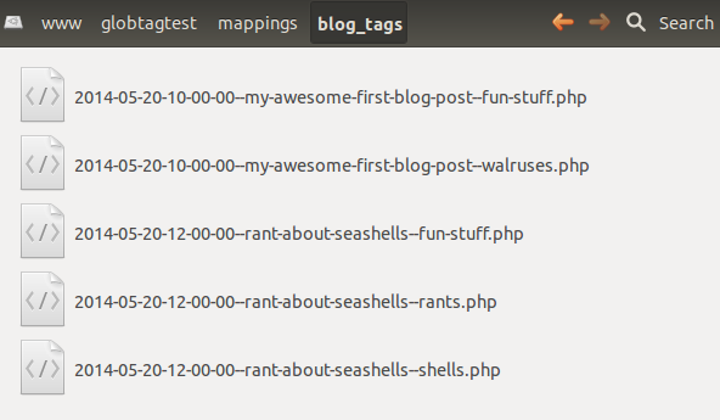
World Locality Transit Graph showing the dataset for Eastern Australia
About the graph
(Note: this section is copied from the README that can be seen on GitHub.)
A "locality", for the purposes of the graph, is:
In a large metropolitan area: a group of neighbourhoods / suburbs, e.g. "inner city", "southern suburbs"; such a locality should (as a rough guide) be 15-30 minutes transit time from its adjacent metropolitan localities
In a (small urban area or) semi-rural area: the whole main town / city, and usually also neighbouring towns / countryside, e.g. "foobar valley", "fizzbuzz peninsula"; such a locality should (as a rough guide) be 1-2 hours transit time from its adjacent semi-rural localities
In a remote rural area: all of the towns / countryside within a large area, e.g. "far north", "highlands"; such a locality should (as a rough guide) be 3-5 hours transit time from all adjacent localities
Additionally, regardless of whether it's big-city or middle-of-nowhere:
Someone who lives in one locality, should consider anyone living in the same locality as being "in my area" (folks in a city of several million people have quite a different definition of "in my area", compared to folks whose next-door neighbour is over the horizon!)
Each locality should have its own identity, both geographical and cultural; a person who lives in a locality should feel some connection (could be positive or negative!) to their locality's identity
Each locality is represented as a node in the graph. Two localities should be connected as "nearby edges" (i.e. there should be an edge connecting their nodes in the graph) if and only if:
They are geographically adjacent
It's possible to travel between them using one or more spontaneous transport modes, e.g. private car, some trains / buses / ferries, walking, bicycle, taxi (not non-spontaneous transport, i.e. not transport that has to be booked in advance, that may have infrequent service, and that may not be available 24/7, e.g. flights, some trains / buses / ferries)
Travel between them using the fastest available spontaneous transport mode is no more than approximately 5 hours (under ideal conditions, i.e. very low traffic, no adverse weather, no roadwork / trackwork)
There is also an edge for every single possible pair of localities (in each connected graph), with a transit time of up to 5.5 hours, which can be seen in the "all edges" map view. These edges are calculated and generated in advance, using the Floyd-Warshall CSV Generator.
Due to the "5-hour max transit time" rule, and due to the "only spontaneous transport modes" rule, it's actually multiple graphs, not just one graph. This is because there is often no way to travel between two localities while adhering to those rules, usually due to a body of water being in the way, but sometimes due to a land route being extremely long and desolate (e.g. crossing the Nullarbor Plain between South Australia and Western Australia takes at least 12 hours of non-stop driving).
Why these rules? Because, being a "transit graph", the idea is that it only models "local" travel, i.e. travel that someone would undertake with little or no notice, at little or no financial cost, ideally (for metropolitan localities) local enough that one could still make it back home for the night, or (for rural and semi-rural localities) at least local enough that one could easily complete the journey one-way in a single day.
So, the aim of this graph is to model, for each locality, all of the other nearby localities that are "close enough", in terms of transit time, for casual travel - perhaps to catch up with friends / family, perhaps for local tourism, perhaps for shopping - to be feasible on a regular basis.
Built as a static site, using Leaflet as the map engine, OpenStreetMap for map data, and Mapbox for map tiles. Graph nodes and edges are stored in CSV files in the csv/ directory of the repo.
So far, there is only data for Australia and New Zealand. More world regions coming soon. If you're keen to help out with expanding the dataset, contributions are welcome! Ideally in the form of GitHub pull requests, but otherwise, just get in touch and send me data.
Cool, but why?
I built it primarily because I have another project in mind, that I may or may not build to completion, and which I may or may not be blogging about in future, for which the dataset in this graph would be really useful.
Also: fun!
Also: as far as I'm aware, nothing like this currently exists.
Also: I'd say it's a good thing to have a free, open, and dead-simple dataset like this, that provides a good alternative / good fallback to, for example, Google Maps's route travel time estimates.
Hope you like the World Locality Transit Graph. Feedback welcome.
]]>
Introducing: Floyd-Warshall CSV Generator2024-06-09T00:00:00Z2024-06-09T00:00:00ZJazahttps://greenash.net.au/thoughts/2024/06/introducing-floyd-warshall-csv-generator/
I built a little Python script called the Floyd-Warshall CSV Generator. It takes a CSV of graph edges as input, and generates a CSV of the edges that are the shortest paths between all pairs of vertices.
That is, it generates all the possible (indirect) paths from one point to all other points, based on the (direct) paths that are already known, with duplicate (undirected) paths filtered out, and with paths whose cost is more than max-weight filtered out.
I wrote this script in order to generate the "all edges" data that's shown in the World Locality Transit Graph, which I'll also be blogging about real soon. Let me know if you put this script to any other interesting uses!
]]>
On FastAPI2024-04-28T00:00:00Z2024-04-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2024/04/on-fastapi/
Over the past year or two, I've been heavily using FastAPI in my day job. I've been around the Python web framework block, and I gotta say, FastAPI really succeeds in its mission of building on the strengths of its predecessors (particularly Django and Flask), while feeling more modern and adhering to certain opinionated principles. In my opinion, it's pretty much exactly what the best-in-breed of the next logical generation of web frameworks should look like.
¡Ándale, ándale, arriba! Image source: The Guardian
Let me start by lauding FastAPI's excellent documentation. Having a track record of rock-solid documentation, was (and still is!) – in my opinion – Django's most impressive achievement, and I'm pleased to see that it's also becoming Django's most enduring legacy. FastAPI, like Django, includes docs changes together with code changes in a single (these days called) pull request; it clearly documents that certain features are deprecated; and its docs often go beyond what is strictly required, by including end-to-end instructions for integrating with various third-party tools and services.
FastAPI's docs raise the bar further still, with more than a dash of humour in many sections, and with a frequent sprinkling of emojis as standard fare. That latter convention I have some reservations about – call me old-fashioned, but you could say that emoji-filled docs is unprofessional and is a distraction. However, they seem to enhance rather than detract from overall quality; and, you know what, they put a non-emoji real-life smile on my face. So, they get my tick of approval.
FastAPI more-or-less sits in the Flask camp of being a "microframework", in that it doesn't include an ORM, a template engine, or various other things that Django has always advertised as being part of its "batteries included" philosophy. But, on the other hand, it's more in the Django camp of being highly opinionated, and of consciously including things with which it wants a hassle-free experience. Most notably, it includes Swagger UI and Redoc out-of-the-box. I personally had quite a painful experience generating Swagger docs in Flask, back in the day; and I've been tremendously pleased with how API doc generation Just Works™ in FastAPI.
Much like with Flask, being a microframework means that FastAPI very much stands on the shoulders of giants. Just as Flask is a thin wrapper on top of Werkzeug, with the latter providing all things WSGI; so too is FastAPI a thin wrapper on top of Starlette, with the latter providing all things ASGI. FastAPI also heavily depends on Pydantic for data schemas / validation, for strongly-typed superpowers, for settings handling, and for all things JSON. I think it's fair to say that Pydantic is FastAPI's secret sauce.
My use of FastAPI so far has been rather unusual, in that I've been building apps that primarily talk to an Oracle database (and, indeed, this is unusual for Python dev more generally). I started out by depending on the (now-deprecated) cx_Oracle library, and I've recently switched to its successor python-oracledb. I was pleased to see that the finefolks at Oracle recently released full async support for python-oracledb, which I'm now taking full advantage of in the context of FastAPI. I wrote a little library called fastapi-oracle which I'm using as a bit of glue code, and I hope it's of use to anyone else out there who needs to marry those two particular bits of tech together.
There has been a not-insignificant amount of chit-chat on the interwebz lately, voicing concern that FastAPI is a one-man show (with its BDFL@tiangolo showing no intention of that changing anytime soon), and that the FastAPI issue and pull request queues receive insufficient TLC. Based on my experience so far, I'm not too concerned about this. It is, generally speaking, not ideal if a project has a bus factor of 1, and if support requests and bug fixes are left to rot.
However, in my opinion, the code and the documentation of FastAPI are both high-quality and highly-consistent, and I appreciate that this is largely thanks to @tiangolo continuing to personally oversee every small change, and that loosening the reins would mean a high risk of that deteriorating. And, speaking of quality, I personally have yet to uncover any bugs either in FastAPI or its core dependencies (which I'm pleasantly surprised by, considering how heavily I've been using it) – it would appear that the items languishing in the queue are lower priority, and it would appear that @tiangolo is on top of critical bugs as they arise.
In summary, I'm enjoying coding with FastAPI, I feel like it's a great fit for building Python web apps in 2024, and it will continue to be my Python framework of choice for the foreseeable future.
]]>
GDPR-compliant Google reCAPTCHA2022-08-28T00:00:00Z2022-08-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/08/gdpr-compliant-google-recaptcha/
Per the EU's GDPR and ePrivacy Directive, you must ask visitors to a website for their consent before setting any cookies, and/or before collecting any user tracking data. And because the GDPR applies to all EU citizens (who are residing within the EU), regardless of where in the world a website or its owner is based, in order to fully comply, in practice you should seek consent for all visitors to all websites globally.
In order to be GDPR-compliant, and in order to just be a good netizen, I made sure, when building GreenAsh v5 earlier this year, to not use services that set cookies at all, wherever possible. In previous iterations of GreenAsh, I used Google Analytics, which (like basically all Google services) is a notorious GDPR offender; this time around, I instead used Cloudflare Web Analytics, which is a good enough replacement for my modest needs, and which ticks all the privacy boxes.
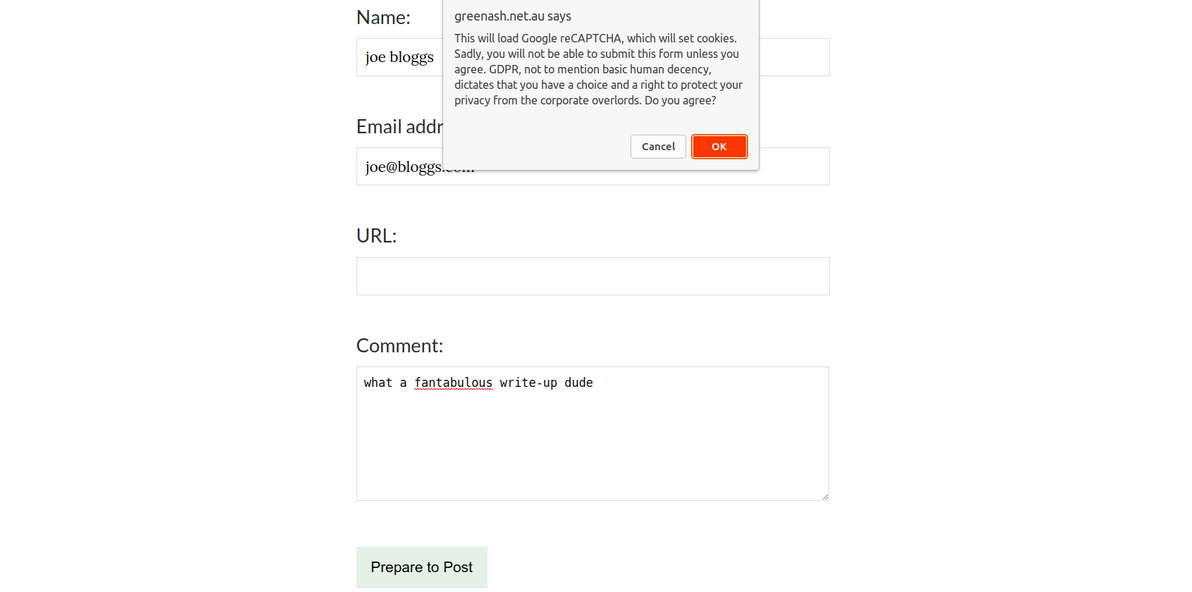
However, on pages with forms at least, I still need Google reCAPTCHA. I'd like to instead use the privacy-conscious hCaptcha, but Netlify Forms only supports reCAPTCHA, so I'm stuck with it for now. Here's how I seek the user's consent before loading reCAPTCHA.
ready(() => {
const submitButton = document.getElementById('submit-after-recaptcha');
if (submitButton == null) {
return;
}
window.originalSubmitFormButtonText = submitButton.textContent;
submitButton.textContent = 'Prepare to ' + window.originalSubmitFormButtonText;
submitButton.addEventListener("click", e => {
if (submitButton.textContent === window.originalSubmitFormButtonText) {
return;
}
const agreeToCookiesMessage =
'This will load Google reCAPTCHA, which will set cookies. Sadly, you will ' +
'not be able to submit this form unless you agree. GDPR, not to mention ' +
'basic human decency, dictates that you have a choice and a right to protect ' +
'your privacy from the corporate overlords. Do you agree?';
if (window.confirm(agreeToCookiesMessage)) {
const recaptchaScript = document.createElement('script');
recaptchaScript.setAttribute(
'src',
'https://www.google.com/recaptcha/api.js?onload=recaptchaOnloadCallback' +
'&render=explicit');
recaptchaScript.setAttribute('async', '');
recaptchaScript.setAttribute('defer', '');
document.head.appendChild(recaptchaScript);
}
e.preventDefault();
});
});
I load this JS on every page, thus putting it on the lookout for forms that require reCAPTCHA (in my case, that's comment forms and the contact form). It changes the form's submit button text from, for example, "Send", to instead be "Prepare to Send" (as a hint to the user that clicking the button won't actually submit the form, there will be further action required before that happens).
It hijacks the button's click event, such that if the user hasn't yet provided consent, it shows a prompt. When consent is given, the Google reCAPTCHA JS is added to the DOM, and reCAPTCHA is told to call recaptchaOnloadCallback when it's done loading. If the user has already provided consent, then the button's default click behaviour of triggering form submission is allowed.
I embed this HTML inside every form that requires reCAPTCHA. It defines the wrapper element into which the reCAPTCHA is injected. And it defines recaptchaOnloadCallback, which changes the submit button text back to what it originally was (e.g. changes it from "Prepare to Send" back to "Send"), and which actually renders the reCAPTCHA widget.
This is what my GDPR-compliant, reCAPTCHA-enabled, Netlify-powered contact form looks like. The data-netlify-recaptcha attribute tells Netlify to require a successful reCAPTCHA challenge in order to accept a submission from this form.
The prompt before the reCAPTCHA in action
That's all there is to it! Not rocket science, but I just thought I'd share this with the world, because despite there being a gazillion posts on the interwebz advising that you "ask for consent before setting cookies", there seem to be surprisingly few step-by-step instructions explaining how to actually do that. And the standard advice appears to be to use a third-party script / plugin that implements an "accept cookies" popup for you, even though it's really easy to implement it yourself.
]]>
Introducing: Instant-runoff voting simulator2022-05-17T00:00:00Z2022-05-17T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/05/introducing-instant-runoff-voting-simulator/
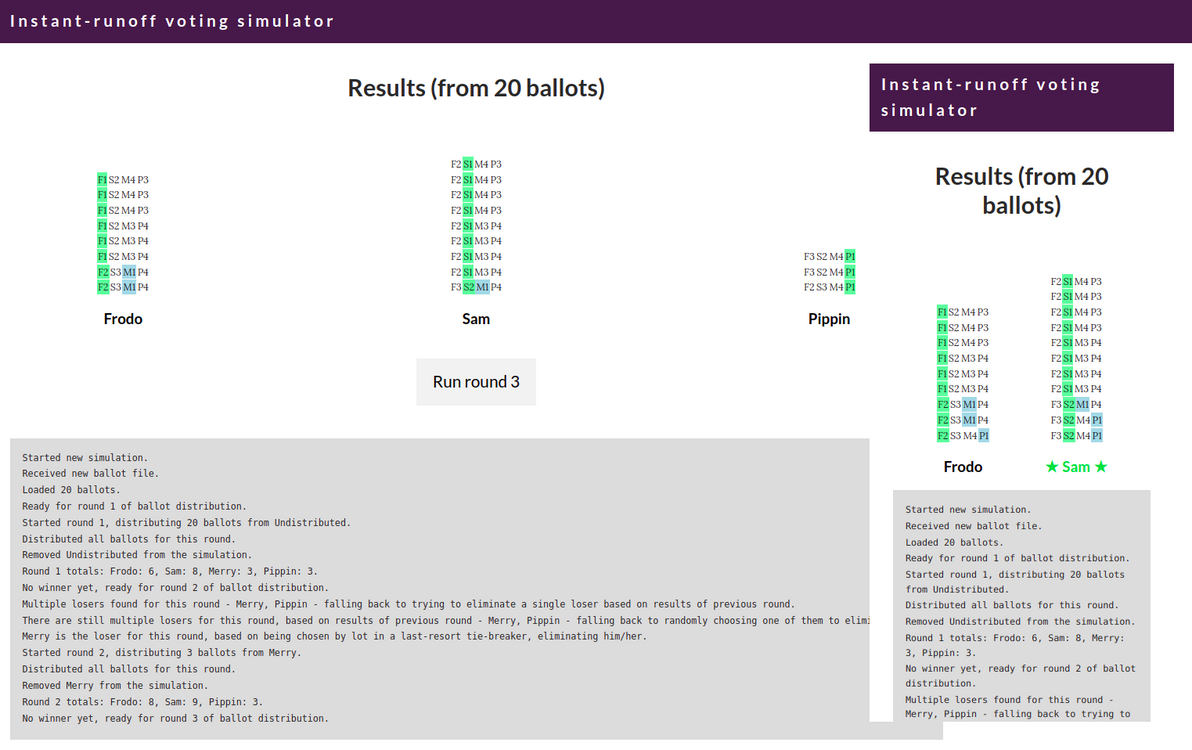
I built a simulator showing how instant-runoff voting (called preferential voting in Australia) works step-by-step. Try it now.
The simulator in action
I hope that, by being an interactive, animated, round-by-round visualisation of the ballot distribution process, this simulation gives you a deeper understanding of how instant-runoff voting works.
There are other tools around that do basically the same thing as this simulator. Kudos to the authors of those tools. However, they only output a text log or a text-based table, they don't provide any visualisation or animation of the vote-counting process. And they spit out the results for all rounds all at once, they don't show (quite as clearly) how the results evolve from one round to the next.
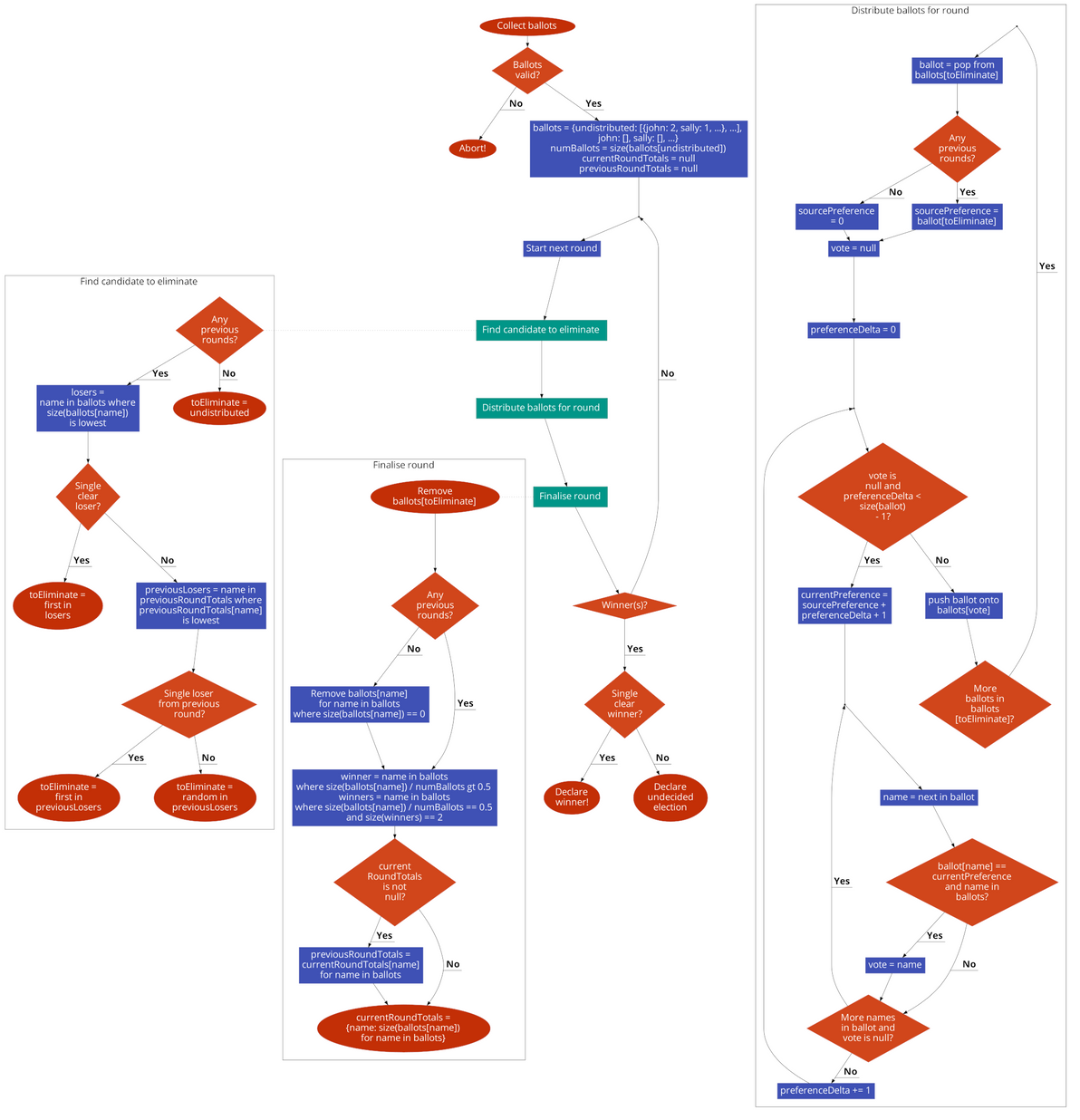
Source code is all up on GitHub. It's coded in vanilla JS, with the help of the lovely Papa Parse library for CSV handling. I made a nice flowchart version of the code too.
With a federal election coming up, here in Australia, in just a few days' time, this simulator means there's now one less excuse for any of my fellow citizens to not know how the voting system works. And, in this election more than ever, it's vital that you properly understand why every preference matters, and how you can make every preference count.
]]>
On Tina2021-06-25T00:00:00Z2021-06-25T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/06/on-tina/
Continuing my foray into the world of Static Site Generators (SSGs), this time I decided to try out one that's quite different: TinaCMS (although Tina itself isn't actually an SSG, it's just an editing toolkit; so, strictly speaking, the SSG that I took for a spin is Next.js). Shiny new toys. The latest and greatest that the JAMstack has to offer. Very much all alpha (I encountered quite a few bugs, and there are still some important features missing entirely). But wow, it really does let you have your cake and eat it too: a fast, dumb, static site when logged out, that transforms into a rich, Git-backed, inline CMS when logged in!
Yes, it's named after that Tina, from Napoleon Dynamite. Image source:Pinterest
Pressing on with my recent tradition of converting old sites of mine from dynamic to static, this time I converted Daydream Believers. I deliberately chose that site, because its original construction with Flask Editable Site had been an experiment, trying to achieve much the same dynamic inline editing experience as that provided by Tina. Plus, the site has been pretty much abandoned by its owners for quite a long time, so (much like my personal sites) there was basically no risk involved in touching it.
To give you a quick run-down of the history, Flask Editable Site was a noble endeavour of mine, about six years ago – the blurb from the demo sums it up quite well:
The aim of this app is to demonstrate that, with the help of modern JS libraries, and with some well-thought-out server-side snippets, it's now perfectly possible to "bake in" live in-place editing for virtually every content element in a typical brochureware site.
This app is not a CMS. On the contrary, think of it as a proof-of-concept alternative to a CMS. An alternative where there's no "admin area", there's no "editing mode", and there's no "preview button".
There's only direct manipulation.
That sounds eerily similar to "the acronym TinaCMS standing for Tina Is Not A CMS" (yes, yet another recursive acronym in the IT world, in the grand tradition of GNU), as explained in the Tina FAQ:
Tina introduces an entirely new paradigm to the content management space, which can make it difficult to grasp. In short, Tina is a toolkit for making your website its own CMS. It's a suite of packages that enables developers to build a customized content management system into the website itself.
(Who knows, maybe Flask Editable Site was one of the things that inspired the guys behind Tina – if so, I'd be flattered – although I don't believe they've heard of it).
Flask Editable Site boasted essentially the same user experience – i.e. that as soon as you log in, everything is editable inline. But the content got saved the old-skool CMS way, in a relational database. And the page(s) got rendered the old-skool CMS way, dynamically at run-time. And all of that required an old-skool deployment, on an actual server running Nginx / PostgreSQL / gunicorn (or equivalents). Plus, the Flask Editable Site inline components didn't look as good as Tina's do out-of-the-box (although I tried my best, I thought they looked half-decent).
So, I rebuilt Daydream Believers in what is currently the recommended Tina way (it's the way the tinacms.org website itself is currently built): TinaCMS running on top of Next.js, and saving content directly to GitHub via its API. Although I didn't use Tina's GitHub media store (which is currently the easiest way to manage images and other media with Tina), I instead wrote an S3 media store for Tina – something that Tina is sorely lacking, and that many other SSGs / headless CMSes already have. I hope to keep working on that draft PR and to get it merged sometime soon. The current draft works, I'm running it in production, but it has some rough edges.
Daydream Believers with TinaCMS editing mode enabled.
The biggest hurdle for me, in building my first Tina site, was the fact that a Tina website must be built in React. I've dabbled in React over the past few years, mainly in my full-time job, not particularly by choice. It's rather ironic that this is my first full project built in React, and it's a static website! It's not that I don't like the philosophy or the syntax of React, I'm actually pretty on board with all that (and although I loathe Facebook, I've never held that against React).
It's just that: React is quite a big learning curve; it bloats a web front-end with its gazillion dependencies; and every little thing in the front-end has to be built (or rebuilt) in React, because it doesn't play nicely with any non-React code (e.g. old-skool jQuery) that touches the DOM directly. Anyway, I've now learnt a fair bit of React (still plenty more learning to go); and the finished site seems to load reasonably fast; and I managed to get the JS from the old site playing reasonably nicely with the new site (some via a hacky plonking of old jQuery-based code inside the main React "app" component, and some via rewriting it as actual React code).
Nevertheless, I'm super impressed with it. This is the kind of delightful user experience that I and many others were trying to build 15+ years ago in Drupal. I've cared about making awesome editable websites for an awfully long time now, and I really am overjoyed to see that awesomeness evolving to a whole new level with Tina.
Compared to the other SSGs that I've used lately – Hugo and Eleventy – Tina (slash Next.js) does have some drawbacks. It's far less mature. It has a slower build time. It doesn't scale as well. The built front-end is fatter. You can't just copy-paste legacy JS into it. You have to accept the complexity cost of React (just to build a static site!). You have to concern yourself with how everything looks in edit mode. Quite a lot of boilerplate code is required for even the simplest site.
You can also accompany traditional SSGs, such as Hugo and Eleventy, with a pretty user-friendly (and free, and SaaS) git-based CMS, such as Forestry (PS: the Forestry guys created Tina) or Netlify CMS. They don't provide any inline editing UI, they just give you a more traditional "admin site". However, they do have pretty good "live preview" functionality. Think of them as a middle ground between a traditional SSG with no editing UI, and Tina with its rich inline editing.
So, would I use Tina again? For a smaller brochureware site, where editing by non-devs needs to be as user-friendly as possible, and where I have the time / money / passion (pick approximately two!) to craft a great experience, sure, I'd love to (once it's matured a bit more). For larger sites (100+ pages), and/or for sites where user-friendly editing isn't that important, I'd probably look elsewhere. Regardless, I'm happy to be on board for the Tina journey ahead.
]]>
On Eleventy2021-04-14T00:00:00Z2021-04-14T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/04/on-eleventy/
Following on from my last experiment with Hugo, I decided to dabble in a different static site generator (SSG). This time, Eleventy. I've rebuilt another one of my golden oldies, Jaza's World, using it. And, similarly, source code is up on GitHub, and the site is hosted on Netlify. I'm pleased to say that Eleventy delivered in the areas where Hugo disappointed me most, although there were things about Hugo that I missed.
11ty!
First and foremost, Eleventy allows virtually all the custom code you might need. This is in stark contrast to Hugo, with which my biggest gripe was its lack of support for any custom code whatsoever, except for template code. The most basic code hook that Eleventy supports – filters – will get you pretty far: I whipped up some filters for date formatting, for array slicing, for getting parent pages, and for getting subsets of tags. Eleventy's custom collections are also handy: for example, I defined a collection for my nav menu items. I didn't find myself needing to write any Eleventy plugins of my own, but my understanding is that you have access to the same Eleventy API methods in a plugin, as you do in a regular site-level .eleventy.js file.
One of Eleventy's most powerful features is its pagination. It's implemented as a "core plugin" (Pagination.js is the only file in Eleventy core's Plugins directory), but it probably makes sense to just think of it as a core feature, period. Its main use case is, unsurprisingly, for paging a list of content. That is, for generating /articles/, /articles/page/2/, /articles/page/99/, and so on. But it can handle any arbitrary list of data, it doesn't have to be "page content". And it can generate pages based on any permalink pattern, which you can set to not even include a "page number" at all. In this way, Eleventy can generate pages "dynamically" from data! Jaza's World doesn't have a monthly archive, but I could have created one using Eleventy pagination in this way (whereas a dynamically-generated monthly archive is currently impossible in Hugo, so I resorted to just manually defining a page for each month).
Jaza's World migrated to 11ty
Eleventy's pagination still has a few rough edges. In particular, it doesn't (really) currently support "double pagination". That is, /section-foo/parent-bar-generated-by-pagination/child-baz-also-generated-by-pagination/ (although it's the same issue even if parent-bar is generated just by a permalink pattern, without using pagination at that parent level). And I kind of needed that feature, like, badly, for the Gallery section of Jaza's World. So I added support for this to Eleventy myself, by way of letting the pagination key be determined dynamically based on a callback function. As of the time of writing, that PR is still pending review (and so for now, on Jaza's World, I'm running a branch build of Eleventy that contains my change). Hopefully it will get in soon, in which case the enhancement request for double pagination (which is currently one of three "pinned" issues in the Eleventy issue tracker) should be able to be considered fulfilled.
JavaScript isn't my favourite language. I've been avoiding heavy front-end JS coding (with moderate success) for some time, and I've been trying to distance myself from back-end Node.js coding too (with less success). Python has been my language of choice for yonks now. So I'm giving Eleventy a good rap despite it being all JS, not because of it. I like that it's a minimalist JS tool, that it's not tied to any massive framework (such as React), and that it appears to be quite performant (I haven't formally benchmarked it against Hugo, but for my modest needs so far, Eleventy has been on par, it generates Jaza's World with its 500-odd pages in about 2 seconds). And hey, JS is as good a language as any these days, for the kind of script snippets you need when using a static site generator.
Eleventy has come a long way in a short time, but nevertheless, I don't feel that it's worthy yet of being called a really solid tool. Hugo is certainly a more mature piece of software, and a more mature community. In particular, Eleventy feels like a one-man show (Hugo suffers from this too, but it seems to have developed a slightly better contributor base). Kudos to zachleat for all the amazing work he has done and continues to do, but for Eleventy to be sustainable long-term, it needs more of a team.
With Jaza's World, I played around with Eleventy a fair bit, and got a real site built and deployed. But there's more I could do. I didn't bother moving any of my custom code into their own files, nor into separate plugins, I just left them in .eleventy.js. I also didn't bother writing JS unit tests – for a more serious project, what I'd really like to do, is to have tests that run in a CI pipeline (ideally in GitHub Actions), and to only kick off a Netlify deployment once there's a green build (rather than the usual setup of Netlify deploying as soon as the master branch in GitHub is updated).
Site building in Eleventy has been fun, I reckon I'll be doing more of it!
]]>
On Hugo2021-02-11T00:00:00Z2021-02-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/02/on-hugo/
After having it on my to-do list for several years, I finally got around to trying out a static site generator (SSG). In particular, Hugo. I decided to take Hugo for a spin, by rebuilding one of my golden oldies, Jaza's World Trip, with it. And, for bonus points, I published the source code on GitHub, and I deployed the site on Netlify. Hugo is great software with a great community, however it didn't quite live up to my expectations.
Hugo: fast like a... gopher? Image source:Hugo
Memory lane
To give you a bit of history: worldtrip was originally built in Drupal (version 4.7), back in 2007. So it started its life as a real, old-school, PHP CMS driven blog. I actually wrote most of the blog entries from internet cafés around the world, by logging in and typing away – often while struggling with a non-English keyboard, a bad internet connection, a sluggish machine, and a malware-infested old Windows. Ah, the memories! And people posted comments too.
Then, in 2014, I converted it to a "static PHP site", which I custom-built. It was static as in "no database" – all the content was in flat files, virtually identical to the "content files" of Hugo and other SSGs – but not quite static as in "plain HTML files". It was still PHP, and so it still needed to be served by a PHP-capable web server (like Apache or Nginx with their various modules).
In retrospect, maybe I should have SSG-ified worldtrip in 2014. But SSGs still weren't much of a thing back then: Hugo was in its infancy; Netlify didn't exist yet; nor did any of the JS-based cool new kids. The original SSG, Jekyll, was around, but it wasn't really on my radar (I didn't try out Jekyll until around 2016, and I never ended up building or deploying a finished site with it). Plus I still wasn't quite ready to end my decade-long love affair with PHP (I finally got out of that toxic relationship for good, a few years later). Nor was I able to yet embrace the idea of hosting a whole web site on anything other than an old-school box: for a decade or so, all I had known was "shared hosting" and VPSes.
Hugo time
So, it's 2021, and I've converted worldtrip yet again, this time to Hugo. It's pretty much unchanged on the surface. The main difference is that the trip photos (both in the "gallery" section, and embedded in blog posts) are now sourced from an S3 bucket instead of from Flickr (I needed to make this change in order to retire my Flickr account). I also converted the location map from a Google map to a Leaflet / Mapbox map (this was also needed, as Google now charges for even the simplest Maps API usage). I could have made those changes without re-building the whole site, but they were a good excuse to do just that.
The Leaflet and Mapbox powered location map.
True to its word, I can attest that Hugo is indeed fast. On my local machine, Hugo generates all of the 2,000+ pages of worldtrip in a little over 2 seconds. And deploying it on Netlify is indeed easy-peasy. And free – including with a custom domain, with SSL, with quite generous bandwidth, with plenty of build minutes – so kudos to Netlify (and I hope they keep on being so generous!).
Hugo had pretty much everything I needed, to make re-building worldtrip a breeze: content types, front matter, taxonomies, menus, customisable URLs, templating (including partials and shortcodes), pagination, and previous / next links. It didn't support absolutely all of worldtrip's features out-of-the-box – but then again, nothing ever does, right? And filling in those remaining gaps was going to be easy, right?
As it turns out, building custom functionality in Hugo is quite hard.
The first pain point that I hit, was worldtrip's multi-level (country / city) taxonomy hierarchy. Others have shared their grief with this, and I shared mine there too. I got it working, but only by coding way more logic into a template than should have been necessary, and by abusing the s%#$ out of Hugo templating's scratch feature. The resulting partial template is an unreadable abomination. It could have been a nice, clean, testable function (and it previously was one, in PHP), were I able to write any actual code in a Hugo site (in Go or in any other language). But no, you can't write actual code in a Hugo site, you can only write template logic.
Update: I just discovered that support for return'ing a value of any type (rather than just rendering a string) was added to Hugo a few years back (and is documented, albeit rather tersely). So I could rely on Hugo's scratch a bit less, if I were to instead return the countries / cities array. But the logic still has to live in a template!
Same with the tag cloud. It's not such a big deal, it's a problem that various people have solved at the template level, and I did so too. What I did for weighted tags isn't totally illegible. But again, it was previously (pre-Hugo) implemented as a nice actual function in code, and now it's shoved into template logic.
The weighted tag cloud.
The photo gallery was cause for considerable grief too. Because I didn't want an individual page to be rendered for each photo, my first approach was to define the gallery items in data files. But I needed the listing to be paginated, and I soon discovered that Hugo's pagination only supports page collections, not arbitrary lists of data (why?!). So, take two, I defined them as headless bundles. But it just so happens that listing headless bundles (as opposed to just retrieving a single one) is a right pain, and if you're building up a list of them and then paginating that list, it's also hacky and very inefficient (when I tried it, my site took 4x longer to build, because it was calling readDir on the whole photo directory, for each paginated chunk).
Finally, I stumbled across Hugo's (quite new) "no render" feature, and I was able to define and paginate my gallery items (without having a stand-alone page for each photo) in an efficient and non-hacky way, by specifying the build options render = "never" and list = "local". I also fixed a bug in Hugo itself (my first tiny bit of code written in golang!), to exclude "no render" pages from the sitemap (as of writing, the fix has been merged but not included in a stable Hugo release), thus making it safe(r) to specify list = "always" (which you might need, instead of list = "local", if you want to list your items anywhere else on the site, other than on their parent page). So, at least with the photo gallery – in contrast to my other above-mentioned Hugo pain points – I'm satisfied with the end result. Nevertheless, a more-than-warranted amount of hair tearing-out did occur.
The worldtrip monthly archive wasn't particularly hard to implement, thanks to this guide that I followed quite closely. But I was disappointed that I had to create a physical "page" content file for each month, in order for Hugo to render it. Because guess what, Hugo doesn't have built-in support for chronological archive pages! And because, since Hugo offers no real mechanism for you to write code anywhere to (programmatically) render such pages, you just have to hack around that limitation. I didn't do what the author of that guide did (he added a stand-alone Node.js script to generate more archive "page" content files when needed), because worldtrip is a retired site that will never need more such pages generated, and because I'd rather avoid having totally-separate-to-Hugo build scripts like that. The monthly archive templates also contain more logic than they ideally should.
The monthly archive index page.
Mixed feelings
So, I succeeded in migrating worldtrip to Hugo. I can pat myself on the back, job well done, jolly good old chap. I don't regret having chosen Hugo: it really is fast; it's a well-written (to my novice golang eyes) and well-maintained open-source codebase; it boasts an active dev and support community; its documentation is of a high standard; and it comes built-in with 95% of the functionality that any static site could possibly need.
I wanted, and I still want, to love Hugo, for those reasons. And just because it's golang (which I have vaguely been wanting to learn lately … although I have invested time in learning the basics of other languages over the past several years, namely Erlang and Rust). And because it really seems like the best-in-breed among SSGs: it's focused on the basics of HTML page generation (not trying to "solve React for static sites", or other such nonsense, at the same time); it takes performance and scalability seriously; and it fosters a good dev, design, and content authoring experience.
However, it seems that, by design, it's completely impossible to write custom code in an actual programming language (not in a presentation-layer template), that's hooked in to Hugo in any way (apart from by hacking Hugo core). I don't mind that Hugo is opinionated. Many great pieces of software are opinionated – Django, for example.
But Django is far more flexible: you can programmatically render any page, with any URL, that takes your fancy; you can move any presentational logic you want into procedural code (usually either in the view layer, to populate template variables, or in custom template tags), to keep your templates simple; and you can model your data however you want (so you're free to implement something like a multi-level taxonomy yourself – although I admit that this isn't a fair apples vs apples comparison, as Django data is stored in a database). I realise that Django – and Rails, and Drupal, and WordPress – all generate dynamic sites; but that's no excuse, an SSG can and should allow the same level of flexibility via custom code.
Hugo is somewhat lacking in flexibility. Image source:pixabay
There has been some (but not that much) discussion about supporting custom code in Hugo (mainly for the purpose of fetching and parsing custom data, but potentially for more things). There are technical challenges (mainly related to Go being a compiled language), but it would be possible (not necessarily in Go, various other real programming languages have been suggested). Also some mention of custom template functions (that thread is already quite old though). Nothing has been agreed upon or built to date. I for one will certainly watch this space.
For my next static site endeavour, at least, I think I'll take a different SSG for a spin. I'm thinking Eleventy, which appears to allow a lot of custom code, albeit all JS. (And my next project will be a migration of another of my golden oldies, most likely Jaza's World, which has a similar tech history to worldtrip).
Will I use Hugo again? Probably. Will I contribute to Hugo more? If I have time, and if I have itches to scratch, then sure. However, I'm a dev, and I like to code. And Hugo, despite having so much going for it, seems to be completely geared towards people who aren't devs, and who just want to publish content. So I don't see myself ever feeling "right at home" with Hugo.
]]>
Private photo collections with AWSPics2021-02-02T00:00:00Z2021-02-02T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/02/private-photo-collections-with-awspics/
I've created a new online home for my formidable collection of 25,000 personal photos. They now all live in an S3 bucket, and are viewable in a private gallery powered by the open-source AWSPics. In general, I'm happy with the new setup.
For the past 15 years, I have painstakingly curated and organised my photos on Flickr. I have no complaints or regrets: Flickr was and still is a fantastic service, and in its heyday it was ahead of its time. However, after 15 years as a loyal Pro member, it's with bittersweet reluctance that I've decided to cancel my Flickr account. The main reason for my parting ways with Flickr, is that its price has increased (and is continuing to increase), quite significantly of late, after being set in stone for many years.
I also just wanted to build (and felt that I was quite overdue in building) a photo solution crafted (at least partially) with my own hands, and that I fully control, rather than just letting SaaS do all the work for me. Similarly, even though I've always trusted and I still trust Flickr with my data, I wanted to migrate my photos to a storage back-end that I own and manage myself, and an S3 bucket is just that (at the least, IaaS is closer to that ideal than SaaS is).
I had never made any of my personal photos private, although I always could have, back in the Flickr days. I never felt that it was necessary. I was young and free, and the photos were all of me hanging out with my friends, and/or gallivanting around the world with other carefree backpackers. But I'm at a different stage of my life now. These days, the photos are all of my kids, and so publishing them for the whole world to see is somewhat less appropriate. And AWSPics makes them all private by default. So, private it is.
Many thanks to jpsim for building AWSPics, it's a great little stack. AWSPics had nearly everything I needed, when I stumbled across it about 3 months ago, and I certainly could have used it as-is, no yours-truly dev required. But, me being a fastidious ol' dev, and it being open-source, naturally I couldn't help but add a few bells and whistles to it. In particular, I scratched my own itch by building support for collections of albums, so that I could preserve the three-level hierarchy of Collections -> Albums -> Pictures that I used religiously on Flickr. I also wrote a whole lot of unit tests for the AWSPics site builder (which is a Node.js Lambda function), before making any changes, to ensure that I didn't break existing functionality. Other than that, I just submitted a few minor bug fixes.
I'm not planning on enhancing AWSPics a whole lot more. It works for my humble needs. I'm a dev, not a designer, nor a photographer. Although 25,000 photos is a lot (and growing), and I feel like I'm pushing the site builder Lambda a bit close to its limits at the moment (it takes over a minute to run, and ideally a Lambda function completes within a few seconds). Adding support for partial site rebuilds (i.e. only rebuild specific albums or collections) would resolve that. Plus I'm sure there are a few more minor bits and pieces I could work on, should I have the time and the inclination.
Well, that's all I have to say about that. Just wanted to formally announce that shift that my photo collection has made, and to give kudos where it's deserved.
]]>
Good devs care about code2021-01-28T00:00:00Z2021-01-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/01/good-devs-care-about-code/
Theories abound regarding what makes a good dev. These theories generally revolve around one or more particular skills (both "hard" and "soft"), and levels of proficiency in said skills, that are "must-have" in order for a person to be a good dev. I disagree with said theories. I think that there's only one thing that makes a good dev, and it's not a skill at all. It's an attitude. A good dev cares about code.
There are many aspects of code that you can care about. Formatting. Modularity. Meaningful naming. Performance. Security. Test coverage. And many more. Even if you care about just one of these, then: (a) I salute you, for you are a good dev; and (b) that means that you're passionate about code, which in turn means that you'll care about more aspects of code as you grow and mature, which in turn means that you'll develop more of them there skills, as a natural side effect. The fact that you care, however, is the foundation of it all.
Put your hands in the air like you just don't care. Image source:TripAdvisor
If you care about code, then code isn't just a means to an end: it's an end unto itself. If you truly don't care about code at all, but only what it accomplishes, then not only are you not a good dev, you're not really a dev at all. Which is OK, not everyone has to be a dev. If what you actually care about is that the "Unfranked Income YTD" value is accurate, then you're probably a (good) accountant. If it's that the sidebar is teal, then you're probably a (good) graphic designer. If it's that national parks are distinguishable from state forests at most zoom levels, then you're probably a (good) cartographer. However, if you copy-pasted and cobbled together snippets of code to reach your goal, without properly reading or understanding or caring about the content, then I'm sorry, but you're not a (good) dev.
Of course, a good dev needs at least some "hard" skills too. But, as anyone who has ever interviewed or worked with a dev knows, those skills – listed so prominently on CVs and in JDs – are pretty worthless if there's no quality included. Great, 10 years of C++ experience! And you've always given all variables one-character names? Great, you know Postgres! But you never add an index until lots of users complain that a page is slow? Great, a Python ninja! What's that, you just write one test per piece of functionality, and it's a Selenium test? Call me harsh, but those sound to me like devs who just don't care.
"Soft" skills are even easier to rattle off on CVs and in JDs, and are worth even less if accompanied by the wrong attitude. Conversely, if a dev has the right attitude, then these skills flourish pretty much automatically. If you care about the code you write, then you'll care about documentation in wiki pages, blog posts, and elsewhere. You'll care about taking the initiative in efforts such as refactoring. You'll care about collaborating with your teammates more. You'll care enough to communicate with your teammates more. "Caring" is the biggest and the most important soft skill of them all!
Plus Jamiroquai dancing skills. Image source:Rick Kuwahara
Formal education in programming (from a university or elsewhere) certainly helps with developing your skills, and it can also start you on your journey of caring about code. But you can find it in yourself to care, and you can learn all the tools of the trade, without any formal education. Many successful and famous programmers are proof of that. Conversely, it's possible to have a top-notch formal education up your sleeve, and to still not actually care about code.
It's frustrating when I encounter code that the author clearly didn't care about, at least not in the same ways that I care. For example, say I run into a thousand-line function. Argh, why didn't they break it up?! It might bother me first and foremost because I'm the poor sod who has to modify that code, 5 years later; that is, now it's my problem. But it would also sadden me, because I (2021 me, at least!) would have cared enough to break it up (or at least I'd like to think so), whereas that dev at that point in time didn't care enough to make the effort. (Maybe that dev was me 5 years ago, in which case I'd be doubly disappointed, although wryly happy that present-day me has a higher care factor).
Some aspects of code are easy to start caring about. For example, meaningful naming. You can start doing it right now, no skills required, except common sense. You can, and should, make this New Year's resolution: "I will not name any variable, function, class, file, or anything else x, I will instead name it num_bananas_in_tummy"! Then follow through on that, and the world will be a better place. Amen.
Others are more challenging. For example, test coverage. You need to first learn how to write and run tests in one or more programming languages. That has gotten much easier over the past few decades, depending on the language, but it's still a learning curve. You also need to learn the patterns of writing good tests (which can be a whole specialised career in itself). Plus, you need to understand why tests (particularly unit tests), and test coverage, are important at all. Only then can you start caring. I personally didn't start writing or caring about tests until relatively recently, so I empathise with those of you who haven't yet got there. I hope to see you soon on the other side.
I suspect that this theory of mine applies in much the same way, to virtually all other professions in the world. Particularly professions that involve craftsmanship, but other professions too. Good pharmacists actually care about chemical compounds. Good chefs actually care about fresh produce. Good tailors actually care about fabrics. Good builders actually care about bricks. It's not enough to just care about the customers. It's not enough to just care about the end product. And it's certainly not enough to just care about the money. In order to truly excel at your craft, you've got to actually care about the raw material.
I'm not writing this as an attack on anyone that I know, or that I've worked with, or whose code I've seen. In fact, I've been fortunate in that almost all fellow devs with whom I have crossed paths, are folks who have demonstrated that they care, and who are therefore, in my humble opinion, good devs. And I'm not trying to make myself out to be the patron saint of caring about code, either. Sorry if I sound patronising in this article. I'm not perfect any more than anyone else is. Plenty of people care more than I do. And different people care about different things. And we're all on a journey: I cared about less aspects of code 10 years ago, than I do now; and I hope to care about more aspects of code than I do today, 10 years in the future.
]]>
Twelve ASX stocks with record growth since 20002018-05-29T00:00:00Z2018-05-29T00:00:00ZJazahttps://greenash.net.au/thoughts/2018/05/twelve-asx-stocks-with-record-growth-since-2000/
I recently built a little web app called What If Stocks, to answer the question: based on a start and end date, and a pool of stocks and historical prices, what would have been the best stocks to invest in? This app isn't rocket science, it just ranks the stocks based on one simple metric: change in price during the selected period.
I imported into this app, price data from 2000 to 2018, for all ASX (Australian Securities Exchange) stocks that have existed for roughly the whole of that period. I then examined the results, for all possible 5-year and 10-year periods within that date range. I'd therefore like to share with you, what this app calculated to be the 12 Aussie stocks that have ranked No. 1, in terms of market price increase, for one or more of those periods.
If you've never heard of this company before, don't worry, neither had I. Incitec Pivot is a fertiliser and explosives chemicals production company. It's the largest fertiliser manufacturer in Australia, and the second-largest explosives chemicals manufacturer in the world. It began in the early 2000s as the merger of former companies Incitec Fertilizers and the Pivot Group.
Incitec Pivot was a very cheaply priced stock for its first few years on the ASX, 2003-2005. Then, between 2005 and 2008, its value rocketed up as it acquired numerous other companies, and significantly expanded its manufacturing operations. So, in terms of a 5-year or 10-year return, it was a fabulous stock to invest in throughout the 2003-2007 period. However, its growth has been mediocre or poor since 2008.
Monadelphous is a mining infrastructure (and other industrial infrastructure) construction company based in Perth. They build, expand, and manage big installations such as LNG plants, iron ore ports, oil pipelines, and water treatment plants, in Northern Australia and elsewhere.
By the volatile standards of the mining industry (which it's basically a part of), Monadelphous has experienced remarkably consistent growth. In particular, it enjoyed almost constant growth from 2000 to 2013, which means that, in terms of a 5-year or 10-year return, it was an excellent stock to invest in throughout the 2000-2007 period. Monadelphous is somewhat vulnerable to mining crashes, although it recovered well after the 2008 GFC. However, its growth has been mediocre or poor for much of the time since 2013.
No. 1 growth stock 2001-2011 ($0.0074 - $4.05, +55,000%), and 2002-2012, and 2003-2013
Fortescue is one of the world's largest iron ore producers. Started in the early 2000s as a tiny company, in the hands of Andrew Forrest (now one of Australia's richest people) it has grown to rival the long-time iron ore giants BHP and Rio Tinto. Fortescue owns and operates some of the world's largest iron ore mines, in the Pilbara region of Western Australia.
Fortescue was a small company and a low-value stock until 2006, when its share price shot up. Apart from a massive spike in 2008 (before the GFC), and various other high times since then, its price has remained relatively flat since then. So, in terms of a 5-year or 10-year return, it was an excellent investment throughout the 2000-2007 period. However, its growth has been mediocre or poor since 2008.
CTI is a freight and heavy hauling company based in Perth. It does a fair chunk of its business hauling and storing materials for the mining industry. However, it also operates a strong consumer parcel delivery service.
CTI experienced its price surge almost entirely during 2005 and 2006. Since then, its price has been fairly stable, except that it rose somewhat during the 2010-2013 mining boom, and then fell back to its old levels during the 2014-2017 mining crash. In terms of a 5-year or 10-year return, it was a good investment throughout the 2000-2011 period.
Credit Corp Group is a debt collection company. As that description suggests, and as some quick googling confirms, they're the kind of company you do not want to have dealings with. They are apparently one of those companies that hounds people who have unpaid phone bills, credit card bills, and the like.
Anyway, getting indebted persons to pay up (with interest, of course) is apparently a business that pays off, because Credit Corp has shown consistent growth for the entire period being analysed here. In terms of a 5-year or 10-year return, it was a solid investment for most of 2000-2018 (and it appears to still be on a growth trajectory), although it yielded not so great returns for those buying in 2003-2007. All up, one of the strongest growth stocks in this list.
Ainsworth Game Technology is a poker machine (aka slot machine) manufacturing company. It's based in Sydney, where it no doubt enjoys plenty of business, NSW being home to half of all pokies in Australia, and to the second-largest number of pokies in the world, beaten only by Las Vegas.
Ainsworth stocks experienced fairly flat long-term growth during 2000-2011, but then in 2012 and 2013 the price rose significantly. They have been back on a downhill slide since then, but remain strong by historical standards. In terms of a 5-year or 10-year return, it was a good investment throughout 2003-2011, a good chunk of the period being analysed.
Copper Strike is a mining company. It appears that in the past, it operated mines of its own (copper mines, as its name suggests). However, the only significant thing that it currently does, is make money as a large shareholder of another ASX-listed mining company, Syrah Resources (ASX:SYR), which Copper Strike spun off from itself in 2007, and whose principal activity is a graphite mine in Mozambique.
Copper Strike has experienced quite consistent strong growth since 2010. In terms of a 5-year or 10-year return, it has been a quality investment since 2004 (which is when it was founded and first listed). However, its relatively tiny market cap, plus the fact that it seems to lack any core business activity of its own, makes it a particularly risky investment for the future.
The only company on this list that absolutely everybody should have heard of, Domino's is Australia's largest pizza chain, and Australia is also home to the biggest market for Domino's in the world. Founded in Australia in 1983, Domino's has been a listed ASX company since 2005.
Domino's has been on a non-stop roller-coaster ride of growth and profit, ever since it first listed in 2005. In terms of a 5-year or 10-year return, it has been a fabulous investment since then, more-or-less up to the present day. However, the stock price of Domino's has been dealt a blow for the past two years or so, in the face of reported weak profits, and claims of widespread underpayment of its employees.
Vita Group is the not-so-well-known name of a well-known Aussie brand, the mobile phone retail chain Fone Zone. Although these days, there are only a few Fone Zone branded stores left, and Vita's main business consists of the 100 or so Telstra retail outlets that it owns and manages across the country.
Vita's share price rose to a great peak in 2016, and then fell. In terms of overall performance since it was listed in 2005, Vita's growth has been fairly flat. In terms of a 5-year or 10-year return, it has been a decent investment throughout 2005-2013. Vita may experience strong growth again in future, but it appears more likely to be a low-growth stable investment (at best) from here on.
Red River is a zinc mining company. Its main operation is the Thalanga mine in northern Queensland.
Red River is one of the most volatile stocks in this list. Its price has gone up and down on many occasions. In terms of a 5-year or 10-year return, it was a good investment for 2011-2013, but it was a dud for investment for 2005-2010.
Pro Medicus is a medical imaging software development company. Its flagship product, called Visage, provides a full suite of desktop and server software for use in radiology. Pro Medicus software is used by a number of health care providers in Australia, the US, and elsewhere.
Pro Medicus has been quite a modest stock for most of its history, reporting virtually flat price growth for a long time. However, since 2015 its price has rocketed up, and it's currently riding a big high. This has apparently been due to the company winning several big contracts, particularly with clinics in the US. It looks on track to continue delivering solid growth.
Macquarie Telecom Group is an enterprise telecommunications and data hosting services company. It provides connectivity services and data centres for various Australian government departments, educational institutions, and medium-to-large businesses.
Macquarie Telecom's share price crashed quite dramatically after the dot-com boom around 2000, and didn't really recover again until after the GFC in 2009. It has been riding the cloud boom for some time now, and it appears to be stable in the long-term. In terms of a 5-year or 10-year return, its viability as a good investment has been patchy throughout the past two decades, with some years faring better than others.
Winners or duds?
How good an investment each of these stocks actually was or is, is a far more complex question than what I'm presenting here. But, for what it's worth, what you have here are 12 stocks which, if you happened to buy and sell any of them at exactly the right time in recent history, would have yielded more bang for your buck than any other stocks over the same period. Given the benefit of hindsight (which is always such a wonderful thing, isn't it?), I thought it would be a fun little exercise to identify the stocks that were winners, based on this most dead-simple of all measures.
The most interesting conclusion that I'd like to draw from this list, is what a surprisingly diverse range of industries it encompasses. There is, of course, an over-representation from mining and commodities (the "wild west" of boom-and-bust companies), with six of the stocks (half of the list) more-or-less being from that sector (although only three are actual mining companies – the others are in: chemical processing; mining infrastructure; and mining transport). However, the other six stocks are quite a mixed bag: finance; gambling; fast food; tech retail; health tech; and telco.
What can we learn from this list, about the types of companies that experience massive stock price growth? Well, to rule out one factor: they can be in any industry. Price surges can be attributed to a range of factors, but I'd say that, for the companies in this list, the most common factor has been the securing of new contracts and of new sales pipelines. For some, it has been all about the value of a particular item of goods or services soaring on the global market at a fortuitous moment. And for others, it has simply been a matter of solid management and consistently good service driving the value of the company up and up over a sustained period.
Some of these companies are considered to be actual winners, i.e. they're companies that the experts have identified, on various occasions, as good investments, for more reasons than just the market price growth that I've pointed out here. Other companies in this list are effectively duds, i.e. experts have generally cast doom and gloom upon them, or have barely bothered to analyse them at all.
I hope you enjoyed this run-down of Aussie stocks that, according to my number-crunching, could have been your cash cows, if only you had been armed with this crystal ball back in the day. In future, I'm hoping to improve What If Stocks to provide more insights, and I'm also hoping to analyse stocks in various other markets other than on the ASX.
Acknowledgement: all price data used in this analysis has been sourced from the Alpha Vantage API. All analysis is based on adjusted close prices, i.e. historical prices adjusted to reflect all corporate actions (stock splits, mergers, and so forth) that have occurred between the historical date and the current date.
Disclaimer: this article does not contain or constitute investment advice in any way. The author of this article has neither any qualifications nor any experience in finance or investment. The author has no position in any of the stocks mentioned, nor does the author endorse any of the stocks mentioned.
]]>
DNA: the most chaotic, most illegible, most mature, most brilliant codebase ever2018-04-21T00:00:00Z2018-04-21T00:00:00ZJazahttps://greenash.net.au/thoughts/2018/04/dna-the-most-chaotic-most-illegible-most-mature-most-brilliant-codebase-ever/
As a computer programmer – i.e. as someone whose day job is to write relatively dumb, straight-forward code, that controls relatively dumb, straight-forward machines – DNA is a fascinating thing. Other coders agree. It has been called the code of life, and rightly so: the DNA that makes up a given organism's genome, is the set of instructions responsible for virtually everything about how that organism grows, survives, behaves, reproduces, and ultimately dies in this universe.
Most intriguing and most tantalising of all, is the fact that we humans still have virtually no idea how to interpret DNA in any meaningful way. It's only since 1953 that we've understood what DNA even is; and it's only since 2001 that we've been able to extract and to gaze upon instances of the complete human genome.
As others have pointed out, the reason why we haven't had much luck in reading DNA, is because (in computer science parlance) it's not high-level source code, it's machine code (or, to be more precise, it's bytecode). So, DNA, which is sequences of base-4 digits, grouped into (most commonly) 3-digit "words" (known as "codons"), is no more easily decipherable than binary, which is sequences of base-2 digits, grouped into (for example) 8-digit "words" (known as "bytes"). And as anyone who has ever read or written binary (in binary, octal, or hex form, however you want to skin that cat) can attest, it's hard!
In this musing, I'm going to compare genetic code and computer code. I am in no way qualified to write about this topic (particularly about the biology side), but it's fun, and I'm reckless, and this is my blog so for better or for worse nobody can stop me.
Authorship and motive
The first key difference that I'd like to point out between the two, is regarding who wrote each one, and why. For computer code, this is quite straightforward: a given computer program was written by one of your contemporary human peers (hopefully one who is still alive, as you can then ask him or her about anything that's hard to grok in the code), for some specific and obvious purpose – for example, to add two numbers together, or to move a chomping yellow pac-man around inside a maze, or to add somersaulting cats to an image.
For DNA, we don't know who, if anyone, wrote the first ever snippet of code – maybe it was G-d, maybe it was aliens from the Delta Quadrant, or maybe it was the random result of various chemicals bashing into each other within the primordial soup. And as for who wrote (and who continues to this day to write) all DNA after that, that too may well be The Almighty or The Borg, but the current theory of choice is that a given snippet of DNA basically keeps on re-writing itself, and that this auto-re-writing happens (as far as we can tell) in a pseudo-random fashion.
This guy didn't write binary or DNA, I'm pretty sure. Image source:Art UK.
Nor do we know why DNA came about in the first place. From a philosophical / logical point of view, not having an answer to the "who" question, kind of makes it impossible to address the "why", by defintion. If it came into existence randomly, then it would logically follow that it wasn't created for any specific purpose, either. And as for why DNA re-writes itself in the way that it does: it would seem that DNA's, and therefore life's, main purpose, as far as the DNA itself is concerned, is simply to continue existing / surviving, as evidenced by the fact that DNA's self-modification results, on average, over the long-term, in it becoming ever more optimally adapted to its surrounding environment.
Management processes
For building and maintaining computer software, regardless of "methodology" (e.g. waterfall, scrum, extreme programming), the vast majority of the time there are a number of common non-dev processes in place. Apart from every geek's favourite bit, a.k.a. "coding", there is (to name a few): requirements gathering; spec writing; code review; testing / QA; version control; release management; staged deployment; and documentation. The whole point of these processes, is to ensure: that a given snippet of code achieves a clear business or technical outcome; that it works as intended (both in isolation, and when integrated into the larger system); that the change it introduces is clearly tracked and is well-communicated; and that the codebase stays maintainable.
For DNA, there is little or no parallel to most of the above processes. As far as we know, when DNA code is modified, there are no requirements defined, there is no spec, there is no review of the change, there is no staging environment, and there is no documentation. DNA seems to follow my former boss's preferred methodology: JFDI. New code is written, nobody knows what it's for, nobody knows how to use it. Oh well. Straight into production it goes.
However, there is one process that DNA demonstrates in abundance: QA. Through a variety of mechanisms, the most important of which is repair enzymes, a given piece of DNA code is constantly checked for integrity errors, and these errors are generally repaired. Mutations (i.e. code changes) can occur during replication due to imperfect copying, or at any other time due to environmental factors. Depending on the genome (i.e. the species) in question, and depending on the gene in question, the level of enforcement of DNA integrity can vary, from "very relaxed" to "very strict". For example, bacteria experience far more mutation between generations than humans do. This is because some genomes consider themselves to still be in "beta", and are quite open to potentially dangerous experimentation, while other genomes consider themselves "mature", and so prefer less change and greater stability. Thus a balance is achieved between preservation of genes, and evolution.
The coding process
For computer software, the actual process of coding is relatively structured and rational. The programmer refers to the spec – which could be anything from a one-sentence verbal instruction bandied over the water-cooler, to a 50-page PDF (preferably it's something in between those two extremes) – before putting hands to keyboard, and also regularly while coding.
The programmer visualises the rough overall code change involved (or the rough overall components of a new codebase), and starts writing. He or she will generally switch between top-down (focusing on the framework and on "glue code") and bottom-up (focusing on individual functions) several times. The code will generally be refined, in response to feedback during code review, to fixing defects in the change, and to the programmer's constant critiquing of his or her own work. Finally, the code will be "done" – although inevitably it will need to be modified in future, in response to new requirements, at which point it's time to rinse and repeat all of the above.
For DNA, on the other hand, the process of coding appears (unless we're missing something?) to be akin to letting a dog randomly roll around on the keyboard while the editor window is open, then cleaning up the worst of the damage, then seeing if anything interesting was produced. Not the most scientific of methods, you might say? But hey, that's science! And it would seem that, amazingly, if you do that on a massively distributed enough scale, over a long enough period of time, you get intelligent life.
DNA modification in progress. Image source:DogsToday.
When you think about it, that approach isn't really dissimilar to the current state-of-the-art in machine learning. Getting anything approaching significant or accurate results with machine learning models, has only been possible quite recently, thanks to the availability of massive data sets, and of massive hardware platforms – and even when you let a ML algorithm loose in that environment for a decent period of time, it produces results that contain a lot of noise. So maybe we are indeed onto something with our current approach to ML, although I don't think we're quite onto the generation of truly intelligent software just yet.
Grokking it
Most computer code that has been written by humans for the past 40 years or so, has been high-level source code (i.e. "C and up"). It's written primarily to express business logic, rather than to tell the Von Neumann machine (a.k.a. the computer hardware) exactly what to do. It's up to the compiler / interpreter, to translate that "call function abc" / "divide variable pqr by 50" / "write the string I feel like a Tooheys to file xyz" code, into "load value of register 123" / "put that value in register 456" / "send value to bus 789" code, which in turn actually gets represented in memory as 0s and 1s.
This is great for us humans, because – assuming we can get our hands on the high-level source code – we can quite easily grok the purpose of a given piece of code, without having to examine the gory details of what the computer physically does, step-by-tiny-tedious-step, in order to achieve that noble purpose.
DNA, as I said earlier, is not high-level source code, it's machine code / bytecode (more likely the latter, in which case the actual machine code of living organisms is the proteins, and other things, that DNA / RNA gets "compiled" to). And it now seems pretty clear that there is no higher source code – DNA, which consists of long sequences of Gs, As, Cs, and Ts, is the actual source. The code did not start in a form where a given gene is expressed logically / procedurally – a form from which it could be translated down to base pairs. The start and the end state of the code is as base pairs.
A code that was cracked - can the same be done for DNA? Image source:The University Network.
It also seems that DNA is harder to understand than machine / assembly code for a computer, because an organic cell is a much more complex piece of hardware than a Von Neumann-based computer (which itself is a specific type of Turing machine). That's why humans were perfectly capable of programming computers using only machine / assembly code to begin with, and why some specialised programmers continue primarily coding at that level to this day. For a computer, the machine itself only consists of a few simple components, and the instruction set is relatively small and unambiguous. For an organic cell, the physical machinery is far more complex (and whether a DNA-containing cell is a Turing machine is itself currently an open research question), and the instruction set is riddled with ambiguous, context-specific meanings.
Since all we have is the DNA bytecode, all current efforts to "decode DNA" focus on comparing long strings of raw base pairs with each other, across different genes / chromosomes / genomes. This is akin to trying to understand what software does by lining up long strings of compiled hex digits for different binaries side-by-side, and spotting sequences that are kind-of similar. So, no offense intended, but the current state-of-the-art in "DNA decoding" strikes me as incredibly primitive, cumbersome, and futile. It's a miracle that we've made any progress at all with this approach, and it's only thanks to some highly intelligent people employing their best mathematical pattern analysis techniques, that we have indeed gotten anywhere.
Where to from here?
Personally, I feel that we're only really going to "crack" the DNA puzzle, if we're able to reverse-engineer raw DNA sequences into some sort of higher-level code. And, considering that reverse-engineering raw binary into a higher-level programming language (such as C) is a very difficult endeavour, and that doing the same for DNA is bound to be even harder, I think we have our work cut out for us.
My interest in the DNA puzzle was first piqued, when I heard a talk at PyCon AU 2016: Big data biology for pythonistas: getting in on the genomics revolution, presented by Darya Vanichkina. In this presentation, DNA was presented as a riddle that more programmers can and should try to help solve. Since then, I've thought about the riddle now and then, and I have occasionally read some of the plethora of available online material about DNA and genome sequencing.
DNA is an amazing thing: for approximately 4 billion years, it has been spreading itself across our planet, modifying itself in bizarre and colourful ways, and ultimately evolving (according to the laws of natural selection) to become the codebase that defines the behaviour of primitive lifeforms such as humans (and even intelligent lifeforms such as dolphins!).
Dolphins! (Brainier than you are). Image source:Days of the Year.
So, let's be realistic here: it took DNA that long to reach its current form; we'll be doing well if we can start to understand it properly within the next 1,000 years, if we can manage it at all before the humble blip on Earth's timeline that is human civilisation fades altogether.
]]>
A lightweight per-transaction Python function queue for Flask2017-12-04T00:00:00Z2017-12-04T00:00:00ZJazahttps://greenash.net.au/thoughts/2017/12/a-lightweight-per-transaction-python-function-queue-for-flask/
The premise: each time a certain API method is called within a Flask / SQLAlchemy app (a method that primarily involves saving something to the database), send various notifications, e.g. log to the standard logger, and send an email to site admins. However, the way the API works, is that several different methods can be forced to run in a single DB transaction, by specifying that SQLAlchemy only perform a commit when the last method is called. Ideally, no notifications should actually get triggered until the DB transaction has been successfully committed; and when the commit has finished, the notifications should trigger in the order that the API methods were called.
There are various possible solutions that can accomplish this, for example: a celery task queue, an event scheduler, and a synchronised / threaded queue. However, those are all fairly heavy solutions to this problem, because we only need a queue that runs inside one thread, and that lives for the duration of a single DB transaction (and therefore also only for a single request).
To solve this problem, I implemented a very lightweight function queue, where each queue is a deque instance, that lives inside flask.g, and that is therefore available for the duration of a given request context (or app context).
The code
The whole implementation really just consists of this one function:
from collections import deque
from flask import g
def queue_and_delayed_execute(
queue_key, session_hash, func_to_enqueue,
func_to_enqueue_ctx=None, is_time_to_execute_funcs=False):
"""Add a function to a queue, then execute the funcs now or later.
Creates a unique deque() queue for each queue_key / session_hash
combination, and stores the queue in flask.g. The idea is that
queue_key is some meaningful identifier for the functions in the
queue (e.g. 'banana_masher_queue'), and that session_hash is some
identifier that's guaranteed to be unique, in the case of there
being multiple queues for the same queue_key at the same time (e.g.
if there's a one-to-one mapping between a queue and a SQLAlchemy
transaction, then hash(db.session) is a suitable value to pass in
for session_hash).
Since flask.g only stores data for the lifetime of the current
request (or for the lifetime of the current app context, if not
running in a request context), this function should only be used for
a queue of functions that's guaranteed to only be built up and
executed within a single request (e.g. within a single DB
transaction).
Adds func_to_enqueue to the queue (and passes func_to_enqueue_ctx as
kwargs if it has been provided). If is_time_to_execute_funcs is
True (e.g. if a DB transaction has just been committed), then takes
each function out of the queue in FIFO order, and executes the
function.
"""
# Initialise the set of queues for queue_key
if queue_key not in g:
setattr(g, queue_key, {})
# Initialise the unique queue for the specified session_hash
func_queues = getattr(g, queue_key)
if session_hash not in func_queues:
func_queues[session_hash] = deque()
func_queue = func_queues[session_hash]
# Add the passed-in function and its context values to the queue
func_queue.append((func_to_enqueue, func_to_enqueue_ctx))
if is_time_to_execute_funcs:
# Take each function out of the queue and execute it
while func_queue:
func_to_execute, func_to_execute_ctx = (
func_queue.popleft())
func_ctx = (
func_to_execute_ctx
if func_to_execute_ctx is not None
else {})
func_to_execute(**func_ctx)
# The queue is now empty, so clean up by deleting the queue
# object from flask.g
del func_queues[session_hash]
To use the function queue, calling code should look something like this:
from flask import current_app as app
from flask_mail import Message
from sqlalchemy.exc import SQLAlchemyError
from myapp.extensions import db, mail
def do_api_log_msg(log_msg):
"""Log the specified message to the app logger."""
app.logger.info(log_msg)
def do_api_notify_email(mail_subject, mail_body):
"""Send the specified notification email to site admins."""
msg = Message(
mail_subject,
sender=app.config['MAIL_DEFAULT_SENDER'],
recipients=app.config['CONTACT_EMAIL_RECIPIENTS'])
msg.body = mail_body
mail.send(msg)
# Added for demonstration purposes, not really needed in production
app.logger.info('Sent email: {0}'.format(mail_subject))
def finalise_api_op(
log_msg=None, mail_subject=None, mail_body=None,
is_db_session_commit=False, is_app_logger=False,
is_send_notify_email=False):
"""Finalise an API operation by committing and logging."""
# Get a unique identifier for this DB transaction
session_hash = hash(db.session)
if is_db_session_commit:
try:
db.session.commit()
# Added for demonstration purposes, not really needed in
# production
app.logger.info('Committed DB transaction')
except SQLAlchemyError as exc:
db.session.rollback()
return {'error': 'error finalising api op'}
if is_app_logger:
queue_key = 'api_log_msg_queue'
func_to_enqueue_ctx = dict(log_msg=log_msg)
queue_and_delayed_execute(
queue_key=queue_key, session_hash=session_hash,
func_to_enqueue=do_api_log_msg,
func_to_enqueue_ctx=func_to_enqueue_ctx,
is_time_to_execute_funcs=is_db_session_commit)
if is_send_notify_email:
queue_key = 'api_notify_email_queue'
func_to_enqueue_ctx = dict(
mail_subject=mail_subject, mail_body=mail_body)
queue_and_delayed_execute(
queue_key=queue_key, session_hash=session_hash,
func_to_enqueue=do_api_notify_email,
func_to_enqueue_ctx=func_to_enqueue_ctx,
is_time_to_execute_funcs=is_db_session_commit)
return {'message': 'api op finalised ok'}
And that code can be called from a bunch of API methods like so:
If make_froggy_brightpink_and_highjump() is called from within a Flask app context, the app's log should include output that looks something like this:
INFO [2017-12-01 09:00:00] Committed DB transaction
INFO [2017-12-01 09:00:00] Froggy colour updated: 123; new value: bright_pink
INFO [2017-12-01 09:00:00] Made froggy jump: 123; jump height: 50 metres
INFO [2017-12-01 09:00:00] Sent email: Made froggy jump
The log output demonstrates that the desired behaviour has been achieved: first, the DB transaction finishes (i.e. the froggy actually gets set to bright pink, and made to jump high, in one atomic write operation); then, the API actions are logged in the order that they were called (first the colour was updated, then the froggy was made to jump); then, email notifications are sent in order (in this case, we only want an email notification sent for when the froggy jumps high – but if we had also asked for an email notification for when the froggy's colour was changed, that would have been the first email sent).
In summary
That's about all there is to this "task queue" implementation – as I said, it's very lightweight, because it only needs to be simple and short-lived. I'm sharing this solution, mainly to serve as a reminder that you shouldn't just use your standard hammer, because sometimes the hammer is disproportionately big compared to the nail. In this case, the solution doesn't need an asynchronous queue, it doesn't need a scheduled queue, and it doesn't need a threaded queue. (Although moving the email sending off to a celery task is a good idea in production; and moving the logging to celery would be warranted too, if it was logging to a third-party service rather than just to a local file.) It just needs a queue that builds up and that then gets processed, for a single DB transaction.
]]>
Using Python's namedtuple for mock objects in tests2017-08-13T00:00:00Z2017-08-13T00:00:00ZJazahttps://greenash.net.au/thoughts/2017/08/using-pythons-namedtuple-for-mock-objects-in-tests/
I have become quite a fan of Python's built-in namedtuple collection lately. As others have already written, despite having been available in Python 2.x and 3.x for a long time now, namedtuple continues to be under-appreciated and under-utilised by many programmers.
# The ol'fashioned tuple way
fruits = [
('banana', 'medium', 'yellow'),
('watermelon', 'large', 'pink')]
for fruit in fruits:
print('A {0} is coloured {1} and is {2} sized'.format(
fruit[0], fruit[2], fruit[1]))
# The nicer namedtuple way
from collections import namedtuple
Fruit = namedtuple('Fruit', 'name size colour')
fruits = [
Fruit(name='banana', size='medium', colour='yellow'),
Fruit(name='watermelon', size='large', colour='pink')]
for fruit in fruits:
print('A {0} is coloured {1} and is {2} sized'.format(
fruit.name, fruit.colour, fruit.size))
namedtuples can be used in a few obvious situations in Python. I'd like to present a new and less obvious situation, that I haven't seen any examples of elsewhere: using a namedtuple instead of MagicMock or flexmock, for creating fake objects in unit tests.
namedtuple vs the competition
namedtuples have a number of advantages over regular tuples and dicts in Python. First and foremost, a namedtuple is (by defintion) more semantic than a tuple, because you can define and access elements by name rather than by index. A namedtuple is also more semantic than a dict, because its structure is strictly defined, so you can be guaranteed of exactly which elements are to be found in a given namedtuple instance. And, similarly, a namedtuple is often more useful than a custom class, because it gives more of a guarantee about its structure than a regular Python class does.
A namedtuple can craft an object similarly to the way that MagicMock or flexmock can. The namedtuple object is more limited, in terms of what attributes it can represent, and in terms of how it can be swapped in to work in a test environment. But it's also simpler, and that makes it easier to define and easier to debug.
Compared with all the alternatives listed here (dict, a custom class, MagicMock, and flexmock – all except tuple), namedtuple has the advantage of being immutable. This is generally not such an important feature, for the purposes of mocking and running tests, but nevertheless, immutability always provides advantages – such as elimination of side-effects via parameters, and more thread-safe code.
Really, for me, the biggest "quick win" that you get from using namedtuple over any of its alternatives, is the lovely built-in string representation that the former provides. Chuck any namedtuple in a debug statement or a logging call, and you'll see everything you need (all the fields and their values) and nothing you don't (other internal attributes), right there on the screen.
# Printing a tuple
f1 = ('banana', 'medium', 'yellow')
# Shows all attributes ordered nicely, but no field names
print(f1)
# ('banana', 'medium', 'yellow')
# Printing a dict
f1 = {'name': 'banana', 'size': 'medium', 'colour': 'yellow'}
# Shows all attributes with field names, but ordering is wrong
print(f1)
# {'colour': 'yellow', 'size': 'medium', 'name': 'banana'}
# Printing a custom class instance
class Fruit(object):
"""It's a fruit, yo"""
f1 = Fruit()
f1.name = 'banana'
f1.size = 'medium'
f1.colour = 'yellow'
# Shows nothing useful by default! (Needs a __repr__() method for that)
print(f1)
# <__main__.Fruit object at 0x7f1d55400e48>
# But, to be fair, can print its attributes as a dict quite easily
print(f1.__dict__)
# {'size': 'medium', 'name': 'banana', 'colour': 'yellow'}
# Printing a MagicMock
from mock import MagicMock
class Fruit(object):
name = None
size = None
colour = None
f1 = MagicMock(spec=Fruit)
f1.name = 'banana'
f1.size = 'medium'
f1.colour = 'yellow'
# Shows nothing useful by default! (and f1.__dict__ is full of a tonne
# of internal cruft, with the fields we care about buried somewhere
# amongst it all)
print(f1)
# <MagicMock spec='Fruit' id='140682346494552'>
# Printing a flexmock
from flexmock import flexmock
f1 = flexmock(name='banana', size='medium', colour='yellow')
# Shows nothing useful by default!
print(f1)
# <flexmock.MockClass object at 0x7f691ecefda0>
# But, to be fair, printing f1.__dict__ shows minimal cruft
print(f1.__dict__)
# {
# 'name': 'banana',
# '_object': <flexmock.MockClass object at 0x7f691ecefda0>,
# 'colour': 'yellow', 'size': 'medium'}
# Printing a namedtuple
from collections import namedtuple
Fruit = namedtuple('Fruit', 'name size colour')
f1 = Fruit(name='banana', size='medium', colour='yellow')
# Shows exactly what we need: what it is, and what all of its
# attributes' values are. Sweeeet.
print(f1)
# Fruit(name='banana', size='medium', colour='yellow')
As the above examples show, without any special configuration, namedtuple's string configuration Just Works™.
namedtuple and fake objects
Let's say you have a simple function that you need to test. The function gets passed in a superhero, which it expects is a SQLAlchemy model instance. It queries all the items of clothing that the superhero uses, and it returns a list of clothing names. The function might look something like this:
# myproject/superhero.py
def get_clothing_names_for_superhero(superhero):
"""List the clothing for the specified superhero"""
clothing_names = []
clothing_list = superhero.clothing_items.all()
for clothing_item in clothing_list:
clothing_names.append(clothing_item.name)
return clothing_names
Since this function does all its database querying via the superhero object that's passed in as a parameter, there's no need to mock anything via funky mock.patch magic or similar. You can simply follow Python's preferred pattern of duck typing, and pass in something – anything – that looks like a superhero (and, unless he takes his cape off, nobody need be any the wiser).
You could write a test for that function, using namedtuple-based fake objects, like so:
# myproject/superhero_test.py
from collections import namedtuple
from myproject.superhero import get_clothing_names_for_superhero
FakeSuperhero = namedtuple('FakeSuperhero', 'clothing_items name')
FakeClothingItem = namedtuple('FakeClothingItem', 'name')
FakeModelQuery = namedtuple('FakeModelQuery', 'all first')
def get_fake_superhero_and_clothing():
"""Get a fake superhero and clothing for test purposes"""
superhero = FakeSuperhero(
name='Batman',
clothing_items=FakeModelQuery(
first=lambda: None,
all=lambda: [
FakeClothingItem(name='cape'),
FakeClothingItem(name='mask'),
FakeClothingItem(name='boots')]))
return superhero
def test_get_clothing_for_superhero():
"""Test listing the clothing for a superhero"""
superhero = get_fake_superhero_and_clothing()
clothing_names = set(get_clothing_names_for_superhero(superhero))
# Verify that list of clothing names is as expected
assert clothing_names == {'cape', 'mask', 'boots'}
The same setup could be achieved using one of the alternatives to namedtuple. In particular, a FakeSuperhero custom class would have done the trick. Using MagicMock or flexmock would have been fine too, although they're really overkill in this situation. In my opinion, for a case like this, using namedtuple is really the simplest and the most painless way to test the logic of the code in question.
In summary
I believe that namedtuple is a great choice for fake test objects, when it fits the bill, and I don't know why it isn't used or recommended for this in general. It's a choice that has some limitations: most notably, you can't have any attribute that starts with an underscore (the "_" character) in a namedtuple. It's also not particularly nice (although it's perfectly valid) to chuck functions into namedtuple fields, especially lambda functions.
Personally, I have used namedtuples in this way quite a bit recently, however I'm still ambivalent about it being the best approach. If you find yourself starting to craft very complicated FakeFoonamedtuples, then perhaps that's a sign that you're doing it wrong. As with everything, I think that this is an approach that can really be of value, if it's used with a degree of moderation. At the least, I hope you consider adding it to your tool belt.
]]>
Splitting a Python codebase into dependencies for fun and profit2015-06-30T00:00:00Z2015-06-30T00:00:00ZJazahttps://greenash.net.au/thoughts/2015/06/splitting-a-python-codebase-into-dependencies-for-fun-and-profit/
When the Python codebase for a project (let's call the project LasagnaFest) starts getting big, and when you feel the urge to re-use a chunk of code (let's call that chunk foodutils) in multiple places, there are a variety of steps at your disposal. The most obvious step is to move that foodutils code into its own file (thus making it a Python module), and to then import that module wherever else you want in the codebase.
Most of the time, doing that is enough. The Python module importing system is powerful, yet simple and elegant.
But… what happens a few months down the track, when you're working on two new codebases (let's call them TortelliniFest and GnocchiFest – perhaps they're for new clients too), that could also benefit from re-using foodutils from your old project? What happens when you make some changes to foodutils, for the new projects, but those changes would break compatibility with the old LasagnaFest codebase?
What happens when you want to give a super-charged boost to your open source karma, by contributing foodutils to the public domain, but separated from the cruft that ties it to LasagnaFest and Co? And what do you do with secretfoodutils, which for licensing reasons (it contains super-yummy but super-secret sauce) can't be made public, but which should ideally also be separated from the LasagnaFest codebase for easier re-use?
Or – not to be forgotten – what happens when, on one abysmally rainy day, you take a step back and audit the LasagnaFest codebase, and realise that it's got no less than 38 different *utils chunks of code strewn around the place, and you ponder whether surely keeping all those utils within the LasagnaFest codebase is really the best way forward?
Moving foodutils to its own module file was a great first step; but it's clear that in this case, a more drastic measure is needed. In this case, it's time to split off foodutils into a separate, independent codebase, and to make it an external dependency of the LasagnaFest project, rather than an internal component of it.
This article is an introduction to the how and the why of cutting up parts of a Python codebase into dependencies. I've just explained a fair bit of the why. As for the how: in a nutshell, pip (for installing dependencies), the public PyPI repo (for hosting open-sourced dependencies), and a private PyPI repo (for hosting proprietary dependencies). Read on for more details.
Levels of modularity
One of the (many) joys of coding in Python is the way that it encourages modularity. For example, let's start with this snippet of completely non-modular code:
There are, in my opinion, three different levels of re-factoring that you can apply, in order to make it more modular. You can think of these levels like the layers of a lasagna, if you want. Or not.
Each successive level of re-factoring involves a bit more work in the short-term, but results in more convenient re-use in the long-term. So, which level is appropriate, depends on the likelihood that you (or others) will want to re-use a given chunk of code in the future.
First, you can split the logic out of the procedural blurg, and into a function in the same file:
And, finally, you can move that file out of your codebase, upload it to a Python package repository (the most common such repository being PyPI), and then declare it as a dependency of your codebase using pip:
As I said, achieving this last level of modularity isn't always necessary or appropriate, due to the overhead involved. For a given chunk of code, there are always going to be trade-offs to consider, and as a developer it's always going to be your judgement call.
Splitting out code
For the times when it is appropriate to go that "last mile" and split code out as an external dependency, there are (in my opinion) insufficient resources regarding how to go about it. I hope, therefore, that this section serves as a decent guide on the matter.
Factor out coupling
The first step in making until-now "project code" an external dependency, is removing any coupling that the chunk of code may have to the rest of the codebase. For example, the foodutils code shown above is nice and de-coupled; but what if it instead looked like so:
foodutils.py:
from mysettings import NUM_QUESTION_MARKS
def greet_dude_with_food(dude_name, food_today):
return "Hey {dude_name}! Want a {food_today} today{q_marks}".format(
dude_name=dude_name,
food_today=food_today,
q_marks='?'*NUM_QUESTION_MARKS)
This would be problematic, because this code relies on the assumption that it lives in a codebase containing a mysettings module, and that the configuration value NUM_QUESTION_MARKS is defined within that module.
We can remove this coupling by changing NUM_QUESTION_MARKS to be a parameter passed to greet_dude_with_food, like so:
The dependent code in this project could then pass in the required config value when it calls greet_dude_with_food, like so:
foodgreeter.py:
from foodutils import greet_dude_with_food
from mysettings import NUM_QUESTION_MARKS
dude_name = 'Johnny'
food_today = 'lasagna'
print(greet_dude_with_food(
dude_name=dude_name,
food_today=food_today,
num_question_marks=NUM_QUESTION_MARKS))
Once the code we're re-factoring no longer depends on anything elsewhere in the codebase, it's ready to be made an external dependency.
New repo for dependency
Next comes the step of physically moving the given chunk of code out of the project's codebase. In most cases, this means deleting the given file(s) from the project's version control repository (you are using version control, right?), and creating a new repo for those file(s) to live in.
For example, if you're using Git, the steps would be something like this:
The given chunk of code now has its own dedicated repo. But it's not yet a project, in its own right, and it can't yet be referenced as a dependency. To do that, we'll need to add some more files to the new repo, mainly consisting of metadata describing "who" this project is, and what it does.
Next, add a version number to the code. The best way to do this, is to add it at the top of the main Python file, e.g. by adding this to the top of foodutils.py:
__version__ = '0.1.0'
After that, we're going to add the standard metadata files that almost all open-source Python projects have. Most importantly, a setup.py file that looks something like this:
import os
import setuptools
module_path = os.path.join(os.path.dirname(__file__), 'foodutils.py')
version_line = [line for line in open(module_path)
if line.startswith('__version__')][0]
__version__ = version_line.split('__version__ = ')[-1][1:][:-2]
setuptools.setup(
name="foodutils",
version=__version__,
url="https://github.com/misterfoo/foodutils",
author="Mister foo",
author_email="mister@foo.com",
description="Utils for handling food.",
long_description=open('README.rst').read(),
py_modules=['foodutils'],
zip_safe=False,
platforms='any',
install_requires=[],
classifiers=[
'Development Status :: 2 - Pre-Alpha',
'Environment :: Web Environment',
'Intended Audience :: Developers',
'Operating System :: OS Independent',
'Programming Language :: Python',
'Programming Language :: Python :: 2',
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.3',
],
)
And also, a README.rst file:
foodutils
=========
Utils for handling food.
Once you've created those files, commit them to the new repo.
Push the repo
Great – the chunk of code now lives in its own repo, and it contains enough metadata for other projects to see what its name is, what version(s) of it there are, and what function(s) it performs. All that needs to be done now, is to decide where this repo will be hosted. But to do this, you first need to answer an important non-technical question: to open-source the code, or to keep it proprietary?
In general, you should open-source your dependencies whenever possible. You get more eyeballs (for free). Famous hairy people like Richard Stallman will send you flowers. If nothing else, you'll at least be able to always easily find your code, guaranteed (if you can't remember where it is, just Google it!). You get the drift. If open-sourcing the code, then the most obvious choice for where to host the repo is GitHub. (However, I'm not evangelising GitHub here, remember there are other options, kids).
Open source is kool, but sometimes you can't or you don't want to go down that route. That's fine, too – I'm not here to judge anyone, and I can't possibly be aware of anyone else's business / ownership / philosophical situation. So, if you want to keep the code all to your little self (or all to your little / big company's self), you're still going to have to host it somewhere. And no, "on my laptop" does not count as your code being hosted somewhere (well, technically you could just keep the repo on your own PC, and still reference it as a dependency, but that's a Bad Idea™). There are a number of hosting options: for example, on a VPS that you control; or using a managed service such as GitHub private, Bitbucket, or Assembla (note: once again, not promoting any specific service provider, just listing the main players as options).
So, once you've decided whether or not to open-source the code, and once you've settled on a hosting option, push the new repo to its hosted location.
Upload to PyPI
Nearly there now. The chunk of code has been de-coupled from its dependent project; it's been put in a new repo with the necessary metadata; and that repo is now hosted at a permanent location somewhere online. All that's left, is to make it known to the universe of Python projects, so that it can be easily listed as a dependency of other Python projects.
If you've developed with Python before (and if you've read this far, then I assume you have), then no doubt you've heard of pip. Being the Python package manager of choice these days, pip is the tool used to manage Python dependencies. pip can find dependencies from a variety of locations, but the place it looks first and foremost (by default) is on the Python Package Index (PyPI).
If your dependency is public and open-source, then you should add it to PyPI. Each time you release a new version, then (along with committing and tagging that new version in the repo) you should also upload it to PyPI. I won't go into the details in this article; please refer to the official docs for registering and uploading packages on PyPI. When following the instructions there, you'll generally want to package your code as a "universal wheel", you'll generally use the PyPI website form to register a new package, and you'll generally use twine to upload the package.
If your dependency is private and proprietary, then PyPI is not an option. The easiest way to deal with private dependencies (also the easiest way to deal with public dependencies, for that matter), is to not worry about proper Python packaging at all, and simply to use pip's ability to directly reference a source repo (including a specific commit / tag), e.g:
However, that has a number of disadvantages, the most visible disadvantage being that pip install will run much slower, because it has to do a git pull every time you ask it to check that foodutils is installed (even if you specify the same commit / tag each time).
A better way to deal with private dependencies, is to create your own "private PyPI". Same as with public packages: each time you release a new version, then (along with committing and tagging that new version in the repo) you should also upload it to your private PyPI. For instructions regarding this, please refer to my guide for how to set up and use a private PyPI repo. Also, note that my guide is for quite a minimal setup, although it contains links to some alternative setup options, including more advanced and full-featured options. (And if using a private PyPI, then take note of my guide's instructions for what to put in your local ~/.pip/pip.conf file).
Reference the dependency
The chunk of code is now ready to be used as an external dependency, by any project. To do this, you simply list the package in your project's requirements.txt file; whether the package is on the public PyPI, or on a private PyPI of your own, the syntax is the same:
foodutils==0.1.0 # From pypi.myserver.com
Then, just run your dependencies through pip as usual:
pip install -r requirements.txt
And there you have it: foodutils is now an external dependency. You can list it as a requirement for LasagnaFest, TortelliniFest, GnocchiFest, and as many other projects as you need.
Final thoughts
This article was born out of a series of projects that I've been working on over the past few months (and that I'm still working on), written mainly in Flask (these apps are still in alpha; ergo, sorry, can't talk about their details yet). The size of the projects' codebases grew to be rather unwieldy, and the projects have quite a lot of shared functionality.
I started out by re-using chunks of code between the different projects, with the hacky solution of sym-linking from one codebase to another. This quickly became unmanageable. Once I could stand the symlinks no longer (and once I had some time for clean-up), I moved these shared chunks of code into separate repos, and referenced them as dependencies (with some being open-sourced and put on the public PyPI). Only in the last week or so, after losing patience with slow pip installs, and after getting sick of seeing far too many -e git+http://git… strings in my requirements.txt files, did I finally get around to setting up a private PyPI, for better dealing with the proprietary dependencies of these codebases.
I hope that this article provides some clear guidance regarding what can be quite a confusing task, i.e. that of creating and maintaining a private Python package index. Aside from being a technical guide, though, my aim in penning this piece is to explain how you can split off component parts of a monolithic codebase into re-usable, independent separate codebases; and to convey the advantages of doing so, in terms of code quality and maintainability.
Flask, my framework of choice these days, strives to consist of a series of independent projects (Flask, Werkzeug, Jinja, WTForms, and the myriad Flask-* add-ons), which are compatible with each other, but which are also useful stand-alone or with other systems. I think that this is a great example for everyone to follow, even humble "custom web-app" developers like myself. Bearing that in mind, devoting some time to splitting code out of a big bad client-project codebase, and creating more atomic packages (even if not open-source) upon whose shoulders a client-project can stand, is a worthwhile endeavour.
]]>
Generating a Postgres DB dump of a filtered relational set2015-06-22T00:00:00Z2015-06-22T00:00:00ZJazahttps://greenash.net.au/thoughts/2015/06/generating-a-postgres-db-dump-of-a-filtered-relational-set/PostgreSQL is my favourite RDBMS, and it's the fave of many others too. And rightly so: it's a good database! Nevertheless, nobody's perfect.
When it comes to exporting Postgres data (as SQL INSERT statements, at least), the tool of choice is the standard pg_dump utility. Good ol' pg_dump is rock solid but, unfortunately, it doesn't allow for any row-level filtering. Turns out that, for a recent project of mine, a filtered SQL dump is exactly what the client ordered.
On account of this shortcoming, I spent some time whipping up a lil' Python script to take care of this functionality. I've converted the original code (written for a client-specific data set) to a more generic example script, which I've put up on GitHub under the name "PG Dump Filtered". If you're just after the code, then feel free to head over to the repo without further ado. If you'd like to stick around for the tour, then read on.
Worlds apart
For the example script, I've set up a simple schema of four entities: worlds, countries, cities, and people. This schema happens to be purely hierarchical (i.e. each world has zero or more countries, each country has zero or more cities, and each city has zero or more people), for the sake of simplicity; but the script could be adapted to any valid set of foreign-key based relationships.
CREATE TABLE world (
name character varying(255) NOT NULL,
created_at timestamp without time zone,
updated_at timestamp without time zone,
active boolean NOT NULL,
uuid bytea,
id integer NOT NULL
);
ALTER TABLE ONLY world
ADD CONSTRAINT world_pkey PRIMARY KEY (id);
CREATE TABLE country (
name character varying(255) NOT NULL,
created_at timestamp without time zone,
updated_at timestamp without time zone,
active boolean NOT NULL,
uuid bytea,
id integer NOT NULL,
world_id integer,
bigness numeric(10,2)
);
ALTER TABLE ONLY country
ADD CONSTRAINT country_pkey PRIMARY KEY (id);
ALTER TABLE ONLY country
ADD CONSTRAINT country_world_id_fkey FOREIGN KEY (world_id)
REFERENCES world(id);
CREATE TABLE city (
name character varying(255) NOT NULL,
created_at timestamp without time zone,
updated_at timestamp without time zone,
active boolean NOT NULL,
uuid bytea,
id integer NOT NULL,
country_id integer,
weight integer,
is_big boolean DEFAULT false NOT NULL,
pseudonym character varying(255) DEFAULT ''::character varying
NOT NULL,
description text DEFAULT ''::text NOT NULL
);
ALTER TABLE ONLY city
ADD CONSTRAINT city_pkey PRIMARY KEY (id);
ALTER TABLE ONLY city
ADD CONSTRAINT city_country_id_fkey FOREIGN KEY (country_id)
REFERENCES country(id);
CREATE TABLE person (
name character varying(255) NOT NULL,
created_at timestamp without time zone,
updated_at timestamp without time zone,
active boolean NOT NULL,
uuid bytea,
id integer NOT NULL,
city_id integer,
person_type character varying(255) NOT NULL
);
ALTER TABLE ONLY person
ADD CONSTRAINT person_pkey PRIMARY KEY (id);
ALTER TABLE ONLY person
ADD CONSTRAINT person_city_id_fkey FOREIGN KEY (city_id)
REFERENCES city(id);
Using this schema, data belonging to two different worlds can co-exist in the same database. For example, we can have data for the world "Krypton" co-exist with data for the world "Romulus":
INSERT INTO world (name, created_at, updated_at, active, uuid, id)
VALUES ('Krypton', '2015-06-01 09:00:00.000000',
'2015-06-06 09:00:00.000000', true,
'\x478a43577ebe4b07ba8631ca228ee42a', 1);
INSERT INTO world (name, created_at, updated_at, active, uuid, id)
VALUES ('Romulus', '2015-06-01 10:00:00.000000',
'2015-06-05 13:00:00.000000', true,
'\x82e2c0ac3ba84a34a1ad3bbbb2063547', 2);
INSERT INTO country (name, created_at, updated_at, active, uuid, id,
world_id, bigness)
VALUES ('Crystalland', '2015-06-02 09:00:00.000000',
'2015-06-08 09:00:00.000000', true,
'\xcd0338cf2e3b40c3a3751b556a237152', 1, 1, 3.86);
INSERT INTO country (name, created_at, updated_at, active, uuid, id,
world_id, bigness)
VALUES ('Greenbloodland', '2015-06-03 11:00:00.000000',
'2015-06-07 13:00:00.000000', true,
'\x17591321d1634bcf986d0966a539c970', 2, 2, NULL);
INSERT INTO city (name, created_at, updated_at, active, uuid, id,
country_id, weight, is_big, pseudonym, description)
VALUES ('Kryptonopolis', '2015-06-05 09:00:00.000000',
'2015-06-11 09:00:00.000000', true,
'\x13659f9301d24ea4ae9c534d70285edc', 1, 1, 100, true,
'Pointyville',
'Nice place, once you get used to the pointiness.');
INSERT INTO city (name, created_at, updated_at, active, uuid, id,
country_id, weight, is_big, pseudonym, description)
VALUES ('Rom City', '2015-06-04 09:00:00.000000',
'2015-06-13 09:00:00.000000', true,
'\xc45a9fb0a92a43df91791b11d65f5096', 2, 2, 200, false,
'',
'Gakkkhhhh!');
INSERT INTO person (name, created_at, updated_at, active, uuid,
city_id, person_type)
VALUES ('Superman', '2015-06-14 09:00:00.000000',
'2015-06-15 22:00:00.000000', true,
'\xbadd1ca153994deca0f78a5158215cf6', 1,
'Awesome Heroic Champ');
INSERT INTO person (name, created_at, updated_at, active, uuid,
city_id, person_type)
VALUES ('General Zod', '2015-06-14 10:00:00.000000',
'2015-06-15 23:00:00.000000', true,
'\x796031428b0a46c2a9391eb5dc45008a', 1,
'Bad Bloke');
INSERT INTO person (name, created_at, updated_at, active, uuid,
city_id, person_type)
VALUES ('Mister Funnyears', '2015-06-14 11:00:00.000000',
'2015-06-15 22:30:00.000000', false,
'\x22380f6dc82d47f488a58153215864cb', 2,
'Mediocre Dude');
INSERT INTO person (name, created_at, updated_at, active, uuid,
city_id, person_type)
VALUES ('Captain Greeny', '2015-06-15 05:00:00.000000',
'2015-06-16 08:30:00.000000', true,
'\x485e31758528425dbabc598caaf86fa4', 2,
'Weirdo');
In this case, our two key stakeholders – the Kryptonians and the Romulans – have been good enough to agree to their respective data records being stored in the same physical database. After all, they're both storing the same type of data, and they accept the benefits of a shared schema in terms of cost-effectiveness, maintainability, and scalability.
However, these two stakeholders aren't exactly the best of friends. In fact, they're not even on speaking terms (have you even seen them both feature in the same franchise, let alone the same movie?). Plus, for legal reasons (and in the interests of intergalactic peace), there can be no possibility of Kryptonian records falling into Romulan hands, or vice versa. So, it really is critical that, as far as these two groups are concerned, the data appears to be completely partitioned.
(It's also lucky that we're using Postgres and Python, which all parties appear to be cool with – the Klingons are mad about Node.js and MongoDB these days, so the Romulans would never have come on board if we'd gone down that path…).
Fortunately, thanks to the wondrous script that's now been written, these unlikely DB room-mates can have their dilithium and eat it, too. The Romulans, for example, can simply specify their World ID of 2:
And they'll get a DB dump of what is (as far as they're concerned) … well, the whole world! (Note: please do not change your dietary habits per above innuendo, dilithium can harm your unborn baby).
And all thanks to a lil' bit of Python / SQL trickery, to filter things according to their world:
# ...
# Thanks to:
# http://bytes.com/topic/python/answers/438133-find-out-schema-psycopg
t_cur.execute((
"SELECT column_name "
"FROM information_schema.columns "
"WHERE table_name = '%s' "
"ORDER BY ordinal_position") % table)
t_fields_str = ', '.join([x[0] for x in t_cur])
d_cur = conn.cursor()
# Start constructing the query to grab the data for dumping.
query = (
"SELECT x.* "
"FROM %s x ") % table
# The rest of the query depends on which table we're at.
if table == 'world':
query += "WHERE x.id = %(world_id)s "
elif table == 'country':
query += "WHERE x.world_id = %(world_id)s "
elif table == 'city':
query += (
"INNER JOIN country c "
"ON x.country_id = c.id ")
query += "WHERE c.world_id = %(world_id)s "
elif table == 'person':
query += (
"INNER JOIN city ci "
"ON x.city_id = ci.id "
"INNER JOIN country c "
"ON ci.country_id = c.id ")
query += "WHERE c.world_id = %(world_id)s "
# For all tables, filter by the top-level ID.
d_cur.execute(query, {'world_id': world_id})
With a bit more trickery thrown in for good measure, to more-or-less emulate pg_dump's export of values for different data types:
# ...
# Start constructing the INSERT statement to dump.
d_str = "INSERT INTO %s (%s) VALUES (" % (table, t_fields_str)
d_vals = []
for i, d_field in enumerate(d_row):
d_type = type(d_field).__name__
# Rest of the INSERT statement depends on the type of
# each field.
if d_type == 'datetime':
d_vals.append("'%s'" % d_field.isoformat().replace('T', ' '))
elif d_type == 'bool':
d_vals.append('%s' % (d_field and 'true' or 'false'))
elif d_type == 'buffer':
d_vals.append(r"'\x" + ("%s'" % hexlify(d_field)))
elif d_type == 'int':
d_vals.append('%d' % d_field)
elif d_type == 'Decimal':
d_vals.append('%f' % d_field)
elif d_type in ('str', 'unicode'):
d_vals.append("'%s'" % d_field.replace("'", "''"))
elif d_type == 'NoneType':
d_vals.append('NULL')
d_str += ', '.join(d_vals)
d_str += ');'
And that's the easy part done! Now, on to working out how to efficiently do Postgres master-slave replication over a distance of several thousand light years, without disrupting the space-time continuum.
(livelong AND prosper);
Hope my little example script comes in handy, for anyone else needing a version of pg_dump that can do arbitrary filtering on inter-related tables. As I said in the README, with only a small amount of tweaking, this script should be able to produce a dump of virtually any relational data set, filtered by virtually any criteria that you might fancy.
Also, this script is for Postgres: the pg_dump utility lacks any query-level filtering functionality, so using it in this way is simply not an option. The script could also be quite easily adapted to other DBMSes (e.g. MySQL, SQL Server, Oracle), although most of Postgres' competitors have a dump utility with at least some filtering capability.
]]>
First experiences developing a single-page JS-driven web app2014-08-26T00:00:00Z2014-08-26T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/08/first-experiences-developing-a-single-page-js-driven-web-app/
For the past few months, my main dev project has been a custom tool that imports metric data from a variety of sources (via APIs), and that generates reports showing that data in numerous graphical and tabular formats. The app is private (and is still in alpha), so I'm afraid I can't go into more detail than that at this time.
I decided (and I was encouraged by stakeholders) to build the tool as a single-page application, i.e. as a web app where almost all of the front-end is powered by JavaScript, and where the page is redrawn via AJAX calls and client-side templates. This was my first experience developing such an app; as such, I'd like to reflect on the choices I made, and on my understanding of the technology as it stands now.
Drowning in frameworks
I never saw one before in my life, and I hope I never see one of those fuzzy miserable things again. Image source:Memory Alpha (originally from Star Trek TOS Season 2 Ep 13).
Building single-page applications is all the rage these days; as such, a gazillion frameworks have popped up, all promising to take the pain out of the dev work for you. In reality, when your problem is that you need to create an app, and you think: "I know, I'll go and choose a JS framework", now you have two problems.
Actually, that's not the full story either. When you choose the wrong JS* framework – due to it being unsuitable for your project, and/or due to your failing to grok it – and you have to look for a framework a second time, and port the code you've already started writing… now you've got three problems!
(* I'd prefer to just refer to these frameworks as "JS", rather than use the much-bandied-about term "MVC", because not all such frameworks are MVC, and because one's project may be unsuitable for client-side MVC anyway).
Ah, the joy of first-time blunders.
I started by choosing Ember.js. It's one of the most popular frameworks at the moment. It does everything you could possibly need for your funky new JS app. Turns out that: (a) Ember was complete overkill for my relatively simple app; and (b) despite my best efforts, I failed to grok Ember, and I felt that my time would be better spent switching to something else and thereafter working more efficiently, than continuing to grapple with Ember's philosophy and complexity.
In the end, I settled on Sammy.js. This is one of the lesser-known frameworks out there. It boasts far less features than Ember.js (and even so, I haven't used all that Sammy.js offers either). It doesn't get in the way of my app's functionality. Many of its features are just a thin wrapper on top of jQuery, which I already know intimately. It adds a few bits 'n' pieces into my existing JS ecosystem, to give my app more structure and more interactivity; rather than nuking my existing ecosystem, and making me feel like single-page JS is a whole new language.
My advice to others who are choosing a whiz-bang JS framework for the first time: don't necessarily go with the most popular or the most full-featured framework you find (although don't discard such options either); think long and hard about what your app will actually do (more on that below), and choose an appropriate framework for your use-case; and make liberal use of online resources such as reviews (I also found TodoMVC extremely useful, plus I used its well-written code samples as the foundation for my own code).
What seems to be the problem?
Nothing to see here, people. Image source:Funny Junk (originally from South Park).
Ok, so you're going to write a single-page JS app. What will your app actually do? "Single-page JS app" can mean anything; and if we're trying to find the appropriate tool for the job, then the job itself needs to be clearly defined. So, let's break it down a bit.
Is the app (mainly) read-write, or is it read-only? This is a critical question, possibly more so than anything else. One of the biggest challenges with rich JS apps, is synchronising data between client and server. If data is only flowing one day (downstream), that's a whole lot less complexity than if data is flowing upstream as well.
Turns out that JS frameworks, in general, have dedicated a lot of their feature set to supporting read-write apps. They usually do this by having "models" (the "M" in "MVC"), which are the "source of truth" on the client-side; and by "binding" these models to elements in the DOM. When the value of a DOM element changes, that triggers a model data change, which in turn (often) triggers a server-side data update. Conversely, when new data arrives from the server, the model data is updated accordingly, and that update then propagates automatically to a value in the DOM.
Even the quintessential "Todo app" example has two-way data. Turns out, however, that my app only has one-way data. My app is all about sending queries to the server (with some simple filters), and receiving metric data in response. What's more, the received data is aggregate data (ready to be rendered as charts and tables), not individual entities that can easily be stored in a model. So, turns out that my life is easier without worrying about models or event bindings at all. Receive JSON, pipe it to the chart renderer (NVD3 for most charts), end of story.
Can displayed data change dynamically within a single JS route, or can it only change when the route changes? Once again, the former entails a lot more complexity than the latter. In my app's case, each JS route (handled by Sammy.js, same as with other frameworks, as "the part of the URL after the hash character") is a single report (containing one or more graphs and tables). The report elements themselves aren't dynamic (except that hovering over various graph elements shows more info). Changing the filters of the current report, or going to a different report, involves executing a new JS route.
So, if data isn't changing dynamically within a single JS route, why bother with complex event bindings? Some simple "old-skool" jQuery event handlers may be all that's necessary.
In summary, in the case of my app, all that it really needed in a JS framework was: client-side routing (which Sammy.js provides using nice, simple callbacks); local storage (Sammy.js has a thin wrapper on top of the HTML5 local storage API); AJAX communication (Sammy.js has a thin wrapper on top of jQuery for this); and templating (out-of-the-box Sammy.js supports John Resig's JS micro-templating system). And that's already a whole lot of funky new client-side components to learn and use. Why complicate things further?
All in all, I enjoyed building my first single-page JS app, and I'm reasonably happy with how it turned out to be architected. The front-end uses Sammy.js, D3.js/NVD3, and Bootstrap. The back-end uses Flask (Python) and MongoDB. Other than the login page and the admin pages, the app only has one non-JSON server-side route (the home page), and the rest is handled with client-side routes. The client-side is fairly simple, compared to many rich JS apps being built today; but then again, every app is unique.
I think that right now, we're still in Wild West times as far as building single-page apps goes. In particular, there are way too many frameworks in abundance; as the space matures, no doubt most of these frameworks will die off, and only a handful will thrive in the long-term. There's also a shortage of good advice about design patterns for single-page apps so far, although Mixu's book is a great foundation resource.
Single-page JS technology has plenty of advantages: it can lead to a more responsive, more beautiful app; and, when done right, its JS component can be architected just as cleanly and correctly as everything would be (traditionally) architected on the server-side. Remember, though, that it's just one piece in the puzzle, and that it only needs to be as complex as the app you're building.
]]>
Mixing GData auth with Google Discovery API queries2014-08-11T00:00:00Z2014-08-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/08/mixing-gdata-auth-with-google-discovery-api-queries/
For those of you who have some experience working with Google's APIs, you may be aware of the fact that they fall into two categories: the Google Data APIs, which is mainly for older services; and the discovery-based APIs, which is mainly for newer services.
There has been considerable confusion regarding the difference between the two APIs. I'm no expert, and I admit that I too have fallen victim to the confusion at times. Both systems now require the use of OAuth2 for authentication (it's no longer possible to access any Google APIs without Oauth2). However, each of Google's APIs only falls into one of the two camps; and once authentication is complete, you must use the correct library (either GData or Discovery, for your chosen programming language) in order to actually perform API requests. So, all that really matters, is that for each API that you plan to use, you're crystal clear on which type of API it is, and you use the correct corresponding library.
The GData Python library has a very handy mechanism for exporting an authorised access token as a blob (i.e. a serialised string), and for later re-importing the blob back as a programmatic access token. I made extensive use of this when I recently worked with the Google Analytics API, which is GData-based. I couldn't find any similar functionality in the Discovery API Python library; and I wanted to interact similarly with the YouTube Data API, which is discovery-based. What to do?
Mix 'n' match
The GData API already supports converting a Credentials object to an OAuth2 token object. This is great for an app that has user-facing OAuth2, where a Credentials object is available at the time of making API requests. However, in my situation – making API requests in a server-side script, that runs via cron with no user-facing OAuth2 – that's not much use. I have the opposite problem: I can easily get the token object, but I don't have any Credentials object already instantiated.
Well, it turns out that manually instantiating your own Credentials object isn't that hard. So, this is how I go about querying the YouTube Data API:
import httplib2
import gdata.gauth
from apiclient.discovery import build
from oauth2client.client import OAuth2Credentials
from mysettings import token_blob_string, \
youtube_playlist_id, \
page_size, \
next_page_token
# De-serialise the access token that can be conveniently stored in a
# Python settings file elsewhere, as a blob (string).
# GData provides the blob functionality, but the Discovery API library
# doesn't.
token = gdata.gauth.token_from_blob(token_blob_string)
# Manually instantiate an OAuth2Credentials object from the
# de-serialised access token.
credentials = OAuth2Credentials(
access_token=token.access_token,
client_id=token.client_id,
client_secret=token.client_secret,
refresh_token=token.refresh_token,
token_expiry=None,
token_uri=token.token_uri,
user_agent=None)
http = credentials.authorize(httplib2.Http())
youtube = build('youtube', 'v3', http=http)
# Profit!
response = youtube.playlistItems().list(
playlistId=youtube_playlist_id,
part="snippet",
maxResults=page_size,
pageToken=next_page_token
).execute()
Easy win
And there you go: you can have your cake and eat it, too! All you need is an OAuth2 access token that you've already saved elsewhere as a blob string; and with that, you can query discovery-based Google APIs from anywhere you want, at any time, with no additional OAuth2 hoops to jump through.
If you want more details on how to serialise and de-serialise access token blobs using the GData Python library, others have explained it step-by-step, I'm not going to repeat all of that here. I hope this makes life a bit easier, for anyone else who's trying to deal with "offline" long-lived access tokens and the discovery-based Google APIs.
]]>
Database-free content tagging with files and glob2014-05-20T00:00:00Z2014-05-20T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/05/database-free-content-tagging-with-files-and-glob/
Tagging data (e.g. in a blog) is many-to-many data. Each content item can have multiple tags. And each tag can be assigned to multiple content items. Many-to-many data needs to be stored in a database. Preferably a relational database (e.g. MySQL, PostgreSQL), otherwise an alternative data store (e.g. something document-oriented like MongoDB / CouchDB). Right?
If you're not insane, then yes, that's right! However, for a recent little personal project of mine, I decided to go nuts and experiment. Check it out, this is my "mapping data" store:
Just a list of files in a directory.
And check it out, this is me querying the data store:
Show me all posts with the tag 'fun-stuff'.
And again:
Show me all tags for the post 'rant-about-seashells'.
And that's all there is to it. Many-to-many tagging data stored in a list of files, with content item identifiers and tag identifiers embedded in each filename. Querying is by simple directory listing shell commands with wildcards (also known as "globbing").
Is it user-friendly to add new content? No! Does it allow the rich querying of SQL and friends? No! Is it scalable? No!
But… Is the basic querying it allows enough for my needs? Yes! Is it fast (for a store of up to several thousand records)? Yes! And do I have the luxury of not caring about user-friendliness or scalability in this instance? Yes!
Implementation
For the project in which I developed this system, I implemented the querying with some simple PHP code. For example, this is my "content item" store:
Another list of files in a directory.
These are the functions to do some basic querying on all content:
<?php
/**
* Queries for all blog pages.
*
* @return
* List of all blog pages.
*/
function blog_query_all() {
$files = glob(BASE_FILE_PATH . 'pages/blog/*.php');
if (!empty($files)) {
foreach (array_keys($files) as $k) {
$files[$k] = str_replace(BASE_FILE_PATH . 'pages/blog/',
'',
$files[$k]);
}
rsort($files);
}
return $files;
}
/**
* Queries for blog pages with the specified year / month.
*
* @param $year
* Year.
* @param $month
* Month
*
* @return
* List of blog pages with the specified year / month.
*/
function blog_query_byyearmonth($year, $month) {
$files = glob(BASE_FILE_PATH . 'pages/blog/' .
$year . '-' . $month . '-*.php');
if (!empty($files)) {
foreach (array_keys($files) as $k) {
$files[$k] = str_replace(BASE_FILE_PATH . 'pages/blog/',
'',
$files[$k]);
}
}
return $files;
}
/**
* Gets the previous blog page (by date).
*
* @param $full_identifier
* Full identifier of current blog page.
*
* @return
* Full identifier of previous blog page.
*/
function blog_get_prev($full_identifier) {
$files = blog_query_all();
$curr_index = array_search($full_identifier . '.php', $files);
if ($curr_index !== FALSE && $curr_index < count($files)-1) {
return str_replace('.php', '', $files[$curr_index+1]);
}
return NULL;
}
/**
* Gets the next blog page (by date).
*
* @param $full_identifier
* Full identifier of current blog page.
*
* @return
* Full identifier of next blog page.
*/
function blog_get_next($full_identifier) {
$files = blog_query_all();
$curr_index = array_search($full_identifier . '.php', $files);
if ($curr_index !== FALSE && $curr_index !== 0) {
return str_replace('.php', '', $files[$curr_index-1]);
}
return NULL;
}
And these are the functions to query content by tag:
<?php
/**
* Queries for blog pages with the specified tag.
*
* @param $slug
* Tag slug.
*
* @return
* List of blog pages with the specified tag.
*/
function blog_query_bytag($slug) {
$files = glob(BASE_FILE_PATH .
'mappings/blog_tags/*--' . $slug . '.php');
if (!empty($files)) {
foreach (array_keys($files) as $k) {
$files[$k] = str_replace(BASE_FILE_PATH . 'mappings/blog_tags/',
'',
$files[$k]);
}
rsort($files);
}
return $files;
}
/**
* Gets a blog page's tags based on its full identifier.
*
* @param $full_identifier
* Blog page's full identifier.
*
* @return
* Tags.
*/
function blog_get_tags($full_identifier) {
$files = glob(BASE_FILE_PATH .
'mappings/blog_tags/' . $full_identifier . '*.php');
$ret = array();
if (!empty($files)) {
foreach ($files as $f) {
$ret[] = str_replace(BASE_FILE_PATH . 'mappings/blog_tags/' .
$full_identifier . '--',
'',
str_replace('.php', '', $f));
}
}
return $ret;
}
That's basically all the "querying" that this blog app needs.
In summary
What I've shared here, is part of the solution that I recently built when I migrated Jaza's World Trip (my travel blog from 2007-2008) away from (an out-dated version of) Drupal, and into a new database-free custom PHP thingamajig. (I'm considering writing a separate article about what else I developed, and I'm also considering cleaning it up and releasing it as a biolerplate PHP project template on GitHub… although not sure if it's worth the effort, we shall see).
This is an old blog site that I wanted to "retire", i.e. to migrate off a CMS platform, and into more-or-less static files. So, the filesystem-based data store that I developed in this case was a good match, because:
No new content will be added to the site in the future
Migrating the site to a different server (in the hypothetical future) would consist of simply copying all the files, and the new server would only need to support PHP (and PHP is the most commonly-supported web server technology in the world)
If the data store performs well with the current volume of content, that's great; I don't care if it doesn't scale to millions of records (due to e.g. files-per-directory OS limits being reached, glob performance worsening), because it will never have that many
Most sites that I develop are new, and they don't fit this use case at all. They need a content management admin interface. They need to scale. And they usually need various other features (e.g. user login) that also commonly rely on a traditional database backend. However, for this somewhat unique use-case, building a database-free tagging data store was a fun experiment!
]]>
Enriching user-entered HTML markup with PHP parsing2012-05-10T00:00:00Z2012-05-10T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/05/enriching-user-entered-html-markup-with-php-parsing/
I recently found myself faced with an interesting little web dev challenge. Here's the scenario. You've got a site that's powered by a PHP CMS (in this case, Drupal). One of the pages on this site contains a number of HTML text blocks, each of which must be user-editable with a rich-text editor (in this case, TinyMCE). However, some of the HTML within these text blocks (in this case, the unordered lists) needs some fairly advanced styling – the kind that's only possible either with CSS3 (using, for example, nth-child pseudo-selectors), with JS / jQuery manipulation, or with the addition of some extra markup (for example, some first, last, and first-in-row classes on the list item elements).
Naturally, IE7+ compatibility is required – so, CSS3 selectors are out. Injecting element attributes via jQuery is a viable option, but it's an ugly approach, and it may not kick in immediately on page load. Since the users will be editing this content via WYSIWYG, we can't expect them to manually add CSS classes to the markup, or to maintain any markup that the developer provides in such a form. That leaves only one option: injecting extra attributes on the server-side.
When it comes to HTML manipulation, there are two general approaches. The first is Parsing HTML The Cthulhu Way (i.e. using Regular Expressions). However, you already have one problem to solve – do you really want two? The second is to use an HTML parser. Sadly, this problem must be solved in PHP – which, unlike some otherlanguages, lacks an obvioustool of choice in the realm of parsers. I chose to use PHP5's built-in DOMDocument library, which (from what I can tell) is one of the most mature and widely-used PHP HTML parsers available today. Here's my code snippet.
Markup parsing function
<?php
/**
* Parses the specified markup content for unordered lists, and enriches
* the list markup with unique identifier classes, 'first' and 'last'
* classes, 'first-in-row' classes, and a prepended inside element for
* each list item.
*
* @param $content
* The markup content to enrich.
* @param $id_prefix
* Each list item is given a class with name 'PREFIX-item-XX'.
* Optional.
* @param $items_per_row
* For each Nth element, add a 'first-in-row' class. Optional.
* If not set, no 'first-in-row' classes are added.
* @param $prepend_to_li
* The name of an HTML element (e.g. 'span') to prepend inside
* each liist item. Optional.
*
* @return
* Enriched markup content.
*/
function enrich_list_markup($content, $id_prefix = NULL,
$items_per_row = NULL, $prepend_to_li = NULL) {
// Trim leading and trailing whitespace, DOMDocument doesn't like it.
$content = preg_replace('/^ */', '', $content);
$content = preg_replace('/ *$/', '', $content);
$content = preg_replace('/ *\n */', "\n", $content);
// Remove newlines from the content, DOMDocument doesn't like them.
$content = preg_replace('/[\r\n]/', '', $content);
$doc = new DOMDocument();
$doc->loadHTML($content);
foreach ($doc->getElementsByTagName('ul') as $ul_node) {
$i = 0;
foreach ($ul_node->childNodes as $li_node) {
$li_class_list = array();
if ($id_prefix) {
$li_class_list[] = $id_prefix . '-item-' . sprintf('%02d', $i+1);
}
if (!$i) {
$li_class_list[] = 'first';
}
if ($i == $ul_node->childNodes->length-1) {
$li_class_list[] = 'last';
}
if (!empty($items_per_row) && !($i % $items_per_row)) {
$li_class_list[] = 'first-in-row';
}
$li_node->setAttribute('class', implode(' ', $li_class_list));
if (!empty($prepend_to_li)) {
$prepend_el = $doc->createElement($prepend_to_li);
$li_node->insertBefore($prepend_el, $li_node->firstChild);
}
$i++;
}
}
$content = $doc->saveHTML();
// Manually fix up HTML entity encoding - if there's a better
// solution for this, let me know.
$content = str_replace('–', '–', $content);
// Manually remove the doctype, html, and body tags that DOMDocument
// wraps around the text. Apparently, this is the only easy way
// to fix the problem:
// http://stackoverflow.com/a/794548
$content = mb_substr($content, 119, -15);
return $content;
}
?>
This is a fairly simple parsing routine, that loops through the li elements of the unordered lists in the text, and that adds some CSS classes, and also prepends a child node. There's some manual cleanup needed after the parsing is done, due to some quirks associated with DOMDocument.
Markup parsing example
For example, say your users have entered the following markup:
You can then whip up some CSS to make your designer happy:
#fruit ul {
list-style-type: none;
}
#fruit ul li {
display: block;
width: 150px;
padding: 20px 20px 20px 45px;
float: left;
margin: 0 0 20px 20px;
background-color: #bbddfb;
position: relative;
}
#fruit ul li.first-in-row {
clear: both;
margin-left: 0;
}
#fruit ul li span {
display: block;
position: absolute;
left: 20px;
top: 23px;
width: 15px;
height: 15px;
background-color: #191970;
}
#fruit ul li.first, #fruit ul li.last {
background-color: #968adc;
}
#fruit ul li.fruit-item-03, #fruit ul li.fruit-item-05 {
background-color: #7bdca6;
}
#fruit ul li.first span, #fruit ul li.last span {
background-color: #4b0082;
}
#fruit ul li.fruit-item-03 span, #fruit ul li.fruit-item-05 span {
background-color: #00611c;
}
Your finished product is bound to win you smiles on every front:
How the parsed markup looks when rendered
Obviously, this is just one example of how a markup parsing function might look, and of the exact end result that you might want to achieve with such parsing. Take everything presented here, and fiddle liberally to suit your needs.
In the approach I've presented here, I believe I've managed to achieve a reasonable balance between stakeholder needs (i.e. easily editable content, good implementation of visual design), hackery, and technical elegance. Also note that this article is not at all CMS-specific (the code snippets work stand-alone), nor is it particularly parser-specific, or even language-specific (although code snippets are in PHP). Feedback welcome.
]]>
Thread progress monitoring in Python2011-06-30T00:00:00Z2011-06-30T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/06/thread-progress-monitoring-in-python/
My recent hobby hack-together, my photo cleanup tool FotoJazz, required me getting my hands dirty with threads for the first time (in Python or otherwise). Threads allow you to run a task in the background, and to continue doing whatever else you want your program to do, while you wait for the (usually long-running) task to finish (that's one definition / use of threads, anyway — a much less complex one than usual, I dare say).
However, if your program hasn't got much else to do in the meantime (as was the case for me), threads are still very useful, because they allow you to report on the progress of a long-running task at the UI level, which is better than your task simply blocking execution, leaving the UI hanging, and providing no feedback.
As part of coding up FotoJazz, I developed a re-usable architecture for running batch processing tasks in a thread, and for reporting on the thread's progress in both a web-based (AJAX-based) UI, and in a shell UI. This article is a tour of what I've developed, in the hope that it helps others with their thread progress monitoring needs in Python or in other languages.
The FotoJazzProcess base class
The foundation of the system is a Python class called FotoJazzProcess, which is in the project/fotojazz/fotojazzprocess.py file in the source code. This is a base class, designed to be sub-classed for actual implementations of batch tasks; although the base class itself also contains a "dummy" batch task, which can be run and monitored for testing / example purposes. All the dummy task does, is sleep for 100ms, for each file in the directory path provided:
#!/usr/bin/env python
# ...
from threading import Thread
from time import sleep
class FotoJazzProcess(Thread):
"""Parent / example class for running threaded FotoJazz processes.
You should use this as a base class if you want to process a
directory full of files, in batch, within a thread, and you want to
report on the progress of the thread."""
# ...
filenames = []
total_file_count = 0
# This number is updated continuously as the thread runs.
# Check the value of this number to determine the current progress
# of FotoJazzProcess (if it equals 0, progress is 0%; if it equals
# total_file_count, progress is 100%).
files_processed_count = 0
def __init__(self, *args, **kwargs):
"""When initialising this class, you can pass in either a list
of filenames (first param), or a string of space-delimited
filenames (second param). No need to pass in both."""
Thread.__init__(self)
# ...
def run(self):
"""Iterates through the files in the specified directory. This
example implementation just sleeps on each file - in subclass
implementations, you should do some real processing on each
file (e.g. re-orient the image, change date modified). You
should also generally call self.prepare_filenames() at the
start, and increment self.files_processed_count, in subclass
implementations."""
self.prepare_filenames()
for filename in self.filenames:
sleep(0.1)
self.files_processed_count += 1
You could monitor the thread's progress, simply by checking obj.files_processed_count from your calling code. However, the base class also provides some convenience methods, for getting the progress value in a more refined form — i.e. as a percentage value, or as a formatted string:
# ...
def percent_done(self):
"""Gets the current percent done for the thread."""
return float(self.files_processed_count) / \
float(self.total_file_count) \
* 100.0
def get_progress(self):
"""Can be called at any time before, during or after thread
execution, to get current progress."""
return '%d files (%.2f%%)' % (self.files_processed_count,
self.percent_done())
The FotoJazzProcessShellRun command-line progress class
FotoJazzProcessShellRun contains all the code needed to report on a thread's progress via the command-line. All you have to do is instantiate it, and pass it a class (as an object) that inherits from FotoJazzProcess (or, if no class is provided, it uses the FotoJazzProcess base class). Then, execute the instantiated object — it takes care of the rest for you:
class FotoJazzProcessShellRun(object):
"""Runs an instance of the thread with shell output / feedback."""
def __init__(self, init_class=FotoJazzProcess):
self.init_class = init_class
def __call__(self, *args, **kwargs):
# ...
fjp = self.init_class(*args, **kwargs)
print '%s threaded process beginning.' % fjp.__class__.__name__
print '%d files will be processed. ' % fjp.total_file_count + \
'Now beginning progress output.'
print fjp.get_progress()
fjp.start()
while fjp.is_alive() and \
fjp.files_processed_count < fjp.total_file_count:
sleep(1)
if fjp.files_processed_count < fjp.total_file_count:
print fjp.get_progress()
print fjp.get_progress()
print '%s threaded process complete. Now exiting.' \
% fjp.__class__.__name__
if __name__ == '__main__':
FotoJazzProcessShellRun()()
At this point, we're able to see the progress feedback in action already, through the command-line interface. This is just running the dummy batch task, but the feedback looks the same regardless of what process is running:
Thread progress output on the command-line.
The way this command-line progress system is implemented, it provides feedback once per second (timing handled with a simple sleep() call), and outputs feedback in terms of both number of files and percentage done. These details, of course, merely form an example for the purposes of this article — when implementing your own command-line progress feedback, you would change these details per your own tastes and needs.
The web front-end: HTML
Cool, we've now got a framework for running batch tasks within a thread, and for monitoring the progress of the thread; and we've built a simple interface for printing the thread's progress via command-line execution.
That was the easy part! Now, let's build an AJAX-powered web front-end on top of all that.
To start off, let's look at the basic HTML we'd need, for allowing the user to initiate a batch task (e.g. by pushing a submit button), and to see the latest progress of that task (e.g. with a JavaScript progress bar widget):
Close your eyes for a second, and pretend we've also just coded up some gorgeous, orgasmic CSS styling for this markup (and don't worry about the class / id names for now, either — they're needed for the JavaScript, which we'll get to shortly). Now, open your eyes, and behold! A glorious little web-based dialog for our dummy task:
Web-based dialog for initiating and monitoring our dummy task.
The web front-end: JavaScript
That's a lovely little interface we've just built. Now, let's begin to actually make it do something. Let's write some JavaScript that hooks into our new submit button and progress indicator (with the help of jQuery, and the jQuery UI progress bar — this code can be found in the static/js/fotojazz.js file in the source code):
This code is best read by starting at the bottom. First off, we call fotojazz.operations.init(). If you look up just a few lines, you'll see that function defined (it's the init: function() one). In the init() function, the first thing we do is initialise a (disabled) jQuery progress bar widget, on our div with class operation-progress. Then, we call process_start(), passing in a process_css_name of 'dummy', and a process_class_name of 'FotoJazzProcess'.
The process_start() function binds all of its code to the click() event of our submit button. So, when we click the button, an AJAX request is sent to the path /process/start/process_class_name/ on the server side. We haven't yet implemented this server-side callback, but for now let's assume that (as its pathname suggests), this callback starts a new process thread, and returns some info about the new thread (e.g. a reference ID, a progress indication, etc). The AJAX 'success' callback for this request then waits 100ms (with the help of setTimeout()), before calling process_progress(), passing it the CSS name and the class name that process_start() originally received, plus data.key, which is the unique ID of the new thread on the server.
The main job of process_progress(), is to make AJAX calls to the server that request the latest progress of the thread (again, let's imagine that the callback for this is done on the server side). When it receives the latest progress data, it then updates the jQuery progress bar widget's value, waits 100ms, and calls itself recursively. Via this recursion loop, it continues to update the progress bar widget, until the process is 100% complete, at which point the JavaScript terminates, and our job is done.
This code is extremely generic and re-usable. There's only one line in all the code, that's actually specific to the batch task that we're running: the process_start('dummy', 'FotoJazzProcess'); call. To implement another task on the front-end, all we'd have to do is copy and paste this one-line function call, changing the two parameter values that get passed to it (along with also copy-pasting the HTML markup to match). Or, if things started to get unwieldy, we could even put the function call inside a loop, and iterate through an array of parameter values.
The web front-end: Python
Now, let's take a look at the Python code to implement our server-side callback paths (which, in this case, are built as views in the Flask framework, and can be found in the project/fotojazz/views.py file in the source code):
from uuid import uuid4
from flask import jsonify
from flask import Module
from flask import request
from project import fotojazz_processes
# ...
mod = Module(__name__, 'fotojazz')
# ...
@mod.route('/process/start/<process_class_name>/')
def process_start(process_class_name):
"""Starts the specified threaded process. This is a sort-of
'generic' view, all the different FotoJazz tasks share it."""
# ...
process_module_name = process_class_name
if process_class_name != 'FotoJazzProcess':
process_module_name = process_module_name.replace('Process', '')
process_module_name = process_module_name.lower()
# Dynamically import the class / module for the particular process
# being started. This saves needing to import all possible
# modules / classes.
process_module_obj = __import__('%s.%s.%s' % ('project',
'fotojazz',
process_module_name),
fromlist=[process_class_name])
process_class_obj = getattr(process_module_obj, process_class_name)
# ...
# Initialise the process thread object.
fjp = process_class_obj(*args, **kwargs)
fjp.start()
if not process_class_name in fotojazz_processes:
fotojazz_processes[process_class_name] = {}
key = str(uuid4())
# Store the process thread object in a global dict variable, so it
# continues to run and can have its progress queried, independent
# of the current session or the current request.
fotojazz_processes[process_class_name][key] = fjp
percent_done = round(fjp.percent_done(), 1)
done=False
return jsonify(key=key, percent=percent_done, done=done)
@mod.route('/process/progress/<process_class_name>/')
def process_progress(process_class_name):
"""Reports on the progress of the specified threaded process.
This is a sort-of 'generic' view, all the different FotoJazz tasks
share it."""
key = request.args.get('key', '', type=str)
if not process_class_name in fotojazz_processes:
fotojazz_processes[process_class_name] = {}
if not key in fotojazz_processes[process_class_name]:
return jsonify(error='Invalid process key.')
# Retrieve progress of requested process thread, from global
# dict variable where the thread reference is stored.
percent_done = fotojazz_processes[process_class_name][key] \
.percent_done()
done = False
if not fotojazz_processes[process_class_name][key].is_alive() or \
percent_done == 100.0:
del fotojazz_processes[process_class_name][key]
done = True
percent_done = round(percent_done, 1)
return jsonify(key=key, percent=percent_done, done=done)
As with the JavaScript, these Python functions are completely generic and re-usable. The process_start() function dynamically imports and instantiates the process class object needed for this particular task, based on the parameter sent to it in the URL path. It then kicks off the thread, and stores the thread in fotojazz_processes, which is a global dictionary variable. A unique ID is generated as the key for this dictionary, and that ID is then sent back to the javascript, via the JSON response object.
The process_progress() function retrieves the running thread by its unique key, and finds the progress of the thread as a percentage value. It also checks if the thread is now finished, as this is valuable information back on the JavaScript end (we don't want that recursive AJAX polling to continue forever!). It also returns its data to the front-end, via a JSON response object.
With code now in place at all necessary levels, our AJAX interface to the dummy batch task should now be working smoothly:
The dummy task is off and running, and the progress bar is working.
Absolutely no extra Python view code is needed, in order to implement new batch tasks. As long as the correct new thread class (inheriting from FotoJazzProcess) exists and can be found, everything Just Works™. Not bad, eh?
Final thoughts
Progress feedback on threads is a fairly common development pattern in more traditional desktop GUI apps. There's a lot of info out there on threads and progress bars in Python's version of the Qt GUI library, for example. However, I had trouble finding much info about implementing threads and progress bars in a web-based app. Hopefully, this article will help those of you looking for info on the topic.
The example code I've used here is taken directly from my FotoJazz app, and is still loosely coupled to it. As such, it's example code, not a ready-to-go framework or library for Python threads with web-based progress indication. However, it wouldn't take that much more work to get the code to that level. Consider it your homework!
Also, an important note: the code demonstrated in this article — and the FotoJazz app in general — is not suitable for a real-life online web app (in its current state), as it has not been developed with security, performance, or scalability in mind at all. In particular, I'm pretty sure that the AJAX in its current state is vulnerable to all sorts of CSRF attacks; not to mention the fact that all sorts of errors and exceptions are liable to occur, most of them currently uncaught. I'm also a total newbie to threads, and I understand that threads in web apps are particularly prone to cause strange explosions. You must remember: FotoJazz is a web-based desktop app, not an actual web app; and web-based desktop app code is not necessarily web-app-ready code.
Finally, what I've demonstrated here is not particularly specific to the technologies I've chosen to use. Instead of jQuery, any number of other JavaScript libraries could be used (e.g. YUI, Prototype). And instead of Python, the whole back-end could be implemented in any other server-side language (e.g. PHP, Java), or in another Python framework (e.g. Django, web.py). I'd be interested to hear if anyone else has done (or plans to do) similar work, but with a different technology stack.