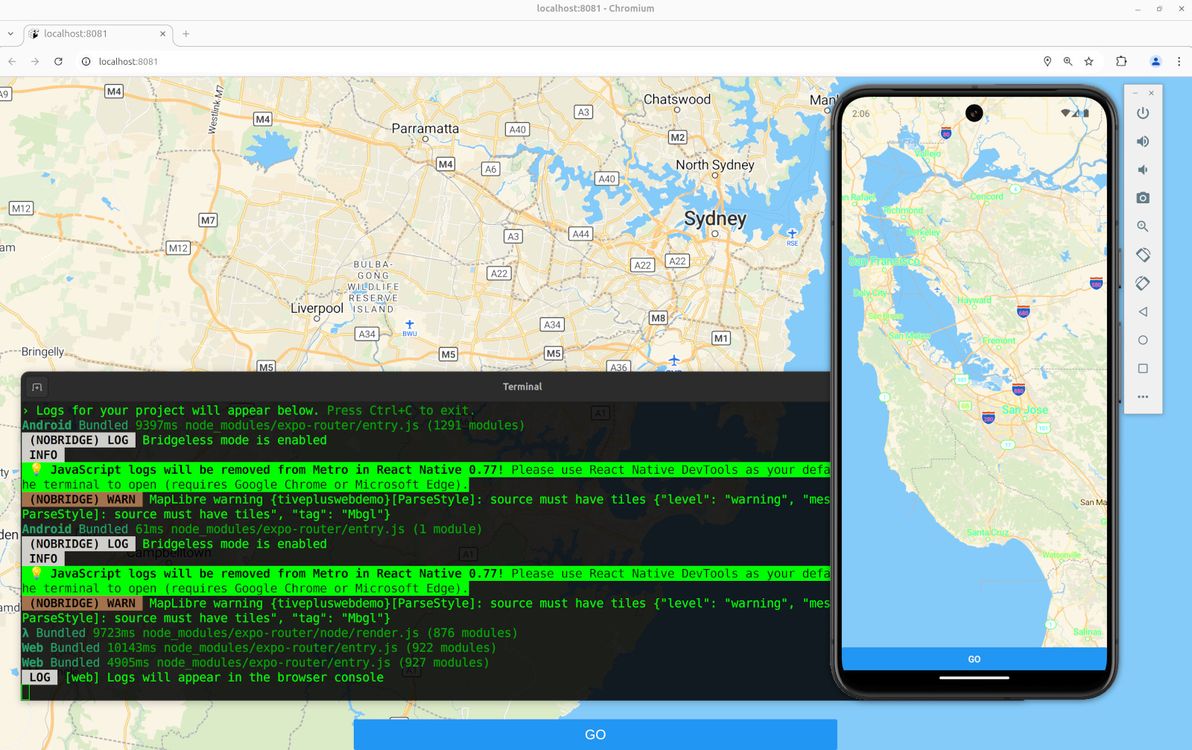
Below is my humble lil' guide to getting MapLibre working for both native and web in Expo. Note: if you want to skip the step-by-step shpiel, and you just want a working example with all the code, feel free to head straight to the Expo MapLibre native + web demo on GitHub.
Map library options
First of all, a quick rundown of the options that one has at one's disposal, when wanting to add a map to an Expo app.
The simplest and the most recommended option is to use react-native-maps. This is the only solution that works with Expo Go, and it's the only one that's documented in the official Expo docs.
However, it's explicitly stated that react-native-maps isn't web-compatible, so if you used it and you also wanted maps on web, your only choice would be to fall back to something like react-google-maps for web. Also, you'd (potentially) have to deal with Apple Maps on iOS vs Google Maps on Android. And – my main reason for steering clear of this option – you'd have to live with the these-days-horrific pricing and draconian ToS of the Google Maps API.
The next option is to use rnmapbox. This is the solution that I instinctively chose first up, and that I stuck with for quite a while, mainly because (for the past several years) I've become accustomed to using Mapbox instead of Google Maps anyway, for maps on old-skool web sites. Plus, rnmapbox claims to (somewhat) support Expo Web.
Unfortunately, "somewhat" is in my opinion an overly optimistic assessment of rnmapbox's web support – basically, instead of trying to go down that route, you should instead fall back to react-map-gl with mapbox-gl-js for web. Plus, I was surprised to learn that Mapbox is no longer the mapping provider of choice for hobbyists, since it decided to stop open-sourcing its mapping library.
Which led me to MapLibre, which is a fork of Mapbox (v1) before the folks at Mapbox decided to release v2 with a non-open-source license. So, with MapLibre (plus MapTiler), I don't have to worry about disagreeable pricing / ToS. And I get basically the same map library on native and web. Although not exactly the same library – it inherits the limitations of the Mapbox libraries, so you need to use maplibre-react-native for native, and fall back to react-map-gl with maplibre-gl-js for web.
Map features
What I needed, and what I'm demo'ing here, is a pretty simple map. It shows the user's location on load (if the user grants location permissions, otherwise it falls back to showing latitude / longitude 0,0 on load). And when the user presses the "Go" button, it grabs the current centre position of the map, and shows the latitude / longitude coordinates of that centre position. That's it!
You're likely to need more functionality than that for a map in your own app. Hopefully this provides you with a humble base to start off from. Good luck getting other bells and whistles working (for native and web)!
Walkthrough
To start off, you'll need an Expo project. If you don't already have one, you can create one with:
npx create-expo-app@latest MyAppThen, you'll need to add both the native and the web mapping libraries as dependencies:
npm install --save @maplibre/maplibre-react-native
npm install --save maplibre-gl
npm install --save react-map-glI like to put everything inside a src/ directory, which is supported but which is not the default for Expo. And I like a structure with various other directories under src/ (see link). My example code from here on assumes that structure. Feel free to suit to your tastes.
You'll need to sign up to MapTiler for an API key. Edit your .env.local file to include this:
EXPO_PUBLIC_MAPTILER_API_KEY=yourmaptilerkeygoeshereDefine this variable in e.g. src/core/config.ts:
export const MAPTILER_API_KEY = process.env.EXPO_PUBLIC_MAPTILER_API_KEY;And define this constant in e.g. src/core/constants.ts:
export const MAPTILER_STYLE_URL =
"https://api.maptiler.com/maps/streets-v2/style.json?key=MAPTILER_API_KEY";The code from here on depends on various utility components, for styling of text and for positioning of elements. I won't go through all those components in this article, I leave it to you to refer to the src/components/ directory.
Before we get into the map code, we need to request location permission, and to get the user's current location (if the user grants permission). I originally had all of this inside the map components, but I then refactored the meat of it out into a utility function, which is very similar to the code in the expo-location docs, and which you can put at e.g. src/core/locationUtils.ts:
import * as Location from "expo-location";
import { Dispatch, SetStateAction } from "react";
export const setCurrentLocationIfAvailable = async (
setLocation: Dispatch<SetStateAction<Location.LocationObjectCoords>>,
setIsLocationUnavailable: Dispatch<SetStateAction<boolean>>,
) => {
let { status } = await Location.requestForegroundPermissionsAsync();
if (status !== "granted") {
setIsLocationUnavailable(true);
return;
}
try {
const currentLocation = await Location.getCurrentPositionAsync({});
setLocation(currentLocation.coords);
} catch (_e) {
setIsLocationUnavailable(true);
}
};Now for the map itself. Let's start by putting the code to render the map for native into a component. This code goes at e.g. src/components/NativeMapView.tsx:
import { StyleSheet } from "react-native";
import * as Location from "expo-location";
import MapLibreGL from "@maplibre/maplibre-react-native";
import { Camera, MapView, MapViewRef } from "@maplibre/maplibre-react-native";
import { Ref, useEffect, useState } from "react";
import { MAPTILER_API_KEY } from "../core/config";
import { MAPTILER_STYLE_URL } from "../core/constants";
import { setCurrentLocationIfAvailable } from "../core/locationUtils";
import { LoadingText } from "./LoadingText";
interface NativeMapViewProps {
mapRef?: Ref<MapViewRef>;
}
export const NativeMapView = (props: NativeMapViewProps) => {
const [location, setLocation] =
useState<Location.LocationObjectCoords | null>(null);
const [isLocationUnavailable, setIsLocationUnavailable] = useState(false);
useEffect(() => {
MapLibreGL.setAccessToken(null);
setCurrentLocationIfAvailable(setLocation, setIsLocationUnavailable);
}, []);
if (!location && !isLocationUnavailable) {
return <LoadingText />;
}
return (
<MapView
ref={props.mapRef}
style={styles.map}
styleURL={MAPTILER_STYLE_URL.replace(
"MAPTILER_API_KEY",
MAPTILER_API_KEY,
)}
>
<Camera
centerCoordinate={
location ? [location.longitude, location.latitude] : [0, 0]
}
zoomLevel={location ? 12 : 2}
animationDuration={0}
/>
</MapView>
);
};
const styles = StyleSheet.create({
map: {
flex: 1,
},
});This just renders the map, centred and zoomed at the user's current location, without any additional behaviour defined. It's important that we only import from @maplibre/maplibre-react-native in this file, and not in any other files that get loaded for both native and web, because web will freak out if it sees that import.
Next comes the code to render the map for web into a component. This code goes at e.g. src/components/WebMapView.tsx:
import { Ref, useEffect, useState } from "react";
import Map, { MapRef } from "react-map-gl/maplibre";
import * as Location from "expo-location";
import { MAPTILER_API_KEY } from "../core/config";
import { MAPTILER_STYLE_URL } from "../core/constants";
import { setCurrentLocationIfAvailable } from "../core/locationUtils";
import { LoadingText } from "./LoadingText";
interface WebMapViewProps {
mapRef?: Ref<MapRef>;
}
export const WebMapView = (props: WebMapViewProps) => {
const [location, setLocation] =
useState<Location.LocationObjectCoords | null>(null);
const [isLocationUnavailable, setIsLocationUnavailable] = useState(false);
useEffect(() => {
setCurrentLocationIfAvailable(setLocation, setIsLocationUnavailable);
}, []);
if (!location && !isLocationUnavailable) {
return <LoadingText />;
}
return (
<Map
ref={props.mapRef}
initialViewState={{
latitude: location ? location.latitude : 0,
longitude: location ? location.longitude : 0,
zoom: location ? 12 : 2,
}}
style={{ width: "100%", height: "100%" }}
mapStyle={MAPTILER_STYLE_URL.replace(
"MAPTILER_API_KEY",
MAPTILER_API_KEY,
)}
/>
);
};Once again, this just renders the map, no additional behaviour. And it's important that we only import from react-map-gl/maplibre in this file, because native will freak out if it sees that import.
Now we're going to render the map together with a "Go" button, and we're going to add some additional behaviour, such that when the button is pressed, we grab the current centre coordinates of the map, and then trigger an event using those coordinates. First, the native code for all that, at e.g. src/components/LatLonMap.tsx:
import { useRef } from "react";
import { Button } from "react-native";
import { CenteredContainer } from "./CenteredContainer";
import { FloatingContainer } from "./FloatingContainer";
import { FullWidthContainer } from "./FullWidthContainer";
import { FullWidthAndHeightContainer } from "./FullWidthAndHeightContainer";
import { NativeMapView } from "./NativeMapView";
import { MapViewRef } from "@maplibre/maplibre-react-native";
interface LatLonMapProps {
onPress?: (latitude: number, longitude: number) => Promise<void>;
}
export const LatLonMap = (props: LatLonMapProps) => {
const mapRef = useRef<MapViewRef>(null);
return (
<FullWidthAndHeightContainer>
<NativeMapView mapRef={mapRef} />
<FloatingContainer>
<CenteredContainer>
<FullWidthContainer>
<Button
onPress={async () => {
if (!mapRef.current) {
throw new Error("Missing mapRef");
}
const center = await mapRef.current.getCenter();
if (props.onPress) {
await props.onPress(center[1], center[0]);
}
}}
title="Go"
/>
</FullWidthContainer>
</CenteredContainer>
</FloatingContainer>
</FullWidthAndHeightContainer>
);
};And the web code for all that, at e.g. src/components/LatLonMap.web.tsx:
import { useRef } from "react";
import { Button } from "react-native";
import { CenteredContainer } from "./CenteredContainer";
import { FloatingContainer } from "./FloatingContainer";
import { FullWidthContainer } from "./FullWidthContainer";
import { FullWidthAndHeightContainer } from "./FullWidthAndHeightContainer";
import { WebMapView } from "./WebMapView";
import { MapRef } from "react-map-gl/maplibre";
interface LatLonMapProps {
onPress?: (latitude: number, longitude: number) => Promise<void>;
}
export const LatLonMap = (props: LatLonMapProps) => {
const mapRef = useRef<MapRef>(null);
return (
<FullWidthAndHeightContainer>
<WebMapView mapRef={mapRef} />
<FloatingContainer>
<CenteredContainer>
<FullWidthContainer>
<Button
onPress={async () => {
if (!mapRef.current) {
throw new Error("Missing mapRef");
}
const center = mapRef.current.getCenter();
if (props.onPress) {
await props.onPress(center.lat, center.lng);
}
}}
title="Go"
/>
</FullWidthContainer>
</CenteredContainer>
</FloatingContainer>
</FullWidthAndHeightContainer>
);
};A few key things to note with the above code samples. First of all, we're using Expo's built-in system of platform-specific filename prefixes, to write both a native version (the "default" version ending in .tsx) and a web version (ending in .web.tsx) of the same component. We're importing our NativeMapView component in one version, and our WebMapView component in the other version. The mapRef variable is of a different type, and has a slightly different interface, in each version.
And, finally, we're defining onPress as a prop that gets passed in (and that gets given the coordinates as simple integer parameters when it's called), rather than defining what happens on button press directly in this component, so that we can implement the "on button press" behaviour just once in the calling code (and so that the calling code, rather than this component, gets to decide what happens on button press, thus making this component more reusable).
We're now done writing components. Let's use our new native- and web-compatible map component on our home screen – code goes at e.g. src/app/index.tsx:
import { router } from "expo-router";
import { LatLonMap } from "../components/LatLonMap";
export default function HomeScreen() {
return (
<LatLonMap
onPress={async (latitude: number, longitude: number) => {
router.replace(`/lat-lon?lat=${latitude}&lon=${longitude}`);
}}
/>
);
}The above code is where we implement the "on button press" behaviour. In this case, the behaviour is to redirect to the /lat-lon screen, and to pass the latitude and longitude values as URL parameters.
Lucky last step is to then display the latitude and longitude to the user – code goes at e.g. src/app/(app)/lat-lon.tsx:
import { Button, StyleSheet } from "react-native";
import { useLocalSearchParams } from "expo-router";
import { Link } from "expo-router";
import { ThemedText } from "../../components/ThemedText";
import { ThemedView } from "../../components/ThemedView";
export default function LatLonScreen() {
const { lat, lon } = useLocalSearchParams();
if (typeof lat !== "string") {
throw new Error("lat is not a string");
}
if (typeof lon !== "string") {
throw new Error("lon is not a string");
}
const latVal = parseFloat(lat);
const lonVal = parseFloat(lon);
return (
<ThemedView style={styles.container}>
<ThemedText>Latitude: {latVal}</ThemedText>
<ThemedText>Longitude: {lonVal}</ThemedText>
<Link href="/" asChild>
<Button onPress={() => {}} title="Back" />
</Link>
</ThemedView>
);
}
const styles = StyleSheet.create({
container: {
flex: 1,
alignItems: "center",
justifyContent: "center",
padding: 20,
},
});Map done
There you have it: a map that looks and behaves virtually the same, on both native and web, implemented in a single codebase, with minimal platform-specific code required. I haven't thoroughly looked into how performant, how buggy, or overall how effective this solution is on all platforms, but hey, it's a start. Hope this helps you in your own Expo mapping endeavours.
]]>