innovations - GreenAshPoignant wit and hippie ramblings that are pertinent to innovations
https://greenash.net.au/thoughts/topics/innovations/
2022-08-28T00:00:00ZGDPR-compliant Google reCAPTCHA2022-08-28T00:00:00Z2022-08-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/08/gdpr-compliant-google-recaptcha/
Per the EU's GDPR and ePrivacy Directive, you must ask visitors to a website for their consent before setting any cookies, and/or before collecting any user tracking data. And because the GDPR applies to all EU citizens (who are residing within the EU), regardless of where in the world a website or its owner is based, in order to fully comply, in practice you should seek consent for all visitors to all websites globally.
In order to be GDPR-compliant, and in order to just be a good netizen, I made sure, when building GreenAsh v5 earlier this year, to not use services that set cookies at all, wherever possible. In previous iterations of GreenAsh, I used Google Analytics, which (like basically all Google services) is a notorious GDPR offender; this time around, I instead used Cloudflare Web Analytics, which is a good enough replacement for my modest needs, and which ticks all the privacy boxes.
However, on pages with forms at least, I still need Google reCAPTCHA. I'd like to instead use the privacy-conscious hCaptcha, but Netlify Forms only supports reCAPTCHA, so I'm stuck with it for now. Here's how I seek the user's consent before loading reCAPTCHA.
ready(() => {
const submitButton = document.getElementById('submit-after-recaptcha');
if (submitButton == null) {
return;
}
window.originalSubmitFormButtonText = submitButton.textContent;
submitButton.textContent = 'Prepare to ' + window.originalSubmitFormButtonText;
submitButton.addEventListener("click", e => {
if (submitButton.textContent === window.originalSubmitFormButtonText) {
return;
}
const agreeToCookiesMessage =
'This will load Google reCAPTCHA, which will set cookies. Sadly, you will ' +
'not be able to submit this form unless you agree. GDPR, not to mention ' +
'basic human decency, dictates that you have a choice and a right to protect ' +
'your privacy from the corporate overlords. Do you agree?';
if (window.confirm(agreeToCookiesMessage)) {
const recaptchaScript = document.createElement('script');
recaptchaScript.setAttribute(
'src',
'https://www.google.com/recaptcha/api.js?onload=recaptchaOnloadCallback' +
'&render=explicit');
recaptchaScript.setAttribute('async', '');
recaptchaScript.setAttribute('defer', '');
document.head.appendChild(recaptchaScript);
}
e.preventDefault();
});
});
I load this JS on every page, thus putting it on the lookout for forms that require reCAPTCHA (in my case, that's comment forms and the contact form). It changes the form's submit button text from, for example, "Send", to instead be "Prepare to Send" (as a hint to the user that clicking the button won't actually submit the form, there will be further action required before that happens).
It hijacks the button's click event, such that if the user hasn't yet provided consent, it shows a prompt. When consent is given, the Google reCAPTCHA JS is added to the DOM, and reCAPTCHA is told to call recaptchaOnloadCallback when it's done loading. If the user has already provided consent, then the button's default click behaviour of triggering form submission is allowed.
I embed this HTML inside every form that requires reCAPTCHA. It defines the wrapper element into which the reCAPTCHA is injected. And it defines recaptchaOnloadCallback, which changes the submit button text back to what it originally was (e.g. changes it from "Prepare to Send" back to "Send"), and which actually renders the reCAPTCHA widget.
This is what my GDPR-compliant, reCAPTCHA-enabled, Netlify-powered contact form looks like. The data-netlify-recaptcha attribute tells Netlify to require a successful reCAPTCHA challenge in order to accept a submission from this form.
The prompt before the reCAPTCHA in action
That's all there is to it! Not rocket science, but I just thought I'd share this with the world, because despite there being a gazillion posts on the interwebz advising that you "ask for consent before setting cookies", there seem to be surprisingly few step-by-step instructions explaining how to actually do that. And the standard advice appears to be to use a third-party script / plugin that implements an "accept cookies" popup for you, even though it's really easy to implement it yourself.
]]>
Introducing: Instant-runoff voting simulator2022-05-17T00:00:00Z2022-05-17T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/05/introducing-instant-runoff-voting-simulator/
I built a simulator showing how instant-runoff voting (called preferential voting in Australia) works step-by-step. Try it now.
The simulator in action
I hope that, by being an interactive, animated, round-by-round visualisation of the ballot distribution process, this simulation gives you a deeper understanding of how instant-runoff voting works.
There are other tools around that do basically the same thing as this simulator. Kudos to the authors of those tools. However, they only output a text log or a text-based table, they don't provide any visualisation or animation of the vote-counting process. And they spit out the results for all rounds all at once, they don't show (quite as clearly) how the results evolve from one round to the next.
Source code is all up on GitHub. It's coded in vanilla JS, with the help of the lovely Papa Parse library for CSV handling. I made a nice flowchart version of the code too.
With a federal election coming up, here in Australia, in just a few days' time, this simulator means there's now one less excuse for any of my fellow citizens to not know how the voting system works. And, in this election more than ever, it's vital that you properly understand why every preference matters, and how you can make every preference count.
]]>
The eccentric tale of Gustave Eiffel and his Tower2018-10-16T00:00:00Z2018-10-16T00:00:00ZJazahttps://greenash.net.au/thoughts/2018/10/the-eccentric-tale-of-gustave-eiffel-and-his-tower/
The Eiffel Tower, as it turns out, is far more than just the most iconic tourist attraction in the world. As the tallest structure ever built by man at the time – and holder of the record "tallest man-made structure in the world" for 41 years, following its completion in 1889 – it was a revolutionary feat of structural engineering. It was also highly controversial – deeply unpopular, one might even say – with some of the most prominent Parisians of the day fiercely protesting against its "monstruous" form. And Gustave Eiffel, its creator, was brilliant, ambitious, eccentric, and thick-skinned.
From reading the wonderful epic novel Paris, by Edward Rutherford, I learned some facts about Gustave Eiffel's life, and about the Eiffel Tower's original conception, its construction, and its first few decades as the exclamation mark of the Paris skyline, that both surprised and intrigued me. Allow me to share these tidbits of history in this here humble article.
Gustave Eiffel hanging out with a model of his Tower. Image source:domain.com.au.
To begin with, the Eiffel Tower was not designed by Gustave Eiffel. The original idea and the first drafts of the design were produced by one Maurice Koechlin, who worked at Eiffel's firm. The same is true of Eiffel's other great claim to fame, the Statue of Liberty (which he built just before the Tower): after Eiffel's firm took over the project of building the statue, it was Koechlin who came up with Liberty's ingenious inner iron truss skeleton, and outer copper "skin", that makes her highly wind-resistant in the midst of blustery New York Harbour. It was a similar story for the Garabit Viaduct, and various other projects: although Eiffel himself was a highly capable engineer, it was Koechlin who was the mastermind, while Eiffel was the salesman and the celebrity.
Eiffel, and his colleagues Maurice Koechlin and Émile Nouguier, were engineers, not designers. In particular, they were renowned bridge-builders of their time. As such, their tower design was all about the practicalities of wind resistance, thermal expansion, and material strength; the Tower's aesthetic qualities were secondary considerations, with architect Stephen Sauvestre only being invited to contribute an artistic touch (such as the arches on the Tower's base), after the initial drafts were completed.
Koechlin's first draft of the Eiffel Tower. Image source:Wikimedia Commons.
The Eiffel Tower was built as the centrepiece of the 1889 Exposition Universelle in Paris, after winning the 1886 competition that was held to find a suitable design. However, after choosing it, the City of Paris then put forward only a small modicum of the estimated money needed to build it, rather than the Tower's full estimated budget. As such, Eiffel agreed to cover the remainder of the construction costs out of his own pocket, but only on the condition that he receive all commercial income from the Tower, for 20 years from the date of its inauguration. This proved to be much to Eiffel's advantage in the long-term, as the Tower's income just during the Exposition Universelle itself – i.e. just during the first six months of its operating life – more than covered Eiffel's out-of-pocket costs; and the Tower has consistently operated at a profit ever since.
Illustration of the Eiffel Tower during the 1889 World's Fair. Image source:toureiffel.paris.
Pioneering construction projects of the 19th century (and, indeed, of all human history before then too) were, in general, hardly renowned for their occupational safety standards. I had always assumed that the building of the Eiffel Tower, which saw workmen reach more dizzying heights than ever before, had taken no small toll of lives. However, it just so happens that Gustave Eiffel was more than a mere engineer and a bourgeois, he was also a pioneer of safety: thanks to his insistence on the use of devices such as guard rails and movable stagings, the Eiffel Tower project amazingly saw only one fatality; and it wasn't even really a workplace accident, as the deceased, a workman named Angelo Scagliotti, climbed the tower while off duty, to impress his girlfriend, and sadly lost his footing.
The Tower's three levels, and its lifts and staircases, have always been accessible to the general public. However, something that not all visitors to the Tower may be aware of, is that near the summit of the Tower, just above the third level's viewing platform, sits what was originally Gustave Eiffel's private apartment. For the 20 years that he owned the rights to the Tower, Eiffel also enjoyed his own bachelor pad at the top! Eiffel reportedly received numerous requests to rent out the pad for a night, but he never did so, instead only inviting distinguished guests of his choosing, such as (no less than) Thomas Edison. The apartment is now open to the public as a museum. Still no word regarding when it will be listed on Airbnb; although another private apartment was more recently added lower down in the Tower and was rented out.
Eiffel's modest abode atop the world, as it looks today. Image source:The Independent.
So why did Eiffel's contract for the rights to the Tower stipulate 20 years? Because the plan was, that after gracing the Paris cityscape for that many years, it was to be torn down! That's right, the Eiffel Tower – which today seems like such an invincible monument – was only ever meant to be a temporary structure. And what saved it? Was it that the City Government came to realise what a tremendous cash cow it could inherit? Was it that Parisians came to love and to admire what they had considered to be a detestable blight upon their elegant city? Not at all! The only thing that saved the Eiffel Tower was that, a few years prior to its scheduled doomsday, a little thing known as radio had been invented. The French military, who had started using the Tower as a radio antenna – realising that it was the best antenna in all of Paris, if not the world at that time – promptly declared the Tower vital to the defence of Paris, thus staving off the wrecking ball.
The big crew gathered at the base of the Tower, Jul 1888. Image source:busy.org.
And the rest, as they say, is history. There are plenty more intriguing anecdotes about the Eiffel Tower, if you're interested in delving further. The Tower continued to have a colourful life, after the City of Paris relieved Eiffel of his rights to it in 1909, and after his death in 1923; and the story continues to this day. So, next time you have the good fortune of visiting La belle Paris, remember that there's much more to her tallest monument than just a fine view from the top.
]]>
Splitting a Python codebase into dependencies for fun and profit2015-06-30T00:00:00Z2015-06-30T00:00:00ZJazahttps://greenash.net.au/thoughts/2015/06/splitting-a-python-codebase-into-dependencies-for-fun-and-profit/
When the Python codebase for a project (let's call the project LasagnaFest) starts getting big, and when you feel the urge to re-use a chunk of code (let's call that chunk foodutils) in multiple places, there are a variety of steps at your disposal. The most obvious step is to move that foodutils code into its own file (thus making it a Python module), and to then import that module wherever else you want in the codebase.
Most of the time, doing that is enough. The Python module importing system is powerful, yet simple and elegant.
But… what happens a few months down the track, when you're working on two new codebases (let's call them TortelliniFest and GnocchiFest – perhaps they're for new clients too), that could also benefit from re-using foodutils from your old project? What happens when you make some changes to foodutils, for the new projects, but those changes would break compatibility with the old LasagnaFest codebase?
What happens when you want to give a super-charged boost to your open source karma, by contributing foodutils to the public domain, but separated from the cruft that ties it to LasagnaFest and Co? And what do you do with secretfoodutils, which for licensing reasons (it contains super-yummy but super-secret sauce) can't be made public, but which should ideally also be separated from the LasagnaFest codebase for easier re-use?
Or – not to be forgotten – what happens when, on one abysmally rainy day, you take a step back and audit the LasagnaFest codebase, and realise that it's got no less than 38 different *utils chunks of code strewn around the place, and you ponder whether surely keeping all those utils within the LasagnaFest codebase is really the best way forward?
Moving foodutils to its own module file was a great first step; but it's clear that in this case, a more drastic measure is needed. In this case, it's time to split off foodutils into a separate, independent codebase, and to make it an external dependency of the LasagnaFest project, rather than an internal component of it.
This article is an introduction to the how and the why of cutting up parts of a Python codebase into dependencies. I've just explained a fair bit of the why. As for the how: in a nutshell, pip (for installing dependencies), the public PyPI repo (for hosting open-sourced dependencies), and a private PyPI repo (for hosting proprietary dependencies). Read on for more details.
Levels of modularity
One of the (many) joys of coding in Python is the way that it encourages modularity. For example, let's start with this snippet of completely non-modular code:
There are, in my opinion, three different levels of re-factoring that you can apply, in order to make it more modular. You can think of these levels like the layers of a lasagna, if you want. Or not.
Each successive level of re-factoring involves a bit more work in the short-term, but results in more convenient re-use in the long-term. So, which level is appropriate, depends on the likelihood that you (or others) will want to re-use a given chunk of code in the future.
First, you can split the logic out of the procedural blurg, and into a function in the same file:
And, finally, you can move that file out of your codebase, upload it to a Python package repository (the most common such repository being PyPI), and then declare it as a dependency of your codebase using pip:
As I said, achieving this last level of modularity isn't always necessary or appropriate, due to the overhead involved. For a given chunk of code, there are always going to be trade-offs to consider, and as a developer it's always going to be your judgement call.
Splitting out code
For the times when it is appropriate to go that "last mile" and split code out as an external dependency, there are (in my opinion) insufficient resources regarding how to go about it. I hope, therefore, that this section serves as a decent guide on the matter.
Factor out coupling
The first step in making until-now "project code" an external dependency, is removing any coupling that the chunk of code may have to the rest of the codebase. For example, the foodutils code shown above is nice and de-coupled; but what if it instead looked like so:
foodutils.py:
from mysettings import NUM_QUESTION_MARKS
def greet_dude_with_food(dude_name, food_today):
return "Hey {dude_name}! Want a {food_today} today{q_marks}".format(
dude_name=dude_name,
food_today=food_today,
q_marks='?'*NUM_QUESTION_MARKS)
This would be problematic, because this code relies on the assumption that it lives in a codebase containing a mysettings module, and that the configuration value NUM_QUESTION_MARKS is defined within that module.
We can remove this coupling by changing NUM_QUESTION_MARKS to be a parameter passed to greet_dude_with_food, like so:
The dependent code in this project could then pass in the required config value when it calls greet_dude_with_food, like so:
foodgreeter.py:
from foodutils import greet_dude_with_food
from mysettings import NUM_QUESTION_MARKS
dude_name = 'Johnny'
food_today = 'lasagna'
print(greet_dude_with_food(
dude_name=dude_name,
food_today=food_today,
num_question_marks=NUM_QUESTION_MARKS))
Once the code we're re-factoring no longer depends on anything elsewhere in the codebase, it's ready to be made an external dependency.
New repo for dependency
Next comes the step of physically moving the given chunk of code out of the project's codebase. In most cases, this means deleting the given file(s) from the project's version control repository (you are using version control, right?), and creating a new repo for those file(s) to live in.
For example, if you're using Git, the steps would be something like this:
The given chunk of code now has its own dedicated repo. But it's not yet a project, in its own right, and it can't yet be referenced as a dependency. To do that, we'll need to add some more files to the new repo, mainly consisting of metadata describing "who" this project is, and what it does.
Next, add a version number to the code. The best way to do this, is to add it at the top of the main Python file, e.g. by adding this to the top of foodutils.py:
__version__ = '0.1.0'
After that, we're going to add the standard metadata files that almost all open-source Python projects have. Most importantly, a setup.py file that looks something like this:
import os
import setuptools
module_path = os.path.join(os.path.dirname(__file__), 'foodutils.py')
version_line = [line for line in open(module_path)
if line.startswith('__version__')][0]
__version__ = version_line.split('__version__ = ')[-1][1:][:-2]
setuptools.setup(
name="foodutils",
version=__version__,
url="https://github.com/misterfoo/foodutils",
author="Mister foo",
author_email="mister@foo.com",
description="Utils for handling food.",
long_description=open('README.rst').read(),
py_modules=['foodutils'],
zip_safe=False,
platforms='any',
install_requires=[],
classifiers=[
'Development Status :: 2 - Pre-Alpha',
'Environment :: Web Environment',
'Intended Audience :: Developers',
'Operating System :: OS Independent',
'Programming Language :: Python',
'Programming Language :: Python :: 2',
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.3',
],
)
And also, a README.rst file:
foodutils
=========
Utils for handling food.
Once you've created those files, commit them to the new repo.
Push the repo
Great – the chunk of code now lives in its own repo, and it contains enough metadata for other projects to see what its name is, what version(s) of it there are, and what function(s) it performs. All that needs to be done now, is to decide where this repo will be hosted. But to do this, you first need to answer an important non-technical question: to open-source the code, or to keep it proprietary?
In general, you should open-source your dependencies whenever possible. You get more eyeballs (for free). Famous hairy people like Richard Stallman will send you flowers. If nothing else, you'll at least be able to always easily find your code, guaranteed (if you can't remember where it is, just Google it!). You get the drift. If open-sourcing the code, then the most obvious choice for where to host the repo is GitHub. (However, I'm not evangelising GitHub here, remember there are other options, kids).
Open source is kool, but sometimes you can't or you don't want to go down that route. That's fine, too – I'm not here to judge anyone, and I can't possibly be aware of anyone else's business / ownership / philosophical situation. So, if you want to keep the code all to your little self (or all to your little / big company's self), you're still going to have to host it somewhere. And no, "on my laptop" does not count as your code being hosted somewhere (well, technically you could just keep the repo on your own PC, and still reference it as a dependency, but that's a Bad Idea™). There are a number of hosting options: for example, on a VPS that you control; or using a managed service such as GitHub private, Bitbucket, or Assembla (note: once again, not promoting any specific service provider, just listing the main players as options).
So, once you've decided whether or not to open-source the code, and once you've settled on a hosting option, push the new repo to its hosted location.
Upload to PyPI
Nearly there now. The chunk of code has been de-coupled from its dependent project; it's been put in a new repo with the necessary metadata; and that repo is now hosted at a permanent location somewhere online. All that's left, is to make it known to the universe of Python projects, so that it can be easily listed as a dependency of other Python projects.
If you've developed with Python before (and if you've read this far, then I assume you have), then no doubt you've heard of pip. Being the Python package manager of choice these days, pip is the tool used to manage Python dependencies. pip can find dependencies from a variety of locations, but the place it looks first and foremost (by default) is on the Python Package Index (PyPI).
If your dependency is public and open-source, then you should add it to PyPI. Each time you release a new version, then (along with committing and tagging that new version in the repo) you should also upload it to PyPI. I won't go into the details in this article; please refer to the official docs for registering and uploading packages on PyPI. When following the instructions there, you'll generally want to package your code as a "universal wheel", you'll generally use the PyPI website form to register a new package, and you'll generally use twine to upload the package.
If your dependency is private and proprietary, then PyPI is not an option. The easiest way to deal with private dependencies (also the easiest way to deal with public dependencies, for that matter), is to not worry about proper Python packaging at all, and simply to use pip's ability to directly reference a source repo (including a specific commit / tag), e.g:
However, that has a number of disadvantages, the most visible disadvantage being that pip install will run much slower, because it has to do a git pull every time you ask it to check that foodutils is installed (even if you specify the same commit / tag each time).
A better way to deal with private dependencies, is to create your own "private PyPI". Same as with public packages: each time you release a new version, then (along with committing and tagging that new version in the repo) you should also upload it to your private PyPI. For instructions regarding this, please refer to my guide for how to set up and use a private PyPI repo. Also, note that my guide is for quite a minimal setup, although it contains links to some alternative setup options, including more advanced and full-featured options. (And if using a private PyPI, then take note of my guide's instructions for what to put in your local ~/.pip/pip.conf file).
Reference the dependency
The chunk of code is now ready to be used as an external dependency, by any project. To do this, you simply list the package in your project's requirements.txt file; whether the package is on the public PyPI, or on a private PyPI of your own, the syntax is the same:
foodutils==0.1.0 # From pypi.myserver.com
Then, just run your dependencies through pip as usual:
pip install -r requirements.txt
And there you have it: foodutils is now an external dependency. You can list it as a requirement for LasagnaFest, TortelliniFest, GnocchiFest, and as many other projects as you need.
Final thoughts
This article was born out of a series of projects that I've been working on over the past few months (and that I'm still working on), written mainly in Flask (these apps are still in alpha; ergo, sorry, can't talk about their details yet). The size of the projects' codebases grew to be rather unwieldy, and the projects have quite a lot of shared functionality.
I started out by re-using chunks of code between the different projects, with the hacky solution of sym-linking from one codebase to another. This quickly became unmanageable. Once I could stand the symlinks no longer (and once I had some time for clean-up), I moved these shared chunks of code into separate repos, and referenced them as dependencies (with some being open-sourced and put on the public PyPI). Only in the last week or so, after losing patience with slow pip installs, and after getting sick of seeing far too many -e git+http://git… strings in my requirements.txt files, did I finally get around to setting up a private PyPI, for better dealing with the proprietary dependencies of these codebases.
I hope that this article provides some clear guidance regarding what can be quite a confusing task, i.e. that of creating and maintaining a private Python package index. Aside from being a technical guide, though, my aim in penning this piece is to explain how you can split off component parts of a monolithic codebase into re-usable, independent separate codebases; and to convey the advantages of doing so, in terms of code quality and maintainability.
Flask, my framework of choice these days, strives to consist of a series of independent projects (Flask, Werkzeug, Jinja, WTForms, and the myriad Flask-* add-ons), which are compatible with each other, but which are also useful stand-alone or with other systems. I think that this is a great example for everyone to follow, even humble "custom web-app" developers like myself. Bearing that in mind, devoting some time to splitting code out of a big bad client-project codebase, and creating more atomic packages (even if not open-source) upon whose shoulders a client-project can stand, is a worthwhile endeavour.
]]>
Five long-distance and long-way-off Australian infrastructure links2015-01-03T00:00:00Z2015-01-03T00:00:00ZJazahttps://greenash.net.au/thoughts/2015/01/five-long-distance-and-long-way-off-australian-infrastructure-links/
Australia. It's a big place. With only a handful of heavily populated areas. And a whole lot of nothing in between.
No, really. Nothing. Image source:Australian Outback Buffalo Safaris.
Over the past century or so, much has been achieved in combating the famous Tyranny of Distance that naturally afflicts this land. High-quality road, rail, and air links now traverse the length and breadth of Oz, making journeys between most of her far-flung corners relatively easy.
Nevertheless, there remain a few key missing pieces, in the grand puzzle of a modern, well-connected Australian infrastructure system. This article presents five such missing pieces, that I personally would like to see built in my lifetime. Some of these are already in their early stages of development, while others are pure fantasies that may not even be possible with today's technology and engineering. All of them, however, would provide a new long-distance connection between regions of Australia, where there is presently only an inferior connection in place, or none at all.
Tunnel to Tasmania
Let me begin with the most nut-brained idea of all: a tunnel from Victoria to Tasmania!
As the sole major region of Australia that's not on the continental landmass, currently the only options for reaching Tasmania are by sea or by air. The idea of a tunnel (or bridge) to Tasmania is not new, it has been sporadically postulated for over a century (although never all that seriously). There's a long and colourful discussion of routes, cost estimates, and geographical hurdles at the Bass Strait Tunnel thread on Railpage. There's even a Facebook page promoting a Tassie Tunnel.
Although it would be a highly beneficial piece of infrastructure, that would in the long-term (among other things) provide a welcome boost to Tasmania's (and Australia's) economy, sadly the Tassie Tunnel is probably never going to happen. The world's longest undersea tunnel to date (under the Tsugaru Strait in Japan) spans only 54km. A tunnel under the Bass Strait, directly from Victoria to Tasmania, would be at least 200km long; although if it went via King Island (to the northwest of Tas), it could be done as two tunnels, each one just under 100km. Both the length and the depth of such a tunnel make it beyond the limits of contemporary engineering.
Aside from the engineering hurdle – and of course the monumental cost – it also turns out that the Bass Strait is Australia's main seismic hotspot (just our luck, what with the rest of Australia being seismically dead as a doornail). The area hasn't seen any significant undersea volcanic activity in the past few centuries, but experts warn that it could start letting off steam in the near future. This makes it hardly an ideal area for building a colossal tunnel.
Railway from Mt Isa to Tennant Creek
Great strides have been made in connecting almost all the major population centres of Australia by rail. The first significant long-distance rail link in Oz was the line from Sydney to Melbourne, which was completed in 1883 (although a change-of-gauge was required until 1962). The Indian Pacific (Sydney to Perth), a spectacular trans-continental achievement and the nation's longest train line – not to mention one of the great railways of the world – is the real backbone on the map, and has been operational since 1970. The newest and most long-awaited addition, The Ghan (Adelaide to Darwin), opened for business in 2004.
The Ghan roaring through the outback. Image source:Fly With Me.
Today's nation-wide rail network (with regular passenger service) is, therefore, at an impressive all-time high. Every state and territory capital is connected (except for Hobart – a Tassie Tunnel would fix that!), and numerous regional centres are in the mix too. Despite the fact that many of the lines / trains are old and clunky, they continue (often stubbornly) to plod along.
If you look at the map, however, you might notice one particularly glaring gap in the network, particularly now that The Ghan has been established. And that is between Mt Isa in Queensland (the terminus of The Inlander service from Townsville), and Tennant Creek in the Northern Territory (which The Ghan passes through). At the moment, travelling continuously by rail from Townsville to Darwin would involve a colossal horse-shoe journey via Sydney and Adelaide, which only an utter nutter would consider embarking upon. Whereas with the addition of this relatively small (1,000km or so) extra line, the journey would be much shorter, and perfectly feasible. Although still long; there's no silver bullet through the outback.
A railway from Mt Isa to Tennant Creek – even though it would traverse some of the most remote and desolate land in Australia – is not a pipe dream. It's been suggested several times over the past few years. As with the development of the Townsville to Mt Isa railway a century ago, it will need the investment of the mining industry in order to actually happen. Unfortunately, the current economic situation means that mining companies are unlikely to invest in such a project at this time; what's more, The Inlander is a seriously decrepit service (at risk of being decommissioned) on an ageing line, making it somewhat unsuitable for joining up with a more modern line to the west.
Nonetheless, I have high hopes that we will see this railway connection built in the not-too-distant future, when the stars are next aligned.
Highway to Cape York
Australia's northernmost region, the Cape York Peninsula, is also one of the country's last truly wild frontiers. There is now a sealed all-weather highway all the way around the Australian mainland, and there's good or average road access to the key towns in almost all regional areas. Cape York is the only place left in Oz that lacks such roads, and that's also home to a non-trivial population (albeit a small 20,000-ish people, the majority Aborigines, in an area half the size of Victoria). Other areas in Oz with no road access whatsoever, such as south-west Tasmania, and most of the east of Western Australia, are lacking even a trivial population.
The biggest challenge to reliable transport in the Cape is the wet season: between December and April, there's so much rainfall that all the rivers become flooded, making roads everywhere impassable. Aside from that, the Cape also presents other obstacles, such as being seriously infested with crocodiles.
There are two main roads that provide access to the Cape: the Peninsula Developmental Road (PDR) from Lakeland to Weipa, and the Northern Peninsula Road (NPR), from the junction north of Coen on to Bamaga. The PDR is slowly improving, but the majority of it is still unsealed and is closed for much of the wet season. The NPR is worse: little (if any) of the route is sealed, and a ferry is required to cross the Jardine River (approaching the road's northern terminus), even at the height of the dry season.
A proper Cape York Highway, all the way from Lakeland to The Tip, is in my opinion bound to get built eventually. I've seen mention of a prediction that we should expect it done by 2050; if that estimate can be met, I'd call it a great achievement. To bring the Cape's main roads up to highway standard, they'd need to be sealed all the way, and there would need to be reasonably high bridges over all the rivers. Considering the very extreme weather patterns up that way, the route will never be completely flood-proof (much as the fully-sealed Barkly Highway through the Gulf of Carpentaria, south of the Cape, isn't flood-proof either); but if a journey all the way to The Tip were possible in a 2WD vehicle for most of the year, that would be a grand accomplishment.
High-speed rail on the Eastern seaboard
Of all the proposals being put forward here, this is by far the most well-known and the most oft talked about. Many Australians are in agreement with me, on the fact that a high-speed rail link along the east coast is sorely needed. Sydney to Canberra is generally touted as an appropriate first step, Sydney to Melbourne is acknowledged as the key component, and Sydney to Brisbane is seen as a very important extension.
Sadly, despite all the good news – the glowing recommendations of the government study; the enthusiasm of countless Australians; and some valiant attempts to stave off inertia – Australia has been waiting for high-speed rail an awfully long time, and it's probably going to have to keep on waiting. Because, with the cost of a complete Brisbane-Sydney-Canberra-Melbourne network estimated at around AUD$100 billion, neither the government nor anyone else is in a hurry to cough up the requisite cash.
This is the only proposal in this article, about an infrastructure link to complement another one (of the same mode) that already exists. I've tried to focus on links that are needed where currently there is nothing at all. However, I feel that this propoal belongs here, because despite its proud and important history, the ageing eastern seaboard rail network is rapidly becoming an embarrassment to the nation.
This Greens flyer says it better than I can. Image source:Adam Bandt MP.
The corner of Australia where 90% of the population live, deserves (and needs) a train service for the future, not one that belongs in a museum. The east coast interstate trains still run on diesel, as the lines aren't even electrified outside of the greater metropolitan areas. The network's few (remaining) passenger services share the line with numerous freight trains. There are still a plethora of old-fashioned level crossings. And the majority of the route is still single-track, causing regular delays and seriously limiting the line's capacity. And all this on two of the world's busiest air routes, with the road routes also struggling under the load.
Come on, Aussie – let's join the 21st century!
Self-sustaining desert towns
My final idea, some may consider a little kookoo, but I truly believe that it would be of benefit to our great sunburnt country. As should be clear by now, immense swathes of Australia are empty desert. There are many dusty roads and 4WD tracks traversing the country's arid centre, and it's not uncommon for some of the towns along these routes to be 1,000km's or more distant from their nearest neighbour. This results in communities (many of them indigenous) that are dangerously isolated from each other and from critical services; it makes for treacherous vehicle journeys, where travellers must bring extra necessities such as petrol and water, just to last the distance; and it means that Australia as a whole suffers from more physical disconnects, robbing contiguity from our otherwise unified land.
Many outback communities and stations are a long way from their nearest neighbours. Image source:news.com.au.
Good transport networks (road and rail) across the country are one thing, but they're not enough. In my opinion, what we need to do is to string out more desert towns along our outback routes, in order to reduce the distances of no human contact, and of no basic services.
But how to support such towns, when most outback communities are struggling to survive as it is? And how to attract more people to these towns, when nobody wants to live out in the bush? In my opinion, with the help of modern technology and of alternative agricultural methods, it could be made to work.
Towns need a number of resources in order to thrive. First and foremost, they need water. Securing sufficient water in the outback is a challenge, but with comprehensive conservation rules, and modern water reuse systems, having at least enough water for a small population's residential use becomes feasible, even in the driest areas of Australia. They also need electricity, in order to use modern tools and appliances. Fortunately, making outback towns energy self-sufficient is easier than it's ever been before, thanks to recent breakthroughs in solar technology. A number of these new technologies have even been pilot-tested in the outback.
In order to be self-sustaining, towns also need to be able to cultivate their own food in the surrounding area. This is a challenge in most outback areas, where water is scarce and soil conditions are poor. Many remote communities rely on food and other basic necessities being trucked in. However, a number of recent initiatives related to desert greening may help to solve this thorny (as an outback spinifex) problem.
Most promising is the global movement (largely founded and based in Australia) known as permaculture. A permaculture-based approach to desert greening has enjoyed a vivid and well-publicised success on several occasions; most notably, Geoff Lawton's project in the Dead Sea Valley of Jordan about ten years ago. There has been some debate regarding the potential ability of permaculture projects to green the desert in Australia. Personally, I think that the pilot projects to date have been very promising, and that similar projects in Australia would be, at the least, a most worthwhile endeavour. There are also various other projects in Australia that aim to create or nurture green corridors in arid areas.
As for where to build a new corridor of desert towns, my preference would be to target an area as remote and as spread-out as possible. For example, along the Great Central Road (which is part of the "Outback Highway"). This might be an overly-ambitious route, but it would certainly be one of the most suitable.
And regarding the "tough nut" of how to attract people to come and live in new outback towns – when it's hard enough already just to maintain the precarious existing population levels – I have no easy answer. It has been suggested that, with the growing number of telecommuters in modern industries (such as IT), and with other factors such as the high real estate prices in major cities, people will become increasingly likely to move to the bush, assuming there's adequately good-quality internet access in the respective towns. Personally, as an IT professional who has worked remotely on many occasions, I don't find this to be a convincing enough argument.
I don't think that there's any silver bullet to incentivising a move to new desert towns. "Candy dangling" approaches such as giving away free houses in the towns, equipping buildings with modern sustainable technologies, or even giving cash gifts to early pioneers – these may be effective in getting a critical mass of people out there, but it's unlikely to be sufficient to keep them there in the long-term. Really, such towns would have to develop a local economy and a healthy local business ecosystem in order to maintain their residents; and that would be a struggle for newly-built towns, the same as it's been a struggle for existing outback towns since day one.
In summary
Love 'em or hate 'em, admire 'em or attack 'em, there's my list of five infrastructure projects that I think would be of benefit to Australia. Some are more likely to happen than others; unfortunately, it appears that none of them is going to be fully realised any time soon. Feedback welcome!
]]>
Database-free content tagging with files and glob2014-05-20T00:00:00Z2014-05-20T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/05/database-free-content-tagging-with-files-and-glob/
Tagging data (e.g. in a blog) is many-to-many data. Each content item can have multiple tags. And each tag can be assigned to multiple content items. Many-to-many data needs to be stored in a database. Preferably a relational database (e.g. MySQL, PostgreSQL), otherwise an alternative data store (e.g. something document-oriented like MongoDB / CouchDB). Right?
If you're not insane, then yes, that's right! However, for a recent little personal project of mine, I decided to go nuts and experiment. Check it out, this is my "mapping data" store:
Just a list of files in a directory.
And check it out, this is me querying the data store:
Show me all posts with the tag 'fun-stuff'.
And again:
Show me all tags for the post 'rant-about-seashells'.
And that's all there is to it. Many-to-many tagging data stored in a list of files, with content item identifiers and tag identifiers embedded in each filename. Querying is by simple directory listing shell commands with wildcards (also known as "globbing").
Is it user-friendly to add new content? No! Does it allow the rich querying of SQL and friends? No! Is it scalable? No!
But… Is the basic querying it allows enough for my needs? Yes! Is it fast (for a store of up to several thousand records)? Yes! And do I have the luxury of not caring about user-friendliness or scalability in this instance? Yes!
Implementation
For the project in which I developed this system, I implemented the querying with some simple PHP code. For example, this is my "content item" store:
Another list of files in a directory.
These are the functions to do some basic querying on all content:
<?php
/**
* Queries for all blog pages.
*
* @return
* List of all blog pages.
*/
function blog_query_all() {
$files = glob(BASE_FILE_PATH . 'pages/blog/*.php');
if (!empty($files)) {
foreach (array_keys($files) as $k) {
$files[$k] = str_replace(BASE_FILE_PATH . 'pages/blog/',
'',
$files[$k]);
}
rsort($files);
}
return $files;
}
/**
* Queries for blog pages with the specified year / month.
*
* @param $year
* Year.
* @param $month
* Month
*
* @return
* List of blog pages with the specified year / month.
*/
function blog_query_byyearmonth($year, $month) {
$files = glob(BASE_FILE_PATH . 'pages/blog/' .
$year . '-' . $month . '-*.php');
if (!empty($files)) {
foreach (array_keys($files) as $k) {
$files[$k] = str_replace(BASE_FILE_PATH . 'pages/blog/',
'',
$files[$k]);
}
}
return $files;
}
/**
* Gets the previous blog page (by date).
*
* @param $full_identifier
* Full identifier of current blog page.
*
* @return
* Full identifier of previous blog page.
*/
function blog_get_prev($full_identifier) {
$files = blog_query_all();
$curr_index = array_search($full_identifier . '.php', $files);
if ($curr_index !== FALSE && $curr_index < count($files)-1) {
return str_replace('.php', '', $files[$curr_index+1]);
}
return NULL;
}
/**
* Gets the next blog page (by date).
*
* @param $full_identifier
* Full identifier of current blog page.
*
* @return
* Full identifier of next blog page.
*/
function blog_get_next($full_identifier) {
$files = blog_query_all();
$curr_index = array_search($full_identifier . '.php', $files);
if ($curr_index !== FALSE && $curr_index !== 0) {
return str_replace('.php', '', $files[$curr_index-1]);
}
return NULL;
}
And these are the functions to query content by tag:
<?php
/**
* Queries for blog pages with the specified tag.
*
* @param $slug
* Tag slug.
*
* @return
* List of blog pages with the specified tag.
*/
function blog_query_bytag($slug) {
$files = glob(BASE_FILE_PATH .
'mappings/blog_tags/*--' . $slug . '.php');
if (!empty($files)) {
foreach (array_keys($files) as $k) {
$files[$k] = str_replace(BASE_FILE_PATH . 'mappings/blog_tags/',
'',
$files[$k]);
}
rsort($files);
}
return $files;
}
/**
* Gets a blog page's tags based on its full identifier.
*
* @param $full_identifier
* Blog page's full identifier.
*
* @return
* Tags.
*/
function blog_get_tags($full_identifier) {
$files = glob(BASE_FILE_PATH .
'mappings/blog_tags/' . $full_identifier . '*.php');
$ret = array();
if (!empty($files)) {
foreach ($files as $f) {
$ret[] = str_replace(BASE_FILE_PATH . 'mappings/blog_tags/' .
$full_identifier . '--',
'',
str_replace('.php', '', $f));
}
}
return $ret;
}
That's basically all the "querying" that this blog app needs.
In summary
What I've shared here, is part of the solution that I recently built when I migrated Jaza's World Trip (my travel blog from 2007-2008) away from (an out-dated version of) Drupal, and into a new database-free custom PHP thingamajig. (I'm considering writing a separate article about what else I developed, and I'm also considering cleaning it up and releasing it as a biolerplate PHP project template on GitHub… although not sure if it's worth the effort, we shall see).
This is an old blog site that I wanted to "retire", i.e. to migrate off a CMS platform, and into more-or-less static files. So, the filesystem-based data store that I developed in this case was a good match, because:
No new content will be added to the site in the future
Migrating the site to a different server (in the hypothetical future) would consist of simply copying all the files, and the new server would only need to support PHP (and PHP is the most commonly-supported web server technology in the world)
If the data store performs well with the current volume of content, that's great; I don't care if it doesn't scale to millions of records (due to e.g. files-per-directory OS limits being reached, glob performance worsening), because it will never have that many
Most sites that I develop are new, and they don't fit this use case at all. They need a content management admin interface. They need to scale. And they usually need various other features (e.g. user login) that also commonly rely on a traditional database backend. However, for this somewhat unique use-case, building a database-free tagging data store was a fun experiment!
]]>
How smart are smartphones?2013-11-02T00:00:00Z2013-11-02T00:00:00ZJazahttps://greenash.net.au/thoughts/2013/11/how-smart-are-smartphones/
As of about two months ago, I am a very late and reluctant entrant into the world of smartphones. All that my friends and family could say to me, was: "What took you so long?!" Being a web developer, everyone expected that I'd already long since jumped on the bandwagon. However, I was actually in no hurry to make the switch.
Techomeanies: sad dinosaur. Image source:Sticky Comics.
Being now acquainted with my new toy, I believe I can safely say that my reluctance was not (entirely) based on my being a "phone dinosaur", an accusation that some have levelled at me. Apart from the fact that they offer "a tonne of features that I don't need", I'd assert that the current state-of-the-art in smartphones suffers some serious usability, accessibility, and convenience issues. In short: these babies ain't so smart as their purty name suggests. These babies still have a lotta growin' up to do.
Hello Operator, how do I send a telegram to Aunt Gertie in Cheshire using Android 4.1.2? Image source:sondasmcschatter.
Touchy
Mobile phones with few buttons are all the rage these days. This is principally thanks to the demi-g-ds at Apple, who deign that we mere mortals should embrace all that is white with chrome bezel.
Apple has been waging war on the button for some time. For decades, the Mac mouse has been a single-button affair, in contrast to the two- or three-button standard PC rodent. Since the dawn of the iEra, a single (wheel-like) button has predominated all iShtuff. (For a bit of fun, watch how this single-button phenomenon reached its unholy zenith with the unveiling of the MacBook Wheel). And, most recently, since Apple's invention of the i(AmTheOneTrue)Phone (of which all other smartphones are but a paltry and pathetic imitation attempted by mere mortals), smartphones have been almost by definition "big on touch-screen, low on touch-button".
Oh sorry, did I forget to mention that I can't resist bashing the Cult of Mac at every opportunity? Image source:Crazy Art Ideas.
I'm not happy about this. I like buttons. You can feel buttons. There is physical space between each button. Buttons physically move when you press them.
You can't feel the icons on a touch screen. A touch screen is one uninterrupted physical surface. And a touch screen doesn't provide any tactile response when pressed.
There is active ongoing research in this field. Just this year, the world's first fully-functional bumpy touchscreen prototype was showcased, by California-based Tactus. However, so far no commercial smartphones have been developed using this technology. Hopefully, in another few years' time, the situation will be different; but for the current state-of-the-art smartphones, the lack of tactile feedback in the touch screens is a serious usability issue.
Related to this, is the touch-screen keyboard that current-generation smartphones provide. Seriously, it's a shocker. I wouldn't say I have particularly fat fingers, nor would I call myself a luddite (am I not a web developer?). Nevertheless, touch-screen keyboards frustrate the hell out of me. And, as I understand it, I'm not alone in my anguish. I'm far too often hitting a letter adjacent to the one I poked. Apart from the lack of extruding keys / tactile feedback, each letter is also unmanageably small. It takes me 20 minutes to write an e-mail on my smartphone, that I can write in about 4 minutes on my laptop.
Touch screens have other issues, too. Manufacturers are struggling to get touch sensitivity level spot-on: from my personal experience, my Galaxy S3 is far too hyper-sensitive, even the lightest brush of a finger sets it off; whereas my fiancée's iPhone 4 is somewhat under-sensitive, it almost never responds to my touch until I start poking it hard (although maybe it just senses my anti-Apple vibes and says STFU). The fragility of touch screens is also of serious concern – as a friend of mine recently joked: "these new phones are delicate little princesses". Fortunately, I haven't had any shattered or broken touch-screen incidents as yet (only a small superficial scratch so far); but I've heard plenty of stories.
Before my recent switch to Samsung, I was a Nokia boy for almost 10 years – about half that time (the recent half) with a 6300; and the other half (the really good ol' days) with a 3100. Both of those phones were "bricks", as flip-phones never attracted me. Both of them were treated like cr@p and endured everything (especially the ol' 3100, which was a wonderfully tough little bugger). Both had a regular keypad (the 3100's keypad boasted particularly rubbery, well-spaced buttons), with which I could write text messages quickly and proficiently. And both sported more button real-estate than screen real-estate. All good qualities that are naught to be found in the current crop of touch-monsters.
Great, but can you make calls with it?
After the general touch-screen issues, this would have to be my next biggest criticism of smartphones. Big on smart, low on phone.
But hey, I guess it's better than "big on shoe, low on phone". Image source:Ars Technica.
Smartphones let you check your email, update your Facebook status, post your phone-camera-taken photos on Instagram, listen to music, watch movies, read books, find your nearest wood-fired pizza joint that's open on Mondays, and much more. They also, apparently, let you make and receive phone calls.
It's not particularly hard to make calls with a smartphone. But, then again, it's not as easy as it was with "dumb phones", nor is it as easy as it should be. On both of the smartphones that I'm now most familiar with (Galaxy S3 and iPhone 4), calling a contact requires more than the minimum two clicks ("open contacts", and "press call"). On the S3, this can be done with a click and a "swipe right", which (although I've now gotten used to it) felt really unintuitive to begin with. Plus, there's no physical "call" button, only a touch-screen "call" icon (making it too easy to accidentally message / email / Facebook someone when you meant to call them, and vice-versa).
Receiving calls is more problematic, and caused me significant frustration to begin with. Numerous times, I've rejected a call when I meant to answer it (by either touching the wrong icon, or by the screen getting brushed as I extract the phone from my pocket). And really, Samsung, what crazy-a$$ Gangman-style substances were you guys high on, when you decided that "hold and swipe in one direction to answer, hold and swipe in the other direction to reject" was somehow a good idea? The phone is ringing, I have about five seconds, so please don't make me think!
In my opinion, there REALLY should be a physical "answer / call" button on all phones, period. And, on a related note, rejecting calls and hanging up (which are tasks just as critical as are calling / answering) are difficulty-fraught too; and there also REALLY should be a physical "hang up" button on all phones, period. I know that various smartphones have had, and continue to have, these two physical buttons; however, bafflingly, neither the iPhone nor the Galaxy include them. And once again, Samsung, one must wonder how many purple unicorns were galloping over the cubicles, when you decided that "let's turn off the screen when you want to hang up, and oh, if by sheer providence the screen is on when you want to hang up, the hang-up button could be hidden in the slid-up notification bar" was what actual carbon-based human lifeforms wanted in a phone?
Hot and shagged out
Two other critical problems that I've noticed with both the Galaxy and the iPhone (the two smartphones that are currently considered the crème de la crème of the market, I should emphasise).
Firstly, they both start getting quite hot, after just a few minutes of any intense activity (making a call, going online, playing games, etc). Now, I understand that smartphones are full-fledged albeit pocked-sized computers (for example, the Galaxy S3 has a quad-core processor and 1-2GB of RAM). However, regular computers tend to sit on tables or floors. Holding a hot device in your hands, or keeping one in your pocket, is actually very uncomfortable. Not to mention a safety hazard.
Secondly, there's the battery-life problem. Smartphones may let you do everything under the sun, but they don't let you do it all day without a recharge. It seems pretty clear to me that while smartphones are a massive advancement compared to traditional mobiles, the battery technology hasn't advanced anywhere near on par. As many others have reported, even with relatively light use, you're lucky to last a full day without needing to plug your baby in for some intravenous AC TLC.
In summary
I've had a good ol' rant, about the main annoyances I've encountered during my recent initiation into the world of smartphones. I've focused mainly on the technical issues that have been bugging me. Various online commentaries have discussed other aspects of smartphones: for example, the oft-unreasonable costs of owning one; and the social and psychological concerns, such as aggression / meanness, impatience / chronic boredom, and endemic antisocial behaviour (that last article also mentions another concern that I've written about before, how GPS is eroding navigational ability). While in general I agree with these commentaries, personally I don't feel they're such critical issues – or, to be more specific, I guess I feel that these issues already existed and already did their damage in the "traditional mobile phone" era, and that smartphones haven't worsened things noticeably. So, I won't be discussing those themes in this article.
Anyway, despite my scathing criticism, the fact is that I'm actually very impressed with all the cool things that smartphones can do; and yes, although I was dragged kicking and screaming, I have also succumbed and joined the "dark side" myself, and I must admit that I've already made quite thorough use of many of my smartphone's features. Also, it must be remembered that – although many people already claim that they "can hardly remember what life was like before smartphones" – this is a technology that's still in its infancy, and it's only fair and reasonable that there are still numerous (technical and other) kinks yet to be ironed out.
]]>
Flattening many-to-many fields for MySQL to CSV export2012-05-23T00:00:00Z2012-05-23T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/05/flattening-many-to-many-fields-for-mysql-to-csv-export/
Relational databases are able to store, with minimal fuss, pretty much any data entities you throw at them. For the more complex cases – particularly cases involving hierarchical data – they offer many-to-many relationships. Querying many-to-many relationships is usually quite easy: you perform a series of SQL joins in your query; and you retrieve a result set containing the combination of your joined tables, in denormalised form (i.e. with the data from some of your tables being duplicated in the result set).
A denormalised query result is quite adequate, if you plan to process the result set further – as is very often the case, e.g. when the result set is subsequently prepared for output to HTML / XML, or when the result set is used to populate data structures (objects / arrays / dictionaries / etc) in programming memory. But what if you want to export the result set directly to a flat format, such as a single CSV file? In this case, denormalised form is not ideal. It would be much better, if we could aggregate all that many-to-many data into a single result set containing no duplicate data, and if we could do that within a single SQL query.
This article presents an example of how to write such a query in MySQL – that is, a query that's able to aggregate complex many-to-many relationships, into a result set that can be exported directly to a single CSV file, with no additional processing necessary.
Example: a lil' Bio database
For this article, I've whipped up a simple little schema for a biographical database. The database contains, first and foremost, people. Each person has, as his/her core data: a person ID; a first name; a last name; and an e-mail address. Each person also optionally has some additional bio data, including: bio text; date of birth; and gender. Additionally, each person may have zero or more: profile pictures (with each picture consisting of a filepath, nothing else); web links (with each link consisting of a title and a URL); and tags (with each tag having a name, existing in a separate tags table, and being linked to people via a joining table). For the purposes of the example, we don't need anything more complex than that.
Here's the SQL to create the example schema:
CREATE TABLE person (
pid int(10) unsigned NOT NULL AUTO_INCREMENT,
firstname varchar(255) NOT NULL,
lastname varchar(255) NOT NULL,
email varchar(255) NOT NULL,
PRIMARY KEY (pid),
UNIQUE KEY email (email),
UNIQUE KEY firstname_lastname (firstname(100), lastname(100))
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;
CREATE TABLE tag (
tid int(10) unsigned NOT NULL AUTO_INCREMENT,
tagname varchar(255) NOT NULL,
PRIMARY KEY (tid),
UNIQUE KEY tagname (tagname)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;
CREATE TABLE person_bio (
pid int(10) unsigned NOT NULL,
bio text NOT NULL,
birthdate varchar(255) NOT NULL DEFAULT '',
gender varchar(255) NOT NULL DEFAULT '',
PRIMARY KEY (pid),
FULLTEXT KEY bio (bio)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE person_pic (
pid int(10) unsigned NOT NULL,
pic_filepath varchar(255) NOT NULL,
PRIMARY KEY (pid, pic_filepath)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE person_link (
pid int(10) unsigned NOT NULL,
link_title varchar(255) NOT NULL DEFAULT '',
link_url varchar(255) NOT NULL DEFAULT '',
PRIMARY KEY (pid, link_url),
KEY link_title (link_title)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE person_tag (
pid int(10) unsigned NOT NULL,
tid int(10) unsigned NOT NULL,
PRIMARY KEY (pid, tid)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
And here's the SQL to insert some sample data into the schema:
INSERT INTO person (firstname, lastname, email) VALUES ('Pete', 'Wilson', 'pete@wilson.com');
INSERT INTO person (firstname, lastname, email) VALUES ('Sarah', 'Smith', 'sarah@smith.com');
INSERT INTO person (firstname, lastname, email) VALUES ('Jane', 'Burke', 'jane@burke.com');
INSERT INTO tag (tagname) VALUES ('awesome');
INSERT INTO tag (tagname) VALUES ('fantabulous');
INSERT INTO tag (tagname) VALUES ('sensational');
INSERT INTO tag (tagname) VALUES ('mind-boggling');
INSERT INTO tag (tagname) VALUES ('dazzling');
INSERT INTO tag (tagname) VALUES ('terrific');
INSERT INTO person_bio (pid, bio, birthdate, gender) VALUES (1, 'Great dude, loves elephants and tricycles, is really into coriander.', '1965-04-24', 'male');
INSERT INTO person_bio (pid, bio, birthdate, gender) VALUES (2, 'Eccentric and eclectic collector of phoenix wings. Winner of the 2003 International Small Elbows Award.', '1982-07-20', 'female');
INSERT INTO person_bio (pid, bio, birthdate, gender) VALUES (3, 'Has purply-grey eyes. Prefers to only go out on Wednesdays.', '1990-11-06', 'female');
INSERT INTO person_pic (pid, pic_filepath) VALUES (1, 'files/person_pic/pete1.jpg');
INSERT INTO person_pic (pid, pic_filepath) VALUES (1, 'files/person_pic/pete2.jpg');
INSERT INTO person_pic (pid, pic_filepath) VALUES (1, 'files/person_pic/pete3.jpg');
INSERT INTO person_pic (pid, pic_filepath) VALUES (3, 'files/person_pic/jane_on_wednesday.jpg');
INSERT INTO person_link (pid, link_title, link_url) VALUES (2, 'The Great Blog of Sarah', 'http://www.omgphoenixwingsaresocool.com/');
INSERT INTO person_link (pid, link_title, link_url) VALUES (3, 'Catch Jane on Blablablabook', 'http://www.blablablabook.com/janepurplygrey');
INSERT INTO person_link (pid, link_title, link_url) VALUES (3, 'Jane ranting about Thursdays', 'http://www.janepurplygrey.com/thursdaysarelame/');
INSERT INTO person_tag (pid, tid) VALUES (1, 3);
INSERT INTO person_tag (pid, tid) VALUES (1, 4);
INSERT INTO person_tag (pid, tid) VALUES (1, 5);
INSERT INTO person_tag (pid, tid) VALUES (1, 6);
INSERT INTO person_tag (pid, tid) VALUES (2, 2);
Querying for direct CSV export
If we were building, for example, a simple web app to output a list of all the people in this database (along with all their biographical data), querying this database would be quite straightforward. Most likely, our first step would be to query the one-to-one data: i.e. query the main 'person' table, join on the 'bio' table, and loop through the results (in a server-side language, such as PHP). The easiest way to get at the rest of the data, in such a case, would be to then query each of the many-to-many relationships (i.e. user's pictures; user's links; user's tags) in separate SQL statements, and to execute each of those queries once for each user being processed.
In that scenario, we'd be writing four different SQL queries, and we'd be executing SQL numerous times: we'd execute the main query once, and we'd execute each of the three secondary queries, once for each user in the database. So, with the sample data provided here, we'd be executing SQL 1 + (3 x 3) = 10 times.
Alternatively, we could write a single query which joins together all of the three many-to-many relationships in one go, and our web app could then just loop through a single result set. However, this result set would potentially contain a lot of duplicate data, as well as a lot of NULL data. So, the web app's server-side code would require extra logic, in order to deal with this messy result set effectively.
In our case, neither of the above solutions is adequate. We can't afford to write four separate queries, and to perform 10 query executions. We don't want a single result set that contains duplicate data and/or excessive NULL data. We want a single query, that produces a single result set, containing one person per row, and with all the many-to-many data for each person aggregated into that person's single row.
Here's the magic SQL that can make our miracle happen:
SELECT person_base.pid,
person_base.firstname,
person_base.lastname,
person_base.email,
IFNULL(person_base.bio, '') AS bio,
IFNULL(person_base.birthdate, '') AS birthdate,
IFNULL(person_base.gender, '') AS gender,
IFNULL(pic_join.val, '') AS pics,
IFNULL(link_join.val, '') AS links,
IFNULL(tag_join.val, '') AS tags
FROM (
SELECT p.pid,
p.firstname,
p.lastname,
p.email,
IFNULL(pb.bio, '') AS bio,
IFNULL(pb.birthdate, '') AS birthdate,
IFNULL(pb.gender, '') AS gender
FROM person p
LEFT JOIN person_bio pb
ON p.pid = pb.pid
) AS person_base
LEFT JOIN (
SELECT join_tbl.pid,
IFNULL(
GROUP_CONCAT(
DISTINCT CAST(join_tbl.pic_filepath AS CHAR)
SEPARATOR ';;'
),
''
) AS val
FROM person_pic join_tbl
GROUP BY join_tbl.pid
) AS pic_join
ON person_base.pid = pic_join.pid
LEFT JOIN (
SELECT join_tbl.pid,
IFNULL(
GROUP_CONCAT(
DISTINCT CONCAT(
CAST(join_tbl.link_title AS CHAR),
'::',
CAST(join_tbl.link_url AS CHAR)
)
SEPARATOR ';;'
),
''
) AS val
FROM person_link join_tbl
GROUP BY join_tbl.pid
) AS link_join
ON person_base.pid = link_join.pid
LEFT JOIN (
SELECT join_tbl.pid,
IFNULL(
GROUP_CONCAT(
DISTINCT CAST(t.tagname AS CHAR)
SEPARATOR ';;'
),
''
) AS val
FROM person_tag join_tbl
LEFT JOIN tag t
ON join_tbl.tid = t.tid
GROUP BY join_tbl.pid
) AS tag_join
ON person_base.pid = tag_join.pid
ORDER BY lastname ASC,
firstname ASC;
If you run this in a MySQL admin tool that supports exporting query results directly to CSV (such as phpMyAdmin), then there's no more fancy work needed on your part. Just click 'Export -> CSV', and you'll have your results looking like this:
pid,firstname,lastname,email,bio,birthdate,gender,pics,links,tags
3,Jane,Burke,jane@burke.com,Has purply-grey eyes. Prefers to only go out on Wednesdays.,1990-11-06,female,files/person_pic/jane_on_wednesday.jpg,Catch Jane on Blablablabook::http://www.blablablabook.com/janepurplygrey;;Jane ranting about Thursdays::http://www.janepurplygrey.com/thursdaysarelame/,
2,Sarah,Smith,sarah@smith.com,Eccentric and eclectic collector of phoenix wings. Winner of the 2003 International Small Elbows Award.,1982-07-20,female,,The Great Blog of Sarah::http://www.omgphoenixwingsaresocool.com/,fantabulous
1,Pete,Wilson,pete@wilson.com,Great dude, loves elephants and tricycles, is really into coriander.,1965-04-24,male,files/person_pic/pete1.jpg;;files/person_pic/pete2.jpg;;files/person_pic/pete3.jpg,,sensational;;mind-boggling;;dazzling;;terrific
The query explained
The most important feature of this query, is that it takes advantage of MySQL's ability to perform subqueries. What we're actually doing, is we're performing four separate queries: one query on the main person table (which joins to the person_bio table); and one on each of the three many-to-many elements of a person's bio. We're then joining these four queries, and selecting data from all of their result sets, in the parent query.
The magic function in this query, is the MySQL GROUP_CONCAT() function. This basically allows us to join together the results of a particular field, using a delimiter string, much like the join() array-to-string function in many programming languages (i.e. like PHP's implode() function). In this example, I've used two semicolons (;;) as the delimiter string.
In the case of person_link in this example, each row of this data has two fields ('link title' and 'link URL'); so, I've concatenated the two fields together (separated by a double-colon (::) string), before letting GROUP_CONCAT() work its wonders.
The case of person_tags is also interesting, as it demonstrates performing an additional join within the many-to-many subquery, and returning data from that joined table (i.e. the tag name) as the result value. So, all up, each of the many-to-many relationships in this example is a slightly different scenario: person_pic is the basic case of a single field within the many-to-many data; person_link is the case of more than one field within the many-to-many data; and person_tags is the case of an additional one-to-many join, on top of the many-to-many join.
Final remarks
Note that although this query depends on several MySQL-specific features, most of those features are available in a fairly equivalent form, in most other major database systems. Subqueries vary quite little between the DBMSes that support them. And it's possible to achieve GROUP_CONCAT() functionality in PostgreSQL, in Oracle, and even in SQLite.
It should also be noted that it would be possible to achieve the same result (i.e. the same end CSV output), using 10 SQL query executions and a whole lot of PHP (or other) glue code. However, taking that route would involve more code (spread over four queries and numerous lines of procedural glue code), and it would invariably suffer worse performance (although I make no guarantees as to the performance of my example query, I haven't benchmarked it with particularly large data sets).
This querying trick was originally written in order to export data from a Drupal MySQL database, to a flat CSV file. The many-to-many relationships were referring to field tables, as defined by Drupal's Field API. I made the variable names within the subqueries as generic as possible (e.g. join_tbl, val), because I needed to copy the subqueries numerous times (for each of the numerous field data tables I was dealing with), and I wanted to make as few changes as possible on each copy.
The trick is particularly well-suited to Drupal Field API data (known in Drupal 6 and earlier as 'CCK data'). However, I realised that it could come in useful with any database schema where a "flattening" of many-to-many fields is needed, in order to perform a CSV export with a single query. Let me know if you end up adopting this trick for schemas of your own.
]]>
Django Facebook user integration with whitelisting2011-11-02T00:00:00Z2011-11-02T00:00:00ZJazahttps://greenash.net.au/thoughts/2011/11/django-facebook-user-integration-with-whitelisting/
It's recently become quite popular for web sites to abandon the tasks of user authentication and account management, and to instead shoulder off this burden to a third-party service. One of the big services available for this purpose is Facebook. You may have noticed "Sign in with Facebook" buttons appearing ever more frequently around the 'Web.
The common workflow for Facebook user integration is: user is redirected to the Facebook login page (or is shown this page in a popup); user enters credentials; user is asked to authorise the sharing of Facebook account data with the non-Facebook source; a local account is automatically created for the user on the non-Facebook site; user is redirected to, and is automatically logged in to, the non-Facebook site. Also quite common is for the user's Facebook profile picture to be queried, and to be shown as the user's avatar on the non-Facebook site.
This article demonstrates how to achieve this common workflow in Django, with some added sugary sweetness: maintaning a whitelist of Facebook user IDs in your local database, and only authenticating and auto-registering users who exist on this whitelist.
Install dependencies
I'm assuming that you've already got an environment set up, that's equipped for Django development. I.e. you've already installed Python (my examples here are tested on Python 2.6 and 2.7), a database engine (preferably SQLite on your local environment), pip (recommended), and virtualenv (recommended). If you want to implement these examples fully, then as well as a dev environment with these basics set up, you'll also need a server to which you can deploy a Django site, and on which you can set up a proper public domain or subdomain DNS (because the Facebook API won't actually talk to or redirect back to your localhost, it refuses to do that).
You'll also need a Facebook account, with which you will be registering a new "Facebook app". We won't actually be developing a Facebook app in this article (at least, not in the usual sense, i.e. we won't be deploying anything to facebook.com), we just need an app key in order to talk to the Facebook API.
Here are the Python dependencies for our Django project. I've copy-pasted this straight out of my requirements.txt file, which I install on a virtualenv using pip install -E . -r requirements.txt (I recommend you do the same):
The first requirement, Django itself, is pretty self-explanatory. The next one, django-allauth, is the foundation upon which this demonstration is built. This app provides authentication and account management services for Facebook (plus Twitter and OAuth currently supported), as well as auto-registration, and profile pic to avatar auto-copying. The version we're using here, is my GitHub fork of the main project, which I've hacked a little bit in order to integrate with our whitelisting functionality.
The Facebook Python SDK is the base integration library provided by the Facebook team, and allauth depends on it for certain bits of functionality. Plus, we've installed django-avatar so that we get local user profile images.
Once you've got those dependencies installed, let's get a new Django project set up with the standard command:
django-admin.py startproject myproject
This will get the Django foundations installed for you. The basic configuration of the Django settings file, I leave up to you. If you have some experience already with Django (and if you've got this far, then I assume that you do), you no doubt have a standard settings template already in your toolkit (or at least a standard set of settings tweaks), so feel free to use it. I'll be going over the settings you'll need specifically for this app, in just a moment.
Fire up ye 'ol runserver, open your browser at http://localhost:8000/, and confirm that the "It worked!" page appears for you. At this point, you might also like to enable the Django admin (add 'admin' to INSTALLED_APPS, un-comment the admin callback in urls.py, and run syncdb; then confirm that you can access the admin). And that's the basics set up!
Register the Facebook app
Now, we're going to jump over to the Facebook side of the setup, in order to register our site as a Facebook app, and to then receive our Facebook app credentials. To get started, go to the Apps section of the Facebook Developers site. You'll probably be prompted to log in with your Facebook account, so go ahead and do that (if asked).
On this page, click the button labelled "Create New App". In the form that pops up, in the "App Display Name" field, enter a unique name for your app (e.g. the name of the site you're using this on — for the example app that I registered, I used the name "FB Whitelist"). Then, tick "I Agree" and click "Continue".
Once this is done, your Facebook app is registered, and you'll be taken to a form that lets you edit the basic settings of the app. The first setting that you'll want to configure is "App Domain": set this to the domain or subdomain URL of your site (without an http:// prefix or a trailing slash). A bit further down, in "Website — Site URL", enter this URL again (this time, with the http:// prefix and a trailing slash). Be sure to save your configuration changes on this page.
Next is a little annoying setting that must be configured. In the "Auth Dialog" section, for "Privacy Policy URL", once again enter the domain or subdomain URL of your site. Enter your actual privacy policy URL if you have one; if not, don't worry — Facebook's authentication API refuses to function if you don't enter something for this, so the URL of your site's front page is better than nothing.
Note: at some point, you'll also need to go to the "Advanced" section, and set "Sandbox Mode" to "Disabled". This is very important! If your app is set to Sandbox mode, then nobody will be able to log in to your Django site via Facebook auth, apart from those listed in the Facebook app config as "developers". It's up to you when you want to disable Sandbox mode, but make sure you do it before non-dev users start trying to log in to your site.
On the main "Settings — Basic" page for your newly-registered Facebook app, take note of the "App ID" and "App Secret" values. We'll be needing these shortly.
Configure Django settings
I'm not too fussed about what else you have in your Django settings file (or in how your Django settings are structured or loaded, for that matter); but if you want to follow along, then you should have certain settings configured per the following guidelines:
(You'll need to re-run syncdb after enabling these apps).
(Note: django-allauth also expects the database schema for the email confirmation app to exist; however, you don't actually need this app enabled. So, what you can do, is add 'emailconfirmation' to your INSTALLED_APPS, then syncdb, then immediately remove it).
Set a value for the AVATAR_STORAGE_DIR setting, for example:
AVATAR_STORAGE_DIR = 'uploads/avatars'
Set a value for the LOGIN_REDIRECT_URL setting, for example:
LOGIN_REDIRECT_URL = '/'
Set this:
ACCOUNT_EMAIL_REQUIRED = True
Additionally, you'll need to create a new Facebook App record in your Django database. To do this, log in to your shiny new Django admin, and under "Facebook — Facebook apps", add a new record:
For "Name", copy the "App Display Name" from the Facebook page.
For both "Application id" and "Api key", copy the "App ID" from the Facebook page.
For "Application secret", copy the "App Secret" from the Facebook page.
Once you've entered everything on this form (set "Site" as well), save the record.
Implement standard Facebook authentication
By "standard", I mean "without whitelisting". Here's how you do it:
Add these imports to your urls.py:
from allauth.account.views import logout
from allauth.socialaccount.views import login_cancelled, login_error
from allauth.facebook.views import login as facebook_login
And (in the same file), add these to your urlpatterns variable:
<div class="socialaccount_ballot">
<ul class="socialaccount_providers">
{% if not user.is_authenticated %}
{% if allauth.socialaccount_enabled %}
{% include "socialaccount/snippets/provider_list.html" %}
{% include "socialaccount/snippets/login_extra.html" %}
{% endif %}
{% else %}
<li><a href="{% url account_logout %}?next=/">Logout</a></li>
{% endif %}
</ul>
</div>
(Note: I'm assuming that by this point, you've set up the necessary URL callbacks, views, templates, etc. to get a working front page on your site; I'm not going to hold your hand and go through all that).
If you'd like, you can customise the default authentication templates provided by django-allauth. For example, I overrode the socialaccount/snippets/provider_list.html and socialaccount/authentication_error.html templates in my test implementation.
That should be all you need, in order to get a working "Login with Facebook" link on your site. So, deploy everything that's been done so far to your online server, navigate to your front page, and click the "Login" link. If all goes well, then a popup will appear prompting you to log in to Facebook (unless you already have an active Facebook session in your browser), followed by a prompt to authorise your Django site to access your Facebook account credentials (to which you and your users will have to agree), and finishing with you being successfully authenticated.
The authorisation prompt during the initial login procedure.
You should be able to confirm authentication success, by noting that the link on your front page has changed to "Logout".
Additionally, if you go into the Django admin (you may first need to log out of your Facebook user's Django session, and then log in to the admin using your superuser credentials), you should be able to confirm that a new Django user was automatically created in response to the Facebook auth procedure. Additionally, you should find that an avatar record has been created, containing a copy of your Facebook profile picture; and, if you look in the "Facebook accounts" section, you should find that a record has been created here, complete with your Facebook user ID and profile page URL.
Facebook account record in the Django admin.
Great! Now, on to the really fun stuff.
Build a whitelisting app
So far, we've got a Django site that anyone can log into, using their Facebook credentials. That works fine for many sites, where registration is open to anyone in the general public, and where the idea is that the more user accounts get registered, the better. But what about a site where the general public cannot register, and where authentication should be restricted to only a select few individuals who have been pre-registered by site admins? For that, we need to go beyond the base capabilities of django-allauth.
Create a new app in your Django project, called fbwhitelist. The app should have the following files (file contents provided below):
models.py :
from django.contrib.auth.models import User
from django.db import models
class FBWhiteListUser(models.Model):
name = models.CharField(max_length=100)
email = models.EmailField(unique=True)
social_id = models.CharField(verbose_name='Facebook user ID',
blank=True, max_length=100)
active = models.BooleanField(default=False)
def __unicode__(self):
return self.name
class Meta:
verbose_name = 'facebook whitelist user'
verbose_name_plural = 'facebook whitelist users'
ordering = ('name', 'email')
def save(self, *args, **kwargs):
try:
old_instance = FBWhiteListUser.objects.get(pk=self.pk)
if not self.active:
if old_instance.active:
self.deactivate_user()
else:
if not old_instance.active:
self.activate_user()
except FBWhiteListUser.DoesNotExist:
pass
super(FBWhiteListUser, self).save(*args, **kwargs)
def delete(self):
self.deactivate_user()
super(FBWhiteListUser, self).delete()
def deactivate_user(self):
try:
u = User.objects.get(email=self.email)
if u.is_active and not u.is_superuser and not u.is_staff:
u.is_active = False
u.save()
except User.DoesNotExist:
pass
def activate_user(self):
try:
u = User.objects.get(email=self.email)
if not u.is_active:
u.is_active = True
u.save()
except User.DoesNotExist:
pass
import re
import urllib2
from django import forms
from django.contrib import admin
from django.contrib.auth.models import User
from allauth.facebook.models import FacebookAccount
from allauth.socialaccount import app_settings
from allauth.socialaccount.helpers import _copy_avatar
from utils import slugify
from models import FBWhiteListUser
class FBWhiteListUserAdminForm(forms.ModelForm):
class Meta:
model = FBWhiteListUser
def __init__(self, *args, **kwargs):
super(FBWhiteListUserAdminForm, self).__init__(*args, **kwargs)
def save(self, *args, **kwargs):
m = super(FBWhiteListUserAdminForm, self).save(*args, **kwargs)
try:
u = User.objects.get(email=self.cleaned_data['email'])
except User.DoesNotExist:
u = self.create_django_user()
if self.cleaned_data['social_id']:
self.create_facebook_account(u)
return m
def create_django_user(self):
name = self.cleaned_data['name']
email = self.cleaned_data['email']
active = self.cleaned_data['active']
m = re.search(r'^(?P<first_name>[^ ]+) (?P<last_name>.+)$', name)
name_slugified = slugify(name)
first_name = ''
last_name = ''
if m:
d = m.groupdict()
first_name = d['first_name']
last_name = d['last_name']
u = User(username=name_slugified,
email=email,
last_name=last_name,
first_name=first_name)
u.set_unusable_password()
u.is_active = active
u.save()
return u
def create_facebook_account(self, u):
social_id = self.cleaned_data['social_id']
name = self.cleaned_data['name']
try:
account = FacebookAccount.objects.get(social_id=social_id)
except FacebookAccount.DoesNotExist:
account = FacebookAccount(social_id=social_id)
account.link = 'http://www.facebook.com/profile.php?id=%s' % social_id
req = urllib2.Request(account.link)
res = urllib2.urlopen(req)
new_link = res.geturl()
if not '/people/' in new_link and not 'profile.php' in new_link:
account.link = new_link
account.name = name
request = None
if app_settings.AVATAR_SUPPORT:
_copy_avatar(request, u, account)
account.user = u
account.save()
class FBWhiteListUserAdmin(admin.ModelAdmin):
list_display = ('name', 'email', 'active')
list_filter = ('active',)
search_fields = ('name', 'email')
fields = ('name', 'email', 'social_id', 'active')
def __init__(self, *args, **kwargs):
super(FBWhiteListUserAdmin, self).__init__(*args, **kwargs)
form = FBWhiteListUserAdminForm
admin.site.register(FBWhiteListUser, FBWhiteListUserAdmin)
(Note: also ensure that you have an empty __init__.py file in your app's directory, as you do with most all Django apps).
Also, of course, you'll need to add 'fbwhitelist' to your INSTALLED_APPS setting (and after doing that, a syncdb will be necessary).
Most of the code above is pretty basic, it just defines a Django model for the whitelist, and provides a basic admin view for that model. In implementing this code, feel free to modify the model and the admin definitions liberally — in particular, you may want to add additional fields to the model, per your own custom project needs. What this code also does, is automatically create both a corresponding Django user, and a corresponding socialaccount Facebook account record (including Facebook profile picture to django-avatar handling), whenever a new Facebook whitelist user instance is created.
Integrate it with django-allauth
In order to let django-allauth know about the new fbwhitelist app and its FBWhiteListUser model, all you need to do, is to add this to your Django settings file:
If you're interested in the dodgy little hacks I made to django-allauth, in order to make it magically integrate with a specified whitelist app, here's the main code snippet responsible, just for your viewing pleasure (from _process_signup in socialaccount/helpers.py):
# Extra stuff hacked in here to integrate with
# the account whitelist app.
# Will be ignored if the whitelist app can't be
# imported, thus making this slightly less hacky.
whitelist_model_setting = getattr(
settings,
'SOCIALACCOUNT_WHITELIST_MODEL',
None
)
if whitelist_model_setting:
whitelist_model_path = whitelist_model_setting.split(r'.')
whitelist_model_str = whitelist_model_path[-1]
whitelist_path_str = r'.'.join(whitelist_model_path[:-1])
try:
whitelist_app = __import__(whitelist_path_str, fromlist=[whitelist_path_str])
whitelist_model = getattr(whitelist_app, whitelist_model_str, None)
if whitelist_model:
try:
guest = whitelist_model.objects.get(email=email)
if not guest.active:
auto_signup = False
except whitelist_model.DoesNotExist:
auto_signup = False
except ImportError:
pass
Basically, the hack attempts to find and to query our whitelist model; and if it doesn't find a whitelist instance whose email matches that provided by the Facebook auth API, or if the found whitelist instance is not set to 'active', then it halts auto-creation and auto-login of the user into the Django site. What can I say… it does the trick!
Build a Facebook ID lookup utility
The Django admin interface so far for managing the whitelist is good, but it does have one glaring problem: it requires administrators to know the Facebook account ID of the person they're whitelisting. And, as it turns out, Facebook doesn't make it that easy for regular non-techies to find account IDs these days. It used to be straightforward enough, as profile page URLs all had the account ID in them; but now, most profile page URLs on Facebook are aliased, and the account ID is pretty well obliterated from the Facebook front-end.
So, let's build a quick little utility that looks up Facebook account IDs, based on a specified email. Add these files to your 'fbwhitelist' app to implement it:
facebook.py :
import urllib
class FacebookSearchUser(object):
@staticmethod
def get_query_email_request_url(email, access_token):
"""Queries a Facebook user based on a given email address. A valid Facebook Graph API access token must also be provided."""
args = {
'q': email,
'type': 'user',
'access_token': access_token,
}
return 'https://graph.facebook.com/search?' + \
urllib.urlencode(args)
views.py :
from django.utils.simplejson import loads
import urllib2
from django.conf import settings
from django.contrib.admin.views.decorators import staff_member_required
from django.http import HttpResponse, HttpResponseBadRequest
from fbwhitelist.facebook import FacebookSearchUser
class FacebookSearchUserView(object):
@staticmethod
@staff_member_required
def query_email(request, email):
"""Queries a Facebook user based on the given email address. This view cannot be accessed directly."""
access_token = getattr(settings, 'FBWHITELIST_FACEBOOK_ACCESS_TOKEN', None)
if access_token:
url = FacebookSearchUser.get_query_email_request_url(email, access_token)
response = urllib2.urlopen(url)
fb_data = loads(response.read())
if fb_data['data'] and fb_data['data'][0] and fb_data['data'][0]['id']:
return HttpResponse('Facebook ID: %s' % fb_data['data'][0]['id'])
else:
return HttpResponse('No Facebook credentials found for the specified email.')
return HttpResponseBadRequest('Error: no access token specified in Django settings.')
urls.py :
from django.conf.urls.defaults import *
from views import FacebookSearchUserView
urlpatterns = patterns('',
url(r'^facebook_search_user/query_email/(?P<email>[^\/]+)/$',
FacebookSearchUserView.query_email,
name='fbwhitelist_search_user_query_email'),
)
Plus, add this to the urlpatterns variable in your project's main urls.py file:
In your MEDIA_ROOT directory, create a file js/fbwhitelistadmin.js, with this content:
(function($) {
var fbwhitelistadmin = function() {
function init_social_id_from_email() {
$('.social_id').append('<input type="submit" value="Find Facebook ID" id="social_id_get_from_email" /><p>After entering an email, click "Find Facebook ID" to bring up a new window, where you can see the Facebook ID of the Facebook user with this email. Copy the Facebook user ID number into the text field "Facebook user ID", and save. If it is a valid Facebook ID, it will automatically create a new user on this site, that corresponds to the specified Facebook user.</p>');
$('#social_id_get_from_email').live('click', function() {
var email_val = $('#id_email').val();
if (email_val) {
var url = 'http://fbwhitelist.greenash.net.au/fbwhitelist/facebook_search_user/query_email/' + email_val + '/';
window.open(url);
}
return false;
});
}
return {
init: function() {
if ($('#content h1').text() == 'Change facebook whitelist user') {
$('#id_name, #id_email, #id_social_id').attr('disabled', 'disabled');
}
else {
init_social_id_from_email();
}
}
}
}();
$(document).ready(function() {
fbwhitelistadmin.init();
});
})(django.jQuery);
And to load this file on the correct Django admin page, add this code to the FBWhiteListUserAdmin class in the fbwhitelist/admin.py file:
class Media:
js = ("js/fbwhitelistadmin.js",)
Additionally, you're going to need a Facebook Graph API access token. To obtain one, go to a URL like this:
Replacing the APP_ID, SITE_URL, and APP_SECRET bits with your relevant Facebook credentials, and replacing TEMP_CODE with the code from the URL above. You should then see a plain-text page response in this form:
access_token=ACCESS_TOKEN
And the ACCESS_TOKEN bit is what you need to take note of. Add this value to your settings file:
Of very important note, is the fact that what you've just saved in your settings is a long-life offline access Facebook access token. We requested that the access token be long-life, with the scope=offline_access parameter in the first URL request that we made to Facebook (above). This means that the access token won't expire for a very long time, so you can safely keep it in your settings file without having to worry about constantly needing to change it.
Exactly how long these tokens last, I'm not sure — so far, I've been using mine for about six weeks with no problems. You should be notified if and when your access token expires, because if you provide an invalid access token to the Graph API call, then Facebook will return an HTTP 400 response (bad request), and this will trigger urllib2.urlopen to raise an HTTPError exception. How you get notified, will depend on how you've configured Django to respond to uncaught exceptions; in my case, Django emails me an error report, which is sufficient notification for me.
Your Django admin should now have a nice enough little addition for Facebook account ID lookup:
Facebook account ID lookup integrated into the whitelist admin.
I say "nice enough", because it would also be great to change this from showing the ID in a popup, to actually populating the form field with the ID value via JavaScript (and showing an error, on fail, also via JavaScript). But honestly, I just haven't got around to doing this. Anyway, the basic popup display works as is — only drawback is that it requires copy-pasting the ID into the form field.
Finished product
And that's everything — your Django-Facebook auth integration with whitelisting should now be fully functional! Give it a try: attempt to log in to your Django site via Facebook, and it should fail; then add your Facebook account to the whitelist, attempt to log in again, and there should be no errors in sight. It's a fair bit of work, but this setup is possible once all the pieces are in place.
I should also mention that it's quite ironic, my publishing this long and detailed article about developing with the Facebook API, when barely a month ago I wrote a scathing article on the evils of Facebook. So, just to clarify: yes, I do still loathe Facebook, my opinion has not taken a somersault since publishing that rant.
However— what can I say, sometimes you get clients that want Facebook integration. And hey, them clients do pay the bills. Also, even I cannot deny that Facebook's enormous user base makes it an extremely attractive authentication source. And I must also concede that since the introduction of the Graph API, Facebook has become a much friendlier and a much more stable platform for developers to work with.
]]>
Generating unique integer IDs from strings in MySQL2010-03-19T00:00:00Z2010-03-19T00:00:00ZJazahttps://greenash.net.au/thoughts/2010/03/generating-unique-integer-ids-from-strings-in-mysql/
I have an interesting problem, on a data migration project I'm currently working on. I'm importing a large amount of legacy data into Drupal, using the awesome Migrate module (and friends). Migrate is a great tool for the job, but one of its limitations is that it requires the legacy database tables to have non-composite integer primary keys. Unfortunately, most of the tables I'm working with have primary keys that are either composite (i.e. the key is a combination of two or more columns), or non-integer (i.e. strings), or both.
Table with composite primary key.
The simplest solution to this problem would be to add an auto-incrementing integer primary key column to the legacy tables. This would provide the primary key information that Migrate needs in order to do its mapping of legacy IDs to Drupal IDs. But this solution has a serious drawback. In my project, I'm going to have to re-import the legacy data at regular intervals, by deleting and re-creating all the legacy tables. And every time I do this, the auto-incrementing primary keys that get generated could be different. Records may have been deleted upstream, or new records may have been added in between other old records. Auto-increment IDs would, therefore, correspond to different composite legacy primary keys each time I re-imported the data. This would effectively make Migrate's ID mapping tables corrupt.
A better solution is needed. A solution called hashing! Here's what I've come up with:
Remove the legacy primary key index from the table.
Create a new column on the table, of type BIGINT. A MySQL BIGINT field allocates 64 bits (8 bytes) of space for each value.
If the primary key is composite, concatenate the columns of the primary key together (optionally separated by a delimiter).
Calculate the SHA1 hash of the concatenated primary key string. An SHA1 hash consists of 40 hexadecimal digits. Since each hex digit stores 24 different values, each hex digit requires 4 bits of storage; therefore 40 hex digits require 160 bits of storage, which is 20 bytes.
Convert the numeric hash to a string.
Truncate the hash string down to the first 16 hex digits.
Convert the hash string back into a number. Each hex digit requires 4 bits of storage; therefore 16 hex digits require 64 bits of storage, which is 8 bytes.
Convert the number from hex (base 16) to decimal (base 10).
Store the decimal number in your new BIGINT field. You'll find that the number is conveniently just small enough to fit into this 64-bit field.
Now that the new BIGINT field is populated with unique values, upgrade it to a primary key field.
Add an index that corresponds to the legacy primary key, just to maintain lookup performance (you could make it a unique key, but that's not really necessary).
Table with integer primary key.
The SQL statement that lets you achieve this in MySQL looks like this:
ALTER TABLE people DROP PRIMARY KEY;
ALTER TABLE people ADD id BIGINT UNSIGNED NOT NULL FIRST;
UPDATE people SET id = CONV(SUBSTRING(CAST(SHA(CONCAT(name, ',', city)) AS CHAR), 1, 16), 16, 10);
ALTER TABLE people ADD PRIMARY KEY(id);
ALTER TABLE people ADD INDEX (name, city);
Note: you will also need to alter the relevant migrate_map_X tables in your database, and change the sourceid and destid fields in these tables to be of type BIGINT.
Hashing has a tremendous advantage over using auto-increment IDs. When you pass a given string to a hash function, it always yields the exact same hash value. Therefore, whenever you hash a given string-based primary key, it always yields the exact same integer value. And that's my problem solved: I get constant integer ID values each time I re-import my legacy data, so long as the legacy primary keys remain constant between imports.
Storing the 64-bit hash value in MySQL is straightforward enough. However, a word of caution once you continue on to the PHP level: PHP does not guarantee to have a 64-bit integer data type available. It should be present on all 64-bit machines running PHP. However, if you're still on a 32-bit processor, chances are that a 32-bit integer is the maximum integer size available to you in PHP. There's a trick where you can store an integer of up to 52 bits using PHP floats, but it's pretty dodgy, and having 64 bits guaranteed is far preferable. Thankfully, all my environments for my project (dev, staging, production) have 64-bit processors available, so I'm not too worried about this issue.
I also have yet to confirm 100% whether 16 out of 40 digits from an SHA1 hash is enough to guarantee unique IDs. In my current legacy data set, I've applied this technique to all my tables, and haven't encountered a single duplicate (I also experimented briefly with CRC32 checksums, and very quickly ran into duplicate ID issues). However, that doesn't prove anything — except that duplicate IDs are very unlikely. I'd love to hear from anyone who has hard probability figures about this: if I'm using 16 digits of a hash, what are the chances of a collision? I know that Git, for example, stores commit IDs as SHA1 hashes, and it lets you then specify commit IDs using only the first few digits of the hash (e.g. the first 7 digits is most common). However, Git makes no guarantee that a subset of the hash value is unique; and in the case of a collision, it will ask you to provide enough digits to yield a unique hash. But I've never had Git tell me that, as yet.
]]>
Media through the ages2009-12-30T00:00:00Z2009-12-30T00:00:00ZJazahttps://greenash.net.au/thoughts/2009/12/media-through-the-ages/
The 20th century was witness to the birth of what is arguably the most popular device in the history of mankind: the television. TV is a communications technology that has revolutionised the delivery of information, entertainment and artistic expression to the masses. More recently, we have all witnessed (and participated in) the birth of the Internet, a technology whose potential makes TV pale into insignificance in comparison (although, it seems, TV isn't leaving us anytime soon). These are fast-paced and momentous times we live in. I thought now would be a good opportunity to take a journey back through the ages, and to explore the forms of (and devices for) media and communication throughout human history.
Our journey begins in prehistoric times, (arguably) before man even existed in the exact modern anatomical form that all humans exhibit today. It is believed that modern homo sapiens emerged as a distinct genetic species approximately 200,000 years ago, and it is therefore no coincidence that my search for the oldest known evidence of meaningful human communication also brought me to examine this time period. Evidence suggests that at around this time, humans began to transmit and record information in rock carvings. These are also considered the oldest form of human artistic expression on the planet.
From that time onwards, it's been an ever-accelerating roller-coaster ride of progress, from prehistoric forms of media such as cave painting and sculpture, through to key discoveries such as writing and paper in the ancient world, and reaching an explosion of information generation and distribution in the Renaissance, with the invention of the printing press in 1450AD. Finally, the modern era of the past two centuries has accelerated the pace to dizzying levels, beginning with the invention of the photograph and the invention of the telegraph in the early 19th century, and culminating (thus far) with mobile phones and the Internet at the end of the 20th century.
List of communication milestones
I've done some research in this area, and I've compiled a list of what I believe are the most significant forms of communication or devices for communication throughout human history. You can see my list in the table below. I've also applied some categorisation to each item in the list, and I'll discuss that categorisation shortly.
Note: pre-modern dates are approximations only, and are based on the approximations of authoritative sources. For modern dates, I have tried to give the date that the device first became available to (and first started to be used by) the general public, rather than the date the device was invented.
Directionality and preservation
My categorisation system in the list above is loosely based on coolscorpio's types of communication. However, I have used the word "directionality" to refer to his "downward, upward and lateral communication"; and I have used the word "preservation" and the terms "transient and permanent" to refer to his "oral and written communication", as I needed terms more generic than "oral and written" for my data set.
Preservation of information is something that we've been thinking about as a species for an awfully long time. We've been able to record information in a permanent, durable form, more-or-less for as long as the human race has existed. Indeed, if early humans hadn't found a way to permanently preserve information, then we'd have very little evidence of their being able to conduct advanced communication at all.
Since the invention of writing, permanent preservation of information has become increasingly widespread*. However, oral language has always been our richest and our most potent form of communication, and it hasn't been until modern times that we've finally discovered ways of capturing it; and even to this very day, our favourite modern oral communication technology — the telephone — remains essentially transient and preserves no record of what passes through it.
Directionality of communication has three forms: from a small group of people (often at the "top") down to a larger group (at the "bottom"); from a large group up to a small one; and between any small groups in society laterally. Human history has been an endless struggle between authority and the masses, and that struggle is reflected in the history of human communication: those at the top have always pushed for the dominance of "down" technologies, while those at the bottom have always resisted, and have instead advocated for more neutral technologies. From looking at the list above, we can see that the dominant communications technologies of the time have had no small effect on the strength of freedom vs authority of the time.
Prehistoric human society was quite balanced in this regard. There were a number of powerful forms of media that only those at the top (i.e. chiefs, warlords) had practical access to. These were typically the more permanent forms of media, such as the paintings on the cave walls. However, oral communication was really the most important media of the time, and it was equally accessible to all members of society. Additionally, societies were generally grouped into relatively small tribes and clans, leaving less room for layers of authority between the top and bottom ranks.
The ancient world — the dawn of human "civilisation" — changed all this. This era brought about three key communications media that were particularly well-suited to a "down" directionality, and hence to empowering authority above the common populace: megalithic architecture (technically pre-ancient, but only just); metallurgy; and writing. Megalithic architecture allowed kings and Pharoahs to send a message to the world, a message that would endure the sands of time; but it was hardly a media accessible to all, as it required armies of labourers, teams of designers and engineers, as well as hordes of natural and mineral resources. Similarly, metallurgy's barrier to access was the skilled labour and the mineral resources required to produce it. Writing, today considered the great enabler of access to information and of global equality, was in the ancient world anything but that, because all but the supreme elite were illiterate, and the governments of the day wanted nothing more but to maintain that status quo.
Gutenberg's invention of the printing press in 1450 AD is generally considered to be the most important milestone in the history of human communication. Most view it purely from a positive perspective: it helped spread literacy to the masses; and it allowed for the spread of knowledge as never before. However, the printing press was clearly a "down" technology in terms of directionality, and this should not be overlooked. To this very day, access to mass printing and distribution services is a privilege available only to those at the very top of society, and it is a privilege that has been consistently used as a means of population control and propaganda. Don't get me wrong, I agree with the general consensus that the positive effects of the printing press far outweigh its downside, and I must also stress that the printing press was an essential step in the right direction towards technologies with more neutral directionality. But essentially, the printing press — the key device that led to the dawn of the Renaissance — only served to further entrench the iron fist of authority that saw its birth in the ancient world.
Modern media technology has been very much a mixed bag. On the plus side, there have been some truly direction-neutral communication tools that are now accessible to all, with photography, video-recording, and sound-recording technologies being the most prominent examples. There is even one device that is possibly the only pure lateral-only communication tool in the history of the world, and it's also become one of the most successful and widespread tools in history: the telephone. On the flip side, however, the modern world's two most successful devices are also the most sinister, most potent "down" directionality devices that humanity has ever seen: TV and radio.
The television (along with film and the cinema, which is also a "down" form of media) is the defining symbol of the 20th century, and it's still going strong into the 21st. Unfortunately, the television is also the ultimate device allowing one-way communication from those at the top of society, to those at the bottom. By its very definition, television is "broadcast" from the networks to the masses; and it's quite literally impossible for it to allow those at the receiving end to have their voices heard. What the Pyramids set in stone before the ancient masses, and what the Gutenberg bibles stamped in ink before the medieval hordes, the television has now burned into the minds of at least three modern generations.
The Internet, as you should all know by now, is changing everything. However, the Internet is also still in its infancy, and the Internet's fate in determining the directionality of communication into the next century is still unclear. At the moment, things look very positive. The Internet is the most accessible and the most powerful direction-neutral technology the world has ever seen. Blogging (what I'm doing right now!) is perhaps the first pure "up" directionality technology in the history of mankind, and if so, then I feel privileged to be able to use it.
The Internet allows a random citizen to broadcast a message to the world, for all eternity, in about 0.001% of the time that it took a king of the ancient world to deliver a message to all the subjects of his kingdom. I think That's Cool™. But the question is: when every little person on the planet is broadcasting information to the whole world, who does everyone actually listen to? Sure, there are literally millions of personal blogs out there, much like this one; and anyone can look at any of them, with just the click of a button, now or 50 years from now (50 years… at least, that's the plan). But even in an information ecosystem such as this, it hasn't taken long for the vast majority of people to shut out all sources of information, save for a select few. And before we know it — and without even a drop of blood being shed in protest — we're back to 1450 AD all over again.
It's a big 'Net out there, people. Explore it.
* Note: I've listed television and radio as being "permanent" preservation technologies, because even though the act of broadcasting is transient, the vast majority of television and radio transmissions throughout modern times have been recorded and formally archived.
]]>
Robotic garbage sorting2008-01-12T00:00:00Z2008-01-12T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/01/robotic-garbage-sorting/
The modern world is producing, purchasing, and disposing of consumer products at an ever-increasing rate. This is hardly news to anyone. Two other facts are also well-known, to anyone who's stopped and thought about them for even five minutes of their life. First, that our planet Earth only has a finite reservoir of raw materials, which is constantly diminishing (thanks to us). And second, that we first-world consumers are throwing the vast majority of our used-up or unwanted products straight into the rubbish bin, with the result that as much as 90% of household waste ends up in landfill.
When you think about all that, it's no wonder they call it "waste" .There's really no other word to describe the process of taking billions of tonnes of manufactured goods — a significant portion of which could potentially be re-used — and tossing them into a giant hole in the ground (or into a giant patch in the ocean). I'm sorry, but it's sheer madness! And with each passing day, we are in ever more urgent need of a better solution than the current "global disposal régime".
Cleaner alternatives
There are a number of alternatives to disposing of our garbage by way of dumping (be it in landfill, in the ocean, underground, or anywhere else). Examples of these alternatives:
We can incinerate our garbage. This does nothing to pollute the surface of the Earth; however, it does pollute our air and our atmosphere (quite severely), and it also means that the materials we incinerate are essentially lost to us forever. They're still floating around within the planet's ecosystem somewhere, but they're not recoverable to us within the foreseeable future.
We can place our garbage in a compost. This is a great, non-polluting, sustainable alternative when it's available: but unfortunately, only organic garbage actually decomposes properly, whereas other garbage (particularly plastic) remains intact in the ground for potentially hundreds of years.
We can even send our garbage into space. To the naïve reader, this may seem like the perfect alternative: non-polluting, not taking up space anywhere, and not our planet's problem anymore. But sending garbage into space is actually none of these things. It does pollute: the conventional rocket technology required to launch it is intensely polluting, as it involves millions of tonnes of fuel. It does take up space: even though we're sending it into space, we're still dumping it — and as far as I'm concerned, dumping is dumping (regardless of location). And contrary to "not being our planet's problem" anymore, sending garbage into space ignores the fundamental fact that the Earth is a giant ecosystem, and that it has finite resources, and that those resources (whatever form they're in, "garbage" or otherwise) should stay within our ecosystem at all costs. Flinging them away outside the planet is equivalent to chopping off your own arm, and flinging it into a shark-infested river. It's gone, it's no longer a part of you.
At the end of the day, none of these fancy and complicated alternatives is all that attractive. There's only one truly sustainable alternative to dumping, and it's the simplest and most basic one of all: reusing and recycling. Reuse, in particular, is the ideal solution for dealing with garbage: it's a potentially 100% non-polluting process; it takes up no more space than it began with; and best of all, it's the ultimate form of waste recovery. It lets us take something that we thought was utterly worthless and ready to rot in a giant heap for 1,000 years, and puts it back into full service fulfilling its original intended purpose. Similarly, recycling is almost an ideal solution as well. Recycling always inevitably involves some pollution as a side-effect of the process: but for many materials, this pollution is quite minimal. And recycling doesn't automatically result in recovery of off-the-shelf consumer goods, as does actual re-use: but it does at least recover the raw materials from which we can re-manufacture those goods.
As far as cleaner alternatives to dealing with our garbage go, re-use and recycling (in that order) are the clear winners. The only remaining question is: if continued dumping is suicide, and if re-use and recycling are so much better, then why — after several decades of having the issue in our faces — have we still only implemented it for such a pathetically small percentage of our waste? And the answer is: re-use and recycling involve sorting through the giant mess that is the modern world's garbage heap; and at present, it's simply too hard (or arguably impossible) to wade through it all. We lack the pressure, the resources, but most of all the technology to effectively carry out the sorting necessary for 100% global garbage re-use and recycling to become a reality.
Human-powered sorting
The push for us humans to take upon ourselves the responsibility of sorting out our trash, for the purposes of re-use and recycling, is something that has been growing steadily over the past 30 years or so. Every first-world country in the world — and an increasing number of developing countries — has in place laws and initiatives, from the municipal to the national level, aimed at groups from households to big businesses, and executed through measures ranging from legislation to education. As such, both re-use and recycling are now a part of everyday life for virtually all of us. And yet — despite the paper bins and the bottle bins now being filled on every street corner — those plain old rubbish bins are still twice the size, and are just as full, and can also be found on every single street corner. The dream of "0% rubbish" is far from a reality, even as we've entered the 21st century.
And the reasons for this disheartening lack of progress? First, the need to initiate more aggressive recycling is not yet urgent enough: in most parts of the world, there's still ample space left for use as landfill, and hence the situation isn't yet dire enough that we feel the pressure to act. Second, reusing and recycling is still a costly and time-consuming process, and neither big groups (such as governments) nor little groups (such as families) are generally willing to make that investment — at the moment, they still perceive the costs as outweighing the benefits. Third and finally, the bottom line is that people are lazy: an enormous amount of items that could potentially be reused or recycled, are simply dumped in the rubbish bin due to carelessness; and no matter how much effort we put into legislation and education, that basic fact of human nature will always plague us.
I retract what I just said, for the case of two special and most impressive contemporary examples. First, there are several towns in Japan where aggressive recycling has actually been implemented successfully: in the town of Kamikatsu in particular, local residents are required to sort their garbage into 44 different recycling categories; and the town's goal of 0% trash by 2020 is looking to be completely realistic. Second, the city of Taipei — in Taiwan — is rolling out tough measures aimed to reduce the city's garbage output to ¼ its current size. However, these two cases concern two quite unique places. Japan and Taiwan are both critically short of land, and thus are under much more pressure than other countries to resolve their landfill and incinerator dependence urgently. Additionally, they're both countries where (traditionally) the government is headstrong, where the people are obedient, and (in my opinion) where the people also have much less of a "culture of laziness" than do other cultures in the world. As such, I maintain that these two examples — despite being inspiring — are exceptional; and that we can't count on human-powered sorting alone, as a solution to the need for more global reuse and recycling.
Robot-powered sorting
Could robots one day help us sort our way out of this mess? If we can't place hope in ourselves, then we should at least endeavour to place some hope in technology instead. Technology never has all the answers (on the contrary, it often presents more problems than it does solutions): but in this case, it looks like some emerging cutting-edge solutions do indeed hold a lot of promise for us.
On the recycling front, there is new technology being developed that allows for the robotic recognition of different types of material compositions, based purely on visual analysis. In particular, the people over at SINTEF (a Norwegian research company) have invented a device that can "see" different types of rubbish, by recognising the unique "fingerprint" that each material exhibits when light is reflected off it. The SINTEF folks have already been selling their technology on the public market for 2 years, in the form of a big box that can have rubbish fed into it, and that will spit the rubbish back out in several different bags — one bag for each type of material that it can distinguish. Well, that's the issue of human laziness overcome on the recycling front: we don't need to (and we can't) rely on millions of consumers to be responsible sorters and disposers; now we can just throw everything into one bin, and the bin itself will be smart enough to do the sorting for us!
On the reuse front, technology is still rather experimental and in its infancy; but even here, the latest research is covering tremendous ground. The most promising thing that I've heard about, is what took place back in 1995 at the University of Chicago's Animate Agent Laboratory: scientists there developed a robot that accepted visual input, and that could identify as garbage random objects on a regular household floor, and dispose of them accordingly. What I'm saying is: the robot could recognise a piece of paper, or an empty soft-drink can, or a towel, or whatever else you might occasionally find on the floor of a household room. Other people have also conducted academic studies into this area, with similarly pleasing results. Very cool stuff.
Technology for reuse is much more important than technology for recycling, because reuse (as I explained above) should always be the first recourse for dealing with rubbish (and with recycling coming second); and because the potential benefits of technology-assisted reuse are so vast. However, technology-assisted reuse is also inherently more difficult, as it involves the robotic recognition of actual, human-centric end-user objects and products; whereas technology-assisted recycling simply involves the recognition of chemical substances. But imagine the opportunities, if robots could actually recognise the nature and purpose of everything that can be found in a modern-day rubbish bin (or landfill heap). Literally billions of items around the world could be sorted, and separated from the useless heap that sits rotting in the ground. Manufactured goods could (when discovered) be automatically sent back to the manufacturer, for repair and re-sale. Goods in reasonable condition could simply be cleaned, and could then be sent directly back to a retailer for repeated sale; or perhaps could instead be sent to a charity organisation, to provide for those in need. Specific types of items could be recognised and given to specific institutions: stationary to schools, linen to hospitals, tools and machinery to construction workers, and so on.
In my opinion, robotic garbage sorting is (let us hope) closer than we think; and when it arrives en masse, it could prove to be the ultimate solution to the issue of global sustainability and waste management. In order for our current ways of mass production and mass consumption to continue — even on a much smaller scale than what we're at now — it's essential that we immediately stop "wasting waste". We need to start reusing everyting, and recycling everything else (in the cases where even robot-assisted reuse is impossible). We need to stop thinking of the world's enormous quantity of garbage as a pure liability, and to start thinking of it as one of our greatest untapped resource reservoirs. And with the help of a little junk-heap sorting — on a scale and at a health and safety risk too great for us to carry out personally, but quite feasible for robots — that reservoir will very soon be tapped.
]]>
The bicycle-powered home2007-12-20T00:00:00Z2007-12-20T00:00:00ZJazahttps://greenash.net.au/thoughts/2007/12/the-bicycle-powered-home/
The exercise bike has been around for decades now, and its popularity is testament to the great ideas that it embodies. Like the regular bicycle, it's a great way to keep yourself fit and healthy. Unlike the regular bicycle, however, it has the disadvantages of not being usable as a form of transport or (for most practical purposes) as a form of other sport, and of not letting you get out and enjoy the fresh air and the outdoor scenery. Fortunately, it's easy enough for a regular bike to double as an exercise bike, with the aid of a device called a trainer, which can hold a regular bike in place for use indoors. Thus, you really can use just one bicycle to live out every dream: it can transport you, it can keep you fit, and it can fill out a rainy day as well.
Want to watch TV in your living room, but feeling guilty about being inside and growing fat all day? Use an exercise bike, and you can burn up calories while enjoying your favourite on-screen entertainment. Feel like some exercise, but unable to step out your front door due to miserable weather, your sick grandma who needs taking care of, or the growing threat of fundamentalist terrorism in your neighbourhood streets? Use an exercise bike, and you can have the wind in your hair without facing the gale outside. These are just some of the big benefits that you get, either from using a purpose-built exercise bike, or from using a regular bike mounted on a trainer.
Now, how about adding one more great idea to this collection. Want to contribute to clean energy, but still enjoy all those watt-guzzling appliances in your home? Use an electricity-generating exercise bike, and you can become a part of saving the world, by bridging the gap between your quadriceps and the TV. It may seem like a crazy idea, only within the reach of long-haired pizza-eating DIY enthusiasts; but in fact, pedal power is a perfectly logical idea: one that's available commercially for home use by anyone, as well as one that's been adopted for large and well-publicised community events. I have to admit, I haven't made, bought or used such a bike myself (yet) — all I've done so far is think of the idea, find some other people (online) who have done more than just think, and then write this blog post — but I'd love to do so sometime in the near future.
I first thought of the idea of an energy-generating exercise bike several weeks ago: I'm not sure what prompted me to think of it; but since then, I've been happy to learn that I'm not the first to think of it, and indeed that many others have gone several steps further than me, and have put the idea into practice in various ways. Below, I've provided an overview of several groups and individuals who have made the pedal-power dream a reality — in one way or another — and who have made themselves known on the web. I hope (and I have little doubt) that this is but the tip of the iceberg, and that there are in fact countless others in this world who have also contributed their time and effort to the cause, but who I don't know about (either because they have no presence on the web, or because their web presence wasn't visible enough for me to pick it up). If you know of any others who deserve a mention — or if you yourself have done something worth mentioning — then mention away. G-d didn't give us the "add comment" button at the bottom of people's blogs for nothing, you know.
Pedal Power en masse
The Pedal Powered Innovations project is run by bicycle-freak Bart Orlando, with the help of volunteers at the Campus Center for Appropriate Technology (a group at Humboldt State University in northern California). Bart and the CCAT people have been working for over a decade now, and in that time they've built some amazing and (at times) impressively large-scale devices, all of which are very cool applications of the "bicycles as electrical generators" idea.
Human Energy Converter (photo)
You can see more photos and more detailed info on their website, but here's a list of just some of the wacky contraptions they've put together:
Human Energy Converter: multi-bike generator system (the original was comprised of 14 individual bikes), used to power microphones for public speeches, stereo systems for outdoor concerts, and sound-and-light for environmental protests.
Household appliance generator: various appliances that have been successfully used through being powered by a bicycle. Examples include a blender, a sewing machine, and a washing machine.
Entertainment device generator: yet more devices that can successfully be bicycle-powered. Examples include TVs, VCRs, and large batteries.
Great work, guys! More than anything, the CCAT project demonstrates just how many different things can potentially be "pedal powered", from the TV in your living room, to the washing machine out back in the laundry, to a large-scale community gathering. It's all just a question of taking all that kinetic energy that gets generated anyway from the act of cycling, and of feeding into a standard AC socket. I'll have to go visit this workshop one day — and to find out if there are any other workshops like this elsewhere in the world.
Pedal-A-Watt in the home
The folks over at Convergence Tech, Inc have developed a commercial product called The Pedal-A-Watt Stationary Bike Power Generator. The product is a trainer (i.e. a holder for a regular road or mountain bike) that collects the electricity produced while pedalling, and that is able to feed up to 200 watts of power into any home device — that's enough to power most smaller TVs, as well as most home PCs. It's been available for 8 years: and although it's quite expensive, it looks to be very high-quality and very cool, not to mention the fact that it will reduce your electricity bill in the long run. Plus, as far as I know, it's almost the only product of its type on the market.
Pedal-A-Watt (photo)
DIY projects
The most comprehensive DIY effort at "pedal power" that I found on the web, is the home-made bicycle powered television that the guys over at Scienceshareware.com have put together. This project is extremely well-documented: as well as a detailed set of instructions (broken down into 10 web pages) on how to achieve the set-up yourself (with numerous technical explanations and justifications accompanying each step), they've also got a YouTube video demonstrating the bike-powered TV. In the demonstration, they show that they were able to not only provide full power to a 50 watt colour TV using a single bicycle; there was also plenty of excess energy that they were able to collect and store inside a car battery. The instructions are very technical (so get ready to pull out those high-school physics and electronics textbooks, guys), but very informative; and they also have no shortage of safety warnings, and of advice on how to carry out the project in your own home reasonably safely.
Another excellent home-grown effort, built and documented last year by the people at the Campaign For Real Events, is their 12-volt exercise bike generator. This bike was originally built for a commercial TV project; but when that project got canned, the bike was still completed, and was instead donated to non-profit community use. The DIY instructions for this bike aren't quite as extensive as the Scienceshareware.com ones, but they're still quite technical (e.g. they include a circuit diagram); and it's still a great example of just what you can do, with an exercise bike and a few other cheaply- or freely-obtainable parts (if you know what you're doing). The Campaign For Real Events group has also, more recently, begun producing "pedal power" devices on a more large-scale basis — except that they're not making them for commercial use, just for various specific community and governmental uses.
Other ideas people
Like myself, plenty of other people have also posted their ideas about "how cool pedal power would be" onto the web. For example, just a few months ago, someone posted a thread on the Make Magazine forum, entitled: How do I build an exercise bike-powered TV? We're not all DIY experts — nor are we all electronics or hardware buffs — but even laymen like you and me can still realise the possibilities that "pedal power" offers, and contribute our thoughts and our opinions on it. And even that is a way of making a difference: by showing that we agree, and that we care, we're still helping to bring "pedal power" closer to being a reality. Not all of the online postings about bicycle-TV combinations are focused on "pedal power", though: many are confined to discussing the use of a bike as an infrared remote control replacement, e.g. triggering the TV getting turned on by starting to pedal on the bike. Also a good idea — although it doesn't involve any electricity savings.
In short, it's green
Yes: it's green. And that's the long and the short of why it's so good, and of why I'm so interested in it. Pedal power may not be the most productive form of clean energy that we have available today: but it's productive enough to power the average electronic devices that one person is likely to use in their home; and (as mentioned above) it has the added benefit of simultaneously offering all the other advantages that come with using an exercise bike. And that's why pedal power just might be the clean energy with less environmental impact, and more added value, than virtually any other form of clean energy on the planet. Plus, its low energy output could also be viewed as an advantage of sorts: if pedal power really did take off, then perhaps it would eventually encourage product manufacturers to produce lower energy-consumption devices; and, in turn, it would thus encourage consumers to "not use more devices than your own two feet can power". This philosophy has an inherent logic and self-sufficiency to it that I really appreciate.
I like cycling. I like this planet. I hope you do too. And I hope that if you do indeed value both of these things, as I do (or that if you at least value the latter), then you'll agree with me that in this time of grave environmental problems — and with dirty forms of electricity production (e.g. coal, oil) being a significant cause of many of these problems — we need all the clean energy solutions we can get our hands on. And I hope you'll agree that as clean energy solutions go, they don't get much sweeter than pedal power. Sure, we can rely on the sun and on photovoltaic collectors for our future energy needs. Sure, we can also rely on the strength of winds, or on the hydraulic force of rivers, or on the volcanic heat emitted from natural geothermal vents. But at the end of the day, everyone knows that if you want to get something done, then you shouldn't rely on anything or anyone except yourself: and with that in mind, what better to rely on for your energy needs, than your own legs and your ability to keep on movin' em?
]]>
Consciously directed healing2007-11-02T00:00:00Z2007-11-02T00:00:00ZJazahttps://greenash.net.au/thoughts/2007/11/consciously-directed-healing/
The human body is a self-sustaining and self-repairing entity. When you cut your hand, when you blister your foot, or when you burn your tongue, you know — and you take it for granted — that somehow, miraculously, your body will heal itself. All it needs is time.
This miracle is possible, because our bodies are equipped with resources more vast and more incredible than most people ever realise, let alone think about. Doctors know these resources inside-out — they're called cells. We have billions upon billions of cells, forming the building-blocks of ourselves: each of them is an independent living thing; and yet each is also purpose-built for serving the whole in a specific way, and is 100% at the disposal of the needs of the whole. We have cells that make us breathe. Cells that make us digest. Cells that make us grow. And, most important of all, cells that tell all the other cells what to do — those are known as brain cells.
In the case of common muscle injuries, it's the tissue cells (i.e. the growing cells — they make us grow by reproducing themselves) and the brain cells, among others, that are largely responsible for repairs. When an injury occurs, the brain cells receive reports of the location and the extent of the problem. They then direct the tissue cells around the affected area to grow — i.e. to reproduce themselves — into the injury, thus slowly bringing new and undamanged tissue to the trouble spot, and bit-by-bit restoring it to its original and intended state. Of course, it's a lot more complicated than that: I'm not a doctor, so I'm not going to pretend I understand it properly. But as far as I'm aware, that's the basics of it.
However, there are many injuries that are simply too severe for the body to repair by itself in this way. In these cases, help may be needed in the form of lotions, medicines, or even surgery. Now, what I want to know is: why is this so? With all its vast resources, what is it that the human body finds so difficult and so time-consuming in healing a few simple cuts and bruises? Surely — with a little bit of help, and a lot more conscious concentration — we should be capable of repairing so much more, all by ourselves.
More brain power
There is a widely-known theory that we humans only use 10% of our brains. Now, this theory has many skeptics: and those skeptics pose extremely valid arguments against the theory. For example, we may only use 10-20% of our brains at any one time, but we certainly use the majority of our brains at some point in our lives. Also, brain research is still (despite years of money and effort) an incredibly young field, and scientists really have no idea how much of our brains we use, at this point in time. However, it still seems fairly likely that we do indeed only use a fraction of our brain's capacity at any given time — even in times of great pain and injury — and that were we able to use more of that capacity, and to use it more effectively, that would benefit us in numerous manifold ways.
I personally am inclined to agree with the myth-toting whackos, at least to some extent: I too believe that the human brain is a massively under-utilised organ of the body; and that modern medicine has yet to uncover the secrets that will allow us to harness that extra brain power, in ways that we can barely imagine. I'm certainly not saying that I agree with the proponents of the Quantum-Touch theory, who claim to be able to "heal others by directing their brain's energy" — that's a bit far-fetched for my liking. Nor am I in any way agreeing with ideas such as psychokinesis, which claims that the mere power of the brain is capable of anything, from levitating distant objects to affecting the thoughts and senses of others. No: I'm not agreeing with anything that dodgy or supernatural-like.
I am, however, saying that the human brain is a very powerful organ, and that if we could utilise it more, then our body would be able to do a lot more things (including the self-healing that it's already been capable of since time immemorial) a lot more effectively.
More concentration
As well as utilising more of our brains, there is also (even more vexingly) the issue of directing all that extra capacity to a particular purpose. Now, in my opinion, this is logically bound to be the trickier bit, from a scientific standpoint. For all practical purposes, we're already able to put our brains into an "extreme mode", where we utilise a lot more capacity all at once. What do you think conventional steroids do? Or the myriad of narcotic "party drugs", such as Speed and Ecstasy, that are so widely sought-after worldwide? Upping the voltage isn't that hard: we've already figured it out. But where does it go? We have no idea how to direct all that extra capacity, except into such useless (albeit fun) pursuits as screaming, running, or dancing like crazy. What a waste.
I don't know what the answer to this one is: whether it be a matter of some future concentration-enhancing medicine; of simply having a super-disciplined mind; or of some combination of this and other solutions. Since nobody to date has conclusively proven and demonstrated that they can direct their brain's extra capacity to somewhere useful, without medical help, I doubt that anything truly amazing is physically possible, with concentration alone. But whatever the solution is, it's only a matter of time before it is discovered; and its discovery is bound to have groundbreaking implications for medicine and for numerous other fields.
Future glimpse
Basically, what I'm talking about in this article is a future wonder-invention, that will essentially allow us to utilise our brain's extra capacity, and to direct that extra capacity to somewhere useful, for the purpose of carrying out conventional self-healing in a much faster and more effective way than is currently possible. This is not about doing anything that's simply impossible, according to the laws of medicine or physics — such as curing yourself of cancer, or vaporising your enemies with a stare — it's about taking something that we do now, and enhancing it. I'm not a scientist or a doctor, I'm just someone who has too much time on his hands, and who occasionally thinks about how cool it would be for the world to have things like this. Nevertheless, I really do believe that consciously directed healing is possible, and that it's only a matter of time before we work out how to do it.
]]>
Developing home + developed income = paradise2007-10-13T00:00:00Z2007-10-13T00:00:00ZJazahttps://greenash.net.au/thoughts/2007/10/developing-home-developed-income-paradise/
Modern economics is infinitely bizarre. We all know it. I'm not here to prove it; I'm just here to provide one more example of it — and the example is as follows. You're an educated, middle-class professional: you've lived in a developed country your whole life; and now you've moved to a developing country. Your work is 99% carried out online, and your clients live all over the world. So you move to this less-affluent country, and you continue to work for your customers in the First World. Suddenly, your home is a dirt-cheap developing nation, and your income is in the way of formidable developed-nation currency.
I've just finished a six-month backpacking tour of South America, and one of my backpacking friends down there is doing just this. He's a web designer (similar to my own profession, that of web developer): essentially the ideal profession for working from anywhere in the world, and for having clients anywhere else in the world. He's just starting to settle down in Buenos Aires, Argentina: a place with a near-Western quality of infrastructure; but a country where the cost of living and the local currency value is significantly lower than that of Western nations. He's the perfect demonstration of this new global employment phenomenon in action. All he needs is a beefy laptop, and a reasonably phat Internet connection. Once he has that, he's set up to live where he will, and to have clients seek him out wherever he may be.
The result of this setup? Well, I'm no economist — so correct me if I'm wrong — but it would seem that the result must invariably be a paradise existence, where you can live like a king and still spend next to nothing!
To tell the truth, I'm really surprised that I haven't heard much about this idea in the media thus far. It seems perfectly logical to me, considering the increasingly globalised and online nature of life and work. If anyone has seen any articles or blog posts elsewhere that discuss this idea, feel free to point them out to me in the comments. I also can't really think of any caveats to this setup. As long as the nature of your work fits the bill, there should be nothing stopping you from "doing the paradise thing", right? As far as I know, it should be fine from a legal standpoint, for most cases. And assuming that your education, your experience, and your contacts are from the Western world, they should be happy to give you a Western standard of pay — it should make no difference to them where you're physically based. Maybe I'm wrong: maybe if too many people did this, such workers would simply end up getting exploited, the same as locals in developing countries get exploited by big Western companies.
But assuming that I'm not wrong, and that my idea can and does work in practice — could this be the next big thing in employment, that we should expect to see happening over the next few years? And if so, what are the implications for those of us that do work online, and that are candidates for this kind of life?
]]>
Let the cameras do the snapping2007-04-11T00:00:00Z2007-04-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2007/04/let-the-cameras-do-the-snapping/
For all of the most memorable moments in life — such as exotic vacations, milestone birthday parties, and brushes with fame — we like to have photographs. Videos are good too — sometimes it's even nice (although something of a luxury) to use more traditional methods, such as composing song, producing paintings, or interpreting the moment with dance — but really, still photographs are by far the most common and the most convenient way to preserve the best moments in life.
For some people, photography is an art and a life-long passion: there is great pride to be had in capturing significant occasions on film or in pixels. But for others (such as myself), taking photos can quickly become little more than a bothersome chore, and one that detracts from the very experiences that you're trying to savour and to have a memento of.
For those of us in the latter category, wouldn't it be great if our cameras just took all the pictures for us, leaving us free to do other things?
Smart cameras
I was thinking about this the other day, after a particularly intense day of photo-taking on my current world trip. I decided that it would be very cool, and that it probably wouldn't be that hard to do (what with the current state of intelligent visual computer systems), and that seriously, it should be realistic for us to expect this kind of technology to hit the shelves en masse within the next 30 years. Max.
Sunset over Lima
Think about it. Robotic cameras that follow you around — perhaps they sit on your shoulder, or perhaps they trail behind you on wheels (or legs!) — and that do all the snapping for you. No need for you to point and shoot. They'll be able to intelligently identify things of interest, such as groups of people, important landmarks, and key moments. They'll have better reflexes than you. They'll know more about lighting, saturation, aperture, shutter speed, and focus, than you could learn in a lifetime. They'll be able to learn as they go, to constantly improve their skills, and to contribute their learning back to a central repository, to be shared by millions of other robotic cameras around the world.
Meanwhile, you'll be able to actually do stuff, apart from worrying about whether or not this is a good time to take a picture.
Not science fiction
What's more, judging by recent developments, this may not be as far off as you think.
Already, numerous researchers and technologists around the world are developing machines and software routines that pave the way for exactly this vision. In particular, some Japanese groups are working on developing robotic cameras for use in broadcasting, to make the cameraman an obsolete occupation on the studio floor. They're calling this automatic program production for television networks, and they're being sponsored and supported by the Japan Broadcasting Corporation.
This is still only early stages. The cameras can be told to focus on particular objects (usually moving people), and they can work with each other to capture the best angles and such. But it's very promising, and it's certainly laying a firm foundation for the cameras of the future, where detecting what to focus on (based on movement, among other metrics) will be the key differentiator between intelligent and dumb photographic systems.
I know that many people will find this vision ludicrous, and that many more will find it to be a scary prediction of the end of photography as a skill and as an art. But really, there's no reason to be afraid. As with everything, robotic cameras will be little more than a tool; and despite being reasonably intelligent, I doubt that they'll ever completely replace the human occupation of photographer. What's more, they'll open up whole new occupations, such as programmers who can develop their own intelligent algorithms (or add-ons for bigger algorithms), which will be valuable and marketable as products.
I realise that not all of you will feel this way; but I for one am looking forward to a future where the cameras do the snapping for me.
]]>
A plain-text program design standard2005-10-07T00:00:00Z2005-10-07T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/10/a-plain-text-program-design-standard/
I've been working on a project at University, in which my team had to produce a large number of software design documents, in order to fulfil the System Architecture objectives of the project. The documents included UML class diagrams, UML sequence diagrams, class-based system specifications, and more.
The design phase of our project is now finished, but all of these documents now have to be translated into working code. This basically involves taking the high-level design structure specified in the design documents, and converting it into skeleton code in the object-oriented programming language of our choice. Once that's done, this 'skeleton code' of stubs has to actually be implemented.
Of course, all of this is manual work. Even though the skeleton code is virtually the same as the system specifications, which in turn are just a text-based representation of the graphical class diagram, each of these artefacts are created using separate software tools, and each of them must be created independently. This is not the first Uni project in which I've had to do this sort of work; but due to the scale of the project I'm currently working on, it really hit me that what we have to do is crazy, and that surely there's a better, more efficient way of producing all these equivalent documents.
Wouldn't it be great if I could write just one design specification, and if from that, numerous diagrams and skeleton code could all be auto-generated? Wouldn't it make everyone's life easier if the classes and methods and operations of a system only needed to be specified in one document, and if that one document could be processed in order to produce all the other equivalent documents that describe this information? What the world needs is a plain-text program design standard.
I say plain-text, because this is essential if the standard is to be universally accessible, easy to parse and process, and open. And yes, by 'standard', I do mean 'open standard'. That is: firstly, a standard in which documents are text rather than binary, and can be easily opened by many existing text editors; and secondly (and more importantly), a standard whose specification is published on the public domain, and that can therefore be implemented and interfaced to by any number of third-party developers. Such a standard would ideally be administered and maintained by a recognised standards body, such as the ISO, ANSI, the OMG, or even the W3C.
I envision that this standard would be of primary use in object-oriented systems, but then again, it could also be used for more conventional procedural systems, and maybe even for other programming paradigms, such as functional programming (e.g. in Haskell). Perhaps it could even be extended to the database arena, to allow automation between database design tasks (e.g. ERD diagramming) and SQL CREATE TABLE statements.
This would be the 'dream standard' for programmers and application developers all over the world. It would cut out an enormous amount of time that is wasted on repetitive and redundant work that can potentially be automated. To make life simpler (and for consistency with all the other standards of recent times), the standard would be an XML-based markup language. At its core would simply be the ability to define the classes, attributes, and operations of a system, in both a diagram-independent and a language-independent manner.
Here's what I imagine a sample of a document written to such a standard might look like (for now, let's call it ODML, or Object Design Markup Language):
(Sorry about the underscores, guys - due to technical difficulties in getting indenting spaces to output properly, I decided to resort to using them instead.)
From this simple markup, programs could automatically generate design documents, such as class diagrams and system specifications. Using the same markup, skeleton code could also be generated for any OO language, such as Java, C#, C++, and PHP.
I would have thought that surely something this cool, and this important, already exists. But after doing some searching on the Web, I was unable to find anything that came even remotely near to what I've described here. However, I'd be most elated to learn that I simply hadn't searched hard enough!
When I explained this idea to a friend of mine, he cynically remarked that were such a standard written, and tools for it developed, it would make developers' workloads greater rather than smaller. He argued that this would be the logical expected result, based on past improvements in productivity. Take the adoption of the PC, for example: once people were able to get more work done in less time, managers the world over responded by simply giving people more work to do! The same applies to the industrial revolution of the 19th century (once workers had machines to help them, they could produce more goods); to the invention of the electric light bulb (if you have light to see at night, then you can work 24/7); and to almost every other technological advancement that you can think of. I don't deny that an effective program design standard would quite likely have the same effect. However, that's an unavoidable side effect of any advancement in productivity, and is no reason to shun the introduction of the advancement.
A plain-text program design standard would make the programmers and system designers of the world much happier people. No question about it. Does such a thing exist already? If so, where the hell do I get it? If not, I hope someone invents it real soon!
]]>
Movies for the masses2005-06-09T00:00:00Z2005-06-09T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/06/movies-for-the-masses/
2005 marks the 100th anniversary of the cinema industry. In 1905 (according to this film history timeline, and this article on film), the world's first movie theatre opened in Pittsburgh, Pennsylvania. The first ever motion picture, called "The Oberammergau Passion", was produced in 1898. What does all this mean? Movies have now been around for 108 years. They're older than almost anyone alive today. They're a part of the lives of all of us, and of everyone we know. The movie is one of the 20th century's greatest triumphs. Compared with other great inventions of the age - such as the atomic bomb - when it comes to sheer popularity, the movie wins hands down.
I've had an amazing vision of something that is bound to happen, very soon, in the world of movies. I will explain my vision at the end. If you're really impatient, then feel free to skip my ramblings, and cut to the chase. Otherwise, I invite you to read on.
Rambling review of American Epic
I just finished watching Part 1 of Cecil B. DeMille: American Epic (on ABC TV). DeMille was one of the greatest filmmakers of all time. I watched this documentary because DeMille produced The Ten Commandments, which is one of my favourite movies of all time. When I saw the ad for this show a few nights ago - complete with clips from the movie, and some of the most captivating music I've ever heard (the music from the movie, that is) - I knew I had to watch it.
This documentary revealed quite a few interesting things about Cecil B. DeMille. Here are the ones that stayed with me:
In his 50+ years of movie-making, he produced an astounding 70+ feature films!
He was actually a failed playwright and actor, who turned to film as an act of desperation. His failure in the world of theatre filled him with an incredible ambition and drive for the rest of his life.
He founded Hollywood. That's right: when he arrived in Los Angeles in 1913, Hollywood was a sleepy village with nothing but farmland around it. He set up the first movie studio ever in Hollywood. He chose to establish himself in the town, because the scenery of the area was just what he needed to film his first movie (The Squaw Man).
He first produced The Ten Commandments in 1923. All those countless times I've watched the 1956 version (I watch it at least once every year): and never once did I realise or suspect that it was actually the second version that he made. The documentary shows clips from the original film, and it's uncanny how striking the resemblances are. The 'day of exodus' scene, the 'chariot chase' scene, and the famous 'splitting of the sea' scene, all look pretty much the same as their later equivalents, just with way worse special effects and no sound.
When he produced The King of Kings in 1927, it originally portrayed the Children of Israel as being responsible for the death of dear old Brian (AKA Jesus). But the outcry from the American Jewish community at the time was so severe, the ending had to be changed before the film was released.
Although his mother was Jewish - and although his biggest film ever was the story of the birth of the Jewish people - he was apparently a tad bit anti-semitic. He considered himself to be a devout Christian, and somewhat resented his Jewish blood. He wouldn't let one of his relatives appear in any of his films, or in any photographs associated with them, because she had a 'Jewish nose' (hey, I know all about that, I know just how she feels!).
Anyway, most of the documentary was about DeMille's work producing silent films, during the 1913-1929 period. Watching these films always gives me a weird feeling, because I've always considered film to be a 'modern' medium, and yet to me, there's absolutely nothing modern about these films. They look ancient. They are ancient. They're archaeological relics. They may as well belong in the realms of Shakespeare, and Plato, and all the other great works of art that are now in the dim dark past. We give these old but great works a benevolent name (how generous of us): we call them classics.
But even at the very start of his producer / director career, the hallmarks of DeMille's work are clear; the same hallmarks that I know and love so well, from my many years of fondness for The Ten Commandments. Even in his original silent, black-and-white-not-even-grey, who-needs-thirty-frames-in-a-second-anyway films, you can see the grandeur, the lavish costumes, the colossal sets, the stunning cast, and the incontestible dignity that is a DeMille movie.
Cut to the chase
Watching all this stuff about the dawn of the film industry, and the man that made Hollywood's first feature films, got me thinking. I thought about how old all those movies are. Old, yet still preserved in the dusty archives of Paramount Pictures (I know because the credits of the documentary said so). Old, yet still funny, still inspiring, still able to be appreciated. Old, but not forgotten.
I wondered if I could get any of these old, silent films from the 1920s (and before) on video or DVD. Probably not, I thought. I wondered if I could get access to them at all. The 1923 original of The Ten Commandments, in particular, is a film that I'd very much like to see in full. But alas, no doubt the only way to access them is to go to the sites where they're archived, and pay a not-too-shabby fee, and have to use clunky old equipment to view them.
Have you ever heard of Project Gutenberg? They provide free, unlimited access to the full text of over 15,000 books online. Most of the books are quite old, and they are able to legally publish them online royalty-free, because the work's copyright has expired, due to lapse of time since the author's death. Project Gutenberg FAQ 11 says that as a general rule, works published in the USA pre-1923 no longer have copyright (this is a rough guideline - many complicated factors will affect this figure on a case-by-case basis).
Project Gutenberg's library consists almost entirely of literary text at the moment. But the time is now approaching (if it hasn't arrived already) when the world's oldest movies will lose their copyright, and will be able to be distributed royalty-free to the general public. Vintage films would make an excellent addition to online archives such as Project Gutenberg. These films are the pioneers of a century of some of the richest works of art and creativity that man has ever produced. They are the pioneers of the world's favourite medium of entertainment. They should be free, they should be online, and they should be available to everyone.
When this happens (and clearly it's a matter or when, not if), it's going to be a fantastic step indeed. The educational and cultural value of these early films is not to be underestimated. These films are part of the heritage of anyone who's spent their life watching movies - that would be most of the developed world.
These films belong to the masses.
]]>
In search of an all-weather bike2005-04-29T00:00:00Z2005-04-29T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/04/in-search-of-an-all-weather-bike/
I ride my bike whenever I can. For me, it's a means of transportation more than anything else. I ride it to get to university; I ride it to get to work; sometimes I even ride it to get to social events. Cycling is a great way to keep fit, to be environmentally friendly, and to enjoy the (reasonably) fresh air.
But quite often, due to adverse weather, cycling is simply not an option. Plenty of people may disagree with me, but I'm sure that plenty will also agree strongly when I say that riding in heavy rain is no fun at all.
There are all sorts of problems with riding in the rain, some being more serious than others. First, there's the problem of you and your cargo getting wet. This can be avoided easily enough, by putting a waterproof cover on your cargo (be it a backpack, saddle bags, or whatever), and by wearing waterproof gear on your person (or by wearing clothes that you don't mind getting wet). Then there's the problem of skidding and having to ride more carefully, which really you can't do much about (even the big pollution machines, i.e. cars, that we share the road with, are susceptible to this problem). And finally, there's the problem of the bike itself getting wet. In particular, problems arise when devices such as the brakes, the chain, and the derailleur are exposed to the rain. This can be averted somewhat by using fenders, or mudguards, to protect the vital mechanical parts of the bike.
But really, all of these are just little solutions to little problems. None of them comes close to solving the big problem of: how can you make your riding experience totally weatherproof? That's what I'm looking for: one solution that will take care of all my problems; a solution that will protect me, my bag, and almost all of my bike, in one fell swoop. What I need is...
A roof for my bike!
But does such a thing exist? Has anyone ever successfully modified their bike, so that it has a kind of roof and side bits that can protect you from the elements? Surely there's someone else in this world as chicken of the rain as me, but also a little more industrious and DIY-like than me?
The perfect solution, in my opinion, would be a kind of plastic cover, that you could attach to a regular diamond-frame bike, and that would allow you to ride your bike anywhere that you normally would, only with the added benefit of protection from the rain. It would be a big bubble, I guess, sort of like an umbrella for you and your bike. Ideally, it would be made of clear plastic, so that you could see out of it in all directions. And it would be good if the front and side sections (and maybe the back too - and the roof) were flaps that you could unzip or unbutton, to let in a breeze when the weather's bad but not torrential. The 'bubble cover' would have to be not much wider than the handlebars of your bike - otherwise the bike becomes too wide to ride down narrow paths, and the coverage of the bike (i.e. where you can take it) becomes restricted.
If it exists, I thought, then surely it'll be on Google. After all, as the ancient latin saying goes: "In Googlis non est, ergo non est" (translation:"If it's not in Google, it doesn't exist"). So I started to search for words and phrases, things that I hoped would bring me closer to my dream of an all-weather bike.
Playing hard to get
I searched for "all-weather bike". Almost nothing. "Weatherproof bike". Almost nothing. "Bike roof". A whole lot of links to bicycle roof racks for your car. "Bike roof -rack". Yielded a few useless links. "Bike with roof". Barely anything. "Waterproof cover +bicycle". Heaps of links to covers that you can put on your bike, to keep it dry when it's lying in the back yard. But no covers that you can use while you're riding the bike.
This was getting ridiculous. Surely if there was something out there, I would have found it by now? Could it be true that nobody in the whole world had made such a device, and published it on the web? No, it couldn't be! This is the information age! There are over 6 billion people in the world, and as many as 20% of them (that's over 1.2 billion people) have access to the Internet. What are the odds that not even 1 person in 1.2 billion has done this?
I must be searching for the wrong thing, I thought. I looked back to my last search: "bike canopy". What else has a canopy? I know! A golf buggy! So maybe, I thought, if I search for information about golf buggies / carts, I'll find out what the usual word is for describing roofs on small vehicles. So I searched for golf buggies. And I found one site that described a golf buggy with a roof as an 'enclosed vehicle'. Ooohhh... enclosed, that sounds like a good word!
So I searched for "enclosed bike". A whole lot of links about keeping your bike enclosed in lockers and storage facilities. Fine, then: "enclosed bike -lockers". Got me to an article about commuting to work by bike. Intersting article, but nothing in it about enclosing your bike.
Velomobiles
Also, further down in the list of results, was the amazing go-one. This is what a go-one looks like:
Go-one velomobile
Now, if that isn't the coolest bike you've ever seen, I don't know what is! As soon as I saw that picture, I thought: man, I want that bike.
The go-one is actually a tricycle, not a bicycle. Specifically, it's a special kind of trike called a recumbent trike. Recumbents have a big comfy seat that you can sit back and relax in, and you stick your feet out in front of you to pedal. Apparently, they're quite easy to ride once you get used to them, and they can even go faster than regular bikes; but I don't see myself getting used to them in a hurry.
The go-one is also a special kind of trike called a velomobile. Velomobiles are basically regular recumbents, with a solid outer shell whacked on the top of them. Almost all the velomobiles and velomobile makers in the world are in Europe - specifically, in the Netherlands and in Germany. But velomobiles are also beginning to infiltrate into the USA; and there's even a velomobile called the Tri-Sled Sorcerer that's made right here in Australia!
Here's a list of some velomobile sites that I found whilst surfing around:
Information about velomobiles from the International Human Powered Vehicles Association. This is the body that officially governs velomobile use worldwide. Has many useful links.
This site is dedicated to recumbents of all types. This article surveys pretty much every velomobile currently available on the commercial market - great if you're looking to get the low-down on all the models. Only bad thing is that half the images are broken.
Velomobiles are the closest thing (and the only thing that comes close at all) to my dream of an enclosed bike. There's no doubt that they shield you from the elements. In fact, most of them have been designed specifically as a replacement for travelling by car. However, there are a few disadvantages that would make them unsuitable for my needs:
Too heavy: can't just lift them up and carry them over railings, up steps, etc.
Too wide: only really suitable for roads, not for footpaths (sidewalks), narrow lanes, and even some bike tracks.
Too expensive: all the currently available velomobiles are really quite expensive. The go-one is one of the pricier ones, with a starting price of 9500 Euro (almost AUD$16,000!), but even the cheaper ones are at least AUD$5,000. Until velomobiles start to come down in price, there's no way that I could afford one.
Still hopeful
I've decided to stop searching for my dream enclosed bike - it looks like the velomobile is the closest I'm going to get to finding it. But who knows? Maybe I still haven't looked in the right places. I don't need something like a velomobile, which is pretty much a pedal-powered car. All I'm looking for is a simple waterproof bubble that can be fitted to a regular bike. I still believe that someone out there has made one. It's just a matter of finding him/her.
If any of you know of such a device, please, post a comment to this article letting me know about it. If I actually find one, I might even try it out!
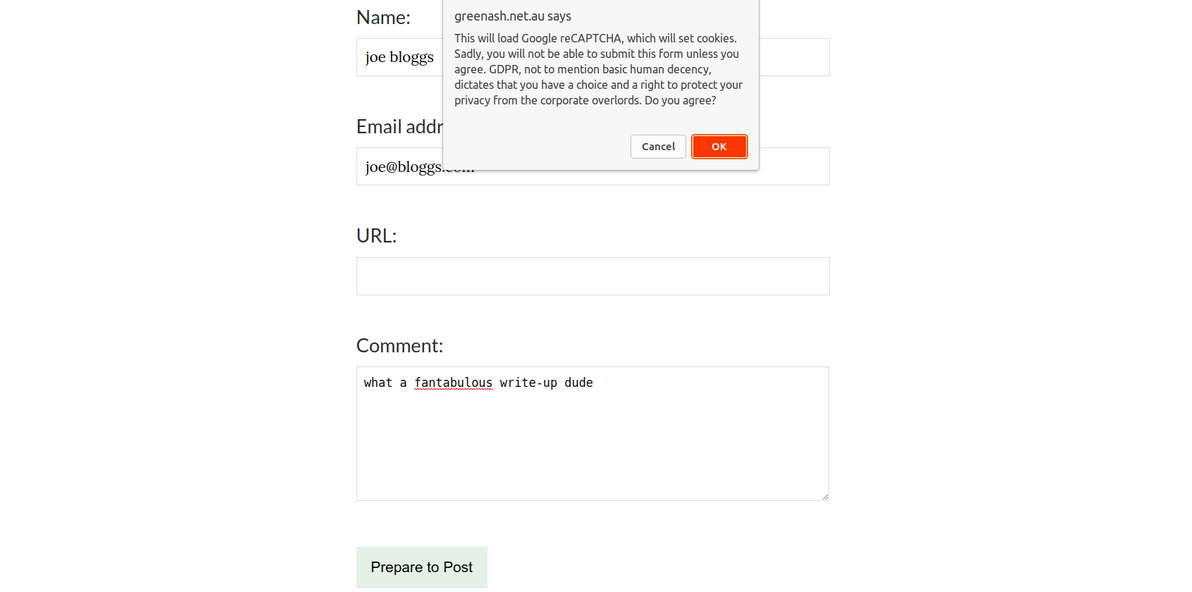
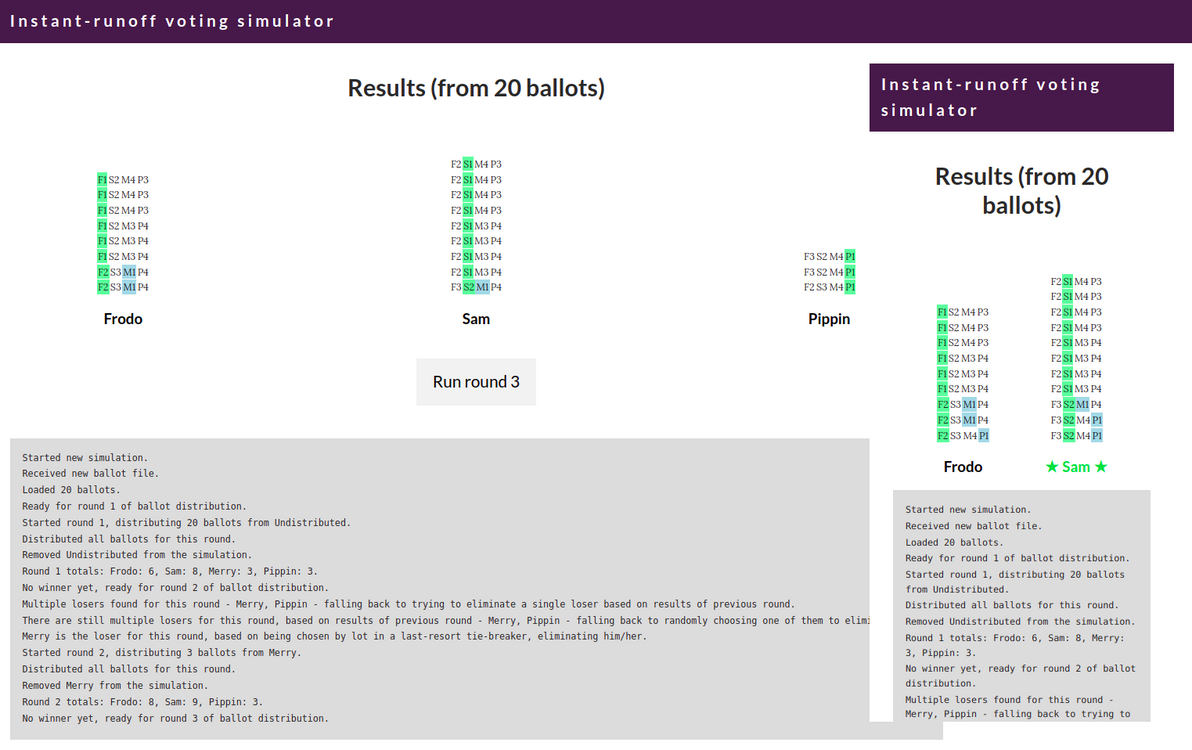
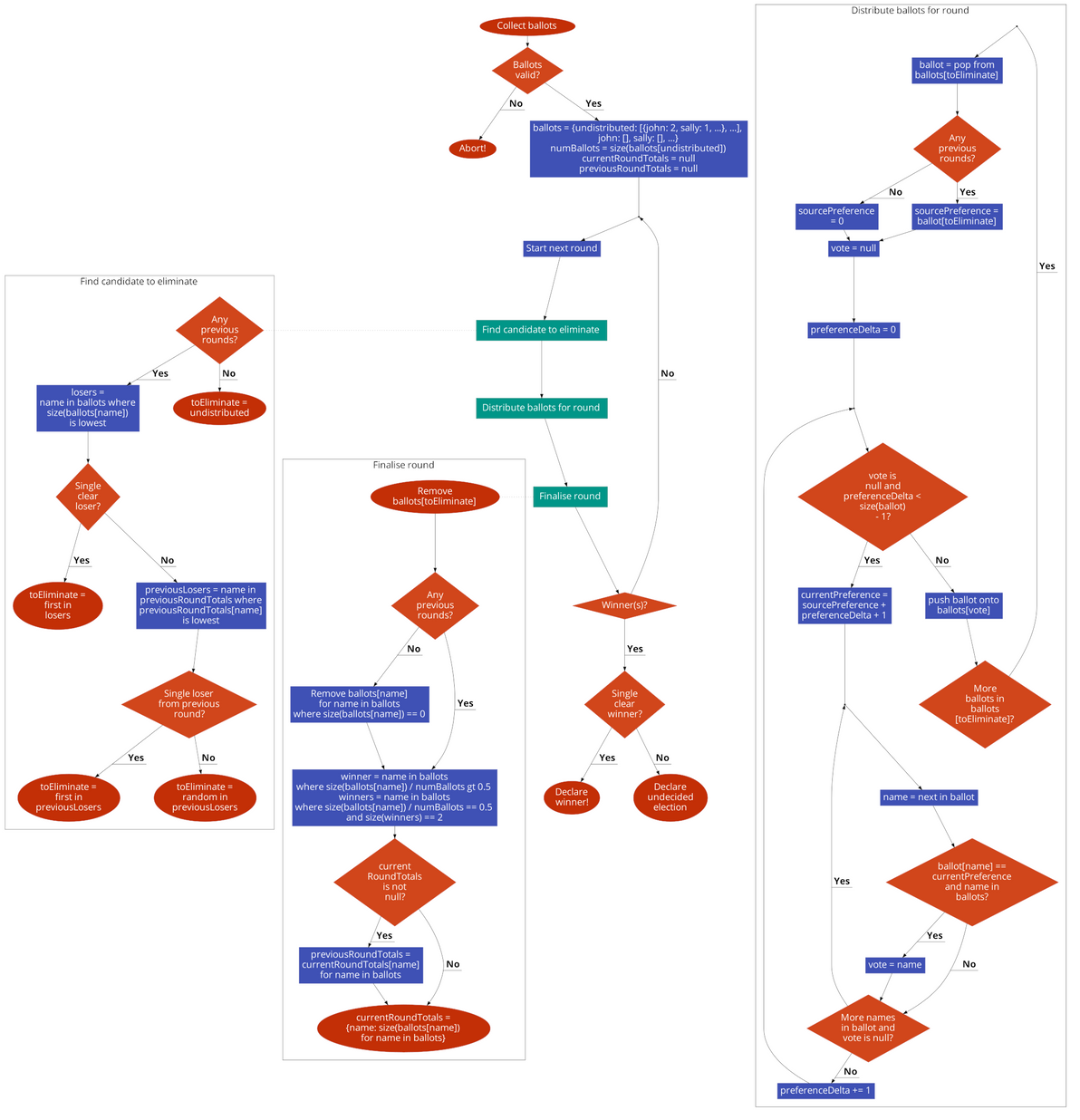








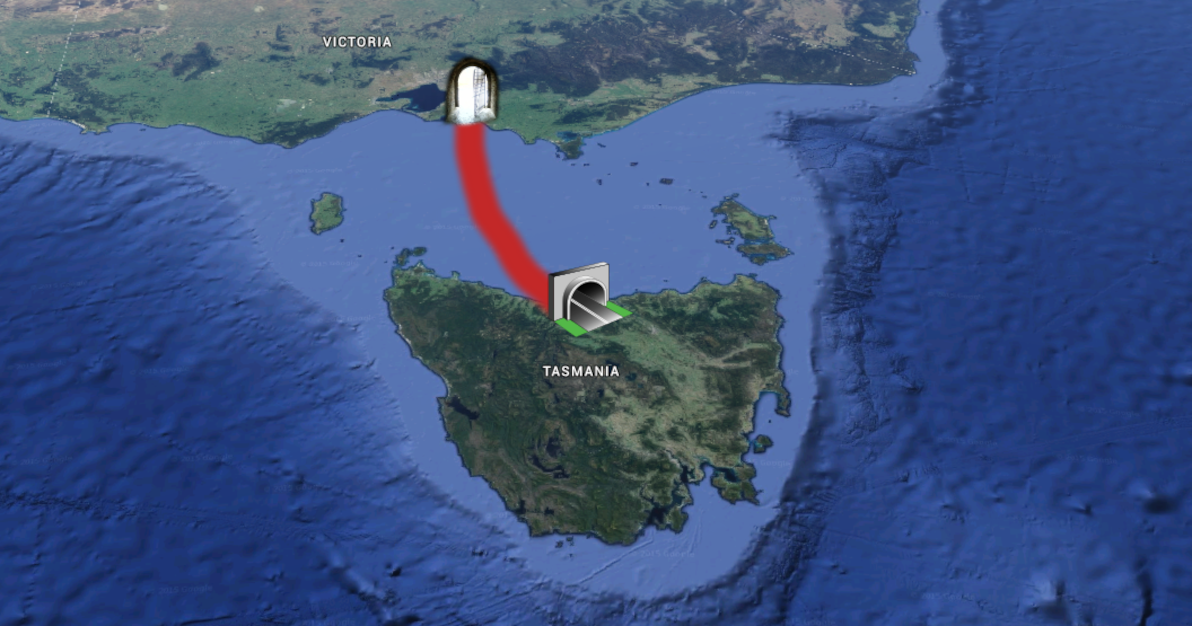




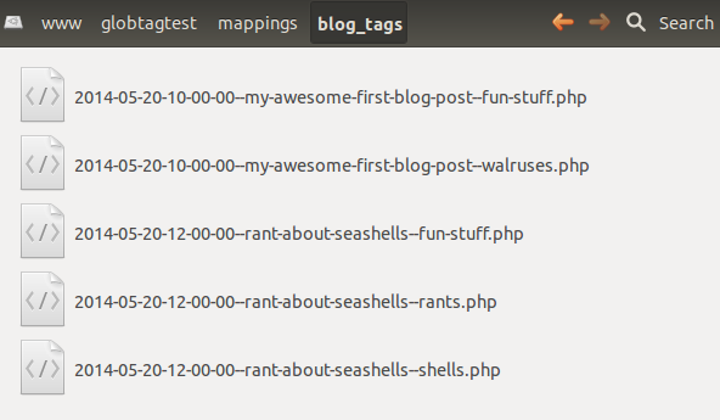
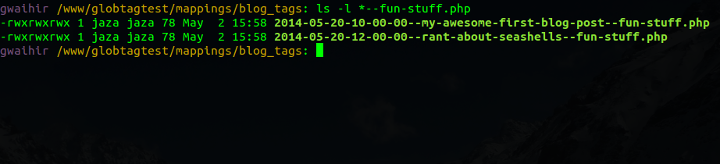

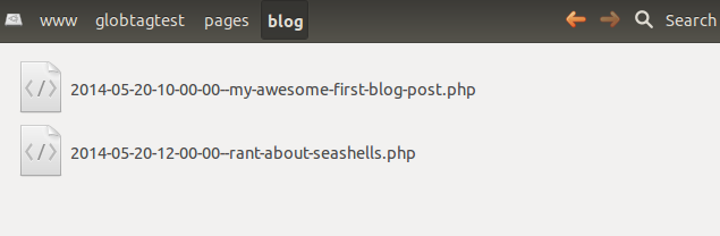



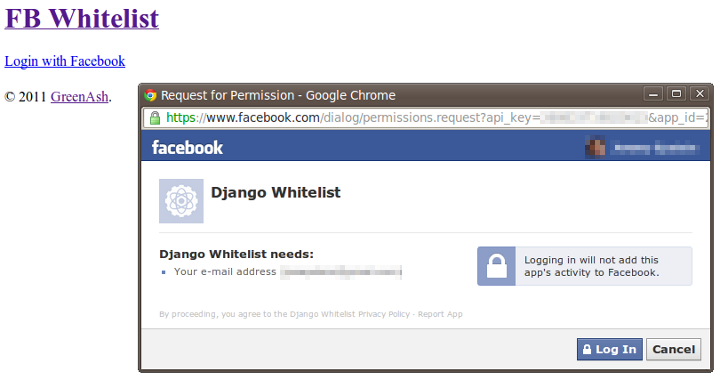
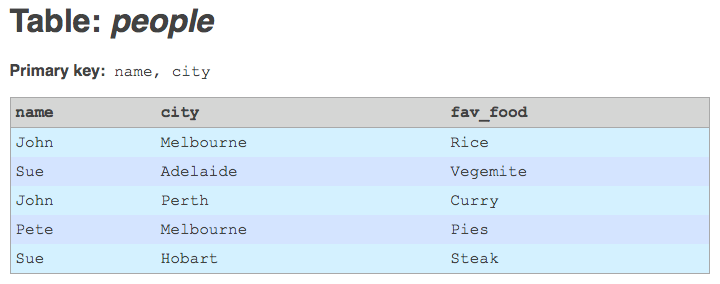
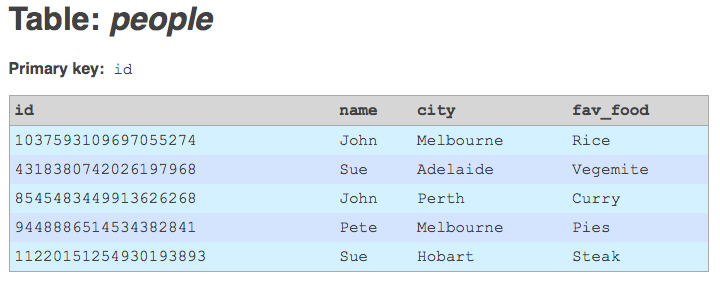




{kind=link}