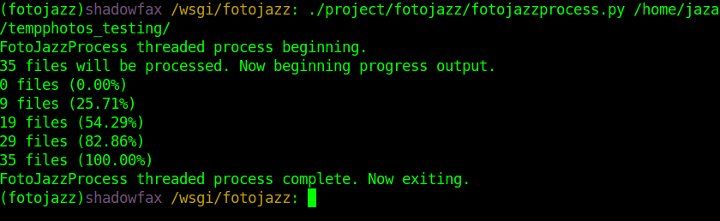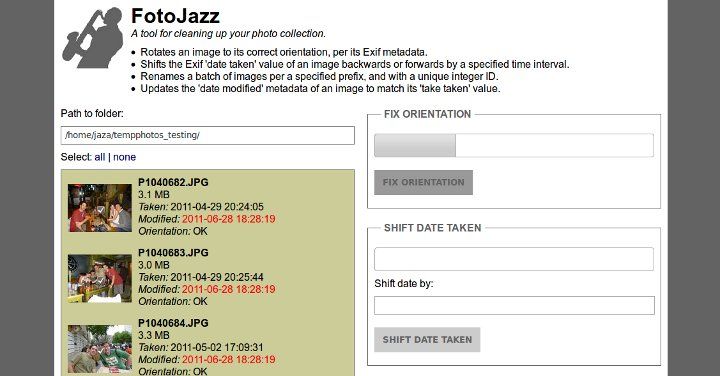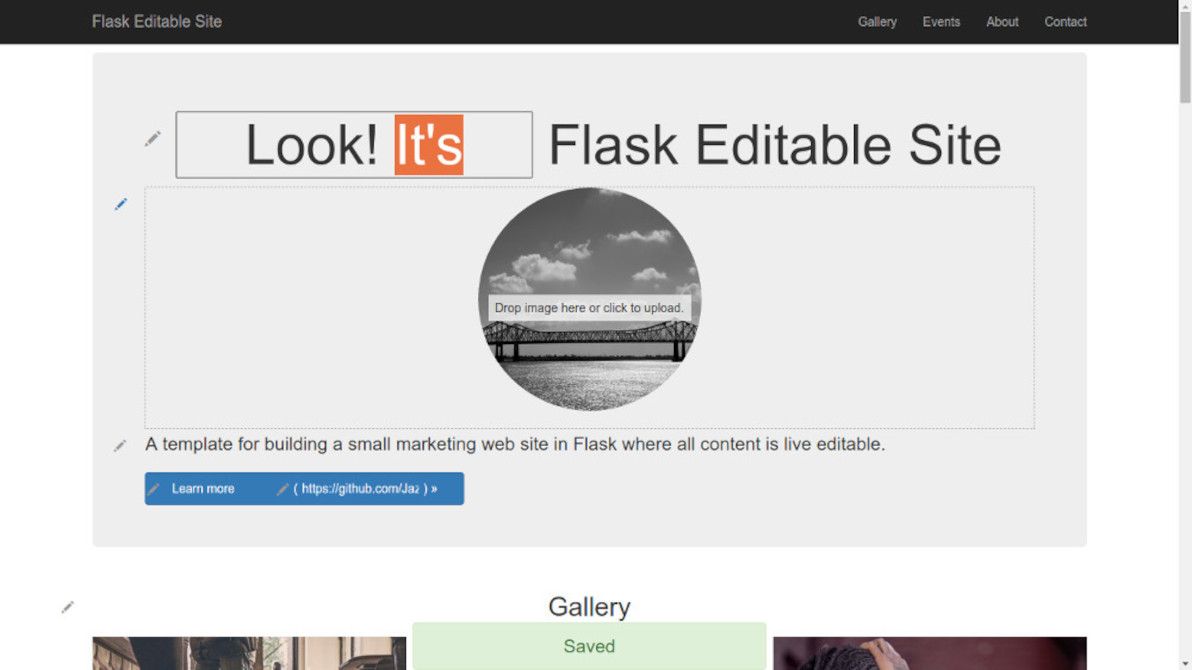
The aim of this app is to demonstrate that, with the help of modern JS libraries, and with some well-thought-out server-side snippets, it's now perfectly possible to "bake in" live in-place editing for virtually every content element in a typical brochureware site.
This app is not a CMS. On the contrary, think of it as a proof-of-concept alternative to a CMS. An alternative where there's no "admin area", there's no "editing mode", and there's no "preview button". There's only direct manipulation.
"Template" means that this is a sample app. It comes with a bunch of models that work out-of-the-box (e.g. text content block, image content block, gallery item, event). However, these are just a starting point: you can and should define your own models when building a real site. Same with the front-end templates: the home page layout and the CSS styles are just examples.
About that "template" idea
I can't stress enough that this is not a CMS. There are of course plenty of CMSes out there already, in Python and in every other language under the sun. Several of those CMSes I have used extensively. I've even been paid to build web sites with them, for most of my professional life so far. I desire neither to add to that list, nor to take on the heavy maintenance burden that doing so would entail.
What I have discovered as a web developer, and what I'm sure that all web developers discover sooner or later, is that there's no such thing as the perfect CMS. Possibly, there isn't even such thing as a good CMS! If you want to build a web site with a content management experience that's highly tailored to the project in question, then really, you have to build a unique custom CMS just for that site. Deride me as a perfectionist if you want, but that's my opinion.
There is such a thing as a good framework. Flask Editable Site, as its name suggests, uses the Flask framework, which has the glorious honour of being my favourite framework these days. And there is definitely such a thing as a good library. Flask Editable Site uses a number of both front-end and back-end libraries. The best libraries can be easily mashed up together in different configurations, on top of different frameworks, to help power a variety of different apps.
Flask Editable Site is not a CMS. It's a sample app, which is a template for building a unique CMS-like app tailor-made for a given project. If you're doing it right, then no two projects based on Flask Editable Site will be the same app. Every project has at least slightly different data models, users / permissions, custom forms, front-end widgets, and so on.
So, there's the practical aim of demonstrating direct manipulation / live editing. However, Flask Editable Site has a philosophical aim, too. The traditional "building a super one-size-fits-all app to power 90% of sites" approach isn't necessarily a good one. You inevitably end up fighting the super-app, and hacking around things to make it work for you. Instead, how about "building and sharing a template for making each site its own tailored app"? How about accepting that "every site is a hack", and embracing that instead of fighting it?
Thanks and acknowledgements
Thanks to all the libraries that Flask Editable Site uses; in each case, I tried to choose the best library available at the present time, for achieving a given purpose:
- Dante
contenteditableWYSIWYG editor, a Medium editor clone. I had previously used MediumEditor, and I recommend it too, but I feel that Dante gives a more polished out-of-the-box experience for now. I think the folks at Medium have done a great job in setting the bar high for beautiful rich-text editing, which is an important part of the admin experience for many web sites / apps. - Dropzone.js image upload widget. C'mon, people, it's 2015. Death to HTML file fields for uploads. Drag and drop with image preview, bring it on. From my limited research, Dropzone.js seems to be the clear leader of this pack at the moment.
- Bootstrap datetimepicker for calendar picker and hour/minute selector.
- Bootstrap 3 for pretty CSS styles and grid layouts. I admit I've become a bit of a Bootstrap addict lately. For developers with non-existent artistic ability, like myself, it's impossible to resist. Font Awesome is rather nice, too.
- Markovify for random text generation. I discovered this one (and several alternative implementations of it) while building Flask Editable Site, and I'm hooked. Adios, Lorem Ipsum, and don't hit the door on your way out.
- Bootstrap Freelancer theme by Start Bootstrap. Although Flask Editable Site uses vanilla Bootstrap, I borrowed various snippets of CSS / JS from this theme, as well as the overall layout.
- cookiecutter-flask, a Flask app template. I highly recommend this as a guide to best-practice directory layout, configuration management, and use of patterns in a Flask app. Thanks to these best practices, Flask Editable Site is also reasonably Twelve-Factor compliant, especially in terms of config and backing services.
Flask Editable Site began as the codebase for The Daydream Believers Performers web site, which I built pro-bono as a side project recently. So, acknowledgements to that group for helping to make Flask Editable Site happen.
For the live editing UX, I acknowledge that I drew inspiration from several examples. First and foremost, from Mezzanine, a CMS (based on Django) which I've used on occasion. Mezzanine puts "edit" buttons in-place next to most text fields on a site, and pops up a traditional (i.e. non contenteditable) WYSIWYG editor when these are clicked.
I also had a peek at Create.js, which takes care of the front-end side of live content editing quite similarly to the way I've cobbled it together. In Flask Editable Site, the combo of Dante editor and my custom "autosave" JS could easily be replaced with Create.js (particularly when using Hallo editor, which is quite minimalist like Dante); I guess it's just a question of personal taste.
Sir Trevor JS is an interesting new kid on the block. I'm quite impressed with Sir Trevor, but its philosophy of "adding blocks of anything down the page" isn't such a great fit for Flask Editable Site, where the idea is that site admins can only add / edit content within specific constraints for each block on the page. However, for sites with no structured content models, where it's OK for each page to be a free canvas (or for a "free canvas" within, say, each blog post on a site), I can see Sir Trevor being a real game-changer.
There's also X-editable, which is the only JS solution that I've come across for nice live editing of list-type content (i.e. checkoxes, radio buttons, tag fields, autocomplete boxes, etc). I haven't used X-editable in Flask Editable Site, because I'm mainly dealing with text and image fields (and for date / time fields, I prefer a proper calendar widget). But if I needed live editing of list fields, X-editable would be my first choice.
Final thoughts
I must stress that, as I said above, Flask Editable site is a proof-of-concept. It doesn't have all the features you're going to need for your project foo. In particular, it doesn't support very many field types: only text ("short text" and "rich text"), date, time, and image. It should also support inline images and (YouTube / Vimeo) videos out-of-the-box, as this is included with Dante, but I haven't tested it. For other field types, forks / pull requests / sister projects are welcome.
If you look at the code (particularly the settings.py file and the home view), you should be able to add live editing of new content models quite easily, with just a bit of copy-pasting and tweaking. The idea is that the editable.views code is generic enough, that you won't need to change it at all when adding new models / fields in your back-end. At least, that's the idea.
Quite a lot of the code in Flask Editable Site is more complex than it strictly needs to be, in order to support "session store mode", where all content is saved to the current user's session instead of to the database (preferably using something like Memcached or temp files, rather than cookies, although that depends on what settings you use). I developed "session store mode" in order to make the demo site work without requiring any hackery such as a scheduled DB refresh (which is the usual solution in such cases). However, I can see it also being useful for sandbox environments, for UAT, and for reviewing design / functionality changes without "real" content getting in the way.
The app also includes a fair bit of code for random generation and selection of sample text and image content. This was also done primarily for the purposes of the demo site. But, upon reflection, I think that a robust solution for randomly populating a site's content is really something that all CMS-like apps should consider more seriously. The exact algorithms and sample content pools for this, of course, are a matter of taste. But the point is that it's not just about pretty pictures and amusing Dickensian text. It's about the mindset of treating content dynamically, and of recognising the bounds and the parameters of each placeholder area on the page. And what better way to enforce that mindset, than by seeing a different random set of content every time you restart the app?
I decided to make this project a good opportunity for getting my hands dirty with thorough unit / functional testing. As such, Flask Editable Site is my first open-source effort that features automated testing via Travis CI, as well as test coverage reporting via Coveralls. As you can see on the GitHub page, tests are passing and coverage is pretty good. The tests are written in pytest, with significant help from webtest, too. I hope that the tests also serve as a template for other projects; all too often, with small brochureware sites, formal testing is done sparingly if at all.
Regarding the "no admin area" principle, Flask Editable Site has taken quite a purist approach to this. Personally, I think that radically reducing the role of "admin areas" in web site administration will lead to better UX. Anything that's publicly visible on the site, should be editable first and foremost via direct manipulation. However, in reality there will always be things that aren't publicly visible, and that admins still need to edit. For example, sites will always need user / role CRUD pages (unless you're happy to only manage users via shell commands). So, if you do add admin pages to a project based on Flask Editable Site, please don't feel as though you're breaking some golden rule.
Hope you enjoy playing around with the app. Who knows, maybe you'll even build something useful based on it. Feedback, bug reports, pull requests, all welcome.
]]>