drupal - GreenAshPoignant wit and hippie ramblings that are pertinent to drupalhttps://greenash.net.au/thoughts/topics/drupal/2014-04-24T00:00:00ZSharing templates between multiple Drupal views2014-04-24T00:00:00Z2014-04-24T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/04/sharing-templates-between-multiple-drupal-views/
Do you have multiple views on your Drupal site, where the content listing is themed to look exactly the same? For example, say you have a custom "search this site" view, a "featured articles" view, and an "articles archive" view. They all show the same fields — for example, "title", "image", and "summary". They all show the same content types – except that the first one shows "news" or "page" content, whereas the others only show "news".
If your design is sufficiently custom that you're writing theme-level Views template files, then chances are that you'll be in danger of creating duplicate templates. I've committed this sin on numerous sites over the past few years. On many occasions, my Views templates were 100% identical, and after making a change in one template, I literally copy-pasted and renamed the file, to update the other templates.
Until, finally, I decided that enough is enough – time to get DRY!
Being less repetitive with your Views templates is actually dead simple. Let's say you have three identical files – views-view-fields--search_this_site.tpl.php, views-view-fields--featured_articles.tpl.php, and views-view-fields--articles_archive.tpl.php. Here's how you clean up your act:
Delete the latter two files.
Add this to your theme's template.php file:
<?php
function mytheme_preprocess_views_view_fields(&$vars) {
if (in_array(
$vars['view']->name, array(
'search_this_site',
'featured_articles',
'articles_archive'))) {
$vars['theme_hook_suggestions'][] =
'views_view_fields__search_this_site';
}
}
Clear your cache (that being the customary final step when doing anything in Drupal, of course).
I've found that views-view-fields.tpl.php-based files are the biggest culprits for duplication; but you might have some other Views templates in need of cleaning up, too, such as:
<?php
function mytheme_preprocess_views_view(&$vars) {
if (in_array(
$vars['view']->name, array(
'search_this_site',
'featured_articles',
'articles_archive'))) {
$vars['theme_hook_suggestions'][] =
'views_view__search_this_site';
}
}
And, if your views include a search / filtering form, perhaps also:
<?php
function mytheme_preprocess_views_exposed_form(&$vars) {
if (in_array(
$vars['view']->name, array(
'search_this_site',
'featured_articles',
'articles_archive'))) {
$vars['theme_hook_suggestions'][] =
'views_exposed_form__search_this_site';
}
}
That's it – just a quick tip from me for today. You can find out more about this technique on the Custom Theme Hook Suggestions documentation page, although I couldn't find an example for Views there, nor anywhere else online for that matter; hence this article. Hopefully this results in a few kilobytes saved, and (more importantly) a lot of unnecessary copy-pasting of template files saved, for fellow Drupal devs and themers.
]]>
The cost of building a "perfect" custom Drupal installation profile2014-04-16T00:00:00Z2014-04-16T00:00:00ZJazahttps://greenash.net.au/thoughts/2014/04/the-cost-of-building-a-perfect-custom-drupal-installation-profile/
With virtually everything in Drupal, there are two ways to accomplish a task: The Easy Way, or The Right™ Way.
Deploying a new Drupal site for the first time is no exception. The Easy Way – and almost certainly the most common way – is to simply copy your local version of the database to production (or staging), along with user-uploaded files. (Your code needs to be deployed too, and The Right™ Way to deploy it is with version-control, which you're hopefully using… but that's another story.)
The Right™ Way to deploy a Drupal site for the first time (at least since Drupal 7, and "with hurdles" since Drupal 6), is to only deploy your code, and to reproduce your database (and ideally also user-uploaded files) with a custom installation profile, and also with significant help from the Features module.
The Right Way can be a deep rabbit hole, though. Image source:SIX Nutrition.
I've been churning out quite a lot of Drupal sites over the past few years, and I must admit, the vast majority of them were deployed The Easy Way. Small sites, single developer, quick turn-around. That's usually the way it rolls. However, I've done some work that's required custom installation profiles, and I've also been trying to embrace Features more; and so, for my most recent project – despite it being "yet another small-scale, one-dev site" – I decided to go the full hog, and to build it 100% The Right™ Way, just for kicks. In order to force myself to do things properly, I re-installed my dev site from scratch (and thus deleted my dev database) several times a day; i.e. I continuously tested my custom installation profile during dev.
Does it give me a warm fuzzy feeling, as a dev, to be able to install a perfect copy of a new site from scratch? Hell yeah. But does that warm fuzzy feeling come at a cost? Hell yeah.
What's involved
For our purposes, the contents of a typical Drupal database can be broken down into three components:
Critical configuration
Secondary configuration
Content
Critical configuration is: (a) stuff that should be set immediately upon site install, because important aspects of the site depend on it; and (b) stuff that cannot or should not be managed by Features. When building a custom installation profile, all critical configuration should be set with custom code that lives inside the profile itself, either in its hook_install() implementation, or in one of its hook_install_tasks() callbacks. The config in this category generally includes: the default theme and its config; the region/theme for key blocks; user roles, basic user permissions, and user variables; date formats; and text formats. This config isn't all that hard to write (see Drupal core's built-in installation profiles for good example code), and it shouldn't need much updating during dev.
Secondary configuration is: (a) stuff that can be set after the main install process has finished; and (b) stuff that's managed by Features. These days, thanks to various helpers such as Strongarm and Features Extra, there isn't much that can't be exported and managed in this way. All secondary configuration should be set in exportable definitions in Features-generated modules, which need to be added as dependencies in the installation profile's .info file. On my recent project, this included: many variables; content types; fields; blocks (including Block Class classes and block content); views; vocabularies; image styles; nodequeues; WYSIWYG profiles; and CER presets.
Secondary config isn't hard to write – in fact, it writes itself! However, it is a serious pain to maintain. Every time that you add or modify any piece of secondary content on your dev site, you need to perform the following workflow:
Does an appropriate feature module already exist for this config? If not, create a new feature module, export it to your site's codebase, and add the module as a dependency to the installation profile's .info file.
Is this config new? If so, manually add it to the relevant feature.
For all new or updated config: re-create the relevant feature module, thus re-exporting the config.
I found that I got in the habit of checking my site's Features admin page, before committing whatever code I was about to commit. I re-exported all features that were flagged with changes, and I tried to remember if there was any new config that needed to be added to a feature, before going ahead and making the commit. Because I decided to re-install my dev site from scratch regularly, and to scrap my local database, I had no choice but to take this seriously: if there was any config that I forgot to export, it simply got lost in the next re-install.
Content is stuff that is not config. Content depends on all critical and secondary config being set. And content is not managed by Features: it's managed by users, once the site is deployed. (Content can now be managed by Features, using the UUID module – but I haven't tried that approach, and I'm not particularly convinced that it's The Right™ Way.) On my recent project, content included: nodes (of course); taxonomy terms; menu items; and nodequeue mappings.
An important part of handing over a presentable site to the client, in my experience, is that there's at least some demo / structural content in place. So, in order to handle content in my "continuously installable" setup, I wrote a bunch of custom Drush commands, which defined all the content in raw PHP using arrays / objects, and which imported all the content using Drupal's standard API functions (i.e. node_save() and friends). This also included user-uploaded files (i.e. images and documents): I dumped all these into a directory outside of my Drupal root, and imported them using the Field API and some raw file-copying snippets.
All rosy?
The upside of it all: I lived the dream on this project. I freed myself from database state. Everything I'd built was safe and secure within the code repo, and the only thing that needed to be deployed to staging / production was the code itself.
Join me, comrades! Join me and all Drupal sites will be equal! (But some more equal than others).
(Re-)installing the site consisted of little more than running (something similar to) these Drush commands:
drush cc all
drush site-install --yes mycustomprofile --account-mail=info@blaaaaaaaa.com --account-name=admin --account-pass=blaaaaaaa
drush features-revert-all --yes
drush mymodule-install-content
The downside of it: constantly maintaining exported features and content-in-code eats up a lot of time. As a rough estimate, I'd say that it resulted in me spending about 30% more time on the project than I would have otherwise. Fortunately, the project was still delivered ahead of schedule and under budget; had constraints been tighter, I probably couldn't have afforded the luxury of this experiment.
Unfortunately, Drupal just isn't designed to store either configuration or content in code. Doing either is an uphill battle. Maintaining all config and content in code was virtually impossible in Drupal 5 and earlier; it had numerous hurdles in Drupal 6; and it's possible (and recommended) but tedious in Drupal 7. Drupal 8 – despite the enormous strides forward that it's making with the Configuration Management Initiative (CMI) – will still, at the end of the day, treat the database rather than code as the "source of truth" for config. Therefore, I assert that, although it will be easier than ever to manage all config in code, the "configuration management" and "continuous deployment" problems still won't be completely solved in Drupal 8.
I've been working increasingly with Django over the past few years, where configuration only exists in code (in Python settings, in model classes, in view callables, etc), and where only content exists in the database (and where content has also been easily exportable / deployable using fixtures, since before Drupal "exportables" were invented); and in that world, these are problems that simply don't exist. There's no need to ever synchronise between the "database version" of config and the "code version" of config. Unfortunately, Drupal will probably never reach this Zen-like ideal, because it seems unlikely that Drupal will ever let go of the database as a config store altogether.
Anyway, despite the fact that a "perfect" installation profile probably isn't justifiable for most smaller Drupal projects, I think that it's still worthwhile, in the same way that writing proper update scripts is still worthwhile: i.e. because it significantly improves quality; and because it's an excellent learning tool for you as a developer.
]]>
Show a video's duration with Media: YouTube and Computed Field2013-03-28T00:00:00Z2013-03-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2013/03/show-a-videos-duration-with-media-youtube-and-computed-field/
I build quite a few Drupal sites that use embedded YouTube videos, and my module of choice for handling this is Media: YouTube, which is built upon the popular Media module. The Media: YouTube module generally works great; but on one site that I recently built, I discovered one of its shortcomings. It doesn't let you display a YouTube video's duration.
I thought up a quick, performant and relatively easy way to solve this. With just a few snippets of custom code, and the help of the Computed Field module, showing video duration (in hours / minutes / seconds) for a Media: YouTube managed asset, is a walk in the park.
Getting set up
First up, install the Media: YouTube module (and its dependent modules) on a Drupal 7 site of your choice. Then, add a YouTube video field to one of the site's content types. For this example, I added a field called 'Video' (field_video) to my content type 'Page' (page). Be sure to select a 'field type' of 'File', and a 'widget' of type 'Media file selector'. In the field settings, set 'Allowed remote media types' to just 'Video', and set 'Allowed URI schemes' to just 'youtube://'.
To configure video display, go to 'Administration > Configuration > Media > File types' in your site admin, and for 'Video', click on 'manage file display'. You should be on the 'default' tab. For 'Enabled displays', enable just 'YouTube Video'. Customise the other display settings to your tastes.
Add a YouTube video to one of your site's pages. For this example, I've chosen one of the many clips highlighting YouTube's role as the zenith of modern society's intellectual capacity: a dancing duck.
To show the video within your site's theme, open up your theme's template.php file, and add the following preprocess function (in this example, my theme is called foobar):
And add the following snippet to your node.tpl.php file or equivalent (in my case, I added it to my node--page.tpl.php file):
<!-- template stuff bla bla bla -->
<?php if (!empty($video)): ?>
<?php print $video; ?>
<?php endif; ?>
<!-- more template stuff bla bla bla -->
The duck should now be dancing for you:
Embrace The Duck.
Getting the duration
On most sites, you won't have any need to retrieve and display the video's duration by itself. As you can see, the embedded YouTube element shows the duration pretty clearly, and that's adequate for most use cases. However, if your client wants the duration shown elsewhere (other than within the embedded video area), or if you're just in the mood for putting the duration between a spantabulously vomitive pair of <font color="pink"><blink>2:48</blink></font> tags, then keep reading.
Unfortunately, the Media: YouTube module doesn't provide any functionality whatsoever for getting a video's duration (or much other video metadata, for that matter). But, have no fear, it turns out that a quick code snippet for querying a YouTube video's duration, based on video ID, is pretty quick and painless in bare-bones PHP. Add this to a custom module on your site (in my case, I added it to my foobar_page.module):
<?php
/**
* Gets a YouTube video's duration, based on video ID.
*
* Copied (almost exactly) from:
* http://stackoverflow.com/questions/9167442/
* get-duration-from-a-youtube-url/9167754#9167754
*
* @param $video_id
* YouTube video ID.
*
* @return
* Video duration (or FALSE on failure).
*/
function foobar_page_get_youtube_video_duration($video_id) {
$data = @file_get_contents('http://gdata.youtube.com/feeds/api/videos/'
. $video_id . '?v=2&alt=jsonc');
if ($data === FALSE) {
return FALSE;
}
$obj = json_decode($data);
return $obj->data->duration;
}
Great – turns out that querying the YouTube API for the duration is very easy. But we don't want to perform an external HTTP request, every time we want to display a video's duration: that would be a potential performance issue (and, in the event that YouTube is slow or unavailable, it would completely hang the page loading process). What we should do instead, is only query the duration from YouTube when we save a node (or other entity), and then store the duration locally for easy retrieval later.
Storing the duration
There are a number of possibilities, for how to store this data. Using Drupal's variable_get() and variable_set() functionality is one option (with either one variable per duration value, or with all duration values stored in a single serialized variable). However, that has numerous disadvantages: it would negatively affect performance (both for retrieving duration values, and for the whole Drupal site); and, at the end of the day, it's an abuse of the Drupal variable system, which is only meant to be used for one-off values, not for values that are potentially set for every node on your site (sadly, it would be far from the first such case of abuse of the Drupal variable system – but the fact that other people / other modules do it, doesn't make it any less dodgy).
Patching the Media: YouTube module to have an extra database field for video duration, and making the module retrieve and store this value, would be another option. However, that would be a lot more work and a lot more code; it would also mean having a hacked version of the module, until (if and when) a patch for the module (that we'd have to submit and refine) gets committed on drupal.org. Plus, it would mean learning a whole lot more about the Field API, the Media module, and the File API than any sane person would care to subject his/her self to.
Enter the Computed Field module. With the help of this handy module, we have the possibility of implementing a better, faster, nicer solution.
Add this to a custom module on your site (in my case, I added it to my foobar_page.module):
Next, install the Computed Field module on your Drupal site. Add a new field to your content type, called 'Video duration' (field_video_duration), with 'field type' and 'widget' of type 'Computed'. On the settings page for this field, you should see the message: "This field is COMPUTED using computed_field_field_video_duration_compute()". In the 'database storage settings', ensure that 'Data type' is 'text', and that 'Data length' is '255'. You can leave all other settings for this field at their defaults.
Re-save the node that has YouTube video content, in order to retrieve and save the new computed field value for the duration.
Displaying the duration
For the formatting of the duration (the raw value of which is stored in seconds), in hours:minutes:seconds format, here's a dodgy custom function that I whipped up. Use it, or don't – totally your choice. If you choose to use, then add this to a custom module on your site:
<?php
/**
* Formats the given time value in h:mm:ss format (if it's >= 1 hour),
* or in mm:ss format (if it's < 1 hour).
*
* Based on Drupal's format_interval() function.
*
* @param $interval
* Time interval (in seconds).
*
* @return
* Formatted time value.
*/
function foobar_page_format_time_interval($interval) {
$units = array(
array('format' => '%d', 'value' => 3600),
array('format' => '%d', 'value' => 60),
array('format' => '%02d', 'value' => 1),
);
$granularity = count($units);
$output = '';
$has_value = FALSE;
$i = 0;
foreach ($units as $unit) {
$format = $unit['format'];
$value = $unit['value'];
$new_val = floor($interval / $value);
$new_val_formatted = ($output !== '' ? ':' : '') .
sprintf($format, $new_val);
if ((!$new_val && $i) || $new_val) {
$output .= $new_val_formatted;
if ($new_val) {
$has_value = TRUE;
}
}
if ($interval >= $value && $has_value) {
$interval %= $value;
}
$granularity--;
$i++;
if ($granularity == 0) {
break;
}
}
return $output ? $output : '0:00';
}
Update your mytheme_preprocess_node() function, with some extra code for making the formatted video duration available in your node template:
<?php
/**
* Preprocessor for node.tpl.php template file.
*/
function foobar_preprocess_node(&$vars) {
if ($vars['node']->type == 'page' &&
!empty($vars['node']->field_video['und'][0]['fid'])) {
$video_file = file_load($vars['node']->field_video['und'][0]['fid']);
$vf = file_view_file($video_file, 'default', '');
$vars['video'] = drupal_render($vf);
if (!empty($vars['node']->field_video_duration['und'][0]['value'])) {
$vars['video_duration'] = foobar_page_format_time_interval(
$vars['node']->field_video_duration['und'][0]['value']);
}
}
}
Finally, update your node.tpl.php file or equivalent:
<!-- template stuff bla bla bla -->
<?php if (!empty($video)): ?>
<?php print $video; ?>
<?php endif; ?>
<?php if (!empty($video_duration)): ?>
<p><strong>Duration:</strong> <?php print $video_duration; ?></p>
<?php endif; ?>
<!-- more template stuff bla bla bla -->
Reload the page on your site, and lo and behold:
We have duration!
Final remarks
I hope this example comes in handy, for anyone else who needs to display YouTube video duration metadata in this way.
I'd also like to strongly note, that what I've demonstrated here isn't solely applicable to this specific use case. With some modification, it could easily be applied to various different related use cases. Other than duration, you could retrieve / store / display any of the other metadata fields available via the YouTube API (e.g. date video uploaded, video category, number of comments). Or, you could work with media from another source, using another Drupal media-enabled module (e.g. Media: Vimeo). Or, you could store externally-queried data for some completely different field. I encourage you to experiment and to use your imagination, when it comes to the Computed Field module. The possibilities are endless.
]]>
Rendering a Silex (Symfony2) app via Drupal 72013-01-25T00:00:00Z2013-01-25T00:00:00ZJazahttps://greenash.net.au/thoughts/2013/01/rendering-a-silex-symfony2-app-via-drupal-7/
There's been a lot of talk recently regarding the integration of the Symfony2 components, as a fundamental part of Drupal 8's core system. I won't rabble on repeating the many things that have already been said elsewhere; however, to quote the great Bogeyman himself, let me just say that "I think this is the beginning of a beautiful friendship".
On a project I'm currently working on, I decided to try out something of a related flavour. I built a stand-alone app in Silex (a sort of Symfony2 distribution); but, per the project's requirements, I also managed to heavily integrate the app with an existing Drupal 7 site. The app does almost everything on its own, except that: it passes its output to drupal_render_page() before returning the request; and it checks that a Drupal user is currently logged-in and has a certain Drupal user role, for pages where authorisation is required.
The result is: an app that has its own custom database, its own routes, its own forms, its own business logic, and its own templates; but that gets rendered via the Drupal theming system, and that relies on Drupal data for authentication and authorisation. What's more, the implementation is quite clean (minimal hackery involved) – only a small amount of code is needed for the integration, and then (for the most part) Drupal and Silex leave each other alone to get on with their respective jobs. Now, let me show you how it's done.
Drupal setup
To start with, set up a new bare-bones Drupal 7 site. I won't go into the details of Drupal installation here. If you need help with setting up a local Apache VirtualHost, editing your /etc/hosts file, setting up a MySQL database / user, launching the Drupal installer, etc, please refer to the Drupal installation guide. For this guide, I'll be using a Drupal 7 instance that's been installed to the /www/d7silextest directory on my local machine, and that can be accessed via http://d7silextest.local.
D7 Silex test site after initial setup.
Once you've got that (or something similar) up and running, and if you're keen to follow along, then keep up with me as I outline further Drupal config steps. Firstly, go to administration > people > permissions > roles, create a new role called 'administrator' (if it doesn't exist already). Then, assign the role to user 1.
Next, download the patches from Need DRUPAL_ROOT in include of template.php and Need DRUPAL_ROOT when rendering CSS include links, and apply them to your Drupal codebase. Note: these are some bugs in core, where certain PHP files are being included without properly appending the DRUPAL_ROOT prefix. As of writing, I've submitted these patches to drupal.org, but they haven't yet been committed. Please check the status of these issue threads – if they're now resolved, then you may not need to apply the patches (check exactly which version of Drupal you're using, as of Drupal 7.19 the patches are still needed).
If you're using additional Drupal contrib or custom modules, they may also have similar bugs. For example, I've also submitted Need DRUPAL_ROOT in require of include files for the Revisioning module (not yet committed as of writing), and Need DRUPAL_ROOT in require of og.field.inc for the Organic Groups module (now committed and applied in latest stable release of OG). If you find any more DRUPAL_ROOT bugs, that prevent an external script such as Symfony2 from utilising Drupal from within a subdirectory, then please patch these bugs yourself, and submit patches to drupal.org as I've done.
Enable the menu module (if it's not already enabled), and define a 'Page' content type (if not already defined). Create a new 'Page' node (in my config below, I assume that it's node 1), with a menu item (e.g. in 'main menu'). Your new test page should look something like this:
D7 Silex test site with test page.
That's sufficient Drupal configuration for the purposes of our example. Now, let's move on to Silex.
Silex setup
To start setting up your example Silex site, create a new directory, which is outside of your Drupal site's directory tree. In this article, I'm assuming that the Silex directory is at /www/silexd7test. Within this directory, create a composer.json file with the following:
Get Composer (if you don't have it), by executing this command:
curl -s http://getcomposer.org/installer | php
Once you've got Composer, installing Silex is very easy, just execute this command from your Silex directory:
php composer.phar install
Next, create a new directory called web in your silex root directory; and create a file called web/index.php, that looks like this:
<?php
/**
* @file
* The PHP page that serves all page requests on a Silex installation.
*/
require_once __DIR__ . '/../vendor/autoload.php';
$app = new Silex\Application();
$app['debug'] = TRUE;
$app->get('/', function() use($app) {
return '<p>You should see this outputting ' .
'within your Drupal site!</p>';
});
$app->run();
That's a very basic Silex app ready to go. The app just defines one route (the 'home page' route), which outputs the text You should see this outputting within your Drupal site! on request. The Silex app that I actually built and integrated with Drupal did a whole more of this – but for the purposes of this article, a "Hello World" example is all we need.
To see this app in action, in your Drupal root directory create a symlink to the Silex web folder:
ln -s /www/silexd7test/web/ silexd7test
Now you can go to http://d7silextest.local/silexd7test/, and you should see something like this:
Silex serving requests stand-alone, under Drupal web path.
So far, the app is running under the Drupal web path, but it isn't integrated with the Drupal site at all. It's just running its own bootstrap code, and outputting the response for the requested route without any outside help. We'll be changing that shortly.
Integration
Open up the web/index.php file again, and change it to look like this:
<?php
/**
* @file
* The PHP page that serves all page requests on a Silex installation.
*/
require_once __DIR__ . '/../vendor/autoload.php';
$app = new Silex\Application();
$app['debug'] = TRUE;
$app['drupal_root'] = '/www/d7silextest';
$app['drupal_base_url'] = 'http://d7silextest.local';
$app['is_embedded_in_drupal'] = TRUE;
$app['drupal_menu_active_item'] = 'node/1';
/**
* Bootstraps Drupal using DRUPAL_ROOT and $base_url values from
* this app's config. Bootstraps to a sufficient level to allow
* session / user data to be accessed, and for theme rendering to
* be invoked..
*
* @param $app
* Silex application object.
* @param $level
* Level to bootstrap Drupal to. If not provided, defaults to
* DRUPAL_BOOTSTRAP_FULL.
*/
function silex_bootstrap_drupal($app, $level = NULL) {
global $base_url;
// Check that Drupal bootstrap config settings can be found.
// If not, throw an exception.
if (empty($app['drupal_root'])) {
throw new \Exception("Missing setting 'drupal_root' in config");
}
elseif (empty($app['drupal_base_url'])) {
throw new \Exception("Missing setting 'drupal_base_url' in config");
}
// Set values necessary for Drupal bootstrap from external script.
// See:
// http://www.csdesignco.com/content/using-drupal-data-functions-
// and-session-variables-external-php-script
define('DRUPAL_ROOT', $app['drupal_root']);
$base_url = $app['drupal_base_url'];
// Bootstrap Drupal.
require_once DRUPAL_ROOT . '/includes/bootstrap.inc';
if (is_null($level)) {
$level = DRUPAL_BOOTSTRAP_FULL;
}
drupal_bootstrap($level);
if ($level == DRUPAL_BOOTSTRAP_FULL &&
!empty($app['drupal_menu_active_item'])) {
menu_set_active_item($app['drupal_menu_active_item']);
}
}
/**
* Checks that an authenticated and non-blocked Drupal user is tied to
* the current session. If not, deny access for this request.
*
* @param $app
* Silex application object.
*/
function silex_limit_access_to_authenticated_users($app) {
global $user;
if (empty($user->uid)) {
$app->abort(403, 'You must be logged in to access this page.');
}
if (empty($user->status)) {
$app->abort(403, 'You must have an active account in order to ' .
'access this page.');
}
if (empty($user->name)) {
$app->abort(403, 'Your session must be tied to a username to ' .
'access this page.');
}
}
/**
* Checks that the current user is a Drupal admin (with 'administrator'
* role). If not, deny access for this request.
*
* @param $app
* Silex application object.
*/
function silex_limit_access_to_admin($app) {
global $user;
if (!in_array('administrator', $user->roles)) {
$app->abort(403,
'You must be an administrator to access this page.');
}
}
$app->get('/', function() use($app) {
silex_bootstrap_drupal($app);
silex_limit_access_to_authenticated_users($app);
silex_limit_access_to_admin($app);
$ret = '<p>You should see this outputting within your ' .
'Drupal site!</p>';
return !empty($app['is_embedded_in_drupal']) ?
drupal_render_page($ret) :
$ret;
});
$app->run();
A number of things have been added to the code in this file, so let's examine them one-by-one. First of all, some Drupal-related settings have been added to the Silex $app object. The drupal_root and drupal_base_url settings, are the critical ones that are needed in order to bootstrap Drupal from within Silex. Because the Silex script is in a different filesystem path from the Drupal site, and because it's also being served from a different URL path, these need to be manually set and passed on to Drupal.
The is_embedded_in_drupal setting allows the rendering of the page via drupal_render_page() to be toggled on or off. The script could work fine without this, and with rendering via drupal_render_page() hard-coded to always occur; allowing it to be toggled is just a bit more elegant. The drupal_menu_active_item setting, when set, triggers the Drupal menu path to be set to the path specified (via menu_set_active_item()).
The route handler for our 'home page' path now calls three functions, before going on to render the page. The first one, silex_bootstrap_drupal(), is pretty self-explanatory. The second one, silex_limit_access_to_authenticated_users(), checks the Drupal global $user object to ensure that the current user is logged-in, and if not, it throws an exception. Similarly, silex_limit_access_to_admin() checks that the current user has the 'administrator' role (with failure resulting in an exception).
To test the authorisation checks that are now in place, log out of the Drupal site, and visit the Silex 'front page' at http://d7silextest.local/silexd7test/. You should see something like this:
Silex denying access to a page because Drupal user is logged out
The drupal_render_page() function is usually – in the case of a Drupal menu callback – passed a callback (a function name as a string), and rendering is then delegated to that callback. However, it also accepts an output string as its first argument; in this case, the passed-in string is outputted directly as the content of the 'main page content' Drupal block. Following that, all other block regions are assembled, and the full Drupal page is themed for output, business as usual.
To see the Silex 'front page' fully rendered, and without any 'access denied' message, log in to the Drupal site, and visit http://d7silextest.local/silexd7test/ again. You should now see something like this:
Silex serving output that's been passed through drupal_render_page().
And that's it – a Silex callback, with Drupal theming and Drupal access control!
Final remarks
The example I've walked through in this article, is a simplified version of what I implemented for my recent real-life project. Some important things that I modified, for the purposes of keeping this article quick 'n' dirty:
Changed the route handler and Drupal bootstrap / access-control functions, from being methods in a Silex Controller class (implementing Silex\ControllerProviderInterface) in a separate file, to being functions in the main index.php file
Changed the config values, from being stored in a JSON file and loaded via Igorw\Silex\ConfigServiceProvider, to being hard-coded into the $app object in raw PHP
Took out logging for the app via Silex\Provider\MonologServiceProvider
My real-life project is also significantly more than just a single "Hello World" route handler. It defines its own custom database, which it accesses via Doctrine's DBAL and ORM components. It uses Twig templates for all output. It makes heavy use of Symfony2's Form component. And it includes a number of custom command-line scripts, which are implemented using Symfony2's Console component. However, most of that is standard Silex / Symfony2 stuff which is not so noteworthy; and it's also not necessary for the purposes of this article.
I should also note that although this article is focused on Symfony2 / Silex, the example I've walked through here could be applied to any other PHP script that you might want to integrate with Drupal 7 in a similar way (as long as the PHP framework / script in question doesn't conflict with Drupal's function or variable names). However, it does make particularly good sense to integrate Symfony2 / Silex with Drupal 7 in this way, because: (a) Symfony2 components are going to be the foundation of Drupal 8 anyway; and (b) Symfony2 components are the latest and greatest components available for PHP right now, so the more projects you're able to use them in, the better.
]]>
Batch updating Drupal 7 field data2012-11-08T00:00:00Z2012-11-08T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/11/batch-updating-drupal-7-field-data/
On a number of my recently-built Drupal sites, I've become a fan of using the Computed Field module to provide a "search data" field, as a Views exposed filter. This technique has been documented by other folks here and there (I didn't invent it), so I won't cover its details here. Basically, it's a handy way to create a search form that searches exactly the fields you're interested in, thus providing you with more fine-grained control than the core Drupal search module, and with much less installation / configuration overhead than Apache Solr.
On one such site, which has about 4,000+ nodes that are searchable via this technique, I needed to add another field to the index, and re-generate the Computed Field data for every node. This data normally only gets re-generated when each individual node is saved. In my case, that would not be sufficient - I needed the entire search index refreshed immediately.
The obvious solution, would be to whip up a quick script that loops through all the nodes in question, and that calls node_save() on each pass through the loop. However, this solution has two problems. Firstly, node_save() is really slow (particularly when the node has a lot of other fields, such as was my case). So slow, in fact, that in my case I was fighting a losing battle against PHP "maximum execution time exceeded" errors. Secondly, node_save() is slow unnecessarily, as it re-saves all the data for all a node's fields (plus it invokes a bazingaful of hooks), whereas we only actually need to re-save the data for one field (and we don't need any hooks invoked, thanks).
In the interests of both speed and cutting-out-the-cruft, therefore, I present here an alternative solution: getting rid of the middle man (node_save()), and instead invoking the field_storage_write callback directly. Added bonus: I've implemented it using the Batch API functionality available via Drupal 7's hook_update_N().
Show me the code
The below code uses a (pre-defined) Computed field called field_search_data, and processes nodes of type event, news or page. It also sets the limit per batch run to 50 nodes. Naturally, all of this should be modified per your site's setup, when borrowing the code.
<?php
/**
* Batch update computed field values for 'field_search_data'.
*/
function mymodule_update_7000(&$sandbox) {
$entity_type = 'node';
$field_name = 'field_search_data';
$langcode = 'und';
$storage_module = 'field_sql_storage';
$field_id = db_query('SELECT id FROM {field_config} WHERE ' .
'field_name = :field_name', array(
':field_name' => $field_name
))->fetchField();
$field = field_info_field($field_name);
$types = array(
'event',
'news',
'page',
);
// Go through all published nodes in all of the above node types,
// and generate a new 'search_data' computed value.
$instance = field_info_instance($entity_type,
$field_name,
$bundle_name);
if (!isset($sandbox['progress'])) {
$sandbox['progress'] = 0;
$sandbox['last_nid_processed'] = -1;
$sandbox['max'] = db_query('SELECT COUNT(*) FROM {node} WHERE ' .
'type IN (:types) AND status = 1 ORDER BY nid', array(
':types' => $types
))->fetchField();
// I chose to delete existing data for this field, so I can
// clearly monitor in phpMyAdmin the field data being re-generated.
// Not necessary to do this.
// NOTE: do not do this if you have actual important data in
// this field! In my case it's just a search index, so it's OK.
// May not be so cool in your case.
db_query('TRUNCATE TABLE {field_data_' . $field_name . '}');
db_query('TRUNCATE TABLE {field_revision_' . $field_name . '}');
}
$limit = 50;
$result = db_query_range('SELECT nid FROM {node} WHERE ' .
'type IN (:types) AND status = 1 AND nid > :lastnid ORDER BY nid',
0, $limit, array(
':types' => $types,
':lastnid' => $sandbox['last_nid_processed']
));
while ($nid = $result->fetchField()) {
$entity = node_load($nid);
if (!empty($entity->nid)) {
$items = isset($entity->{$field_name}[$langcode]) ?
$entity->{$field_name}[$langcode] :
array();
_computed_field_compute_value($entity_type, $entity, $field,
$instance, $langcode, $items);
if ($items !== array() ||
isset($entity->{$field_name}[$langcode])) {
$entity->{$field_name}[$langcode] = $items;
// This only writes the data for the single field we're
// interested in to the database. Much less expensive than
// the easier alternative, which would be to node_save()
// every node.
module_invoke($storage_module, 'field_storage_write',
$entity_type, $entity, FIELD_STORAGE_UPDATE,
array($field_id));
}
}
$sandbox['progress']++;
$sandbox['last_nid_processed'] = $nid;
}
if (empty($sandbox['max'])) {
$sandbox['#finished'] = 1.0;
}
else {
$sandbox['#finished'] = $sandbox['progress'] / $sandbox['max'];
}
if ($sandbox['#finished'] == 1.0) {
return t('Updated \'search data\' computed field values.');
}
}
The feature of note in this code, is that we're updating Field API data without calling node_save(). We're doing this by manually generating the new Computed Field data, via _computed_field_compute_value(); and by then invoking the field_storage_write callback with the help of module_invoke().
Unfortunately, doing it this way is a bit complicated - these functions expect a whole lot of Field API and Entity API parameters to be passed to them, and preparing all these parameters is no walk in the park. Calling node_save() takes care of all this legwork behind the scenes.
This approach still isn't lightning-fast, but it performs significantly better than its alternative. Plus, by avoiding the usual node hook invocations, we also avoid any unwanted side-effects of simulating a node save operation (e.g. creating a new revision, affecting workflow state).
To execute the procedure as it's implemented here, all you need to do is visit update.php in your browser (or run drush updb from your terminal), and it will run as a standard Drupal database update. In my case, I chose to implement it in hook_update_N(), because: it gives me access to the Batch API for free; it's guaranteed to run only once; and it's protected by superuser-only access control. But, for example, you could also implement it as a custom admin page, calling the Batch API from a menu callback within your module.
Just one example
The use case presented here – a Computed Field used as a search index for Views exposed filters – is really just one example of how this technique could come in handy. What I'm trying to provide in this article, is a code template that can be applied to any scenario in which a single field (or a small number of fields) needs to be modified across a large volume of existing nodes (or other entities).
I can think of quite a few other potential scenarios. A custom "phone" field, where a region code needs to be appended to all existing data. A "link" field, where any existing data missing a "www" prefix needs to have it added. A node reference field, where certain saved Node IDs need to be re-mapped to new values, because the old pages have been archived. Whatever your specific requirement, I hope this code snippet makes your life a bit easier, and your server load a bit lighter.
]]>
Introducing the Drupal Handy Block module2012-06-08T00:00:00Z2012-06-08T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/06/introducing-the-drupal-handy-block-module/
I've been noticing more and more lately, that for every new Drupal site I build, I define a lot of custom blocks. I put the code for these blocks in one or more custom modules, and most of them are really simple. For me, at least, the most common task that these blocks perform, is to display one or more fields of the node (or other entity) page currently being viewed; and in second place, is the task of displaying a list of nodes from a nodequeue (as I'm rather a Nodequeue module addict, I tend to have nodequeues strewn all over my sites).
In short, I've gotten quite bored of copy-pasting the same block definition code over and over, usually with minimal changes. I also feel that such simple block definitions don't warrant defining a new custom module – as they have zero interesting logic / functionality, and as their purpose is purely presentational, I'd prefer to define them at the theme level. Additionally, every Drupal module has both administrative overhead (need to install / enable it on different environments, need to manage its deployment, etc), and performance overhead (every extra PHP include() call involves opening and reading a new file from disk, and every enabled Drupal module is a minimum of one extra PHP file to be included); so, less enabled modules means a faster site.
To make my life easier – and the life of anyone else in the same boat – I've written the Handy Block module. (As the project description says,) if you often have a bunch of custom modules on your site, that do nothing except implement block hooks (along with block callback functions), for blocks that do little more than display some fields for the entity currently being viewed, then Handy Block should… well, it should come in handy! You'll be able to do the same thing in just a few lines of your template.php file; and then, you can delete those custom modules of yours altogether.
The custom module way
Let me give you a quick example. Your page node type has two fields, called sidebar_image and sidebar_text. You'd like these two fields to display in a sidebar block, whenever they're available for the page node currently being viewed.
Using a custom module, how would you achieve this?
First of all, you have to build the basics for your new custom module. In this case, let's say you want to call your module pagemod – you'll need to start off by creating a pagemod directory (in, for example, sites/all/modules/custom), and writing a pagemod.info file that looks like this:
name = Page Mod
description = Custom module that does bits and pieces for page nodes.
core = 7.x
files[] = pagemod.module
You'll also need an almost-empty pagemod.module file:
<?php
/**
* @file
* Custom module that does bits and pieces for page nodes.
*/
Your module now exists – you can enable it if you want. Now, you can start building your sidebar block – let's say that you want to call it sidebar_snippet. First off, you need to tell Drupal that the block exists, by implementing hook_block_info() (note: this and all following code goes in pagemod.module, unless otherwise indicated):
Next, you need to define what gets shown in your new block. You do this by implementing hook_block_view():
<?php
/**
* Implements hook_block_view().
*/
function pagemod_block_view($delta = '') {
switch ($delta) {
case 'sidebar_snippet':
return pagemod_sidebar_snippet_block();
}
}
To keep things clean, it's a good idea to call a function for each defined block in hook_block_view(), rather than putting all your code directly in the hook function. Right now, you only have one block to render; but before you know it, you may have fifteen. So, let your block do its stuff here:
<?php
/**
* Displays the sidebar snippet on page nodes.
*/
function pagemod_sidebar_snippet_block() {
// Pretend that your module also contains this function - for code
// example, see handyblock_get_curr_page_node() in handyblock.module.
$node = pagemod_get_curr_page_node();
if (empty($node->nid) || !($node->type == 'page')) {
return;
}
if (!empty($node->field_sidebar_image['und'][0]['uri'])) {
// Pretend that your module also contains this function - for code
// example, see tpl_field_vars_styled_image_url() in
// tpl_field_vars.module
$image_url = pagemod_styled_image_url($node->field_sidebar_image
['und'][0]['uri'],
'sidebar_image');
$body = '';
if (!empty($node->field_sidebar_text['und'][0]['safe_value'])) {
$body = $node->field_sidebar_text['und'][0]['safe_value'];
}
$block['content'] = array(
'#theme' => 'pagemod_sidebar_snippet',
'#image_url' => $image_url,
'#body' => $body,
);
return $block;
}
}
Almost done. Drupal now recognises that your block exists, which means that you can enable your block and assign it to a region on the administer -> structure -> blocks page. Drupal will execute the code you've written above, when it tries to display your block. However, it won't yet display anything much, because you've defined your block as having a custom theme function, and that theme function hasn't been written yet.
Because you're an adherent of theming best practices, and you like to output all parts of your page using theme templates rather than theme functions, let's register this themable item, and let's define it as having a template:
And, as the final step, you'll need to create a pagemod-sidebar-snippet.tpl.php file (also in your pagemod module directory), to actually output your block:
Give your Drupal cache a good ol' clear, and voila – it sure took a while, but you've finally got your sidebar block built and displaying.
The Handy Block way
Now, to contrast, let's see how you'd achieve the same result, using the Handy Block module. No need for any of the custom pagemod module stuff above. Just enable Handy Block, and then place this code in your active theme's template.php file:
The MYTHEME_handyblock() callback automatically takes care of all three of the Drupal hook implementations that you previously had to write manually: hook_block_info(), hook_block_view(), and hook_theme(). The MYTHEME_handyblock_BLOCKNAME_alter() callback lets you do whatever you want to your block, after automatically providing the current page node as context, and setting the block's theme callback (in this case, the callback is controlling the block's visibility based on whether an image is available or not; and it's populating the block with the image and text fields).
Handy Block has done the "paperwork" (i.e. the hook implementations), such that Drupal expects a handyblock-sidebar-snippet.tpl.php file for this block (in your active theme's directory). So, let's create one (looks the same as the old pagemod-sidebar-snippet.tpl.php template):
After completing these steps, clear your Drupal cache, and assign your block to a region – and hey presto, you've got your custom block showing. Only this time, no custom module was needed, and significantly fewer lines of code were written.
In summary
Handy Block is not rocket science. (As the project description says,) this is a convenience module, for module developers and for themers. All it really does, is automate a few hook implementations for you. By implementing the Handy Block theme callback function, Handy Block implements hook_theme(), hook_block_info(), and hook_block_view() for you.
Handy Block is for Drupal site builders, who find themselves building a lot of blocks that:
Display more than just static text (if that's all you need, just use the 'add block' feature in the Drupal core block module)
Display something which is pretty basic (e.g. fields of the node currently being viewed), but which does require some custom code (albeit code that doesn't warrant a whole new custom module on your site)
Require a custom theme template
I should also mention that, before starting work on Handy Block, I had a look around for similar existing Drupal modules, and I found two interesting candidates. Both can be used to do the same thing that I've demonstrated in this article; however, I decided to go ahead and write Handy Block anyway, and I did so because I believe Handy Block is a better tool for the job (for the target audience that I have in mind, at least). Nevertheless, I encourage you to have a look at the competition as well.
The first alternative is CCK Blocks. This module lets you achieve similar results to Handy Block – however, I'm not so keen on it for several reasons: all its config is through the Admin UI (and I want my custom block config in code); it doesn't let you do anything more than output fields of the entity currently being viewed (and I want other options too, e.g. output a nodequeue); and it doesn't allow for completely custom templates for each block (although overriding its templates would probably be adequate in many cases).
The second alternative is Bean. I'm actually very impressed with what this module has to offer, and I'm hoping to take it for a spin sometime soon. However, for me, it seems that the Bean module is too far in the opposite extreme (compared to CCK Blocks) – whereas CCK blocks is too "light" and only has an admin UI for configuration, the Bean module is too complicated for simple use cases, as it requires implementing no small amount of code, within some pretty complex custom hooks. I decided against using Bean, because: it requires writing code within custom modules (not just at the theme layer); it's designed for things more complicated than just outputting fields of the entity currently being viewed (e.g. for performing custom Entity queries in a block, but without the help of Views); and it's above the learning curve of someone who primarily wears a Drupal themer hat.
Apart from the administrative and performance benefits of defining custom blocks in your theme's template.php file (rather than in a custom module), doing all the coding at the theme level also has another advantage. It makes custom block creation more accessible to people who are primarily themers, and who are reluctant (at best) module developers. This is important, because those big-themer-hat, small-developer-hat people are the primary target audience of this module (with the reverse – i.e. big-developer-hat, small-themer-hat people – being the secondary target audience).
Such people are scared and reluctant to write modules; they're more comfortable sticking to just the theme layer. Hopefully, this module will make custom block creation more accessible, and less daunting, for such people (and, in many cases, custom block creation is a task that these people need to perform quite often). I also hope that the architecture of this module – i.e. a callback function that must be implemented in the active theme's template.php file, not in a module – isn't seen as a hack or as un-Drupal-like. I believe I've justified fairly thoroughly, why I made this architecture decision.
I also recommend that you use Template Field Variables in conjunction with Handy Block (see my previous article about Template Field Variables). Both of them are utility modules for themers. The idea is that, used stand-alone or used together, these modules make a Drupal themer's life easier. Happy theming, and please let me know your feedback about the module.
]]>
Introducing the Drupal Template Field Variables module2012-05-29T00:00:00Z2012-05-29T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/05/introducing-the-drupal-template-field-variables-module/
Drupal 7's new Field API is a great feature. Unfortunately, theming an entity and its fields can be quite a daunting task. The main reason for this, is that the field variables that get passed to template files are not particularly themer-friendly. Themers are HTML markup and CSS coders; they're not PHP or Drupal coders. When themers start writing their node--page.tpl.php file, all they really want to know is: How do I output each field of this page [node type], exactly where I want, and with minimal fuss?
It is in the interests of improving the Drupal Themer Experience, therefore, that I present the Template Field Variables module. (As the project description says,) this module takes the mystery out of theming fieldable entities. For each field in an entity, it extracts the values that you actually want to output (from the infamous "massive nested arrays" that Drupal provides), and it puts those values in dead-simple variables.
What we've got
Let me tell you a story, about an enthusiastic fledgling Drupal themer. The sprightly lad has just added a new text field, called byline, to his page node type in Drupal 7. He wants to output this field at the bottom of his node--page.tpl.php file, in a blockquote tag.
Using nothing but Drupal 7 core, how does he do it?
He's got two options. His first option — the "Drupal 7 recommended" option — is to use the Render API, to hide the byline from the spot where all the node's fields get outputted by default; and to then render() it further down the page.
Well, says the budding young themer, that sure sounds easy enough. So, the themer goes and reads up on how to use the Render API, finds the example snippets of hide($content['bla']); and print render($content['bla']);, and whips up a template file:
<?php
/* My node--page.tpl.php file. It rocks. */
?>
<?php // La la la, do some funky template stuff. ?>
<?php // Don't wanna show this in the spot where Drupal vomits
// out content by default, let's call hide(). ?>
<?php hide($content['field_byline']); ?>
<?php // Now Drupal can have a jolly good ol' spew. ?>
<?php print render($content); ?>
<?php // La la la, more funky template stuff. ?>
<?php // This is all I need in order to output the byline at the
// bottom of the page in a blockquote, right? ?>
<blockquote><?php print render($content['field_byline']); ?></blockquote>
Now, let's see what page output that gives him:
<!-- La la la, this is my page output. -->
<!-- La la la, Drupal spewed out all my fields here. -->
<!-- La la... hey!! What the..?! Why has Drupal spewed out a -->
<!-- truckload of divs, and a label, that I didn't order? -->
<!-- I just want the byline, $#&%ers!! -->
<blockquote><div class="field field-name-field-byline field-type-text field-label-above"><div class="field-label">Byline: </div><div class="field-items"><div class="field-item even">It's hip to be about something</div></div></div></blockquote>
Our bright-eyed Drupal theming novice was feeling pretty happy with his handiwork so far. But now, disappointment lands. All he wants is the actual value of the byline. No div soup. No random label. He created a byline field. He saved a byline value to a node. Now he wants to output the byline, and only the byline. What more could possibly be involved, in such a simple task?
He racks his brains, searching for a solution. He's not a coder, but he's tinkered with PHP before, and he's pretty sure it's got some thingamybob that lets you cut stuff out of a string that you don't want. After a bit of googling, he finds the code snippets he needs. Ah! He exclaims. This should do the trick:
<?php // I knew I was born to be a Drupal ninja. Behold my
// marvellous creation! ?>
<blockquote><?php print str_replace('<div class="field field-name-field-byline field-type-text field-label-above"><div class="field-label">Byline: </div><div class="field-items"><div class="field-item even">', '', str_replace('</div></div></div>', '', render($content['field_byline']))); ?></blockquote>
Now, now, Drupal veterans – don't cringe. I know you've all seen it in a real-life project. Perhaps you even wrote it yourself, once upon a time. So, don't be too quick to judge the young grasshopper harshly.
However, although the str_replace() snippet does indeed do the trick, even our newbie grasshopper recognises it for the abomination and the kitten-killer that it is, and he cannot live knowing that a git blame on line 47 of node--page.tpl.php will forever reveal the awful truth. So, he decides to read up a bit more, and he finally discovers that the recommended solution is to create your own field.tpl.php override file. So, he whips up a one-line field--field-byline.tpl.php file:
<?php print render($item); ?>
And, at long last, he's got the byline and just the byline outputting… and he's done it The Drupal Way!
The newbie themer begins to feel more at ease. He's happy that he's learnt how to build template files in a Drupal 7 theme, without resorting to hackery. To celebrate, he snacks on juicy cherries dipped in chocolate-flavoured custard.
But a niggling concern remains at the back of his mind. Perhaps what he's done is The Drupal Way, but he's still not convinced that it's The Right Way. It seems like a lot of work — calling hide(); in one spot, having to call print render(); (not just print) further down, having to override field.tpl.php — and all just to output a simple little byline. Is there really no one-line alternative?
Ever optimistic, the aspiring Drupal themer continues searching, until at last he discovers that it is possible to access the raw field values from a node template. And so, finally, he settles for a solution that he's more comfortable with:
<?php
/* My node--page.tpl.php file. It rocks. */
?>
<?php // La la la, do some funky template stuff. ?>
<?php // Still need hide(), unless I manually output all my node fields,
// and don't call print render($content);
// grumble grumble... ?>
<?php hide($content['field_byline']); ?>
<?php // Now Drupal can have a jolly good ol' spew. ?>
<?php print render($content); ?>
<?php // La la la, more funky template stuff. ?>
<?php // Yay - I actually got the raw byline value to output here! ?>
<blockquote><?php print check_plain($node->field_byline[$node->language][0]['value']); ?></blockquote>
And so the sprightly young themer goes on his merry way, and hacks up .tpl.php files happily ever after.
Why all that sucks
That's the typical journey of someone new to Drupal theming, and/or new to the Field API, who wants to customise the output of fields for an entity. It's flawed for a number of reasons:
We're making themers learn how to make function calls unnecessarily. It's OK to make them learn function calls if they need to do something fancy. But in the case of the Render API, they need to learn two – hide() and render() – just to output something. All they should need to know is print.
We're making themers understand a complex, unnecessary, and artificially constructed concept: the Render API. Themers don't care how Drupal constructs the page content, they don't care what render arrays are (or if they exist); and they shouldn't have to care.
We're making it unnecessarily difficult to output raw values, using the recommended theming method (i.e. using the Render API). In order to output raw values using the render API, you basically have to override field.tpl.php in the manner illustrated above. This will prove to be too advanced (or simply too much effort) for many themers, who may resort to the type of string-replacement hackery described above.
The only actual method of outputting the raw value directly is fraught with problems:
It requires a long line of code, that drills deep into nested arrays / objects before it can print the value
Those nested arrays / objects are hard even for experienced developers to navigate / debug, let alone newbie themers
It requires themers to concern themselves with field translation and with the i18n API
Guesswork is needed for determining the exact key that will yield the outputtable value, at the end of the nested array (usually 'value', but sometimes not, e.g. 'url' for link fields)
It's highly prone to security issues, as there's no way that novice themers can be expected to understand when to use 'value' vs 'safe_value', when check_plain() / filter_xss_admin() should be called, etc. (even experienced developers often misuse or omit Drupal's string output security, as anyone who's familiar with the Drupal security advisories would know)
In a nutshell: the current system has too high a learning curve, it's unnecessarily complex, and it unnecessarily exposes themers to security risks.
A better way
Now let me tell you another story, about that same enthusiastic fledgling Drupal themer, who wanted to show his byline in a blockquote tag. This time, he's using Drupal 7 core, plus the Template Field Variables module.
First, he opens up his template.php file, and adds the following:
After doing this (and after clearing his cache), he opens up his node (of type 'page') in a browser; and because he's set 'debug' => TRUE (above), he sees this output on page load:
$body =
<p>There was a king who had twelve beautiful daughters. They slept in
twelve beds all in one room; and when they went to bed, the doors were
shut and locked up; but every morning their shoes were found to be
quite worn through as if they had been danced in all night; and yet
nobody could find out how it happened, or where they had been.</p>
<p>Then the king made it known to all the land, that if any person
could discover the secret, and find out where it was that the
princesses danced in the night, he should have the one he liked best
for his wife, and should be king after his ...
$byline =
It's hip to be about something
And now, he has all the info he needs in order to write his new node--page.tpl.php file, which looks like this:
<?php
/* My node--page.tpl.php file. It rocks. */
?>
<?php // La la la, do some funky template stuff. ?>
<?php // No spewing, please, Drupal - just the body field. ?>
<?php print $body; ?>
<?php // La la la, more funky template stuff. ?>
<?php // Output the byline here, pure and simple. ?>
<blockquote><?php print $byline; ?></blockquote>
He sets 'debug' => FALSE in his template.php file, he reloads the page in his browser, and… voila! He's done theming for the day.
About the module
The story that I've told above, describes the purpose and function of the Template Field Variables module better than a plain description can. (As the project description says,) it's a utility module for themers. Its only purpose is to make Drupal template development less painful. It has no front-end. It stores no data. It implements no hooks. In order for it to do anything, some coding is required, but only coding in your theme files.
I've illustrated here the most basic use case of Template Field Variables, i.e. outputting simple text fields. However, the module's real power lies in its ability to let you print out the values of more complex field types, just as easily. Got an image field? Want to print out the URL of the original-size image, plus the URLs of any/all of the resized derivatives of that image… and all in one print statement? Got a date field, and want to output the 'start date' and 'end date' values with minimal fuss? Got a nodereference field, and want to output the referenced node's title within an h3 tag? Got a field with multiple values, and want to loop over those values in your template, just as easily as you output a single value? For all these use cases, Template Field Variables is your friend.
If you never want to again see a template containing:
And if, from this day forward, you only ever want to see a template containing:
<?php print $foo; ?>
Then I really think you should take Template Field Variables for a spin. You may discover, for the first time in your life, that Drupal theming can actually be fun. And sane.
]]>
Flattening many-to-many fields for MySQL to CSV export2012-05-23T00:00:00Z2012-05-23T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/05/flattening-many-to-many-fields-for-mysql-to-csv-export/
Relational databases are able to store, with minimal fuss, pretty much any data entities you throw at them. For the more complex cases – particularly cases involving hierarchical data – they offer many-to-many relationships. Querying many-to-many relationships is usually quite easy: you perform a series of SQL joins in your query; and you retrieve a result set containing the combination of your joined tables, in denormalised form (i.e. with the data from some of your tables being duplicated in the result set).
A denormalised query result is quite adequate, if you plan to process the result set further – as is very often the case, e.g. when the result set is subsequently prepared for output to HTML / XML, or when the result set is used to populate data structures (objects / arrays / dictionaries / etc) in programming memory. But what if you want to export the result set directly to a flat format, such as a single CSV file? In this case, denormalised form is not ideal. It would be much better, if we could aggregate all that many-to-many data into a single result set containing no duplicate data, and if we could do that within a single SQL query.
This article presents an example of how to write such a query in MySQL – that is, a query that's able to aggregate complex many-to-many relationships, into a result set that can be exported directly to a single CSV file, with no additional processing necessary.
Example: a lil' Bio database
For this article, I've whipped up a simple little schema for a biographical database. The database contains, first and foremost, people. Each person has, as his/her core data: a person ID; a first name; a last name; and an e-mail address. Each person also optionally has some additional bio data, including: bio text; date of birth; and gender. Additionally, each person may have zero or more: profile pictures (with each picture consisting of a filepath, nothing else); web links (with each link consisting of a title and a URL); and tags (with each tag having a name, existing in a separate tags table, and being linked to people via a joining table). For the purposes of the example, we don't need anything more complex than that.
Here's the SQL to create the example schema:
CREATE TABLE person (
pid int(10) unsigned NOT NULL AUTO_INCREMENT,
firstname varchar(255) NOT NULL,
lastname varchar(255) NOT NULL,
email varchar(255) NOT NULL,
PRIMARY KEY (pid),
UNIQUE KEY email (email),
UNIQUE KEY firstname_lastname (firstname(100), lastname(100))
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;
CREATE TABLE tag (
tid int(10) unsigned NOT NULL AUTO_INCREMENT,
tagname varchar(255) NOT NULL,
PRIMARY KEY (tid),
UNIQUE KEY tagname (tagname)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1;
CREATE TABLE person_bio (
pid int(10) unsigned NOT NULL,
bio text NOT NULL,
birthdate varchar(255) NOT NULL DEFAULT '',
gender varchar(255) NOT NULL DEFAULT '',
PRIMARY KEY (pid),
FULLTEXT KEY bio (bio)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE person_pic (
pid int(10) unsigned NOT NULL,
pic_filepath varchar(255) NOT NULL,
PRIMARY KEY (pid, pic_filepath)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE person_link (
pid int(10) unsigned NOT NULL,
link_title varchar(255) NOT NULL DEFAULT '',
link_url varchar(255) NOT NULL DEFAULT '',
PRIMARY KEY (pid, link_url),
KEY link_title (link_title)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
CREATE TABLE person_tag (
pid int(10) unsigned NOT NULL,
tid int(10) unsigned NOT NULL,
PRIMARY KEY (pid, tid)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
And here's the SQL to insert some sample data into the schema:
INSERT INTO person (firstname, lastname, email) VALUES ('Pete', 'Wilson', 'pete@wilson.com');
INSERT INTO person (firstname, lastname, email) VALUES ('Sarah', 'Smith', 'sarah@smith.com');
INSERT INTO person (firstname, lastname, email) VALUES ('Jane', 'Burke', 'jane@burke.com');
INSERT INTO tag (tagname) VALUES ('awesome');
INSERT INTO tag (tagname) VALUES ('fantabulous');
INSERT INTO tag (tagname) VALUES ('sensational');
INSERT INTO tag (tagname) VALUES ('mind-boggling');
INSERT INTO tag (tagname) VALUES ('dazzling');
INSERT INTO tag (tagname) VALUES ('terrific');
INSERT INTO person_bio (pid, bio, birthdate, gender) VALUES (1, 'Great dude, loves elephants and tricycles, is really into coriander.', '1965-04-24', 'male');
INSERT INTO person_bio (pid, bio, birthdate, gender) VALUES (2, 'Eccentric and eclectic collector of phoenix wings. Winner of the 2003 International Small Elbows Award.', '1982-07-20', 'female');
INSERT INTO person_bio (pid, bio, birthdate, gender) VALUES (3, 'Has purply-grey eyes. Prefers to only go out on Wednesdays.', '1990-11-06', 'female');
INSERT INTO person_pic (pid, pic_filepath) VALUES (1, 'files/person_pic/pete1.jpg');
INSERT INTO person_pic (pid, pic_filepath) VALUES (1, 'files/person_pic/pete2.jpg');
INSERT INTO person_pic (pid, pic_filepath) VALUES (1, 'files/person_pic/pete3.jpg');
INSERT INTO person_pic (pid, pic_filepath) VALUES (3, 'files/person_pic/jane_on_wednesday.jpg');
INSERT INTO person_link (pid, link_title, link_url) VALUES (2, 'The Great Blog of Sarah', 'http://www.omgphoenixwingsaresocool.com/');
INSERT INTO person_link (pid, link_title, link_url) VALUES (3, 'Catch Jane on Blablablabook', 'http://www.blablablabook.com/janepurplygrey');
INSERT INTO person_link (pid, link_title, link_url) VALUES (3, 'Jane ranting about Thursdays', 'http://www.janepurplygrey.com/thursdaysarelame/');
INSERT INTO person_tag (pid, tid) VALUES (1, 3);
INSERT INTO person_tag (pid, tid) VALUES (1, 4);
INSERT INTO person_tag (pid, tid) VALUES (1, 5);
INSERT INTO person_tag (pid, tid) VALUES (1, 6);
INSERT INTO person_tag (pid, tid) VALUES (2, 2);
Querying for direct CSV export
If we were building, for example, a simple web app to output a list of all the people in this database (along with all their biographical data), querying this database would be quite straightforward. Most likely, our first step would be to query the one-to-one data: i.e. query the main 'person' table, join on the 'bio' table, and loop through the results (in a server-side language, such as PHP). The easiest way to get at the rest of the data, in such a case, would be to then query each of the many-to-many relationships (i.e. user's pictures; user's links; user's tags) in separate SQL statements, and to execute each of those queries once for each user being processed.
In that scenario, we'd be writing four different SQL queries, and we'd be executing SQL numerous times: we'd execute the main query once, and we'd execute each of the three secondary queries, once for each user in the database. So, with the sample data provided here, we'd be executing SQL 1 + (3 x 3) = 10 times.
Alternatively, we could write a single query which joins together all of the three many-to-many relationships in one go, and our web app could then just loop through a single result set. However, this result set would potentially contain a lot of duplicate data, as well as a lot of NULL data. So, the web app's server-side code would require extra logic, in order to deal with this messy result set effectively.
In our case, neither of the above solutions is adequate. We can't afford to write four separate queries, and to perform 10 query executions. We don't want a single result set that contains duplicate data and/or excessive NULL data. We want a single query, that produces a single result set, containing one person per row, and with all the many-to-many data for each person aggregated into that person's single row.
Here's the magic SQL that can make our miracle happen:
SELECT person_base.pid,
person_base.firstname,
person_base.lastname,
person_base.email,
IFNULL(person_base.bio, '') AS bio,
IFNULL(person_base.birthdate, '') AS birthdate,
IFNULL(person_base.gender, '') AS gender,
IFNULL(pic_join.val, '') AS pics,
IFNULL(link_join.val, '') AS links,
IFNULL(tag_join.val, '') AS tags
FROM (
SELECT p.pid,
p.firstname,
p.lastname,
p.email,
IFNULL(pb.bio, '') AS bio,
IFNULL(pb.birthdate, '') AS birthdate,
IFNULL(pb.gender, '') AS gender
FROM person p
LEFT JOIN person_bio pb
ON p.pid = pb.pid
) AS person_base
LEFT JOIN (
SELECT join_tbl.pid,
IFNULL(
GROUP_CONCAT(
DISTINCT CAST(join_tbl.pic_filepath AS CHAR)
SEPARATOR ';;'
),
''
) AS val
FROM person_pic join_tbl
GROUP BY join_tbl.pid
) AS pic_join
ON person_base.pid = pic_join.pid
LEFT JOIN (
SELECT join_tbl.pid,
IFNULL(
GROUP_CONCAT(
DISTINCT CONCAT(
CAST(join_tbl.link_title AS CHAR),
'::',
CAST(join_tbl.link_url AS CHAR)
)
SEPARATOR ';;'
),
''
) AS val
FROM person_link join_tbl
GROUP BY join_tbl.pid
) AS link_join
ON person_base.pid = link_join.pid
LEFT JOIN (
SELECT join_tbl.pid,
IFNULL(
GROUP_CONCAT(
DISTINCT CAST(t.tagname AS CHAR)
SEPARATOR ';;'
),
''
) AS val
FROM person_tag join_tbl
LEFT JOIN tag t
ON join_tbl.tid = t.tid
GROUP BY join_tbl.pid
) AS tag_join
ON person_base.pid = tag_join.pid
ORDER BY lastname ASC,
firstname ASC;
If you run this in a MySQL admin tool that supports exporting query results directly to CSV (such as phpMyAdmin), then there's no more fancy work needed on your part. Just click 'Export -> CSV', and you'll have your results looking like this:
pid,firstname,lastname,email,bio,birthdate,gender,pics,links,tags
3,Jane,Burke,jane@burke.com,Has purply-grey eyes. Prefers to only go out on Wednesdays.,1990-11-06,female,files/person_pic/jane_on_wednesday.jpg,Catch Jane on Blablablabook::http://www.blablablabook.com/janepurplygrey;;Jane ranting about Thursdays::http://www.janepurplygrey.com/thursdaysarelame/,
2,Sarah,Smith,sarah@smith.com,Eccentric and eclectic collector of phoenix wings. Winner of the 2003 International Small Elbows Award.,1982-07-20,female,,The Great Blog of Sarah::http://www.omgphoenixwingsaresocool.com/,fantabulous
1,Pete,Wilson,pete@wilson.com,Great dude, loves elephants and tricycles, is really into coriander.,1965-04-24,male,files/person_pic/pete1.jpg;;files/person_pic/pete2.jpg;;files/person_pic/pete3.jpg,,sensational;;mind-boggling;;dazzling;;terrific
The query explained
The most important feature of this query, is that it takes advantage of MySQL's ability to perform subqueries. What we're actually doing, is we're performing four separate queries: one query on the main person table (which joins to the person_bio table); and one on each of the three many-to-many elements of a person's bio. We're then joining these four queries, and selecting data from all of their result sets, in the parent query.
The magic function in this query, is the MySQL GROUP_CONCAT() function. This basically allows us to join together the results of a particular field, using a delimiter string, much like the join() array-to-string function in many programming languages (i.e. like PHP's implode() function). In this example, I've used two semicolons (;;) as the delimiter string.
In the case of person_link in this example, each row of this data has two fields ('link title' and 'link URL'); so, I've concatenated the two fields together (separated by a double-colon (::) string), before letting GROUP_CONCAT() work its wonders.
The case of person_tags is also interesting, as it demonstrates performing an additional join within the many-to-many subquery, and returning data from that joined table (i.e. the tag name) as the result value. So, all up, each of the many-to-many relationships in this example is a slightly different scenario: person_pic is the basic case of a single field within the many-to-many data; person_link is the case of more than one field within the many-to-many data; and person_tags is the case of an additional one-to-many join, on top of the many-to-many join.
Final remarks
Note that although this query depends on several MySQL-specific features, most of those features are available in a fairly equivalent form, in most other major database systems. Subqueries vary quite little between the DBMSes that support them. And it's possible to achieve GROUP_CONCAT() functionality in PostgreSQL, in Oracle, and even in SQLite.
It should also be noted that it would be possible to achieve the same result (i.e. the same end CSV output), using 10 SQL query executions and a whole lot of PHP (or other) glue code. However, taking that route would involve more code (spread over four queries and numerous lines of procedural glue code), and it would invariably suffer worse performance (although I make no guarantees as to the performance of my example query, I haven't benchmarked it with particularly large data sets).
This querying trick was originally written in order to export data from a Drupal MySQL database, to a flat CSV file. The many-to-many relationships were referring to field tables, as defined by Drupal's Field API. I made the variable names within the subqueries as generic as possible (e.g. join_tbl, val), because I needed to copy the subqueries numerous times (for each of the numerous field data tables I was dealing with), and I wanted to make as few changes as possible on each copy.
The trick is particularly well-suited to Drupal Field API data (known in Drupal 6 and earlier as 'CCK data'). However, I realised that it could come in useful with any database schema where a "flattening" of many-to-many fields is needed, in order to perform a CSV export with a single query. Let me know if you end up adopting this trick for schemas of your own.
]]>
Enriching user-entered HTML markup with PHP parsing2012-05-10T00:00:00Z2012-05-10T00:00:00ZJazahttps://greenash.net.au/thoughts/2012/05/enriching-user-entered-html-markup-with-php-parsing/
I recently found myself faced with an interesting little web dev challenge. Here's the scenario. You've got a site that's powered by a PHP CMS (in this case, Drupal). One of the pages on this site contains a number of HTML text blocks, each of which must be user-editable with a rich-text editor (in this case, TinyMCE). However, some of the HTML within these text blocks (in this case, the unordered lists) needs some fairly advanced styling – the kind that's only possible either with CSS3 (using, for example, nth-child pseudo-selectors), with JS / jQuery manipulation, or with the addition of some extra markup (for example, some first, last, and first-in-row classes on the list item elements).
Naturally, IE7+ compatibility is required – so, CSS3 selectors are out. Injecting element attributes via jQuery is a viable option, but it's an ugly approach, and it may not kick in immediately on page load. Since the users will be editing this content via WYSIWYG, we can't expect them to manually add CSS classes to the markup, or to maintain any markup that the developer provides in such a form. That leaves only one option: injecting extra attributes on the server-side.
When it comes to HTML manipulation, there are two general approaches. The first is Parsing HTML The Cthulhu Way (i.e. using Regular Expressions). However, you already have one problem to solve – do you really want two? The second is to use an HTML parser. Sadly, this problem must be solved in PHP – which, unlike some otherlanguages, lacks an obvioustool of choice in the realm of parsers. I chose to use PHP5's built-in DOMDocument library, which (from what I can tell) is one of the most mature and widely-used PHP HTML parsers available today. Here's my code snippet.
Markup parsing function
<?php
/**
* Parses the specified markup content for unordered lists, and enriches
* the list markup with unique identifier classes, 'first' and 'last'
* classes, 'first-in-row' classes, and a prepended inside element for
* each list item.
*
* @param $content
* The markup content to enrich.
* @param $id_prefix
* Each list item is given a class with name 'PREFIX-item-XX'.
* Optional.
* @param $items_per_row
* For each Nth element, add a 'first-in-row' class. Optional.
* If not set, no 'first-in-row' classes are added.
* @param $prepend_to_li
* The name of an HTML element (e.g. 'span') to prepend inside
* each liist item. Optional.
*
* @return
* Enriched markup content.
*/
function enrich_list_markup($content, $id_prefix = NULL,
$items_per_row = NULL, $prepend_to_li = NULL) {
// Trim leading and trailing whitespace, DOMDocument doesn't like it.
$content = preg_replace('/^ */', '', $content);
$content = preg_replace('/ *$/', '', $content);
$content = preg_replace('/ *\n */', "\n", $content);
// Remove newlines from the content, DOMDocument doesn't like them.
$content = preg_replace('/[\r\n]/', '', $content);
$doc = new DOMDocument();
$doc->loadHTML($content);
foreach ($doc->getElementsByTagName('ul') as $ul_node) {
$i = 0;
foreach ($ul_node->childNodes as $li_node) {
$li_class_list = array();
if ($id_prefix) {
$li_class_list[] = $id_prefix . '-item-' . sprintf('%02d', $i+1);
}
if (!$i) {
$li_class_list[] = 'first';
}
if ($i == $ul_node->childNodes->length-1) {
$li_class_list[] = 'last';
}
if (!empty($items_per_row) && !($i % $items_per_row)) {
$li_class_list[] = 'first-in-row';
}
$li_node->setAttribute('class', implode(' ', $li_class_list));
if (!empty($prepend_to_li)) {
$prepend_el = $doc->createElement($prepend_to_li);
$li_node->insertBefore($prepend_el, $li_node->firstChild);
}
$i++;
}
}
$content = $doc->saveHTML();
// Manually fix up HTML entity encoding - if there's a better
// solution for this, let me know.
$content = str_replace('–', '–', $content);
// Manually remove the doctype, html, and body tags that DOMDocument
// wraps around the text. Apparently, this is the only easy way
// to fix the problem:
// http://stackoverflow.com/a/794548
$content = mb_substr($content, 119, -15);
return $content;
}
?>
This is a fairly simple parsing routine, that loops through the li elements of the unordered lists in the text, and that adds some CSS classes, and also prepends a child node. There's some manual cleanup needed after the parsing is done, due to some quirks associated with DOMDocument.
Markup parsing example
For example, say your users have entered the following markup:
You can then whip up some CSS to make your designer happy:
#fruit ul {
list-style-type: none;
}
#fruit ul li {
display: block;
width: 150px;
padding: 20px 20px 20px 45px;
float: left;
margin: 0 0 20px 20px;
background-color: #bbddfb;
position: relative;
}
#fruit ul li.first-in-row {
clear: both;
margin-left: 0;
}
#fruit ul li span {
display: block;
position: absolute;
left: 20px;
top: 23px;
width: 15px;
height: 15px;
background-color: #191970;
}
#fruit ul li.first, #fruit ul li.last {
background-color: #968adc;
}
#fruit ul li.fruit-item-03, #fruit ul li.fruit-item-05 {
background-color: #7bdca6;
}
#fruit ul li.first span, #fruit ul li.last span {
background-color: #4b0082;
}
#fruit ul li.fruit-item-03 span, #fruit ul li.fruit-item-05 span {
background-color: #00611c;
}
Your finished product is bound to win you smiles on every front:
How the parsed markup looks when rendered
Obviously, this is just one example of how a markup parsing function might look, and of the exact end result that you might want to achieve with such parsing. Take everything presented here, and fiddle liberally to suit your needs.
In the approach I've presented here, I believe I've managed to achieve a reasonable balance between stakeholder needs (i.e. easily editable content, good implementation of visual design), hackery, and technical elegance. Also note that this article is not at all CMS-specific (the code snippets work stand-alone), nor is it particularly parser-specific, or even language-specific (although code snippets are in PHP). Feedback welcome.
]]>
Generating unique integer IDs from strings in MySQL2010-03-19T00:00:00Z2010-03-19T00:00:00ZJazahttps://greenash.net.au/thoughts/2010/03/generating-unique-integer-ids-from-strings-in-mysql/
I have an interesting problem, on a data migration project I'm currently working on. I'm importing a large amount of legacy data into Drupal, using the awesome Migrate module (and friends). Migrate is a great tool for the job, but one of its limitations is that it requires the legacy database tables to have non-composite integer primary keys. Unfortunately, most of the tables I'm working with have primary keys that are either composite (i.e. the key is a combination of two or more columns), or non-integer (i.e. strings), or both.
Table with composite primary key.
The simplest solution to this problem would be to add an auto-incrementing integer primary key column to the legacy tables. This would provide the primary key information that Migrate needs in order to do its mapping of legacy IDs to Drupal IDs. But this solution has a serious drawback. In my project, I'm going to have to re-import the legacy data at regular intervals, by deleting and re-creating all the legacy tables. And every time I do this, the auto-incrementing primary keys that get generated could be different. Records may have been deleted upstream, or new records may have been added in between other old records. Auto-increment IDs would, therefore, correspond to different composite legacy primary keys each time I re-imported the data. This would effectively make Migrate's ID mapping tables corrupt.
A better solution is needed. A solution called hashing! Here's what I've come up with:
Remove the legacy primary key index from the table.
Create a new column on the table, of type BIGINT. A MySQL BIGINT field allocates 64 bits (8 bytes) of space for each value.
If the primary key is composite, concatenate the columns of the primary key together (optionally separated by a delimiter).
Calculate the SHA1 hash of the concatenated primary key string. An SHA1 hash consists of 40 hexadecimal digits. Since each hex digit stores 24 different values, each hex digit requires 4 bits of storage; therefore 40 hex digits require 160 bits of storage, which is 20 bytes.
Convert the numeric hash to a string.
Truncate the hash string down to the first 16 hex digits.
Convert the hash string back into a number. Each hex digit requires 4 bits of storage; therefore 16 hex digits require 64 bits of storage, which is 8 bytes.
Convert the number from hex (base 16) to decimal (base 10).
Store the decimal number in your new BIGINT field. You'll find that the number is conveniently just small enough to fit into this 64-bit field.
Now that the new BIGINT field is populated with unique values, upgrade it to a primary key field.
Add an index that corresponds to the legacy primary key, just to maintain lookup performance (you could make it a unique key, but that's not really necessary).
Table with integer primary key.
The SQL statement that lets you achieve this in MySQL looks like this:
ALTER TABLE people DROP PRIMARY KEY;
ALTER TABLE people ADD id BIGINT UNSIGNED NOT NULL FIRST;
UPDATE people SET id = CONV(SUBSTRING(CAST(SHA(CONCAT(name, ',', city)) AS CHAR), 1, 16), 16, 10);
ALTER TABLE people ADD PRIMARY KEY(id);
ALTER TABLE people ADD INDEX (name, city);
Note: you will also need to alter the relevant migrate_map_X tables in your database, and change the sourceid and destid fields in these tables to be of type BIGINT.
Hashing has a tremendous advantage over using auto-increment IDs. When you pass a given string to a hash function, it always yields the exact same hash value. Therefore, whenever you hash a given string-based primary key, it always yields the exact same integer value. And that's my problem solved: I get constant integer ID values each time I re-import my legacy data, so long as the legacy primary keys remain constant between imports.
Storing the 64-bit hash value in MySQL is straightforward enough. However, a word of caution once you continue on to the PHP level: PHP does not guarantee to have a 64-bit integer data type available. It should be present on all 64-bit machines running PHP. However, if you're still on a 32-bit processor, chances are that a 32-bit integer is the maximum integer size available to you in PHP. There's a trick where you can store an integer of up to 52 bits using PHP floats, but it's pretty dodgy, and having 64 bits guaranteed is far preferable. Thankfully, all my environments for my project (dev, staging, production) have 64-bit processors available, so I'm not too worried about this issue.
I also have yet to confirm 100% whether 16 out of 40 digits from an SHA1 hash is enough to guarantee unique IDs. In my current legacy data set, I've applied this technique to all my tables, and haven't encountered a single duplicate (I also experimented briefly with CRC32 checksums, and very quickly ran into duplicate ID issues). However, that doesn't prove anything — except that duplicate IDs are very unlikely. I'd love to hear from anyone who has hard probability figures about this: if I'm using 16 digits of a hash, what are the chances of a collision? I know that Git, for example, stores commit IDs as SHA1 hashes, and it lets you then specify commit IDs using only the first few digits of the hash (e.g. the first 7 digits is most common). However, Git makes no guarantee that a subset of the hash value is unique; and in the case of a collision, it will ask you to provide enough digits to yield a unique hash. But I've never had Git tell me that, as yet.
]]>
Hook soup2009-06-17T00:00:00Z2009-06-17T00:00:00ZJazahttps://greenash.net.au/thoughts/2009/06/hook-soup/
Of late, I seem to keep stumbling upon Drupal hooks that I've never heard of before. For example, I was just reading a blog post about what you can't modify in a _preprocess() function, when I saw mention of hook_theme_registry_alter(). What a mouthful. I ain't seen that one 'til now. Is it just me, or are new hooks popping up every second day in Drupal land? This got me wondering: exactly how many hooks are there in Drupal core right now? And by how much has this number changed over the past few Drupal versions? Since this information is conveniently available in the function lists on api.drupal.org, I decided to find out for myself. I counted the number of documented hook_foo() functions for Drupal core versions 4.7, 5, 6 and 7 (HEAD), and this is what I came up with (in pretty graph form):
Drupal hooks by core version
And those numbers again (in plain text form):
Drupal 4.7: 41
Drupal 5: 53
Drupal 6: 72
Drupal 7: 183
Aaaagggghhhh!!! Talk about an explosion — what we've got on our hands is nothing less than hook soup. The rate of growth of Drupal hooks is out of control. And that's not counting themable functions (and templates) and template preprocessor functions, which are the other "magically called" functions whose mechanics developers need to understand. And as for hooks defined by contrib modules — even were we only counting the "big players", such as Views — well, let's not even go there; it's really too massive to contemplate.
In fairness, there are a number of good reasons why the amount of hooks has gone up so dramatically in Drupal 7:
Splitting various "combo" hooks into a separate hook for each old $op parameter, the biggest of these being the death of hook_nodeapi()
The rise and rise of the _alter() hooks
Birth of fields in core
Birth of file API in core
Nevertheless, despite all these good reasons, the number of core hooks in HEAD right now is surely cause for concern. More hooks means a higher learning curve for people new to Drupal, and a lot of time wasted in looking up API references even for experienced developers. More hooks also means a bigger core codebase, which goes against our philosophy of striving to keep core lean, mean and super-small.
In order to get a better understanding of why D7 core has so many hooks, I decided to do a breakdown of the hooks based on their type. I came up with the "types" more-or-less arbitrarily, based on the naming conventions of the hooks, and also based on the purpose and the input/output format of each hook. The full list of hooks and types can be found further down. Here's the summary (in pretty graph form):
Hook breakdown by type
And those numbers again (in plain text form):
Type
No. of hooks
misc action
44
info
30
alter
27
delete
20
insert
13
load
12
update
10
validate
6
form
4
misc combo
4
prepare
4
view
4
presave
3
check
2
As you can see, most of the hooks in core are "misc action" hooks, i.e. they allow modules to execute arbitrary (or not-so-arbitrary) code in response to some sort of action, and that action isn't covered by the other hook types that I used for classification. For the most part, the misc action hooks all serve an important purpose; however, we should be taking a good look at them, and seeing if we really need a hook for that many different events. DX is a balancing act between flexibility-slash-extensibility, and flexibility-slash-extensibility overload. Drupal has a tendency to lean towards the latter, if left unchecked. Also prominent in core are the "info" and "alter" hooks which, whether they end in the respective _info or _alter suffixes or not, return (for info) or modify (for alter) a more-or-less non-dynamic structured array of definitions. The DX balancing act applies to these hooks just as strongly: do we really need to allow developers to define and to change that many structured arrays, or are some of those hooks never likely to be implemented outside of core?
I leave further discussion on this topic to the rest of the community. This article is really just to present the numbers. If you haven't seen enough numbers or lists yet, you can find some more of them below. Otherwise, glad I could inform you.
(D7 list accurate as of 17 Jun 2009; type breakdown for D7 list added arbitrarily by yours truly)
]]>
Installing the uploadprogress PECL extension on Leopard2009-05-28T00:00:00Z2009-05-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2009/05/installing-the-uploadprogress-pecl-extension-on-leopard/
The uploadprogress PECL extension is a PHP add-on that allows cool AJAX uploading like never before. Version 3 of Drupal's FileField module is designed to work best with uploadprogress enabled. As such, I found myself installing a PECL extension for the first time. No doubt, many other Drupal developers will soon be finding themselves in the same boat.
Unfortunately, for those of us on Mac OS X 10.5 (Leopard), installing uploadprogress ain't all smooth sailing. The problem is that the extension must be compiled from source in order to be installed; and on Leopard machines, which all run on a 64-bit processor, it must be compiled as a 64-bit binary. However, the gods of Mac (in their infinite wisdom) decided to include with Leopard (after Xcode is installed) a C compiler that still behaves in the old-school way, and that by default does its compilation in 32-bit mode. This is a right pain in the a$$, and if you're unfamiliar with the consequences of it, you'll likely see a message like this coming up in your Apache error log when you try to install uploadprogress and restart your server:
PHP Warning: PHP Startup: Unable to load dynamic library '/usr/local/php5/lib/php/extensions/no-debug-non-zts-20060613/uploadprogress.so' - (null) in Unknown on line 0
Hmmm… (null) in Unknown on line 0. WTF is that supposed to mean? (You ask). Well, it means that the extension was compiled for the wrong environment; and when Leopard tries to execute it, a low-level error called a segmentation fault occurs. In short, it means that your binary is $#%&ed.
But fear not, Leopard PHP developers! Here are some instructions for how to install uploadprogress by compiling it as a 64-bit binary:
Download and extract the latest tarball of the source code for uploadprogress.
If using the Entropy PHP package (which I would highly recommend for all Leopard users), follow the advice from this forum thread (2nd comment, by Taracque), and change all your php binaries in /usr/bin to be symlinks to the proper versions in /usr/local/php5/bin.
cd to the directory containing the extracted tarball that you downloaded, e.g. cd /download/uploadprogress-1.0.0
Type: sudo phpize
Analogous to these instructions on SOAP, type: MACOSX_DEPLOYMENT_TARGET=10.5 CFLAGS="-arch x86_64 -g -Os -pipe -no-cpp-precomp" CCFLAGS="-arch x86_64 -g -Os -pipe" CXXFLAGS="-arch x86_64 -g -Os -pipe" LDFLAGS="-arch x86_64 -bind_at_load" ./configure This is the most important step, so make sure you type it in correctly! (If you get any sort of "permission denied" errors with this, then type sudo su before running it, and type exit after running it).
Type: sudo make
Type: sudo make install
Add the line extension=uploadprogress.so to your php.ini file (for Entropy users, this can be found at /usr/local/php5/lib/php.ini )
Restart apache by typing: sudo apachectl restart
If all is well, then a phpinfo() check should output an uploadprogress section, with a listing for the config variables uploadprogress.file.contents_template, uploadprogress.file.filename_template, and uploadprogress.get_contents. Your Drupal status report should be happy, too. And, of course, FileField will totally rock.
]]>
Self-referencing symlinks can hang your IDE2009-04-15T00:00:00Z2009-04-15T00:00:00ZJazahttps://greenash.net.au/thoughts/2009/04/self-referencing-symlinks-can-hang-your-ide/
One of my current Drupal projects (live local) has been giving me a headache lately, due to a small but very annoying problem. My PHP development tools of choice, at the moment, are Eclipse PDT and TextMate. Both of these generally work great for me. I prefer TextMate if I have the choice (better config options + much more usable), but I switch to Eclipse whenever I need a good debugger (or a bit of contextual help / autocomplete). However, they haven't been working well for me in this case. Every time I try to load in the source code for this one particular project, the IDE either hangs indefinitely (in Eclipse), or it slows down to a crawl (in TextMate). I've been tearing my hair out, trying to work out the cause of this problem, which has forced me to edit individual files for several weeks, and which has meant that I can't have a debugger or an IDE workspace for this project. Finally, I've nailed it: self-referencing symlinks are the culprit.
The project is a Drupal multisite setup, and like most multisite setups, it uses a bunch of symlinks in order for multiple subdomains to share a single codebase. For each subdomain, I create a symlink that points to the directory in which it resides; in effect, each symlink points to itself. When Apache comes along, it treats a symlink as the "directory" for a subdomain, and it follows it. By the time Drupal is invoked, we're in the root of the Drupal codebase shared by all the subdomains. Everything works great. All our favourite friends throw a party. Champagne bottles pop.
The bash command to create the symlinks is pretty simple — for each symlink, it looks something like this:
ln -s . subdomain
Unfortunately, a symlink like this does not play well with certain IDEs that try to walk your filesystem. When they hit such a symlink, they get stuck infinitely recursing (or at least, they keep recursing for a long time before they give up). The solution? Simple: delete such symlinks from your development environment. If this is what's been dragging your system down, then removing them will instantly cure all your woes. For each symlink, deleting it is as simple as:
rm subdomain
(Don't worry, deleting a symlink doesn't also delete the thing that it's pointing at).
It seems obvious, now that I've worked it out; but this annoying "slow-down" of Eclipse and TextMate had me stumped for quite a while until today. I've only recently switched to Mac, and I've only made the switch because I'm working at Digital Eskimo, which is an all-out Mac shop. I'm a Windows user most of the time (God help me), and Eclipse on Windows never gave me this problem. I use the new Vista symbolic links functionality, which actually works great for me (and which is possibly the only good reason to upgrade from XP to Vista). Eclipse on Windows apparently doesn't try to follow Vista symlinks. This is probably why it took me so long so figure it out (that, and Murphy's Law) — I already had the symlinks when I started the project on Windows, and Eclipse wasn't hanging on me then.
I originally thought that the cause of the problem was Git. Live local is the first project that I've managed with Git, and I know that Git has a lot of metadata, as well as compressed binary files for all the non-checked-out branches and tags of a repository. These seemed likely candidates for making Eclipse and TextMate crash, especially since neither of these tools have built-in support for Git. But I tried importing the project without any Git metadata, and it was still hanging forever. I also thought maybe it was some of the compressed JavaScript in the project that was to blame (e.g. jQuery, TinyMCE). Same story: removing the compressed JS files and importing the directory was still ridiculoualy slow.
IDEs should really be smart enough to detect self-referencing or cyclic symlinks, and to stop themselves from recursing infinitely over them. There is actually a bug filed for TextMate already, so maybe this will be fixed in future versions of TextMate. Couldn't find a similar bug report for Eclipse. Anyway, for now, you'll just have to be careful when using symlinks in your (Drupal or other) development environment. If you have symlinks, and if your IDE is crashing, then try taking out the symlinks, and see if all becomes merry again. Also, I'd love to hear if other IDEs handle this better (e.g. Komodo, PHPEdit), or if they crash just as dismally when faced with symlinks that point to themselves.
]]>
Deployment and migration: hot at DrupalCon DC2009-03-19T00:00:00Z2009-03-19T00:00:00ZJazahttps://greenash.net.au/thoughts/2009/03/deployment-and-migration-hot-at-drupalcon-dc/
There was no shortage of kick-a$$ sessions at the recent DrupalCon DC. The ones that really did it for me, however, were those that dealt with the thorny topic of deployment and migration. This is something that I've been thinking about for quite a long time, and it's great to see that a lot of other Drupal people have been doing likewise.
The thorniness of the topic is not unique to Drupal. It's a tough issue for any system that stores a lot of data in a relational database. Deploying files is easy: because files can be managed by anynumber of modern VCSes, it's a snap to version, to compare, to merge and to deploy them. But none of this is easily available when dealing with databases. The deployment problem is similar for all of the popular open source CMSes. There are also solutions available for many systems, but they tend to vary widely in their approach and in their effectiveness. In Drupal's case, the problem is exacerbated by the fact that a range of different types of data are stored together in the database (e.g. content, users, config settings, logs). What's more, different use cases call for different strategies regarding what to stage, and what to "edit live".
Context, Spaces and Exportables
The fine folks from Development Seed gave a talk entitled: "A Paradigm for Reusable Drupal Features". I understand that they first presented the Context and Spaces modules about six months ago, back in Szeged. At the time, these modules generated quite a buzz in the community. Sadly, I wasn't able to make it to Szeged; just as well, then, that I finally managed to hear about them in DC.
Context and Spaces alone don't strike me as particularly revolutionary tools. The functionality that they offer is certainly cool, and it will certainly change the way we make Drupal sites, but I heard several people at the conference describe them as "just an alternative to Panels", and I think that pretty well sums it up. These modules won't rock your world.
Exportables, however, will.
The concept of exportables is simply the idea that any piece of data that gets stored in a Drupal database, by any module, should be able to be exported as a chunk of executable PHP code. Just think of the built-in "export" feature in Views. Now think of export (and import) being as easy as that for any Drupal data — e.g. nodes, users, terms, even configuration variables. Exportables isn't an essential part of the Context and Spaces system, but it has been made an integral part of it, because Context and Spaces allows for most data entities in core to be exported (and imported) as exportables, and because Context and Spaces wants all other modules to similarly allow for their data entities to be handled as exportables.
The "exportables" approach to deployment has these features:
The export code can be parsed by PHP, and can then be passed directly to Drupal's standard foo_save() functions on import. This means minimal overhead in parsing or transforming the data, because the exported code is (literally) exactly what Drupal needs in order to programmatically restore the data to the database.
Raw PHP code is easier for Drupal developers to read and to play with than YetAnotherXMLFormat or MyStrangeCustomTextFormat.
Exportables aren't tied directly to Drupal's database structure — instead, they're tied to the accepted input of its standard API functions. This makes the exported data less fragile between Drupal versions and Drupal instances, especially compared to e.g. raw SQL export/import.
Exportables generally rely on data entities that have a unique string identifier. This makes them difficult to apply, because most entities in Drupal's database currently only have numeric IDs. Numeric, auto-incrementing IDs are hard for exportables to deal with, because they cause conflict when deploying data from one site to another (numeric IDs are not unique between Drupal instances). The solution to this is to encourage the wider use of string-based, globally unique IDs in Drupal.
Exportables can be exported to files, which can then be managed using a super-cool VCS, just like any other files.
Using exportables as a deployment and migration strategy for Drupal strikes me as ingenious in its simplicity. It's one of those solutions that it's easy to look at, and say: "naaaaahhhh… that's too simple, it's not powerful enough"; whereas we should instead be looking at it, and saying: "woooaaahhh… that's so simple, yet so powerful!" I have high hopes for Context + Spaces + Exportables becoming the tool of choice for moving database changes from one Drupal site to another.
Deploy module
Greg Dunlap was one of the people who hosted the DC/DC Staging and Deployment Panel Discussion. In this session, he presented the Deploy module. Deploy really blew me away. The funny thing was, I'd had an idea forming in my head for a few days prior to the conference, and it had gone something like this:
"Gee, wouldn't it be great if there was a module that just let you select a bunch of data items [on a staging Drupal site], through a nice easy UI, and that deployed those items to your live site, using web services or something?"
Well, that's exactly what Deploy does! It can handle most of the database-stored entities in Drupal core, and it can push your data from one Drupal instance to another, using nothing but a bit of XML-RPC magic, along with Drupal's (un)standard foo_get() and foo_save() functions. Greg (aka heyrocker) gave a live demo during the session, and it was basically a wet dream for anyone who's ever dealt with ongoing deployment and change management on a Drupal site.
Deploy is very cool, and it's very accessible. It makes database change deployment as easy as a point-and-click operation, which is great, because it means that anyone can now manage a complex Drupal environment that has more than just a single production instance. However, it lacks most of the advantages of exportables; particularly, it doesn't allow exporting to files, so you miss out on the opportunity to version and to compare the contents of your database. Perhaps the ultimate tool would be to have a Deploy-like front-end built on top of an Exportables framework? Anyway, Deploy is a great piece of work, and it's possible that it will become part of the standard toolbox for maintainers of small- and medium-sized Drupal sites.
Other solutions
The other solutions presented at the Staging and Deployment Panel Discussion were:
Sacha Chua from IBM gave an overview of her "approach" to deployment, which is basically a manual one. Sacha keeps careful track of all the database changes that she makes on a staging site, and she then writes a code version of all those changes in a .install file script. Her only rule is: "define everything in code, don't have anything solely in the database". This is a great rule in theory, but in practice it's currently a lot of manual work to rigorously implement. She exports whatever she can as raw PHP (e.g. views and CCK types are pretty easy), and she has a bunch of PHP helper scripts to automate exporting the rest (and she has promised to share these…), but basically this approach still needs a lot of work before it's efficient enough that we can expect most developers to adopt it.
Kathleen Murtagh presented the DBScripts module, which is her system of dealing with the deployment problem. The DBScripts approach is basically to deploy database changes by dumping, syncing and merging at the MySQL / filesystem level. This is hardly an ideal approach: dealing with raw SQL dumps can get messy at the best of times. However, DBScripts is apparently stable and can perform its job effectively, so I guess that Kathleen knows how to wade through that mess, and come out clean on the other side. DBScripts will probably be superseded by alternative solutions in the future; but for now, it's one of the better options out there that actually works.
Shaun Haber from Warner Bros Records talked about the scripts that he uses for deployment, which are (I think?) XML-based, and which attempt to manually merge data where there may potentially be conflicting numeric IDs between Drupal instances. These scripts were not demo'ed, and they sound kinda nasty — there was a lot of talk about "pushing up" IDs in one instance, in order to merge in data from another instance, and other similarly dangerous operations. The Warner Records solution is custom and hacky, but it does work, and it's a reflection of the measures that people are prepared to take in order to get a viable deployment solution, for lack of an accepted standard one as yet.
There were also other presentations given at DC/DC, that dealt with the deployment and migration topic:
Moshe Weitzman and Mike Ryan (from Cyrve) gave the talk "Migration: not just for the birds", where they demo'ed the cool new Table Wizard module, a generic tool that they developed to assist with large-scale data migration from any legacy CMS into Drupal. Once you've got the legacy data into MySQL, Table Wizard takes care of pretty much everything else for you: it analyses the legacy data and suggests migration paths; it lets you map legacy fields to Drupal fields through a UI; and it can test, perform, and re-perform the actual migration incrementally as a cron task. Very useful tool, especially for these guys, who are now specialising in data migration full-time.
I unfortunately missed this one, but Chris Bryant gave the talk "Drupal Patterns — Managing and Automating Site Configurations". Along with Context and Spaces, the Patterns module is getting a lot of buzz as one of the latest-and-greatest tools that's going to change the way we do Drupal. Sounds like Patterns is taking a similar approach to Context and Spaces, except that it's centred around configuration import / export rather than "feature" definitions, and that it uses YAML/XML rather than raw PHP Exportables. I'll have to keep my eye on this one as well.
Come a long way
I have quite a long history with the issue of deployment and migration in Drupal. Back in 2006, I wrote the Import / Export API module, whose purpose was primarily to help in tackling the problem once and for all. Naturally, it didn't tackle anything once and for all. The Import / Export API was an attempt to solve the issue in as general a way as possible. It tried to be a full-blown Data API for Drupal, long before Drupal even had a Data API (in fact, Drupal still doesn't have a proper Data API!). In the original version (for Drupal 4.7), the Schema API wasn't even available.
The Import / Export API works in XML by default (although the engine is pluggable, and CSV is also supported). It bypasses all of Drupal's standard foo_load() and foo_save() functions, and deals directly with the database — which, at the end of the day, has more disadvantages than advantages. It makes an ambitious attempt to deal with non-unique numeric IDs across multiple instances, allowing data items with conflicting IDs to be overwritten, modified, ignored, etc — inevitably, this is an overly complex and rather fragile part of the module. However, when it works, it does allow any data between any two Drupal sites to be merged in any shape or form you could imagine — quite cool, really. It was, at the end of the day, one hell of a learning experience. I'm confident that we've come forward since then, and that the new solutions being worked on are a step ahead of what I fleshed out in my work back in '06.
In my new role as a full-time developer at Digital Eskimo, and particularly in my work on live local, I've been exposed to the ongoing deployment challenge more than ever before. Sacha Chua said in DC that (paraphrased):
"Manually re-doing your database changes through the UI of the production site is currently the most common deployment strategy for Drupal site maintainers."
And, sad as that statement sounds, I can believe it. I feel the pain. We need to sort out this problem once and for all. We need a clearer separation between content and configuration in Drupal, and site developers need to be able to easily define where to draw that line on a per-site basis. We need a proper Data API so that we really can easily and consistently migrate any data, managed by any old module, between Drupal instances. And we need more globally unique IDs for Drupal data entities, to avoid the nightmare of merging data where non-unique numeric IDs are in conflict. When all of that happens, we can start to build some deployment tools for Drupal that seriously rock.
]]>
First DrupalCamp Australia was a success2008-11-13T00:00:00Z2008-11-13T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/11/first-drupalcamp-australia-was-a-success/
A few weeks ago (on Sat 18th Oct 2008), we (a.k.a. the Sydney Drupal Users' Group) held the first ever DrupalCamp Australia. Sorry for the late blog post — but hey, better late than never. This was Sydney's second full-day Drupal event, and as with the first one (back in May), it was held at the University of Sydney (many thanks to Jim Woulfe from the Faculty of Pharmacy, for providing the venue). This was Sydney's biggest Drupal event to date: we had an incredible turnout of 50 people (that's right — we were booked out), and for part of the day we had two presentation tracks running in adjacent rooms.
DrupalCamp Australia logoMorning welcome to DrupalCamp AustraliaGeeks in a room
Congratulations to everyone who presented: the overall quality of the presentations was excellent. I'm afraid I didn't see all of the talks, but I'd like to thank the people whose talks I can remember, including: Peter Moulding on the Domain Access module and on multi-site setups; Justin Freeman (from Agileware) on various modules, including Export to OpenOffice (not yet released); Jeff Hanbury (from Marmaladesoul) on Panels and theming; Justin Randell on what's new in Drupal 7; myself on "patch politics" and CVS; Gordon Heydon on Git and on E-Commerce; Erle Pereira on Drupal basics; and Simon Roberts on unit testing. Apologies for anyone I've missed (please buzz me and I'll add you).
Thanks to the organisations that sponsored this event (yes, we now have sponsors!) — they're listed on the event page. Mountains of thanks to Ryan Cross for organising the whole thing, and for being the rock of the group for the past year or so. Ryan also designed the funky logo for this event, which in my opinion is a very spiffy-looking logo indeed. And finally, thanks to everyone who attended (especially the usual suspects from Melbourne, Canberra, Brisbane, and even New Zealand): you made the day what it was. Viva Drupal Sydney!
]]>
Drupal and Apache in Vista: some tips2008-06-05T00:00:00Z2008-06-05T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/06/drupal-and-apache-in-vista-some-tips/
I bought a new laptop at the start of this year, and since then I've experienced the "privilege"pile of festering camel dung that is being a user of Windows Vista. As with most things in Vista, installing Drupal and Apache is finickier than it used to be, back on XP. When I first went through the process, I encountered a few particularly weird little gotchas, and I scribbled them down for future reference. Here are some things to look out for, when the inevitable day comes in which you too will shine the light of Drupal upon the dark and smelly abyss of Vista:
Don't use the stop / start / restart Apache controls in the start menu (start > programs > Apache > control), as they are unreliable; use services.msc insetad (start > run > "services.msc").
Don't edit httpd.conf through the filesystem — use the 'edit httpd.conf' icon in the start menu instead (start > programs > Apache > configure), as otherwise your saved changes may not take effect.
If you're seeing the error message "http request status - fails" on Drupal admin pages, then try editing your 'c:\windows\system32\drivers\etc\hosts' file, and taking out the IPv6 mapping of localhost, as this can confuse the Windows mapping of 127.0.0.1 to localhost (restart for this to take effect).
Don't use Vista! If, however, you absolutely have no choice, then refer to steps 1-3.
]]>
Drupal at the 2008 Sydney CeBIT Expo2008-05-26T00:00:00Z2008-05-26T00:00:00ZJazahttps://greenash.net.au/thoughts/2008/05/drupal-at-the-2008-sydney-cebit-expo/
The past week has been a big one, for the small but growing Sydney Drupal Users' Group. Last week, on Tuesday through Thursday (May 20-22), we manned the first-ever Drupal stall at the annual Sydney CeBIT Expo. CeBIT is one of the biggest technology shows in Australia — and the original CeBIT in Germany is the biggest exhibition in the world. For three days, we helped "spread the word" by handing out leaflets, running lives demos, and talking the talk to the Expo's many visitors.
Ryan and James at CeBIT 2008Drupal demo laptops at CeBIT 2008
The Sunday before (May 18), we also arranged a full-day get-together at the University of Sydney, as a warm-up for CeBIT: there were a few informal presentations, and we got some healthy geeked-up discussion happening.
Drupal May 2008 meetup at Sydney UniDinner and drinks after the May 2008 Drupal meetup
Thanks to everyone who travelled to Sydney for the meetup and Expo, from places far and wide. Kudos to Michael and Alan from CaignWebs in Brisbane; to Simon Roberts from Melbourne; and especially to the fine folks from Catalyst IT in New Zealand, who hopped over the ditch just to say hello. Many thanks also to everyone who helped with organising the past week's events. Along with everyone (mentioned above) who visited from other cities, the events wouldn't have happened without the help of Ashley, of Drew, and particularly of Ryan.
I gave a presentation at the Sunday meetup, entitled: "Drupal's System Requirements: Past, Present and Future". I talked about the minimum PHP5 and MySQL5 version requirements that will be introduced as of Drupal 7, and the implications of this for Drupal's future. The presentation sparked an interesting discussion on PDO and on Objest-Oriented-ness. You can find my slides below. Other presentations included: "Drupal's Boost module (by Simon); "The Drupy (Drupal in Python) project" (by the Catalyst guys); and "The Drupal Sydney Community" (by Ryan).
]]>
Useful SQL error reporting in Drupal 62007-10-13T00:00:00Z2007-10-13T00:00:00ZJazahttps://greenash.net.au/thoughts/2007/10/useful-sql-error-reporting-in-drupal-6/
The upcoming Drupal 6 has a very small but very useful new feature, which went into CVS quietly and with almost no fanfare about 6 weeks ago. The new feature is called "useful SQL error reporting". As any Drupal developer would know, whenever you're coding away at that whiz-bang new module, and you've made a mistake in one of your module's database queries, Drupal will glare at you with an error such as this:
SQL error reporting in Drupal 5
Text reads:
user warning: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'd5_node n INNER JOIN d5_users u ON u.uid = n.uid INNER JOIN d5_node_revisions r ' at line 1 query: SELECT n.nid, n.vid, n.type, n.status, n.created, n.changed, n.comment, n.promote, n.sticky, r.timestamp AS revision_timestamp, r.title, r.body, r.teaser, r.log, r.format, u.uid, u.name, u.picture, u.data FROMMM d5_node n INNER JOIN d5_users u ON u.uid = n.uid INNER JOIN d5_node_revisions r ON r.vid = n.vid WHERE n.nid = 1 <strong>in C:\www\drupal5\includes\database.mysql.inc on line 172.</strong>
That message is all well and good: it tells you that the problem is an SQL syntax error; it prints out the naughty query that's causing you the problem; and it tells you that Drupal's "includes/database.mysql.inc" file is where the responsible code lies. But that last bit — about the "database.mysql.inc" file — isn't quite true, is it? Because although that file does indeed contain the code that executed the naughty query (namely, the db_query() function in Drupal's database abstraction system), that isn't where the query actually is.
In Drupal 6, this same message becomes a lot more informative:
SQL error reporting in Drupal 6
Text reads:
user warning: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'd6_node n INNER JOIN d6_users u ON u.uid = n.uid INNER JOIN d6_node_revisions r ' at line 1 query: SELECT n.nid, n.vid, n.type, n.language, n.title, n.uid, n.status, n.created, n.changed, n.comment, n.promote, n.moderate, n.sticky, n.tnid, n.translate, r.nid, r.vid, r.uid, r.title, r.body, r.teaser, r.log, r.timestamp AS revision_timestamp, r.format, u.name, u.data FROMMM d6_node n INNER JOIN d6_users u ON u.uid = n.uid INNER JOIN d6_node_revisions r ON r.vid = n.vid WHERE n.nid = 2 <strong>in C:\www\drupal\modules\node\node.module on line 669.</strong>
This may seem like a small and insignificant new feature. But considering that a fair chunk of the average Drupal developer's debugging time is consumed by fixing SQL errors, it's going to be a godsend for many, many people. The value and the usefulness of this feature, for developers and for others, should not be underestimated.
I believe that someone was videoing my presentation, but I'm not sure if the video is online yet, or if it will be; and if it is online, I don't know where. I also don't know if I'm supposed to be posting my slides to some official spot, rather than just posting them here, where you can find them through Planet Drupal. So if anyone knows the answers to these things, please post your answers here as comments. Anyway, glad you found this, and enjoy the slides.
]]>
GreenAsh ground-up videocast: Part III: Custom theming with Drupal 4.72006-12-31T00:00:00Z2006-12-31T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/12/videocast-custom-theming-drupal-4-7/
This video screencast is part III of a series that documents the development of a new, real-life Drupal website from the ground up. It shows you how to create a custom theme that gives your site a unique look-and-feel, using Drupal's built-in PHPTemplate theme engine. Tasks that are covered include theming blocks, theming CCK node types, and theming views. Video produced by GreenAsh Services, and sponsored by Hambo Design. (21:58 min 24.1MB H.264)
I hope that all you fellow Drupalites have enjoyed this series, and I wish you a very happy new year!
This is the final episode in this series. If you haven't done so already, go and watch part I and part II.
Note: to save the video to your computer, right-click it and select 'Save Link As...' (or equivalent action). You will need QuickTime v7 or higher in order to watch the video.
]]>
GreenAsh ground-up videocast: Part II: Installing and using add-on modules with Drupal 4.72006-12-24T00:00:00Z2006-12-24T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/12/videocast-installing-addon-modules-drupal-4-7/
This video screencast is part II of a series that documents the development of a new, real-life Drupal website from the ground up. It shows you how to install a number of the more popular add-on modules from the contributions repository, and it steps through a detailed demonstration of how to configure these modules. The add-on modules that are covered include Views, CCK, Pathauto, and Category. Video produced by GreenAsh Services, and sponsored by Hambo Design. (28:44 min — 35.1MB H.264)
Stay tuned for part III, which will be the final episode in this series, and which will cover custom theming with PHPTemplate. If you haven't done so already, go and watch part I.
Note: to save the video to your computer, right-click it and select 'Save Link As...' (or equivalent action). You will need QuickTime v7 or higher in order to watch the video.
]]>
GreenAsh ground-up videocast: Part I: Installing and configuring Drupal 4.72006-12-17T00:00:00Z2006-12-17T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/12/videocast-installing-and-configuring-drupal-4-7/
This video screencast is part I of a series that documents the development of a new, real-life Drupal website from the ground up. It shows you how to download Drupal 4.7, install it, and perform some basic initial configuration tasks. Video produced by GreenAsh Services, and sponsored by Hambo Design. (11:35 min — 10.2MB H.264)
Stay tuned for part II, which will cover the installation and configuration of add-on modules, such as Views, CCK, Pathauto, and Category; and part III, which will cover custom theming with PHPTemplate.
Note: to save the video to your computer, right-click it and select 'Save Link As...' (or equivalent action). You will need QuickTime v7 or higher in order to watch the video.
]]>
GreenAsh 3.0: how did they do it?2006-10-04T00:00:00Z2006-10-04T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/10/greenash-3-0-how-did-they-do-it/
After much delay, the stylish new 3rd edition of GreenAsh has finally hit the web! This is the first major upgrade that GreenAsh has had in almost 2 years, since it was ported over from home-grown CMS (v1) to Drupal (v2). I am proud to say that I honestly believe this to be the cleanest (inside and out), the most mature, and the sexiest edition to date. And as you can see, it is also one of the biggest upgrades that the site has ever had, and possibly the last really big upgrade that it will have for quite some time.
The site has been upgraded from its decaying and zealously hacked Drupal 4.5 code base, to the latest stable (and much-less-hacked) 4.7 code base. This fixes a number of security vulnerabilities that previously existed, as well as bringing the site back into the cutting edge of the Drupal world, and making it compatible with all the latest goodies that Drupal has to offer.
New theme
GreenAsh 3.0 sports a snazzy new theme, complete with fresh branding, graphics, and content layout. The new theme is called Lorien, and as with previous site designs, it gives GreenAsh a public face using nothing but accessible, validated, and standards-compliant markup:
GreenAsh 3.0
GreenAsh 2.0 was styled with the Mithrandir theme:
GreenAsh 2.0
And GreenAsh 1.0, which was not Drupal-powered, did not technically have a 'theme' at all; but for historical purposes, let's call its design the GreenAsh theme:
GreenAsh 1.0
New modules
GreenAsh 3.0 is also using quite a few new modules that are only available in more recent versions of Drupal. The views module is being used to generate custom node listings in a number of places on the site, including for all of the various bits that make up the new front page, and also for the revamped recent posts page. The pathauto module is now generating human-readable URLs for all new pages of the site, in accordance with the site's navigation structure. Because the URL format of the site's pages has changed, a number of old URLs are now obselete, and these are being redirected to their new equivalents, with the help of the path redirect module.
The improved captcha module is providing some beginner-level maths questions to all aspiring new users, anonymous commenters, and anonymous contact form submitters, and is proving to be an effective combatant of spam. Also, the very nifty nice menus module is being used for administrator-only menus, to provide a simple and unobtrusive navigational addition to the site when needed.
Best of all, the site has finally been switched over to the category module, which was built and documented by myself, and which had the purpose from the very beginning of being installed right here, in order to meet the hefty navigational and user experience demands that I have placed upon this site. Switching to the category module was no small task: it required many hours of careful data migration, site re-structuring, and menu item mayhem. I certainly do not envy anyone who is making the switch from a taxonomy or book installation to a category module installation. But, despite the migration being not-for-the-faint-hearted, everything seems to be running smoothly now, and the new system is providing a vastly improved end-user and site administrator experience.
New user experience
I have implemented a number of important changes to the user experience of the site, which will hopefully make your visit to the site more enjoyable and useful:
Re-designed front page layout
Switch to a simple and uncluttered 1-column layout for all other pages
New category-module-powered navigation links and table-of-contents links
Automatic new user account approval after 72 hours
Removed a number of pages from the site's hierarchy, to reduce unnecessary information overload
Ongoing effort
Obviously, there are still a number of loose ends to tie up. For example, the content on some pages may still require updating. Additionally, some pages are still yet to be added (such as the listings in the sites folio). Further tweaks and adjustments will probably also be made to the look and feel of the site in the near future, to continue to improve it and to make it distinctly branded.
Feedback, comments, suggestions, criticisms, cookies, cakes, donations, and lingerie are all welcome to be thrown my way. Throwing apple cores is discouraged: if you think the new site stinks that badly, why not be constructive and throw a can of deodorant instead? Anyway, I really do hope you all like the site post-upgrade, and I wish you all the best in your exploration of the new and improved GreenAsh 3.0!
]]>
Import / Export API: final thoughts2006-09-07T00:00:00Z2006-09-07T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/09/import-export-api-final-thoughts/
The Summer of Code has finally come to an end, and it's time for me to write up my final thoughts on my involvement in it. The Import / Export API module has been a long and challenging project, but it's also been great fun and has, in my opinion, been a worthwhile cause to devote my time to. My mentor has given my work the final tick of approval (which is great!), and I personally feel that the project has been an overwhelming success.
Filling out the final student evaluation for the SoC was an interesting experience, because it made me realise that as someone with significant prior experience in developing for my mentor organisation (i.e. Drupal), I was actually in the minority. Many of the questions didn't apply to me, or weren't entirely relevant, as they assumed that I was just starting out with my mentor organisation, and that the SoC was my 'gateway' to learning the ropes of that organisation. I, on the other hand, already had about 18 months of experience as a Drupal developer when the SoC began, and I always viewed SoC as an opportunity to work on developing an important large-scale module (that I wouldn't have had time to develop otherwise), rather than as a 'Drupal boot camp'.
The Import / Export API is also something of a unique project, in that it's actually quite loosely coupled to Drupal. I never envisaged that it would turn out like this, but the API is actually so loosely coupled, that it could very easily be used as an import / export tool for almost any other application. This makes me question whether it would have been better to develop the API as a completely stand-alone project, with zero dependency on Drupal, rather than as a Drupal module, with a few (albeit fairly superficial) dependencies. In this context, the API is a bit like CiviCRM, in that it is basically a fully-functional application (or library, in the API's case) all by itself, but in that it relies on Drupal for a few lil' things, such as providing a pretty face to the user, and integration as part of a content-managed web site.
The module today
For those of you that haven't tried it out yet, the API is an incredibly useful and flexible tool, when it comes to getting data in and out of your site. The module currently supports importing and exporting any entity in Drupal core, in either XML or in CSV format. Support for CCK nodes, node types, and fields is also currently included. All XML tags or CSV field names can have custom mappings defined during import or export. At the moment, the UI is very basic (the plan is to work on this some more in the future), but it exposes the essential functionality of the API well enough, and it's reasonably easy to use.
The module is superior to existing import modules, because it allows you to import a variety of different entities, but to maintain and to manage the relationships between those entities. For example: nodes, comments, and users are all different entities, but they are also all related to each other; nodes are written by users, and comments are written about particular nodes by users. You could import nodes and users using the node_import and user_import modules. But these two modules would not make any effort to link your nodes to your users, or to maintain any link that existed in your imported data. The Import / Export API recognises and maintains all such links.
As for stability, the API still has a few significant known bugs lurking around in it, but overall it's quite stable and reliable. The API is still officially in beta mode, and more beta testing is still very much welcome. Many thanks to the people who have dedicated their time to testing and bug fixing thus far (you know who you are!) - it wouldn't be the useful tool that it is without your help.
The module tomorrow
And now for the most important question of all: what is the future of the API? What additional features would I (and others) like to see implemented post-SoC? What applications are people likely to build on top of it? And will the module, in some shape or form, to a greater or lesser extent, ever become part of Drupal core?
First, the additional features. I was hoping to get some of these in as part of the SoC timeframe, but as it turned out, I barely had time to meet the base requirements that I originally set for myself. So here's my wish list for the API (and in my case, mere wishing ain't gonna make 'em happen - only coding will!):
File handling. The 'file' field type in the current API is nothing more than a stub - at present, it's almost exactly the same as the 'string' field type. I would like to actually implement file handling, so that files can be seamlessly imported and exported, along with the database-centric data in a Drupal site. Many would argue that this is critical functionality. I feel you, folks - that's why this is no. 1.
Filtering and sorting in queries. The 'db' engines of the API are cutting-edge in their support for references and relationships, but they currently lack all but the most basic support for filtering and sorting in database queries. Ideally, the API will have an extensible system for this, similar to what is currently offered for node queries by the views module. A matching UI of views' calibre would be awesome, too.
Good-looking and flexible UI. The current UI is about as basic as it gets. The long-term plan is to move the UI out into a separate project (it's already a separate module), and to expose much more of the API through the interface, e.g. disabling import / export of specified fields, forcing of ID key generation / key matching and updating, control over alternate key handling. There are also plenty of cosmetic improvements that could be made to the UI, e.g. more wizard-like form dialogs (I think I'll wait for Drupal 5.0 / FAPI 2.0 before doing this), flexible control of output format (choice between file download, save output on server, display raw output, etc).
Validate and submit (and more?) callbacks. This is really kind of dependent on the API's status in regards to going into Drupal core (see further down). But the general plan is to implement FAPI-like validate and submit callbacks within the API's data definition system.
Next, there are the possible applications of the API. The API is a great foundation for a plethora of possibilities. I have faith that, over the course of the near future, developers will start to have a look at the API, and that they will recognise its potential, and that they will start to develop really cool things on top of it. Of course, I may be wrong. It's possible that almost no developers will ever look at the API, and that the API will rot away in the dark corners of Drupal contrib, before sinking slowly into the depths of oblivion. But I hope that doesn't happen.
Some of the possible applications that have come to my mind, and that other people have mentioned to me:
Finally, there is the question of whether or not (and what parts of) the API will ever find itself in Drupal core. From the very beginning, my mentor Adrian has been letting me in on his secret super-evil plan for world domination (or, at the least, for Drupal domination). I can confide to all of you that getting parts of the API in core is part of this plan. In particular, the data definition system is a potential candidate for what will be the new 'data model / data layer / data API' foundation of FAPI 3.0 (i.e. Drupal post-upcoming-5.0-release).
However, I cannot guarantee that the data definition system of the API will ever make it into core, and I certainly cannot predict in what form it will be by the time that it gets in (if it gets in, that is). Adrian has let slip a few ideas of his own lately (in the form of PHP pseudo-code), and his ideas for a data definition system seem to be quite different from mine. No doubt every other Drupal developer will also have their own ideas on this - after all, it will be a momentous change for Drupal when it happens, and everyone has a right to be a part of that change. Anyway, Adrian has promised to reveal his grand plans for FAPI 3.0 during his presentation at the upcoming Brussels DrupalCon (which I unfortunately won't be able to attend), so I'm sure that after that has happened, we'll all be much more enlightened.
The API's current data definition system is not exactly perfectly suited for Drupal core. It was developed specifically to support a generic import / export system, and that fact shows itself in many ways. The system is based around directly reflecting the structure of the Drupal database, for the purposes of SQL query generation and plain text transformation. That will have to change if the system goes into Drupal core, because Drupal core has very different priorities. Drupal core is concerned more with a flexible callback system, with a robust integration into the form generation system, and with rock-solid performance all round. Whether the data definition system of the API is able to adapt to meet these demands, is something that remains to be seen.
Further resources
Well, that's about all that I have to say about the Import / Export API module, and about my involvement in the 2006 Google Summer of Code. But before you go away, here are some useful links to get you started on your forays into the world of importing and exporting in Drupal:
Many thanks to Angie Byron (a.k.a. webchick) for your great work last year on the Forms API QuickStart guide and reference guide documents, which proved to be an invaluable template for me to use in writing these documents for the Import / Export API. Thanks also, Angie, for your great work as part of the SoC organising team this year!
And, last but not least, a big thankyou to Adrian, Sami, Rob, Karoly, Moshe, Earl, Dan, and everyone else who has helped me to get through the project, and to learn heaps and to have plenty of fun along the way. I couldn't have done it without you - all of you!
SoC - it's been a blast. ;-)
]]>
Import / Export API: progress report #42006-08-11T00:00:00Z2006-08-11T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/08/import-export-api-progress-report-4/
In a small, poorly ventilated room, somewhere in Australia, there are four geeky fingers and two geeky thumbs, and they are attached to two geeky hands. All of the fingers and all of the thumbs are racing haphazardly across a black keyboard, trying to churn out PHP; but mostly they're just tapping repeatedly, and angrily, on the 'backspace' key. A pair of eyes squint tiredly at the LCD monitor before them, trying to discern whether the miniscule black dot that they perceive is a speck of dirt, or yet another pixel that has gone to pixel heaven.
But the black dot is neither of these things. The black dot is but a figment of this young geek's delirious and overly-caffeinated imagination. Because, you see, on this upside-down side of the world, where the seasons are wrong and the toilets flush counter-clockwise, there is a Drupaller who has been working on the Summer of Code all winter long. And he has less than two weeks until the deadline!
That's right: in just 10 days, the Summer of Code will be over, and the Drupal Import / Export API will (hopefully) have met its outcomes, and will be ready for public use. That is the truth. Most of the other statements that I made above, however, are not the truth. In fact:
I still don't drink any coffee at all (and I call myself a geek?!);
as far as I can see (and I may be wrong, I admit), my monitor is still pixel-perfect.
Anyway, on to the real deal...
The current status of the Import / Export API is as follows. The DB, XML, and CSV engines are now all complete, and are (I hope) at beta-quality. However, they are still in need of a fair bit of testing and bug fixing. The same can be said for the alternate key and ID key handling systems. The data definitions for all Drupal 4.7 core entities (except for a few that weren't on the to-do list) are now complete.
There are two things that still need to be done urgently. The first of these is a system for passing custom mappings (and other attributes), for any field, into the importexportapi_get_data() function. The whole point of the mapping system is that field mappings are completely customisable, but this point cannot be realised until custom mappings can actually be provided to the API. The second of these is the data definitions for CCK fields and node types. Many people have been asking me about this, including my mentor Adrian, and it will certainly be very cool when it is ready and working.
One more thing that also needs to be done before the final deadline, is to write a very basic UI module, that allows people to actually demo the API. I won't be able to build my dream import / export whiz-bang get-and-put-anything-in-five-easy-steps UI in 10 days. But I should be able to build something functional enough, that it allows people (such as my reviewers) to test out and enjoy the key things that the API can do. Once this UI module is written, I will be removing all of the little bits of UI cruftiness that are currently in the main module.
Was there something I didn't mention? Ah, yes. Documentation, documentation, documentation - how could I forget thee? As constant as the northern star, and almost as hard to find, the task of documentation looms over us all. I will be endeavouring to produce a reference guide for the import / export API within the deadline, which will be as complete as possible. But no guarantees that it will be complete within that time. The reference guide will focus on documenting the field types and their possible attributes, much like the Drupal forms API reference does. Other docs - such as tutorials, explanations, and tips - will come later.
There are many things that the API is currently lacking, and that I would really like to see it ultimately have. Most of these things did not occur to me until I was well into coding the project, and none of them will actually be coded until after the project has finished. One of these things is an extensible query filtering and sorting system, much like the system that the amazing views module boasts. Another is a validation and fine-grained error-handling system (mainly for imports).
But more on these ideas another time. For now, I have a module to finish coding.
]]>
Import / Export API: progress report #32006-07-15T00:00:00Z2006-07-15T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/07/import-export-api-progress-report-3/
The Summer of Code is now past its half-way mark. For some reason, I passed the mid-term evaluation, and I'm still here. Blame my primary mentor, Adrian, who was responsible for passing me with flying colours. The API is getting ever closer to meeting its success criteria, although not as close as I'd hoped for it to be by this point.
My big excuse for being behind schedule is that I got extremely sidetracked, with my recent work on the Drupal core patch to get a subset of CCK into core (CCK is the Content Construction Kit module, the successor to Flexinode, a tool for allowing administrators to define new structured content types in Drupal). However, this patch is virtually complete now, so it shouldn't be sidetracking me any more.
A very crude XML import and export is now possible. This is a step up from my previous announcements, where I had continually given the bad news that importing was not yet ready at all. You can now import data from an XML file into the database, and stuff will actually happen! But just what you can import is very limited; and if you step outside of that limit, then you're stepping beyond the API's still-constricted boundaries.
The ID and reference handling system - which is set to be one of the API's killer features - is only half-complete at present. I've spent a lot of time today working on the ID generation system, which is an important part of the overall reference handling system, and which is now almost done. This component of the API required a lot of thinking and planning before it happened, as can be seen by the very complicated Boolean decision table that I've documented. This is for working out the various scenarios that need to be handled, and for planning the control logic that determines what actions take place for each scenario.
Unfortunately, as I said, the reference handling system is only half-done. And it's going to stay that way for a while, because I'm away on vacation for the next full week. I hate to just pack up and leave at this critical juncture of development, but hey: I code all year round, and I only get to ski for one week of the year! Anyway, despite being a bit behind schedule, I'm very happy with the quality and the cleanliness of the code thus far (same goes for the documentation, within and outside of the code). And in the Drupal world, the general attitude is that it's better to get something done a bit late, as long as it's done right. I hope that I'm living up to that attitude, and I wish that the rest of the world followed the same mantra.
]]>
Drupal lite: Drupal minus its parts2006-06-28T00:00:00Z2006-06-28T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/06/drupal-lite-drupal-minus-its-parts/
It is said that a house is the sum of its parts. If you take away all the things that make it a house, then it is no longer a house. But how much can you remove, before it can no longer be called a house? This is an age-old question in the school of philosophy, and it is one for which every person has a different answer. If you take away the doors, the windows, the roof, the floorboads, the inside walls, the power lines, and the water pipes, is it still a house? In developing Drupal Lite, I hope to have answered this question in relation to Drupal. What are the absolute essentials, without which Drupal simply cannot be called Drupal? If you remove nodes, users, and the entire database system from Drupal, is it still Drupal?
Drupal Lite is, as its name suggests, a very lightweight version of Drupal, that I whipped up in about two hours last night. I developed it because I've been asked to develop a new site, which will consist mainly of static brochureware pages, with a contact form or two, and perhaps a few other little bits of functionality; but which will have to run with no database. Of course, I could just do it the ol' fashioned way, with static HTML pages, and with a CGI script for the contacts forms. Or I could whip up some very basic PHP for template file inclusion.
But muuum, I wanna use Druuupal!
Too bad, right? No database, no Drupal - right? Wrong.
Drupal Lite would have to be the lightest version of Drupal known to man. It's even lighter than what I came up with the last time that I rewrote Drupal to be lighter. And unlike with my previous attempt, I didn't waste time doing anything stupid, like attempting to rewrite Drupal in an object-oriented fashion. In fact, I barely did any hacking at all. I just removed an enormous amount of code from Drupal core, and I made some small modifications to a few little bits (such as the module loader, and the static variable system), to make them database-unreliant.
This has all been done for a practical purpose. But it brings up the interesting question: just how much can you remove from Drupal, before what you've got left can no longer be called Drupal? The answer, in my opinion, is: lots. Everything that is database-reliant has been removed from Drupal Lite. This includes: nodes; users; blocks; filters; logs; access control (for all practical purposes); caching (at present - until file-based caching gets into core); file management; image handling; localization; search; URL aliasing (could have been rewritten to work with conf variables - but I didn't bother); and, of course, the DB abstraction system itself.
This proves, yet again, that Drupal is a hacker's paradise. It really is so solid - you can cut so much out of it, and if you (sort of) know what you're doing, it still works. There are just endless ways that you can play with Drupal, and endless needs that you can bend it to.
So what's left, you ask? What can Drupal still do, after it is so savagely crippled, and so unjustly robbed of many of its best-known features? Here's what Drupal Lite can offer you:
Persistent variables (by setting the $conf variable in your settings.php file)
Module loading
Hook system
Menu callback
Theming
Forms API (although there's not much you can do with submitted form data, except for emailing it, or saving it to a text file)
Clean URLs
Breadcrumbs
User messages
404 / 403 handling
Error handling
Page redirection
Site offline mode
Basic formatting, validation, filtering, and security handling
Link and base URL handling
Unicode handling
Multisite setup (in theory - not tested)
This is more than enough for most brochureware sites. I also wrote a simple little module called 'static', that lets you define menu callbacks for static pages, and to include the content of such pages automatically, from separate template-ish files. This isn't as good as pages that are editable by non-geeky site admins (for which you need the DB and the node system), but it still allows you to cleanly define/write the content for each page; and the content of the template file for each page is virtually identical to the content of a node's body, meaning that such pages could easily be imported into a real Drupal site in future.
Speaking of which, compatibility with the real Drupal is a big feature of Drupal Lite. Any modules that are developed for Drupal Lite should work with Drupal as well. PHPTemplate (or other) themes written for Drupal Lite should work with a real Drupal site, except that themes don't have any block or region handling in Drupal Lite. Overall, converting a Drupal Lite site to the Real Deal™ should be a very easy task; and this is important for me, since I'd probably do that conversion for the site I'll be working on, if more server resources ever become available.
Drupal Lite is not going to be maintained (much), and I most certainly didn't write it as a replacement for Drupal. I just developed it for a specific need that I have, and I'm making it publicly available for anyone else who has a similar need. Setting up Drupal Lite basically consists of setting a few $conf values in settings.php, and creating your static page template files.
If you're interested, download Drupal Lite and have a peek under the hood. The zipped file is a teeny 81k - so when you do look under the hood, don't be surprised at how little you'll find! Otherwise, I'd be interested to just hear your thoughts.
A note to my dear friend Googlebot: in your infinite wisdom, I hope that you'll understand the context in which I used the phrase "hacker's paradise" in the text above. Please forgive me for this small travesty, and try to avoid indexing this page under the keyword "Windows 98". ;-)
]]>
Import / Export API: progress report #22006-06-26T00:00:00Z2006-06-26T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/06/import-export-api-progress-report-2/
The mid-program mentor evaluation (a.k.a. crunch time) for the Summer of Code is almost here, and as such, I've been working round-the-clock to get my project looking as presentable as possible. The Import / Export API module has made significant progress since my last report, but there's still plenty of work left to be done.
It gives me great pride to assert that if you download the module right now, you'll find that it actually does something. :-) I know, I know - it doesn't do much (in fact, I may simply be going delusional and crazy from all the coding I've been doing, and it may actually do nothing) - but what it does do is pretty cool. The XML export engine is now functional, which means that you can already use the module to export any entities that currently have a definition available (which is only users and roles, at present), as plain-text XML:
XML export screenshot
The import system isn't quite ready to go as yet, but the XML-to-array engine is pretty much done, and with a little more work, the array-to-DB engine will be done as well.
The really exciting stuff, however, has been happening under the hood, in the dark and mysterious depths of the API's code. Alright, alright - exciting if you're the kind of twisted individual that believes recursive array building and refactored function abstraction are hotter than Angelina's Tomb Raiders™. But hey, who doesn't?
Some of the stuff that's been keeping me busy lately:
The new Get and Put API has been implemented. All engines now implement either a 'get' or a 'put' operation (e.g. get data from the database, put data into an XML string). All exports and imports are now distinctly broken up into a 'get' and a 'put' component, with the data always being in a standard structured form in-between.
Nested arrays are now fully supported, even though I couldn't find any structures in Drupal that require a nested array definition (I wrote a test module that uses nested arrays, just to see that it works).
The definition building system has been made more powerful. Fields can now be modified at any time after the definition 'library' is first built. Specific engines can take the original definitions, and build them using their own custom callbacks, for adding and modifying custom attributes.
Support for Alternate key fields has been added. This means that you can export unique identifiers that are more human-friendly than database IDs (e.g. user names instead of user IDs), and these fields will automatically get generated whenever their ID equivalents are found in a definition. This will get really cool when the import system is ready - you will be able to import data that only has alternate keys, and not ID keys - and the system will be able to translate them for you.
Also, for those of you that want to get involved in this project, and to offer your feedback and opinions, head on over to the Import / Export API group, which is part of the new groups.drupal.org community site, and which is open for anyone to join. I'd love to hear whatever you may have to say about the module - anything from questions about how it can help you in your quest for the holy grail (sorry, only African Swallows can be exported at this time, support for European Swallows is not yet ready), to complaints about it killing your parrot (be sure that it isn't just resting) - all this and more is welcome.
I hope to have more code, and another report, ready in the near future. Thanks for reading this far!
]]>
Import / Export API: progress report #12006-06-06T00:00:00Z2006-06-06T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/06/import-export-api-progress-report-1/
It's been almost two weeks since the 2006 Summer of Code began, and with it, my work to develop an import / export API module for Drupal. In case you missed it, my work is being documented on this wiki. My latest code is now also available as a project on drupal.org. Since I've barely started, I think that this is a stupid time to sit back and reflect on what I've done so far. But I'm doing it anyway.
Let's start with some excuses. I'm working full-time at the moment, I've got classes on in between, and I just joined the cast of an amateur musical (seriously, what was I thinking?). So due to my current shortage of time, I've decided to focus on documentation for now, which - let's face it - should ideally be done in large quantities before any code is produced, anyway. So I've posted a fair bit of initial documentation on the wiki, including research on existing import / export solutions in Drupal, key features of the new API, and possible problems that will be encountered.
Last weekend, I decided that I was kind of sick of documentation, and that I could ignore the urge to code no longer. Hence, the beginnings of the API are now in place, and are up in Drupal CVS. I will no doubt be returning to documentation over the next few days, in the hope of fattening up my shiny new wiki, which is currently looking rather anorexic.
On a related note: anonymous commenting has been disabled on the wiki, as it was receiving unwelcome comment spam. If you want to post comments, you will HaveToLogin using your name InCamelCase (which is getting on my nerves a bit - but I have to admit that it does the job and does it well).
So far, I've coded the first draft of the data definition for the 'user' entity, and in the process, I've defined-through-experimentation what a data definition will look like in my module. The data definition attributes and structure are currently undocumented, and I see no reason to change that until it all matures a lot more. But ultimately, the plan is to have a reference for it, similar to the Drupal forms API reference.
There are six 'field types' in the current definition system: string (the default), int, float, file, array, and entity. An 'entity' is the top-level field, and is for all practical purposes not a field, but is rather the thing that fields go in. An array is for holding lists of values, and is what will be used for representing 1-M (and even N-M) data within the API. Note to self: support for nested arrays is currently lacking, and is desperately needed.
I have also coded the beginnings of the export engine. This engine is currently capable of taking a data definition, querying the database according to that definition, and providing an array of results, that are structured into the definition (as 'value' fields), and that can then be passed to the rendering part of the engine. The next step is to actually write the rendering part of the engine, and to plug an XML formatter into this engine to begin with. Once that's done, it will be possible to test the essentials of the export process (i.e. database -> array data -> text file data) from beginning to end. I think it's important to show this end-to-end functionality as early on as possible, to prove to myself that I'm on the right track, and to provide real feedback that the system is working. Once this is done, the complexities can be added (e.g. field mapping system, configurable field output).
Overall, what I've coded so far looks very much like a cross between the forms API (with _alter() hooks, recursive array building, and extensible definitions), and the views module (with a powerful definition system, that gets used to build queries). Thank you to the respective authors of both these systems: Adrian / Vertice (one of my mentors); and Earl / Merlinofchaos (who is not my mentor, but who is a mentor, as well as a cool cool coder). Your efforts have provided me with heaps of well-engineered code to copy - er, I mean, emulate! If my project is able to be anywhere near as flexible or as powerful as either of these two systems, I will be very happy.
Thanks also to Adrian and to Sami for the feedback that you've given me so far. I've been in contact with both of my mentors, and both of them have been great in terms of providing advice and guidance.
]]>
An undo button for Drupal2006-05-24T00:00:00Z2006-05-24T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/05/an-undo-button-for-drupal/
Every time that you perform any action in a desktop application, you can hit the trusty 'undo' button, to un-wreak any havoc that you may have just wreaked. Undo and redo functionality comes free with any text-based desktop application that you might develop, because it's a stock standard feature in virtually every standard GUI library on the planet. It can also be found in most other desktop applications, such as graphics editors, animation packages, and even some games. Programming this functionality into applications such as live client-side editors is extremely easy, because the data is all stored directly in temporary memory, and so keeping track of the last 'however many' changes is no big deal.
One of the biggest shortcomings of web applications in general, is that they lack this crucial usability (and arguably security) feature. This is because web applications generally work with databases (or with other permanent storage systems, such as text files) when handling data between multiple requests. They have no other choice, since all temporary memory is lost as soon as a single page request finishes executing. However, despite this, implementing an 'undo' (and 'redo') system in Drupal should be a relatively simple task - much simpler, in fact, than you might at first think.
Consider this: virtually all data in Drupal is stored in a database - generally, a single database; and all queries on that database are made through the db_query() function, which is the key interface in Drupal's database abstraction layer. Also, all INSERT, UPDATE, and DELETE queries in Drupal are (supposed to be) constructed with placeholders for actual values, and with variables passed in separately, to be checked before actually getting embedded into a query.
It would therefore be a simple task to change the db_query() function, so that it recorded all INSERT, UPDATE, and DELETE queries, and the values that they affect, somewhere in the database (obviously, the queries for keeping track of all other queries would have to be excluded from this, to prevent infinite loops from occurring). This could even be done with Drupal's existing watchdog system, but a separate system with its own properly-structured database table(s) would be preferable.
Once this base system is in place, an administrative front-end could be developed, to browse through the 'recently executed changes' list, to undo or redo the last 'however many' changes, and to set the amount of time for which changes should be stored (just as can be done for logs and statistics already in Drupal), among other things. Because it is possible to put this system in place for all database queries in Drupal, undo and redo functionality could apply not just to the obvious 'content data' (e.g. nodes, comments, users, terms / vocabularies, profiles), but also to things that are more 'system data' (e.g. variables, sequences, installed modules / themes).
An 'undo / redo' system would put Drupal at the bleeding edge of usability in the world of web applications. It would also act as a very powerful in-built data auditing and monitoring system, which is an essential feature for many of Drupal's enterprise-level clientele. And, of course, it would provide top-notch data security, as it would virtually guarantee that any administrative blunder, no matter how fatal, can always be reverted. Perhaps there could even be a special 'emergency undo' interface (e.g. an 'undo.php' page, similar to 'update.php'), for times when a change has rendered your site inaccessible. Think of it as Drupal's 'emergency boot disk'.
This is definitely something to add to my todo list, hopefully for getting done between now and the 4.8 code freeze. However, with my involvement in the Google Summer of Code seeming very likely, I may not have much time on my hands for it.
]]>
Australia's first Drupal meetup, and my weekend in Melbourne2006-04-23T00:00:00Z2006-04-23T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/04/australias-first-drupal-meetup-and-my-weekend-in-melbourne/
I've just gotten back from a weekend away in Melbourne (I live in Sydney), during which I attended Australia's first ever Drupal meetup! We managed a turnout of 7 people, which made for a very cosy table at the Joe's Garage cafe.
The people present were:
Gordon and John at the Melbourne meetupDavid and Simon at the Melbourne meetupMichael and Andrew at the Melbourne meetupAndrew and Jeremy at the Melbourne meetup
As you can see, Gordon impressed us all by getting a T-shirt custom-made with the Druplicon graphic on it:
Gordon with the Druplicon T-shirt
The meetup went on for about 2 hours, during which time we all introduced ourselves, asked a barrage of questions, told a small number of useful answers (and plenty of useless ones), drank a variety of hot beverages, and attempted to hear each other above the noisy (but very good) jazz music.
As the most experienced Drupalite in Australia, Gordon was the one that did the most answering of questions. Gordon was the person that arranged this meetup (thanks for organising it, mate!), as well as the only one among us who works full-time as a Drupal consultant (with John and myself working as consultants part-time). What's more, Gordon is now the maintainer of the E-Commerce module.
However, I still had time to do a bit of category module evangelism, which has become my number one hobby of late.
One of the hottest topics on everyone's mind was the need for training, in order to bring more Drupal contributors and consultants into the fold. This is an issue that has received a lot of attention recently in the Drupal community, and we felt that the need is just as great in Australia as it is elsewhere. Australia is no exception to the trend of there being more Drupal work than there is a supply of skilled Drupal developers.
While I was in Melbourne, I had a chance to catch up with some friends of mine, and also to do a bit of sightseeing. Here are some of the sights and sounds of Melbourne:
Melbourne's Yarra RiverTrams in MelbourneFlinders St StationFederation Square
I was also very pleased (and envious) to see that Melbourne is a much more bicycle-friendly city than Sydney:
Cyclists in MelbourneBike racks in Melbourne CBD
In summary, it was well worth going down to Melbourne for the weekend, and the highlight of the weekend was definitely the Drupal meetup! I am very proud to be one of the people that attended the historic first ever Aussie Drupal get-together, and I really hope that there will be many more.
So, why didn't I go to DrupalCon Vancouver? Well, Vancouver is just a little bit further away for me than Melbourne. That's why I think the next worldwide DrupalCon should be in Sydney. ;-)
]]>
An IE AJAX gotcha: page caching2006-03-13T00:00:00Z2006-03-13T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/03/an-ie-ajax-gotcha-page-caching/
While doing some AJAX programming, I discovered a serious and extremely frustrating bug when using XMLHTTP in Internet Explorer. It appears that IE is prone to malfunctioning, unless a document accessed through AJAX has its HTTP header set to disallow caching. Beware!
I was working on the Drupalactiveselect module, which allows one select box on a form to update the options in another form dynamically, through AJAX. I was having a very strange problem, where the AJAX worked fine when I first loaded the page in IE, but then refused to work properly whenever I refreshed or re-accessed the page. Only closing and re-opening the browser window would make it work again. Past the first time / first page load, everything went haywire.
Finally, I found a page suggesting that I set the HTTP response headers to disallow caching. It worked! My beautiful AJAX is now working in IE, just as well as it is working in decent browsers (i.e. Firefox et al). What I did was put the following response headers in the page (using the PHP header() function):
<?php header("Expires: Sun, 19 Nov 1978 05:00:00 GMT");
header("Last-Modified: " . gmdate("D, d M Y H:i:s") . " GMT");
header("Cache-Control: no-store, no-cache, must-revalidate");
header("Cache-Control: post-check=0, pre-check=0", false);
header("Pragma: no-cache");
?>
These are the same response headers that the Drupal core uses for cached pages (that's where I copied them from). Evidently, when IE is told to invoke an AJAX HTTP request on a page that it thinks it should 'cache', it simply can't handle it.
So, for anyone else that finds that their AJAX code is bizarrely not working in IE after the first page load, this may be the answer! May this post end your troubles sooner rather than later.
]]>
A patch of flowers, a patch of code2006-01-20T00:00:00Z2006-01-20T00:00:00ZJazahttps://greenash.net.au/thoughts/2006/01/a-patch-of-flowers-a-patch-of-code/
The word patch has several different meanings. The first is that with which a gardener would be familiar. Every gardener has a little patch of this planet that he or she loves and tends to. In the gardening sense, a patch is a rectangular plot of land filled with dirt and flora; but, as gardeners know, it is also so much more than that. It is a living thing that needs care and attention; and in return, it brings great beauty and a feeling of fulfilment. A patch is also a permanent space on the land - a job that is never finished, some would say - and for as long as it is tended, it will flower and blossom.
Another meaning of patch is that usually applied to clothing and fabrics. To a tailor or a seamstress, a patch is a small piece of material, sewn over a hole or a rent in a garment. It is an imperfect and often temporary fix for a permanently damaged spot. A patch in this sense, therefore, connotes ugliness and scarring. A seamstress is hardly going to put as much time and attention into a patch as she would into a new garment: why bother, when it is only a 'quick fix', and will never look perfect anyway? There is no pride to be gained in making unseemly little patches. Designing and crafting something new, where all of the parts blend together into a beautiful whole, is considered a much more noble endeavour.
The latter and less glamorous meaning of this word seems to be the one that applies more widely. When a doctor tends your wounds, he or she may tell you that you're being patched up. Should you ever happen to meet a pirate, you may notice that he wears an eye patch (as well as saying "arrr, me hearties, where be ye wallets and mobile phones?"). And if you're a software programmer, and you find a bug in your program, then you'll know all about patching them pesky bugs, to try and make them go away.
But is it really necessary for software patches to live up to their unsightly reputation? Do patches always have to be quick 'n' dirty fixes, done in order to fix a problem that nobody believes will ever heal fully? Must they always be temporary fixes that will last only a few weeks, or perhaps a few months, before they have to be re-plastered?
As with most rhetorical questions that are asked by the narrator of a piece of writing, and that are constructed to be in a deliberately sarcastic tone, the answer to all of the above is, of course, 'no'. ;-)
I used to believe that software patches were inherently dirty things. This should come as no surprise, seeing that the only time I ever used to encounter patches, was when I needed to run Windows™ Update, which invariably involves downloading a swarm of unruly patches, 99% of which I am quite certain were quick and extremely dirty fixes. I'm sure that there are many others like me, who received their education on the nature of patches from Microsoft; but such people are misinformed, because this is analogous to being educated on the nature of equality by growing up in Soviet Russia.
Now, I'm involved in the Drupal project as a developer. Drupal is an open-source project - like many others - where changes are made by first being submitted to the community, in the form of a patch. I've seen a number of big patches go through the process of review and refinement, before finally being included in Drupal; and more recently, I've written some patches myself, and taken them through this process. Just yesterday, I got a fairly big patch of mine committed to Drupal, after spending many weeks getting feedback on it and improving it.
Developing with Drupal has taught me one very important thing about patches. When done right, they are neither quick nor dirty fixes. Patching the right way involves thinking about the bigger picture, and about making the patch fit in seamlessly with everything that already exists. It involves lengthy reviews and numerous modifications, often by a whole team of people, in order to make it as close to perfect as it can practically be.
But most of all, true patching involves dedication, perseverance, and love. A patch done right is a patch that you can be proud of. It doesn't give the garment an ugly square mark that people would wish to hide; it makes the garment look more beautiful than ever it was before. Patching is not only just as noble an endeavour as is designing and building software from scratch; it is even more so, because it involves building on the amazing and well-crafted work of others; and when done right, it allows the work of many people to amazingly (miraculously?) work together in harmony.
And as for patches being temporary and transient - that too is a myth. Any developer knows that once they make a contribution to a piece of software, they effectively own a little piece of its code. They become responsible for maintaining that piece, for improving it, and for giving it all the TLC that it needs. If they stick around and nurture their spot, then in time it will blossom, and its revitalising scent will spread and sweeten all the other spots around it.
Let's stop thinking about patches in their negative sense, and start thinking about them in their positive sense. That's the first step, and the hardest of all. After that, the next step - making and maintaining patches in the positive sense - will be child's play.
]]>
One year of Drupal2005-12-26T00:00:00Z2005-12-26T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/12/one-year-of-drupal/
Last week marked my first Drupalversary: I have been a member of drupal.org for one year! Since starting out as yet another webmaster looking for a site management solution, I have since become an active member of the Drupal community, a professional Drupal consultant, a module developer, and a core system contributor. Now it's time to look back at the past year, to see where Drupal has come, to see what it's done for me (and vice versa), and to predict what I'll be up to Drupal-wise over the course of the next year.
In November last year, I was still desperately endeavouring to put together my own home-grown CMS, which I planned to use for managing the original GreenAsh website. I was learning first-hand what a mind-bogglingly massive task it is to write a CMS, whilst I was also still getting my fingers around the finer points of PHP. Despair was setting in, and I was beginning to look around for a panacea, in the form of an existing open source application.
But the open source CMS offerings that I found didn't give me much hope. PHP-Nuke didn't just make me sick - it gave me radiation poisoning. e107 promised amazing ease-of-use - and about as much flexibility as a 25-year home loan. Plone offered everything I could ever ask for - and way more than I ever would ask for, including its own specialised web server (yeah - just what I need for my shared hosting environment!). Typo3 is open source and mature - but it wants to be commercial, and its code architecture just doesn't cut it. Mambo (whose developers have now all run away and formed Joomla) came really close to being the one for me, but it just wasn't flexible, hackable, or lovable enough to woo me over. And besides, look what a mess its community is in now.
And then, one day, I stumbled upon SpreadFirefox, which at the time sported a little 'Powered by CivicSpace' notice at the bottom of its front page; and which in turn led me to CivicSpace Labs; which finally led me to Drupal, where I fell in love, and have stayed ever since. And that's how I came to meet Drupal, how I came to use it for this site and for many others, and how I came to be involved with it in ever more and more ways.
Over the past year, I've seen many things happen over in DrupalLand - to name a few: the 4.6.0 official release; threereal-worldconferences (all of which were far, far away from Sydney, and which I unhappily could not attend); an infrastructure collapse and a major hardware migration; involvement in the Google Summer of Code; major code overhauls (such as the Forms API); a massive increase in the user community; and most recently, the publishing of the first ever Drupal book. It's been an awesome experience, watching and being a part of the rapid and exciting evolution of this piece of software; and learning how it is that thousands of people dispersed all over the world are able to co-operate together, using online tools (many of which the community has itself developed), to build the software platform that is powering more and more of the next generation of web sites.
So what have I done for Drupal during my time with it so far? Well, my number one obsession from day one has been easy and powerful site structuring, and I have contributed to this worthwhile cause (and infamous Drupal weak spot) in many ways. I started out last January by hacking away at the taxonomy and taxonomy_context modules (my first foray into the Drupal code base), and working out how to get beautiful breadcrumbs, flexible taxonomy hierarchies, and meaningful URL aliasing working on this site. I published my adventures in a three-part tutorial, making taxonomy work my way. These tutorials are my biggest contribution to Drupal documentation to date, and have been read and praised by a great many Drupal users. The work that I did for these tutorials paved the way for the later release of the distant parent and taxonomy_assoc modules (taxonomy_assoc being my first Drupal module), which make site structuring just that little bit more powerful, for those wishing to get more out of the taxonomy system.
The category module has been my dream project for most of this year, and I've been trying to find time to work on it ever since I published my proposal about it back in May. It's now finally released - even if it's not quite finished and still has plenty of bugs - and I'm already blown away by how much easier it's made my life than the old ways of "taxonomy_hack". I plan to launch an official support and documentation site for the category module soon, and to make the module's documentation as good as can be. I've also been responding to taxonomy-related support requests in the drupal.org forums for a long time now, and I sincerely hope that the category module is able to help all the users that I've encountered (and many more yet to come) who find that the taxonomy system is unable to meet their needs.
For much of the past year, I've also been involved in professional work as a Drupal consultant. Most notable has been my extended work on the Mighty Me web site, which is still undergoing its final stage of development, and which will hopefully be launched soon. I also developed a Drupal pilot site for WWF-Australia (World Wide Fund for Nature), which unfortunately did not proceed past the pilot stage, but which I nevertheless continued to be involved in developing (as a non-Drupal site). As well as some smaller development jobs, I also provided professional Drupal teaching to fellow web designers on several occasions, thereby spreading the 'Drupal word', and hopefully bringing more people into the fold.
So what have I got planned in the Drupal pipeline for the next year? Drupal itself certainly has plenty of exciting developments lined up for the coming year, and I can hardly hope to rival those, although I will do my best to make my contributions shine. Getting the category module finished and stable for the Drupal 4.7 platform is obviously my primary goal. I'd also like to upgrade this site and some others to Drupal 4.7, and do some serious theme (re-)designing. I've only just started getting involved in contributing code to the Drupal core, in the form of patches, and I'd like to do more of this rather than less. Another idea that's been in my head for some time has been to sort out the hacks that I've got, for filtering out duplicate statistics and non-human site visitors from my access logs and hit counters, and turning them into a proper module called the 'botstopper' module. I don't know how much more than that I can do, as I will be having a lot of work and study commitments this year, and they will probably be eating into much of my time. But I'll always find time for posting messages in the Drupal forums, for adding my voice to the mailing lists, and even for hanging out on the Drupal IRC channels.
My first year of Drupal has been an experience that I am deeply grateful for. I have worked with an amazing piece of software, and I have been given incredibly worthwhile professional and personal opportunities; but above all, I have joined a vibrant and electric community, and have come to know some great people, and to learn a whole world of little gems from them. Drupal's second greatest strength is its power as a community-building platform. Its greatest strength is the power and the warmth of the Drupal community itself.
]]>
Showing sneak previews in Drupal2005-04-05T00:00:00Z2005-04-05T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/04/showing-sneak-previews-in-drupal/
Drupal comes with a powerful permissions system that lets you control exactly who has access to what on your site. However, one thing that you can't do with Drupal is prohibit users from viewing certain content, but still let them see a preview of it. This quick-hack tutorial shows you how to do just that.
There are several modules (most of them non-core) available for Drupal, that let you restrict access to content through various different mechanisms. The module that I use is taxonomy access, and this hack is designed to work primarily with content that is protected using this module. However, the principle of the hack is so basic, you could apply it to any of the different node protection and node retrieval mechanisms that Drupal offers, with minimal difficulty (this is me guessing, by the way - maybe it's actually not easy - why don't you find out? :-)).
This hack is a patch for Drupal's core taxonomy module (4.5.x version). Basically, what it does is eliminate the mechanisms in the taxonomy system that check access permissions when a node is being previewed. The taxonomy system doesn't handle the full text viewing of a node - that's managed by the node system and by the many modules that extend it - so there is no way that this patch will allow unauthorised access to the full text of your nodes! Don't worry about that happening - you would have to start chopping code off the node system before that becomes even a possibility.
Important note: this patch only covers node previews in taxonomy terms, not node previews in other places on your site (e.g. on the front page - assuming that your front page is the default /q=node path). If you display protected content on the front page of your site, you'll need to patch the node system in order to get the previews showing up on that front page. Since GreenAsh only displays protected content in taxonomy listings, I've never needed (and hence never bothered) to hack anything else except the taxonomy system in this regard.
Protect your nodes
Showing you the patch isn't going to be very useful unless you've got some protected nodes in your system already. So if you haven't already gone and got taxonomy_access, and used it to restrict access to various categories of nodes, then please do so now!
The patch
As I said, it's extremely simple. All you have to to is open up your modules/taxonomy.module file, and find the following code:
<?php
/**
* Finds all nodes that match selected taxonomy conditions.
*
* @param $tids
* An array of term IDs to match.
* @param $operator
* How to interpret multiple IDs in the array. Can be "or" or "and".
* @param $depth
* How many levels deep to traverse the taxonomy tree. Can be a nonnegative
* integer or "all".
* @param $pager
* Whether the nodes are to be used with a pager (the case on most Drupal
* pages) or not (in an XML feed, for example).
* @return
* A resource identifier pointing to the query results.
*/
function taxonomy_select_nodes($tids = array(), $operator = 'or', $depth = 0, $pager = TRUE) {
if (count($tids) > 0) {
// For each term ID, generate an array of descendant term IDs to the right depth.
$descendant_tids = array();
if ($depth === 'all') {
$depth = NULL;
}
foreach ($tids as $index => $tid) {
$term = taxonomy_get_term($tid);
$tree = taxonomy_get_tree($term->vid, $tid, -1, $depth);
$descendant_tids[] = array_merge(array($tid), array_map('_taxonomy_get_tid_from_term', $tree));
}
if ($operator == 'or') {
$str_tids = implode(',', call_user_func_array('array_merge', $descendant_tids));
$sql = 'SELECT DISTINCT(n.nid), n.sticky, n.created FROM {node} n '. node_access_join_sql() .' INNER JOIN {term_node} tn ON n.nid = tn.nid WHERE tn.tid IN ('. $str_tids .') AND n.status = 1 AND '. node_access_where_sql() .' ORDER BY n.sticky DESC, n.created DESC';
$sql_count = 'SELECT COUNT(DISTINCT(n.nid)) FROM {node} n '. node_access_join_sql() .' INNER JOIN {term_node} tn ON n.nid = tn.nid WHERE tn.tid IN ('. $str_tids .') AND n.status = 1 AND '. node_access_where_sql();
}
else {
$joins = '';
$wheres = '';
foreach ($descendant_tids as $index => $tids) {
$joins .= ' INNER JOIN {term_node} tn'. $index .' ON n.nid = tn'. $index .'.nid';
$wheres .= ' AND tn'. $index .'.tid IN ('. implode(',', $tids) .')';
}
$sql = 'SELECT DISTINCT(n.nid), n.sticky, n.created FROM {node} n '. node_access_join_sql() . $joins .' WHERE n.status = 1 AND '. node_access_where_sql() . $wheres .' ORDER BY n.sticky DESC, n.created DESC';
$sql_count = 'SELECT COUNT(DISTINCT(n.nid)) FROM {node} n '. node_access_join_sql() . $joins .' WHERE n.status = 1 AND '. node_access_where_sql() . $wheres;
}
if ($pager) {
$result = pager_query($sql, variable_get('default_nodes_main', 10) , 0, $sql_count);
}
else {
$result = db_query_range($sql, 0, 15);
}
}
return $result;
}
?>
Now replace it with this code:
<?php
/**
* Finds all nodes that match selected taxonomy conditions.
* Hacked to ignore node access conditions, so that nodes are always listed in taxonomy listings,
* but cannot actually be opened without the proper permissions - by Jaza on 2005-01-16.
*
* @param $tids
* An array of term IDs to match.
* @param $operator
* How to interpret multiple IDs in the array. Can be "or" or "and".
* @param $depth
* How many levels deep to traverse the taxonomy tree. Can be a nonnegative
* integer or "all".
* @param $pager
* Whether the nodes are to be used with a pager (the case on most Drupal
* pages) or not (in an XML feed, for example).
* @return
* A resource identifier pointing to the query results.
*/
function taxonomy_select_nodes($tids = array(), $operator = 'or', $depth = 0, $pager = TRUE) {
if (count($tids) > 0) {
// For each term ID, generate an array of descendant term IDs to the right depth.
$descendant_tids = array();
if ($depth === 'all') {
$depth = NULL;
}
foreach ($tids as $index => $tid) {
$term = taxonomy_get_term($tid);
$tree = taxonomy_get_tree($term->vid, $tid, -1, $depth);
$descendant_tids[] = array_merge(array($tid), array_map('_taxonomy_get_tid_from_term', $tree));
}
if ($operator == 'or') {
$str_tids = implode(',', call_user_func_array('array_merge', $descendant_tids));
$sql = 'SELECT DISTINCT(n.nid), n.sticky, n.created FROM {node} n '. /* node_access_join_sql() .*/ ' INNER JOIN {term_node} tn ON n.nid = tn.nid WHERE tn.tid IN ('. $str_tids .') AND n.status = 1 '. /*AND '. node_access_where_sql() .*/ ' ORDER BY n.sticky DESC, n.created DESC';
$sql_count = 'SELECT COUNT(DISTINCT(n.nid)) FROM {node} n '. /*node_access_join_sql() .*/ ' INNER JOIN {term_node} tn ON n.nid = tn.nid WHERE tn.tid IN ('. $str_tids .') AND n.status = 1 '/*. AND '. node_access_where_sql()*/;
}
else {
$joins = '';
$wheres = '';
foreach ($descendant_tids as $index => $tids) {
$joins .= ' INNER JOIN {term_node} tn'. $index .' ON n.nid = tn'. $index .'.nid';
$wheres .= ' AND tn'. $index .'.tid IN ('. implode(',', $tids) .')';
}
$sql = 'SELECT DISTINCT(n.nid), n.sticky, n.created FROM {node} n './*'. node_access_join_sql() .*/ $joins .' WHERE n.status = 1 './*AND '. node_access_where_sql() .*/ $wheres .' ORDER BY n.sticky DESC, n.created DESC';
$sql_count = 'SELECT COUNT(DISTINCT(n.nid)) FROM {node} n './*'. node_access_join_sql() .*/ $joins .' WHERE n.status = 1 './*AND '. node_access_where_sql() .*/ $wheres;
}
if ($pager) {
$result = pager_query($sql, variable_get('default_nodes_main', 10) , 0, $sql_count);
}
else {
$result = db_query_range($sql, 0, 15);
}
}
return $result;
}
?>
As you can see, all the node_access functions, which are used to prevent the SQL queries from retrieving protected content, have been commented out. So when retrieving node previews, the taxonomy system now effectively ignores all access rights, and always displays a preview no matter who's viewing it. It's only when you try to actually go to the full-text version of the node that you'll get an 'access denied' error.
Drupal does not allow this behaviour at all (unless you hack it), and rightly so, because it is obviously bad design to show users a whole lot of links to pages that they can't actually access. But there are many situations where you want to give your visitors a 'sneak preview' of what a certain piece of content is, and the only way to do it is using something like this. It's a form of advertising: by displaying only a part of the node, you're enticing your visitors to do whatever it is that they have to do (e.g. register, pay money, poison your mother-in-law) in order to access it. So, because I think other Drupal admins would also find this functionality useful, I've published it here.
Thanks to the path module and its URL aliasing functionality, Drupal is one of the few CMSs that allows your site to have friendly and meaningful URLs for every page. So whereas in other systems, your average URL might look something like this:
In Drupal, your average URL (potentially - if you bother to alias everything) would look more like this:
www.mysite.com/my_favourite_model_aeroplanes
This was actually the pivotal feature that made me choose Drupal, as my favourite platform for web development. After I started using Drupal, I discovered that it hadn't always had such pretty URLs: and even now, the URLs are not so great when its URL rewriting facility is off (e.g. index.php?q=node/81); and still not perfect when URL rewriting is on, but aliases are not defined (e.g. node/81). But at its current stage of development, Drupal allows you to provide reasonably meaningful path aliases for every single page of your site.
In my opinion, the aliasing system is reasonable, but not good enough. In particular, a page's URL should reflect its position in the site's master hierarchy. Just as breadcrumbs tell you where you are, and what pages (or categories) are 'above' you, so too should URLs. In fact, I believe that a site's URLs should match its breadcrumbs exactly. This is actually how most of Drupal's administration pages work already: for example, if you go to the admin/user/configure/permission page of your Drupal site, you will see that the breadcrumbs (in combination with tabs and the page heading) mark your current location as:
home -> administer -> users -> configure -> permissions
Unfortunately, the hierarchies and the individual URLs for the administration pages are hard-coded, and there is currently no way to create similar structures (with matching URLs) for the public pages of your site.
Battle plan
Our aim, for this final part of the series, is to create a patch that allows Drupal to automatically generate hierarchical URL aliases, based (primarily) on our site's taxonomy structure. We should not have to modify the taxonomy system at all in order to do this: path aliases are handled only by path.module, and by a few mechanisms within the core code of Drupal. We can already assign simple aliases both to nodes, and to taxonomy terms, such as:
taxonomy/term/7 : research_papers
So what we want is a system that will find the alias of the current page, and the alises of all its parents, and join them together to form a hierarchical URL, such as:
(if an article with this name - or a similar name - actually exists on the Internet, then please let me know about it as a matter of the utmost urgency ;-))
As with part 2, in order to implement the patch that I cover in this article, it is essential that you've already read (and hopefully implemented) the patches from part 1 (basic breadcrumbs and taxonomy), and preferable (although not essential) that you've also gone through part 2 (cross-vocabulary taxonomy hierarchies). Once again, I am assuming that you've still got your Drupal test site that we set up in part 1, and that you're ready to keep going from where we finished last time.
The general rule, when writing patches for any piece of software, is to try and modify add-on modules instead of core components wherever possible, and to modify the code of the core system only when there is no other alternative. In the first two parts of the series, we were quite easily able to stay on the good side of this rule. The only places where we have modified code so far is in taxonomy.module and taxonomy_context.module. But aliasing, as I said, is handled both by path.module and by the core system; so this time, we may have no choice but to join the dark side, and modify some core code.
Ancient GreenAsh proverb: When advice on battling the dark side you need, then seek it you must, from Master Yoda.
Right now we do need some advice; but unfortunately, since I was unable to contact the great Jedi master himself (although I did find a web site where Yoda will tell you the time), we'll have to make do by consulting the next best thing, drupal.org.
Let's have a look at the handbook entry that explains Drupal's page serving mechanism (page accessed on 2005-02-14 - contents may have changed since then). The following quote from this page might be able to help us:
Drupal handbook: If the value of q [what Drupal calls the URL] is a path alias, Drupal replaces the value of q with the actual path that the value of q is aliased to. This sleight-of-hand happens before any modules see the value of q. Cool.
Module initialization now happens via the module_init() function.
(The part of the article that this quote comes from, is talking about code in the includes/common.inc file).
Oh-oh: that's bad news for us! According to this quote, when a page request is given to Drupal, the core system handles the conversion of aliases to system paths, before any modules are loaded. This means that not only are alias-to-path conversions (and vice versa) handled entirely by the Drupal core; but additionally, the architecture of Drupal makes it impossible for this functionality to be controlled from within a module! Upon inspecting path.module, I was able to verify that yes, indeed, this module only handles the administration of aliases, not the actual use of them. The code that's responsible for this lies within two files - bootstrap.inc and common.inc - that together contain a fair percentage of the fundamental code comprising the Drupal core. So roll your sleeves up, and prepare to get your hands really dirty: this time, we're going to be patching deep down at the core.
Step 1: give everything an alias
Implementing a hierarchical URL aliasing system isn't going to be of much use, unless everything in the hierarchy has an alias. So before we start coding, let's go the the administer -> url aliases page of the test site, and add the following aliases (you can change the actual alias names to suit your own tastes, if you want):
System path
Alias
taxonomy/term/1
posts
taxonomy/term/2
news
taxonomy/term/3
by_priority_news
taxonomy/term/4
important_news
You should already have an alias in place for node/1, but if you don't, add one now. After doing this, the admin page for your aliases should look like this:
List of URL aliases (screenshot)
Step 2: the alias output patch
Drupal's path aliasing system requires two distinct subsystems in order to work properly: the 'outgoing' system, which converts an internal system path into its corresponding alias (if any), before outputting it to the user; and the 'incoming' system, which converts an aliased user-supplied path back into its corresponding internal system path. We are going to begin by patching the 'outgoing' system.
Open up the file includes/bootstrap.inc, and find the following code in it:
<?php
/**
* Given an internal Drupal path, return the alias set by the administrator.
*/
function drupal_get_path_alias($path) {
if (($map = drupal_get_path_map()) && ($newpath = array_search($path, $map))) {
return $newpath;
}
elseif (function_exists('conf_url_rewrite')) {
return conf_url_rewrite($path, 'outgoing');
}
else {
// No alias found. Return the normal path.
return $path;
}
}
?>
Now replace it with this code:
<?php
/**
* Given an internal Drupal path, return the alias set by the administrator.
* Patched to return an extended alias, based on context.
* Patch done by x on xxxx-xx-xx.
*/
function drupal_get_path_alias($path) {
if (($map = drupal_get_path_map()) && ($newpath = array_search($path, $map))) {
return _drupal_get_path_alias_context($newpath, $path, $map);
}
elseif (function_exists('conf_url_rewrite')) {
return conf_url_rewrite($path, 'outgoing');
}
else {
// No alias found. Return the normal path.
return $path;
}
}
/**
* Given an internal Drupal path, and the alias of that path, return an extended alias based on context.
* Written by Jaza on 2004-12-26.
* Implemented by x on xxxx-xx-xx.
*/
function _drupal_get_path_alias_context($newpath, $path, $map) {
//If the alias already has a context defined, do nothing.
if (strstr($newpath, "/")) {
return $newpath;
}
// Break up the original path.
$path_split = explode("/", $path);
$anyslashes = FALSE;
$contextpath = $newpath;
// Work out the new path differently depending on the first part of the old path.
switch (strtolower($path_split[0])) {
case "node":
// We are only interested in pages of the form node/x (not node/add, node/x/edit, etc)
if (isset($path_split[1]) && is_numeric($path_split[1]) && $path_split[1] > 0) {
$nid = $path_split[1];
$result = db_query("SELECT * FROM {node} WHERE nid = %d", $nid);
if ($node = db_fetch_object($result)) {
//Find out what 'Sections' term (and 'Forums' term, for forum topics) this node is classified as.
$result = db_query("SELECT tn.* FROM {term_node} tn INNER JOIN {term_data} t ON tn.tid = t.tid WHERE tn.nid = %d AND t.vid IN (1,2)", $nid);
switch ($node->type) {
case "page":
case "story":
case "weblink":
case "webform":
case "poll":
while ($term = db_fetch_object($result)) {
// Grab the alias of the parent term, and add it to the front of the full alias.
$result = db_query("SELECT * FROM {url_alias} WHERE src = 'taxonomy/term/%d'", $term->tid);
if ($alias = db_fetch_object($result)) {
$contextpath = $alias->dst. "/". $contextpath;
if (strstr($alias->dst, "/"))
$anyslashes = TRUE;
}
// Keep grabbing more parent terms and their aliases, until we reach the top of the hierarchy.
$result = db_query("SELECT parent as 'tid' FROM {term_hierarchy} WHERE tid = %d", $term->tid);
}
break;
case "forum":
// Forum topics must be treated differently to other nodes, since:
// a) They only have one parent, so no loop needed to traverse the hierarchy;
// b) Their parent terms are part of the forum module, and so the path given must be relative to the forum module.
if ($term = db_fetch_object($result)) {
$result = db_query("SELECT * FROM {url_alias} WHERE src = 'forum/%d'", $term->tid);
if ($alias = db_fetch_object($result)) {
$contextpath = "contact/forums/". $alias->dst. "/". $contextpath;
if (strstr($alias->dst, "/"))
$anyslashes = TRUE;
}
}
break;
case "image":
// For image nodes, override the default path (image/) with this custom path.
$contextpath = "images/". $contextpath;
break;
}
}
// If the aliases of any parent terms contained slashes, then an absolute path has been defined, so scrap the whole
// context-sensitve path business.
if (!$anyslashes) {
return $contextpath;
}
else {
return $newpath;
}
}
else {
return $newpath;
}
break;
case "taxonomy":
// We are only interested in pages of the form taxonomy/term/x
if (isset($path_split[1]) && is_string($path_split[1]) && $path_split[1] == "term" && isset($path_split[2]) &&
is_numeric($path_split[2]) && $path_split[2] > 0) {
$tid = $path_split[2];
// Change the boolean variable below if you don't want the cross-vocabulary-aware query.
$distantparent = TRUE;
if ($distantparent) {
$sql_taxonomy = 'SELECT t.* FROM {term_data} t, {term_hierarchy} h LEFT JOIN {term_distantparent} d ON h.tid = d.tid '.
'WHERE h.tid = %d AND (d.parent = t.tid OR h.parent = t.tid)';
}
else {
$sql_taxonomy = 'SELECT t.* FROM {term_data} t, {term_hierarchy} h '.
'WHERE h.tid = %d AND h.parent = t.tid';
}
while (($result = db_query($sql_taxonomy, $tid)) && ($term = db_fetch_object($result))) {
// Grab the alias of the current term, and the aliases of all its parents, and put them all together.
$result = db_query("SELECT * FROM {url_alias} WHERE src = 'taxonomy/term/%d'", $term->tid);
if ($alias = db_fetch_object($result)) {
$contextpath = $alias->dst. "/". $contextpath;
if (strstr($alias->dst, "/")) {
$anyslashes = TRUE;
}
}
$tid = $term->tid;
}
// Don't use the hierarchical alias if any absolute-path aliases were found.
if (!$anyslashes) {
return $contextpath;
}
else {
return $newpath;
}
}
else {
return $newpath;
}
break;
case "forum":
// If the term is a forum topic, then display the path relative to the forum module.
return "contact/forums/". $contextpath;
break;
case "image":
// We only want image pages of the form image/tid/x
// (i.e. image gallery pages - not regular taxonomy term pages).
if (isset($path_split[1]) && is_string($path_split[1]) && $path_split[1] == "tid" && isset($path_split[2]) &&
is_numeric($path_split[2]) && $path_split[2] > 0) {
$tid = $path_split[2];
// Since taxonomy terms for images are not of the form image/tid/x, this query does not need to be cross-vocabulary aware.
$sql_taxonomy = 'SELECT t.* FROM {term_data} t, {term_hierarchy} h '.
'WHERE h.tid = %d AND h.parent = t.tid';
while (($result = db_query($sql_taxonomy, $tid)) && ($term = db_fetch_object($result))) {
// Grab the alias of this term, and the aliases of its parent terms.
$result = db_query("SELECT * FROM {url_alias} WHERE src = 'image/tid/%d'", $term->tid);
if ($alias = db_fetch_object($result)) {
$contextpath = $alias->dst. "/". $contextpath;
if (strstr($alias->dst, "/")) {
$anyslashes = TRUE;
}
}
$tid = $term->tid;
}
// The alias must be relative to the image galleries page.
$contextpath = "images/galleries/". $contextpath;
if (!$anyslashes) {
return $contextpath;
}
else {
return $newpath;
}
}
else {
return $newpath;
}
break;
default:
return $newpath;
}
}
?>
Phew! That sure was a long function. It would probably be better to break it up into smaller functions, but in order to keep all the code changes in one place (rather than messing up bootstrap.inc further), we'll leave it as it is for this tutorial.
As you can see, we've modified drupal_get_path_alias() so that it calls our new function, _drupal_get_path_alias_context(), and relies on that function's output to determine its return value (note the underscore at the start of the new function - this denotes that it is a 'helper' function that is not called externally). The function is too long and complex to analyse in great detail here: the numerous comments that pepper its code will help you to understand how it works.
Notice that the function as I use it is designed to produce hierarchical aliases for a whole lot of different node types (the regular method works for page, story, webform, weblink, and poll; and special methods are used for forum and image). You can add or remove node types from this list, depending on what modules you use on your specific site(s), and also depending on what node types you want this system to apply to. Please observe that book nodes are not covered by this function; this is because:
I don't use book.module - I find that a combination of several other modules (mainly taxonomy and taxonomy_context) achieve similar results to a book hierarchy, but in a better way;
Book hierarchies have nothing to do with taxonomy hierarchies - they are a special type of system where one node is actually the child of another node (rather than being the child of a term) - but my function is designed specifically to parse taxonomy hierarchies;
Books and taxonomy terms are incompatible - you cannot assign a book node under a taxonomy hierarchy - so making a node part of a book hierarchy means that you're sacrificing all the great things about Drupal's taxonomy system.
So if you've been reading this article because you're looking for a way to make your book hierarchies use matching hierarchical URLs, then I'm very sorry, but you've come to the wrong place. It probably wouldn't be that hard to extend this function so that it includes book hierarchies, but I'm not planning to make that extension any time in the near future. This series is about using taxonomy, not about using the book module. And I am trying to encourage you to use taxonomy, as an alternative (in some cases) to the book module, because I personally believe that taxonomy is a much better system.
After you've implemented this new function of mine, reload the front page of your test site. You'll see that hierarchical aliases are now being outputted for all your taxonomy terms, and for your node. Cool! That looks pretty awesome, don't you think? However (after you've calmed down, put away the champagne, and stopped celebrating), if you try following (i.e. clicking) any of these links, you'll see that they don't actually work yet; you just get a 'page not found' error, like this one:
Node page not found (screenshot)
This is because we've implemented the 'outgoing' system for our hierarchical aliases, but not the 'incoming' system. So Drupal now knows how to generate these aliases, but not how to turn them back into system paths when the user follows them.
Step 3: the alias input patch
While the patch for the 'outgoing' system was very long and intricate, in some ways, working out how to patch the 'incoming' system is even more complicated; because although we don't need to write nearly as much code for the 'incoming' system, we need to think very carefully about how we want it to work. Let's go through some thought processes before we actually get to the patch:
The module that handles the management of aliases is path.module. This module has a rule that every alias in the system must be unique. We haven't touched the path module, so this rule is still in place. We're also storing the aliases for each page just as we always did - as individual paths that correspond to their matching Drupal system paths - we're only joining the aliases together when they get outputted.
If we think about this carefully, it means that in our new hierarchical aliasing system, we can always evaluate the alias just by looking at the part of it that comes after the last slash. That is, our patch for the 'incoming' system will only need to look at the end of the alias: it can quite literally ignore the rest.
Keeping the system like this has one big advantage and one big disadvantage. The big advantage is that the alias will still resolve, whether the user types in only the last part of it, or the entire hierarchical alias, or even something in between - so there is a greater chance that the user will get to where they want to go. The big disadvantage is that because every alias must still be unique, we cannot have two context-sensitive paths that end in the same way. For example, we cannot have one path posts/news/computer_games, and another path hobbies/geeky/computer_games - as far as Drupal is concerned, they're the same path - and the path module simply will not allow two aliases called 'computer_games' to be added. This disadvantage can be overcome by using slightly more detailed aliases, such as computer_games_news and computer_games_hobbies (you might have noticed such aliases being used here on GreenAsh), so it's not a terribly big problem.
There is another potential problem with this system - it means that you don't have enough control over the URLs that will resolve within your own site. This is a security issue that could have serious and embarrassing side effects, if you don't do anything about it. For example, say you have a hierarchical URL products/toys/teddy_bear, and a visitor to your site liked this page so much, they wanted to put a link to it on their own web site. They could link to products/toys/teddy_bear, products/teddy_bear, teddy_bear, etc; or, they might link to this_site_stinks/teddy_bear, or elvis_is_still_alive_i_swear/ and_jfk_wasnt_shot_either/ and_man_never_landed_on_the_moon_too/ teddy_bear, or some other really inappropriate URL that shouldn't be resolving as a valid page on your web site. In order to prevent this from happening, we will need to check that every alias in the hierarchy is a valid alias on your site: it doesn't necessarily matter whether the combination of aliases forms a valid hierarchy, just that all of the aliases are real and are actually stored in your Drupal system.
OK, now that we've got all those design quandaries sorted out, let's do the patch. Open up the file includes/common.inc, and find the following code in it:
<?php
/**
* Given a path alias, return the internal path it represents.
*/
function drupal_get_normal_path($path) {
if (($map = drupal_get_path_map()) && isset($map[$path])) {
return $map[$path];
}
elseif (function_exists('conf_url_rewrite')) {
return conf_url_rewrite($path, 'incoming');
}
else {
return $path;
}
}
?>
Now replace it with this code:
<?php
/**
* Given a path alias, return the internal path it represents.
* Patched to search for the last part of the alias by itself, before searching for the whole alias.
* Patch done by x on xxxx-xx-xx.
*/
function drupal_get_normal_path($path) {
$path_split = explode("/", $path);
// $path_end holds ONLY the part of the URL after the last slash.
$path_end = end($path_split);
$path_valid = TRUE;
$map = drupal_get_path_map();
foreach ($path_split as $path_part) {
// If each part of the path is valid, then this is a valid hierarchical URL.
if (($map) && (!isset($map[$path_part]))) {
$path_valid = FALSE;
}
}
if (($map) && (isset($map[$path_end])) && ($path_valid)) {
// If $path_end is a proper alias, then resolve the path solely according to $path_end.
return $map[$path_end];
}
elseif (($map) && (isset($map[$path]))) {
return $map[$path];
}
elseif (function_exists('conf_url_rewrite')) {
return conf_url_rewrite($path, 'incoming');
}
else {
return $path;
}
}
?>
After you implement this part of the patch, all your hierarchical URLs should resolve, much like this:
Test node with working alias (screenshot)
That's all, folks
Congratulations! You have now finished my tutorial on creating automatically generated hierarchical URL aliases, which was the last of my 3-part series on getting the most out of Drupal's taxonomy system. I hope that you've gotten as much out of reading this series, as I got out of writing it. I also hope that I've fulfilled at least some of the aims that I set out to achieve at the beginning, such as lessening the frustration that many people have had with taxonomy, and bringing out some new ideas for the future direction of the taxonomy system.
I also should mention that as far as I'm concerned, the content of this final part of the series (hierarchical URL aliasing) is the best part of the series by far. I only really wrote parts 1 and 2 as a means to an end - the things that I've demonstrated in this final episode are the things that I'm really proud of. As you can see, everything that I've gone through in this series - hierarchical URL aliases in particular - has been successfully implemented on this very site, and is now a critical functional component of the code that powers GreenAsh. And by the way, hierarchical URL aliases work even better when used in conjunction with the new autopath module, which generates an alias for your nodes if you don't enter one manually.
As with part 2, the code in this part is not perfect, has not been executed all that gracefully, and is completely lacking a frontend administration interface. My reasons excuses for this are the same as those given in part 2; and as with cross-vocabulary hierarchies, I hope to improve the code for hierarchical URL aliases in the future, and hopefully to release it as a contributed Drupal module some day. But rather than keep you guys - the Drupal community - waiting what could be a long time, I figure that I've got working code right here and right now, so I might as well share it with you, because I know that plenty of you will find it useful.
The usual patches and replacement modules can be found at the bottom of the page. I hope that you've found this series to be beneficial to you: feel free to voice whatever opinions or criticisms you may have by posting a comment (link at the bottom of the page). And who knows... there may be more Drupal goodies available on GreenAsh sometime in the near future!
In part 1 of this series, we examined a few of the bugs in the breadcrumb generation mechanisms employed by Drual's taxonomy system. We didn't really implement anything new: we just patched up some of the existing functionality so that it worked better. Our 'test platform' for Drupal now boasts beautiful breadcrumbs - both for nodes and for terms - that reflect a master taxonomy hierarchy quite accurately (as they should).
Now, things are going to start getting more serious. We're going to be adding a new custom table to Drupal's database structure, putting some data in it, and changing code all over the place in order to use this new data. The result of this: a cross-vocabulary hierarchy structure, in which a term in one vocab may have a 'distant parent' in another one.
Before you read on, though, please be aware that I'm assuming you've already read and (possibly) implemented what was introduced in part 1, basic breadcrumbs and taxonomy. I will be jumping in right at the deep end in this article. There is no sprawling introduction, no guide to setting up your clean Drupal installation, and no instructions on adding categories and content. Basically, if you're planning on doing the stuff in this article, you should have already done all the stuff in the previous one: and that includes the patches to taxonomy and taxonomy_context, because the patches here are dependant on those I've already demonstrated.
Still here? Glad to have you, soldier hacker. OK, our goal in this tutorial is to allow a term in one vocabulary to have a 'distant parent' in another one. Our changes cannot break the existing system, which relies on the top-level term(s) in any vocabulary having a parent ID of 0 (i.e. having no parent): seeing that we will have to give some top-level terms an actual (i.e. non-zero) parent ID, in order to achieve our goal, things could get a bit tricky if we're not careful. Once we've implemented such a system, we want to see it being reflected in our breadcrumbs: that is, we want breadcrumbs that at times span more than one vocabulary.
But... why?
Why do we need to be able to link together terms in different vocabularies, you ask? We can see why by looking at what we've got now in our current Drupal test system. At the moment, there are two vocabularies: Sections (which has a top-level term posts, and news, which is a child of posts); and News by priority (which also has a top-level term - browse by priority - and a child term important). So this is our current taxonomy hierarchy:
(Sections) Posts -> News
(News by priority) Browse by priority -> Important
But the term browse by priority is really a particular method of browsing news items. It only applies to news items, not to nodes categorised in any of the other terms in Sections. So really, our hierarchy should be like this:
(Sections) Posts -> News -> (News by priority) Browse by priority -> Important
Once we've changed the hierarchy so that it makes more sense, the potential next step becomes obvious. We can make more vocabularies, and link them to the term news, and classify news items according to many different structures! For example:
Posts -> News -> Browse by priority -> Important
Posts -> News -> Browse by category -> Computer hardware
Posts -> News -> Browse by mood -> Angry
Posts -> News -> Browse by length -> Long and rambling
And so, by doing this, we really have achieved the best of both worlds: we can utilise the power of taxonomy exactly as it was designed to be utilised - for categorising nodes under many different vocabularies, according to many different criteria; plus, at the same time we can still maintain a single master hierarchy for the entire site! Cool, huh?
Now, while you may be nodding your head right now, and thinking: "yeah, that is pretty cool"; I know that you might also be shaking your head, and still wondering: "why?" And after explaining my motivations, I can understand why many of you would fail to see the relevance or the usefulness of such a system in any site of your own. This is something that not every site needs - it's only for sites where you have lots of nodes, and you need (or want) to classify them in many different ways - and it's also simply not for everyone: many of you, I'm sure, would prefer sticking to the current system, which is more flexible than mine, albeit with some sacrifice to your site's structure. So don't be alarmed if you really don't want to implement this, but you do want to implement the hierarchical URL system in part 3: it is quite possible to skip this, and go straight on to the final part of the series, and still have a fully functional code base.
Step 1: modify the database
OK, let's get started! In order to get through this first part of the tutorial, it is essential that you have a backend database tool at your disposal. If you don't have it already, I highly recommend that you grab a copy of phpMyAdmin, which uses a PHP-based web interface, and is the world's most popular MySQL administration tool (for a good reason, too). Some other alternatives include Drupal's dba.module (which I hear is alright); and for those of you that are feeling particularly geeky, there is always the MySQL command line tool itself (part of all MySQL installations). If you're using PostgreSQL, then I'm afraid my only experience with this environment is one where I used a command line tool, so I don't know what to recommend to you. Also, nothing in this tutorial has been tested in PostgreSQL: you have been warned.
Using your admin tool, open up the database for your Drupal test site, and have a look at the tables (there's quite a lot of them). For this tutorial, we're only interested in those beginning with term_, as they're the ones that store information about our taxonomy terms. The first table you should get to know is term_data, as this is where the actual terms are stored. If you browse the contents of this table, you should see something like this:
Contents of term_data table (screenshot)
The table that we're really interested in, however, is term_hierarchy: this is where Drupal stores the parent(s) of each taxonomy term for your site. If you browse the contents of term_hierarchy, what you see should look a fair bit like this:
Contents of term_hierarchy table (screenshot)
Looking at this can be a bit confusing, because all you can see are the term IDs, and no actual names. If you want to map the IDs to their corresponding terms, you might want to keep term_data open in another window as a reference.
As you can see, each term has another term as its parent, except the top-level terms, which have a tid of zero (0). Now, if you wanted to make some of those top-level terms the children of other terms (in different vocabs), the first solution you'd think of would undoubtedly be to simply change those tids from zero to something else. You can try this if you want; or you can save yourself the hassle, and trust me when I tell you: it doesn't work. If you do this, then when you go into the administer -> categories page on your site, the term whose parent ID you changed - and all its children - will have disappeared off the face of the output. And what's more, doing this won't make Drupal generate the cross-vocabulary breadcrumbs that we're aiming for. So we need to think of a plan B.
What we need is a way to let Drupal know about our cross-vocabulary hierarchies, without changing anything in the term_hierarchy table. And the way that we're going to do this is by having another table, with exactly the same structure as term_hierarchy, but with a record of all the terms on our site that have distant parents (instead of those that have local parents). We're going to create a new table in our database, called term_distantparent. To do this, open up the query interface in your admin tool, and enter the following SQL code:
CREATE TABLE term_distantparent (
tid int(10) unsigned NOT NULL default 0,
parent int(10) unsigned NOT NULL default 0,
PRIMARY KEY (tid),
KEY IdxDistantParent (parent)
) TYPE=MyISAM;
As the code tells us, this table is to have a tid column and a parent column (just like term_hierarchy); its primary key (value that must be unique for each row) is to be tid; and the parent column is to be indexed for fast access. The table is to be of type MyISAM, which is the default type for MySQL, and which is used by all tables in a standard Drupal database. The screenshot below shows how phpMyAdmin describes our new table, after it's been created:
Newly created term_distantparent table (screenshot)
The next step, now that we have this shiny new table, is to insert some data into it. In order to work out what values need to be inserted, you should refer to your term_data table. Find the tid of the term news (2 for me), and of the term browse by priority (3 for me). Then use this SQL script to insert a cross-vocabulary relationship into your new table (substituting the correct values for your database, if need be):
You will now be able to browse the contents of your term_distantparent table, and what you see should look like this:
Term_distantparent with data (screenshot)
Step 2: modify the SQL
Our Drupal database now has all the information it needs to map together a cross-vocabulary hierarchy. All we have to do now is tell Drupal where this data is, and what should be done with it. We will do this by modifying the SQL that the taxonomy module currently uses for determining the current term and its parents.
Open up taxonomy.module, and find the following piece of code:
<?php
/**
* Find all parents of a given term ID.
*/
function taxonomy_get_parents($tid, $key = 'tid') {
if ($tid) {
$result = db_query('SELECT t.* FROM {term_hierarchy} h, {term_data} t WHERE h.parent = t.tid AND h.tid = %d ORDER BY weight, name', $tid);
$parents = array();
while ($parent = db_fetch_object($result)) {
$parents[$parent->$key] = $parent;
}
return $parents;
}
else {
return array();
}
}
?>
Now replace it with this code:
<?php
/**
* Find all parents of a given term ID.
* Patched to allow cross-vocabulary relationships.
* Patch done by x on xxxx-xx-xx.
*/
function taxonomy_get_parents($tid, $key = 'tid', $distantparent = FALSE) {
if ($tid) {
if ($distantparent) {
// Cross-vocabulary-aware SQL query
$sql_distantparent = 'SELECT t.* FROM {term_data} t, {term_hierarchy} h LEFT JOIN {term_distantparent} d ON h.tid = d.tid '.
'WHERE h.tid = %d AND (d.parent = t.tid OR h.parent = t.tid)';
$result = db_query($sql_distantparent, $tid);
} else {
//Original drupal query
$result = db_query('SELECT t.* FROM {term_hierarchy} h, {term_data} t WHERE h.parent = t.tid AND h.tid = %d ORDER BY weight, name', $tid);
}
$parents = array();
while ($parent = db_fetch_object($result)) {
$parents[$parent->$key] = $parent;
}
return $parents;
}
else {
return array();
}
}
?>
The original SQL query was designed basically to look in term_hierarchy for the parents of a given term, and to return any results found. The new query, on the other hand, looks in both term_distantparent and in term_hierarchy for parents of a given term: if results are found in the former table, then they are returned; otherwise, results from the latter are returned. This means that distant parents are now looked for as a matter of priority over local parents (so for all those terms with a local parent ID of zero, the local parent is discarded); and it also means that the existing (local parent) functionality of the taxonomy system functions exactly as it did before, so nothing has been broken.
Notice that an optional boolean argument has been added to the function, with a default value of false ($distantparent = FALSE). When the function is called without this new argument, it uses the original SQL query; only when called with the new argument (and with it set to TRUE) will the distant parent query become activated. This is to prevent any problems for other bits of code (current or future) that might be calling the function, and expecting it to work in its originally intended way.
Step 3: modify the dependent functions
We've now implemented everything that logically needs to be implemented, in order for Drupal to function with cross-vocabulary hierarchies. All that must be done now is some slight modifications to the dependent functions: that is, the functions that make use of the code containing the SQL we've just modified. This should be easy for anyone who's familiar with ("Hi Everybody!" "Hi...") Dr. Nick from The Simpsons, as he gives us the following advice when trying to isolate a problem: "The knee bone's connected to the: something. The something's connected to the: red thing. The red thing's connected to my: wristwatch. Uh-oh." So let's see if we can apply Dr. Nick's method to the problem at hand - only let's hope we have more success with it than he did. And by the way, feel free to sing along as we go.
The taxonomy_get_parents() function is called by the: taxonomy_get_parents_all() function.
So find the following code in taxonomy.module:
<?php
/**
* Find all ancestors of a given term ID.
*/
function taxonomy_get_parents_all($tid) {
$parents = array();
if ($tid) {
$parents[] = taxonomy_get_term($tid);
$n = 0;
while ($parent = taxonomy_get_parents($parents[$n]->tid)) {
$parents = array_merge($parents, $parent);
$n++;
}
}
return $parents;
}
?>
And replace it with this code:
<?php
/**
* Find all ancestors of a given term ID.
* Patched to call helper functions using the optional "distantparent" argument, so that cross-vocabulary-aware queries are activated.
* Patch done by x on xxxx-xx-xx.
*/
function taxonomy_get_parents_all($tid, $distantparent = FALSE) {
$parents = array();
if ($tid) {
$parents[] = taxonomy_get_term($tid);
$n = 0;
while ($parent = taxonomy_get_parents($parents[$n]->tid, 'tid', $distantparent)) {
$parents = array_merge($parents, $parent);
$n++;
}
}
return $parents;
}
?>
What's next, Dr. Nick?
The taxonomy_get_parents_all() function is called by the: taxonomy_context_get_breadcrumb() function.
Ooh... hang on, Dr. Nick. Before we go off and replace the code in this function, we should be aware that we already modified its code in part 1, in order to implement our breadcrumb patch. So we have to make sure that when we add our new code, we also keep the existing changes. This is why both the original and the new code below still have the breadcrumb patch in them.
OK, now find the following code in taxonomy_context.module:
<?php
/**
* Return the breadcrumb of taxonomy terms ending with $tid
* Patched to display the current term only for nodes, not for terms
* Patch done by x on xxxx-xx-xx
*/
function taxonomy_context_get_breadcrumb($tid, $mode) {
$breadcrumb[] = l(t("Home"), "");
if (module_exist("vocabulary_list")) {
$vid = taxonomy_context_get_term_vocab($tid);
$vocab = taxonomy_get_vocabulary($vid);
$breadcrumb[] = l($vocab->name, "taxonomy/page/vocab/$vid");
}
if ($tid) {
$parents = taxonomy_get_parents_all($tid);
if ($parents) {
$parents = array_reverse($parents);
foreach ($parents as $p) {
// The line below implements the breadcrumb patch
if ($mode != "taxonomy" || $p->tid != $tid)
$breadcrumb[] = l($p->name, "taxonomy/term/$p->tid");
}
}
}
return $breadcrumb;
}
?>
And replace it with this code:
<?php
/**
* Return the breadcrumb of taxonomy terms ending with $tid
* Patched to display the current term only for nodes, not for terms
* Patch done by x on xxxx-xx-xx
* Patched to call taxonomy_get_parents_all() with the optional $distantparent argument set to TRUE, to implement cross-vocabulary hierarches.
* Patch done by x on xxxx-xx-xx
*/
function taxonomy_context_get_breadcrumb($tid, $mode) {
$breadcrumb[] = l(t("Home"), "");
if (module_exist("vocabulary_list")) {
$vid = taxonomy_context_get_term_vocab($tid);
$vocab = taxonomy_get_vocabulary($vid);
$breadcrumb[] = l($vocab->name, "taxonomy/page/vocab/$vid");
}
if ($tid) {
// New $distantparent argument added with value TRUE
$parents = taxonomy_get_parents_all($tid, TRUE);
if ($parents) {
$parents = array_reverse($parents);
foreach ($parents as $p) {
// The line below implements the breadcrumb patch
if ($mode != "taxonomy" || $p->tid != $tid)
$breadcrumb[] = l($p->name, "taxonomy/term/$p->tid");
}
}
}
return $breadcrumb;
}
?>
Any more, Dr. Nick?
The taxonomy_context_get_breadcrumb() function is called by the: taxonomy_context_init() function.
That's alright: we're not passing the $distantparent argument up the line any further, and we already fixed up the call from this function in part 1.
After that, Dr. Nick?
The taxonomy_context_init() function is called by the: Drupal _init hook.
Hooray! We've reached the end of our great long function-calling chain; Drupal handles the rest of the function calls from here on. Thanks for your help, Dr. Nick! We should now be able to test out our cross-vocabulary hierarchy, by loading a term that has a distant parent somewhere in its ancestry, and having a look at the breadcrumbs. Try opening the page for the term important (you can find a link to it from your node) - it should look something like this:
Term with cross-vocabulary breadcrumbs (screenshot)
And what a beautiful sight that is! Breadcrumbs that span more than one vocabulary: simply perfect.
Room for improvement
What I've presented in this tutorial is a series of code patches, and a database modification. I've used minimal tools and made minimal changes, and what I set out to achieve now works. However, I am more than happy to admit that the whole thing could have been executed much better, and that there is plenty of room for improvement, particularly in terms of usability (and reusability).
My main aim - by implementing a cross-vocabulary hierarchy - was to get the exact menu structure and breadcrumb navigation that I wanted. Because this was all I really cared about, I have left out plenty of things that other people might consider an essential (but missing) part of my patch. For example, I have not implemented distant children, only distant parents. This means that if you're planning to use taxonomy_context for automatically generating a list of subterms (which I don't do), then distant children won't be generated unless you add further functionality to my patch.
There is also the obvious lack of any frontend admin interface whatsoever for managing distant parents. Using my patch as it is, distant parents must be managed by manually adding rows to the database table, using a backend admin tool such as phpMyAdmin. It would be great if my patch had this functionality, but since I haven't needed it myself as yet, and I haven't had the time to develop it either, it's simply not there.
The $distantparent variable should ideally be able to be toggled through a frontend interface, so that the entire cross-vocabulary functionality could be turned on or off by the site's administrator, without changing the actual code. The reasons for this being absent are the same as the reasons (given above) for the lack of a distant parent editing interface. Really, in order for this system to be executed properly, either the taxonomy interface needs to be extended quite a bit, or an entire distantparent module needs to be written, to implement all the necessary frontend administration features.
At the moment, I'm still relatively new to Drupal, and have no experience in using Drupal's core APIs to write a proper frontend interface (let alone a proper Drupal module). Hopefully, I'll be able to get into this side of Drupal sometime in the near future, and learn how to actually develop proper stuff for Drupal, in which case I'll surely be putting the many and varied finishing touches on cross-vocabulary hierarchies - finishing touches that this tutorial is lacking.
As with part 1, patches and replacement code can be found at the bottom of the page (patches are to be run against a clean install, not against code from part 1). Stay tuned for part 3 - the grand finale to this series - in which we put together everything we've done so far, and much more, in order to produce an automatic hierarchical URL aliasing system, such that the URLs on every page of your site match your breadcrumbs and your taxonomy structure. Until then, happy coding!
]]>
Basic breadcrumbs and taxonomy2005-02-09T00:00:00Z2005-02-09T00:00:00ZJazahttps://greenash.net.au/thoughts/2005/02/basic-breadcrumbs-and-taxonomy/
Part 1 of"making taxonomy work my way".
Update (6th Apr 2005):parts of this tutorial no longer need to be followed. Please see this comment before implementing anything shown here.
As any visitor to this site will soon realise, I love Drupal, the free and open source Content Management System (CMS) without which GreenAsh would be utterly defunct. However, even I must admit that Drupal is far from perfect. Many aspects of it - in particular, some of its modules - leave much to be desired. The taxonomy module is one such little culprit.
If you browse through someoftheforumtopics at drupal.org, you'll see that Drupal's taxonomy system is an extremely common cause of frustration and confusion, for beginners and veterans alike. Many people don't really know what the word 'taxonomy' means, or don't see why Drupal uses this word (instead of just calling it 'categories'). Some have difficulty grasping the concept of a many-to-many relationship, which taxonomy embraces with its open and flexible classification options. And quite a few people find it frustrating that taxonomy has so much potential, but that very little of it has actually been implemented. And then there are the bugs.
In this series, I show you how to patch up some of taxonomy's bugs; how to combine it with other Drupal modules to make it more effective; and also how to extend it (by writing custom code) so that it does things that it could never do before, but that it should have been able to do right from the start. In sharing all these new ideas and techniques, I hope to make life easier for those of you that use and depend on taxonomy; to give hope to those of you that have given up altogether on taxonomy; to open up new possibilities for the future of the official taxonomy module (and for the core Drupal platform); and to kindle discussion and criticism on the material that I present.
The primary audience of this series is fellow web developers that are a part of the Drupal community. In order to appreciate the ideas presented here, and to implement the examples given, it is recommended that you have at the very least used and administered a Drupal site before. Knowledge of PHP programming and of MySQL / PostgreSQL (or even other SQL) queries would be good. You do not need to be a hardcore Drupal developer to understand this series - I personally do not consider myself to be one (yet :-)) - but it would be good if you've tinkered with Drupal's code and have at least some familiarity with it, as I do. If you're not part of this audience, then by all means read on, but don't be surprised if very soon (if not already!) you have no idea what I'm talking about.
I thought part 1 was about breadcrumbs...??
And it is - you're quite right! So, now that I've got all that introductory stuff out of the way, let's get down to the guts of this post, which is - as the title suggests - basic breadcrumbs and taxonomy (for those of you that don't see any bread, be it white, multi-grain, or wholemeal, check out this definition of a breadcrumb).
Because let's face it, that's what breadcrumbs are: basic. It's one of those fundamental things that you'd expect would work 100% right out of the box: you make a new site, you post content to it, you assign the content a category, and you take it for granted that a breadcrumb will appear, showing you where that post belongs in your site's category tree. At least, I thought it was basic when I started out on this side of town. Jakob Nielson (the web's foremost expert on usability) thinks so too, as this article on deep linking shows. But apparently, Drupal thinks differently.
It's the whole many-to-many relationship business that makes things complicated in Drupal. With a CMS that supports only one-to-many relationships (that is, each piece of content has only one parent category - but the parent category can have many children), making breadcrumbs is simple: you just trace a line from a piece of content, to its parent, to it's parent's parent, and so on. But with Drupal's taxonomy, one piece of content might have 20 parents, and each of them might have another 10 each. Try tracing a line through that jungle! The fact that although you can use many-to-many relationships, you don't have to, doesn't make a difference: taxonomy was designed to support complex relationships, and if it is to do that properly, it has to sacrifice breadcrumbs. And that's the way it works in Drupal: the taxonomy system seldom displays breadcrumbs for terms, and never displays them for nodes.
Well, I have some slightly different ideas to Drupal's taxonomy developers, when it comes to breadcrumbs. Firstly, I believe that an entire site should fall under a single 'master' category hierarchy, and that breadcrumbs should be displayed on every single page of the site without fail, reflecting a page's position in this hierarchy. I also believe that this master hierarchy system can co-exist with the power and flexibility that is inherent to Drupal's taxonomy system, but that additional categories should be considered 'secondary' to the master one.
Look at the top of this page. Check out those neat breadcrumbs. That's what this entire site looks like (check for yourself if you don't believe me). By the end of this first part of the series, you will be able to make your site's breadcrumbs as good as that. You'll also have put in place the foundations for yet more cool stuff, that can be done by extending the power of taxonomy.
Get your environment ready
In order to develop and document the techniques shown here, I have used a test environment, i.e. a clean copy of Drupal, installed on my local machine (which is Apache / PHP / MySQL enabled). If you want to try this stuff out for yourself, then I suggest you do the same. Here's my advice for setting up an environment in which you can fiddle around:
Grab a clean copy of Drupal (i.e. one that you've just downloaded fresh from drupal.org, and that you haven't yet hacked to death). I'm not stopping you from using a hacked version, but don't look at me when none of my tricks work on your installation. I've used Drupal 4.5.2 to do everything that you'll see here (latest stable release as at time of writing), so although I encourage you to use the newest version - if a newer stable release is out as at the time of you reading this (it's always good to keep up with the official releases) - naturally I make no guarantee that these tricks will work on anything other than vanilla 4.5.2.
Install your copy of Drupal. I'm assuming that you know how to do this, so I'll be brief: unzip the files; set up your database (I use MySQL, and make no guarantee that my stuff will work with PostgreSQL); tinker with conf.php; and I think that's about it.
Configure your newly-installed Drupal site: create the initial account; configure the basic settings (e.g. site name, mission / footer, time zone, cache off, clean URLs on); and enable a few core modules (in particular path module, forum and menu would be good too, you can choose some others if you want). The taxonomy module should be enabled by default, but just check that it is.
Download and install taxonomy_context.module (24 Sep 2004 4.5.x version used in my environment). I consider this module to be essential for anyone who wants to do anything half-decent using taxonomy: most of its features - such as basic breadcrumbing capabilities and term descriptions - are things that really should be part of the core taxonomy module. You will need taxonomy_context for virtually everything that I will be showing you in this series. Note: make sure you move the file taxonomy_context.module from your /modules/taxonomy_context folder, to your /modules folder, otherwise certain things will not work.
Once you've done all that, you have set yourself up with a base system that you can use to implement all my tricks! Your Drupal site should now look something like this:
Very basic drupal site (screenshot)
Add some taxonomy terms and some content
I have written some simple instructions (below) for adding the dummy taxonomy that I used in my test environment. Your taxonomy does not have to be exactly the same as mine, although the structure that I use should be followed, as it is important in achieving the right breadcrumb effect:
In the navigation menu for your new site, go to administer -> categories, then click the add vocabulary tab.
Add a new vocabulary called 'Sections'. Make it required for all node types except forum topics, and give it a single or multiple hierarchy. Also give it a light weight (e.g. -8).
Add a term called 'posts' to your new 'Sections' vocab.
Add another term called 'news', as a child of 'posts'.
Add another vocab called 'News by priority'. Make it apply only to stories, give it a single or multiple hierarchy, don't make it required, and give it a heavier weight than the 'Sections' vocab. Note: it was a deliberate choice to give this vocab a name that suggests it is a child of the term 'news' in the 'Sections' vocab. This was done in preparation for part 2 of this series, setting up a cross-vocabulary hierarchy. If you have no interest in part 2, then you can call this vocab whatever you want (but you still need a second vocab).
Add a term 'browse by priority' to the 'news by priority' vocab. Note: the use of a name that is almost identical to the vocab's name is deliberate - the reason for this is explained in part 2 of the series.
Add another term 'important' as a child of 'browse by priority'.
Well done - you've just set up a reasonably complex taxonomy structure. Your 'categories' page should now look something like this:
Test site with categories (screenshot)
Now that you have some categories in place, it's time to create a node and assign it some terms. So in the navigation menu, go to create content -> story; enter a title and an alias for your node; make it part of the 'news' section, and the 'important' priority; enter some body text; and then submit it. Your node should look similar to this:
Node with categories assigned (screenshot)
First bug: nodes have no breadcrumbs
OK, so now that you've created a node, and you've assigned some categories to it, let's examine the state of those breadcrumbs. If you go to a taxonomy page, such as the page for the term 'news', you'll see that breadcrumbs are being displayed very nicely, and that they reflect our 'sections' hierarchy (e.g. home -> posts -> news). But if you go to a node page (of which there is only one, at the moment - unless you've created more), a huge problem is glaring (or failing to glare, in this case) right at you: there are no breadcrumbs!
But don't panic - the solution is right here. First, you must bring up the Drupal directory on your filesystem, and open the file /modules/taxonomy_context.module. Find the following code in taxonomy_context (Note: the taxonomy_context module is updated regularly, so this code and other code in the tutorials may not exactly match the code that you have):
<?php
/**
* Implementation of hook_init
* Set breadcrumb, and show some infos about terms, subterms
*/
function taxonomy_context_init() {
$mode = arg(0);
$paged = !empty($_GET["from"]);
if (variable_get("taxonomy_context_use_style", 1)) {
drupal_set_html_head('<style type="text/css" media="all">@import "modules/taxonomy_context/taxonomy_context.css";
</style>');
}
if (($mode == "node") && (arg(1)>0)) {
$node = node_load(array("nid" => arg(1)));
$node_type = $node->type;
}
// Commented out in response to issue http://drupal.org/node/11407
// if (($mode == "taxonomy") || ($node_type == "story") || ($node_type == "page")) {
// drupal_set_breadcrumb( taxonomy_context_get_breadcrumb($context->tid));
// }
}
?>
And replace it with this code:
<?php
/**
* Implementation of hook_init
* Set breadcrumb, and show some infos about terms, subterms
* Patched to make breadcrumbs on nodes work, by using taxonomy_context_get_context() call
* Patch done by x on xxxx-xx-xx
*/
function taxonomy_context_init() {
$mode = arg(0);
$paged = !empty($_GET["from"]);
// Another little patch to make the CSS link only get inserted once
static $taxonomy_context_css_inserted = FALSE;
if (variable_get("taxonomy_context_use_style", 1) && !$taxonomy_context_css_inserted) {
drupal_set_html_head('<style type="text/css" media="all">@import "modules/taxonomy_context/taxonomy_context.css";
</style>');
$taxonomy_context_css_inserted = TRUE;
}
if (($mode == "node") && (arg(1)>0)) {
$node = node_load(array("nid" => arg(1)));
$node_type = $node->type;
}
// Commented out in response to issue [http://]drupal.org/node/11407
// Un-commented for breadcrumb patch
// NOTE: you don't have to have all the node types below - only story and page are essential
$context = taxonomy_context_get_context();
$context_types = array(
"story",
"page",
"image",
"weblink",
"webform",
"poll"
);
if ( ($mode == "taxonomy") || (is_numeric(array_search($node_type, $context_types))) ) {
drupal_set_breadcrumb( taxonomy_context_get_breadcrumb($context->tid, $mode));
}
}
?>
Note: when copying any of the code examples here, you should replace the lines that say "Patch done by x on xxxx-xx-xx" with your name, and the date that you copied the code. This makes it easier to keep track of any deviations that you make from the official Drupal code base, and means that upgrading to a new version of Drupal is only 'very difficult', instead of 'impossible' ;-).
This patch makes breadcrumbs appear for any node type that is included in the $content_types array (which you should edit to suit your needs), based on the site's taxonomy hierarchy. After implementing this patch, you should see something like this when you view a node:
Basic node with breadcrumbs (screenshot)
Second bug: node breadcrumbs based on the wrong vocab
We've made a good start: previously, nodes had no breadcrumbs at all, and now they do have breadcrumbs (and they're based on taxonomy). But they don't reflect the right vocab! Remember what I said earlier about a single 'master' taxonomy hierarchy for your site, and about other taxonomies being 'secondary'? In our site, the master vocab is 'Sections'. However, the breadcrumbs for our node are reflecting 'News by priority', which is a secondary vocab. We need to find a way of telling Drupal on which vocab to base its breadcrumbs for nodes.
Once again, bring up the Drupal directory on your filesystem, and this time open the file /modules/taxonomy.module. Find the following code in taxonomy:
<?php
/**
* Find all terms associated to the given node.
*/
function taxonomy_node_get_terms($nid, $key = 'tid') {
static $terms;
if (!isset($terms[$nid])) {
$result = db_query('SELECT t.* FROM {term_data} t, {term_node} r WHERE r.tid = t.tid AND r.nid = %d ORDER BY weight, name', $nid);
$terms[$nid] = array();
while ($term = db_fetch_object($result)) {
$terms[$nid][$term->$key] = $term;
}
}
return $terms[$nid];
}
?>
And replace it with this code:
<?php
/**
* Find all terms associated to the given node.
* SQL patch made by x on xxxx-xx-xx, to sort taxonomies by vocab weight rather than by term weight
*/
function taxonomy_node_get_terms($nid, $key = 'tid') {
static $terms;
if (!isset($terms[$nid])) {
$result = db_query('SELECT t.* FROM {term_data} t, {term_node} r, {vocabulary} v '.
'WHERE r.tid = t.tid AND t.vid = v.vid AND r.nid = %d ORDER BY v.weight, v.name', $nid);
$terms[$nid] = array();
while ($term = db_fetch_object($result)) {
$terms[$nid][$term->$key] = $term;
}
}
return $terms[$nid];
}
?>
Drupal doesn't realise this, but it already knows which vocab is the master vocab. We specified it to be 'Sections' when we gave it a lighter weight than 'News by priority'. In my system, the rule is that the vocab with the lightest weight (or the lowest name alphabetically) becomes the master one. So all we had to do in this patch, was to tell Drupal how to find the master vocab, based on this rule.
This was done by changing the SQL, so that when Drupal looks for all terms associated to a particular node, it sorts those terms by putting the ones with a vocab of the lightest weight first. Previously, it sorted terms according to the weight of the actual term. The original version makes sense for nodes that have several terms in one vocabulary, and also for terms that have more than one parent; but it doesn't make sense for nodes that have terms in more than one vocabulary, and this is a key feature of Drupal that many sites utilise.
After you implement this patch (assuming that you followed the earlier instruction about making the 'sections' vocab of a lighter weight than the 'news by priority' vocab), you can rest assured that the breadcrumb trail will always be for the 'sections' vocab, with any node that is so classified. Your node should now look something like this:
Node with correct breadcrumbs (screenshot)
Note that this patch also changes the order in which a node's terms are printed out (sorted by vocab weight also).
Third bug: taxonomy breadcrumbs include the current term
While the previous bug only affected the breadcrumbs on node pages, this one only affects breadcrumbs on taxonomy term pages. Try viewing a node: you will see that the breadcrumb trail includes the parent terms of that page, but that the current page itself is not included. This is how it should be: you don't want the current page at the end of the breadcrumb, because you can determine the current page by looking at the title! And also, each part of the breadcrumb trail is a link, so if the current page is part of the trail, then every page on your site has a link to itself (very unprofessional).
If you view a taxonomy term, you will see that the term you are looking at is part of the breadcrumb trail for that page. To fix this final bug (for part 1 of this series), bring up your Drupal directory again, open /modules/taxonomy_context.module, and find the following code in taxonomy_context:
<?php
/**
* Return the breadcrumb of taxonomy terms ending with $tid
*/
function taxonomy_context_get_breadcrumb($tid) {
$breadcrumb[] = l(t("Home"), "");
if (module_exist("vocabulary_list")) {
$vid = taxonomy_context_get_term_vocab($tid);
$vocab = taxonomy_get_vocabulary($vid);
$breadcrumb[] = l($vocab->name, "taxonomy/page/vocab/$vid");
}
if ($tid) {
$parents = taxonomy_get_parents_all($tid);
if ($parents) {
$parents = array_reverse($parents);
foreach ($parents as $p) {
$breadcrumb[] = l($p->name, "taxonomy/term/$p->tid");
}
}
}
return $breadcrumb;
}
?>
Now replace it with this code:
<?php
/**
* Return the breadcrumb of taxonomy terms ending with $tid
* Patched to display the current term only for nodes, not for terms
* Patch done by x on xxxx-xx-xx
*/
function taxonomy_context_get_breadcrumb($tid, $mode) {
$breadcrumb[] = l(t("Home"), "");
if (module_exist("vocabulary_list")) {
$vid = taxonomy_context_get_term_vocab($tid);
$vocab = taxonomy_get_vocabulary($vid);
$breadcrumb[] = l($vocab->name, "taxonomy/page/vocab/$vid");
}
if ($tid) {
$parents = taxonomy_get_parents_all($tid);
if ($parents) {
$parents = array_reverse($parents);
foreach ($parents as $p) {
// The line below implements the breadcrumb patch
if ($mode != "taxonomy" || $p->tid != $tid)
$breadcrumb[] = l($p->name, "taxonomy/term/$p->tid");
}
}
}
return $breadcrumb;
}
?>
The logic in the if statement that we've added does two things to fix up this bug: if we're not looking at a taxonomy term (and are therefore looking at a node), then always display the current term in the breadcrumb (thus leaving the already perfect breadcrumb system for nodes untouched); and if we're looking at a taxonomy term, and the breadcrumb we're about to print is a link to the current term, then don't print it. Note that this patch will only work if you've moved your taxonomy_context.module file, as explained earlier (it's really weird, I know, but if you leave the file in its subfolder, then this patch has no effect whatsoever - and I have no idea why).
After implementing this last patch, your taxonomy pages should now look something like this:
Taxonomy page with correct breadcrumb (screenshot)
That's all (for now)
Congratulations! If you've implemented everything in this tutorial, then you've now created a Drupal-powered web site that produces super-cool breadcrumbs based on a taxonomy hierarchy. Next time you're at a party, and are making endeavours with someone of the opposite gender, try that line on them (and let me know just how badly it went down). If you haven't implemented anything, then I can't help but call you a tad bit lazy: but hey, at least you read it all!
If you've been wondering where you can get a proper patch file with which to try this stuff out, you'll find two of them at the bottom of the page. See the Drupal handbook entry on using patch files if you've never used Drupal patches before. The patch code is identical to the code cited in this text: as with the cited code, the diff was performed against a vanilla 4.5.2 source tree. Also at the bottom of the page, you can download the entire code for taxonomy.module and taxonomy_context.module: you can put these files straight in your Drupal /modules folder, and all you have to do then is rename them.
Armed with the knowledge that you now have, you can hopefully utilise the power of taxonomy quite a bit better than you could before. But this is only the beginning.
Continue on to part 2, where we get our hands (and our Drupal code base) really dirty by implementing a cross-vocabulary hierarchy system, allowing one taxonomy term to be a child of another term in a different vocabulary, and hence producing (among other things) even sweeter breadcrumbs!


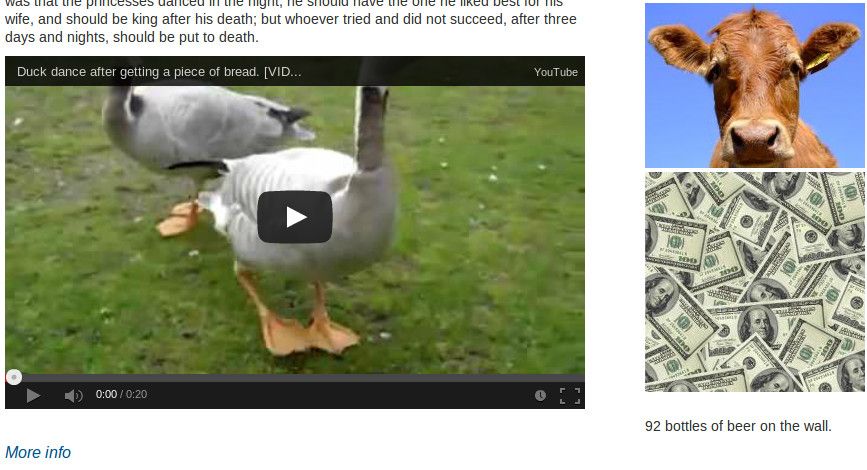
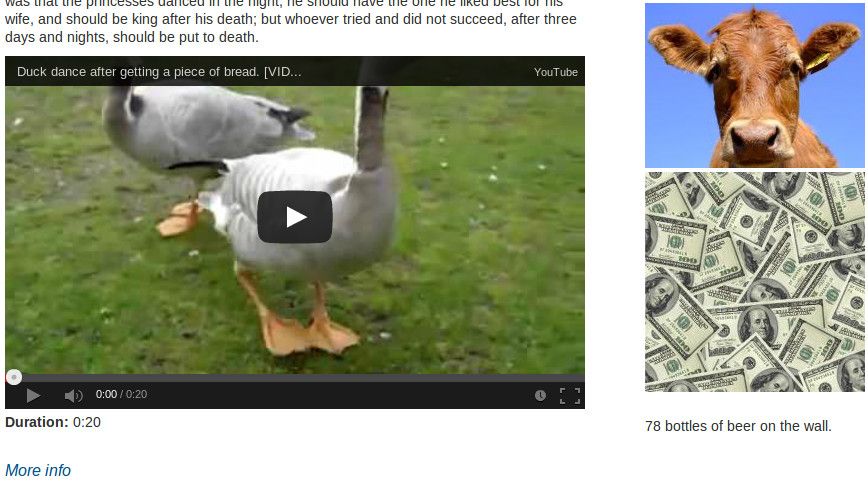
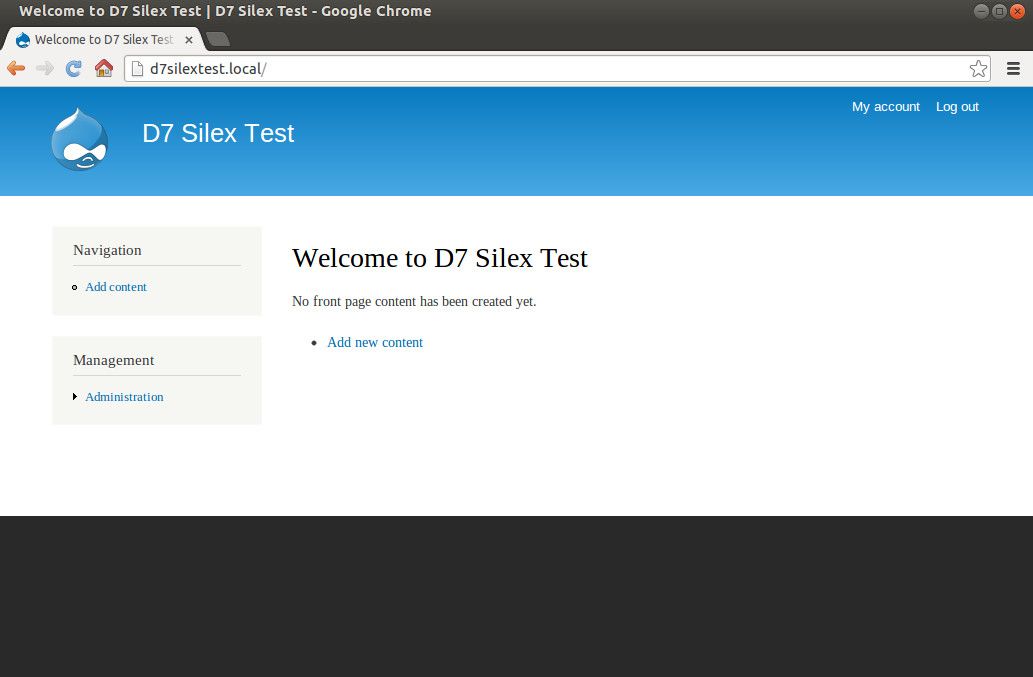
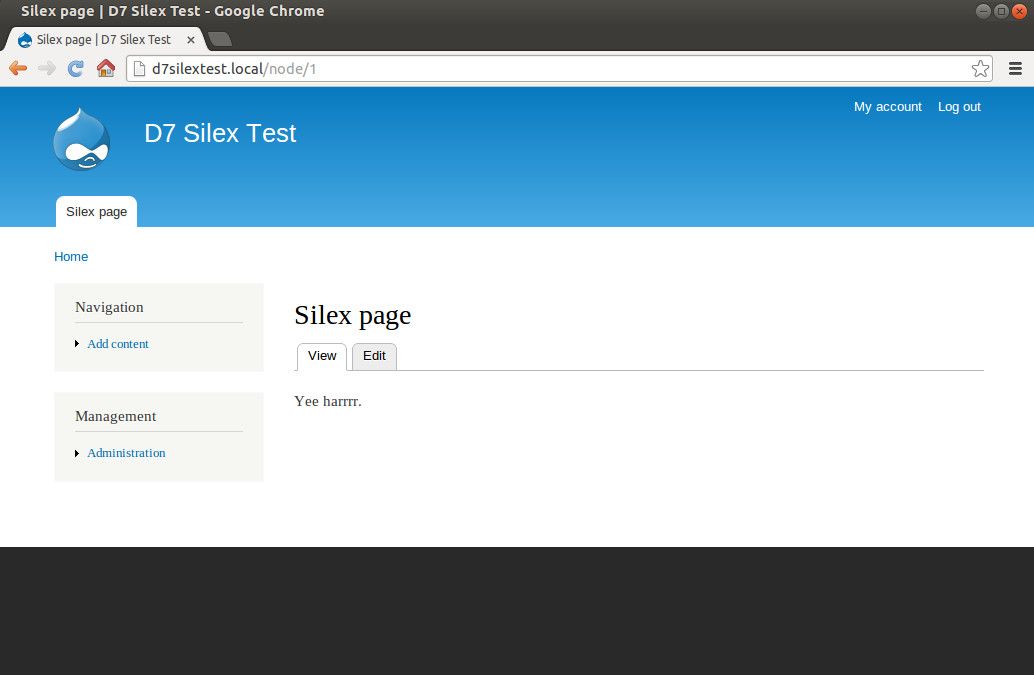
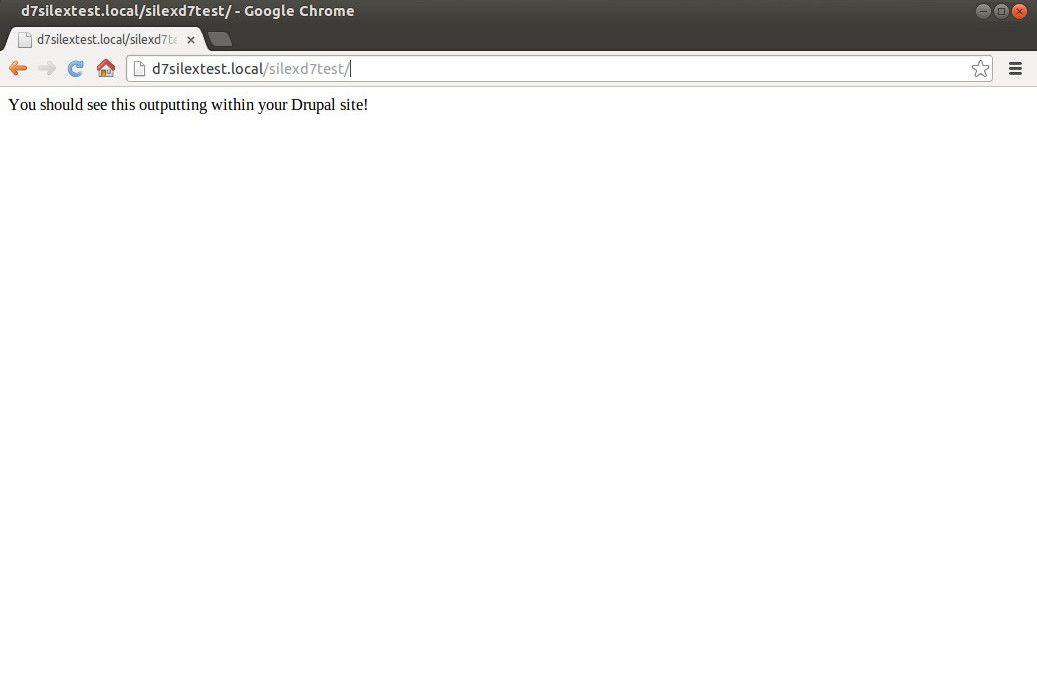
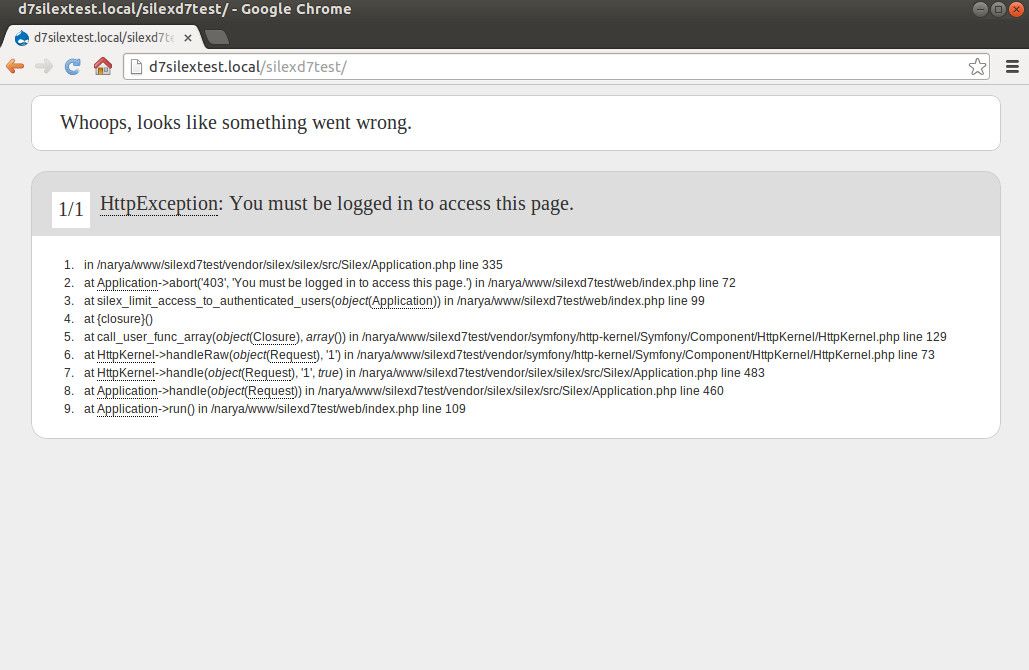
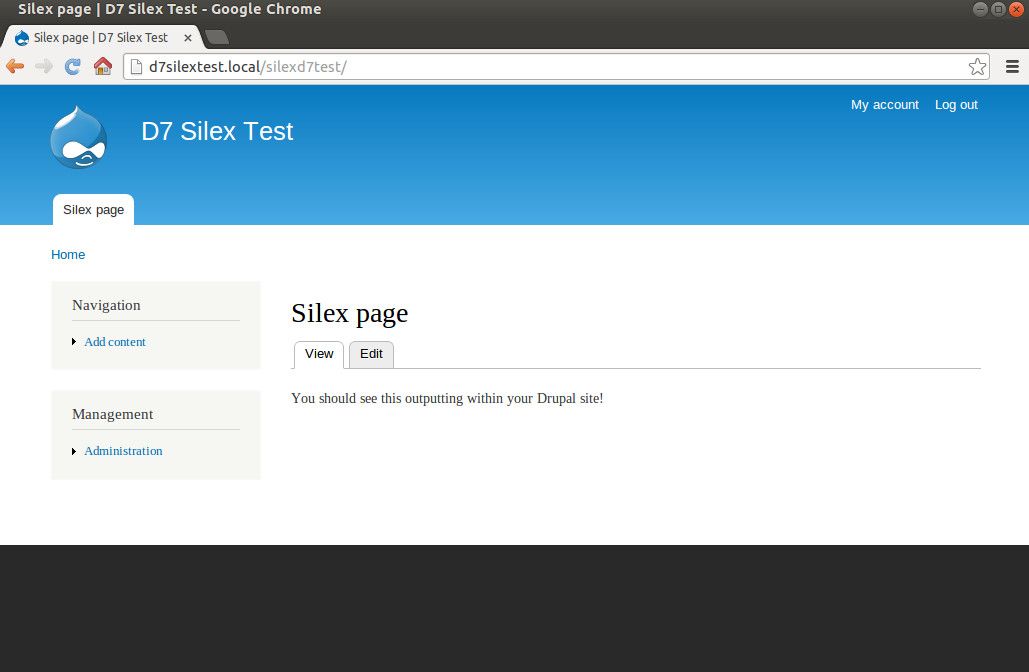

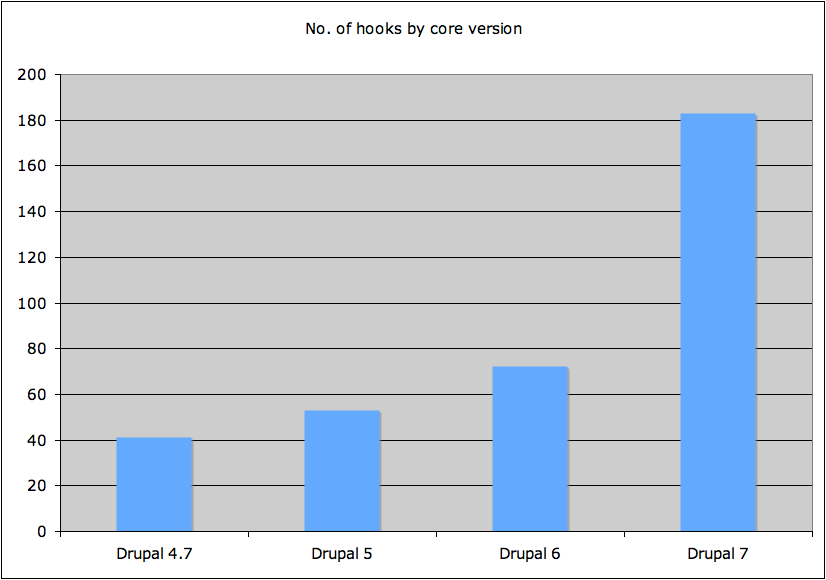
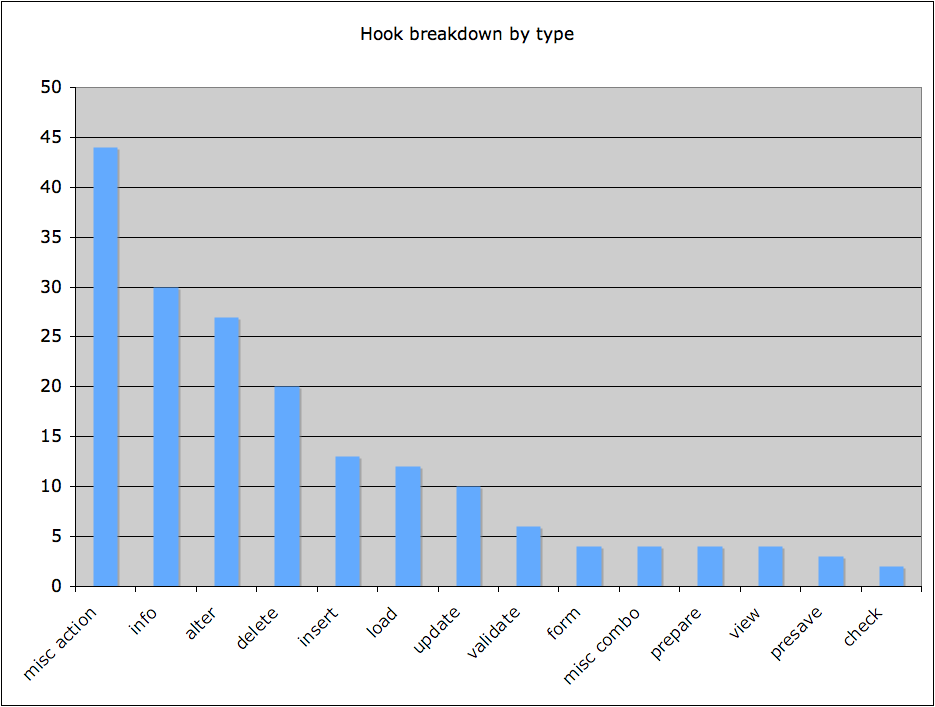






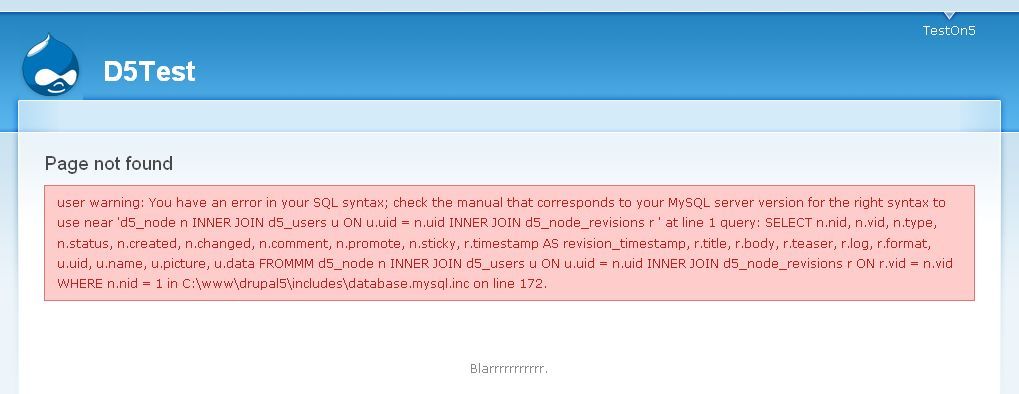
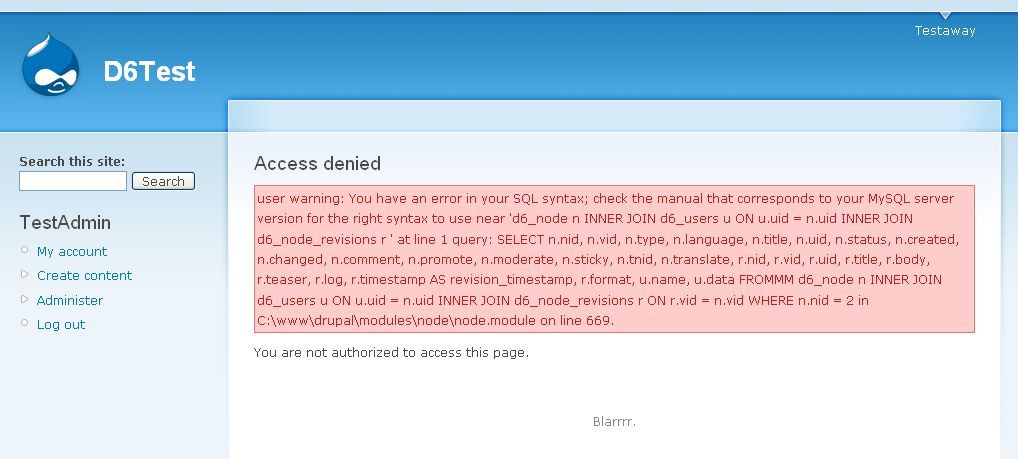











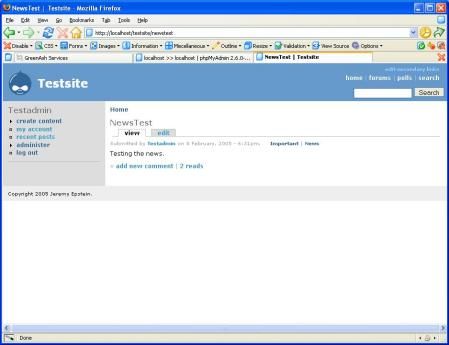
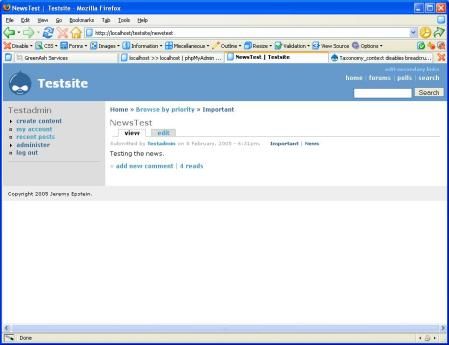
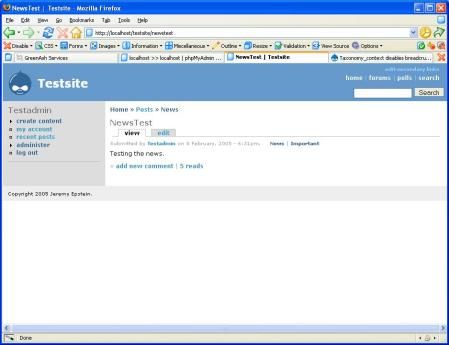
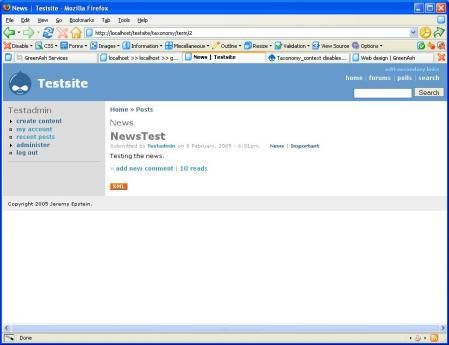
{kind=link}
{kind=link}