cloud - GreenAshPoignant wit and hippie ramblings that are pertinent to cloudhttps://greenash.net.au/thoughts/topics/cloud/2022-03-22T00:00:00ZI don't need a VPS anymore2022-03-22T00:00:00Z2022-03-22T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/03/i-dont-need-a-vps-anymore/
I've paid for either a "shared hosting" subscription, or a VPS subscription, for my own use, for the last two decades. Mainly for serving web traffic, but also for backups, for Git repos, and for other bits and pieces.
No more defending against evil villains! Image source: Meme Generator
In its place, I've taken the plunge and fully embraced SaaS. In particular, I've converted most of my personal web sites, and most of the other web sites under my purview, to be statically generated, and to be hosted on Netlify. I've also moved various backups to S3 buckets, and I've moved various Git repos to GitHub.
And so, you may lament that I'm yet one more netizen who has Less Power™ and less control. Yet another lost soul, entrusting these important things to the corporate overlords. And you have a point. But the case against SaaS is one that's getting harder to justify with each passing year. My new setup is (almost entirely) free (as in beer). And it's highly available, and lightning-fast, and secure out-of-the-box. And sysadmin is now Somebody Else's Problem. And the amount of ownership and control that I retain, is good enough for me.
The number one thing that I loathed about managing my own VPS, was security. A fully-fledged Linux instance, exposed to the public Internet 24/7, is a big responsibility. There are plenty of attack vectors: SSH credentials compromise; inadequate firewall setup; HTTP or other DDoS'ing; web application-level vulnerabilities (SQL injection, XSS, CSRF, etc); and un-patched system-level vulnerabilities (Log4j, Heartbleed, Shellshock, etc). Unless you're an experienced full-time security specialist, and you're someone with time to spare (and I'm neither of those things), there's no way you'll ever be on top of all that.
With the new setup, I still have some responsibility for security, but only the level of responsibility that any layman has for any managed online service. That is, responsibility for my own credentials, by way of a secure password, which is (wherever possible) complimented with robust 2FA. And, for GitHub, keeping my private SSH key safe (same goes for AWS secret tokens for API access). That's it!
I was also never happy with the level of uptime guarantee or load handling offered by a VPS. If there was a physical hardware fault, or a data centre networking fault, my server and everything hosted on it could easily become unreachable (fortunately this seldom happened to me, thanks to the fine folks at BuyVM). Or if there was a sudden spike in traffic (malicious or not), my server's CPU / RAM could easily get maxxed out and become unresponsive. Even if all my sites had been static when they were VPS-hosted, these would still have been constant risks.
Don't worry. I've sent an email. Image source: YouTube
With the new setup, both uptime and load have a much higher guarantee level, as my sites are now all being served by a CDN, either CloudFront or Netlify's CDN (which is similar enough to CloudFront). Pretty much the most highly available, highly resilient services on the planet. (I could have hooked up CloudFront, or another CDN, to my old VPS, but there would have been non-trivial work involved, particularly for dynamic content; whereas, for S3 / CloudFront, or for Netlify, the CDN Just Works™).
And then there's cost. I had quite a chunky 4GB RAM VPS for the last few years, which was costing me USD$15 / month. Admittedly, that was a beefier box than I really needed, although I had more intensive apps running on it, several years ago, than I've had running over the past year or two. And I felt that it was worth paying a bit extra, if it meant a generous buffer against sudden traffic spikes that might gobble up resources.
Ain't nothin' like a beefy server setup. Image source: The Register
Whereas now, my main web site hosting service, Netlify, is 100% free! (There are numerous premium bells and whistles that Netlify offers, but I don't need them). And my main code hosting service, GitHub, is 100% free too. And AWS is currently costing me less than USD$1 / month (with most of that being S3 storage fees for my private photo collection, which I never stored on my old VPS, and for which I used to pay Flickr quite a bit more money than that anyway). So I consider the whole new setup to be virtually free.
Apart from the security burden, sysadmin is simply never something that I've enjoyed. I use Ubuntu exclusively as my desktop OS these days, and I've managed a number of different Linux server environments (of various flavours, most commonly Ubuntu) over the years, so I've picked up more than a thing or two when it comes to Linux sysadmin. However, I've learnt what I have, out of necessity, and purely as a means to an end. I'm a dev, and what I actually enjoy doing, and what I try to spend most of my time doing, is dev work. Hosting everything in SaaS land, rather than on a VPS, lets me focus on just that.
In terms of ownership, like I said, I feel that my new setup is good enough. In particular, even though the code and the content for my sites now has its source of truth in GitHub, it's Git, it's completely exportable and sync-able, I can pull those repos to my local machine and to at-home backups as often as I want. Same for my files for which the source of truth is now S3, also completely exportable and sync-able. And in terms of control, obviously Netlify / S3 / CloudFront don't give me as many knobs and levers as things like Nginx or gunicorn, but they give me everything that I actually need.
I think I own my new setup well enough. Image source: Wikimedia Commons
Purists would argue that I've never even done real self-hosting, that if you're serious about ownership and control, then you host on bare metal that's physically located in your home, and that there isn't much difference between VPS- and SaaS-based hosting anyway. And that's true: a VPS is running on hardware that belongs to some company, in a data centre that belongs to some company, only accessible to you via network infrastructure that belongs to many companies. So I was already a heretic, now I've slipped even deeper into the inferno. So shoot me.
20-30 years ago, deploying stuff online required your own physical servers. 10-20 years ago, deploying stuff online required at least your own virtual servers. It's 2022, and I'm here to tell you, that deploying stuff online purely using SaaS / IaaS offerings is an option, and it's often the quickest, the cheapest, and the best-quality option (although can't you only ever pick two of those? hahaha), and it quite possibly should be your go-to option.
]]>
Email-based comment moderation with Netlify Functions2022-03-17T00:00:00Z2022-03-17T00:00:00ZJazahttps://greenash.net.au/thoughts/2022/03/email-based-comment-moderation-with-netlify-functions/
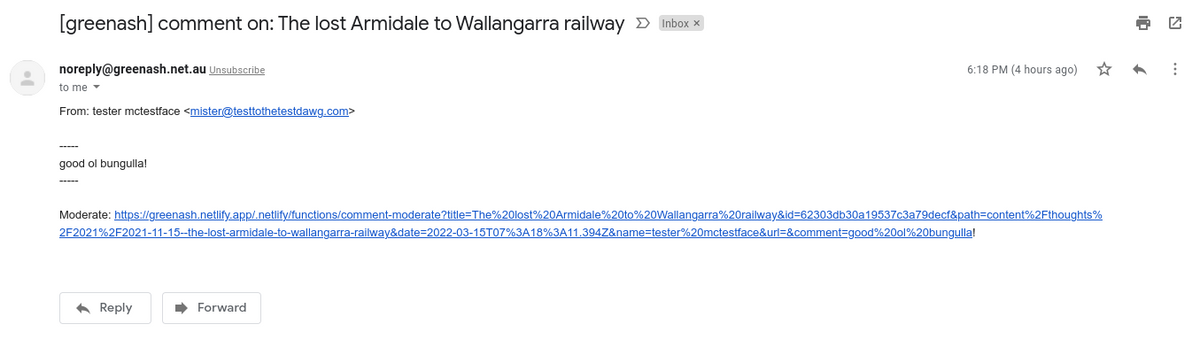
The most noteworthy feature of the recently-launched GreenAsh v5, programming-wise, is its comment submission system. I enjoyed the luxury of the robust batteries-included comment engines of Drupal and Django, back in the day; but dynamic functionality like that isn't as straight-forward in the brave new world of SSG's. I promised that I'd provide a detailed run-down of what I built, so here goes.
Some of GreenAsh's oldest published comments, looking mighty fine in v5.
In a nutshell, the way it works is as follows:
The user submits their comment via a simple HTML form powered by Netlify Forms
The submission gets saved to the Netlify Forms data store
The submission-created event handler sends the site admin (me!) an email containing the submission data and a URL
The site admin opens the URL, which displays an HTML form populated with the submission data
After eyeballing the submission data, the site admin enters a secret token to authenticate
The site admin clicks "Approve", which writes the new comment to a JSON file, pushes the code change to the site's repo via the GitHub Contents API, and deletes the submission from the data store via the Netlify Forms API (or the site admin clicks "Delete", in which case it just deletes the submission from the data store)
Netlify rebuilds the site in response to a GitHub code change as usual, thus publishing the comment
The initial form submission is basically handled for me, by Netlify Forms. The bit where I had to write code only begins at the submission-created event handler. I could have POSTed form submissions directly to a serverless function, and that would have allowed me a lot more usage for free. Netlify Forms is a premium product, with a not-particularly-generous free tier of only 100 (non-spam) submissions per site per month. However, I'd rather use it, and live with its limits, because:
It has solid built-in spam protection, and defence against spam is something that was my problem for nearly the past 20 years, and I'd really really like for it to be Somebody Else's Problem from now on
It has its own data store of submissions, which I don't strictly need (because I'm emailing myself each submission), but which I consider really nice to have, if for any reason the email notifications don't reach me (and I also have many years of experience with unreliable email delivery), and which would be a pain (and totally not worth it) to build myself in a serverless way (would need something like DynamoDB, API Gateway, various lambda's, it would be a whole project in itself)
I can interact with that data store via a nice API
I can review spam submissions in the Netlify Forms UI (which is good, because I don't get notified of them, so otherwise I'd have no visibility over them)
Even if I bypassed Netlify Forms, I'd still have to send myself a customised email notification, which I do, using the SparkPost Transmissions API, which has a free tier limit of 500 emails per month anyway
So, the way the event handler works, is that all you have to do, in order to hook up a function, is to create a file in your repo with the correct magic name netlify/functions/submission-created.js (that's magic that isn't as well-documented as it could be, if you ask me, which is why I'm pointing it out here as explicitly as possible). You can see my full event handler code on GitHub. Here's the meat of it:
The way I'm crafting the notification email, is pretty similar to the way my comment notification emails worked before in Django. That is, the email includes the commenter's name and email, and the comment body, in readable plain text. And it includes a URL that you can follow, to go and moderate the comment. In Django, that was simply a URL to the relevant page in the admin. But this is a static site, it has no admin. So it's a URL to a form, and the URL includes all of the submission data, encoded into it as GET parameters.
How the comment notification email looks in GMail
Clicking the URL then displays an HTML form, which is generated by another serverless function, the code for which you can find here. That HTML form doesn't actually need to be generated by a function, it could itself be a static page (containing some client-side JS to populate the form fields from GET parameters), but it was just as easy to make it a function, and it effectively costs me no money either way, and I thought, meh, I'm in functions land anyway.
All the data in that form gets populated from what's encoded in the clicked-on URL, except for token, which I have to enter in manually. But, because it's a standard HTML password field, I can tell my browser to "remember password for this site", so it gets populated for me most of the time. And it's dead-simple HTML, so I was able to make it responsive with minimal effort, which is good, because it means I can moderate comments on my phone if I'm out and about.
The comment moderation form
Having this intermediary HTML form is necessary, because a clickable URL in an email can't POST directly (and I certainly don't want to actually write comments to the repo in a GET request). It's also good, because it means that the secret token has to be entered manually in the browser, which is more secure, and less mistake-prone, than the alternative, which would be sending the secret token in the notification email, and including it in the URL. And it gives me a slightly nicer UI (slightly nicer than email, that is) in which to eyeball the comment, and it gives me the opportunity to edit the comment before publishing it (which I sometimes do, usually just to fix formatting, not to censor or distort what people have to say!).
Next, we get to the business of actually approving or rejecting the comment. You can see my full comment action code on GitHub. Here's where the approval happens:
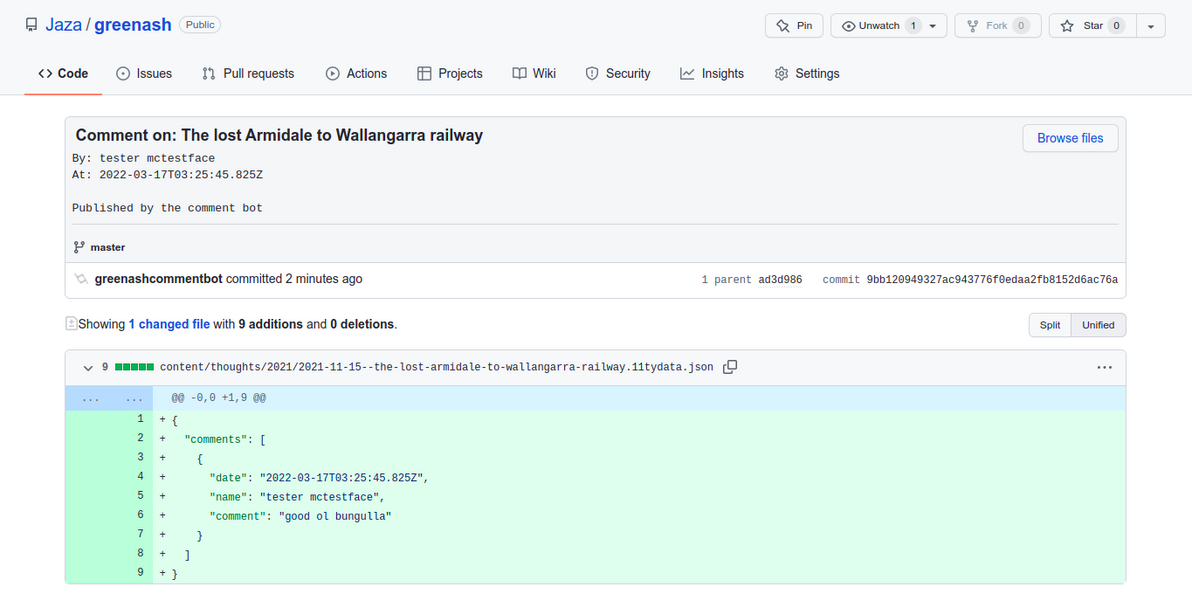
I'm using Eleventy's template data files (i.e. posts/subdir/my-first-blog-post.11tydata.json style files) to store the comments, in simple JSON files alongside the thought content files themselves, in the repo. So the comment approval function has to append to the relevant JSON file if it already exists, otherwise it has to create the relevant JSON file from scratch. That's why the first thing the function does, is try to get the existing JSON file and its comments, and if none exists, then it sets the list of existing comments to an empty array.
The function appends the new comment to the existing comments array, it serializes the new array to JSON, and it writes the new JSON file to the repo. Both interactions with the repo – reading the existing comments file, and writing the new file – are done using the GitHub Contents API, as simple HTTP calls (the PUT call results in a new commit on the repo's default branch). This way, the function doesn't have to actually interact with Git, i.e. it doesn't have to clone the repo, read from the filesystem, perform a commit, or push the change (and, therefore, nor does it need an SSH key, it just needs a GitHub API key).
The newly-approved comment in the GitHub UI's commit details screen
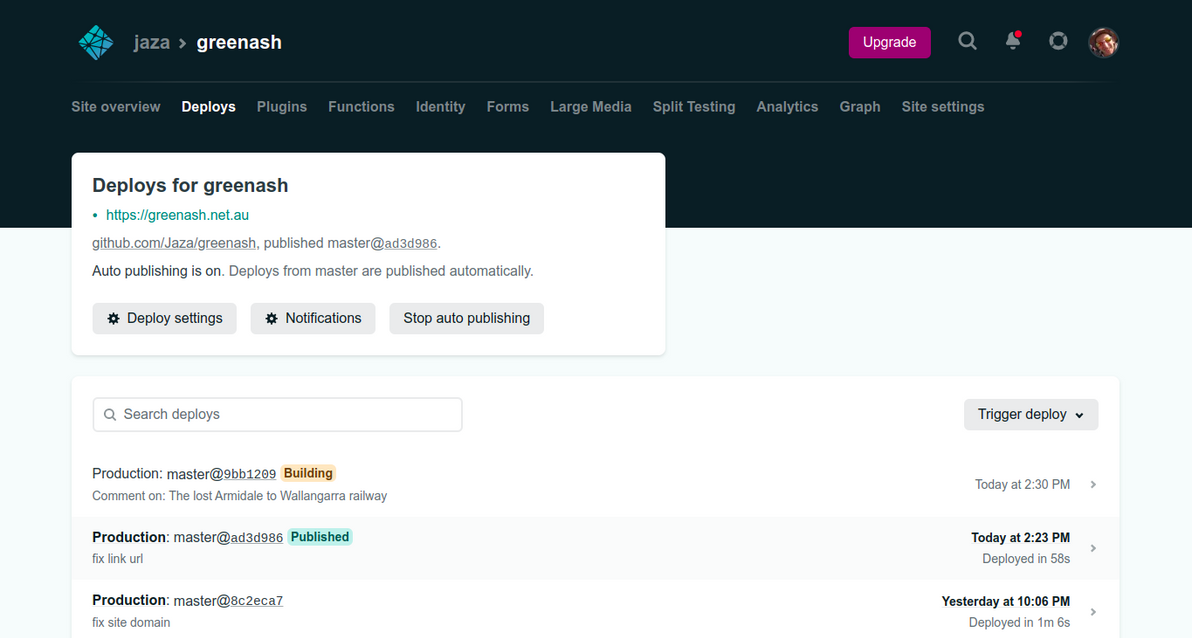
From that point on, just like for any other commit pushed to the repo's default branch, Netlify receives a webhook notification from GitHub, and that triggers a standard Netlify deploy, which builds the latest version of the site using Eleventy.
Netlify re-deploying the site with the new comment
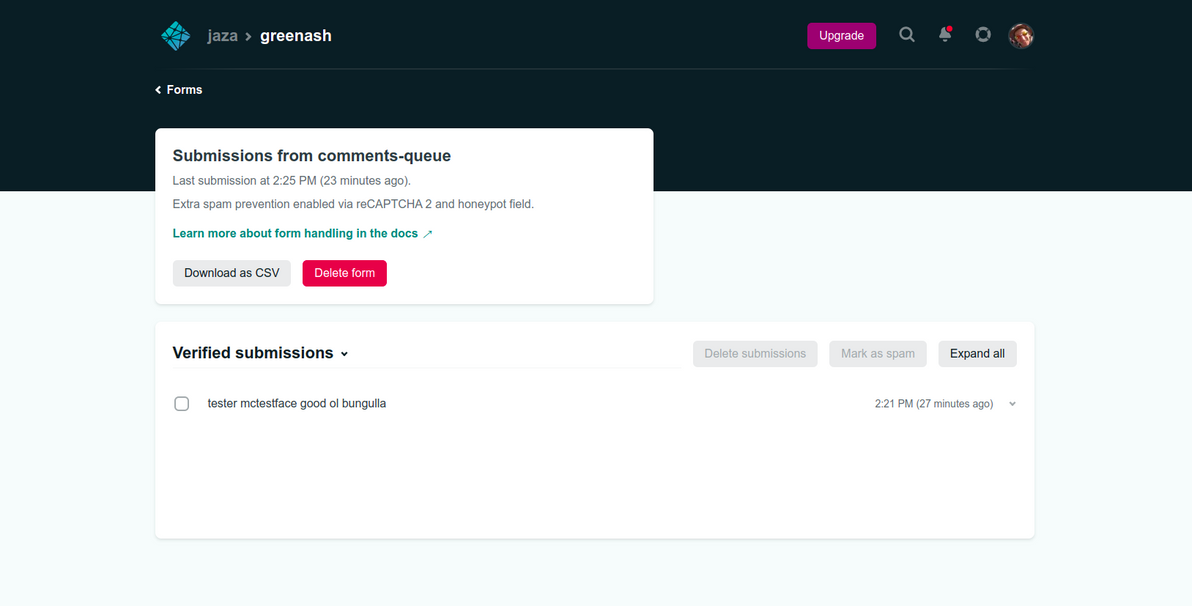
The only other thing that the comment approval function does, is the same thing (and the only thing) that the comment rejection function does, which is to delete the submission via the Netlify Forms API. This isn't strictly necessary: I could just let the comments sit in the Netlify Forms data store forever (and as far as I know, Netlify has no limit on how many submissions it will store indefinitely for free, only on how many submissions it will process per month for free).
But by deleting each comment from there after I've moderated it, the Netlify Forms data store becomes a nice "todo queue", should I ever need one to refer to (i.e. should my inbox not be a good enough such queue). And I figure that a comment really doesn't need to be stored anywhere else, once it's approved and committed in Git (and, conversely, it really doesn't need to be stored anywhere at all, once it's rejected).
The new comment can be seen in the Netlify UI before it gets approved or rejected
The old Django-powered site was set up to immediately publish comments (i.e. no moderation) on thoughts that were less than one month old; and to publish comments after they'd been moderated, for thoughts that were up to one year old; and to close comment submission, for thoughts that were more than one year old.
Publishing comments immediately upon submission (or, at least, within a minute or two of submission, allowing for Eleventy build time / Netlify deploy time) would be possible in the new site, but personally I'm not comfortable with letting actual Git commits (as opposed to just database inserts) get triggered directly like that. So all comments will now be moderated. And, for now, I'm keeping comment submission open for all thoughts, old or new, and hopefully Netlify's spam protection will prove tougher than my old defences (the only reason why I'd closed comments for older thoughts, in the past, was due to a deluge of spam).
I should also note that the comment form on the new site has a (mandatory) "email" field, same as on the old site. However, on the old site, I was able to store the emails of commenters in the Django database indefinitely, but to not render them in the front-end, thus keeping them confidential. In the new site, I don't have that luxury, because if the emails are in Git, then (even if they're not rendered in the front-end) they're publicly visible on GitHub (unless I were to make the whole repo private, which I specifically don't want to do, I want the site itself to be open source!).
So, in the new site, emails of commenters are included in the notification email that gets sent to me (so that I can contact the commenter should I want to or need to), and they're stored (usually only temporarily) in the Netlify Forms data store, but they don't make it anywhere else. Rest assured, commenters, I respect your privacy, I will never publish your email address.
Commenting: because everyone's voice deserves to be heard! Image source:Illawarra Mercury
Well, there you have it, my answer to "what about comments" in the static serverless SaaS web of 2022. For your information, there's another, more official solution for powering comments with Netlify and Eleventy, with a great accompanying article.. And, full disclosure, I copied quite a few bits and pieces from that project. My main gripe with the approach taken there, is that it uses Slack, instead of email, for the notifications. It's not that I don't like Slack – I've been using it every day for work, across several jobs, for many years now (albeit not by choice) – but, call me old-fashioned if you will, I prefer good ol' email.
You've read this far, all about my whiz bang new comments system. Now, the least you can do is try it out, the form's directly below. :D
]]>
Private photo collections with AWSPics2021-02-02T00:00:00Z2021-02-02T00:00:00ZJazahttps://greenash.net.au/thoughts/2021/02/private-photo-collections-with-awspics/
I've created a new online home for my formidable collection of 25,000 personal photos. They now all live in an S3 bucket, and are viewable in a private gallery powered by the open-source AWSPics. In general, I'm happy with the new setup.
For the past 15 years, I have painstakingly curated and organised my photos on Flickr. I have no complaints or regrets: Flickr was and still is a fantastic service, and in its heyday it was ahead of its time. However, after 15 years as a loyal Pro member, it's with bittersweet reluctance that I've decided to cancel my Flickr account. The main reason for my parting ways with Flickr, is that its price has increased (and is continuing to increase), quite significantly of late, after being set in stone for many years.
I also just wanted to build (and felt that I was quite overdue in building) a photo solution crafted (at least partially) with my own hands, and that I fully control, rather than just letting SaaS do all the work for me. Similarly, even though I've always trusted and I still trust Flickr with my data, I wanted to migrate my photos to a storage back-end that I own and manage myself, and an S3 bucket is just that (at the least, IaaS is closer to that ideal than SaaS is).
I had never made any of my personal photos private, although I always could have, back in the Flickr days. I never felt that it was necessary. I was young and free, and the photos were all of me hanging out with my friends, and/or gallivanting around the world with other carefree backpackers. But I'm at a different stage of my life now. These days, the photos are all of my kids, and so publishing them for the whole world to see is somewhat less appropriate. And AWSPics makes them all private by default. So, private it is.
Many thanks to jpsim for building AWSPics, it's a great little stack. AWSPics had nearly everything I needed, when I stumbled across it about 3 months ago, and I certainly could have used it as-is, no yours-truly dev required. But, me being a fastidious ol' dev, and it being open-source, naturally I couldn't help but add a few bells and whistles to it. In particular, I scratched my own itch by building support for collections of albums, so that I could preserve the three-level hierarchy of Collections -> Albums -> Pictures that I used religiously on Flickr. I also wrote a whole lot of unit tests for the AWSPics site builder (which is a Node.js Lambda function), before making any changes, to ensure that I didn't break existing functionality. Other than that, I just submitted a few minor bug fixes.
I'm not planning on enhancing AWSPics a whole lot more. It works for my humble needs. I'm a dev, not a designer, nor a photographer. Although 25,000 photos is a lot (and growing), and I feel like I'm pushing the site builder Lambda a bit close to its limits at the moment (it takes over a minute to run, and ideally a Lambda function completes within a few seconds). Adding support for partial site rebuilds (i.e. only rebuild specific albums or collections) would resolve that. Plus I'm sure there are a few more minor bits and pieces I could work on, should I have the time and the inclination.
Well, that's all I have to say about that. Just wanted to formally announce that shift that my photo collection has made, and to give kudos where it's deserved.